1. Introduction
It is well known that the larynx is the main organ of natural voice production for normal human beings to communicate, however, there are still many patients who suffer from larynx diseases or have no larynx (due to laryngectomies, which are the total removal of the larynx for the treatment of laryngeal cancer, other laryngeal lesions, and so on), which would lead to the loss of their vocal function. Therefore, various speech production substitutes have been developed and used practically in order to reconstruct speech functions [
1,
2,
3,
4], including the esophageal speech and the trachea-esophageal speech production methods, Tapia’s artificial larynx, and the electrolarynx (EL) [
1]. Comparing these post- laryngectomy forms of speech production, the electrolarynx, which is a hand-held battery-powered device that is typically held against the neck at the level of the former glottis to excite the vocal tract acoustically [
5], has several special advantages, such as being easier to use, production of longer sentences without special care, and being more effective in communication than other methods of voice rehabilitation in many situations. Therefore, the electrolarynx is the main method adopted for voice rehabilitation after laryngectomies, and has been clinically proven to be an important method of oral communication for laryngectomees for more than 50 years.
Unfortunately, both the EL device and the resulting speech have several serious shortcomings, especially the radiated noise during phonation, which is due to the fact that part of the sound energy produced is not able to pass through the neck tissue but rather is radiated directly from the instrument itself. Data from previous studies reported that this radiated noise was about 20-25 dB when the mouth was closed [
5], and varied over 4-15 dB across subjects for the same device [
6]. This radiated noise, therefore, may not only cause a stronger concentration of noise energy between 400-1 KHz and 2-4 kHz in EL speech, but also result in loss of speech intelligibility [
7]. In addition, the masking effect of the noise can contribute to the unnaturalness and poor quality of EL speech.
Besides the acoustic shielding technology which is applied on the EL device itself [
8], more and more signal processing techniques have been developed to improve EL speech [
9,
10,
11,
12]. To summarize these papers, two main speech enhancement algorithms have been developed to reduce the radiated noise of EL speech, and improve its intelligibility and naturalness. One method is the subtractive-type algorithm [
12,
13], which is the most widely used, and has been shown to be an effective approach for noise canceling. Due to the simplicity of implementation, and low computational load, the spectral subtraction method is the primary choice for real time applications [
9,
12]. In general, this method enhances the speech spectrum by subtracting an average noise spectrum from the noisy speech spectrum; here the noise is assumed to be uncorrelated and additive to the speech signal. The phase of the noisy speech is kept unchanged, since it is assumed that the phase distortion is not perceived by human ear. However, a serious drawback of this method is that the enhanced speech is accompanied by an unpleasant musical noise artifact which is characterized by tones with random frequencies. Although many solutions have been proposed to reduce the musical noise in the subtractive-type algorithms [
11,
14,
15,
16,
17], results performed with these algorithms show that there is a need for further improvement, especially under very low signal-noise ratio (SNR) conditions. Another method uses adaptive noise canceling [
10,
18], which removes the noise components of the primary input signal that depend on the reference input signal and are based on second-order statistics. However, many other noise components in the primary input signal, which depend on the noise reference signal through higher-order statistics may exist in the enhanced speech, which affects the effect of noise reduction.
Also, a previous perceptual study of EL speech suggested that the intelligibility of EL speech would be decreased if the signal-to-noise ratio (SNR) decreased [
19]. It is also noted that the low-energy EL speech can be easily masked by the different environment noises [
12], the reduction of speech quality, furthermore, causes listener fatigue. Therefore, it is important to investigate a new efficiently algorithm to eliminate both additive noise and the radiated noise. This would not only improve the life quality of the laryngectomees, since the EL is the only equipment for them to communicate, but also increase the quality of the EL speech for better understanding, especially in environment noise and electronic noise (low SNR) conditions.
Unlike white Gaussian noise, which has a flat spectrum, the spectrum of EL noise and the additive environment noise are not flat. Thus, the noise signal does not affect the speech signal uniformly over the whole spectrum. Some frequencies are affected more adversely than others. This means that this kind of noise is “COLORED”. In order to prevent destructive subtraction of the speech while removing most of the residual noise, it is necessary to propose a non-linear approach to improve the subtraction procedure.
