1. Introduction
Researchers in Human–Computer Interaction (HCI) have made substantial breakthroughs in the field of cognitive science. HCI [
1,
2,
3] focuses on the concept that the human instructs the machine to accomplish the computational task. In contrast, the latest research sheds light on a novel method called Human–Machine Cooperation (HMC) [
4,
5,
6,
7], where the machine dominates the computation process with
limited help from the human. HMC aims to balance the advantages and disadvantages of human computation (accurate but costly) and machine computation (cheap but inaccurate).
This paper rethinks the hierarchical clustering with HMC and validates this approach in image clustering applications, including plant species clusterings and face clusterings [
8]: (1) plant species clusterings aim to group leaf images by species. However, accurate clustering may require human experience (depending on the application), leading to an overly large amount of human computations. To reduce the amount of human computations, the machine can preliminarily cluster the leaf images, using existing approaches that measure the similarity of two leaf images. While automatic clusterings for leaf images are quite noisy [
9], we observe that even a person can compare two leaf images and provide an accurate assessment of their similarity. Therefore, HMCs are valuable; and (2) in surveillance videos, real-time face clusterings are critical for determining whether the same person has visited a number of locations or not. Video images have variations in pose, illumination and resolution, and thus automatic clusterings are quite error-prone. However, a person can readily look at two face images to determine their similarity. Therefore, HMCs are also valuable.
We mainly focus on the HMC-based agglomerative hierarchical clusterings, and we assume that the distances between pairs of data points are known a priori. Traditional approaches without HMCs start by treating each data point as a singleton cluster, and then repeatedly merge the two closest clusters until a stop criterion is met. An inefficient HMC strategy could be a sequential approach: (1) the machine first computes some complete clustering results, through using different merging criteria; (2) then, the human picks out the most correct one as the final result. A better HMC strategy that takes less time and human computation involves real-time cooperations. When the machine encounters an uncertain pair of data points in the middle of the cluster-building process, it can ask for human help through question operations. Then, the human would tell the machine whether that pair of data points are in the same cluster or not. The number of questions a machine can ask is limited by a fixed budget, due to the cost of human computations. We are interested in the machine’s strategy on handling the question operations, which is challenging in terms of three problems (“which”, “when”, and “how”).
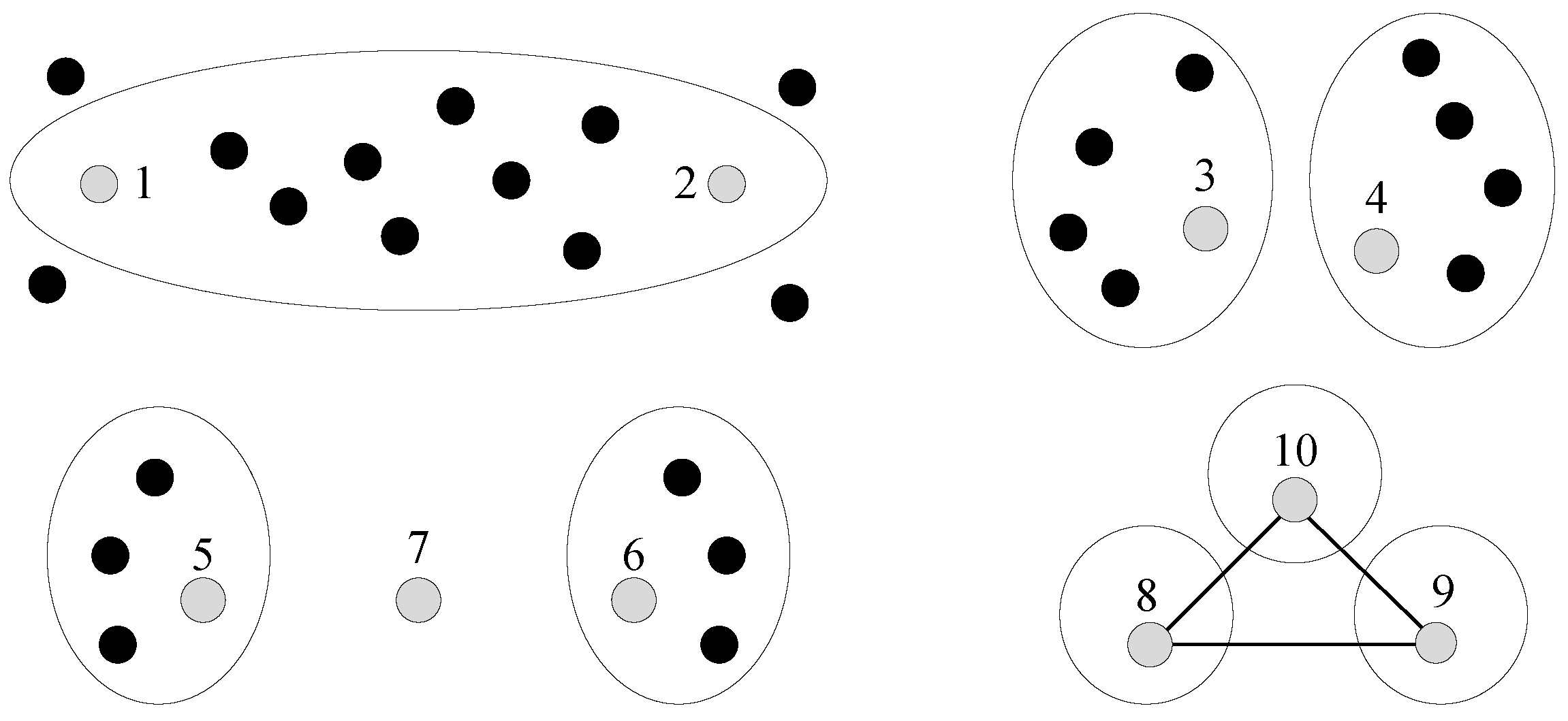
Which question (i.e., pair of data points) should the machine ask? Suppose the machine is in the middle of the cluster-building process. Then,
Figure 1 shows some interesting cases as follows: (1) data points 1 and 2 are currently in the same cluster, but the distance between them is large. Hence, the machine may want human assistance to check their assignment; (2) data points 3 and 4 are currently in different clusters, but the distance between them is small. These two clusters that contain 3 and 4 may merge into a larger one; (3) the data point 7 is in the middle of two clusters. The machine can decide whether to add 7 to 5’s cluster or 6’s cluster, by asking the human two questions. Moreover, this problem is further complicated, due to the
transitive relations of questions. As shown in
Figure 1, let us assume that two questions return answers (from the human) in which data points 8 and 10 (the first question’s answer), as well as 9 and 10 (the second question’s answer), are in the same cluster. Based on these answers, the machine can derive that 8 and 9 are in the same cluster by transitivity.
