Processing KNN Queries in Grid-Based Sensor Networks

Abstract
:1. Introduction
- An efficient sensor deployment strategy is used to construct the sensor network.
- An effective mechanism is designed to quantify the uncertainty of objects moving in such a sensor network.
- A grid index with update operations is developed to manage moving objects in the sensor network.
- A query processing algorithm is developed to efficiently answer the KNN query. Also, a reasonable probability is designed to quantify the possibility of each object being the query result.
- A comprehensive set of experiments is conducted to evaluate the efficiency of the proposed methods.
2. Uncertain Model
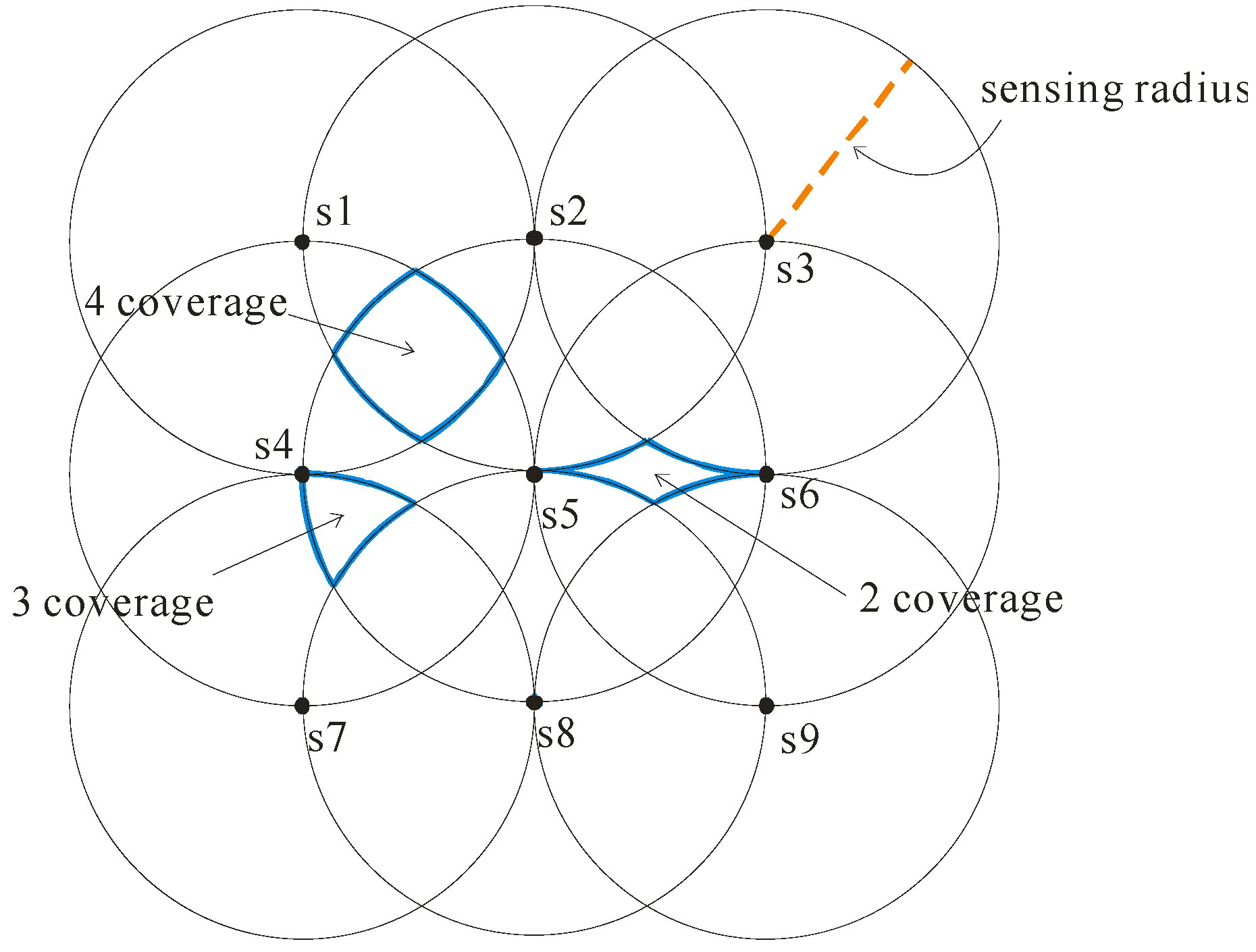
2.1. Sensor Deployment
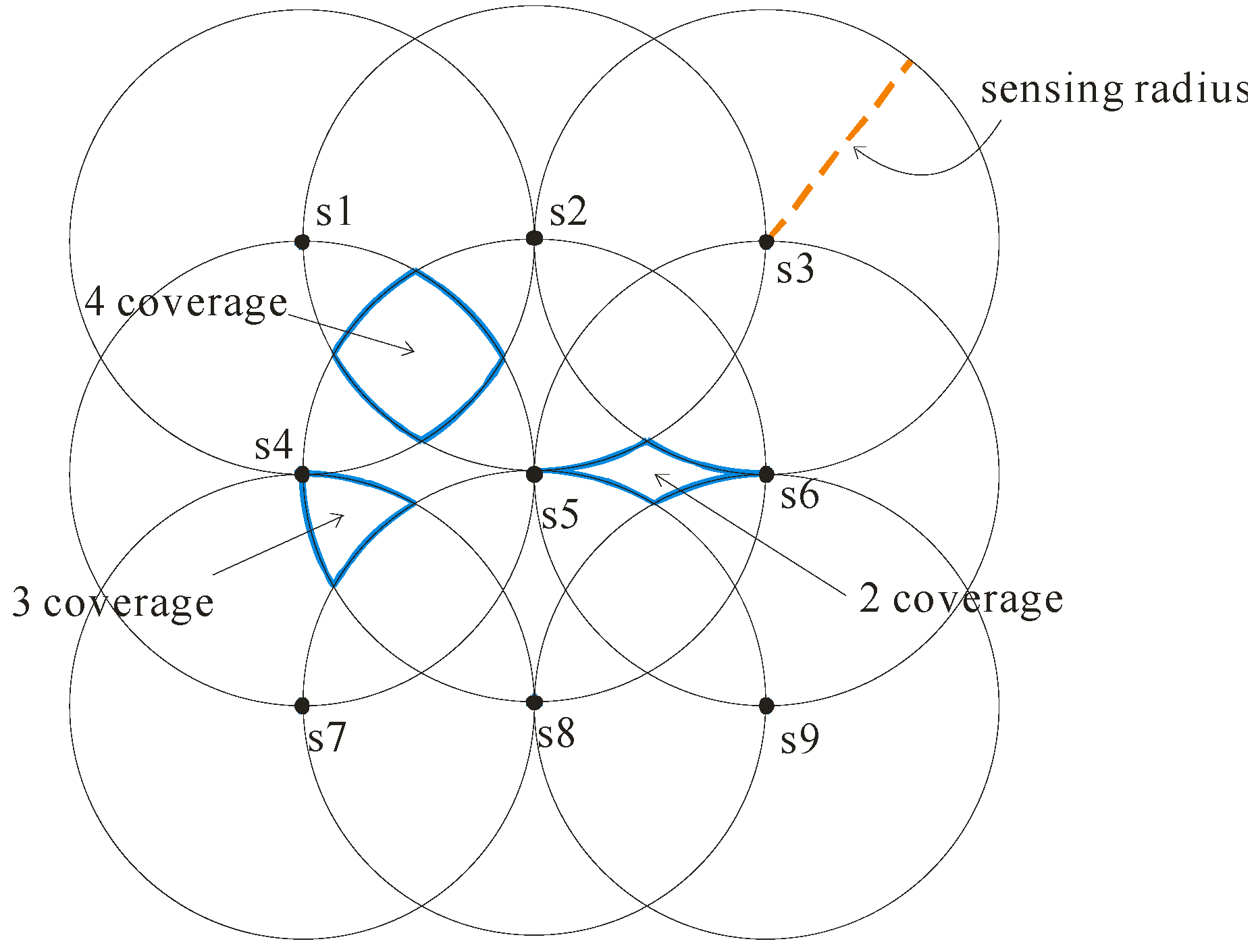
