
Ising-Based Kernel Clustering †



Abstract
1. Introduction
2. Ising-Based Combinatorial Clustering
2.1. Ising Model
2.2. Combinatorial Clustering
2.3. Problems
3. Ising-Based Kernel Clustering
3.1. Kernel Method for Combinatorial Clustering
3.2. QUBO Formulation for Ising-Based Kernel Clustering
3.3. QUBO Matrix Generation by Matrix–Matrix Calculations
- is a K-dimensional identity matrix.
- is a K-dimensional upper triangular matrix with 0 for the diagonal components and 1 for the upper triangular components.
- is defined as a matrix with for the diagonal components and 0 for the other components.
- is a matrix consisting of only the diagonal components of the Gram matrix . has zero non-diagonal components.
- is a matrix consisting of only the upper triangular components of the Gram matrix . has zero diagonal and lower triangular components.
4. Evaluation
4.1. Experimental Environments
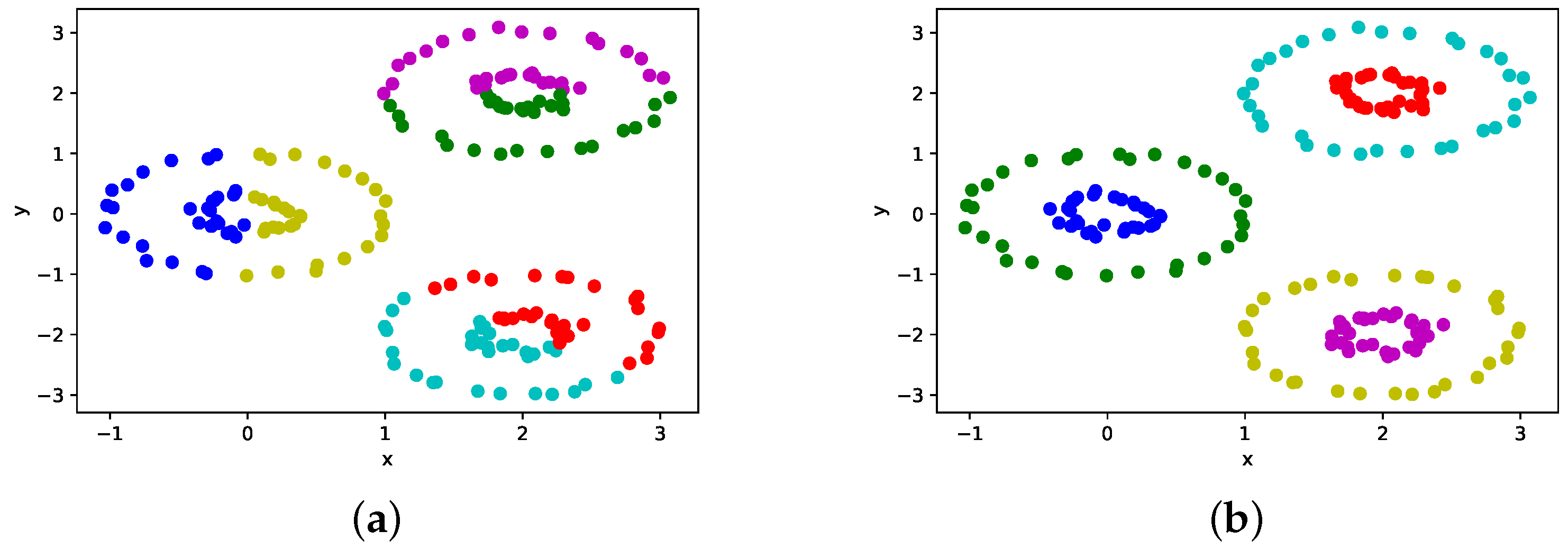
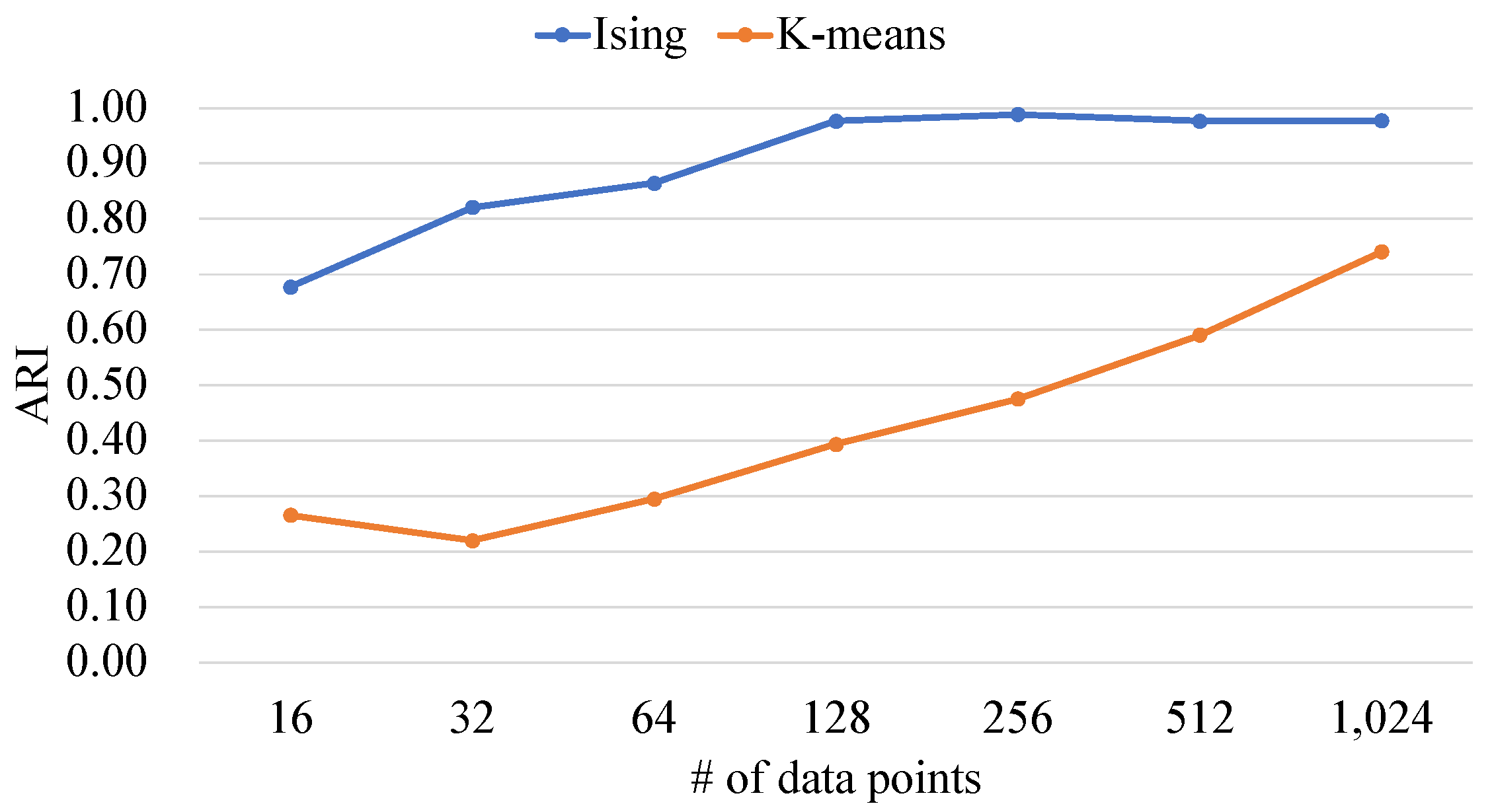
4.2. Quality
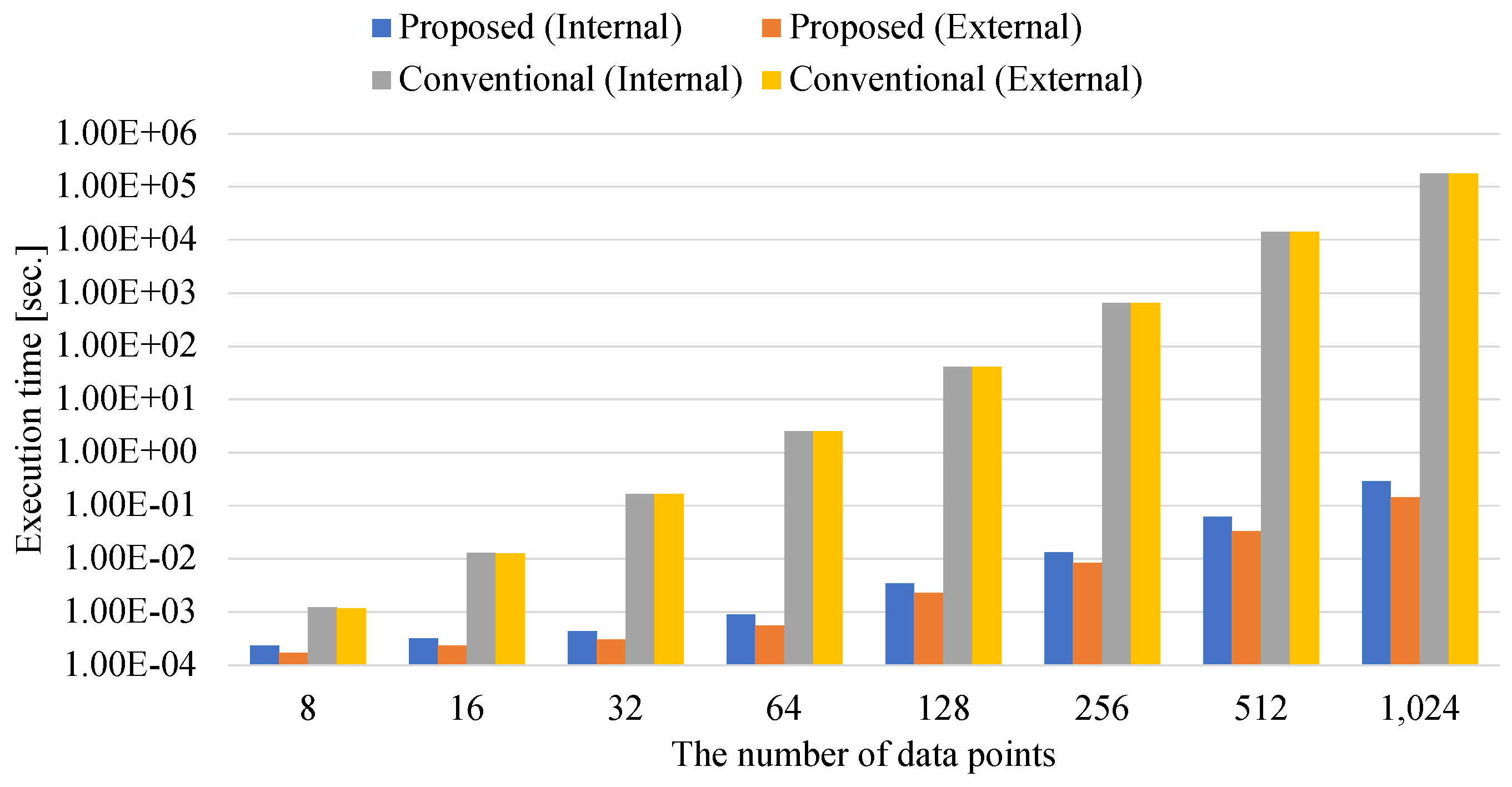
4.3. Execution Time
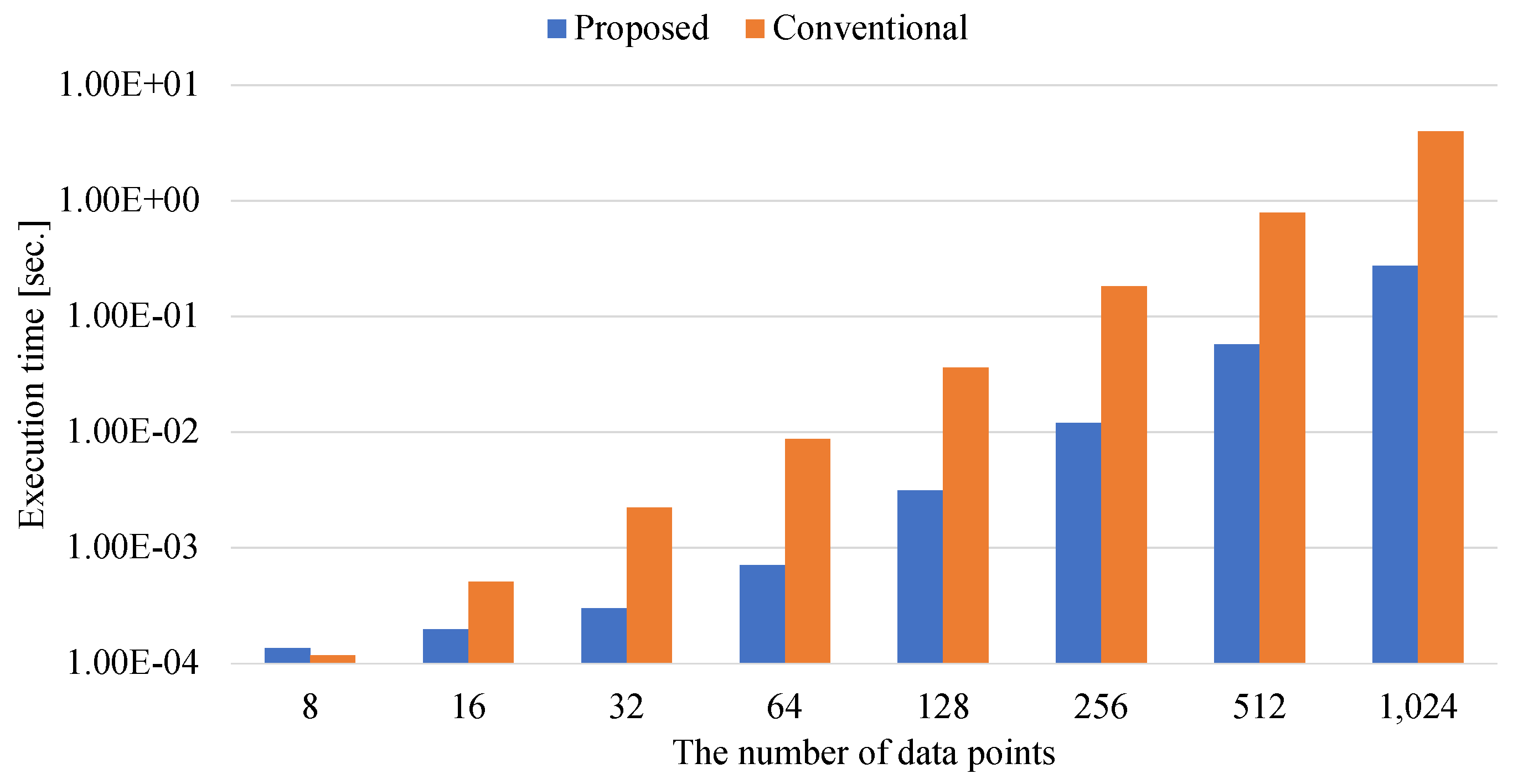
4.4. Comparisons with Kernel K-Means
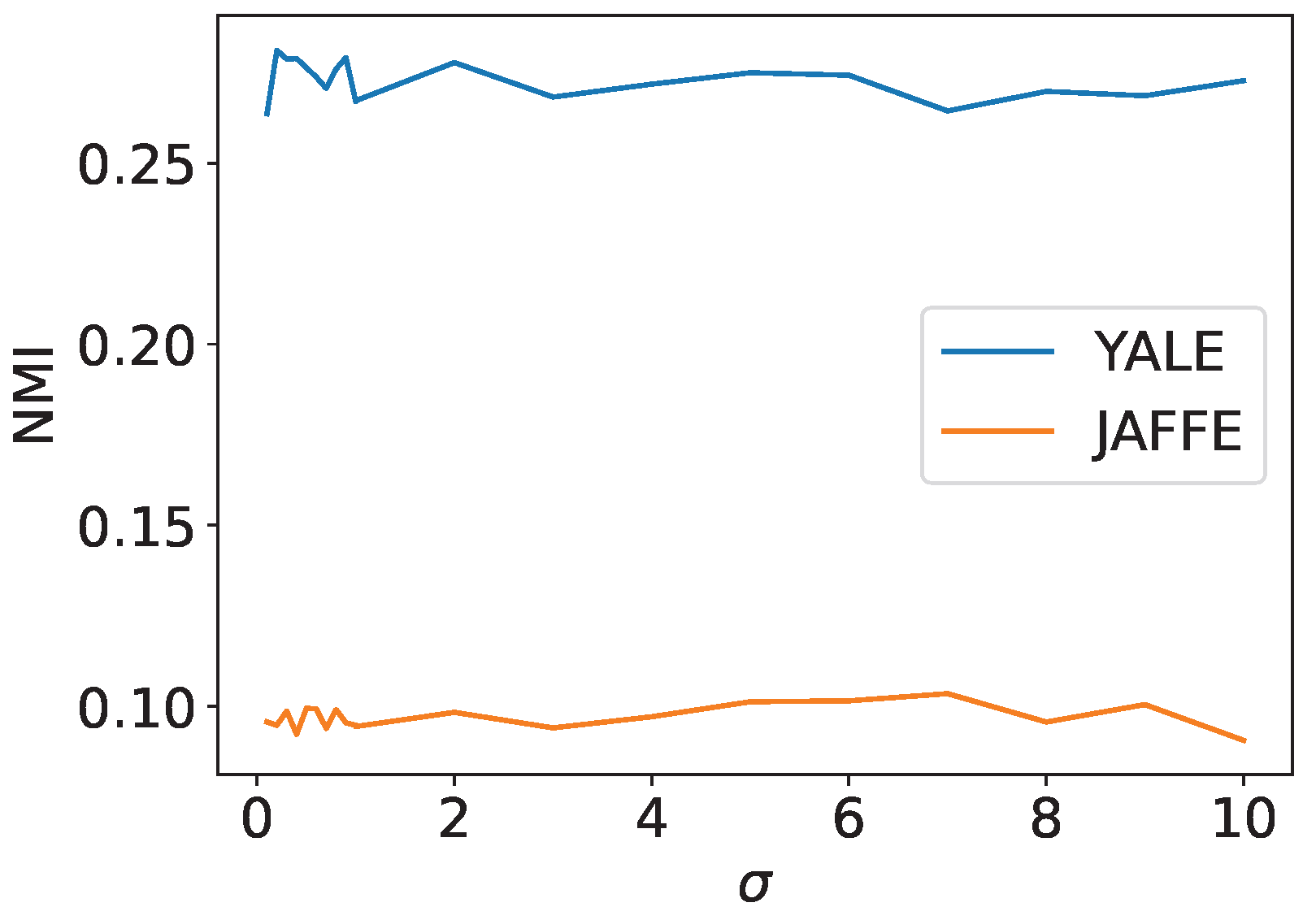
4.5. Experiments on Real Datasets
5. Related Work
