1. Introduction
Most natural events are stochastic [
1] because they involve uncertain interactions of random internal “environments”. To study these events, researchers have applied probability theory, which is a tool encompassing a branch of mathematics that aids in the analysis of the behavior of stochastic events. Probability theory, in particular, and stochastic processes, in general, are among the most fundamental fields of mathematics. They have applications in signal processing, pattern recognition, classification, forecasting, medical diagnosis, and many other applications. In practice, probability distributions find application in diverse fields such as electron emission, radar detection, weather prediction, remote sensing, economics, noise modelling, etc. [
2,
3,
4,
5]. Once the probabilistic model is well-defined, subsequent analysis often involves the theory of “estimation” (synonymously, learning, or training, depending on the application domain). Such estimation is always valuable, but it is nonetheless challenging [
6], especially when the available data are limited [
7,
8].
In this context, the PDF of a random variable is central to various aspects of the analysis and characterization of the data and the model. Many studies have emphasized the need for estimating the PDF [
9], which is challenging due to the absence of efficient construction methods.
Suppose that
is a set of observed data with
N samples randomly distributed with an unknown PDF. The given
is characterized by its PDF (
) of the underlying random variable, which satisfies the fundamental properties of a PDF:
Once the PDF has been estimated based on a well-defined criterion, one also needs an assessment method to compare with the set of observed data to identify the accuracy of our estimation. This PDF can be used to study the statistical properties of the dataset, estimate future outcomes, generate more samples, and so on. Numerous methods have been proposed for estimating the PDF, and these can be classified into two approaches, namely, using parametric or nonparametric models
Unlike parametric models, which make assumptions about the parametric form of the PDF, nonparametric density estimation does not assume the form of the distribution from which the samples are drawn [
10]. In parametric models, one develops a model to fit a probability distribution for the observed data, followed by the determination of the parameters of this distribution. The procedure is summarized into four steps:
- 1.
Select some known candidate probability distribution models based on the physical characteristics of the process and known characteristics of the distribution of the available samples.
- 2.
Determine the parameters of the candidate models.
- 3.
Assess the goodness-of-fit of the fitted generative model using established statistical tests and graphical analysis.
- 4.
Choose the model that yields the best results [
2,
11,
12].
However, these methods cannot cover all data because some datasets do not follow specific distributional shapes. As a result, these methods may fail to accurately approximate the true but unknown PDF [
3]. Nevertheless, they contribute to solving many applications.
In nonparametric density estimation, we resort to techniques to find a model to fit the idealistic probability distribution of the observed data [
13]. For example, a histogram approximation is one of the earliest density estimation methods, introduced by Karl Pearson [
14]. Here, the entire range of values is divided into a series of intervals, referred to as “bins”, followed by adding up the number of samples falling into each bin. Although the so-called bin width is an arbitrary value, extensive research has been done to find a robust way to indicate the effective bin width [
15,
16]. Moreover, some bins will be empty, while others may have few occurrences. Thus, the PDF will ultimately vary between adjacent bins because of fluctuations in the number of occurrences. By increasing the bin size, each bin tends to contain more samples [
17]; however, many important details will be filtered out. This weakness causes the inferred PDF to be discontinuous, and so it cannot be viewed as an accurate method, especially if the derivatives of the histogram are required.
These drawbacks led to the development of more advanced methods, such as Kernel Density Estimation (KDE), Adaptive KDE, Gaussian Mixture Model (GMM), Quantized Histogram-Based Smoothing (QHBS), and the one-point Padé approximation model [
18].
KDE [
19] is a common density estimator resulting in smooth and continuous densities. It estimates the PDF by deploying a kernel function at each data point and then computing the sum of these kernels to construct a nonparametric estimate of the PDF. The kernel is usually a symmetric, differentiable function, such as the Gaussian. The bandwidth hyperparameter, which defines the width of the kernel, is crucial in determining the smoothness of the resulting estimate.
Adaptive KDE [
20] is a form of KDE in which the bandwidth is not constant but instead changes according to the local density of the data. This approach allows for a more accurate depiction of the features of the distribution, especially in regions with dense data, while producing a smoother estimate where there are fewer data points.
GMM [
21,
22] is a parametric density estimation technique that assumes that the data have been produced by a weighted sum of Gaussian distributions. GMM models the mixture density by estimating the parameters of the (assumed) source Gaussian distributions. Each component of the mixture in the form of Gaussian has its own mean and covariance, while the overall density function is the weighted sum of these individual Gaussian densities. GMM offers a number of advantages over other models and can capture more complex and multi-modal distributions. It is, however, a parametric approach whose accuracy depends on the degree to which its underlying assumptions are met.
QHBS [
23] is an approach to address the challenges posed by conventional histograms. It approximates the PDF by smoothing a histogram in a manner that reduces the discontinuities and enhances the smoothness of the resulting density estimate. This approach splits the data into sets of bins and then employs a quantization procedure to soften the estimates and thus produce a smoother, continuous, and differentiable representation of the PDF.
Each of these methods has its strengths and challenges. For instance, while KDE and Adaptive KDE offer smooth and continuous density estimates, selecting the appropriate kernel function and bandwidth can be difficult. On the other hand, methods like GMM and QHBS can address multimodal and discontinuous distributions effectively, but GMM requires knowledge of the number of component distributions, while QHBS is sensitive to the number of bins used in the underlying histogram. Despite these challenges, these methods are widely used in practice due to their ability to provide accurate and flexible density estimates in various applications.
