



The Scientific Landscape of Hyper-Heuristics: A Bibliometric Analysis Based on Scopus



Abstract
1. Introduction
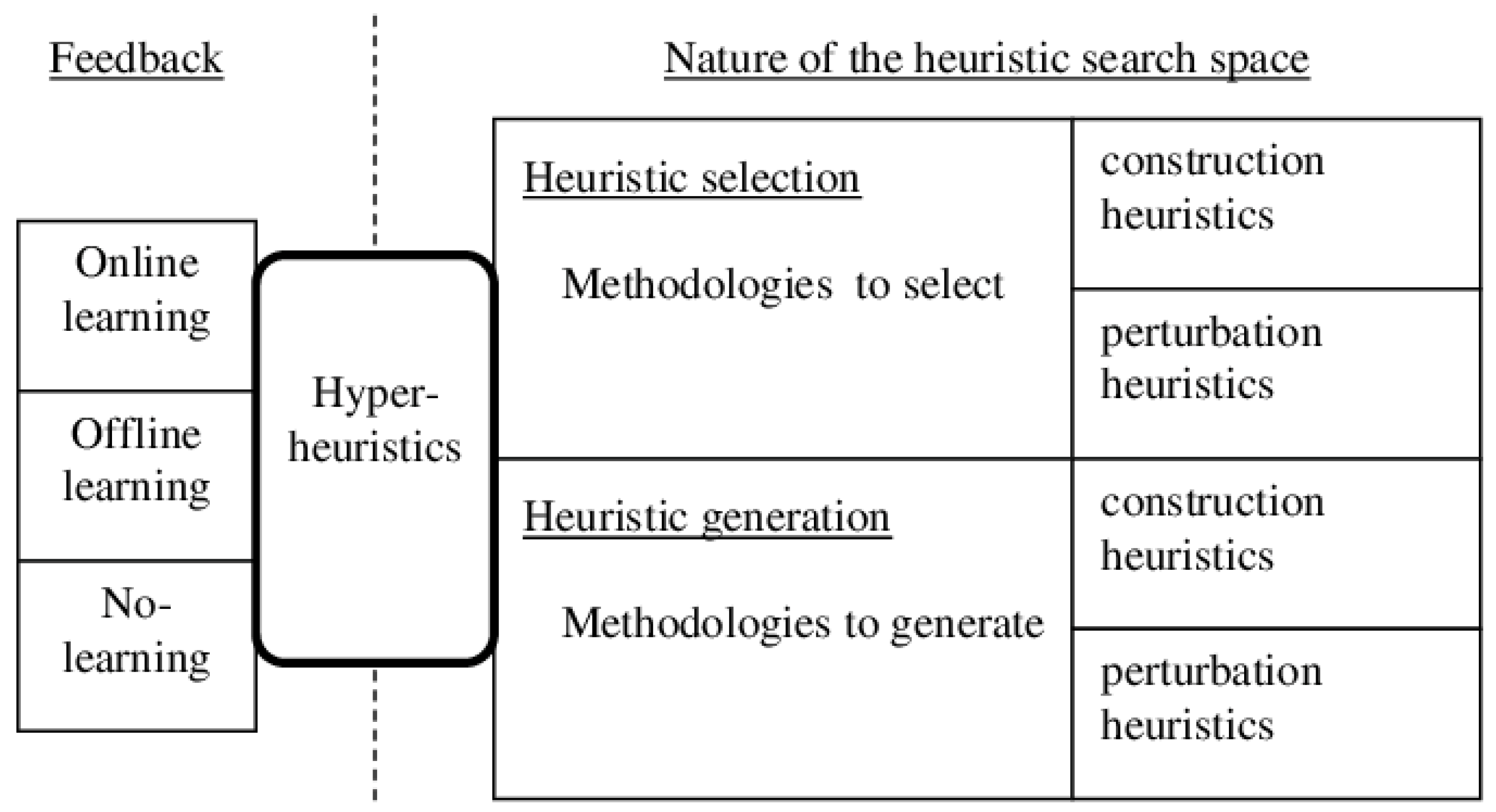
2. Background
3. Related Studies
- How has the hyper-heuristics research landscape evolved over time, as reflected in publication trends?
- What key terms define the intellectual core of hyper-heuristics research?
- How have the thematic priorities within hyper-heuristics research shifted over the years?
- What are the dominant research themes and application areas within the hyper-heuristic domain?
- Which countries and regions are at the forefront of hyper-heuristics research?
- Who are the key thought leaders and influential researchers shaping the field of hyper-heuristics?
- Which journals serve as the main outlets for disseminating cutting-edge hyper-heuristics research?
