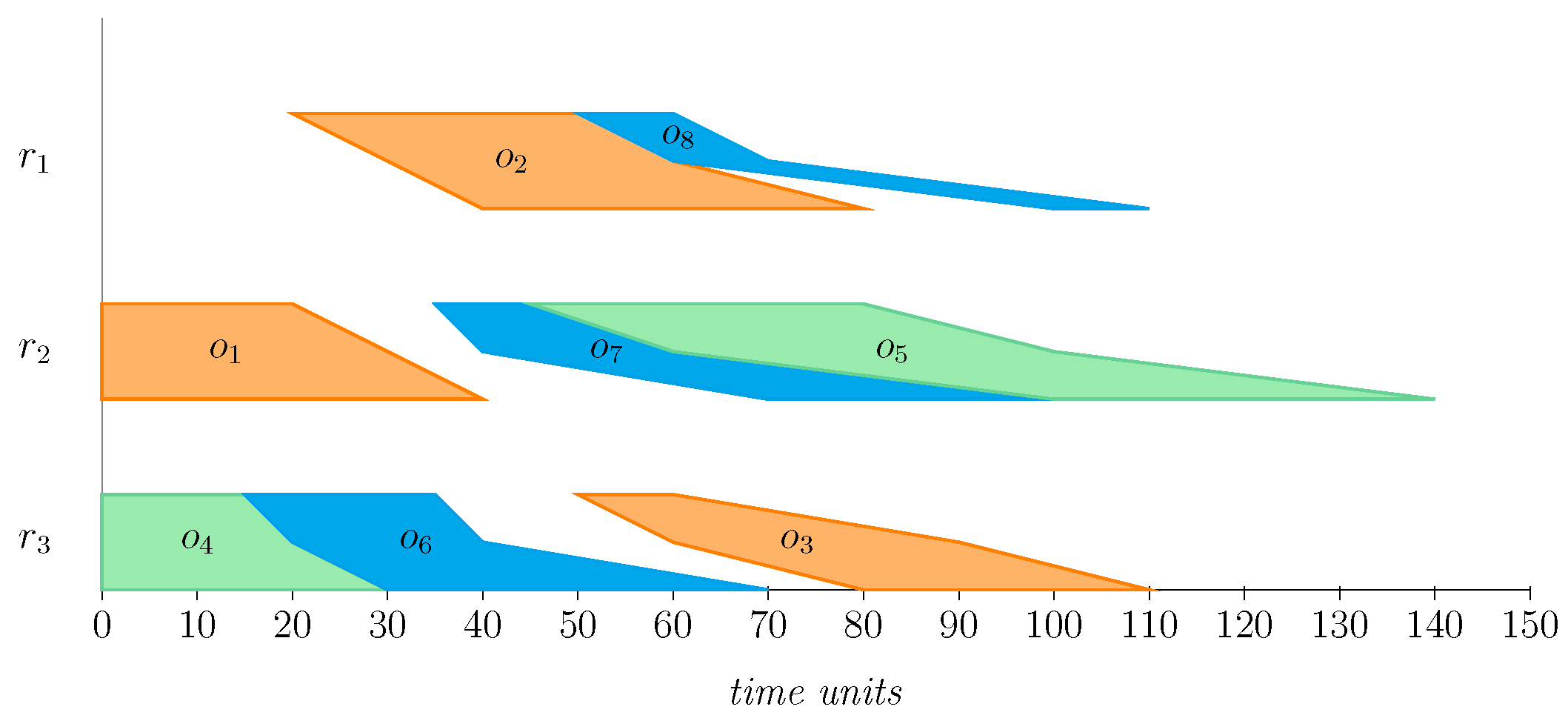1. Introduction
Scheduling is concerned with distributing and planning the execution of multiple tasks on a limited set of resources under different constraints, usually with the goal of optimising some objectives [
1,
2]. This kind of problem has multiple applications not only in industry and logistics but also in areas such as healthcare, education, or cloud computing [
3,
4,
5,
6,
7].
The problems in the family known as job shop scheduling are especially significant because they can be used to model many real-world situations [
8]. In a job shop, tasks or operations are part of jobs, so operations in a job must be executed in a given order. In the flexible variant, operations can be executed with different resources, so a resource-allocation problem arises in addition to the problem of sequencing operations belonging to different jobs within each resource [
9,
10]. In addition to presenting a challenge due to its complexity, the flexible job shop problem attracts special attention due to its relevance in modern industrial problems [
11,
12].
The majority of the research devoted to scheduling assumes that all parameter values are deterministic and well known in advance. However, in real life, it is often the case that some factors, e.g., processing times, are subject to variability due to machine or human influences. This source of uncertainty should not be dismissed; instead, the proper management of the non-deterministic elements of the scheduling process is especially important in Industry 5.0 solutions [
13]. In particular, uncertainty in operation processing times can be addressed with stochastic models or, alternatively, using fuzzy numbers. Following the pioneering works [
14,
15] fuzzy sets and fuzzy numbers have been amply used in scheduling [
16,
17,
18,
19]. The reviews [
20,
21] provide many examples where fuzzy numbers have been successfully applied to shop scheduling problems. In the particular case of the fuzzy flexible job shop scheduling problem, some works consider traditional production-related objectives, for instance, weighted tardiness and earliness [
22], makespan [
23], or makespan and total workload [
24], while others focus on energy efficiency [
25,
26]. We can also find multiobjective proposals that combine the optimisation of energy consumption together with more traditional objectives, such as makespan or deadline satisfaction [
27,
28,
29,
30]. A survey of solving methods can be found in [
31].
Associated with a schedule are the concepts of idle and waiting times. Idle time is the time spent with the resources waiting to process operations, while the waiting time, its counterpart from the job point of view, is the time spent by jobs waiting for the resources to become available. Idle and waiting times can be of interest for several reasons: they can be part of a constraint, they may constitute an objective in themselves, they may be a component of some other performance objective function, or it may be necessary to compute them as part of a solution method.
Idle and waiting times act as hard constraints when no-wait or no-idle schedules are required. In other cases, a strict no-wait or no-idle constraint might be relaxed and, instead, waiting or idle times need to be kept as small as possible for technological reasons. For example, in food industries, an excessive waiting time after an operation might cause the produced goods to be spoilt and unusable for later operations, or in chemical industries, it can be the case that no waiting time can be allowed between warming and manufacturing operations in the same job. Likewise, it may be undesirable or simply not allowed to have idle resources, for instance, when machines require consumable products, such as paints or powders, that become unusable if the machine stays idle for too long (e.g., paint becomes dried or powder oxidises), or in the steel industry, where furnaces must be kept at a high temperature at all times, regardless of whether they are active or idle. More generally, idle times can be relevant indicators of the efficiency of production systems, especially in those where expensive resources are part of the considered production layout since idle times are directly related to resource utilisation. Also, minimising the total core idle time (i.e., the idle time within the system) is strongly aligned with minimising the makespan, a classical objective in scheduling. Beyond manufacturing, in service environments where the resources are human workers (e.g., in healthcare), it may be desirable to minimise idle times not only to reduce costs and gain efficiency but also to maximise workers’ satisfaction [
32,
33,
34].