Although we have presented only a rather brief review of these schemes, it can serve as a backdrop to our current work. In this paper, we shall argue that, unlike the previous methods, the use of the
moments of the data can serve to yield an even more effective method to estimate the PDF, which also quite naturally leads us to the Padé transform, explained below.
Note that we will synonymously refer to this phenomenon as the Padé approximation and the Padé Transform. Amindavar and Ritcey first proposed the use of the Padé approximation for estimating PDFs [
24]. We include Amindavar’s original method in our quantitative evaluations below, here referred to as the “one-point Padé approximation model”. As originally formulated, this approach suffers from several challenges, which are mentioned in [
24]. First, the Padé approximation method is only applicable to strictly positive data. Second, this method exhibits substantial distortion on the left side of the approximated PDF. Third, the original method did not demonstrate accurate PDF modelling when moments must be estimated directly from sample data. As detailed below, our proposed approach overcomes these challenges to arrive at a novel density estimation technique.
1.1. Organization of the Paper
In the next section, we briefly recall the basic concepts of the Padé approximation and moment estimation, both of which are used frequently in this research, and will be necessary for developing our proposed method. The subsequent section will illustrate the one-point Padé approximation method, which is an essential section to facilitate understanding of the concepts of our work. After that, the proposed method is introduced in reasonable depth. To demonstrate the efficiency of our work, we examine our work by invoking several criteria. Thereafter, the comparison between the proposed method and some of the mentioned methods will be presented. As shown in
Section 5, the proposed method is a robust, accurate, and automatic way to estimate the PDF. It would be an efficient way to find an unknown PDF for many applications, especially if the sample size is small.
1.2. On the Experimental Results
It is prudent if we say a few sentences about the datasets, distributions, and experimental results that we have presented here. It is, of course, infeasible and impossible to survey and test all the techniques for estimating PDFs, and to further test them for all the possible distributions. Rather, we have compared our new scheme against a competitive representative method in the time domain. With regard to the frequency domain, we have compared our scheme against the Padé approximation, whose advantages are discussed in a subsequent section. Further, all the algorithms have been tested for four distributions with distinct properties and characteristics, namely Gaussian mixtures, the beta, the Gamma, and the exponential distribution.
3. The Padé Approximation Using Artificial Samples
Many branches of science have invoked the Padé approximation as a tool to convert a series into a rational function. Similarly, in our study, we have applied it indirectly to samples to approximate an unknown PDF. The previously discussed method estimated
using the Padé approximation. However, its accuracy decreases significantly as
, causing distortion in that portion of the PDF. Moreover, all the samples in the previous method must be positive. To resolve this, we propose to utilize two datasets. The first is the given dataset. Thereafter, we create a new dataset from the original one, and the two of them will simultaneously be utilized to solve the problem. Suppose a given sample is randomly distributed from an unknown distribution
(Equation (
18)). We then generate
N samples from
by mirroring
across the y-axis, creating the series
:
As illustrated in Equation (
19), all elements of the
series will be mirrored values of
. Consequently, the estimated PDF using the
dataset, denoted as
, is precisely the reflection of our PDF function,
, across the negative Y-axis. To address the weakness of the one-point Padé approximation, in the following we will estimate the left part of
using the right part
. Consequently, we estimate the right part of
with the help of
, leading to a more accurate estimation of the function. Now, to calculate
from
, we follow the same procedure. To implement the one-sided Laplace transform, firstly, we need non-zero integer samples. Therefore, we shift all elements of
by the maximum amount of the
series + 1, which is
:
Proceeding now from Equation (
3):
is the moment generating function of our new training samples. So we continue:
It is easy to see that
is the mirrored form of our desired PDF. However, due to the use of the Padé approximation, this estimation suffers from the same issue we discussed before: it is only reliable when
is sufficiently large. Now, our objective is to utilize the right side of
to replace the distorted part of
. To achieve this, we need to roll back the entire shifting process. Considering Equation (
19) and then combining Equation (
21) and Equation (
15), we have:
The estimated PDF
is given by:
is the estimation of the series
. An acceptable point
C is required to be considered as the “centroid” for combining these two functions. The final result is equal to:
The denominators of sub-equations are necessary to ensure that the integral of
is equal to unity. Selecting the best value for
C is one of the challenges that should be taken into account. In this paper, we select the mean of
because it yields good experimental results. For illustrative purposes, we apply the method in some examples. With this approach, one can approximate the function; however, a discontinuity may arise. The function is not smooth at the point
C, and there is a jump at the point
C. For illustrative purposes, we first apply the method in one example, and then we highlight the issue. Finally, we propose a method by which we can render the function to be continuous at this point. The ideal Gaussian PDF given in Equation (
17) was used to generate normally (Gaussian) distributed samples. Thereafter, we randomly selected 200 samples,
, with the help of an inverse transform sampling method [
30].
