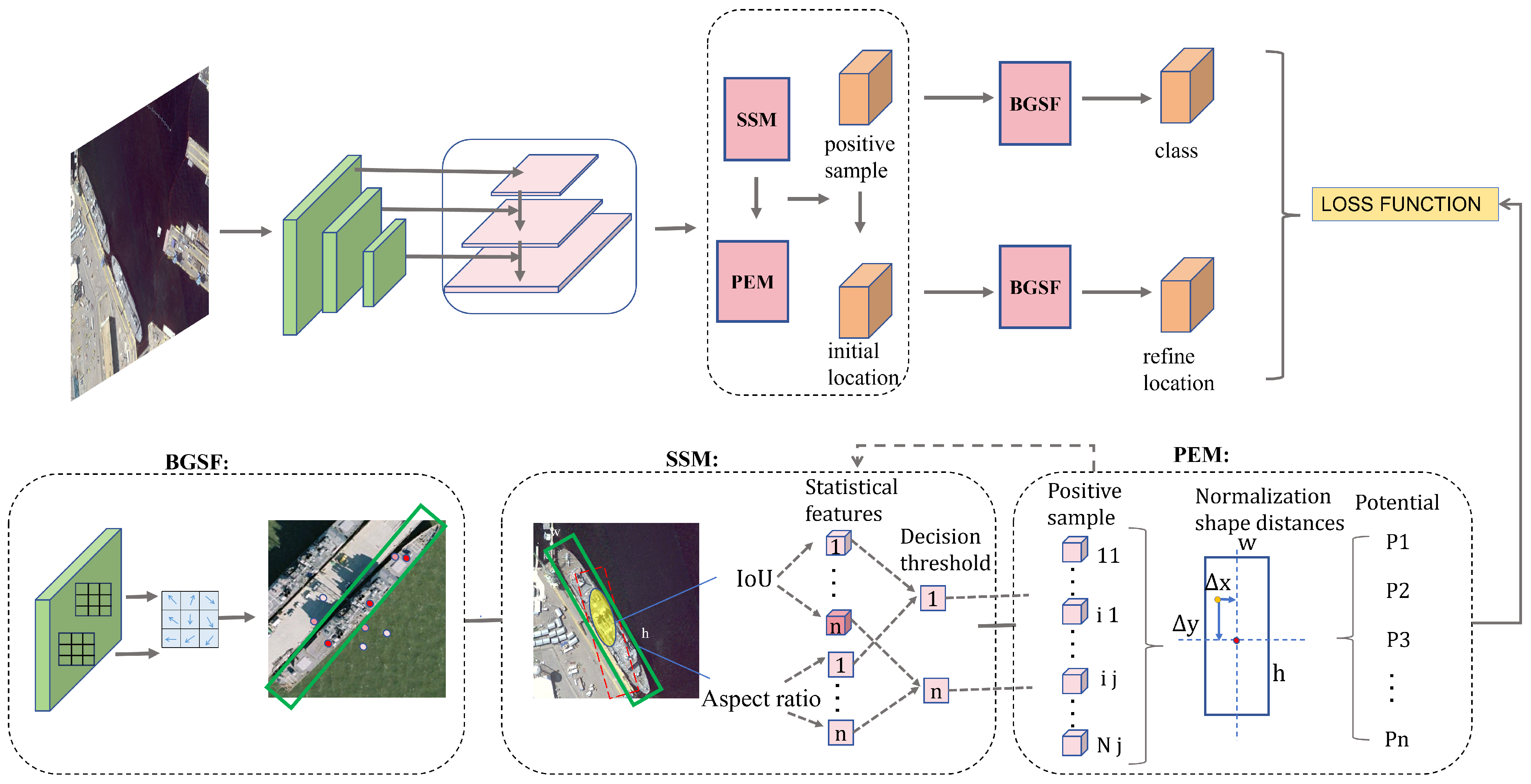
7.1. Ablation Study Analysis
- (1)
Ablation Study on Module Effectiveness
Ablation studies were carried out on the HRSC2016 and UCAS-AOD datasets to assess the impact of different modules on performance. The results on the HRSC2016 dataset are presented in
Table 2. An mAP of 85.1% was achieved by the baseline model, primarily because standard CNN convolution structures struggle to effectively model and extract features for elongated targets with multiple rotational directions.
