This section presents our proposed algorithm and analyzes its performance.
3.1. Basic Idea
The basic task of the algorithm is to replace a pair
occurring in a string by a new symbol
Z and generate a production
to
, where all occurrences of
that are determined to be replaced are replaced by a same
Z. We note, however, that not all occurrences of
are replaced by
Z. The critical task is to determine which occurrence of
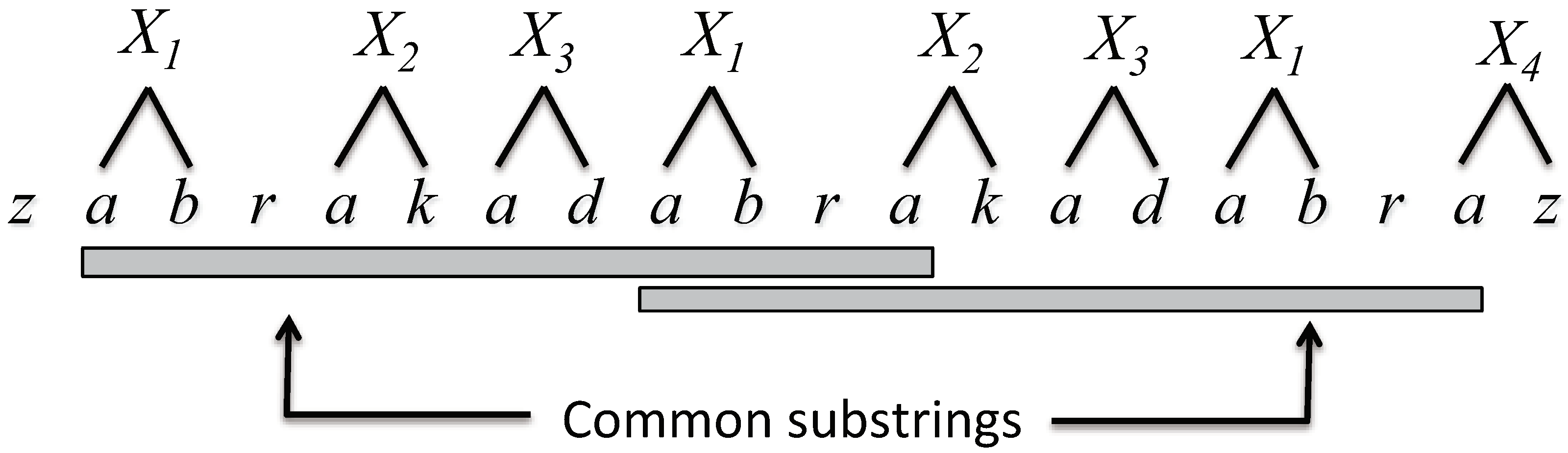
is replaced such that replaced pairs in common substrings are almost synchronized as shown in
Figure 1. That is, the aim of this algorithm becomes to minimize the number of different nonterminals generated.
Here we explain the three decision rules for the replacement. The rules introduced in this paper are modified version of the Sakamoto
et al.’s algorithm [
25] to extend to our online compression in the next subsection.
The first rule (repetitive pair): Let a current string contain a maximal repetition . We generate for an appropriate nonterminal A, and replace if k is even, or replace if k is odd.
The second rule (minimal pair): We assume a total order over ; that is, any symbol is represented by an integer. If a current string contains a substring such that , then the occurrence of is called minimal. The second decision rule is to replace all such pairs in by an appropriate nonterminal.
