
An Effective and Efficient MapReduce Algorithm for Computing BFS-Based Traversals of Large-Scale RDF Graphs


Abstract
:1. Introduction
- In April 2009, EBay was using two Data Warehouses, namely Teradata and Greenplum, the former having 6.5 PB of data in form of 17 trillion records already stored, and collecting more than 150 billion new records/day, leading to an ingest rate well over 50 TB/day [2].
- In May 2009, Facebook estimates an amount of 2.5 PB of user data, with more than 15 TB of new data per day [3].
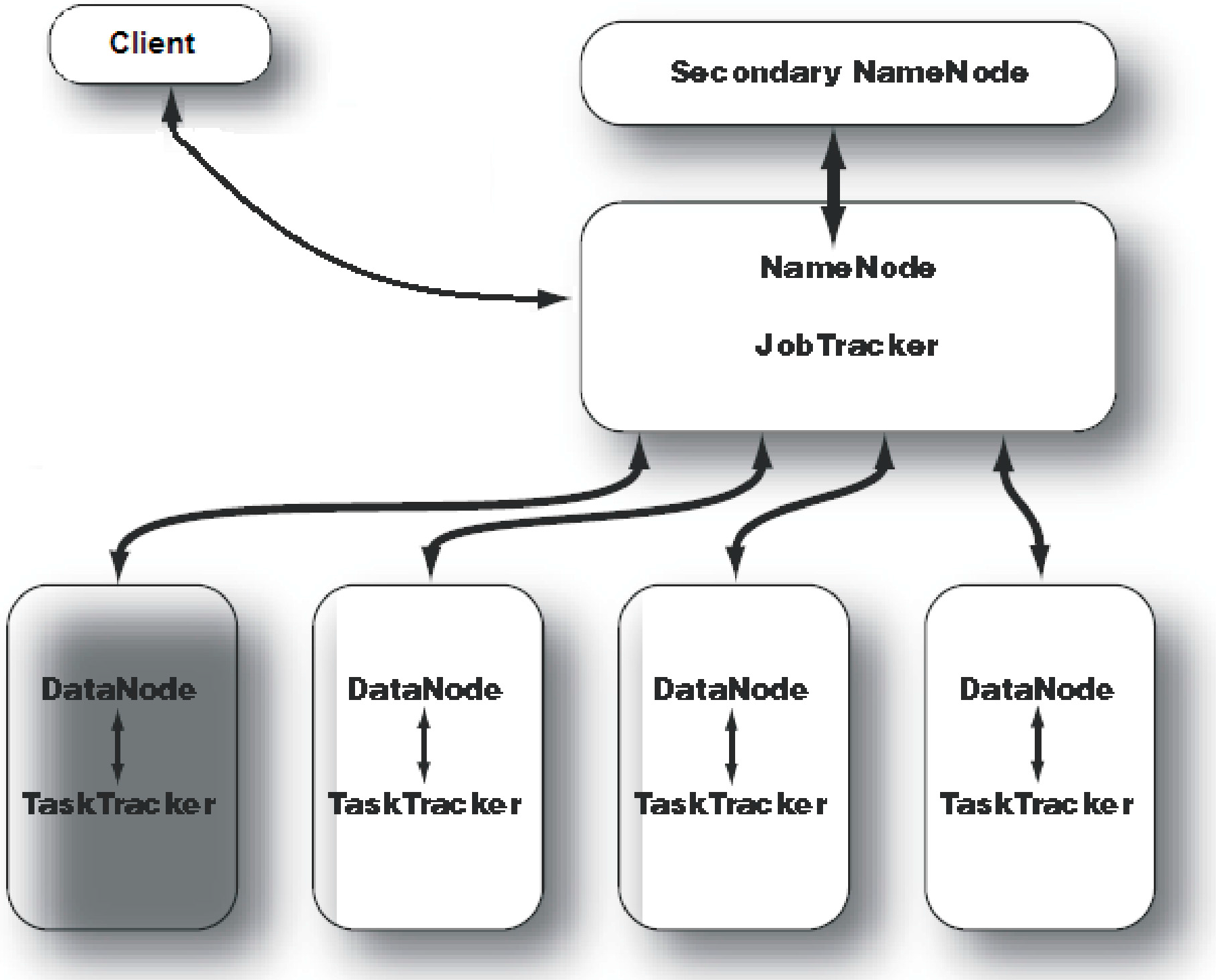
2. Hadoop: An Overview
- (1)
- accessible—it can be executed on large clusters or on Cloud computing services;
- (2)
- robust—it was designed to run on commodity hardware; a major aspect considered during its development was the tolerance to frequent hardware failures and crash recovery;
- (3)
- scalable—it scales easily for processing increased amount of data by transparently adding more nodes to the cluster;
- (4)
- simple—it allows developers to write specific code in a short time.
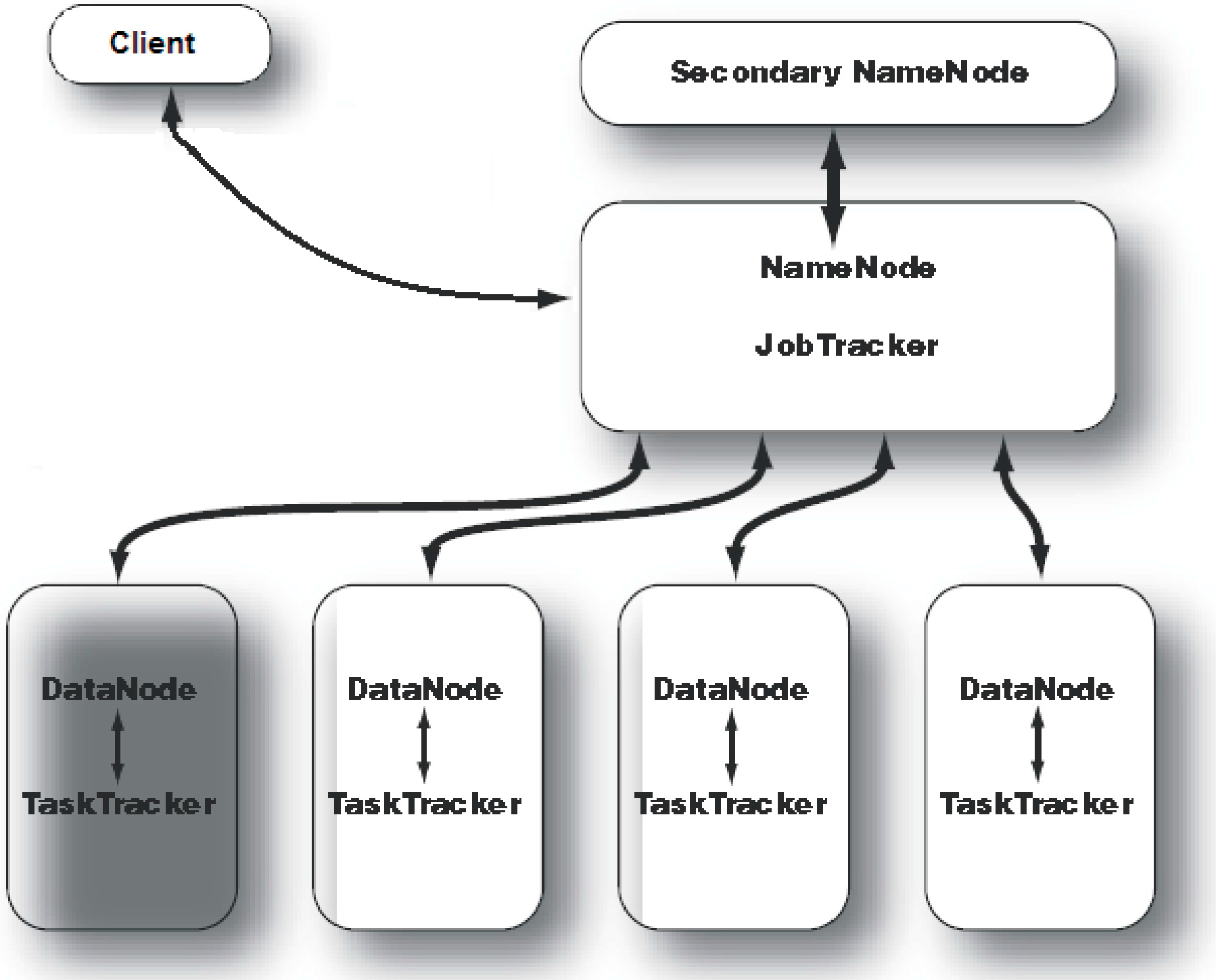
3. MapReduce: Principles of Distributed Programming over Large-Scale Data Repositories
- There is a previous well-known strategy in computer science for solving problems: divide-et-impera. According to this paradigm, when we have to solve a problem whose general solution is unknown, then the problem is decomposed in smaller sub-problems, the same strategy is applied for it, and the results/partial solutions corresponding to each sub-problem into a general solution are combined. The decomposing process continues until the size of the sub-problem is small enough to be handled individually.