After incorporating BGSF, the detector’s performance improved by 3.4%. This demonstrates that, in rotation detectors, guiding the convolution kernel at each position within the receptive field based on edge location features enables free deformation and displacement. The targets’ shape and directional information is better captured by the network due to this, thereby enhancing the detector’s performance.
After incorporating SSM, the detector’s performance further improved by 2.1%. This is because the module introduces shape-related parameters into the sample selection process, enabling a more comprehensive representation of elongated targets during threshold-based discrimination. This improvement benefits subsequent regression and classification tasks.
Adding PEM resulted in an additional performance gain of 1.8%. By incorporating positional information of each sample in the loss function, the model prioritizes high-potential positive samples during the training process, thereby further boosting detector performance.
When both SSM and PEM were used simultaneously, the detector achieved a performance increase of 4.1%. When both BGSF and SSM were used simultaneously, the detector achieved a performance increase of 4.7%. Finally, when all three modules (BGSF, SSM, and PEM) were used together, the detector’s performance improved by 6.1%, showcasing the complementary nature of these modules.
As shown in
Table 3, similar experimental outcomes were observed on the UCAS-AOD dataset. The integration of different modules demonstrated superior performance compared to using a single module. BGSF and SSM collectively enhanced feature extraction by adapting to target shapes while enabling high-potential sample selection, resulting in better classification and regression outcomes. Additionally, the experiments confirmed that the proposed modules do not conflict with one another. When all modules were used together, the model achieved an mAP of 91.3%, demonstrating the effectiveness of the proposed network.
- (2)
Evaluation of Internal Module Parameters
In SSM, w is set to 4 by default, and is used to adjust the gradual reduction of the weighting parameter as the aspect ratio of objects increases. In datasets featuring predominantly high-aspect-ratio objects, increased values of w typically enhance performance.
Experiments were carried out on the HRSC2016 and UCAS-AOD dataset to further validate the effectiveness of SSM. The outcomes are comprehensively presented in
Table 4 and
Table 5. We introduced a weighted factor function based on the elongation ratio to adjust the threshold parameter for sample selection. As shown in
Table 4, the HRSC2016 dataset contains a high proportion of elongated targets. When the parameter
w approached 0, such as
w = 0.3, the decision threshold was close to 0, causing nearly all anchor boxes to be classified as positive samples. This resulted in many low-potential negative samples being incorrectly treated as positives, significantly impairing the model’s training, and the mAP dropped to 89.5%.
As w increased, the decision threshold also increased, leading to improved detection performance. When w was set to around 4, the model achieved its best performance. At this value, the elongated objects in the dataset were assigned an appropriate decision threshold, avoiding premature exclusion while balancing sample selection. The mAP at this setting was 91.3%.
However, when w continued to increase and approached 7, the threshold became overly dependent on statistical information and neglected the shape characteristics of the targets. Consequently, the mAP dropped to 90.1%, indicating a loss of effectiveness in distinguishing elongated targets.
7.2. Comparative Experiments
- (1)
Results on the UCAS-AOD Dataset
Our proposed SSAD-Net was compared with several methods on the UCAS-AOD dataset. As shown in
Table 6, our approach achieved outstanding results, particularly for the ship and airplane categories, with APs of 89.58% and 94.13%, respectively. Furthermore, we achieved the best overall mAP of 91.34% across all categories.
Partial visual detection outcomes for ground targets from the UCAS-AOD dataset are shown in
Figure 3. As illustrated, our network can accurately detect densely arranged targets with multiple orientations. For arbitrarily oriented targets, the anchor boxes adaptively align with the spatial orientation of these targets to ensure precise rotation compatibility.
As depicted in the figure, our detector effectively identifies densely packed airplanes of varying sizes and orientations, even in complex scenes with highly intricate spatial arrangements. Additionally, our network demonstrates robust detection performance in urban road environments with dense, small-scale vehicles. These results highlight the ability of our detector to handle densely packed targets across diverse arrangements, indicating strong generalization capabilities.
