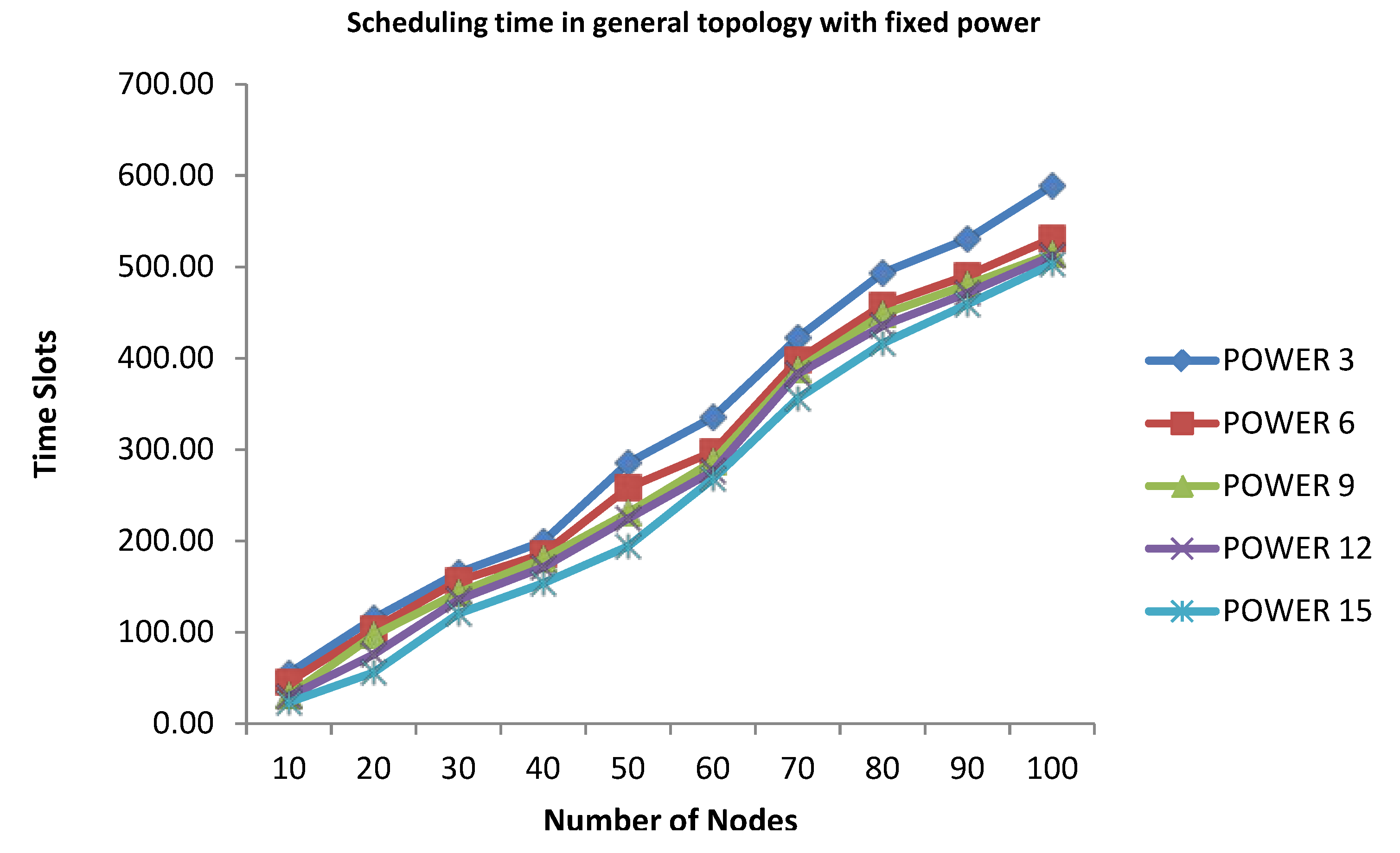
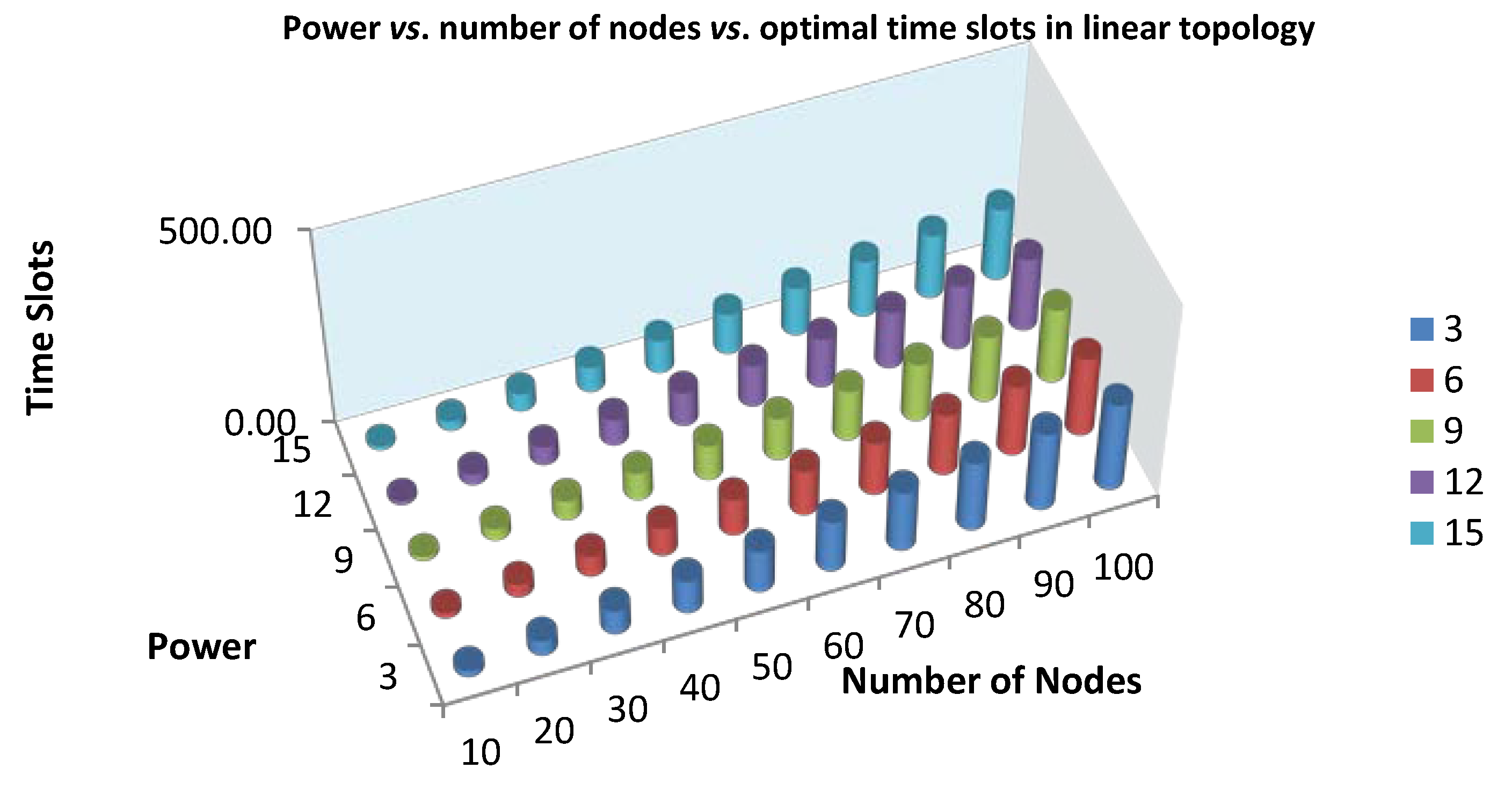
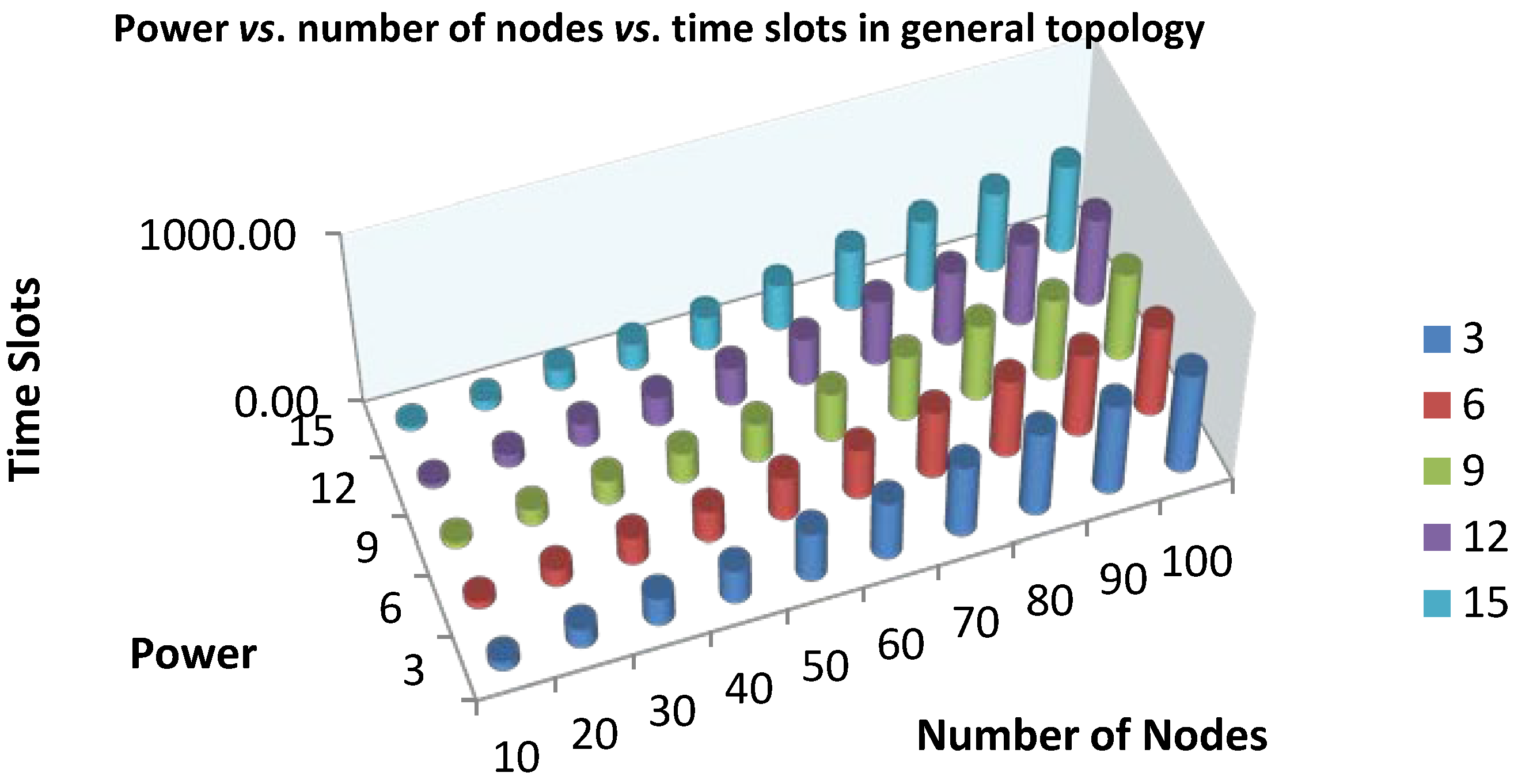
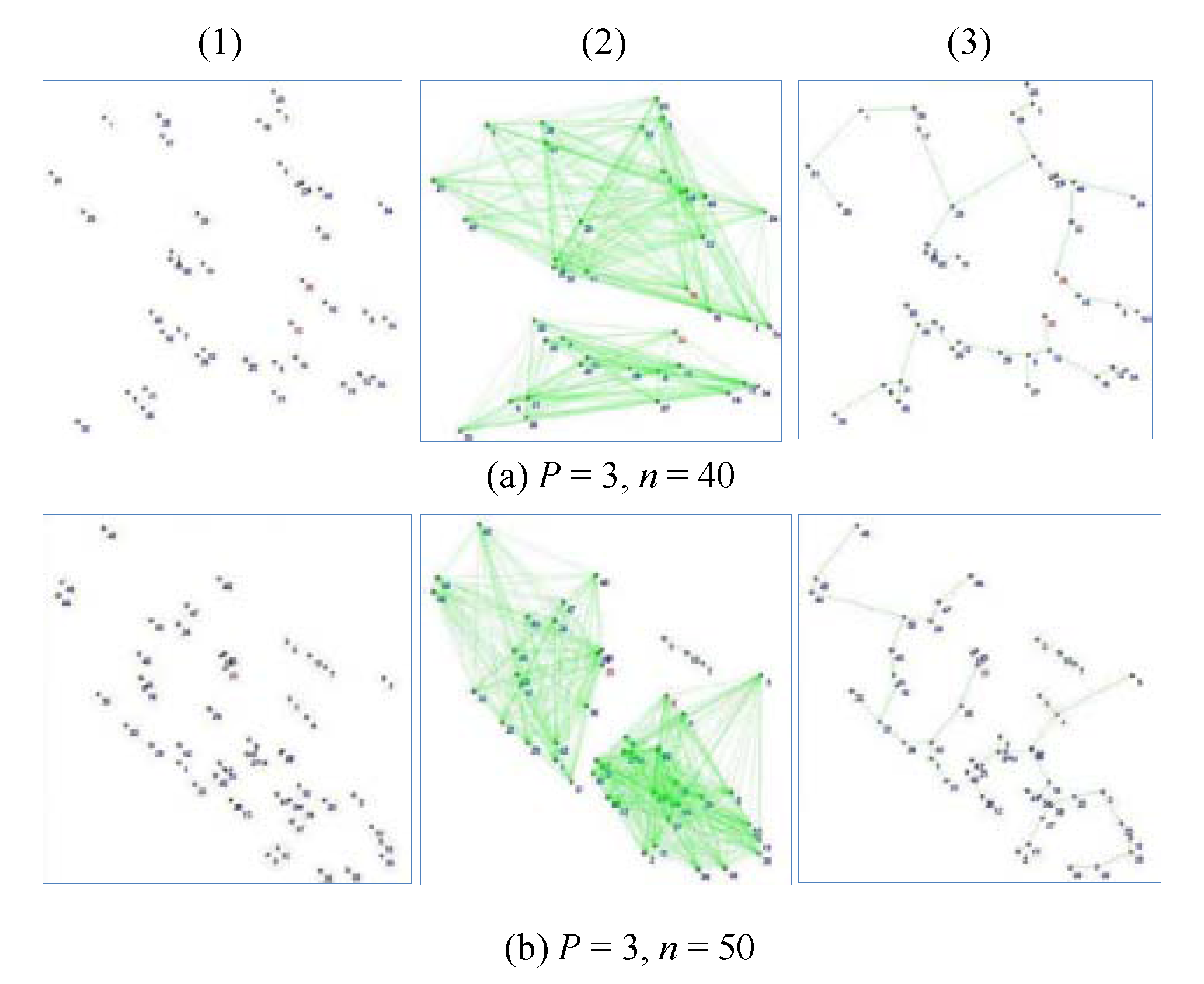
4.1. The Finding Minimum Scheduling Time for Convergecast (FMSTC) Algorithm
In this section, we describe the proposed algorithm to find the minimum scheduling time in a general topology.
