

Research on a Fast Image-Matching Algorithm Based on Nonlinear Filtering
Abstract
1. Introduction
2. Theoretical Analysis
2.1. Nonlinear Diffusion Filtering
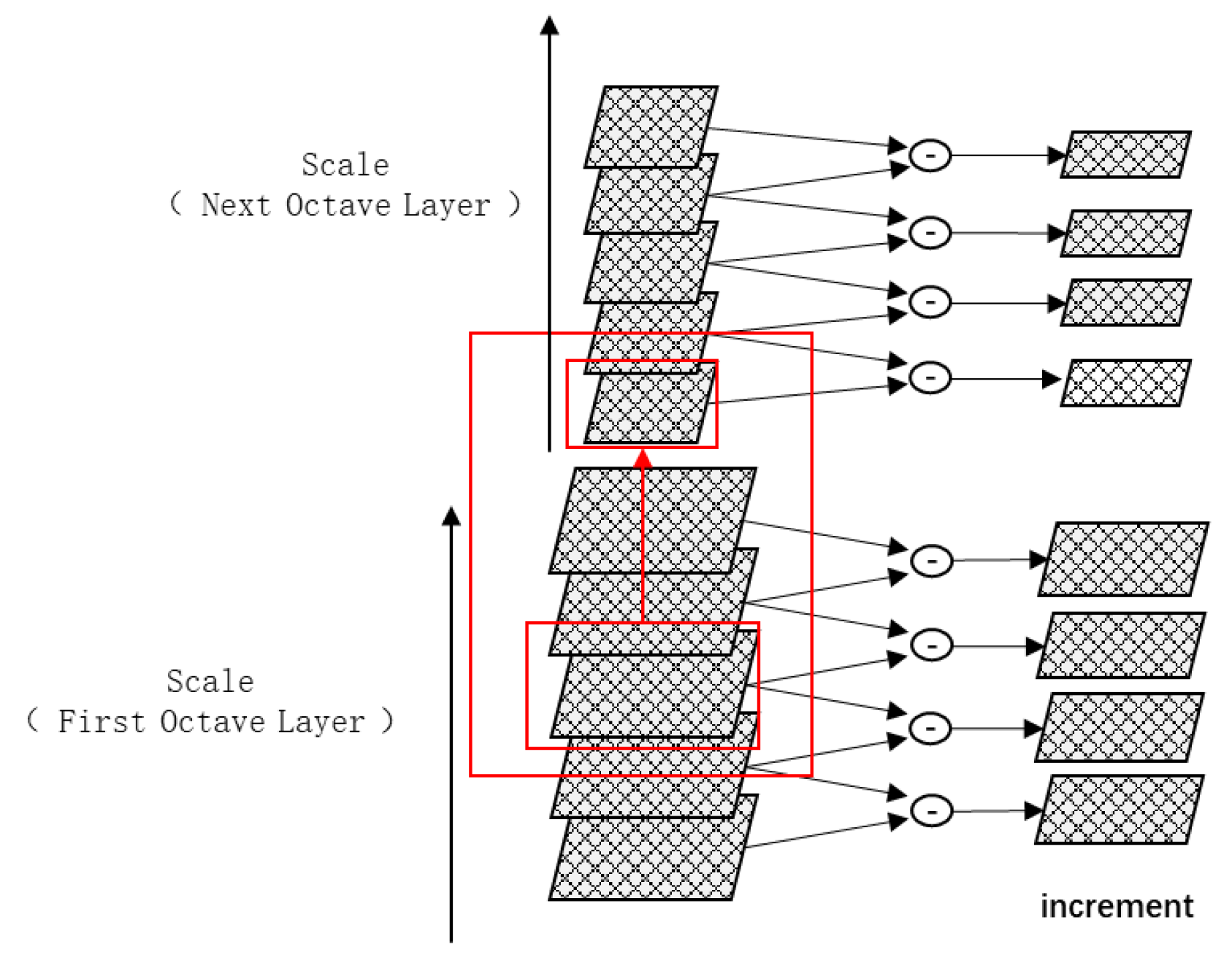
2.2. Downsampling
2.3. BRIEF Descriptor
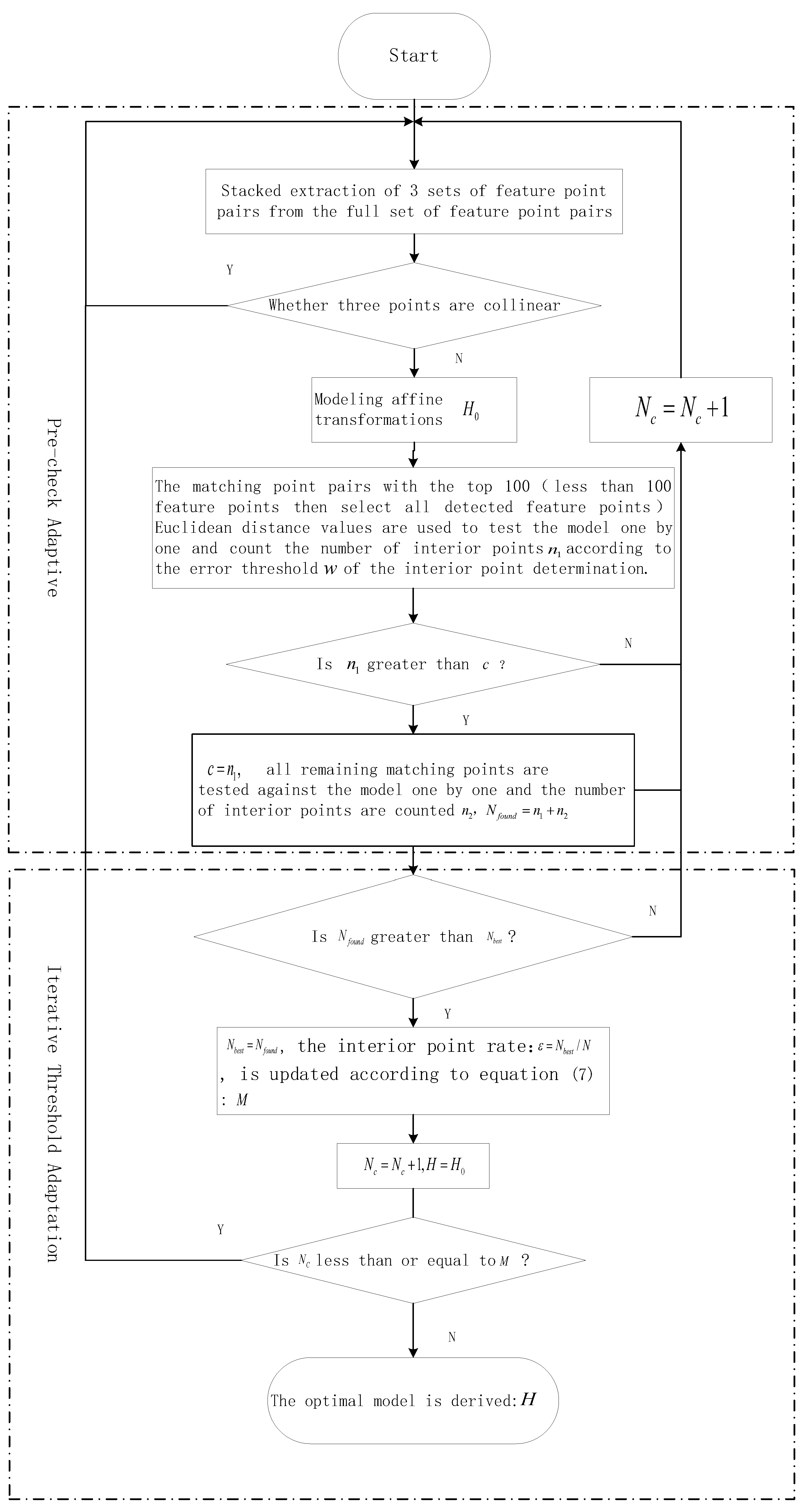
2.4. Adaptive RANSAC Algorithm
3. Experimental Results and Analysis
3.1. Image Information Comparison and Evaluation
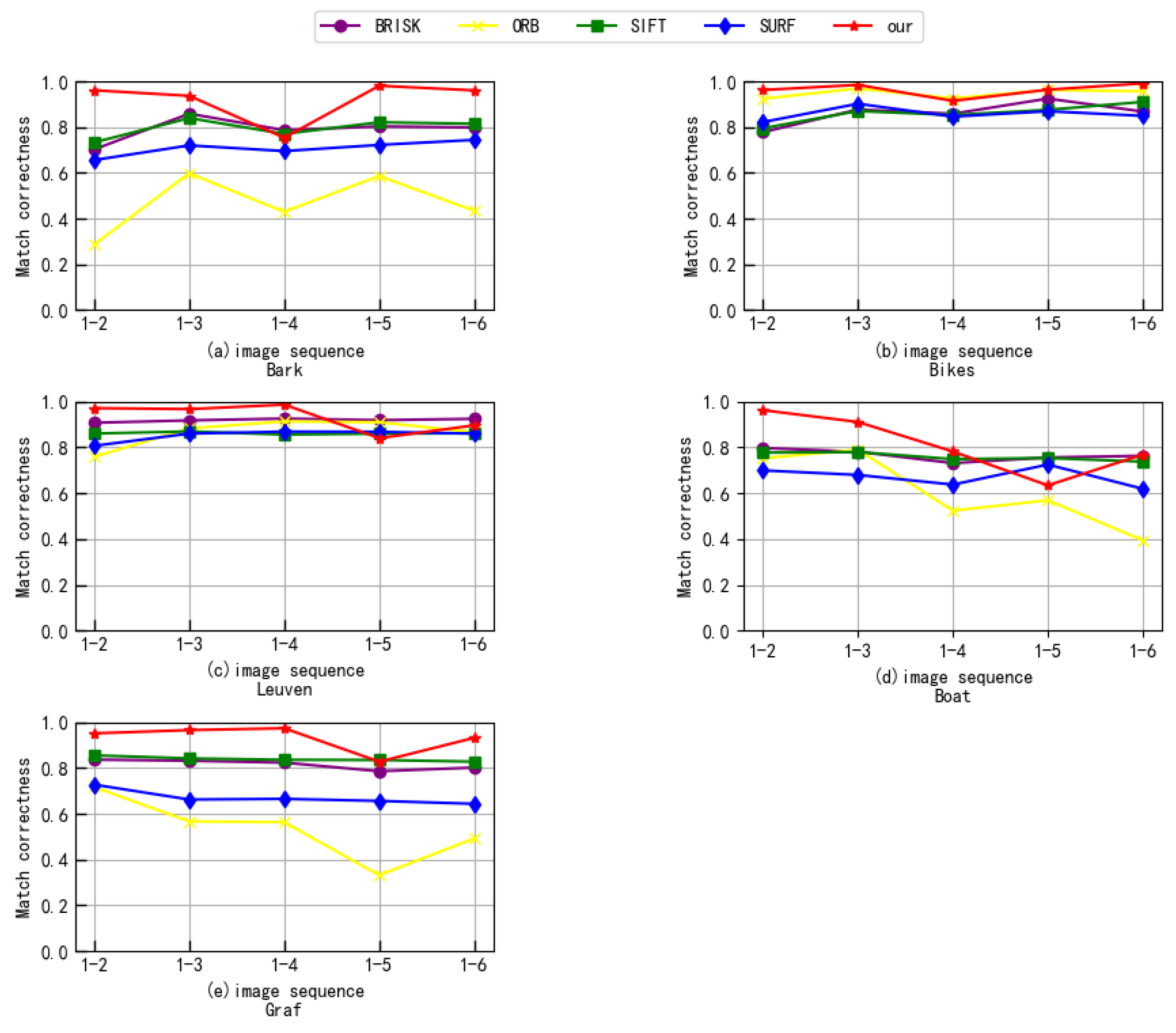
3.2. Robustness Evaluation
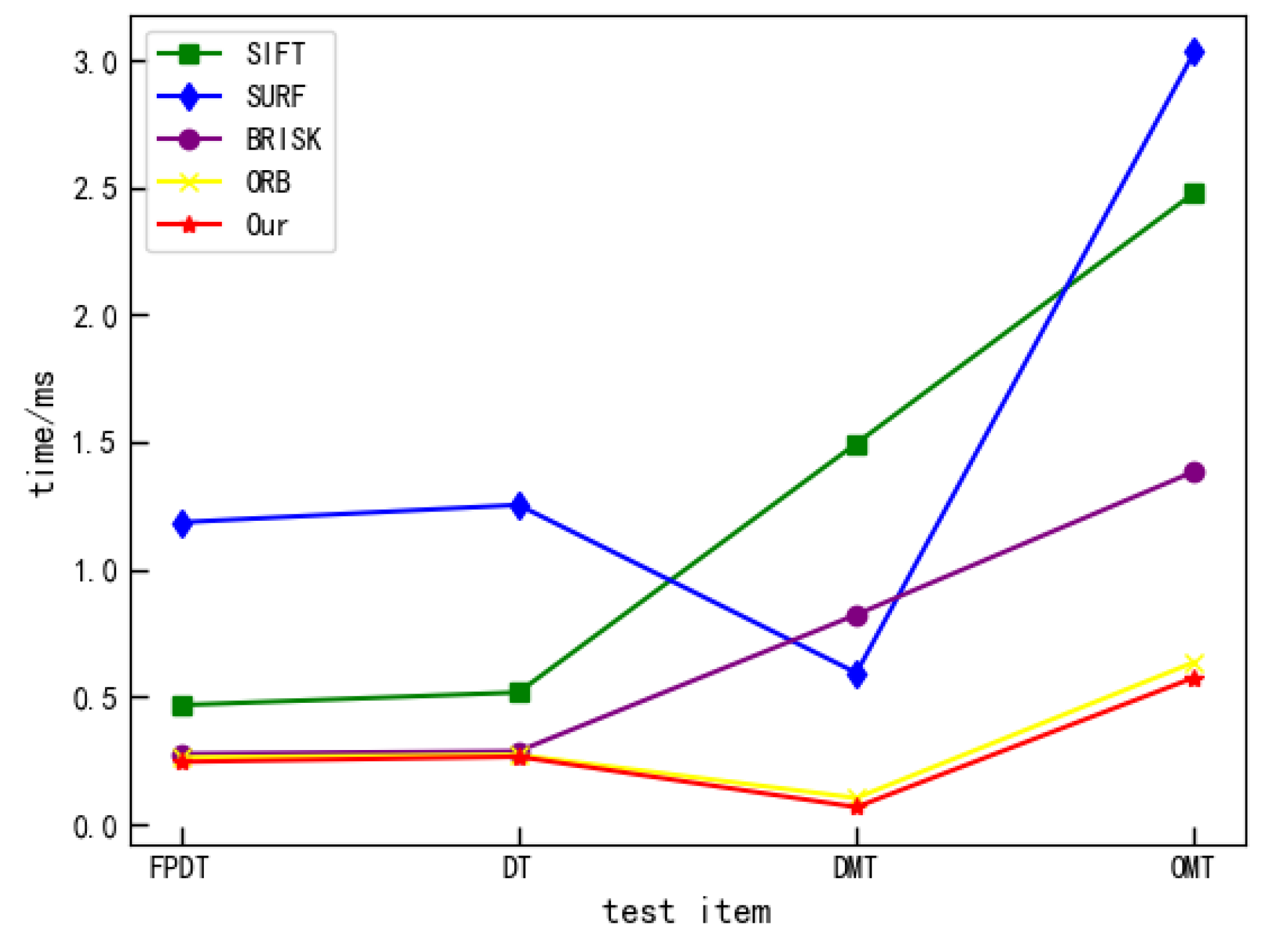
3.3. Real-Time Evaluation
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Huang, Y. Research on Matching Method Based on Time-Varying Images. Master’s Thesis, Institute of Remote Sensing and Digital Earth, Chinese Academy of Sciences, University of Chinese Academy of Sciences, Beijing, China, 2018. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Mikolajczyk, K.; Schmid, C. A Performance Evaluation of Local Descriptors. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 1615–1630. [Google Scholar] [CrossRef] [PubMed]
