
A Linear Interpolation and Curvature-Controlled Gradient Optimization Strategy Based on Adam



Abstract
1. Introduction
2. LCMAdam Algorithm Design
2.1. Adam Optimization Algorithm
2.2. Curvature-Controlled Gradient Strategy
2.3. Linear Interpolation Strategy
2.4. LCMAdam Algorithm
| Algorithm 1: LCMAdam |
| , regularization constant , perform End for Return |
3. Experimental Design and Analysis of Results
3.1. Experimental Environment Configuration
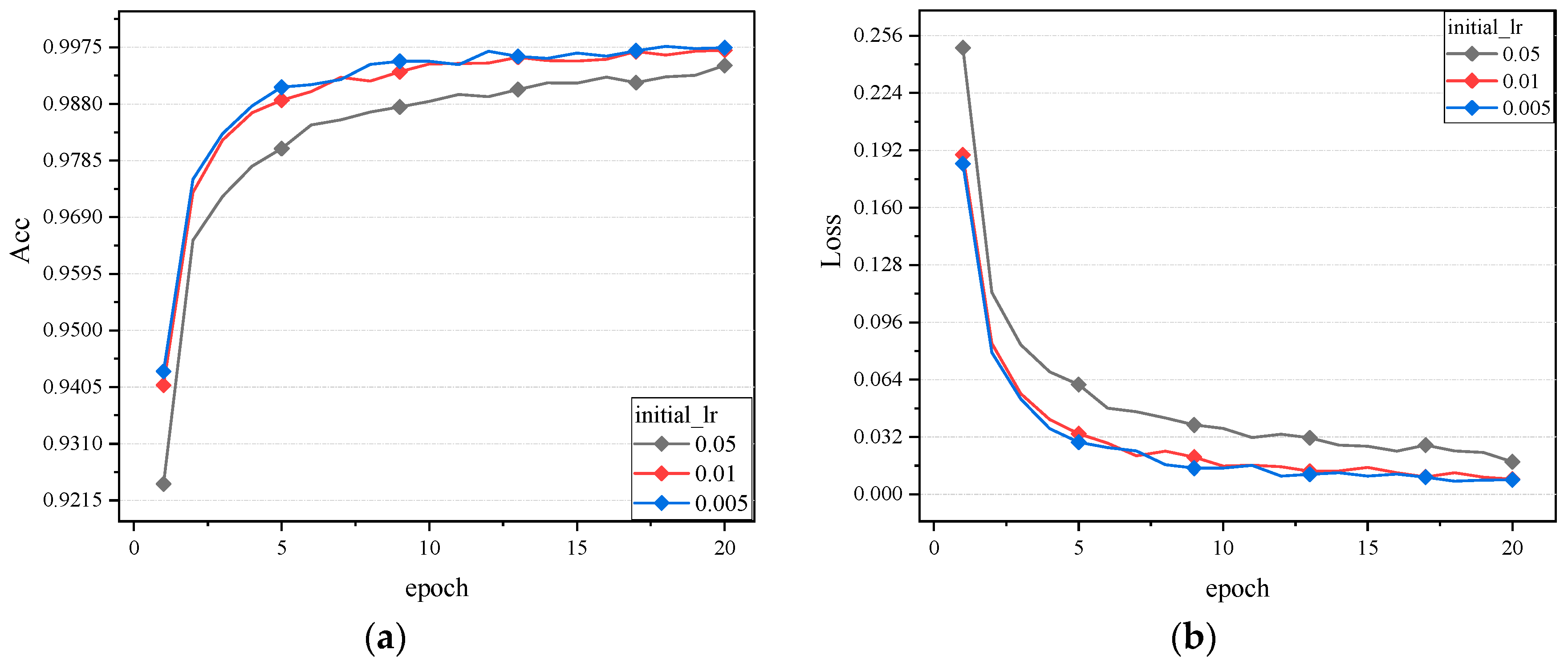