4. Methods, Techniques, and Instruments
- Removal of diacritics: All accented characters (e.g., á, é, í, ó, ú, ñ, ä, ë, ï, ö, ü) were replaced with their unaccented counterparts.
- Standardization of hyper-heuristic term: The terms “hyper-heuristic” and “hyper heuristic” were unified as “hyperheuristic” for consistency in the analysis. While the hyphenated form is grammatically correct, the unhyphenated version simplifies text processing for the Python (3.12.3) library.
- Plural form reduction: Plural forms of “heuristic” were converted to the singular form.
- Term unification for multi-objective and optimization: The terms “multi-objective” and “optimization” were standardized by removing hyphens and replacing “optimisation” with “optimization”.
5. Results
5.1. Publications per Year
5.2. Keywords Analysis
- Optimization Problems (with a particular focus on scheduling and routing)
- Job Shop Scheduling. A classic manufacturing problem involving multiple machines and jobs.
- Flexible Job Shop. A variant of job shop scheduling where machines can be assigned to different tasks.
- Vehicle Routing Problem. Optimizing routes for vehicles to serve multiple customers efficiently.
- Location Routing Problem. Determining optimal locations for facilities and routes for vehicles.
- Traveling Salesman Problem. Finding the shortest route that visits all cities exactly once.
- Intelligent Optimization Algorithms
- 6.
- Particle Swarm Optimization. A metaheuristic inspired by the behavior of bird flocks and fish schools.
- 7.
- Genetic Programming. A genetic algorithm that evolves computer programs to solve problems.
- 8.
- Ant Colony Optimization. A metaheuristic inspired by the behavior of ants searching for food.
5.3. Topics
- Topic 0. Scheduling and Production OptimizationThis topic centers on applying hyper-heuristics for solving complex scheduling and production planning problems, particularly in manufacturing contexts such as job shop and flow shop scheduling. The most representative studies address the design of scheduling rules and dispatching strategies using multi-objective optimization, genetic programming, and Q-learning to enhance energy efficiency and throughput. The representative keywords listed above underscore the practical orientation of this research area toward industrial applications, with a notable emphasis on rules-based systems and simulation-based optimization frameworks.
- Topic 1. Metaheuristic Optimization and Framework DevelopmentThis topic focuses on designing and tuning generalized hyper-heuristic frameworks for combinatorial optimization problems. The dominant approach involves hybrid methods aimed at selecting or generating heuristics dynamically. Representative studies explore hyper-heuristic architectures adaptable across domains, emphasizing performance analysis, algorithm generality, and reusing heuristic components within flexible solution frameworks.
- Topic 2. Vehicle Routing and LogisticsThis topic uses hyper-heuristics to tackle vehicle routing problems, focusing on environmental and operational constraints. Prominent subtopics include green vehicle routing, simultaneous pickup and delivery, and heterogeneous fleets. The literature emphasizes cost and carbon footprint reduction, traffic considerations, and real-world logistics constraints. Key studies propose hybrid metaheuristics and reinforcement learning strategies tailored to dynamic routing scenarios, suggesting a trend toward sustainable and adaptive transport logistics optimization.
- Topic 3. Cloud Computing and Resource ManagementResearch on this topic targets the optimization of cloud-based systems through hyper-heuristics that manage computing resources, energy consumption, and task scheduling. Articles highlight applications in scientific workflow scheduling and multi-objective cost management in cloud environments. The field increasingly integrates low-level scheduling heuristics with optimization methods to improve scalability and efficiency in distributed computing infrastructures.
- Topic 4. Machine Learning and Data MiningThis topic integrates hyper-heuristics with machine learning tasks, such as feature selection, classification, and cyber-security analytics. Techniques like support vector machines, decision trees, and ensemble learning are frequently used. Representative studies focus on optimizing algorithm selection or parameter tuning to improve model accuracy and robustness, particularly for large-scale datasets.
- Topic 5. Educational TimetablingThis topic encompasses the development of hyper-heuristics to solve educational timetabling problems. Key contributions include iterative local search strategies, hybrid methods combining add–delete mechanisms, and selection hyper-heuristics tuned for institutional constraints. The articles emphasize real-world applications, including school and university timetabling, incorporating hard and soft constraint handling, and addressing scalability and robustness in schedule generation.
- Topic 6. Traveling Salesman ProblemThis topic explores hyper-heuristic approaches for solving variants of the traveling salesman problem, including multi-depot and modified cost functions. This line of research emphasizes generating adaptive heuristics for pathfinding tasks under various constraints and problem sizes.