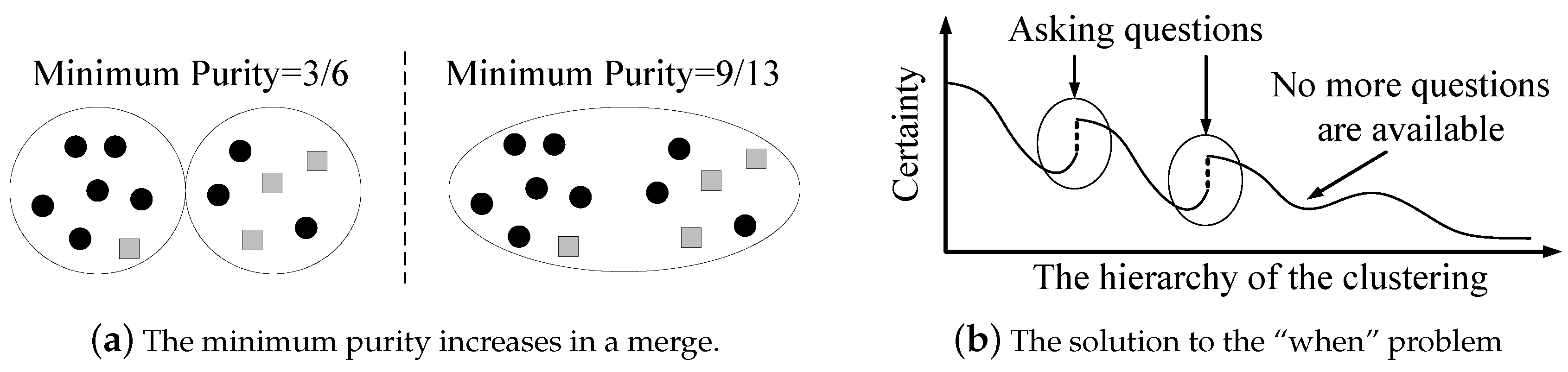
When should the machine ask the question? Asking a question can bring up the correctness of the clustering result, since the machine may have made some errors. If the machine asks questions in the early clustering stage, then it benefits from getting a good start (or foundation) as a trade-off on the risk: it may not reserve enough question operations for very hard decisions that may appear later. The number of available questions is important: if the machine holds a large number of available questions, then it can be aggressive (i.e., ask early); otherwise, it may be conservative (i.e., ask later).
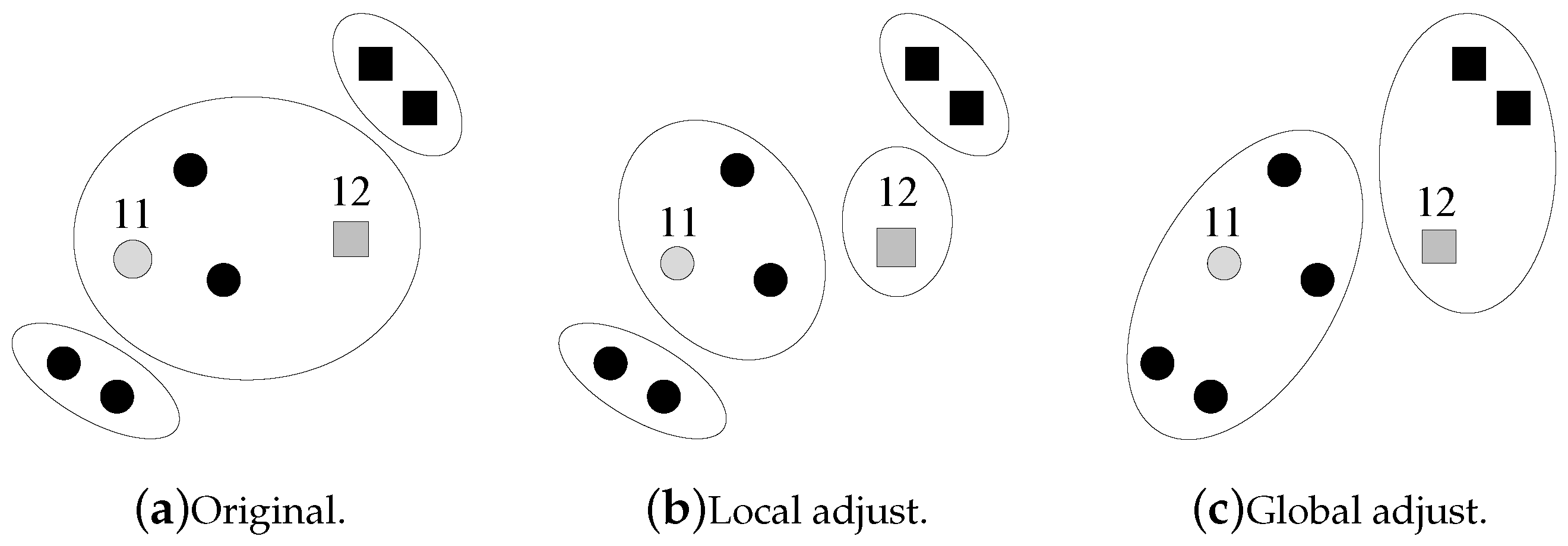
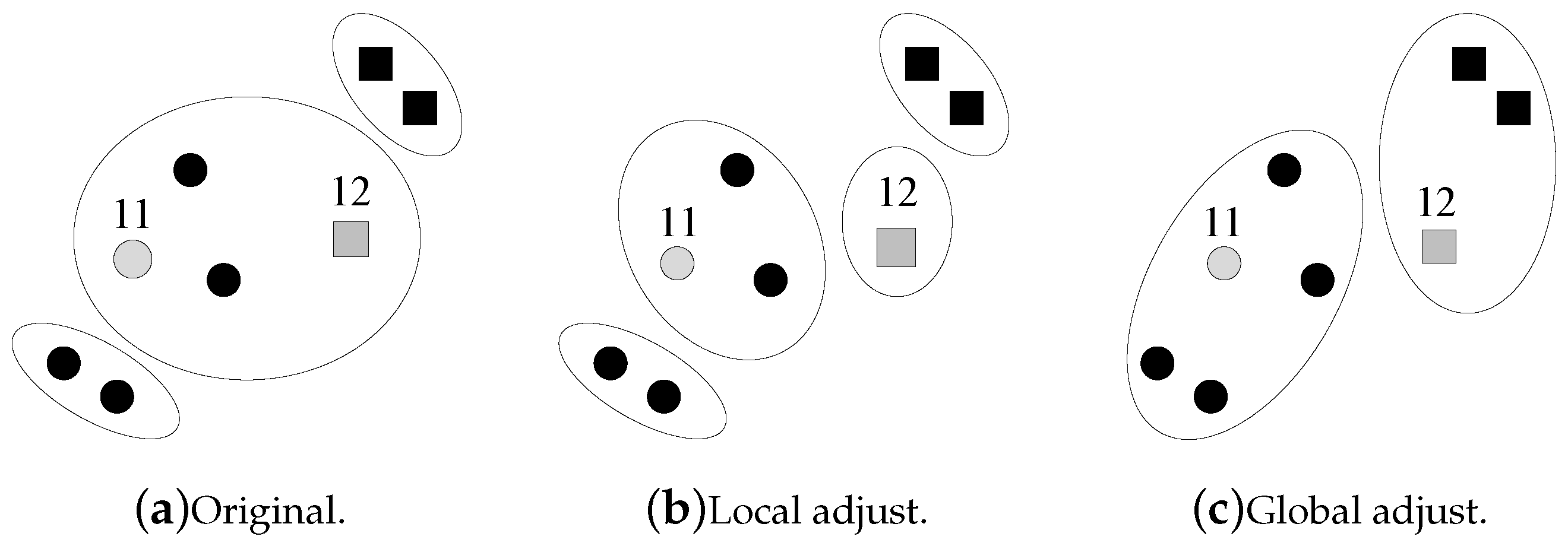
How does the machine adjust the current clustering result after obtaining the question’s answer from the human? If the human agrees with the machine’s clustering result, then everything is fine. Otherwise, the machine needs to adjust its clustering result, which is very complex due to the
coupled errors shown in
Figure 2.