Idle times have garnered increasing attention with the growth of energy-aware or green scheduling. According to [
35], studies on energy-efficient scheduling are classified into four groups based on energy-saving methods. The first is to reduce unnecessary idle time: it is estimated that, in actual manufacturing processes, machine tools stay idle most of the time and consume about 80% of energy while being in this idle state; in consequence, over 30% of the articles reviewed in [
36] consider idle energy consumption as part of the objective function to be minimised. The second approach is to directly turn off the resources when the idle time is long enough and the energy savings compensate for the cost of turning on/off. The third approach is to adjust the machine speed when energy consumption depends on it. Finally, the fourth one is to favour off-peak production: given that, in peak time, electricity costs (and associated pollution) are high, scheduling part of the production at a non-peak time can save a significant amount of electricity cost and mitigate pollution.
We find in the literature many recent examples of green scheduling (many flexible job shop problems) where idle times play an important part. In [
35], they consider an energy-efficient flexible job shop under time-of-use pricing and scheduled downtime. With prices of electricity varying over discrete time intervals, the key is to take advantage of idle times and shift the inevitable idle time to peak periods and the production to off-peak periods in order to minimise the energy cost. The flexible job shop problem is also addressed in [
37,
38]. In the former, the objective is to minimise the total energy consumption by adopting an on/off strategy that takes into account idle times. In the latter, energy consumption is composed of processing energy consumption, idle energy consumption, setup energy consumption, and common energy consumption. A multiobjective dynamic version of the flexible job shop scheduling problem minimising both energy and completion time is tackled in [
39] through idle machine time arrangement and machine speed level selection. Inspired by real-world problems, in [
40], they present an approach to minimising idle energy consumption and apply it to a heat-intensive process employing a steel-hardening furnace, which requires a high power input to reach and maintain the specific operating temperature, so a considerable amount of energy is consumed even during the periods when no material is being processed. Ref. [
41] addresses scheduling in virtual network functions, modelled as a job shop problem, with the goal of simultaneously minimising the makespan and the idle energy loss. In [
42] we find another multiobjective scheduling problem, here applied to bakery production, taking into account the reduction in oven idle times as a means of reducing energy consumption. The results show that, by penalising the best makespan by a marginal amount, alternative optimal solutions obtain a considerable reduction in oven idle time by up to 61%, resulting in a strategy that allows small and medium-sized bakeries to lower production costs and reduce
emissions.
Clearly, to enhance its scope of application and come closer to solving real-world problems, fuzzy scheduling also needs to handle and take into account idle times. However, computing idle times between operations in a resource or the total time a resource is idle is far from trivial in the fuzzy setting since it is not possible to directly extend the equations and techniques from the deterministic framework. This may be the reason why few attempts have been made in this direction, with a few exceptions. Idle times between operations are used to calculate the idle energy consumption in a fuzzy job shop in [
43], while multiobjective versions of this problem are tackled in [
44,
45]. In the first case, idle gaps are used to right-shift operations with the goal of reducing the energy consumption of a given schedule, and in the second case, MIP post-processing makes use of these idle times to also improve the energy cost of a schedule.
Below, we will address the fuzzy flexible job shop problem. We will illustrate the difficulties inherent to computing idle times in the fuzzy framework. We will propose two different ways of computing the idle times between operations in a resource, as well as a third way of directly computing the total idle time in a resource. We will argue that, although, in the deterministic setting these three approaches are equivalent and yield the same value for the total core idle time in a schedule, that is not the case under uncertainty. We will finally conduct an experimental study to empirically evaluate the three proposals for computing idle times in fuzzy schedules.
2. The Fuzzy Flexible Job Shop Problem
The flexible job shop scheduling problem consists in scheduling a set of operations (also called tasks) in a set of m resources (also called machines) subject to a set of constraints. Operations are organised in a set, , of n jobs, so operations within a job must be sequentially scheduled. Given an operation, , will denote the job in that this operation belongs to, and will denote the relative position of o in the job, . Each operation, , can only be processed in resources from a given subset, , with a processing time, , which is dependent on the resource, , where it is executed. Furthermore, the following statements are assumed:
All jobs and resources are available at the first instant of time.
Preemption is not allowed; i.e., each operation must be completed without interruption once started.
Machines cannot perform more than one operation at a time.
Transportation times between resources and setup times are negligible.
Operations are assumed to be successfully completed after the first attempt; the scrap rate is zero.
The available capacity of resources is known; there are no stoppages, breakdowns, etc.
Buffers with infinite capacity are available for all resources.
Under this problem formulation, the idle time is the time spent by a resource waiting for an operation to process it. The total idle time in a resource can usually be decomposed into front, back, and core idle times. The front idle time is the time a resource waits before starting the first operation (while other resources are already working), the back idle time is the time between the instant when a resource completes its last operation and the instant the last resource finishes working, and the core idle time refers to the time a resource is idle between operations, that is, once it has finished processing one operation and is waiting for the next operation to start being processed.
The objective of this paper is to minimise the total core idle time (that is, the sum of core idle times for all resources) in the fuzzy flexible job shop. In the following subsections, we will describe how to work with fuzzy processing times and how they affect idle time calculations. The notation used throughout the paper is summarised in
Table 1.
2.1. Fuzzy Processing Times
It is fairly common in the literature to model uncertain processing times as triangular fuzzy numbers (TFNs), defined by an interval,
, of possible values (its support) and a modal value,
[
16]. A TFN can be represented as a triplet,
, so its membership function is given by the following:
Arithmetic operations on TFNs are defined based on the Extension Principle [
46], so for two TFNs,
and
, the sum is a TFN defined as follows:
And their difference is a TFN defined as follows:
At first, the resulting expression for the subtraction may seem counter-intuitive. However, notice that the smallest possible value that the uncertain variable,
a, described by
, may take is
, while the greatest possible value for the uncertain variable,
b, described by
, is
and, hence, the smallest possible value for their difference is
. Analogously, the greatest possible value for the difference will be
. This results in support for the difference where the extreme values of the two involved TFNs can be said to be “crossed”. Interestingly enough, the same expressions for the sum and the difference are obtained if we reconstruct them via interval computation from the alpha-cuts [
16,
46]. A consequence of these definitions is that, in the set of TFNs, the difference is not necessarily the inverse of the sum, that is,
. This is because underlying the definition (
3) that results from the Extension Principle is the assumption that the uncertain variables
a and
b associated with
and
are non-interactive; i.e., they can take values in their support independently of each other. Therefore, when the TFNs
and
are linked, the resulting difference may be an “over-uncertain” or “pessimistic” quantity. This may prove to be an issue in certain applications; it is, for instance, the main difficulty in critical-path analysis and backpropagation in activity networks with fuzzy durations [
16].
Unlike the cases of addition and subtraction, the set of TFNs is not closed under the extended maximum. For this reason, in fuzzy scheduling, it is usual to approximate the maximum of two TFNs via interpolation as follows:
The approximation always preserves the support and the modal value, and, if the result of the extended maximum is a TFN, it coincides with the approximated value (cf. [
47]).
Given that the set of TFNs is not endowed with a natural total order, it is common practice to resort to some ranking method to make comparisons. A widely used one is that based on expected values. For a TFN,
, its expected value is as follows:
So, any two TFNs
and
can be compared as follows:
Accordingly, we will write
when
. The ranking induced via the expected value coincides with several other rankings from the literature; it is also related to classical interval comparisons via imprecise probabilities, and it has been empirically shown to result in more robust solutions when used in fuzzy scheduling [
47,
48].