Table 1 described the algorithm based on the assumptions in the previous section.
Table 1.
FMSTC Algorithm
| Steps | Procedures |
|---|
| 1 | In a given network
G = (V, E), where V is the set of vertices (sensor nodes), E is the set of edges (links between nodes), and s is a sink node (s ∈ V, s ≠ vi). All the nodes have unique ids.
Find nodes set Ns = { v1, v2, v3…, vi}, where ∀vi ∈ V and vi is the transmission range of s.
If the node vi which is in the transmission range of s is in the transmission range of the other node vj, ( vi & vj∈ Ns, vi ≠ vj).
Calculate the weight W(⋅|⋅) of each link from s to vi and vj, i.e. W(vi|s) and W(vj|s), where W(⋅) = ⌈ |l| ⌉ − 1 and |l| is the distance between s to vi or vj. Select the lowest id node for the nodes set Ns, if W(vi|s) is equal to W(vj|s). Exclude the node vj from the nodes set Ns if W(vi|s) is less than W(vj|s), or vice versa. Repeat (i) through (iii) until it has a complete set of Ns.
|
| 2. | Construct the independent minimum spanning tree set, ST = {t1, t2, t3…, tn}, where each tree in ST is rooted from each node in Ns. – modified Khan et al. [29] algorithm
If there exist a node vk which satisfies the following condition − vk ∈ ti & vk ∈ tj (ti & tj ∈ ST), then calculate the weight W(⋅) of each link from vk to vtia and vtjb, where vtia ∈ ti and vtjb ∈ tj. Add vk to ti if W(vtia|vk) is less than W(vtjb|vk), or vice versa. Repeat (a) & (b) until it has a complete set of ST.
|
| 3 | For each tree in ST, reconstruct to a line topology based on the distance between nodes of the tree. |
| 4 | Get the minimum scheduling time for the given network applying Choi et al. (2011) algorithm. |
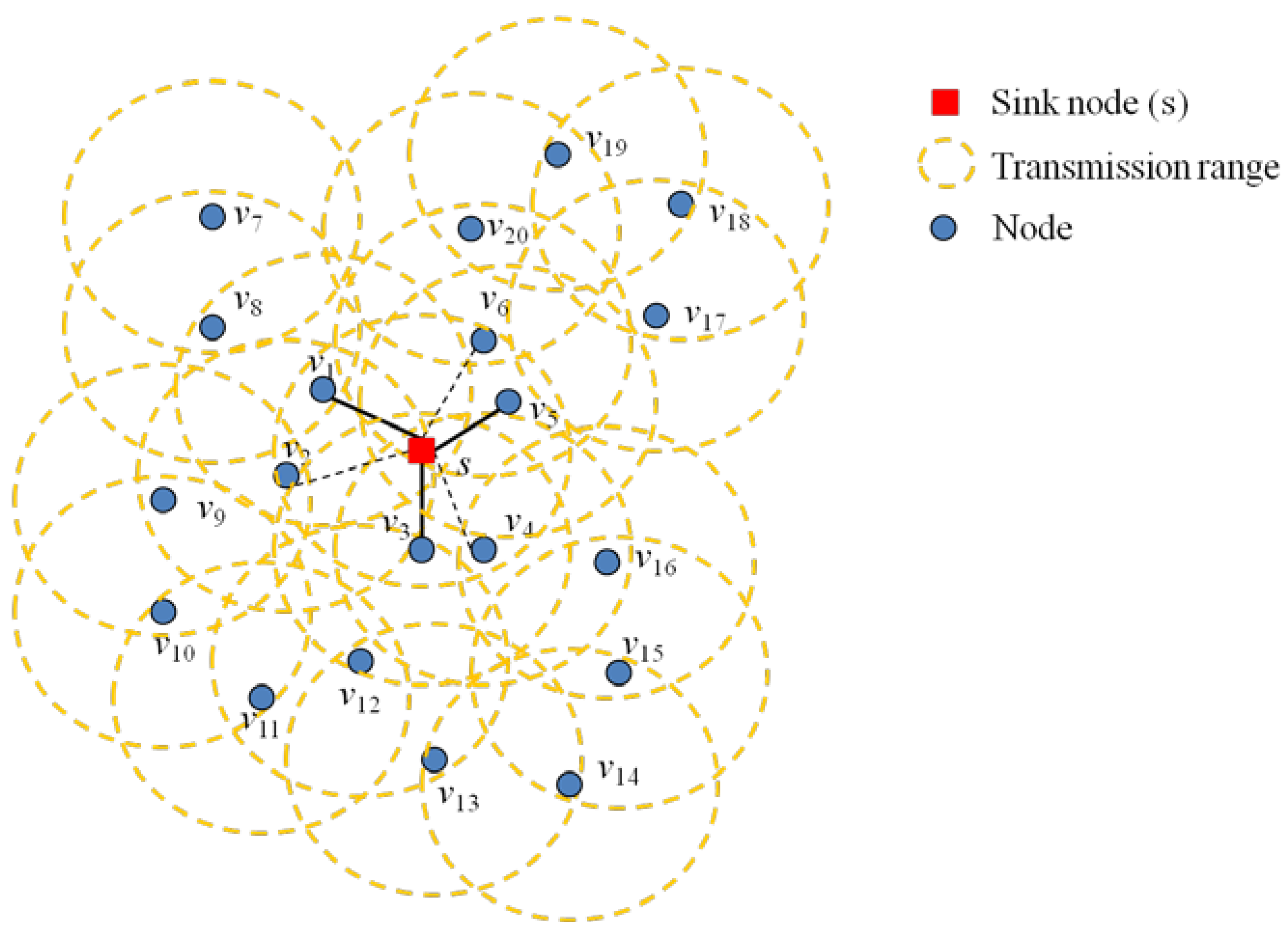
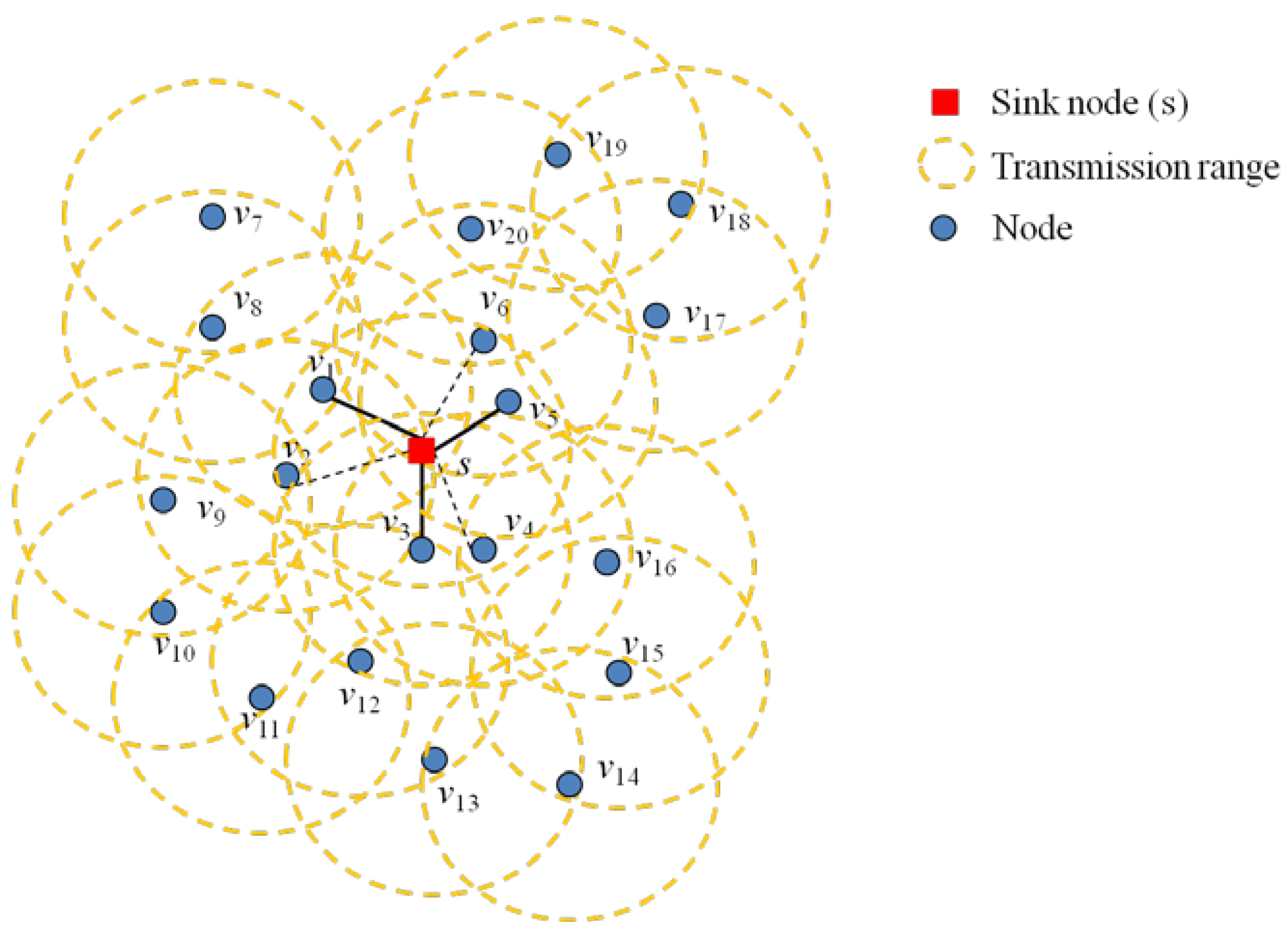
In step 1, the algorithm constructs the node set (
Ns), which has nodes around the transmission range of the sink node (
s). The algorithm selects a node that is closer to the sink node.