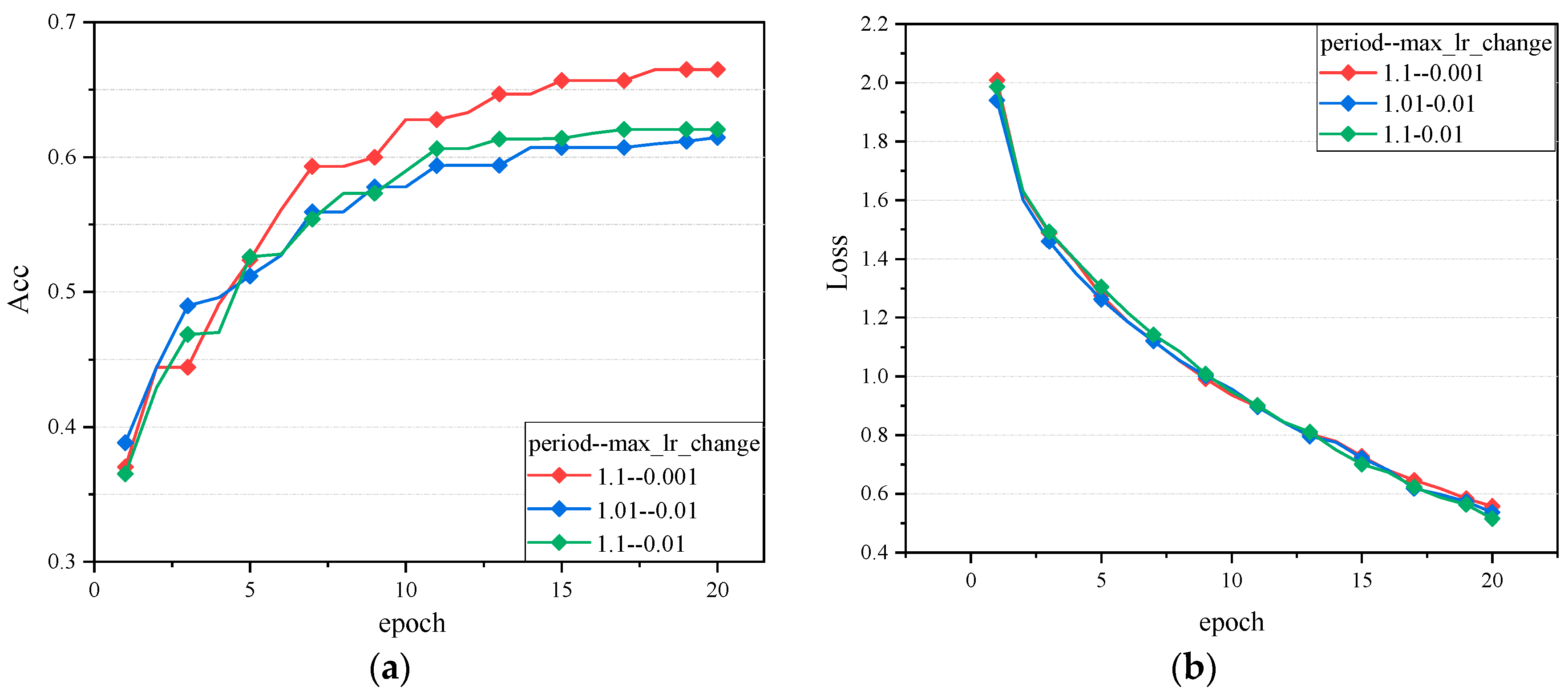
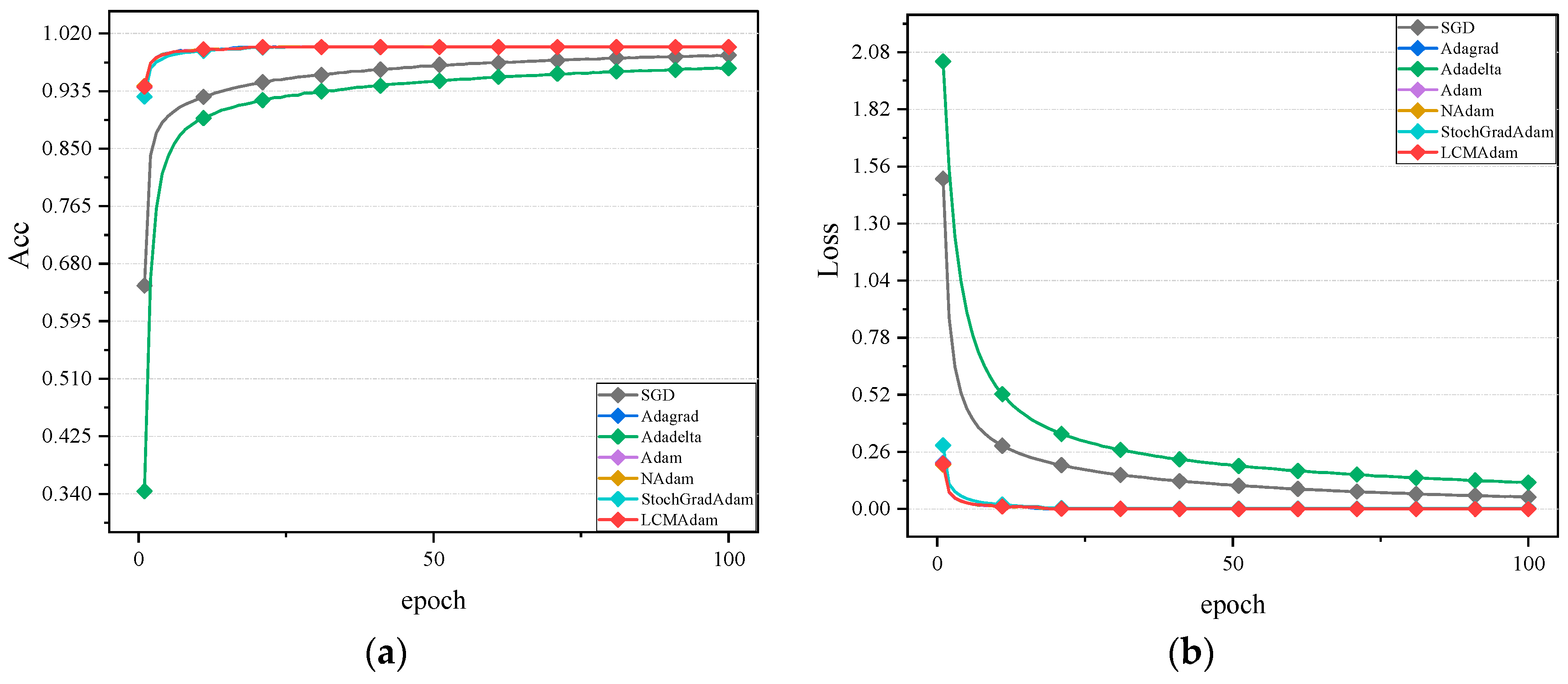
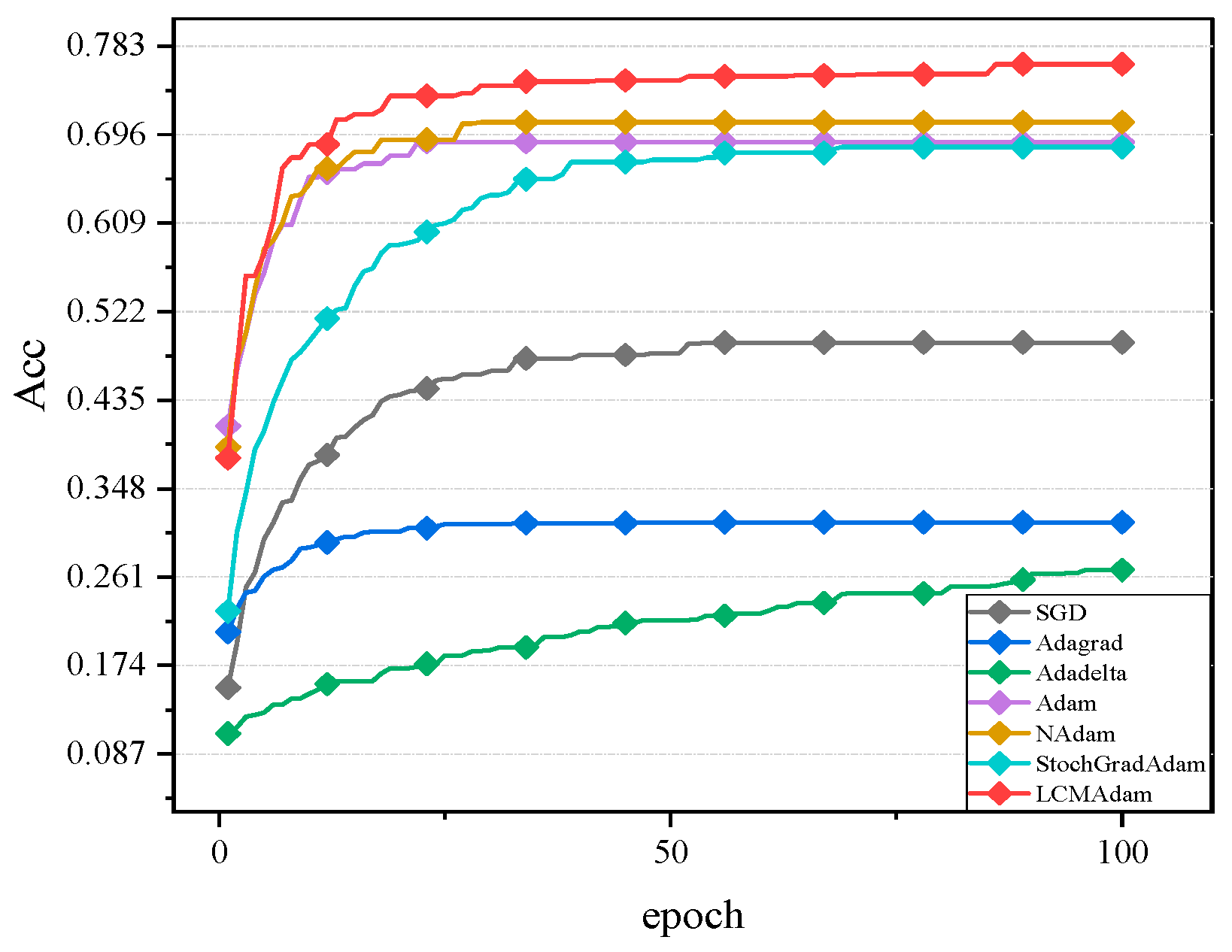
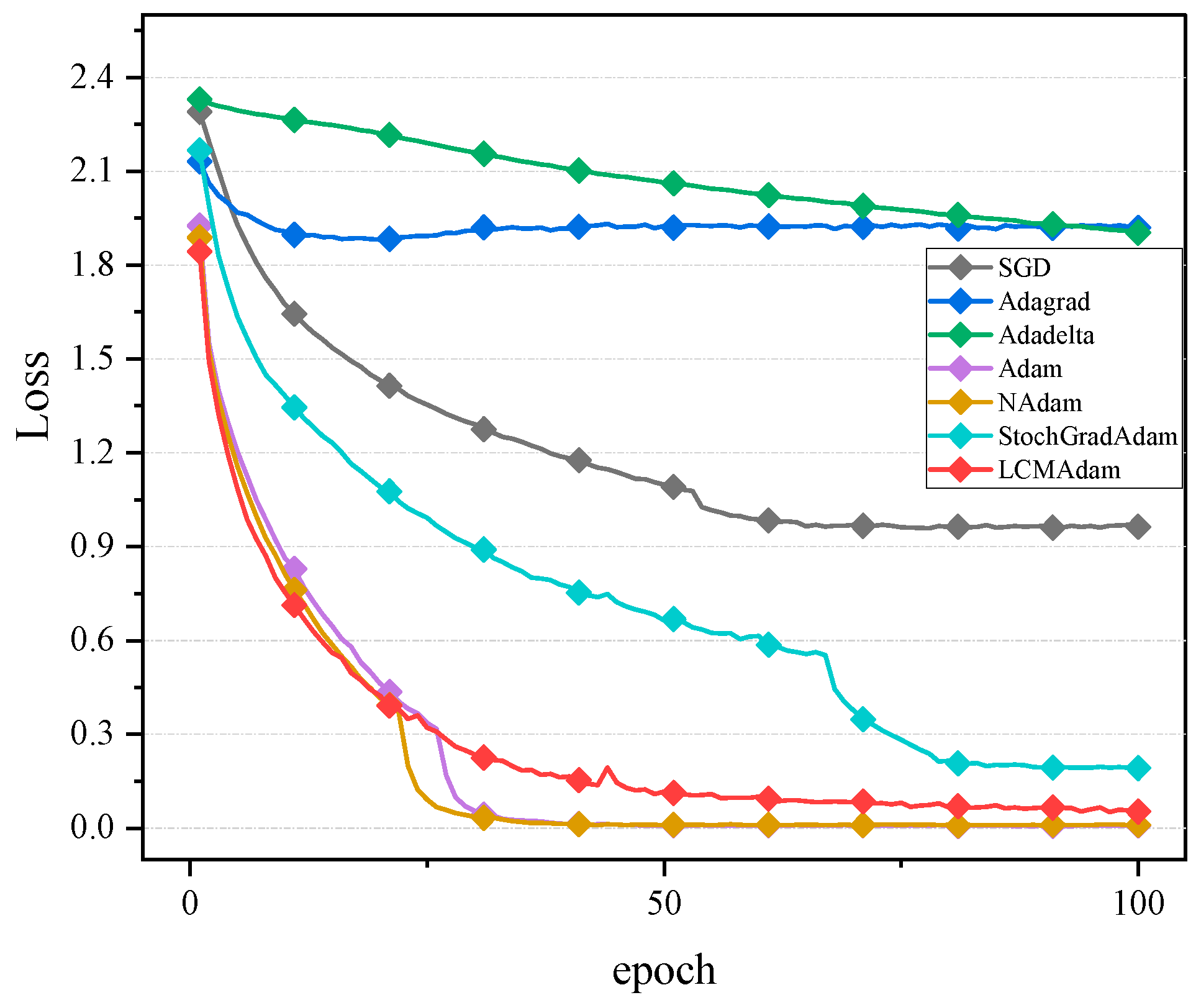
