

SPL-YOLOv8: A Lightweight Method for Rape Flower Cluster Detection and Counting Based on YOLOv8n

Abstract
1. Introduction
2. Data and Methods
2.1. Dataset
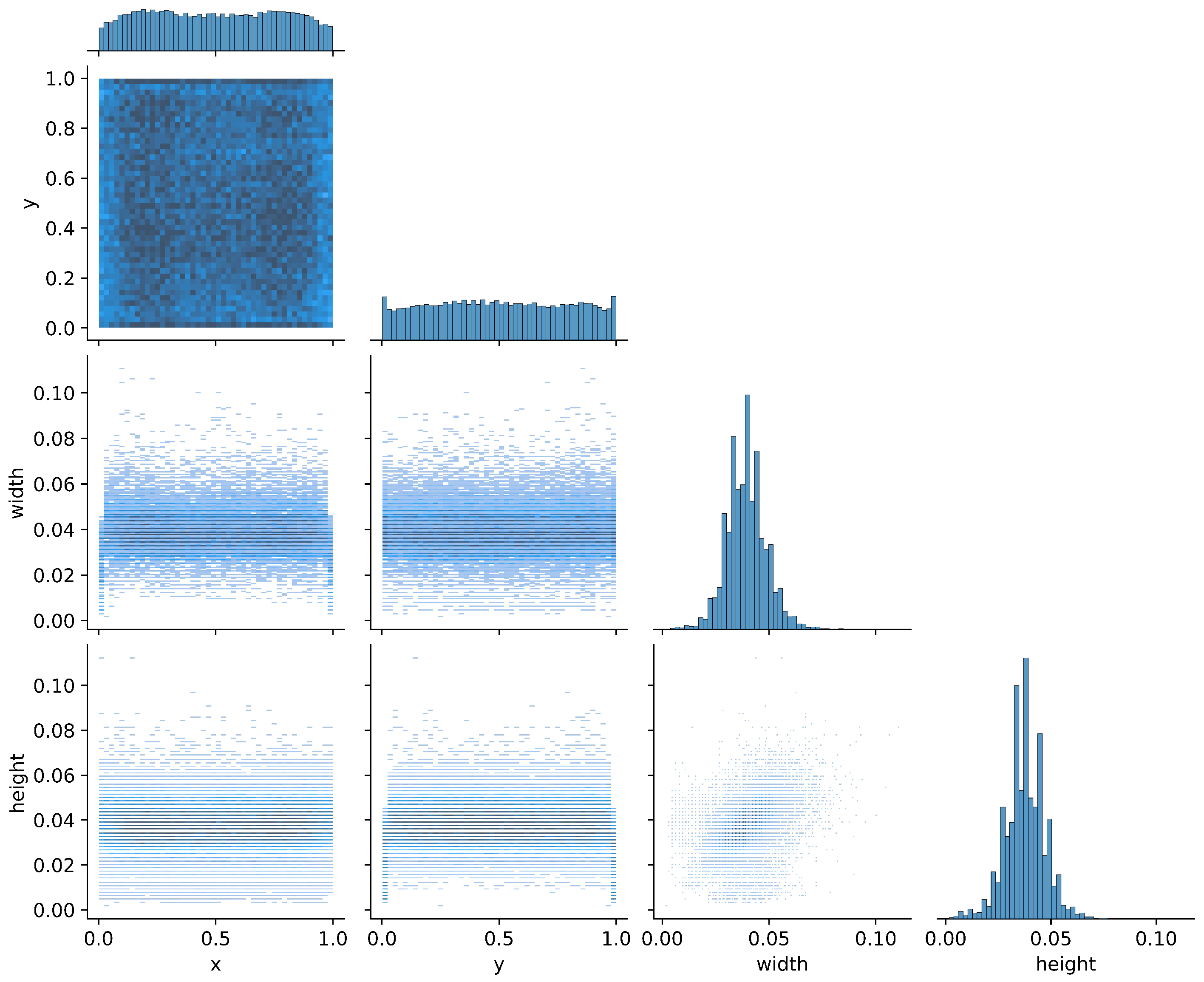
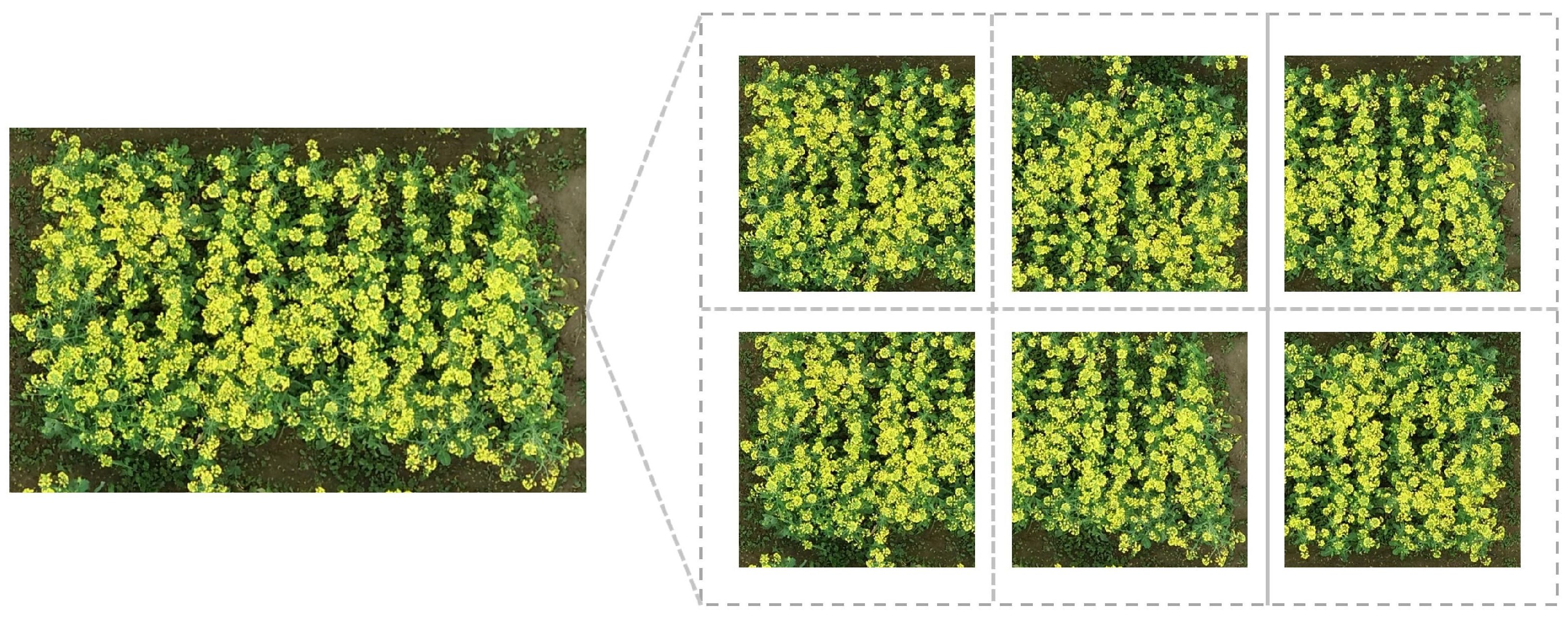
2.1.1. Dataset Construction
2.1.2. Dataset Splitting
2.2. Methods
2.2.1. YOLOv8 Network
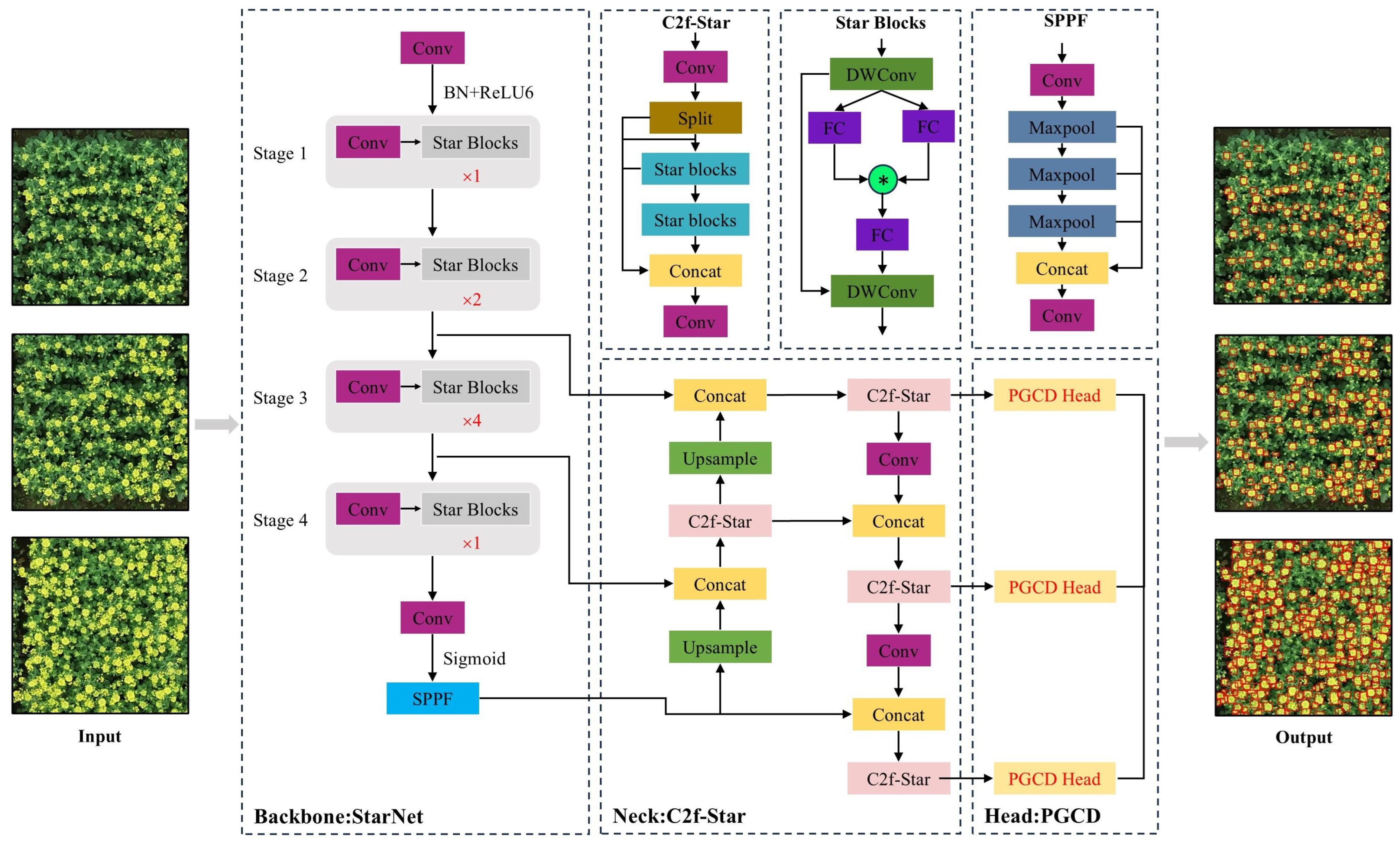
2.2.2. Overall Architecture of the SPL-YOLOv8 Model
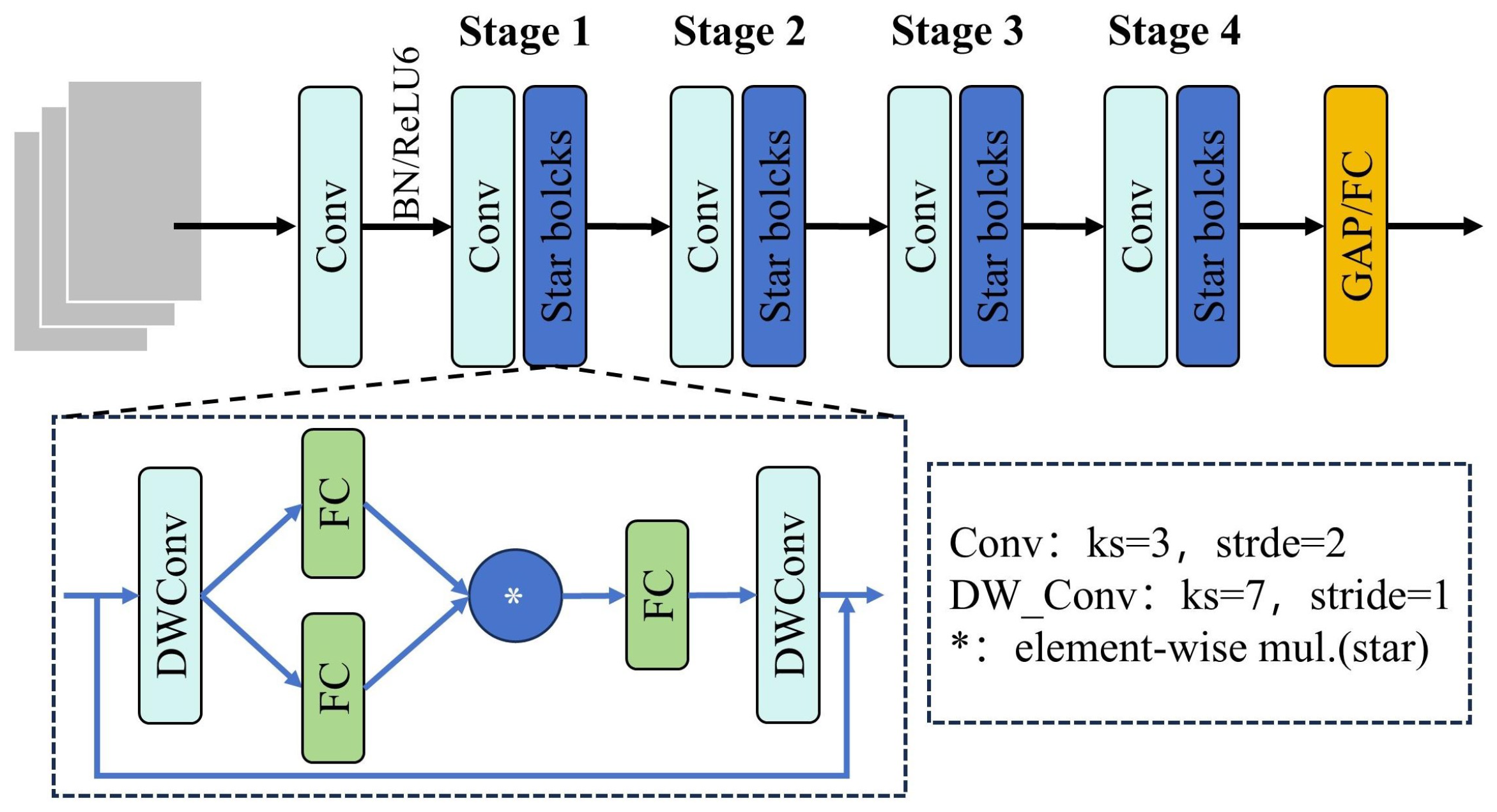
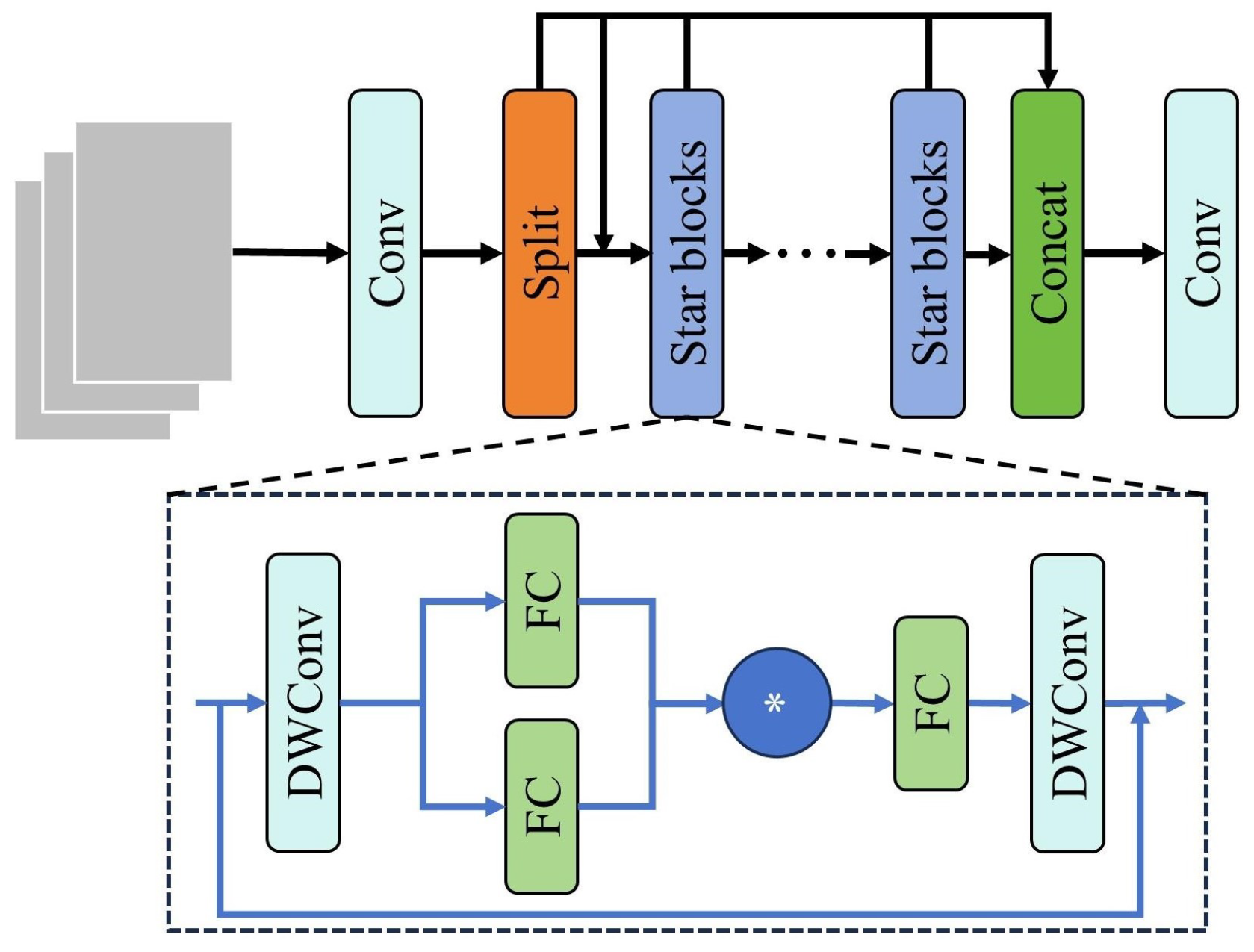
2.2.3. StarNet Backbone Network
2.2.4. C2f-Star Module
2.2.5. PGCD Detection Head
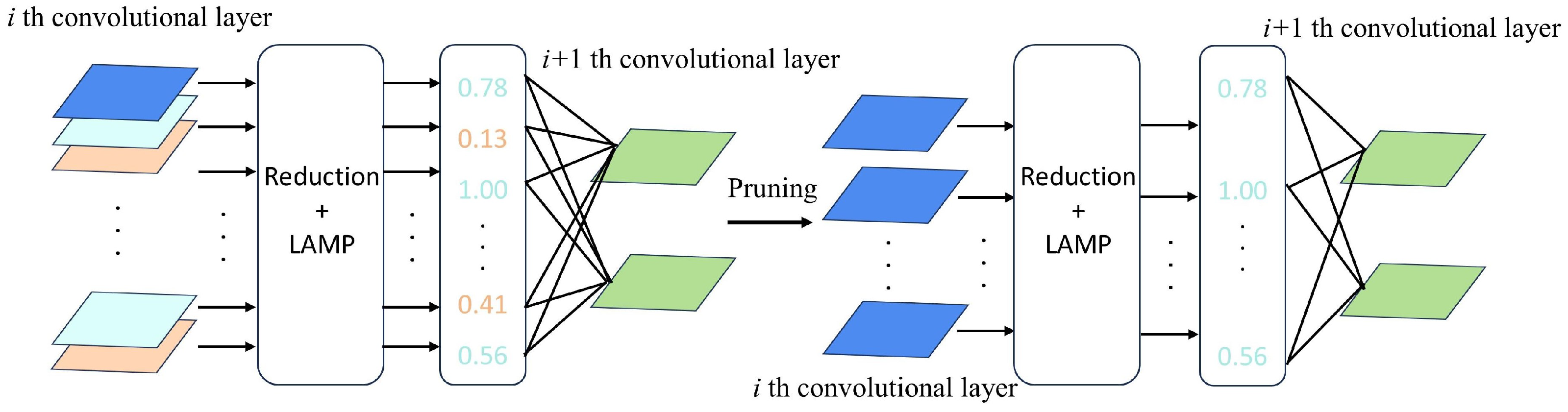
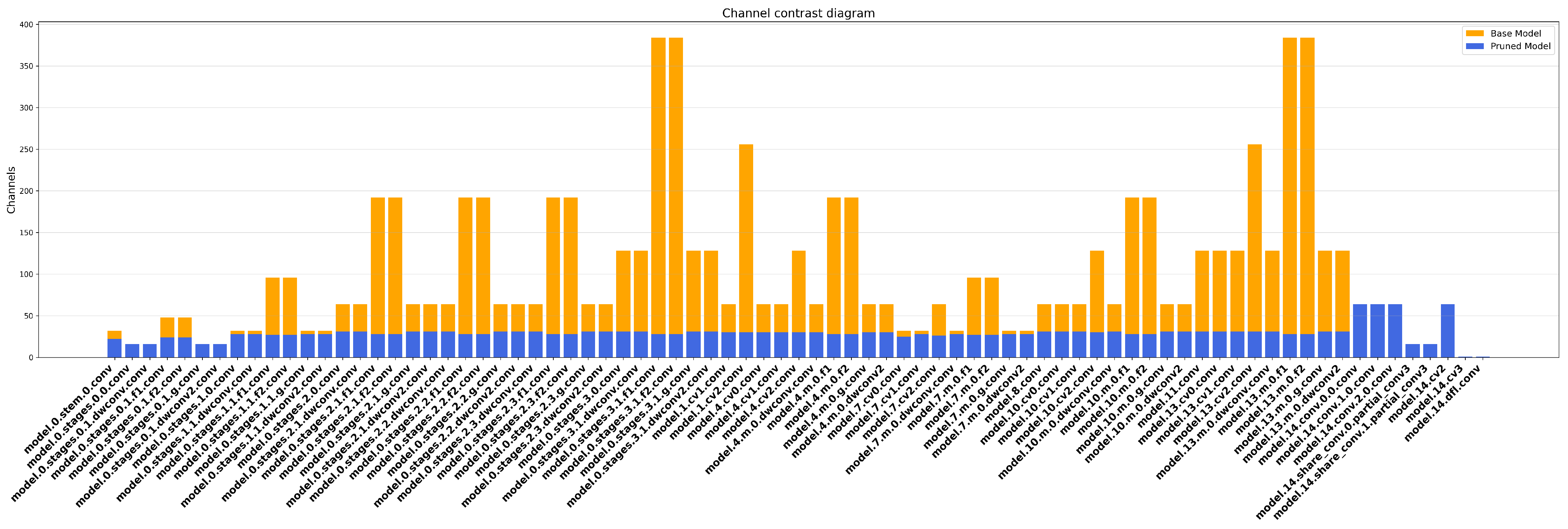
2.2.6. LAMP
| Algorithm 1: Channel Pruning Based on LAMP Scores. |
Input: Model parameters before pruning.
|
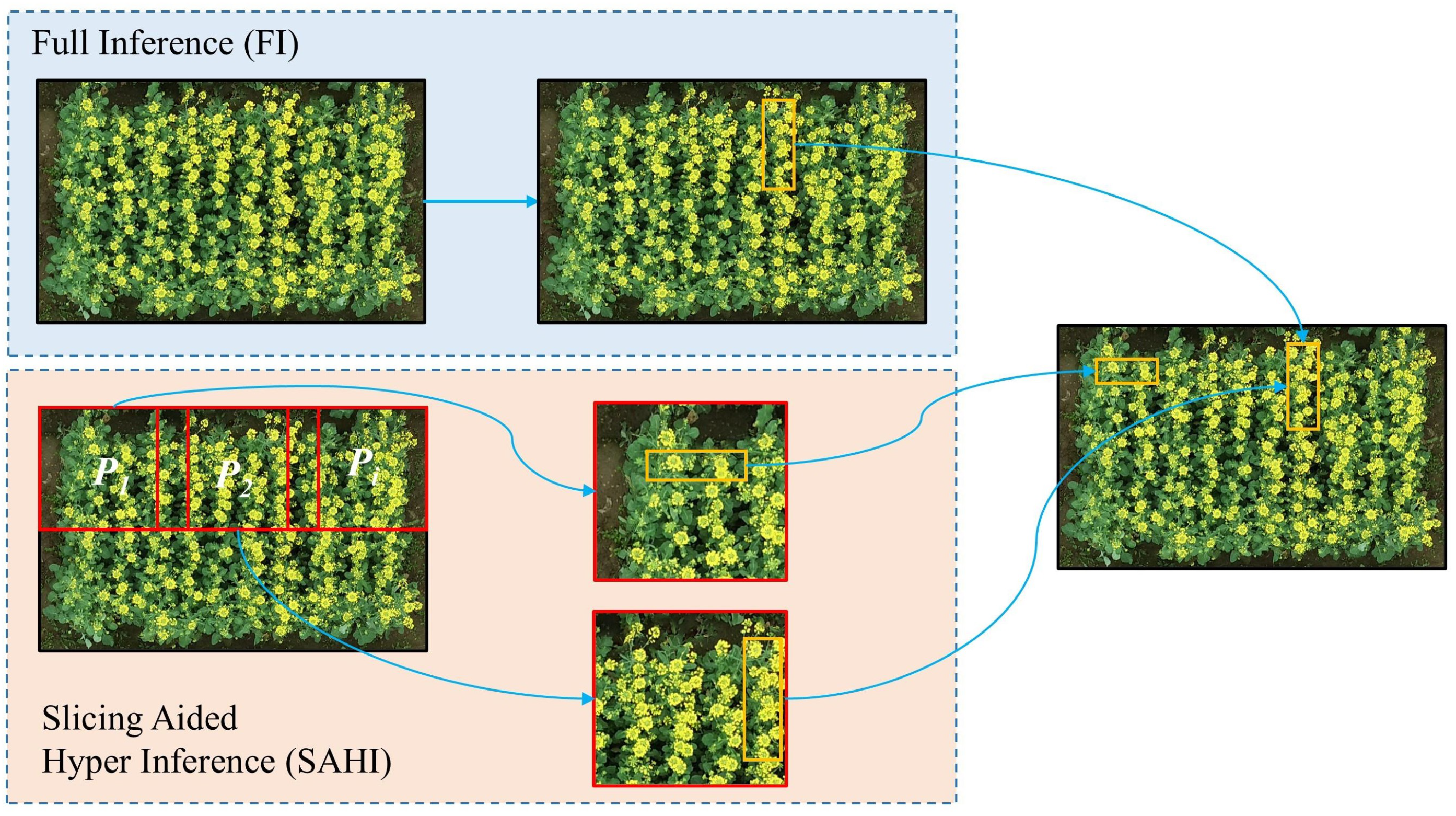
2.2.7. SAHI
3. Experimental Setup and Evaluation Metrics
3.1. Experimental Environment
3.2. Evaluation Metrics
4. Results and Analysis
4.1. Backbone Network Ablation Study
4.2. Module Ablation Experiments
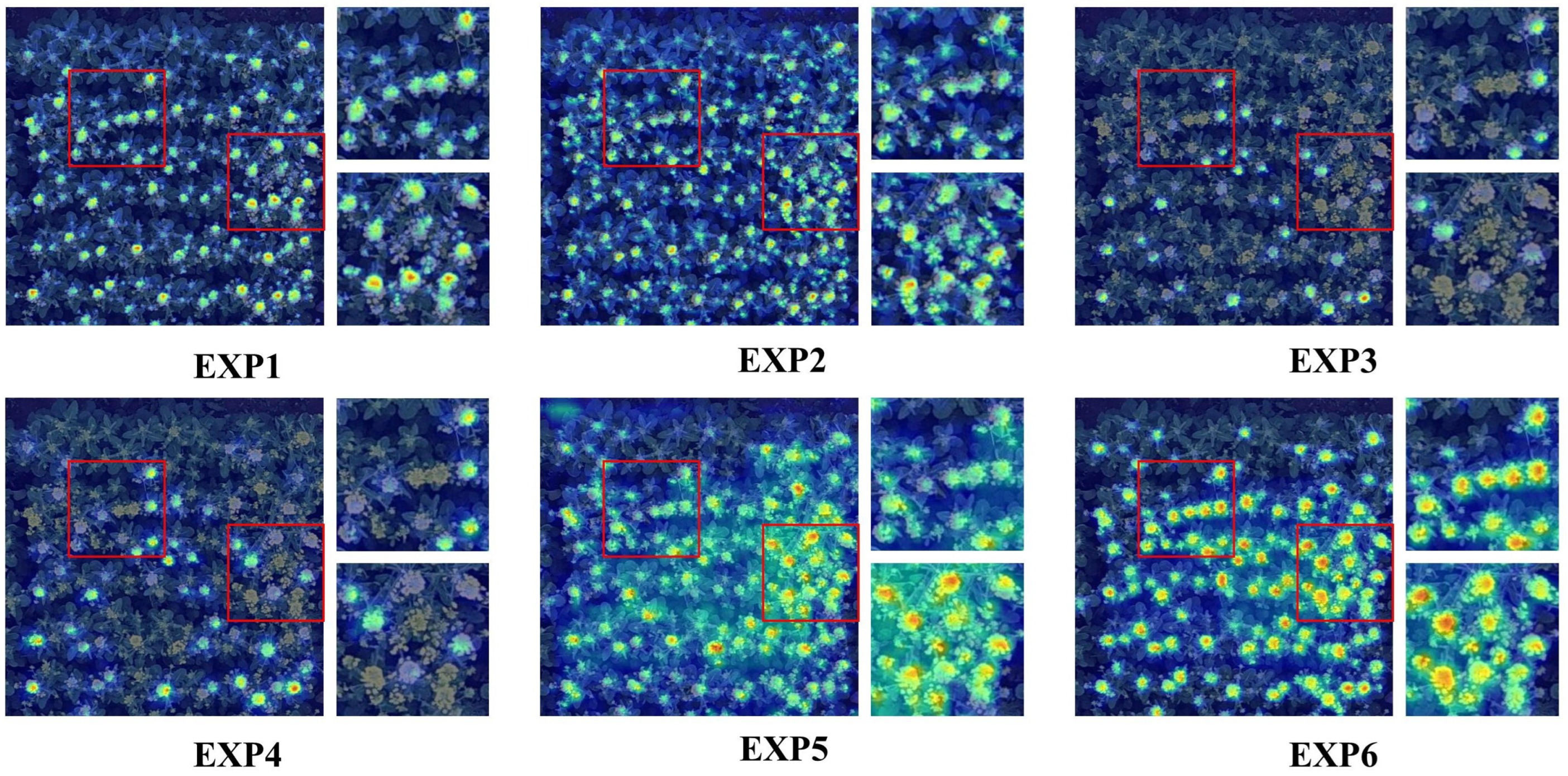
4.3. Model Pruning Experiments
4.4. Comparative Experiments with Different Detection Models
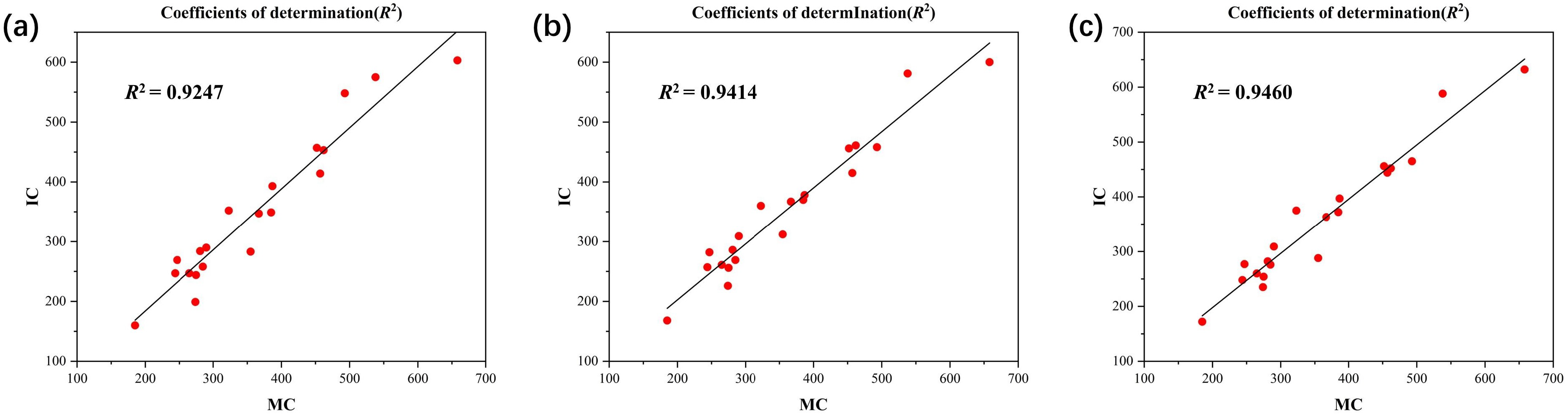
4.5. Counting Results and Robustness Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhang, X.; He, Y. Rapid estimation of seed yield using hyperspectral images of oilseed rape leaves. Ind. Crops Prod. 2013, 42, 416–420. [Google Scholar] [CrossRef]
- Feng, H.; Wang, H. Security strategy for the nation’s edible vegetable oil supplies under the new circumstances. Chin. J. Oil Crop Sci. 2024, 46, 221–227. [Google Scholar]
- Mamalis, M.; Kalampokis, E.; Kalfas, I.; Tarabanis, K. Deep learning for detecting verticillium fungus in olive trees: Using yolo in uav imagery. Algorithms 2023, 16, 343. [Google Scholar] [CrossRef]
- Roman, A.; Rahman, M.M.; Haider, S.A.; Akram, T.; Naqvi, S.R. Integrating Feature Selection and Deep Learning: A Hybrid Approach for Smart Agriculture Applications. Algorithms 2025, 18, 222. [Google Scholar] [CrossRef]
