3.2.1. Days of Yore
The first mention we found of a computer algorithm being used to generate primes dates to more than 60 years ago [
13]. The topic was submitted by T.C.Wood in 1961 as a very short article: a third of a column on a two-column page in
Communications of ACM journal, containing less than 50 words of text plus 9 lines of archaic code, with
labels and
gotos. The algorithm, called
Algorithm 35: Sieve, was described as using the Sieve of Eratosthenes, but is actually it a brute-force, trial-division-based sieve—as memory was a very scarce resource for computers, this approach was more realistic, although much heavier in terms of complexity [
8]. Still, we can identify two of the main optimization points that differentiate a basic but sound SoE implementation from a naive one: skipping even numbers and processing primes only up to
—we shall call these first
primes
the root primes. Two re-visitations of
Algorithm 35 were published in the following year ([
14,
15]), proving that the generation of prime numbers was a topic of interest.
The next articles about prime sieving appeared in 1967, when B.A.Chartres published
Algorithm 310: Prime Number Generator 1 [
16] and
Algorithm 311: Prime Number Generator 2 [
17]. Chartres tried to find innovative techniques that would use as little RAM as possible—his idea was to advance with all the primes’ multiples in parallel and as in sync as possible, instead of processing each one separately and sequentially. Basically, Chartres reversed the logic of SoE, condensing the repeated sweeps of the original in a single, unified wave—we call this orchestrated tide of multiples
the front-wave, and each number that is not touched by the front-wave is a prime. The list of candidates is parsed only once, in strict order, so there is no need to store it in the memory. However, we need to keep two parallel lists: one for the primes themselves; one for the current multiples. Chartres exploited two main sieving optimization tips: (1) for each
p in the root primes, we need to sweep only from
up, and (2) we can skip over some classes of candidates and multiples of
p to avoid a lot of useless operations—Chartres skips multiples of 2 and 3 by cleverly alternating between steps 2 and 4, thus hitting only candidates and multiples in the form
. The front-wave idea is introduced in Generator 1 and then optimized in Generator 2 by implementing the
pattern and keeping the front-wave ordered (using merge sort) to avoid repeated full scans.
R. Singleton followed this up in 1969 with
Algorithm 356 [
18], an optimized version of Generator 2—using a pragmatic tree/heap sort, he streamlined a lot of the complications Chartres used to maintain the front-wave order (see Algorithm 5).
| Algorithm 5 Chartres’ Generator 2—Singleton 356 optimized version |
Initialize two vectors: IQ, the front-wave vector (the current multiples of root primes) organized as a heap, and JQ, a parallel vector with the information for the next step: if negative, if positive Initialize iqi and jqi, the values corresponding to the current smallest element in the front-wave (they are not kept in the heap) For each candidate, If (⇒ n is composite)
Otherwise, (⇒ n is prime)
|
Formula (
7) was not known in 1967, but is very useful when striving to obtain a more economic sizing of pre-allocated vectors IQ and JQ, Anyway, the space complexity of this algorithm is quite interesting for its class.
Both Chartres and Singleton produced their texts before Dijkstra’s “Go To Considered Harmful” article [
19] became really influential, so their original algorithmic expressions are very archaic and quite difficult for the modern reader to follow—most of these algorithms had to be translated into more current jargon and adjusted for readability. In the accompanying code, there is an updated, structured version of this algorithm (function
Singleton_optimized311).
Singleton extends the punctual front-wave idea to an interval and published his results in the same year as
Algorithm 357 [
20]—this is arguably the most important contribution to prime sieving, introducing four very important ideas:
- (1)
Pre-compute the list of root primes before starting to comb for all primes;
- (2)
Extend the idea of punctual front-wave to a segment, thus achieving the first incremental sieve and prefiguring segmentation;
- (3)
Develops the idea of taking the pattern (all prime numbers but 2 and 3 are of this form) to the next step (), thus laying the foundation for the wheels technique;
- (4)
Use the bit-level representation in the context of the
pattern to compress 30 numbers into only one byte. The community took it from here, as demonstrated in the review of R. Morgan [
21].