- Topic 7. Evolutionary Computation for Routing ProblemsThis topic highlights the application of evolutionary algorithms, especially genetic programming and co-evolutionary strategies, to solve routing problems characterized by uncertainty and capacity constraints. Recent years have focused on capacitated arc routing problems and real-time path planning under uncertain demand or environmental conditions. Representative studies explore the interaction between reactive and predictive routing elements, indicating a shift toward hyper-heuristic systems that adapt to dynamic and stochastic problem instances.
- Topic 8. Healthcare Scheduling and Resource AllocationThis topic addresses the scheduling of healthcare personnel and resources, particularly nurse rostering and patient care coordination. Hyper-heuristics in this context aim to satisfy complex institutional requirements such as coverage, shift preferences, and workload balancing. The integration of domain-specific knowledge, such as multi-stage rostering models and hidden Markov models, shows how hyper-heuristics are tailored to the unique constraints of healthcare systems, emphasizing both efficiency and fairness.
- Topic 9. Unmanned Aerial Vehicle (UAV) Path Planning and OptimizationThis emerging topic covers UAV mission planning through hyper-heuristic approaches, focusing on multi-objective optimization for coverage, surveillance, and communication tasks. Research emphasizes clustering, swarm intelligence, and real-time path adjustment in uncertain environments to optimize autonomous flight operations.
- Topic 10. Software Testing and Quality AssuranceThis topic focuses on improving software testing processes through hyper-heuristics that guide test case selection, generation, and prioritization. Studies involve experimental comparisons of selection and acceptance mechanisms, often within combinatorial test generation frameworks. High-impact articles explore feature model variability testing and hyper-heuristics integration into automated quality assurance pipelines, reflecting a push toward intelligent software verification under resource constraints.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Citations | Representative Articles | Topic |
|---|---|---|
| 151 | Zhao et al. [25]: A Hyperheuristic With Q-Learning for the Multiobjective Energy-Efficient Distributed Blocking Flow Shop Scheduling Problem | Topic 0 |
| 63 | Nguyen et al. [26]: A Hybrid Genetic Programming Algorithm for Automated Design of Dispatching Rules | |
| 61 | Freitag and Hildebrandt [27]: Automatic design of scheduling rules for complex manufacturing systems by multi-objective simulation-based optimization | |
| 110 | Sabar et al. [28]: A dynamic multiarmed bandit-gene expression programming hyper-heuristic for combinatorial optimization problems | Topic 1 |
| 99 | Sabar et al. [29]: Automatic design of a hyper-heuristic framework with gene expression programming for combinatorial optimization problems | |
| 92 | Zhao et al. [30]: A Novel Cooperative Multi-Stage Hyper-Heuristic for Combination Optimization Problems | |
| 95 | Olgun et al. [31]: A hyper-heuristic for the green vehicle routing problem with simultaneous pickup and delivery | Topic 2 |
| 91 | Qin et al. [32]: A novel reinforcement learning-based hyper-heuristic for heterogeneous vehicle routing problem | |
| 42 | Leng, L. et al. [33]: Decomposition-based hyperheuristic approaches for the bi-objective cold chain considering environmental effects | |
| 182 | Tsai et al. [23]: A hyper-heuristic scheduling algorithm for cloud | Topic 3 |
| 63 | Alkhanak and Lee [24]: A hyper-heuristic cost optimisation approach for Scientific Workflow Scheduling in cloud computing | |
| 35 | Al-Khanak et al. [34]: A heuristics-based cost model for scientific workflow scheduling in cloud | |
