1. Introduction
As Internet technology advances and mobile devices become more prevalent, an increasing number of users are willing to share location information and experiences on their social media accounts. Location-based social network (LBSN) service providers offer a platform for these users to share. By analyzing the vast amount of data generated by users, these providers can recommend points-of-interest (POIs) that users may find interesting. This not only enhances user experience and convenience but also boosts revenue for service providers.
To accurately predict users’ future visits, it is essential that we capture users’ preferences based on their historical behaviors. Early methods primarily relied on manually constructed feature extraction and traditional machine-learning techniques [
1,
2,
3,
4]. However, due to the shortcomings in feature engineering, which need domain expertise, and the great challenge of big data, deep-learning methods have replaced most of the methods, with the ability to automatically extract various features [
5,
6,
7,
8,
9]. In recent years, an increasing number of studies have employed graph neural network models to capture global connections between POIs [
10,
11,
12,
13]. These models typically consist of two stages: (1) constructing a graph based on the features of POIs, such as using the geographical distance between two POIs or the order of consecutive POIs visited by users; and (2) continuously updating the node representation vectors through message passing mechanisms. However, due to lack of data labels, these models may not produce high-quality representation vectors. In order to improve the quality of representation vectors, some models have adopted contrastive learning, which shows significant advantages in unsupervised representation learning. As a self-supervised learning method, it captures the internal connections within the data by constructing positive and negative samples, thereby mitigating the impact of data sparsity [
14]. Graph contrastive learning, which combines graph neural networks with contrastive learning, has been proven to enhance the robustness of representation vectors in graphs. In recommendation systems, the existing research constructs different graphs on both sides of users and POIs to assist in the interaction graph between users and POIs, so as to learn the representations of users and POIs.
However, although these studies have improved the performance of recommendation systems to some extent, they also have certain limitations: (1) Most studies are based on homogeneous relations between nodes, overlooking the heterogeneous relations in real life, which is more common. The homogeneous relation implies that the interactions belong to the same type or role, like the relation between two POIs, while the heterogeneous relation involves multiple types of roles or connections. It is conspicuous that heterogeneous relations are more ubiquitous in the real world. If we transform the heterogeneous relations into heterogeneous graphs, we can represent different relations between different kinds of nodes, like the interaction between users and POIs. Merely considering homogeneous relations may oversimplified the multi-role system. Although some research papers have considered heterogeneous relations, most only focus on the interaction between users and POIs, neglecting the potential connections between them. Additionally, not all datasets provide sufficient user information, which limits our ability to construct user views for contrastive learning from existing datasets. For example, the widely used datasets Foursquare-NYC and TKY do not include users’ attributes or relations, limiting the construction of users’ view for contrastive learning. (2) The graphs used in most studies are constructed based on predefined rules and remain unchanged during training. For example, [
15] designs a graph capturing users’ transition patterns and [
16] figureproposes to use hypergraph to capture high-order relations. These graphs are used in the entire training process without any optimization. However, these artificially created graphs may lack accuracy, contain noise, or miss key connections, ultimately leading to poorer performance. (3) In order to accurately recommend POIs to users, the model needs to consider other factors, such as temporal and spatial factors in addition to the sequential patterns. Some works [
17,
18] choose to separately consider sequential and spatial factors, successfully capturing users’ geographical preference, but are likely to recommend POIs in the neighborhood. It remains a critical factor to capture the connections between different check-ins and potentially influential factors.
