Classifying species is a critical task in biodiversity monitoring; this process is often resource-intensive and prone to human error, particularly when dealing with unknown or undescribed species. The challenge lies in developing an automated system capable of accurately classifying both described and undescribed species while addressing the limitations of existing approaches, which often fail to effectively utilize multimodal data such as images and DNA barcodes. The primary goal of this research is to design an efficient and accurate machine learning-based system for classifying species and grouping undescribed species at the genus level. This system aims to support global biodiversity monitoring by overcoming the limitations of manual taxonomy and existing computational approaches. The specific goals of this work are as follows:
In this section, we will first explain the datasets used and proposed in this paper, then the methods to extract features from an image and the related DNA barcoding; finally, the methods to classify a given vector will be explained. As previously explained, we will use SVM and neural networks as classifiers, where neural networks are trained by rearranging the vector as a three-channel matrix. We assess the performance using five datasets:
3.1. Dataset with Simulated Undescribed Species
In accordance with the methodology outlined in the original paper, the data utilized in our experiments were obtained from the Barcode of Life Data System (BOLD) [
6], which is a cloud-based data storage and analysis platform developed at the Centre for Biodiversity Genomics in Canada. The data consist of 32,424 image samples, e.g., see
Figure 2, of insect species from four Insecta orders,
Diptera,
Coleoptera,
Lepidoptera, and
Hymenoptera, each associated with a DNA barcode COI mitochondrial sequence of that species.
Due to the fact that we did not have access to the original images used in [
16], we resorted to downloading the data from the BOLD Systems platform to recreate a dataset that closely matches [
16]. However, we encountered some discrepancies: some species names have been updated, and certain species have been split into two distinct categories. As a result, our dataset exhibits some differences compared to [
16].
Table 1 highlights these differences.
Next, we split the data following the methodology described in [
16]. We considered all genera containing three or more species and we randomly selected 30% of the species within each of these genera as “undescribed” (only the genus is known while the species is unknown) and added all the samples from these species in the test set. We then split the remaining described data into 80% for the training + validation and 20% for the test set. Hence, the final test set consists of this 20% together with the previously designated undescribed species. This process is described by Algorithm 1. After applying Algorithm 1 to obtain a training + validation set and a test set, we apply it again on the training + validation set to obtain a training set with only described species and a validation set with both described and undescribed species. It is necessary that the undescribed species in the validation set are different species from the undescribed species in the test set; this is important to avoid class leaking from the test set to the validation set, ensuring that the undescribed species in the test set remain unseen during validation.
| Algorithm 1 Split dataset to simulate undescribed species |
| Require: D ▹ Dataset to split, containing species and their genus |
| Ensure: training, test ▹ Split dataset with undescribed species |
| 1: | Initialize |
| 2: | Group species in D by genus |
| 3: | for all genus g in D where do |
| 4: | Randomly select 30% of species in g as |
| 5: | Add all samples in D with species to |
| 6: | Remove samples with species from D |
| 7: | end for |
| 8: | Split the remaining D into (80%) and (20%) |
| 9: | = ∪ |
| 10: | return , |
We did not use the validation set for the training or the hyperparameter tuning of our models described in
Section 3.4, but we provide this validation set to be used in future works that use the same dataset in order to be able to compare our results.
3.4. Feature Extraction
All the models presented in this section have been trained only on the training set of the dataset with simulated undescribed species presented in
Section 3.1, without any hyperparameter tuning using the validation set. After the training, the weights of the models have been saved and used to extract the features from the other datasets.
We reproduced the methodology detailed in [
16] using our data. To reproduce their DNA feature extraction technique, we used the same Convolutional Neural Network (CNN) architecture but we changed the activation function of the fully-connected layer from Tanh to LeakyReLU because we experienced vanishing gradient. For the image features, we used a pre-trained Resnet101 that gave us a vector of 2048 features. The Resnet was not fine-tuned, as described in [
16].
