
Interpretation for Variational Autoencoder Used to Generate Financial Synthetic Tabular Data

 , and
, and
Abstract
1. Introduction
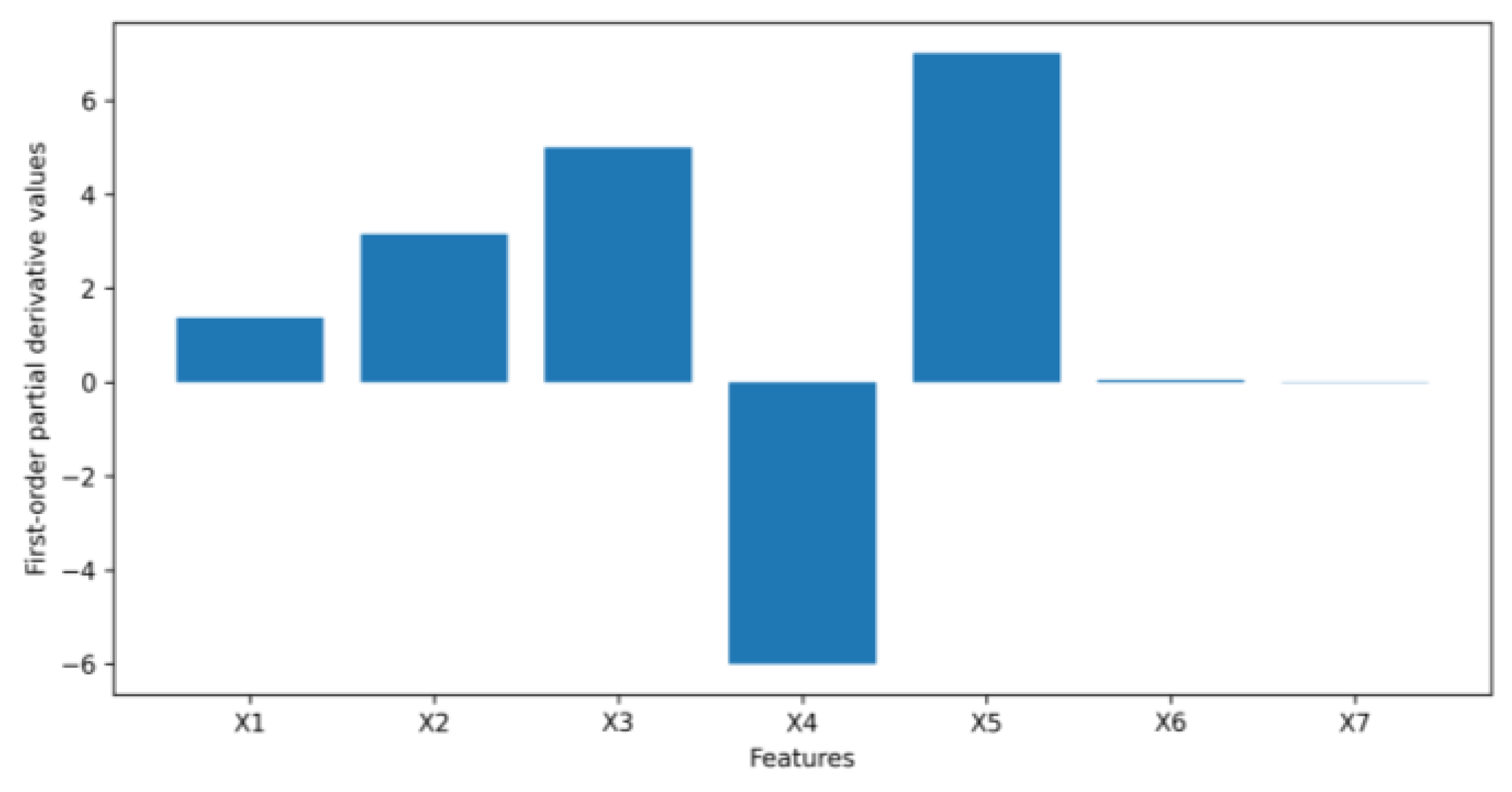