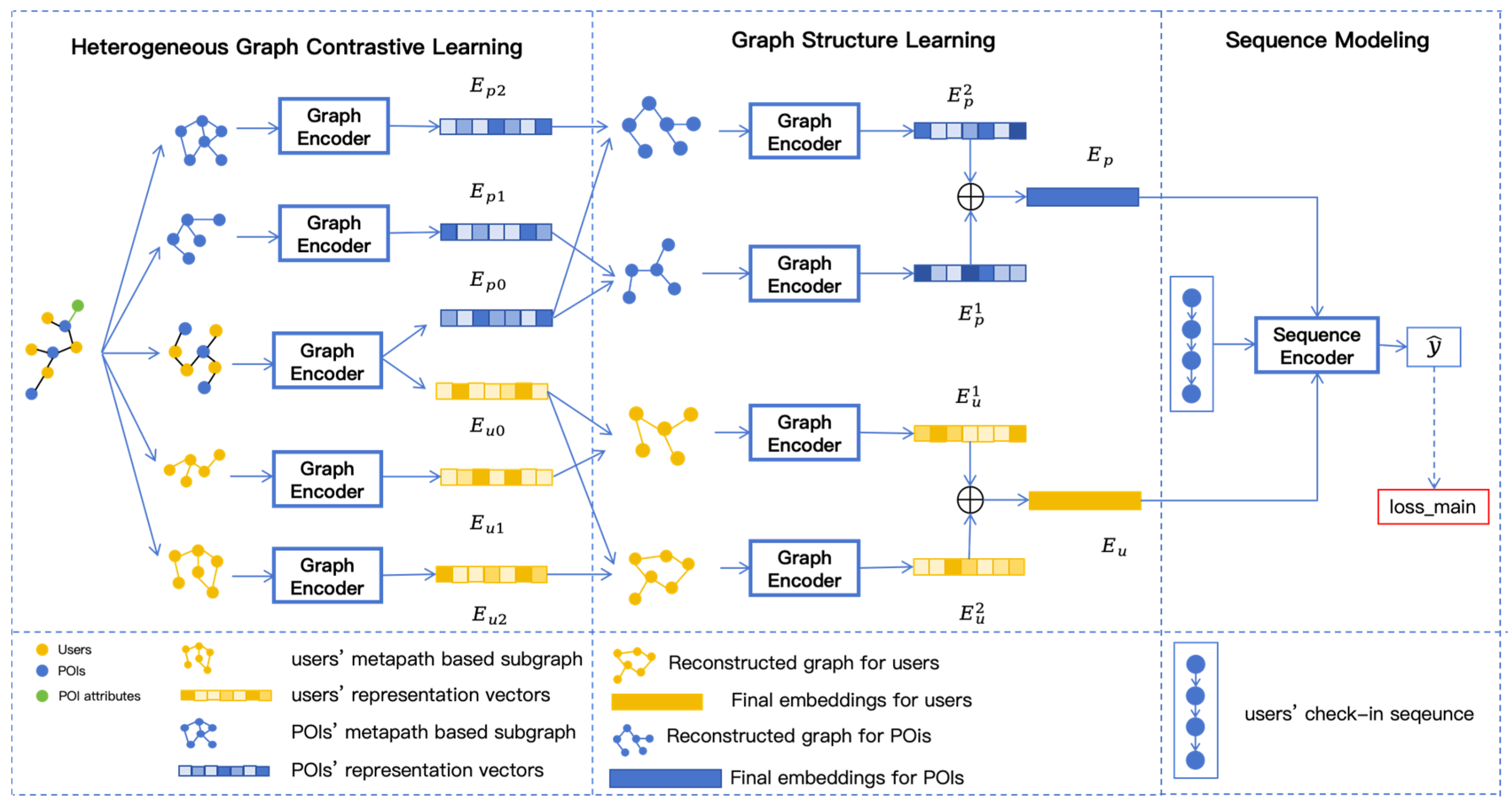
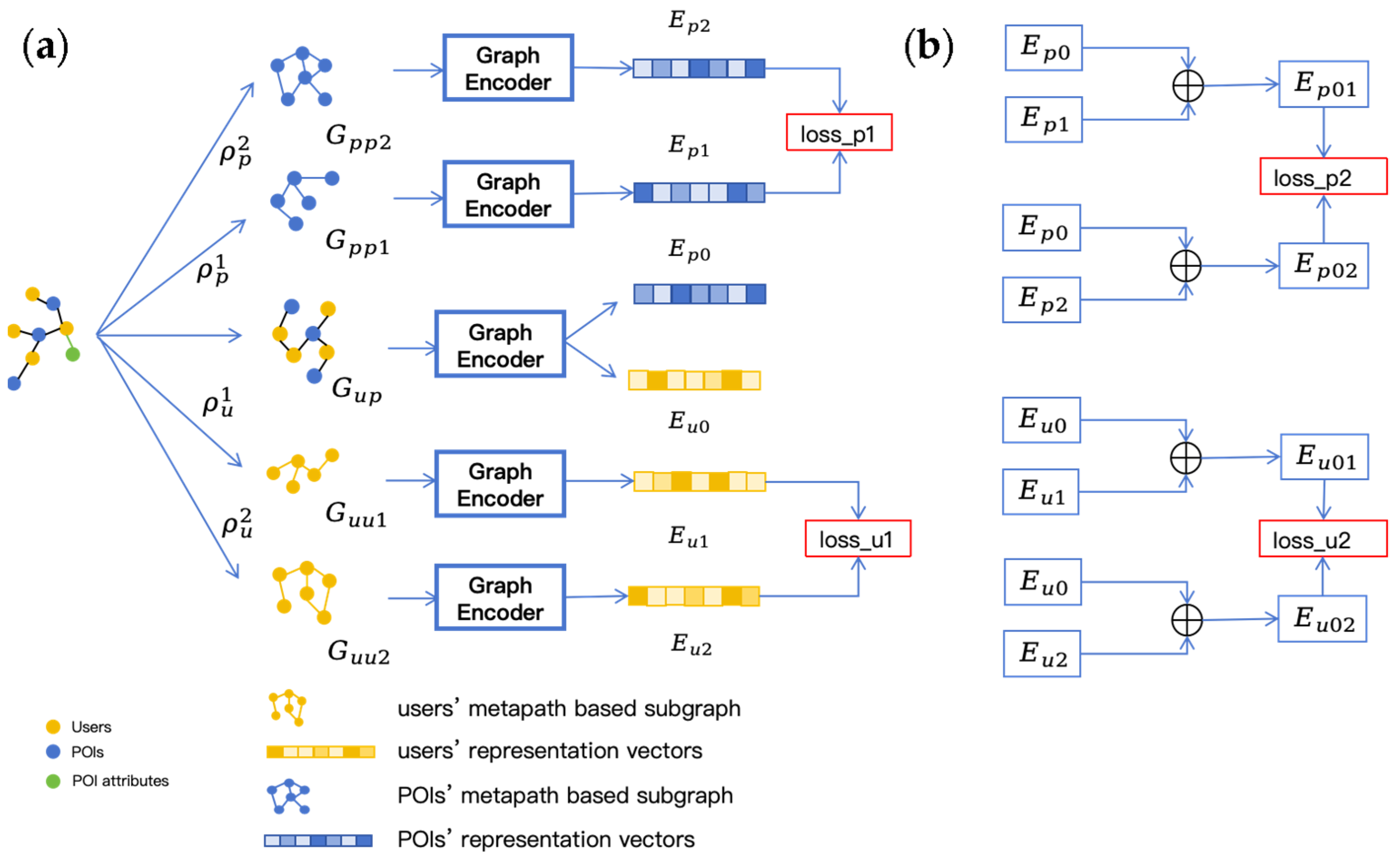
To address the aforementioned limitation (1), this paper employs a heterogeneous graph neural network to model the heterogeneous relations between users and POIs. When considering heterogeneous graphs, most studies only consider whether there is an interaction relation between users and POIs, often overlooking the potential high-order connections between them. Additionally, not all datasets contain sufficient information, particularly about users. The lack of user information can hinder the construction of a graph that accurately reflects user relations. To tackle these issues, we introduce a method using meta-paths as the solution. We firstly use the provided information in the datasets to construct a heterogeneous graph, including users, POIs, and POI attributes. As a valid tool for analyzing heterogeneous graphs, meta-paths can help identify potential connections between users and POIs. For instance, the meta-path UPU represents two users who have visited the same POI. By using different meta-paths, we can capture various types of connections between users and POIs, thereby constructing different meta-path-based subgraphs. To enhance the quality of the representation vectors, contrastive learning is applied to promote the representation learning of the heterogeneous graph and the meta-path subgraphs. Specifically, it designs two kinds of contrastive learning methods based on different meta-paths to learn the representation vectors of users and POIs.