Algorithm 6 expresses the gist of 357, somewhat updated, streamlined, and simplified. In the accompanying code, there is a structured version of the algorithm (function
Sieve357).
| Algorithm 6 357—First incremental sieve |
Initialize two vectors: IQ, the front-wave vector (the current multiples of root primes), and JQ, a parallel vector with the root primes themselves At each call - (a)
Extend the vectors with the new root primes - (b)
Strike out all composites (based on IQ) in a working segment of fixed size M - (c)
Identify the primes in the working segment - (d)
Reset for the next call
|
Table 2 shows the timings for the algorithms above (in those basic versions), for several
. To provide a baseline, timings for a basic version of SoE are included.
NOTE: The timings are not necessarily meaningful as absolute values (will vary greatly from one architecture or implementation language to another), but are useful in a performance analysis, when comparing one algorithm to another—that is why all the timings in this paper were measured on the same desktop computer with 32 GB RAM and Intel Core i9-9900KF CPU @ 4.9 MHz all cores. For better standardization of results, all the components of the generation process must be included in the timings that are to be compared, including any data preparation that occurred before sieving (like the generation of root primes) or after sieving (like effectively obtaining the value of all prime numbers and placing those values in order). Usually, an optimizing compiler will discard futile code, so it is often not sufficient to simply compute the number in the source code without using it: one must assure that the number is really computed in the compiled code executed in the benchmarking process.
It is evident that Trial-division technique is useless above 1 million. 356 is clearly superior, but still impractical over 100 million. Basic SoE is relatively decent bellow 1 billion, but the time and memory requirements are too big for any practical usage at really large values. 357 has great potential for locality, which is very important in modern CPUs; thus, it performs significantly better than any basic SoE. The performance to compute single-threadedly all primes below 10 billion in under 20 seconds using a generic, unrefined algorithm from 55 years ago is commendable.
3.2.2. From Linear to Sub-Linear
The first linear algorithms appeared in the late 1970s, published by Mairson [
22], Pratt [
23] and Gries/Misra [
24].
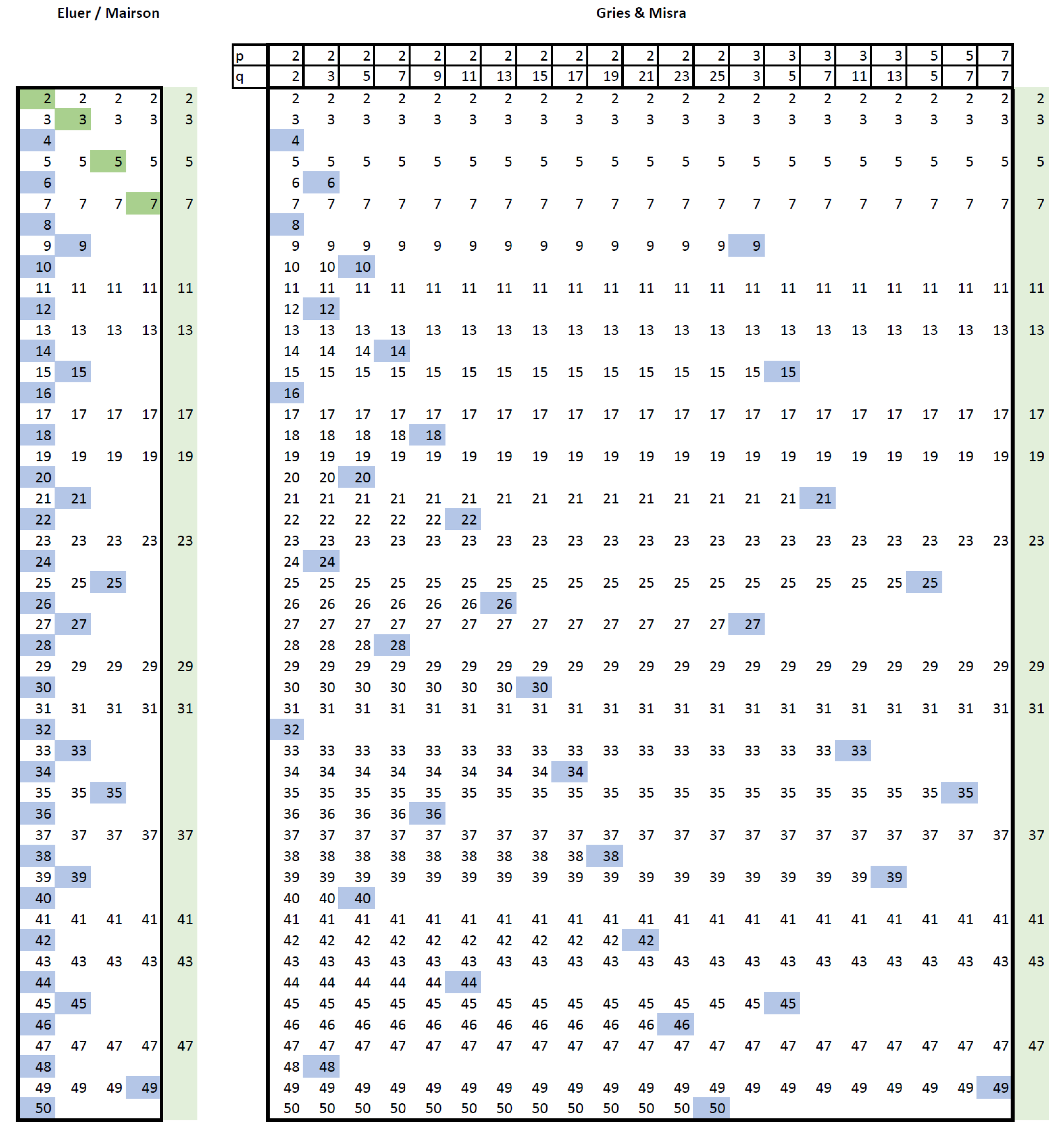
Mairson’s 1977 article introduces an algorithm using an intricate data structure based on a triple vector representation of a double linked list and strives to compute each composite only once. The algorithm is very similar to SoE+, as you can see in
Figure 2. It is not clear if Mairson knew about Euler’s sieve—in any case, this is not mentioned in the paper. Mairson claimed a sub-linear time complexity for his algorithm; however, in practice, the memory complexity is very high and the performance is not optimal, as shown in
