


Optimization of Offshore Saline Aquifer CO2 Storage in Smeaheia Using Surrogate Reservoir Models





Abstract
1. Introduction
2. Theory
2.1. Artificial Neural Network
2.2. Genetic Algorithm
3. Methodology
3.1. Case Study Description and Its Numerical Model
3.2. Updating the Numerical Model
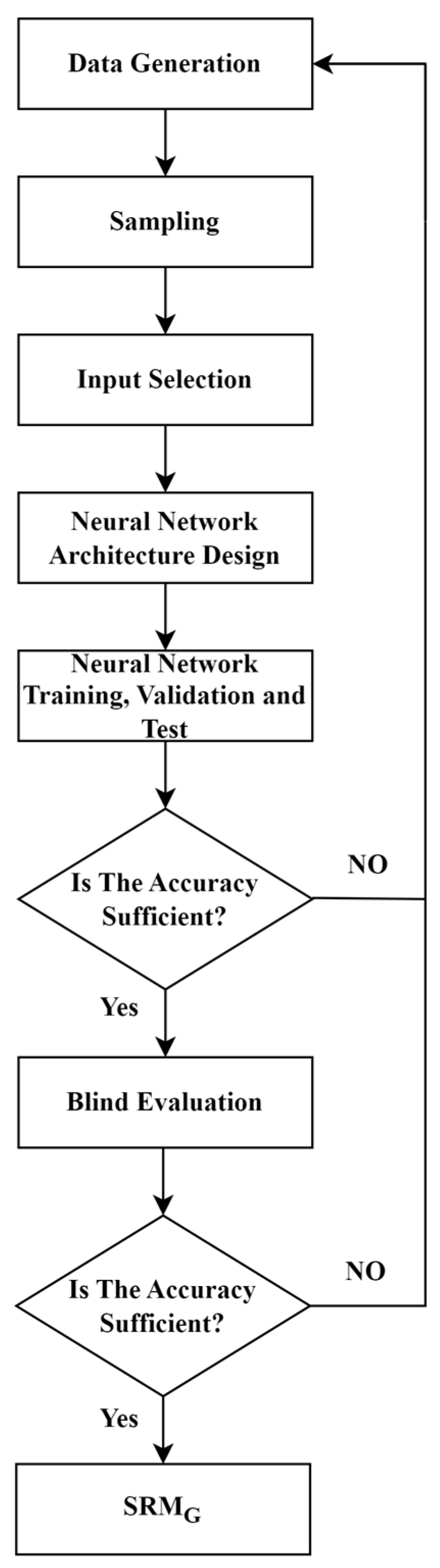
3.3. CO2 Storage Optimization via Proxy Modeling
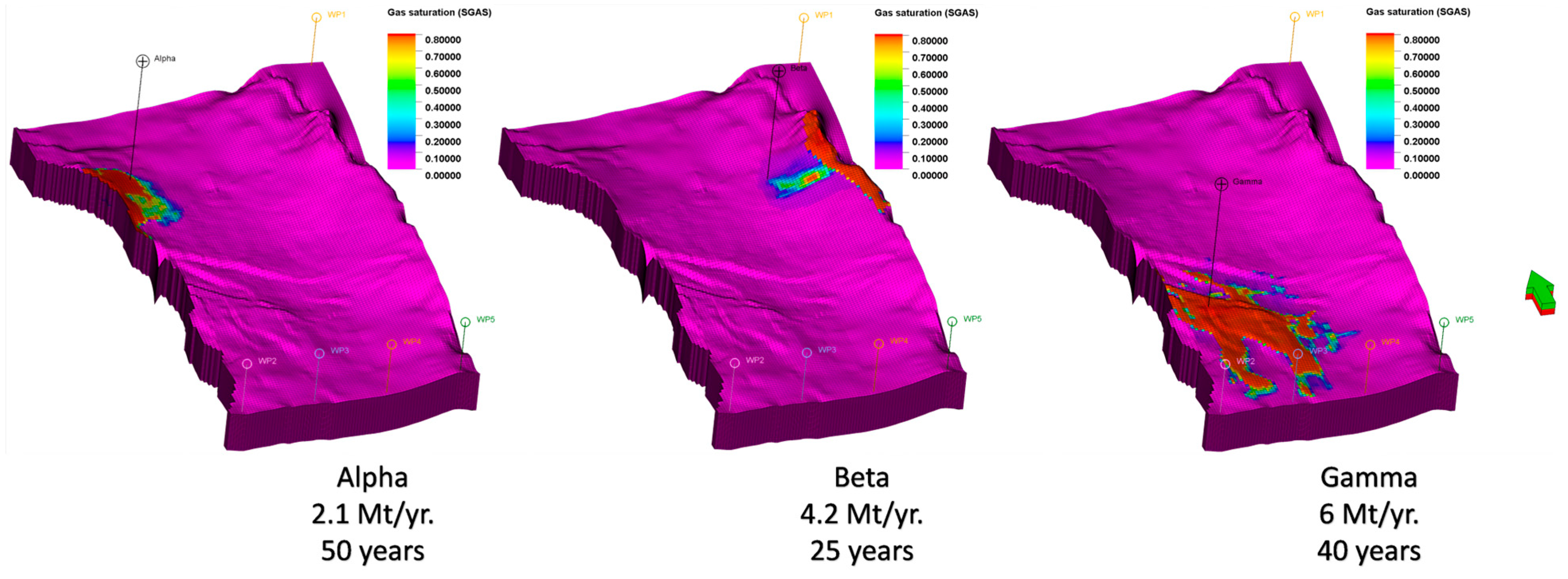
- To maximize the amount of CO2 injected while maintaining a safe pressure level at the top of the injection area to avoid fractures in the caprock and to prevent the CO2 plume from moving towards zone Beta.
Proxy Modeling
4. Results
4.1. Model Training
4.2. Blind Validation
4.3. Optimization
5. Discussion
6. Conclusions
- In this work, a non-cascading grid-based SRM was deemed appropriate for long-term surrogate reservoir modeling and optimization in the context of Smeaheia storage.
- Proxy models built for replicating both CO2 saturation and pressure data showed excellent accuracy compared with the results of the numerical simulator. Data sampling for the former could be conducted by assessing the degree of property fluctuation over time, as opposed to pressure data, which necessitates random samples.
- The pressure SRM exhibited less than 0.5% error, which shows its applicability in future studies, especially when it comes to coupling it with geomechanical models.
- To effectively tackle the issue of accumulated error at the CO2 plume boundary when SRM is applied at high injection rates, it is recommended to use higher maximum injection rates that exceed the maximum rate for model application in the training phase.
- By leveraging the SRMs, an optimization process consisting of 10,000 iterations was successfully completed within a time frame of 50 min, achieved by constraining the simulation volume. This is a huge reduction in computational time compared with optimization using the numerical model.
- Finally, the study demonstrated that CO2 can be injected in Smeaheia at a rate of around 3.4 Mt per year to safely store about 170 Mt CO2 in 50 years.
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Nomenclature
| Adam | adaptive moment estimation |
| ANN | artificial neural network |
| b | bias |
| CCS | carbon capture and storage |
| CFNN | cascade forward neural network |
| CNN | convolutional neural network |
| d | distance |
| DNN | deep neural network |
| EOR | enhanced oil recovery |
| GA | genetic algorithm |
| i | cell number in x direction |
| j | cell number in y direction |
| k | cell number in z direction |
| kh | horizental permeability |
| kv | vertical permeability |
| LSTM | long short-term memory |
| MAE | mean absolute error |
| MSE | mean squared error |