In addition, we consider the following precedence relation between any pair of two TFNs,
and
:
with strong precedence,
, if and only if
.
2.2. Fuzzy Schedules
A solution to the problem, commonly called a schedule and denoted as
, consists of both a resource assignment,
, and a starting time assignment,
, for all operations. This solution is feasible if and only if all precedence and capacity constraints hold. More formally, for an operation,
, let
be the resource to which it is assigned in
, and let
and
be, respectively, its starting and completion times in the solution
. Then, precedence constraints hold for
if and only if, for any pair of operations,
,
and capacity constraints hold if and only if
Notice that a feasible starting time assignment, , induces an ordering for all the operations in the same resource. In the sequel, given a resource, , let denote the first operation to be processed in r according to schedule , and let be the last operation to be processed in r. Also, for an operation, , let (resp. ) denote its immediate predecessor (resp. successor) in its job, (resp. ) its immediate predecessor (resp. successor) in its resource according to the ordering induced via , and the operation’s processing time in the resource to which it is assigned.
A feasible schedule is semi-active if no operation,
o, can start earlier (in the sense that it can be assigned another starting time,
, such that
) without changing the order of processing on any of the resources. In consequence, for a semi-active schedule, the starting time of any operation,
o, is the earliest starting time of that operation according to the job and resource processing orders:
where
(resp.
) is taken to be
if
, that is,
o is the first operation in its job (resp.
o is the first operation in its resource,
).
For so-called regular objective functions (those which are non-decreasing functions of the jobs’ completion times), optimal schedules are necessarily semi-active. Assuming semi-active schedules reduces the total number of feasible schedules from infinity to a finite (albeit possibly large) number, with each set of resource orderings providing a single semi-active schedule. For this reason, it is common in the scheduling literature to consider only semi-active schedules. Unless otherwise stated, this will also be assumed here.
2.3. Comparing Fuzzy Schedules
The quality of a schedule, , is usually measured in terms of a performance or cost function, , so the objective is to find a schedule that minimises f. When working with fuzzy durations, the cost of a fuzzy schedule, , becomes a TFN , representing the possible values that the cost, f, may take when is executed.
When the performance of a schedule,
, is given by a TFN
, the expected value,
, summarises the schedule’s performance in a single crisp value (which allows for comparisons between schedules in the absence of a natural order in the set of TFNs). The quality of a fuzzy schedule
can be further assessed using the measures proposed in [
26]. These are concerned, first, with the level of uncertainty in the value
and, second, with the robustness and accuracy of the fuzzy number
as a predictor of the actual performance of the schedule when it is executed in a real scenario.
2.3.1. Measures Based on Fuzzy Values
Further insight into a schedule’s quality may be gained by considering, in addition to the expected value of fuzzy numbers, two additional features of a TFN :
The spread (S) of a TFN
, given by
is a measure of the level of uncertainty in the TFN. Although uncertainty is unavoidable, a solution with a smaller spread in
should be preferred.
The modal value position (MVP), defined as
is a number in
, which is negative when the TFN’s modal value
is to the left of the support’s midpoint, positive when the modal value is to the right of the midpoint, and zero when the TFN is symmetric. It could somehow be seen as a measure of the skewness of the TFN. Values closer to 0 seem preferable in the sense that they are less biased to either optimistic or pessimistic values.
2.3.2. Measures Based on Possible Crisp Realisations
According to the semantics of fuzzy schedules proposed in [
49], a fuzzy schedule,
, is an a priori or predictive solution providing a possibility distribution (in the form of TFNs) for the starting times of all operations and, in consequence, for the values of the resulting performance function,
f. When operations are actually executed according to the resource assignment and the ordering induced via the schedule, uncertainty is no longer present: for each operation,
o, its executed processing time,
, is a crisp value in support of the fuzzy processing time
; i.e., it is a possible crisp realisation of the fuzzy processing time. The vector of executed processing times,
, where
, is a vector of possible realisations of the fuzzy processing times, also called a possible scenario. In consequence, the performance
of the executed schedule is a crisp value in support of the fuzzy performance
. Thus, the executed schedule can be seen as the a posteriori realisation of the fuzzy schedule
.
Under these semantics, the quality of the a priori fuzzy schedule can be measured relative to its a posteriori performance in a possible scenario or, more generally, across a set of different possible scenarios. To this end, let be a set of possible scenarios. We can define the following measures for :
Relative distance to the expected value (RDEV) in a possible scenario:
If this value is negative, that is, the cost in the executed schedule is smaller than expected, it means that the a priori schedule objective function is pessimistic. On the contrary, if is positive, the a priori schedule could be seen as optimistic. Overall, the smaller the absolute value of , the closer the predicted performance of the solution to the real performance once the schedule is executed.
Used uncertainty (UU) in a set of possible scenarios:
This is a value in measuring the proportion of the support of the predicted fuzzy objective function that is actually covered across the range of possible scenarios in . When is representative enough of all the possible scenarios, a value of close to 1 means that the range of values considered as possible by the TFN is actually obtainable in real situations. On the other hand, small values of would mean that the fuzzy schedule incorporates “artificial” uncertainty by considering possible values of f that are in fact never achieved, thus being less informative.
3. Idle Times with Fuzzy Durations
In a deterministic setting, given a schedule, , it is trivial to compute core idle time before an operation, o: it suffices to subtract the completion time of its immediate predecessor in the resource from the starting time of o. Then, the core idle time for a resource r, , is obtained by adding the core idle time for all the operations assigned to the resource. Equivalently, can be obtained as the difference between the time span since the resource starts processing the first operation until the last operation is finished and the total time spent by the resource executing operations. Finally, the total core idle time, , is the sum of core idle times across all resources .
Our goal will be to find a schedule minimising the total core idle time. However, extending these definitions to the fuzzy context is not trivial. The cause is the assumption of independence underlying the definition of the fuzzy subtraction, together with the fact that it is not the inverse of the sum (thus losing the equivalence between the two ways of defining the core idle time for a resource).
In the sequel, we propose three different ways of computing the core idle time of a resource, , given a fuzzy schedule, , . In the first two cases, we start by proposing a means to compute the core idle time, , of every operation, o, scheduled in the resource, r, and we then obtain as the sum of core idle times across all operations executed in r. In the last case, we adopt a less granular approach and define directly as the time span between the starting of the first operation in the resource and the completion of the last operation in the same resource, minus the time spent by the resource processing its operations.