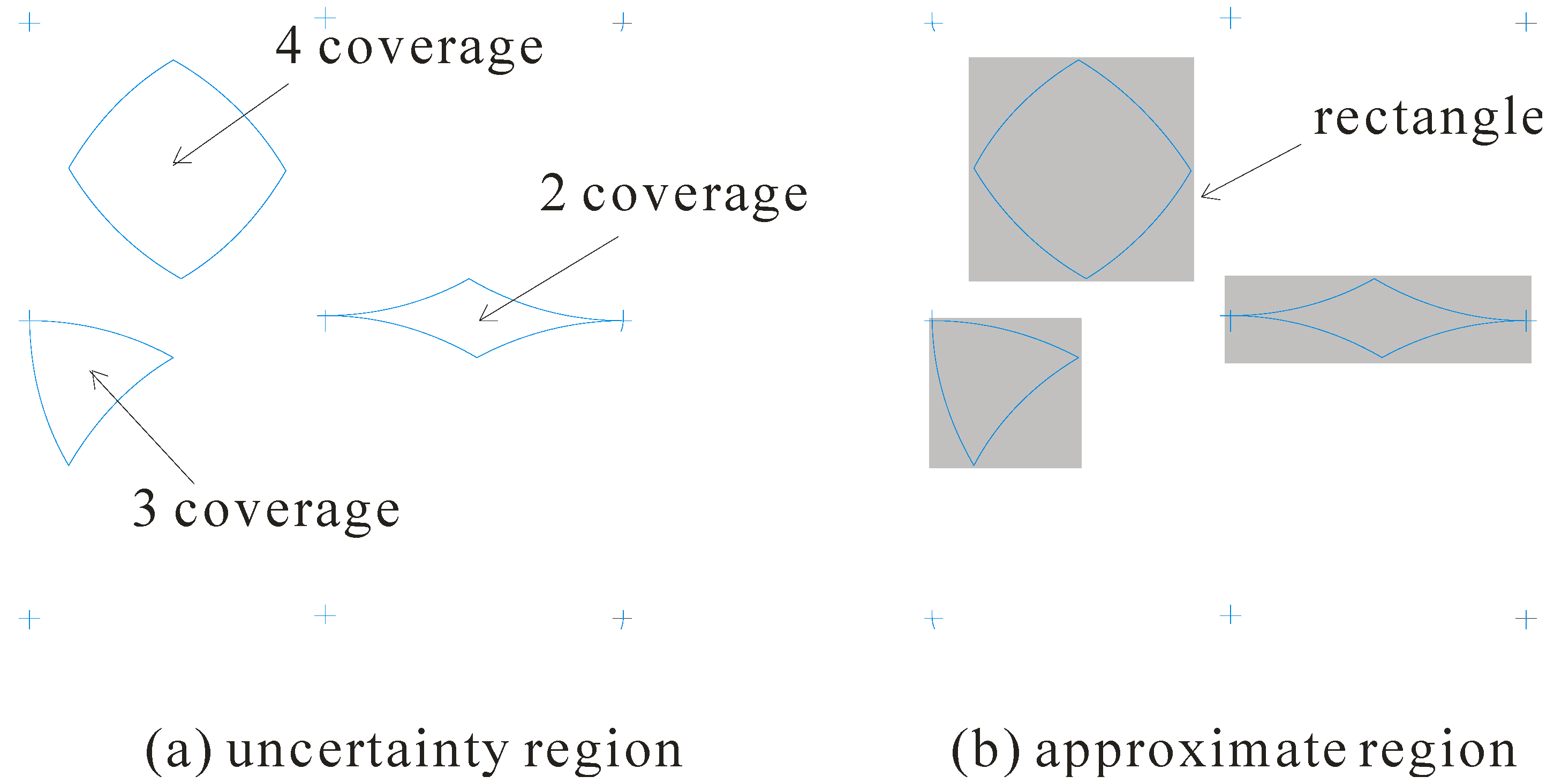
2.2. Object Uncertainty

3. Index Structure
3.1. Grid Index
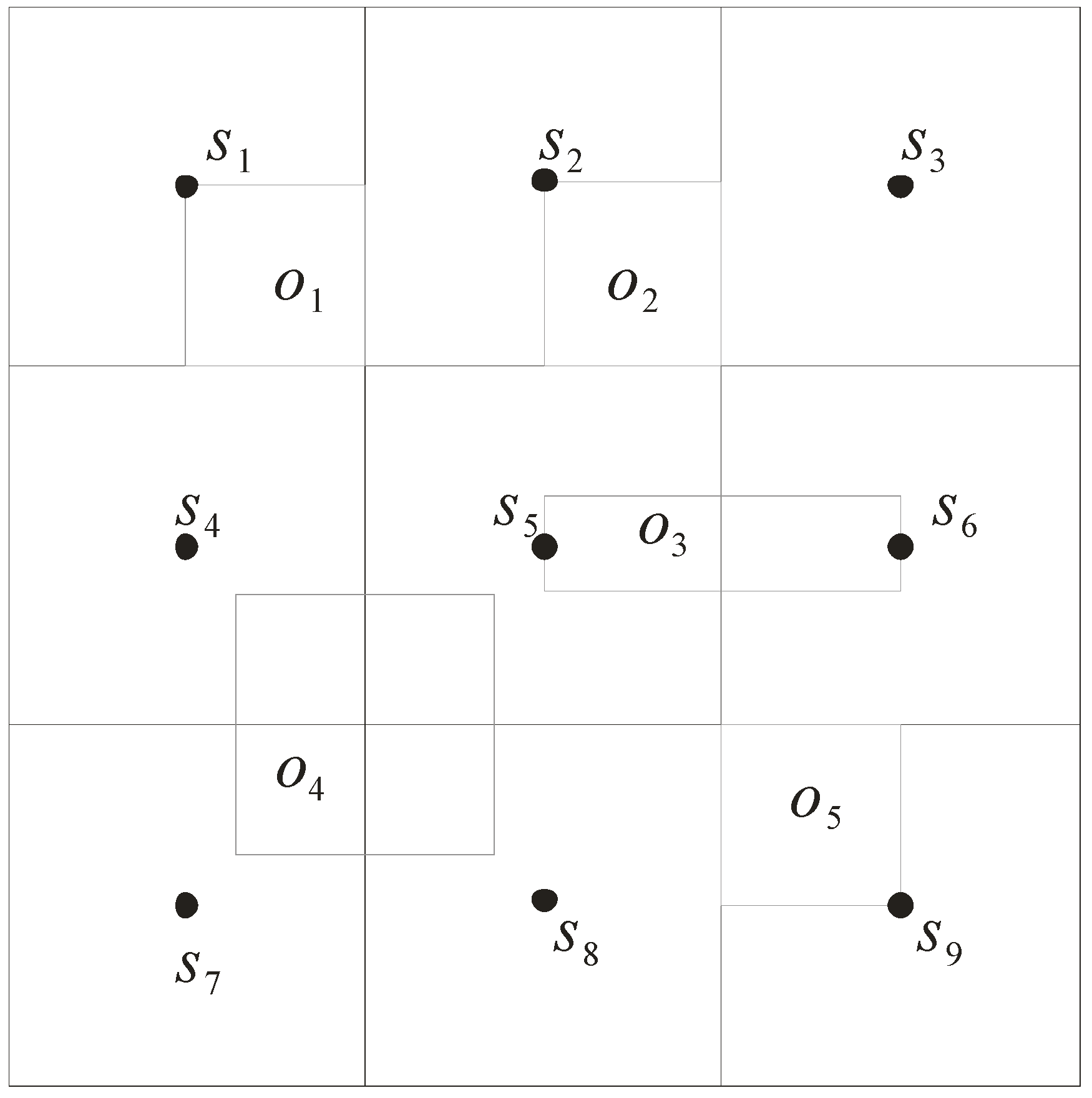
3.2. Data Structures
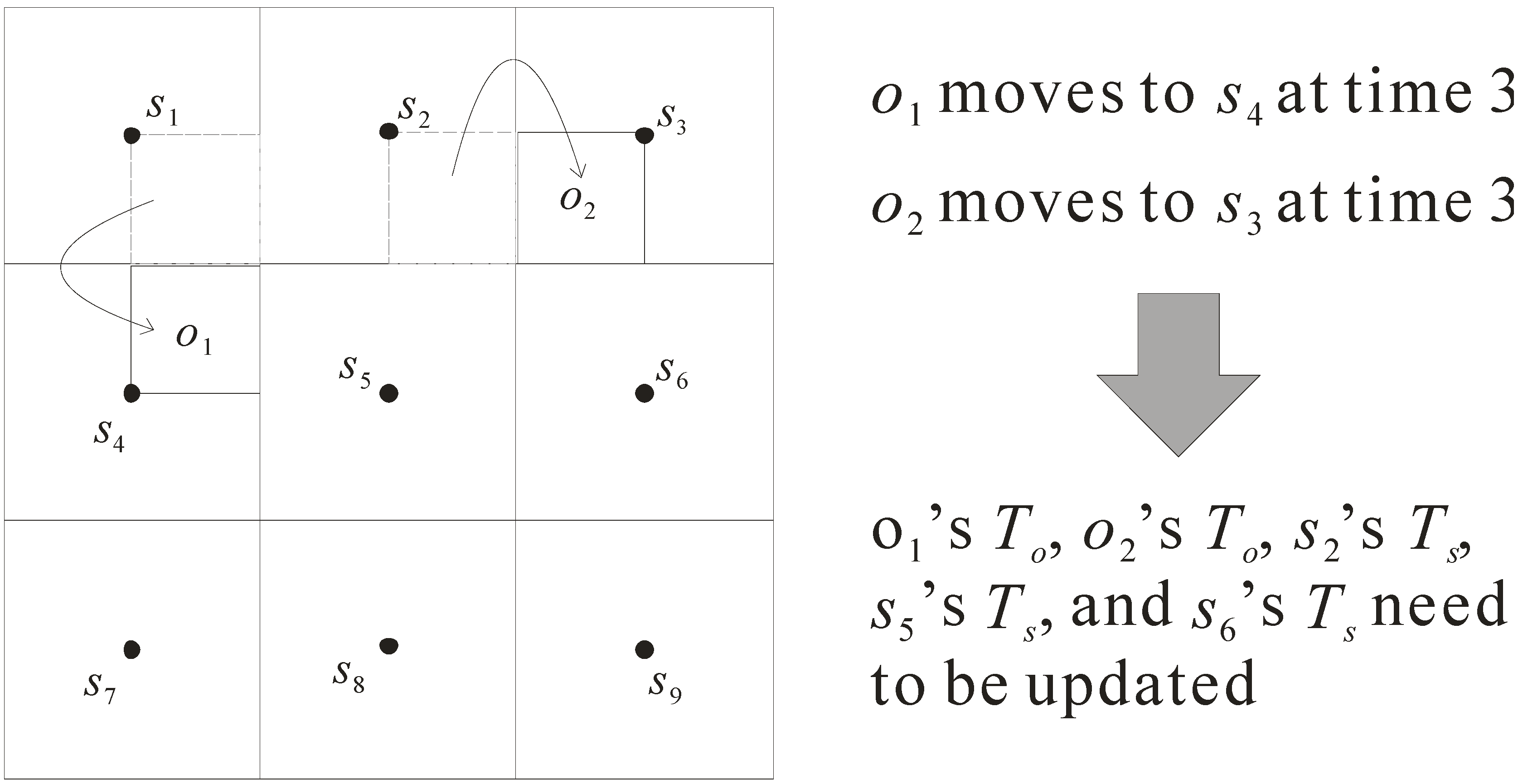
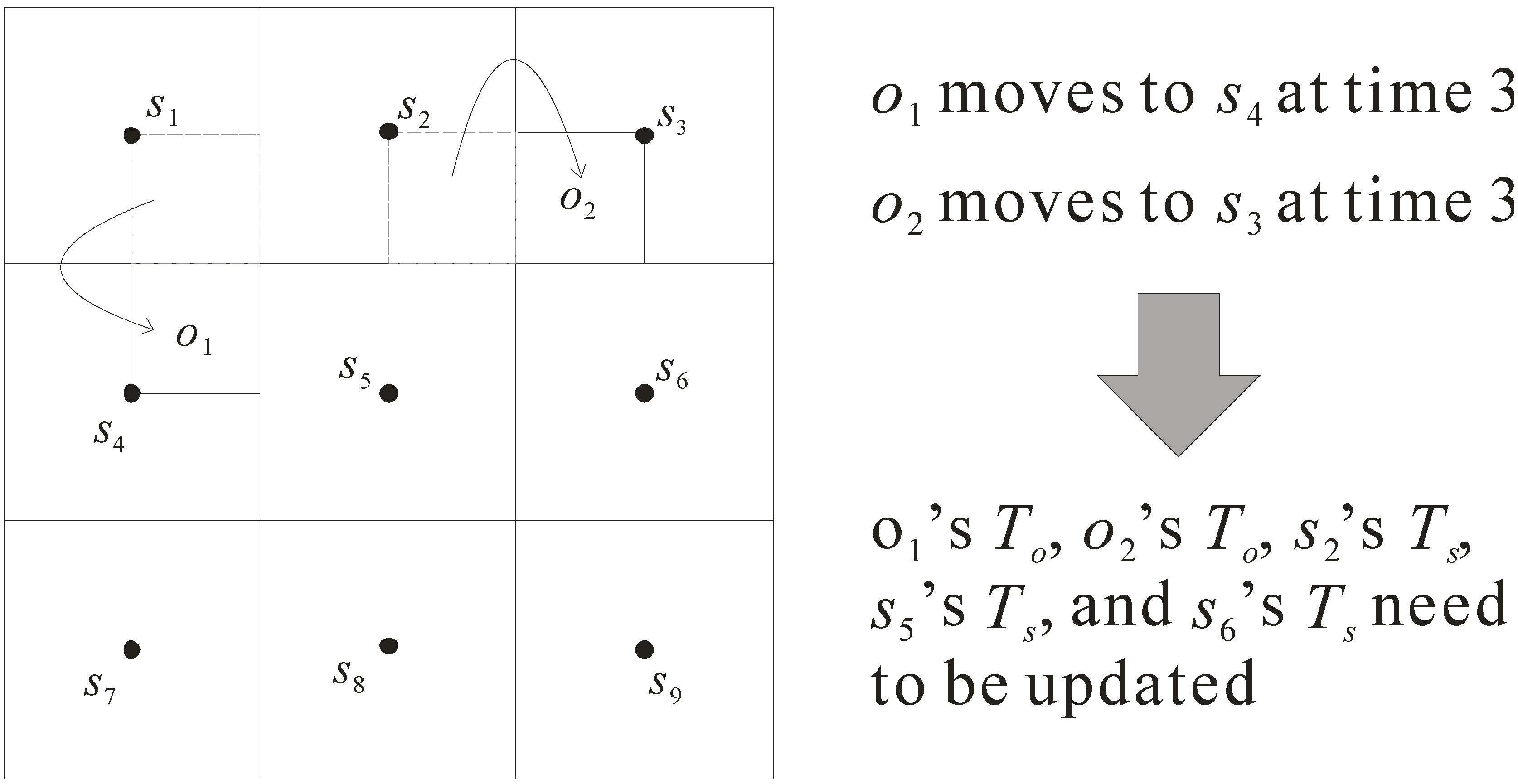
3.3. Index Updates
- Updating To of object o1: when o1 moves, sensor s2 cannot monitor o1 while sensor s5 begins to monitor o1. Therefore, its table To is changed from (o1, {s1, s2, s4}, 0, o1-data) to (o1, {s1, s4, s5}, 3, o1-data).
- Updating To of object o2: once o2 moves, sensor s5 cannot monitor o2 but s6 can monitor o2. As such, the table To is updated from (o2, {s2, s3, s5}, 0, o2-data) to (o2, {s2, s3, s6}, 3, o2-data).
- Updating Ts of sensor s2: due to the movement of o1, the table Ts of s2 needs to be updated. It is changed from (s2, 60, {o1, o2}) to (s2, 60, {o2}).
