



UAV (Unmanned Aerial Vehicle): Diverse Applications of UAV Datasets in Segmentation, Classification, Detection, and Tracking

 ,
,  ,
, 
Abstract
1. Introduction
- Our study is driven by the increasing importance of UAV datasets in several research domains such as object detection, traffic monitoring, action identification, surveillance in low-light conditions, single object tracking, and forest segmentation utilizing point cloud or LiDAR point process modeling. Through an in-depth analysis of current datasets, their uses, and prospects, this paper intends to provide valuable insights that will assist researchers in harnessing these resources for creative solutions. Furthermore, they will acquire knowledge of existing constraints and prospective opportunities, enhancing their research endeavors.
- We conduct an extensive analysis of a dataset consisting of 15 UAVs, showcasing its diverse applications in research.
- We emphasize the applications and advancements of several novel methods utilizing these datasets based on UAVs.
- Our study also delves into the potential for future research and the feasibility of utilizing these UAV datasets, engaging in in-depth discussions on these topics.
2. Methodology
Search Terms
- (“unmanned aerial vehicle” OR UAV OR drone OR Satellite) AND (“dataset” OR “image dataset” OR “dataset papers”)
- (UAV OR “unmanned aerial vehicle”) AND (“disaster dataset” OR “traffic surveillance”)
3. Literature Review
3.1. RescueNet
3.2. UAV-Human
3.3. AIDER
3.4. AU-AIR
3.5. ERA
3.6. UAVid
3.7. VRAI
3.8. FOR-Instance
3.9. VERI-Wild
3.10. UAV-Assistant
3.11. KITE
3.12. UAV-Gesture
3.13. UAVDark135
3.14. DarkTrack2021
3.15. BioDrone
4. Data Diversity of UAV
4.1. Overview of UAV Dataset Uses
4.1.1. Disaster Management
4.1.2. Surveillance
4.1.3. Agriculture
4.1.4. Environmental Monitoring
4.1.5. Human Behavior Analysis
4.2. Variability of UAV Databases
4.2.1. Data Types
4.2.2. Capture Conditions
4.2.3. Application Contexts
4.3. Methods Applied to the UAV Dataset
4.3.1. Machine Learning and Deep Learning
- The RescueNet dataset employs models like PSPNet, DeepLabv3+, and Attention UNet for semantic segmentation to assess disaster damage.
- The UAVid Dataset presents deep learning baseline methods like Multi-Scale-Dilation net. The ERA dataset establishes a benchmark for event recognition in aerial videos by utilizing pre-existing deep learning models like the VGG models (VGG-16, VGG19) [29], Inception-v3 [65], the ResNet models (ResNet-50, ResNet-101, and ResNet-152) [30], MobileNet, the DenseNet models (DenseNet-121, DenseNet-169, and DenseNet-201) [35], and NASNet-L [66].
- In the VRAI dataset, ensemble techniques were utilized such as Triplet Loss, Contrastive Loss, ID Classification Loss, and Triplet + ID Loss, and multi-task and multi-task + discriminative parts were introduced. These ensemble methods performed better than the state-of-the-art methods in their claim.
4.3.2. Transfer Learning
- Pre-trained YOLOv3-Tiny and MobileNetv2-SSDLite models, for example, are used for real-time object detection in the AU-AIR [9] dataset.
4.3.3. Event Recognition
- The ERA dataset has been subjected to various methods for event recognition in aerial videos, including DenseNet-201 and Inception-v3. These methods have demonstrated notable accuracy in identifying dynamic events from UAV footage.
- The BioDrone dataset assesses single object tracking (SOT) models and investigates new optimization approaches for the cutting-edge KeepTrack method for robust vision, which is presented by flapping-wing unmanned aerial vehicles [20].
4.3.4. Multimodal Analysis
4.3.5. Creative Algorithms
- The UAV-Gesture [17] dataset employs advanced gesture recognition algorithms to enable UAV navigation and control based on human gestures.
- The UAVDark135 [18] makes use of ADTrack, a tracker that adapts to varying lighting conditions and makes use of discriminative correlation filters. It also has anti-dark capabilities.
- To address the issue of fisheye video distortions, the authors of the UAV-Human [7] dataset suggest a fisheye-based action recognition method that uses flat RGB videos as guidance.
- To classify disaster events from a UAV, the authors of the AIDER [8] dataset created a lightweight (CNN) architecture that they named ERNet.
- VERI-Wild [14] introduces FDA-Net, a novel method for vehicle identification. It includes an embedding discriminator and a feature distance adversary network to enhance the model’s capacity to differentiate between various automobiles.
4.3.6. Managing Diverse Conditions
5. The Potential of Computer Vision Research in UAV Datasets
5.1. Leveraging UAV Datasets for Computer Vision Applications
5.1.1. Human Behavior Understanding and Gesture Recognition
5.1.2. Emergency Response and Disaster Management
5.1.3. Traffic Surveillance and Vehicle Re-Identification
5.1.4. Event Recognition and Video Understanding
5.1.5. Nighttime Tracking and Low-Light Conditions
5.1.6. Object Tracking and Robust Vision
5.1.7. Urban Scene Segmentation and Forestry Analysis
5.1.8. Multimodal Data Synthesis and UAV Control
5.2. Development of Novel Methods Using UAV Datasets
6. Limitations of UAVs
6.1. Data Quality and Consistency
6.2. Limited Scope and Diversity
6.3. Annotation Challenges
6.4. Computational and Storage Demands
6.5. Integration with Other Data Sources
6.6. Real-Time Data Processing
6.7. Ethical and Legal Considerations
7. Prospects for Future UAV Research
7.1. Enhancing Dataset Diversity and Representativeness
7.2. Incorporating Multimodal Data Integration
7.3. Advancing Real-Time Data Processing and Transmission
7.4. Improving Annotation Quality and Efficiency
7.5. Addressing Ethical and Privacy Concerns
7.6. Expanding Application-Specific Datasets
7.7. Enhancing Interoperability and Standardization
7.8. Utilizing Advanced Machine Learning Techniques
7.9. Leveraging Advanced Machine Learning Techniques
7.10. Fostering Collaborative Research and Open Data Initiatives
8. Results and Discussion of Reviewed Papers
8.1. AU-AIR
8.2. FOR-Instance
8.3. UAV-Assistant
8.4. AIDER
8.5. DarkTrack2021
8.6. UAV-Human
8.7. UAVDark135
8.8. VRAI
8.9. UAV-Gesture
8.10. UAVid
8.11. VERI-Wild
9. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A. Visual Representation of Reviewed Datasets
Appendix A.1. AIDER