These two sets, namely
and
, are samples that are generated to calculate the right and left parts of the PDF, respectively. As shown in
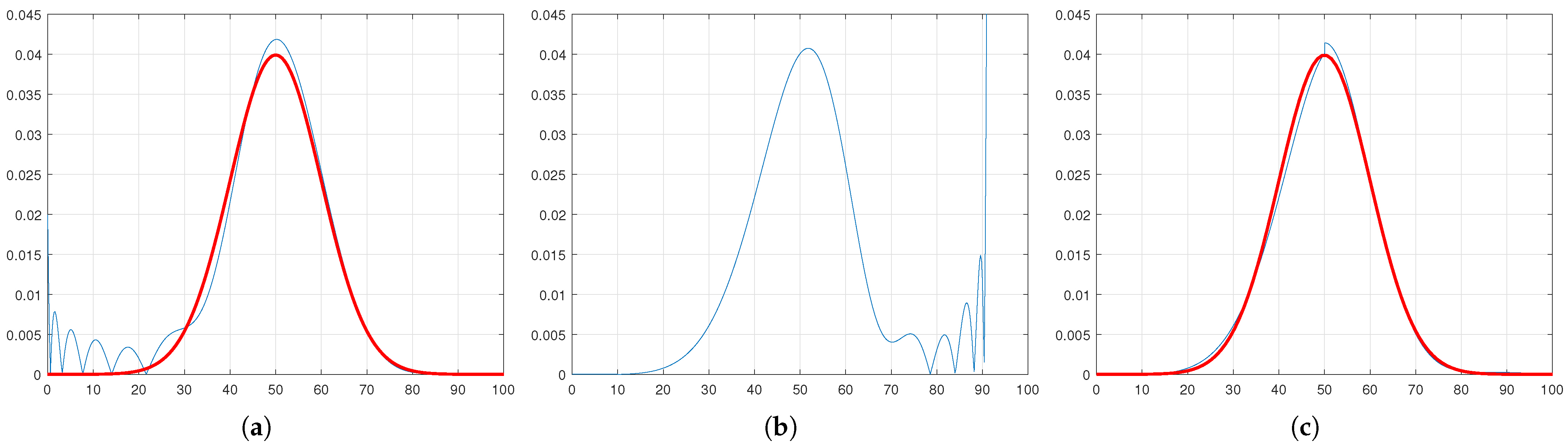
Figure 1, after applying the approximant method, the left and right parts of the PDF are calculated separately. For example,
is the dataset utilized to draw the left part of the PDF.
In the same vein,
and
are functions that draw the left and right sides of the learned PDF, respectively. After performing this operation, we obtain:
In
Figure 2, we display the left and right parts of the PDF. The blue series represents the ideal PDF, while the red series represents the estimated PDF. Subsequently, these PDFs are combined to create a less noisy PDF; see
Figure 2c, which is highly similar to the ideal PDF. However, as we discussed earlier, there is a discontinuity at the midpoint (50). To address this, in the next section (
Section 4) we introduce a sigmoid-based smoothing function to eliminate this discontinuity.
4. Using a Sigmoid-Based Transition
When dealing with piecewise functions, abrupt transitions between segments can introduce discontinuities or undesirable behaviour. To achieve a smooth transition between two functions, we can use a sigmoid-based blending approach [
31]. This method is particularly useful in scenarios where continuity and differentiability are important, such as in working with PDFs or control systems. The sigmoid function is defined as:
The sigmoid function is defined as a smooth, continuous curve that transitions from 0 to 1. Here, t is the independent variable, c is the transition point, and k controls the steepness of the transition. The parameter k determines how sharply the curve transitions. For small values of k, the transition is gradual, blending the functions smoothly over a wider range. For larger values of k, the transition becomes sharper, closely approximating a step function at .
To smoothly blend two functions,
and
, around the transition point,
c, we define the blended function by Equation (
33) as:
This formulation ensures that as , , and the blended function approaches . Similarly, as , , and the blended function approaches . Around , the two functions are smoothly combined based on the sigmoid weighting. The sigmoid-based transition is commonly used in various applications, such as in control systems, where it facilitates gradual shifts between control regimes, and signal processing, where it is employed for blending signals or applying gradual filters. This approach provides a robust mechanism for creating smooth, continuous transitions between functions, enhancing both stability and interpretability in mathematical models. In our work, we used the sigmoid function for PDF reconstruction. This function ensures smooth transitions between the mirrored and original PDFs, effectively eliminating the discontinuity point.
