1. Introduction
The introduction of generic equivalents of brand-name pharmaceuticals into worldwide marketplaces has been a major approach for cutting medication costs and hence reducing their proportion to total healthcare expenses. Given the importance of generic drugs in healthcare, it is critical that their pharmaceutical quality and in vivo performance be accurately evaluated [
1]. Bioequivalence (BE) testing is a critical component of drug development for the evaluation of generics. For the registration of a generic formulation, the pharmaceutical company must provide supporting evidence to the regulatory body on the proposed generic content, development, manufacture, quality, stability, and in vitro and in vivo performance [
2]. According to the FDA and EMA, the BE of two products lies in their pharmaceutical equivalence, their bioavailabilities after administration that must fall within acceptable established boundaries, meaning that they do not differ significantly. This statement is quantified in a range that both regulatory bodies agree on 80.00–125.00%, in order to pass the 90% confidence interval for the ratio of Test (T) to Reference (R) products [
3,
4,
5].
Highly variable drugs (HVDs) are a class of pharmacological products that have a within-subject variability (CVw) equal to or bigger than 30% of the maximum concentration (Cmax) and/or the area under the concentration–time curve (AUC). The BE of HVDs is a concern because the high variability necessitates a large number of patients to provide acceptable statistical power [
1,
6,
7]. Moreover, there have been reported difficulties in achieving the conventional BE requirements for HVDs. There are examples of a highly variable reference product failing to demonstrate BE when compared to itself in BE research with the typical design/sample size [
8,
9]. FDA and EMA propose specific scaled limits for HVDs with the magnitude of the widening being determined by the CVw of the BE study [
3,
4,
5].
Nowadays, technological advancements can efficiently address modern challenges in the pharmaceutical field [
10,
11]. The status quo of traditional clinical studies lacks pioneering solutions, particularly in areas like patient recruitment and monitoring through the entire process. Clinical and BE studies are adversely affected by delays and tremendous costs, with the additional risk of the drug not reaching the market [
10,
11,
12]. Across the field, time-consuming procedures can be optimized and automated with the integration of artificial intelligence (AI). From creating recommendation systems to data augmentation, AI holds the potential in the advancement of the pharmaceutical field [
10,
11,
13,
14].
Generative AI models can help overcome limitations and accelerate advancements in healthcare. Generative AI has a variety of applications that can contribute, from data analysis to optimization of a clinical study [
15,
16,
17]. Models like generative adversarial networks (GANs) can play a vital role in assisting the field, such as in trial design and participant recruitment, thus automating the existing procedures, identifying complex patterns and offering innovative solutions [
16,
17,
18,
19]. This can revolutionize the clinical setting by improving the decision-making process and providing diagnoses and treatments more efficiently than traditional methods [
18]. Currently, generative AI demonstrates its impact in cancer diagnoses and detection, bariatric surgery, neurological clinical decisions, etc. Undoubtedly, the emergence and applicability of generative AI reinforces its characterization as the “second machine age” [
15].
Existing studies that use AI algorithms (particularly early-generation models such as vanilla GANs), often encounter substantial challenges when applied to tabular clinical datasets. In contrast to image or text data, tabular clinical data are inherently heterogeneous, typically comprising a complex mix of continuous and categorical variables. These datasets frequently exhibit skewed distributions, missing values, and intricate inter-variable dependencies, all of which pose significant modeling difficulties [
20]. Vanilla GANs, originally developed for image generation tasks, are not inherently designed to manage these complexities. Consequently, they often struggle to accurately capture the true underlying structure of tabular clinical data, resulting in synthetic datasets that lack fidelity and realism. This limitation becomes particularly critical when attempting to replicate key pharmacokinetic parameters, such as Cmax and AUC, which are fundamental to BE evaluations. Inadequate synthetic reproduction of these parameters can compromise the reliability of BE assessments, diminish the regulatory applicability of the generated data, and ultimately constrain the broader adoption of synthetic data solutions in clinical research and drug development. Also, they frequently need large datasets for training, which increases the computational cost, as well as result in low interpretability due to model complexity (e.g., TVAE, CTGAN, CTAB-GAN, StaSy) [
21].
In our previous study, we introduced the idea of using Wasserstein GANs (WGANs) in clinical studies and used Monte Carlo simulations to evaluate their performance [
22]. In that study, the data generated from the WGANs outperformed the sample, in terms of
t-test evaluation, while also performing similarly to the original distributions. The similarity was assessed on the simultaneous success or not of the
t-test criterion between the original and sample distribution, and the original and generated distribution [
22]. This behavior of the WGANs model led us to further investigate its applicability in more extreme scenarios such as those of the HVDs in BE studies.
The aim of the study is to suggest a novel approach for incorporating WGANs in the traditional BE study setting to address the problem of patient recruitment and decision-making. The methodology was further implemented in real BE datasets after the Monte Carlo simulations to assess their validity. By providing a framework for generating realistic synthetic datasets (“virtual patients”) that preserve the inherent variability of pharmacokinetic parameters we aim to potentially reduce the need for large sample sizes and complex replicate designs. By exploiting the ability of WGANs to model complex, high-variability distributions with stable training, this approach could improve the efficiency of BE studies, reduce the false negative rejections of HVDs based on the small sample, decrease participant burden, and ultimately facilitate faster access to generic drugs.
3. Results
Initial scenarios were focused on generating 2×N data, while the second part of the analysis focused on the generation of 3×N data.