Appendix A.2. BioDrone

Appendix A.3. ERA

Appendix A.4. FOR-Instance

Appendix A.5. UAVDark135

Appendix A.6. UAV-Human

Appendix A.7. UAVid

Appendix A.8. DarkTrack2021

Appendix A.9. VRAI

Appendix A.10. VERI-Wild

Appendix A.11. RescueNet

Appendix A.12. UAV-Assistant

Appendix A.13. AU-AIR
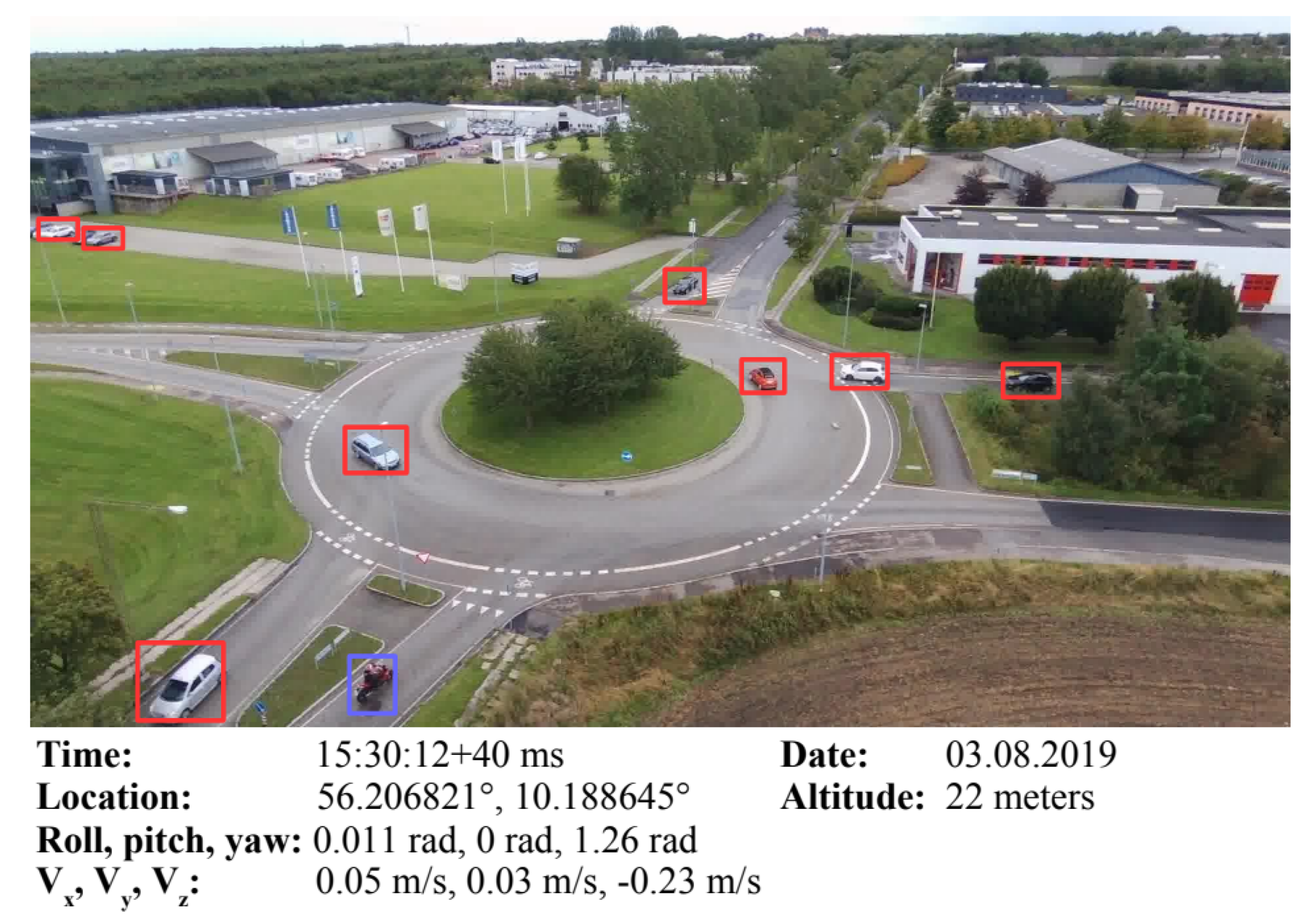
Appendix A.14. UAV-Gesture