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kadowaki, T.; Nishimori, H. Quantum annealing in the transverse Ising model. Phys. Rev. E 1998, 58, 5355. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Goto, H.; Tatsumura, K.; Dixon, A.R. Combinatorial optimization by simulating adiabatic bifurcations in nonlinear Hamiltonian systems. Sci. Adv. 2019, 5, eaav2372. [Google Scholar] [CrossRef] [PubMed]
- Aramon, M.; Rosenberg, G.; Valiante, E.; Miyazawa, T.; Tamura, H.; Katzgraber, H.G. Physics-inspired optimization for quadratic unconstrained problems using a digital annealer. Front. Phys. 2019, 7, 48. [Google Scholar] [CrossRef]
- Yamaoka, M.; Yoshimura, C.; Hayashi, M.; Okuyama, T.; Aoki, H.; Mizuno, H. A 20k-spin Ising chip to solve combinatorial optimization problems with CMOS annealing. IEEE J. Solid-State Circuits 2015, 51, 303–309. [Google Scholar]
- Irie, H.; Wongpaisarnsin, G.; Terabe, M.; Miki, A.; Taguchi, S. Quantum Annealing of Vehicle Routing Problem with Time, State and Capacity. In Quantum Technology and Optimization Problems; QTOP 2019; Lecture Notes in Computer Science; Feld, S., Linnhoff-Popien, C., Eds.; Springer: Cham, Switzerland, 2017; Volume 11413. [Google Scholar]
- Neukart, F.; Compostella, G.; Seidel, C.; Von Dollen, D.; Yarkoni, S.; Parney, B. Traffic flow optimization using a quantum annealer. Front. ICT 2017, 4, 29. [Google Scholar] [CrossRef]
- Ohzeki, M. Breaking limitation of quantum annealer in solving optimization problems under constraints. Sci. Rep. 2020, 10, 1–12. [Google Scholar] [CrossRef]