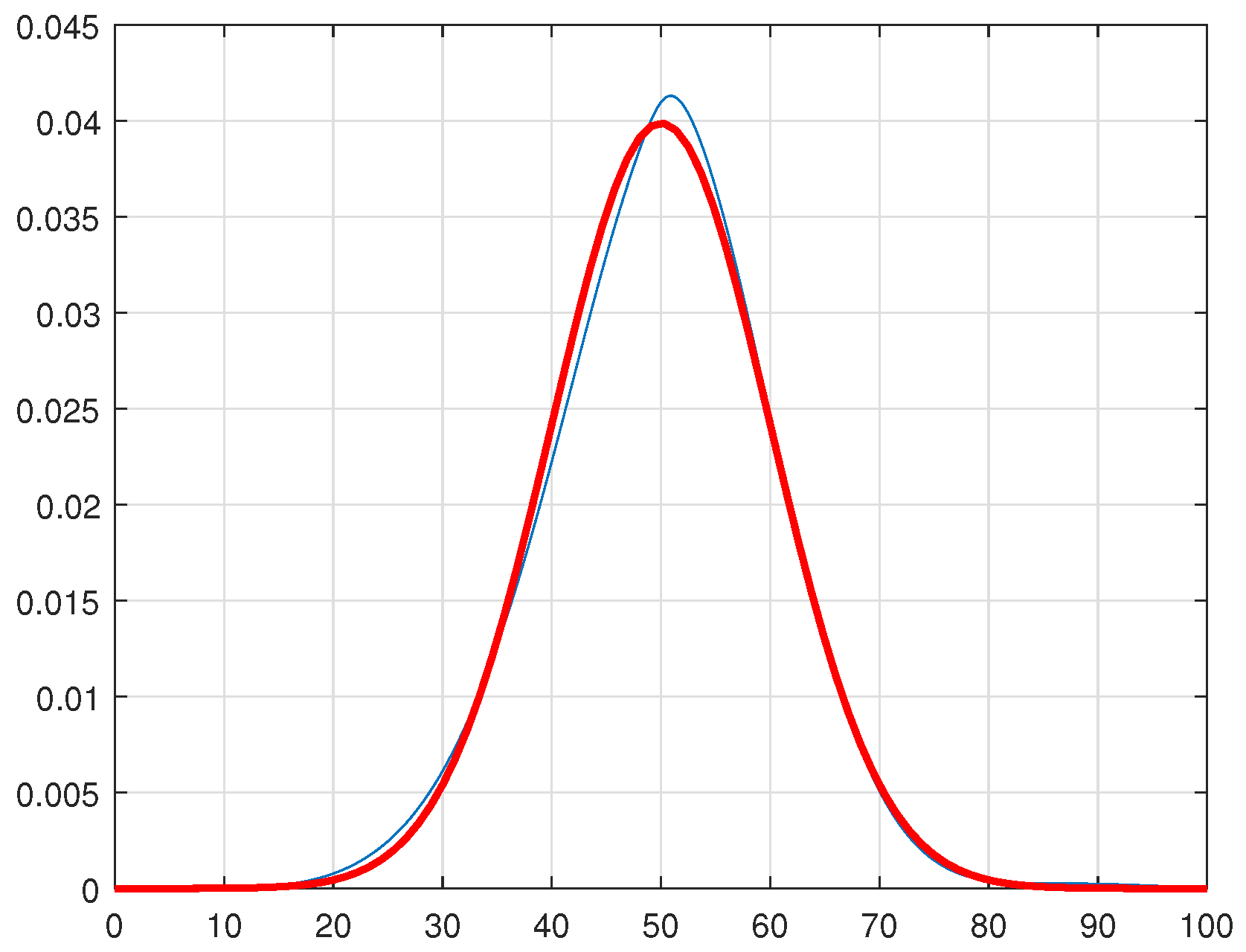
The result of applying the smoothing algorithm to the example from
Section 3 is seen in
Figure 3.
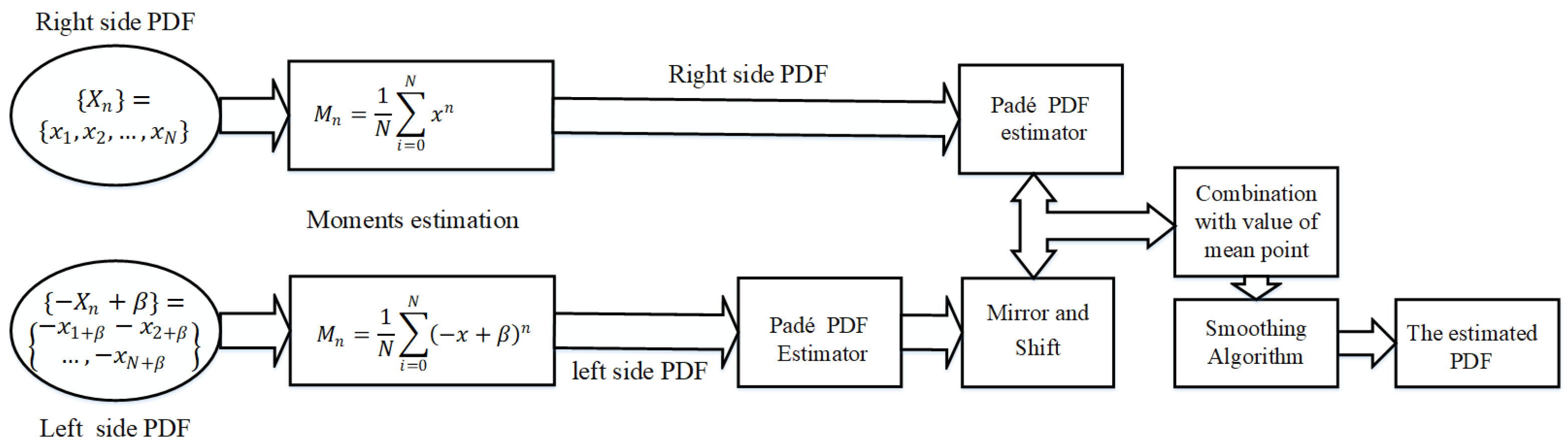
To illustrate the proposed method within the broader context,
Figure 4 presents a schematic diagram of the PA procedure. This figure outlines the sequential steps required to achieve an accurate approximation. Specifically, using Equation (
33), we depict the final estimation obtained by combining the two estimations.
In addressing the challenge of estimating the probability density function for negative random variables, we utilized a methodology involving horizontally shifting all samples to create a new dataset comprising only positive values. This positive dataset was then utilized to accurately approximate the probability density function. The process was initiated by aggregating all samples with a maximum absolute value, and subsequently, employing the same procedure outlined in
Section 3 to estimate the PDF. In the final step, the samples were reverted to their original positions. To illustrate this procedure, consider the example in which
is a series of 500 samples randomly generated from a Gaussian distribution with a mean of zero and a variance of 20, i.e., (
).
In the first step, all the samples were transformed into positive samples by shifting by the Min(
), such that they were strictly positive.