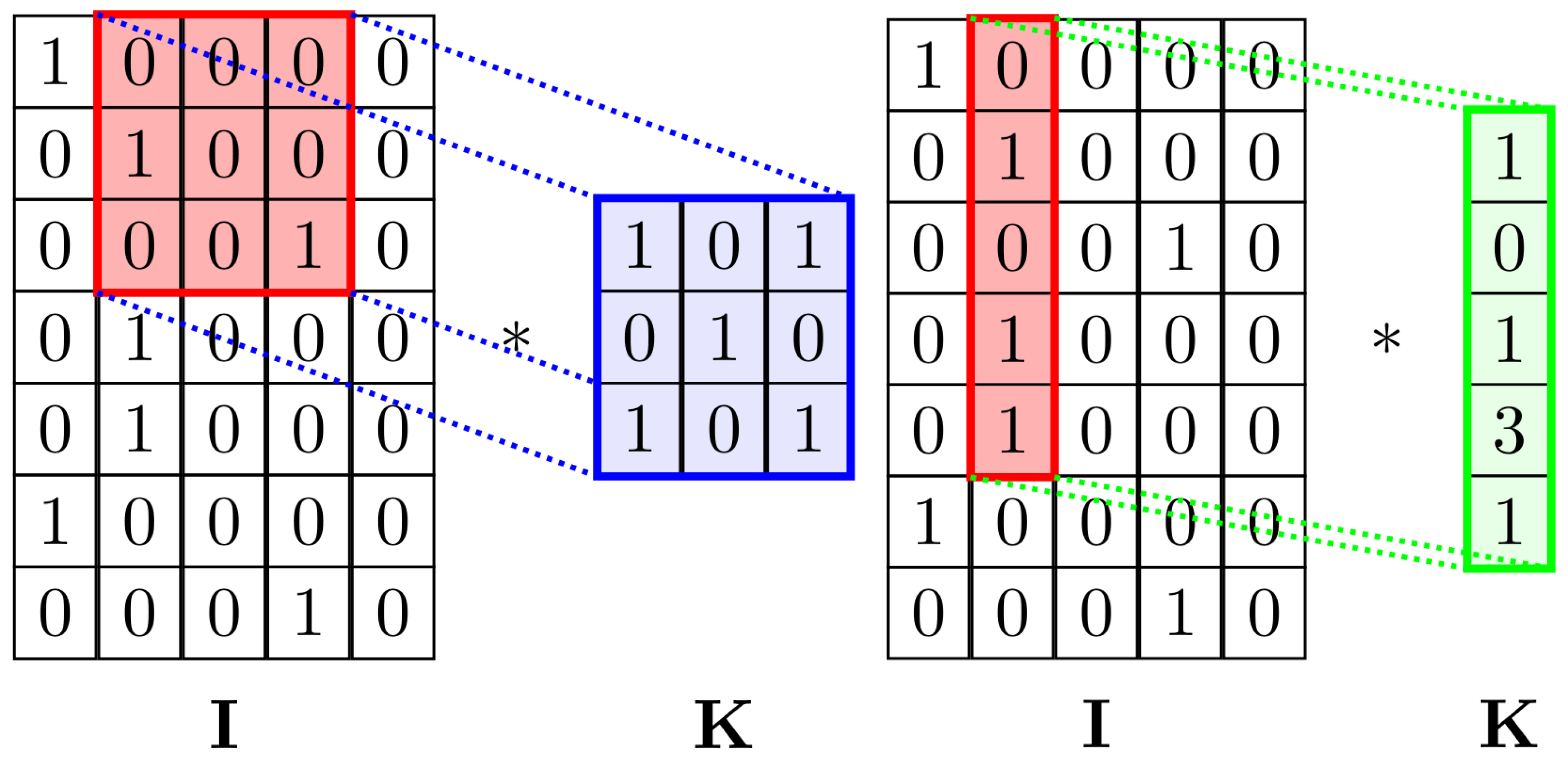
Our method also used a CNN to extract the DNA features. Our CNN architecture consists of 2 convolutional layers, both of which use a one-dimensional () kernel (in order to avoid reducing too much the output dimension), batch normalization, and LeakyReLU as the activation function. A dropout layer is used (70% dropout rate) after the second convolutional layer. The vectors are then flattened and projected on a linear layer of size 1500, followed by another dropout (70% dropout rate) and a LeakyReLU as mentioned before. The output is finally projected on a linear layer of size equal to the number of classes.