Figure 2 explains this step. The nodes,
v1,
v2,
v3,
v4,
v5 and
v6, are in the transmission range of the sink node,
s. First, the algorithm needs to find a node set,
Ns, from these nodes. If the algorithm finds that node
v1 and
v2 are in the range of the sink node,
s, it calculates the weight from
s to
v1 and
s to
v2. Then, it selects the node,
v1, which has the smaller weight than that of
v2. The algorithm applies for the nodes,
v3,
v4,
v5 and
v6, and selects the nodes,
v3 and
v5, which have a smaller weight than those of
v4 and
v6. The complete set of nodes,
Ns, is defined as follows:
Figure 2.
Node set (Ns) in the FMSTC algorithm (v1, v3 and v6, respectively, are chosen instead of v2, v4 and v5, because they are closer to the sink node (s)).
Figure 2.
Node set (Ns) in the FMSTC algorithm (v1, v3 and v6, respectively, are chosen instead of v2, v4 and v5, because they are closer to the sink node (s)).
Once it has the complete set of nodes,
Ns, it starts to construct the minimum spanning tree for each node in
Ns that will be the root of each spanning tree. There are algorithms for constructing minimum spanning trees [
9,
10,
17,
28]. However, those algorithms are not suitable for WSNs, because WSNs are energy-constraint sensor networks. Therefore, we modified Khan’s algorithm, which is adaptable in WSNs, to get the minimum spanning tree from each node in
Ns. Khan
et al. [
29] constructed a minimum spanning tree based on a rank function, which is decided by the random number and the unique
id for each node. In this study, we use the weight of each distance instead of a random number, i.e., transmission range and node
ids. The proposed algorithm constructs a minimum cost spanning tree; referred to as FMLSP (find minimum low cost spanning tree). Once the algorithm constructs all the minimum cost spanning trees, we assume that each of the trees is an independent set, i.e., each tree; there is no conflict to send a message because of the transmission range. The algorithm (referred to as FMLSP) is described in
Table 2.
Table 2.
FMLSP Algorithm
| Steps | Procedures |
|---|
| 1 | All the nodes in the given network G = (V, E) have unique ids.
Select a node vi which has minimum number id from the given Ns set. Then put the node in the independent minimum spanning set ti, ti = {vi}.
Find all the neighboring nodes from vi. |
| | If there exists only one neighboring node
vj, which is within the transmission range, put the node in the independent minimum spanning tree ti, ti = {vi, vj}.
|
| | - b.
If there exist more than two neighboring nodes within the transmission range,
vj and vk, calculate the weights from vi to vj and vk, i.e. W( vj| vi) and W( vk| vi) ( j ≠ k)
If W(vj|vi) is less than W(vk|vi), put the node vi to the independent minimum spanning set ti, ti = {vi, vj}, or vice versa, ti = {vi, vk}. If W(vj|vi) is equal to W(vk|vi), put the node with smaller id number to the independent minimum spanning set ti.
|
| | - c.
If there exists a node vm which is included in more than two independent minimum spanning trees, i.e. vm ∈ ti and vm ∈ tj, calculate the weights from vm to vtia and vtjb, where vtia ∈ ti and vtjb ∈ tj.
If W(vtia|vm) is less than W(vtjb|vm), put the node vm to the independent minimum spanning set ti, ti = {vi…, vm}, or vice versa, tj = {vj…, vm}. If W(vtia|vm) is equal to W(vtjb|vm), put the node vm in the independent minimum spanning tree with smaller id number.
|
| | - d.
Repeat (a) through (c) until it completes the construction of the independent minimum spanning tree for each node in Ns.
|
| 2 | While there exists a branch in the given independent minimum spanning tree ti, repeat Step 1(b) through 1(d) within the independent minimum spanning tree ti to construct the sub-tree tij. |
The algorithm finds the minimum spanning tree set,
ti, for each node in
Ns. First, it finds all neighbor nodes in its transmission range. If two nodes are in the same transmission range, it calculates the weight for each link from a root node to a neighboring node. The algorithm selects the smaller weight to add to the node to the tree. If the weight of the link is the same for both of the nodes, the algorithm selects the node with the smaller id to add it to the tree. If the algorithm finds that a node is in the ranges of both of the trees, it measures a weight for each link and adds the node to the tree that has the smaller weight link. The algorithm also adds the node to the tree that has the smaller
id if the weights of two links are the same in the case of a node that is in range of both of the trees. The algorithm repeats, until it gets the complete independent set of tree
ti. After it gets a complete set of tree
ti, it starts to find sub-tree set
tij from
ti. This process is for the next step of the FMSTC algorithm. The FMSTC algorithm builds the line topology after constructing a minimum spanning tree. This sub-tree set,
tij, allows us to complete an independent set of tree
ti by repeating the process described above.
Figure 3 explains the sub-tree set environment.
Figure 3.
Building a sub-tree set.
Figure 3.
Building a sub-tree set.
