


Smooth Information Criterion for Regularized Estimation of Item Response Models


Abstract
1. Introduction
2. Smooth Information Criterion
3. Simulation Study 1: Differential Item Functioning
3.1. Method
3.2. Results
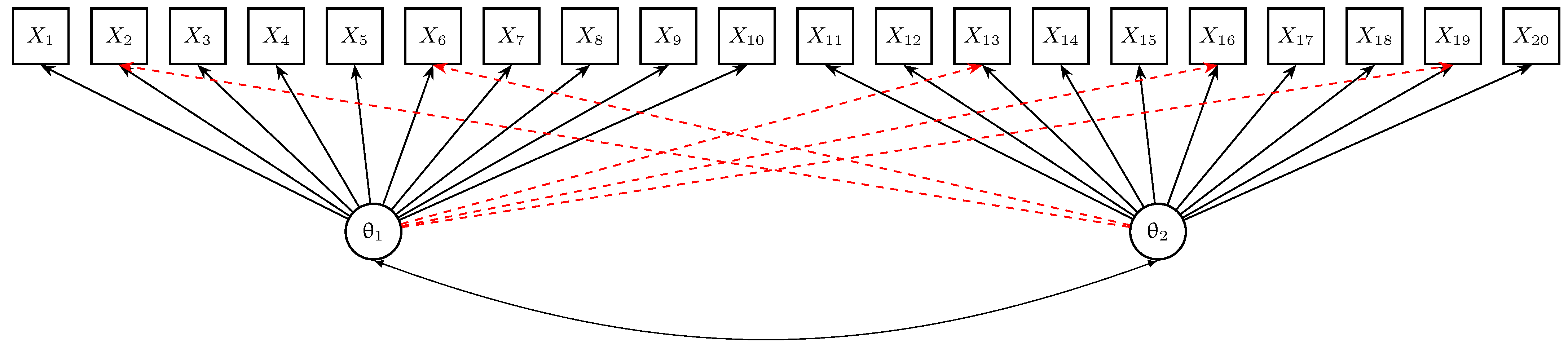
4. Simulation Study 2: Multidimensional Logistic Item Response Model
4.1. Method
4.2. Results
5. Simulation Study 3: Mixed Rasch/2PL Model
5.1. Method
5.2. Results
6. Discussion
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| 2PL | two-parameter logistic |
| AIC | Akaike information criterion |
| BIC | Bayesian information criterion |
| DGM | data-generating model |
| DIF | differential item functioning |
| IRF | item response function |
| IRT | item response theory |
| LASSO | least absolute shrinkage and selection operator |
| ML | maximum likelihood |
| RMSE | root mean square error |
| SAIC | smooth Akaike information criterion |
| SBIC | smooth Bayesian information criterion |
| SCAD | smoothly clipped absolute deviation |
| SIC | smooth information criterion |
References
- Baker, F.B.; Kim, S.H. Item Response Theory: Parameter Estimation Techniques; CRC Press: Boca Raton, FL, USA, 2004. [Google Scholar] [CrossRef]
- Bock, R.D.; Gibbons, R.D. Item Response Theory; Wiley: Hoboken, NJ, USA, 2021. [Google Scholar] [CrossRef]
- Chen, Y.; Li, X.; Liu, J.; Ying, Z. Item response theory—A statistical framework for educational and psychological measurement. arXiv 2021, arXiv:2108.08604. [Google Scholar]
- van der Linden, W.J.; Hambleton, R.K. (Eds.) Handbook of Modern Item Response Theory; Springer: New York, NY, USA, 1997. [Google Scholar] [CrossRef]
- Yen, W.M.; Fitzpatrick, A.R. Item response theory. In Educational Measurement; Brennan, R.L., Ed.; Praeger Publishers: Westport, CT, USA, 2006; pp. 111–154. [Google Scholar]
- van der Linden, W.J. Unidimensional logistic response models. In Handbook of Item Response Theory, Volume 1: Models; van der Linden, W.J., Ed.; CRC Press: Boca Raton, FL, USA, 2016; pp. 11–30. [Google Scholar]
- Reckase, M.D. Logistic multidimensional models. In Handbook of Item Response Theory, Volume 1: Models; van der Linden, W.J., Ed.; CRC Press: Boca Raton, FL, USA, 2016; pp. 189–210. [Google Scholar]
- Swaminathan, H.; Rogers, H.J. Normal-ogive multidimensional models. In Handbook of Item Response Theory, Volume 1: Models; van der Linden, W.J., Ed.; CRC Press: Boca Raton, FL, USA, 2016; pp. 167–187. [Google Scholar]
- Birnbaum, A. Some latent trait models and their use in inferring an examinee’s ability. In Statistical Theories of Mental Test Scores; Lord, F.M., Novick, M.R., Eds.; MIT Press: Reading, MA, USA, 1968; pp. 397–479. [Google Scholar]
- Fan, J.; Li, R.; Zhang, C.H.; Zou, H. Statistical Foundations of Data Science; Chapman and Hall/CRC: Boca Raton, FL, USA, 2020. [Google Scholar] [CrossRef]
- Goretzko, D.; Bühner, M. Note: Machine learning modeling and optimization techniques in psychological assessment. Psychol. Test Assess. Model. 2022, 64, 3–21. Available online: https://tinyurl.com/bdehjkzz (accessed on 2 April 2024).