- Stollenwerk, T.; O’Gorman, B.; Venturelli, D.; Mandra, S.; Rodionova, O.; Ng, H.; Sridhar, B.; Rieffel, E.G.; Biswas, R. Quantum annealing applied to de-conflicting optimal trajectories for air traffic management. IEEE Trans. Intell. Transp. Syst. 2019, 21, 285–297. [Google Scholar] [CrossRef]
- Ohzeki, M.; Miki, A.; Miyama, M.J.; Terabe, M. Control of automated guided vehicles without collision by quantum annealer and digital devices. Front. Comput. Sci. 2019, 1, 9. [Google Scholar] [CrossRef]
- Snelling, D.; Devereux, E.; Payne, N.; Nuckley, M.; Viavattene, G.; Ceriotti, M.; Wokes, S.; Di Mauro, G.; Brettle, H. Innovation in Planning Space Debris Removal Missions Using Artificial Intelligence and Quantum-Inspired Computing. In Proceedings of the 8th European Conference on Space Debris, Darmstadt, Germany, 20–23 April 2021. [Google Scholar]
- Cohen, E.; Mandal, A.; Ushijima-Mwesigwa, H.; Roy, A. Ising-based consensus clustering on specialized hardware. In International Symposium on Intelligent Data Analysis; Springer: Cham, Switzerland, 2020; pp. 106–118. [Google Scholar]
- Arthur, D.; Date, P. Balanced k-Means Clustering on an Adiabatic Quantum Computer. Quantum Inf. Process. 2020, 20, 294. [Google Scholar] [CrossRef]
- Date, P.; Arthur, D.; Pusey-Nazzaro, L. QUBO formulations for training machine learning models. Sci. Rep. 2021, 11, 10029. [Google Scholar] [CrossRef]