3.1. A Naive Approach
The most straightforward approach to computing the time a resource,
r, is idle waiting for an operation,
o, under a fuzzy schedule,
, denoted as
, is to subtract the completion time of the operation’s immediate resource predecessor,
, from the starting time of
o. This is a direct translation of how the idle time can be computed in a deterministic setting, and it has been applied several times in the fuzzy scheduling literature [
43,
44,
45]. Taking into account that negative values for idle times are impossible, this translates into the following definition:
That is, if
o is the first operation to be processed in its resource
, the idle time before
o is null, and otherwise, it is the difference between the operation’s starting time and its predecessor’s completion time, discounting negative values (which we know are impossible). Then, the core idle time for resource
r is given by the sum of idle time for the operations scheduled in
r:
The problem with this straightforward extension of the deterministic definition is that, as mentioned in
Section 2.1, the fuzzy subtraction assumes that the variables involved are non-interactive. Making such an assumption for two consecutive operations in a resource is at least naive and, in most cases, problematic. Indeed, in a feasible schedule, an operation,
o, cannot start before its immediate processor is completed, so there is a clear dependence between
and
. This dependence is highly marked in the case of semi-active schedules, where
is defined in terms of
, as shown in Equation (
11). As a result, computing the idle time for an operation,
o, using (
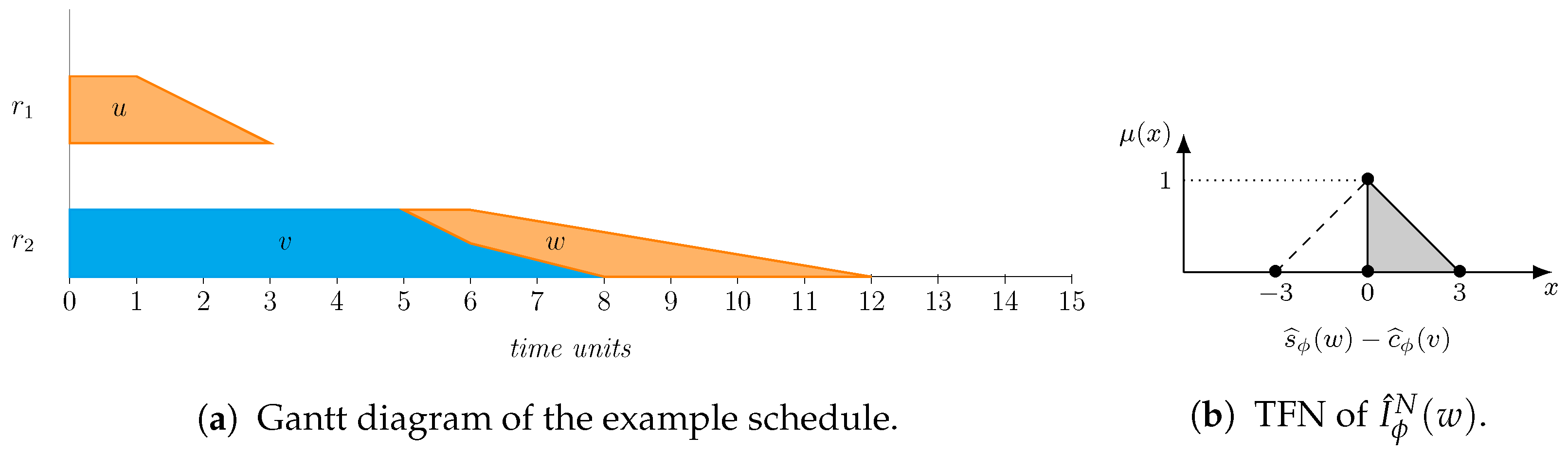
16) will most likely result in a quantity with added artificial uncertainty in the sense that many values in its support are actually unattainable. Let us illustrate this with an example:
Let
u,
v, and
w be the only three operations in a schedule
where
u, the job predecessor of
w, is processed on its own in a resource, while
v is the resource predecessor of
w in a second resource. Let the processing times of these tasks be
,
, and
. Clearly, if
u and
v start at instant 0, their completion times are, respectively,
and
. Hence, the completion time of
u cannot affect the starting time of
w,
, which, for any feasible schedule, must be such that
, with an equality for semi-active schedules, i.e.,
. The Gantt chart of the schedule, adapted to TFNs, as proposed in [
50], can be seen in
Figure 1. Now, if we compute the difference,
. This number is counterintuitive for two reasons. First, allowing for negative idle time values does not make any sense. This is solved by taking the maximum with,
; so, according to (
16), the idle time for
w is
. We depict the resulting TFN in
Figure 1b, where the dashed line represents the negative side that is removed, with the area under the membership function for
shaded in grey. The second reason is that common sense dictates that the idle time between two contiguous operations should be zero, as the absence of a gap between
v and
w in
Figure 1 illustrates, but even after eliminating negative values,
considers as possible idle times as large as 3. The source of these issues is the wrong underlying assumption that
and
are independent; so, for instance,
could be 5 when
is 8 (even if we know this is impossible in a feasible schedule). That is, the independence assumption introduces artificial uncertainty in the resulting difference.
3.2. An Approach Incorporating Schedule Knowledge
If we consider again the previous example, the problem stems from the fact that
and
are linked variables. Indeed, the starting time of
w is computed according to Equation (
11); that is,
. Substituting in the difference component of the idle time (
16),
Now, given the way in which the difference and the maximum are defined in (
3) and (
4), we can rearrange the elements in this equation, so
Of course, in a fuzzy schedule, is an uncertain quantity, but we know that the underlying variable cannot take two different values in the same schedule, so, in this context, must be , which means that the idle time for w should, in fact, be equal to .
Notice that this expression makes sense from the scheduling point of view since it means that the idle time is the time difference between the completion time of the job predecessor and the resource predecessor, i.e., the time the resource has to wait once it has finished processing the resource predecessor of operation,
o, until the other predecessor of
o is completed. This suggests an alternative definition of the idle time of an operation,
o, which takes into account our knowledge of schedules:
That is, in general, we take the idle time for o to be the difference between the completion times of its predecessors in the resource and the job (discounting negative values), with three exceptions. In the case that o is either the first operation in its job or the first operation to be processed in its resource, the idle time will be . Additionally, unlike in the traditional job shop, in the flexible variant, it is possible that both the resource and the job predecessor are executed in the same resource, that is, ; due to resource constraints, one must be executed before the other, and operation o can thus start as soon as the latest predecessor is completed, resulting in no idle time.
Once the idle time for an operation is defined, the core idle time for resource
r is again given by the sum of idle time for the operations scheduled in
r:
Let us go back to the toy example of
Section 3.1; if the idle time of operation
w is computed using (
18), we have
. This results in a TFN without added artificial uncertainty, as expected.
3.3. A Coarser Approach
Both the expressions from (
17) and (
19) correspond to a fine-grained approach where idle times are computed for each operation, and then they are aggregated to obtain the resource core idle time. However, it is sometimes the case that individual idle times for operations are of no interest, and only the resource idle time as a whole is necessary. In these situations, where not so much granularity is necessary, it is possible to compute the core idle time for resource
r in a coarser manner, as follows:
where
is the workload for resource
r, that is, the time in which it is active processing operations, defined as the sum of the processing times of all operations assigned to the resource.
The rationale behind this expression, assuming that at least one operation is scheduled in resource r, is to calculate the time span between the starting time of the first operation to be processed in the resource and the completion time of the last operation in that resource and then subtract the total time in which the resource is actually active. Again, we discount negative values, which we know are not possible, and the result will be the core idle time of the resource.
3.4. The Total Core Idle Time
Regardless of how the core idle time,
, for each resource,
, is computed, the total core idle time of a schedule is obtained as the sum across all resources of their core idle time:
We may add a superscript,
, if we want to highlight that this function is computed using (
17), (
19), or (
20), respectively.