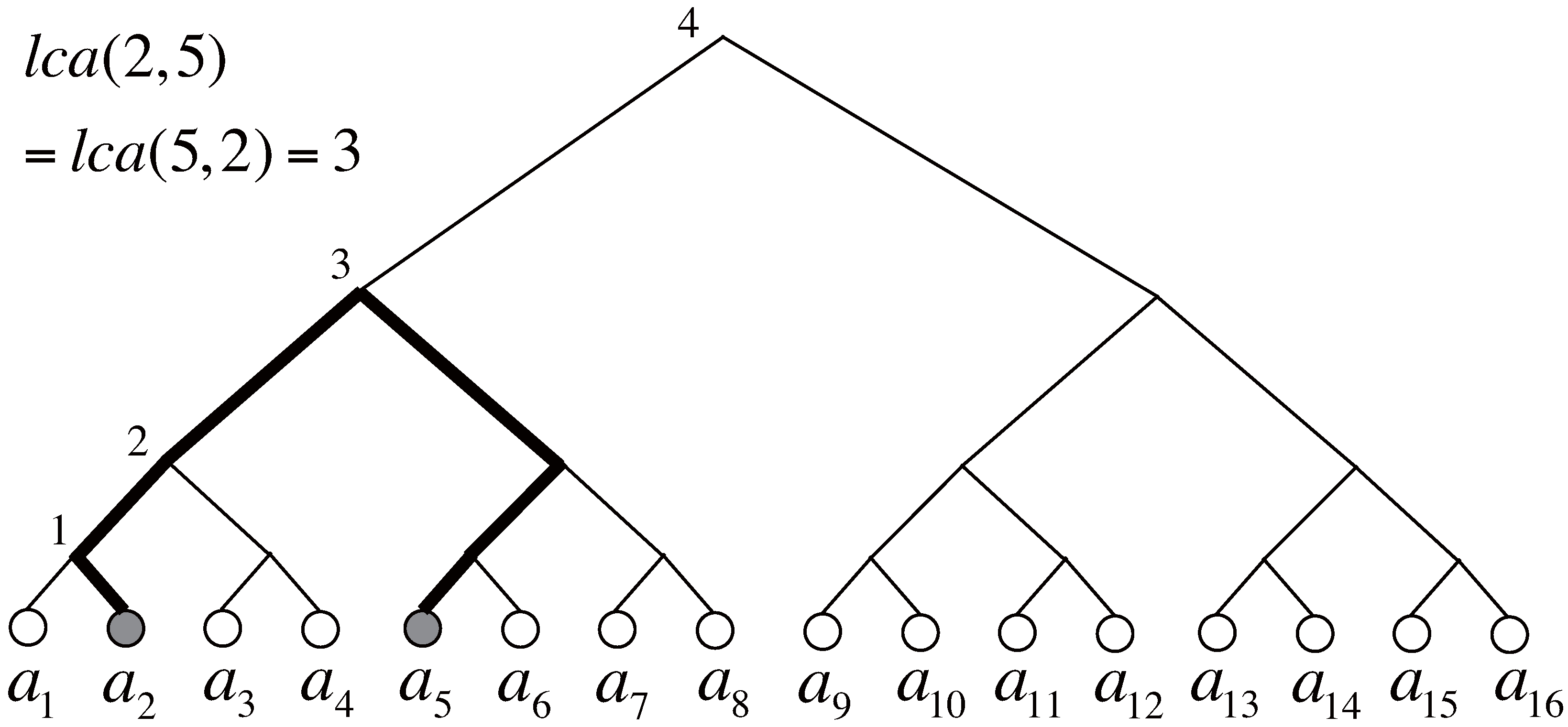
In order to introduce the third decision rule, we explain the notion of the lowest common ancestor on a tree.
Definition 1. Let p be a positive integer and . The index tree is the rooted, ordered complete binary tree whose leaves are labeled with from the left. The height of a node v refers to the number of edges in the longest path from v to a descendant of v. Then, the height of the lowest common ancestor of leaves is denoted by (We can get the for any leaves i and j of (virtual) complete binary tree in time/space under RAM model [28].) for short. Figure 2 shows an example of the index tree and lowest common ancestor.
The third rule (maximal pair): For a fixed order of alphabet, let a current string contain a substring such that the integers are either increasing or decreasing in this order. If , then the occurrence of the middle pair is called maximal. The third decision rule is to replace all such pairs by an appropriate nonterminal.
We call pairs replaced by the above rules special pairs which appear in almost synchronized position in the common substrings. Be careful that we need to set the priority of the decision rules because such cases possibly overlap and we cannot apply the repetitive and minimal rules simultaneously. For example, the substring contains such overlapping pairs. We therefore apply the repetitive and minimal rules in this order to keep uniqueness of the replacement. Indeed, no cases overlap with this priority.