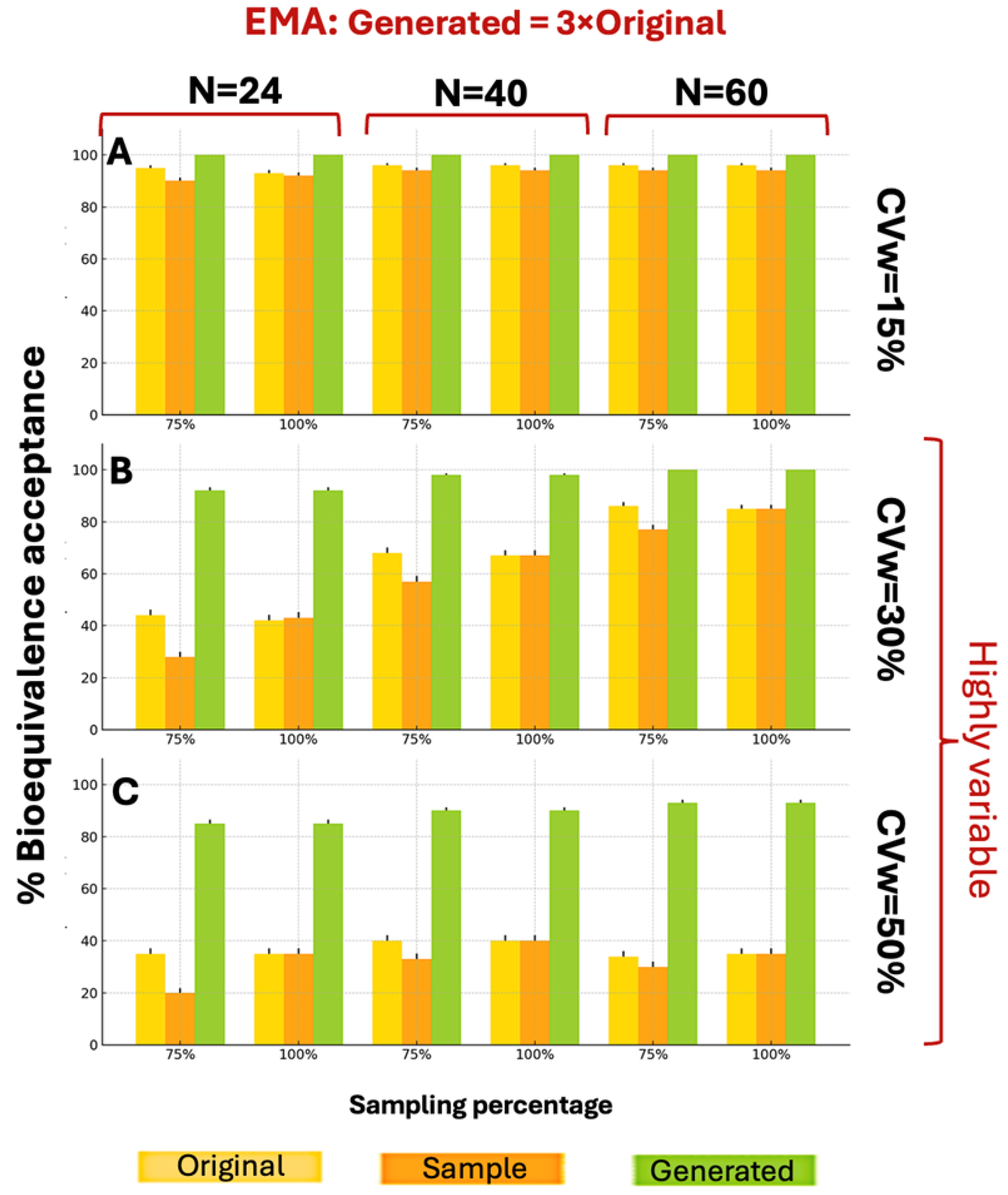
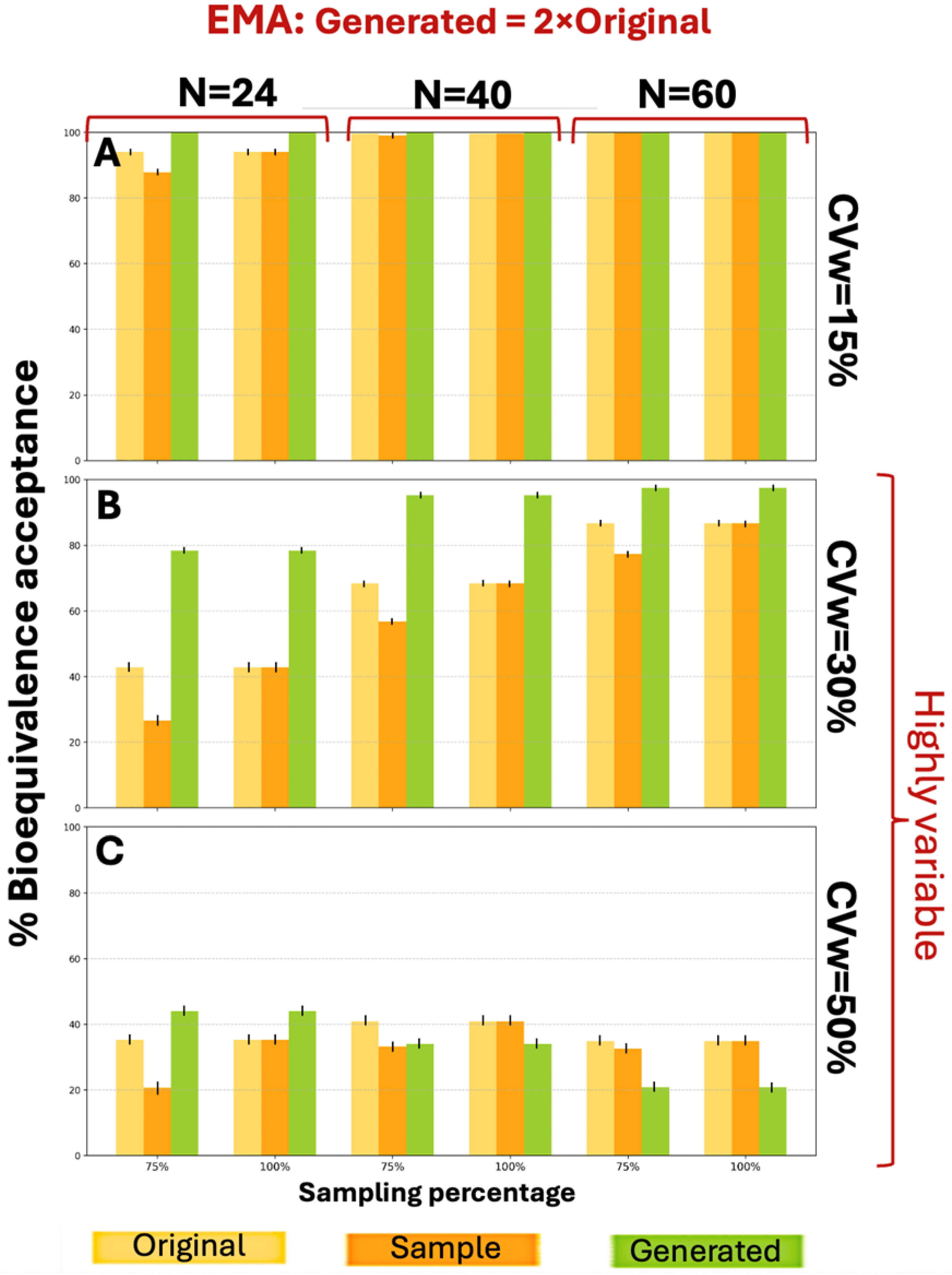
Figure A3 shows the BE acceptance percentage results for the three distributions (original, sample, and generated) according to EMA guidelines. For a CVw value of 15% the generated data exhibited better performance compared to the original data for N = 24 and N = 40 (for 75% sampling), while for the other scenarios the generated data performed equally to the original. For CVw = 30% the generated data consistently outperformed the original data. Similarly,
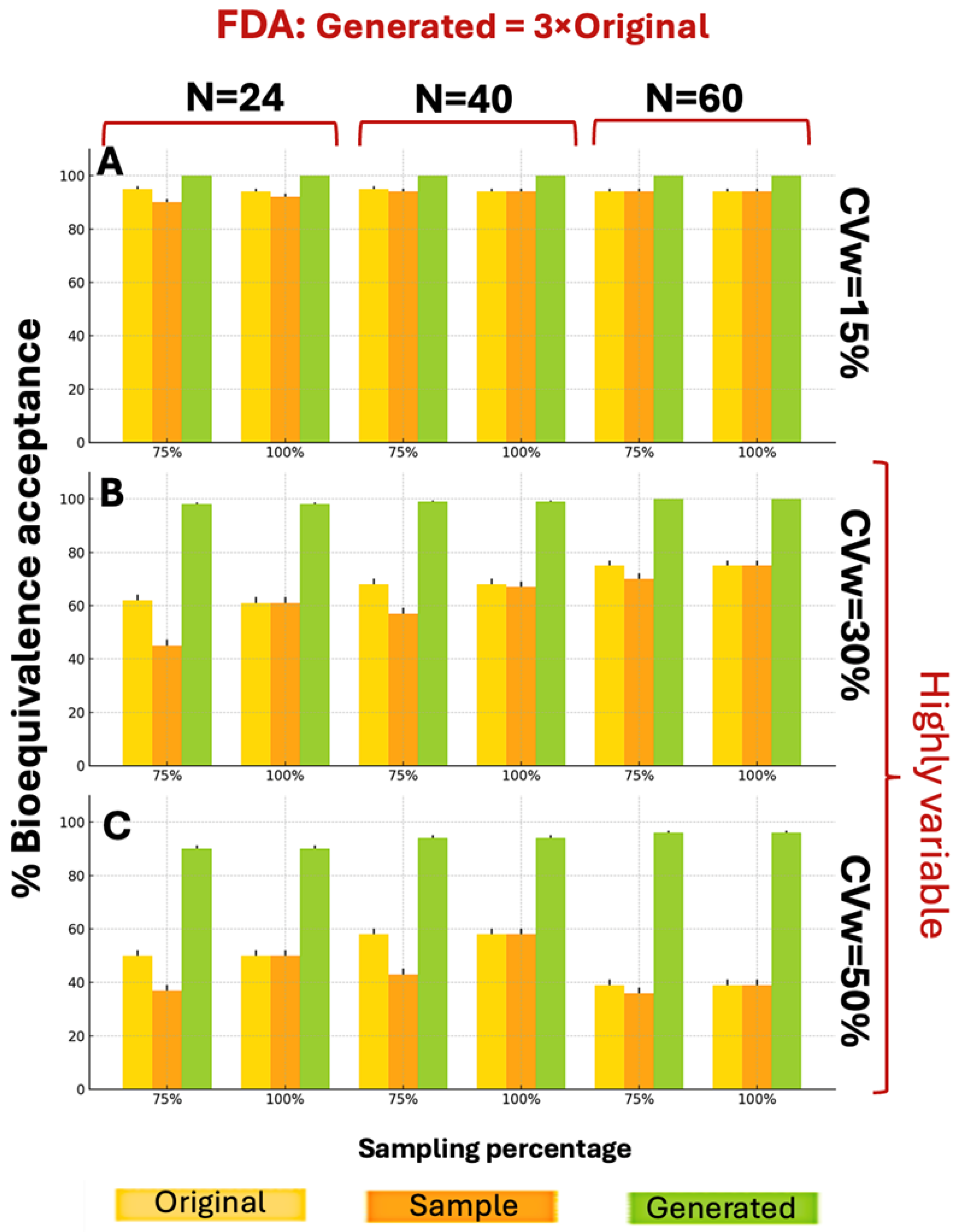
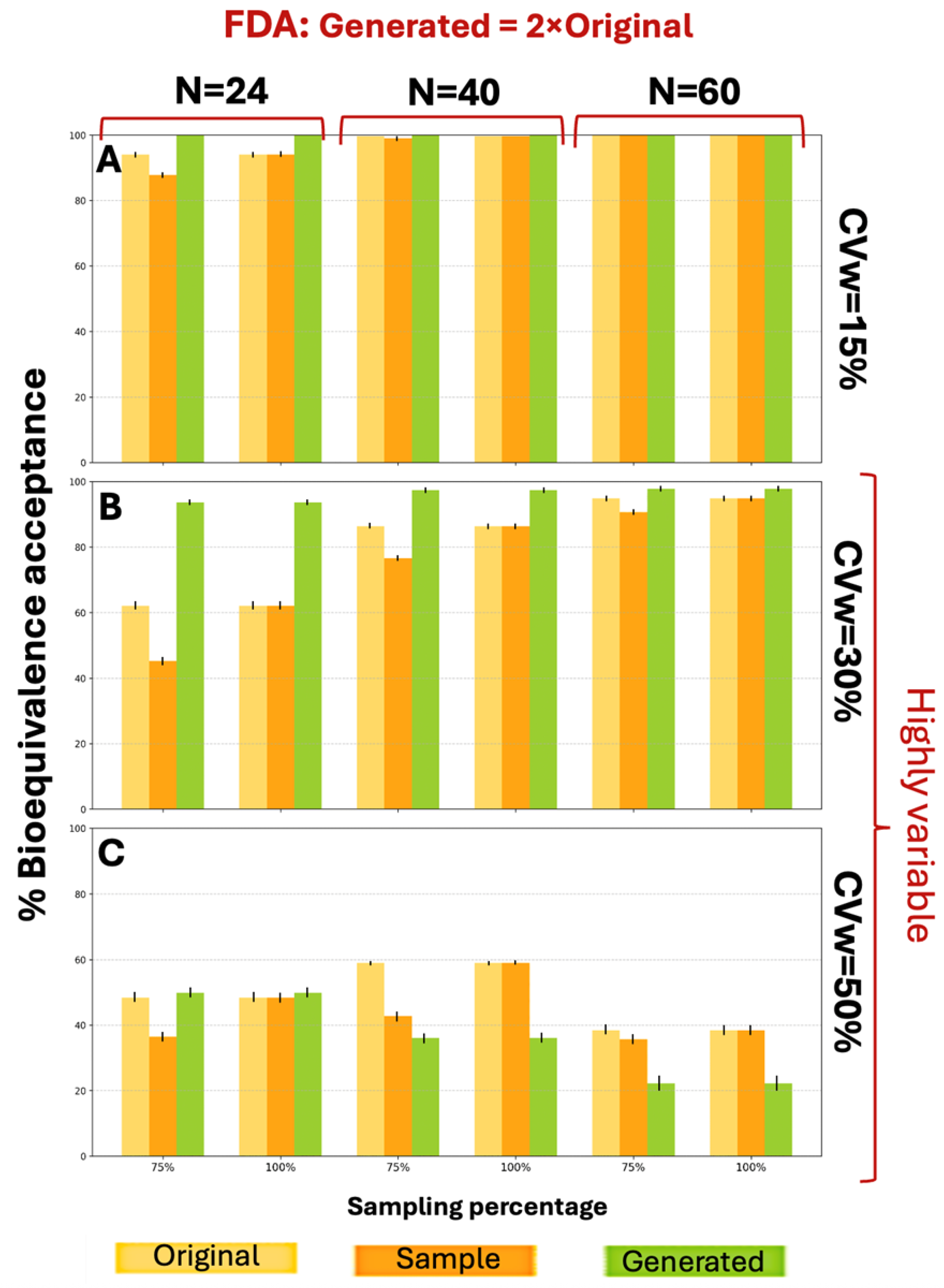
Figure A4 presents the BE acceptance results under FDA criteria. For CVw values of 15% and 30%, distributions generated at twice the original size showed better performance across all parameter combinations, achieving higher BE acceptance percentages. The WGAN datasets capture variability and uncertainty in two ways. The first is the application of the BE acceptance percentage as a probabilistic metric. For each scenario, the percentage is based on thousands of simulation iterations and captures the uncertainty in the outcome, indicating how frequently synthetic data can produce an acceptable result. The second one is the variation between runs. The standard deviation across the scenarios is represented by error bars in each figure. At CVw = 50%, the generated distributions achieved higher percentages for smaller sample sizes (N = 24) but lower percentages for larger samples (N = 40, N = 60) under both EMA and FDA guidelines.
Due to the limited number of available samples, data augmentation was restricted to 2×N and 3×N of the original dataset size. The process initially began with a 2×N augmentation; however, based on preliminary results, it was subsequently extended to a 3×N augmentation. This larger augmentation yielded improved performance, approaching the optimal results one might expect. The decision to limit augmentation at this scale was made to avoid over-reliance on a small sample base and to prevent the generation of synthetic data that could lead to overfitting.
The generated distributions of the 3×N augmentation consistently showed better BE acceptance compared to both original and sample distributions, under the EMA guidelines.