- Updating Ts of sensor s5: because the locations of o1 and o2 are changed, the table Ts of s5 needs to be updated. It is changed from (s5, 60, {o2}) to (s5, 60, {o1}).
- Updating Ts of sensor s6: as object o2 moves, sensor s6’s table Ts is updated. It is changed from (s6, 60, {null}) to (s6, 60, {o2}).
4. Query Processing Algorithm
4.1. Parameters and Pruning Criteria
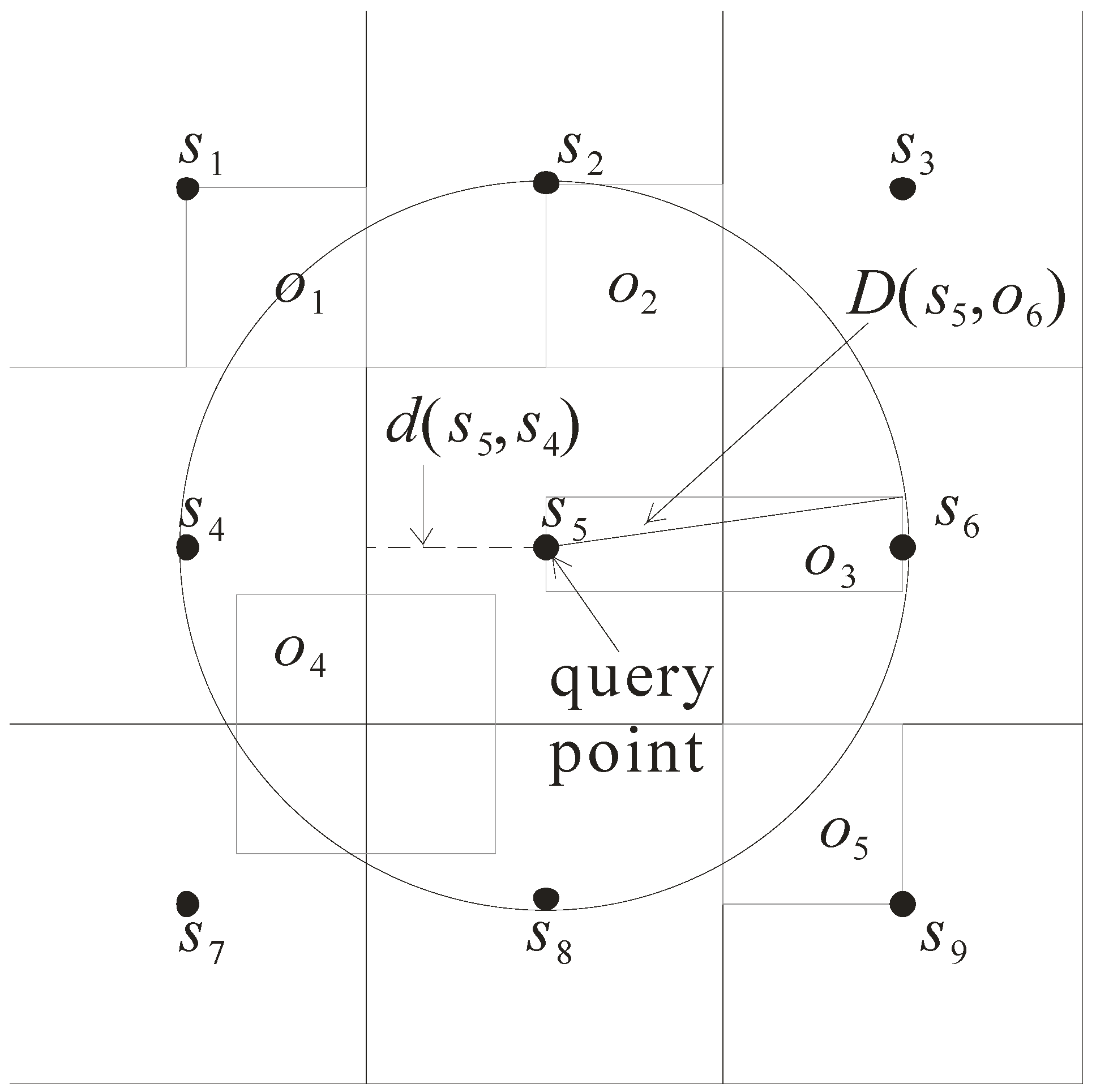
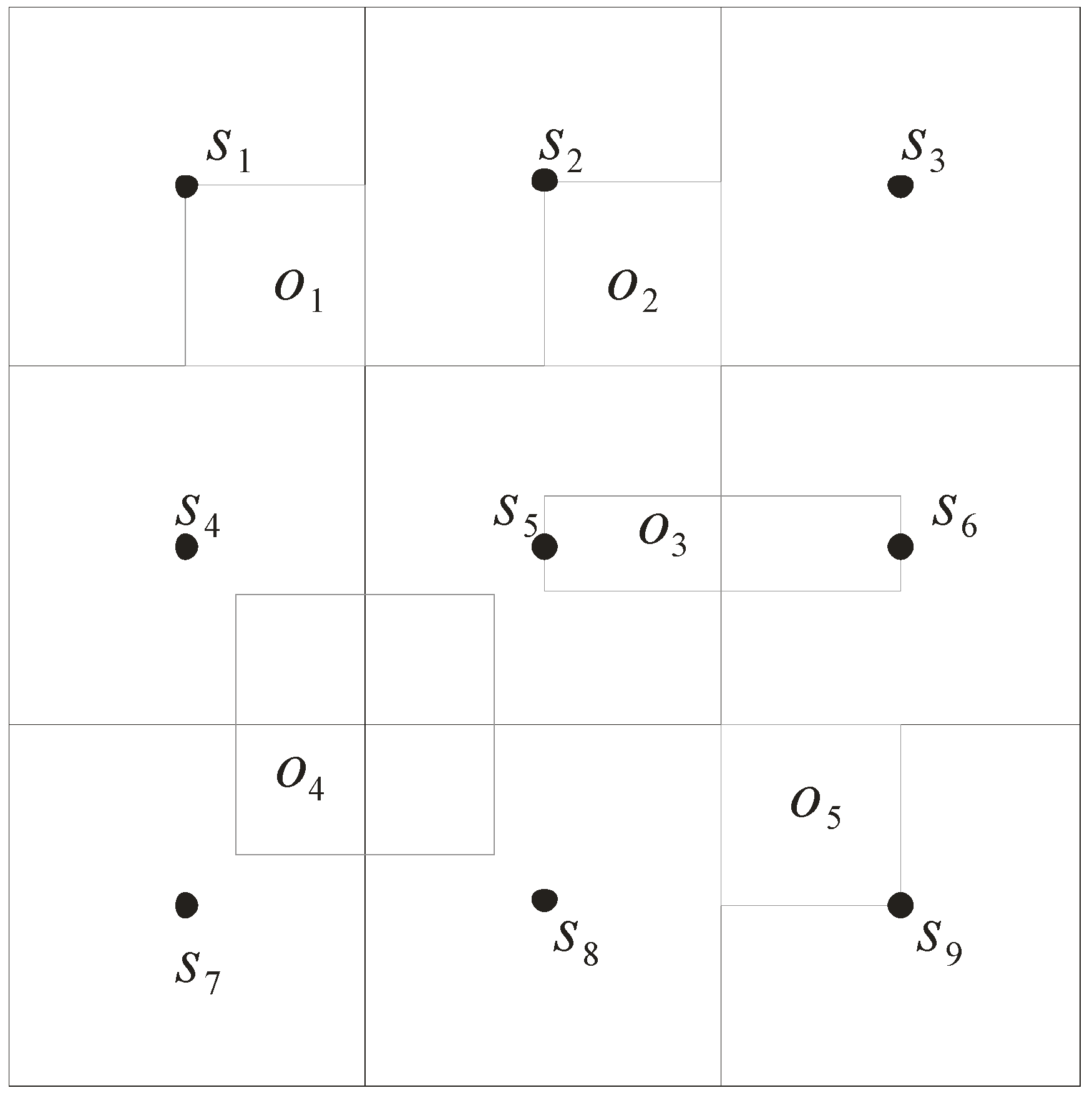
- Distance d(s, o): it refers to the minimal distance between the sensor s and the approximate region of object o. As shown in Figure 5, d(s5, o1) is the minimal distance of the sensor s5 to the approximate region of o1. Note that the minimal distance d(s5, o3) is equal to 0 as s5 is enclosed in the approximate region of o3.
