
Applying Recommender Systems to Predict Personalized Film Age Ratings for Parents



Abstract

1. Introduction
2. Related Work
2.1. Film Age Rating Systems
- The MPAA (Motion Picture Association of America) was established in the USA. The MPAA is one of the most well-known film classification systems and has been in use since 1968 [8]. Its key ratings include the following
- –
- G (General Audience): Suitable for all ages.
- –
- PG (Parental Guidance): Some material may not be suitable for children.
- –
- PG-13: Parents are strongly advised that some content may be inappropriate for children under 13 years of age.
- –
- R (Restricted): Viewers under 17 years of age require an accompanying adult.
- –
- NC-17: No one 17 and under admitted.
- The BBFC (British Board of Film Classification) was established in the UK [10].The BBFC has been classifying films since 1912, offering ratings that guide the public and protect younger viewers:
- –
- U (Universal): Suitable for all.
- –
- PG (Parental Guidance): General viewing, but some scenes may be unsuitable for young children.
- –
- 12A: Children under 12 years of age must be accompanied by an adult.
- –
- 15: Only suitable for viewers aged 15 and older.
- –
- 18: Only suitable for adults.
- CNC (Centre National du Cinéma et de l’Image Animée) was established in France [11].The French system, managed by the CNC, uses a stricter approach to age ratings, with a strong emphasis on protecting minors from harmful content:
- –
- U: Suitable for all.
- –
- 10: Not recommended for children under 10.
- –
- 12: Not recommended for children under 12.
- –
- 16: Not recommended for children under 16.
- –
- 18: Only suitable for adults.
- FSK (Freiwillige Selbstkontrolle der Filmwirtschaft) was established in Germany [12].The German film classification system is managed by the FSK and offers the following categories:
- –
- 0: Suitable for all.
- –
- 6: Suitable for ages 6 and older.
- –
- 12: Suitable for ages 12 and older.
- –
- 16: Suitable for ages 16 and older.
- –
- 18: Only suitable for adults.
- The ACB (Australian Classification Board) was established in Australia [13] and has been in use since 1968.Australia’s film rating system offers the following categories:
- –
- G: Suitable for all.
- –
- PG: Parental guidance recommended for viewers under 15.
- –
- M: Recommended for viewers 15 and over.
- –
- MA15+: Restricted to viewers 15 and older unless accompanied by an adult.
- –
- R18+: Restricted to adult viewers (18+).
- –
- X18+: Explicit adult content.
2.2. Recommender Systems
- Item-to-item correlation: Recommendations are based on similarities between items, utilizing their properties and associations.
- User-to-user correlation: Suggestions are generated based on demographic similarities among users.
- User-to-item correlation: Recommendations arise from matching users with items they have previously rated or expressed a preference for.
3. Problem Formulation
4. Proposed Methodology
4.1. Training Phase
- The data transformation phase employs a modified, generalized version of one-hot encoding, in order to transform the age values into different age categories (see Figure 1). Therefore, to train each recommender system, , where , we create triples for any triplet of the original training set. Here, denotes the beliefs of the parent, p, and film, f, for the age category, i. According to the definition of , can be defined by the following delta function, according to :However, better results are obtained when we allow non-zero values for values of i in the neighborhood of . As an example, one approach involves using a partially linear function (triangular function), as defined in Equation (3), so that the belief of the parent gradually decreases as we move away from the selected age category :where the parameter (e.g., ) corresponds to the slope of the triangular function. It should be noted that when , we have the special case of the delta function.
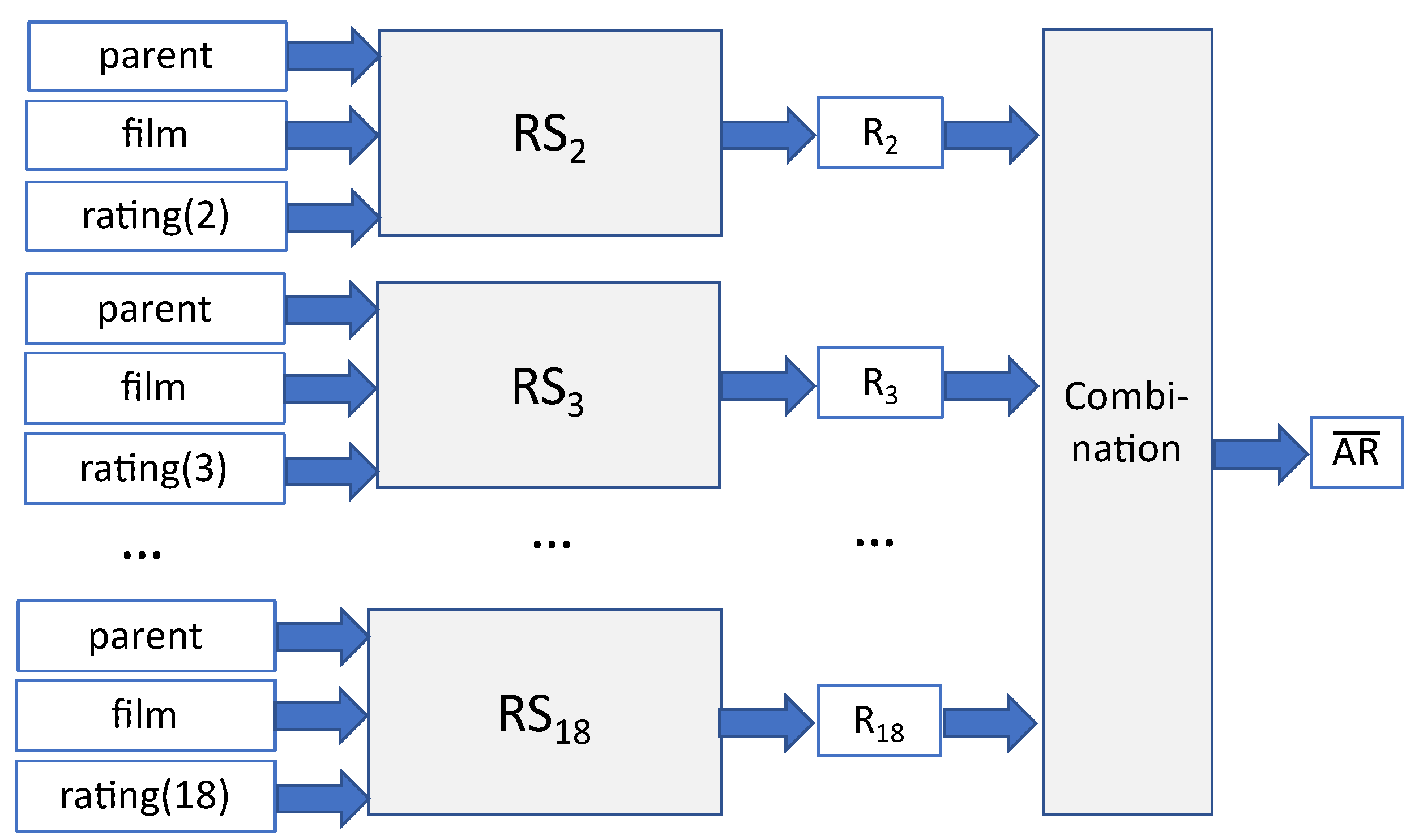
- According to the proposed methodology, the training set for each recommender system , defined on line 5 in Algorithm 1 is based on Equation (3). Finally, the trainRS procedure on line 7 in Algorithm 1 trains the recommender system by using the training set (i.e., the triplets