Appendix A.15. Kite

References
- Mohsan, S.A.H.; Khan, M.A.; Noor, F.; Ullah, I.; Alsharif, M.H. Towards the unmanned aerial vehicles (UAVs): A comprehensive review. Drones 2022, 6, 147. [Google Scholar] [CrossRef]
- Hu, S.; Zhao, X.; Huang, L.; Huang, K. Global instance tracking: Locating target more like humans. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 576–592. [Google Scholar] [CrossRef] [PubMed]
- Duangsuwan, S.; Prapruetdee, P.; Subongkod, M.; Klubsuwan, K. 3D AQI Mapping Data Assessment of Low-Altitude Drone Real-Time Air Pollution Monitoring. Drones 2022, 6, 191. [Google Scholar] [CrossRef]
- Meimetis, D.; Papaioannou, S.; Katsoni, P.; Lappas, V. An Architecture for Early Wildfire Detection and Spread Estimation Using Unmanned Aerial Vehicles, Base Stations, and Space Assets. Drones Auton. Veh. 2024, 1, 10006. [Google Scholar] [CrossRef]
- Liu, Y.; Nie, J.; Li, X.; Ahmed, S.H.; Lim, W.Y.B.; Miao, C. Federated Learning in the Sky: Aerial-Ground Air Quality Sensing Framework With UAV Swarms. IEEE Internet Things J. 2021, 8, 9827–9837. [Google Scholar] [CrossRef]
- Rahnemoonfar, M.; Chowdhury, T.; Murphy, R. RescueNet: A high resolution UAV semantic segmentation dataset for natural disaster damage assessment. Sci. Data 2023, 10, 913. [Google Scholar] [CrossRef]
- Li, T.; Liu, J.; Zhang, W.; Ni, Y.; Wang, W.; Li, Z. Uav-human: A large benchmark for human behavior understanding with unmanned aerial vehicles. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 16266–16275. [Google Scholar]
- Kyrkou, C.; Theocharides, T. Deep-Learning-Based Aerial Image Classification for Emergency Response Applications Using Unmanned Aerial Vehicles. In Proceedings of the CVPR Workshops, Long Beach, CA, USA, 16–17 June 2019; pp. 517–525. [Google Scholar]
- Bozcan, I.; Kayacan, E. Au-air: A multi-modal unmanned aerial vehicle dataset for low altitude traffic surveillance. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 8504–8510. [Google Scholar]
- Mou, L.; Hua, Y.; Jin, P.; Zhu, X.X. Era: A data set and deep learning benchmark for event recognition in aerial videos [software and data sets]. IEEE Geosci. Remote Sens. Mag. 2020, 8, 125–133. [Google Scholar] [CrossRef]
- Lyu, Y.; Vosselman, G.; Xia, G.S.; Yilmaz, A.; Yang, M.Y. UAVid: A semantic segmentation dataset for UAV imagery. ISPRS J. Photogramm. Remote Sens. 2020, 165, 108–119. [Google Scholar] [CrossRef]
- Wang, P.; Jiao, B.; Yang, L.; Yang, Y.; Zhang, S.; Wei, W.; Zhang, Y. Vehicle re-identification in aerial imagery: Dataset and approach. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 460–469. [Google Scholar]
- Puliti, S.; Pearse, G.; Surovỳ, P.; Wallace, L.; Hollaus, M.; Wielgosz, M.; Astrup, R. For-instance: A uav laser scanning benchmark dataset for semantic and instance segmentation of individual trees. arXiv 2023, arXiv:2309.01279. [Google Scholar]
- Lou, Y.; Bai, Y.; Liu, J.; Wang, S.; Duan, L. Veri-wild: A large dataset and a new method for vehicle re-identification in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3235–3243. [Google Scholar]
- Albanis, G.; Zioulis, N.; Dimou, A.; Zarpalas, D.; Daras, P. Dronepose: Photorealistic uav-assistant dataset synthesis for 3d pose estimation via a smooth silhouette loss. In Proceedings of the Computer Vision–ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 663–681. [Google Scholar]
- Oneata, D.; Cucu, H. Kite: Automatic speech recognition for unmanned aerial vehicles. arXiv 2019, arXiv:1907.01195. [Google Scholar]
- Perera, A.G.; Wei Law, Y.; Chahl, J. UAV-GESTURE: A dataset for UAV control and gesture recognition. In Proceedings of the European Conference on Computer Vision (ECCV) Workshops, Munich, Germany, 8–14 September 2018. [Google Scholar]
- Li, B.; Fu, C.; Ding, F.; Ye, J.; Lin, F. All-day object tracking for unmanned aerial vehicle. IEEE Trans. Mob. Comput. 2022, 22, 4515–4529. [Google Scholar] [CrossRef]
- Ye, J.; Fu, C.; Cao, Z.; An, S.; Zheng, G.; Li, B. Tracker meets night: A transformer enhancer for UAV tracking. IEEE Robot. Autom. Lett. 2022, 7, 3866–3873. [Google Scholar] [CrossRef]
- Zhao, X.; Hu, S.; Wang, Y.; Zhang, J.; Hu, Y.; Liu, R.; Ling, H.; Li, Y.; Li, R.; Liu, K.; et al. Biodrone: A bionic drone-based single object tracking benchmark for robust vision. Int. J. Comput. Vis. 2024, 132, 1659–1684. [Google Scholar] [CrossRef]
- Oktay, O.; Schlemper, J.; Folgoc, L.L.; Lee, M.; Heinrich, M.; Misawa, K.; Mori, K.; McDonagh, S.; Hammerla, N.Y.; Kainz, B.; et al. Attention u-net: Learning where to look for the pancreas. arXiv 2018, arXiv:1804.03999. [Google Scholar]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Rahnemoonfar, M.; Chowdhury, T.; Sarkar, A.; Varshney, D.; Yari, M.; Murphy, R.R. Floodnet: A high resolution aerial imagery dataset for post flood scene understanding. IEEE Access 2021, 9, 89644–89654. [Google Scholar] [CrossRef]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5386–5395. [Google Scholar]
- Fang, H.S.; Xie, S.; Tai, Y.W.; Lu, C. Rmpe: Regional multi-person pose estimation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2334–2343. [Google Scholar]
- Srisamosorn, V.; Kuwahara, N.; Yamashita, A.; Ogata, T.; Shirafuji, S.; Ota, J. Human position and head direction tracking in fisheye camera using randomized ferns and fisheye histograms of oriented gradients. Vis. Comput. 2020, 36, 1443–1456. [Google Scholar] [CrossRef]
- Delibasis, K.K.; Plagianakos, V.P.; Maglogiannis, I. Pose recognition in indoor environments using a fisheye camera and a parametric human model. In Proceedings of the 2014 International Conference on Computer Vision Theory and Applications (VISAPP), Lisbon, Portugal, 5–8 January 2014; Volume 2, pp. 470–477. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Gilbert, A.; Trumble, M.; Malleson, C.; Hilton, A.; Collomosse, J. Fusing visual and inertial sensors with semantics for 3d human pose estimation. Int. J. Comput. Vis. 2019, 127, 381–397. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Kundu, A.; Vineet, V.; Koltun, V. Feature space optimization for semantic video segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3168–3175. [Google Scholar]
- Chang, J.Y.; Lee, K.M. 2D–3D pose consistency-based conditional random fields for 3d human pose estimation. Comput. Vis. Image Underst. 2018, 169, 52–61. [Google Scholar] [CrossRef]
- Nguyen, A.; Le, B. 3D point cloud segmentation: A survey. In Proceedings of the 2013 6th IEEE Conference on Robotics, Automation and Mechatronics (RAM), Manila, Philippines, 12–15 November 2013; pp. 225–230. [Google Scholar]
- Wei, X.S.; Zhang, C.L.; Liu, L.; Shen, C.; Wu, J. Coarse-to-fine: A RNN-based hierarchical attention model for vehicle re-identification. In Proceedings of the Computer Vision–ACCV 2018: 14th Asian Conference on Computer Vision, Perth, Australia, 2–6 December 2018; Revised Selected Papers, Part II 14. Springer: Berlin/Heidelberg, Germany, 2019; pp. 575–591. [Google Scholar]
- Liu, X.; Zhang, S.; Huang, Q.; Gao, W. Ram: A region-aware deep model for vehicle re-identification. In Proceedings of the 2018 IEEE International Conference on Multimedia and Expo (ICME), San Diego, CA, USA, 23–27 July 2018; pp. 1–6. [Google Scholar]
