
Application of Split Coordinate Channel Attention Embedding U2Net in Salient Object Detection

Abstract
1. Introduction
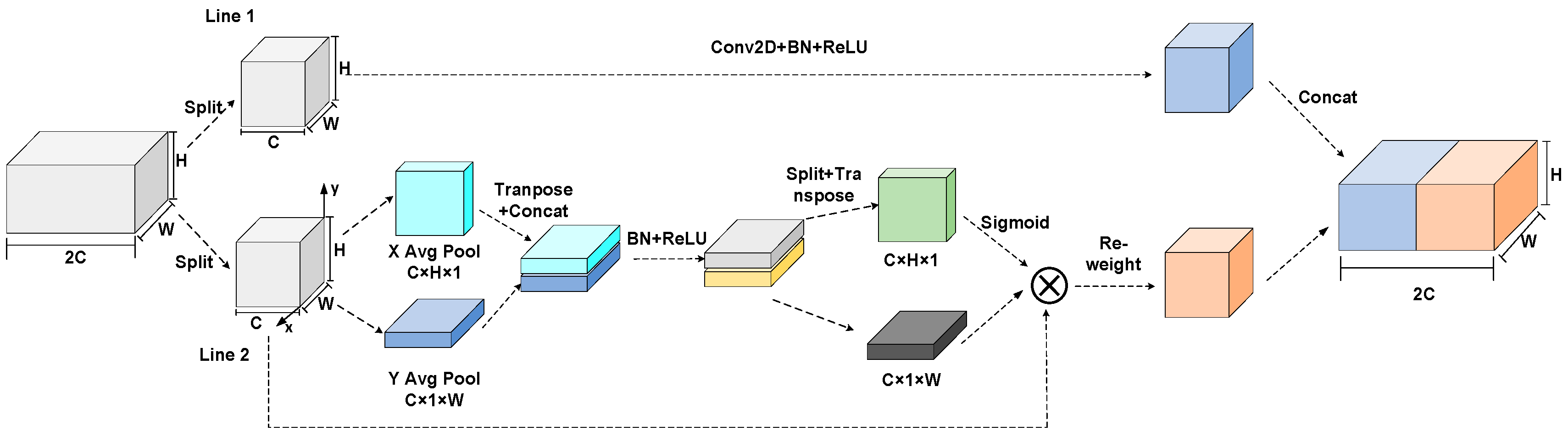
- This paper proposes an attention module called split coordinate channel attention (SCCA), which splits input channels to capture high-level semantic information and location information simultaneously.
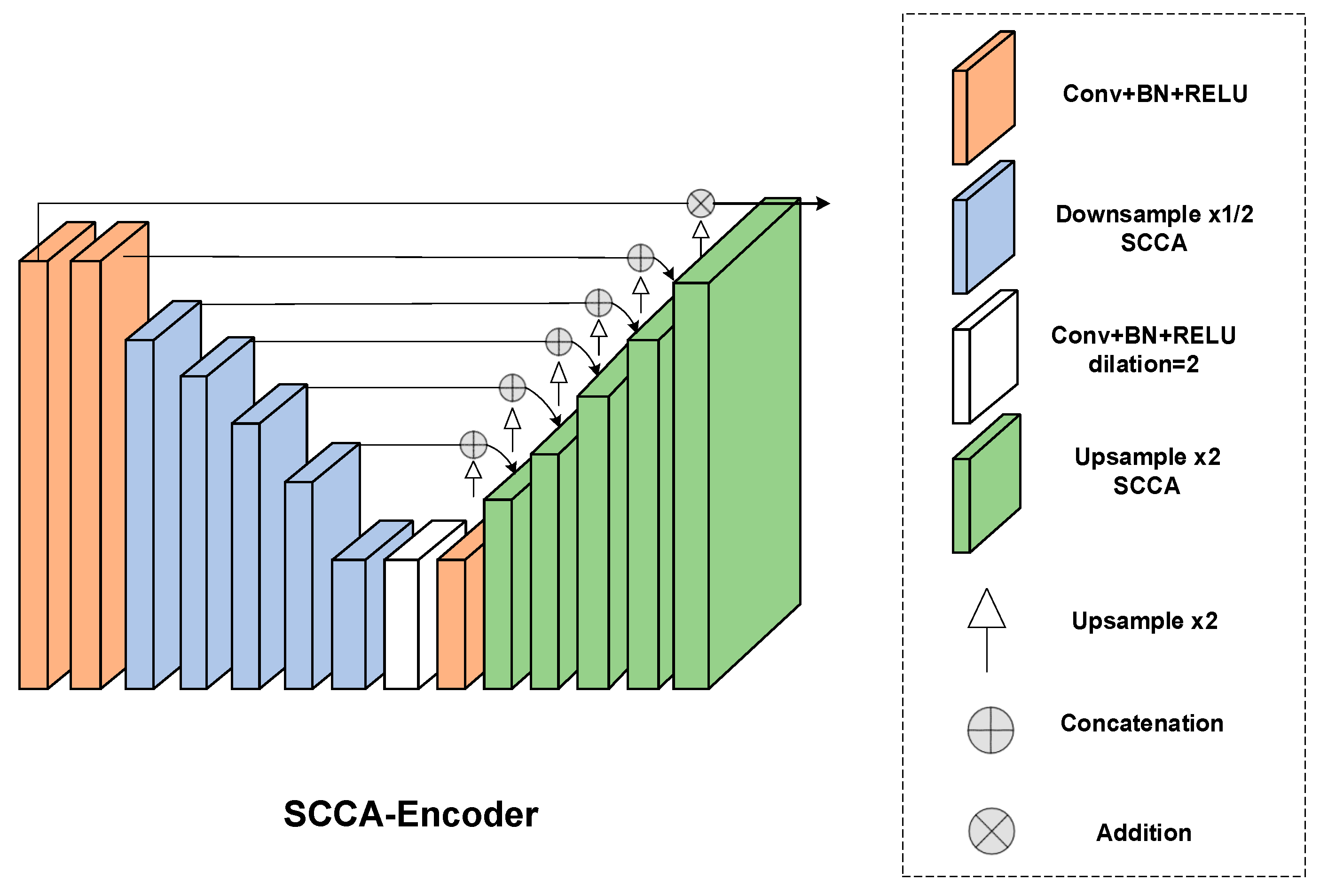
- This paper replaces the encoder and decoder of U2Net [14] with SCCA and devises a novel loss function C2 loss to prioritize