Figure 2a shows the current clustering result of the machine. Then, the machine asks a question on data points 11 and 12, and the human returns an answer that 11 and 12 are not in the same cluster. This answer brings a different clustering result, as shown in
Figure 2c. Instead of locally splitting the cluster that contains 11 and 12 into two smaller clusters, the machine may need a global adjustment on the current clustering result.
Moreover, the problems of “which”, “when”, and “how” are not independent of each other. To solve the “when” problem, the machine needs to estimate the benefit brought by asking a question (as to balance the risk). Hence, the “when” problem is highly related to the “which” problem, since the machine should select the most beneficial pair of data points to ask. Meanwhile, the “how” problem is also related to the “which” problem, since the selected pair of data points may have an influence on the adjustment strategy (local or global). This paper explores the insights of these problems as our key contributions. We propose insightful solutions to the problems of “which”, “when”, and “how”.
The paper is organized as follows. We present the framework in
Section 2. Related works are described in
Section 3. The problems of “which”, “when”, and “how” are studied in
Section 4.
Section 5 gives out an overview of the proposed algorithm. Experiments are conducted in
Section 6. Finally, in
Section 7, we conclude the paper.
3. Related Work
Recently, combining human and machine intelligence in crowdsourcing [
12] has become a hot research area. When the machine cannot solve its task, it can ask for human help. The machine takes the part of the job that it can understand, while passing the incomprehensible part to the human. Crowdsourcing acts as the bridge that connects the machine and the human. The question response time is reported to be low enough, which provides the possibility for real-time HMCs [
13]. While researchers [
8,
12] studied different kinds of HMC problems, we mainly focus on real-time HMCs in hierarchical clusterings [
14,
15].
Our work is related to the active learning techniques [
16,
17,
18,
19]. The key idea behind active learning is that a machine learning algorithm can achieve a better accuracy with fewer training labels if it is allowed to choose the data from which it learns [
19]. An active learner may pose queries, usually in the form of asking the human to label unlabeled data instances. Active learning is a special case of semi-supervised learning [
20,
21], while our clustering problem is unsupervised. Our problem is a dynamic one that involves time; this differs from active learning, which is static. Our approach is a special time-sensitive density-weighted uncertainty-sampling-based active learning method.
Our approach can be classified as a hybrid approach of the constraint-based clustering and the budgeted learning. The constraint-based clustering [
22,
23,
24,
25,
26] is initialized with pre-given constraints before executing the clustering algorithm, while our approach dynamically introduces the constraints (i.e., question answers) within the algorithm execution. We also study the time to introduce the constraint, which is represented by the “when” problem. On the other hand, although the budgeted learning [