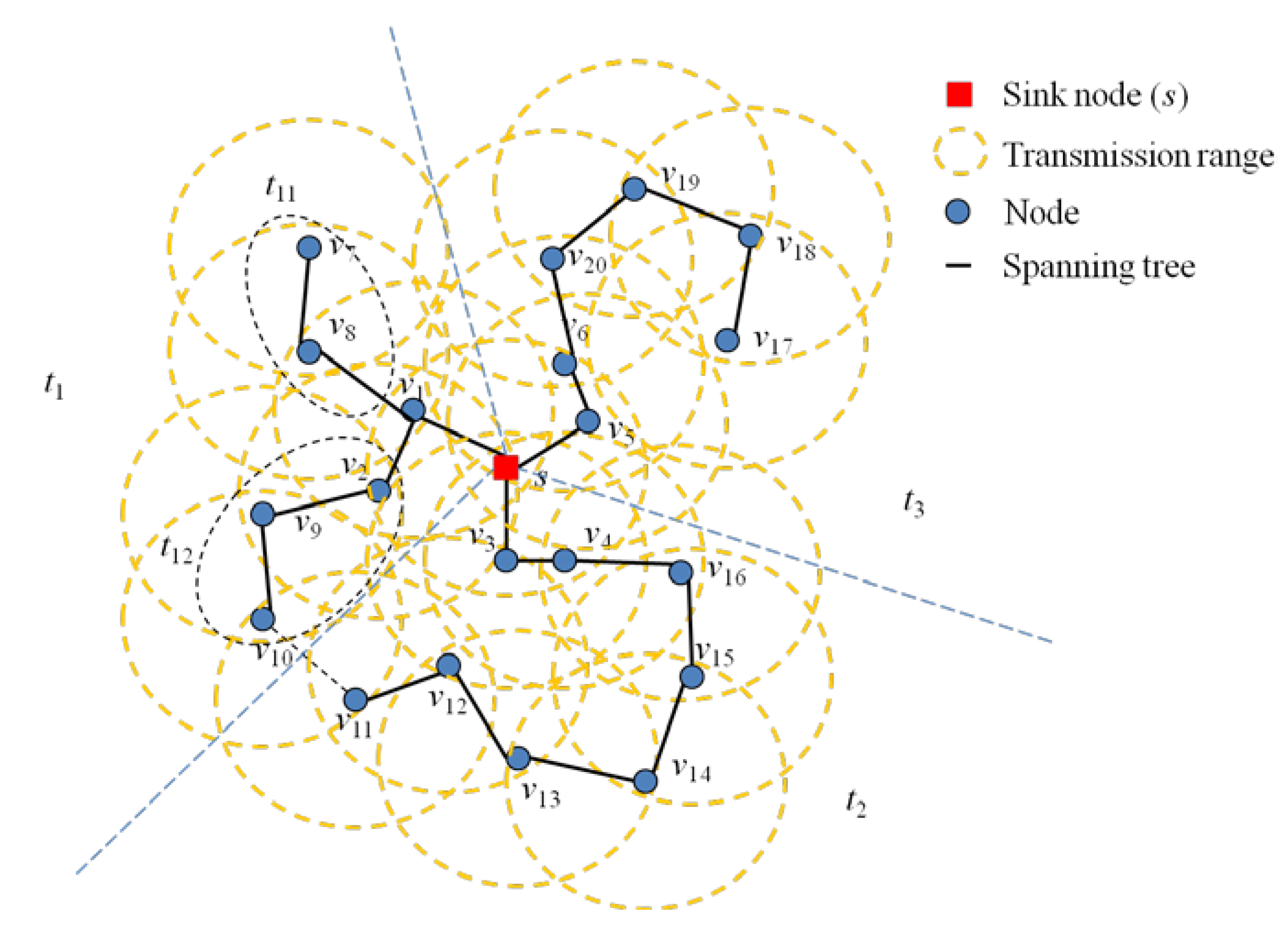
In
Figure 3, the spanning tree,
t1, has Nodes
v1,
v2,
v7,
v8,
v9 and
v10;
t1 = {
v1,
v2,
v7,
v8,
v9,
v10}. A node,
v1, is connected to sink node, and Nodes
v2 and
v7 are connected to
v1. With a tree,
t1, we can produce two sub-trees
t11 = {
v7,
v8} and
t12 = {
v2,
v9,
v10}, i.e.,
t11 ⊂
t1 and
t12 ⊂
t1.We eventually construct the line topology in the given minimum spanning tree set with this process.
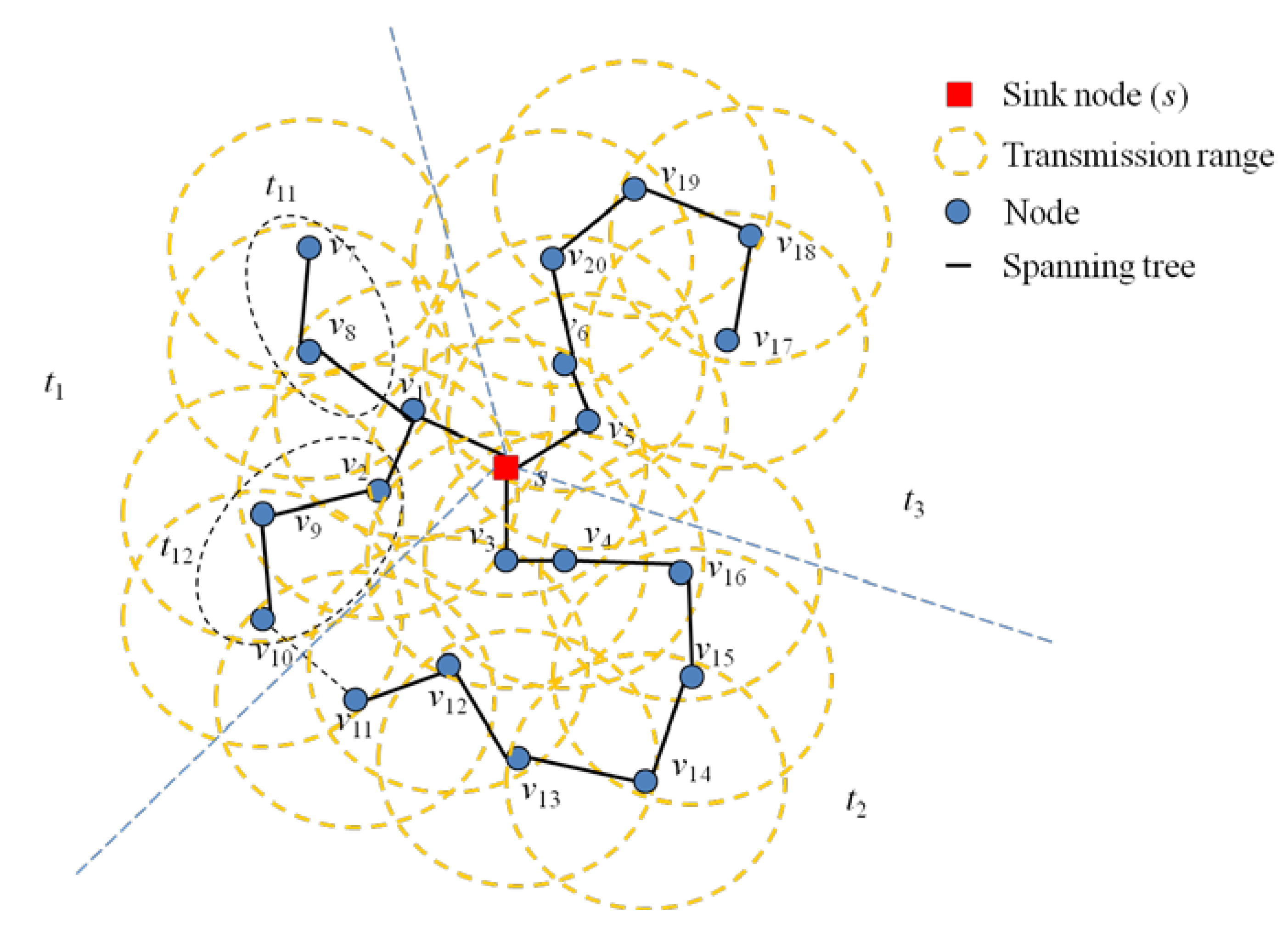
Figure 4 explains the algorithm to produce minimum spanning tree set
ti. There are three minimum spanning trees:
t1,
t2 and
t3.
Figure 4.
Constructing the minimum spanning trees for nodes in the node set (Ns) using the FMLSP algorithm.