edges and objects. By implementing these improvement strategies, this paper presents SCCA-U2Net for salient object detection.
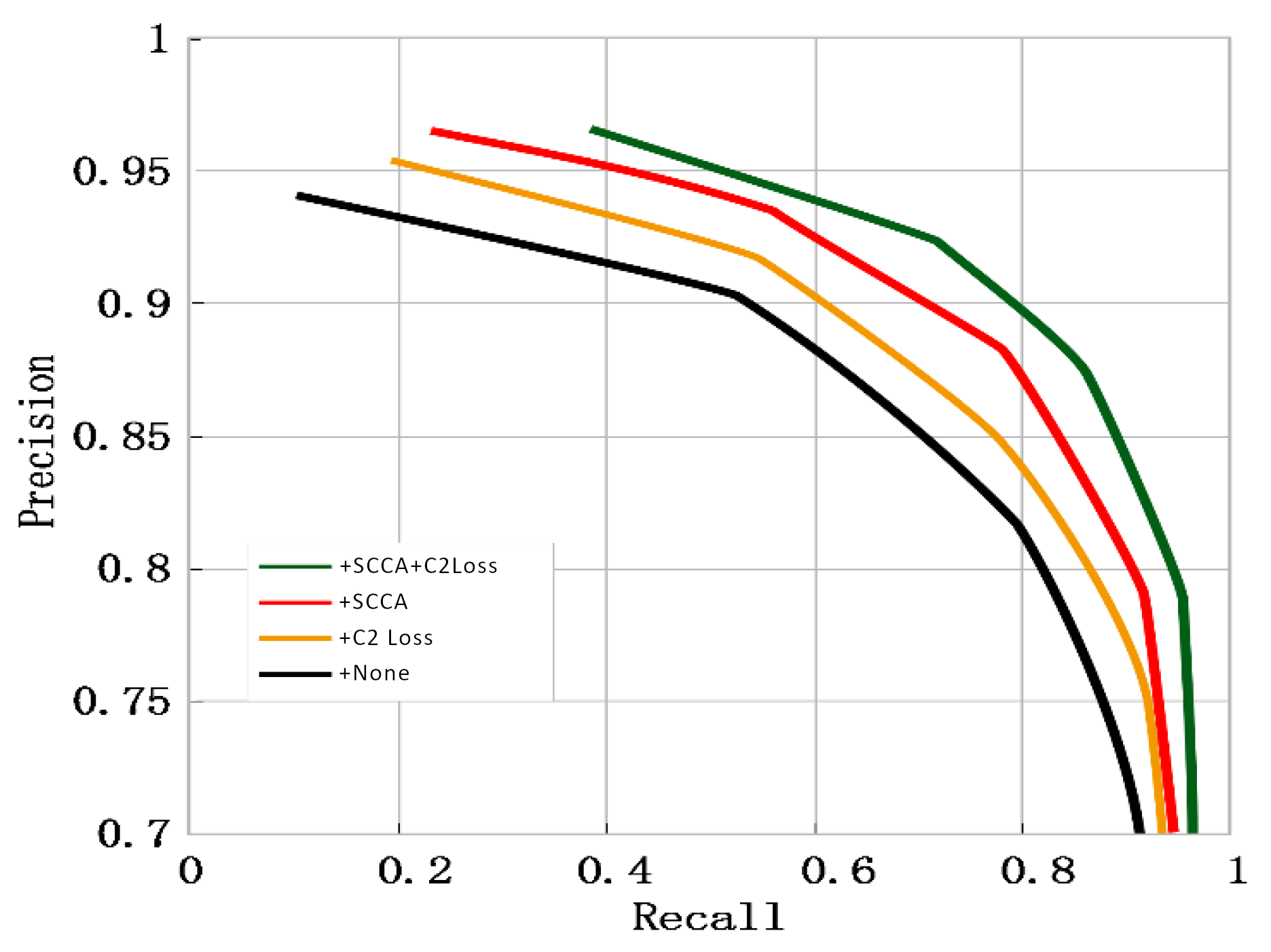
- SCCA-U2Net achieves top-three results on four metrics in salient object detection tasks on the DUTS and HKU-IS datasets and outperforms nine other advanced attention modules. Ablation studies demonstrate the superiority of SCCA-U2Net, and this paper provides visualizations of comparing detection results.
2. Related Work
2.1. Salient Object Detection Research