- Finch, H. Applied Regularization Methods for the Social Sciences; Chapman and Hall/CRC: Boca Raton, FL, USA, 2022. [Google Scholar] [CrossRef]
- Jacobucci, R.; Grimm, K.J.; Zhang, Z. Machine Learning for Social and Behavioral Research; Guilford Publications: New York, NY, USA, 2023. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Wainwright, M. Statistical Learning with Sparsity: The Lasso and Generalizations; CRC Press: Boca Raton, FL, USA, 2015. [Google Scholar] [CrossRef]
- Fan, J.; Li, R. Variable selection via nonconcave penalized likelihood and its oracle properties. J. Am. Stat. Assoc. 2001, 96, 1348–1360. [Google Scholar] [CrossRef]
- Zhang, H.; Li, S.J.; Zhang, H.; Yang, Z.Y.; Ren, Y.Q.; Xia, L.Y.; Liang, Y. Meta-analysis based on nonconvex regularization. Sci. Rep. 2020, 10, 5755. [Google Scholar] [CrossRef] [PubMed]
- Orzek, J.H.; Arnold, M.; Voelkle, M.C. Striving for sparsity: On exact and approximate solutions in regularized structural equation models. Struct. Equ. Model. 2023, 30, 956–973. [Google Scholar] [CrossRef]
- Zhang, S.; Chen, Y. Computation for latent variable model estimation: A unified stochastic proximal framework. Psychometrika 2022, 87, 1473–1502. [Google Scholar] [CrossRef] [PubMed]
- Battauz, M. Regularized estimation of the nominal response model. Multivar. Behav. Res. 2020, 55, 811–824. [Google Scholar] [CrossRef] [PubMed]
- Oelker, M.R.; Tutz, G. A uniform framework for the combination of penalties in generalized structured models. Adv. Data Anal. Classif. 2017, 11, 97–120. [Google Scholar] [CrossRef]
- Robitzsch, A. Implementation aspects in regularized structural equation models. Algorithms 2023, 16, 446. [Google Scholar] [CrossRef]
- Robitzsch, A. Model-robust estimation of multiple-group structural equation models. Algorithms 2023, 16, 210. [Google Scholar] [CrossRef]
- Cavanaugh, J.E.; Neath, A.A. The Akaike information criterion: Background, derivation, properties, application, interpretation, and refinements. WIREs Comput. Stat. 2019, 11, e1460. [Google Scholar] [CrossRef]
- Neath, A.A.; Cavanaugh, J.E. The Bayesian information criterion: Background, derivation, and applications. WIREs Comput. Stat. 2012, 4, 199–203. [Google Scholar] [CrossRef]
- Burnham, K.P.; Anderson, D.R. Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach; Springer: New York, NY, USA, 2002. [Google Scholar] [CrossRef]
- O’Neill, M.; Burke, K. Variable selection using a smooth information criterion for distributional regression models. Stat. Comput. 2023, 33, 71. [Google Scholar] [CrossRef] [PubMed]
- Bollen, K.A.; Noble, M.D. Structural equation models and the quantification of behavior. Proc. Natl. Acad. Sci. USA 2011, 108, 15639–15646. [Google Scholar] [CrossRef] [PubMed]
- Oelker, M.R.; Pößnecker, W.; Tutz, G. Selection and fusion of categorical predictors with L0-type penalties. Stat. Model. 2015, 15, 389–410. [Google Scholar] [CrossRef]
- Shen, X.; Pan, W.; Zhu, Y. Likelihood-based selection and sharp parameter estimation. J. Am. Stat. Assoc. 2012, 107, 223–232. [Google Scholar] [CrossRef] [PubMed]
- Holland, P.W.; Wainer, H. (Eds.) Differential Item Functioning: Theory and Practice; Lawrence Erlbaum: Hillsdale, NJ, USA, 1993. [Google Scholar] [CrossRef]
- Mellenbergh, G.J. Item bias and item response theory. Int. J. Educ. Res. 1989, 13, 127–143. [Google Scholar] [CrossRef]
- Millsap, R.E. Statistical Approaches to Measurement Invariance; Routledge: New York, NY, USA, 2011. [Google Scholar] [CrossRef]
- Bechger, T.M.; Maris, G. A statistical test for differential item pair functioning. Psychometrika 2015, 80, 317–340. [Google Scholar] [CrossRef] [PubMed]