- The basic data structures are key-value pairs and lists. The design of MapReduce algorithms involves usage of key-value pairs over arbitrary data sets.
- decomposition of the problem and allocation of sub-problems to workers;
- synchronization among workers;
- communication of the partial results and their merge for computing local solutions;
- management of software/hardware failures;
- management of workers’ failures.
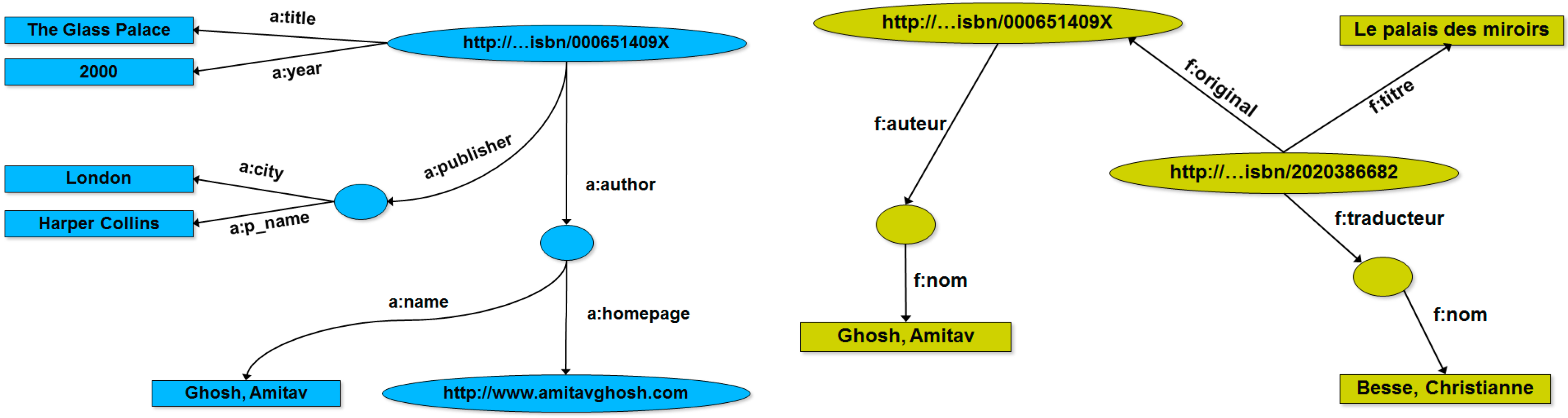
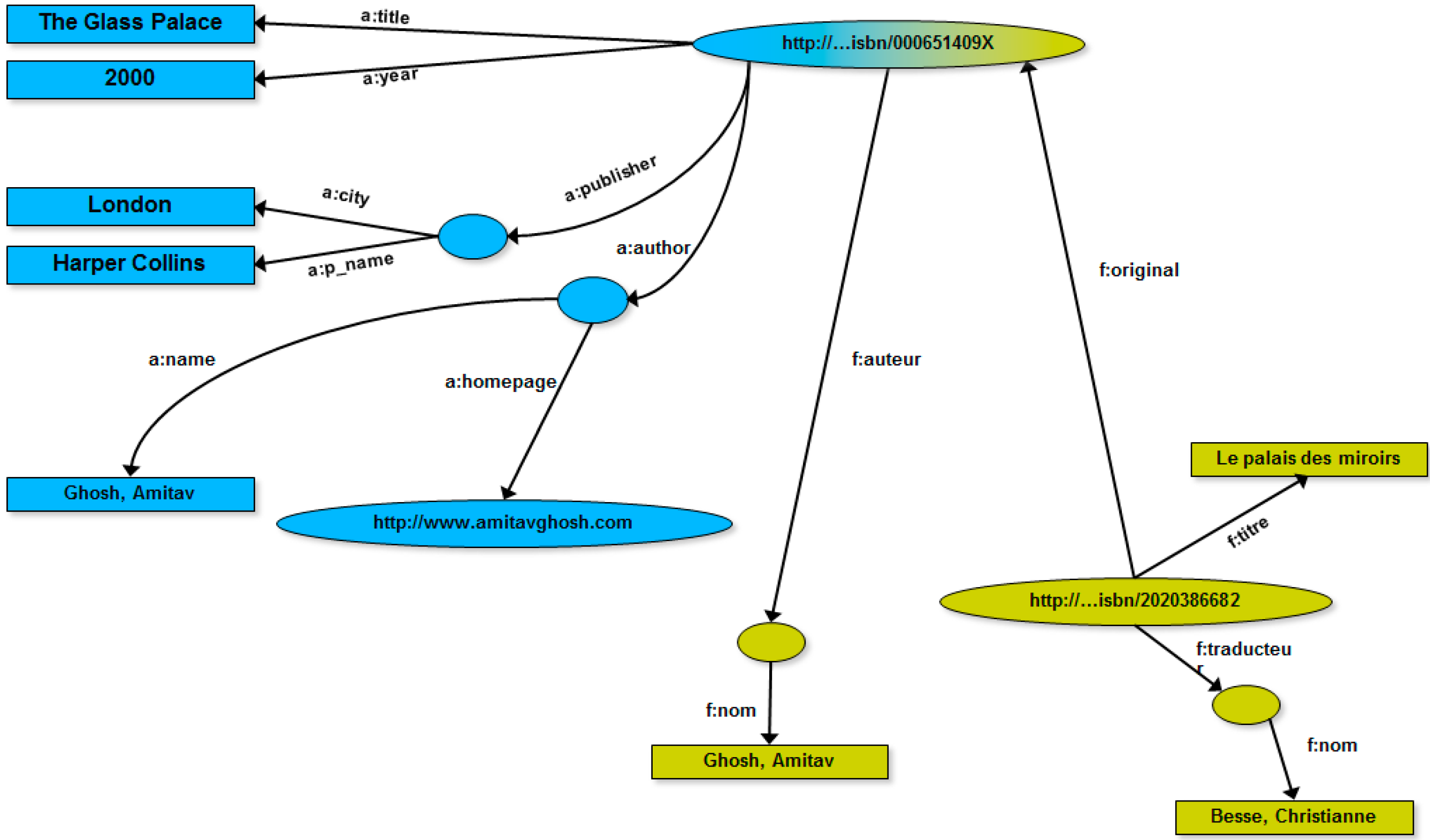
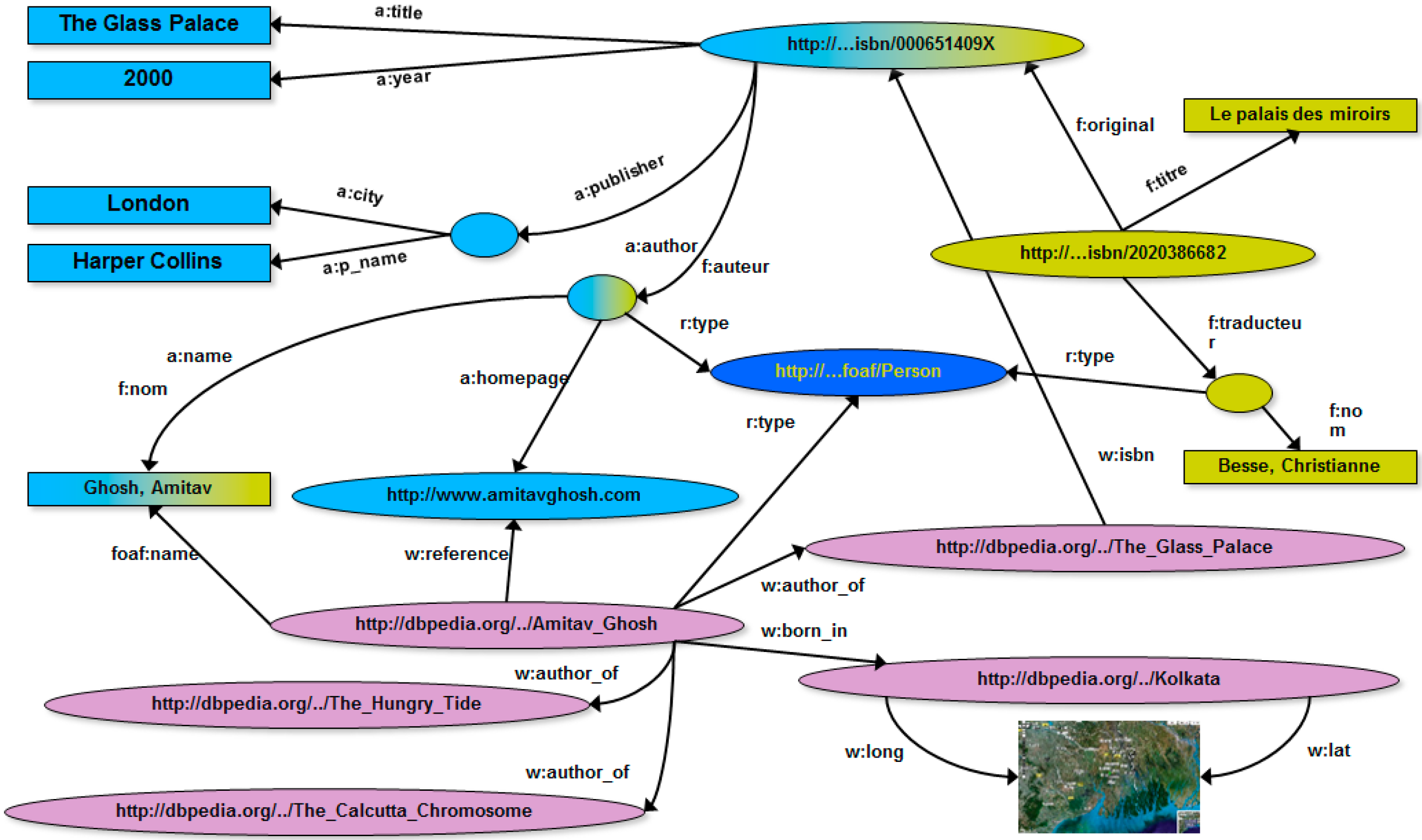
4. RDF Graphs: Definitions, Concepts, Examples