- Friedman, J.; Hastie, T.; Tibshirani, R. The Elements of Statistical Learning; Springer: New York, NY, USA, 2001; Volume 1. [Google Scholar]
- Kumar, V.; Bass, G.; Tomlin, C.; Dulny, J. Quantum annealing for combinatorial clustering. Quantum Inf. Process. 2018, 17, 39. [Google Scholar] [CrossRef]
- Kumagai, M.; Komatsu, K.; Takano, F.; Araki, T.; Sato, M.; Kobayashi, H. Combinatorial Clustering Based on an Externally-Defined One-Hot Constraint. In Proceedings of the 2020 Eighth International Symposium on Computing and Networking (CANDAR), Naha, Japan, 24–27 November 2020; pp. 59–68. [Google Scholar]
- Kumagai, M.; Komatsu, K.; Takano, F.; Araki, T.; Sato, M.; Kobayashi, H. An External Definition of the One-Hot Constraint and Fast QUBO Generation for High-Performance Combinatorial Clustering. Int. J. Netw. Comput. 2021, 11, 463–491. [Google Scholar] [CrossRef]
- Komatsu, K.; Kumagai, M.; Qi, J.; Sato, M.; Kobayashi, H. An Externally-Constrained Ising Clustering Method for Material Informatics. In Proceedings of the 2021 Ninth International Symposium on Computing and Networking Workshops (CANDARW), Matsue, Japan, 23–26 November 2021; pp. 201–204. [Google Scholar]
- Zhang, Y.; Bai, X.; Fan, R.; Wang, Z. Deviation-Sparse Fuzzy C-Means With Neighbor Information Constraint. IEEE Trans. Fuzzy Syst. 2019, 27, 185–199. [Google Scholar] [CrossRef]