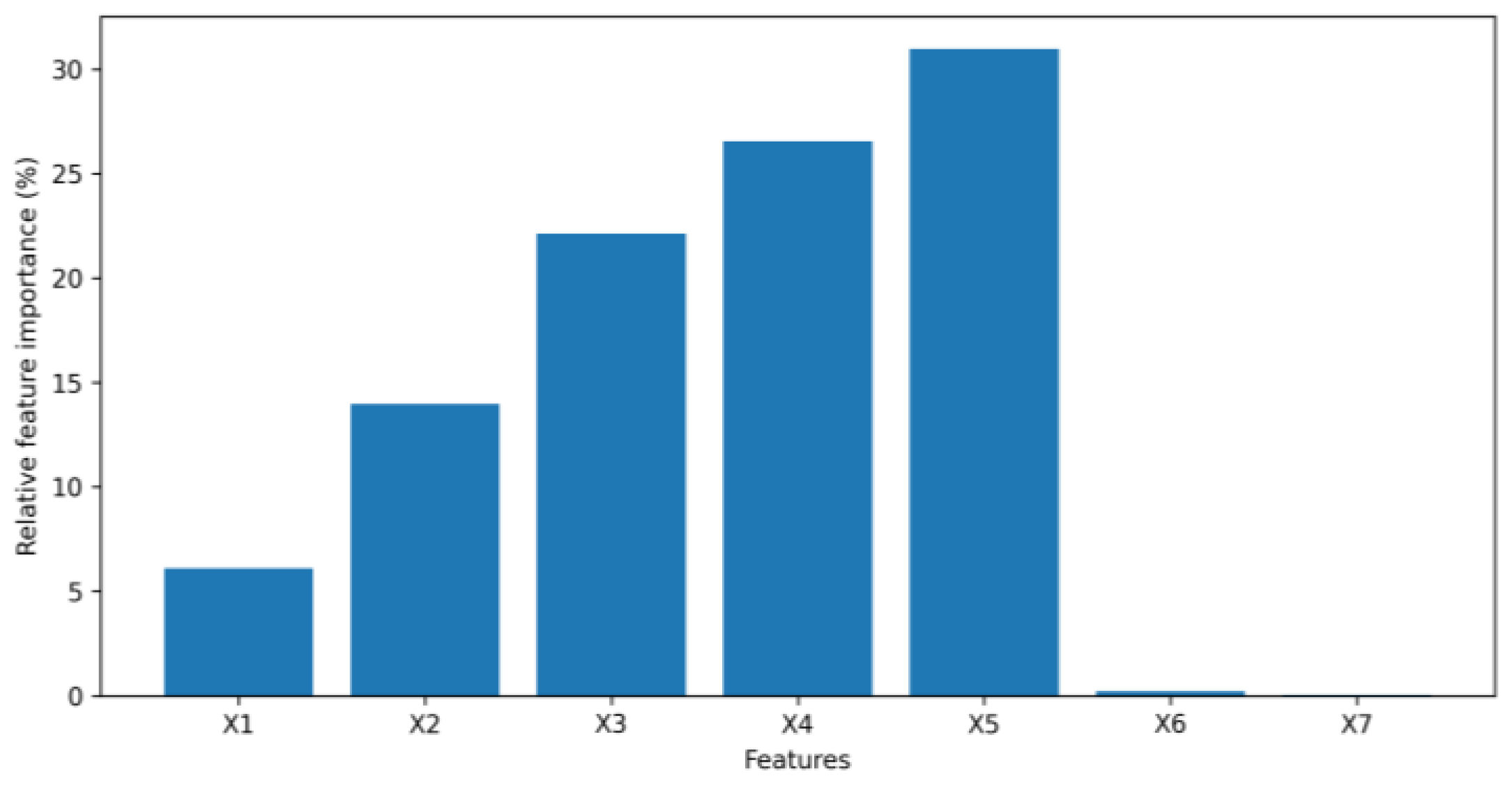
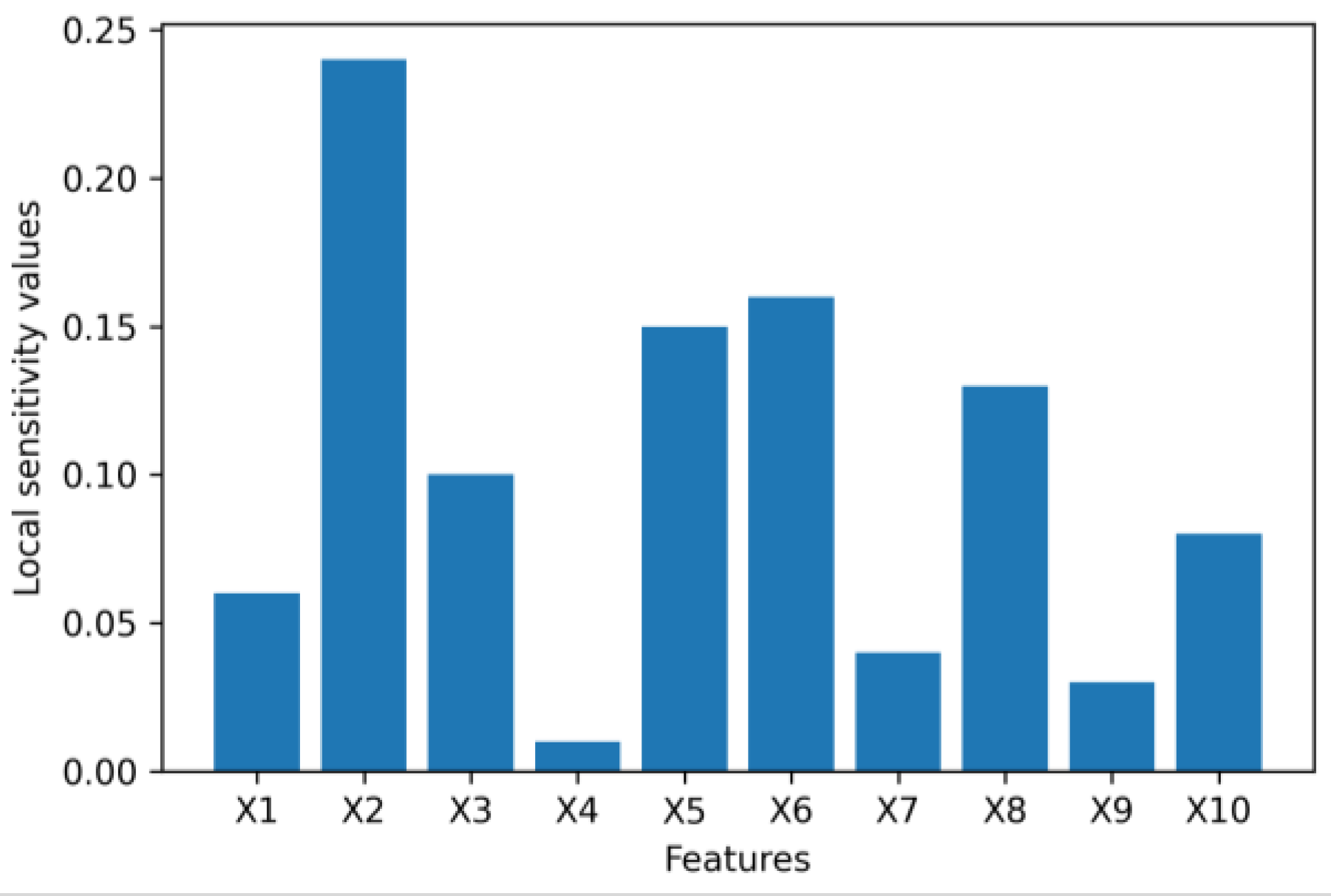
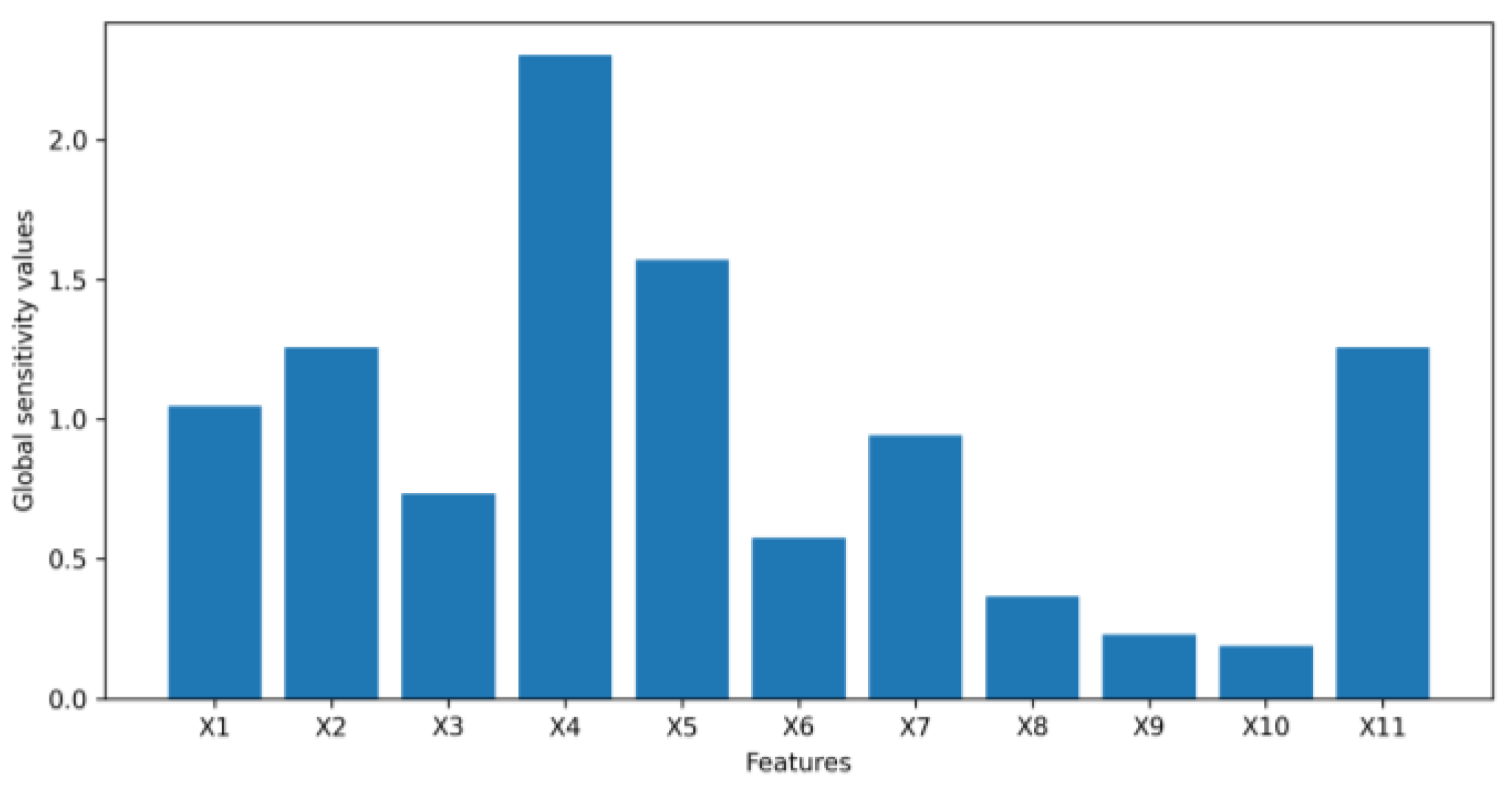
- We extend the idea of first-order sensitivity to a generative model, VAE, to assess the input feature importance when a VAE is used to generate financial synthetic tabular data. As experimental results in this paper show, measuring feature importance by sensitivity can provide both global and local explanations for how a VAE synthesizes tabular data intuitively and efficiently.