that correspond to the same age category).The final recommendation combines the resulting recommendations of the recommender systems , (see Figure 2). The output of each recommender system for a parent, p, and an item, f, corresponds to the predicted belief of that user that that item is appropriate for that age category. One natural way to combine the resulting recommendations, as conducted in classification problems, is to select the age category with the highest recommendation (see Equation (4)) to produce a single cage category as the final output, as follows:However, taking into account that the age categories are numerical values, better results are obtained when we obtain the expected value of the recommendation, as defined in the following equation:
| Algorithm 1: The training phase of the proposed method. |
input: output:  |
4.2. Testing Phase
| Algorithm 2: The proposed application method of recommender systems to predict personalized film age ratings for parents. This algorithm shows the testing phase of the proposed method. |
input: output: 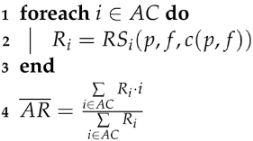 |
5. Experimental Results
5.1. Dataset
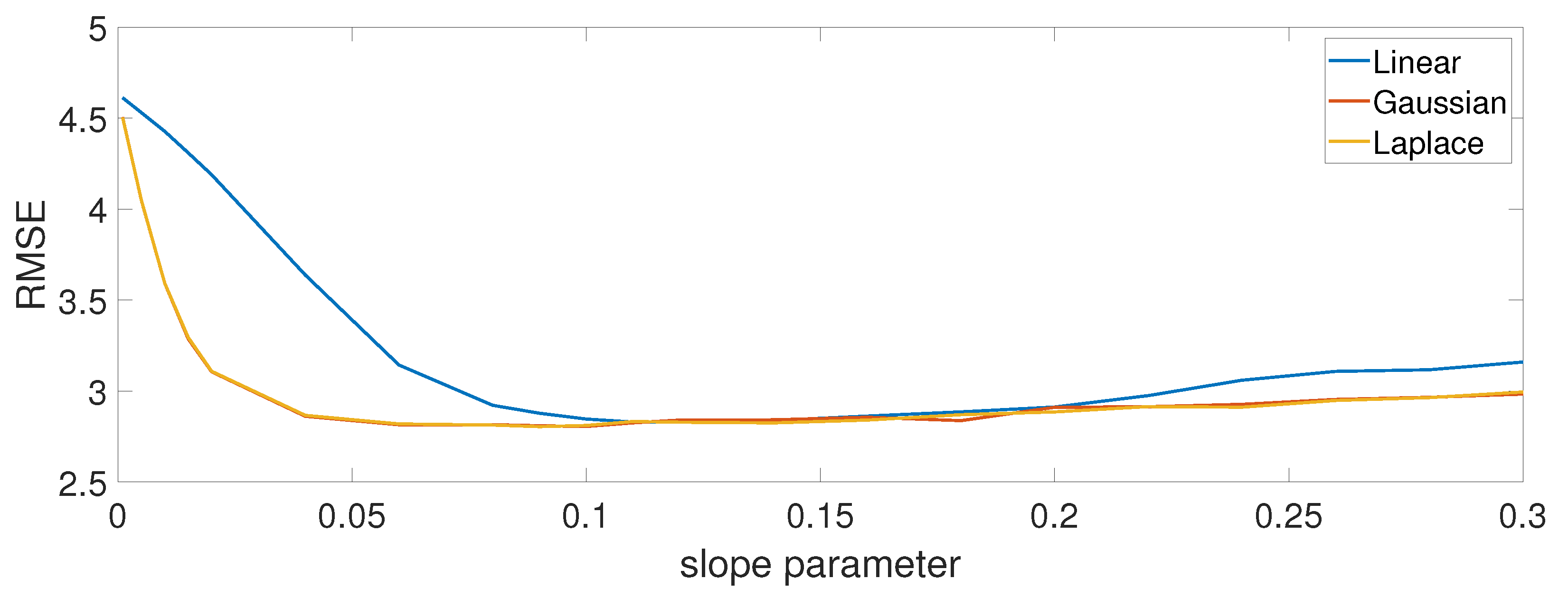
5.2. Performance Evaluation
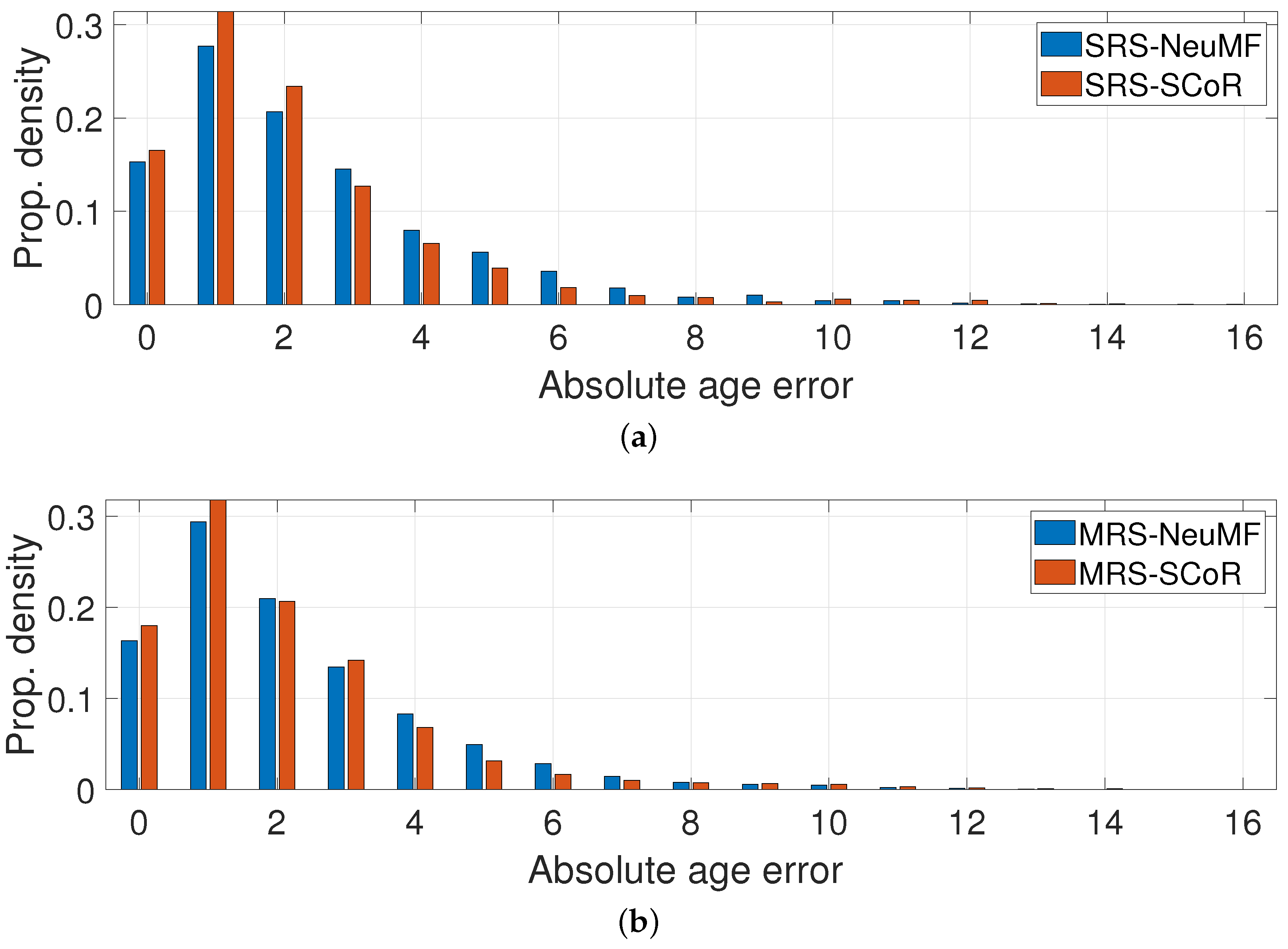
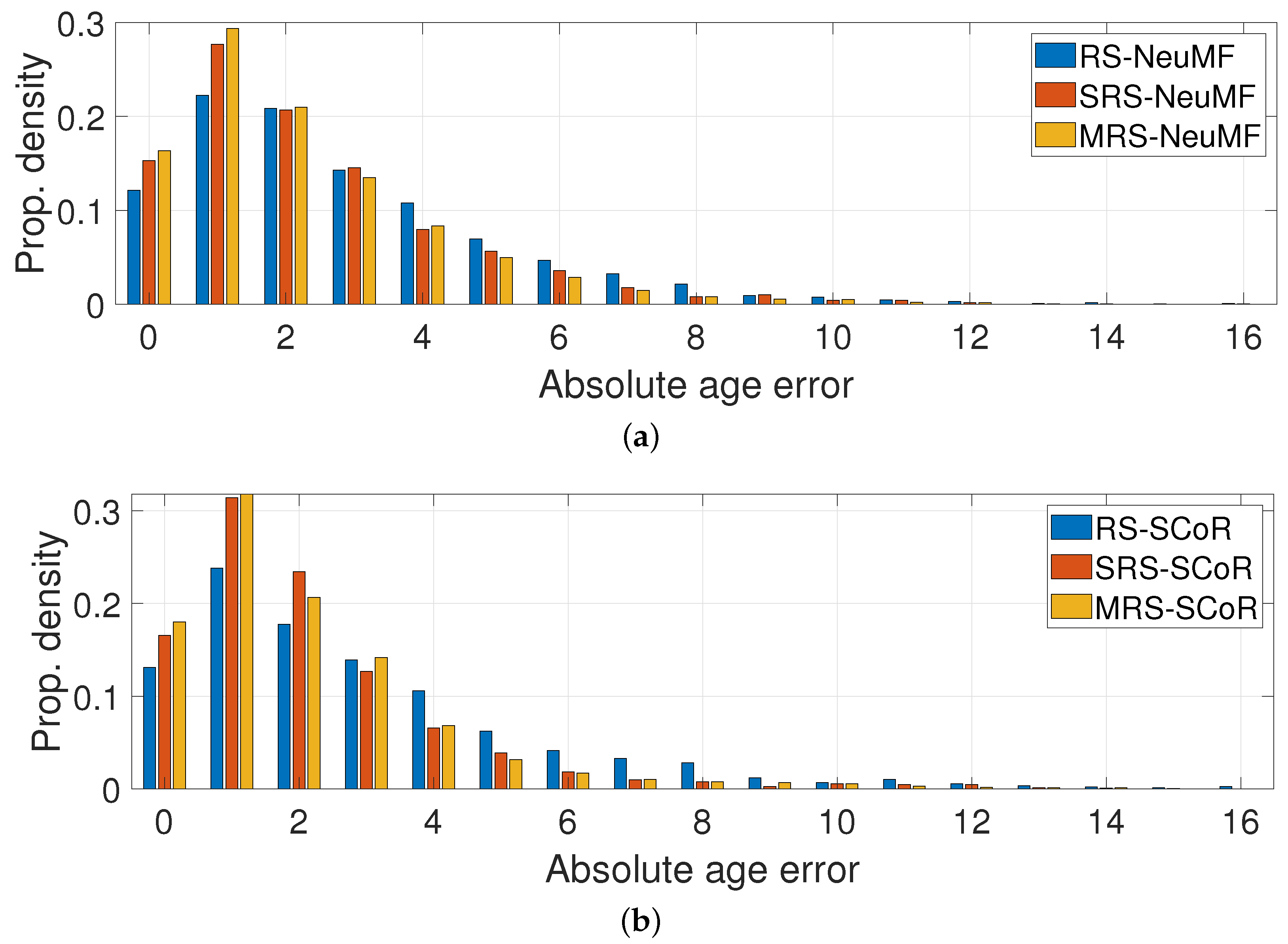
- In the first group (MRSs—multiple recommender systems), the approach used was the one described in this paper (see Figure 2).