- Tang, Y.; Pan, Z.; Pedrycz, W.; Ren, F.; Song, X. Viewpoint-Based Kernel Fuzzy Clustering With Weight Information Granules. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 7, 342–356. [Google Scholar] [CrossRef]
- Kumagai, M.; Komatsu, K.; Sato, M.; Kobayashi, H. Ising-Based Combinatorial Clustering Using the Kernel Method. In Proceedings of the 2021 IEEE 14th International Symposium on Embedded Multicore/Many-Core Systems-on-Chip (MCSoC), Singapore, 20–23 December 2021; pp. 197–203. [Google Scholar]
- Yamada, Y.; Momose, S. Vector engine processor of NEC’s brand-new supercomputer SX-Aurora TSUBASA. In Proceedings of the Intenational symposium on High Performance Chips (Hot Chips2018), Cupertino, CA, USA, 19–21 August 2018; Volume 30, pp. 19–21. [Google Scholar]
- Komatsu, K.; Momose, S.; Isobe, Y.; Watanabe, O.; Musa, A.; Yokokawa, M.; Aoyama, T.; Sato, M.; Kobayashi, H. Performance evaluation of a vector supercomputer SX-Aurora TSUBASA. In Proceedings of the SC18: International Conference for High Performance Computing, Networking, Storage and Analysis, Dallas, TX, USA, 11–16 November 2018; pp. 685–696. [Google Scholar]
- Takano, F.; Suzuki, M.; Kobayashi, Y.; Araki, T. QUBO Solver for Combinatorial Optimization Problems with Constraints. Technical Report 4, NEC Corporation, 2019. Available online: https://ken.ieice.org/ken/paper/20191128b1rz/eng/ (accessed on 1 April 2023).