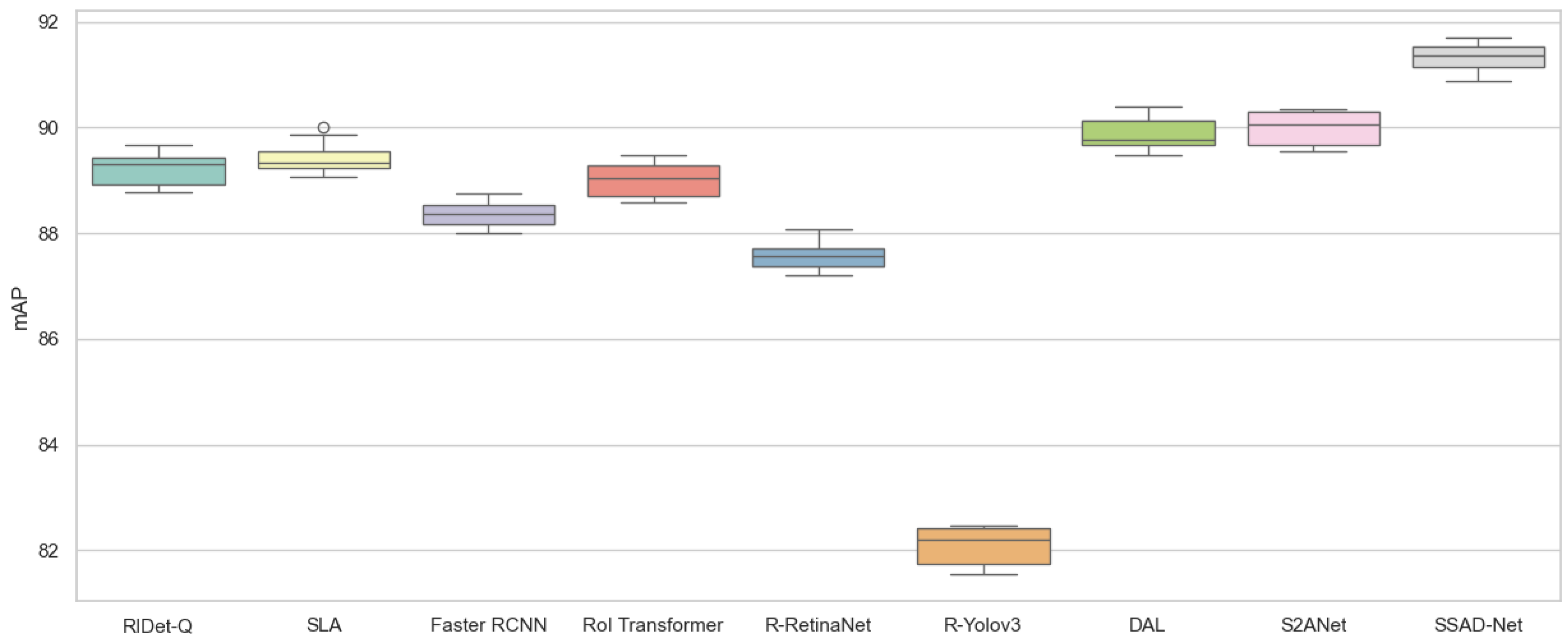
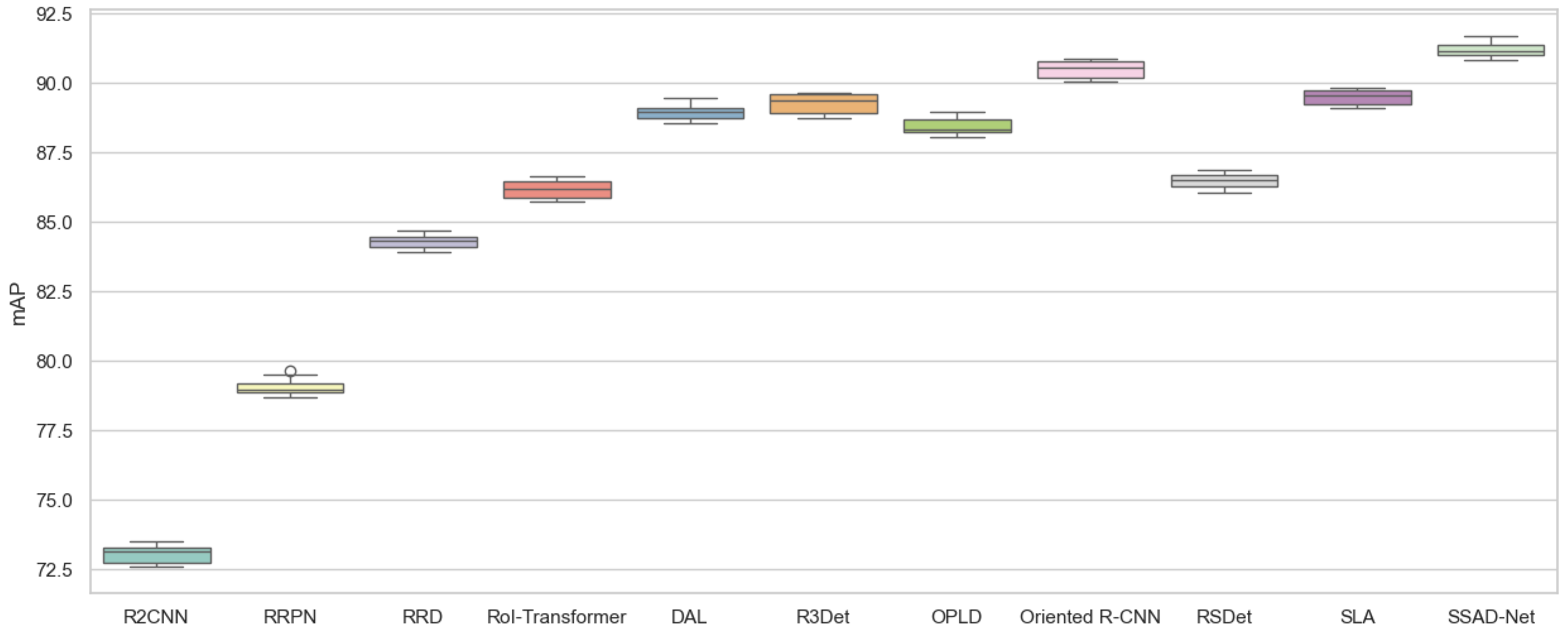
To further explore performance variations, we used box plots to display the distribution of mAP values across different methods. These box plots, as shown in
Figure 4 and
Figure 5, clearly illustrate the distribution and central tendency of the results. The box plots demonstrate that, compared to the baseline model, SSAD-Net consistently achieves the highest performance in most cases. The relatively narrow interquartile range indicates that the model exhibits stable performance across multiple trials.
For the UCAS-AOD dataset, SSAD-Net achieved an mAP of 91.34%, with a 95% confidence interval of [91.17%, 92.50%], outperforming other methods. This demonstrates that it significantly exceeds the performance of the second-best method, S2ANet, which has an mAP of 89.99% and a confidence interval of [89.78%, 90.20%].
Table 6.