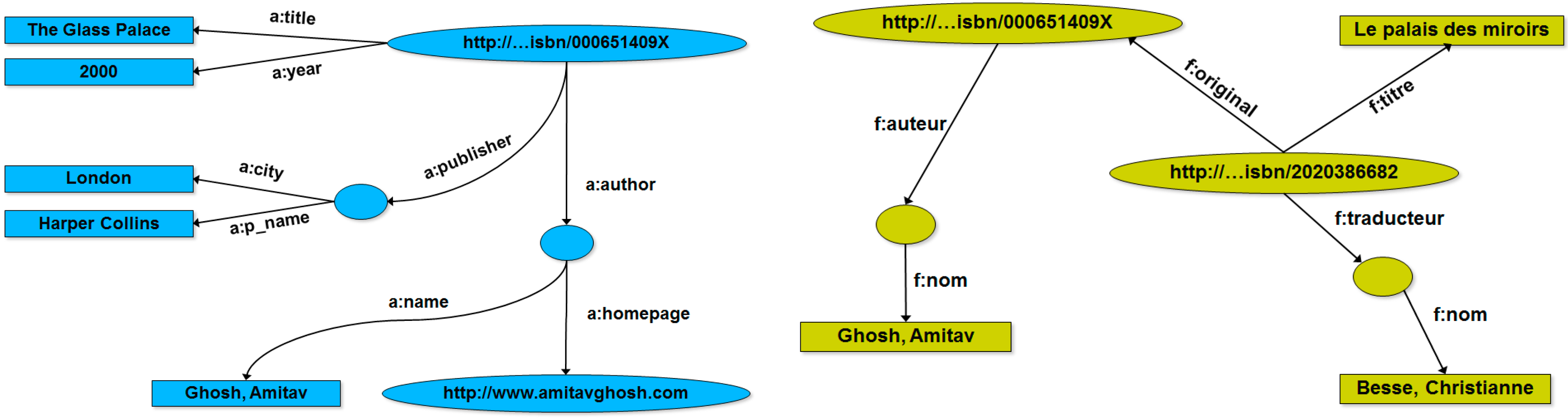
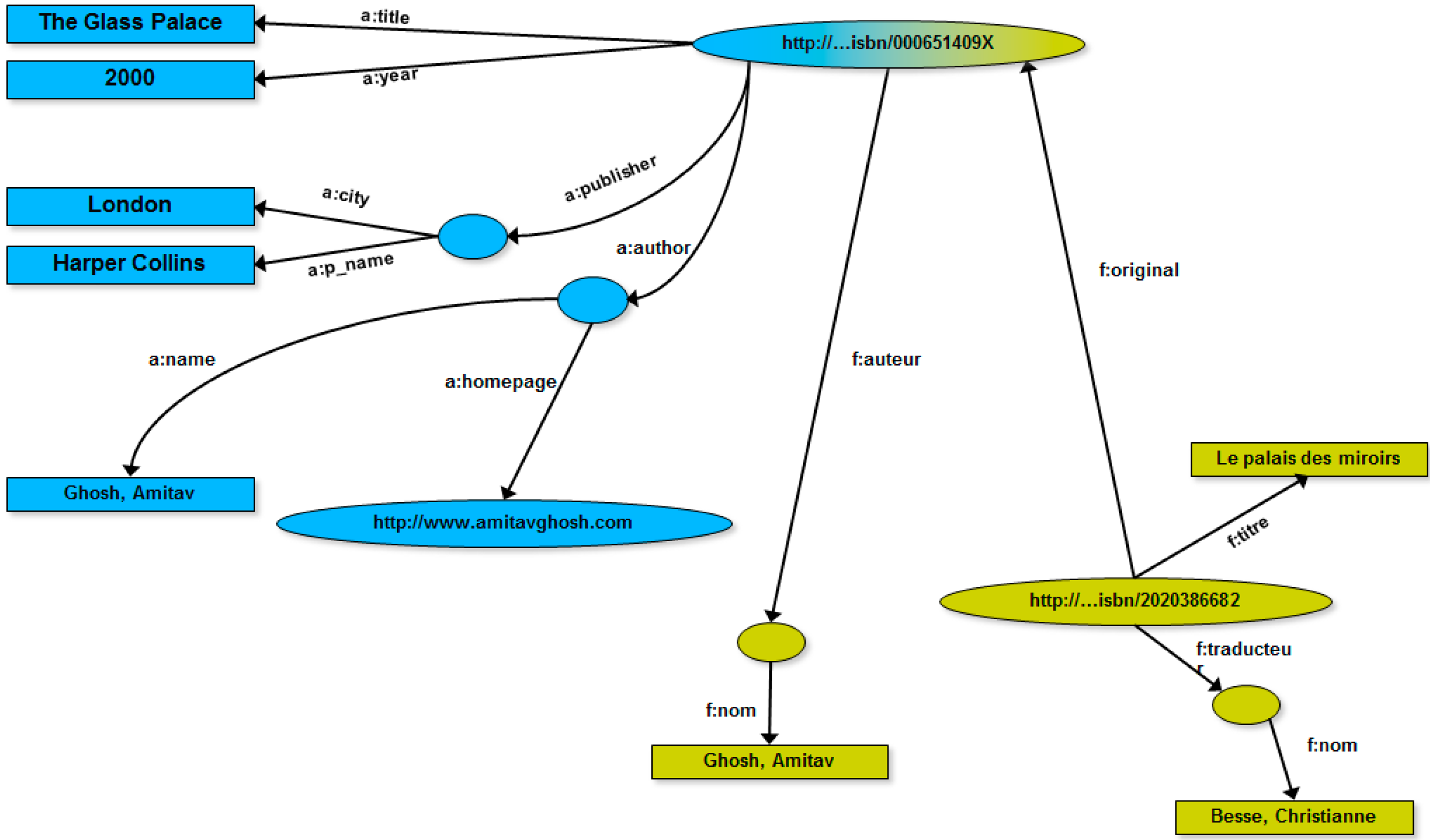
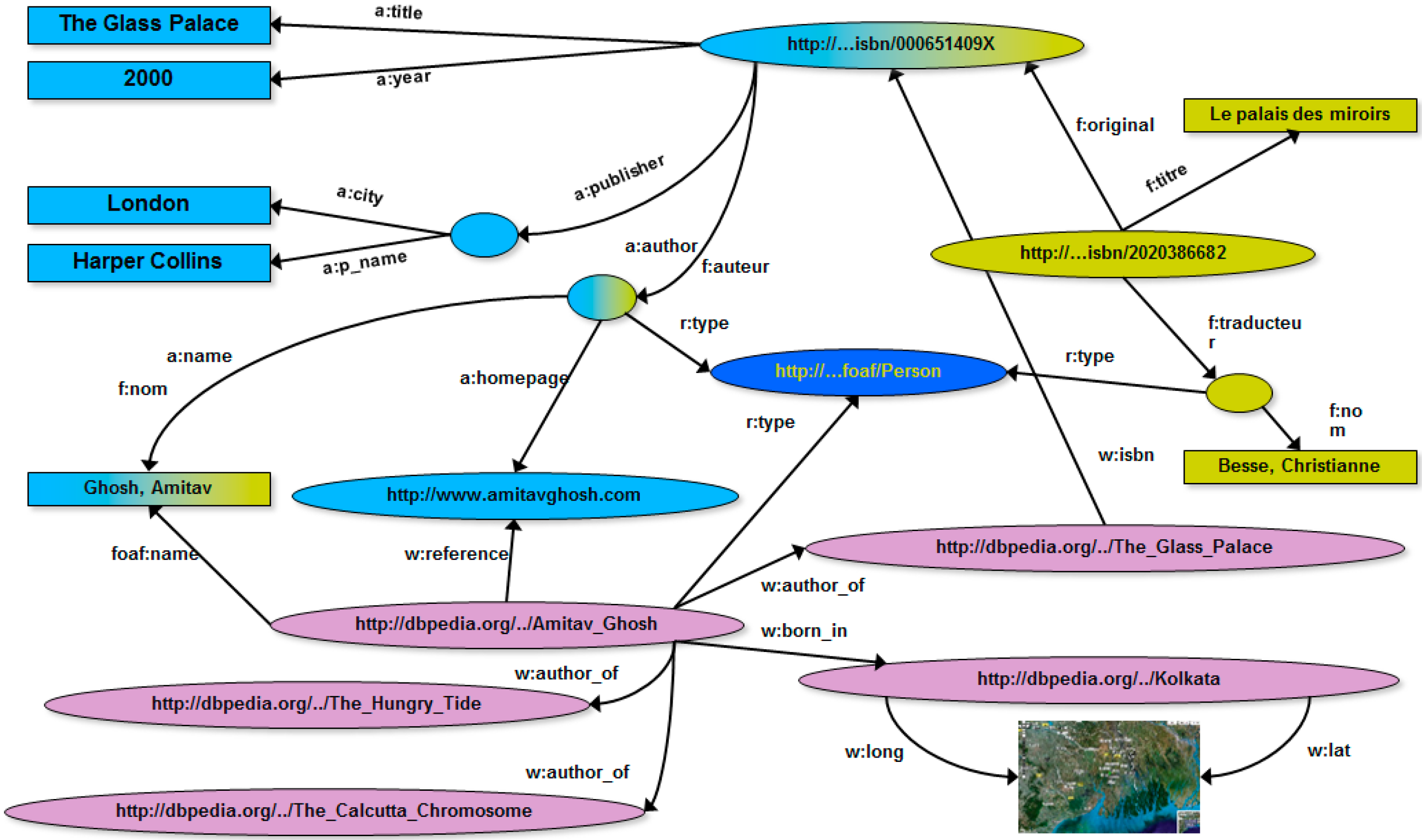
5. Related Work
- Parallel BFS-based and DFS-based traversal strategies;
- MapReduce algorithms for big data processing;
- MapReduce algorithms over RDF databases;
- MapReduce algorithms over RDF graphs.
