1. Introduction
Video surveillance systems have become an essential component of our security infrastructure, playing a critical role in monitoring and ensuring safety in various settings, like public spaces, transportation systems, and commercial establishments. Since surveillance systems are used in various areas and environments, it has always been difficult to identify abnormal activity accurately and quickly in recordings. Further, more than 1 billion security cameras were used worldwide in 2023 [
1], and that number is projected to exceed 2.24 billion by 2030, with a compound annual growth rate of 12.2% [
2]. This growing volume of video data generated by these systems demands an efficient and reliable method for anomaly detection, which remains a challenging task due to the dynamic and complex nature of video content. Traditional approaches often rely on manual monitoring or primitive automated techniques, which are time consuming and prone to errors and inefficiencies. Since abnormal activities are rare compared to normal ones, identifying and detecting anomalies is more complicated than other video analysis forms because of the data imbalances between normal and abnormal segments. This has increased interest in leveraging advanced machine learning methods, particularly deep learning, to automate and improve anomaly detection accuracy in video surveillance.
Video anomaly detection involves identifying events or patterns in video data that deviate from the norm. These abnormalities might be anything from identifying safety risks in industrial settings to strange behaviors in crowded areas. The critical challenge in video anomaly identification is the wide range of behaviors that are considered normal in various contexts but anomalies in others; for instance, running is a typical activity for people as part of an exercise routine but running inside a bank could be perceived as anomalous or suspicious behavior. Moreover, anomalous events are complicated in nature, are often rare, and vary greatly in appearance and nature. Traditional machine learning and deep learning methods are the two main categories of anomaly detection approaches. Traditional machine learning techniques have shown impressive results in many video anomaly areas, such as abnormal human action recognition, by capturing shallow features from video data [
3]. These techniques included support vector machines (SVMs) [
4], Markov models [
5], Bayesian networks [
6], random forests (RFs) [
7], probabilistic-based models [
8], sparse reconstruction [
9], histograms of optical flows (HOFs) [
10], and histograms of oriented gradients (HOGs) features [
11,
12]. On the other hand, they mostly rely on handcrafted features and preprocessing, which take a lot of time and resources to complete. According to Hu et al. [
13], they perform poorly in real-world scenarios and do not scale well for various datasets. The use of deep learning techniques introduced novel strategies that surpass conventional approaches and tackle the drawbacks related to traditional machine learning [
14,
15,
16]. We do not address traditional machine learning techniques in this work; instead, we concentrate on the most recent advancements in deep learning models.
Recent improvements in deep learning have produced effective techniques for analyzing videos, which have significantly improved anomaly identification. These techniques, in particular, convolutional neural networks (CNNs) and recurrent neural networks (RNNs), have demonstrated remarkable potential in terms of capturing the temporal dynamics and spatial characteristics of videos. Nevertheless, they typically require an extensive amount of labeled data and have trouble capturing the nuances and variability of anomalies, which can result in errors like missed detections and false positives. Notably, the attention mechanism in deep learning allows models to focus on the most relevant parts of the input data, enhancing their ability to learn context-dependent features for tasks such as language translation, image recognition, and sequence prediction. It dynamically weighs the significance of different input components, improving the model’s interpretability and performance by mimicking cognitive attention in human learning. For example, Tian et al. [
17] showed how dilated convolutions and self-attention may be used in weakly-supervised video anomaly detection, emphasizing how well they can capture temporal information and enhance the discriminability of anomalies. Furthermore, the incorporation of attention mechanisms and memory units into transformer models has recently been investigated in more detail to improve the models’ effectiveness in video anomaly detection. [
18] used the transformer’s network capability to maintain global and local associations in videos to offer a method for weakly supervised video anomaly detection utilizing “Dual Memory Units with Uncertainty Regulation”.
Deep learning-based video anomaly detection (VAD) models presently employ unsupervised or weakly supervised learning, since collecting anomalous data is difficult. Unsupervised learning techniques often rely on autoencoders [
19,
20,
21] or pre-trained CNNs [
22,
23] to extract features, and then identify anomalies by reconstructing frames or predicting future frames. For weakly supervised learning techniques, only video-level labels are needed [
24,
25,
26] which use multi-instance learning to differentiate between normality and abnormality. Hence, this research focuses on unsupervised approaches since they are more appropriate for real-world application settings.
The introduction of the transformer model, basically developed for natural language processing tasks, has opened new directions in computer vision, including video anomaly detection. With their ability to focus on the most relevant portions of the input data, vision transformers (ViTs), first introduced by Dosovitskiy et al. [
27], provide a paradigm change away from the inductive biases of CNNs. ViTs can capture global context and long-range interdependence thanks to their attention mechanism, which is very useful for interpreting complex scenarios in video surveillance. In addition, ViTs learn robust and discriminative features that are not limited to local neighborhoods, as CNNs are, which accounts for their efficacy in anomaly detection.