- Kirkegaard, J.A.; Lilley, J.M.; Brill, R.D.; Ware, A.H.; Walela, C.K. The critical period for yield and quality determination in canola (Brassica napus L.). Field Crops Res. 2018, 222, 180–188. [Google Scholar] [CrossRef]
- Matar, S.; Kumar, A.; Holtgräwe, D.; Weisshaar, B.; Melzer, S. The transition to flowering in winter rapeseed during vernalization. Plant Cell Environ. 2021, 44, 506–518. [Google Scholar] [CrossRef]
- Li, J.; Wang, E.; Qiao, J.; Li, Y.; Li, L.; Yao, J.; Liao, G. Automatic rape flower cluster counting method based on low-cost labelling and UAV-RGB images. Plant Methods 2023, 19, 40. [Google Scholar] [CrossRef]
- Li, J.; Li, Y.; Qiao, J.; Li, L.; Wang, X.; Yao, J.; Liao, G. Automatic counting of rapeseed inflorescences using deep learning method and UAV RGB imagery. Front. Plant Sci. 2023, 14, 1101143. [Google Scholar] [CrossRef]
- Han, J.; Zhang, Z.; Cao, J. Developing a new method to identify flowering dynamics of rapeseed using landsat 8 and sentinel-1/2. Remote Sens. 2020, 13, 105. [Google Scholar] [CrossRef]
- d’Andrimont, R.; Taymans, M.; Lemoine, G.; Ceglar, A.; Yordanov, M.; van der Velde, M. Detecting flowering phenology in oil seed rape parcels with Sentinel-1 and-2 time series. Remote Sens. Environ. 2020, 239, 111660. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Vail, S.; Duddu, H.S.; Parkin, I.A.; Guo, X.; Johnson, E.N.; Shirtliffe, S.J. Phenotyping flowering in canola (Brassica napus L.) and estimating seed yield using an unmanned aerial vehicle-based imagery. Front. Plant Sci. 2021, 12, 686332. [Google Scholar] [CrossRef] [PubMed]
- Gong, G.; Wang, X.; Zhang, J.; Shang, X.; Pan, Z.; Li, Z.; Zhang, J. MSFF: A Multi-Scale Feature Fusion Convolutional Neural Network for Hyperspectral Image Classification. Electronics 2025, 14, 797. [Google Scholar] [CrossRef]