| 64 | Barros et al. [35]: Evolutionary Design of Decision-Tree Algorithms Tailored to Microarray Gene Expression Data Sets | Topic 4 |
| 41 | Sabar et al. [36]: A Bi-objective Hyper-Heuristic Support Vector Machines for Big Data Cyber-Security | |
| 41 | Asta and Özcan [37]: A tensor-based selection hyper-heuristic for cross-domain heuristic search | |
| 73 | Soria-Alcaraz et al. [38]: Effective learning hyper-heuristics for the course timetabling problem | Topic 5 |
| 54 | Soria-Alcaraz et al. [39]: Iterated local search using an add and delete hyper-heuristic for university course timetabling | |
| 38 | Ahmed et al. [40]: Solving high school timetabling problems worldwide using selection hyper-heuristics | |
| 100 | Choong et al. [41]: An artificial bee colony algorithm with a Modified Choice Function for the traveling salesman problem | Topic 6 |
| 59 | Pandiri and Singh, A. [42]: A hyper-heuristic based artificial bee colony algorithm for k-Interconnected multi-depot multi-traveling salesman problem | |
| 41 | Gharehchopogh et al. [43]: An Improved Farmland Fertility Algorithm with Hyper-Heuristic Approach for Solving Travelling Salesman Problem | |
| 40 | Liu et al. [44]: A predictive-reactive approach with genetic programming and cooperative coevolution for the uncertain capacitated arc routing problem | Topic 7 |
| 37 | Maclachlan et al. [45]: Genetic programming hyper-heuristics with vehicle collaboration for uncertain capacitated arc routing problems | |
| 29 | Wang et al. [46]: Genetic programming with niching for uncertain capacitated arc routing problem | |
| 43 | Smet et al. [47]: Modelling and evaluation issues in nurse rostering | Topic 8 |
| 37 | Asta et al. [48]: A tensor-based hyper-heuristic for nurse rostering | |
| 28 | Kheiri et al. [49]: A hyper-heuristic approach based upon a hidden Markov model for the multi-stage nurse rostering problem | |
| 22 | Wei et al. [50]: Autonomous path planning of AUV in large-scale complex marine environment based on swarm hyper-heuristic algorithm | Topic 9 |
| 8 | Bozorgi et al. [51]: A smart optimizer approach for clustering protocol in UAV-assisted IoT wireless networks | |
| 3 | Zhao et al. [52]: Clustering-based hyper-heuristic algorithm for multi-region coverage path planning of heterogeneous UAVs | |
| 112 | Zamli et al. [53]: A Tabu Search hyper-heuristic strategy for t-way test suite generation | Topic 10 |
| 77 | Zamli et al. [54]: An experimental study of hyper-heuristic selection and acceptance mechanism for combinatorial t-way test suite generation | |
| 41 | Strickler et al. [55]: Deriving products for variability test of Feature Models with a hyper-heuristic approach |
5.4. Sources
5.5. Countries
5.6. Authors
6. Discussion and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Cowling, P.; Kendall, G.; Soubeiga, E. A Hyperheuristic Approach to Scheduling a Sales Summit. In Practice and Theory of Automated Timetabling III. PATAT 2000; Lecture Notes in Computer Science; Burke, E., Erben, W., Eds.; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2079. [Google Scholar] [CrossRef]
- Burke, E.; Kendall, G.; Soubeiga, E. A Tabu-Search Hyperheuristic for Timetabling and Rostering. J. Heuristics 2003, 9, 451–470. [Google Scholar] [CrossRef]
- Burke, E.; MacCarthy, B.; Petrovic, S.; Qu, R. Knowledge discovery in a hyper-heuristic for course timetabling using case-based reasoning. In Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Berlin/Heidelberg, Germany, 2003; Volume 2740, pp. 276–287. [Google Scholar] [CrossRef]
- Misir, M. Selection-Based Per-Instance Heuristic Generation for Protein Structure Prediction of 2D HP Model. In Proceedings of the 2021 IEEE Symposium Series on Computational Intelligence, SSCI 2021, Orlando, FL, USA, 5–7 December 2021. [Google Scholar] [CrossRef]