27,
28,
29,
30] focuses on the time for the machine to learn the samples, it does not consider the clustering constraints. Our problem is a special budgeted and constrained clustering.
Our work is also related to the cognitive science field. For example, Roads et al. [
5] improved image classifications with HMC via cognitive theories of similarity. Given a query image and a set of reference images, individuals are asked to select the best matching reference. Based on the similarity choice, a predictive model was developed to optimize the selection of reference images, using the existing psychological literature. Chang et al. [
6] developed Alloy, which is a hybrid HMC approach to efficiently search for global contexts in crowdsourcing. Alloy supports greater global context through a new “sample and search” crowd pattern, which changes the crowd’s task from classifying a fixed subset of items to actively sampling and querying the entire dataset. Böck et al. [
31] summarized user behaviors to improve the efficiency of HMC. Multimodal user behaviors (such as characteristics, emotions and feelings) are analyzed for the machine’s algorithm design.
4. “Which”, “When”, and “How”
This section explores the solutions for the “which”, “when”, and “how” problems, respectively.
4.1. The “Which” Problem
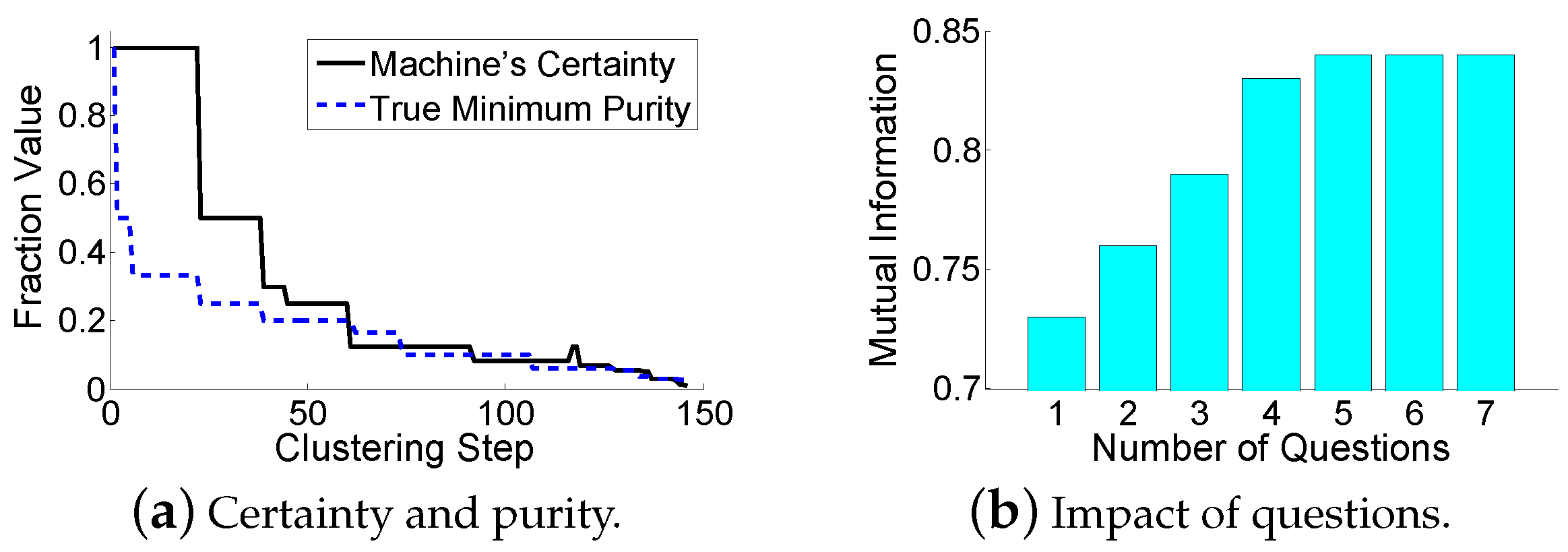
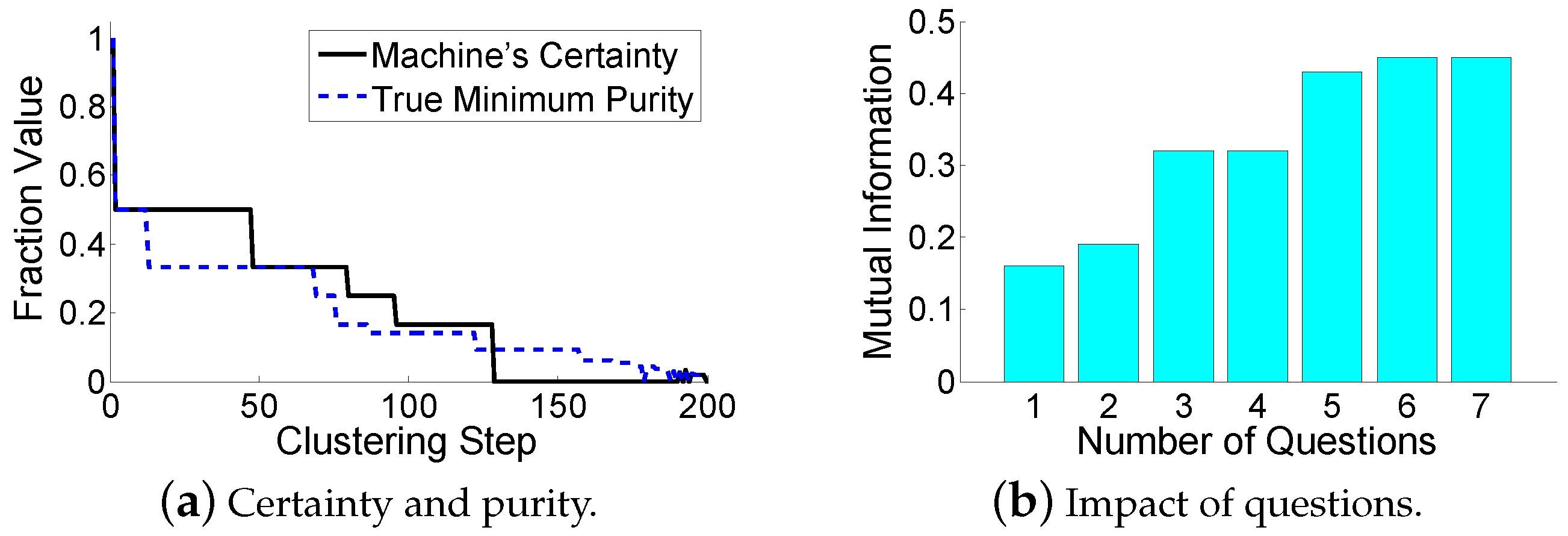
For the “which” problem, a previous work [
8] proposed that the machine should ask the pair of nodes leading to a quick convergence, which does not improve the clustering accuracy. However, the goal of HMCs is to balance the advantages and disadvantages of human computation and machine computation. The former method is accurate but costly, while the latter one is cheap but inaccurate. Therefore, using human resources to save the machine’s computations is meaningless in HMCs. Our objective is to improve the machine’s clustering accuracy with limited real-time help from humans. To better explain our idea, several definitions [
32] are introduced as follows.
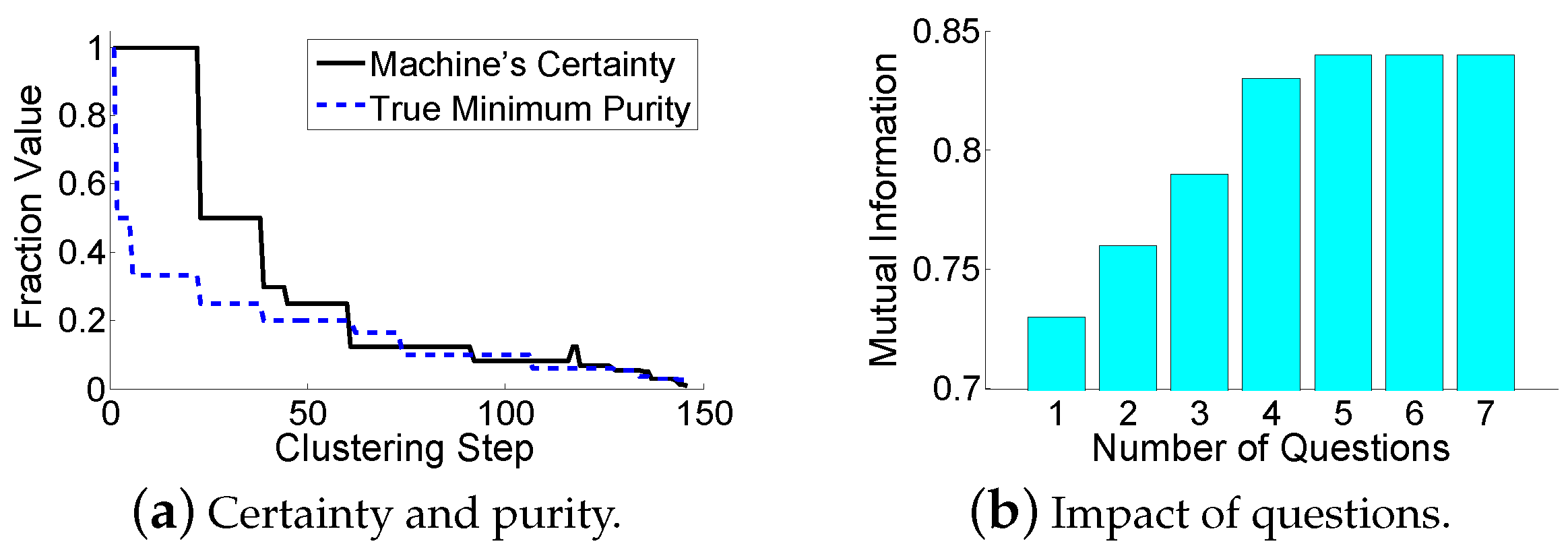
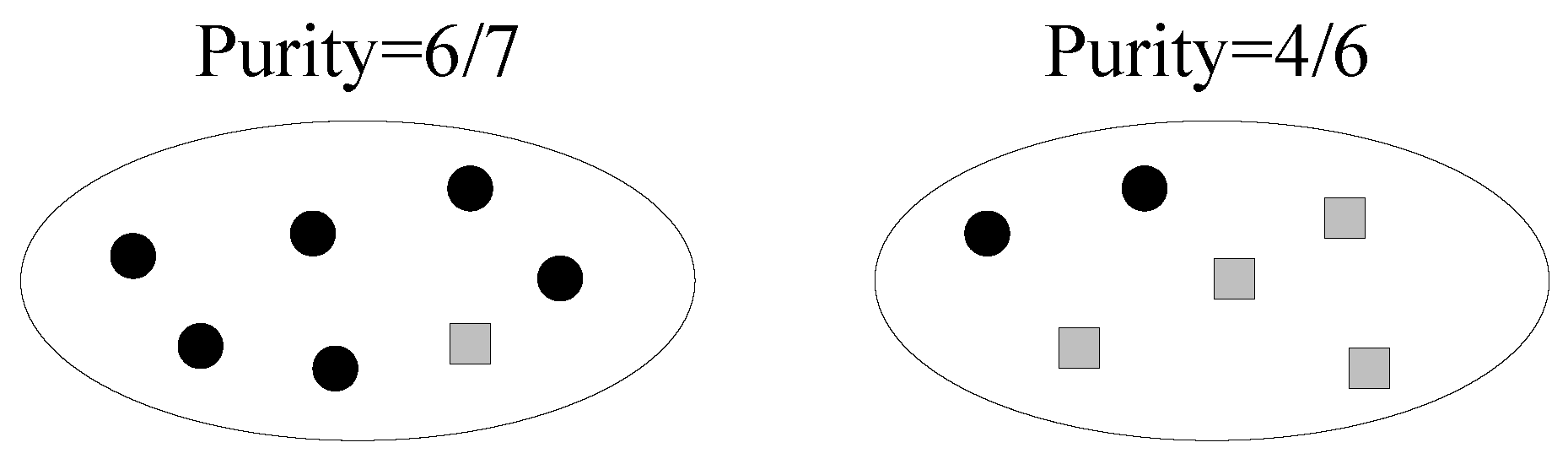
Definition 1. The purity of a cluster is the fraction of the dominant data point type in it. The minimum purity is the minimum purity among all clusters. The cluster with the minimum purity is called the dirtiest cluster.
Note that the definition of the minimum purity does not involve the cluster size. Therefore, a smaller cluster is more likely to have a lower purity, since an incorrectly clustered data point takes a larger fraction in the cluster. We intend to make small clusters pure, in order to limit error propagations. An example of the minimum purity is shown in
Figure 3. The minimum purity is
. A high minimum purity means that each cluster is pure. If the minimum purity of the machine’s current clustering result is very low, then the machine should ask questions. However, the machine does not know the true minimum purity during its cluster-building process. The only thing it can do is to
estimate the minimum purity. Therefore, we have the following definition:
Definition 2. The machine’s certainty estimates the minimum purity of the current clustering result.
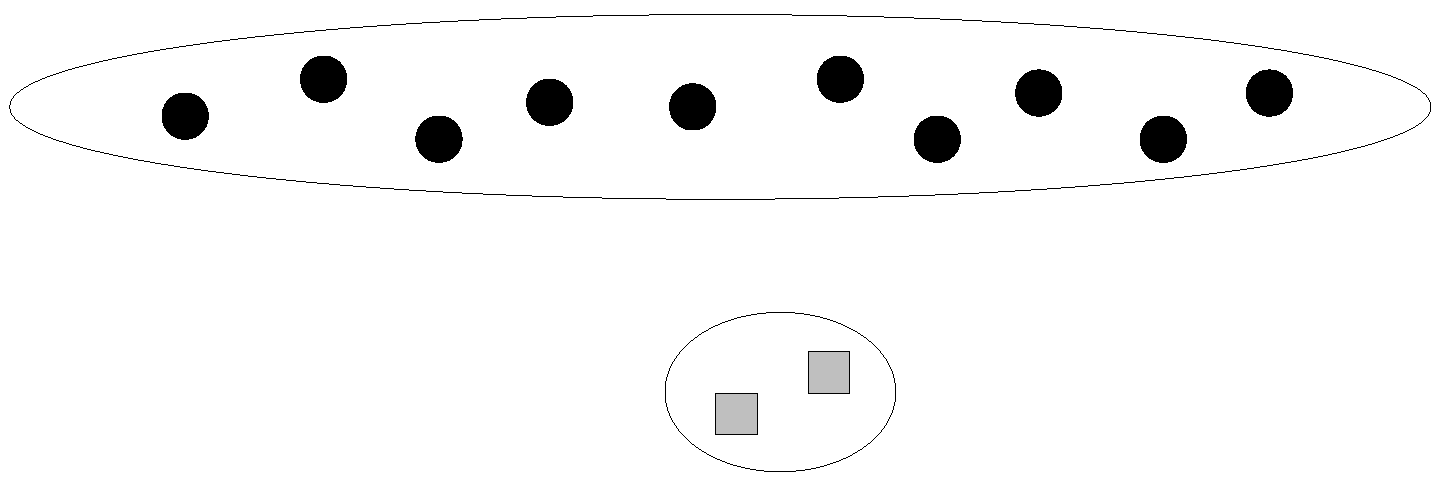
The minimum purity can be used by the machine to verify the estimated-dirtiest cluster through question operations. A high certainty means that the machine considers its current clustering result to be correct, while a low certainty means that the machine doubts the accuracy of its current clustering result. Intuitively, the distance between the two clusters that are going to be merged in the next step may reveal the purity. One may think that merging two far-distance clusters leads to a low purity. However, this is incorrect in the sense that all currently existing clusters are far away from each other. Another method is to use the ratio of (1) the smallest distance between two different clusters to (2) the largest distance between two data points within the same cluster. A larger ratio seems to represent a higher purity, since clusters are far away from each other, and each cluster’s size is small. However, this method is also incorrect. As shown in
Figure 4, the ratio can be small, but the purity is high.
Our solution to the “which” problem is a special
density-weighted uncertainty-sampling-based approach [
33]. It focuses on the neighborhood consistency of pairs of data points. The neighbors of a data point are its
k-nearest neighbors. If all neighbors of a data point have consistent behaviours (in terms of their clusters), then the machine’s certainty is high. We use
local structures of pairs of data points to estimate the purity. Suppose data points
i and
j are in the same cluster
C. We then have:
where
is the percentage of data point
i’s neighbors that are currently in
C. The corresponding
i and
j that lead to the minimum certainty of
C are called
the most questionable pair of data points in
C. The certainty is defined through pairwise data points, since the question operation has the format of comparing two data points.
is an estimation of the cluster
C’s purity, which falls into the range of
. It reaches 1 if and only if all neighbors of data points in
C also fall into the same cluster. It reaches 0 when all neighbors of a pair of data points are not in
C. Therefore, the machine should greedily pick the most questionable pair of data points corresponding to the dirtiest cluster, which is our solution to the “which” problem. If we go back to the toy example in
Figure 1, then the data points 1 and 2 bring a low certainty, which fits our demands. This solution also considers the cases of data points 3, 4, 5, 6, and 7. When increasingly more clusters merge, these cases will be reduced to the former case. Therefore, the machine only needs to ask questions after making errors (rather than before making errors). Upon obtaining an answer to a question, the machine derives the transitive relationships of questions (mentioned in
Figure 1), as to detect more errors. The original question’s answer and the derived answers are recorded, and the corresponding pairs of data points are removed for the future questions. In addition, for the initialization, we start to calculate the purity of a cluster, only if the number of data points within the cluster is larger than a threshold.