- Doebler, A. Looking at DIF from a new perspective: A structure-based approach acknowledging inherent indefinability. Appl. Psychol. Meas. 2019, 43, 303–321. [Google Scholar] [CrossRef] [PubMed]
- San Martin, E. Identification of item response theory models. In Handbook of Item Response Theory, Volume 2: Statistical Tools; van der Linden, W.J., Ed.; CRC Press: Boca Raton, FL, USA, 2016; pp. 127–150. [Google Scholar] [CrossRef]
- Belzak, W.; Bauer, D.J. Improving the assessment of measurement invariance: Using regularization to select anchor items and identify differential item functioning. Psychol. Methods 2020, 25, 673–690. [Google Scholar] [CrossRef] [PubMed]
- Belzak, W.C.M.; Bauer, D.J. Using regularization to identify measurement bias across multiple background characteristics: A penalized expectation-maximization algorithm. J. Educ. Behav. Stat. 2024. Epub ahead of print. [Google Scholar] [CrossRef]
- Chen, Y.; Li, C.; Ouyang, J.; Xu, G. DIF statistical inference without knowing anchoring items. Psychometrika 2023, 88, 1097–1122. [Google Scholar] [CrossRef] [PubMed]
- Robitzsch, A. Comparing robust linking and regularized estimation for linking two groups in the 1PL and 2PL models in the presence of sparse uniform differential item functioning. Stats 2023, 6, 192–208. [Google Scholar] [CrossRef]
- Schauberger, G.; Mair, P. A regularization approach for the detection of differential item functioning in generalized partial credit models. Behav. Res. Methods 2020, 52, 279–294. [Google Scholar] [CrossRef] [PubMed]
- Tutz, G.; Schauberger, G. A penalty approach to differential item functioning in Rasch models. Psychometrika 2015, 80, 21–43. [Google Scholar] [CrossRef]
- Wang, C.; Zhu, R.; Xu, G. Using lasso and adaptive lasso to identify DIF in multidimensional 2PL models. Multivar. Behav. Res. 2023, 58, 387–407. [Google Scholar] [CrossRef] [PubMed]
- Pohl, S.; Schulze, D.; Stets, E. Partial measurement invariance: Extending and evaluating the cluster approach for identifying anchor items. Appl. Psychol. Meas. 2021, 45, 477–493. [Google Scholar] [CrossRef] [PubMed]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation: Vienna, Austria, 2023; Available online: https://www.R-project.org/ (accessed on 15 March 2023).
- Robitzsch, A. sirt: Supplementary Item Response Theory Models. 2024. R Package Version 4.1-15. Available online: https://CRAN.R-project.org/package=sirt (accessed on 6 February 2024.).
- Reckase, M.D. Multidimensional Item Response Theory Models; Springer: New York, NY, USA, 2009. [Google Scholar] [CrossRef]
- Chen, J. A partially confirmatory approach to the multidimensional item response theory with the Bayesian lasso. Psychometrika 2020, 85, 738–774. [Google Scholar] [CrossRef] [PubMed]
- Chen, Y.; Li, X.; Liu, J.; Ying, Z. Robust measurement via a fused latent and graphical item response theory model. Psychometrika 2018, 83, 538–562. [Google Scholar] [CrossRef] [PubMed]
- Sun, J.; Chen, Y.; Liu, J.; Ying, Z.; Xin, T. Latent variable selection for multidimensional item response theory models via L1 regularization. Psychometrika 2016, 81, 921–939. [Google Scholar] [CrossRef]
- Goretzko, D. Regularized exploratory factor analysis as an alternative to factor rotation. Eur. J. Psychol. Assess. 2023. Epub ahead of print. [Google Scholar] [CrossRef]
- Scharf, F.; Nestler, S. Should regularization replace simple structure rotation in exploratory factor analysis? Struct. Equ. Modeling 2019, 26, 576–590. [Google Scholar] [CrossRef]
- OECD. PISA 2015. Technical Report; OECD: Paris, France, 2017; Available online: https://bit.ly/32buWnZ (accessed on 2 April 2024).
