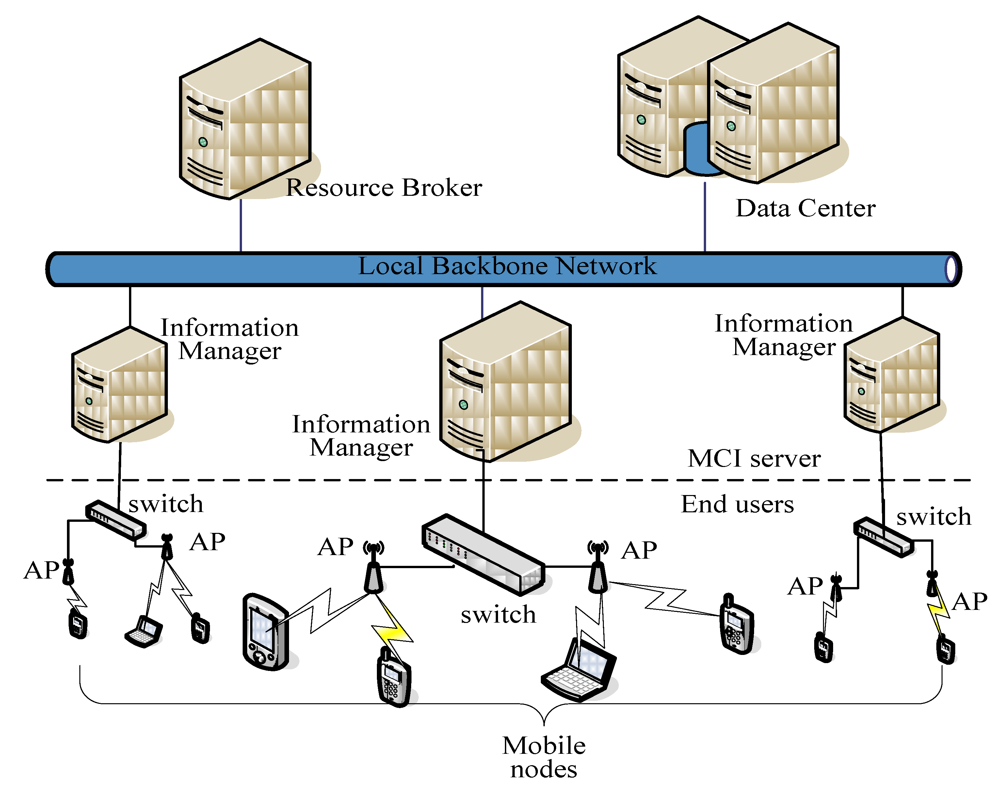
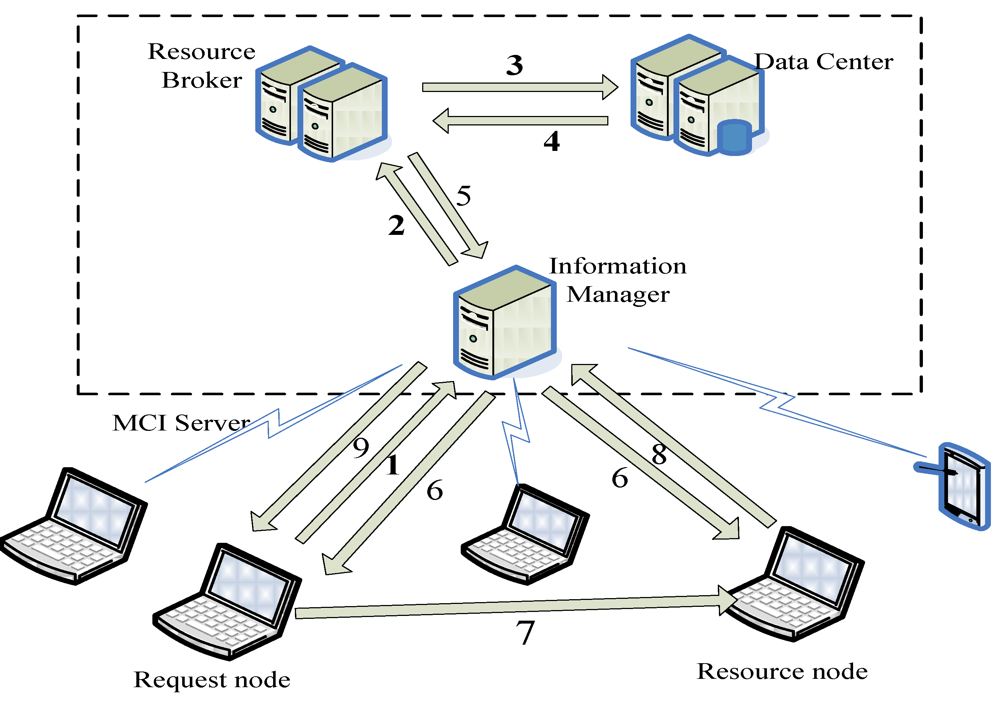
Data Center maintains a table, called the performance table, which records network status and node information collected by Information Manager, and several score tables that list the features of a node and their scores. Here, a request node is a node from which users submit their user requests, whereas a resource node is a node that serves users with its own resources. Request nodes and resource nodes together are called user nodes, and a request node may also be a resource node.