- Distance D(s, o): it refers to the maximal distance between the sensor s and the approximate region of object o. Consider again the example in Figure 5. D(s5, o5) is the maximal distance between the sensor s5 and the approximate region o5.
- Distance d(s, s’): it refers to the minimal distance from the sensor s to the grid cell monitored by the sensor s’. For example, d(s5, s3) is the minimal distance between s5 and the grid cell monitored by s3.
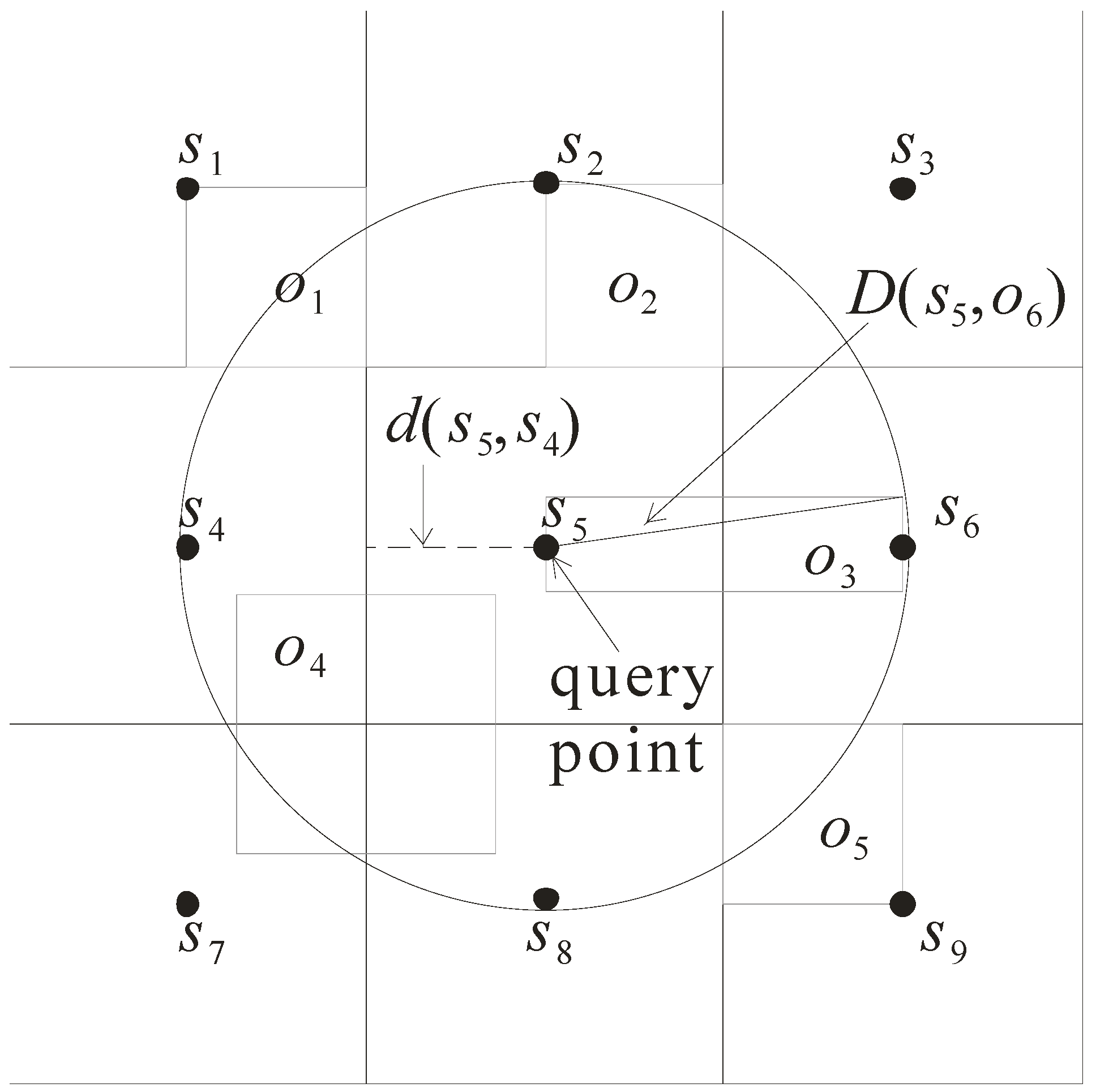
- Pruning criterion 1: if the maximal distance D(s, o) of sensor s to object o is less than the minimal distance d(s, o’) of sensor s to object o’, then o’ cannot be the NN and thus is pruned.
- Pruning criterion 2: if the maximal distance D(s, o) of sensor s to object o is less than the minimal distance d(s, s’) of sensor s to the grid cell monitored by another sensor s’, then the objects monitored by sensor s’ can be pruned as their distances to sensor s must be greater than that of object o.

4.2. Detailed Steps
- Step 1: starting from the grid cell monitored by the sensor s issuing the query, each grid cell is visited according to its distance to the sensor s. When a grid cell is visited, d(s, o) and D(s, o) of objects enclosed by this grid cell are computed. This step proceeds until d(s, s’) of the visited grid cell is greater than D(s, o) of an object. That is, all the unvisited cells are pruned.
- Step 2: sorting D(s, o) of the objects kept from Step 1 so as to derive a smallest D(s, o), defined as the pruning distance. For each object, if its d(s, o) is greater than the pruning distance, then it can be pruned. As such, in this step, d(s, o) of each object is compared against the pruning distance. Only the objects whose d(s, o) is less than or equal to the pruning distance are kept for the next step.
- Step 3: for each object kept from Step 2, its probability of being the query result is computed (which will be discussed later).
Algorithm 1: Query Processing Algorithm
Input: A sensor s issuing the query and a value of K
Output: The K-nearest neighbors of s
foreach grid cell monitored by sensor s’ do
compute d(s, s’);
if d(s, s’) ≤ D(s, o) of K objects then
compute d(s, o) and D(s, o) of objects enclosed by the grid cell and insert the objects into set O;
sort objects in O in ascending order of D(s, o) and set pruning distance to K-th smallest D(s, o);
foreach object o є O do
if D(s, o) is greater than the pruning distance then remove o from O;
foreach object o є O do compute its probability;
return the K objects with highest probabilities.
5. Probability Model
- P(o) = (A1(o) + A2(o) + … + An(o))/A(o), where Ai(o) (1 ≤ i ≤ n) is the area of the ith region of object o that overlaps the circle whose radius is equal to the length of the pruning distance (here, the circle is denoted as C), and A(o) refers to the area of the approximate region of object o.