To address the aforementioned limitation (2), we utilize graph structure learning to continuously refine the artificially constructed graph. The artificially constructed graph may contain noise and is not always complete. To tackle this problem, researchers have introduced graph structure learning, which aims to learn a more optimal graph structure though the training pipeline rather than directly using the original one without any modification. Most graph structure learning methods use a hybrid approach, where both the graph structure and GNN parameters are updated in conjunction with downstream tasks. In this study, the meta-path subgraphs used to learn the representations of users and POIs are artificially constructed graphs. Directly utilizing these graphs might result in inaccurate connections between nodes. Therefore, this paper employs graph structure learning to continuously optimize the structure of these meta-path subgraphs, thereby achieving more accurate relations between nodes.
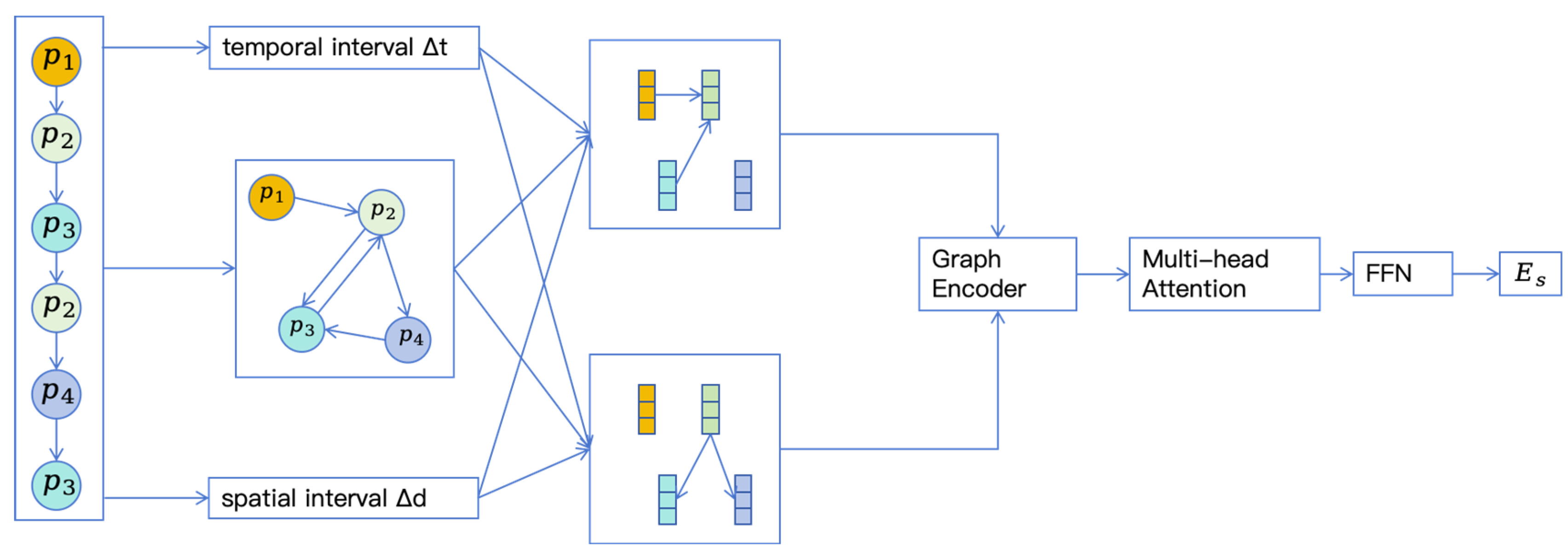
To address the aforementioned limitation (3), this paper employs graph neural networks to model users’ preferences in check-in sequences. To capture the connections between different check-ins, we first convert each check-in sequence into a sequence graph, and then use graph neural networks to learn these connections, treating the POIs visited by users as nodes and encoding the users’ sequence graphs using a graph encoder based on the attention mechanism. Given that users’ check-in behaviors are influenced by multiple factors, this paper incorporates time, space, and sequence into the computation of the graph convolutional neural network, thereby better generating the users’ preference representations.