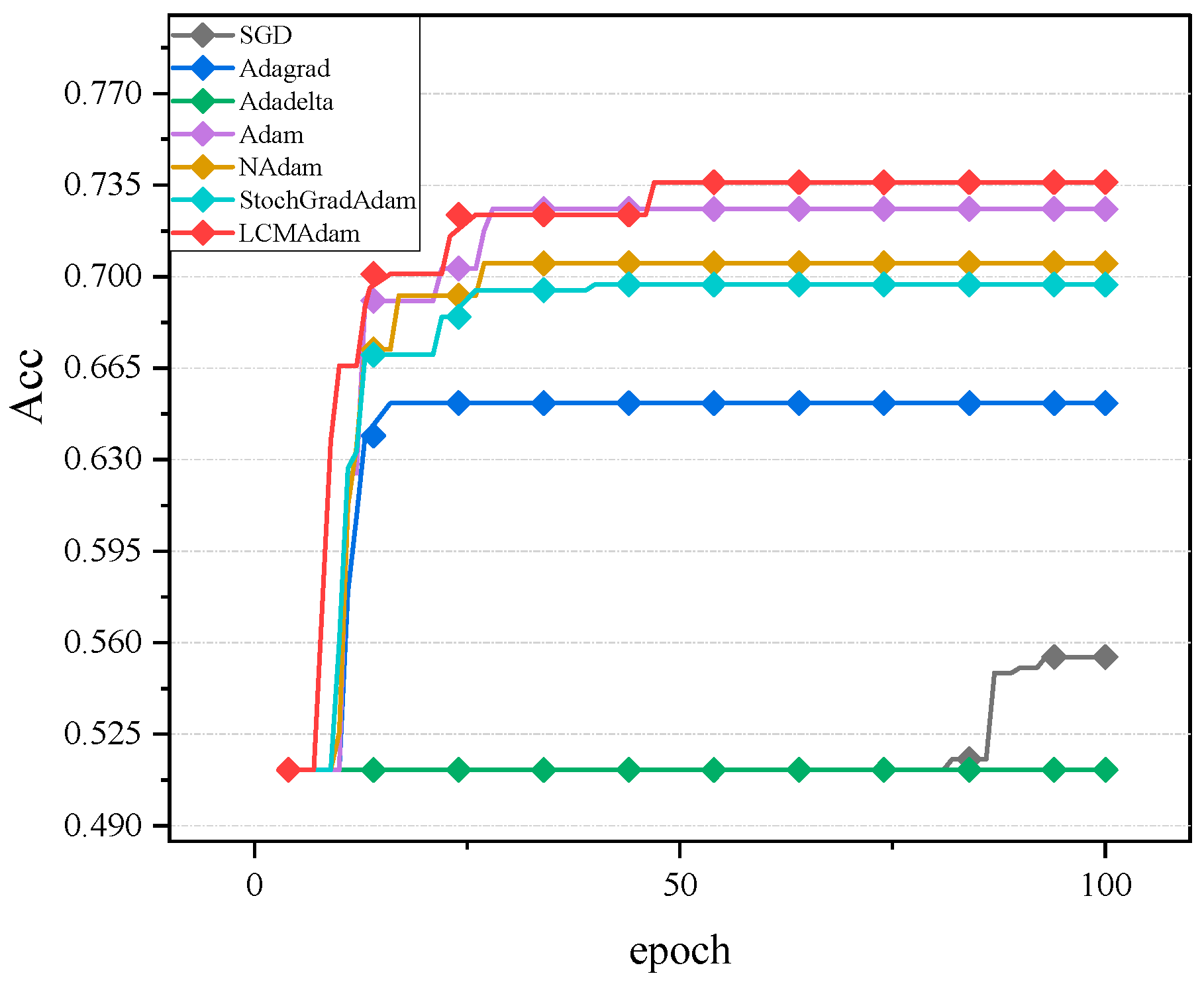
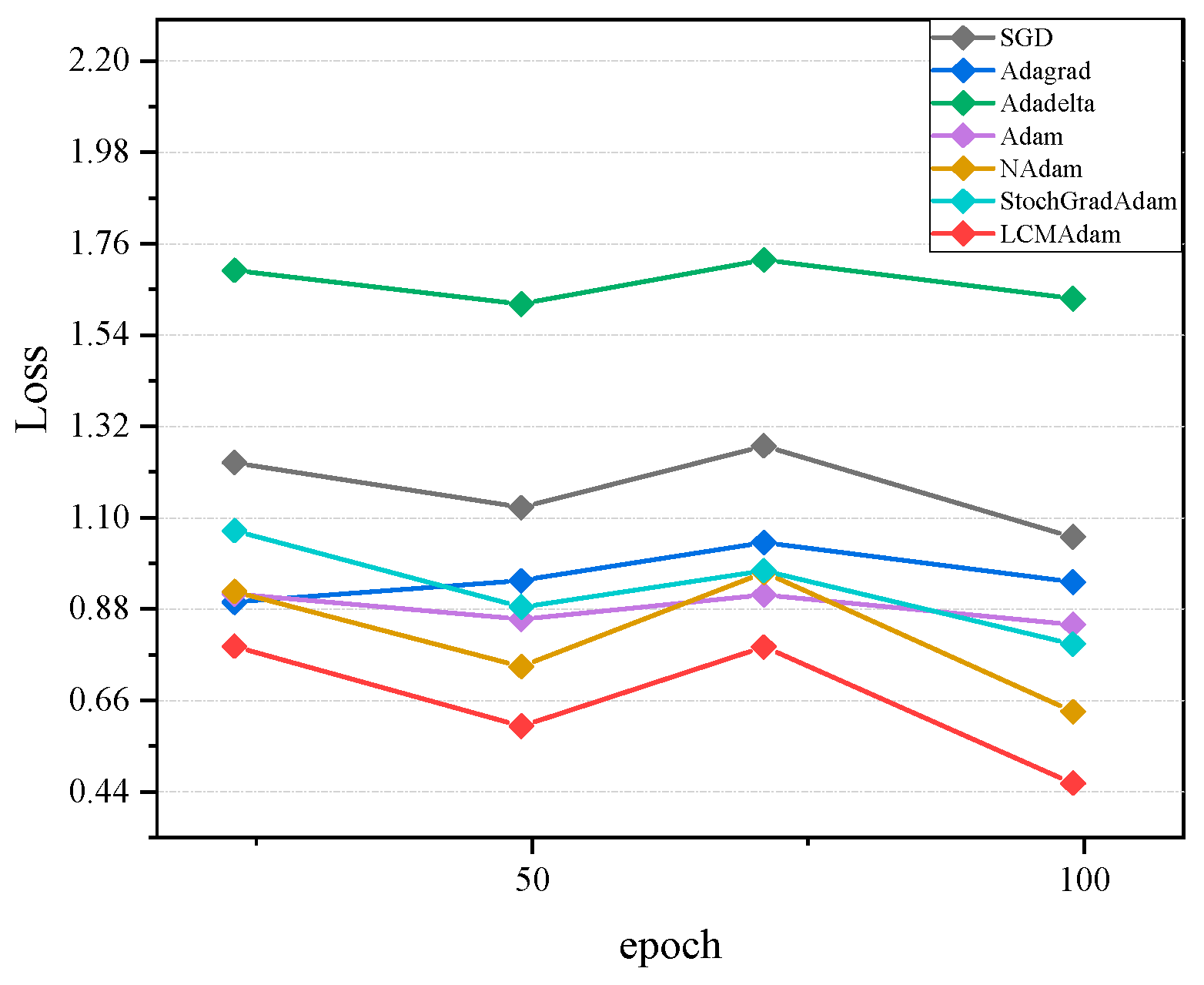
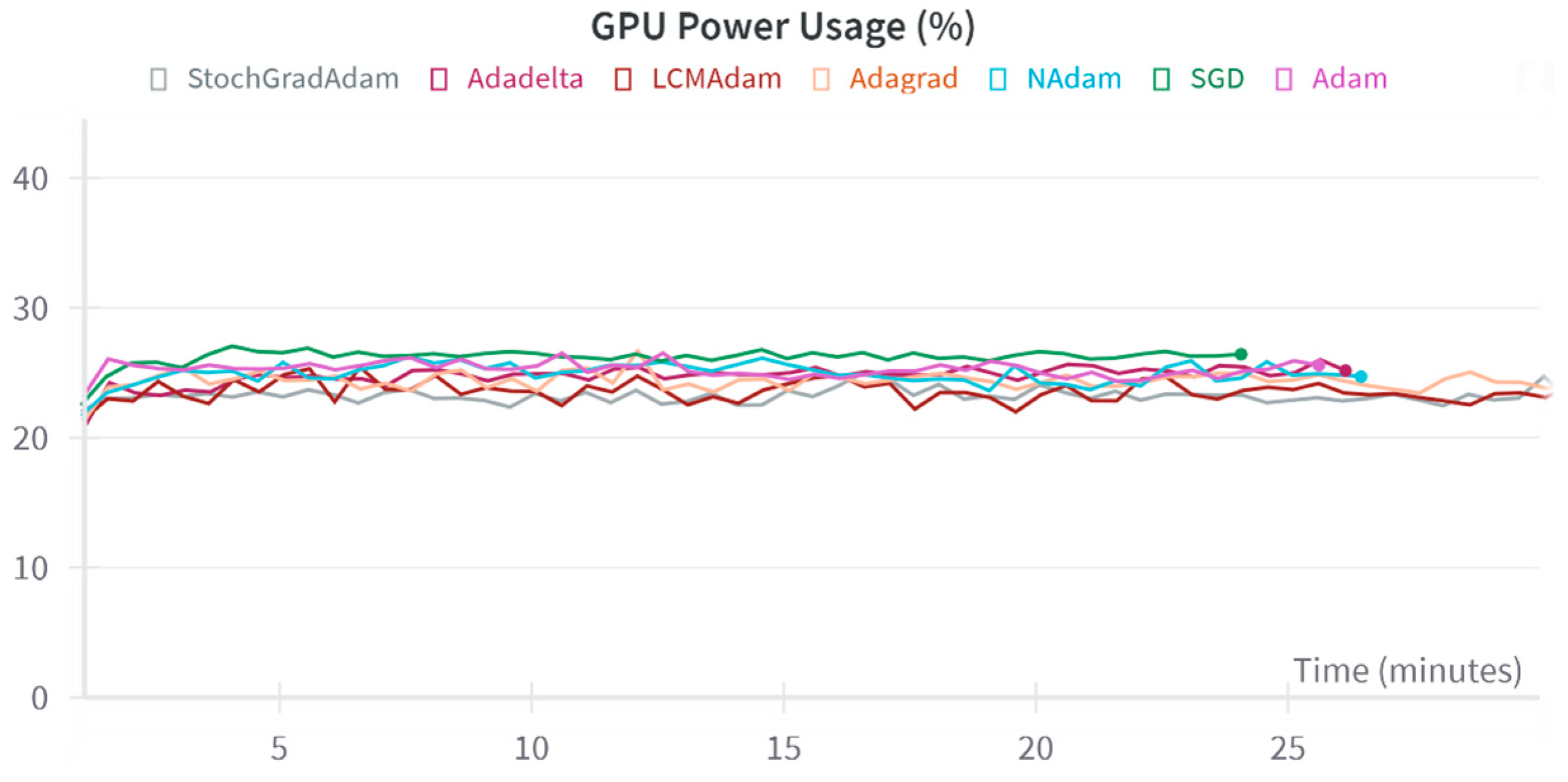
3.2. Experimental Results and Analysis
- (1)
- Algorithm selection: the SGD, Adagrad, Adadelta, Adam, Nadam, StochGradAdam, and LCMAdam algorithms were selected for comparison.