Figure 3 illustrates the BE acceptance percentages under EMA guidelines when generating 3×N distributions. The 3×N generation scenarios demonstrated superior BE acceptance compared to 2×N scenarios across all parameter combinations. While WGANs struggled with 2×N data at CVw = 50%, the 3×N approach overcame this limitation, achieving BE acceptance percentages consistently above 80%, compared to the sample maximum of 40%.
WGANs consistently outperformed both original and sample distributions across all CVw values and parameters, under the FDA guidelines, showcasing similar behavior as
Figure 3. According to
Figure 4, for CVw ranging from 15% to 50%, the generated data achieved higher BE acceptance percentages than original or sample distributions, exceeding 89% in all scenarios. Notably, 10 of the 18 scenarios reached 100% generated BE acceptance. These superior results with 3×N generation confirm the appropriateness of this approach.
Considering the similarity parameter, for the EMA scenarios the original distribution and the synthetic one have a higher similarity in 14/18 scenarios compared to the original and sample. For the FDA guidelines, 12/18 scenarios performed better in the similarity parameter of the original and the synthetic distributions compared to the original and sample. In the following tables (
Table 3 and
Table 4) are presented the results for the EMA and FDA scenarios, respectively. As CVw and the augmentation scale (×N) increase, the similarity original vs. synthetic becomes lower. It should be emphasized that in all scenarios with low to medium sample sizes and variability, the synthetic datasets exhibited a higher percentage of similarity compared to the sample data. However, as expected, the percentage similarity decreased under conditions of high sample size and variability—an underlying factor contributing to the superior performance of the synthetic data.
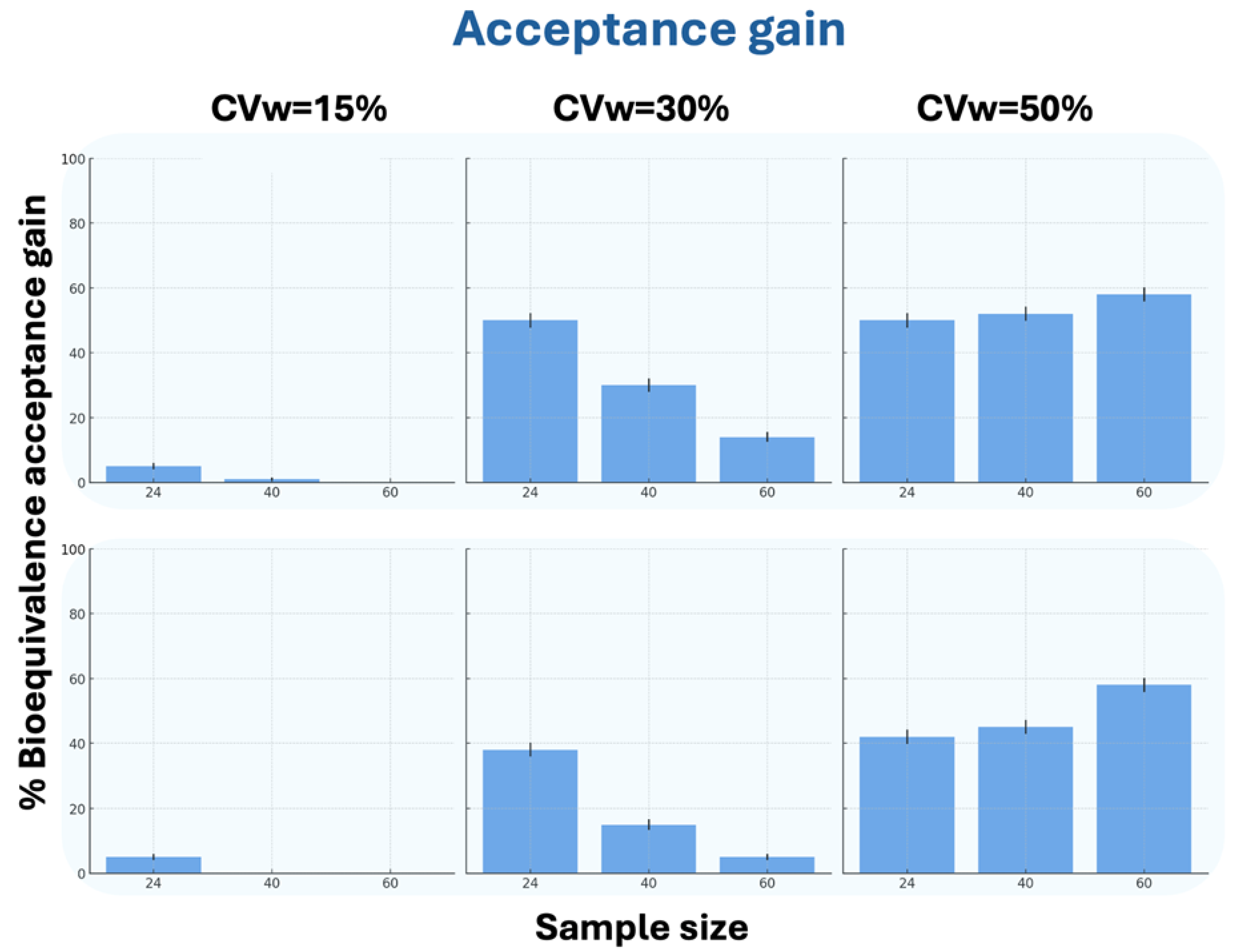
In terms of BE acceptance gain, in all scenarios except N = 60 at CVw = 15% (where generated data matched the original), the WGANs showed superior performance. For CVw = 30%, the generated data showed higher acceptance percentages with decreasing N values, while for CVw = 50%, the percentages increased with increasing N values. The results for N = 24 were notably similar between CVw = 30% and CVw = 50%. Interestingly, WGAN performance improved with increasing CVw, showing significantly better BE acceptance gain at 50% variability compared to 15%.
Figure 5 demonstrates the WGANs’ effectiveness in terms of the BE acceptance gain between generated and original data.