- Wijayanto, F.; Mul, K.; Groot, P.; van Engelen, B.G.M.; Heskes, T. Semi-automated Rasch analysis using in-plus-out-of-questionnaire log likelihood. Brit. J. Math. Stat. Psychol. 2021, 74, 313–339. [Google Scholar] [CrossRef] [PubMed]
- Rasch, G. Probabilistic Models for Some Intelligence and Attainment Tests; Danish Institute for Educational Research: Copenhagen, Denmark, 1960. [Google Scholar]
- Beisemann, M.; Holling, H.; Doebler, P. Every trait counts: Marginal maximum likelihood estimation for novel multidimensional count data item response models with rotation or L1-regularization for simple structure. PsyArXiv 2024. [Google Scholar] [CrossRef]
- Chen, Y.; Liu, J.; Xu, G.; Ying, Z. Statistical analysis of Q-matrix based diagnostic classification models. J. Am. Stat. Assoc. 2015, 110, 850–866. [Google Scholar] [CrossRef] [PubMed]
- McNeish, D.M. Using lasso for predictor selection and to assuage overfitting: A method long overlooked in behavioral sciences. Multivar. Behav. Res. 2015, 50, 471–484. [Google Scholar] [CrossRef] [PubMed]
- Bai, J. Panel data models with interactive fixed effects. Econometrica 2009, 77, 1229–1279. [Google Scholar] [CrossRef]
- Imai, K.; Ratkovic, M. Estimating treatment effect heterogeneity in randomized program evaluation. Ann. Appl. Stat. 2013, 7, 443–470. [Google Scholar] [CrossRef]
- White, H. Maximum likelihood estimation of misspecified models. Econometrica 1982, 50, 1–25. [Google Scholar] [CrossRef]
- Boos, D.D.; Stefanski, L.A. Essential Statistical Inference; Springer: New York, NY, USA, 2013. [Google Scholar] [CrossRef]
- Huang, P.H. Penalized least squares for structural equation modeling with ordinal responses. Multivar. Behav. Res. 2022, 57, 279–297. [Google Scholar] [CrossRef] [PubMed]
- Asparouhov, T.; Muthén, B. Penalized structural equation models. Struct. Equ. Modeling 2023. Epub ahead of print. [Google Scholar] [CrossRef]


{kind=link}
| (Average) Absolute Bias | (Average) RMSE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Par | DIF | AIC | SAIC | BIC | SBIC | AIC | SAIC | BIC | SBIC | |
| Balanced DIF | ||||||||||
| 500 | 0.001 | 0.004 | 0.000 | 0.003 | 0.104 | 0.090 | 0.113 | 0.104 | ||
| small | 1000 | 0.002 | 0.000 | 0.001 | 0.001 | 0.069 | 0.064 | 0.075 | 0.070 | |
| 2000 | 0.001 | 0.001 | 0.000 | 0.000 | 0.048 | 0.046 | 0.046 | 0.047 | ||
| 500 | 0.005 | 0.000 | 0.007 | 0.004 | 0.101 | 0.093 | 0.096 | 0.098 | ||
| large | 1000 | 0.003 | 0.004 | 0.001 | 0.001 | 0.071 | 0.066 | 0.067 | 0.068 | |
| 2000 | 0.002 | 0.001 | 0.002 | 0.002 | 0.050 | 0.049 | 0.049 | 0.049 | ||
| 500 | 0.002 | 0.002 | 0.007 | 0.001 | 0.071 | 0.070 | 0.070 | 0.070 | ||
| small | 1000 | 0.001 | 0.001 | 0.002 | 0.001 | 0.046 | 0.046 | 0.046 | 0.046 | |