Based on the aforementioned reasons and to take advantage of both ViTs and CNNs, we propose an unsupervised frame-based spatiotemporal video anomaly detection technique that automatically detects anomaly frames in surveillance videos by utilizing a pre-trained ViT transformer model with the attention of spatiotemporal relationships among objects (STR attention model) [
28]. The proposed model was trained and validated over three video anomaly benchmark datasets in the literature; the UCSD-Ped2 [
29] dataset, the CHUCK Avenue [
30] dataset, and the largest benchmark available, the sophisticated ShanghaiTech [
31] dataset. In addition, we challenged the proposed model against the recent, very large Charlotte Anomaly Dataset (CHAD) [
32] to prove its efficacy with very large video anomaly datasets. Due to the lack of intrinsic inductive biases of CNNs in ViTs, the STR attention model allowed better capturing of the spatiotemporal relationships among objects in successive frames, including spatial locations, movement speeds and directions, and morphological changes, which enhanced the detection accuracy of abnormal frames. In addition, the existing self-attention ViT-based models use the transformers to capture relationships between long-range pixels and the global contexts of the images. Hence, we utilized the STRA model which is a spatiotemporal-based model that leverages these features by obtaining the relationships among objects in the input sequence of the fames, which strengthens the learned features of the normal videos’ events and situations. This allows the proposed framework to strongly reconstruct normal frames and detect the poorly reconstructed frames as anomalous. Moreover, to tackle the problem of detection accuracy degradation when training the vision transformers on small and medium-sized datasets, an advanced training strategy was applied by dually combining the datasets and grouping all of them to form various synthetic heterogeneous datasets, then training the proposed model on the datasets individually and on the different combinations that improved anomaly detection accuracy for the models trained on the combined datasets. In addition, two different up-sampling approaches are introduced to enlarge the size of the smaller datasets, i.e., the UCSD-Ped2 and CHUCK Avenue. This strategy proved the robustness and effectiveness of the introduced spatiotemporal ViT-based model in identifying anomalies in larger heterogeneous video anomaly datasets captured in different environmental and lighting conditions and varied resolution and quality, which is a step towards developing a real-time video anomaly detection multi-modal surveillance system. The contributions of this work are summarized below:
An unsupervised framework for video anomaly detection-based ViT transformer and spatiotemporal block using an encoder–decoder architecture to address and effectively detect diverse video abnormalities;
Proposing a hybrid deep learning framework which is, to the best of our knowledge, the first one to combine the ViT model with the convolutional STR attention block for video anomaly detection;
Adopting a different training strategy by creating different combinations of the utilized datasets to improve the performance of the proposed model for identifying anomalies in videos, despite the diverse environmental difficulties, lighting settings, and video quality of these datasets, towards developing a video anomaly detection multi-modal surveillance system;
Conducting a comprehensive evaluation using publicly available video anomaly detection datasets for the introduced framework shows that when compared to cutting-edge methods, the proposed approach produces outstanding results.
The rest of this paper is structured as follows:
Section 2 covers related VAD work, while
Section 3 provides background information about the underlying used techniques. Details about the proposed model are provided in
Section 4, while the experiments using the introduced model, their findings on the datasets, and the discussion are shown in
Section 5. Finally, the conclusion is in
Section 6.
3. Background
There is an increasing need for reliable anomaly detection systems in the rapidly developing industry of video surveillance. Conventional methods have frequently relied on techniques that work well for identifying local patterns but poorly in terms of fully understanding complex and dynamic situations. This research investigates a novel hybrid deep learning model that combines the advantages of autoencoders, CNNs, and vision transformers (ViTs) to overcome these drawbacks. Through the integration of these technologies, the proposed model is able to improve the accuracy and reliability of anomaly identification in a variety of surveillance contexts, while also capturing the complex spatiotemporal correlations present in videos. This background serves as the foundation upon which our hybrid model is built, enabling it to achieve superior performance on benchmark datasets and offering a comprehensive solution to the challenges faced in video anomaly detection.
3.1. Vision Transformers
The ViT emerged as a novel deep learning model initially developed for natural language processing (NLP) tasks [
67], which has acquired attention recently in the field of image analysis, especially for anomaly detection in images. ViTs deviate from the conventional deep learning models by employing self-attention mechanisms rather than the traditional convolutional layers, enabling them to capture the global dependencies among image patches effectively. This model processes an image by dividing it into non-overlapping patches, which are then projected into vectors through linear projection. The integration of positional encodings with these patch embeddings ensures that the model retains the spatial context of the image, which is crucial for understanding the global layout of the image components. In contrast to traditional methods, a ViT’s self-attention mechanism in the transformer encoder enables it to concentrate on various regions of the picture according to contextual importance, which enables a more comprehensive and nuanced analysis.
After the preliminary processing, the vision transformer improves the feature extraction process by using residual connections, layer normalization, and multi-head self-attention processes. This enhances the model’s ability to identify complex patterns and relationships in the analyzed image. This advanced architecture enables the transformer to process the image patches in a manner that captures both local and global contextual information, leading to highly accurate image classification outcomes. With a multi-layer perceptron (MLP) head acting as the classification layer at the end of the model, the input images are given class labels according to the characteristics that the transformer encoder retrieved. The ViT’s unique approach, which makes use of the self-attention mechanism for image classification tasks, represents a significant shift from traditional convolution-based methods, offering a promising new direction for advancing the capabilities of deep learning models in image analysis and other fields.
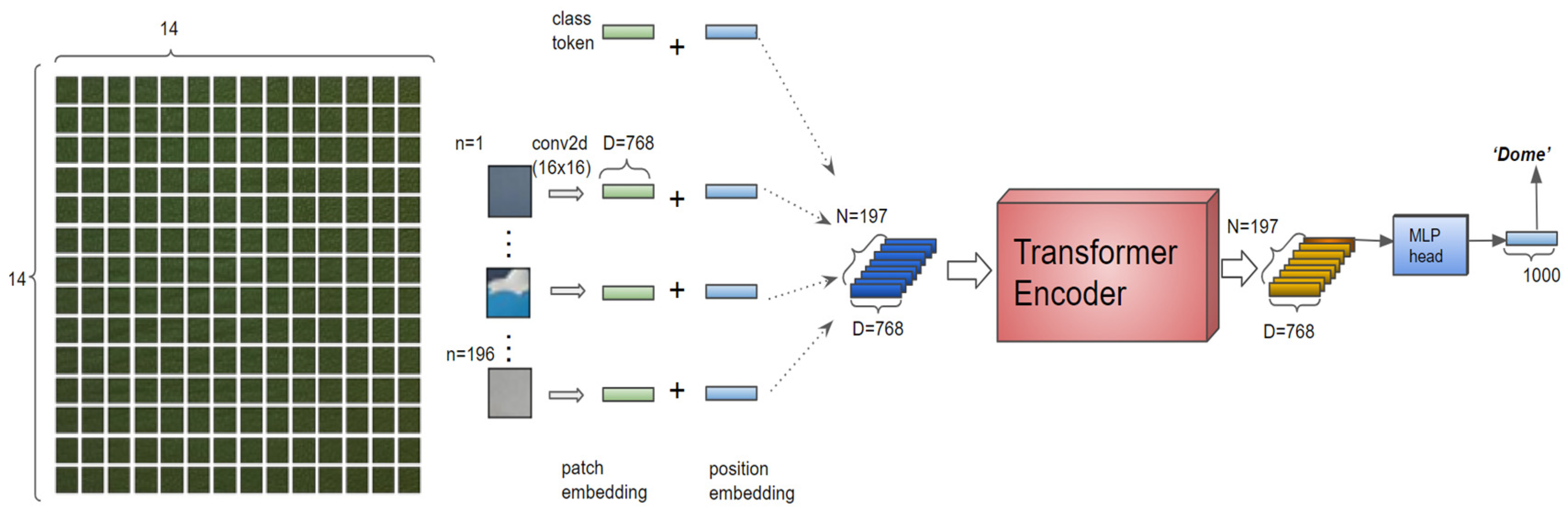
The vision transformer (ViT) architecture, as shown in
Figure 1 [
68], could be summarized in several key stages, described as follows:
Patch extraction: the input image is divided into fixed-size patches (e.g., 16 × 16 pixels). This step transforms the 2D image into a sequence of flattened 2D patches;
Patch embedding: via a trainable linear projection, each extracted patch is projected linearly into a higher-dimensional vector (embedding). This procedure modifies the image patches so the transformer can process them, like embedding tokens in NLP tasks;
Positional encoding: positional encodings are added to the patch embeddings to retain the positional information of each patch. This step ensures the model can recognize where each patch is located in the image, which is crucial for understanding the overall structure of the image;
Transformer encoder: this is the core of the ViT. This encoder consists of multiple layers, each containing two main components, a multi-head self-attention mechanism and a position-wise feed-forward network. Layer normalization is applied before each component, and residual connections are used after each component;
Multi-head self-attention: this mechanism allows the model to weigh the importance of different patches relative to each other, enabling the capture of global dependencies across the entire image;
Feed-forward network: after attention aggregation, each patch embedding is processed independently by a feed-forward network, which allows for nonlinear transformations of the patch representations;
Classification head: finally, the output from the transformer encoder is passed through a classification head, typically a multi-layer perceptron (MLP), to produce the final class predictions. This head processes the global representation of the image derived from the concatenated patch embeddings.