The transformed samples, denoted as
, were obtained using the following equation:
The proposed method was then applied to this set which results in an estimate of the PDF (see
Figure 5).
5. Quantitative and Comparative Assessment
In this section, we report the results obtained by conducting several experiments to assess the performance of the proposed method. The experiments can be summarized as follows. Firstly, the proposed method was applied to datasets generated from well-known probability distributions. The results were then compared with the ideal PDF. Subsequently, the proposed method was compared with other state-of-the-art methods. We aimed to show that our new approach could produce favourable outcomes when working with fewer samples, i.e., in scenarios where data are limited, which is a common occurrence in real-world situations. In addition, we have made the MATLAB code, implementing all the proposed methods, publicly available in the following GitHub repository:
https://github.com/hamidddds/Twosided_PadeAproximation (accessed on 23 January 2025).
In our research project, we conducted a series of tests to thoroughly investigate the problem using three datasets of varying sizes. The first dataset consisted of 300 samples, which we categorized as a large dataset, providing a robust representation for comprehensive analysis. The second dataset contained 100 samples, classified as a medium-sized dataset, offering a sufficient number of samples for a balanced evaluation. Lastly, the third dataset comprised only 50 samples, representing a very small dataset specifically designed to simulate challenging scenarios in which access to extensive data is limited. This enabled us to assess how well the performance varied across the sample sizes. In real-world applications, sample sizes of 50 are often insufficient to accurately calculate all data properties in specific ranges. In many cases, scientists address this limitation by making assumptions about the underlying structure of the density and then using parametric methods to estimate the parameters, although the overall accuracy of the results tends to decrease, particularly when incorrect assumptions are made regarding the density. Despite these challenges, we included these small sample sizes to demonstrate that, even in harsh conditions, our method can capture some characteristics of the data and perform reasonably well. However, it is important to note that such small sample sizes are highly sensitive to data sparsity, which can significantly impact performance. Clearly, it is important to mention that the accuracy of all estimations improved with increasing numbers of samples.
In this article, we employ five techniques for comparison with our proposed approach: Kernel Density Estimation (KDE), Adaptive KDE, Gaussian Mixture Model (GMM), Quantized Histogram-Based Smoothing (QHBS), and the one-point approximation model. Since our method is based on the one-point Padé approximation model, we have included it as a reference point for evaluating our approach. The KDE is a nonparametric technique that smooths data points to estimate the underlying PDF without assuming a specific distribution. It employs a kernel function, such as the Gaussian, and a bandwidth parameter to control the level of smoothing. In this study, a Gaussian kernel was used, with the bandwidth calculated using Silverman’s rule of thumb [
32]. The Adaptive KDE enhances the standard KDE by dynamically adjusting the bandwidth based on the density of data points. This adaptability enables it to handle varying data densities efficiently, capturing intricate details in densely populated regions while ensuring uniformity in sparser areas. The Adaptive KDE utilized the same Gaussian kernel but varied the bandwidth locally to reflect data density. The GMM is a parametric technique that represents the PDF as a combination of weighted Gaussian components. It estimates the parameters using methods such as expectation–maximization, providing an effective approach for clustering and density estimation. While the GMM performs well when data adhere to Gaussian assumptions, it may face challenges with non-Gaussian distributions. In this study, a three-component Gaussian model was employed, a configuration commonly observed in many applications [
33,
34,
35]. The QHBS combines histogram-based density estimation with smoothing techniques. It divides the data into segments, or bins, estimates the density within each bin, and then applies smoothing to reduce abrupt changes in the data distribution. For this study, the number of bins was set to 20 to balance detail and smoothness [
36].
To evaluate the performance of our proposed approach, we utilized six metrics: the Wasserstein Distance, the Bhattacharyya Distance, the Correlation Coefficient, the Kullback–Leibler (KL) Divergence, the L1 Distance, and the L2 Distance. The Wasserstein Distance evaluates the cost of transforming one probability distribution into another by examining variations in their distributions, making it responsive to the distribution’s shape and useful for assessing alignment. A score of zero for the Wasserstein Distance signifies similarity between distributions. The Bhattacharyya Distance measures the overlap between two distributions, helping us understand how well two methods approximate densities by directly reflecting their probabilistic similarity. A smaller Bhattacharyya Distance suggests a better approximation quality, with zero indicating a perfect overlap. The Correlation Coefficient assesses the linear relationship between distributions, providing a clear interpretation of their alignment. A Correlation Coefficient of 1 signifies perfect linear correlation, whereas a value of 0 indicates no linear relationship between them. The KL Divergence measures the difference between two distributions, revealing the drawbacks of approximating one using the other. It is useful for identifying subtle variations in the distribution of probability mass. A lower KL Divergence is preferred, as it signifies greater similarity between distributions, with zero indicating identical distributions. The L1 Distance (also known as Manhattan or Taxicab Distance) calculates the sum of absolute differences between corresponding elements in two vectors or distributions. It is particularly effective in high-dimensional spaces and provides an intuitive measure of dissimilarity. A smaller L1 Distance indicates greater similarity between distributions, with zero representing identical distributions. The L2 Distance (commonly referred to as Euclidean Distance) measures the straight-line distance between two points in a multidimensional space using the Pythagorean theorem. It is widely used for numerical data and provides a geometric interpretation of similarity. Like L1, an L2 Distance of zero indicates identical distributions, while larger values signify greater dissimilarity. These measures collectively provide a comprehensive foundation for assessing the accuracy, reliability, and alignment of density estimation methods across various dimensions and scenarios.