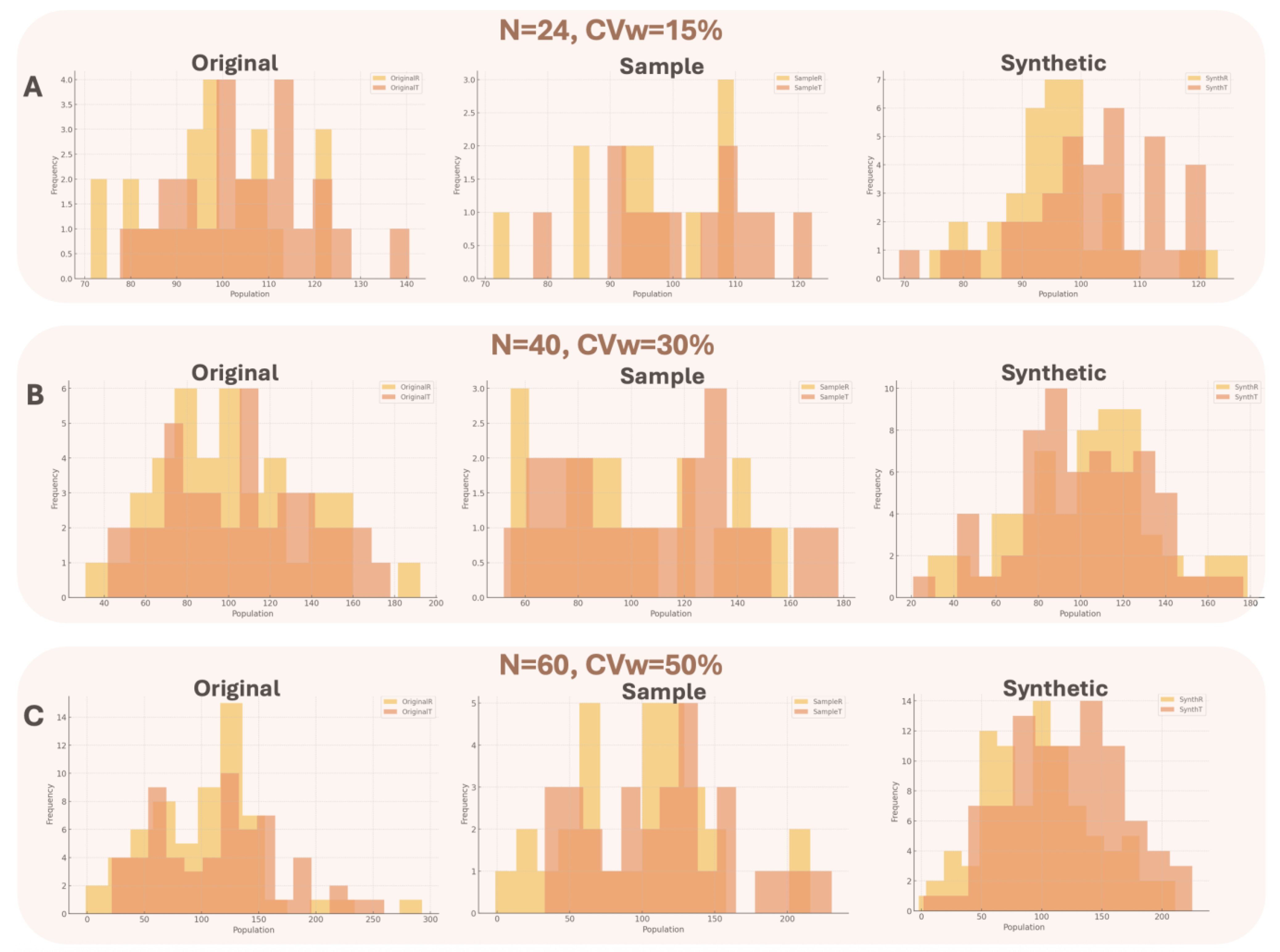
For all different executed scenarios, the generated distributions were better resembling the original, rather than the sample compared to the original distribution based on the statistical tests that were carried out. The tests were important to validate data distribution overlap and consisted of visual inspection (histograms for the original, sample and synthetic data) and calculation of Szymkiewicz–Simpson and Bhattacharyya distances for all datasets. To make all the estimations, three different original datasets were generated, referring to (1) N = 24, CVw = 15%, (2) N = 40, CVw = 30%, and (3) N = 60, CVw = 50%. The chosen values have been selected to be in line with the results of
Figure 3,
Figure 4 and
Figure 5.
Figure A5 provides a visual overview of the distributions of the original, sample, and synthetic data.
The Szymkiewicz–Simpson coefficient measures the overlap between two probability distributions and the closer the value to 1 then there is a better similarity. The Bhattacharyya distance measures the distance between two probability distributions and the closer the value to 0, then the more identical the distributions are. For the purpose of this analysis, “distribution overlap” refers to the comparison between the Test and Reference distributions, which differ by an average of 10%, across several scenarios.
The statistical criteria indicated that in all cases, the synthetic distribution maintained the same (or even superior) discriminatory power compared to the original data and significantly outperformed the sample data.
Table A1 demonstrated the results of the different statistical tests. Overall, three distinct conditions were studied: low sample size/low variability (Panel A), medium sample size/moderately high variability (Panel B), and large sample size/high variability (Panel C). In Panel A, the statistical criteria demonstrated that the synthetic data had better discriminatory power than the original data (and much better than the sample data). In Panel B, where the distributions begin to spread out, the discriminatory power decreases across all datasets, though the synthetic data continue to deliver strong performance. Finally, in Panel C, where data are highly dispersed due to very high variability, the discriminatory power between the T and R distributions is, as expected, further reduced—but the synthetic data still exhibit the best performance.
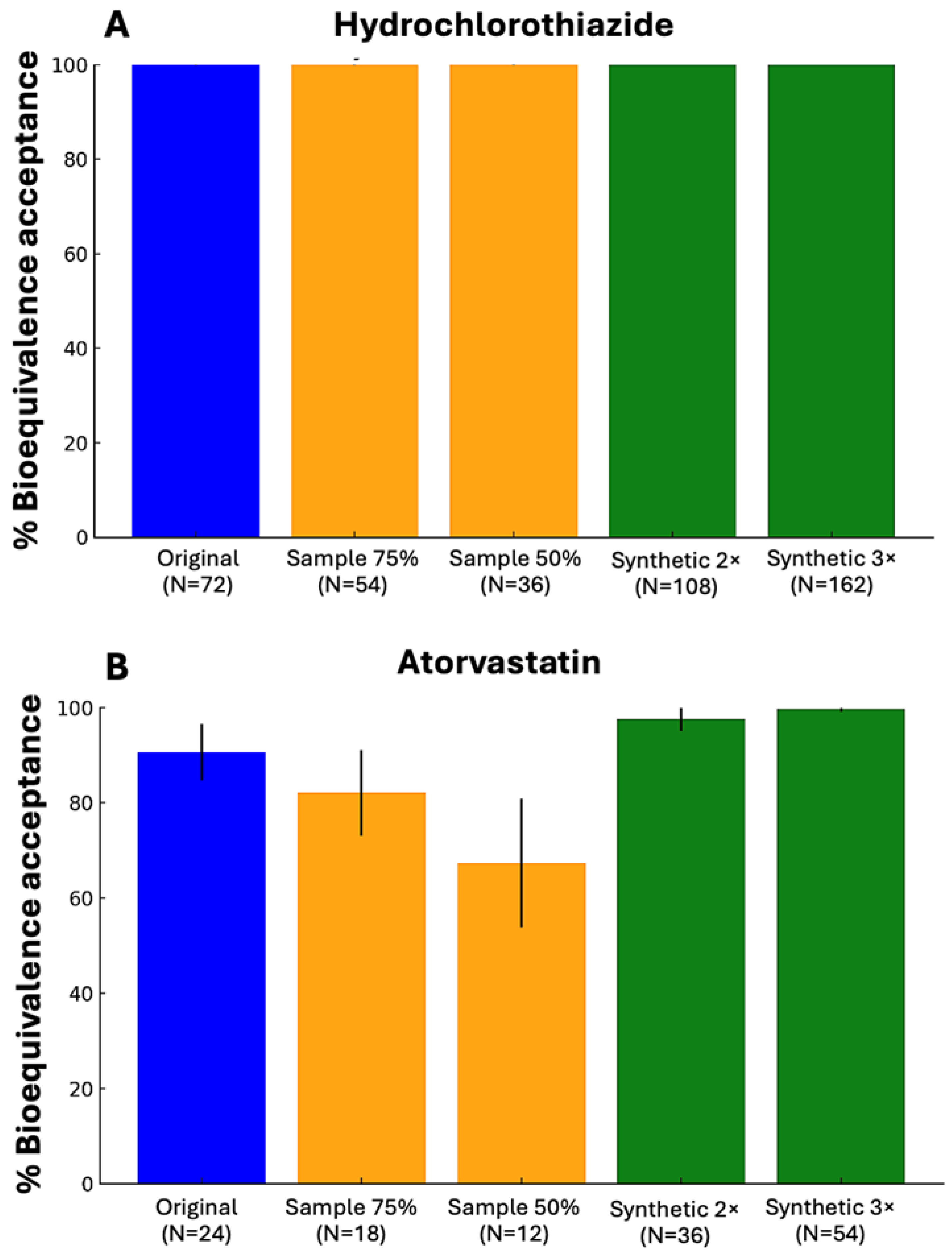
The implementation of WGANs in real BE data, showed that in both studied drugs, the generated data either provided the same results as the original dataset (hydrochlorothiazide) or outperformed the original dataset (atorvastatin). The study with hydrochlorothiazide performed on 72 subjects and the CVw for the Cmax value was 29.2% [
27]. On the other hand, for the simvastatin study the number of subjects was 24 and had a CVw value of 16.76%, regarding the Cmax value [
28]. The assessment was performed based on the percentage of BE acceptance, comparing the results of the original dataset, the 75% and 50% sample and the generation of 2×N and 3×N the original dataset. For atorvastatin, the sample had a smaller BE acceptance compared to both the original and the synthetic data.