3.1.2. Node and Request Classification
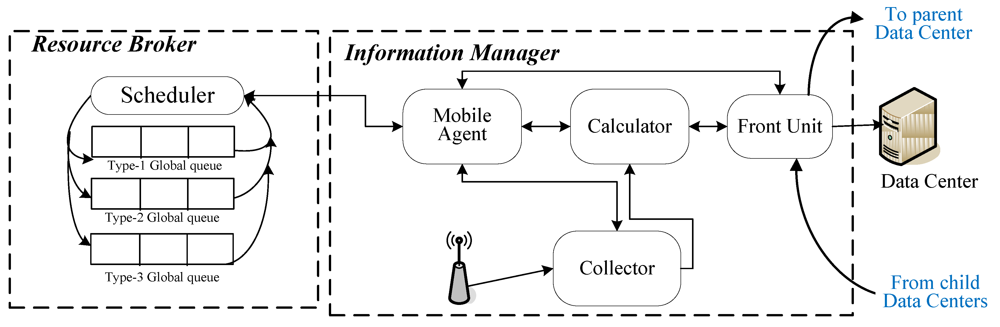
The entry values in the performance table are collected with different methods, e.g., the available memory size, CLWQ and CPU utilization rate, are gathered by Ganglia by actively polling resource nodes. The bandwidth is gathered by the TCP/IP network sensor in the NWS. The Information Manager periodically retrieves the performance table to calculate the performance scores,
i.e., the fourth from last column of
Table 1, for all resource nodes in the system. The score of a node
x, denoted by Score(
x), is defined as:
which was proposed by Leu
et al. in [
21] where
p (= 5) is the number of resource features collected in the performance table,
i.e., columns 2 to 6, and SC
xk is the score of the
kth resource feature (1 ≤
k ≤
p). With
Score()s, the nodes in the underlying grid system are classified into three performance levels (
i.e., the third from last column of
Table 1). Those with
Score() ≥ belong to level 1, those with 16
≥ Score() ≥ 15 (
Score() ≤ 14) are level 2 (level 3). Each level has its corresponding serving user requests, e.g., IPTV due to its tight time constraint belongs to level 1.
Furthermore, at any moment each resource node can be in one of the three states: idle, busy and isolated. A node N in idle state means that it is currently executing no jobs. As stated above, when Resource Broker/Scheduler allocates a resource node to a request, the request becomes a job to be served by the node. N in its busy state means that N is executing a job. The isolated state indicates that N does not share its resources with others, and a node in isolated state cannot send requests to acquire resources. N in its isolated state may occur in two cases: when N is executing some particular jobs, e.g., processing private information, and when it is temporarily inconvenient for the user of N to share his/her own resources with others. To isolate N from the system, we can terminate N’s Gmond tool [
8]. Then Resource Broker will not allocate N to serve user requests.
User requests are also classified into three types.
(1) Type 1: Real-time requests which will become time-constrained jobs, e.g., requesting a video TV program through IPTV.
(2) Type 2: Normal processes, e.g., ordinary applications.
(3) Type 3: Non-real-time data transmission and data storage, e.g., FTP and email delivery.
A type-i request when sent to Resource Broker will be enqueued in a type-i global queue, i = 1, 2, 3.
3.1.3. Semi-Preemptive Mode Resource Allocation
Before sending a request to Resource Broker, a user has to describe which type the request is. Note that a node’s performance score is dynamic, e.g., an originally level-1 resource node may become level-2 or level-3 if its load is now heavy, AMS is not huge enough and CLWQ is long.
Generally, there are at least two methods that can be employed to allocate different levels of resource nodes to different types of requests.
(1) Level-i resource nodes can only be allocated to serve type-i requests.
(2) Level-i resource nodes can only be allocated to serve type-j requests where i ≤ j, e.g., level-1 resource nodes can serve type-1, type-2, and type-3 requests, and level-3 nodes can only be allocated to serve type-3 requests.
However, with the first method, when many type-i requests and few type-j requests, i ≠ j, arrive, but currently no level-i resource nodes are available, many type-i requests have to wait in the type-i global queue for a long time, leaving many level-j resource nodes idle. When a few type-i and many type-j requests are submitted at the same time, i≤ j, the second method can solve the type-j’s long waiting-time problem since level-i resource nodes can be allocated to serve the remaining type-j requests.