Performance comparison of different methods on the UCAS-AOD dataset.
Table 6.
Performance comparison of different methods on the UCAS-AOD dataset.
| Methods | Backbone | Car | Airplane | mAP (%) |
|---|
| RIDet-Q [32] | ResNet50 | 88.50 | 89.96 | 89.23 |
| SLA [33] | ResNet50 | 88.57 | 90.30 | 89.44 |
| Faster RCNN [34] | ResNet50 | 86.87 | 89.86 | 88.36 |
| RoI Transformer [35] | ResNet50 | 88.02 | 90.02 | 89.02 |
| R-RetinaNet [31] | ResNet50 | 84.64 | 90.51 | 87.57 |
| R-Yolov3 [36] | Darknet53 | 74.63 | 89.52 | 82.08 |
| DAL [10] | ResNet50 | 89.25 | 90.49 | 89.87 |
| S2ANet [37] | ResNet50 | 89.56 | 90.42 | 89.99 |
| SSAD-Net | ResNet50 | 89.58 | 94.13 | 91.34 |
- (2)
Results on the HRSC2016 Dataset
Our proposed SSAD-Net was compared with several state-of-the-art methods on the HRSC2016 dataset. Our network achieved the best overall mAP of 91.2% across all categories, as shown in
Table 7.