4.2. The “When” Problem
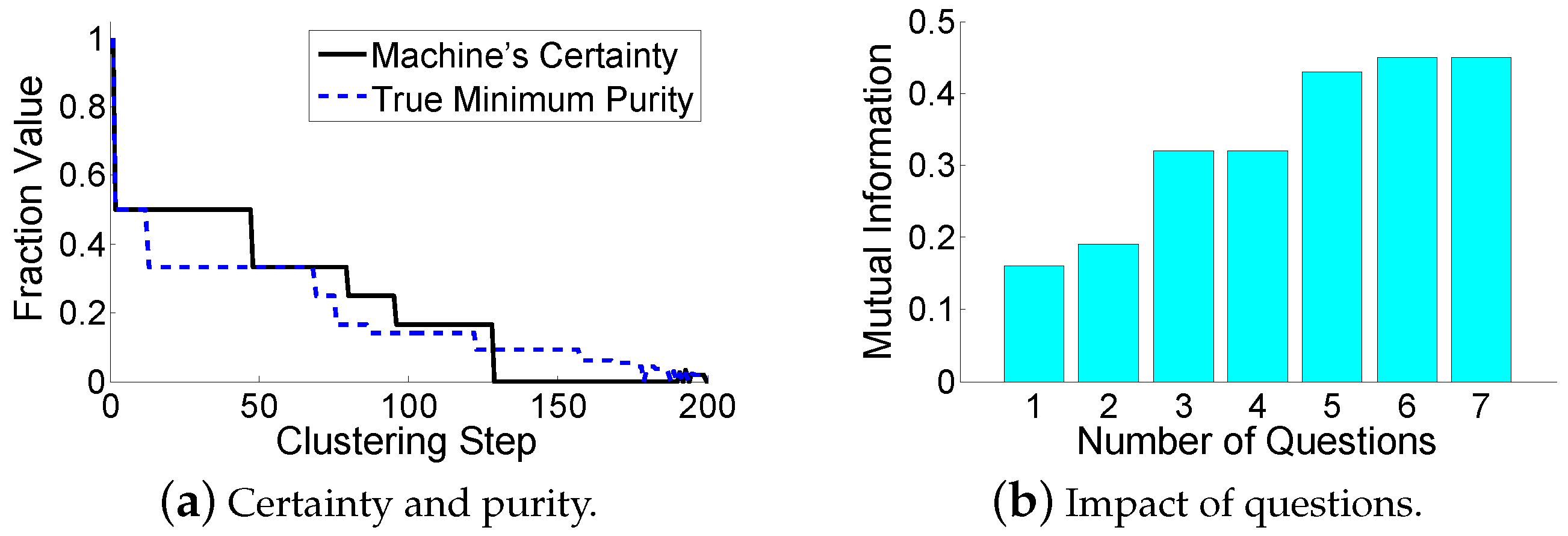
In this subsection, we focus on the “when” problem. If the machine asks questions in the early clustering stage, then it benefits from getting a good start (or foundation) as a trade-off on the risk: it may not reserve enough question operations for very hard decisions that may appear in the later clustering stage. The benefit of asking a question can be estimated through the current machine’s certainty. The risk means that the machine has used up its questions, and then encounters a low certainty case in the later clustering stage.
We want to
maximize the minimum purity during the cluster-building process. The total number of questions (denoted by
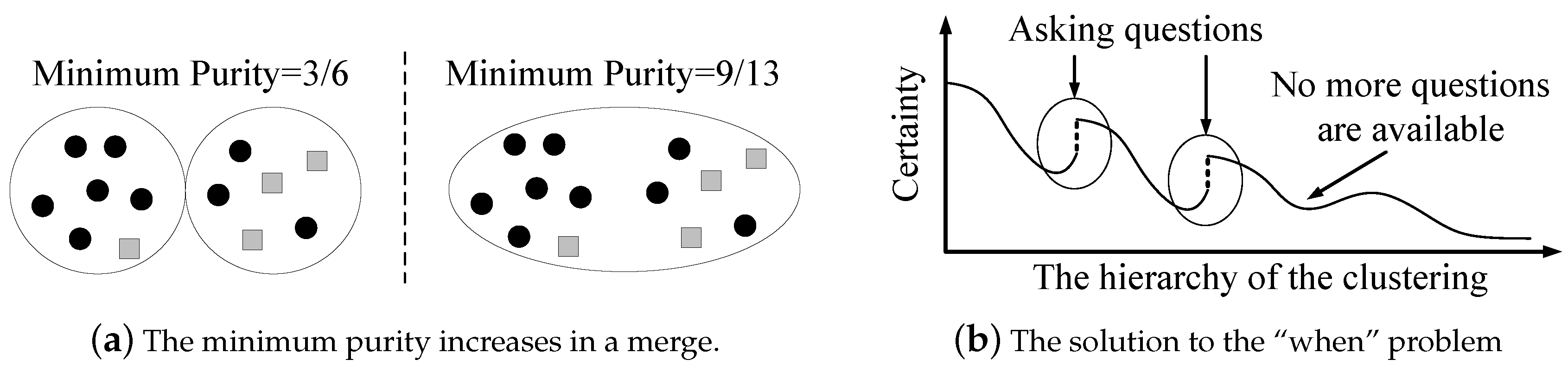
Q) is limited, since human computations are relatively costly. One may think that the minimum purity monotonously decreases when the hierarchy of the clustering moves up, and thus the machine should ask questions when it encounters a significant certainty reduction. However, the machine is likely to encounter numerous certainty reductions during the cluster-building process, while the available question operations may not be enough. Moreover, how could the machine determine whether a certainty reduction is significant or not? This is very challenging, and can be data-sensitive. The key observation is that the minimum purity may increase, as shown in
Figure 5a. In the left part of
Figure 5a, the purity of these two clusters are
(black circle dominates) and
(a tie), respectively. Hence, the minimum purity is
. In the right part of
Figure 5a, the purity (and the minimum purity) is
(black circle dominates). When the machine merges a cluster with a high purity and a cluster with the lowest purity, the minimum purity may increase. Therefore, during the cluster-building process, the minimum purity may decrease with some oscillations, i.e.,
local minimums exist. These local minimums indicate the time for the machine to ask questions. This is because increased minimum purity means
error propagation, where a cluster with a high purity is contaminated by a dirty one. Error propagations should be controlled.