Table 3. The basic operations used to identify the composites may have
O; but when these operations are considered together with all the overhead necessary to maintain the relatively complex data structure, the things get rapidly out of control—see Algorithm 7 (function
Mairson in the accompanying code offers an accurate rendition of the algorithm).
Figure 2.
Combing techniques (): in each iteration (column) the blue values are struck out.
Figure 2.
Combing techniques (): in each iteration (column) the blue values are struck out.
| Algorithm 7 Mairson’s “sub-linear” sieve |
llink is only necessary for crossof, but still required in this version of the algorithm To remain faithful, the implementation used here keeps the 1-based indexes
|


To optimize the memory footprint, Misra [
25] proposes to eliminate multiples in reverse order, thus avoiding the need for a third vector (Pritchard later used this idea for his sieve). However, finding the start position (the position of the first value to eliminate) has a serious negative impact on the processing time, which we value the most.
In the same year as Mairson, V. Pratt published a paper [
23] about MACLISP/CGOL, where he proposes, as an example, another linear sieve, credited to Ross Gale and Vaughan Pratt. The logic behind this sieve is a little more convoluted—for each prime
p, it strikes out composites formed by the powers of
p and all reasonable composites stricken out in the previous iteration(s). The substance of the algorithm is presented in Algorithm 8.
| Algorithm 8 Gale and Pratt sieve |
The management of the lists can be quite taxing; Here is the first practical occurrence of the bit coding technique, as indicated by Singleton:
|
The sieve packs information at the bit level and skips all even candidates, thus a respectable performance and a relatively good memory footprint are obtained from the start. An updated but accurate version of this algorithm, translated into C++, can be found in the accompanying code (function GalePratt).
Another version of SoE+ was published [
24] by Gries/Misra the following year, capitalizing on the work of Mairson. Mairson’s sieve was advertised as linear, but practice proved it to be much less efficient than 357. Gries/Misra had a similar idea for sifting primes through candidates and strove to achieve linearity by proposing a streamlined technique to manage the data. The sieve is also reminiscent of that of Gale/Pratt, processing composites formed by powers of the current
p. While Mairson iterates for each first number
p left in the list and strikes out the products between
p and every number left in the list at that point, Gries/Misra iterate for each first number
p left in the list and strike out the products between all powers of
p and the next numbers in the list.