- Colucci, G.P.; Battilani, P.; Camardo Leggieri, M.; Trinchero, D. Algorithms for Plant Monitoring Applications: A Comprehensive Review. Algorithms 2025, 18, 84. [Google Scholar] [CrossRef]
- Sári-Barnácz, F.E.; Zalai, M.; Milics, G.; Tóthné Kun, M.; Mészáros, J.; Árvai, M.; Kiss, J. Monitoring Helicoverpa armigera Damage with PRISMA Hyperspectral Imagery: First Experience in Maize and Comparison with Sentinel-2 Imagery. Remote Sens. 2024, 16, 3235. [Google Scholar] [CrossRef]
- Sun, Z.; Li, Q.; Jin, S.; Song, Y.; Xu, S.; Wang, X.; Cai, J.; Zhou, Q.; Ge, Y.; Zhang, R.; et al. Simultaneous prediction of wheat yield and grain protein content using multitask deep learning from time-series proximal sensing. Plant Phenomics 2022, 2022, 9757948. [Google Scholar] [CrossRef]
- Shi, Z.; Wang, L.; Yang, Z.; Li, J.; Cai, L.; Huang, Y.; Zhang, H.; Han, L. Unmanned Aerial Vehicle-Based Hyperspectral Imaging Integrated with a Data Cleaning Strategy for Detection of Corn Canopy Biomass, Chlorophyll, and Nitrogen Contents at Plant Scale. Remote Sens. 2025, 17, 895. [Google Scholar] [CrossRef]
- Sun, K.; Yang, J.; Li, J.; Yang, B.; Ding, S. Proximal Policy Optimization-Based Hierarchical Decision-Making Mechanism for Resource Allocation Optimization in UAV Networks. Electronics 2025, 14, 747. [Google Scholar] [CrossRef]
- Xue, X.; Niu, W.; Huang, J.; Kang, Z.; Hu, F.; Zheng, D.; Wu, Z.; Song, H. TasselNetV2++: A dual-branch network incorporating branch-level transfer learning and multilayer fusion for plant counting. Comput. Electron. Agric. 2024, 223, 109103. [Google Scholar] [CrossRef]
- Zhang, X.; Zhu, D.; Wen, R. SwinT-YOLO: Detection of densely distributed maize tassels in remote sensing images. Comput. Electron. Agric. 2023, 210, 107905. [Google Scholar] [CrossRef]
- Bai, X.; Gu, S.; Liu, P.; Yang, A.; Cai, Z.; Wang, J.; Yao, J. Rpnet: Rice plant counting after tillering stage based on plant attention and multiple supervision network. Crop J. 2023, 11, 1586–1594. [Google Scholar] [CrossRef]