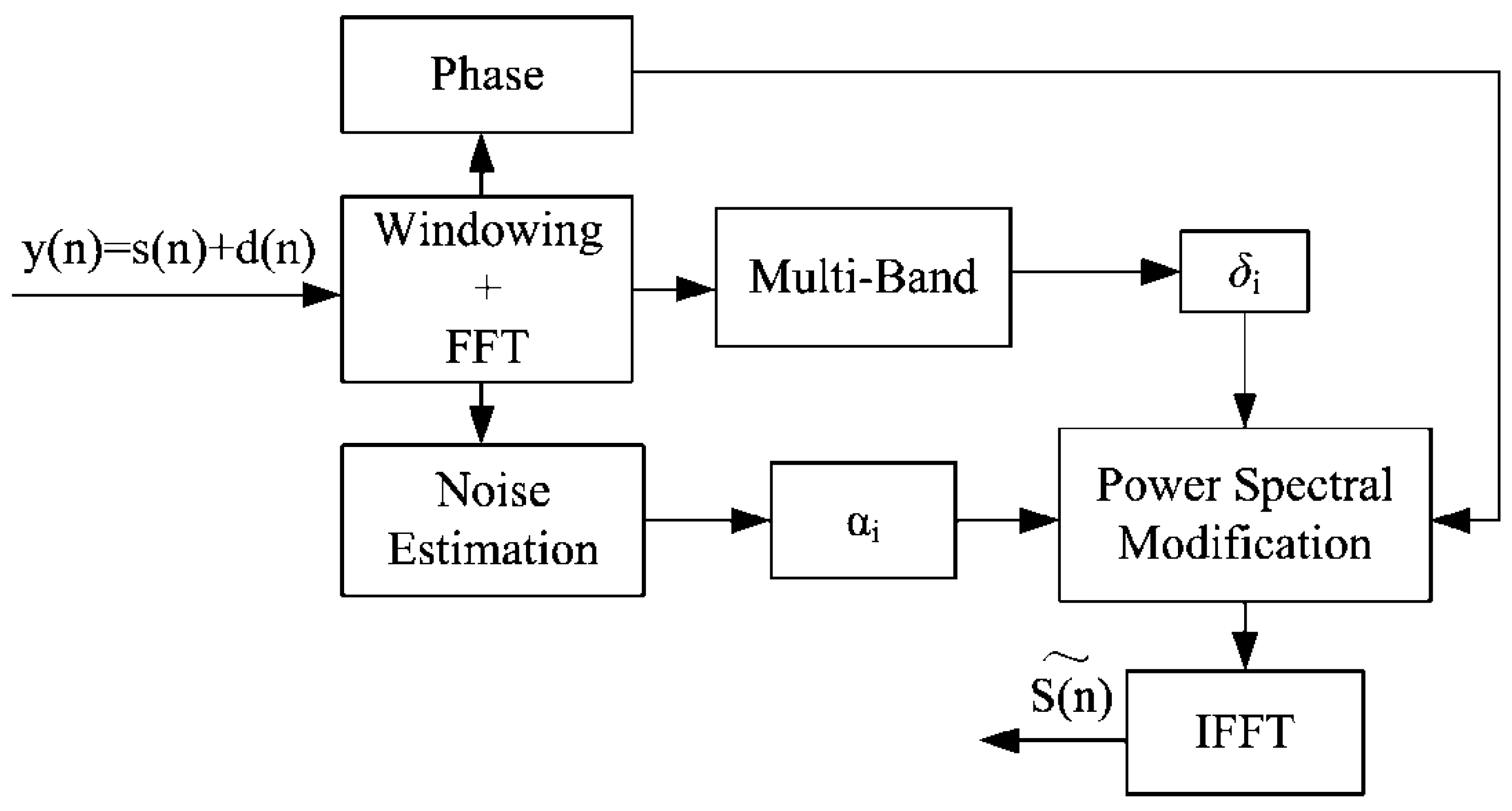
Therefore, this investigation was motivated by the need to improve EL speech, especially in electronic environments. A multi-band spectral subtraction algorithm is proposed that takes into account the variation of signal-to-noise ratio across the speech spectrum using a different over-subtraction factor of each frequency band to reduce colored noise. According to the features of the EL speech, we also give some recommended over-subtraction factors to effectively improve the EL speech quality.
3. Results and Discussions
In order to evaluate and compare the performance of the proposed enhancement algorithm, three other algorithms are performed in this study, they are: traditional spectral subtraction method, basic Wiener filtering, and a noise-estimation algorithm [
23]. For the purpose of analyzing the time-frequency distribution of the original/enhanced speech, speech spectrograms were provided since they have been identified as a well-suited tool for observing both the residual noise and speech distortion. In addition, results are also measured objectively by Signal-to Noise ratio (SNR) and subjectively by Mean Opinion Score (MOS) in conditions of different additive white Gaussian noise as well as Bobble noise (for MOS) for the algorithm evaluation.