5.1. Parallel BFS-Based and DFS-Based Traversal Strategies
5.2. MapReduce Algorithms for Big Data Processing
5.3. MapReduce Algorithms for RDF Databases
5.4. MapReduce Algorithms for RDF Graphs
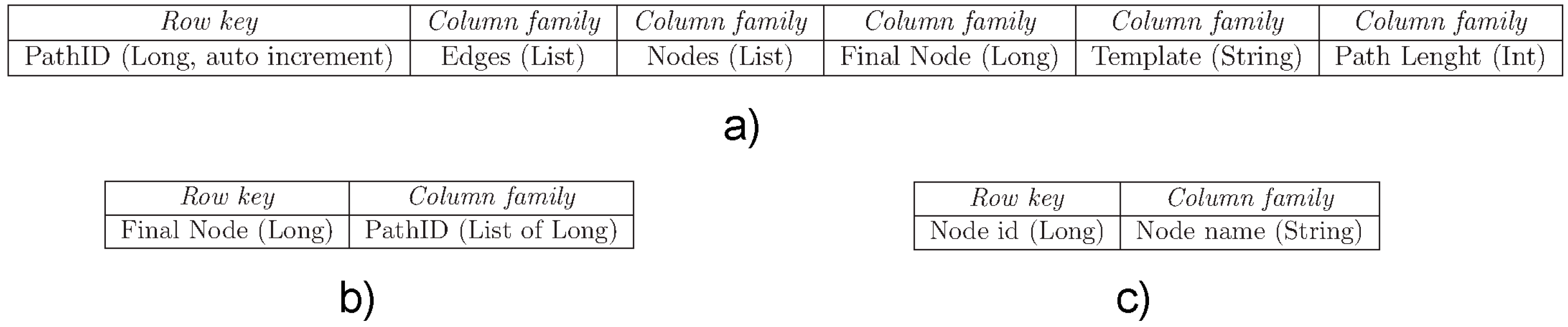
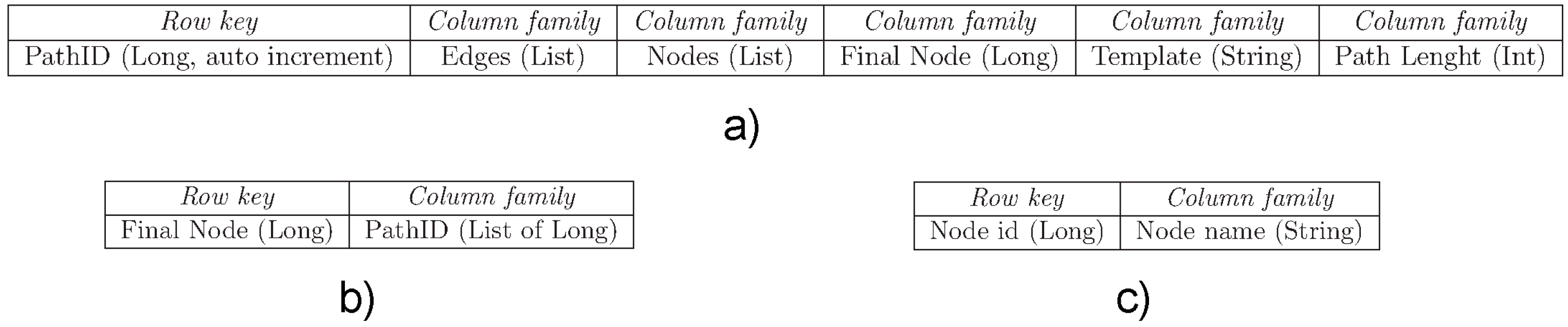
6. BFS-Based Implementation of RDF Graph Traversals over MapReduce
| Algorithm 1: BFS(u, n, L) |
Input: u – source node from which the visit starts; n – number of vertices; L – adjacency lists Output: Q – list of visited nodes Begin Q ← ∅; visited ← ∅; for (i = 0 to n – 1) do visited[i] = 0; endfor; visited[u] = 1; Q ← u; while (Q ≠ ∅) do u ← Q; for (each v ∈ Lu) do // Lu is the adjacency list of u if (visited[v] == 0) then visited[v] = 1; Q ← v; endif; endfor; endwhile; return Q; End; |
- 1 3,2, | GREY | 1
- 10 12, | WHITE | ?
- 11 10, | WHITE | ?
- 12 NULL, | WHITE | ?
- 13 NULL, | WHITE | ?
- 14 6,12, | WHITE | ?
| Algorithm 2: Map(key, value) |
Input: key – ID of the current node; value – node information Output: void – a new node is emitted Begin u ← (Node)value; if (u.color == GREY) then for (each v ∈ Lu) do // Lu is the adjacency list of u v ← new Node(); v.color == GREY; // mark v as unexplored for (each c ∈ Pu) do // Pu is the path list of u c.ID = u.ID; c.tag = u.tag; v.add(c); endfor; emit(v.ID,v); endfor; u.color = BLACK; // mark u as explored endif; emit(key,u); return; End; |
| Algorithm 3: Reduce(key, values) |
Input: key – ID of the current node; values – node information list Output: void – updates for the current node are emitted Begin newNode ← new Node(); for (each u ∈ values) do merge(newNode.edgeList(),u.edgeList()); // merge the newNode’s edge list with u’s edge list merge(newNode.tagList(),u.tagList()); // merge the newNode’s tag list with u’s tag list newNode.setToDarkest(newNode.color,u.color); // set color of newNode to the darkest color endfor; // between the newNode’s color and the u’s color update(WHITE,GREY,BLACK); // update the number of processed nodes having color WHITE, GREY, BLACK emit(key.newNode); // emit updates for the current node return; End; |
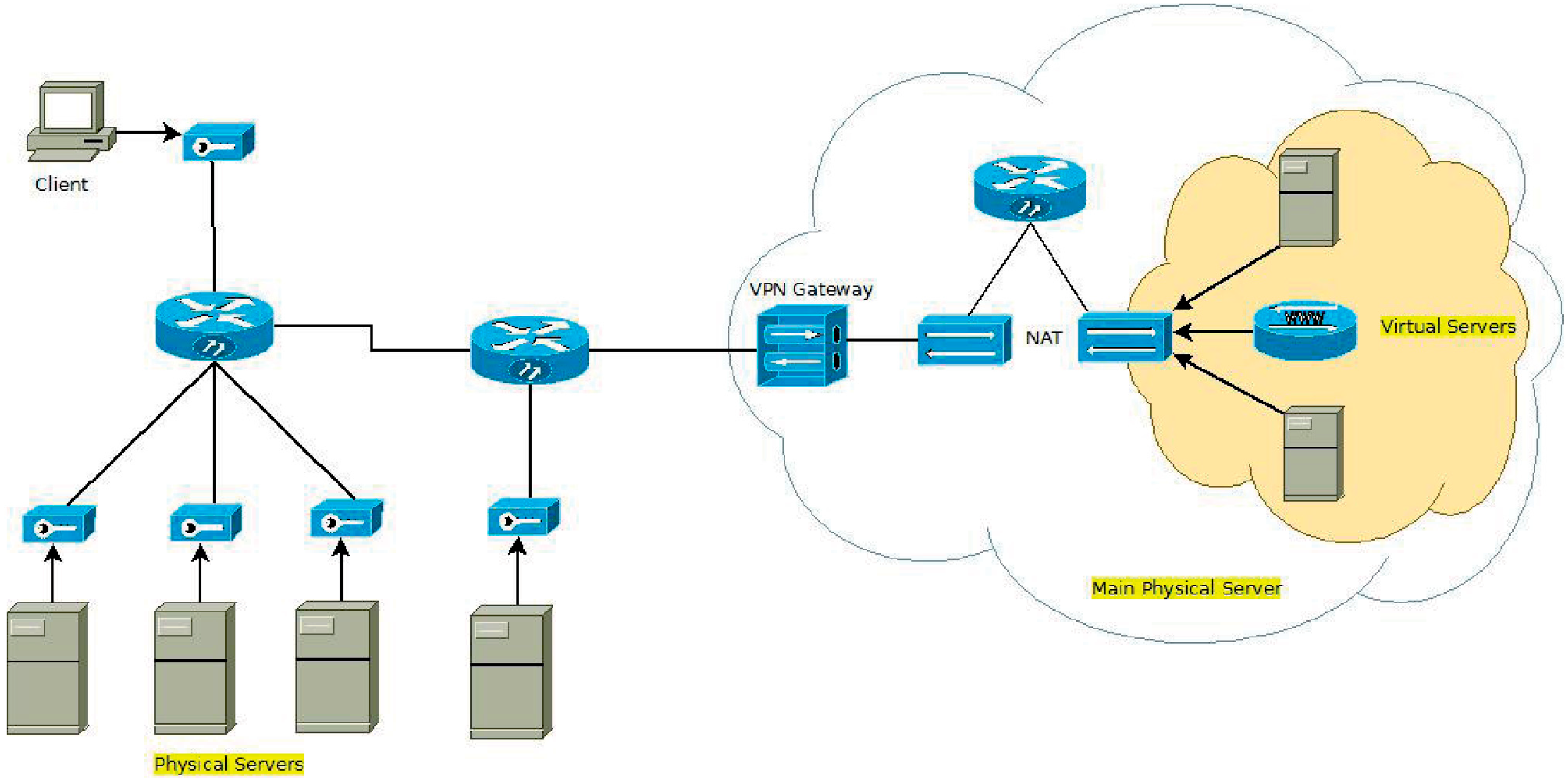
7. Experimental Analysis and Results


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Core Num. | Core Speed (GHz) | HDD | RAM (GB) |
|---|---|---|---|
| 6 | 2.4 | 1 | 6 |
| 8 | 2.4 | 1 | 2 |
| 4 | 2.7 | 1 | 4 |
| 4 | 2.7 | 1 | 4 |
| 4 | 2.7 | 1 | 4 |
| Reading-Like Operations | Writing-Like Operations | |
|---|---|---|
| Throughput (Op/s) | 1300 | 3500 |
| Cold-Cache Mode | Warm-Cache Mode | |
|---|---|---|
| Retrieval Time for 1 M Rows (ms) | 5.5 | 1.3 |
8. Conclusions and Future Work
Author Contributions
Conflicts of Interest
References
- Dean, J.; Ghemawat, S. MapReduce: Simplified Data processing on Large Clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Ebay Data Warehouses. Available online: http://www.dbms2.com/2009/04/30/ebays-two-enormous-data-warehouses/ (accessed on October 31 2015).
- Facebook Hadoop and Hive. Available online: http://www.dbms2.com/2009/05/11/facebook-hadoop-and-hive/ (accessed on October 31 2015).
- Facebook. Available online: http://developers.facebook.com/ (accessed on October 31 2015).
- MySpace. Available online: http://wiki.developer.myspace.com/index.php?title=Main_Page (accessed on October 31 2015).
- NetFlix Documentation. Available online: http://developer.netflix.com/docs (accessed on October 31 2015).
- Leskovec, J.; Kleinberg, J.M.; Faloutsos, C. Graphs over Time: Densification Laws, Shrinking Diameters and Possible Explanations. In Proceedings of the Eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining, Chicago, IL, USA, 21–24 August 2005; pp. 177–187.