- Yadav, P.K.; Thomasson, J.A.; Hardin, R.; Searcy, S.W.; Braga-Neto, U.; Popescu, S.C.; Rodriguez, R., III; Martin, D.E.; Enciso, J. AI-Driven Computer Vision Detection of Cotton in Corn Fields Using UAS Remote Sensing Data and Spot-Spray Application. Remote Sens. 2024, 16, 2754. [Google Scholar] [CrossRef]
- Zhang, M.; Chen, W.; Gao, P.; Li, Y.; Tan, F.; Zhang, Y.; Ruan, S.; Xing, P.; Guo, L. YOLO SSPD: A small target cotton boll detection model during the boll-spitting period based on space-to-depth convolution. Front. Plant Sci. 2024, 15, 1409194. [Google Scholar] [CrossRef]
- Qian, Y.; Qin, Y.; Wei, H.; Lu, Y.; Huang, Y.; Liu, P.; Fan, Y. MFNet: Multi-scale feature enhancement networks for wheat head detection and counting in complex scene. Comput. Electron. Agric. 2024, 225, 109342. [Google Scholar] [CrossRef]
- Terven, J.; Córdova-Esparza, D.-M.; Romero-González, J.-A. A comprehensive review of yolo architectures in computer vision: From yolov1 to yolov8 and yolo-nas. Mach. Learn. Knowl. Extr. 2023, 5, 1680–1716. [Google Scholar] [CrossRef]
- Ma, X.; Dai, X.; Bai, Y.; Wang, Y.; Fu, Y. Rewrite the stars. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 17–21 June 2024; pp. 5694–5703. [Google Scholar]
- Wang, N.; Liu, H.; Li, Y.; Zhou, W.; Ding, M. Segmentation and phenotype calculation of rapeseed pods based on YOLO v8 and mask R-convolution neural networks. Plants 2023, 12, 3328. [Google Scholar] [CrossRef]
- Liu, L.; Zhang, S.; Bai, Y.; Li, Y.; Zhang, C. Improved light-weight military aircraft detection algorithm of YOLOv8. J. Comput. Eng. Appl. 2024, 60, 114–125. [Google Scholar]
- Akyon, F.C.; Altinuc, S.O.; Temizel, A. Slicing aided hyper inference and fine-tuning for small object detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 966–970. [Google Scholar]
- Woo, S.; Debnath, S.; Hu, R.; Chen, X.; Liu, Z.; Xie, S.; He, K. ConvNeXt V2: Co-designing and Scaling ConvNets with Masked Autoencoders. arXiv 2023, arXiv:2301.00808. [Google Scholar]