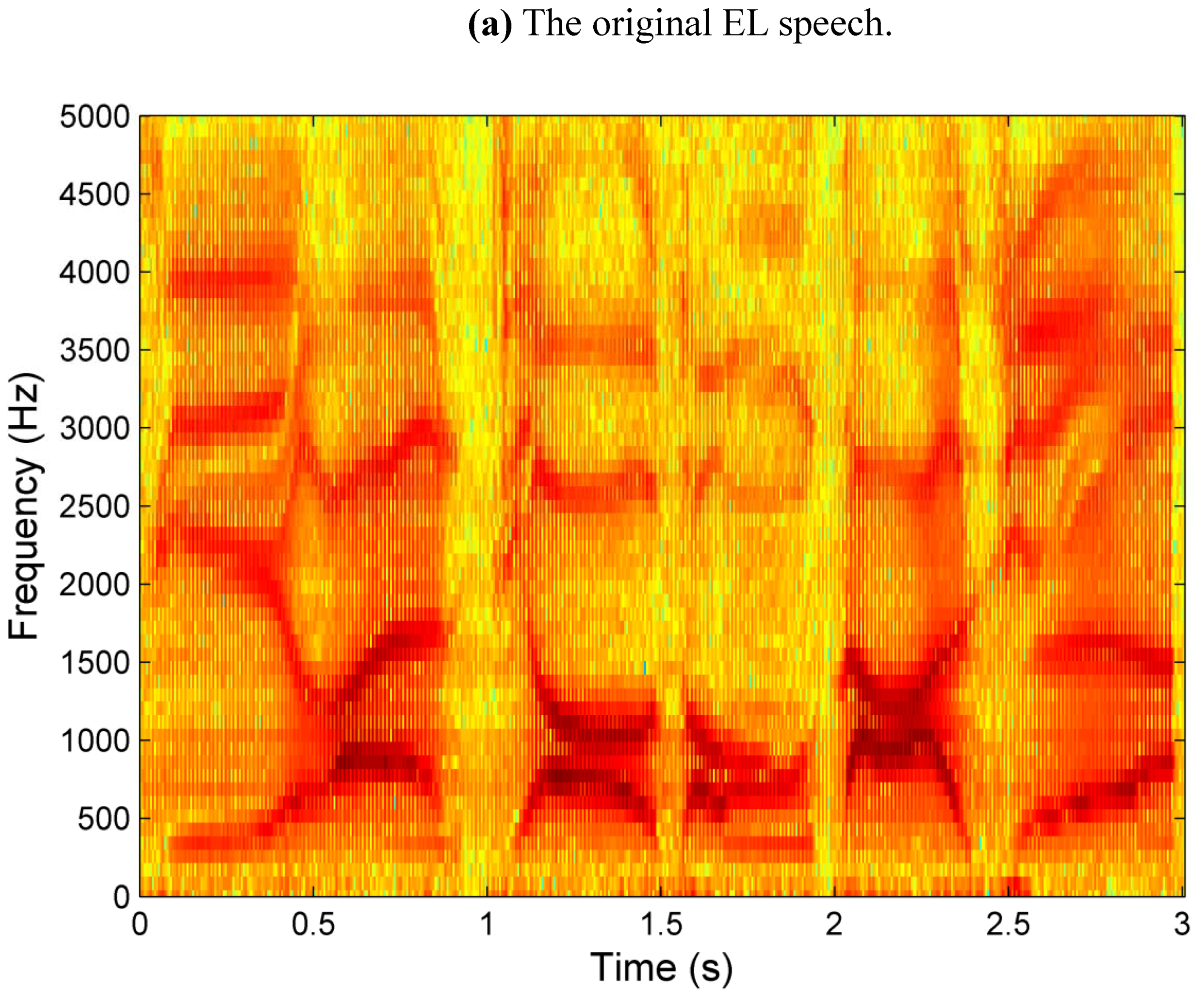
Figure 3 shows the spectrograms of the original EL speech (a), and the enhanced speech using traditional spectral subtraction algorithm (b), basic Wiener filtering (c), noise-estimation algorithm (d), and the proposed multi-band spectral subtraction algorithm in this study (e). The speech material is a Chinese sentence “Xi An Jiao Tong Da Xue” (‘Xi’an Jiaotong University’ in English).