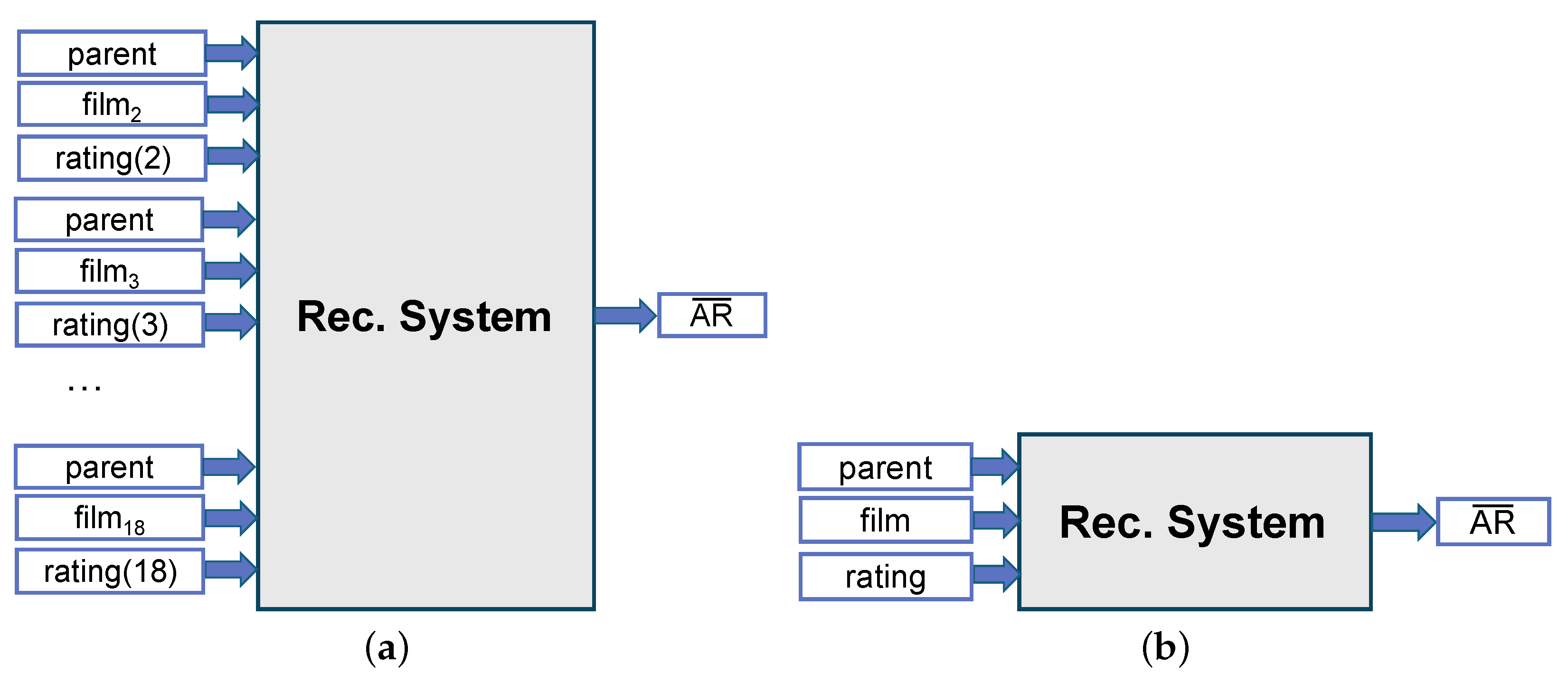
- The second group (SRS—single recommender system) was a variation of the first, where only one recommender system was used, which was trained on the data of all age categories, instead of a separate independent recommender system per age category (see Figure 5a).
- Finally, the “RS” group corresponds to the experiments performed without any dataset transformation, where both recommender systems used (SCoR and NeuMF) were trained on the original age values (see Figure 5b). Those experiments were performed in order to demonstrate the necessity of the data transformation in the first phase.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bronfenbrenner, U. Ecological systems theory (1992). In Making Human Beings Human: Bioecological Perspectives on Human Development; SAGE Publishing: Thousand Oaks, CA, USA, 2005; pp. 106–173. [Google Scholar]
- Erikson, E.H. Childhood and Society; W.W. Norton and Company: New York, NY, USA, 1950. [Google Scholar]
- Kelly, K.; Garbacz, A.; Albers, C. Theories of School Psychology Critical Perspectives; Routledge: London, UK, 2020; pp. 138–151. [Google Scholar]
- Piotrowski, J.T.; Valkenburg, P.M. Finding Orchids in a Field of Dandelions: Understanding Children’s Differential Susceptibility to Media Effects. Am. Behav. Sci. 2015, 59, 1776–1789. [Google Scholar] [CrossRef]
- Gentile, D.; Bushman, B. Reassessing Media Violence Effects Using a Risk and Resilience Approach to Understanding Aggression. Psychol. Pop. Media Cult. 2012, 1, 138–151. [Google Scholar] [CrossRef]
- Masten, A. Ordinary magic: Resilience processes in development. Am. Psychol. 2001, 56, 227–238. [Google Scholar] [CrossRef]
- Daskalaki, E.; Panagiotakis, C.; Papadakis, H.; Fragopoulou, P. Age recommendations for children’s films: Associations between advisories on a US site and parents’ ratings. J. Child. Media 2022, 16, 532–542. [Google Scholar] [CrossRef]
- Motion Picture Association. Available online: https://www.motionpictures.org/ (accessed on 26 September 2024).