Figure 2 depicts the steps of Mairson vs. Gries/Misra primes combing algorithms. Each column contains all the numbers remaining in that step, with those marked for deletion highlighted blue. Both techniques strike out each composite exactly once, hence the basic linear character of the algorithms, but Mairson may strike out numbers that are to be used later in the same iteration, leading to more complications in data management to preserve the numbers that are marked until the end of the current cycle. Moreover, Gries/Misra eliminate the need for the third vector, lowering the memory requirements: see Algorithm 9 (all the details are provided in the accompanying code).
| Algorithm 9 Gries/Misra linear sieve |
|

The same article [
24] includes a discussion regarding the underlying data structure, showing how one can substitute a pointers vector with a vector of booleans to achieve further memory savings. Due to the great similarity between the two, these optimizations can also be applied to Mairson.
In theory, Gries/Misra should perform marginally better, because the same number of composites are removed and data management is simpler—in practice, because Gries/Misra has much worse locality (fewer composites are identified per cycle, so a lot of cache is trashed), Mairson performs better.
The next big thing in prime sieving appeared in 1981, in a paper from Paul Pritchard, introducing what is probably the most beautiful prime sieving algorithm:
Wheel of Pritchard (SoP) [
26]. The algorithm was further clarified by the author in [
27]. SoP technique is derived from Mairson’s, except it does not parse the whole set of candidates for each
p to eliminate multiples, but instead tries to iteratively and incrementally generate the smallest possible set of candidates to work on. In order to understand the algorithm, we need to recap some basic mathematical ideas:
Let us construct a set (wheel)
with all
, where
is coprime with all primes
for
. First, it is evident that any
is coprime with any other
, so we can use these as values for
. Thus, it is clear that any
will remain coprime with all
. Extending this to all such
p where
and then removing all multiples of
will give us the new
, hence the iterative algorithm used to generate primes. Unfortunately,
increases very steeply with
n, so it is very hard to create a table representation of the algorithm progression. Nevertheless, one can find some very intuitive animation for the Wheel of Pritchard on the internet, for example, at
https://en.wikipedia.org/wiki/Sieve_of_Pritchard (accessed on 24 March 2024).
The next step is to construct a data structure that is clever enough not to destroy the performance of the sieve. Pritchard’s idea is to use a single vector
s that keeps all identified
in the lower part, and in the rest of the structure, the current
−
s combines both
and
from a double linked list in one vector, capitalizing on the fact that, except 2, even numbers are not prime, so
will be
and
will be
. See Algorithm 10 and accompanying code for details.
| Algorithm 10 Sieve of Pritchard |
|
The theoretical complexity of SoP is sublinear: O, the best one achieved so far.
Pritchard published another meaningful and influential work in 1983 [
28], which is important as it formalizes the so-called
static or
fixed wheel and proves the linear character of the sieve when a static wheel of the order
is used (
P is the Primorial). The results were somewhat refined by Sorenson in 1990 [
29], and especially in [
30,
31]. Moreover, in 1991, Sorenson showed why SoE is still superior, in practice, to all other theoretically linear algorithms [
32]. The timings for a basic but quite large (W8) fixed wheel SoE are given in
Table 3—for small values of
, the total duration is penalized by the time that is necessary to generate the wheel; for middle values, a static wheel can be marginally more efficient than 357, but at very large values, it loses efficiency. To recover, the wheel size must be increased, which adds to the total duration and so on.
Several years passed before the next attempt to create something innovative: in 1986, Bengelloun [
33] tried to address the problem that all the linear algorithms to date have a fixed superior limit
up to which they compute the primes, meaning that if you want to find the next prime number that is greater than
, you will have to restart the process with another max value, which may not be very convenient. To resolve this, Bengelloun keeps track of the lowest prime factor (
) of composites in a vector that increases incrementally with
n—each number is tested against the previous data, so, theoretically, the algorithm could continue ad infinitum. Unfortunately, the performance is not at all satisfactory for large numbers, but the idea is quite beautiful in its simplicity and is worth mentioning: for each odd composite, another, greater composite is stroked out. The underlying idea is that any composite
n can be expressed as
, where
p is the lowest prime factor of
n. Then, after obtaining,
the immediate next prime greater than
p, the number
, is struck out by inscribing
in the
vector at position
. See Algorithm 11 and accompanying code for details.
| Algorithm 11 Bengelloun Continuous Incremental Primal Sieve |
|

This incremental sieve was improved by Pritchard in 1994 [
34], and transformed in a incremental additive and sub-linear sieve using wheels.