If pairs and are special pairs and a substring contains no special pairs, then we suitably determine replaced pairs in with left priority, that is, if is odd then the pairs are replaced, otherwise . By this replacement, the length of the interval not replaced for a string becomes at most one.
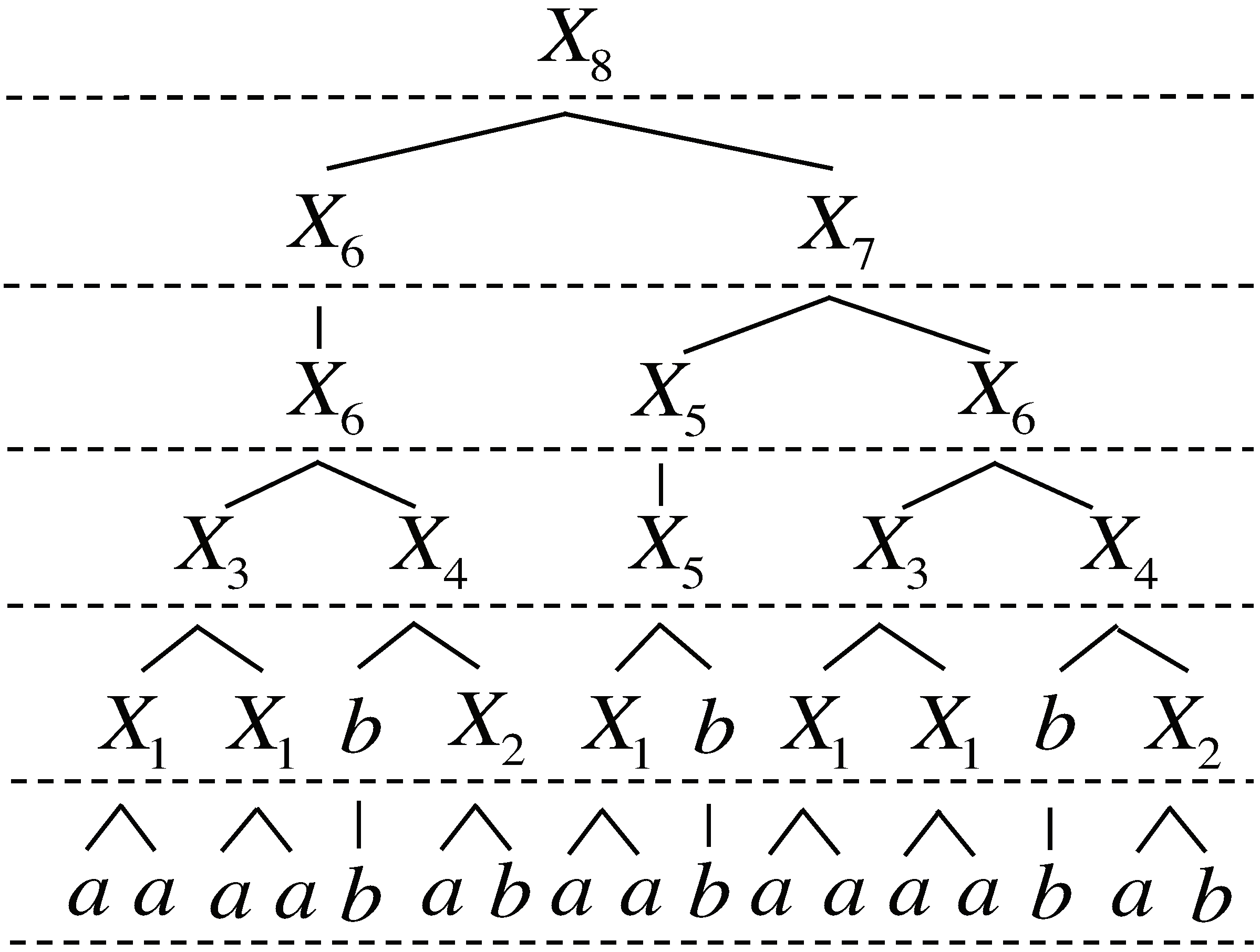
In the case of offline compression, it is easy to generate a grammar by the replacement rules. After we replace pairs in a input string
w, we recursively continue this process for a new string produced by replacing pairs until the replaced string becomes only one symbol as shown in
Figure 3. We note the height of a parse tree is bounded by
, where
, because the algorithm replace at least one of
or
. In the next subsection, we will apply the basic idea to the online algorithm.