Now, let us go back to the trade-off between a good start and the risk. The existence of error propagations make us consider a higher priority of the risk. Errors made by the machine are inevitable, so the machine should save the limited questions on preventing error propagations, which appear rarely, but are disastrous. Therefore, our solution for the “when” problem is that the machine asks a question whenever (1) it encounters a certainty gain and (2) it has available questions to ask, as shown in
Figure 5b. Instead of receiving an incorrect certainty gain that may result in error propagations, the machine actively asks questions to verify the correctness. This strategy will maximally restrict the error propagations. If the machine goes to the end of the clustering-building process with unspent questions, it will ask those questions at the end.
4.3. The “How” Problem
This subsection focuses on the “how” problem. Once the human’s answer disagrees with the machine’s result, the machine should adjust its clustering result, which is complex due to the coupled errors. Suppose i and j are the most questionable pair of data points in the estimated-dirtiest cluster C, where the human’s answer disagrees with this result. Local adjustment refers to the case where the machine splits C into two clusters that, respectively, include i and j. Global adjustment refers to the case where the machine gives up the current result and re-starts the clustering from the beginning. Local adjustments have a low time complexity and a low accuracy, while global adjustments have a high time complexity and a high accuracy.
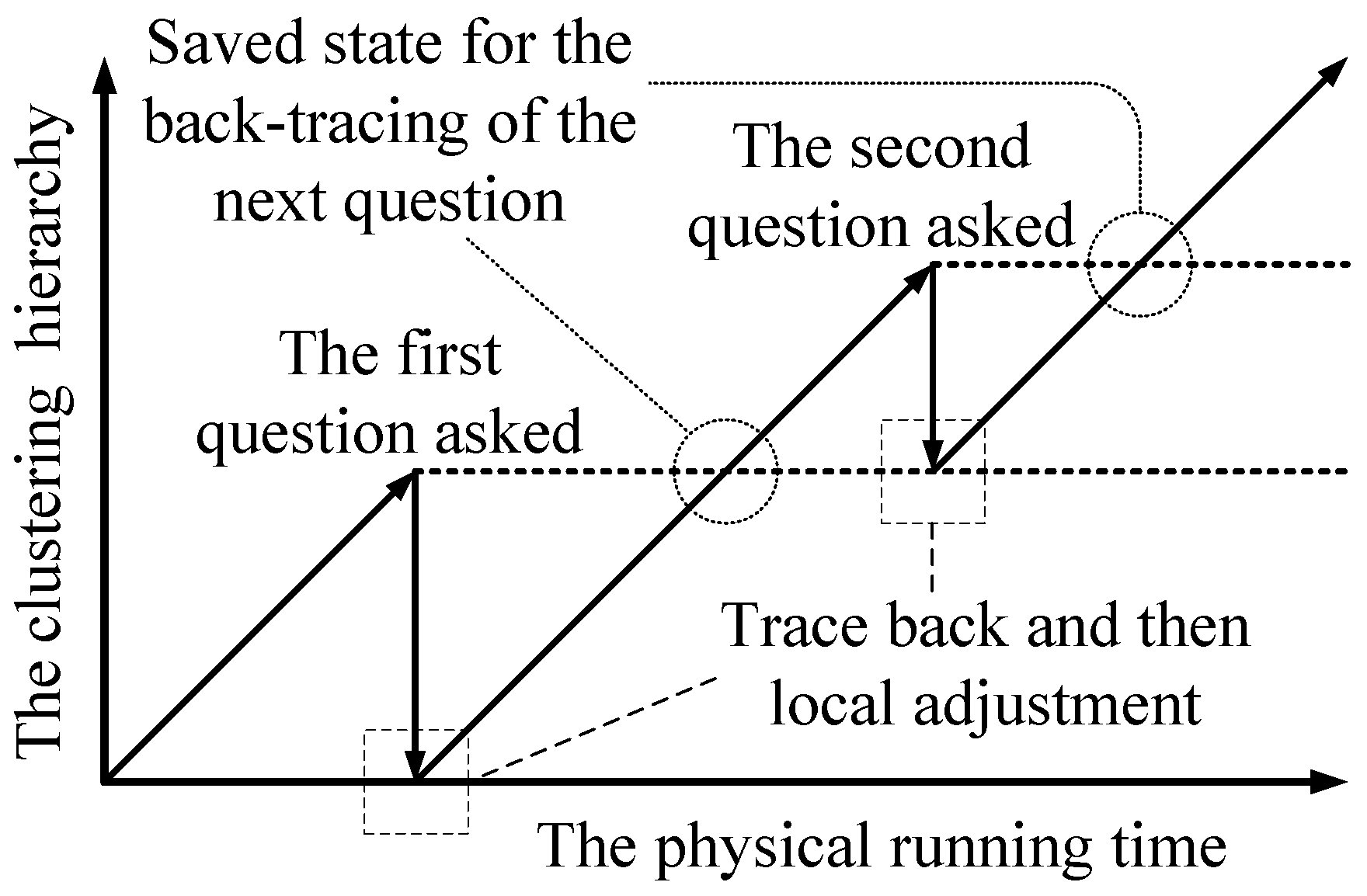
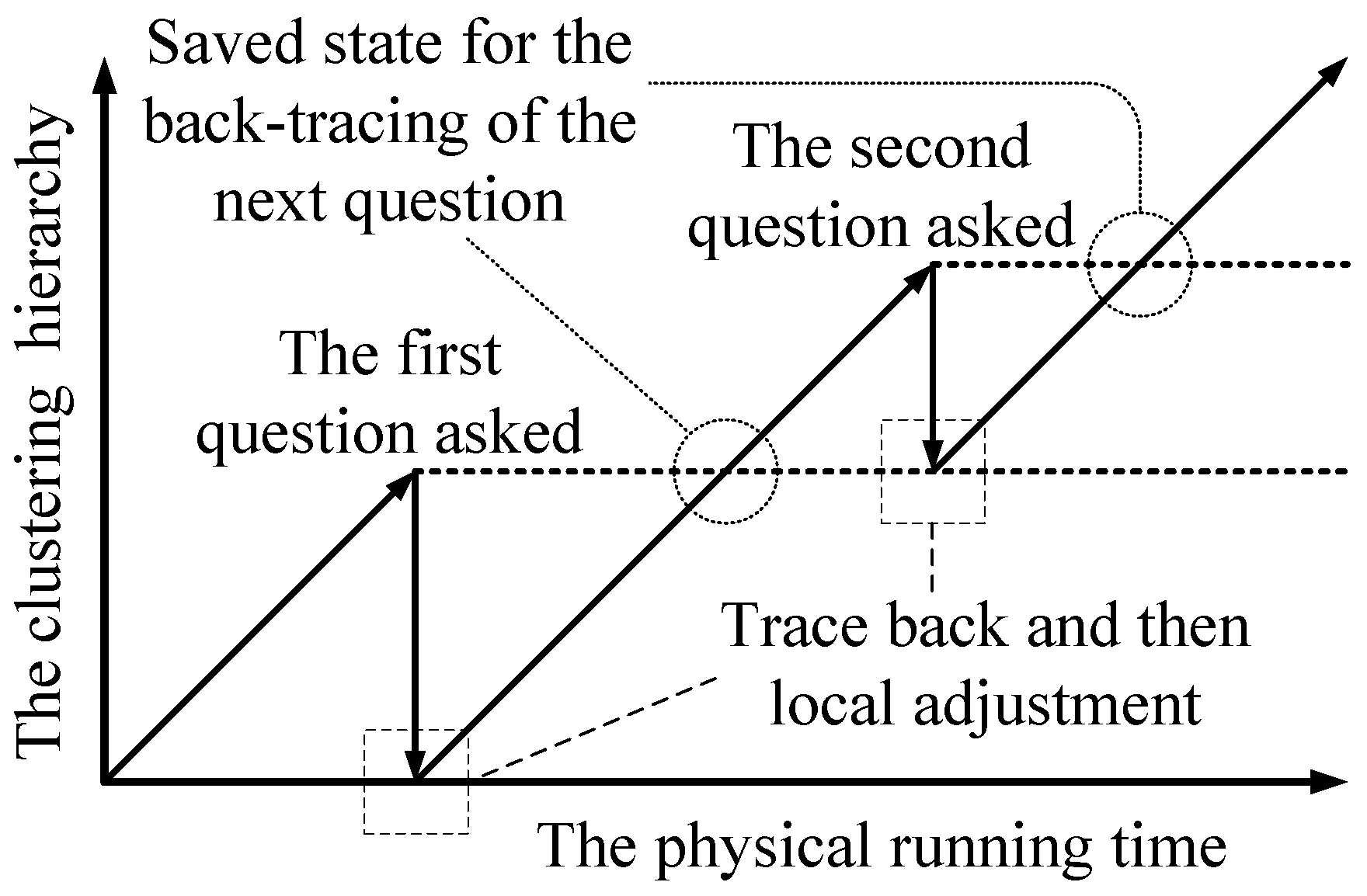
Our solution to the “how” problem is (1) first tracing back to a previous clustering state; (2) then doing local adjustment; and (3) finally resuming the building of the clustering hierarchy. It is shown in
Figure 6 (assume that the human’s answer disagrees with the machine’s clustering results for the two questions). The depth of the back-tracing represents the trade-off between the time complexity and the accuracy. To limit the depth of the back-tracing, the machine only traces back to the hierarchy of the latest adjustment, as shown in
Figure 6 (for the first question, the machine traces back to the initial state). After doing local adjustment, the machine resumes building the clustering hierarchy without question operations. The question operations are disabled until the machine goes back up the hierarchy that was present when it asked the question. Once the adjustment of the current question is finished, the state of the clustering is saved as the point to trace back to for the next question. Since each hierarchical state is calculated at most twice, this scheme
at most doubles the time complexity.
Let us go over the machine’s process of dealing with the human’s answers. Suppose i and j are the most questionable pair of data points in the dirtiest cluster C: (1) if the human returns an answer that i and j are in the same cluster (agree with the machine), then everything is fine. i and j are removed for further questioning, and their distance is set to be 0; (2) if the human returns an answer that i and j are not in the same cluster (disagree with the machine), the machine traces back and then uses the local adjustment, which is referred to as a local splitting of C. In other words, C is divided into two clusters. The remaining data points in C choose to join i’s cluster or j’s cluster, according to the distance (join the nearest one). i and j are removed for the further questions, and their distance is set to be infinity. After this local adjustment, the machine resumes building the clustering hierarchy. The questions are disabled until the machine goes back to the point in the hierarchy at which it asked the question. In addition, note that the transitive relations of questions may bring the machine a derived answer in which two data points in different clusters should be in the same cluster. For this case, we refer to the local adjustment as a merge of the two clusters corresponding to those two data points. The distance between those two data points is set to be zero.