Figure 4.
Constructing the minimum spanning trees for nodes in the node set (Ns) using the FMLSP algorithm.
Three nodes (
v1,
v3,
v5) are selected from a sink node. The FMSTC algorithm starts to construct a minimum spanning tree rooted from each node (
v1,
v3,
v5). It produces three spanning trees, which are
t1,
t2 and
t3. The tree,
t1, has two leaf nodes, which need to be divided into two sub-spanning trees. The algorithm produces the sub-trees,
t11 and
t12, from
t1. Therefore, there are five spanning trees produced in the graph:
the node,
v10, is in the spanning tree,
t12, because it is close to Node
v9, even though it is also in the transmission range of
v11, which is in
t2.
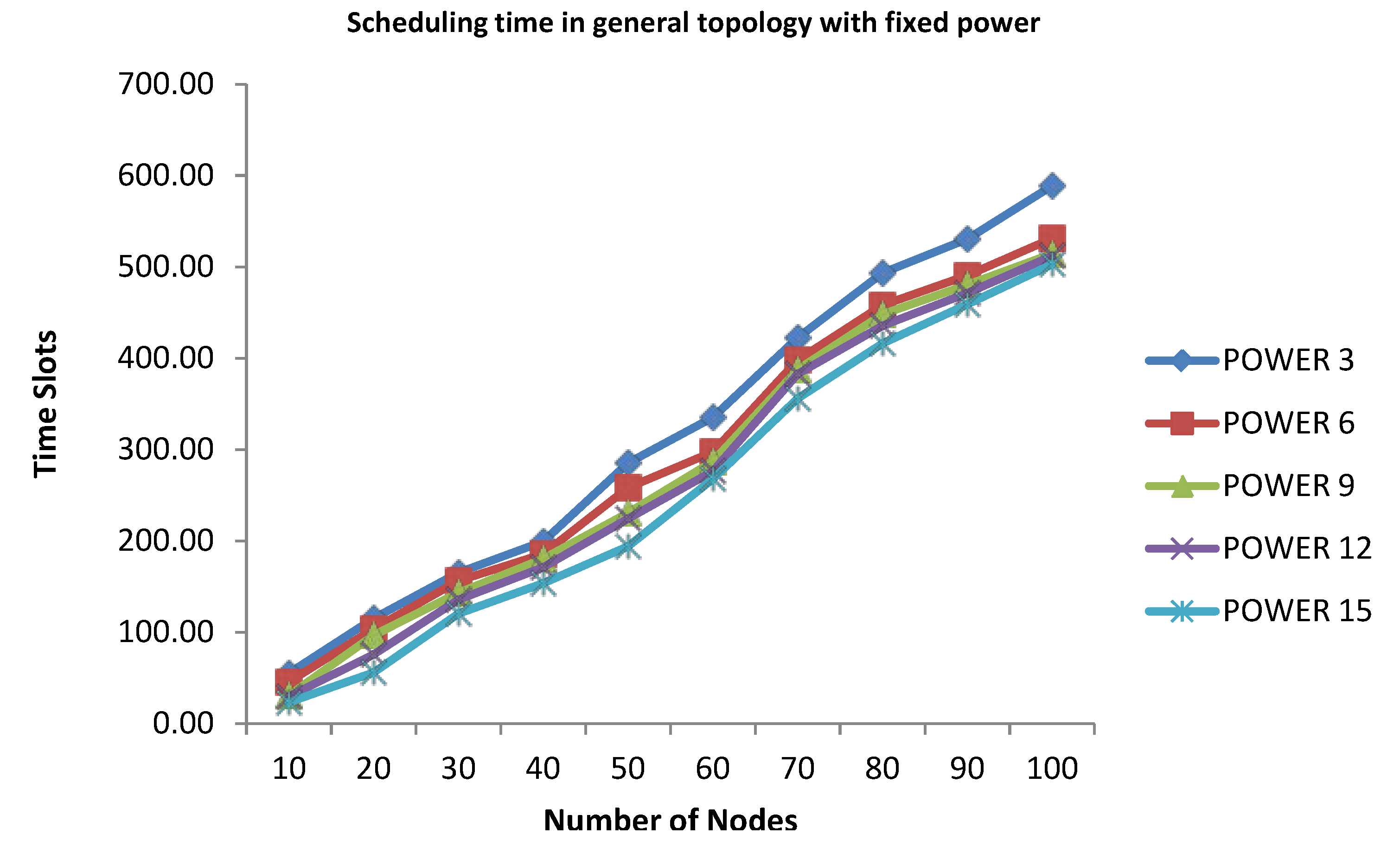
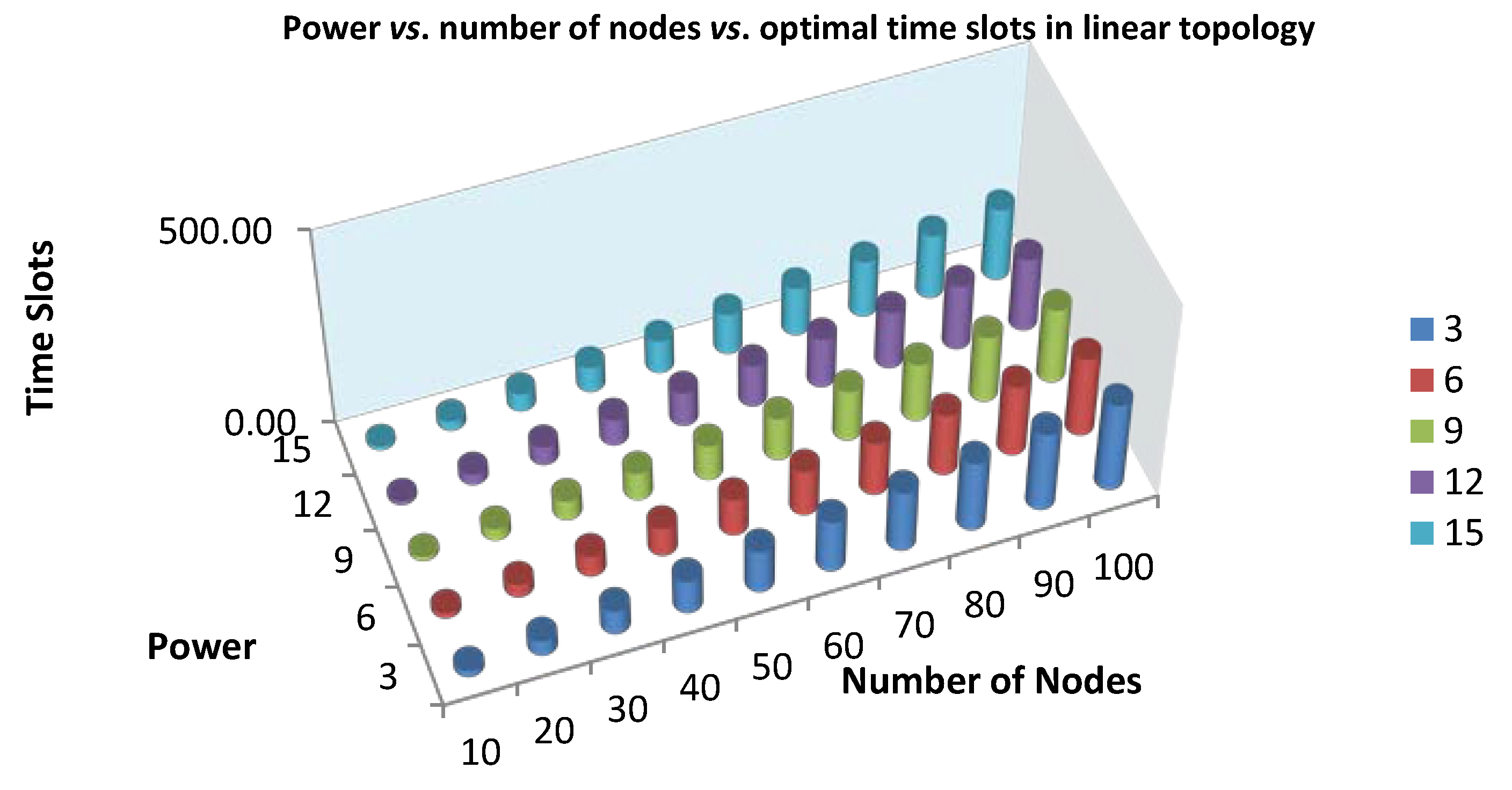
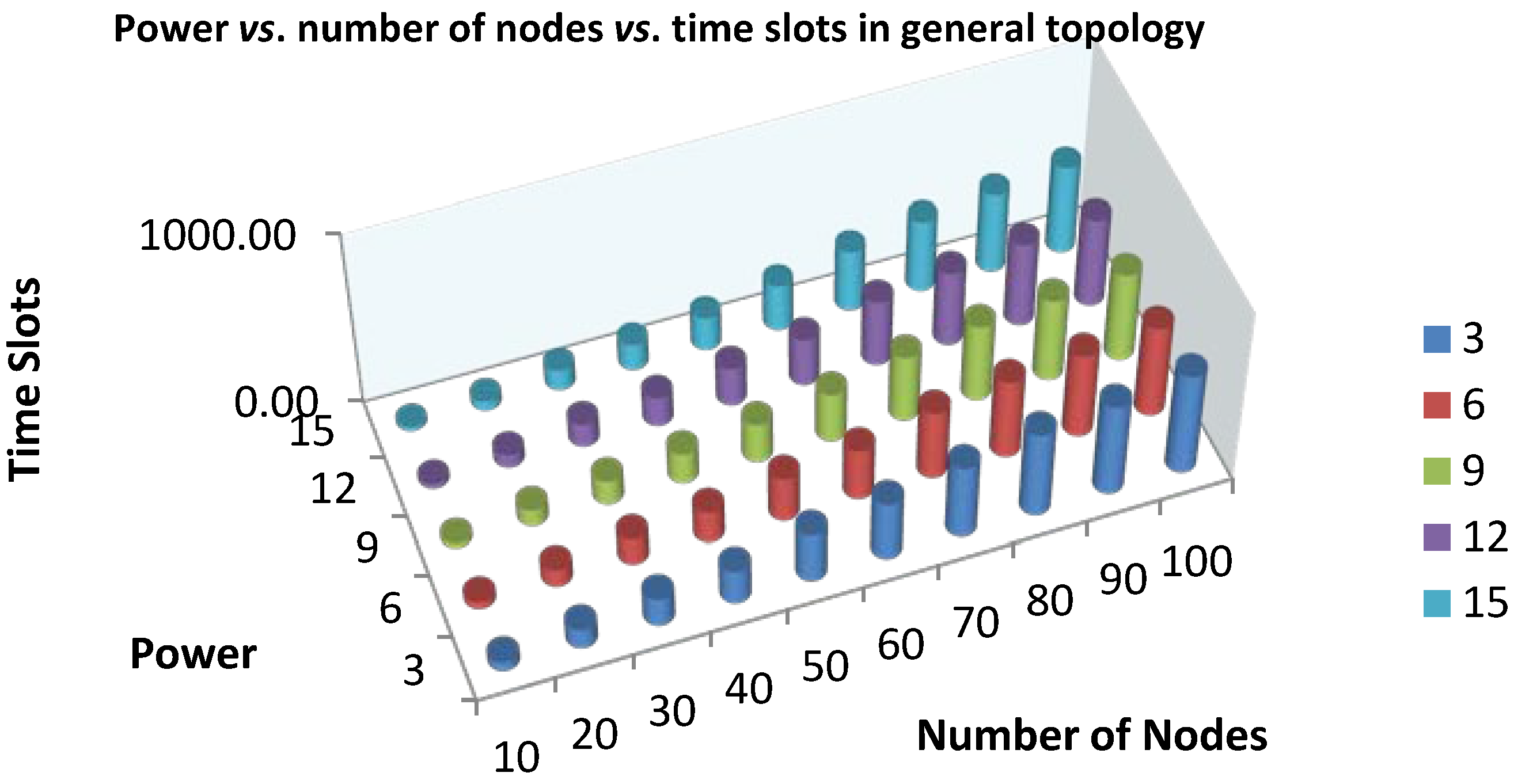
4.2. Applying Linear Structure to Get the Minimum Scheduling Time for Convergecast
The algorithm produces the line structure of each spanning tree. We applied the algorithm of Choi
et al. [
3] to get the minimum scheduling time. The authors have proposed an optimal convergecast scheduling algorithm based on the line topology with a fixed transmission range. The developed algorithm consists of four different algorithms. When the number of sensors is in a range less than the transmission range, the SIMPLE algorithm is used to send a message to the sink node directly. If the number of sensors is placed in the
p ≤
n ≤
p(
p + 1) range, where
n is the number of sensors and
p is the transmission power, then apply the TABLE and ADJUST algorithms. If the number of sensors is placed in the
p (
p + 1) <
n range, then apply the REDUCE algorithm first to use TABLE and ADJUST. The algorithms, SIMPLE, TABLE, ADJUST and REDUCE, are described in more detail as follows:
(1) If n < p, then apply the SIMPLE algorithm, which can allocate n time slots for the messages (mi, 1 ≤ i ≤ n) to send a message from node i to the sink node at time slot i, because each node directly sends the message to the sink node in the given condition.
(2) If p ≤ n ≤ p(p + 1), then apply the TABLE and ADJUST algorithms. The TABLE algorithm allows us to allocate 2p(p + 1) − p time slots to deliver any p(p + 1) messages; on the other hand, the ADJUST algorithm reallocates it for p(p + 1) nodes and then allocates the time slots for n nodes.
(3) If p(p + 1) < n, then apply the REDUCE algorithm with (n − p) nodes and then apply the TABLE and ADJUST algorithms.