- Common Sense Media. Available online: https://www.commonsensemedia.org/ (accessed on 26 September 2024).
- British Board of Film Classification. Available online: https://www.bbfc.co.uk/ (accessed on 26 September 2024).
- Centre National du Cinéma et de l’Image Animée. Available online: https://www.cnc.fr/ (accessed on 26 September 2024).
- Freiwillige Selbstkontrolle der Filmwirtschaft. Available online: https://www.fsk.de/ (accessed on 26 September 2024).
- Australian Classification Board. Available online: https://www.classification.gov.au/ (accessed on 26 September 2024).
- Bobadilla, J.; Ortega, F.; Hernando, A.; Gutiérrez, A. Recommender systems survey. Knowl.-Based Syst. 2013, 46, 109–132. [Google Scholar] [CrossRef]
- Papadakis, H.; Panagiotakis, C.; Fragopoulou, P. SCoR: A Synthetic Coordinate based System for Recommendations. Expert Syst. Appl. 2017, 79, 8–19. [Google Scholar] [CrossRef]
- He, X.; Liao, L.; Zhang, H.; Nie, L.; Hu, X.; Chua, T.S. Neural collaborative filtering. In Proceedings of the 26th International Conference on World Wide Web, Perth, Australia, 3–7 April 2017; pp. 173–182. [Google Scholar]
- Panagiotakis, C.; Papadakis, H.; Papagrigoriou, A.; Fragopoulou, P. Improving recommender systems via a dual training error based correction approach. Expert Syst. Appl. 2021, 183, 115386. [Google Scholar] [CrossRef]
- Xie, W.; Ouyang, Y.; Ouyang, J.; Rong, W.; Xiong, Z. User occupation aware conditional restricted boltzmann machine based recommendation. In Proceedings of the 2016 IEEE International Conference on Internet of Things (iThings), Chengdu, China, 15–18 December 2016; pp. 454–461. [Google Scholar]
- Guo, G.; Zhang, J.; Thalmann, D. Merging trust in collaborative filtering to alleviate data sparsity and cold start. Knowl.-Based Syst. 2014, 57, 57–68. [Google Scholar] [CrossRef]
- Zhou, Y.; Wilkinson, D.; Schreiber, R.; Pan, R. Large-Scale Parallel Collaborative Filtering for the Netflix Prize. In Proceedings of the International Conference on Algorithmic Applications in Management, Shanghai, China, 23–25 June 2008; Springer: Berlin/Heidelberg, Germany, 2008; pp. 337–348. [Google Scholar]