Nevertheless, the second method may introduce another problem, e.g., many type-1 requests are submitted, but currently insufficient level-1 resource nodes can serve them immediately. The reason is that many originally level-1 resource nodes are now serving type-2 and type-3 requests and become level-2 or level-3 resource nodes where originally level-i resource nodes (o-level-i resource nodes for short) are those nodes belonging to level-i when they are idle, i = 1, 2. Hence, some of these type-1 requests have to wait for a long time in the type-1 global queue.
One may always point out that preemptive allocation can solve this problem, i.e., an o-level-1 resource node, e.g., N, which is now serving a type-2 or type-3 request may be preempted so that it can recover to level-1 immediately. This is true. But this also means that the resources consumed to serve the preempted job are wasted.
(1) Resource Allocation
To solve these problems, in this study, we propose a semi-preemptive approach, which reserves R1% of o-level-1 (R2% of o-level-2) resource nodes to serve type-1 (type-2) requests. The purpose is to compensate for the above-mentioned cases. Let Ri be the reserved percentage of level-i resources for type-i request, i = 1, 2, then
The denominators and numerators of Equation (2) are acquired, based on periodical statistics. In other words, at most R2’ (= 100 − R2)% of the o-level-2 (R1’ (= 100 − R1) %, of o-level-1) resource nodes can be dynamically allocated to serve type-3 (type-2 and type-3) requests.
Table 7.
The percentages of o-level-i resource nodes that can serve type-j requests, 1 ≤ i, j ≤ 3.
Table 7.
The percentages of o-level-i resource nodes that can serve type-j requests, 1 ≤ i, j ≤ 3.
| Req.\Nodes | O-level-1 resource nodes of R1 % | O-level-1 resource nodes of R1’% | O-level-2 resource nodes of R2% | O-level-2 resource nodes of R2’% | Level-3 resource nodes |
|---|
| Type-1 | 1 | 2 | - | 3 | 4 |
| Type-2 | - | 4 | 1 | 2 | 3 |
| Type-3 | - | 3 | - | 2 | 1 |
Percentages of o-level-
i resource nodes that can serve type-
j requests, 1 ≤
i,
j ≤ 3, are summarized in
Table 7 in which the numbers in a row represent the order in which the resource nodes are allocated to the corresponding types of requests. When the percentage of o-level-1 resource nodes assigned to serve type-1 requests reaches R1%, and now new type-1 requests arrive, Resource Broker will allocate o-level-1 resource nodes belonging to the R1’% to serve them. If no more o-level-1 is now available, then o-level-2 resource nodes that belong to the R2’% will be allocated to the new type-1 requests. R2% of o-level-2 resource nodes are reserved to serve type-2 requests only. As the R2’% of resource nodes is also used up, level-3 resource nodes will be allocated to these type-1 requests.
Similarly, when a type-2 request arrives, Resource Broker will first allocate o-level-2 resource nodes belonging to R2 % to serve the request. If no more o-level-2 resource nodes belonging to R2 % are available, those belonging to R2’% will be allocated. When no more o-level-2 resource nodes are available, level-3 resource nodes will be allocated. The fourth choice for a type-2 request is the R1’% of o-level-1 resource nodes. The chosen priorities of resource nodes for type-3 requests are level-3 (see type-3 row of
Table 7), R2’% of o-level-2 and then R1’% of o-level-1 resource nodes.
(2) Resource Preemption
There are two cases in which preemption is required. The first is that when a type-1 request arrives, no resource nodes of all levels that can serve type-1 requests are available. Maybe some of R2% of o-level-2 resource nodes are available, but due to our allocation policy, they cannot be allocated to serve type-1 requests. The second case is that when a type-2 request arrives, no level-2 (including R2% and R2’%), level-3 and R1’% of level-1 resource nodes are available.
When the first case occurs, Resource Broker first preempts an o-level-1 resource node that is serving a type-3 or type-2 request in the situation where the one serving a type-3 request will be chosen first (see
Table 8). Of course, these o-level-1 resource nodes are those belonging to the R1’% portion. O-level-1 resource nodes that are serving type-1 requests will not be preempted. However, if no o-level-1 resource nodes are now serving type-3 requests, one of the o-level-1 resource nodes now serving a level-2 request will be preempted. If all o-level-1 resource nodes are serving type-1 requests, some o-level-2 resource nodes will be preempted. The row type-1 in
Table 8 summarizes the preemption priorities. If no resource nodes are preempted, implying that all resources nodes are executing type-1 requests, the type-1 request will be re-enqueued in the type-1 global queue.