The main idea behind using the
convolution instead of
as in the original paper was to maintain the shape of the second dimension of the tensor constant without using padding. This allows the CNN to focus on finding local patterns in neighboring nucleotides (
Figure 3). Using
kernels would mean also considering convolutions across the one-hot encoding of a single nucleotide, possibly losing positional information and finding irrelevant relations.
Furthermore, for extracting the image features, we used the intermediate layer of the discriminator of a conditional Generative Adversarial Network (GAN) model, named Rebooted Auxiliary Classifier Generative Adversarial Network (ReACGAN). ReACGAN [
35] is a newer version of the ACGAN model (a model of conditional GAN) with the purpose of improving the stability of the training by using residual connections (similar to ResNet), spectral normalization, embedding normalization, conditional batch normalization, and a different loss. ReACGAN aims to solve the exploding gradient and mode collapse problems that occur in ACGAN when the dataset contains a high number of classes. Since we were experiencing mode collapse with regular ACGANs due to having a large number of classes, we decided to use this improved version. The residual connections are the same as in ResNet.
Spectral normalization, introduced in [
36] to stabilize the training of the discriminator, is applied to both the layers of the generator and the discriminator in the ReACGAN. It works on the weight matrix
W applying (Equation (
1)), where
h is a randomly initialized vector. This is equivalent to dividing the matrix by its maximum singular value.
Conditional batch normalization (Equation (
3)) differs from regular batch normalization (Equation (
2)) by determining the values of the parameters
and
using a linear layer from the input features instead of learning one value for them. In conditional GANs it allows the model to learn different scaling factors for different classes of samples (e.g., different species or genera).
where
and
are the mean and the standard deviation of the values of elements of the batch. It has been proved, by [
35], that in ACGAN discriminators the gradients scale with the norm of the sample embedding (the feature extracted by the discriminator).
Finally, the D2D-CE (data-to-data cross-entropy) loss is used. Normally, ACGANs compute the cross-entropy between the feature extracted by the discriminator (called sample embedding) and the embedding of the class label which is called proxy (in ACGANs, a one-hot encoding of the label can be used instead of an embedding of the class label).
In [
35] it is showed how normalizing the sample embedding and the label proxy avoids the exploding gradient problem that appears at early training and is one of the causes of early mode collapse.
Equations (
4) and (
5) describe the common cross-entropy and the D2D-CE loss functions, respectively. Both are expressed by considering
, the feature embedding vector extracted from image
x by the penultimate layer of the discriminator, and
, which is the weight matrix of the last layer of the discriminator.
The D2D-CE (Equation (
5)) is a modified version of CE (Equation (
4)), where
and
,
P is a projection carried out by a linear layer,
= min(·,0)
= max(·,0),
is the set of indices of the samples in the minibatch for which the label is different from
(it is the real label); the margins
and
and the temperature
are hyperparameters, and we use the implementation and the values of the hyperparameters suggested in [
37].
Also in D2D-CE, the denominator (Equation (
5)) of the softmax still computes the similarity between the sample embedding and the proxy (either one-hot or embedding) in order to consider data-to-class similarities, but in the denominator, we split the summation in two: a term equal to the numerator plus a term that computes the similarities between the sample embeddings for images of the batch belonging to different classes (
). This second term does not consider data-to-class relationships because it does not involve the weights of the last layer
. Conversely, it considers relationships between the sample embeddings of different classes. For this reason, the loss function is called Data-to-Data CE.
This makes it so that by minimizing the loss, we make the sample embeddings more similar to the corresponding class proxies, but at the same time, we make the sample embeddings of images belonging to different classes different between each other. This idea is similar to the contrastive loss used in siamese networks.