- Doe, J.; Smith, J.; Roe, R. FarnerNet: A Lightweight Convolutional Neural Network for Agricultural Image Analysis. J. Agric. Inform. 2023, 15, 123–135. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Li, Y.; Yuan, G.; Wen, Y.; Hu, E.; Evangelidis, G.; Tulyakov, S.; Wang, Y.; Ren, J. EfficientFormer: Vision Transformers at MobileNet Speed. Adv. Neural Inf. Process. Syst. 2022, 35, 12934–12949. [Google Scholar]
- Liu, Z.; Mao, H.; Wu, C.Y.; Feichtenhofer, C.; Darrell, T.; Xie, S. EfficientViT: Lightweight Vision Transformers for Real-Time Semantic Segmentation. arXiv 2022, arXiv:2205.14756. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. BiFormer: Bidirectional Network for Visual Recognition. arXiv 2022, arXiv:2204.07369. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Li, H.; Kadav, A.; Durdanovic, I.; Samet, H.; Graf, H.P. Pruning Filters for Efficient ConvNets. arXiv 2016, arXiv:1608.08710. [Google Scholar]
- Fang, G.; Ma, X.; Song, M.; Mi, M.B.; Wang, X. Depgraph: Towards any structural pruning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 16091–16101. [Google Scholar]
- Zhou, X.; Wang, D.; Krähenbühl, P. Objects as Points. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; pp. 962–971. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal Loss for Dense Object Detection. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision (ECCV), Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Xu, X.F.; Zhao, W.F.; Zou, H.Q.; Zhang, L.; Pan, Z.Y. Detection algorithm of safety helmet wear based on MobileNet-SSD. Comput. Eng. 2021, 47, 9. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Stoken, A.; Borovec, J.; Kwon, Y.; Michael, K.; Fang, J.; Wong, C.; Zeng, Y.; V, A.; et al. ultralytics/yolov5: v6. 2-YOLOv5 Classification Models, Apple M1, Reproducibility, ClearML and Deci. ai Integrations. 2022. Available online: https://ui.adsabs.harvard.edu/abs/2022zndo...7002879J/abstract (accessed on 8 July 2025).