Let us illustrate the three different ways in which
can be computed with a toy example. Suppose that we have the schedule
depicted in
Figure 2, comprising eight operations scheduled in three resources. To represent the different values of the operations in the schedule, we will use grids as the following:
where each row corresponds to the operations scheduled in a resource. This way, the processing times of operations are as follows:
Their starting times are given by the following:
And their completion times are given by:
If we compute operations’ idle times,
, using the naive approach from (
16), we obtain the following values:
This results in resource core idle times
,
, and
and, thus, a total core idle time,
If operation idle times are instead computed with the knowledge-based approach, as proposed in (
18), we obtain the following values of
for all operations:
These yield resource core idle times
,
, and
, so the total core idle time will be
Finally, using the coarse approach to directly compute the core idle time of resources as per (
20), we obtain
,
, and
. Then, the total core idle time according to this method is
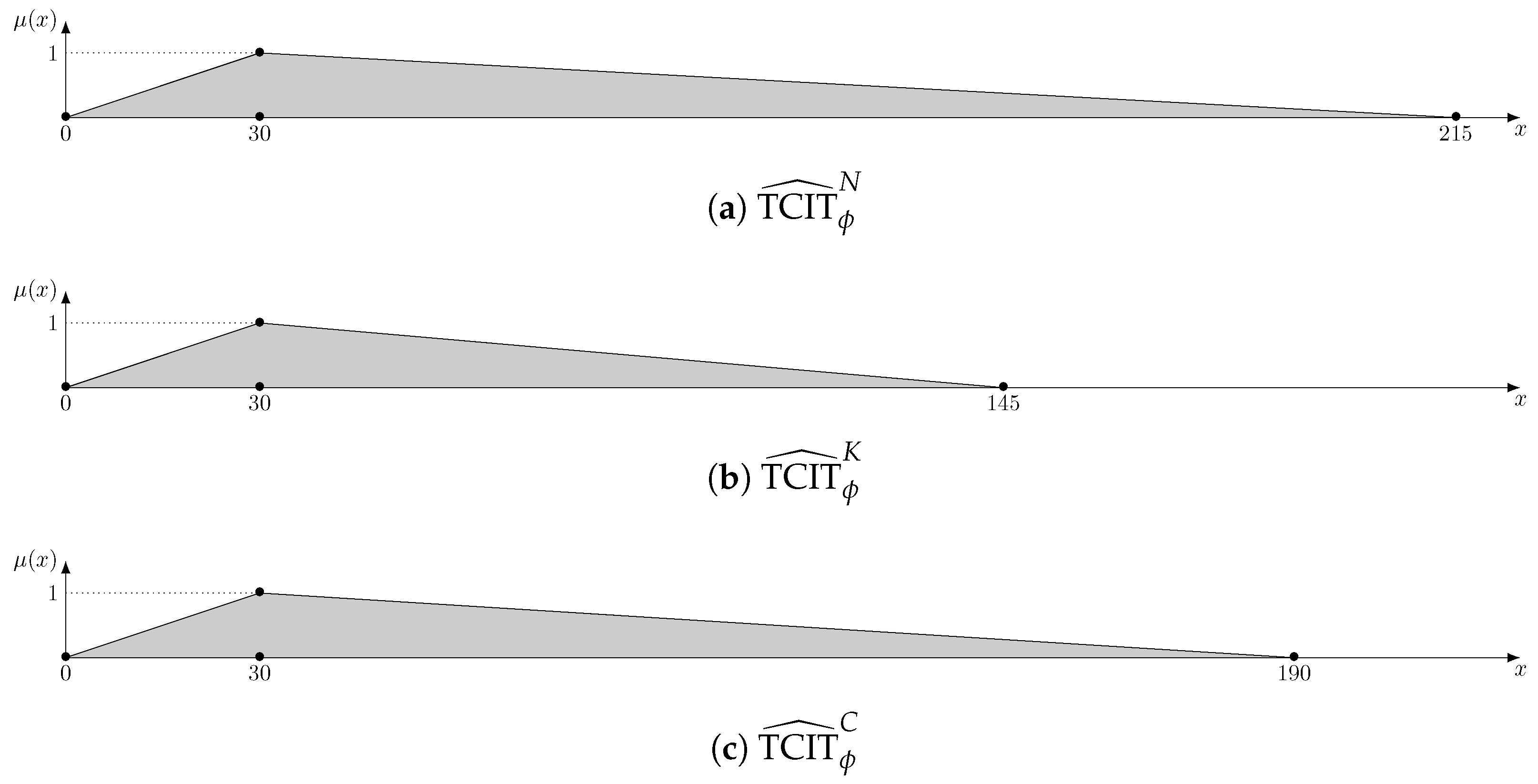
We can appreciate how, unlike the deterministic case, in the fuzzy framework, each approach yields a different value for
. The three different TFNs can be seen in
Figure 3. It is clear that the support (and, hence, the spread) of the resulting TFN is different in each case. Given their definitions, it is guaranteed that the spread of
will always be less than or equal to the spread of
, i.e., computing the total core idle time with the knowledge-based approach accumulates less uncertainty, as illustrated by the example. In this particular case, the spread for
is also larger than the one for
. However, it is not guaranteed that this will always be so, as shown in the experimental results in
Section 4. The example also illustrates that the modal value of
is always the same, regardless of the approach used to compute it. This is a direct consequence of how arithmetic operations are performed on TFNs. Finally, notice how, by truncating negative values, in all three cases, uncertainty accumulates towards the right-hand side, resulting in skewed TFNs.
4. Results
The objective of the experimental study is to empirically assess the three different approaches introduced in
Section 3 in order to compute the total core idle time for fuzzy schedules. We will use 12 benchmark instances from the literature [
25]:
07a,
08a,
09a,
10a,
11a, and
12a with 15 jobs, 8 resources, and 293 operations (denoted as
in the following) and
13a,
14a,
15a,
16a,
17a, and
18a of size
. In instances
07a,
08a,
09a,
13a,
14a, and
15a, operations have the same processing time, regardless of the resources where they are executed, while instances
10a,
11a,
12a,
16a,
17a, and
18a have resource-dependent processing times. There are also three increasing flexibility levels, with
07a,
10a,
13a, and
16a being those instances with the lowest flexibility and
09a,
12a,
15a and
18a being those instances with the highest flexibility.
The study follows the methodology proposed in [
26]. For each instance, schedules will be generated and compared in terms of their performance regarding
using first the measures introduced in
Section 2.3.1 and then those introduced in
Section 2.3.2. In both cases, this will be done with two types of experiments: over random solutions and with solutions obtained with a search algorithm. The goal of the random-solution experiments is to evaluate the three alternatives for computing
without the possible bias that may be introduced via any solver, whereas the searched-solution experiments pretend to compare the three models when embedded in a search algorithm, with the objective of evaluating their capability of guiding the search towards good schedules. In both sets of experiments, 100 schedules are obtained per instance; notice that, for the searched-solution comparisons, this means generating 100 schedules for each of the three models (
, and
) under consideration.