6. Performance Evaluation
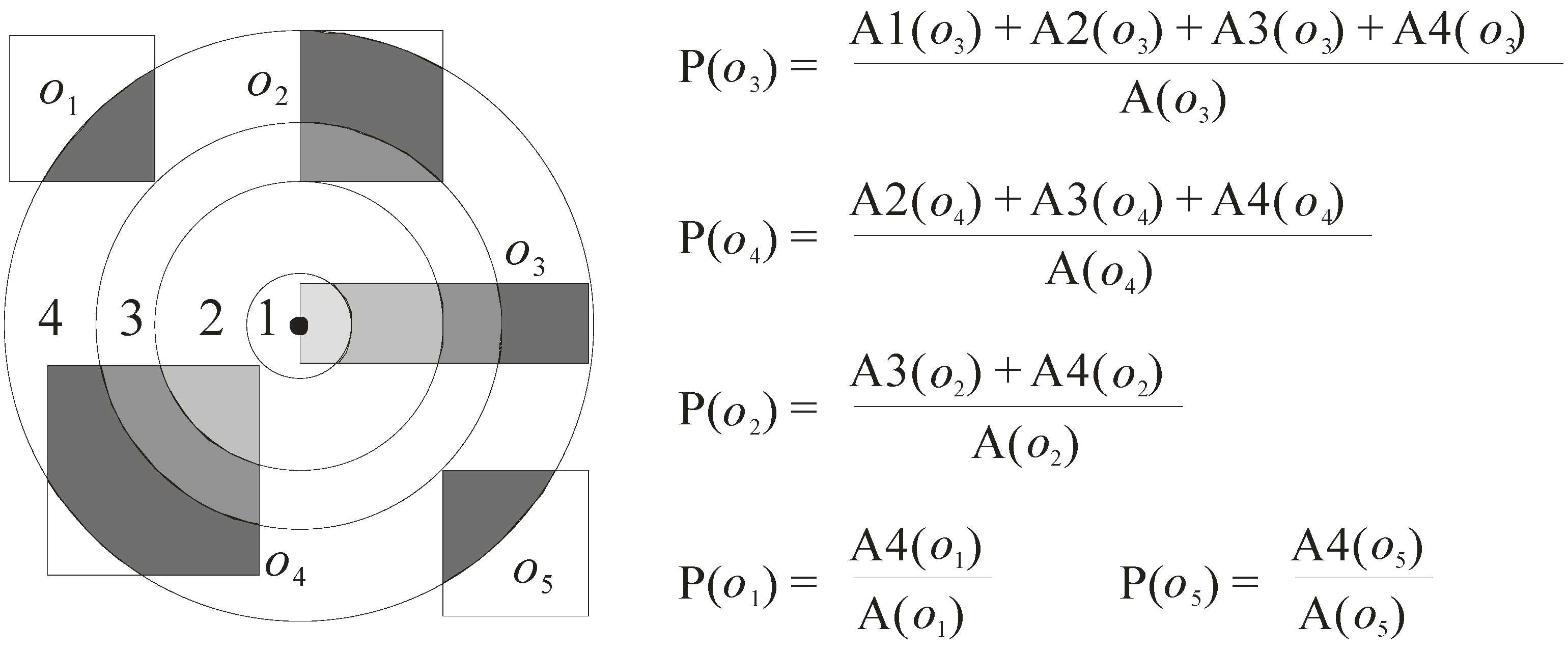
6.1. Experimental Settings

{kind=link}
{kind=link}
{kind=link}
{kind=link}
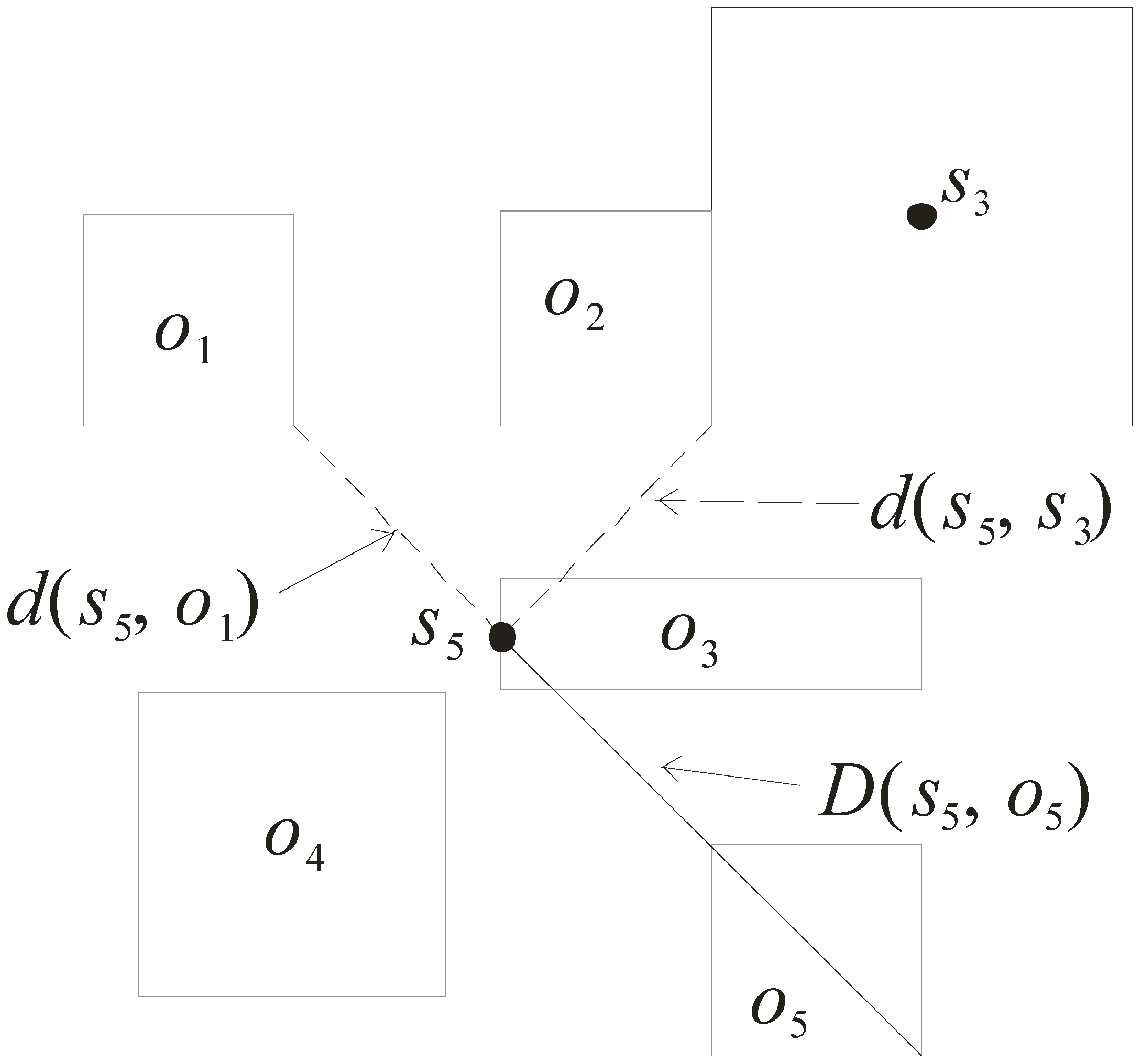{kind=link}
{kind=link}
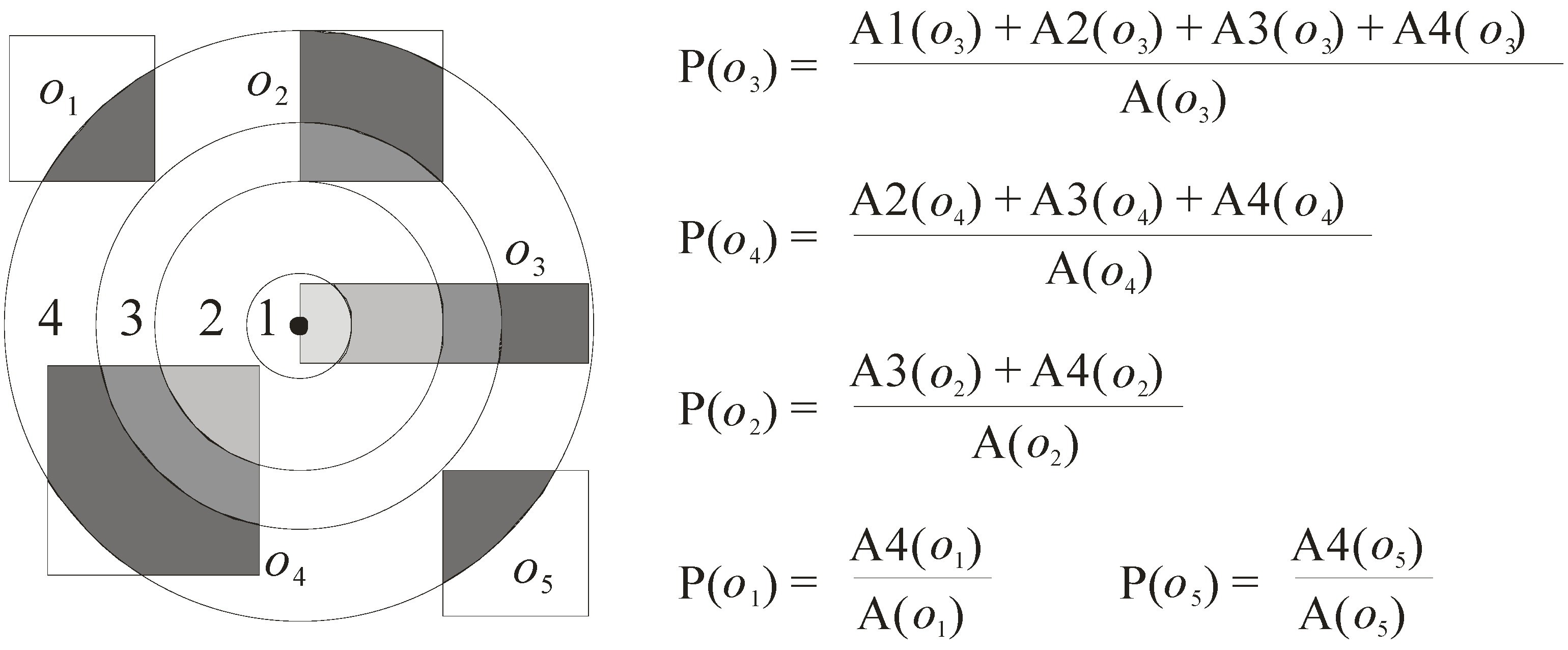{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Default | Range |
|---|---|---|
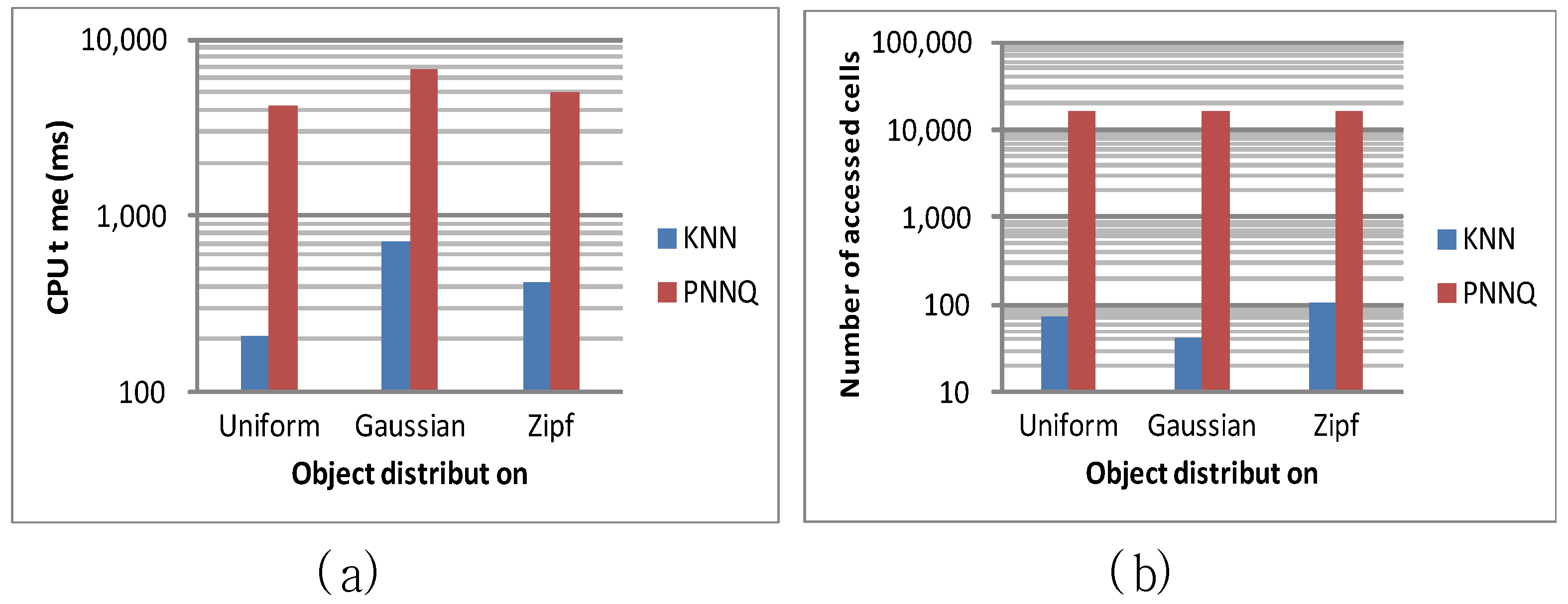
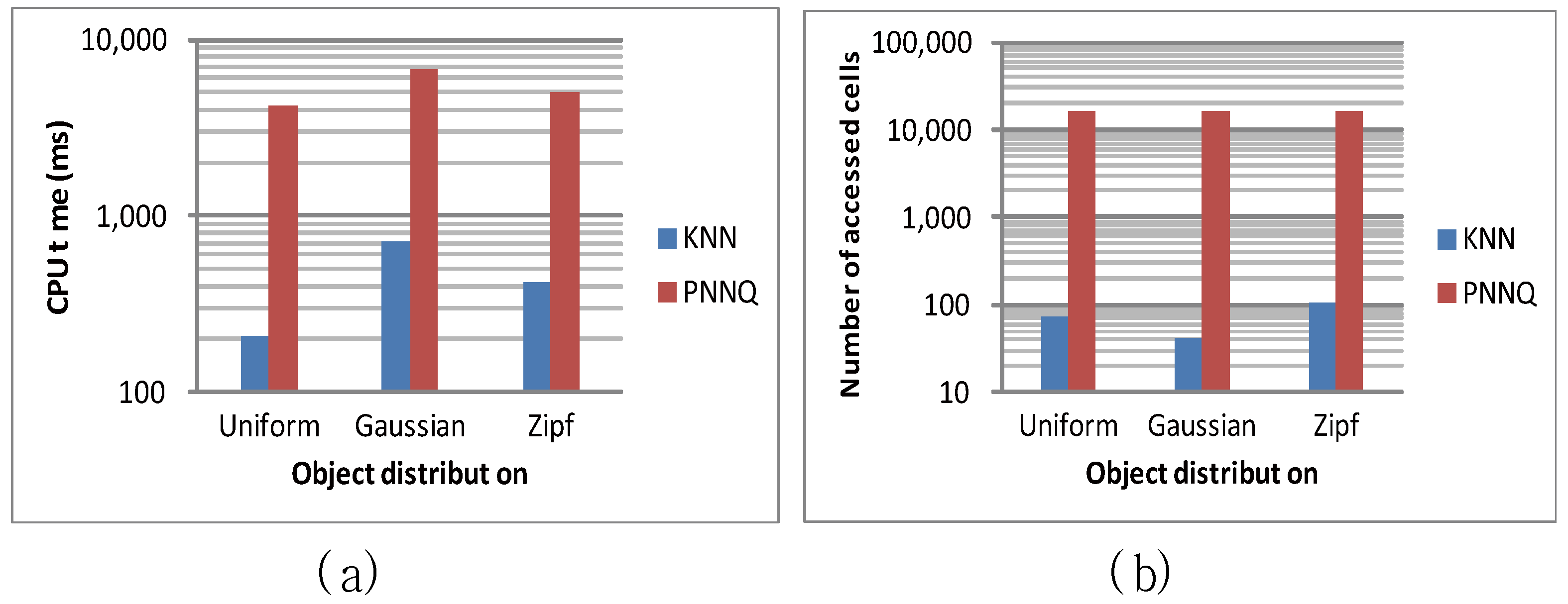
| Object distribution | uniform | uniform, Gaussian, zipf |
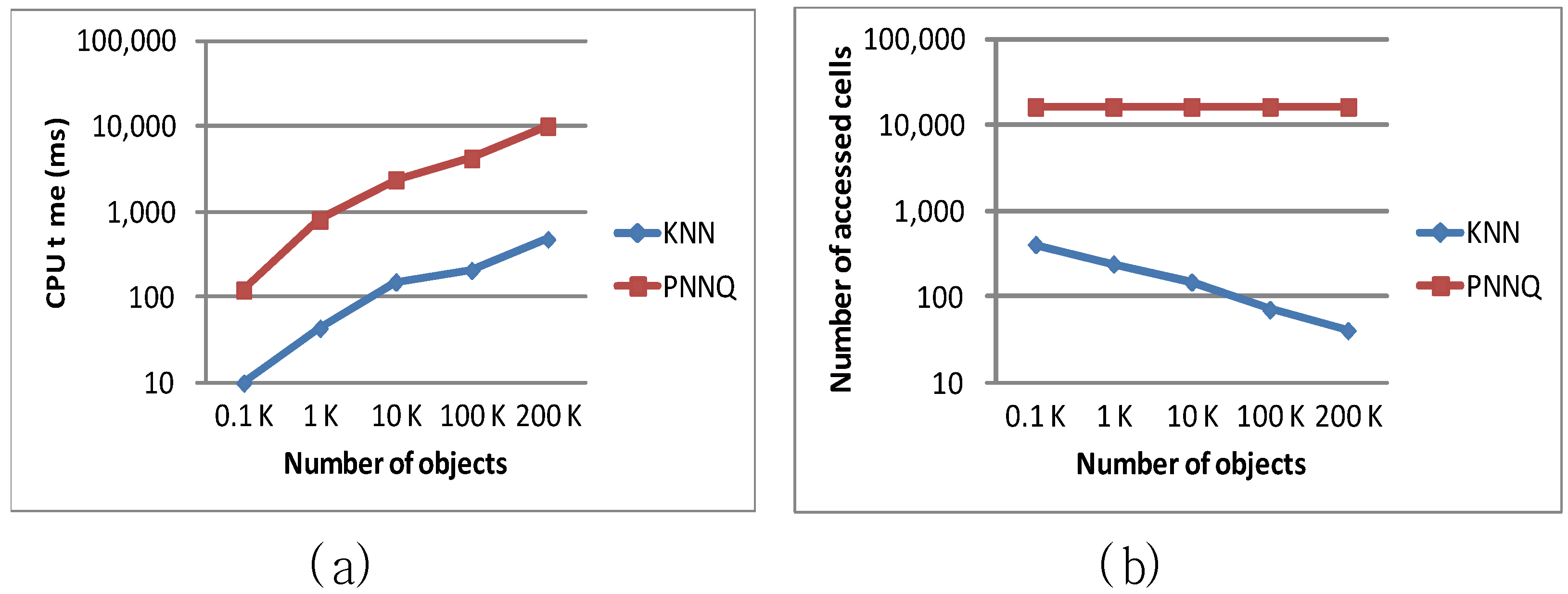
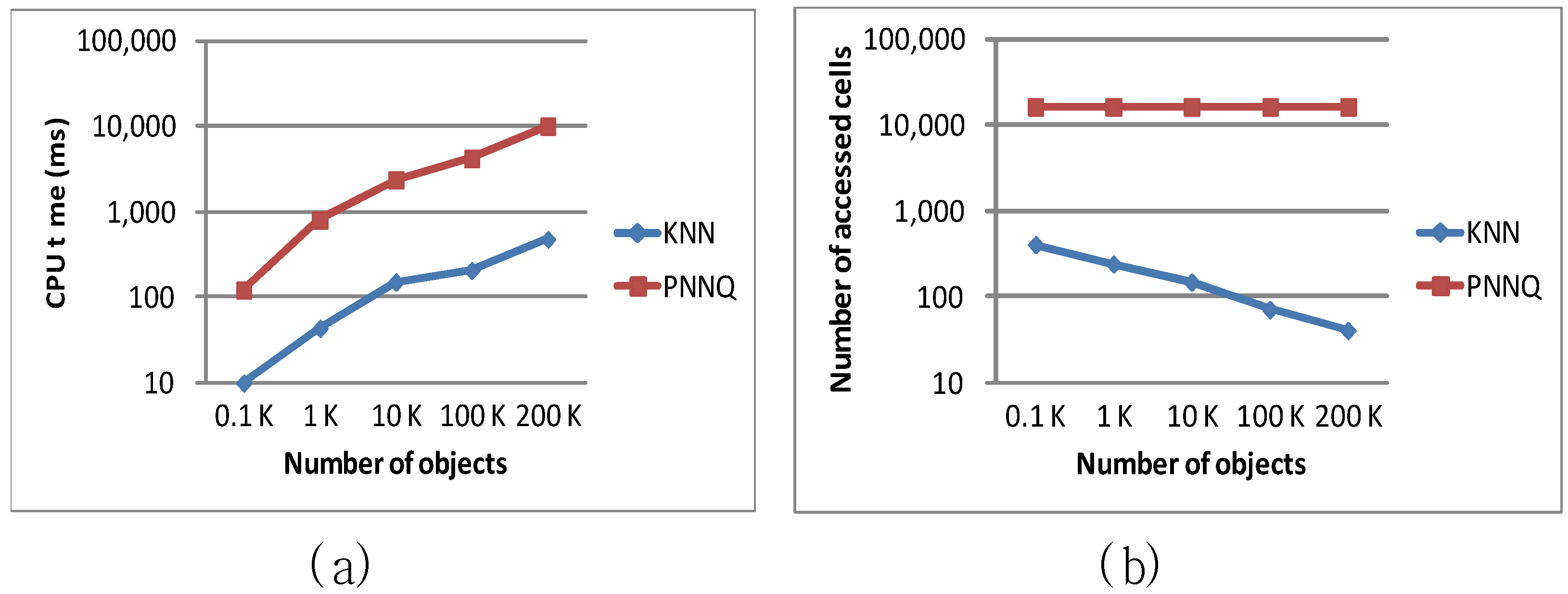
| Object number (K) | 100 | 0.1, 1, 10, 100, 200 |
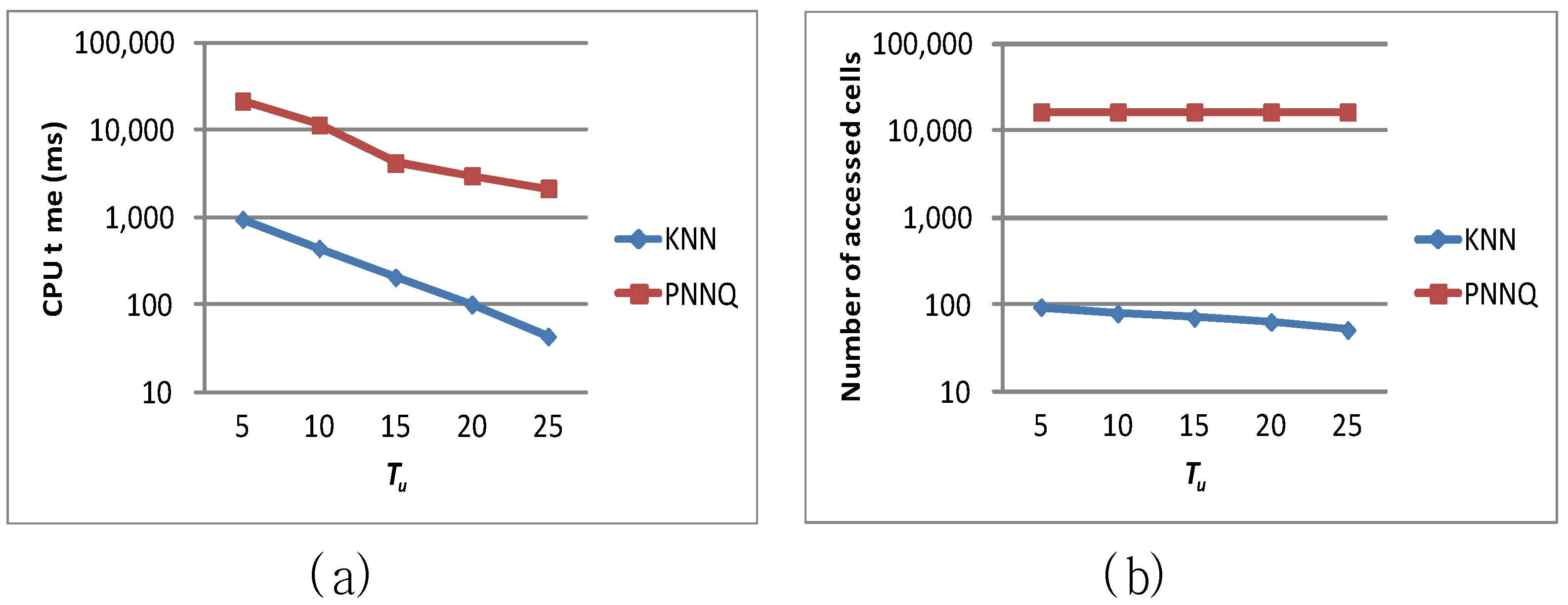
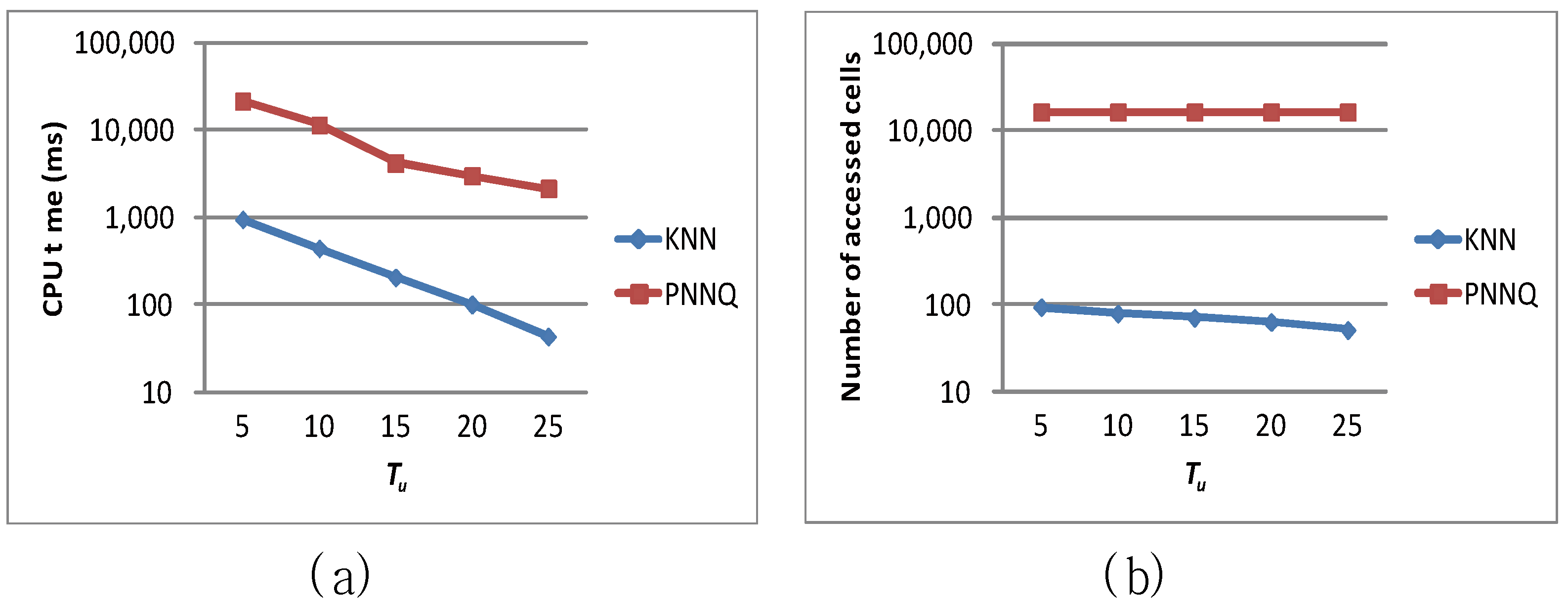
| Tu | 15 | 5, 10, 15, 20, 25 |
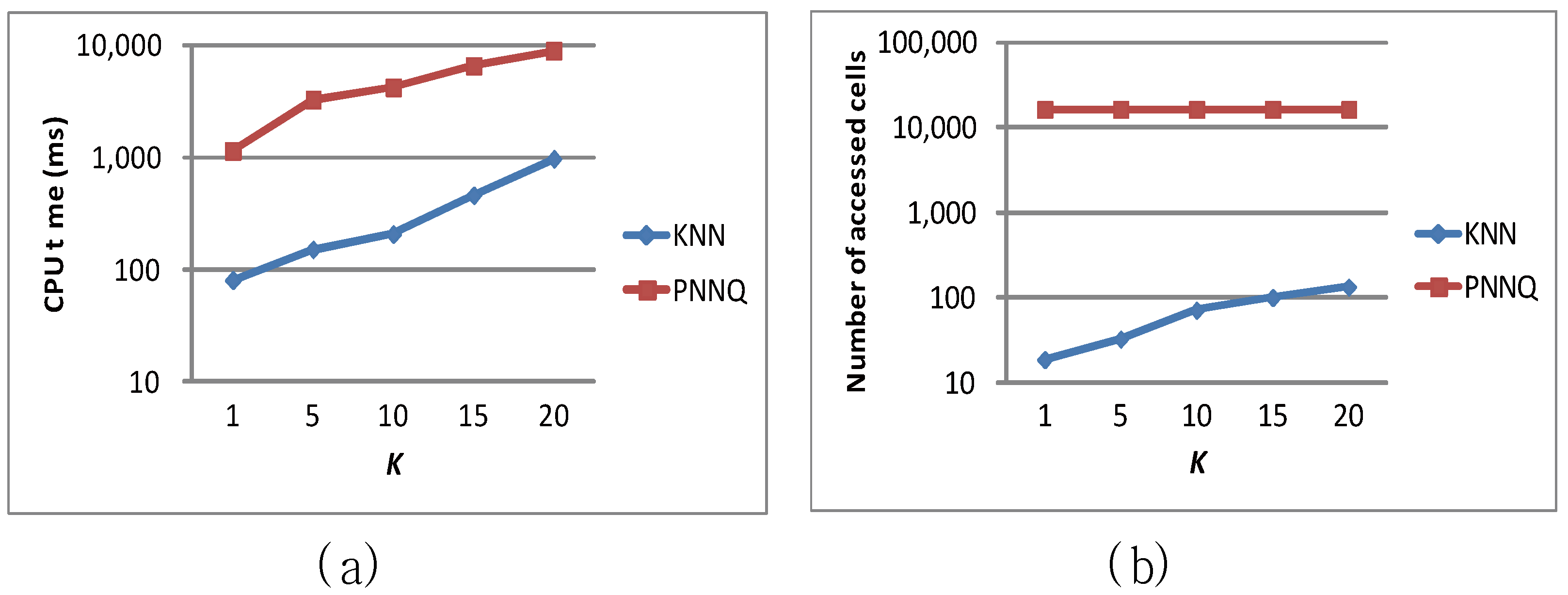
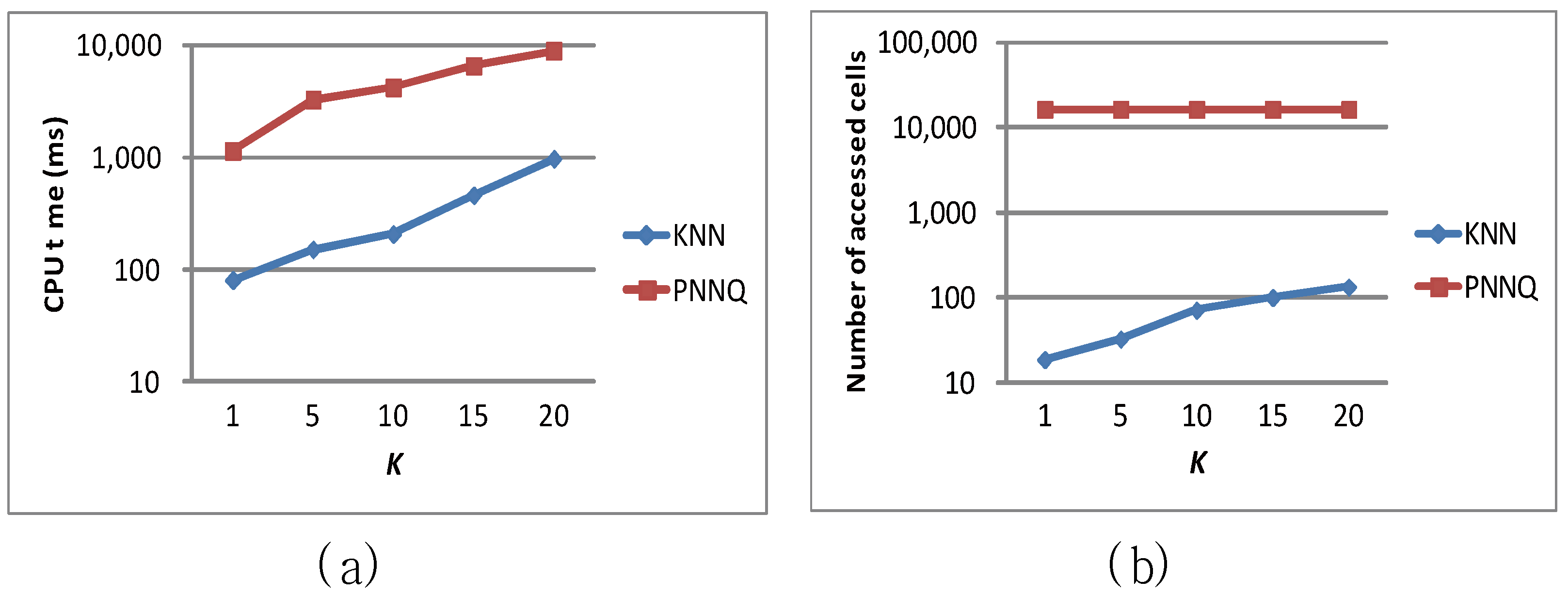
| K | 10 | 1, 5, 10, 15, 20 |
6.2. Efficiency Evaluation
7. Related Work
8. Conclusions
Acknowledgments
Conflicts of Interest
References
- Zhang, J.; Zhu, M.; Papadias, D.; Tao, Y.; Lee, D.L. Location-based Spatial Queries. In Proceedings of the 2003 ACM SIGMOD international conference on Management of data, San Diego, CA, USA, 9–12 June 2003; pp. 443–454.
- Saltenis, S.; Jensen, C.S.; Leutenegger, S.T.; Lopez, M.A. Indexing the Positions of Continuously Moving Objects; ACM SIGMOD: Dallas, TX, USA, 2000. [Google Scholar]