3.2. CNNs and Autoencoders for Video Anomaly Detection
CNNs were designed to learn the spatial hierarchies of data automatically and adaptively. Furthermore, the convolutional layers apply filters to picture areas to preserve the spatial relationships between pixels and capture local characteristics. Due to their design, CNNs are superior in image classification and recognition tasks because they can learn progressively complicated patterns as input data flow through successive layers [
69]. Although CNNs utilize filters on different picture regions, this naturally restricts the network’s capacity to capture global relationships, even if it works incredibly well for identifying local characteristics. Thus, their capacity to comprehend the full context of an image is still restricted.
Using a nonlinear mapping function, a deep AE transforms the input data into their hidden low-dimensional representation. The objective is to train the AE to recreate the input patterns at the network’s output. AEs cannot replicate anomalous data samples when trained on regular data samples. Therefore, deviations from the training model caused by abnormal activities lead to poor reconstruction (high reconstruction error).
5. Experiments
5.1. Datasets
The proposed framework was evaluated using three challenging, publicly available anomaly datasets that are commonly used as benchmark datasets; the UCSD-Ped2, CUHK Avenue, and ShanghaiTech, and the extra-large CHAD anomaly dataset.
UCSD-Pedestrian 2 (Ped2) [
29] is considered one of the most popular datasets for unsupervised video abnormality detection. Researchers at the University of California, San Diego (UCSD) produced this dataset in 2010 to record usual pedestrian activity and rare anomalies in a controlled setting. The videos were taken from the same area at various times of the day, with varying lighting and shadow effects, which complicate the anomaly identification procedure. In this dataset, pedestrians crossed in front of the camera. Normal circumstances usually involve people strolling along walkways, but abnormalities are distinguished by the appearance of strange objects (like carts, bicycles, skateboards, etc.), strange motion patterns (like skating on a board), and people walking on grass. Ped2 consists of 16 videos with 2550 frames for training and 12 videos with 2010 frames for testing, each with a size of 240 by 360 pixels;
The CUHK Avenue [
30]: the Chinese University of Hong Kong (CUHK) produced the CUHK Avenue dataset in 2013, which provides a broader variety of anomalies in an open campus setting. The videos are captured from a single scene of the campus avenue. With 21 test films and 16 training videos, there are a total of 15,324 frames for testing and 15,328 frames for training in this dataset. The resolution of each frame is 360 by 640 pixels, and around 47 anomalous behaviors, such as loitering, throwing objects, and running through the gate, were noted. The CUHK Avenue dataset’s training and testing clips are no longer than two minutes;
ShanghaiTech [
31]: the most extensive and available unsupervised dataset for video anomaly detection, consisting of 437 clips from 13 cameras positioned across the ShanghaiTech campus at a frame resolution of 856 × 480 pixels. It has 107 test videos with both normal and abnormal occurrences; there are a total of 130 abnormal events, and 330 training clips containing 274,515 frames with only normal events. Every scenario in the videos has a different cast of individuals, difficult lighting, and unusual camera angles. Among the human anomalies in the dataset are activities like skateboarding, riding motorcycles and bikes, chasing, fighting, and jogging. All videos have frame and pixel annotations;
The CHAD [
32] is a multi-camera anomaly dataset set in a commercial parking lot, which includes 420 videos with over 1.15 million high-resolution frames from four camera views. Scenes 1–3 and Scene 4 are captured at 30 frames per second, and at 1920 × 1080 resolution and 1280 × 720 resolution, respectively. According to its authors, it is the largest fully annotated anomaly detection dataset, offering detailed person annotations from continuous video streams captured by stationary cameras. The CHAD provides human detection, tracking, and pose annotations encompassing four types: frame-level anomaly labels, person bounding boxes, person ID labels, and human key points. It includes 59,172 anomalous frames representing 22 distinct behaviors categorized into group and individual activities, and 1,093,477 normal frames. The group activities comprise fighting, punching, pushing, pulling, slapping, strangling, theft, etc., while the individual activities include throwing, running, riding, falling, littering, etc.
The summary for the four video anomaly datasets is shown in
Table 1. Different samples from the datasets displayed in
Figure 5 vary from normal to anomaly, with short descriptions for anomaly samples.
To add another complexity level to the model to prove its effectiveness in detecting abnormalities in videos, we opted to make new mixed datasets by combining the utilized datasets in permutations, as shown in
Table 2. This mechanism will allow the model to be trained on heterogeneous and very large-sized data with extremely diverse environmental conditions and data qualities.