- Page, M.J.; Moher, D.; Bossuyt, P.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Akl, E.A.; Brennan, S.E.; et al. PRISMA 2020 explanation and elaboration: Updated guidance and exemplars for reporting systematic reviews. BMJ 2021, 372, n160. [Google Scholar] [CrossRef] [PubMed]
- Hjeij, M.; Vilks, A. A brief history of heuristics: How did research on heuristics evolve? Humanit. Soc. Sci. Commun. 2023, 10, 64. [Google Scholar] [CrossRef]
- Benaissa, B.; Kobayashi, M.; Ali, M.A.; Khatir, T.; Elmeliani, M.E.A.E. Metaheuristic optimization algorithms: An overview. HCMCOU J. Sci.—Adv. Comput. Struct. 2024, 14, 33–61. [Google Scholar] [CrossRef]
- Burke, E.K.; Hyde, M.R.; Kendall, G.; Ochoa, G.; Ozcan, E.; Woodward, J.R. A Classification of Hyper-heuristics Approaches-Revisited. In Handbook of Metaheuristics; Springer: Berlin/Heidelberg, Germany, 2017. [Google Scholar] [CrossRef]
- Pillay, N. A review of hyper-heuristics for educational timetabling. Ann. Oper. Res. 2016, 239, 3–38. [Google Scholar] [CrossRef]
- Liu, F.; Lu, C.; Gui, L.; Zhang, Q.; Tong, X.; Yuan, M. Heuristics for Vehicle Routing Problem: A Survey and Recent Advances. arXiv 2023, arXiv:2303.04147. [Google Scholar] [CrossRef]
- Vela, A.; Valencia-Rivera, G.H.; Cruz-Duarte, J.M.; Ortiz-Bayliss, J.C.; Amaya, I. Hyper-Heuristics and Scheduling Problems: Strategies, Application Areas, and Performance Metrics. IEEE Access 2025, 13, 14983–14997. [Google Scholar] [CrossRef]
- Burke, E.; Hyde, M.; Kendall, G.; Ochoa, G.; Özcan, E. A classification of hyper-heuristic approaches. In International Series in Operations Research and Management Science; Springer: Berlin/Heidelberg, Germany, 2010; pp. 449–468. [Google Scholar] [CrossRef]
- Li, C.; Wei, X.; Wang, J.; Wang, S.; Zhang, S. A review of reinforcement learning based hyper-heuristics. PeerJ Comput. Sci. 2024, 10, e2141. [Google Scholar] [CrossRef]
- Sanchez, M.; Cruz-Duarte, J.M.; Ortiz-Bayliss, J.C.; Ceballos, H.; Terashima-Marin, H.; Amaya, I. A Systematic Review of Hyper-Heuristics on Combinatorial Optimization Problems. IEEE Access 2020, 8, 128068–128095. [Google Scholar] [CrossRef]
- Gárate-Escamilla, A.K.; Amaya, I.; Cruz-Duarte, J.M.; Terashima-Marín, H.; Ortiz-Bayliss, J.C. Identifying Hyper-Heuristic Trends through a Text Mining Approach on the Current Literature. Appl. Sci. 2022, 12, 10576. [Google Scholar] [CrossRef]
- Pereira, V.; Basilio, M.; Santos, C. PyBibX—A Python library for bibliometric and scientometric analysis powered with artificial intelligence tools. Data Technol. Appl. 2025, 59, 302–337. [Google Scholar] [CrossRef]
- Bornmann, L.; Mutz, R. Growth rates of modern science: A bibliometric analysis based on the number of publications and cited references. J. Assoc. Inf. Sci. Technol. 2015, 66, 2215–2222. [Google Scholar] [CrossRef]
- de Santiago, V.A.; Özcan, E.; Balera, J.M. Many-Objective Test Case Generation for Graphical User Interface Applications via Search-Based and Model-Based Testing. Expert Syst. Appl. 2022, 208, 118075. [Google Scholar] [CrossRef]
- Sulaiman, R.; Jawawi, D.A.; Halim, S. Cost-Effective Test Case Generation with the Hyper-Heuristic for Software Product Line Testing. Adv. Eng. Softw. 2023, 175, 103335. [Google Scholar] [CrossRef]
- Zhao, D.; Shao, K.; Zhu, Y.; Li, D.; Chen, Y.; Wang, H.; Liu, D.; Zhou, T.; Wang, C. Review of deep reinforcement learning and discussions on the development of computer Go. Kongzhi Lilun Yu Yingyong/Control. Theory Appl. 2016, 33, 701–717. [Google Scholar] [CrossRef]
- Zhang, Y.; Bai, R.; Qu, R.; Tu, C.; Jin, J. A deep reinforcement learning based hyper-heuristic for combinatorial optimisation with uncertainties. Eur. J. Oper. Res. 2022, 300, 418–427. [Google Scholar] [CrossRef]
- Kallestad, J.; Hasibi, R.; Hemmati, A.; Sörensen, K. A general deep reinforcement learning hyperheuristic framework for solving combinatorial optimization problems. Eur. J. Oper. Res. 2023, 309, 446–468. [Google Scholar] [CrossRef]