- (2)
- Number of training rounds: to ensure a fair comparison, the number of training rounds (Epoch) in the experiment was set to 100.
- (3)
- Batch size: to maintain consistency in the experiment, we set the batch size to 128.
- (4)
- Learning rate setting: the initial learning rate of all algorithms was set to 0.001. The maximum learning rate of the LCMAdam algorithm was set to 0.005, the minimum learning rate was set to 0.001, and the maximum change of learning rate was set to 0.001.
- (5)
- Other hyperparameters: the cycle length (period) in the LCMAdam optimizer was set to 1.1.
- (6)
- Multiple experiments: since the LCMAdam algorithm needed to adjust the cycle length and the maximum variation in the learning rate, we conducted multiple experiments on each dataset and selected the best results as the experimental results.
- (7)
- Experimental results: 17 comparative experiments were conducted on MNIST, CIFAR10, and Stomach datasets, and the average of the 17 results was taken as the final result to reflect the advantages of the LCMAdam algorithm in solving the Adam algorithm problem and improving the generalization ability.
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| LCMAdam | Linear Curvature Momentum Adam |
| GR | correction factor |
| initial_lr | maximum learning rate |
| min_lr | minimum learning rate |
| max_lr_change | maximum variation in the learning rate |
| period | cycle length |
References
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2017. [Google Scholar] [CrossRef]
- Chakrabarti, K.; Chopra, N. A Control Theoretic Framework for Adaptive Gradient Optimizers in Machine Learning. arXiv 2023. [Google Scholar] [CrossRef]
- Ding, K.; Xiao, N.; Toh, K.-C. Adam-family Methods with Decoupled Weight Decay in Deep Learning. arXiv 2023. [Google Scholar] [CrossRef]
- Liu, M.; Zhang, W.; Orabona, F.; Yang, T. Adam+: A Stochastic Method with Adaptive Variance Reduction. arXiv 2020. [Google Scholar] [CrossRef]
- Asadi, K.; Fakoor, R.; Sabach, S. Resetting the Optimizer in Deep RL: An Empirical Study. arXiv 2023. [Google Scholar] [CrossRef]
- Chen, A.C.H. Exploring the Optimized Value of Each Hyperparameter in Various Gradient Descent Algorithms. arXiv 2022. [Google Scholar] [CrossRef]
- Yuan, W.; Gao, K.-X. EAdam Optimizer: How ε Impact Adam. arXiv 2020. [Google Scholar] [CrossRef]
- Xia, L.; Massei, S. AdamL: A fast adaptive gradient method incorporating loss function. arXiv 2023. [Google Scholar] [CrossRef]
- Tian, R.; Parikh, A.P. Amos: An Adam-style Optimizer with Adaptive Weight Decay towards Model-Oriented Scale. arXiv 2022. [Google Scholar] [CrossRef]
- Heo, B.; Chun, S.; Oh, S.J.; Han, D.; Yun, S.; Kim, G.; Uh, Y.; Ha, J.-W. AdamP: Slowing Down the Slowdown for Momentum Optimizers on Scale-invariant Weights. arXiv 2021. [Google Scholar] [CrossRef]
- Dozat, T. Incorporating Nesterov Momentum into Adam. 2016. Available online: https://openreview.net/forum?id=OM0jvwB8jIp57ZJjtNEZ (accessed on 6 April 2024).