2.2. U2net Algorithm
3. Proposed Method
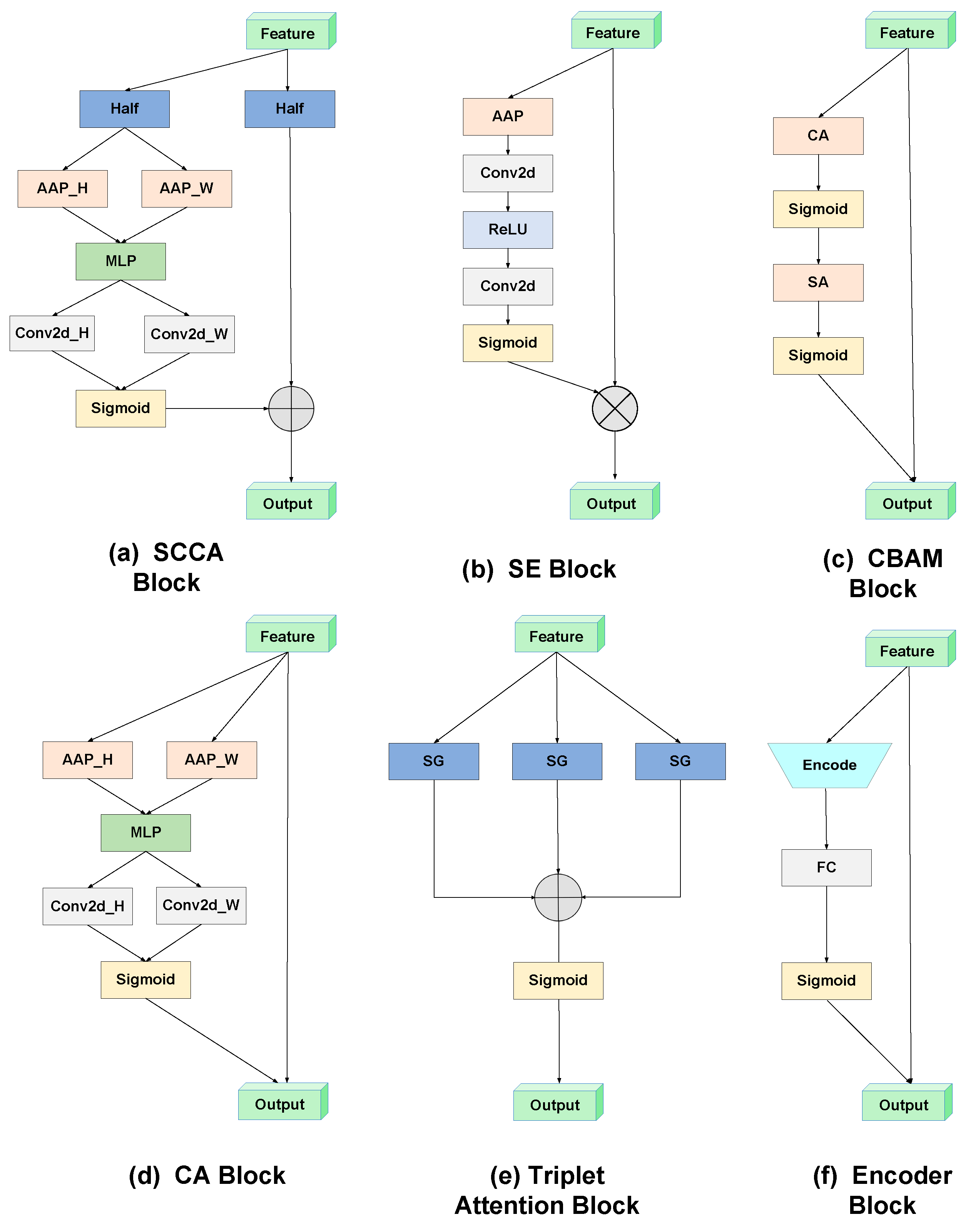
3.1. Split Channel Coordinate Attention
3.2. C2 Loss
3.3. Improved U2Net
4. Results and Discussion
4.1. Experiment Processing
- Model parameter initialization, including the training device, number of input batches, number of iterations, weight decay, learning rate, validation intervals, and whether to use mixed precision;
- Input the training dataset in batches and perform scaling, random cropping, random flipping, and regularization of the images;
- Model training, calculate the loss of the training process;
- Update the weight values according to the direction of the loss gradient and update the learning rate according to the measurement;
- If the maximum number of iterations is reached, the training is terminated, and the weight value is retained. Otherwise, the mean absolute error is calculated, the experimental round is iterated, and the training step is continued until the maximum number of iterations is reached;
- Input pictures and predict the binarized images.