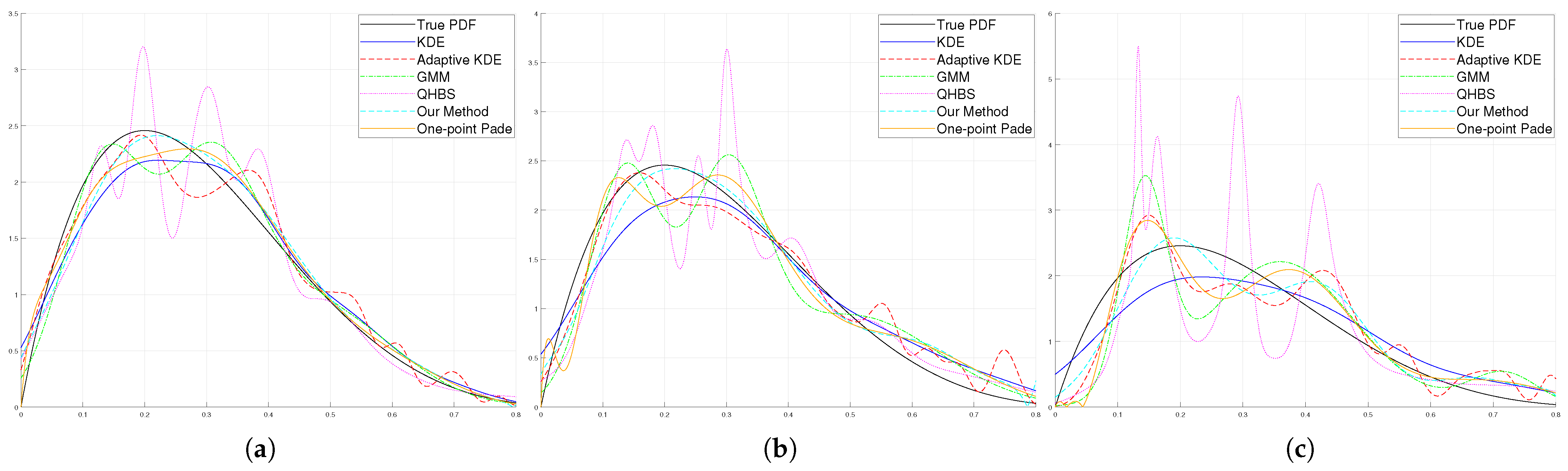
5.1. Example 1: Gaussian Mixture
For the first experiment, we chose a Gaussian mixture distribution model. This is because many real-world problems are based on Gaussian distributions or their combinations so as to simulate real-world problems. The multi-modal distribution was constructed by summing three Gaussian distributions:
The value of 0.75 ensured that the properties of a probability distribution were preserved, with its integral being equal to unity. In this equation,
represents a Gaussian distribution with mean
and standard deviation
, as defined in Equation (
37). The coefficients before the Gaussian distributions were chosen arbitrarily.
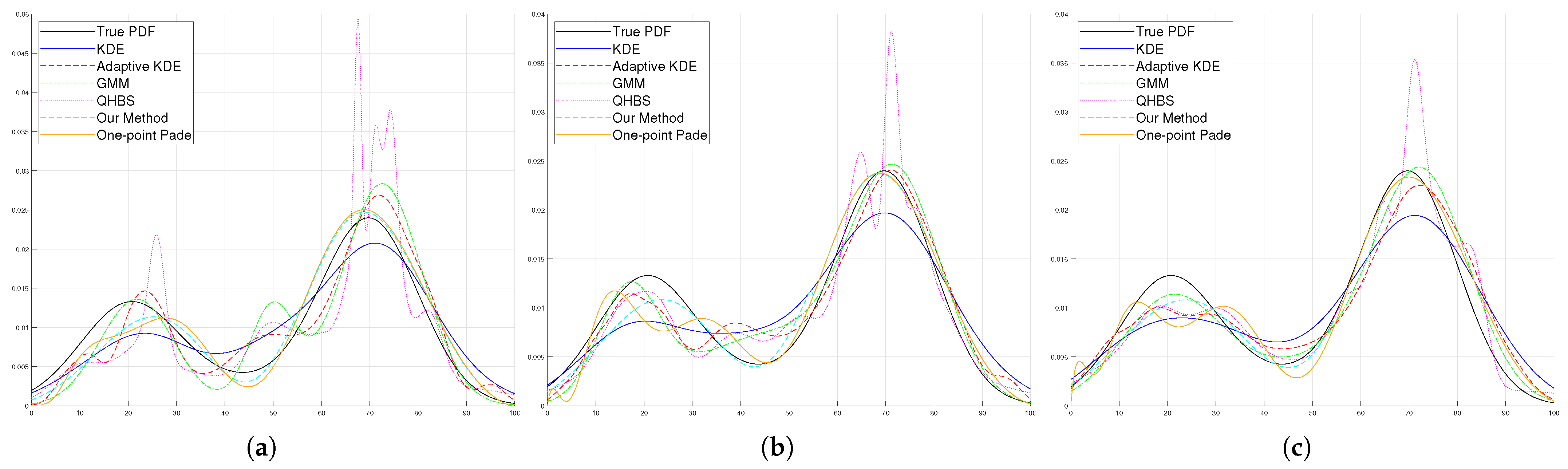
The results of the experiments are displayed in
Figure 6.