Figure 6 demonstrates the above-mentioned results of real world BE data for hydrochlorothiazide and atorvastatin by implementing WGANs.
4. Discussion
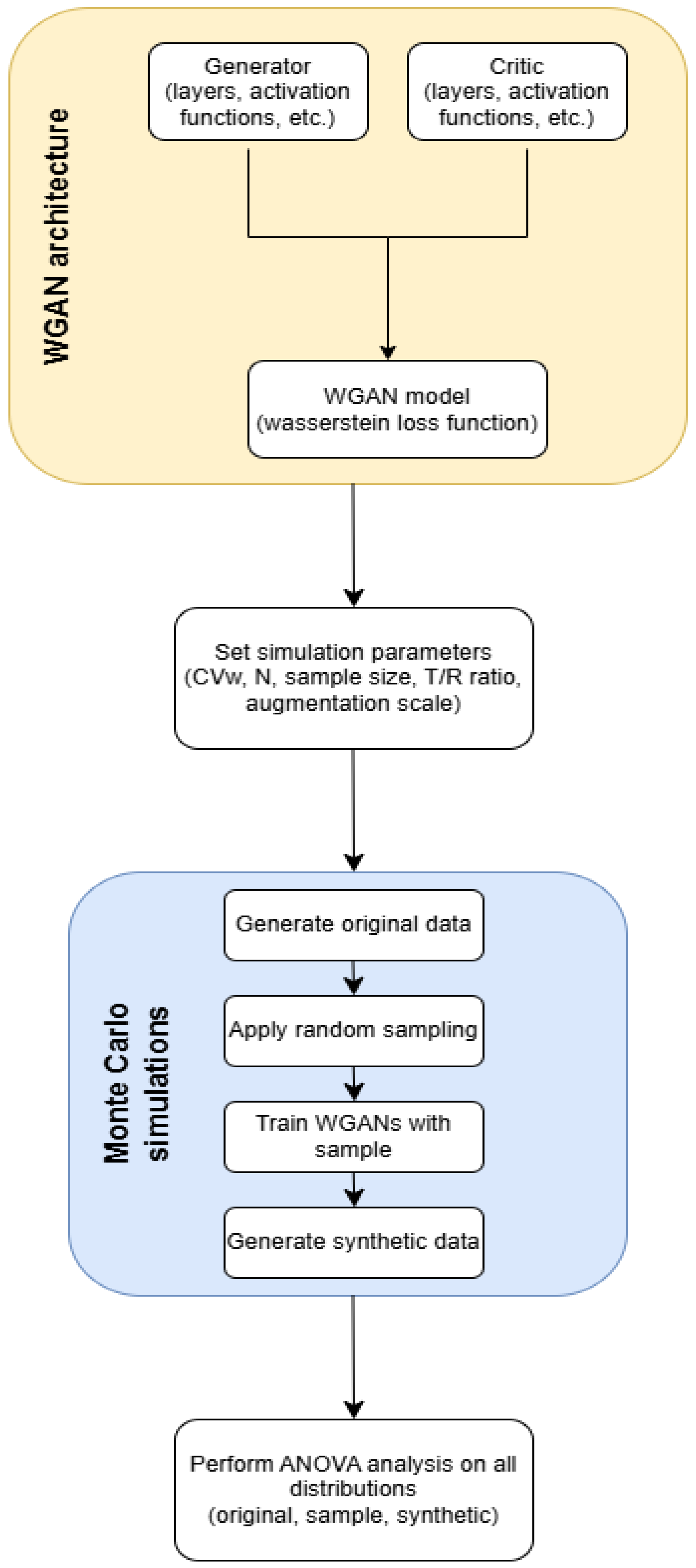
The purpose of this study was to investigate the potential of WGANs to solve the problem of high variability in BE studies. These restrictions result in higher costs, longer procedures, and logistical issues in finding enough participants, all of which are substantial hurdles to medication development and licensing processes. By using WGANs to virtually increase sample sizes, this work aims to give a novel method for reducing reliance on large populations. In this study, WGANs were used to generate data that simulated the HVDs in BE studies. The methodology involved applying the WGAN model on data that replicated BE research using Monte Carlo simulations. To model the BE setting, we constructed simulations of 2 × 2 crossover studies. The WGAN performance was evaluated by comparing the generated, sample, and original data for BE acceptance and similarity. To validate the process’s resilience and robustness, thousands of Monte Carlo simulations were executed.
In this study, we applied Monte Carlo simulations to systematically investigate a broad spectrum of experimental conditions. Specifically, we simulated 36 unique scenarios derived from a full factorial design encompassing three levels of sample size, three levels of data variability, two regulatory contexts, and two synthetic sample sizes (i.e., 3 × 3 × 2 × 2). This comprehensive simulation framework enabled a rigorous evaluation of the generative model performance and robustness across diverse conditions. Moreover, the use of simulated data was rather important in assessing the similarity between original, sampled, and synthetic data distributions, as described in
Table 3 and
Table 4. Simulated data provided the necessary control and transparency to perform robust comparisons and compute statistical similarity metrics, tasks that would be almost impossible using real-world datasets due to the lack of ground truth and inherent variability.
The study findings reveal that creating 3×N data using WGANs results in much higher BE acceptance percentages than both the original and sample distributions. For CVw values of 15% and 30%, the generated data consistently outperformed the original and sample distributions according to EMA and FDA criteria for both 2×N and 3×N. When CVw = 50%, the generated distributions showed higher BE acceptance for smaller sample sizes but lower acceptance for bigger sample sizes for 2×N generation. However, for 3×N data, the produced distributions consistently demonstrated higher BE acceptance across all scenarios. This was most noticeable at CVw = 50%, when the 3×N-generated data obtained BE acceptance percentages greater than 80%, compared to the sample’s maximum of 40%. The results showed that the WGANs approach is beneficial in situations with higher variabilities, underlining the possibility for adopting WGANs to increase the efficiency of BE studies.