| 2000 | 0.001 | 0.001 | 0.001 | 0.002 | 0.032 | 0.032 | 0.032 | 0.032 | ||
| 500 | 0.003 | 0.001 | 0.000 | 0.002 | 0.068 | 0.067 | 0.067 | 0.067 | ||
| large | 1000 | 0.002 | 0.003 | 0.002 | 0.002 | 0.045 | 0.044 | 0.044 | 0.044 | |
| 2000 | 0.001 | 0.001 | 0.001 | 0.001 | 0.035 | 0.035 | 0.035 | 0.035 | ||
(no DIF) | 500 | 0.006 | 0.006 | 0.003 | 0.004 | 0.216 | 0.187 | 0.108 | 0.148 | |
| small | 1000 | 0.005 | 0.003 | 0.002 | 0.002 | 0.139 | 0.113 | 0.061 | 0.069 | |
| 2000 | 0.002 | 0.002 | 0.001 | 0.001 | 0.098 | 0.073 | 0.032 | 0.028 | ||
| 500 | 0.003 | 0.005 | 0.003 | 0.002 | 0.201 | 0.188 | 0.082 | 0.142 | ||
| large | 1000 | 0.006 | 0.004 | 0.001 | 0.002 | 0.140 | 0.115 | 0.047 | 0.067 | |
| 2000 | 0.006 | 0.002 | 0.001 | 0.001 | 0.098 | 0.073 | 0.031 | 0.030 | ||
(DIF) | 500 | 0.025 | 0.024 | 0.182 | 0.077 | 0.349 | 0.330 | 0.496 | 0.398 | |
| small | 1000 | 0.006 | 0.008 | 0.062 | 0.041 | 0.211 | 0.213 | 0.315 | 0.276 | |
| 2000 | 0.003 | 0.003 | 0.010 | 0.011 | 0.137 | 0.135 | 0.155 | 0.157 | ||
| 500 | 0.026 | 0.024 | 0.022 | 0.022 | 0.311 | 0.302 | 0.340 | 0.311 | ||
| large | 1000 | 0.017 | 0.017 | 0.015 | 0.015 | 0.212 | 0.207 | 0.210 | 0.208 | |
| 2000 | 0.007 | 0.004 | 0.004 | 0.003 | 0.149 | 0.146 | 0.146 | 0.146 | ||
| Unbalanced DIF | ||||||||||
| 500 | 0.093 | 0.099 | 0.115 | 0.091 | 0.157 | 0.139 | 0.163 | 0.144 | ||
| small | 1000 | 0.050 | 0.047 | 0.049 | 0.033 | 0.111 | 0.087 | 0.110 | 0.085 | |
| 2000 | 0.025 | 0.008 | 0.013 | 0.004 | 0.069 | 0.048 | 0.072 | 0.048 | ||
| 500 | 0.053 | 0.072 | 0.024 | 0.020 | 0.145 | 0.122 | 0.143 | 0.100 | ||
| large | 1000 | 0.024 | 0.030 | 0.003 | 0.002 | 0.084 | 0.076 | 0.077 | 0.068 | |
| 2000 | 0.004 | 0.012 | 0.001 | 0.000 | 0.053 | 0.059 | 0.048 | 0.048 | ||
| 500 | 0.004 | 0.004 | 0.001 | 0.003 | 0.067 | 0.067 | 0.067 | 0.067 | ||
| small | 1000 | 0.000 | 0.000 | 0.001 | 0.000 | 0.048 | 0.048 | 0.048 | 0.048 | |
| 2000 | 0.000 | 0.000 | 0.001 | 0.000 | 0.032 | 0.031 | 0.031 | 0.031 | ||
| 500 | 0.000 | 0.001 | 0.000 | 0.001 | 0.065 | 0.065 | 0.064 | 0.065 | ||
| large | 1000 | 0.000 | 0.001 | 0.001 | 0.000 | 0.046 | 0.046 | 0.045 | 0.045 | |
| 2000 | 0.001 | 0.002 | 0.001 | 0.001 | 0.031 | 0.032 | 0.031 | 0.032 | ||
(no DIF) | 500 | 0.114 | 0.108 | 0.035 | 0.062 | 0.296 | 0.251 | 0.170 | 0.207 | |
| small | 1000 | 0.072 | 0.055 | 0.028 | 0.016 | 0.207 | 0.150 | 0.143 | 0.095 | |
| 2000 | 0.037 | 0.013 | 0.015 | 0.001 | 0.122 | 0.079 | 0.098 | 0.023 | ||
| 500 | 0.079 | 0.114 | 0.032 | 0.030 | 0.255 | 0.236 | 0.206 | 0.144 | ||
| large | 1000 | 0.038 | 0.051 | 0.005 | 0.003 | 0.133 | 0.145 | 0.072 | 0.065 | |
| 2000 | 0.010 | 0.025 | 0.001 | 0.001 | 0.055 | 0.107 | 0.023 | 0.030 | ||
(DIF) | 500 | 0.185 | 0.221 | 0.399 | 0.262 | 0.405 | 0.409 | 0.553 | 0.462 | |