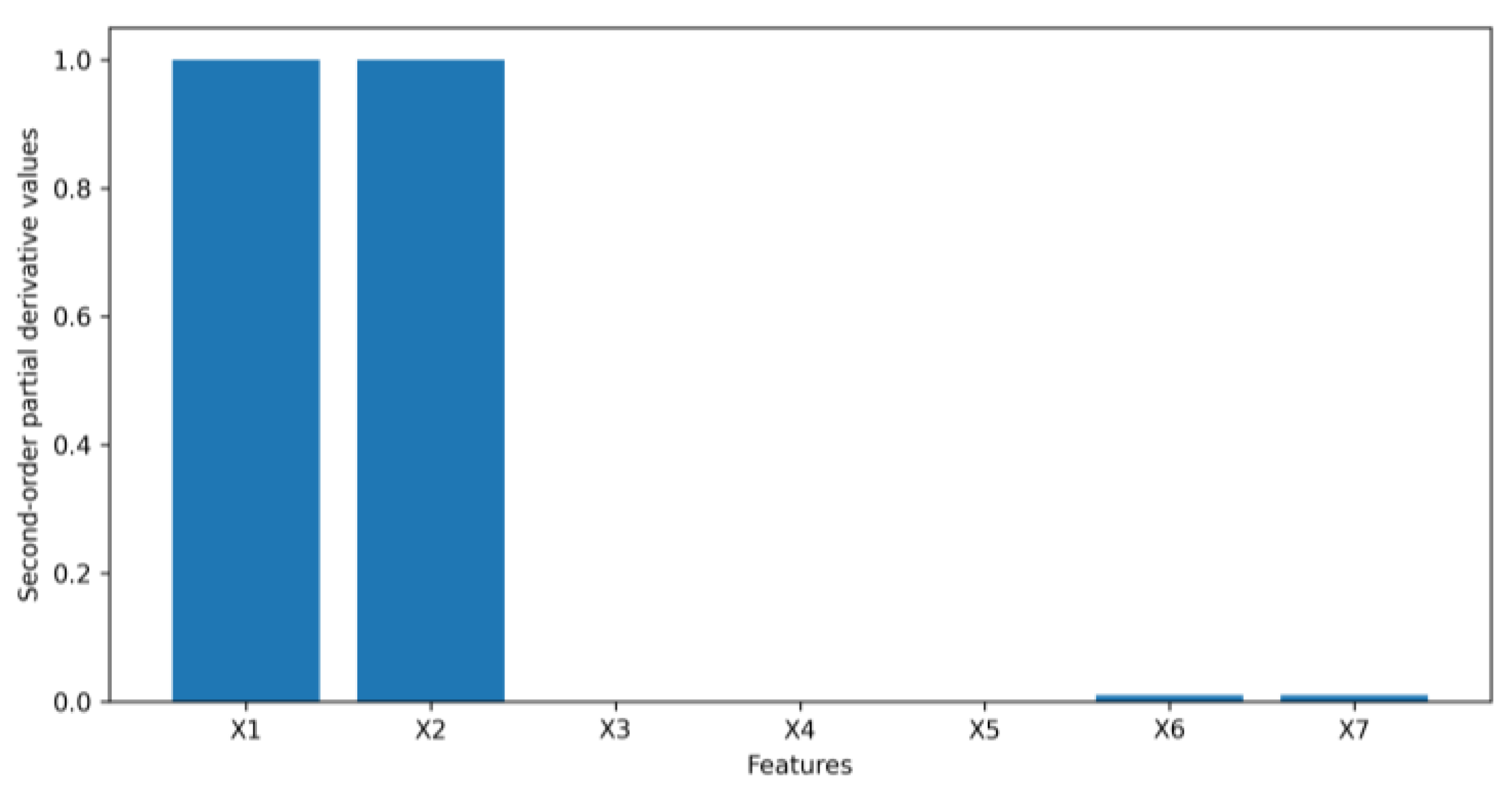