- Kalashnikov, D.V.; Prabhakar, S.; Hambrusch, S.; Aref, W. Efficient evaluation of continuous range queries on moving objects. In Proceedings of the International Conference on Database and Expert Systems Applications, Aix en, France, 2–6 September 2002; pp. 731–740.
- Tao, Y.; Papadias, D. Time Parameterized Queries in Spatio-Temporal Databases. In Proceedings of the 2002 ACM SIGMOD international conference on Management of data, Madison, WI, USA, 3–6 June 2002; pp. 322–333.
- Mokbel, M.F.; Xiong, X.; Aref, W.G. Sina: Scalable Incremental Processing of Continuous Queries in Spatio-Temporal Databases. In Proceedings of the 2004 ACM SIGMOD international conference on Management of data, Paris, France, 13–18 June 2004; pp. 623–634.
- Mouratidis, K.; Hadjieleftheriou, M.; Papadias, D. Conceptual Partitioning: An Efficient Method for Continuous Nearest Neighbor Monitoring. In proceedings of the 2005 ACM SIGMOD international conference on Management of data, Baltimore, MD, USA, 14–16 June 2005; pp. 634–645.
- Jung, C.; Lee, S.J.; Bhuse, V. The minimum scheduling time for convergecast in wireless sensor networks. Algorithms 2014, 7, 145–165. [Google Scholar] [CrossRef]
- Ma, W.; Zhang, J. Algorithm based on heuristic strategy to infer lossy links in wireless sensor networks. Algorithms 2014, 7, 397–404. [Google Scholar] [CrossRef]
- Nikoletseas, S.; Spirakis, P.G. Probabilistic distributed algorithms for energy efficient routing and tracking in wireless sensor networks. Algorithms 2009, 2, 121–157. [Google Scholar] [CrossRef]