As a solution method for the searched-solution comparisons, we employ the tabu search algorithm proposed in [
51] for the classical job shop, extending the neighbourhood function so that every operation is moved to all feasible positions both in its current resource and in others where it can be executed. This is probably the most naive neighbourhood available, as it tries to reschedule every operation in every position, but at the same time, it ensures connectivity and is agnostic to the models, minimising their influence on the results. At every iteration, a tabu search generates all possible neighbours and selects the best one that is not tabu. Then, it stores the inverse of the move performed to obtain the selected neighbour in a memory structure, called the tabu list, so, in the next iterations, that move is forbidden, thus avoiding the undoing of recently made moves. In this way, the tabu search is able to escape local optima. In addition, the tabu list also serves as a diversification mechanism, as different movements are encouraged. A detailed pseudocode can be found in
Figure A1. The tabu search parameters are set to the values used in [
26] for the same set of instances. This algorithm will be used in all experiments, with the only change being the objective function, which will vary in order to test the different proposals.
4.1. Comparisons Based on Fuzzy TCIT Values
As mentioned in
Section 2.3.1, fuzzy TCIT values can be compared in terms of their expected value, their spread,
S, and their modal value position,
.
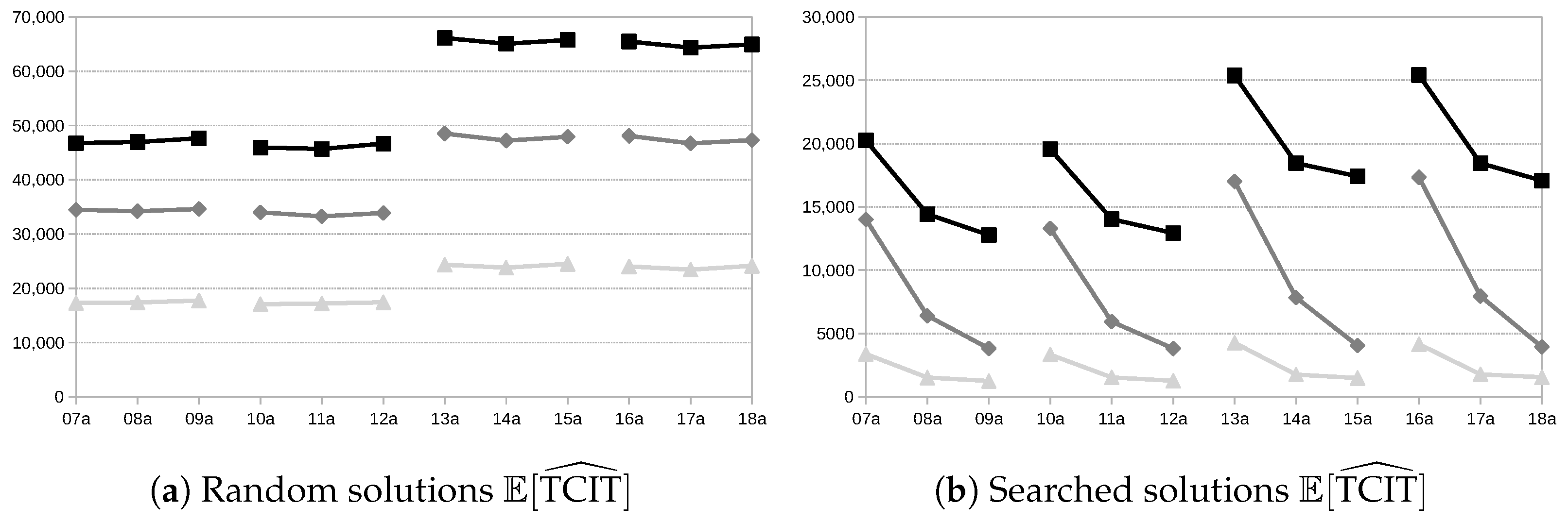
Figure 4 shows the average
values obtained for each instance in the two types of experiments.
Figure 4a corresponds to the average values obtained when evaluating the random schedules with the three models for computing
.
Figure 4b depicts average values obtained when evaluating the schedules obtained with the tabu search using each of the three models. In both experiments, there is clearly a difference between the three methods for computing the fuzzy TCIT:
yields better average expected values than
, and this, in turn, yields better values than
.
Furthermore, for the random solutions experiment, the variation in the expected value seems to depend only on the problem size and not on the flexibility level, as illustrated by the flat lines. This makes sense since, the larger the number of operations, the larger the number of possible gaps, and, as they are not optimised in any way, the longer the total idle time. However, for the searched-solution experiment, differences exist depending not only on the instance size but also on the flexibility level. This may be because greater flexibility provides the search algorithm with more opportunities to move operations between resources and fill inactivity gaps, thus reducing the total core idle time. It is remarkable that, here, seems to yield better improvements when greater flexibility is introduced, coming closer to . On the other hand, the improvement of the naive approach does not seem to be as pronounced when flexibility increases. Also, expected values are significantly higher than . This is expected because, although has been defined to reduce artificial uncertainty due to dependencies between operations, there are still relations that we cannot easily account for. Thus, the sum of idle times between operations, that is the sum of multiple subtractions, is going to have predictably more artificial uncertainty than the coarser approach, which only makes one subtraction, as the results demonstrate.
When the spread is considered, the obtained graphs are very similar. The reason is that, in these benchmark instances, operations have similar-magnitude processing times with different values for each of the three components of the TFNs. As computing starting times according to Equation (
11) are accumulative, the greater the number of already-scheduled operations, the larger the expected value of the TFN and the difference between the first and third components. Then, as the subtraction according to Equation (
3) is computed by crossing the value of the lower and upper values of the two TFNs involved, it is predictable that larger expected values also mean larger spread values.