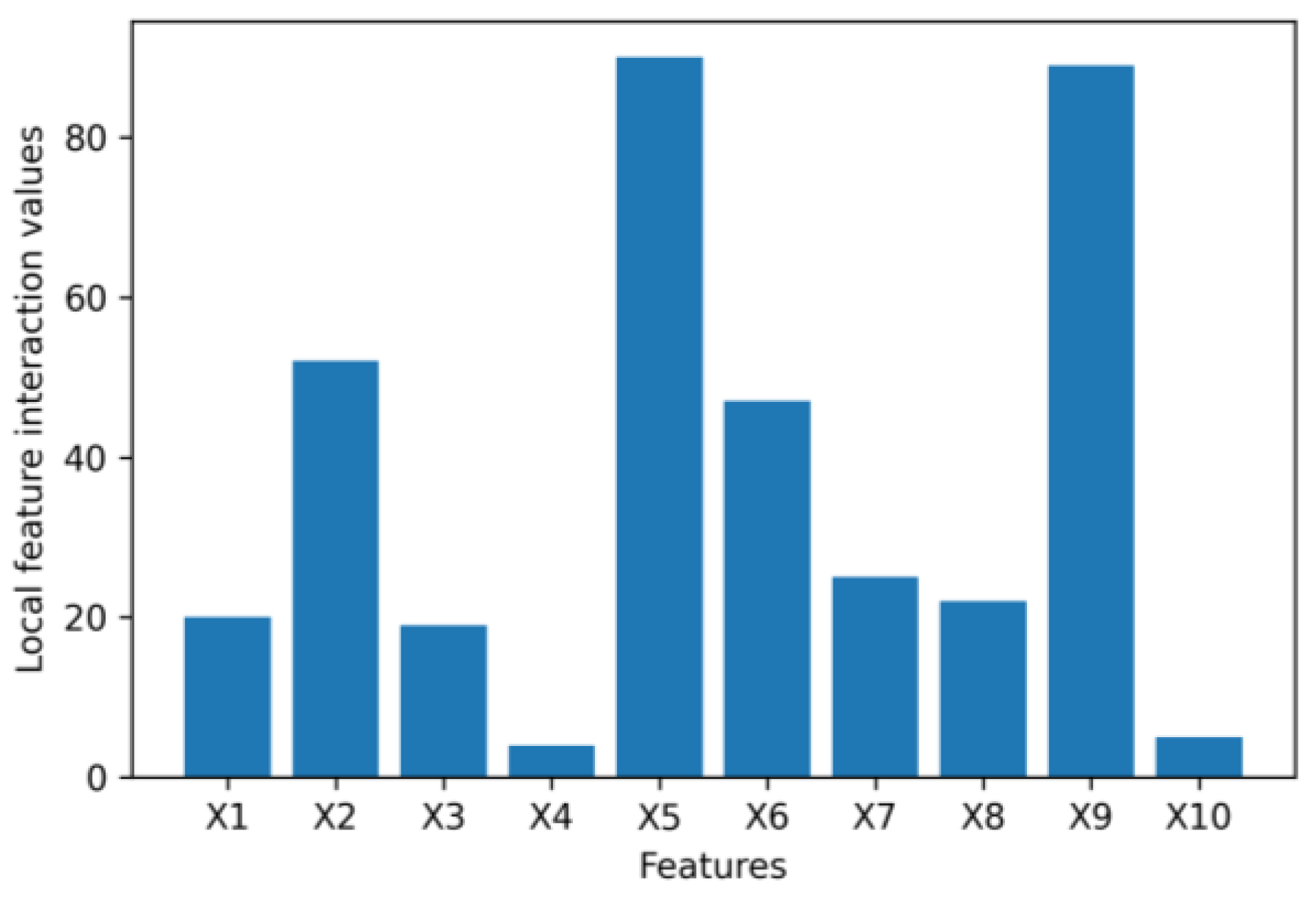