- Rublee, E.; Rabaud, V.; Konolige, K.; Bradski, G. ORB: An efficient alternative to SIFT or SURF. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Barcelona, Spain, 6–13 November 2011. [Google Scholar]
- Hu, Y.; Rui, T.; Yang, C. Research on fast alignment of UAV aerial images based on improved SIFT. Comput. Sci. 2021, 48, 134–138. [Google Scholar]
- Feng, Z.; Wang, M. Image matching algorithm based on Harris and improved SIFT algorithm. J. Fuzhou Univ. Nat. Sci. Ed. 2012, 40, 176–180. [Google Scholar]
- Li, W.; Li, L. An improved image matching algorithm. Ind. Control Comput. 2021, 34, 27–29. [Google Scholar]
- Leutenegger, S.; Chli, M.; Siegwart, R.Y. BRISK: Binary Robust invariant scalable keypoints. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–13 November 2011; IEEE: Piscataway, NJ, USA, 2011. [Google Scholar]
- Zhang, S.; Zhu, W. Super-resolution reconstruction based on SIFT matching and RANSAC algorithm. Surv. Mapp. Bull. 2019, 511, 119–122. [Google Scholar]
- Sujin, J.S.; Sophia, S. High-performance image forgery detection via adaptive SIFT feature extraction for low-contrast or small or smooth copy–move region images. Soft Comput. 2024, 28, 437–445. [Google Scholar] [CrossRef]
- Calonder, M. BRIEF: Computing a Local Binary Descriptor Very Fast. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 1281–1298. [Google Scholar] [CrossRef] [PubMed]
- Wang, F.; Chu, Z.; Zhu, D. An image feature detection algorithm based on nonlinear diffusion filtering. Adv. Lasers Optoelectron. 2019, 56, 124–130. [Google Scholar]
- Calonder, M.; Lepetit, V.; Strecha, C.; Fua, P. BRIEF: Binary Robust Independent Elementary Features. In Proceedings of the Computer Vision—ECCV 2010, 11th European Conference on Computer Vision, Heraklion, Crete, Greece, 5–11 September 2010. Part IV. [Google Scholar]
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications To Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Wang, H.; Zhang, S.; Xu, K. Research on real-time adaptive RANSAC algorithm applied to image matching. Electro-Opt. Control 2020, 27, 90–93, 97. [Google Scholar]