5.2. Model Implementation and Assessment Metrics
The proposed framework was implemented using Python 3 and Pytorch backend on a machine equipped with an NVIDIA GeForce RTX 3080 GPU and 16 GB of memory for the experiments. The input video frame was resized to 224 × 224 × 3 dimensions to capture its characteristics from the ViT. The Adam optimizer [
70] was used to train and optimize the model with a learning rate of 1e
−4, batch size 16, and a five-frame input sequence length. The hidden dimension in MLP in ViT was set to 128, 512, 1024 and 1024, for the UCSD, Avenue, Shanghai, and CHAD, respectively.
The performance of the model was assessed using the area under the receiver operating characteristic (ROC) curve, following the other research such as [
26,
49,
56,
64,
71,
72]. The AUC ROC was employed to determine the capability of the introduced method to discriminate between normal and abnormal frames. Accordingly, the existence of abnormalities in the recordings at the frame level was assessed following the assessment methodologies [
73,
74,
75]. The true positive rate (TPR) against the false positive rate (FPR) curve constitutes the ROC curve. The TPR and FPR are computed using Equations (10) and (11), respectively.
The abbreviations TP and FN stand for true positive and false negative, respectively, whereas FP and TN are abbreviations for false positive and true negative.
5.3. Preprocessing
Due to the remarkable difference in sizes among the four utilized datasets, as shown in
Table 1, two different up-sampling approaches were applied as preprocessing steps to the UCSD and Avenue datasets to enlarge their sizes and study the effect of augmentation on the learning process of the proposed model. To add another level of complexity, the three datasets, UCSD-Ped2, CUHK Avenue, and ShanghaiTech, were merged interchangeably, and the model was trained using the merged versions to prove the effectiveness and robustness of the proposed model for large datasets. The up-sampling step was conducted using two different approaches.
Approach (A) aims to increase the size of the dataset by five times, where each original frame is boosted by five augmented frames. The applied transformation operations were flip and crop. In the flip operation, the image is randomly flipped horizontally with a 50% chance, while in crop the image is randomly cropped to 224 × 224 pixels;
Approach (B) involves applying a series of transformations, both individually and in dual combinations, to each frame to obtain a 1:10 original–augmented frame ratio. These transformations include random cropping to a size of 224 × 224 pixels, random horizontal flipping, random rotation within a range of 0 to 60 degrees, and random affine transformations that include slight translations (up to a 10% shift in x and y directions), scaling (between 90% and 110% of the original size), and shearing (distortion) by up to 10 degrees.
These approaches significantly increase the diversity of the training dataset by introducing various geometric changes in perspective that generally improve the robustness and generalization ability of the training models.
Table 3 shows the number of frames in each dataset after applying different up-sampling approaches.
5.4. Results and Discussion
This section gives a thorough investigation about our experimental evaluation of the model using a variety of large-scale anomaly detection datasets. Different experiments based on the encoder–decoder architecture were launched, where the pre-trained ViT model is considered an encoder with the decoder constituting the “baseline” architecture. Then, the STR attention block was involved after the ViT to show the usefulness of using the spatiotemporal characteristics for video anomaly detection.
The proposed model architecture for anomaly identification produced outstanding results, as shown in
Table 4, which demonstrates the effectiveness of using the STR attention model for improving anomaly detection accuracy.
Table 4 compares the results of using the STR attention model to the results of using the framework without it. Accordingly, the obtained results show that the proposed architecture can successfully detect anomalies with high detection rates by utilizing the local characteristics and global dependencies (context) of the video frames captured by the proposed model for the video anomaly detection process. Moreover, the detection accuracy results depicting the efficacy of the proposed model are shown in
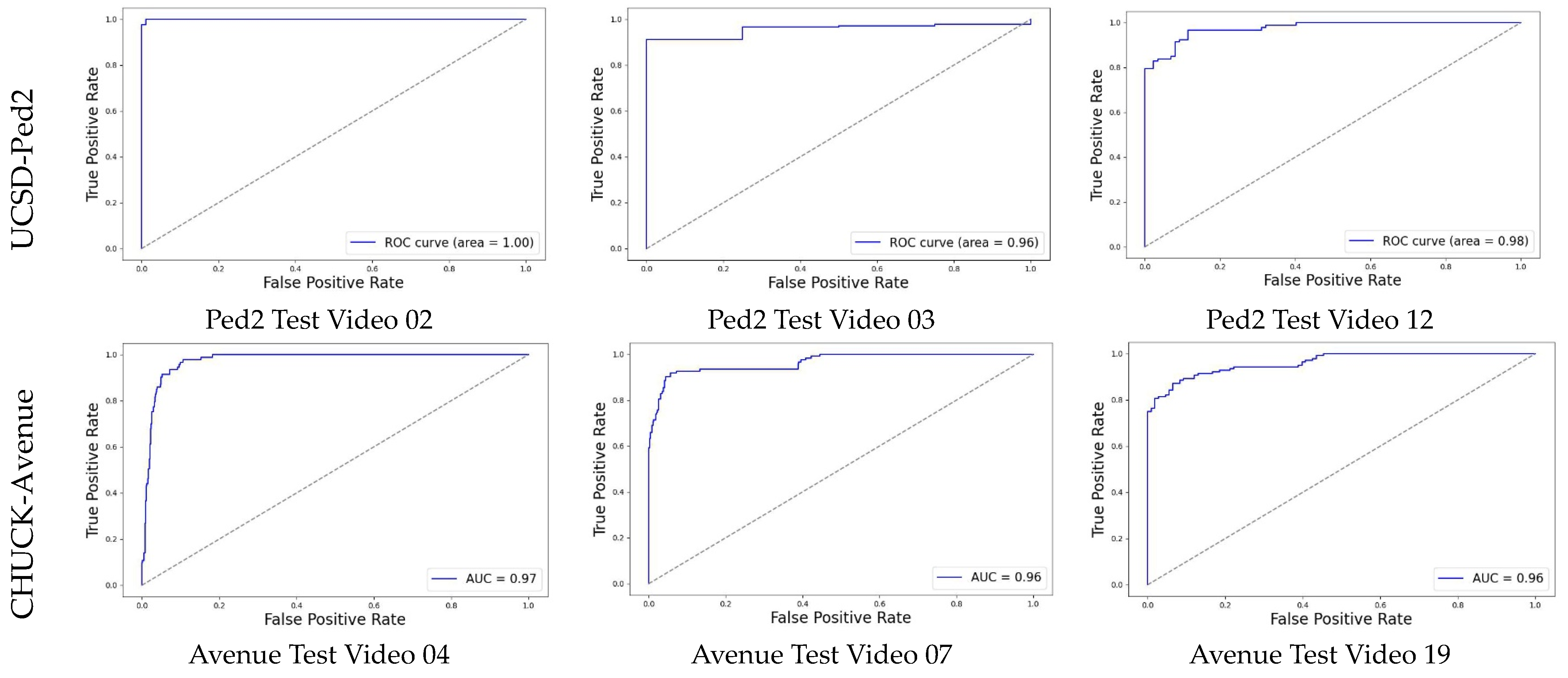
Figure 6. The figure shows the ROC results for different test videos from the four datasets, which demonstrate the effectiveness of using the ViT transformer coupled with the spatiotemporal attention model to enhance the detection accuracy of normal/abnormal frames for surveillance videos.