- Swendsen, R.H.; Wang, J.S. Replica Monte Carlo Simulation of Spin-Glasses. Phys. Rev. Lett. 1986, 57, 2607–2609. [Google Scholar] [CrossRef]
- Harris, C.R.; Millman, K.J.; van der Walt, S.J.; Gommers, R.; Virtanen, P.; Cournapeau, D.; Wieser, E.; Taylor, J.; Berg, S.; Smith, N.J.; et al. Array programming with NumPy. Nature 2020, 585, 357–362. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Tzortzis, G.F.; Likas, A.C. The global kernel k-means algorithm for clustering in feature space. IEEE Trans. Neural Netw. 2009, 20, 1181–1194. [Google Scholar] [CrossRef]
- Belhumeur, P.; Hespanha, J.; Kriegman, D. Eigenfaces vs. Fisherfaces: Recognition using class specific linear projection. IEEE Trans. Pattern Anal. Mach. Intell. 1997, 19, 711–720. [Google Scholar] [CrossRef]
- Lyons, M.; Akamatsu, S.; Kamachi, M.; Gyoba, J. Coding facial expressions with Gabor wavelets. In Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition, Nara, Japan, 14–16 April 1998; pp. 200–205. [Google Scholar] [CrossRef]
- Liu, X. SimpleMKKM: Simple Multiple Kernel K-Means. IEEE Trans. Pattern Anal. Mach. Intell. 2023, 45, 5174–5186. [Google Scholar] [CrossRef] [PubMed]
- Kang, Z.; Peng, C.; Cheng, Q.; Liu, X.; Peng, X.; Xu, Z.; Tian, L. Structured graph learning for clustering and semi-supervised classification. Pattern Recognit. 2021, 110, 107627. [Google Scholar] [CrossRef]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2001, 14, 1–8. [Google Scholar]