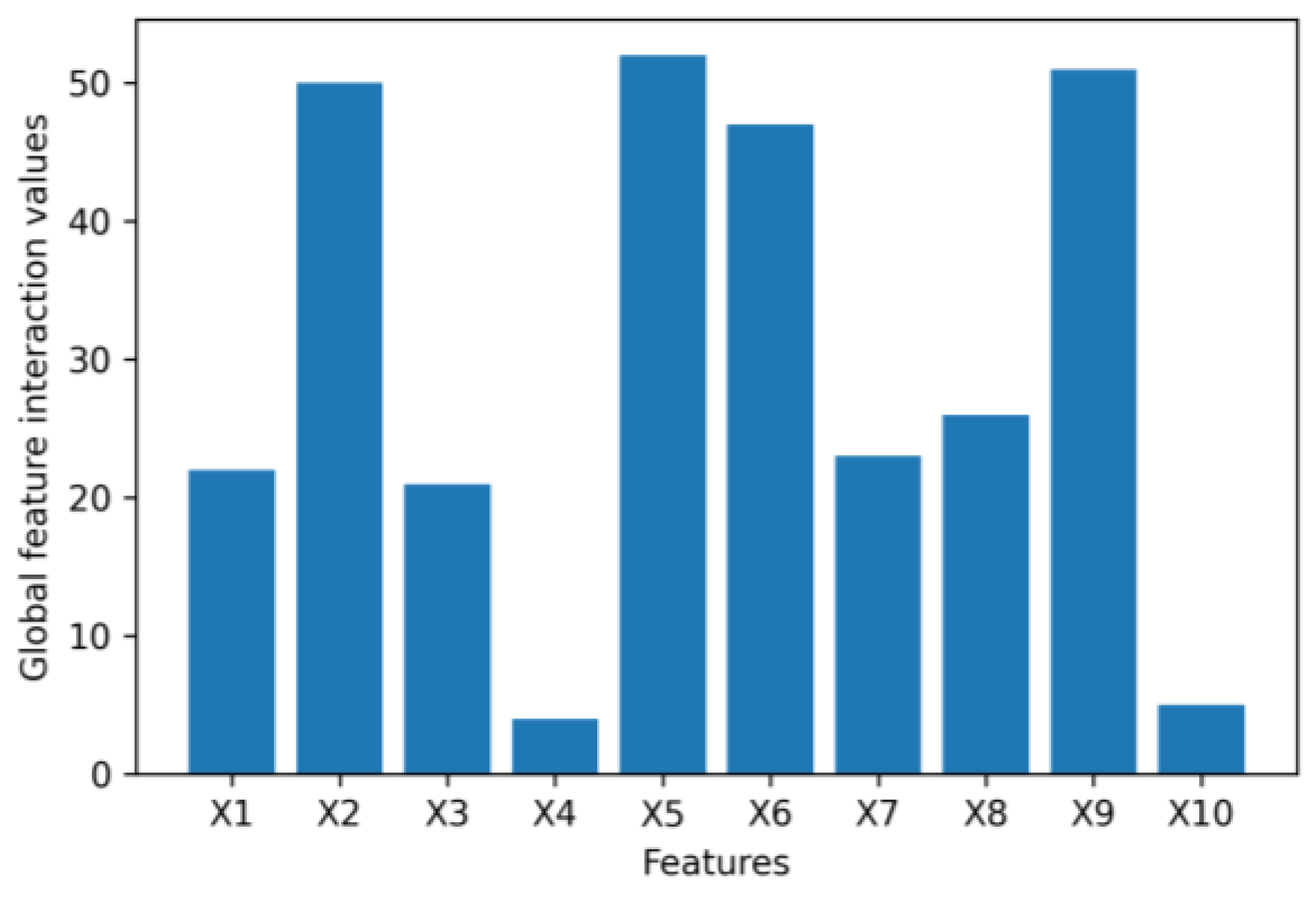