- Elahi, M.; Ricci, F.; Rubens, N. A survey of active learning in collaborative filtering recommender systems. Comput. Sci. Rev. 2016, 20, 29–50. [Google Scholar] [CrossRef]
- Papadakis, H.; Papagrigoriou, A.; Panagiotakis, C.; Kosmas, E.; Fragopoulou, P. Collaborative filtering recommender systems taxonomy. Knowl. Inf. Syst. 2022, 64, 35–74. [Google Scholar] [CrossRef]
- Goldberg, K.; Roeder, T.; Gupta, D.; Perkins, C. Eigentaste: A Constant Time Collaborative Filtering Algorithm. Inf. Retr. 2001, 4, 133–151. [Google Scholar] [CrossRef]
- Gorrell, G. Generalized Hebbian Algorithm for Incremental Singular Value Decomposition in Natural Language Processing. In Proceedings of the 11st Conference of the European Chapter of the Association for Computational Linguistics, Trento, Italy, 3–7 April 2006; pp. 97–104. [Google Scholar]
- Mobasher, B.; Burke, R.D.; Sandvig, J.J. Model-Based Collaborative Filtering as a Defense against Profil Injection Attacks. In Proceedings of the The Twenty-First National Conference on Artificial Intelligence and the Eighteenth Innovative Applications of Artificial Intelligence Conference, Boston, MA, USA, 16–20 July 2006; pp. 1388–1393. [Google Scholar]
- Koren, Y.; Bell, R.; Volinsky, C. Matrix factorization techniques for recommender systems. Computer 2009, 42, 30–37. [Google Scholar] [CrossRef]
- Gao, C.; Zheng, Y.; Li, N.; Li, Y.; Qin, Y.; Piao, J.; Quan, Y.; Chang, J.; Jin, D.; He, X.; et al. A survey of graph neural networks for recommender systems: Challenges, methods, and directions. Acm Trans. Recomm. Syst. 2023, 1, 1–51. [Google Scholar] [CrossRef]
- He, X.; Du, X.; Wang, X.; Tian, F.; Tang, J.; Chua, T.S. Outer Product-based Neural Collaborative Filtering. arXiv 2018, arXiv:1808.03912. [Google Scholar]
- Berg, R.V.D.; Kipf, T.N.; Welling, M. Graph convolutional matrix completion. arXiv 2017, arXiv:1706.02263. [Google Scholar]