| Npop | population size |
| Nvar | number of optimization variables |
| NSGA | non-dominated sorting genetic algorithm |
| P | pressure |
| Q | flow rate |
| ReLU | rectified linear unit |
| RNN | recurrent neural network |
| Sg | gas saturation |
| SIMPLEX | simple optimization technique by linear programming |
| SPM | smart proxy model |
| SRM | surrogate reservoir model |
| SRMG | grid-based surrogate reservoir model |
| T | time step |
| tanh | tangent hyperbolic |
| W | kernel |
| WAG | water alternating gas |
| σ | activation function |
| ϕ | porosity |
References
- UNFCCC. Adoption of the Paris Agreement. In Proceedings of the Paris Climate Change Conference, Paris, France, 12 December 2015. [Google Scholar]
- Masson-Delmotte, V.; Zhai, P.; Portner, H.-O.; Roberts, D.; Skea, J.; Shukla, P.R.; Pirani, A.; Moufouma-Okia, W.; Pean, C.; Pidcock, R.; et al. Global Warming of 1.5 °C; IPCC: Geneva, Switzerland, 2018. [Google Scholar]
- IEA. Net Zero by 2050: A Roadmap for the Global Energy Sector; IEA: Paris, France, 2021. [Google Scholar]
- Bandilla, K.W. Carbon capture and storage. In Future Energy; Elsevier: Amsterdam, The Netherlands, 2020; pp. 669–692. [Google Scholar]
- Metz, B.; Davidson, O.; De Coninck, H.; Loos, M.; Meyer, L. IPCC Special Report on Carbon Dioxide Capture and Storage; IPCC: Geneva, Switzerland, 2005. [Google Scholar]
- Rackley, S. Introduction to geological storage. In Carbon Capture and Storage; Butterworth-Heinemann: Boston, MA, USA, 2017; pp. 285–304. [Google Scholar]
- Li, Q.; Liu, G. Risk assessment of the geological storage of CO2: A review. In Geologic Carbon Sequestration; Springer: Cham, Switzerland, 2016; pp. 249–284. [Google Scholar] [CrossRef]
- Li, Q.; Han, Y.; Liu, X.; Ansari, U.; Cheng, Y.; Yan, C. Hydrate as a by-product in CO2 leakage during the long-term sub-seabed sequestration and its role in preventing further leakage. Environ. Sci. Pollut. Res. 2022, 29, 77737–77754. [Google Scholar] [CrossRef] [PubMed]
- Rocca, V. The sealing efficiency of cap rocks–laboratory tests and an empirical correlation. GEAM (Geoing. Ambient. E Mineraria) 2021, 58, 41–48. [Google Scholar] [CrossRef]
- Li, Q.; Wang, Y.; Wang, F.; Wu, J.; Usman Tahir, M.; Li, Q.; Yuan, L.; Liu, Z. Effect of thickener and reservoir parameters on the filtration property of CO2 fracturing fluid. Energy Sources Part A Recovery Util. Environ. Eff. 2020, 42, 1705–1715. [Google Scholar] [CrossRef]
- Ajayi, T.; Gomes, J.S.; Bera, A. A review of CO2 storage in geological formations emphasizing modeling, monitoring and capacity estimation approaches. Pet. Sci. 2019, 16, 1028–1063. [Google Scholar] [CrossRef]
- Harding, F.C.; James, A.T.; Robertson, H.E. The engineering challenges of CO2 storage. Proc. Inst. Mech. Eng. Part A J. Power Energy 2018, 232, 17–26. [Google Scholar] [CrossRef]