Table 1,
Table 2 and
Table 3 detail the outcomes for varying sample sizes. We observed that, for small and medium and large sample sizes, our method outperformed the strategies proposed in prior studies. As the sample size increased, the GMM technique surpassed our method in performance. The GMM’s reliance on the underlying distribution has been noted for its effectiveness in estimating Gaussian density functions. However, when handling datasets where the histogram shape diverges significantly from a Gaussian distribution, its accuracy tends to decline. This makes parameter estimation challenging for methods like the GMM. Our method excels in such scenarios, as evidenced by Examples 2, 3, and 4 below. Notably, it produced results without visible distortions at the beginning of the graph, highlighting its robustness under these conditions.
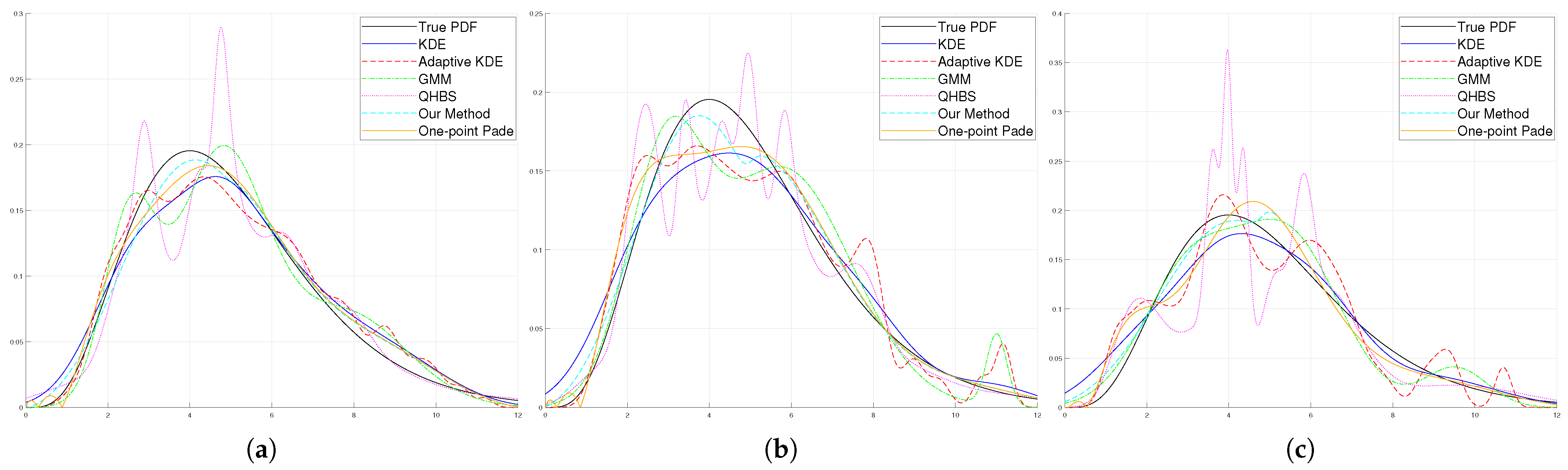
5.2. Example 2: The Beta Distribution
The next distribution model that we consider is the Beta distribution. The Beta distribution is a continuous probability distribution defined on the interval [0, 1], making it suitable for modelling probabilities and proportions. It is governed by two shape parameters,
and
, which influence the distribution’s shape, allowing it to be symmetric, skewed, or U-shaped. The Beta distribution is extensively utilized in Bayesian statistics as a conjugate prior for binomial and Bernoulli processes, enabling efficient updates of beliefs based on observed data. In our experiment, the parameters were chosen as
and
to evaluate the performance of our method in comparison to other methods. The formula for the PDF of the Beta distribution is shown in Equation (
38). The results of the simulations are given in
Figure 7.
The results (see
Table 4,
Table 5 and
Table 6) demonstrate that our method outperformed competing approaches and secured first place in the competition. For a sample size of 50, the results indicate that KDE achieved superior performance in terms of the Correlation Coefficient, showing an advantage in this specific criterion. However, across other evaluation metrics our method consistently delivered better performance.
5.3. Example 3: The Gamma Distribution
In our study, we also examined the Gamma distribution, which is recognized for its versatility in effectively representing both symmetrical and skewed datasets. This particular distribution provides valuable perspectives when estimating PDFs. It finds applications in fields such as finance (for predicting waiting durations), engineering (for analyzing failures), and various scientific phenomena that involve the duration until a specific event occurs. Noteworthy is the fact that the Exponential distribution, Erlang distribution, and chi-squared distribution are special cases of the Gamma distribution. The formula for the Gamma distribution is given in Equation (
39).
In our experiment, we assumed that
was equal to 5 and
was equal to 1. The results, as shown in
Figure 8 and
Table 7,
Table 8 and
Table 9, demonstrate the effectiveness of the proposed method, where it outperforms all other methods on all performance metrics and for all sample sizes.