| small | 1000 | 0.089 | 0.111 | 0.158 | 0.117 | 0.270 | 0.285 | 0.368 | 0.319 | |
| 2000 | 0.036 | 0.010 | 0.020 | 0.010 | 0.167 | 0.135 | 0.179 | 0.151 | ||
| 500 | 0.075 | 0.112 | 0.037 | 0.029 | 0.339 | 0.312 | 0.354 | 0.303 | ||
| large | 1000 | 0.036 | 0.050 | 0.005 | 0.004 | 0.212 | 0.199 | 0.207 | 0.196 | |
| 2000 | 0.011 | 0.020 | 0.004 | 0.004 | 0.138 | 0.144 | 0.137 | 0.138 | ||
| Type-I Error Rate | Power Rate | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| DIF | AIC | SAIC | BIC | SBIC | AIC | SAIC | BIC | SBIC | |
| Balanced DIF | |||||||||
| 500 | 17.0 | 13.7 | 2.1 | 6.2 | 83.6 | 85.8 | 52.7 | 73.3 | |
| small | 1000 | 14.4 | 8.2 | 1.4 | 2.1 | 97.0 | 96.1 | 81.5 | 87.3 |
| 2000 | 14.4 | 6.2 | 0.7 | 0.5 | 99.9 | 99.8 | 97.6 | 97.5 | |
| 500 | 15.3 | 14.2 | 1.2 | 5.8 | 99.7 | 99.8 | 97.5 | 99.4 | |
| large | 1000 | 15.0 | 9.0 | 0.8 | 2.0 | 100 | 100 | 99.9 | 100 |
| 2000 | 14.5 | 6.2 | 0.6 | 0.6 | 100 | 100 | 100 | 100 | |
| Unbalanced DIF | |||||||||
| 500 | 25.8 | 23.8 | 4.8 | 11.3 | 68.9 | 65.6 | 30.6 | 54.0 | |
| small | 1000 | 21.0 | 15.8 | 5.1 | 3.7 | 89.4 | 85.4 | 71.3 | 79.9 |
| 2000 | 13.6 | 9.1 | 2.7 | 0.4 | 97.7 | 99.6 | 95.9 | 98.1 | |
| 500 | 14.5 | 28.9 | 3.4 | 6.3 | 98.0 | 99.0 | 96.7 | 98.9 | |
| large | 1000 | 9.6 | 22.4 | 0.6 | 2.0 | 99.8 | 100 | 99.7 | 100 |
| 2000 | 3.4 | 21.5 | 0.3 | 0.6 | 100 | 100 | 100 | 100 | |
| Absolute Bias | RMSE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Par | CL | AIC | SAIC | BIC | SBIC | AIC | SAIC | BIC | SBIC | |
| 500 | 0.064 | 0.054 | 0.104 | 0.070 | 0.151 | 0.102 | 0.134 | 0.110 | ||
| small | 1000 | 0.040 | 0.070 | 0.088 | 0.085 | 0.157 | 0.096 | 0.124 | 0.104 | |
| 2000 | 0.015 | 0.018 | 0.059 | 0.065 | 0.077 | 0.052 | 0.082 | 0.081 | ||
| 500 | 0.055 | 0.062 | 0.136 | 0.073 | 0.167 | 0.109 | 0.179 | 0.117 | ||
| large | 1000 | 0.029 | 0.054 | 0.074 | 0.057 | 0.144 | 0.100 | 0.124 | 0.099 | |
| 2000 | 0.010 | 0.014 | 0.016 | 0.014 | 0.062 | 0.047 | 0.058 | 0.051 | ||
| 500 | 0.041 | 0.016 | 0.015 | 0.008 | 0.243 | 0.113 | 0.130 | 0.095 | ||
| small | 1000 | 0.025 | 0.028 | 0.008 | 0.014 | 0.188 | 0.119 | 0.092 | 0.088 | |
| 2000 | 0.011 | 0.006 | 0.006 | 0.003 | 0.102 | 0.062 | 0.049 | 0.034 | ||
| 500 | 0.044 | 0.016 | 0.024 | 0.011 | 0.282 | 0.119 | 0.181 | 0.109 | ||
| large | 1000 | 0.027 | 0.028 | 0.013 | 0.015 | 0.183 | 0.127 | 0.096 | 0.095 | |
| 2000 | 0.009 | 0.009 | 0.005 | 0.002 | 0.094 | 0.067 | 0.049 | 0.030 | ||
| 500 | 0.102 | 0.141 | 0.238 | 0.177 | 0.287 | 0.287 | 0.306 | 0.296 | ||
| small | 1000 | 0.075 | 0.118 | 0.211 | 0.192 | 0.237 | 0.235 | 0.288 | 0.273 | |
| 2000 | 0.021 | 0.033 | 0.132 | 0.154 | 0.140 | 0.146 | 0.231 | 0.243 | ||
| 500 | 0.078 | 0.130 | 0.295 | 0.166 | 0.341 | 0.353 | 0.452 | 0.379 | ||