In the second case, only o-level-2 resource nodes that are serving type-3 requests (Of course, these resource nodes belong to the R2’% portion) will be preempted to serve the type-2 request. However, if no o-level-2 resource nodes are running type-3 requests, then one of the o-level-1 resource nodes now serving type-3 requests will be preempted. If no o-level-1 and o-level-2 resource nodes are preempted, indicating that they are all running type-1 and/or type-2 requests, one of the level-3 resource nodes currently serving type-3 requests will be preempted. If no resource nodes have been preempted, implying all resource nodes are running type-1 and/or type-2 requests, the request will be re-enqueued to the type-2 global queue.
Table 8.
The preemptive order of type-1 and type-2 requests. The lower the number, the higher the chosen priority.
Table 8.
The preemptive order of type-1 and type-2 requests. The lower the number, the higher the chosen priority.
| Request type | O-level-1 | O-level-2 | Level-3 |
|---|
| | R1’% of resources currently Serving Type-3 requests | R1’% of resources currently Serving Type-2 requests | R2’% of resources currently Serving Type-3 requests | R2’% of resources currently Serving Type-2 requests | Currently Serving Type-3 req. | Currently serving Type-2 req. |
| Type 1 | 1 | 2 | 3 | 4 | 5 | 6 |
| Type 2 | 2 | - | 1 | - | 3 | - |
When a type-3 request arrives, and no level-3, level-2 of R2’%, level-1 of R1’% nodes are available (see
Table 7), the request will be re-enqueued to the type-3 global queue. No preemption will be performed.
Once a resource node N is preempted, the request that N is now serving, e.g., request y, will be re-enqueued to N’s waiting queue, instead of its global queue, as the highest priority request to be executed by N when N finishes the job of the preempting request, and those requests which are now in N’s waiting queue will stay in the queue following their original waiting sequence to wait to be served by N.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