- Santibanez-Borda, E.; Govindan, R.; Elahi, N.; Korre, A.; Durucan, S. Maximising the dynamic CO2 storage capacity through the optimisation of CO2 injection and brine production rates. Int. J. Greenh. Gas Control 2019, 80, 76–95. [Google Scholar] [CrossRef]
- Nguyen, Q.M.; Onur, M.; Alpak, F.O. Multi-objective optimization of subsurface CO2 capture, utilization, and storage using sequential quadratic programming with stochastic gradients. Comput. Geosci. 2024, 28, 195–210. [Google Scholar] [CrossRef]
- Edouard, M.N.; Okere, C.J.; Ejike, C.; Dong, P.; Suliman, M.A.M. Comparative numerical study on the co-optimization of CO2 storage and utilization in EOR, EGR, and EWR: Implications for CCUS project development. Appl. Energy 2023, 347, 121448. [Google Scholar] [CrossRef]
- Jiang, X. A review of physical modelling and numerical simulation of long-term geological storage of CO2. Appl. Energy 2011, 88, 3557–3566. [Google Scholar] [CrossRef]
- Akai, T.; Kuriyama, T.; Kato, S.; Okabe, H. Numerical modelling of long-term CO2 storage mechanisms in saline aquifers using the Sleipner benchmark dataset. Int. J. Greenh. Gas Control 2021, 110, 103405. [Google Scholar] [CrossRef]
- Zubarev, D.I. Pros and cons of applying proxy-models as a substitute for full reservoir simulations. Presented at the SPE Annual Technical Conference and Exhibition, New Orleans, LA, USA, 4–7 October 2009. [Google Scholar] [CrossRef]
- Jaber, A.K.; Al-Jawad, S.N.; Alhuraishawy, A.K. A review of proxy modeling applications in numerical reservoir simulation. Arab. J. Geosci. 2019, 12, 701. [Google Scholar] [CrossRef]
- Ng, C.S.W.; Nait Amar, M.; Jahanbani Ghahfarokhi, A.; Imsland, L.S. A Survey on the Application of Machine Learning and Metaheuristic Algorithms for Intelligent Proxy Modeling in Reservoir Simulation. Comput. Chem. Eng. 2023, 170, 108107. [Google Scholar] [CrossRef]
- Hosseini Boosari, S.S. Predicting the dynamic parameters of multiphase flow in CFD (Dam-Break simulation) using artificial intelligence-(cascading deployment). Fluids 2019, 4, 44. [Google Scholar] [CrossRef]
- Amini, S.; Mohaghegh, S. Application of Machine Learning and Artificial Intelligence in Proxy Modeling for Fluid Flow in Porous Media. Fluids 2019, 4, 126. [Google Scholar] [CrossRef]
- Mohaghegh, S.D.; Amini, S.; Gholami, V.; Gaskari, R.; Bromhal, G. Grid-Based Surrogate Reservoir Modeling (SRM) for fast track analysis of numerical reservoir simulation models at the grid block level. Presented at the SPE Western Regional Meeting, Bakersfield, CA, USA, 21–23 March 2012. [Google Scholar] [CrossRef]
- Mohaghegh, S. Data-Driven Analytics for the Geological Storage of CO2; CRC Press: Boca Raton, FL, USA, 2018; p. 302. [Google Scholar]