Based on the above analysis, we propose a model named Heterogeneous Graph Structure Learning for Next POI Recommendation (HGSL-POI). This model integrates heterogeneous graph contrastive learning, graph structure learning, and sequence modeling. Specifically, we consider the heterogeneous information between users, POIs, and POI attributes, and construct meta-path-based subgraphs for both users and POIs based on different meta-paths. Then, representation vectors for users and POIs are aligned through two contrastive learning methods, which differ in whether they consider the heterogeneous relation when computing the contrastive loss between different meta-path subgraphs. Next, the representation vectors obtained from contrastive learning are used to reconstruct the corresponding meta-path subgraphs, and graph neural networks are employed to obtain the representation vectors for users and POIs from the reconstructed graphs. Finally, the learned representation vectors for users and POIs are used to learn user sequences, where different types of factors will be included in this stage.
In summary, the main contributions of this paper are summarized as follows:
- (1)
In this paper, heterogeneous graph contrastive learning is introduced into the process of representation learning. Considering the missing information may impact how we construct contrastive views, we use the provided information to construct a heterogeneous graph. Then, meta-paths are used to construct meta-path subgraphs of users and POIs, respectively, and two kinds of contrastive learning methods are adopted to improve the quality of the representation vectors of users and POIs.
- (2)
Considering that the artificially constructed graph may have downsides such as noise and missing edges, graph structure learning is used to continuously update the graph structure, and takes the representation vectors generated by the updated graph as the input of the subsequent sequence modeling.
- (3)
This paper models the users’ check-in sequences from the perspective of the graph, better capturing the relation between different check-ins. In addition to the sequential factor, we also include temporal and spatial factors into the modeling process to better capture the users’ preferences.
- (4)
A large number of experiments are carried out on the public datasets, and the experimental results confirm the effectiveness of the model.
3. Problem Definition
We use to represent the user set, to represent the POI set, and to represent the attributes which the POIs have, where M, N, and K are the total number of users, POIs, and attributes, respectively. Each POI p is denoted by a quadruple p = (id, lon, lat, attr), which includes the id, longitude, latitude, and attributes of the POI.
Check-in. A check-in is represented by a triplet q = (u, p, t), which represents that user u visited POI p at time t.
Sequence and check-in history. A sequence is a set of continuous check-ins of a user within a period of time. We use to represent the m-th sequence of user u, which includes n check-ins. denotes the k-th check-in of the sequence, where k is a positive integer. Considering two sequences and , if ends before starts, we denote as the historical sequences of . The historical sequences of a user includes the sequences belonging to the same user and different users. All the check-in sequences of the same user constitute the check-in history of the user, which is denoted by , where is the number of check-in sequences of user u.
The next point-of-interest recommendation aims to provide a list of POIs which a user is most likely to visit in the future, based on the current sequence and the historical sequences of all users. This list ranks the POIs in order of the probabilities. Specifically, given the set of all users’ historical check-in sequences
and the current sequence
of user
, the next point-of-interest recommendation is to predict where the users will visit at the future time
:
where
represents the probability of the user visiting POI
, f represents the model parameters, and
represents the historical sequences of the user, including the sequences of the same user and different users.
6. Conclusions
In this paper, we propose the model HGSL-POI, which integrates heterogeneous graph contrastive learning, graph structure learning, and sequence modeling for the next point-of-interest (POI) recommendation. Specifically, we first construct a heterogeneous graph based on users, POIs, and POI attributes. Then, we use different meta-paths to generate different meta-path-based subgraphs for users and POIs, as well as the interaction graph between users and POIs. Then, we design two kinds of contrastive learning to align the representation vectors of different nodes. They capture the relations from different perspectives. Given that manually defined graphs may contain noise or incompleteness, we use graph structure learning to refine the meta-path subgraphs. For each subgraph, we use the representation vectors derived from that subgraph and representations of the same node type from the interaction graph to refine the graph structure. Finally, we transform each sequence into a graph based on the order of the visits. Then, we propose an attention-based graph encoder to learn the users’ sequence preferences and make predictions.