Figure 3.
Spectrogram of the sentence “Xi An Jiao Tong Da Xue”.
Figure 3.
Spectrogram of the sentence “Xi An Jiao Tong Da Xue”.
Due to its different speech production theory and working conditions, EL speech has some special attributes. As stated before, the most special is that radiated noise, the additive environment noise may also combined in the origin EL speech. These noises can be clearly seen from
Figure 3(a), especially in speech-pause region.
Figure 3(b) shows that the spectral subtraction algorithm is effective in reducing the radiated noises, both in the speech and non-speech section. However, there are still too much residual noise remains in the enhanced speech, especially in the high-frequency section, suggesting that the noise reduction is not satisfactory.
Figure 3(c)-(d) indicate that much noise still remains in the EL speech enhanced by the basic Wiener filtering and the noise-estimation algorithm, suggest that the noise reduction is not satisfactory. The proposed algorithm appears to be much better in reducing radiated noise as shown in
Figure 3(e), since which can not only greatly reduces the low-frequency noise, but also eliminates the high-frequency noise completely. Observing the speech-pause regions, the residual noise is almost absent. Moreover, it is clearly visible that the residual noise is reduced to a large extent and has lost its structure. These results suggest that the proposed algorithm achieves a better reduction of the whole-frequency noise for EL speech than other enhancement methods.
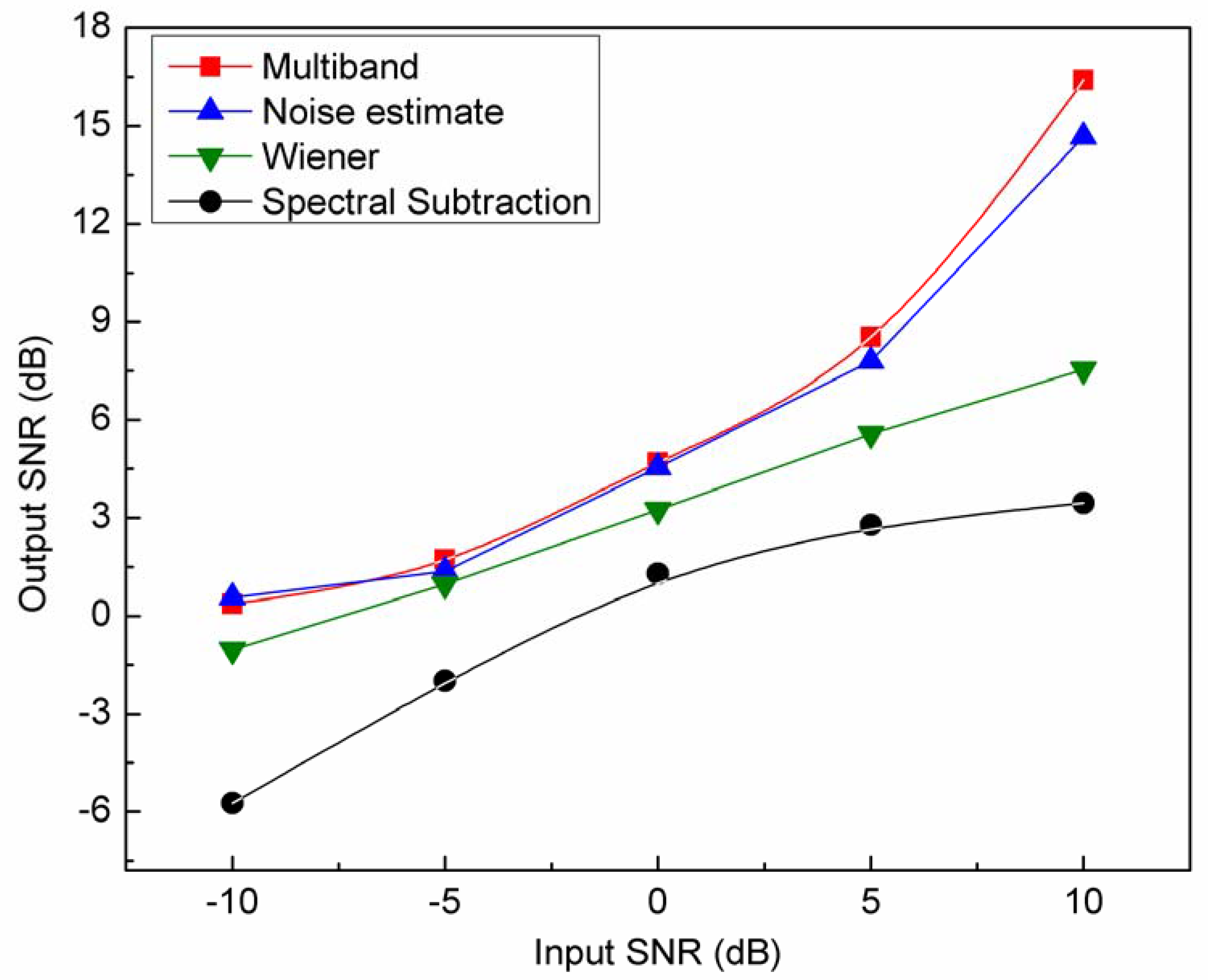
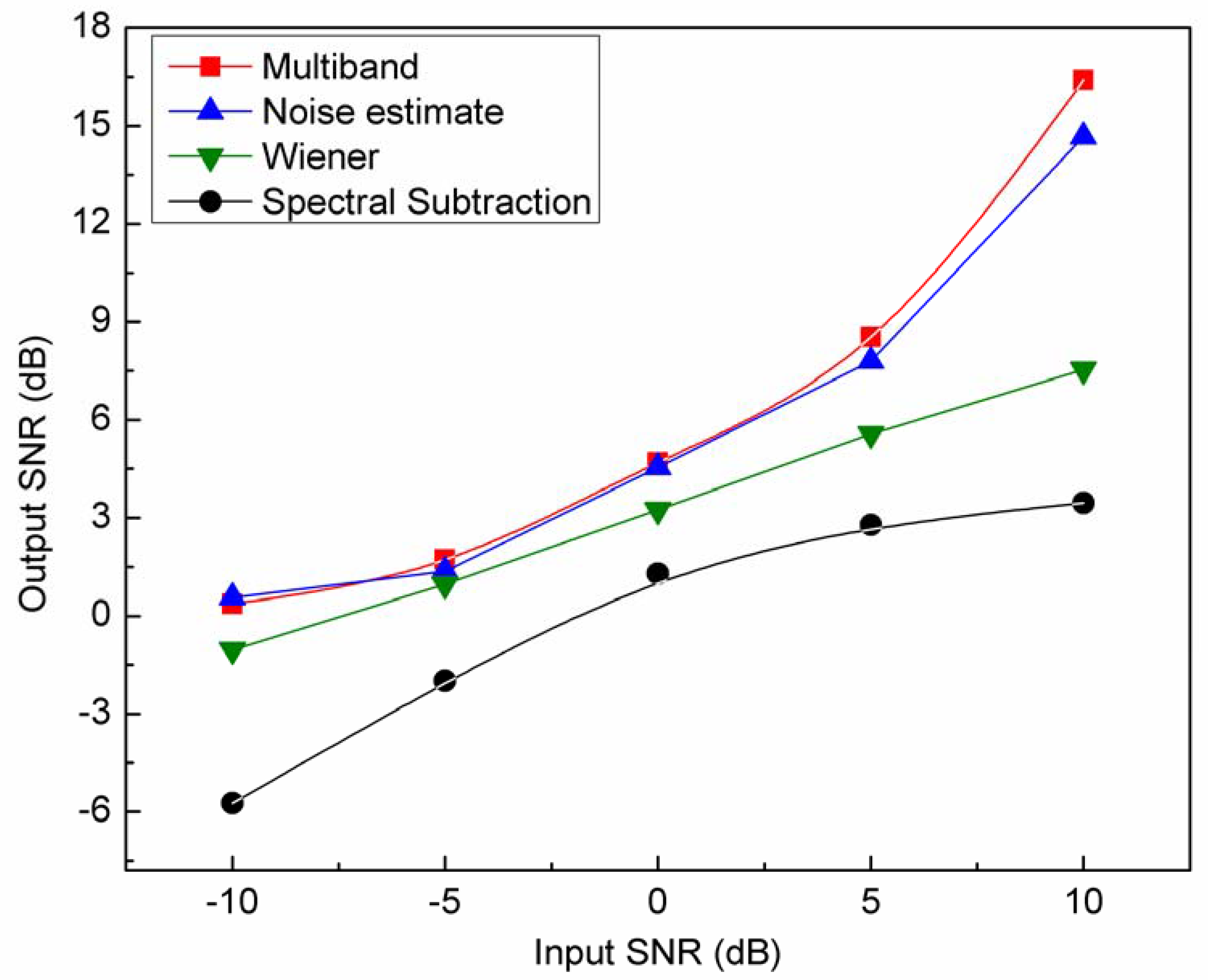
The SNR measures were used for evaluation of the proposed multi-band spectral subtraction algorithm objectively. The results of SNR for the white noise experiments are shown in
Figure 4, for five sentences produced by two male laryngectomees (these five SNRs are averaged). Methods compared included the traditional spectral subtraction algorithm (spectral subtraction), basic Wiener filtering (Wiener), noise-estimation algorithm (noise-estimation), and the proposed multi-band spectral subtraction algorithm (multi-band). From the figure, the proposed multi-band spectral subtraction method and the noise-estimation method have the best performance for this noise condition. Each of these gave about 6 dB improvement at the lower SNRs increasing to about 12 dB improvement at the higher SNRs than traditional spectral subtraction method. The multi-band method shows the best SNR improvement, and did slightly better than the noise-estimation method, especially for the higher SNR noise cases.