- Bahmani, B.; Kumar, R.; Vassilvitskii, S. Densest Subgraph in Streaming and MapReduce. Proc. VLDB Endow. 2012, 5, 454–465. [Google Scholar] [CrossRef]
- Zhong, N.; Yau, S.S.; Ma, J.; Shimojo, S.; Just, M.; Hu, B.; Wang, G.; Oiwa, K.; Anzai, Y. Brain Informatics-Based Big Data and the Wisdom Web of Things. IEEE Intell. Syst. 2015, 30, 2–7. [Google Scholar] [CrossRef]
- Lane, J.; Kim, H.J. Big Data: Web-Crawling and Analysing Financial News Using RapidMiner. Int. J. Bus. Inf. Syst. 2015, 19, 41–57. [Google Scholar] [CrossRef]
- W3C. RDF 1.1 Concepts and Abstract Syntax—W3C Recommendation 25 February 2014. Available online: http://www.w3.org/TR/rdf11-concepts/ (accessed on October 31 2015).
- Cappellari, P.; Virgilio, R.D.; Roantree, M. Path-Oriented Keyword Search over Graph-Modeled Web Data. World Wide Web 2012, 15, 631–661. [Google Scholar] [CrossRef]
- Bröcheler, M.; Pugliese, A.; Subrahmanian, V.S. Dogma: A Disk-Oriented Graph Matching Algorithm for RDF Databases. In The Semantic Web—ISWC; Springer: Berlin Heidelberg, Germany, 2009; pp. 97–113. [Google Scholar]
- Fan, W.; Li, J.; Ma, S.; Tang, N.; Wu, Y.; Wu, Y. Graph Pattern Matching: From Intractable to Polynomial Time. Proc. VLDB Endow. 2010, 3, 264–275. [Google Scholar] [CrossRef]
- Zhang, S.; Yang, J.; Jin, W. Sapper: Subgraph Indexing and Approximate Matching in Large Graphs. Proc. VLDB Endow. 2010, 3, 1185–1194. [Google Scholar] [CrossRef]
- Yu, B.; Cuzzocrea, A.; Jeong, D.H.; Maydebura, S. On Managing Very Large Sensor-Network Data Using Bigtable. In Proceedings of the 12th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGrid), Ottawa, ON, Canada, 13–16 May 2012; pp. 918–922.
- Yu, B.; Cuzzocrea, A.; Jeong, D.; Maybedura, S. A Bigtable/MapReduce-based Cloud Infrastructure for Effectively and Efficiently Managing Large-Scale Sensor Networks. In Data Management in Cloud, Grid and P2P Systems; Springer: Berlin Heidelberg, Germany, 2012; pp. 25–36. [Google Scholar]
- Hadoop. Available online: http://wiki.apache.org/hadoop (accessed on October 31 2015).
- Cuzzocrea, A.; Furfaro, F.; Mazzeo, G.M.; Saccà, D. A Grid Framework for Approximate Aggregate Query Answering on Summarized Sensor Network Readings. In Proceedings of the OTM Confederated International Workshops and Posters, GADA, JTRES, MIOS, WORM, WOSE, PhDS, and INTEROP 2004, Agia Napa, Cyprus, 25–29 October 2004; pp. 144–153.
- Cuzzocrea, A.; Furfaro, F.; Greco, S.; Masciari, E.; Mazzeo, G.M.; Saccà, D. A Distributed System for Answering Range Queries on Sensor Network Data. In Proceedings of the Third IEEE International Conference on Pervasive Computing and Communications Workshops, 2005. PerCom 2005 Workshops, Kauai Island, HI, USA, 8–12 March 2005; pp. 369–373.
- Cuzzocrea, A. Data Transformation Services over Grids With Real-Time Bound Constraints. In On the Move to Meaningful Internet Systems: OTM 2008; Springer: Berlin Heidelberg, Germany, 2008; pp. 852–869. [Google Scholar]
- Ghemawat, S.; Gobioff, H.; Leung, S.T. The Google Fle System. In Proceedings of the Nineteenth ACM Symposium on Operating Systems Principles, Bolton Landing, NY, USA, 19–22 October 2003; pp. 29–43.
- Apache Nutch. Available online: http://nutch.apache.org/ (accessed on October 31 2015).
- Amazon. Available online: http://www.amazon.com (accessed on October 31 2015).
- Elastic MapReduce Web Service. Available online: http://aws.amazon.com/elasticmapreduce/ (accessed on October 31 2015).
- Amazon Elastic Compute Cloud—EC2. Available online: http://wiki.apache.org/hadoop/AmazonEC2 (accessed on October 31 2015).