5. Algorithm Overview
5.1. Algorithm Design
The whole algorithm is presented in Algorithm 3, which is the detailed implementation of Algorithm 2. In Algorithm 3, line 5 corresponds to the “when” problem: the key insight is that questions are asked to limit the error propagations. Line 6 corresponds to the “which” problem: the key insight is that local structures of pairs of data points can be used to determine the most questionable pair of data points. Then, line 7 shows the transitive relations that can be used to derive more answers. If one of these answers disagrees with the current clustering result (i.e., the machine has made some errors), then adjustments are applied (lines 8 to 13), which correspond to the “how” problem. The key insight is that the back-tracing scheme can balance the time complexity and the adjustment accuracy. Line 14 shows that one question operation is used up. In the next subsection, further analysis shows that the time complexity of Algorithm 3 stays asymptotically the same with Algorithm 1, which is . We do not further discuss the stop criterion (line 3 in Algorithm 3). A simple stop criterion is used: the iteration stops, when the number of existing clusters reduces to a threshold. A better stop criterion is to be addressed in our future work.
| Algorithm 3: The Proposed Algorithm. |
| Data: Distances between pairs of data points; The number of available questions (i.e., Q). |
| Result: The clustering result. |
![]() |
5.2. Time Complexity Analysis
This section discusses the time complexity of Algorithm 3. First, we clarify the time complexity of Algorithm 1. In Algorithm 1, finding the closest two clusters at each clustering step takes , since there are at most pairs of clusters. Meanwhile, we have at most clustering steps (i.e., the number of iterations). Thus, the time complexity of Algorithm 1 is . However, this time complexity can be reduced, if each cluster keeps a sorted list (or heap) on its distances to all the other clusters: then, finding the closest two clusters at each clustering step is reduced to . Considering that maintaining the sorted list (or heap) needs an additional time complexity of , the time complexity of Algorithm 1 should be .
Then, let us focus on the time complexity of Algorithm 3. First, note that the additional time complexity is brought by lines 5 to 14. Then, to calculate the certainty, lines 5 and 6 take for each clustering step, since each cluster can maintain and update the certainties brought by pairs of data points. Exhaustive derivation of transitive relations in line 7 takes in total . As previously mentioned, the tracing-back scheme (lines 10 and 11) at most doubles the time complexity. The local adjustments take for each time, up to in total. Saving the current clustering state (line 13) takes for each time, also up to in total. Therefore, the overall time complexity is . Both k and Q are relatively small numbers, when compared to N. Note that k is used to define the neighborhood of one data point. Q is also limited, due to relatively costly human computations. Therefore, the time complexity of Algorithm 3 is , which is asymptotically the same as that of Algorithm 1. We assume that the human answers a question instantaneously. In other words, we consider that the computational time for the machine’s task is much longer than the question response time.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}