- Huang, H.C.; Chuang, Y.Y.; Chen, C.S. Affinity aggregation for spectral clustering. In Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition, Providence, RI, USA, 16–21 June 2012; pp. 773–780. [Google Scholar] [CrossRef]
- Du, L.; Zhou, P.; Shi, L.; Wang, H.; Fan, M.; Wang, W.; Shen, Y.D. Robust Multiple Kernel K-Means Using L21-Norm. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 3476–3482. [Google Scholar]
- Huang, H.C.; Chuang, Y.Y.; Chen, C.S. Multiple Kernel Fuzzy Clustering. IEEE Trans. Fuzzy Syst. 2012, 20, 120–134. [Google Scholar] [CrossRef]
- Kang, Z.; Peng, C.; Cheng, Q. Twin Learning for Similarity and Clustering: A Unified Kernel Approach. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 2080–2086. [Google Scholar]
- Nie, F.; Wang, X.; Huang, H. Clustering and Projected Clustering with Adaptive Neighbors. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; Association for Computing Machinery: New York, NY, USA, 2014; pp. 977–986. [Google Scholar] [CrossRef]
- Bauckhage, C.; Ojeda, C.; Sifa, R.; Wrobel, S. Adiabatic Quantum Computing for Kernel k = 2 Means Clustering; LWDA: Concord, MA, USA, 2018; pp. 21–32. [Google Scholar]
- Cohen, E.; Senderovich, A.; Beck, J.C. An Ising framework for constrained clustering on special purpose hardware. In Integration of Constraint Programming, Artificial Intelligence, and Operations Research; Hebrard, E., Musliu, N., Eds.; Springer: Cham, Switzerland, 2020; pp. 130–147. [Google Scholar]