- Golzari, A.; Sefat, M.H.; Jamshidi, S. Development of an adaptive surrogate model for production optimization. J. Pet. Sci. Eng. 2015, 133, 677–688. [Google Scholar] [CrossRef]
- Ng, C.S.W.; Jahanbani Ghahfarokhi, A.; Nait Amar, M.; Torsæter, O. Smart proxy modeling of a fractured reservoir model for production optimization: Implementation of metaheuristic algorithm and probabilistic application. Nat. Resour. Res. 2021, 30, 2431–2462. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Ng, C.S.W.; Jahanbani Ghahfarokhi, A.; Nait Amar, M. Adaptive Proxy-based Robust Production Optimization with Multilayer Perceptron. Appl. Comput. Geosci. 2022, 16, 100103. [Google Scholar] [CrossRef]
- Ng, C.S.W.; Jahanbani Ghahfarokhi, A.; Nait Amar, M. Production optimization under waterflooding with long short-term memory and metaheuristic algorithm. Petroleum 2023, 9, 53–60. [Google Scholar] [CrossRef]
- Agada, S.; Geiger, S.; Elsheikh, A.; Oladyshkin, S. Data-driven surrogates for rapid simulation and optimization of WAG injection in fractured carbonate reservoirs. Pet. Geosci. 2017, 23, 270–283. [Google Scholar] [CrossRef]
- Nait Amar, M.; Zeraibi, N.; Redouane, K. Optimization of WAG process using dynamic proxy, genetic algorithm and ant colony optimization. Arab. J. Sci. Eng. 2018, 43, 6399–6412. [Google Scholar] [CrossRef]
- Nait Amar, M.; Zeraibi, N.; Jahanbani Ghahfarokhi, A. Applying hybrid support vector regression and genetic algorithm to water alternating CO2 gas EOR. Greenh. Gases Sci. Technol. 2020, 10, 613–630. [Google Scholar] [CrossRef]
- Sun, Z.; Xu, J.; Espinoza, D.N.; Balhoff, M.T. Optimization of subsurface CO2 injection based on neural network surrogate modeling. Comput. Geosci. 2021, 25, 1887–1898. [Google Scholar] [CrossRef]
- Liu, S.; Agarwal, R.; Sun, B.; Wang, B.; Li, H.; Xu, J.; Fu, G. Numerical simulation and optimization of injection rates and wells placement for carbon dioxide enhanced gas recovery using a genetic algorithm. J. Clean. Prod. 2021, 280, 124512. [Google Scholar] [CrossRef]
- Agarwal, R.K. Modeling, simulation, and optimization of geological sequestration of CO2. J. Fluids Eng. 2019, 141, 100801. [Google Scholar] [CrossRef]
- Cameron, D.A.; Durlofsky, L.J. Optimization of well placement, CO2 injection rates, and brine cycling for geological carbon sequestration. Int. J. Greenh. Gas Control 2012, 10, 100–112. [Google Scholar] [CrossRef]
- Luo, J.; Ma, X.; Ji, Y.; Li, X.; Song, Z.; Lu, W. Review of machine learning-based surrogate models of groundwater contaminant modeling. Environ. Res. 2023, 238, 117268. [Google Scholar] [CrossRef]