- Tsai, C.-W.; Huang, W.-C.; Chiang, M.-H.; Chiang, M.-C.; Yang, C.-S. A hyper-heuristic scheduling algorithm for cloud. IEEE Trans. Cloud Comput. 2014, 2, 236–250. [Google Scholar] [CrossRef]
- Alkhanak, E.N.; Lee, S.P. A hyper-heuristic cost optimisation approach for Scientific Workflow Scheduling in cloud computing. Future Gener. Comput. Syst. 2018, 86, 480–506. [Google Scholar] [CrossRef]
- Zhao, F.; Di, S.; Wang, L. A Hyperheuristic With Q-Learning for the Multiobjective Energy-Efficient Distributed Blocking Flow Shop Scheduling Problem. IEEE Trans. Cybern. 2023, 53, 3337–3350. [Google Scholar] [CrossRef]
- Nguyen, S.; Mei, Y.; Xue, B.; Zhang, M. A Hybrid Genetic Programming Algorithm for Automated Design of Dispatching Rules. Evol. Comput. 2019, 27, 467–496. [Google Scholar] [CrossRef] [PubMed]
- Freitag, M.; Hildebrandt, T. Automatic design of scheduling rules for complex manufacturing systems by multi-objective simulation-based optimization. CIRP Ann. 2016, 65, 433–436. [Google Scholar] [CrossRef]
- Sabar, N.R.; Ayob, M.; Kendall, G.; Qu, R. A dynamic multiarmed bandit-gene expression programming hyper-heuristic for combinatorial optimization problems. IEEE Trans. Cybern. 2015, 45, 217–228. [Google Scholar] [CrossRef]
- Sabar, N.R.; Ayob, M.; Kendall, G.; Qu, R. Automatic design of a hyper-heuristic framework with gene expression programming for combinatorial optimization problems. IEEE Trans. Evol. Comput. 2015, 19, 309–325. [Google Scholar] [CrossRef]
- Zhao, F.; Di, S.; Cao, J.; Tang, J.; Jonrinaldi. A Novel Cooperative Multi-Stage Hyper-Heuristic for Combination Optimization Problems. Complex Syst. Model. Simul. 2021, 1, 91–108. [Google Scholar] [CrossRef]
- Olgun, B.; Koç, Ç.; Altıparmak, F. A Hyper Heuristic for the Green Vehicle Routing Problem with Simultaneous Pickup and Delivery. Comput. Ind. Eng. 2021, 153, 107010. [Google Scholar] [CrossRef]
- Qin, W.; Zhuang, Z.; Huang, Z.; Huang, H. A novel reinforcement learning-based hyper-heuristic for heterogeneous vehicle routing problem. Comput. Ind. Eng. 2021, 156, 107252. [Google Scholar] [CrossRef]
- Leng, L.; Zhang, J.; Zhang, C.; Zhao, Y.; Wang, W.; Li, G. Decomposition-based hyperheuristic approaches for the bi-objective cold chain considering environmental effects. Comput. Oper. Res. 2020, 123, 105043. [Google Scholar] [CrossRef]
- Al-Khanak, E.N.; Lee, S.P.; Ur Rehman Khan, S.; Behboodian, N.; Khalaf, O.I.; Verbraeck, A.; van Lint, H. A heuristics-based cost model for scientific workflow scheduling in cloud. Comput. Mater. Contin. 2021, 67, 3265–3282. [Google Scholar] [CrossRef]
- Barros, R.C.; Basgalupp, M.P.; Freitas, A.A.; de Carvalho, A.C.P.L.F. Evolutionary Design of Decision-Tree Algorithms Tailored to Microarray Gene Expression Data Sets. IEEE Trans. Evol. Comput. 2014, 18, 873–892. [Google Scholar] [CrossRef]
- Sabar, N.R.; Yi, X.; Song, A. A Bi-objective Hyper-Heuristic Support Vector Machines for Big Data Cyber-Security. IEEE Access 2018, 6, 10421–10431. [Google Scholar] [CrossRef]
- Asta, S.; Özcan, E. A Tensor-Based Selection Hyper-Heuristic for Cross-Domain Heuristic Search. Inf. Sci. 2015, 299, 412–432. [Google Scholar] [CrossRef]
- Soria-Alcaraz, J.A.; Ochoa, G.; Swan, J.; Carpio, M.; Puga, H.; Burke, E.K. Effective learning hyper-heuristics for the course timetabling problem. Eur. J. Oper. Res. 2014, 238, 77–86. [Google Scholar] [CrossRef]
- Soria-Alcaraz, J.A.; Özcan, E.; Swan, J.; Kendall, G.; Carpio, M. Iterated local search using an add and delete hyper-heuristic for university course timetabling. Appl. Soft Comput. J. 2016, 40, 581–593. [Google Scholar] [CrossRef]
- Ahmed, L.N.; Özcan, E.; Kheiri, A. Solving High School Timetabling Problems Worldwide Using Selection Hyper-Heuristics. Expert Syst. Appl. 2015, 42, 5463–5471. [Google Scholar] [CrossRef]
- Choong, S.S.; Wong, L.-P.; Lim, C.P. An Artificial Bee Colony Algorithm with a Modified Choice Function for the Traveling Salesman Problem. In Proceedings of the 2017 IEEE International Conference on Systems, Man, and Cybernetics, SMC 2017, Banff, AB, Canada, 5–8 October 2017; pp. 357–362. [Google Scholar] [CrossRef]