- Li, C.; Li, L.; Jiang, H.; Weng, K.; Geng, Y.; Li, L.; Ke, Z.; Li, Q.; Cheng, M.; Nie, W.; et al. YOLOv6: A single-stage object detection framework for industrial applications. arXiv 2022, arXiv:2209.02976. [Google Scholar]
- Wang, C.Y.; Bochkovskiy, A.; Liao, H.Y.M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 7464–7475. [Google Scholar]
- Wang, A.; Chen, H.; Liu, L.; Chen, K.; Lin, Z.; Han, J. Yolov10: Real-time end-to-end object detection. Adv. Neural Inf. Process. Syst. 2024, 37, 107984–108011. [Google Scholar]
- Khanam, R.; Hussain, M. Yolov11: An overview of the key architectural enhancements. arXiv 2024, arXiv:2410.17725. [Google Scholar]
- Wang, J.; Zhang, Y.; Li, X.; Zhang, J. RT-DETR: Real-Time Detection Transformer. arXiv 2023, arXiv:2304.08069. [Google Scholar]
- Zhang, Y.; Zhou, D.; Chen, S.; Gao, S.; Ma, Y. Single-Image Crowd Counting via Multi-Column Convolutional Neural Network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 589–597. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. CSRNet: Dilated Convolutional Neural Networks for Understanding the Highly Congested Scenes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 1091–1100. [Google Scholar]
- Lu, H.; Cao, Z.; Xiao, Y.; Zhuang, B.; Shen, C. TasselNet: Counting Maize Tassels in the Wild via Local Counts Regression. Agric. For. Meteorol. 2019, 264, 225–236. [Google Scholar] [CrossRef] [PubMed]
- Lu, H.; Cao, Z. TasselNetV2+: A fast implementation for high-throughput plant counting from high-resolution RGB imagery. Front. Plant Sci. 2020, 11, 541960. [Google Scholar] [CrossRef] [PubMed]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Precision P/% | Recall R/% | AP50/% | Parameters/M | GFLOPs/G | Model Size/MB |
|---|---|---|---|---|---|---|---|
| CNN | baseline | 90.3 | 84.5 | 92.2 | 2.86 | 8.1 | 6.3 MB |
| convnextv2 | 90.0 | 85.4 | 92.4 | 5.40 | 14.1 | 11.6 MB | |
| Fasternet | 89.0 | 85.7 | 92.6 | 3.98 | 10.7 | 8.6 MB | |