Table 3 explains the minimum time schedule for using these algorithms.
Table 3.
Time schedule with TABLE when n = 10, p = 3.
Table 3.
Time schedule with TABLE when n = 10, p = 3.
| Time | Node |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 1 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 11 | 0 | 0 |
| 2 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 0 |
| 3 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 13 |
| 4 | 1 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 |
| 5 | 2 | 0 | 0 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 0 |
| 6 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 0 | 0 |
| 7 | 4 | 0 | 0 | 0 | 0 | 11 | 0 | 0 | 0 | 0 | 0 |
| 8 | 5 | 0 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 |
| 9 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 13 | 0 | 0 | 0 |
| 10 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 15 | 0 |
| 11 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 16 |
| 12 | 0 | 0 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | 18 | 0 |
| 13 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 19 |
| 14 | 8 | 0 | 0 | 0 | 0 | 0 | 15 | 0 | 0 | 0 | 0 |
| 15 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 16 | 0 | 0 | 0 |
| 16 | 11 | 0 | 0 | 0 | 0 | 0 | 18 | 0 | 0 | 0 | 0 |
| 17 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 19 | 0 | 0 | 0 |
| 18 | 0 | 0 | 0 | 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 19 | 0 | 0 | 0 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 20 | 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 21 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 22 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 24 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
The above table is the output of the TABLE algorithm and function TABLE, with 11 nodes, including the sink node and three transmission ranges. We want to deliver the individual contents to the sink node, where the content number is the message originating from the cell number. The algorithms assumed that they can use virtual nodes, which are not physically used. The virtual node numbers used in this algorithm are {11, 12, 13, 15, 16, 18, 19}. In the table, the content “0” means there is no message delivered at the assigned time slot. For example, for the node number “1” and time slot “1”, there is content from the node “4”. For the node number “8” and time slot “1”, there is content from the node “11”, which is the virtual node.