- Zhang, C.; Shao, Y.; Sun, H.; Xing, L.; Zhao, Q.; Zhang, L. The WuC-Adam algorithm based on joint improvement of Warmup and cosine annealing algorithms. Math. Biosci. Eng. MBE 2024, 21, 1270–1285. [Google Scholar] [CrossRef]
- Jiang, Y.; Liu, J.; Xu, D.; Mandic, D.P. UAdam: Unified Adam-Type Algorithmic Framework for Non-Convex Stochastic Optimization. arXiv 2023. [Google Scholar] [CrossRef]
- Pan, Y.; Li, Y. Toward Understanding Why Adam Converges Faster Than SGD for Transformers. arXiv 2023. [Google Scholar] [CrossRef]
- Shao, Y.; Fan, S.; Sun, H.; Tan, Z.; Cai, Y.; Zhang, C.; Zhang, L. Multi-Scale Lightweight Neural Network for Steel Surface Defect Detection. Coatings 2023, 13, 1202. [Google Scholar] [CrossRef]
- Shao, Y.; Zhang, C.; Xing, L.; Sun, H.; Zhao, Q.; Zhang, L. A new dust detection method for photovoltaic panel surface based on Pytorch and its economic benefit analysis. Energy AI 2024, 16, 100349. [Google Scholar] [CrossRef]
- Liu, H.; Tian, X. An Adaptive Gradient Method with Energy and Momentum. Ann. Appl. Math. 2022, 38, 183–222. [Google Scholar] [CrossRef]
- Hotegni, S.S.; Berkemeier, M.; Peitz, S. Multi-Objective Optimization for Sparse Deep Multi-Task Learning. arXiv 2024. [Google Scholar] [CrossRef]
- Yun, J. StochGradAdam: Accelerating Neural Networks Training with Stochastic Gradient Sampling. arXiv 2024. [Google Scholar] [CrossRef]
- Fakhouri, H.N.; Alawadi, S.; Awaysheh, F.M.; Alkhabbas, F.; Zraqou, J. A cognitive deep learning approach for medical image processing. Sci. Rep. 2024, 14, 4539. [Google Scholar] [CrossRef]
- Liu, Z.; Zhang, Z.; Lei, Z.; Omura, M.; Wang, R.-L.; Gao, S. Dendritic Deep Learning for Medical Segmentation. IEEECAA J. Autom. Sin. 2024, 11, 803–805. [Google Scholar] [CrossRef]
- Liu, C.; Fan, F.; Schwarz, A.; Maier, A. AnatoMix: Anatomy-aware Data Augmentation for Multi-organ Segmentation. arXiv 2024. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Software | Version |
|---|---|
| Python | 3.10 |
| Torch | 2.0.1 |
| Torchvision | 0.15.0 |
| Lightning | 2.1.2 |
| Cuda | Cu118 |
| Dataset | Number of Samples | Training Set | Test Set | Validation Set | Category | Data Characteristics |
|---|---|---|---|---|---|---|
| MNIST | 70,000 | 55,000 | 5000 | 10,000 | 10 | Image size unification, data diversity, moderate data volume |
| CIFAR10 | 60,000 | 45,000 | 5000 | 10,000 | 10 | RGB image, relatively small scale, small image size |
| Stomach | 1885 | 900 | 485 | 500 | 8 | RGB image, few categories, recognition difficulty |
| Dataset | Optimization Algorithm | Accuracy | Loss |
|---|---|---|---|
| MNIST | SGD | 97.18% | 0.092 |
| Adagrad | 98.68% | 0.067 | |
| Adalelta | 96.42% | 0.1297 | |
| Adam | 98.64% | 0.060 | |
| NAdam | 98.44% | 0.0638 | |
| StochGradAdam | 98.11% | 0.0695 | |
| LCMAdam | 98.49% | 0.060 | |
| CIFAR10 | SGD | 48.32% | 1.466 |
| Adagrad | 29.87% | 1.95 | |
| Adalelta | 25.97% | 1.973 | |
| Adam | 68.49% | 1.22 | |
| NAdam | 69.85% | 1.685 | |
| StochGradAdam | 69.06% | 1.032 | |
| LCMAdam | 75.20% | 1.28 | |
| Stomach | SGD | 57.60% | 1.171 |
| Adagrad | 69.99% | 0.9581 | |
| Adalelta | 56.00% | 1.665 | |
| Adam | 74.20% | 0.883 | |
| NAdam | 74.80% | 0.817 | |
| StochGradAdam | 70.20% | 0.9307 | |
| LCMAdam | 76.80% | 0.66 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, H.; Zhou, W.; Shao, Y.; Cui, J.; Xing, L.; Zhao, Q.; Zhang, L. A Linear Interpolation and Curvature-Controlled Gradient Optimization Strategy Based on Adam. Algorithms 2024, 17, 185. https://doi.org/10.3390/a17050185
Sun H, Zhou W, Shao Y, Cui J, Xing L, Zhao Q, Zhang L. A Linear Interpolation and Curvature-Controlled Gradient Optimization Strategy Based on Adam. Algorithms. 2024; 17(5):185. https://doi.org/10.3390/a17050185
Chicago/Turabian StyleSun, Haijing, Wen Zhou, Yichuan Shao, Jiaqi Cui, Lei Xing, Qian Zhao, and Le Zhang. 2024. "A Linear Interpolation and Curvature-Controlled Gradient Optimization Strategy Based on Adam" Algorithms 17, no. 5: 185. https://doi.org/10.3390/a17050185
APA StyleSun, H., Zhou, W., Shao, Y., Cui, J., Xing, L., Zhao, Q., & Zhang, L. (2024). A Linear Interpolation and Curvature-Controlled Gradient Optimization Strategy Based on Adam. Algorithms, 17(5), 185. https://doi.org/10.3390/a17050185