Partial visual detection results for ground targets from the HRSC2016 dataset are shown in
Figure 6. It can be observed that our network accurately detects elongated targets. For arbitrarily oriented objects, the anchor boxes precisely align with their spatial orientations, achieving rotational adaptability. Even in scenarios where multiple elongated ships are densely packed together, our detector accurately identifies these targets under various spatial arrangements. Additionally, for ships with different aspect ratios but belonging to the same class, our detector consistently classifies them into the same category.
These results highlight the effectiveness of our network in facilitating the precise detection of elongated targets. BGSF enhances the network’s ability to respond to feature variations across different objects in the image, thereby improving feature extraction for elongated, variably scaled, and multi-directionally rotated targets. SSM adjusts the sample selection strategy based on object shape characteristics, designing reasonable thresholds that prevent high-potential samples from being prematurely discarded. PEM assigns potential information to each positive sample, ensuring that high-potential positive samples—but farther from the object center—receive higher training weights, resulting in stronger feedback during training.
Finally, these modules operate independently in feature extraction and sample selection, ensuring no conflicts arise between them. This modularity enables the network to consistently achieve superior detection results for challenging targets on the HRSC2016 dataset.
Similarly, as shown in the box plot for the HRSC2016 dataset, SSAD-Net achieved an mAP of 91.2%, significantly outperforming the previous state-of-the-art methods, including RSDet and Oriented R-CNN, with a p-value less than 0.05.
Table 7.
Performance comparison of different methods on the HRSC2016 dataset.
Table 7.
Performance comparison of different methods on the HRSC2016 dataset.
| Methods | Backbone | mAP (%) |
|---|
| R2CNN [38] | ResNet101 | 73.07 |
| RRPN [18] | ResNet101 | 79.08 |
| RRD [39] | VGG16 | 84.30 |
| RoI-Transformer [35] | ResNet101 | 86.20 |
| DAL [10] | ResNet101 | 88.95 |
| R3Det [16] | ResNet101 | 89.26 |
| OPLD [40] | ResNet50 | 88.44 |
