
Using Deep-Learned Vector Representations for Page Stream Segmentation by Agglomerative Clustering



Abstract
1. Introduction
- RQ1
- RQ2
- How can we adapt agglomerative clustering to PSS, and does this lead to an improved performance?
- RQ3
- Does treating the number of documents, K, in a stream as given lead to a substantially higher classification performance?
2. Background and Related Work
2.1. Agglomerative Clustering
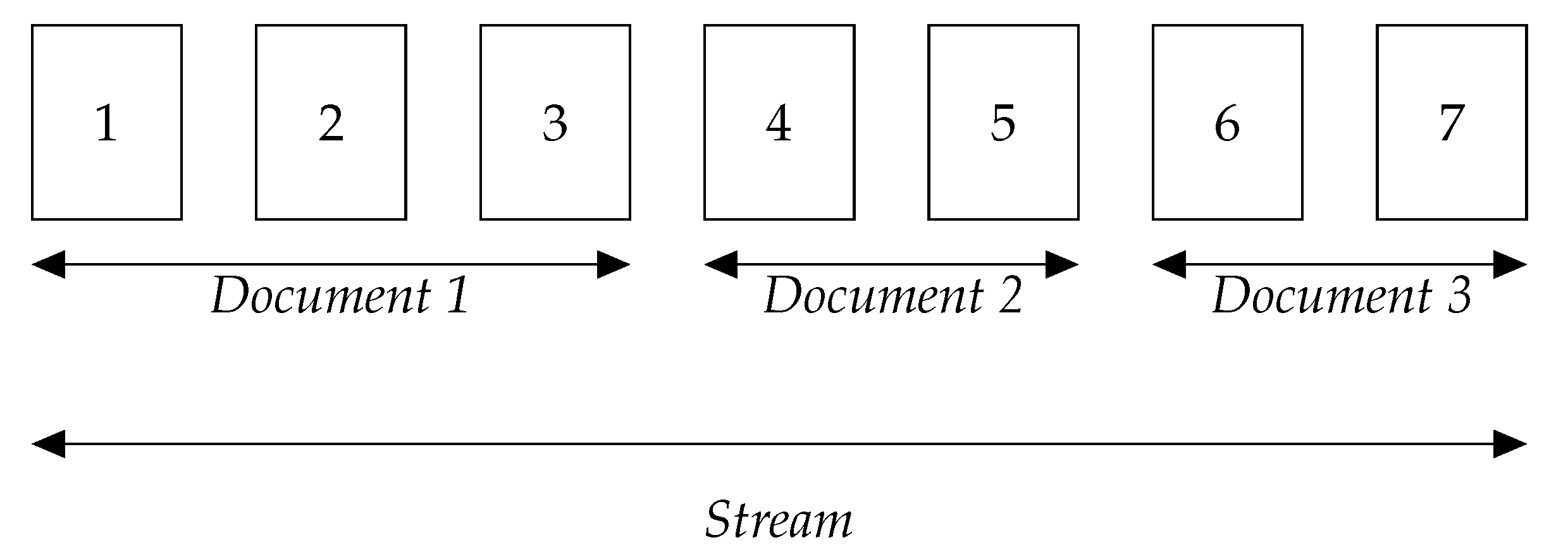
2.2. Page Stream Segmentation
3. Materials and Methods
3.1. Materials
3.2. Method
3.3. Metrics
4. Results and Discussion
4.1. RQ1: How Much Does Supervision Help Clustering?
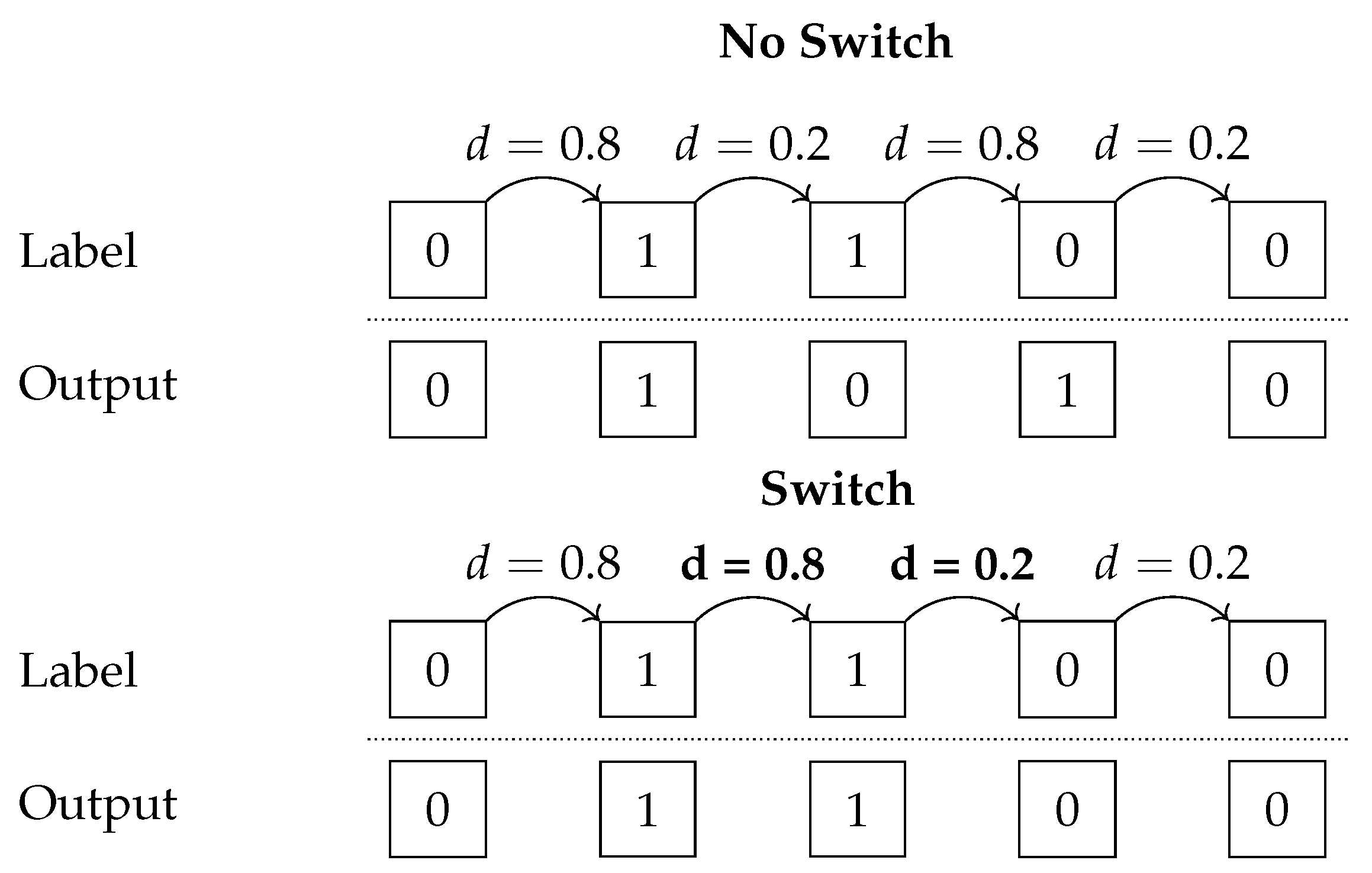
4.2. RQ2: What Goes Wrong with Clustering and Can We Repair It?
4.3. RQ3: How Much Does Knowing K Help?
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Demirtaş, M.A.; Oral, B.; Akpınar, M.Y.; Deniz, O. Semantic Parsing of Interpage Relations. arXiv 2022, arXiv:2205.13530. [Google Scholar]
- Wiedemann, G.; Heyer, G. Multi-modal page stream segmentation with convolutional neural networks. Lang. Resour. Eval. 2021, 55, 127–150. [Google Scholar] [CrossRef]
- Guha, A.; Alahmadi, A.; Samanta, D.; Khan, M.Z.; Alahmadi, A.H. A Multi-Modal Approach to Digital Document Stream Segmentation for Title Insurance Domain. IEEE Access 2022, 10, 11341–11353. [Google Scholar] [CrossRef]
- Braz, F.A.; da Silva, N.C.; Lima, J.A.S. Leveraging effectiveness and efficiency in Page Stream Deep Segmentation. Eng. Appl. Artif. Intell. 2021, 105, 104394. [Google Scholar] [CrossRef]
- Collins-Thompson, K.; Nickolov, R. A clustering-based algorithm for automatic document separation. In Proceedings of the SIGIR 2002 Workshop on Information Retrieval and OCR: From Converting Content to Grasping, Meaning, Tampere, Finland, 11–15 August 2002. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Ward, J.H., Jr. Hierarchical Grouping to Optimize an Objective Function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Su, C.; Zhou, J.; Bao, F.; Takagi, T.; Sakurai, K. Collaborative agglomerative document clustering with limited information disclosure. Secur. Commun. Netw. 2013, 7, 964–978. [Google Scholar] [CrossRef]