- Zhang, X. Research on Image-Based RANSAC Algorithm and Hardware Implementation. Master’s Thesis, Xi’an Electronic Science and Technology University, Xi’an, China, 2018. [Google Scholar]
- Song, W. RANSAC Algorithm and Its Application in Remote Sensing Image Processing. Master’s Thesis, North China Electric Power University, Beijing, China, 2011. [Google Scholar]
- Shokri, S.; Sadeghi, M.T.; Marvast, M.A.; Narasimhan, S. Soft sensor design for hydrodesulfurization process using support vector regression based on WT and PCA. J. Cent. South Univ. 2015, 22, 511–521. [Google Scholar] [CrossRef]
- Suo, C.; Yang, D.; Liu, Y. Comparison of SIFT, SURF, BRISK, ORB, and FREAK algorithms from multiple perspectives. Beijing Surv. Mapp. 2014, 4, 22–26. [Google Scholar]
- Liu, K.; Wang, K.; Yang, X.M. Fast binary descriptor based on DoG detection of image feature points. Opt. Precis. Eng. 2020, 28, 485–496. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methodologies | Bark | Bikes | Leuven | Boat | Graf | Average |
|---|---|---|---|---|---|---|
| SIFT | 78.90 | 86.03 | 86.26 | 76.00 | 83.80 | 82.20 |