| StarNet | 90.5 | 84.6 | 92.4 | 2.11 | 6.5 | 4.7 MB | |
| ViT | MobileNet | 89.7 | 84.8 | 92.2 | 5.78 | 17.5 | 12.4 MB |
| EfficientFormerV2 | 89.8 | 86.1 | 92.8 | 4.87 | 11.7 | 41.4 MB | |
| efficientViT | 90.1 | 84.2 | 92.1 | 3.82 | 9.4 | 8.8 MB | |
| Biformer | 90.2 | 86.0 | 92.7 | 4.52 | 11.4 | 43.5 MB | |
| Swintransformer | 89.8 | 86.8 | 93.0 | 38.54 | 45.1 | 58.6 MB |
| Exp No. | StarNet | C2f-Star | PGCD | AP50/% | Parameters/M | GFLOPs/G | Model Size/MB |
|---|---|---|---|---|---|---|---|
| Exp 1 | × | × | × | 92.2 | 2.86 | 8.1 | 6.5 |
| Exp 2 | ✓ | × | × | 92.1 | 2.11 | 6.5 | 4.7 |
| Exp 3 | × | ✓ | × | 90.8 | 2.67 | 7.7 | 5.9 |
| Exp 4 | × | × | ✓ | 91.3 | 2.18 | 5.4 | 5.4 |
| Exp 5 | ✓ | ✓ | × | 92.0 | 1.92 | 6.1 | 4.3 |
| Exp 6 | ✓ | ✓ | ✓ | 92.4 | 1.24 | 3.4 | 2.8 |
| Pruning Method | Name | Pruning Rate | AP50/% | Parameters/M | GFLOPs/G | Model Size/MB | fps |
|---|---|---|---|---|---|---|---|
| SPL-YOLOv8 | / | / | 92.4 | 1.24 | 3.4 | 2.8 MB | 166.2 |
| lamp | EXP1 | 1.5 | 92.3 (−0.1%) | 0.49 (39.5%) | 2.2 (64.7%) | 1.3 MB | 141.3 (−14.9%) |
| EXP2 | 2.0 | 92.2 (−0.2%) | 0.27 (21.7%) | 1.7 (50%) | 0.8 MB | 167.7 (+0.9%) | |
| EXP3 | 2.5 | 91.4 (−1.0%) | 0.18 (14.5%) | 1.3 (38.2%) | 0.6 MB | 169.6 (2.0%) | |
| EXP4 | 3.0 | 92.2 (−0.2%) | 0.13 (10.4%) | 1.1 (32.3%) | 0.5 MB | 171.1 (+2.9%) | |
| l1 | EXP1 | 1.5 | 85.7 (−7.2%) | 0.98 (79.3%) | 2.9 (85.3%) | 2.6 MB | 187.5 (+12.8%) |
| EXP2 | 2.0 | 88.6 (−4.1%) | 0.92 (74.2%) | 1.7 (50.0%) | 2.3 MB | 176.5 (+6.2%) | |
| EXP3 | 2.5 | 88.7 (−4.0%) | 0.88 (71.0%) | 0.88 (25.8%) | 2.1 MB | 180.3 (+8.5%) | |
| EXP4 | 3.0 | 87.3 (−5.5%) | 0.72 (58.1%) | 0.72 (21.2%) | 1.8 MB | 182.8 (+10.0%) | |
| Group-Sl | EXP1 | 1.5 | 90.6 (−1.9%) | 0.79 (63.7%) | 2.3 (67.7%) | 2.2 MB | 167.2 (+0.6%) |
| EXP2 | 2.0 | 91.3 (−1.2%) | 0.59 (47.6%) | 1.7 (50.0%) | 1.5 MB | 165.9 (−0.2%) | |
| EXP3 | 2.5 | 89.8 (−2.8%) | 0.45 (36.3%) | 1.3 (38.2%) | 1.3 MB | 160.2 (−3.7%) | |