- Bertini, J.R.; Ferreira Batista, S.; Funcia, M.A.; Mendes da Silva, L.O.; Santos, A.A.S.; Schiozer, D.J. A comparison of machine learning surrogate models for net present value prediction from well placement binary data. J. Pet. Sci. Eng. 2022, 208, 109208. [Google Scholar] [CrossRef]
- García-Feal, O.; González-Cao, J.; Fernández-Nóvoa, D.; Astray Dopazo, G.; Gómez-Gesteira, M. Comparison of machine learning techniques for reservoir outflow forecasting. Nat. Hazards Earth Syst. Sci. 2022, 22, 3859–3874. [Google Scholar] [CrossRef]
- Shahkarami, A.; Mohaghegh, S. Applications of smart proxies for subsurface modeling. Pet. Explor. Dev. 2020, 47, 400–412. [Google Scholar] [CrossRef]
- Wang, S.; Xiang, J.; Wang, X.; Feng, Q.; Yang, Y.; Cao, X.; Hou, L. A deep learning based surrogate model for reservoir dynamic performance prediction. Geoenergy Sci. Eng. 2024, 233, 212516. [Google Scholar] [CrossRef]
- Omosebi, O.A.; Oldenburg, C.M.; Reagan, M. Development of lean, efficient, and fast physics-framed deep-learning-based proxy models for subsurface carbon storage. Int. J. Greenh. Gas Control 2022, 114, 103562. [Google Scholar] [CrossRef]
- Gholami, V. On the Optimization of CO2-EOR Process Using Surrogate Reservoir Model; West Virginia University: Morgantown, WV, USA, 2014. [Google Scholar]
- Amini, S. Developing a Grid-Based Surrogate Reservoir Model Using Artificial Intelligence; West Virginia University: Morgantown, WV, USA, 2015. [Google Scholar]
- Matthew, D.A.; Jahanbani Ghahfarokhi, A.; Ng, C.S.; Nait Amar, M. Proxy Model Development for the Optimization of Water Alternating CO2 Gas for Enhanced Oil Recovery. Energies 2023, 16, 3337. [Google Scholar] [CrossRef]
- Naghizadeh, A.; Jafari, S.; Norouzi-Apourvari, S.; Schaffie, M.; Hemmati-Sarapardeh, A. Multi-objective optimization of water-alternating flue gas process using machine learning and nature-inspired algorithms in a real geological field. Energy 2024, 293, 130413. [Google Scholar] [CrossRef]
- Mao, J.; Jahanbani Ghahfarokhi, A. A review of intelligent decision-making strategy for geological CO2 storage: Insights from reservoir engineering. Geoenergy Sci. Eng. 2024, 240, 212951. [Google Scholar] [CrossRef]
- Equinor. Smeaheia—Bringing Large Scale CO2 Storage to European Industry. Available online: https://www.equinor.com/energy/smeaheia (accessed on 19 April 2024).
- Equinor; Gassnova. Smeaheia Dataset. Published on CO2 DataShare. 2021. Available online: https://co2datashare.org/dataset/smeaheia-dataset (accessed on 23 February 2021).
- Erichsen, E.; Rørvik, K.L.; Kearney, G.; Haaberg, K. Troll Kystnær Subsurface Evaluation Report; Gassnova SF: Trondheim, Norway, 2013. [Google Scholar]
- Statoil. Report on Subsurface Evaluation of Smeaheia. June 2016. Available online: https://co2datashare.org/dataset/smeaheia-dataset (accessed on 23 February 2021).