- NetFlix. Available online: https://www.netflix.com/ (accessed on October 31 2015).
- Hulu. Available online: http://www.hulu.com/ (accessed on October 31 2015).
- HBase—Apache Software Foundation Project Home Page. Available online: http://hadoop.apache.org/hbase/ (accessed on October 31 2015).
- Abadi, D.J.; Boncz, P.A.; Harizopoulos, S. Column oriented Database Systems. Proc. VLDB Endow. 2009, 2, 1664–1665. [Google Scholar] [CrossRef]
- Cattell, R. Scalable SQL and NoSQL Data Stores. SIGMOD Rec. 2010, 39, 12–27. [Google Scholar] [CrossRef]
- Shvachko, K.; Kuang, H.; Radia, S.; Chansler, R. The Hadoop Distributed File System. In Proceedings of the IEEE 26th Symposium on Mass Storage Systems and Technologies (MSST), Incline Village, NV, USA, 3–7 May 2010; pp. 1–10.
- Chang, F.; Dean, J.; Ghemawat, S.; Hsieh, W.C.; Wallach, D.A.; Burrows, M.; Chandra, T.; Fikes, A.; Gruber, R.E. Bigtable: A Distributed Storage System for Structured Data. ACM Trans. Comput. Syst. 2008, 26. [Google Scholar] [CrossRef]
- Lin, J.; Dyer, C. Data-Intensive Text Processing with MapReduce. In Synthesis Lectures on Human Language Technologies; Morgan & Claypool Publishers: San Rafael, CA, USA, 2010. [Google Scholar]
- Bloom, B.H. Space/Time Trade-Offs in Hash Coding with Allowable Errors. Commun. ACM 1970, 13, 422–426. [Google Scholar] [CrossRef]
- Snappy: A Fast Compressor/Decompressor. Available online: https://google.github.io/snappy/ (accessed on October 31 2015).
- Broekstra, J.; Kampman, A.; van Harmelen, F. Sesame: A Generic Architecture for Storing and Querying RDF and RDF Schema. In The Semantic Web—ISWC; Springer: Berlin Heidelberg, Germany, 2002; pp. 54–68. [Google Scholar]
- Decker, S.; Melnik, S.; van Harmelen, F.; Fensel, D.; Klein, M.C.A.; Broekstra, J.; Erdmann, M.; Horrocks, I. The Semantic Web: The Roles of XML and RDF. IEEE Intern. Comput. 2000, 4, 63–74. [Google Scholar] [CrossRef]
- Beckett, D.J. The Design and Implementation of the Redland RDF Application Framework. Comput. Netw. 2002, 39, 577–588. [Google Scholar] [CrossRef]
- Huang, J.; Abadi, D.J.; Ren, K. Scalable SPARQL Querying of Large RDF Graphs. Proc. VLDB Endow. 2011, 4, 1123–1134. [Google Scholar]
- Herman, I. Introduction to Semantic Web Technologies. SemTech. 2010. Available online: http://www.w3.org/2010/Talks/0622-SemTech-IH/ (accessed on October 31 2015). – material redistributed under the Creative Common License (http://creativecommons.org/licenses/by-nd/3.0/ – accessed on October 31, 2015).
- Wikipedia. Available online: https://www.wikipedia.org/ (accessed on October 31 2015).
- DBpedia. Available online: http://wiki.dbpedia.org/ (accessed on October 31 2015).
- W3C. RDQL—A Query Language for RDF—W3C Member Submission 9 January 2004. Available online: http://www.w3.org/Submission/RDQL/ (accessed on October 31 2015).
- Gabrilovich, E.; Markovitch, S. Computing Semantic Relatedness Using Wikipedia-based Explicit Semantic Analysis. In Proceedings of the 20th International Joint Conference on Artifical Intelligence, Hyderabad, India, 6–12 January 2007; pp. 1606–1611.
- Chandramouli, N.; Goldstein, J.; Duan, S. Temporal Analytics on Big Data for Web Advertising. In Proceedings of the 2012 IEEE 28th International Conference on Data Engineering (ICDE), Washington, DC, USA, 1–5 April 2012; pp. 90–101.
- Chen, C.C.Y.; Das, S.K. Breadth-First Traversal of Trees and Integer Sorting in Parallel. Inf. Process. Lett. 1992, 41, 39–49. [Google Scholar] [CrossRef]
- Niewiadomski, R.; Amaral, J.N.; Holte, R.C. A Parallel External-Memory Frontier Breadth-First Traversal Algorithm for Clusters of Workstations. In Proceedings of the International Conference on Parallel Processing, Columbus, OH, USA, 14–18 August 2006; pp. 531–538.
- Chen, C.C.Y.; Das, S.K.; Akl, S.G. A Unified Approach to Parallel Depth-First Traversals of General Trees. Inf. Process. Lett. 1991, 38, 49–55. [Google Scholar] [CrossRef]
- Dittrich, J.; Quiané-Ruiz, J.A. Efficient Big Data Processing in Hadoop MapReduce. Proc. VLDB Endow. 2012, 5, 2014–2015. [Google Scholar] [CrossRef]
- Chen, Y.; Alspaugh, S.; Katz, R.H. Interactive Analytical Processing in Big Data Systems: A Cross-Industry Study of MapReduce Workloads. Proc. VLDB Endow. 2012, 5, 1802–1813. [Google Scholar] [CrossRef]
- Papailiou, N.; Tsoumakos, D.; Konstantinou, I.; Karras, P.; Koziris, N. H2RDF: Adaptive Query Processing on RDF Data in the Cloud. In Proceedings of the 21st International Conference on World Wide Web, Lyon, France, 16–20 April 2012; pp. 397–400.
- W3C. SPARQL 1.1 Overview—W3C Recommendation 21 March 2013. Available online: http://www.w3.org/TR/sparql11-overview/ (accessed on October 31 2015).
- Przyjaciel-Zablocki, M.; Schätzle, A.; Skaley, E.; Hornung, T.; Lausen, G. Map-Side Merge Joins for Scalable SPARQL BGP Processing. In Proceedings of the 2013 IEEE 5th International Conference on Cloud Computing Technology and Science (CloudCom), Bristol, UK, 2–5 December 2013; pp. 631–638.
- Jiang, H.; Chen, Y.; Qiao, Z.; Weng, T.H.; Li, K.C. Scaling Up MapReduce-based Big Data Processing on Multi-GPU Systems. Clust. Comput. 2015, 18, 369–383. [Google Scholar] [CrossRef]
- Wang, Y.; Liu, Z.; Liao, H.; Li, C. Improving the Performance of GIS Polygon Overlay Computation with MapReduce for Spatial Big Data Processing. Clust. Comput. 2015, 18, 507–516. [Google Scholar] [CrossRef]
- Kaoudi, Z.; Manolescu, I. RDF in the Clouds: A Survey. VLDB J. 2015, 24, 67–91. [Google Scholar] [CrossRef]
- Rohloff, K.; Schantz, R.E. High-Performance, Massively Scalable Distributed Systems Using the MapReduce Software Framework: The SHARD Triple-Store. In Proceedings of the Programming Support Innovations for Emerging Distributed Applications, Reno, NV, USA, 17 October 2010.
- Ladwig, G.; Harth, A. CumulusRDF: Linked Data Management on Nested Key-Value Stores. In Proceedings of the 7th International Workshop on Scalable Semantic Web Knowledge Base Systems (SSWS2011) at the 10th International Semantic Web Conference, Bonn, Germany, 23–27 October 2011; pp. 30–42.