Figure 4.
SNR results for white noise case at -10, -5, 0, +5, and +10 dB SNR levels
Figure 4.
SNR results for white noise case at -10, -5, 0, +5, and +10 dB SNR levels
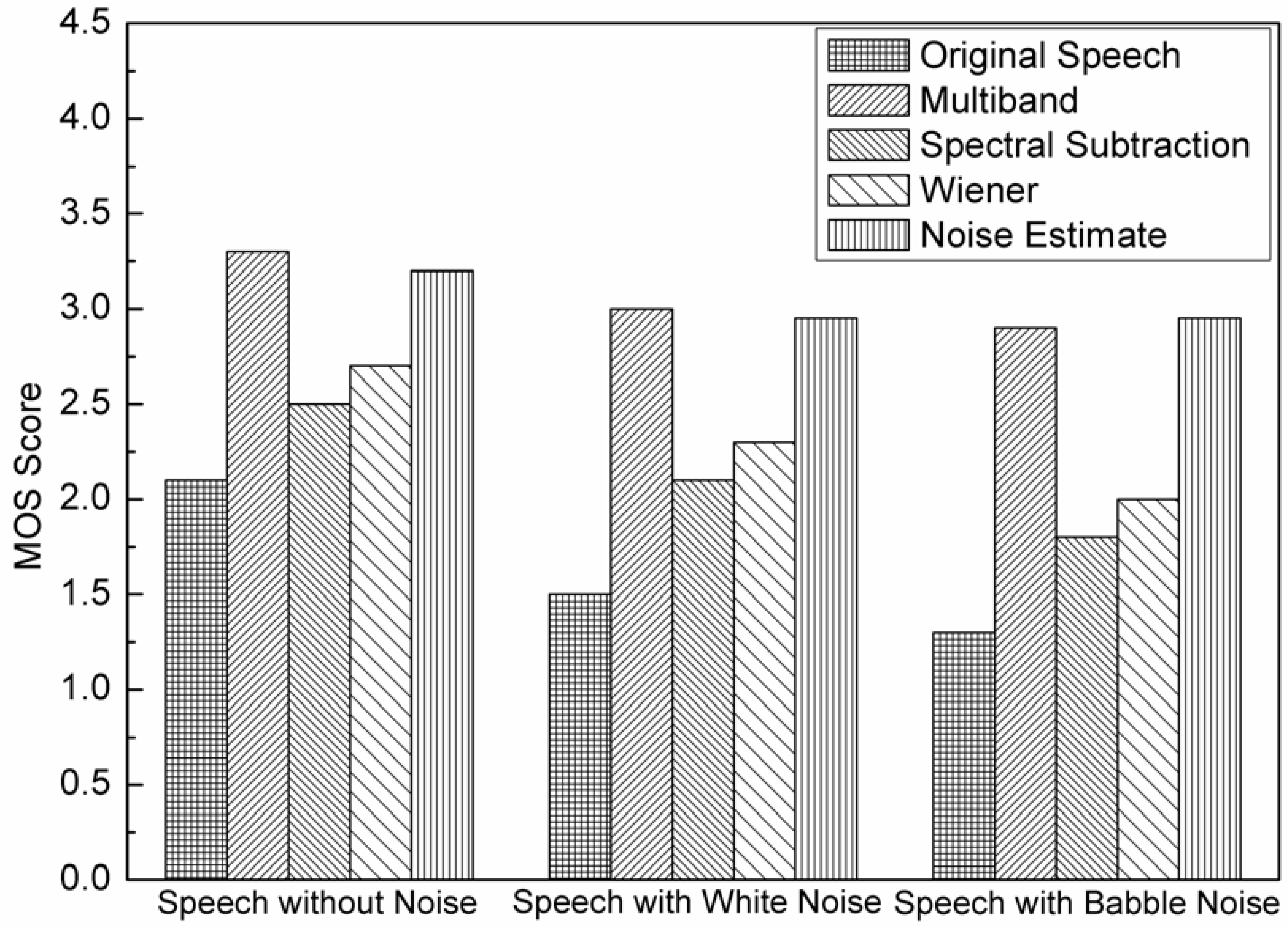
Subjective results using Mean Opinion Scores (MOS) for these enhancement algorithms for five sentences produced by two male laryngectomees (averaged) are shown in
Figure 5. The noisy speech in the case of additive White and Babble noise has an input SNR of 0 dB. It can be seen from figure that the score of the enhanced speech obtained from using the multi-band algorithm is the highest, followed by that from the noise estimation and the Wiener filtering algorithms. This is true for both the original speech and the noisy speech. There is an interesting difference between the MOS results and the SNR results. The noise estimation algorithm received higher scores than would have been suggested by SNR, especially for the Babble noise, its score is little higher than the proposed method. The most likely explanation for this phenomenon is that the presence or absence of the residual musical noise and speech distortion in the enhanced speech, which are known to have significant impact on perception but have only mild influence on SNR values. It also can be seen from the speech spectrograms (
Figure 3) that the spectrogram of the noise-estimation algorithm is more “smooth” than that from the proposed algorithm, which means less residual musical noise and speech distortion. Actually, the noise-estimation algorithm may suit for highly non-stationary noise environments, and the proposed algorithm may suit for colored noise environments.
The results of the perceptual experiment also suggested that the enhanced speech with the proposed multi-band spectral subtraction algorithm is more pleasant, the residual noise is better reduced, and with minimal, if any, speech distortion. This is because that the over-subtraction factor of each frequency band can be adjusted, which can prevent speech from quality deterioration during spectral subtraction process.