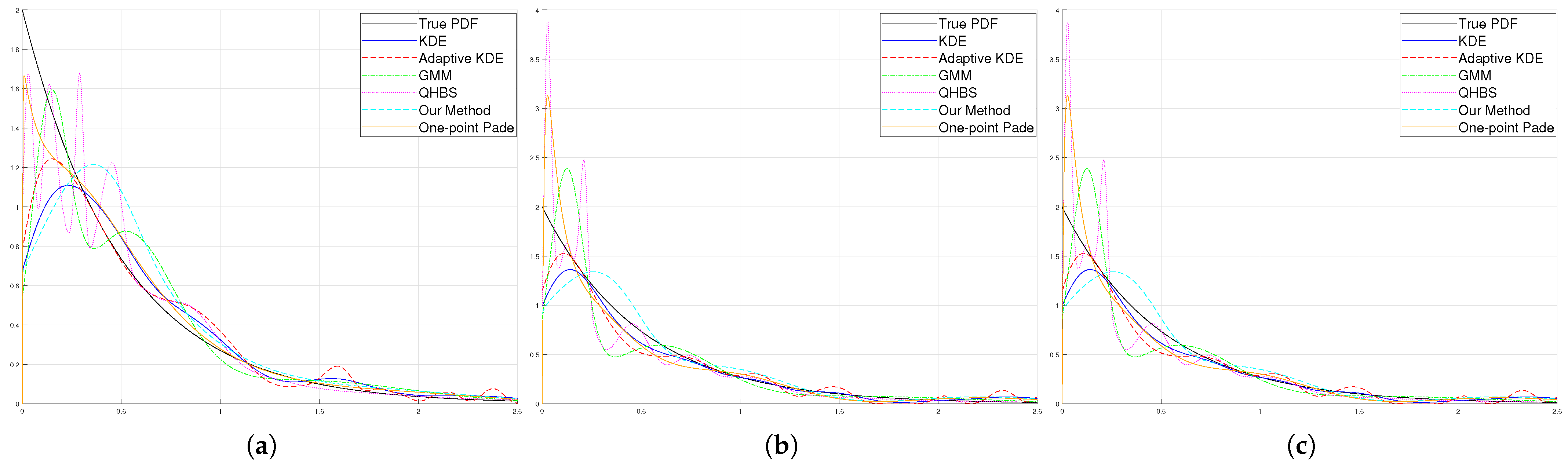
5.4. Example 4: The Exponential Distribution
The above example illustrates the nature of moment-based methods, which are flexible with a limited number of samples. The next distribution model that we consider is the Exponential distribution. The Exponential distribution is commonly used to model the time between events in a Poisson process and is defined by a rate parameter,
. The formula for the Probability Density Function (PDF) of the Exponential distribution is shown in Equation (
40). In our experiments,
was set to 1. The results of the simulations are given in
Figure 9.
Upon reviewing the data shown in
Figure 7 and
Table 10,
Table 11 and
Table 12, it is noticeable that the effectiveness of all techniques has decreased. The main cause for this decline is attributed to the fact that the Exponential distribution presents difficulties in capturing its characteristics near zero, which poses a challenge for the techniques to accurately depict its traits in this region. In some instances, it seems that the One-Point Padé approximation demonstrates better performance. The reason for this could be that the One-Point Padé approximation introduces a distortion near zero, which in this scenario appears advantageous at first glance. The distortion aids in approximating the behaviour near zero to match the characteristics of the Exponential function in that region. Nevertheless, it is crucial to realize that this can give a false impression of enhanced performance, as the distortion does not accurately represent the true nature of the Exponential distribution.
6. Discussion and Conclusions
In this paper, we have considered the problem of estimating the PDF of observed data. Our novel scheme uses two powerful mathematical tools: the concept of moments and the relatively little-known Padé approximation. While moments incorporate crucial information which is central to both the time and frequency domains, the Padé approximation provides an effective means of obtaining convergent series from the data. Both of these phenomena are used in our new method to estimate the PDF in an inter-twined manner.
The method we propose is nonparametric. It invokes the concept of matching the moments of the original function and its learned PDF, and this, in turn is achieved by using the Padé approximation. Apart from the theoretical analysis, we have also experimentally evaluated the validity and efficiency of our scheme.
Although the Padé approximation is asymmetric, we have taken advantage of this asymmetry to our advantage. We have done this by working with two “mirrored” versions of the data so as to obtains different versions of the PDF. We have then effectively “superimposed” (or coalesced) them together to yield the final composite PDF. We are not aware of any other research that utilizes such a composite strategy, in any signal processing domain.
To evaluate the performance of the proposed method, we have employed synthetic samples obtained from various well-known distributions, including mixture densities. The accuracy of the proposed method has also been compared with that obtained by other approaches representative of the families of time- and frequency-domain methods available in the literature.
Our method has shown promising results across the distributions tested. However, we recognize the potential for further exploration. While our chosen examples demonstrate the method’s efficacy, future work could involve testing on a broader range of distributions, including heavy-tailed and multimodal distributions. This extended testing could provide additional insights into the method’s performance under diverse scenarios and potentially uncover new areas for refinement or application.
Moreover, in future research, we intend to explore methods that could enhance the robustness of the proposed approach, particularly in handling outliers. The current method, like other nonparametric density estimation techniques, may be sensitive to extreme values, as sample moments, which can be influenced by outliers. Although this issue can be mitigated through outlier detection and censoring prior to density estimation, we anticipate a potential for improvement. One promising direction would be to investigate the integration of more robust estimators for sample moments into the density estimation method. This could potentially increase the method’s resilience to outliers, without compromising its performance on “clean” data, thereby expanding its applicability to datasets possessing more challenging characteristics.
The results underscore the robustness and effectiveness of our method, particularly in scenarios when the sample sizes are considerably reduced. Thus, this research confirms how the state-of-the-art of estimating nonparametric PDFs can be enhanced by the Padé approximation, offering notable advantages over existing methods in terms of accuracy. As far as we know, the theoretical results that we have proven, and the experimental results that confirm them, are novel and rather pioneering.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}