4.2. Experiment Details
4.3. Dataset
4.4. Evaluation Metrics
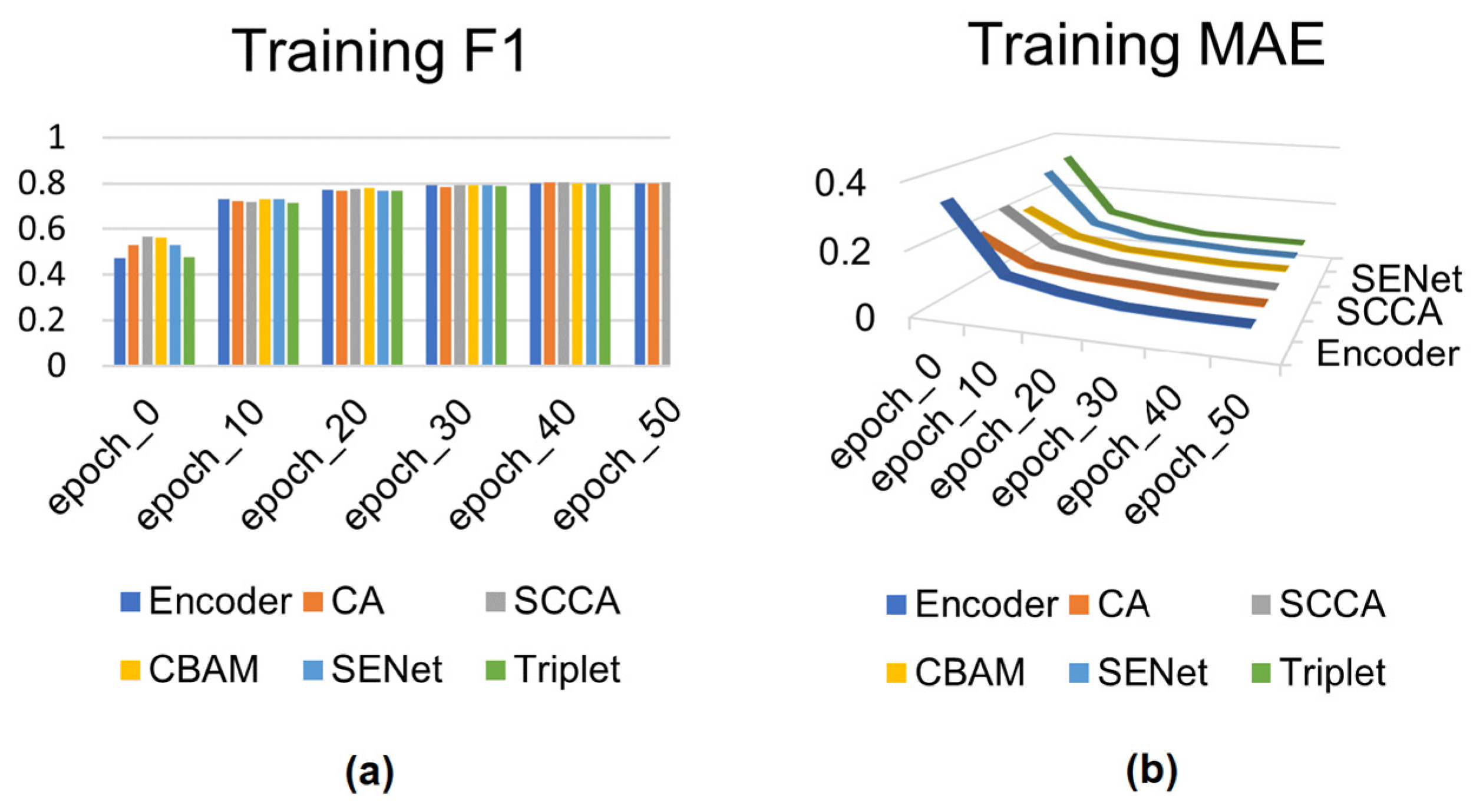
4.5. Training Process
4.6. Comparison Analysis
4.7. Ablation Studies
4.8. Visualization
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sharma, N.; Sharma, R.; Jindal, N. Machine learning and deep learning applications—A vision. Glob. Transit. Proc. 2021, 2, 24–28. [Google Scholar] [CrossRef]
- Shinde, P.P.; Shah, S. A review of machine learning and deep learning applications. In Proceedings of the 2018 Fourth International Conference on Computing Communication Control and Automation (ICCUBEA), Pune, India, 16–18 August 2018; IEEE: New York, NY, USA, 2018; pp. 1–6. [Google Scholar]
- Chai, J.; Zeng, H.; Li, A.; Ngai, E.W. Deep learning in computer vision: A critical review of emerging techniques and application scenarios. Mach. Learn. Appl. 2021, 6, 100134. [Google Scholar] [CrossRef]
- Xu, S.; Wang, J.; Shou, W.; Ngo, T.; Sadick, A.-M.; Wang, X. Computer vision techniques in construction: A critical review. Arch. Comput. Methods Eng. 2021, 28, 3383–3397. [Google Scholar] [CrossRef]
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep learning for computer vision: A brief review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Niu, Z.; Zhong, G.; Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 2021, 452, 48–62. [Google Scholar] [CrossRef]
- Brauwers, G.; Frasincar, F. A general survey on attention mechanisms in deep learning. IEEE Trans. Knowl. Data Eng. 2021, 35, 3279–3298. [Google Scholar] [CrossRef]
- Guo, M.H.; Xu, T.X.; Liu, J.J.; Liu, Z.N.; Jiang, P.T.; Mu, T.J.; Zhang, S.H.; Martin, R.R.; Cheng, M.M.; Hu, S.M. Attention mechanisms in computer vision: A survey. Comput. Vis. Media 2022, 8, 331–368. [Google Scholar] [CrossRef]
- Tong, W.; Chen, W.; Han, W.; Li, X.; Wang, L. Channel-attention-based DenseNet network for remote sensing image scene classification. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2020, 13, 4121–4132. [Google Scholar] [CrossRef]
- Zhou, T.; Fan, D.-P.; Cheng, M.-M.; Shen, J.; Shao, L. RGB-D salient object detection: A survey. Comput. Vis. Media 2021, 7, 37–69. [Google Scholar] [CrossRef] [PubMed]
- Ji, Y.; Zhang, H.; Zhang, Z.; Liu, M. CNN-based encoder-decoder networks for salient object detection: A comprehensive review and recent advances. Inf. Sci. 2021, 546, 835–857. [Google Scholar] [CrossRef]
- Wang, L.; Lu, H.; Wang, Y.; Feng, M.; Wang, D.; Yin, B.; Ruan, X. Learning to detect salient objects with image-level supervision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21 July 2017; pp. 136–145. [Google Scholar]