- Pandiri, V.; Singh, A. A hyper-heuristic based artificial bee colony algorithm for k-Interconnected multi-depot multi-traveling salesman problem. Inf. Sci. 2018, 463–464, 261–281. [Google Scholar] [CrossRef]
- Gharehchopogh, F.S.; Abdollahzadeh, B.; Arasteh, B. An Improved Farmland Fertility Algorithm with Hyper-Heuristic Approach for Solving Travelling Salesman Problem. CMES—Comput. Model. Eng. Sci. 2023, 135, 1981–2006. [Google Scholar] [CrossRef]
- Liu, Y.; Mei, Y.; Zhang, M.; Zhang, Z. A predictive-reactive approach with genetic programming and cooperative coevolution for the uncertain capacitated arc routing problem. Evol. Comput. 2019, 28, 289–316. [Google Scholar] [CrossRef]
- Maclachlan, J.; Mei, Y.; Branke, J.; Zhang, M. Genetic Programming Hyper-Heuristics with Vehicle Collaboration for Uncertain Capacitated Arc Routing Problems. Evol. Comput. 2019, 28, 563–593. [Google Scholar] [CrossRef]
- Wang, S.; Mei, Y.; Zhang, M.; Yao, X. Genetic programming with niching for uncertain capacitated arc routing problem. IEEE Trans. Evol. Comput. 2022, 26, 73–87. [Google Scholar] [CrossRef]
- Smet, P.; Bilgin, B.; De Causmaecker, P.; Vanden Berghe, G. Modelling and evaluation issues in nurse rostering. Ann. Oper. Res. 2014, 218, 303–326. [Google Scholar] [CrossRef]
- Asta, S.; Özcan, E.; Curtois, T. A Tensor Based Hyper-Heuristic for Nurse Rostering. Knowl.-Based Syst. 2016, 98, 185–199. [Google Scholar] [CrossRef]
- Kheiri, A.; Gretsista, A.; Keedwell, E.; Lulli, G.; Epitropakis, M.G.; Burke, E.K. A hyper-heuristic approach based upon a hidden Markov model for the multi-stage nurse rostering problem. Comput. Oper. Res. 2021, 130, 105221. [Google Scholar] [CrossRef]
- Wei, D.; Wang, F.; Ma, H. Autonomous path planning of AUV in large-scale complex marine environment based on swarm hyper-heuristic algorithm. Appl. Sci. 2019, 9, 2654. [Google Scholar] [CrossRef]
- Bozorgi, S.M.; Golsorkhtabaramiri, M.; Yazdani, S.; Adabi, S. A smart optimizer approach for clustering protocol in UAV-assisted IoT wireless networks. Internet Things 2023, 21, 100683. [Google Scholar] [CrossRef]
- Zhao, B.; Huo, M.; Li, Z.; Yu, Z.; Qi, N. Clustering-based hyper-heuristic algorithm for multi-region coverage path planning of heterogeneous UAVs. Neurocomputing 2024, 610, 128528. [Google Scholar] [CrossRef]
- Zamli, K.Z.; Alkazemi, B.Y.; Kendall, G. A Tabu Search hyper-heuristic strategy for t-way test suite generation. Appl. Soft Comput. J. 2016, 44, 57–74. [Google Scholar] [CrossRef]
- Zamli, K.Z.; Din, F.; Kendall, G.; Ahmed, B.S. An Experimental Study of Hyper-Heuristic Selection and Acceptance Mechanism for Combinatorial t-Way Test Suite Generation. Inf. Sci. 2017, 399, 121–153. [Google Scholar] [CrossRef]
- Strickler, A.; Prado Lima, J.A.; Vergilio, S.R.; Pozo, A.T.R. Deriving products for variability test of Feature Models with a hyper-heuristic approach. Appl. Soft Comput. J. 2016, 49, 1232–1242. [Google Scholar] [CrossRef]
- Zhao, X.; Zhang, H.; Yang, C.; Li, B. Chapter 9 An Overview of Artificial Intelligence Research and Development in China. In The New Silk Road Leads Through the Arab Peninsula: Mastering Global Business and Innovation; Emerald Publishing Limited: Leeds, UK, 2019; pp. 143–151. [Google Scholar] [CrossRef]
- Merigó, J.M.; Yang, J.-B. A bibliometric analysis of operations research and management science. Omega 2017, 73, 37–48. [Google Scholar] [CrossRef]














| Article | POT | CtA | KA | TA | CA | AA | JA |
|---|---|---|---|---|---|---|---|
| Sanchez et al. [14] | ☓ | ☓ | ☓ | ☓ | ☓ | ||
| Gárate-Escamilla et al. [15] | ☓ | ☓ | ☓ | ☓ | |||
| Current work | ☓ | ☓ | ☓ | ☓ | ☓ | ☓ | ☓ |
| Search Keywords (SK), Document Type (DT) | Result |
|---|---|
| SK = hyper-heuristic, DT = all | 1740 |