| large | 1000 | 0.036 | 0.066 | 0.151 | 0.107 | 0.228 | 0.245 | 0.336 | 0.291 | |
| 2000 | 0.011 | 0.009 | 0.025 | 0.028 | 0.123 | 0.116 | 0.161 | 0.161 | ||
| Type-I Error Rate | Power Rate | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| CL | AIC | SAIC | BIC | SBIC | AIC | SAIC | BIC | SBIC | |
| 500 | 16.7 | 5.1 | 2.1 | 2.5 | 41.2 | 30.6 | 9.4 | 22.4 | |
| small | 1000 | 18.7 | 8.8 | 2.0 | 3.2 | 58.0 | 46.5 | 17.9 | 24.3 |
| 2000 | 15.1 | 6.2 | 1.7 | 0.7 | 86.5 | 82.4 | 44.0 | 38.3 | |
| 500 | 18.5 | 4.8 | 3.1 | 2.8 | 68.5 | 59.5 | 27.3 | 52.0 | |
| large | 1000 | 17.0 | 10.0 | 2.5 | 3.2 | 87.4 | 81.0 | 59.2 | 70.6 |
| 2000 | 13.3 | 7.8 | 1.3 | 0.7 | 98.6 | 98.7 | 92.3 | 92.6 | |
| (Average) Absolute Bias | (Average) RMSE | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Par | Dev | AIC | SAIC | BIC | SBIC | AIC | SAIC | BIC | SBIC | |
| Balanced deviations from the Rasch model | ||||||||||
| 500 | 0.053 | 0.038 | 0.004 | 0.010 | 0.099 | 0.082 | 0.070 | 0.072 | ||
| small | 1000 | 0.062 | 0.005 | 0.012 | 0.004 | 0.107 | 0.054 | 0.051 | 0.056 | |
| 2000 | 0.109 | 0.001 | 0.025 | 0.009 | 0.167 | 0.032 | 0.044 | 0.037 | ||
| 500 | 0.018 | 0.014 | 0.004 | 0.006 | 0.069 | 0.065 | 0.064 | 0.064 | ||
| large | 1000 | 0.016 | 0.002 | 0.002 | 0.002 | 0.050 | 0.044 | 0.041 | 0.041 | |
| 2000 | 0.007 | 0.000 | 0.000 | 0.000 | 0.035 | 0.033 | 0.030 | 0.030 | ||
| 500 | 0.035 | 0.017 | 0.001 | 0.002 | 0.124 | 0.091 | 0.048 | 0.047 | ||
| small | 1000 | 0.048 | 0.003 | 0.002 | 0.001 | 0.119 | 0.060 | 0.027 | 0.020 | |
| 2000 | 0.096 | 0.001 | 0.003 | 0.000 | 0.166 | 0.042 | 0.023 | 0.003 | ||
| 500 | 0.018 | 0.012 | 0.002 | 0.002 | 0.101 | 0.082 | 0.046 | 0.044 | ||
| large | 1000 | 0.017 | 0.003 | 0.001 | 0.000 | 0.066 | 0.058 | 0.023 | 0.014 | |
| 2000 | 0.007 | 0.001 | 0.000 | 0.000 | 0.033 | 0.040 | 0.010 | 0.003 | ||
| 500 | 0.071 | 0.070 | 0.127 | 0.137 | 0.224 | 0.239 | 0.283 | 0.289 | ||
| small | 1000 | 0.081 | 0.024 | 0.075 | 0.101 | 0.184 | 0.154 | 0.212 | 0.237 | |
| 2000 | 0.120 | 0.003 | 0.072 | 0.045 | 0.199 | 0.085 | 0.159 | 0.156 | ||
| 500 | 0.014 | 0.017 | 0.015 | 0.018 | 0.207 | 0.215 | 0.230 | 0.231 | ||
| large | 1000 | 0.019 | 0.006 | 0.006 | 0.008 | 0.139 | 0.136 | 0.138 | 0.143 | |
| 2000 | 0.004 | 0.004 | 0.003 | 0.004 | 0.095 | 0.095 | 0.093 | 0.094 | ||
| Unbalanced deviations from the Rasch model | ||||||||||
| 500 | 0.008 | 0.032 | 0.084 | 0.083 | 0.076 | 0.081 | 0.110 | 0.109 | ||
| small | 1000 | 0.015 | 0.008 | 0.028 | 0.055 | 0.051 | 0.050 | 0.061 | 0.078 | |
| 2000 | 0.011 | 0.003 | 0.002 | 0.015 | 0.036 | 0.032 | 0.031 | 0.040 | ||
| 500 | 0.001 | 0.001 | 0.001 | 0.001 | 0.069 | 0.062 | 0.061 | 0.060 | ||
| large | 1000 | 0.005 | 0.001 | 0.000 | 0.001 | 0.046 | 0.043 | 0.040 | 0.040 | |