When we send Contents 4, 5 and 6 to Nodes 1, 2 and 3, we move the non-conflicting messages in the same time slot as follows:
When sending 4 to 1, then move 11 to 8, and 18 to 15, and so on, up to n + p2 (here, 10 + 9 = 19);
when sending 5 to 2, then move 12 to 9 and 19 to 16, when sending 6 to 3; then move 13 to 10.
When we send Contents 1, 2 and 3 to the sink node, we also move the non-conflicting messages in the same time slot as follows:
When sending 1 to the sink node (0), then move 8 to 5 and 15 to 12;
when sending 2 to the sink node (0), then move 9 to 6 and 16 to 13;
when sending 3 to the sink node (0), then move 10 to 7.
When we send Contents 4, 5 and 6 to the sink node, we move non-conflicting messages as follows:
When sending 4 to 1, then move 11 to 5 and 18 to 12;
when sending 5 to 1, then move 12 to 6 and 19 to 13;
when sending 6 to 1, then move 13 to 7.
When we send Contents 8 and 9 to Nodes 2 and 3, we can move 15 to 9 and 16 to 10.
When we send Contents 11 and 12 to Nodes 2 and 3, we can move 18 to 9 and 19 to 10.
When we send Contents 8 and 9 to the sink node, we can move 15 to 6 and 16 to 7.
After we send Content 15 to 3 in time slot 18 and 18 to 3 in time slot 19, Contents 15 and 18 arrive at the sink node in Time Slots 20 and 21.
Table 4 is made, and it has
p(
p + 1) messages in the sink node, because n is always less than or equal to
p(
p + 1).
Table 4.
Time schedule with ADJUST − (1) when n = 10, p = 3.
Table 4.
Time schedule with ADJUST − (1) when n = 10, p = 3.
| Time | Node |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 1 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 11 | 0 | 0 |
| 2 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 12 | 0 |
| 3 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 13 |
| 4 | 1 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 |
| 5 | 2 | 0 | 0 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 0 |
| 6 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 0 | 0 |
| 7 | 4 | 0 | 0 | 0 | 0 | 11 | 0 | 0 | 0 | 0 | 0 |
| 8 | 5 | 0 | 0 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 |
| 9 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 13 | 0 | 0 | 0 |
| 10 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 15 | 0 |
| 11 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 16 |
| 12 | 0 | 0 | 11 | 0 | 0 | 0 | 0 | 0 | 0 | 18 | 0 |
| 13 | 0 | 0 | 0 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 19 |
| 14 | 8 | 0 | 0 | 0 | 0 | 0 | 15 | 0 | 0 | 0 | 0 |
| 15 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 16 | 0 | 0 | 0 |
| 16 | 11 | 0 | 0 | 0 | 0 | 0 | 18 | 0 | 0 | 0 | 0 |
| 17 | 12 | 0 | 0 | 0 | 0 | 0 | 0 | 19 | 0 | 0 | 0 |
| 18 | 0 | 0 | 0 | 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 19 | 0 | 0 | 0 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 20 | 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 21 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 22 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 24 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
In the sink node, we have messages, i.e., 1, 2, 3, 4, 5, 6, 8, 9, 11, 12, 15 and 18. That means we missed Messages 7 and 10. For 7, we find the smallest number, but greater than n (=10), among those received, which is 11.
After searching 11 among Column 7, 6 and 5, we can find it at Table (7, 5) and replace the content with 7. The next 11 is located in column 2 (5 − 3 = 2) which is the Table (12, 2), and we replace the content with 7. The next, 11, is located in 0 (2 − 3 = −1, but the negative number is always 0 here), which is the Table (0, 16); replace Table (0, 16) with 7. We can execute the same algorithm for the content of 10. Then, we can get
Table 5.
Table 5.
Time schedule with ADJUST − (2) when n = 10, p = 3.
Table 5.
Time schedule with ADJUST − (2) when n = 10, p = 3.
| Time | Node |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 1 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 11 | 0 | 0 |
| 2 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 0 |
| 3 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 13 |
| 4 | 1 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 |
| 5 | 2 | 0 | 0 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 0 |
| 6 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 0 | 0 |
| 7 | 4 | 0 | 0 | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 |
| 8 | 5 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 0 | 0 | 0 |
| 9 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 13 | 0 | 0 | 0 |
| 10 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 15 | 0 |
| 11 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 16 |
| 12 | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 18 | 0 |
| 13 | 0 | 0 | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 19 |
| 14 | 8 | 0 | 0 | 0 | 0 | 0 | 15 | 0 | 0 | 0 | 0 |
| 15 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 16 | 0 | 0 | 0 |
| 16 | 7 | 0 | 0 | 0 | 0 | 0 | 18 | 0 | 0 | 0 | 0 |
| 17 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 19 | 0 | 0 | 0 |
| 18 | 0 | 0 | 0 | 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 19 | 0 | 0 | 0 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 20 | 15 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 21 | 18 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 22 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 23 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 24 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
The next step of the algorithm deletes all numbers greater than
n and deletes all rows that do not contain any number from one to
n.
Table 6 shows the minimum time schedule when the number of nodes
n = 10 and the transmission range
p = 3.
Table 6.
Completed time schedule when n = 10, p = 3.
Table 6.
Completed time schedule when n = 10, p = 3.
| Time | Node |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 1 | 0 | 4 | 0 | 0 | 0 | 0 | 0 | 0 | 11 | 0 | 0 |
| 2 | 0 | 0 | 5 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 0 |
| 3 | 0 | 0 | 0 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 1 | 0 | 0 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 |
| 5 | 2 | 0 | 0 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 0 |
| 6 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 0 | 0 |
| 7 | 4 | 0 | 0 | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 |
| 8 | 5 | 0 | 0 | 0 | 0 | 0 | 10 | 0 | 0 | 0 | 0 |
| 9 | 6 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 10 | 0 | 0 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 11 | 0 | 0 | 0 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 12 | 0 | 0 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 13 | 0 | 0 | 0 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 14 | 8 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 15 | 9 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 16 | 7 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 17 | 10 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
The example we used is when the number of nodes is less than
p (
p + 1),
n <
p(
p + 1). If the number of nodes is greater than
p(
p + 1),
n >
p(
p + 1), the REDUCE algorithm is applied to make the condition,
n <
p(
p + 1); then, use the TABLE and ADJUST algorithm to get the minimum time schedule. For example, If
n = 14 and
p = 3, we have nodes,
n = {1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14}; then, make it
n = {4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14} using
Table 7, as follows.
Table 7.
Time schedule with REDUCE when n = 14, p = 3.
Table 7.
Time schedule with REDUCE when n = 14, p = 3.
| Time | Node |
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 1 | 1 | - | - | - | - | 8 | - | - | - | - | - | - | - | - | - |
| 2 | 2 | - | - | - | - | - | 9 | - | - | - | - | - | - | - | - |
| 3 | 3 | - | - | - | - | - | - | 10 | - | - | - | - | - | - | - |
| 4 | - | 4 | - | - | - | - | - | - | 11 | - | - | - | - | - | - |
| 5 | - | - | 5 | - | - | - | - | - | - | 12 | - | - | - | - | - |
| 6 | - | - | - | 6 | - | - | - | - | - | - | 13 | - | - | - | - |
| 7 | - | - | - | - | 7 | - | - | - | - | - | - | 14 | - | - | - |
After 2p + 1 = 7 steps, we have n = {4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14}. This is the same as the problem with n = 10 and p = 3 from this point. Then, we use the TABLE and ADJUST algorithms to get the minimum time schedule.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}