| Oriented R-CNN [41] | ResNet101 | 90.50 |
| RSDet [42] | ResNet50 | 86.50 |
| SLA [33] | ResNet101 | 89.51 |
| SSAD-Net | ResNet50 | 91.20 |
- (3)
Comprehensive Discussion
The detection results for scenes with feature bias are shown in
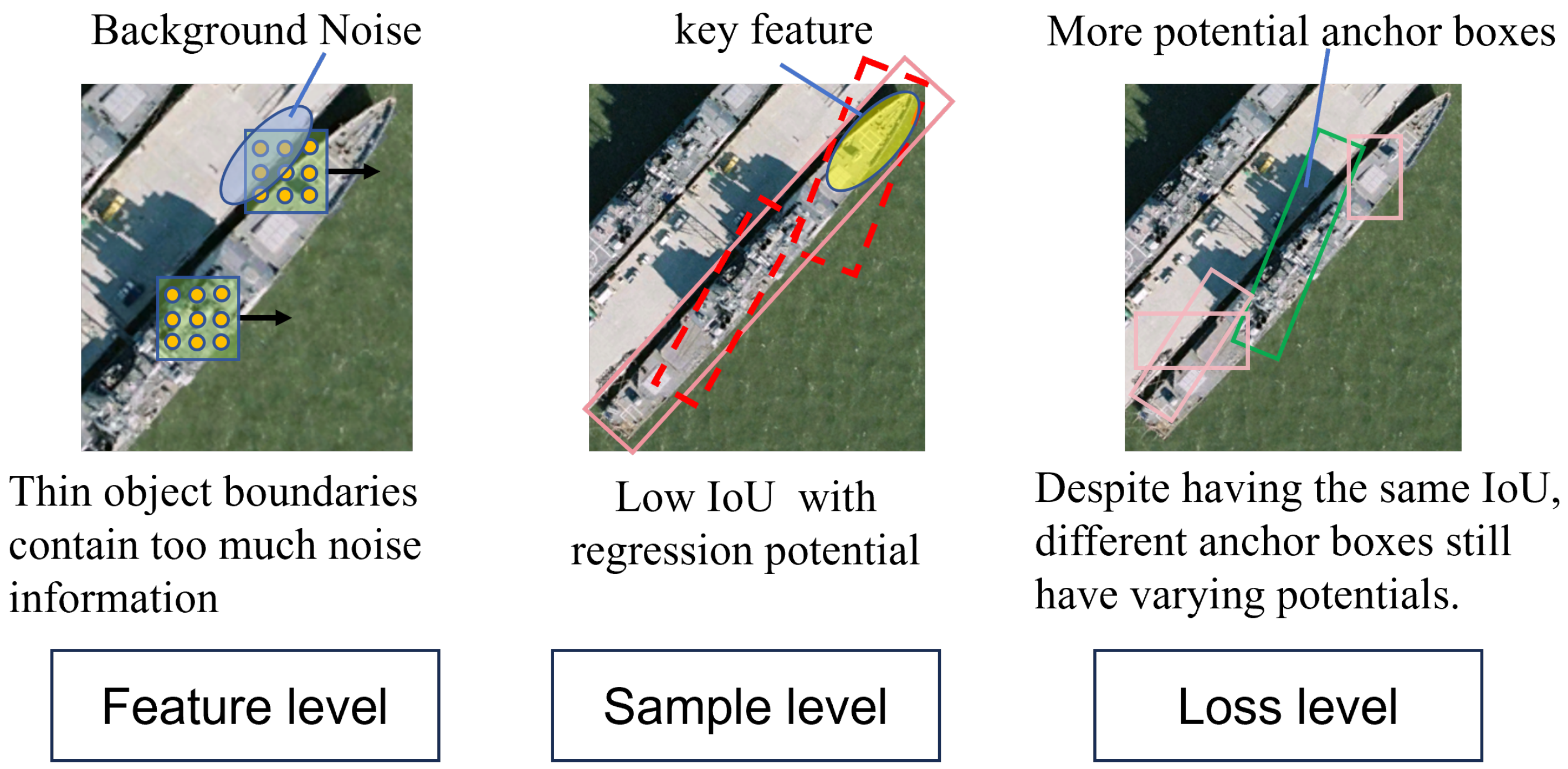
Figure 7. These results demonstrate that our detection method performs effectively in addressing issues caused by occlusion, camouflage, and low-light conditions, which often lead to feature discrepancies. This is due to our network’s ability to extract and focus on key features of the target, ensuring robust detection even under challenging conditions. The network’s adaptive feature alignment capabilities, along with the integration of modules like Boundary-Guided Spatial Feature Perception and Shape-Sensing, allow for accurate target identification and localization, even when the object is partially occluded or surrounded by complex backgrounds. This highlights the robustness and effectiveness of our method in real-world remote sensing applications, where environmental factors can significantly impact detection performance.
Our experimental results on the HRSC2016 and UCAS-AOD datasets highlight the effectiveness of SSAD-Net in detecting elongated and multi-directionally rotated targets. In object detection, the focus has often been on the independent aspects of predefined candidate anchor box settings and feature modeling within the ground truth boxes, while neglecting the influence of the intersection form and content between the predefined boxes and ground truth boxes on the detection performance. In SSAD-Net, we address this issue by considering three perspectives: feature extraction, shape sensing, and training feedback. By tackling these key challenges, we demonstrate that SSAD-Net outperforms existing methods and achieves superior performance across various scenarios.
Although SSAD-Net performs well in detecting complex targets, the computational complexity introduced by the dynamic modules may limit its real-time performance, especially when applied to larger datasets. Furthermore, further investigation is needed to improve the model’s performance in cases of highly occluded or cluttered targets, and to reduce its dependence on high-quality, well-annotated data.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}