3.2. Algorithmic Detail
The offline algorithm makes a bottom-up parse tree represented as a CFG. On the other hand, the online algorithm approximates the compression by simulating the left to right construction of a parse tree. To do this, we must determine a replaced pair by only a short substring. By the priority of the rules, we can determine that the pair for any position is the special pair or not by checking the rules simultaneously. In addition, the following lemma enable us to determine a replaced pair from the only a substring of length five.
Lemma 1. Assume that replaced pairs in are already determined, whether becomes a replaced pair or not depends on the interval .
Proof. We consider to decide whether the substring includes the special pair under the assumption that is already replaced. We first need to check a repetitive pair is included or not because of the strongest rule. For the case that , we replace as a repetitive pair. For the case that , we preferentially select as a replaced pair. We also pay attention to the case such that , then we forcibly replace because is the beginning of maximal repetition. For the minimal or maximal pair, we can decide is minimal and maximal pair by computing with and , respectively. If is minimal or maximal pair, then is not selected as a replaced pair by the priority. Thus there is no conditional statement using the outside of the interval for computing special pairs. □
From the Lemma 1, we describe the Algorithm 1 that is the statement to determine
is replaced or not. Note if
contains no special pair, we determine
as a replaced pair. By using Algorithm 1, it is easy to replace pairs in one pass over a string.
| Algorithm 1 : a string w and a position i. |
| 1: /* decides a pair is replaced or not */ |
| 2: if is the repetitive pair then |
| 3: return ; |
| 4: else if is the repetitive pair then |
| 5: /* is preferentially replaced. */ |
| 6: return ; |
| 7: else if is the repetitive pair then |
| 8: /* is forcibly replaced by the priority of the repetitive pair. */ |
| 9: return ; |
| 10: else if is the minimal or maximal pair then |
| 11: return ; |
| 12: else if is the minimal or maximal pair then |
| 13: /* is preferentially replaced. */ |
| 14: return ; |
| 15: else |
| 16: /* contains no special pair. */ |
| 17: return ; |
| 18: end if |
The compression algorithm determine replaced pairs in short buffers corresponding to each level of a parse tree. Let h is the height of the parse tree. We first prepare queues implemented by circular buffers. Each has a role as a buffer to store a segment of string w at the ith level of the parse tree, where the input string corresponds to first level of the tree. The number h of queues is bounded by because of the height of parse tree. We define basic operations for such queues as follows:
: add the symbol x into the tail of the queue .
: return the head of the queue and remove it.
: return the head of the queue .
: return the length of the queue .
The head of the queue is denoted by and thus the tail corresponds to . Each queue is used for deciding a replaced pair using the function and its maximum length can be bounded by .
By the Lemma 1, we can restrict the maximum length of any queue by a constant longer than five.
For linear time compression, we must prepare another data structure
called
reverse dictionary:
returns a nonterminal
z associated with the pair
by
. In case
,
creates a new nonterminal symbol
and returns
. For instance, if we have a dictionary
,
returns
,
creates a new nonterminal
and returns it. If we use randomization,
can be computed in
worst case time and inserting a new production rule can be achieved in
amortized time within
space using dynamic perfect hashing [
29].
Next we outline the online algorithm. We describe the online version of LCA in Algorithm 2 as well as its recursive function
in Algorithm 3. All queues are initialized to contain only
dummy symbol , which is required to compute the first pair at the each queue. In the lines 2–5 of Algorithm 2, input characters are enqueued to
one by one. In Algorithm 3, if there is
such that
, the algorithm decides the replaced pair in
. In case
is replaced by an appropriate nonterminal
z,
is dequeued and
z is enqueued to
. In case
is replaced by
z,
is dequeued and
is enqueued to
. The symbol
in the first case and
in the second case are remaining in
to determine the next replaced pair after a new symbol is enqueued to
.