- Huang, D.; Wang, C.D.; Peng, H.; Lai, J.; Kwoh, C.K. Enhanced Ensemble Clustering via Fast Propagation of Cluster-Wise Similarities. IEEE Trans. Syst. Man, Cybern. Syst. 2021, 51, 508–520. [Google Scholar] [CrossRef]
- Huang, D.; Wang, C.D.; Lai, J.H. Fast Multi-view Clustering via Ensembles: Towards Scalability, Superiority, and Simplicity. IEEE Trans. Knowl. Data Eng. 2023, 1–16, early access. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| # of Instances | # of Classes | Image Size | |
|---|---|---|---|
| YALE | 165 | 15 | |
| JAFFE | 213 | 10 |
| Ising-Based Kernel Clustering | SGMK | |
|---|---|---|
| YALE | ||
| JAFFE |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumagai, M.; Komatsu, K.; Sato, M.; Kobayashi, H. Ising-Based Kernel Clustering. Algorithms 2023, 16, 214. https://doi.org/10.3390/a16040214
Kumagai M, Komatsu K, Sato M, Kobayashi H. Ising-Based Kernel Clustering. Algorithms. 2023; 16(4):214. https://doi.org/10.3390/a16040214
Chicago/Turabian StyleKumagai, Masahito, Kazuhiko Komatsu, Masayuki Sato, and Hiroaki Kobayashi. 2023. "Ising-Based Kernel Clustering" Algorithms 16, no. 4: 214. https://doi.org/10.3390/a16040214
APA StyleKumagai, M., Komatsu, K., Sato, M., & Kobayashi, H. (2023). Ising-Based Kernel Clustering. Algorithms, 16(4), 214. https://doi.org/10.3390/a16040214