It is crucial to note that WGANs perform better, the smaller the sample and the bigger the generation, as can be seen from our current research, where the 3×N results offered better results than the 2×N, but also from our previous one [
22]. WGANs have significant advantages even over the scaled limits used by regulatory bodies in BE studies for HVDs. One of WGANs key features is their ability to generate data that nearly resembles the original distributions while dealing with variability. Traditional procedures, such as applying bootstrapping, rely on assumptions that may not adequately convey the complexities of real clinical data. WGANs, on the other hand, can model and create data that accurately represent the original data, including pharmacokinetic parameter fluctuations that are common in HVDs. This flexibility allows WGANs to generate more accurate estimates of BE, even when the observed data does not completely coincide with the regulatory standards. Furthermore, WGANs can improve statistical power by providing more data points to optimize the analysis without the requirement for bigger sample sizes. By creating realistic synthetic datasets, WGANs provide a more nuanced approach to assessing BE, potentially increasing the efficiency of BE studies and providing better tools for regulatory decision-making, particularly in cases where data variability would otherwise prevent clear conclusions from being drawn using traditional methods.
The WGAN-generated data were evaluated for BE acceptance percentages under EMA and FDA guidelines for highly variable drugs. It is important to emphasize that the performance of WGANs was compared against the scaled approaches of EMA and FDA. These regulatory approaches permit wider acceptance limits than the traditional 80–125% range, allowing handling the high variability of certain drugs. In contrast, the WGAN-approach was strictly assessed using the classic 80–125% limits, without the benefit of scaling. Additionally, the evaluation included scenarios of high variabilities (i.e., CVw = 50%), further intensifying the stringency of the assessment. The statistical evaluation metrics and the visual inspection showed favorable results considering overfitting/underfitting problems for the synthetic distributions that resembled the original, better than the sample. Despite these challenging scenarios, the WGAN approach demonstrated favorable performance, highlighting its potential as a robust method for addressing challenges in BE studies. To conclude, our study demonstrated the potential of implementing WGANs in real BE data, where the results from the two scenarios that were examined showed promising results. However, more thorough analysis must be conducted to evaluate a variety of different real case scenarios.
Furthermore, in our research, the type of input data can mirror variables from BE studies, and the technique of obtaining them is identical. These values may be pharmacokinetic, such as Cmax or AUC. WGANs generate the type of data in the input by producing data points that are similar to the original while yet being uniquely different. Another advantage of using WGANs relies on the fact that the BE study can be performed not only with a reduced sample size, but also with the typical 2 × 2 crossover design. In other words, there is no need to use replicate or semi-replicate designs, which are more complex, time-consuming, expensive, and prone to high dropout rates. Once the WGAN approach is validated in practice and a regulatory framework is established, it can provide all these advantages.
AI-based solutions have the potential to drastically lower healthcare expenditures in many aspects of the industry. AI enables more personalized healthcare interventions based on an individual’s disease profile, diagnostic information, or treatment responses, thereby improving treatment outcome prediction, developing new drug designs, and improving patient care [
29]. Furthermore, AI can help minimize variability in care, increase precision, speed discovery, and address inequities, all while empowering patients and healthcare professionals through advanced medical research and analytic technologies [
30]. The impact of AI on healthcare is already visible, such as a 30% reduction in emergency room wait times, a 70% reduction in transfer delays from operating rooms, and faster ambulance dispatch times, demonstrating how AI is revolutionizing care delivery, diagnosis, treatment, and patient lifestyle [
31]. Furthermore, AI has sped drug discovery procedures and automated target identification for pharmaceutical companies, while also allowing AI-assisted clinical trials to manage massive datasets with high accuracy. Medical AI systems help patients by evaluating medical data and providing insights that improve their quality of life [
32].
However, it is critical to understand the ethical and legal frameworks that govern the risks and advantages of AI technologies. Key considerations include data privacy, algorithmic bias, and transparency, as well as ensuring that AI research is in line with society objectives [
33,
34]. The problems posed by generative AI, such as data security breaches, bias, and misinformation, necessitate stringent regulation [
31]. Furthermore, interdisciplinary collaboration and dynamic regulatory mechanisms are critical for navigating the ethical problems of generative AI while balancing innovation and safety [
35,
36,
37].
While the study demonstrates the efficacy of WGANs in terms of HVDs in BE experiments, several limitations must be addressed. The methodology is heavily dependent on Monte Carlo simulations to mimic BE study conditions. While this approach provides controlled scenarios, it lacks the complexity and variability inherent in real-world clinical data. In other words, the proposed approach has not been validated with real-world datasets, which would be crucial to confirm the applicability of WGANs in actual BE study settings. Controlling bias when training WGANs on small samples can be risky. However, our methodology relies on steps that help mitigate this risk. First, the scenarios that were chosen to be executed provides a ground truth to compare the generated data against by visually inspecting them and ensure that no same values were in the original and the generated distributions. Also, WGANs offer greater stability than GANs because of the introduction of Wasserstein loss function, which helps reduce mode collapse and the consistent generation of the same data. Finally, the choice of small augmentation scales was intended to avoid over-reliance on limited information and minimizing overfitting to noise. Although the results align with FDA and EMA guidelines, the practical acceptance of WGAN-generated data in actual regulatory settings remains uncertain. It should be underlined that the use of generative AI, such as WGANs, may introduce challenges related to algorithmic bias, and regulatory acceptance. Future studies could overcome these constraints by using real-word datasets and evaluating once again the WGAN performance. Furthermore, optimization strategies could be developed to lower computing demands while retaining data quality. Finally, one of the challenges with generative algorithms is that they often work like a “black box”. In other words, it is hard to understand how they make decisions or reach conclusions. But once regulatory authorities create clear rules and guidelines for their use, what seems like a drawback could actually become a strength. These algorithms could then be seen as fair and unbiased tools, operating consistently without being influenced by human interference. This could build trust and make them even more valuable in the long run.
It should be noted that the WGAN technique does not result in uniform BE acceptance in all circumstances. Our results show that the model performance changes depending on the level of variability and sample size. In cases with smaller augmentation scales or higher variability, the generated data did not match the BE approval criteria, which was consistent with the original data results. While this study focused on analyzing BE acceptance percentages and similarity metrics, as well as showcase the incompetence of the sample compared to the original distribution in various scenarios, future work will include a thorough examination of potential false positive cases in which BE is not attained in the original dataset but is accepted in the WGAN-generated data. However, this will aid in determining the method’s specificity and further confirm its robustness under regulatory criteria.
WGANs have several advantages that make them suitable for clinical simulation. First and foremost, they provide more consistent training and convergence than GANs, allowing them to avoid concerns such as mode collapse. Additionally, the Wasserstein distance might better indicate learning progress and data quality. They offer greater flexibility in capturing complex distributions, such as those observed in the pharmacokinetics of highly variable medicines. However, their usage in clinical simulations is not without difficulties, as interpretability remains limited, particularly in understanding how the model arrives at specific outcomes. Regulatory approval is currently low, as synthetic data must undergo rigorous validation. Bias control and transparency remain active areas of research. As a result, while WGANs are technically great for modeling, their clinical applicability is dependent on thorough validation, real-world testing, and clear regulatory frameworks, all of which we are presently investigating in follow-up work using real BE datasets.