- Cheng, R.; Kalashnikov, D.V.; Prabhakar, S. Querying Imprecise Data in Moving Object Environments. IEEE Trans. Knowl. Data Eng. 2009, 16, 1112–1127. [Google Scholar] [CrossRef]
- Sistla, A.P.; Wolfson, O.; Chamberlain, S.; Dao, S. Modeling and Querying Moving Objects. In Proceedings of the International Conference on Data Engineering, Birmingham, UK, 7–11 April 1997; pp. 422–432.
- Wolfson, O.; Sistla, P.; Xu, B.; Zhou, J.; Chamberlain, S.; Yesha, T.; Rishe, N. Tracking Moving Objects Using Database Technology in DOMINO. In Proceedings of the Fourth Workshop on Next Generation Information Technologies and Systems, Zikhron-Yaakov, Israel, 5–7 July 1999.
- Benetis, R.; Jensen, C.S.; Karciauskas, G.; Saltenis, S. Nearest Neighbor and Reverse Nearest Neighbor Queries for Moving Objects. In Proceedings of the International Database Engineering and Applications Symposium, Edmonton, Canada, 17–19 July 2002; pp. 44–53.
- Raptopoulou, K.; Papadopoulos, A.N.; Manolopoulos, Y. Fast Nearest-Neighbor Query Processing in Moving-Object Databases. GeoInformatica 2003, 7, 113–137. [Google Scholar] [CrossRef]
- Iwerks, G.; Samet, H.; Smith, K. Continuous K-Nearest Neighbor Queries for Continuously Moving Points with Updates. In Proceedings of the International Conference on Very Large Data Bases, Berlin, Germany, 9–12 September 2003; pp. 512–523.
- Song, Z.; Roussopoulos, N. K-Nearest Neighbor Search for Moving Query Point. In Proceedings of 7th International Symposium on Advances in Spatial and Temporal Databases, Redondo Beach, CA, USA, 12–15 July 2001; pp. 79–96.