- Peddinti, V.; Povey, D.; Khudanpur, S. A time delay neural network architecture for efficient modeling of long temporal contexts. In Proceedings of the Interspeech, Dresden, Germany, 6–10 September 2015; pp. 3214–3218. [Google Scholar]
- Povey, D.; Ghoshal, A.; Boulianne, G.; Burget, L.; Glembek, O.; Goel, N.; Hannemann, M.; Motlicek, P.; Qian, Y.; Schwarz, P.; et al. The Kaldi speech recognition toolkit. In Proceedings of the IEEE 2011 Workshop on Automatic Speech Recognition and Understanding, Waikoloa, HI, USA, 11–15 December 2011. [Google Scholar]
- Vondrick, C.; Patterson, D.; Ramanan, D. Efficiently scaling up crowdsourced video annotation: A set of best practices for high quality, economical video labeling. Int. J. Comput. Vis. 2013, 101, 184–204. [Google Scholar] [CrossRef]
- Chéron, G.; Laptev, I.; Schmid, C. P-cnn: Pose-based cnn features for action recognition. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 3218–3226. [Google Scholar]
- Mueller, M.; Smith, N.; Ghanem, B. A benchmark and simulator for UAV tracking. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 445–461. [Google Scholar]
- Li, S.; Yeung, D.Y. Visual object tracking for unmanned aerial vehicles: A benchmark and new motion models. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Mayer, C.; Danelljan, M.; Paudel, D.P.; Van Gool, L. Learning target candidate association to keep track of what not to track. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 13444–13454. [Google Scholar]
- Henriques, J.F.; Caseiro, R.; Martins, P.; Batista, J. High-speed tracking with kernelized correlation filters. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 37, 583–596. [Google Scholar] [CrossRef]
- Dimensions AI: The Most Advanced Scientific Research Database. Available online: https://up42.com/blog/full-spectrum-multispectral-imagery-and-hyperspectral-imagery (accessed on 12 November 2024).
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for Semantic Segmentation. arXiv 2021, arXiv:2105.05633. [Google Scholar]
- Tran, D.; Bourdev, L.; Fergus, R.; Torresani, L.; Paluri, M. Learning Spatiotemporal Features with 3D Convolutional Networks. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 4489–4497. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. arXiv 2015, arXiv:1411.4038. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional Networks for Biomedical Image Segmentation. arXiv 2015, arXiv:1505.04597. [Google Scholar]
- Yang, L.; Luo, P.; Loy, C.C.; Tang, X. A Large-Scale Car Dataset for Fine-Grained Categorization and Verification. arXiv 2015, arXiv:1506.08959. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 815–823. [Google Scholar] [CrossRef]
- Liu, X.; Liu, W.; Mei, T.; Ma, H. A Deep Learning-Based Approach to Progressive Vehicle Re-identification for Urban Surveillance. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Volume 9906, pp. 869–884. [Google Scholar] [CrossRef]
- Liu, H.; Tian, Y.; Wang, Y.; Pang, L.; Huang, T. Deep Relative Distance Learning: Tell the Difference between Similar Vehicles. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2167–2175. [Google Scholar] [CrossRef]
- Yuan, Y.; Yang, K.; Zhang, C. Hard-Aware Deeply Cascaded Embedding. arXiv 2017, arXiv:1611.05720. [Google Scholar]
- Zheng, Z.; Zheng, L.; Yang, Y. Unlabeled Samples Generated by GAN Improve the Person Re-identification Baseline in vitro. arXiv 2017, arXiv:1701.07717. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2020, arXiv:1703.10593. [Google Scholar]
- Tekin, B.; Sinha, S.N.; Fua, P. Real-Time Seamless Single Shot 6D Object Pose Prediction. arXiv 2018, arXiv:1711.08848. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression. arXiv 2019, arXiv:1902.09630. [Google Scholar]
- O’shea, K.; Nash, R. An introduction to convolutional neural networks. arXiv 2015, arXiv:1511.08458. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar]
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning transferable architectures for scalable image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar]
- Sy Nguyen, V.; Jung, J.; Jung, S.; Joe, S.; Kim, B. Deployable Hook Retrieval System for UAV Rescue and Delivery. IEEE Access 2021, 9, 74632–74645. [Google Scholar] [CrossRef]
- Zhao, J.; Zhang, X.; Gao, C.; Qiu, X.; Tian, Y.; Zhu, Y.; Cao, W. Rapid Mosaicking of Unmanned Aerial Vehicle (UAV) Images for Crop Growth Monitoring Using the SIFT Algorithm. Remote Sens. 2019, 11, 1226. [Google Scholar] [CrossRef]
- Yu, J.; Gao, H.; Zhou, D.; Liu, J.; Gao, Q.; Ju, Z. Deep Temporal Model-Based Identity-Aware Hand Detection for Space Human–Robot Interaction. IEEE Trans. Cybern. 2022, 52, 13738–13751. [Google Scholar] [CrossRef]
- Saeed, Z.; Yousaf, M.H.; Ahmed, R.; Velastin, S.A.; Viriri, S. On-board small-scale object detection for unmanned aerial vehicles (UAVs). Drones 2023, 7, 310. [Google Scholar] [CrossRef]
- Walambe, R.; Marathe, A.; Kotecha, K. Multiscale object detection from drone imagery using ensemble transfer learning. Drones 2021, 5, 66. [Google Scholar] [CrossRef]
- Gupta, H.; Verma, O.P. Monitoring and surveillance of urban road traffic using low altitude drone images: A deep learning approach. Multimed. Tools Appl. 2022, 81, 19683–19703. [Google Scholar] [CrossRef]
- Bountos, N.I.; Ouaknine, A.; Rolnick, D. FoMo-Bench: A multi-modal, multi-scale and multi-task Forest Monitoring Benchmark for remote sensing foundation models. arXiv 2024, arXiv:2312.10114. [Google Scholar]
- Zhang, C.; Song, C.; Zaforemska, A.; Zhang, J.; Gaulton, R.; Dai, W.; Xiao, W. Individual tree segmentation from UAS Lidar data based on hierarchical filtering and clustering. Int. J. Digit. Earth 2024, 17, 2356124. [Google Scholar] [CrossRef]
- Albanis, G.N.; Zioulis, N.; Chatzitofis, A.; Dimou, A.; Zarpalas, D.; Daras, P. On end-to-end 6DOF object pose estimation and robustness to object scale. In Proceedings of the ML Reproducibility Challenge, online, 23–28 August 2020. [Google Scholar]
- Chen, B.; Parra, A.; Cao, J.; Li, N.; Chin, T.J. End-to-end learnable geometric vision by backpropagating pnp optimization. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8100–8109. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Kyrkou, C.; Theocharides, T. EmergencyNet: Efficient aerial image classification for drone-based emergency monitoring using atrous convolutional feature fusion. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 1687–1699. [Google Scholar] [CrossRef]
- Alrayes, F.S.; Alotaibi, S.S.; Alissa, K.A.; Maashi, M.; Alhogail, A.; Alotaibi, N.; Mohsen, H.; Motwakel, A. Artificial intelligence-based secure communication and classification for drone-enabled emergency monitoring systems. Drones 2022, 6, 222. [Google Scholar] [CrossRef]
- Fu, C.; Yao, L.; Zuo, H.; Zheng, G.; Pan, J. SAM-DA: UAV Tracks Anything at Night with SAM-Powered Domain Adaptation. arXiv 2024, arXiv:2307.01024. [Google Scholar]
- Fu, C.; Lu, K.; Zheng, G.; Ye, J.; Cao, Z.; Li, B.; Lu, G. Siamese Object Tracking for Unmanned Aerial Vehicle: A Review and Comprehensive Analysis. arXiv 2022, arXiv:2205.04281. [Google Scholar] [CrossRef]