- Gergatsoulis, M.; Nomikos, C.; Kalogeros, E.; Damigos, M. An Algorithm for Querying Linked Data Using Map-Reduce. In Proceedings of the 6th International Conference, Globe 2013, Prague, Czech, 28–29 August 2013; pp. 51–62.
- Schätzle, A.; Przyjaciel-Zablocki, M.; Lausen, G. PigSPARQL: Mapping SPARQL to Pig Latin. In Proceedings of the International Workshop on Semantic Web Information Management, Athens, Greece, 12–16 June 2011.
- Olston, C.; Reed, B.; Srivastava, U.; Kumar, R.; Tomkins, A. Pig Latin: A Not-So-Foreign Language for Data Processing. In Proceedings of the 2008 ACM SIGMOD International Conference on Management of Data, Vancouver, BC, Canada, 2 March 2008; pp. 1099–1110.
- Nie, Z.; Du, F.; Chen, Y.; Du, C.; Xu, L. Efficient SPARQL Query Processing in MapReduce through Data Partitioning and Indexing. In Web Technologies and Applications; Springer: Berlin Heidelberg, Germany, 2012; pp. 628–635. [Google Scholar]
- Du, J.H.; Wang, H.; Ni, Y.; Yu, Y. HadoopRDF: A Scalable Semantic Data Analytical Engine. In Intelligent Computing Theories and Applications; Springer: Berlin Heidelberg, Germany, 2012; Volume 2, pp. 633–641. [Google Scholar]
- Punnoose, R.; Crainiceanu, A.; Rapp, D. Rya: A Scalable RDF Triple Store for the Clouds. In Proceedings of the 1st International Workshop on Cloud Intelligence, Istanbul, Turkey, 31 August 2012.
- Urbani, J.; Maassen, J.; Drost, N.; Seinstra, F.J.; Bal, H.E. Scalable RDF Data Compression with MapReduce. Concurr. Comput. Pract. Exp. 2013, 25, 24–39. [Google Scholar] [CrossRef]
- Ravindra, P.; Anyanwu, K. Nesting Strategies for Enabling Nimble MapReduce Dataflows for Large RDF Data. Int. J. Semant. Web Inf. Syst. 2014, 10, 1–26. [Google Scholar] [CrossRef]
- Ravindra, P.; Anyanwu, K. Scaling Unbound-Property Queries on Big RDF Data Warehouses Using MapReduce. In Proceedings of the 18th International Conference on Extending Database Technology (EDBT), Brussels, Belgium, 23–27 March 2015; pp. 169–180.
- Apache Pig. Available online: https://pig.apache.org/ (accessed on October 31 2015).
- Choi, P.; Jung, J.; Lee, K.H. RDFChain: Chain Centric Storage for Scalable Join Processing of RDF Graphs Using MapReduce and HBase. In Proceedings of the 12th International Semantic Web Conference and the 1st Australasian Semantic Web Conference, Sydney, Australia, 21–25 October 2013; pp. 249–252.
- Kim, H.S.; Ravindra, P.; Anyanwu, K. Scan-Sharing for Optimizing RDF Graph Pattern Matching on MapReduce. In Proceedings of the 2012 IEEE 5th International Conference on Cloud Computing (CLOUD), Honolulu, HI, USA, 24–29 June 2012; pp. 139–146.
- Ravindra, P.; Kim, H.S.; Anyanwu, K. An Intermediate Algebra for Optimizing RDF Graph Pattern Matching on MapReduce. In The Semanic Web: Research and Applications; Springer: Berlin Heidelberg, Germany, 2011; pp. 46–61. [Google Scholar]
- Zhang, X.; Chen, L.; Wang, M. Towards Efficient Join Processing over Large RDF Graph Using MapReduce. In Scientific and Statistical Database Management; Springer: Berlin Heidelberg, Germany, 2012; pp. 250–259. [Google Scholar]
- Apache Jena Core RDF API. Available online: http://jena.apache.org/documentation/rdf/index.html (accessed on October 31 2015).
- Vitolo, C.; Elkhatib, Y.; Reusser, D.; Macleod, C.J.A.; Buytaert, W. Web Technologies for Environmental Big Data. Environ. Model. Softw. 2015, 63, 185–198. [Google Scholar] [CrossRef]
- Jacob, F.; Johnson, A.; Javed, F.; Zhao, M.; McNair, M. WebScalding: A Framework for Big Data Web Services. In Proceedings of the IEEE First International Conference on Big Data Computing Service and Applications (BigDataService), Redwood City, CA, USA, 30 March–2 April 2015; pp. 493–498.
- Cooper, B.F.; Silberstein, A.; Tam, E.; Ramakrishnan, R.; Sears, R. Benchmarking Cloud Serving Systems with YCSB. In Proceedings of the 1st ACM Symposium on Cloud Computing, SoCC 2010, Indianapolis, IN, USA, 10–11 June 2010; pp. 143–154.
- Silberstein, A.; Sears, R.; Zhou, W.; Cooper, B.F. A Batch of PNUTS: Experiences Connecting Cloud Batch and Serving Systems. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; pp. 1101–1112.
- Apache Spark. Available online: https://spark.apache.org/ (accessed on October 31 2015).
- Abedjan, Z.; Grütze, T.; Jentzsch, A.; Naumann, F. Profiling and Mining RDF Data with ProLOD++. In Proceedings of the IEEE 30th International Conference on Data Engineering, Chicago, IL, USA, 30 March–4 April 2014; pp. 1198–1201.
- Kushwaha, N.; Vyas, O.P. Leveragi0ng Bibliographic RDF Data for Keyword Prediction with Association Rule Mining (ARM). Data Sci. J. 2014, 13, 119–126. [Google Scholar] [CrossRef]
- Cuzzocrea, A. A Framework for Modeling and Supporting Data Transformation Services over Data and Knowledge Grids with Real-Time Bound Constraints. Concurr. Comput. Pract. Exp. 2011, 23, 436–457. [Google Scholar] [CrossRef]
- Cuzzocrea, A.; Saccà, D. Exploiting Compression and Approximation Paradigms for Effective And Efficient Online Analytical Processing over Sensor Network Readings in Data Grid Environments. Concurr. Comput. Pract. Exp. 2013, 25, 2016–2035. [Google Scholar] [CrossRef]
© 2016 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons by Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cuzzocrea, A.; Cosulschi, M.; De Virgilio, R. An Effective and Efficient MapReduce Algorithm for Computing BFS-Based Traversals of Large-Scale RDF Graphs. Algorithms 2016, 9, 7. https://doi.org/10.3390/a9010007
Cuzzocrea A, Cosulschi M, De Virgilio R. An Effective and Efficient MapReduce Algorithm for Computing BFS-Based Traversals of Large-Scale RDF Graphs. Algorithms. 2016; 9(1):7. https://doi.org/10.3390/a9010007
Chicago/Turabian StyleCuzzocrea, Alfredo, Mirel Cosulschi, and Roberto De Virgilio. 2016. "An Effective and Efficient MapReduce Algorithm for Computing BFS-Based Traversals of Large-Scale RDF Graphs" Algorithms 9, no. 1: 7. https://doi.org/10.3390/a9010007
APA StyleCuzzocrea, A., Cosulschi, M., & De Virgilio, R. (2016). An Effective and Efficient MapReduce Algorithm for Computing BFS-Based Traversals of Large-Scale RDF Graphs. Algorithms, 9(1), 7. https://doi.org/10.3390/a9010007