| SK = hyperheuristic, DT = all | 606 |
| SK = hyper-heuristic OR hyperheuristic, DT = all | 1847 |
| SK = hyper-heuristic OR hyperheuristic, DT = article | 768 |
| SK = hyper-heuristic OR hyperheuristic, DT = article, duplicates removed | 767 |
| Metric | Value |
|---|---|
| Timespan | 2003–2025 |
| Total Number of Countries | 68 |
| Total Number of Sources | 288 |
| Total Number of Documents | 767 |
| Average Documents per Author | 1.6 |
| Average Documents per Source | 2.66 |
| Average Documents per Year | 34.86 |
| Total Number of Authors | 1744 |
| Total Number of Author Keywords | 1797 |
| Total Single-Authored Documents | 17 |
| Total Multi-Authored Documents | 750 |
| Average Collaboration Index | 3.64 |
| Max H-Index | 23 |
| Total Number of Citations | 17,861 |
| Average Citations per Author | 10.24 |
| Average Citations per Document | 23.29 |
| Average Citations per Source | 62.02 |
| Suggested Group | Associated Words | |
|---|---|---|
| Scheduling and Production Optimization | Scheduling, programming, genetic, rules, shop, job, time, results, manufacturing, production | Topic 0 (177) |
| Metaheuristic Optimization and Framework Development | Optimization, level, search, selection, framework, results, approach, performance, low, different | Topic 1 (127) |
| Vehicle Routing and Logistics | Cost, routing, vehicle, model, logistics, carbon, time, traffic, results, level | Topic 2 (61) |
| Cloud Computing and Resource Management | Resource, cloud, energy, computing, scheduling, network, sensor, performance, task, consumption | Topic 3 (51) |
| Machine Learning and Data Mining | Classification, data, feature, learning, SVM, accuracy, decision, tree, dataset, machine | Topic 4 (42) |
| Educational Timetabling | Timetabling, exam, approach, research, graph, course, table, educational, ITC, instances | Topic 5 (31) |
| Traveling Salesman Problem | City, salesman, approach, traveling, facility, tour, solution, instances, search, neighborhood | Topic 6 (15) |
| Evolutionary Computation for Routing Problems | Routing, uncertain, policies, arc, genetic, programming, capacitated, policy, vehicles | Topic 7 (14) |
| Healthcare Scheduling and Resource Allocation | Rostering, patient, nurse, pas, hospital, care, approach, scheduling, solutions, crowd | Topic 8 (14) |
| Unmanned Aerial Vehicle (UAV) Path Planning and Optimization | UAV, swarm, coverage, path, planning, optimal, optimization, DSO, environment, marine | Topic 9 (13) |
| Software Testing and Quality Assurance | Testing, software, strategies, generation, cases, SPL, coverage, pairwise, selection, approach | Topic 10 (13) |
| Country | Number of Collaborations |
|---|---|
| United Kingdom | 26 |
| China | 23 |
| Australia | 14 |
| United States of America | 12 |
| Canada | 11 |
| Malaysia | 11 |
| Mexico | 10 |
| Saudi Arabia | 10 |
| Singapore | 10 |
| Brazil | 9 |
| Egypt | 9 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Peñate-Rodríguez, H.C.; Rivera, G.; Sánchez-Solís, J.P.; Florencia, R. The Scientific Landscape of Hyper-Heuristics: A Bibliometric Analysis Based on Scopus. Algorithms 2025, 18, 294. https://doi.org/10.3390/a18050294
Peñate-Rodríguez HC, Rivera G, Sánchez-Solís JP, Florencia R. The Scientific Landscape of Hyper-Heuristics: A Bibliometric Analysis Based on Scopus. Algorithms. 2025; 18(5):294. https://doi.org/10.3390/a18050294
Chicago/Turabian StylePeñate-Rodríguez, Helen C., Gilberto Rivera, J. Patricia Sánchez-Solís, and Rogelio Florencia. 2025. "The Scientific Landscape of Hyper-Heuristics: A Bibliometric Analysis Based on Scopus" Algorithms 18, no. 5: 294. https://doi.org/10.3390/a18050294
APA StylePeñate-Rodríguez, H. C., Rivera, G., Sánchez-Solís, J. P., & Florencia, R. (2025). The Scientific Landscape of Hyper-Heuristics: A Bibliometric Analysis Based on Scopus. Algorithms, 18(5), 294. https://doi.org/10.3390/a18050294