| 2000 | 0.002 | 0.003 | 0.002 | 0.002 | 0.034 | 0.032 | 0.030 | 0.029 | ||
| 500 | 0.009 | 0.005 | 0.008 | 0.004 | 0.099 | 0.078 | 0.057 | 0.047 | ||
| small | 1000 | 0.014 | 0.003 | 0.002 | 0.001 | 0.068 | 0.056 | 0.027 | 0.019 | |
| 2000 | 0.010 | 0.002 | 0.001 | 0.000 | 0.044 | 0.042 | 0.015 | 0.005 | ||
| 500 | 0.003 | 0.003 | 0.001 | 0.001 | 0.105 | 0.079 | 0.046 | 0.041 | ||
| large | 1000 | 0.004 | 0.001 | 0.001 | 0.000 | 0.069 | 0.053 | 0.025 | 0.013 | |
| 2000 | 0.003 | 0.001 | 0.001 | 0.000 | 0.047 | 0.039 | 0.014 | 0.002 | ||
| 500 | 0.029 | 0.069 | 0.194 | 0.205 | 0.180 | 0.207 | 0.281 | 0.289 | ||
| small | 1000 | 0.012 | 0.014 | 0.069 | 0.145 | 0.103 | 0.116 | 0.182 | 0.240 | |
| 2000 | 0.012 | 0.001 | 0.002 | 0.037 | 0.068 | 0.067 | 0.075 | 0.129 | ||
| 500 | 0.008 | 0.006 | 0.007 | 0.005 | 0.129 | 0.126 | 0.127 | 0.127 | ||
| large | 1000 | 0.011 | 0.007 | 0.006 | 0.006 | 0.091 | 0.089 | 0.089 | 0.089 | |
| 2000 | 0.003 | 0.003 | 0.003 | 0.003 | 0.062 | 0.061 | 0.061 | 0.061 | ||
| Type-I Error Rate | Power Rate | ||||||||
|---|---|---|---|---|---|---|---|---|---|
| Dev | AIC | SAIC | BIC | SBIC | AIC | SAIC | BIC | SBIC | |
| Balanced deviations from the Rasch model | |||||||||
| 500 | 14.6 | 7.7 | 1.3 | 1.2 | 68.8 | 61.6 | 40.6 | 39.6 | |
| small | 1000 | 18.5 | 6.5 | 0.7 | 0.3 | 77.6 | 85.5 | 63.6 | 55.9 |
| 2000 | 36.4 | 7.7 | 0.6 | 0.0 | 78.8 | 98.7 | 75.5 | 79.8 | |
| 500 | 11.4 | 6.6 | 1.3 | 1.2 | 97.9 | 95.8 | 93.8 | 93.6 | |
| large | 1000 | 9.3 | 6.6 | 0.6 | 0.2 | 99.7 | 99.8 | 99.4 | 98.9 |
| 2000 | 4.4 | 7.4 | 0.1 | 0.0 | 100 | 100 | 100 | 100 | |
| Unbalanced deviations from the Rasch model | |||||||||
| 500 | 11.4 | 5.7 | 1.8 | 1.1 | 80.4 | 69.5 | 30.9 | 29.9 | |
| small | 1000 | 10.8 | 5.9 | 0.8 | 0.3 | 97.9 | 94.0 | 72.5 | 50.9 |
| 2000 | 8.3 | 7.7 | 0.4 | 0.1 | 99.9 | 99.9 | 98.2 | 87.3 | |
| 500 | 13.7 | 5.9 | 1.2 | 1.0 | 100 | 100 | 99.9 | 99.9 | |
| large | 1000 | 12.1 | 5.8 | 0.7 | 0.2 | 100 | 100 | 100 | 100 |
| 2000 | 10.9 | 7.3 | 0.4 | 0.0 | 100 | 100 | 100 | 100 | |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Robitzsch, A. Smooth Information Criterion for Regularized Estimation of Item Response Models. Algorithms 2024, 17, 153. https://doi.org/10.3390/a17040153
Robitzsch A. Smooth Information Criterion for Regularized Estimation of Item Response Models. Algorithms. 2024; 17(4):153. https://doi.org/10.3390/a17040153
Chicago/Turabian StyleRobitzsch, Alexander. 2024. "Smooth Information Criterion for Regularized Estimation of Item Response Models" Algorithms 17, no. 4: 153. https://doi.org/10.3390/a17040153
APA StyleRobitzsch, A. (2024). Smooth Information Criterion for Regularized Estimation of Item Response Models. Algorithms, 17(4), 153. https://doi.org/10.3390/a17040153