The effect of using augmentation and combined datasets is presented in
Table 5, which shows that the augmentation techniques improved the ViT + STR attention model’s anomaly detection accuracy for the Avenue datasets when strategy ‘B’ was applied. This demonstrated the usefulness of the model in identifying anomalies when trained on large datasets. Furthermore, merging the datasets improves the individual and overall detection rate when the STR attention model is applied, even though each dataset contains movies of varying qualities and a range of shooting scenarios, colors, and angles. Additionally, by combining the larger dataset with other datasets, as shown in
Table 6, the accuracy of anomaly identification significantly improves. The combination strategy is considered a leading idea for developing automated real-time video surveillance anomaly detection systems. It is well known that those surveillance systems have heterogeneous captured videos with different environmental circumstances and various anomaly types.
Based on the results obtained from the ShanghaiTech dataset, which proves the ability of the proposed model, ViT + STRA, to detect anomalies in large datasets and to leverage our findings about the efficiency of the proposed model when trained on larger datasets, we trained the model on the CHAD dataset. Precisely, we utilized a subset of the CHAD dataset of videos captured by Cam 1 and Cam 2 to train and evaluate the proposed model. The new subset comprises 492,671 normal frames for training and 62,879 frames for testing, totaling 555,550 frames, which is much bigger than the ShanghaiTech and considered an extra-large dataset. The model achieved an impressive average ROC of 68% for Cam 1 and Cam 2 combined as a test set.
5.5. Comparative Methods
As demonstrated in
Table 7, the proposed method achieved comparable performance for both the UCSD and Avenue datasets compared to the state-of-the-art (SOTA) approaches. Notably, the two datasets are characterized by small and medium size, respectively, and the model was designed to deal with the large datasets. For the Shanghai University of Science and Technology dataset, there are thirteen distinct complicated contexts and situations, including dense crowds, varied movement patterns, and unusual occurrences. Nevertheless, the proposed model showed a 7.3% increase in detection performance over existing VAD methods on this dataset, which is considered the large-scale benchmark dataset currently available in the video anomaly detection domain. The proposed method’s power is demonstrated by its comparison with other recent SOTA methods, such as the spatiotemporal convolutional autoencoder model introduced by Kommanduri and Ghorai [
76] and the transformer memory autoencoder approach used by Wang et al. [
77], which yielded detection superiorities of 8.4% and 9.6% for the Shanghai dataset, respectively. In addition, it achieved a superior result compared to the recent work in [
66] which employed an attention U-Net based on multi-scale feature extraction with a data augmentation network, achieving +0.6% for the Avenue dataset, but the authors did not use the Shanghai dataset in their experiments. As a result, the proposed model made progress towards finding a high-detection performance solution to the problem of finding abnormalities in large, diverse, and heterogeneous anomaly datasets. Therefore, this research may contribute to the development of reliable real-time video anomaly detection systems.
Table 8 shows a comparison of the introduced framework against the state of the art. There are few works that employed the CHAD for video anomaly detection because the CHAD is a recent dataset, for example, Yao et al. [
89] evaluated some pose-based techniques on this dataset. From
Table 8, it is obvious that our ViT + STRA framework outperforms these techniques, taking into consideration that the TSGAD [
90], GEPC [
91], and STG-NF [
92] techniques were trained on Cam 1 or Cam 2 individually. On the other hand, our model was trained on a combined set of Cam 1 and Cam 2, which makes it more complex and presents more challenges for the proposed model to detect anomalies.
Based on
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8, we could conclude that: (1) the proposed model obtains a higher AUC of 82.1% on the complicated ShanghaiTech; (2) on the UCSD, Avenue, and ShanghaiTech databases, it produces an AUC performance boost over the baseline of 1.1%, 0.3%, and 4.6%, respectively; (3) the combination of the various training datasets demonstrates the efficacy of the proposed method for learning and extracting spatiotemporal characteristics and its robustness for identifying anomalies under different conditions and scenarios for very large datasets; (4) the recent video anomaly CHAD dataset achieved the highest average AUC of 68% on Cam 1 and Cam 2, with a superiority of +8.6% and +1.2% for Cam 1 and Cam 2, respectively, over SOTA, and (5) the model demonstrated an outstanding ability to identify abnormal events and objects in videos compared to SOTA.
5.6. Case Studies with Visualizations
To gain further insight into the effectiveness of the proposed model,
Figure 7,
Figure 8,
Figure 9,
Figure 10 and
Figure 11 display the anomaly scores for different videos from the three datasets with some key normal and abnormal frames, with the anomaly ground truth shaded in pink. Two different anomaly scores from each of the Ped2 and Avenue datasets are displayed, as the two datasets represent single-scene videos (taken from a fixed position camera from a fixed view angle). For the ShanghaiTech dataset, there are thirteen distinct scenarios; hence, we display three different scenes with two situations for each. In addition, we show two different videos for each Cam 1 scene and Cam 2 scene from the CHAD dataset. The proposed approach responds successfully to anomaly event occurrences that are shown by the rising anomaly scores during the anomaly periods and the falling anomaly scores for the regular situations.