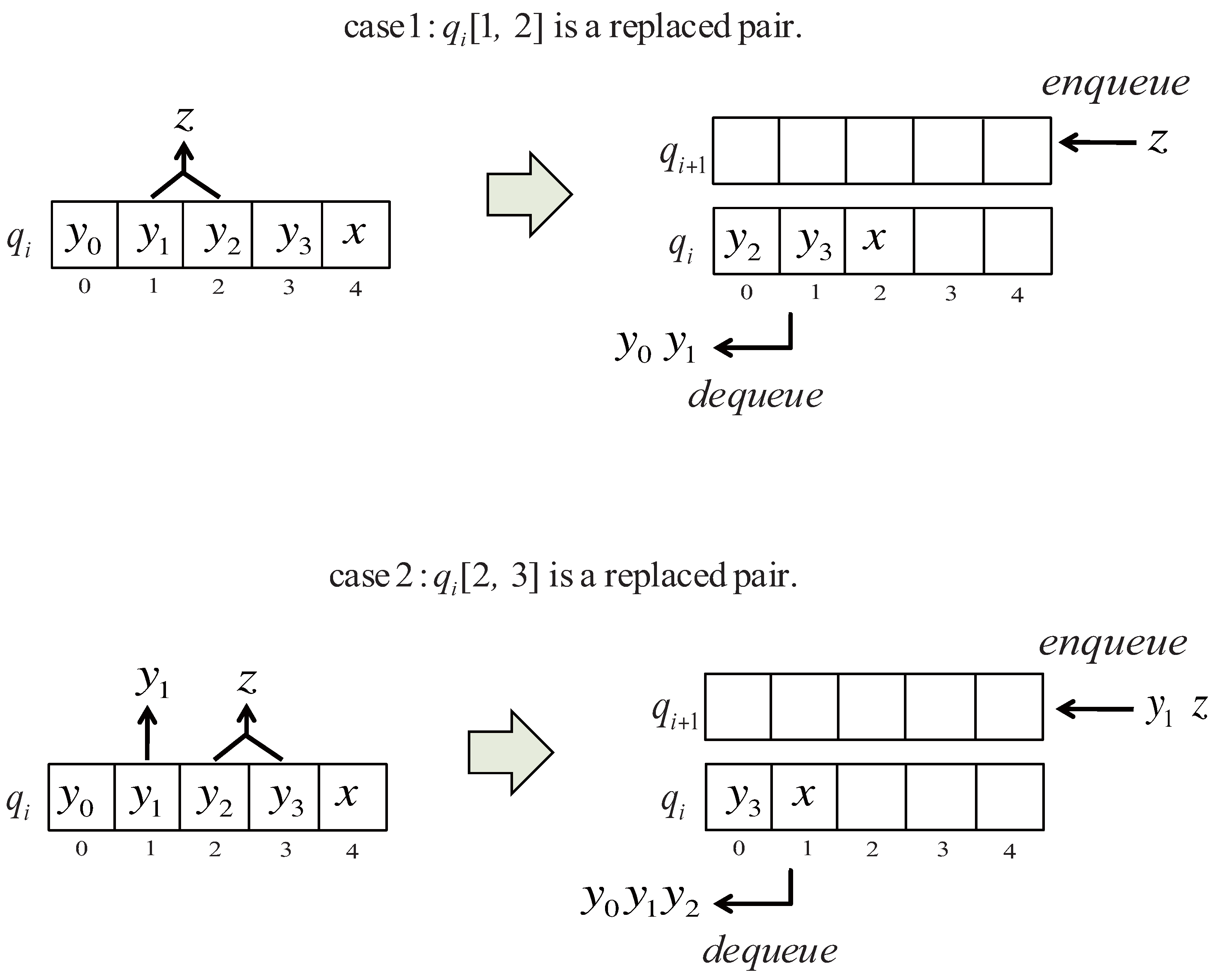
Figure 4 describes the action of the function
. The algorithm recursively continues the above process until all input characters are enqueued. As the post-processing, the symbols remaining in the queues
are replaced by appropriate nonterminals in the left to right order. Finally the produced dictionary is returned.