- Azmat, U.; Alotaibi, S.S.; Mudawi, N.A.; Alabduallah, B.I.; Alonazi, M.; Jalal, A.; Park, J. An Elliptical Modeling Supported System for Human Action Deep Recognition Over Aerial Surveillance. IEEE Access 2023, 11, 75671–75685. [Google Scholar] [CrossRef]
- Lin, W.; Karlinsky, L.; Shvetsova, N.; Possegger, H.; Kozinski, M.; Panda, R.; Feris, R.; Kuehne, H.; Bischof, H. MAtch, eXpand and Improve: Unsupervised Finetuning for Zero-Shot Action Recognition with Language Knowledge. arXiv 2023, arXiv:2303.08914. [Google Scholar]
- Radford, A.; Kim, J.W.; Hallacy, C.; Ramesh, A.; Goh, G.; Agarwal, S.; Sastry, G.; Askell, A.; Mishkin, P.; Clark, J.; et al. Learning Transferable Visual Models From Natural Language Supervision. arXiv 2021, arXiv:2103.00020. [Google Scholar]
- Rasheed, H.; Khattak, M.U.; Maaz, M.; Khan, S.; Khan, F.S. Fine-tuned CLIP Models are Efficient Video Learners. arXiv 2023, arXiv:2212.03640. [Google Scholar]
- Huang, Z.; Qin, Y.; Lin, X.; Liu, T.; Feng, Z.; Liu, Y. Motion-Driven Spatial and Temporal Adaptive High-Resolution Graph Convolutional Networks for Skeleton-Based Action Recognition. IEEE Trans. Circuits Syst. Video Technol. 2023, 33, 1868–1883. [Google Scholar] [CrossRef]
- Hu, Z.; Pan, Z.; Wang, Q.; Yu, L.; Fei, S. Forward-reverse adaptive graph convolutional networks for skeleton-based action recognition. Neurocomput. 2022, 492, 624–636. [Google Scholar] [CrossRef]
- Zhu, J.; Tang, H.; Cheng, Z.Q.; He, J.Y.; Luo, B.; Qiu, S.; Li, S.; Lu, H. DCPT: Darkness Clue-Prompted Tracking in Nighttime UAVs. arXiv 2024, arXiv:2309.10491. [Google Scholar]
- Bhat, G.; Danelljan, M.; Gool, L.V.; Timofte, R. Learning discriminative model prediction for tracking. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6182–6191. [Google Scholar]
- Ye, J.; Fu, C.; Zheng, G.; Cao, Z.; Li, B. DarkLighter: Light Up the Darkness for UAV Tracking. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3079–3085. [Google Scholar] [CrossRef]
- Fu, C.; Cao, Z.; Li, Y.; Ye, J.; Feng, C. Siamese Anchor Proposal Network for High-Speed Aerial Tracking. arXiv 2021, arXiv:2012.10706. [Google Scholar]
- Ferdous, S.N.; Li, X.; Lyu, S. Uncertainty aware multitask pyramid vision transformer for uav-based object re-identification. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 2381–2385. [Google Scholar]
- Chen, S.; Ye, M.; Du, B. Rotation invariant transformer for recognizing object in uavs. In Proceedings of the 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; pp. 2565–2574. [Google Scholar]
- Azmat, U.; Alotaibi, S.S.; Abdelhaq, M.; Alsufyani, N.; Shorfuzzaman, M.; Jalal, A.; Park, J. Aerial Insights: Deep Learning-Based Human Action Recognition in Drone Imagery. IEEE Access 2023, 11, 83946–83961. [Google Scholar] [CrossRef]
- Papaioannidis, C.; Makrygiannis, D.; Mademlis, I.; Pitas, I. Learning Fast and Robust Gesture Recognition. In Proceedings of the 2021 29th European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021; pp. 761–765. [Google Scholar] [CrossRef]
- Yang, F.; Sakti, S.; Wu, Y.; Nakamura, S. Make Skeleton-based Action Recognition Model Smaller, Faster and Better. arXiv 2020, arXiv:1907.09658. [Google Scholar]
- Wang, L.; Li, R.; Wang, D.; Duan, C.; Wang, T.; Meng, X. Transformer Meets Convolution: A Bilateral Awareness Network for Semantic Segmentation of Very Fine Resolution Urban Scene Images. arXiv 2022, arXiv:2106.12413. [Google Scholar] [CrossRef]
- Li, R.; Wang, L.; Zhang, C.; Duan, C.; Zheng, S. A2-FPN for semantic segmentation of fine-resolution remotely sensed images. Int. J. Remote Sens. 2022, 43, 1131–1155. [Google Scholar] [CrossRef]
- Wang, L.; Li, R.; Zhang, C.; Fang, S.; Duan, C.; Meng, X.; Atkinson, P.M. UNetFormer: A UNet-like transformer for efficient semantic segmentation of remote sensing urban scene imagery. ISPRS J. Photogramm. Remote Sens. 2022, 190, 196–214. [Google Scholar] [CrossRef]
- Yang, M.Y.; Kumaar, S.; Lyu, Y.; Nex, F. Real-time semantic segmentation with context aggregation network. ISPRS J. Photogramm. Remote Sens. 2021, 178, 124–134. [Google Scholar] [CrossRef]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Bisenet: Bilateral segmentation network for real-time semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 325–341. [Google Scholar]
- Meng, D.; Li, L.; Liu, X.; Li, Y.; Yang, S.; Zha, Z.J.; Gao, X.; Wang, S.; Huang, Q. Parsing-based view-aware embedding network for vehicle re-identification. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7103–7112. [Google Scholar]
- He, L.; Liao, X.; Liu, W.; Liu, X.; Cheng, P.; Mei, T. Fastreid: A pytorch toolbox for general instance re-identification. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 9664–9667. [Google Scholar]
- Alfasly, S.; Hu, Y.; Li, H.; Liang, T.; Jin, X.; Liu, B.; Zhao, Q. Multi-label-based similarity learning for vehicle re-identification. IEEE Access 2019, 7, 162605–162616. [Google Scholar] [CrossRef]
- Shen, F.; Xie, Y.; Zhu, J.; Zhu, X.; Zeng, H. Git: Graph interactive transformer for vehicle re-identification. IEEE Trans. Image Process. 2023, 32, 1039–1051. [Google Scholar] [CrossRef]
- Liu, X.; Liu, W.; Zheng, J.; Yan, C.; Mei, T. Beyond the parts: Learning multi-view cross-part correlation for vehicle re-identification. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020; pp. 907–915. [Google Scholar]
- Shen, F.; Zhu, J.; Zhu, X.; Xie, Y.; Huang, J. Exploring spatial significance via hybrid pyramidal graph network for vehicle re-identification. IEEE Trans. Intell. Transp. Syst. 2021, 23, 8793–8804. [Google Scholar] [CrossRef]
- Kuma, R.; Weill, E.; Aghdasi, F.; Sriram, P. Vehicle re-identification: An efficient baseline using triplet embedding. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–9. [Google Scholar]
- Khorramshahi, P.; Peri, N.; Chen, J.c.; Chellappa, R. The devil is in the details: Self-supervised attention for vehicle re-identification. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 369–386. [Google Scholar]
- Luo, H.; Gu, Y.; Liao, X.; Lai, S.; Jiang, W. Bag of tricks and a strong baseline for deep person re-identification. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Ye, J.; Fu, C.; Zheng, G.; Paudel, D.P.; Chen, G. Unsupervised Domain Adaptation for Nighttime Aerial Tracking. arXiv 2022, arXiv:2203.10541. [Google Scholar]
- Cao, Z.; Fu, C.; Ye, J.; Li, B.; Li, Y. SiamAPN++: Siamese Attentional Aggregation Network for Real-Time UAV Tracking. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 3086–3092. [Google Scholar] [CrossRef]
- Li, R.; Zheng, S.; Zhang, C.; Duan, C.; Wang, L.; Atkinson, P.M. ABCNet: Attentive bilateral contextual network for efficient semantic segmentation of Fine-Resolution remotely sensed imagery. ISPRS J. Photogramm. Remote Sens. 2021, 181, 84–98. [Google Scholar] [CrossRef]
- Srinivas, A.; Lin, T.Y.; Parmar, N.; Shlens, J.; Abbeel, P.; Vaswani, A. Bottleneck Transformers for Visual Recognition. arXiv 2021, arXiv:2101.11605. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Dataset Details | Paper Findings | Limitations | Future Work |