For instance,
Figure 7 depicts the anomaly scores for test videos 02 and 04 from the UCSD-Ped dataset. When the cyclist’s anomalous event, shaded in pink, happened in
Figure 7a, the score increased and remained high until it reached the end of the anomaly period. Furthermore,
Figure 7b shows how the anomaly score rises as soon as the anomaly object, the cart, enters the picture and stays high for the duration that the anomaly objects, the cart and the cyclist, remain in the scene. Moreover,
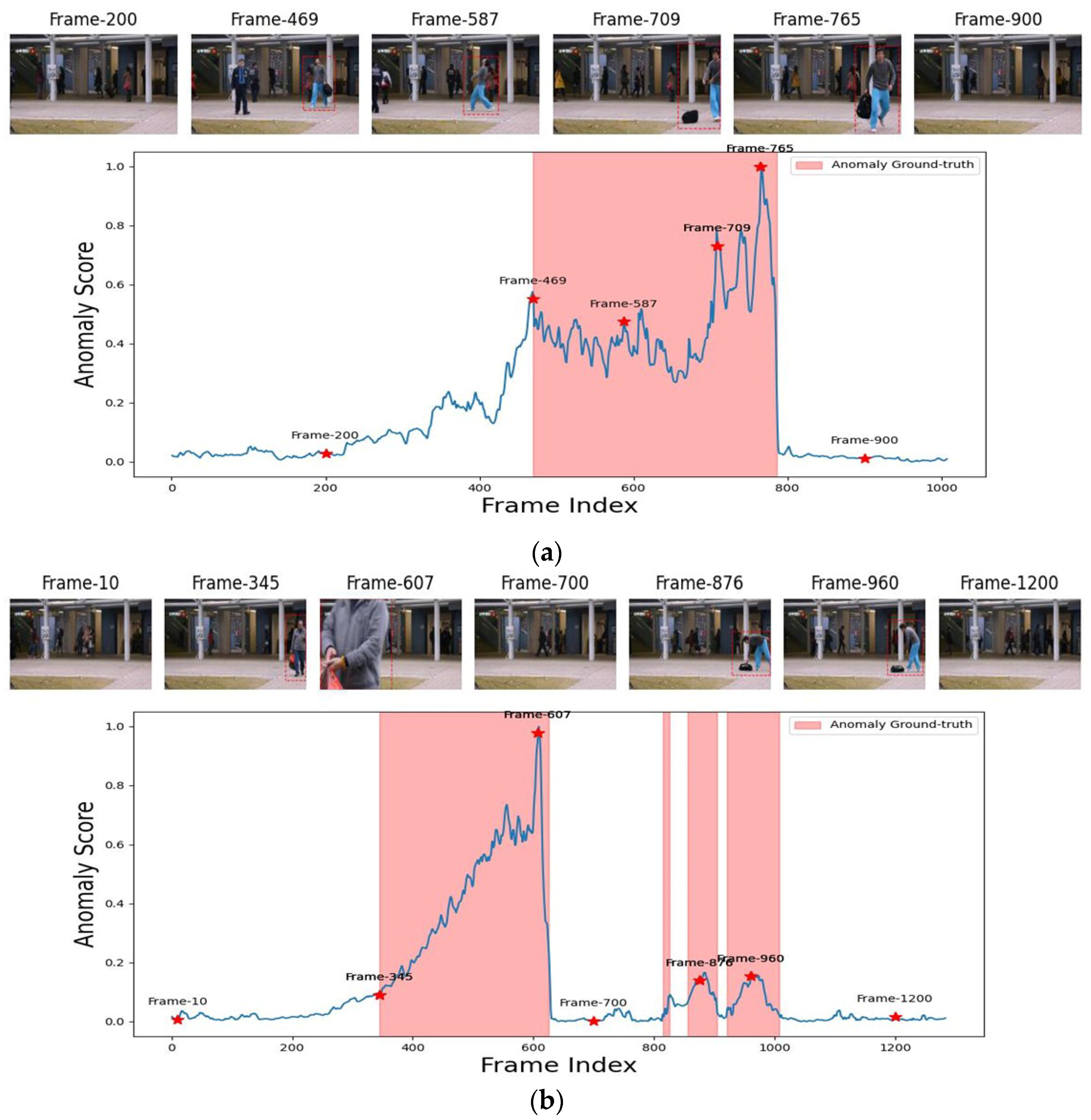
Figure 8 displays the anomaly scores for test clips 05 and 06 from the Avenue dataset. The anomaly score in
Figure 8a indicates that the anomalous event “playing with the bag” is correctly identified. The anomalous events in test video 06 (throwing bag and wrong direction) may be seen in
Figure 8b during four periods, three of which are very short and represent a guy throwing a bag. Despite this, the proposed model was able to identify the anomalous times.