Figure 5.
Acceptability scores of the original and enhanced EL speech. The noisy speech in the case of additive noise has an input SNR of 0 dB.
Figure 5.
Acceptability scores of the original and enhanced EL speech. The noisy speech in the case of additive noise has an input SNR of 0 dB.
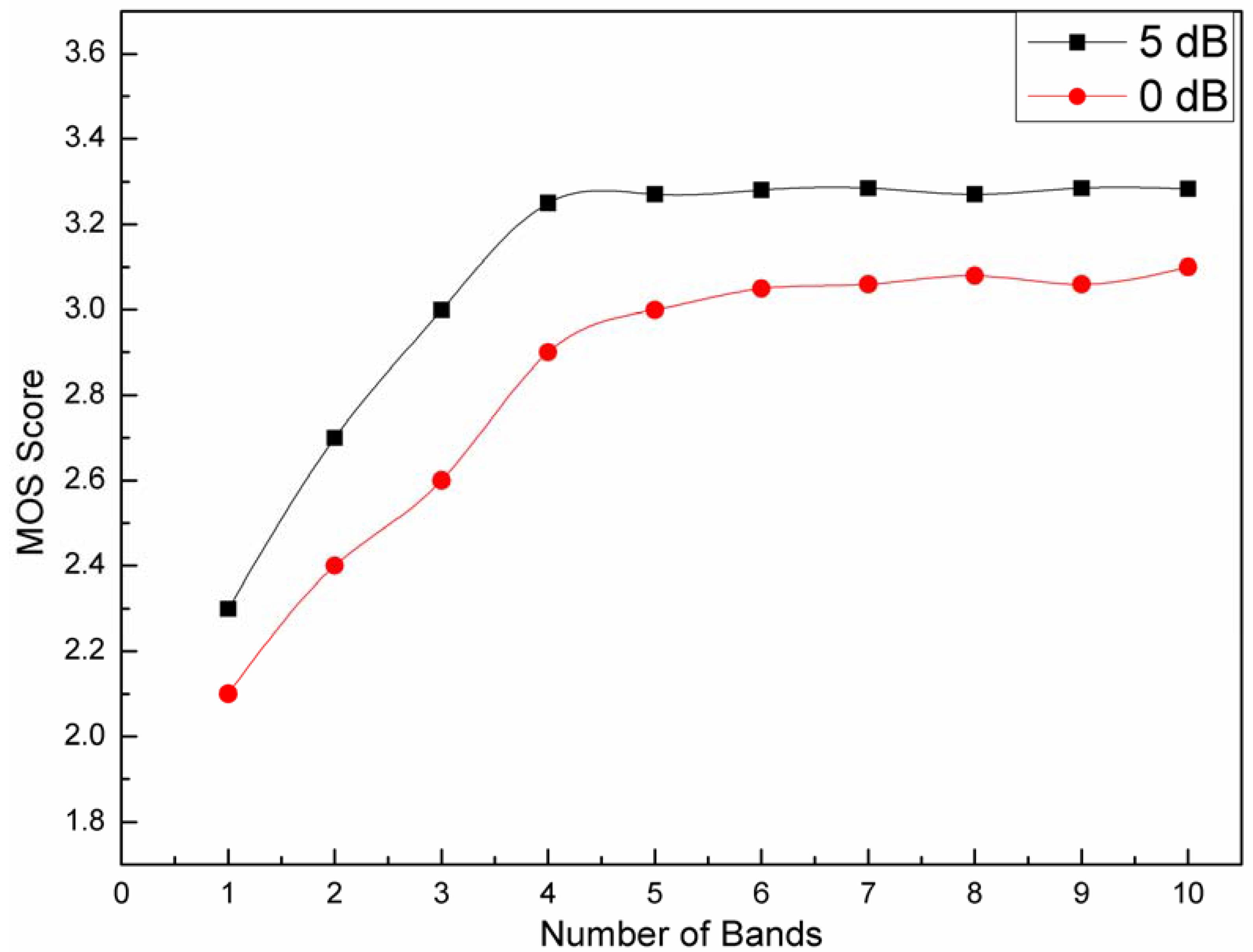
It can be seen from theory of the multi-band algorithm that the number of bands may have important effects on the quality of enhanced speech. Therefore, we varied the number of bands from 1 to 10 in this study to determine the optimal number of bands. Linear frequency spacing was used, and the performed speech quality was examined using Subjective measures (MOS).
Figure 6 plots the averaged MOS scores for five enhanced sentences (produced by two male laryngectomees) for different number of bands. It can be seen from the figure that the MOS score has a great improvement when the number of bands increased from 1 to 5 for both 5 and 0 dB. For the bands larger than 5, the score does show a slight increase in performance, however, it is too slight to perceivable in speech quality. Therefore, the optimal number of bands can be determined as 5 for EL speech. This number is almost consistent with the result of Kamath
et al., which for normal speech was 4. In addition, when the total number of bands is one, then the approach of multi-band spectral subtraction algorithm reduces to the traditional power spectral subtraction approach [
20].
Figure 6.
Acceptability scores of the performance of the multi-band spectral subtraction approach for different number of bands for the enhanced speech. The noisy speech in the case of additive White noise has an input SNR of 5 and 0 dB.
Figure 6.
Acceptability scores of the performance of the multi-band spectral subtraction approach for different number of bands for the enhanced speech. The noisy speech in the case of additive White noise has an input SNR of 5 and 0 dB.