|---|---|---|---|---|
| RescueNet [6] | High-resolution images with pixel-level annotations for 10 classes, collected via UAVs after Hurricane Michael. | Attention-based and transformer-based methods performed best. Transfer learning from RescueNet to FloodNet improved segmentation. | Time-consuming annotation process and potential lack of comprehensive post-disaster elements. | Further evaluation across different disaster scenarios to enhance robustness. |
| UAV-Human [7] | Comprises 67,428 multi-modal video sequences for action recognition, pose estimation, person re-identification, and attribute recognition. | Highest action recognition accuracies with night-vision and IR videos. Pose estimation methods achieved mAP scores of 56.5 and 56.9. | Potential overfitting, lack of subject diversity, and constrained capturing conditions. | Increase sample size and diversity, and capture conditions to enhance model robustness and generalization. |
| AIDER [8] | Includes 2565 manually gathered images of disaster events with augmentations. | Development of ERNet, achieving near state-of-the-art accuracy (90%) and over 50 fps on a CPU platform. | Does not extensively discuss real-time implementation challenges, robustness in diverse conditions, or hyperparameter tuning. | Integrate ERNet with algorithms for detecting people and vehicles, use additional modalities like infrared cameras, and optimize the model for improved generalization and accuracy. |
| AU-AIR [9] | A total 32,823 labeled video frames with object annotations and flight data. | YOLOv3-tiny and MobileNetv2-SSD Lite for real-time object detection on UAVs showed potential for onboard computer applicability. | Focus on traffic surveillance may limit applicability to other scenarios, lacks advanced baselines for tasks like UAV navigation. | Enhance dataset diversity, incorporate more environmental contexts, and develop additional baselines leveraging sensor data for broader applications. |
| ERA [10] | A total 2,864 videos capturing events in a wide range of settings and sizes. | DenseNet-201 achieved the highest accuracy of 62.3% in single-frame classification. | Dataset size, class imbalance, and challenge of distinguishing events from normal videos. | Focus on attribute recognition, temporal cue exploitation, and addressing challenging cases like human action recognition. |
| UAVid [11] | Contains 30 video sequences featuring high-resolution 4K images with 8 labeled classes for semantic segmentation. | Multi-Scale-Dilation Net achieved an average IoU score of around 50%. | Class imbalance, particularly in urban street scenes, potentially affecting model performance and generalization. | Balance method complexity with practical implementation, expand dataset size and object categories, address class imbalance, and explore other applications like object detection and tracking. |
| Dataset | Dataset Details | Paper Findings | Limitations | Future Work |
|---|---|---|---|---|
| VRAI [12] | A total 137,613 images of 13,022 vehicles with detailed annotations captured by two UAVs. | Outperforms existing methods in vehicle ReID techniques using GANs and attention models. | Comparison scope, domain specificity, annotation complexity, scalability, and real-world deployment insights. | Explore transfer learning, enhance scalability, integrate advanced techniques, focus on real-world applications, and improve annotation strategies. |
| FOR-Instance [13] | Five collections from around the world for individual tree segmentation from UAV-based laser scanning data. | Supports both instance and semantic segmentation, adaptable to deep learning frameworks. | Potential overfitting, lack of generalizability to other forest types, challenges with unclassified points. | Incorporate more data types, develop advanced deep learning architectures, study tree species classification, and conduct longitudinal studies on forest changes. |
| VERI-Wild [14] | Over 400,000 images of 40,671 vehicle IDs captured from a real CCTV camera system over one month. | FDA-Net outperforms existing methods, achieving highest Rank-1 and Rank-5 accuracies. | Potential biases due to urban district focus and dataset-specific adversarial scheme. | Explore more challenging real-world factors, generate comprehensive datasets, and leverage GANs to improve cross-view ReID performance. |
| UAV-Assistant [15] | Data synthesis pipeline combining egocentric UAV views and exocentric user views with smooth silhouette loss. | Smooth silhouette loss enhances 3D pose estimation accuracy. | Lack of real-world data poses a challenge to generalizability, and determining optimal kernel size for smoothing filter. | Optimize parameters, explore additional loss functions, and validate approach in real-world scenarios. |
| KITE [16] | Focus on UAV control speech recognition with multimodal systems. | Recurrent neural networks (RNNs) for language modeling and visual cues integration. | Imperfect command–image associations, biases from semi-automatic methods for training data generation. | Address biases, enhance dataset generalizability, and explore other architectural decisions. |
| UAV-Gesture [17] | Contains 119 high-definition video clips of 13 gestures for UAV navigation and command. | Annotates body joints and gesture classes in 37,151 frames using an extended version of VATIC. | Limited gesture set and non-expert actors may affect dataset quality. | Leverage dataset for gesture and action recognition in UAV control, expand and refine dataset for broader research applications. |
| UAVDark 135 [18] | Over 125k manually annotated frames for dark tracking methods. | ADTrack demonstrates superiority in bright and dark conditions. | Lacks broader comparison with other state-of-the-art trackers. | Further research on real-time tracking algorithms, new image enhancement methods, multi-sensor fusion techniques, and hardware optimization strategies. |
| DarkTrack2021 [19] | Has 110 annotated sequences totaling over 100,000 frames for low-light UAV tracking. | SCT demonstrated significant performance gains for nighttime UAV tracking. | Comparisons with daytime tracking scenarios needed to be improved. | Explore advanced transformer architectures, attention mechanisms, noise reduction strategies, and real-world validation. |
| BioDrone [20] | Comprises 600 videos annotated and labeled at the frame level for single object tracking using bionic drone-based systems. | Comprehensive evaluation platform for robust vision research. | Focus on bionic UAVs may limit generalization, potential biases in annotations. | Improve tracking algorithms, address computational complexity and real-time performance. |
| Dataset Name | Experimental Methods in Base Dataset Publication | Analysis of Results |
|---|---|---|
| RescueNet [6] | PSPNet, DeepLabv3+, Attention UNet, Segmenter [51] | Attention UNet achieved the best performance among all evaluated models. PSPNet showed better performance compared to DeepLabv3+ by using pyramid pooling. DeepLabv3+ provided moderate results, improving on the loss of boundary information. Segmenter showed varying results depending on the backbone (ViT-Tiny vs. ViT-Small), with heavier backbones achieving better results. |