- Brobakken, I.I. Modeling of CO2 Storage in the Smeaheia Field; NTNU: Trondheim, Norway, 2018. [Google Scholar]
- Amiri, B. A Fast and Accurate Investigation into CO2 Storage Challenges by Making a Proxy Model on a Developed Static Model with the Application of Artificial Intelligence/Machine Learning; under Creative Commons Attribution Non-Commercial No Derivatives License; Polytechnic of Turin, Webthesis Portal of Polytechnic of Turin: Torino, Italy, 2022. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Sevastopol, CA, USA, 2019. [Google Scholar]
- Silva, I.N.; Spatti, D.H.; Flauzino, R.A.; Liboni, L.H.B.; Alves, S.R. Artificial Neural Networks: A Practical Course; Springer: Cham, Switzerland, 2017; pp. XX, 307. [Google Scholar]
- Rasamoelina, A.D.; Adjailia, F.; Sinčák, P. A Review of Activation Function for Artificial Neural Network. In Proceedings of the 2020 IEEE 18th World Symposium on Applied Machine Intelligence and Informatics (SAMI), Herlany, Slovakia, 23–25 January 2020; pp. 281–286. [Google Scholar]
- Aggarwal, C.C. (Ed.) Training Deep Neural Networks. In Neural Networks and Deep Learning: A Textbook; Springer International Publishing: Cham, Switzerland, 2018; pp. 105–167. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control, and Artificial Intelligence; MIT Press: Cambridge, MA, USA, 1975. [Google Scholar]
- Goldberg, D.E. Computer-Aided Gas Pipeline Operation Using Genetic Algorithms and Rule Learning; University of Michigan: Ann Arbor, MI, USA, 1983. [Google Scholar]
- Haupt, R.L.; Haupt, S.E. Practical Genetic Algorithms; John Wiley & Sons, Inc.: Hoboken, NJ, USA, 2004. [Google Scholar]
- Hendrix, E.M.; Boglárka, G.-T. Introduction to Nonlinear and Global Optimization; Springer: Berlin/Heidelberg, Germany, 2010; Volume 37. [Google Scholar]
- Sivanandam, S.; Deepa, S. Introduction to Genetic Algorithms, 1st ed.; Springer: Berlin/Heidelberg, Germany, 2008; pp. IX, 92. [Google Scholar]
- Kramer, O. Genetic Algorithm Essentials; Springer: Cham, Switzerland, 2017; pp. IX, 92. [Google Scholar]
- Equinor; Gassnova. Smeaheia Dataset License. Available online: https://co2datashare.org/view/license/26af9426-203f-4993-9d41-2e1bf191ceaf (accessed on 23 February 2021).
- SLB. Software: Petrel 2017.4; 2018. Available online: https://www.software.slb.com/software-news/support-news/petrel/petrel-2017-4_studio-2017-4 (accessed on 5 June 2018).
- SLB. Software: ECLIPSE 2017.1; 2017. Available online: https://www.software.slb.com/software-news/software-top-news/eclipse/eclipse-2017-1 (accessed on 20 July 2017).
- Nazarian, B.; Thorsen, R.; Ringrose, P. Storing CO2 in a Reservoir Under Continuous Pressure Depletion; a Simulation Study. In Proceedings of the 14th Greenhouse Gas Control Technologies Conference, Melbourne, Australia, 21–26 October 2018. [Google Scholar]
- Blank, J.; Deb, K. pymoo: Multi-Objective Optimization in Python. IEEE Access 2020, 8, 89497–89509. [Google Scholar] [CrossRef]
- Agarap, A.F. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Han, J.; Moraga, C. The influence of the sigmoid function parameters on the speed of backpropagation learning. In International Workshop on Artificial Neural Networks; Springer: Berlin/Heidelberg, Germany, 1995; pp. 195–201. [Google Scholar] [CrossRef]
- Chollet, F. Keras. Available online: https://keras.io (accessed on 27 March 2015).