- Alfred, R.; Fun, T.S.; Tahir, A.; On, C.K.; Anthony, P. Concepts Labeling of Document Clusters Using a Hierarchical Agglomerative Clustering (HAC) Technique. In Proceedings of the The 8th International Conference on Knowledge Management in Organizations; Uden, L., Wang, L.S., Corchado Rodríguez, J.M., Yang, H.C., Ting, I.H., Eds.; Springer: Dordrecht, The Netherlands, 2013; pp. 263–272. [Google Scholar]
- Franciscus, N.; Ren, X.; Wang, J.; Stantic, B. Word Mover’s Distance for Agglomerative Short Text Clustering. In Proceedings of the Intelligent Information and Database Systems; Nguyen, N.T., Gaol, F.L., Hong, T.P., Trawiński, B., Eds.; Springer: Cham, Switzerland, 2019; pp. 128–139. [Google Scholar]
- Wu, J.W.; Tseng, J.C.; Tsai, W.N. An Efficient Linear Text Segmentation Algorithm Using Hierarchical Agglomerative Clustering. In Proceedings of the 2011 Seventh International Conference on Computational Intelligence and Security, Sanya, China, 3–4 December 2011; pp. 1081–1085. [Google Scholar] [CrossRef]
- Bodrunova, S.S.; Orekhov, A.V.; Blekanov, I.S.; Lyudkevich, N.S.; Tarasov, N.A. Topic Detection Based on Sentence Embeddings and Agglomerative Clustering with Markov Moment. Future Internet 2020, 12, 144. [Google Scholar] [CrossRef]
- Meilender, T.; Belaïd, A. Segmentation of continuous document flow by a modified backward-forward algorithm. In Proceedings of the Document Recognition and Retrieval XVI, International Society for Optics and Photonics, San Jose, CA, USA, 18–22 January 2009; Volume 7247, p. 724705. [Google Scholar]
- Agin, O.; Ulas, C.; Ahat, M.; Bekar, C. An approach to the segmentation of multi-page document flow using binary classification. In Proceedings of the Sixth International Conference on Graphic and Image Processing (ICGIP 2014), Beijing, China, 24–26 October 2014; Wang, Y., Jiang, X., Zhang, D., Eds.; International Society for Optics and Photonics, SPIE: Bellingham, WA, USA, 2015; Volume 9443, pp. 216–222. [Google Scholar]
- Rusinol, M.; Frinken, V.; Karatzas, D.; Bagdanov, A.D.; Lladós, J. Multimodal page classification in administrative document image streams. Int. J. Doc. Anal. Recognit. (IJDAR) 2014, 17, 331–341. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Kirillov, A.; He, K.; Girshick, R.; Rother, C.; Dollár, P. Panoptic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9404–9413. [Google Scholar]