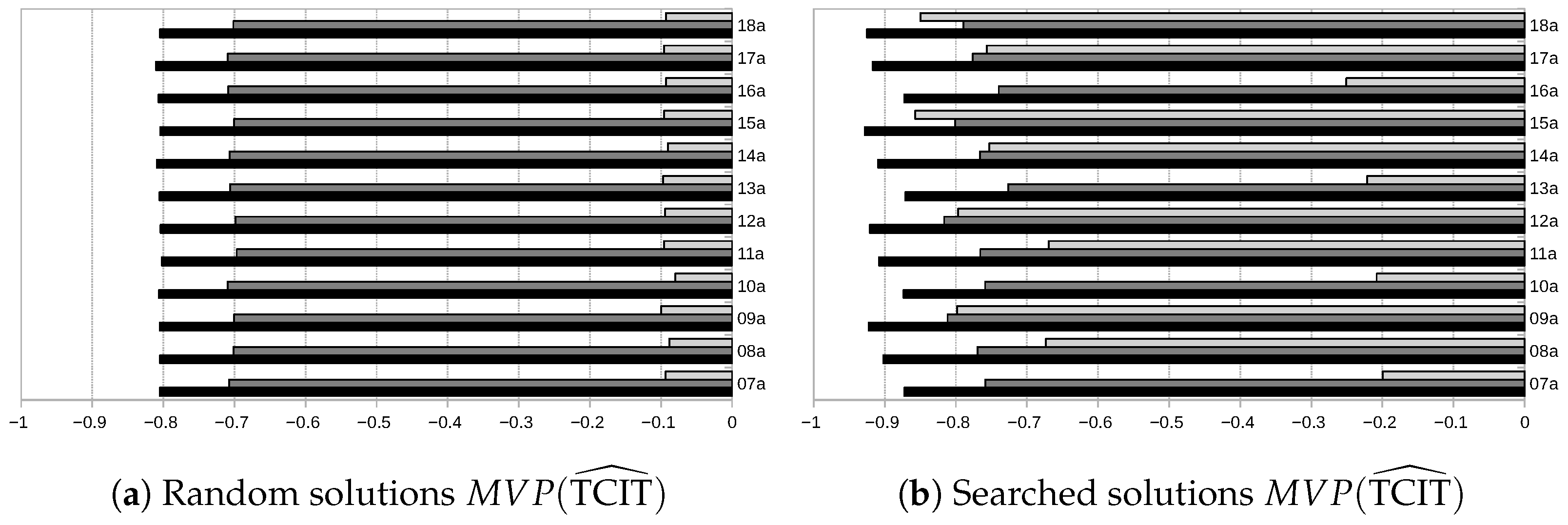
Finally,
Figure 5 shows the
values obtained in the experiments. Notice that, both in the random solutions and the searched solutions experiments,
is negative, meaning that the modal point is situated to the left of the support’s midpoint; i.e., the TFNs are skewed to the right. The main reason for this behaviour is that, in all functions, we are removing negative values because negative times are not possible, but this trimming will only take place on the left side of TFNs. Also, notice that, in the searched-solution experiments, the absolute value of
is closer to −1 compared to the random solutions. This is because better solutions mean smaller gaps between operations in the same resource, and then, the probability for the predecessor in the resource being the operation defining the starting time is higher, introducing a dependency between these operations that increases the chances of having negative numbers for idle times. However, the conclusion should not be that being closer to
is better. The reason is that the processing times of operations are almost symmetrical, but
does not maintain this symmetry, which means that we are accumulating artificial uncertainty on one of the sides. Notice that this effect is aggravated when there is higher flexibility, and that it is much more pronounced for
. This phenomenon can be illustrated as follows. Suppose that, during the tabu search, there is a resource where an operation can be scheduled without altering the starting time of the first operation already scheduled in the resource or the completion time of the last operation in the resource. Then, the minuend in (
20) (i.e., the time span between the start of the first operation and the end of the last one) is not altered, while the subtrahend, the sum of processing times of operations assigned to the resource, grows. In consequence, the first component of the difference will be smaller, more likely negative, and, therefore, more likely to be truncated to 0, resulting in a TFN more skewed to the right. When the flexibility level is low, so is the possibility of moving operations to a different resource, while higher flexibility increases the options to move operations between resources, leading to the described behaviour.
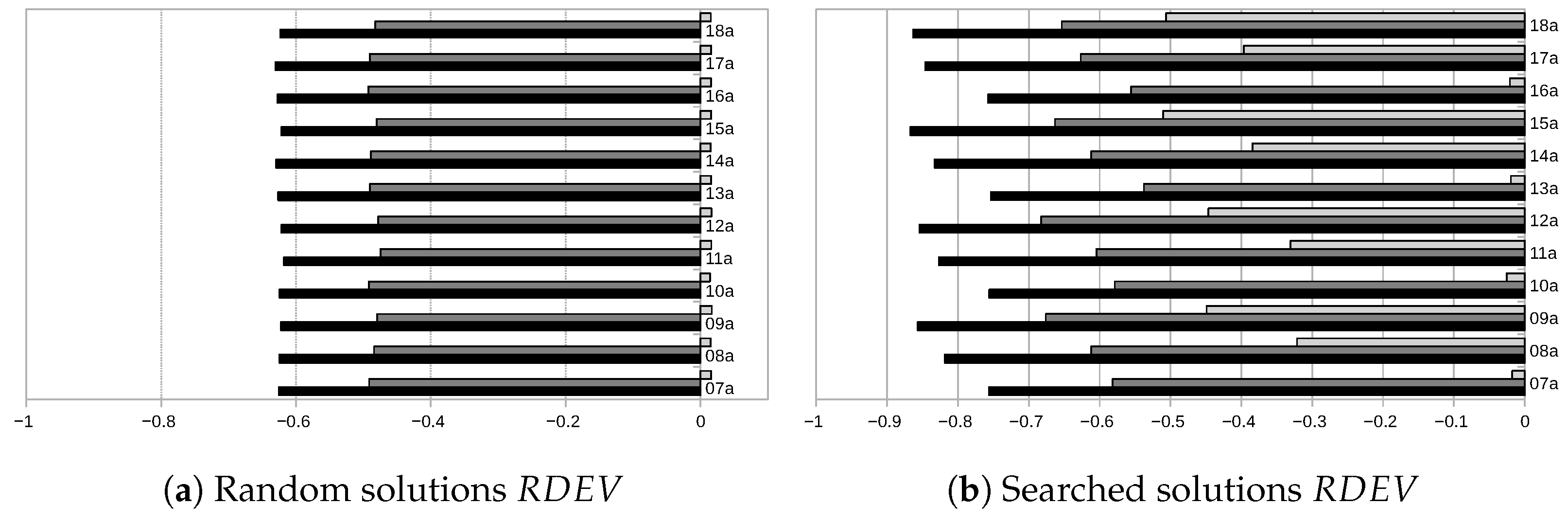
4.2. Comparisons Based on Crisp Scenarios
We now evaluate the three models for computing
using the measures described in
Section 2.3.2. To this end, we will use a unique set of 1000 crisp possible scenarios,
, derived from the fuzzy instances. These scenarios are generated by setting the processing time of every operation in each allowed resource to a random value derived from a uniform distribution in support of the TFNs.
Figure 6 shows, for each instance, the average
across all scenarios in
, both for the random and searched solutions experiments. Clearly, both the results obtained with
and
on the crisp scenarios are closer to the predicted expected value than those obtained with
. Those obtained via the coarser approach are the closest to the expected value, evidencing the lower amount of artificial uncertainty that it introduces. One remarkable detail, when comparing random- and searched-solution cases for
, is that, in the random-solution experiment, the relative distance values are positive; i.e., the TCIT values obtained with the executed schedules are, on average, larger than expected. In other words, the predicted estimate provided via
is slightly optimistic. However, when integrated into the tabu search, the relative deviation becomes negative. As was the case with
, this can be explained because truncating negative values (which are more likely after an improving local search move) cause the
to be skewed to the right, with a subsequent deviation in the expected values.