- Papadakis, H.; Papagrigoriou, A.; Kosmas, E.; Panagiotakis, C.; Markaki, S.; Fragopoulou, P. Content-based recommender systems taxonomy. Found. Comput. Decis. Sci. 2023, 48, 211–241. [Google Scholar] [CrossRef]
- Pasquale Lops, M.d.G.; Semeraro, G. Content-based Recommender Systems: State of the Art and Trends. In Recommender Systems Handbook; Springer: Berlin/Heidelberg, Germany, 2010; pp. 73–106. [Google Scholar]
- Logesh, R.; Subramaniyaswamy, V. Exploring hybrid recommender systems for personalized travel applications. In Cognitive Informatics and Soft Computing; Springer: Berlin/Heidelberg, Germany, 2019; pp. 535–544. [Google Scholar]
- Adomavicius, G.; Kwon, Y. Improving aggregate recommendation diversity using ranking-based techniques. IEEE Trans. Knowl. Data Eng. 2012, 24, 896–911. [Google Scholar] [CrossRef]


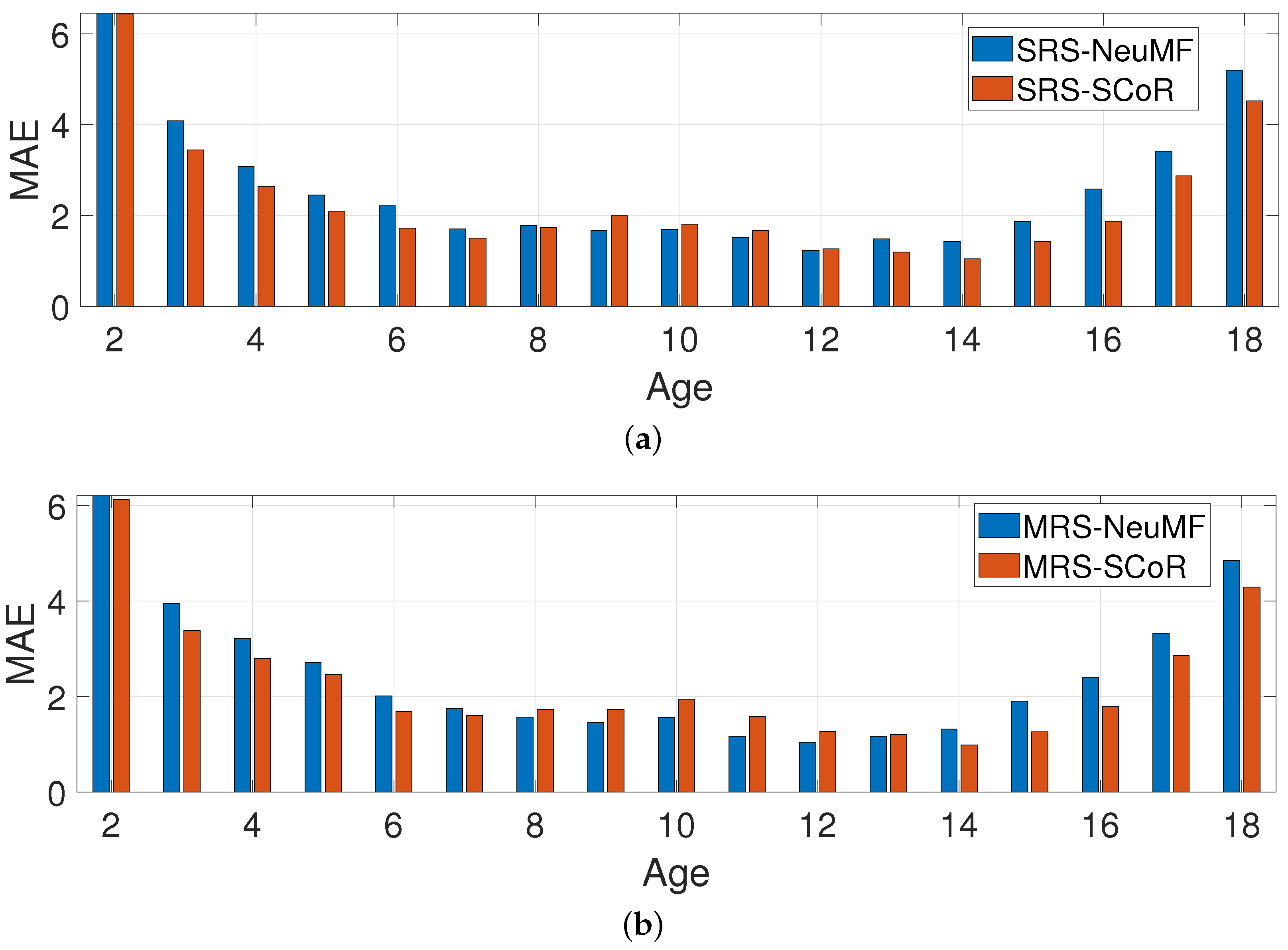
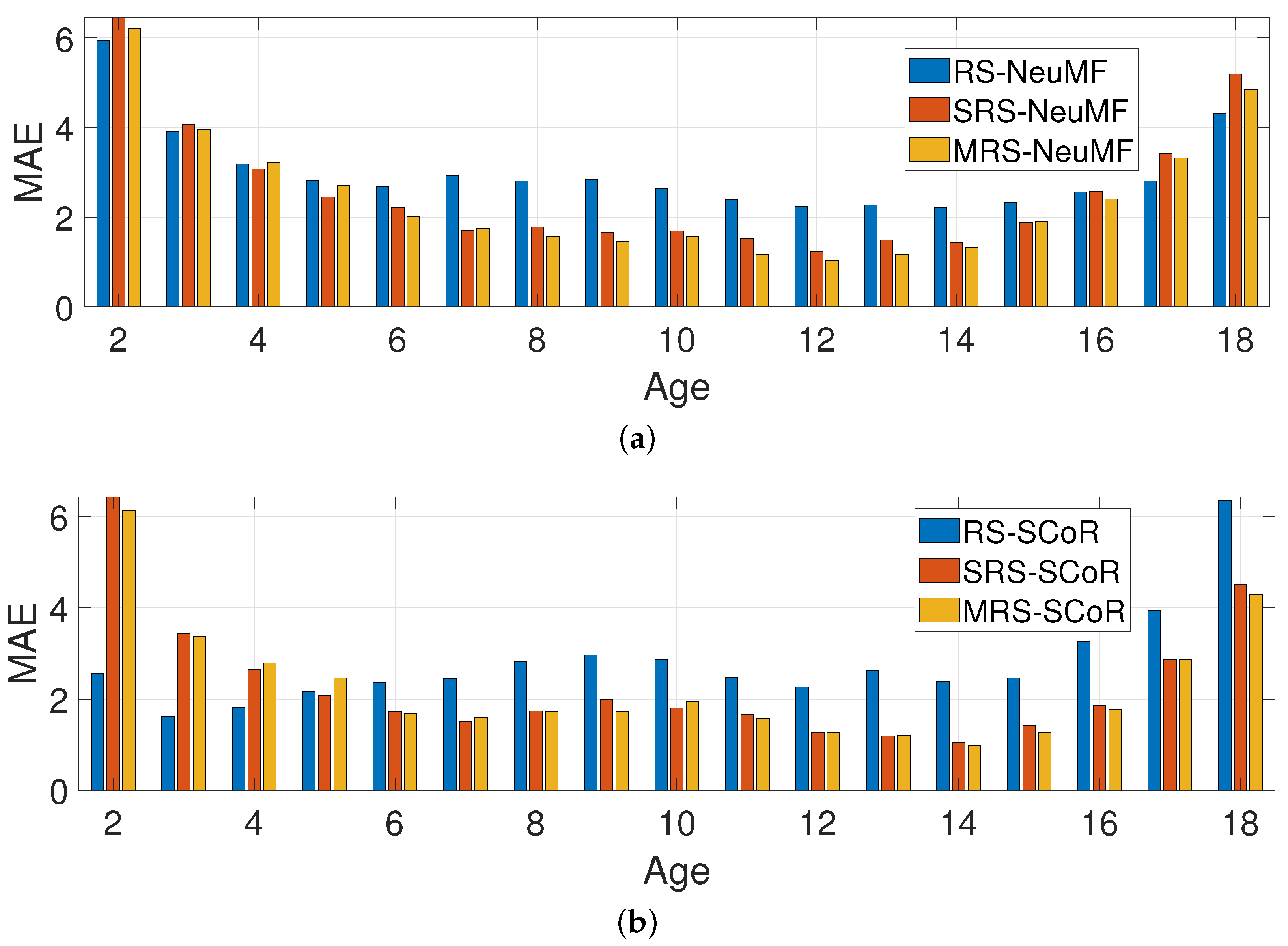

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| RMSE | RS | SRS | MRS |
|---|---|---|---|
| SCoR | 3.99 | 2.88 | 2.83 |
| NeuMF | 3.67 | 3.14 | 2.93 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papadakis, H.; Fragopoulou, P.; Panagiotakis, C. Applying Recommender Systems to Predict Personalized Film Age Ratings for Parents. Algorithms 2024, 17, 578. https://doi.org/10.3390/a17120578
Papadakis H, Fragopoulou P, Panagiotakis C. Applying Recommender Systems to Predict Personalized Film Age Ratings for Parents. Algorithms. 2024; 17(12):578. https://doi.org/10.3390/a17120578
Chicago/Turabian StylePapadakis, Harris, Paraskevi Fragopoulou, and Costas Panagiotakis. 2024. "Applying Recommender Systems to Predict Personalized Film Age Ratings for Parents" Algorithms 17, no. 12: 578. https://doi.org/10.3390/a17120578
APA StylePapadakis, H., Fragopoulou, P., & Panagiotakis, C. (2024). Applying Recommender Systems to Predict Personalized Film Age Ratings for Parents. Algorithms, 17(12), 578. https://doi.org/10.3390/a17120578