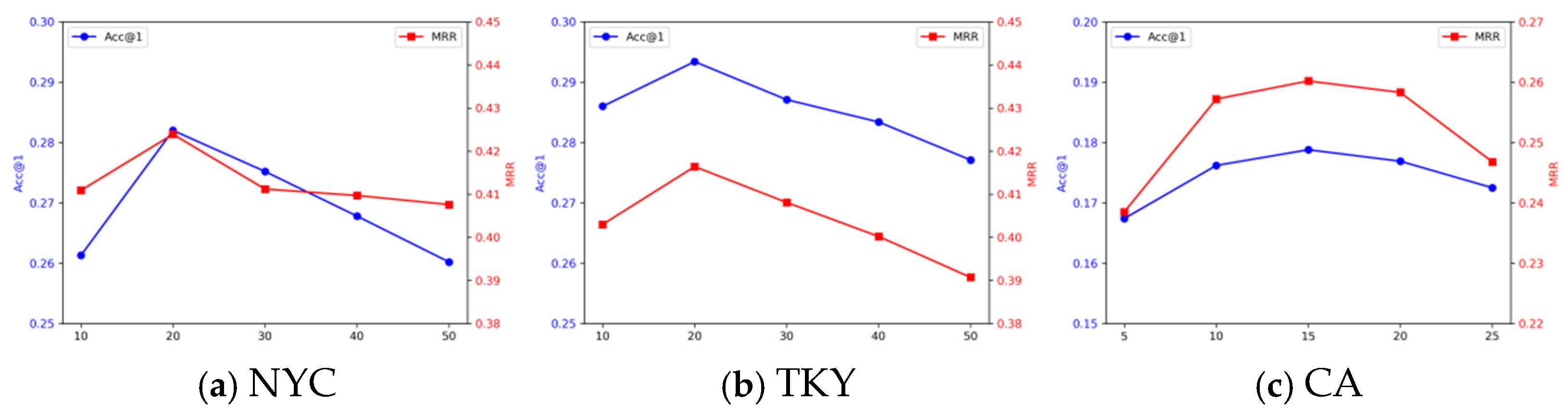
We perform a set of experiments on three public datasets and achieve superior performance in nearly all the comparison experiments. The experiments on different user behaviors show our model can be applied to different scenarios. Moreover, we analyze the effectiveness of our proposed meta-path-based methods. It shows comparable results compared with the results from the real-world data. The method is not a substitute for real-world data, but can be valid when users’ side information, like friendship, is missing. The ablation experiments confirm the effectiveness of our proposed components.
There are also some limitations in the research. We can focus on designing more effective contrastive learning methods to extract the most useful information from the graph, thereby directly improving the relevance to the downstream tasks. Additionally, the cold-start problem is vital in recommendation systems. Users or POIs without any check-ins can be great challenges when constructing heterogeneous graphs and meta-path-based subgraphs.