| EXP4 | 3.0 | 91.2 (−1.3%) | 0.34 (27.4%) | 1.1 (32.3%) | 1.0 MB | 174.7 (+5.1%) |
| Models | AP50/% | Parameters/M | GFLOPs/G | Model Size/MB | Weighted Score |
|---|---|---|---|---|---|
| Centernet | 90.3 | 31.15 | 109.7 | 124.9 | 0.71 |
| Retinanet | 80.4 | 34.65 | 163.5 | 138.9 | 0.59 |
| EfficientDet-D0 | 85.6 | 3.94 | 2.8 | 17.9 | 0.66 |
| SSD | 89.6 | 22.52 | 273.2 | 90.6 | 0.64 |
| MobileNet-SSD | 78.2 | 17.54 | 44.3 | 43.4 | 0.55 |
| YOLOv3 | 84.2 | 58.67 | 155.3 | 235.1 | 0.53 |
| YOLOv4 | 72.2 | 60.08 | 141.0 | 244.1 | 0.43 |
| YOLOv5n | 92.2 | 1.68 | 4.1 | 3.9 | 0.75 |
| YOLOv5s | 92.1 | 6.68 | 15.8 | 14.4 | 0.71 |
| YOLOv6 | 90.2 | 4.02 | 9.5 | 16.6 | 0.68 |
| YOLOv7 | 91.0 | 5.85 | 10.1 | 18.5 | 0.69 |
| YOLOv8n | 92.2 | 2.86 | 8.1 | 6.5 | 0.74 |
| YOLOv10n | 92.4 | 2.16 | 6.5 | 5.8 | 0.75 |
| YOLOv11n | 92.7 | 2.46 | 6.3 | 5.5 | 0.76 |
| RT-DETR-r18 | 92.7 | 18.95 | 56.9 | 40.5 | 0.73 |
| RT-DETR-r34 | 92.9 | 29.67 | 88.8 | 63.0 | 0.73 |
| SPL-YOLOv8 (ours) | 92.1 | 1.24 | 3.4 | 2.8 | 0.75 |
| SPL-YOLOv8-prune (ours) | 92.2 | 0.13 | 1.1 | 0.5 | 0.77 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fang, Y.; Yang, C.; Li, J.; Tu, J. SPL-YOLOv8: A Lightweight Method for Rape Flower Cluster Detection and Counting Based on YOLOv8n. Algorithms 2025, 18, 428. https://doi.org/10.3390/a18070428
Fang Y, Yang C, Li J, Tu J. SPL-YOLOv8: A Lightweight Method for Rape Flower Cluster Detection and Counting Based on YOLOv8n. Algorithms. 2025; 18(7):428. https://doi.org/10.3390/a18070428
Chicago/Turabian StyleFang, Yue, Chenbo Yang, Jie Li, and Jingmin Tu. 2025. "SPL-YOLOv8: A Lightweight Method for Rape Flower Cluster Detection and Counting Based on YOLOv8n" Algorithms 18, no. 7: 428. https://doi.org/10.3390/a18070428
APA StyleFang, Y., Yang, C., Li, J., & Tu, J. (2025). SPL-YOLOv8: A Lightweight Method for Rape Flower Cluster Detection and Counting Based on YOLOv8n. Algorithms, 18(7), 428. https://doi.org/10.3390/a18070428