| UAV-Human [7] | Guided Transformer I3D Network, Video Transformers, Full Model (Author’s novel method) | Night-vision and IR videos outperformed previous findings in low-light conditions, achieving 28.72% and 26.56% accuracy, respectively. However, depth sequences face noise issues, and fisheye distortion impacts performance. In ablation studies, using KL Divergence Constraint resulted in 21.68% accuracy, while employing guidance loss and Video Transformers yielded 21.49% accuracy without RGB stream guidance. Overall, the full model had the highest accuracy among fisheye-based methods. |
| AIDER [8] | Novel networks (ERNet, SCFCNet, SCNet, baseNet), VGG16, ResNet50, MobileNet | The VGG16 model had the highest accuracy at 91.9% but a low frame rate of 2, while consuming 59.3 MB of memory. MobileNet had a high frame rate of 20 but lower accuracy at 88.5%. Custom networks like ERNet and SCFCNet had good accuracy at 90.1% and 87.7% with high frame rates of 53 and 76, making them suitable for real-time UAV applications. |
| AU-AIR [9] | YOLOv3-tiny, MobileNetv2-SSD Lite | YOLOv3-tiny achieved higher mAP (38.2%) and better FPS (22) compared to MobileNetv2-SSDLite (32.8% mAP and 19 FPS), highlighting its better performance for real-time object detection tasks using UAVs. |
| ERA [10] | VGG-16, DenseNet-121, NASNet-L, C3D [52] | DenseNet-121 achieved the highest overall accuracy (62.3%) among the models, followed by NASNet-L (60.2%) and VGG-16 (51.9%). The C3D models had the lowest accuracy (around 30%). |
| Dataset Name | Experimented Methods on Dataset | Analysis of Results |
|---|---|---|
| UAVid [11] | FCN-8s [53], Dilation Net, U-Net [54], MS-Dilation Net | MS-Dilation Net achieved the highest mean IoU score of 57.3% with pre-training and feature space optimization, demonstrating the best performance among the models evaluated. |
| VRAI [11] | MGN, RAM, RNN-HA, Ensemble methods (e.g., ID Classification Loss, Triplet + ID Loss), Novel methods (Multi-task, Multi-task + Discriminative Parts) | The multi-task model with discriminative parts achieved the highest mAP (78.63%) and CMC-1 (80.30%). The models using Triplet + ID Loss also showed high performance, particularly with Resnet-101 and Resnet-152 backbones. |
| FOR-instance [13] | None, as the paper is solely focused on constructing the dataset and explaining how to utilize it for model. | N/A |
| VERI-Wild [14] | GoogLeNet [55], Triplet [56], Softmax [57], CCL [58], HDC [59], Unlabeled GAN [60,61], EN (Embedding Network with Triplet and Softmax Loss), FDA-Net ⊖ Att, FDA-Net | FDA-Net consistently outperforms the other models across different settings, achieving the highest mAP (35.11%) and match rate (R = 1 of 64.03% for small dataset). The proposed FDA-Net model demonstrates its effectiveness in vehicle re-identification tasks. |
| UAV-Assistant (UAVA) [15] | Singleshotpose [62], Direct, IoU-based experimental methods (e.g., I0.1, I0.2, I0.1-0.4, G0.1, S0.1, S0.2), Generalized IoU-based method (Gauss0.1) [63] | Gauss0.1 showed the best overall performance, particularly in the 6D Pose-5 and 6D Pose-10 metrics. Metrics such as NPE, OE, and CPE were used, with lower values indicating better performance and higher values for Acc5 and Acc10 indicating better performance. |
| KITE [16] | Baseline Systems (Unadapted System, Domain-Specific System), Domain Adaptation (Text-Only Adaptation, Rescoring), Multi-Modal Experiments (Text and Visual Information) | Domain adaptation and multi-modal approaches significantly improved the performance of speech recognition systems for UAV control. The Unadapted System had a WER of 56.2%, while the Domain-Specific System achieved 11.7%. |
| UAV-Gesture [17] | Pose-based CNN (P-CNN) | P-CNN achieved an overall accuracy of 91.9% for gesture recognition. The dataset included 119 video clips, 37,151 annotated frames, and 13 gestures, providing a robust resource for gesture and action recognition research. |
| DarkTrack2021 [19] | Novel ensemble method: SCT | The full implementation of SCT (Spatial-Channel Transformer) with all components enabled showed the highest improvement in tracking performance, with success rate and precision gains of 13.3% and 15.4%, respectively. |
| UAVDark135 [18] | ADTrack, State-of-the-art trackers (e.g., AutoTrack, SiamFC++, ARCF-HC, SiamRPN++) | ADTrack outperformed all other models in both bright and dark conditions, showing superior performance with the highest DP and AUC scores on the UAVDark135 dataset. |
| BioDrone [20] | KeepTrack, UAV-KT, Generic SOT Trackers | UAV-KT, designed for flapping-wing UAVs, showed a 5% improvement over KeepTrack in precision, normalized precision, and success scores. Generic SOT Trackers were compared for robustness and performance across various conditions. |
| Employed Method | Name of the Dataset | Benefit from the Use of Method |
|---|---|---|
| Attention UNet28, ViT-Tiny, ViT-Small | RescueNet [6] | Improved disaster response strategies and enhanced model performance in segmentation tasks through transfer learning |
| Fisheye-based action recognition approach, HigherHRNet, AlphaPose | UAV-Human [7] | Robust models for human behavior understanding |
| ERNet | AIDER [8] | High performance with minimal memory requirements, suitable for real-time aerial image classification |
| YOLOv3-Tiny, MobileNetv2-SSDLite | AU-AIR [9] | Real-time object detection on UAVs, bridging the gap between computer vision and robotics |
| DenseNet-201, I3D-Inception-v1, TRN-Inception-v3 | ERA [10] | High performance in single-frame and video classification tasks |
| Multi-Scale-Dilation net, FSO, 3D CRF | UAVid [11] | Enhanced semantic segmentation performance in urban scenes, addressing large-scale variation and moving object recognition |
| Convolutional and connection layers, weight matrices, weighted pooling | VRAI [12] | Superior vehicle re-identification performance |
| Aggregating tree-wise F1 scores, weighting coefficients for averaging F1 scores | FOR-instance [13] | Improved methods for individual tree segmentation, crucial for understanding forest ecosystems |
| FDA-Net (Feature Distance Adversary Network) | VERI-Wild [14] | Enhanced discriminative capability in vehicle re-identification tasks |
| Smooth silhouette loss | UAV-Assistant (UAVA) [15] | Improved performance in 3D pose estimation tasks |
| Time-delay neural network, domain adaptation techniques | KITE [16] | Enhanced UAV command recognition systems through visual context and domain adaptation |
| Pose-based Convolutional Neural Network (P-CNN) | UAV-Gesture [17] | High accuracy in gesture recognition for UAV control |
| Spatial-Channel Transformer, curve projection model | DarkTrack2021 [19] | Improved nighttime UAV tracking accuracy by enhancing low-light images |
| Illumination adaptive, anti-dark capabilities, efficient image enhancer | UAVDark135 [18] | Superior performance in all-day aerial object tracking, adaptability to different light conditions |