- Rong, W.; Li, Z.; Zhang, W.; Sun, L. An improved CANNY edge detection algorithm. In Proceedings of the 2014 IEEE International Conference on Mechatronics and Automation, Tianjin, China, 3–6 August 2014; IEEE: New York, NY, USA, 2014; pp. 577–582. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Dehghan, M.; Zaiane, O.R.; Jagersand, M. U2-Net: Going deeper with nested U-structure for salient object detection. Pattern Recognit. 2020, 106, 107404. [Google Scholar] [CrossRef]
- Wang, W.; Zhao, S.; Shen, J.; Hoi, S.C.; Borji, A. Salient object detection with pyramid attention and salient edges. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 1448–1457. [Google Scholar]
- Wei, J.; Wang, S.; Huang, Q. F³Net: Fusion, feedback and focus for salient object detection. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12321–12328. [Google Scholar]
- Qin, X.; Zhang, Z.; Huang, C.; Gao, C.; Dehghan, M.; Jagersand, M. Basnet: Boundary-aware salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7479–7489. [Google Scholar]
- Zhao, X.; Pang, Y.; Zhang, L.; Lu, H.; Zhang, L. Suppress and balance: A simple gated network for salient object detection. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part II 16. Springer International Publishing: Berlin/Heidelberg, Germany, 2020; pp. 35–51. [Google Scholar]
- Chen, T.; Hu, X.; Xiao, J.; Zhang, G.; Wang, S. CFIDNet: Cascaded feature interaction decoder for RGB-D salient object detection. Neural Comput. Appl. 2022, 34, 7547–7563. [Google Scholar] [CrossRef]
- Liao, G.; Gao, W.; Li, G.; Wang, J.; Kwong, S. Cross-collaborative fusion-encoder network for robust RGB-thermal salient object detection. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 7646–7661. [Google Scholar] [CrossRef]
- Wang, Q.; Liu, Y.; Xiong, Z.; Yuan, Y. Hybrid feature aligned network for salient object detection in optical remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2022, 60, 5624915. [Google Scholar] [CrossRef]
- Zhou, X.; Shen, K.; Weng, L.; Cong, R.; Zheng, B.; Zhang, J.; Yan, C. Edge-guided recurrent positioning network for salient object detection in optical remote sensing images. IEEE Trans. Cybern. 2022, 53, 539–552. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.H.; Liu, Y.; Zhang, L.; Cheng, M.M.; Ren, B. EDN: Salient object detection via extremely-downsampled network. IEEE Trans. Image Process. 2022, 31, 3125–3136. [Google Scholar] [CrossRef]
- Ji, Y.; Zhang, H.; Jie, Z.; Ma, L.; Wu, Q.M.J. CASNet: A cross-attention siamese network for video salient object detection. IEEE Trans. Neural Netw. Learn. Syst. 2020, 32, 2676–2690. [Google Scholar] [CrossRef]