Because the subtraction parameters are fixed for a given frame, the traditional spectral subtraction algorithm cannot reduce the noise effectively, especially for the colored noise. These limitations will be worse for the enhancement of EL speech in the case of combined electronic noise. With regard to the multi-band spectral subtraction algorithm, the over-subtraction factor of each frequency band can be adjusted, so that this algorithm can realize a good tradeoff between reducing noise, increasing intelligibility, and keeping the distortion acceptable to a human listener. The results also indicate that the proposed algorithm can not only reduce the residual noise but also improve the low-frequency deficit of EL speech.
The proposed algorithm also has strong flexibility to adapt complicated speech environment for EL device users, because the over-subtraction factor of each frequency band can be adjusted, so that the proposed algorithm is able to fit other different or complex speech environment. This makes it possible to obtain better speech quality via speech enhancement under some rigorous speech environment.
As a single channel subtractive-type speech enhanced methods, the proposed algorithm in this paper can be applied into the enhancement of EL speech in a practical electronic situation. For example, an EL speech enhanced system embedded with this algorithm can be developed. With the help of digital signal processing (DSP) technology, the speech enhancement function can be realized with a microprocessor and implanted into an EL-telephone, EL-microphone, or other electronic media. Different enhancement algorithms can be selected through the switch based on different noisy conditions. Along with the development of efficient enhancement methods, the quality of EL speech will be extensively improved for better perception.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}