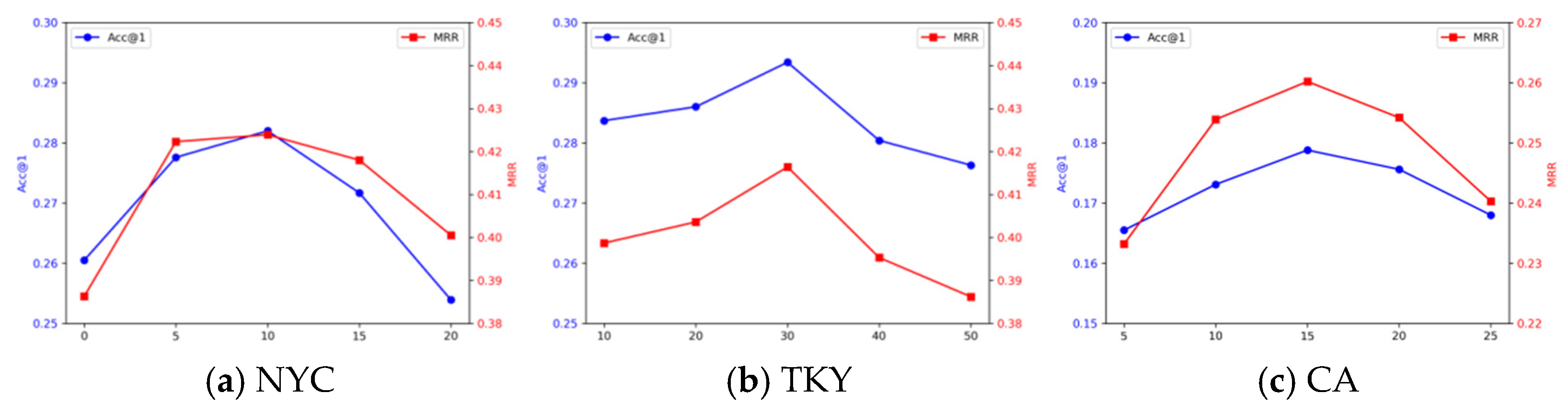
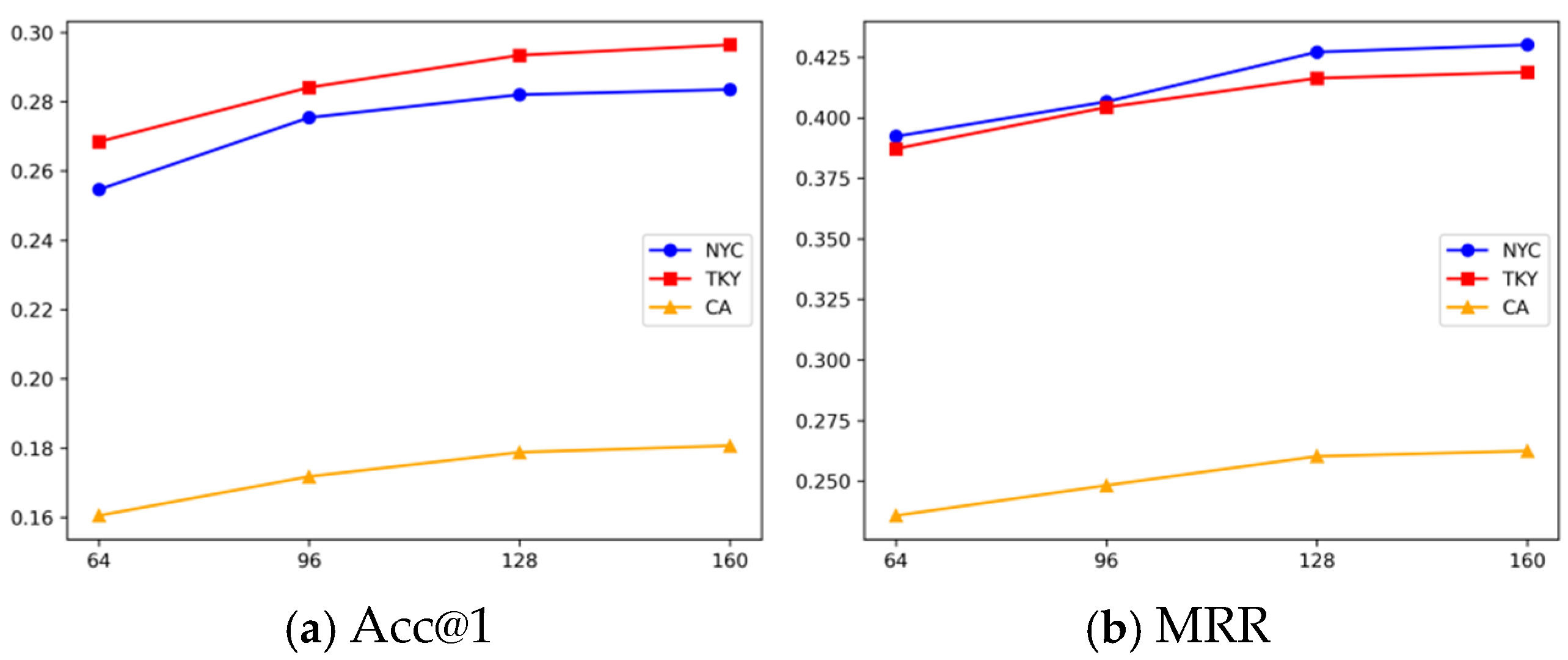