The intuition behind this loss is that we make the discriminator use visual features from the images to distinguish images of different classes instead of just making it only guess the class directly. If this intuition is correct, it would be useful for our purpose since our objective is not just to generate realistic images but to also obtain useful features that encode the class of the insect. Some sample obtained by ReACGAN are shown in
Figure 4.
The last step to obtain the final version of D2DCE (Equation (
5)) is to consider the 3 hyperparameters: the margins
and
and the temperature
. Since the model is too big for our dataset, we pre-trained it on a dataset of arbitrary animals taken from various internet datasets for 25 epochs. Then, we fine-tuned it on our dataset for 12 epochs.
The dataset for the pre-training of the ReACGAN contains [
38] and some other datasets from kaggle with pictures of insects and other animals. The whole pre-training dataset can be found at [
39].
3.5. Discrete Wavelet Transform
In numerical analysis and functional analysis, a discrete wavelet transform (DWT) is a type of wavelet transform where the wavelets are discretely sampled. A significant advantage of DWT compared to Fourier transforms is its ability to provide temporal resolution, capturing both frequency and time location information [
40].
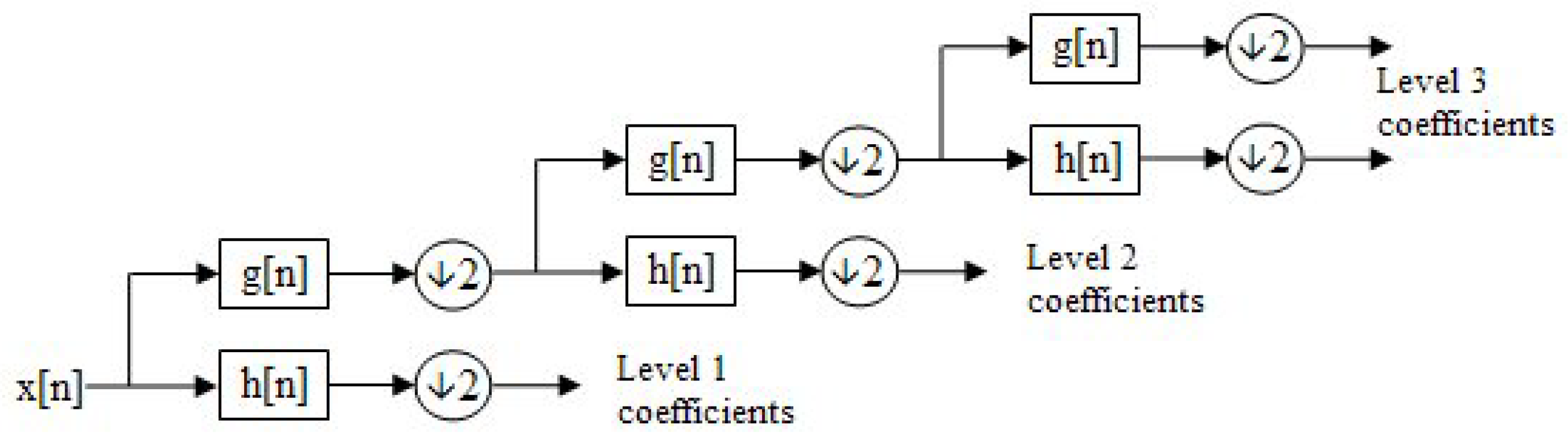
Given a 1D discrete signal , the DWT is calculated by passing the signal through two filters:
The outputs of these filters are downsampled by a factor of 2 to reduce the number of coefficients, effectively halving the time resolution. The signal decomposition can be expressed as follows:
where
comprises the approximation coefficients (low-frequency components) and
comprises the detail coefficients (high-frequency components).
The filtering and downsampling process is recursive. After each decomposition, the approximation coefficients are further decomposed into new approximation and detail coefficients at the next level.