| KeepTrack-optimized UAV-KT | BioDrone [20] | Addresses challenges in tracking tiny targets with drastic appearance changes, providing a robust benchmark for vision research |
| Dataset Name | Reference | Methods | Performance | |||||
|---|---|---|---|---|---|---|---|---|
| AU-AIR [9] | [69] | YOLOv3 | mAP | Speed (FPS) | ||||
| 59.83 | 29 | |||||||
| YOLOv4 | mAP | Speed (FPS) | ||||||
| 67.35 | 24 | |||||||
| RSSD-TA-LSTM-GID | mAP | Speed (FPS) | ||||||
| 71.68 | 23 | |||||||
| [70] | res2net50 | mAP | Speed (FPS) | |||||
| 88.93 | 45.73 | |||||||
| rs2net101 | mAP | Speed (FPS) | ||||||
| 90.52 | 7.21 | |||||||
| hourglass-104 | mAP | Speed (FPS) | ||||||
| 91.62 | 7.19 | |||||||
| [71] | RetinaNet | Voting Strategy | mAP (%) | |||||
| Unanimous | 6.63 | |||||||
| YOLO + RetinaNet | Voting Strategy | mAP (%) | ||||||
| Consensus | 3.69 | |||||||
| RetinaNet + SSD | Voting Strategy | mAP (%) | ||||||
| Consensus | 4.03 | |||||||
| [72] | Faster R-CNN | mAP (%) | ||||||
| 13.77 | ||||||||
| SSD | mAP (%) | |||||||
| 9.1 | ||||||||
| YOLOv3 | mAP (%) | |||||||
| 13.33 | ||||||||
| YOLOv4 | mAP (%) | |||||||
| 25.94 | ||||||||
| FOR-instance [13] | [73] | PointNet | mIoU | micro F1 | ||||
| 35.65 | 52.56 | |||||||
| PointNet++ | mIoU | micro F1 | ||||||
| 33.00 | 49.57 | |||||||
| Point Transformers | mIoU | micro F1 | ||||||
| 22.97 | 37.13 | |||||||
| [74] | HFC (on CULS plot 1) | Precision | Recall | F1 score | ||||
| 0.89 | 0.8 | 0.84 | ||||||
| HFC (on NIBIO plot) | Precision | Recall | F1 score | |||||
| 0.89 | 0.85 | 0.87 | ||||||
| HFC (on NIBIO2 plot) | Precision | Recall | F1 score | |||||
| 0.85 | 0.85 | 0.85 | ||||||
| HFC (on SCION plot) | Precision | Recall | F1 score | |||||
| 0.95 | 0.90 | 0.92 | ||||||
| HFC (on RMIT plot) | Precision | Recall | F1 score | |||||
| 0.89 | 0.85 | 0.87 | ||||||
| HFC (on TUWEIN plot) | Precision | Recall | F1 score | |||||
| 0.84 | 0.85 | 0.87 | ||||||
| UAV-Assistant [15] | [75] | BPnP [76] | ACC2 | ACC5 | ||||
| 95.2 | 98.36 | |||||||
| 55.31 | 85.34 | |||||||
| HigherHRNet [25] | ACC2 | ACC5 | ||||||
| 89.92 | 97.75 | |||||||
| HRNet [77] | ACC2 | ACC5 | ||||||
| 90.75 | 98.04 | |||||||
| Dataset Name | Reference | Methods | Performance | |||||
|---|---|---|---|---|---|---|---|---|
| AIDER [8] | [78] | EmergencyNet | memory (MB) 0.368 | F1 Score (%) 95.7 | ||||
| VGG16 | memory (mB) 59.39 | F1 Score (%) 96.4 | ||||||
| ResNet50 | memory (MB) 96.4 | F1 Score (%) 96.1 | ||||||
| [79] | AISCC-DE2MS | MSE 0.042 | PSNR 61.898 | |||||
| Genetic Algorithm | MSE 0.06 | PSNR 60.349 | ||||||
| Cat Swarm Algorithm | MSE 0.12 | PSNR 57.339 | ||||||
| Artificial Bee Colony Algorithm | MSE 0.165 | PSNR 55.956 | ||||||
| DarkTrack2021 [19] | [80] | SAM-DA-Track | AUC 0.451 | Precision (normalized) 0.524 | Precision 0.593 | |||
| UDAT | AUC 0.421 | Precision (normalized) 0.499 | Precision 0.570 | |||||
| SiamBAN | AUC 0.422 | Precision (normalized) 0.491 | Precision 0.566 | |||||
| [81] | SiamAPN | DP 0.43 | NDP 0.389 | AUC 0.446 | ||||
| SiamAPN++ | DP 0.494 | NDP 0.446 | AUC 0.375 | |||||
| UAV-Human [7] | [82] | Proposed Novel Method | Precision 0.49 | Recall 0.49 | F1 Score 0.48 | |||
| [83] | CLIP [84] | Top1/Top5 (Filtering ratio 90%) 1.79/7.05 | ||||||
| ViFi CLIP [85] | Top1/Top5 (Filtering ratio 90%) 4.67/15.18 | |||||||
| [86] | 2s-MS&TA-HGCN-FC (Novel method) | CSv1 44.33 | CSv2 70.69 | |||||
| 4s-MS&TA-HGCN-FC (Novel method) | CSv1 45.72 | CSv2 71.84 | ||||||
| FR-AGCN [87] | CSv1 43.98 | CSv2 69.5 | ||||||
| UAVDark135 [18] | [88] | DCPT | Success Rate 0.577 | Precision 0.703 | Normalized Precision 0.701 | |||
| DIMP50-SCT | Success Rate 0.562 | Precision 0.717 | Normalized Precision 0.71 | |||||
| DIMP18 [89] | Success Rate 0.542 | Precision 0.702 | Normalized Precision 0.69 | |||||
| [90] | DL+SiamAPN | Success Rate 0.389 | Precision 0.516 | |||||
| SiamAPN [91] | Success Rat 0.3 | Precision 0.424 | ||||||
| DL+DIMP50 | Success Rate 0.544 | Precision 0.7 | ||||||
| DIMP50 [19] | Success Rate 0.526 | Precision 0.672 | ||||||
| VRAI [12] | [92] | Proposed Novel Method | mAP 0.828 | R-1 Accuracy 0.844 | ||||
| TransReID [93] | mAP 0.814 | R-1 Accuracy 0.826 | ||||||
| [93] | RotTrans | mAPR-1 Accuracy 0.848 | mAPR-1 Accuracy 0.838 | |||||
| TransReID | mAP 0.786 | R-1 Accuracy 0.803 | ||||||
| Dataset Name | Reference | Methods | Performance | |||||
|---|---|---|---|---|---|---|---|---|
| UAV-Gesture [17] | [94] | Novel Multifeature+CNN method | Accuracy 0.95 | |||||
| P-CNN [45] | Accuracy 0.91 | |||||||
| MLP_7j [95] | Accuracy 0.94 | |||||||
| [95] | DD-Net_7j [96] | Accuracy 0.915 | ||||||
| P-CNN | Accuracy 0.919 | |||||||
| MLP_7j | Accuracy 0.948 | |||||||
| UAVid [11] | [97] | BANet | mIoU (%) 64.6 | |||||
| MSD benchmark [11] | mIoU (%) 57.0 | |||||||
| [98] | A²-FPN | mIoU (%) 65.7 | ||||||
| MSD benchmark | mIoU (%) 57.0 | |||||||
| [99] | UNetFormer | mIoU (%) 67.8 | ||||||
| ABCNet | mIoU (%) 63.8 | |||||||
| BANet | mIoU (%) 64.6 | |||||||
| BoTNet | mIoU (%) 63.2 | |||||||
| [100] | MSD benchmark | mIoU (%) 57.0 | FPS 1.00 | |||||
| BiSeNet [101] | mIoU (%) 61.5 | FPS 11.08 | ||||||
| CAN | mIoU (%) 63.5 | FPS 15.14 | ||||||
| VERI-Wild [14] | [102] | FDA-Net [14] | mAP (small) 0.351 | mAP (medium) 0.298 | mAP (large) 0.228 | |||
| PVEN | mAP (small) 0.825 | mAP (medium) 0.77 | mAP (large) 0.697 | |||||
| [103] | MLSL [104] | mAP (large) 0.366 | R-1 accuracy (large) 0.775 | |||||
| FastReID | mAP (large) 0.773 | R-1 accuracy (large) 0.925 | ||||||
| [105] | GiT | mAP (T10000) 0.675 | R-1 accuracy (T10000) 0.854 | |||||
| PCRNet [106] | mAP (T10000) 0.671 | R-1 accuracy (T10000) 0.85 | ||||||
| [107] | HPGN | mAP (T10000) 0.65 | R-1 accuracy (T10000) 0.8268 | |||||
| Triplet Embedding [108] | mAP (T10000) 0.516 | R-1 accuracy (T10000) 0.699 | ||||||
| [109] | Baseline [110] | mAP (large) 0.65 | R-1 accuracy (large) 0.95 | |||||
| SAVER | mAP (large) 0.677 | R-1 accuracy (large) 0.958 | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rahman, M.M.; Siddique, S.; Kamal, M.; Rifat, R.H.; Gupta, K.D. UAV (Unmanned Aerial Vehicle): Diverse Applications of UAV Datasets in Segmentation, Classification, Detection, and Tracking. Algorithms 2024, 17, 594. https://doi.org/10.3390/a17120594
Rahman MM, Siddique S, Kamal M, Rifat RH, Gupta KD. UAV (Unmanned Aerial Vehicle): Diverse Applications of UAV Datasets in Segmentation, Classification, Detection, and Tracking. Algorithms. 2024; 17(12):594. https://doi.org/10.3390/a17120594
Chicago/Turabian StyleRahman, Md. Mahfuzur, Sunzida Siddique, Marufa Kamal, Rakib Hossain Rifat, and Kishor Datta Gupta. 2024. "UAV (Unmanned Aerial Vehicle): Diverse Applications of UAV Datasets in Segmentation, Classification, Detection, and Tracking" Algorithms 17, no. 12: 594. https://doi.org/10.3390/a17120594
APA StyleRahman, M. M., Siddique, S., Kamal, M., Rifat, R. H., & Gupta, K. D. (2024). UAV (Unmanned Aerial Vehicle): Diverse Applications of UAV Datasets in Segmentation, Classification, Detection, and Tracking. Algorithms, 17(12), 594. https://doi.org/10.3390/a17120594