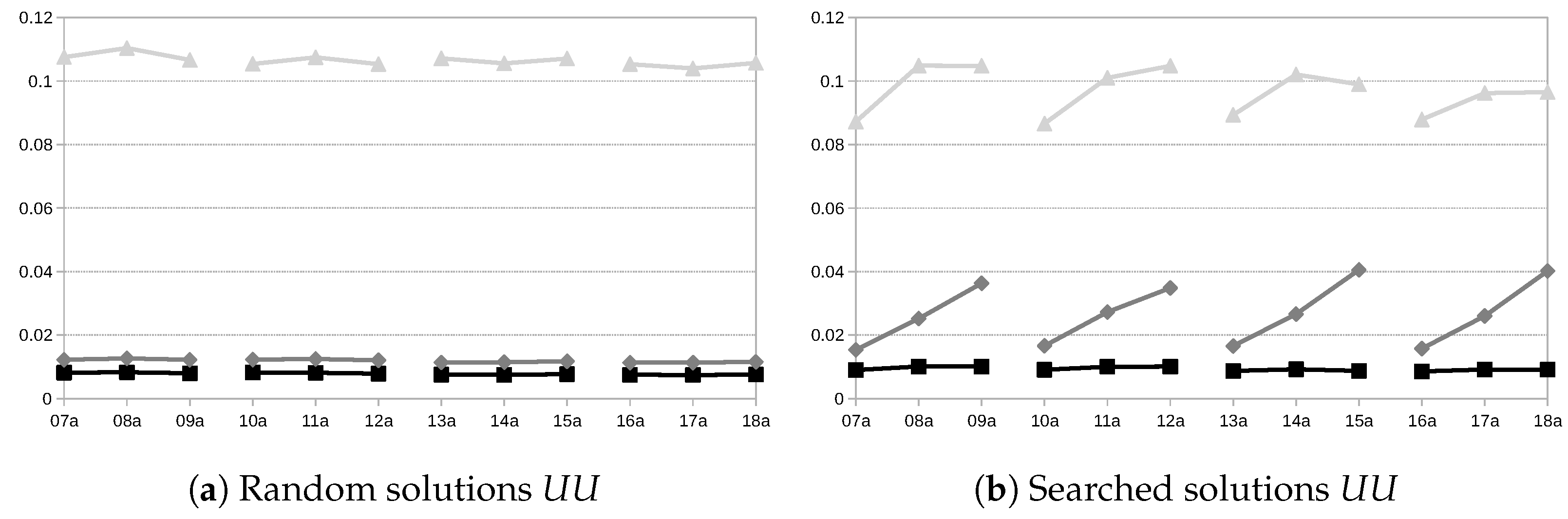
Finally,
Figure 7 depicts the results obtained when considering the used uncertainty measure,
. For random solutions, there is no difference in
with different flexibility levels. However, in the case of searched solutions, there exist interesting differences between the three approaches. In the case of
, increasing flexibility also causes the used uncertainty to increase. However, for
, increasing flexibility does not make any difference in either the random or searched solutions. The case of
is even more curious, as the initial increase in flexibility allows for higher
, but adding more flexibility can even cause the
values to decrease. Also, notice that the
values are quite small. This is because a wider use of the support
would require most crisp realisations for the processing times to be extreme values in the support of each TFN representing processing times, which would contradict the possibility distribution given by each TFN.
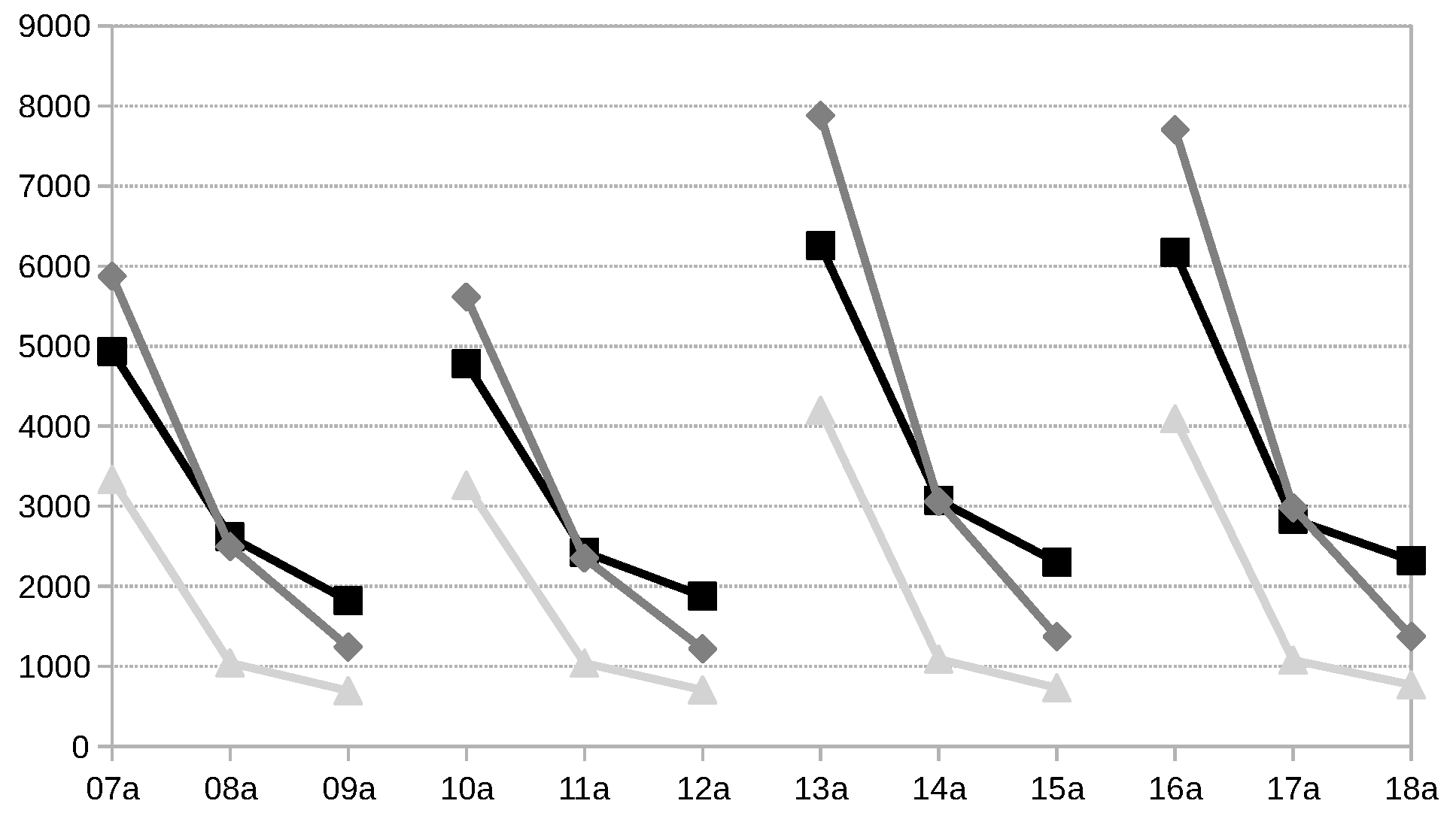
In addition to the above assessment, we can also evaluate the crisp TCIT that is obtained with the schedules obtained using the tabu search with each model for computing
. The objective is to assess the TCIT that can be obtained according to simulations, rather than using a central tendency measure such as the expected value, which, as we have seen, can be deviated due to the artificial uncertainty that is introduced.
Figure 8 shows the average executed TCIT across the 1000 crisp scenarios and the 100 different schedules.
These results show a completely different behaviour with respect to the one observed when comparing based on the fuzzy values. It seems that, according to simulations, in those instances with less flexibility, seems to work better than ; however, as flexibility increases, making the problems harder, takes the lead. There is no clear explanation for this behaviour other than that instances with less flexibility allow to make very few moves between resources, so most moves in the tabu search are limited to reordering of operations in one resource, and then having less artificial uncertainty in the idle times does not suppose a big advantage, as there would be few chances to find an operation that fills the gap. Meanwhile, involves higher artificial uncertainty that skews TFNs more to the right, which means a higher deviation towards the worst case, which, for this set of instances, seems to be a beneficial trait in the guiding function for lower-flexibility cases. In any case, remains the dominating alternative and the better approach when the problem at hand does not require computing idle times at the operation level.



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}