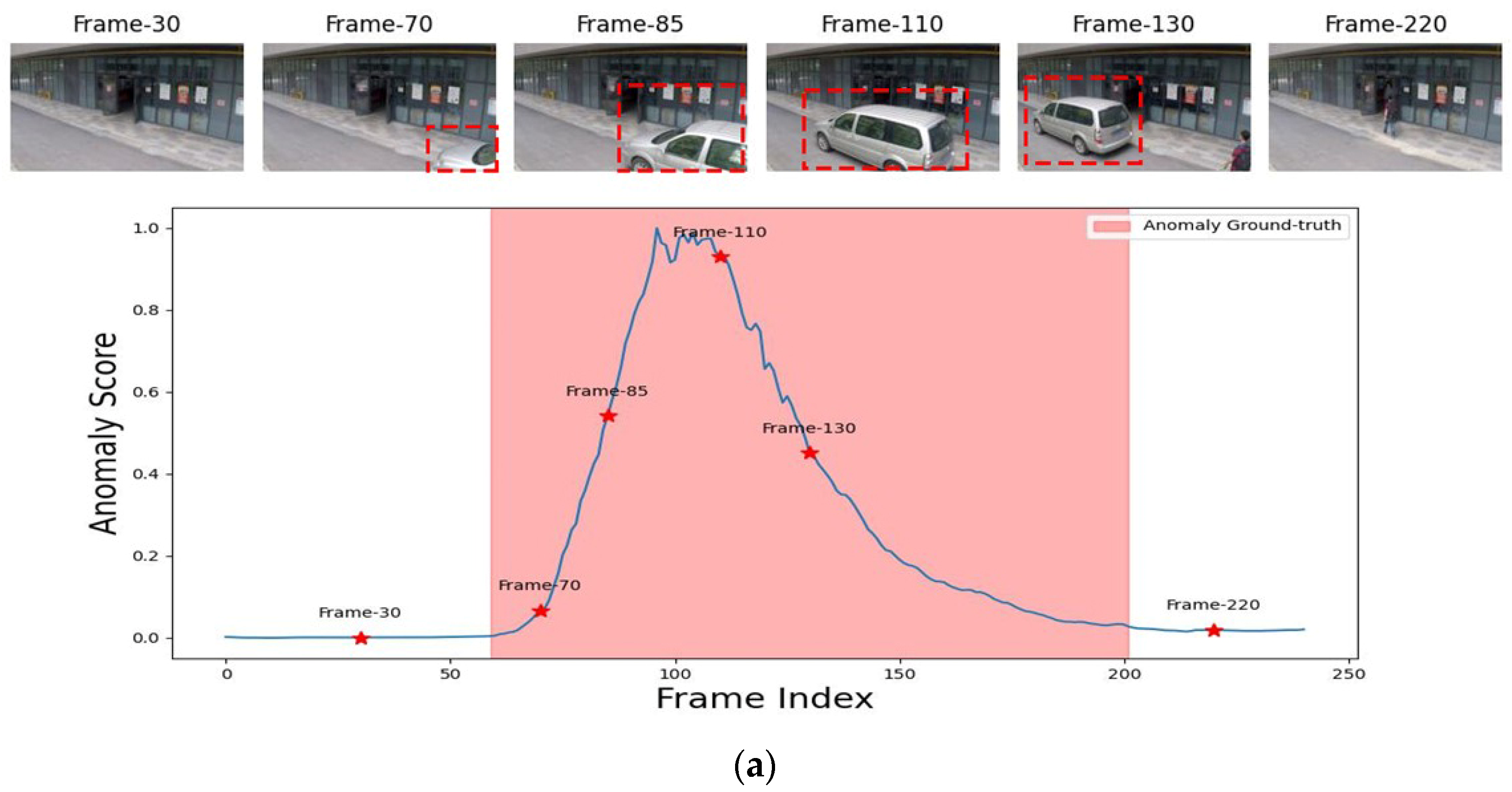
Figure 9,
Figure 10 and
Figure 11 represent the anomaly scores for test videos from three distinct scenes from the challenging ShanghaiTech dataset. The anomaly scores in the figures demonstrate how the anomaly events/periods in every video were identified successfully with high scores. The presence of the motorcyclist in the scene raised the abnormality score in test video 0016 from scene 01, as shown in
Figure 9a, which is the same behavior that occurred in
Figure 9b with the biker’s existence in test video 0177 from the same scene. For scene 03, two test video anomaly scores, 0031 and 0032, are shown in
Figure 10. The first shows a guy who hijacks the bag from his colleague and then starts chasing. In the latter, the anomalous event was represented by a person falling to the ground. As seen in
Figure 10a, the model was able to correctly identify the complex abnormal situation with a high anomaly score, in the same manner as for the anomalous period in
Figure 10b. In
Figure 11, which exhibits the anomaly scores with shaded ground truth for videos 0144 and 0147 from the Shanghai scene 06, the model optimally recognized the unusually moving car on the sidewalk with extremely high scores, as shown in
Figure 11a. On the other hand,
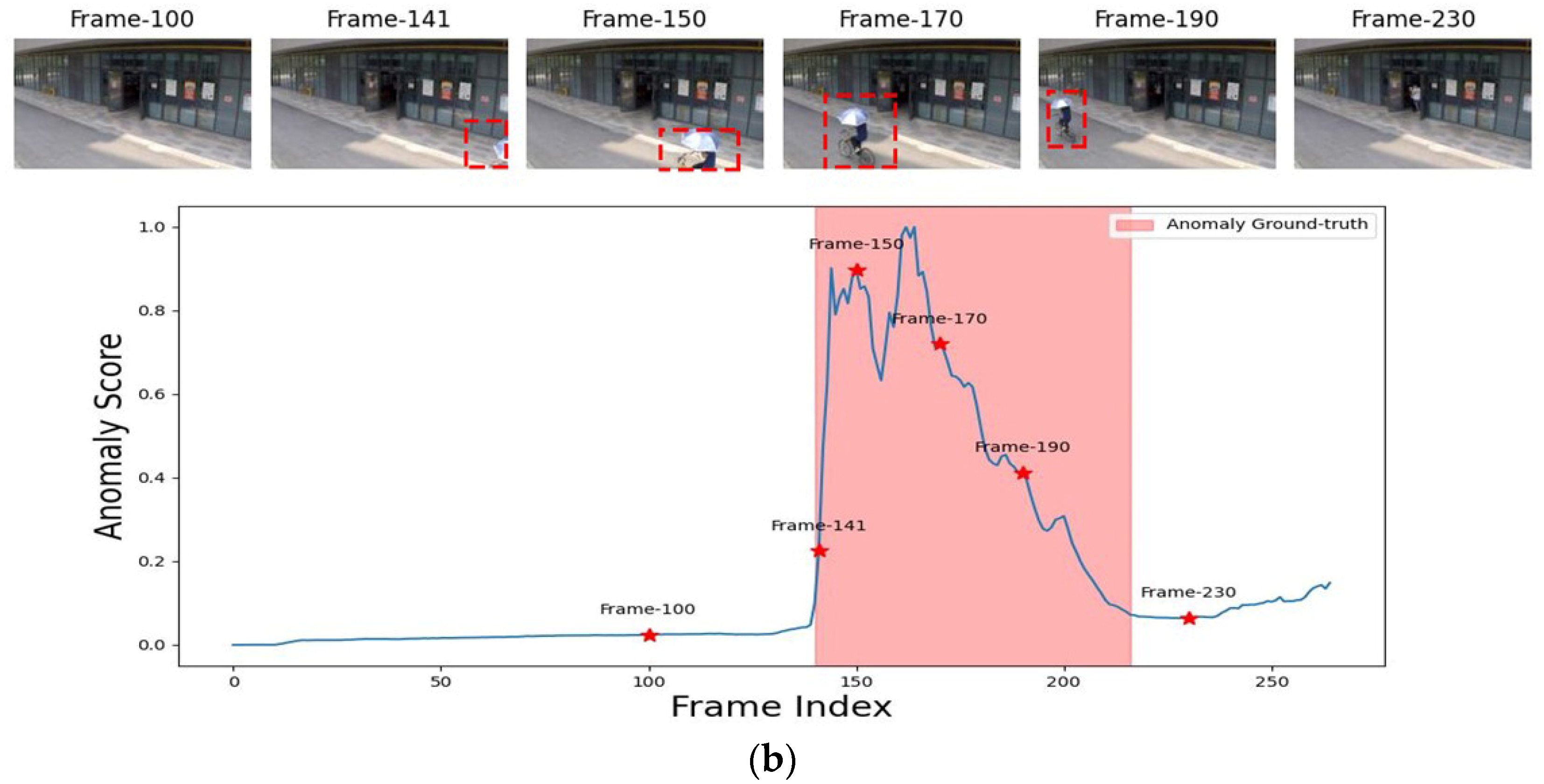
Figure 11b depicts a cyclist with an umbrella and shows that the anomaly score was extremely high when this anomalous event occurred. As a result, the above figures show that the model performed exceptionally well in detecting distinct anomalous events and objects in the three different datasets. It demonstrated its efficacy in differentiating between normal and abnormal events in videos by producing high anomaly scores for anomalous intervals and low scores for normal ones.