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Features | Range |
|---|---|
| Cell Index (i, j, k) | i: [1–106] j: [1–174] k: [1–100] |
| Cell Coordinate (X, Y, Z) | X: [5.54 × 105–5.75334 × 105] m Y: [6.7126 × 106–6.7474 × 106] m Z: [−1.916 × 103–8.7 × 102] m |
| Horizontal and Vertical Permeability (kh, kv) | kh: [1.8 × 10−1–7.10365 × 103] mD kv: [1.8 × 10−2–7.1036 × 103] mD |
| Porosity | ϕ: [1.3 × 10−1–3.7 × 10−1] |
| Distance to injection well and production wells | d: [0–3.9754 × 104] m |
| Injection Rate | Q: [1.8 × 106–7.6 × 106] Sm3/day |
| Initial Gas Saturation | Sg initial = 0.0 |
| Initial Pressure | P: [5.822 × 101–1.9651 × 102] bar |
| Tier Model of Initial Gas Saturation, Initial Pressure, Permeability, and Porosity | Same as the property range |
| Time step | T: [0–100] |
| Model | Optimizer | Hidden Layer | Units | Activation | Initial Learning Rate |
|---|---|---|---|---|---|
| CO2 Saturation | Adam | 5 | 128–512 | ReLU, Sigmoid | 5 × 10−4 |
| Pressure | Adam | 3 | 128–512 | ReLU, Sigmoid | 5 × 10−4 |
| Performance Metrics | Training | Validation | Testing |
|---|---|---|---|
| MSE | 7.91 × 10−5 | 8.14 × 10−5 | 8.13 × 10−5 |
| MAE | 4.2 × 10−3 | 4.2 × 10−3 | 4.2 × 10−3 |
| Performance Metrics | Training | Validation | Testing |
|---|---|---|---|
| MSE | 2.65 × 10−7 | 2.66 × 10−7 | 2.64 × 10−7 |
| MAE | 3.53 × 10−4 | 3.54 × 10−4 | 3.53 × 10−4 |
| Real MAE (bar) | 4.88 × 10−2 | 4.89 × 10−2 | 4.89 × 10−2 |
| MAE | 1st Time Step | 25th Time Step | 50th Time Step | 75th Time Step | 100th Time Step |
|---|---|---|---|---|---|
| For CO2 saturation | 7.08 × 10−6 | 1.03 × 10−4 | 1.80 × 10−4 | 2.54 × 10−4 | 3.32 × 10−4 |
| For Pressure (bar) | 7.02 × 10−2 | 6.53 × 10−2 | 5.41 × 10−2 | 6.4 × 10−2 | 8.44 × 10−2 |
| Rank | Rate (Sm3/day) | Time Step | Injected Volume (Sm3) |
|---|---|---|---|
| 1 | 4.683495 × 106 | 100 | 8.5473 × 1010 |
| 2 | 4.683444 × 106 | 100 | 8.5472 × 1010 |
| 3 | 4.683330 × 106 | 100 | 8.5470 × 1010 |
| 4 | 4.682244 × 106 | 100 | 8.5450 × 1010 |
| 5 | 4.681683 × 106 | 100 | 8.5440 × 1010 |
| 6 | 4.681379 × 106 | 100 | 8.5435 × 1010 |
| 7 | 4.681288 × 106 | 100 | 8.5433 × 1010 |
| 8 | 4.680804 × 106 | 100 | 8.5424 × 1010 |
| 9 | 4.680091 × 106 | 100 | 8.5411 × 1010 |
| 10 | 4.678354 × 106 | 100 | 8.5379 × 1010 |
| 11 | 4.677049 × 106 | 100 | 8.5356 × 1010 |
| 12 | 4.67539 × 106 | 100 | 8.5325 × 1010 |
| 13 | 4.673537 × 106 | 100 | 8.5292 × 1010 |
| 14 | 4.673406 × 106 | 100 | 8.5289 × 1010 |
| 15 | 4.671223 × 106 | 100 | 8.5249 × 1010 |
| 16 | 4.669713 × 106 | 100 | 8.5222 × 1010 |
| 17 | 4.668789 × 106 | 100 | 8.5205 × 1010 |
| 18 | 4.667985 × 106 | 100 | 8.5190 × 1010 |
| 19 | 4.666322 × 106 | 100 | 8.5160 × 1010 |
| 20 | 4.665829 × 106 | 100 | 8.5151 × 1010 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Amiri, B.; Jahanbani Ghahfarokhi, A.; Rocca, V.; Ng, C.S.W. Optimization of Offshore Saline Aquifer CO2 Storage in Smeaheia Using Surrogate Reservoir Models. Algorithms 2024, 17, 452. https://doi.org/10.3390/a17100452
Amiri B, Jahanbani Ghahfarokhi A, Rocca V, Ng CSW. Optimization of Offshore Saline Aquifer CO2 Storage in Smeaheia Using Surrogate Reservoir Models. Algorithms. 2024; 17(10):452. https://doi.org/10.3390/a17100452
Chicago/Turabian StyleAmiri, Behzad, Ashkan Jahanbani Ghahfarokhi, Vera Rocca, and Cuthbert Shang Wui Ng. 2024. "Optimization of Offshore Saline Aquifer CO2 Storage in Smeaheia Using Surrogate Reservoir Models" Algorithms 17, no. 10: 452. https://doi.org/10.3390/a17100452
APA StyleAmiri, B., Jahanbani Ghahfarokhi, A., Rocca, V., & Ng, C. S. W. (2024). Optimization of Offshore Saline Aquifer CO2 Storage in Smeaheia Using Surrogate Reservoir Models. Algorithms, 17(10), 452. https://doi.org/10.3390/a17100452