| Algorithm 2 LCA-online. |
| 1: ; initialize queues; |
| 2: repeat |
| 3: input a new character c; |
| 4: ; |
| 5: until c is not the end of the inputs. |
| 6: ; |
| 7: while is not empty do |
| 8: replace the symbols remained in , |
| 9: and then enqueue the string replaced in into ; |
| 10: ; |
| 11: end while |
| 12: output ; |
| Algorithm 3 : a queue and a symbol x. |
| 1: ; |
| 2: if then |
| 3: if then |
| 4: ; |
| 5: ; ; |
| 6: ; |
| 7: ; /* update */ |
| 8: ; |
| 9: else |
| 10: ; |
| 11: ; |
| 12: ; |
| 13: ; ; |
| 14: ; |
| 15: ; /* update */ |
| 16: ; |
| 17: end if |
| 18: end if |
3.3. Performance Analysis
First, we estimate the running time of LCA-online. We use the following notation indicating the string enqueued to a queue.
Definition 2. For each queue , let denote the string obtained by concatenating all symbols enqueued to from left to right order.
Note that
corresponds to the
ith level of string in a parse tree produced by replacing pairs as shown in
Figure 3. We first prove the following characteristic.
Theorem 2. The running time of LCA-online is bounded by , where n is the input length.
Proof. For any , the inequality holds because the algorithm replaces at least one of and . Therefore, and the total number of symbols inserted into all queues is bounded by . In any queue, computing a replaced pair is time because we can verify in time whether or not contains one of the repetitive, minimal, and maximal pairs. Also, computing the appropriate nonterminal for any pair can be computed in time. Hence, the running time is bounded by time. □
Next, we prove that the approximation ratio of LCA-online is reasonable. The approximation ratio of the compression algorithm is the upper bound of for the output grammar size g and the minimum grammar size when arbitrary input string is given.
Definition 3. Let be a string and be an occurrence of a substring α in . We call a boundary occurrence if and .
Definition 4. Let be a string enqueued to . Then is the shortest substring of which derives a string containing .
Lemma 2. Let be any boundary occurrences. For input string length n, there exists an integer such that .
Proof. Let us consider the index tree . If a string of length m is a monotonic; i.e., either or , and are monotonic, then m is bounded by . Therefore, at least one of minimal pair or maximal pair must appear within consecutive symbols having no repetition. Thus, a prefix of longer than contains at least one of minimal/maximal pair; it also appears in at the corresponding position. Hence, the replacements of inside and , i.e., and completely synchronize. Hence, for . ȃ□
Theorem 3. The approximation ratio of LCA-online is , where g is the output grammar size, is the minimum grammar size, and n is the length of the input string.
Proof. We estimate the number of different nonterminals produced by LCA-online. Let be the -factorization of an input string w. Let denote the maximum number of different nonterminals generated in a single queue after the compression of w is completed. From the definition of -factorization, any factor occurs in the prefix , or . First, we consider the case that is a boundary occurrence. By Lemma 2, any two occurrences of are respectively transformed to and such that , , and . In the case that is not a boundary occurrence, for some string and repetitions . For repetitions and , the number of different nonterminals produced by the replacement of and is bounded by . If is a boundary occurrence, this case is the same as the one in which is a boundary occurrence. If is not a boundary occurrence, for some string , and and . In this case, any occurrence of inside is transformed to exactly same string. Thus, for a single queue, we can estimate . Because the number of queues is at most , the size of the final dictionary is . □
Finally, we estimate the space complexity of our algorithm.
Theorem 4. The space required by LCA-online is bounded by , where is the minimum grammar size and n is the input string length.
Proof. The number of queues is bounded by and the length of any queue is . Thus, required space for the queues is . For the reverse dictionary, the space is bounded by the generated grammar size. By the Theorem 3, the space of the reverse dictionary is bounded by . Thus, the total space is bounded by . □









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}