The anomaly scores for four test videos with two scenarios from the CHAD dataset are displayed in
Figure 12 and
Figure 13. The figures depict that the proposed model was able to identify different abnormal events with high score values. The abnormal event of “biking” from the Test 1_066_1 video of the CHAD-Cam 1 scenario is represented in
Figure 12a, which shows that the abnormal event was successfully recognized. The “falling” and “running” events from the Test 1_084_1 movie of the same situation, as seen in
Figure 12b, were also recognized with strong anomaly scores in the same way. For Test 2_077_1 from CHAD-Cam 2, two people appeared to fight, “one is strangling the other”, then they chased, and the model was able to detect the whole complicated event, as shown in
Figure 13a. A runner who appeared in
Figure 13b, from the Test 2_095_1 video, was identified correctly with high anomaly scores, even though it appears as a small object, far from the camera position, and intertwined with objects in the scene background.
On the other hand, it was found that some ShanghaiTech test videos contain badly annotated frames (minor falsely annotated frames), such as frames No. 151, 157, and 162 in video 06_0144, frame No. 184 in video 06_0147, and frame No. 72 in video 06_0150. In addition to frame No. 161 in video 03_0033 and frame No. 202 in video 02_0164, falsely annotated frames were excluded from the test. Accordingly, these videos need to be revised by the dataset authors.
It is worth noting that the introduced approach does not perform optimally on all three datasets for the following reasons: the three datasets differ significantly in terms of shooting situations, colors, and perspectives, making it challenging for a system to produce comparable results across all datasets. Moreover, ViTs do not have CNNs’ inherent inductive biases, and they frequently need a massive amount of data to be trained efficiently. However, they can outperform CNNs when they are trained, particularly on large-scale datasets. The proposed ViT + STRA-attention model proved this point when mixed combinations of the datasets were used as the detection accuracy improved despite the diverse natures of the three datasets, which include various illumination and environmental conditions, various view angles, different scenes with different quality and resolutions, and the large number and diversity of anomalous events and objects in the datasets. Moreover, CNNs use convolutional layers, assuming the spatial hierarchies and localizations in images. This strong inductive bias allows CNNs to learn well from very limited datasets by using the intrinsic structure of visual data. In contrast, ViTs use self-attention processes to identify associations between patches in pictures by treating them as a succession of patches. Because it makes no assumptions about the intrinsic order or locality among the patches, this method has less inductive bias concerning the spatial structure of images. This gives ViTs great flexibility and not only enables them to extract intricate relationships, but also implies that for them to learn these patterns efficiently, more data are needed. This reduced inductive bias might cause underfitting for the smaller training datasets, whereby the ViT might not pick up enough information about the relevant characteristics of the pictures to operate effectively on unobserved data. In addition, we believe that the proposed model is more sophisticated and thus able to perform on small datasets such as the UCSD-Ped2, since it consists of low-quality grey frames, however, it achieved promising results of 95.6%. On the other hand, a better performance was obtained with the much larger Avenue dataset, making it superior to the Shanghai dataset which is considered the largest dataset available for VAD. Additionally, VIT + STR attention enhances the detection of larger datasets (i.e., Shanghai and Avenue) compared to the baseline model for the different combinations of the datasets, as shown in
Table 6. We call the combined versions ‘very large datasets’. In addition, it outperforms the SOTA techniques for the Cam 1 and Cam 2 data from the largest CHAD dataset with AUC scores of 71.8% and 64.2%, respectively. This shows the ability of the proposed model to extract robust, effective, and complex features and successfully identify anomalies with high scores from extremely diverse videos captured from different environments, with different qualities, and in different conditions that contain a wide range of various anomaly events and types.
However, we think that by taking into account the following issues and constraints, our framework might be improved in the future:
We could benefit from the recent memory-augmented neural networks (MANNs) to improve the suggested approach. MANNs are networks that preserve a larger collection of representations throughout time by selectively storing and updating only the relevant information. Hence, these networks may be augmented in our model to improve its capacity to recognize more subtle and complicated patterns. Memory networks have efficient scaling abilities and adaptability to various scenarios and circumstances. Further, this could lead to high-accuracy anomaly detection for larger datasets, which is our focus in this research, and enhance anomaly detection in videos for real-time systems. As in real-world applications, the characteristics of anomalies could vary over time; hence, scaling capacity and adaptability are essential. Consequently, normal and abnormal behaviors may be distinguished more precisely;
It is important to note that the thorough results of each threshold are the basis for the proposed model’s performance evaluation. Nevertheless, only the optimal threshold may be chosen for real-world use. A dynamic threshold-based anomaly detection technique was presented by Jia et al. [
93], which offers an alternative viewpoint on how to improve our approach;
Since not every frame in a video is worth detecting, frame summarization may also improve. More video data can be analyzed simultaneously and processing power can be conserved if the frames that are more likely to be abnormal can be identified. The literature [
94,
95] motivated our investigation into future work.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}