- Nehme, R.V.; Rundensteiner, E.A. SCUBA: Scalable Cluster-Based Algorithm for Evaluating Continuous Spatio-Temporal Queries on Moving Objects. In Proceedings of the 10th International Conference on Extending Database Technology, Munich, Germany, 26–31 March 2006; pp. 1001–1019.
- Xiong, X.; Mokbel, M.F.; Aref, W.G. SEA-CNN: Scalable Processing of Continuous K-Nearest Neighbor Queries in Spatio-temporal Databases. In Proceedings of the International Conference on Data Engineering, Tokyo, Japan, 5–8 April 2005; pp. 643–654.
- Yu, X.; Pu, K.Q.; Koudas, N. Monitoring K-Nearest Neighbor Queries Over Moving Objects. In Proceedings of the International Conference on Data Engineering, Tokyo, Japan, 5–8 April 2005; pp. 631–642.
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Y.-K. Processing KNN Queries in Grid-Based Sensor Networks. Algorithms 2014, 7, 582-596. https://doi.org/10.3390/a7040582
Huang Y-K. Processing KNN Queries in Grid-Based Sensor Networks. Algorithms. 2014; 7(4):582-596. https://doi.org/10.3390/a7040582
Chicago/Turabian StyleHuang, Yuan-Ko. 2014. "Processing KNN Queries in Grid-Based Sensor Networks" Algorithms 7, no. 4: 582-596. https://doi.org/10.3390/a7040582
APA StyleHuang, Y.-K. (2014). Processing KNN Queries in Grid-Based Sensor Networks. Algorithms, 7(4), 582-596. https://doi.org/10.3390/a7040582