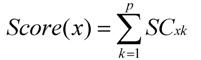






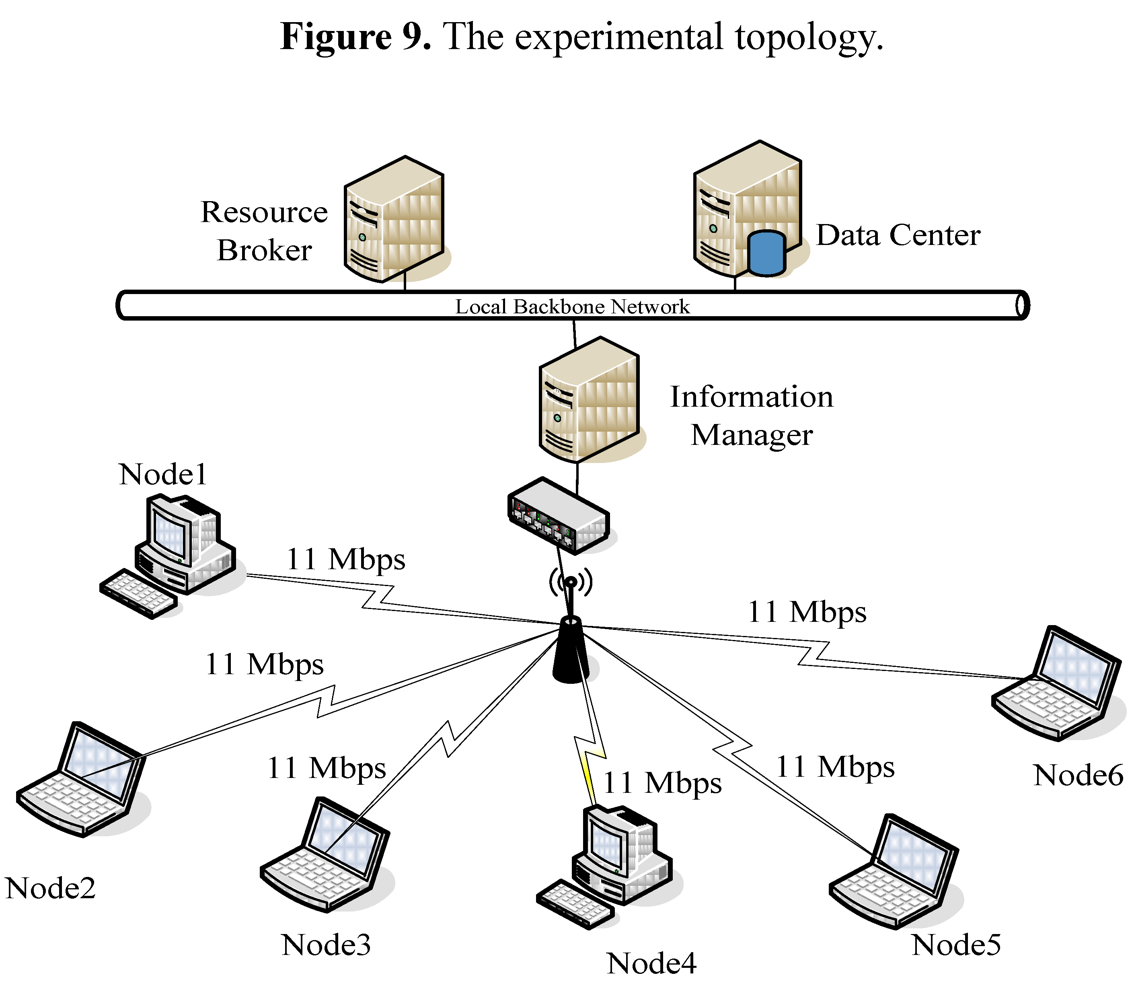
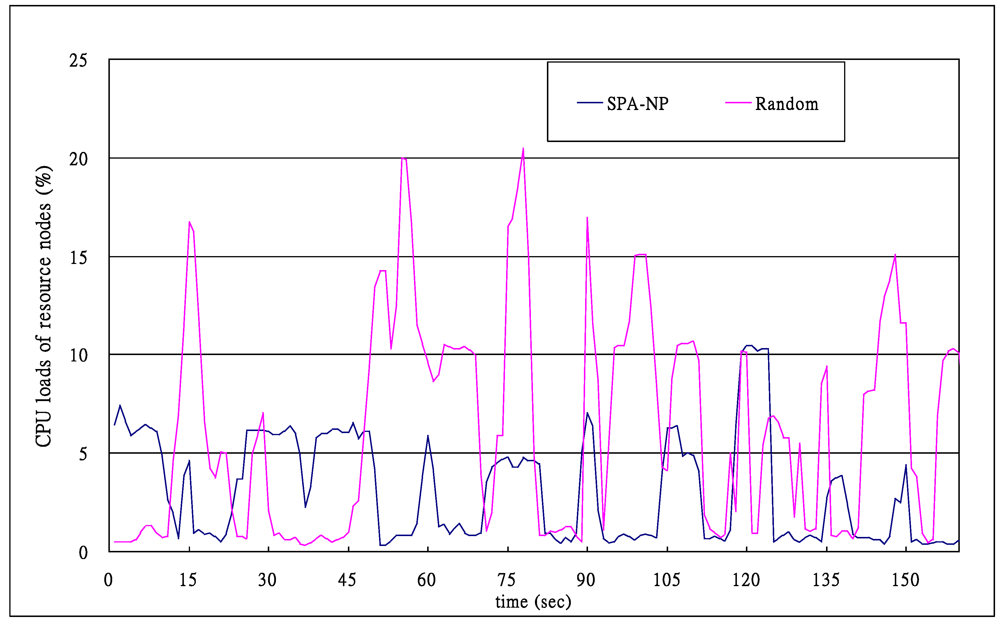
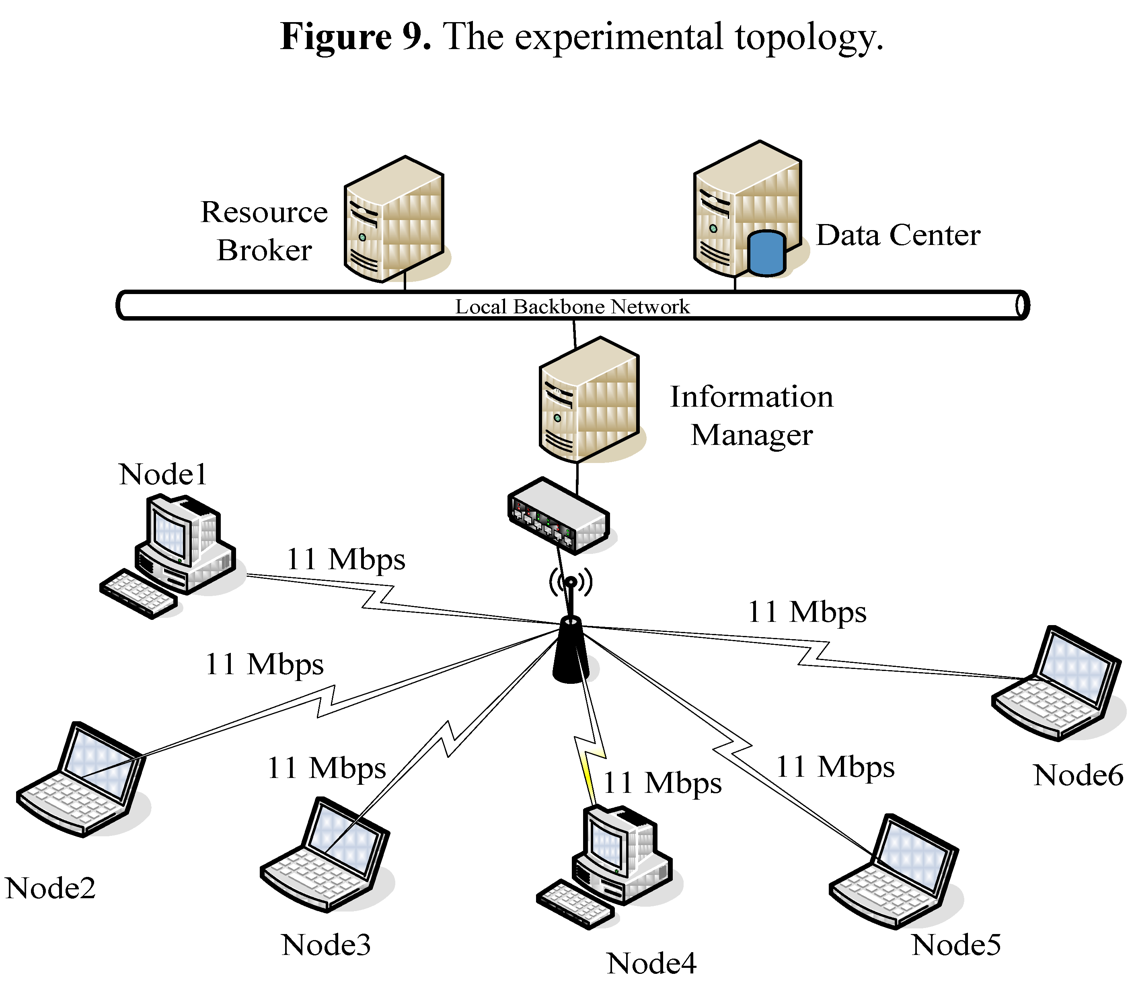
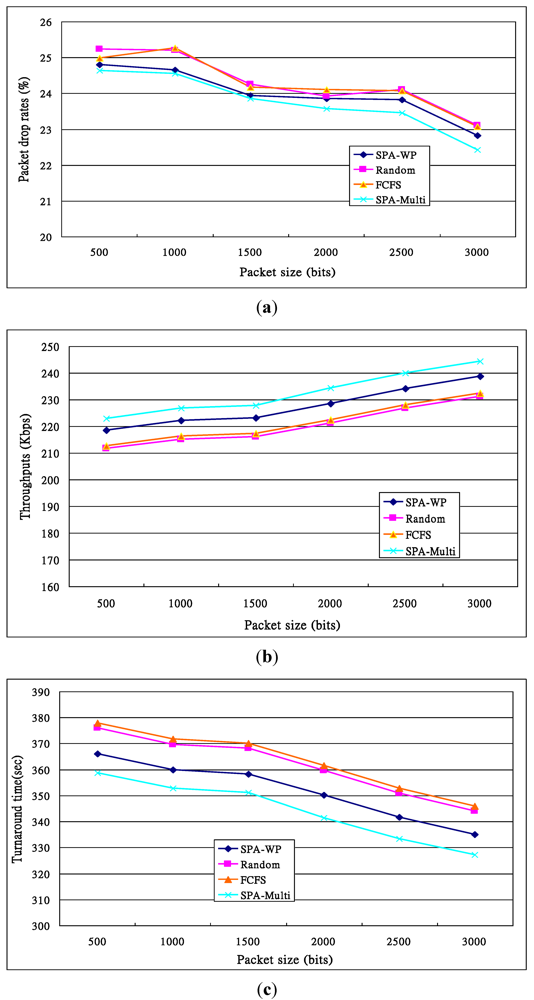
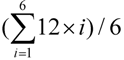 ) s. A node was allocated 10 requests by Resource Broker in average, and the turnaround time of first request was 42 s on average, the second request needed to wait for 42 s and the 10th request waited 420 s. So the ideal average turnaround time was 231 (=
) s. A node was allocated 10 requests by Resource Broker in average, and the turnaround time of first request was 42 s on average, the second request needed to wait for 42 s and the 10th request waited 420 s. So the ideal average turnaround time was 231 (= 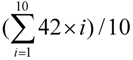 ) s.