Various machine learning and generative AI algorithms have been explored or proposed for synthetic data generation in the context of BE studies, each bringing its own set of advantages and inherent limitations. Variational Autoencoders (VAEs) [
38], while effective in learning compact latent representations of complex data, often produce overly smoothed outputs due to their probabilistic nature. This smoothing effect limits their ability to accurately simulate the sharp fluctuations and variability typically observed in highly variable drugs, a critical requirement in BE analyses. Traditional GANs [
23], although powerful in certain domains, are prone to issues such as training instability and mode collapse, particularly when applied to small or noisy clinical datasets where sample sizes are constrained. Conditional GANs (cGANs) attempt to address some of these challenges by incorporating auxiliary information to guide generation. However, cGANs generally require large, well-annotated datasets to achieve stable training dynamics and maintain generation quality [
39], conditions that are often difficult to meet in BE studies. Other conventional synthetic data generation techniques, such as the Synthetic Minority Over-sampling Technique (SMOTE), focus primarily on balancing datasets by generating new synthetic samples but tend to produce limited diversity and struggle with datasets containing a mixture of continuous and categorical variables [
39]—a common characteristic of clinical pharmacokinetic data. Recently, diffusion models have emerged as highly effective generators, particularly in the image domain, demonstrating remarkable capabilities in producing high-fidelity synthetic images. Nonetheless, their application to clinical or tabular datasets remains nascent, and their computational demands are considerable [
40], posing practical challenges for their widespread adoption in resource-constrained regulatory environments. In contrast, WGANs present a compelling alternative by offering more stable and consistent training, greater resilience against mode collapse, and superior distributional fidelity. WGANs are particularly adept at capturing complex variability, a critical feature for accurately replicating pharmacokinetic profiles and ensuring regulatory acceptability in BE simulations. These comparative advantages, especially the balance between training robustness and synthetic realism under regulatory constraints, motivated our selection of WGANs as the foundational model for this study.
The study by Papadopoulos et al. [
38] of our research group was the first study to introduce the idea of using synthetic data in clinical trials, in particular data that are generated from VAEs. That study proposed the use of synthetic data in BE investigations of HVDs, with the goal of essentially increasing sample sizes and improving statistical power while maintaining the conventional BE acceptance limits (80–125%). In contrast, we use WGANs, which are known for their steady training dynamics and ability to predict complex data distributions. While VAEs encode and decode data in a latent space and may produce blurrier outputs due to their probabilistic nature, WGANs use a generator-critic architecture that produces sharper and more realistic synthetic data, better reflecting the variability in pharmacokinetic parameters inherent in HVDs. Furthermore, our method focuses on modeling and conserving variability rather than simply minimizing it through sample enlargement. Importantly, we address regulatory acceptability more explicitly by suggesting validation paths and integrating our strategy with existing EMA and FDA standards, laying the groundwork for future real-world integration. Thus, while both studies aim to improve BE evaluation using generative AI, they differ greatly in technique, output quality, and regulatory direction. It should be mentioned that analyzing the behavior of the latent space, particularly under high-variability scenarios, can provide valuable insights into how WGANs learn and represent the underlying data distribution. However, the primary focus of the present study was to evaluate the quality of the generated data. We intend to investigate the latent space structure in future work, with the aim of gaining a deeper understanding of model robustness and data diversity.
As the use of synthetic data will expand in healthcare and pharmaceutical research, there is a pressing need for a specific regulatory framework to ensure its appropriate and reliable application. To address this need in the case of BE of HVDs, we are currently developing a framework to support the acceptance of synthetic data in clinical and scientific evaluations. This effort is grounded in a thorough analysis of BE outcomes across a wide range of scenarios, based solely on real-world data. By systematically evaluating BE acceptance under diverse and extensive conditions, we aim to establish clear, evidence-based criteria that can inform regulatory bodies on when and how synthetic data may be accepted. This work is a crucial step toward building trust and promoting the responsible integration of synthetic data into regulatory decision-making.
Overall, it should be stated that this work sets the groundwork for introducing WGANs as a new approach to tackling BE studies for highly variable drugs. The research highlights how WGANs can help address challenges like reducing input samples while maintaining solid, reliable output results, essential for studying drugs with high variability. It should be underlined that this study aimed to present a generalized framework for the application of WGANs in the evaluation of BE for HVDs. For this reason, all simulations were deliberately designed to be broad and not tailored to specific drug characteristics. Consequently, the findings are not confined to any single drug type and are applicable across a wide range of drug classes. The proposed methodology is inherently replicable and can be used irrespective of the therapeutic category.
In this study, our aim was to develop a robust framework for generating realistic synthetic datasets (referred to as “virtual patients”) that can preserve the inherent variability of pharmacokinetic parameters critical for BE assessments. By creating synthetic data that captures the complexity of real clinical datasets, we seek to potentially reduce the need for large sample sizes and intricate replicate study designs, which are often necessary to manage high inter-individual variability. To achieve this, we exploited the capabilities of WGANs, which are particularly well-suited for modeling complex, high-variability distributions with enhanced training stability. Through this approach, the aim was to improve the efficiency and statistical power of BE studies, minimize the risk of false negative outcomes, especially for highly variable drugs.
While this study highlights the potential of WGANs for generating virtual populations in BE studies involving HVDs, several limitations must be acknowledged. The methodology relies mainly on Monte Carlo simulations, rather than real-world datasets, limiting its direct applicability. The specific use of WGANs, favored for their stability via the Wasserstein loss function, helped reduce risks like mode collapse and overfitting, especially through small augmentation scales and validation against ground truths. However, the absence of extensive real clinical data validation remains a gap. Future research should focus on applying WGANs to real-world BE datasets to verify performance under realistic conditions. Additionally, strategies to optimize computational efficiency without compromising data quality are needed. As WGANs and other generative models often operate as “black boxes”, establishing regulatory frameworks will be crucial. Clear guidelines could transform perceived opacity into a strength, framing these models as consistent and unbiased tools for clinical research.
To truly unlock the potential of WGANs, more studies using real-world clinical data are needed. Testing this method in real-life scenarios would allow researchers to refine it and make it more reliable across diverse situations. On top of that, it is crucial to establish clear criteria and conditions before WGANs can become part of regulatory practice. These criteria would ensure the method meets the strict scientific and compliance standards set by regulatory authorities like the EMA and FDA.
Overall, in this study, we address a key challenge in BE assessments for highly variable drugs: the reduced statistical power resulting from high intra-subject variability, which often leads to an increased false negative rate. Traditionally, this issue is moderated by increasing the sample size of the BE study, which enhances statistical power. However, recruiting additional participants is often costly, time-consuming, and raises ethical considerations. To overcome these limitations, our study follows the same principle of increasing sample size, but in a virtual setting. We use a Wasserstein Generative Adversarial Network to generate AI-synthesized virtual volunteers that mimic the statistical characteristics of real participants. By augmenting the dataset with these synthetic samples, we aim to strengthen the reliability of BE outcomes while reducing the practical and ethical constraints of conventional clinical trial expansion.
The ultimate aim of this study was to demonstrate how the integration of data augmentation techniques (in particular with the use of generative AI algorithms) could significantly transform clinical research by achieving substantial cost savings, accelerating study timelines, and minimizing human exposure. It is proposed in this study that this can be achieved by partially replacing real volunteers with “virtual subjects”, thereby sharply reducing the number of participants needed in certain phases of clinical trials. Our results showed that WGANs were able to generate virtual populations with BE acceptance rates and similarity levels that matched or even surpassed those of the original population. This approach proved highly effective across a range of scenarios, enabling marked expansions in BE study sample sizes, while simultaneously lowering operational costs, reducing logistical burdens, and speeding up trial completion. By requiring fewer human participants, this strategy also promoted more ethical research practices by limiting unnecessary human exposure. Although the application of AI in clinical research held tremendous promise for revolutionizing healthcare, realizing these benefits would require a cautious path forward. Rigorous scientific evaluation, continuous validation, and the development of strong regulatory frameworks are essential to ensure the safe, ethical, and sustainable integration of AI-driven methodologies into clinical research.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}