| SURF | 70.72 | 85.72 | 85.34 | 67.30 | 67.03 | 75.22 |
| BRISK | 78.91 | 86.05 | 91.92 | 76.63 | 81.57 | 83.02 |
| ORB | 46.67 | 94.64 | 86.68 | 60.52 | 53.31 | 68.36 |
| Our | 91.83 | 96.21 | 93.28 | 81.22 | 92.90 | 91.09 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yin, C.; Zhang, F.; Hao, B.; Fu, Z.; Pang, X. Research on a Fast Image-Matching Algorithm Based on Nonlinear Filtering. Algorithms 2024, 17, 165. https://doi.org/10.3390/a17040165
Yin C, Zhang F, Hao B, Fu Z, Pang X. Research on a Fast Image-Matching Algorithm Based on Nonlinear Filtering. Algorithms. 2024; 17(4):165. https://doi.org/10.3390/a17040165
Chicago/Turabian StyleYin, Chenglong, Fei Zhang, Bin Hao, Zijian Fu, and Xiaoyu Pang. 2024. "Research on a Fast Image-Matching Algorithm Based on Nonlinear Filtering" Algorithms 17, no. 4: 165. https://doi.org/10.3390/a17040165
APA StyleYin, C., Zhang, F., Hao, B., Fu, Z., & Pang, X. (2024). Research on a Fast Image-Matching Algorithm Based on Nonlinear Filtering. Algorithms, 17(4), 165. https://doi.org/10.3390/a17040165