) s.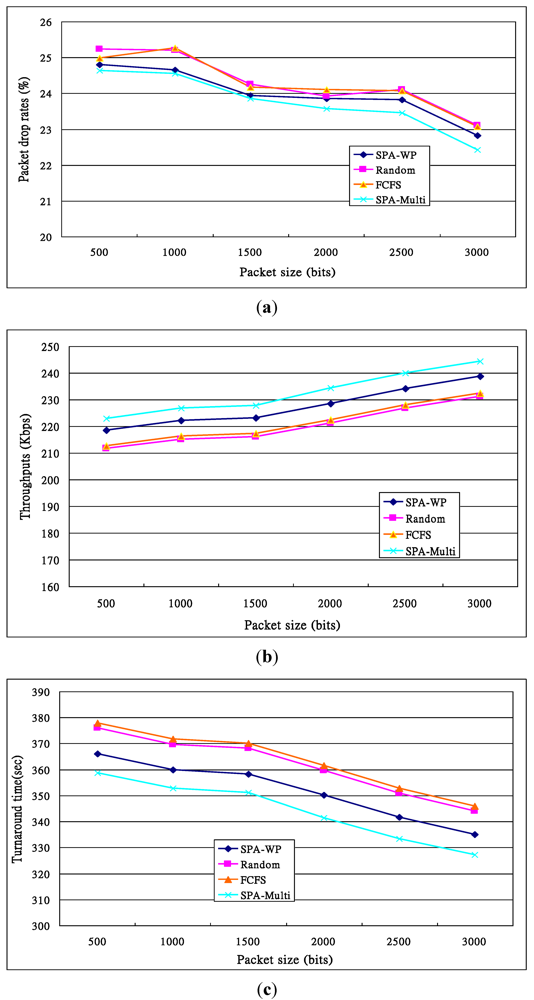
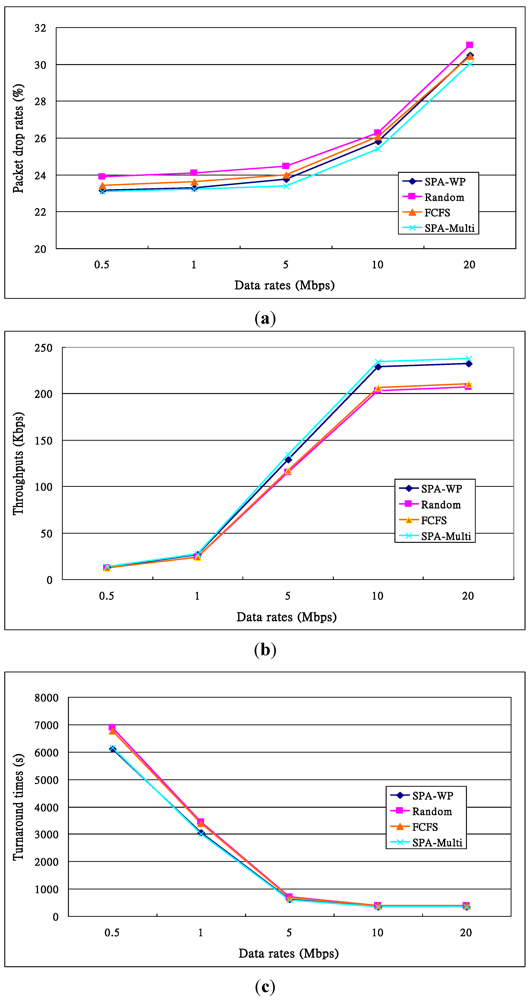
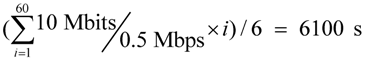 . Others can be calculated by a similar method.
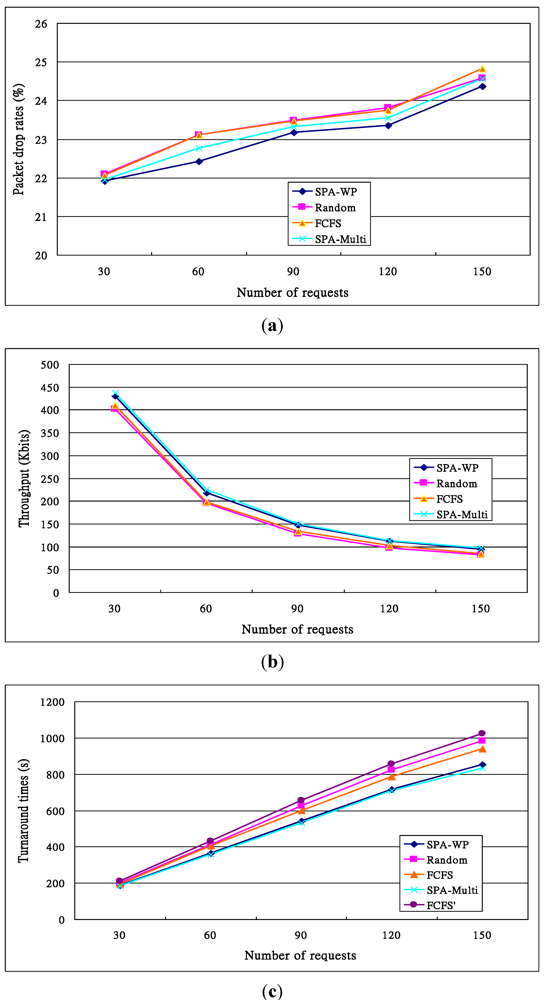
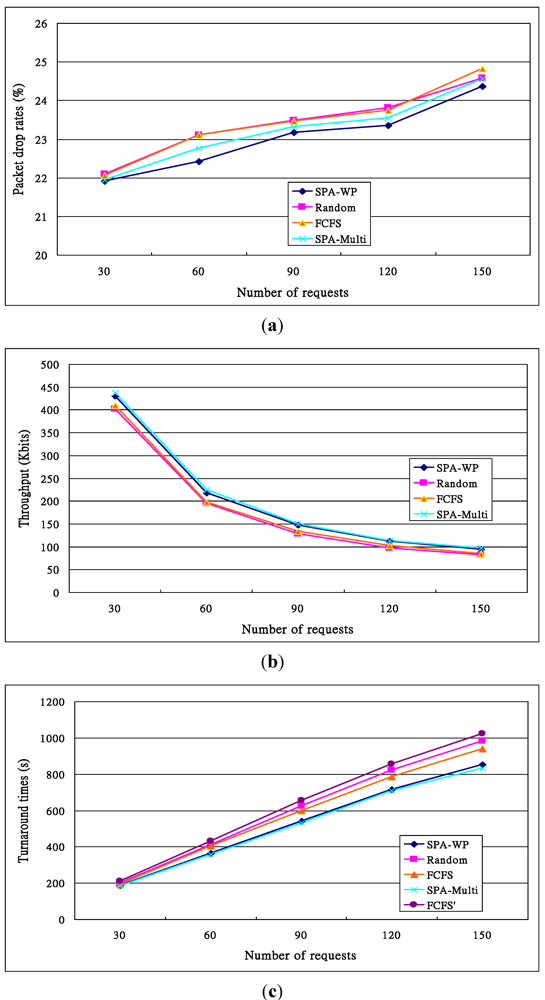
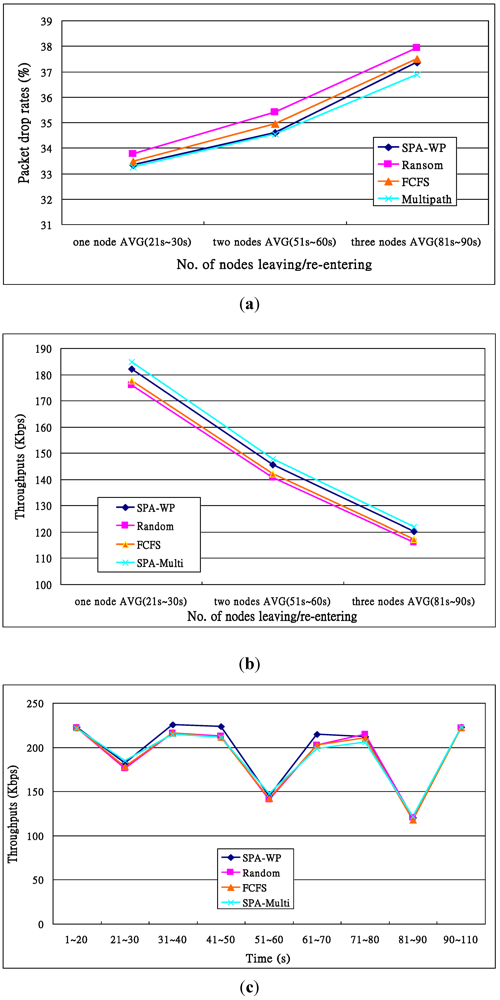
. Others can be calculated by a similar method.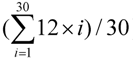 )). Others’ theoretical values can be calculated in the same way. With the FCFS, the performance of nodes 1 and 4 was better than that of nodes 5 and 6 so that the FCFS’s turnaround times were shorter than those of the Random, since about 66% of requests were served by the two nodes. However, if nodes 1 and 4 were the latest two nodes entering the system, the turnaround times, denoted FCFS’ in Figure 13c, were longer than those of the Random. The turnaround times with the SPA-WP and the SPA-Multipath were shorter than those with the Random and FCFS. The reason is described above.
)). Others’ theoretical values can be calculated in the same way. With the FCFS, the performance of nodes 1 and 4 was better than that of nodes 5 and 6 so that the FCFS’s turnaround times were shorter than those of the Random, since about 66% of requests were served by the two nodes. However, if nodes 1 and 4 were the latest two nodes entering the system, the turnaround times, denoted FCFS’ in Figure 13c, were longer than those of the Random. The turnaround times with the SPA-WP and the SPA-Multipath were shorter than those with the Random and FCFS. The reason is described above.