This decomposition process is visualized as a binary tree, see
Figure 5, where each node represents a sub-space with distinct time-frequency localization. This structure is commonly referred to as a filter bank.
The proposed approach utilizes the following mother wavelets:
We did not perform a study to overfit which wavelets to use, instead using the ones available in MATLAB and using the default parameters; the same set is used for all the datasets, so we assume that there is no risk of overfitting. Below is the pseudocode for the described approach; see pseudocode Algorithm 2. This process is applied three times to create the 3 channels of the matrix used for feeding ResNet50.
| Algorithm 2 DWT approach for reshaping data |
Ensure: Define the feature vector that describes a given pattern Initialize a square matrix Mat of size filled with zeros. Define = ; ▹ Original feature vector for = 1:inf do ▹ Iterate over wavelet types; = ; ▹ Fill the matrix Mat with wavelet coefficients for = 1:( - 4) do▹ Discard the last 4 levels due to low dimensionality [, ] = apply wavelet to ‘vector’; ▹ Randomly choose mother wavelet for this iteration, extract approximation and detail coefficients. Such choice is random for each network, obviously for each pattern in a given network the same set of mother wavelets is used. = ; ▹ Use approximation vector for next iteration - Check(filter==1, , ) At the first filter bank level, approximation and detail coefficients are resized to 25% of their size. - Check(filter==2, , ) At the second filter bank level, coefficients are resized to 50%. ▹ the rationale is to avoid reducing the dimensionality of the other levels, important to underline that the output matrix will be resized to the size required by ResNet50 (i.e., square matrix of size 224 with 3 channels) Mat(row, :) = ; Mat(row+1, :) = ; row = row + 2; end for if > size(Mat, 2) then▹ Exit condition: if row is higher than the number of rows of Mat break; end if end for
|
3.6. Classification Approaches: Support Vector Machine and ResNet50
One of the most influential approaches to supervised learning is the support vector machine [
41]. This method is parameterized by a set of
N weights
and a bias term
. In a binary classification task, the SVM predicts a class
for a sample vector
using the following decision function:
which defines a hyperplane in
referred to as margin. The margin, or the distance between the hyperplane and the closest points from each class, is maximized during training to achieve optimal separation. For multi-class classification, the problem becomes more complex and can be approached in various ways. A common method is the one-vs-one strategy, which divides the task into multiple binary classification problems, one for each pair of classes. The final prediction is computed by majority voting, often incorporating distance from the margin as a tiebreaker. However, this approach requires training an SVM for every class pair, which can significantly increase computational costs. Another strategy is the one-vs-all, which requires to train a model for each unique class in order to distinguish it from all the other classes. The final prediction is computed by selecting the class for which the model predicts the highest margin. Compared to the one-vs-one strategy, the one-vs-all is more robust to an imbalanced dataset and is particularly fast to train, especially when the number of classes is large. Here, we used the one-vs-all approach and the LibSVM toolbox (
https://www.csie.ntu.edu.tw/~cjlin/libsvm/, accessed on 8 February 2025).
ResNet (Residual Network), introduced by Hen [
42], is a deep learning architecture designed to address the vanishing gradient problem in training deep neural networks. It introduces residual connections, or skip connections, that allow gradients to flow directly through the network, bypassing one or more layers. This is achieved by reformulating the layers to learn a residual mapping
, where
is the original mapping, and the output is
. ResNet is highly effective for multi-class classification tasks. The network consists of stacked residual blocks, each comprising convolutional layers, batch normalization, and ReLU activations, with a skip connection that adds the input of the block to its output. The architecture scales to hundreds or thousands of layers while maintaining high performance. ResNet models are often initialized with weights pre-trained on the dataset ImageNet [
43], leveraging features learned from over a million diverse images, a technique also known as transfer learning. This approach accelerates convergence, improves performance on downstream tasks, and is computationally efficient compared to training a deep network from scratch. Each net is trained for 10 epochs, with a batch size equal to 30, a learning rate 0.001, and stochastic gradient descent (SGD) for optimization.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}