In 1987, Paul Pritchard performed an interesting analysis [
35] of the linear algorithms found so far and synthesized them all by generalizing families of variations in the generic process of eliminating composites
c, with two general expressions:
based on least prime factor: , where lpf (from this family, Mairson, Gries/Misra, SoP, and Bengelloun can be derived, but also two new siblings—called simply 3.2 and 3.3—with the same linear character);
based on greatest prime factor: , where gpf (from this family, Gale and Pratt can be derived, but also two new siblings—called 4.3 and 4.4—with the same linear character).
Finally, in 2003, we received a new, completely different type of sieve: a quadratic sieve—
Sieve of Atkin (SoA) [
36]—which has a theoretical complexity equal to SoP. (
An interesting fact is that SoA was cited by Galway [
37]
in 2000, some years before the official publication; Galway referenced a paper of Atkin/Bernstein from 1999, and the URL cited by Galway for that paper—
http://pobox.com/~djb/papers/primesieves.dvi—
accessed on 10 April 2024).
SoA is based on the mathematical properties of some quadratic forms, thus being more related to SoS than SoE. It is quite promising, but relatively boring from the algorithmic perspective in its basic implementation. It capitalizes on the fact that all the numbers that (a) have an odd number of positive solutions at these equations:
, where d = 1 or 5, x and
, where d = 7, x and
, where d = 11,
and (b) are squarefree (not a multiple of a square) are primes (in the original paper, one can find the justification for these properties, based on some more general
considerations). Frequent modulos and multiplications impair the performance, but the results are quite decent. See Algorithm 12 and function
Atkin in the accompanying code for further details).
| Algorithm 12 Sieve of Atkin |
Initialize a sieve vector For all eligible pairs (x,y) mark the values of the quadratic forms in the vector Remove from the vector all values corresponding to:
- (a)
even number of solutions - (b)
multiples of squares
Count or otherwise use the primes indicated by the vector
|
The original technique is somewhat improved by Galway in [
37], where the sieve is further segmented. Also, in [
38], one can find some other interesting theoretical considerations regarding SoA.
Table 3 presents single-threaded timings for all these algorithms, including 357 as a baseline:
Table 3.
Timings (ms) for linear and sub-linear algorithms.
Table 3.
Timings (ms) for linear and sub-linear algorithms.
| N | | Algorithms |
|---|
|
Mairson
|
Gale/Pratt
|
Gries/Misra
|
Pritchard
|
Bengelloun
|
Atkin
|
W8 SoE
|
357
|
|---|
| 9592 | 1 | 1 | 1 | 1 | 1 | 1 | 24 | - |
| 78,498 | 8 | 4 | 9 | 4 | 9 | 4 | 26 | 2 |
| 664,579 | 189 | 35 | 207 | 107 | 110 | 43 | 32 | 19 |
| 5,761,455 | 1768 | 391 | 2204 | 1230 | 1336 | 796 | 167 | 174 |
| 50,847,534 | 22,351 | 9615 | 24,143 | 15,738 | 13,761 | 9035 | 1771 | 1707 |
| 455,052,511 | - | - | - | - | - | 125,367 | 22,968 | 18,415 |
In conclusion, all the sub-linear sieves were better than a basic SoE, but they still were not close to the incremental 357 that, on modern CPUs, will use the cache for important performance gains. SoP is very clever, but the complex data management overhead cancels out the gain in complexity; Bengelloun has very bad locality and uses divisions when it encounters composites, and this lowers the performance for big numbers, when primes become more and more scarce; Gale/Pratt was quite optimized from its inception, requires fewer operations to manage its data structure, and remains a good performer in its class of SoE-derived linear sieves, where only static wheels can save the day; Atkin is the best performer for large values, but still worse than 357.











{kind=link}
{kind=link}