- Canny, J.F. Finding Edges and Lines in Images; AITR-720; Theory of Computing Systems/Mathematical Systems Theory; Artificial lntelligence Laboratory: Cambridge, MA, USA, 1983; Volume 16. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Misra, D.; Nalamada, T.; Arasanipalai, A.U.; Hou, Q. Rotate to attend: Convolutional triplet attention module. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3139–3148. [Google Scholar]
- Yang, Y.; Deng, H. GC-YOLOv3: You only look once with global context block. Electronics 2020, 9, 1235. [Google Scholar] [CrossRef]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective kernel networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Zhu, Z.; Xu, M.; Bai, S.; Huang, T.; Bai, X. Asymmetric non-local neural networks for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27–28 October 2019; pp. 593–602. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Attention | Size | DUTS | HKU-IS | ||||
|---|---|---|---|---|---|---|---|
| Times | MAE | F1-Score | Times | MAE | F1-Score | ||
| Encoder | 1.29 | 0.387 | 0.071 | 0.801 | 0.020 | 0.032 | 0.932 |
| CA | 0.58 | 0.555 | 0.072 | 0.802 | 0.054 | 0.033 | 0.927 |
| SCCA | 0.57 | 0.424 | 0.067 | 0.806 | 0.054 | 0.028 | 0.938 |
| CBAM | 0.6 | 0.609 | 0.074 | 0.801 | 0.089 | 0.032 | 0.930 |
| SENet | 0.5 | 0.436 | 0.071 | 0.802 | 0.021 | 0.031 | 0.931 |
| Triplet | 0.88 | 0.544 | 0.071 | 0.801 | 0.034 | 0.034 | 0.924 |
| GCB | 0.57 | 0.582 | 0.070 | 0.800 | 0.038 | 0.036 | 0.919 |
| SKNet | 6.65 | 1.086 | 0.840 | 0.792 | 0.072 | 0.040 | 0.894 |
| NLB | 35.01 | 1.568 | 0.180 | 0.768 | 1.002 | 0.048 | 0.882 |
| APNB | 35.01 | 1.653 | 0.160 | 0.770 | 1.004 | 0.048 | 0.884 |
| SCCA | C2 Loss | Size | DUTS | HKU-IS | ||||
|---|---|---|---|---|---|---|---|---|
| Times | MAE | F1-Score | Times | MAE | F1-Score | |||
| × | × | 1.29 | 0.387 | 0.071 | 0.801 | 0.020 | 0.032 | 0.932 |
| √ | × | 0.57 | 0.424 | 0.067 | 0.806 | 0.054 | 0.028 | 0.938 |
| × | √ | 1.29 | 0.402 | 0.069 | 0.804 | 0.032 | 0.030 | 0.934 |
| √ | √ | 0.57 | 0.424 | 0.066 | 0.809 | 0.056 | 0.028 | 0.939 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, Y.; Wu, Y. Application of Split Coordinate Channel Attention Embedding U2Net in Salient Object Detection. Algorithms 2024, 17, 109. https://doi.org/10.3390/a17030109
Wu Y, Wu Y. Application of Split Coordinate Channel Attention Embedding U2Net in Salient Object Detection. Algorithms. 2024; 17(3):109. https://doi.org/10.3390/a17030109
Chicago/Turabian StyleWu, Yuhuan, and Yonghong Wu. 2024. "Application of Split Coordinate Channel Attention Embedding U2Net in Salient Object Detection" Algorithms 17, no. 3: 109. https://doi.org/10.3390/a17030109
APA StyleWu, Y., & Wu, Y. (2024). Application of Split Coordinate Channel Attention Embedding U2Net in Salient Object Detection. Algorithms, 17(3), 109. https://doi.org/10.3390/a17030109