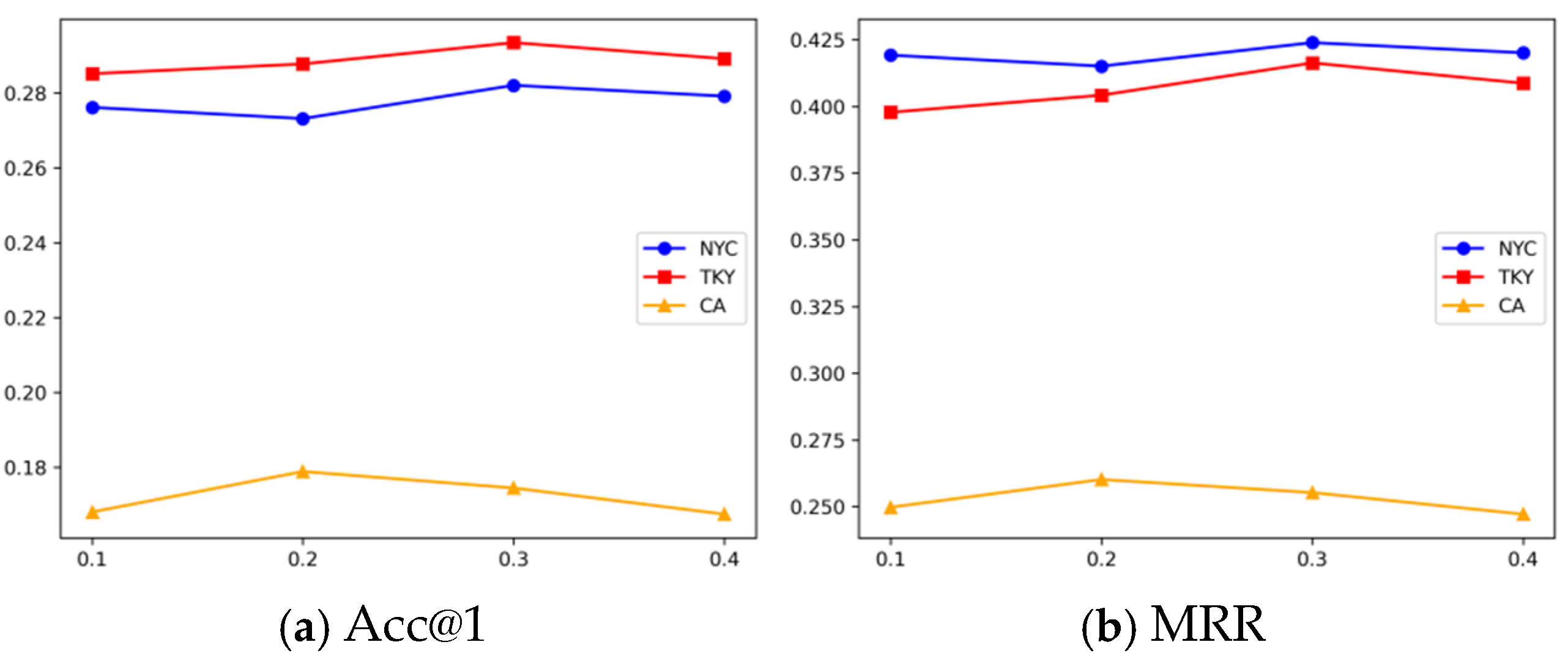

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}