- Beeferman, D.; Berger, A.; Lafferty, J. Statistical models for text segmentation. Mach. Learn. 1999, 34, 177–210. [Google Scholar] [CrossRef]
- Pevzner, L.; Hearst, M.A. A critique and improvement of an evaluation metric for text segmentation. Comput. Linguist. 2002, 28, 19–36. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Das, A.; Vedantam, R.; Cogswell, M.; Parikh, D.; Batra, D. Grad-CAM: Why did you say that? Visual Explanations from Deep Networks via Gradient-based Localization. arXiv 2016, arXiv:1611.07450. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Page F1 | Panoptic Quality |
|---|---|---|
| Baseline | ||
| Mean Document Length Baseline | 0.28 | 0.14 |
| Classification Approach | ||
| VGG16 | 0.86 | 0.68 |
| VGG16 (K-given) | 0.92 | 0.87 |
| Clustering Approach | ||
| Clustering with finetuned embeddings | 0.54 | 0.25 |
| Clustering with finetuned embeddings (switch) | 0.61 | 0.52 |
| Clustering with pretrained embeddings | 0.49 | 0.24 |
| Clustering- with pretrained embeddings (switch) | 0.43 | 0.29 |
| Prediction | 1 | 0 |
|---|---|---|
| 1 | 0.25 | 0.76 |
| 0 | 0.73 | 0.25 |
| FP | FN | Total | |
|---|---|---|---|
| Normal | 239 | 707 | 946 |
| Top-K | 477 | 477 | 954 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Busch, L.; van Heusden, R.; Marx, M. Using Deep-Learned Vector Representations for Page Stream Segmentation by Agglomerative Clustering. Algorithms 2023, 16, 259. https://doi.org/10.3390/a16050259
Busch L, van Heusden R, Marx M. Using Deep-Learned Vector Representations for Page Stream Segmentation by Agglomerative Clustering. Algorithms. 2023; 16(5):259. https://doi.org/10.3390/a16050259
Chicago/Turabian StyleBusch, Lukas, Ruben van Heusden, and Maarten Marx. 2023. "Using Deep-Learned Vector Representations for Page Stream Segmentation by Agglomerative Clustering" Algorithms 16, no. 5: 259. https://doi.org/10.3390/a16050259
APA StyleBusch, L., van Heusden, R., & Marx, M. (2023). Using Deep-Learned Vector Representations for Page Stream Segmentation by Agglomerative Clustering. Algorithms, 16(5), 259. https://doi.org/10.3390/a16050259