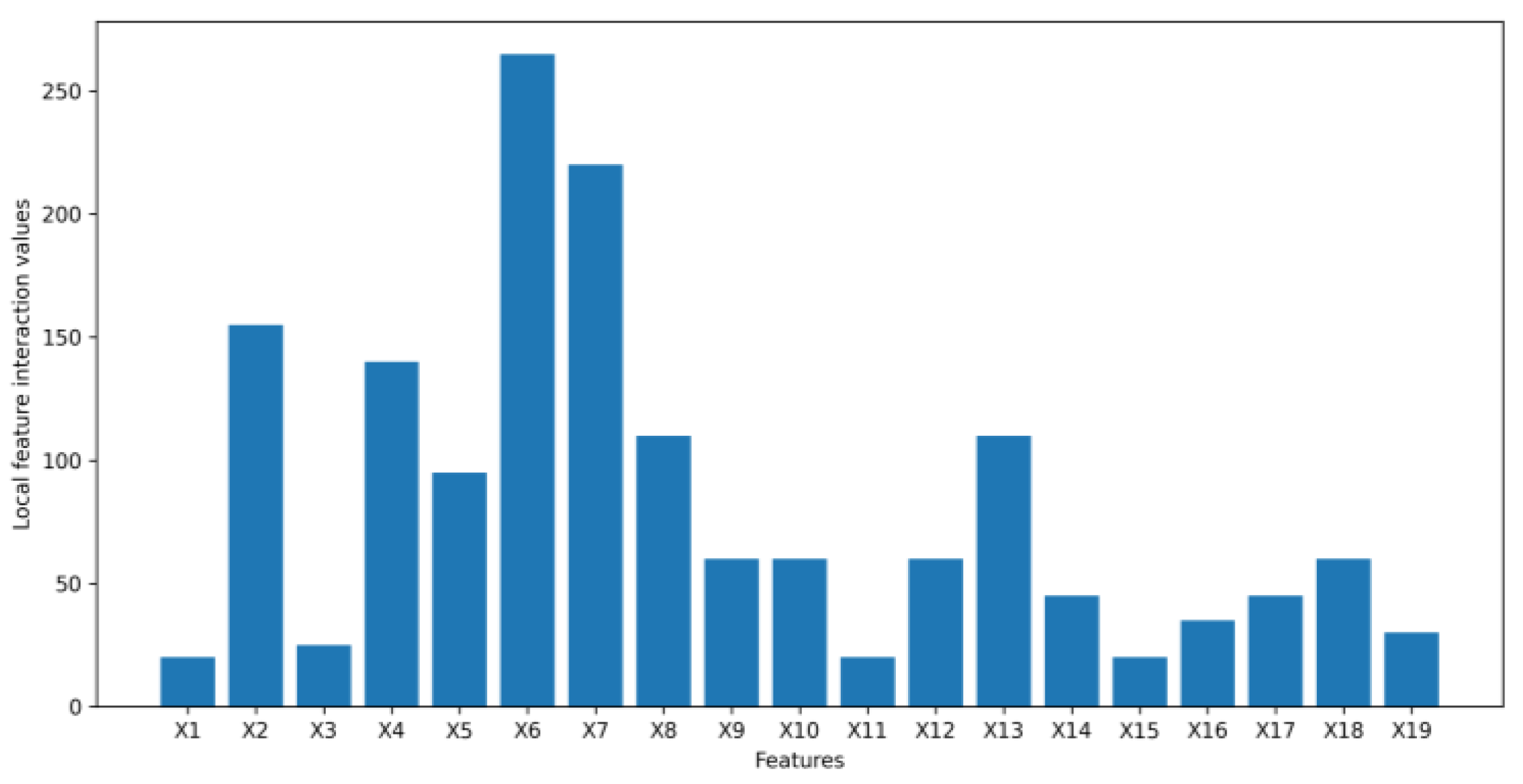
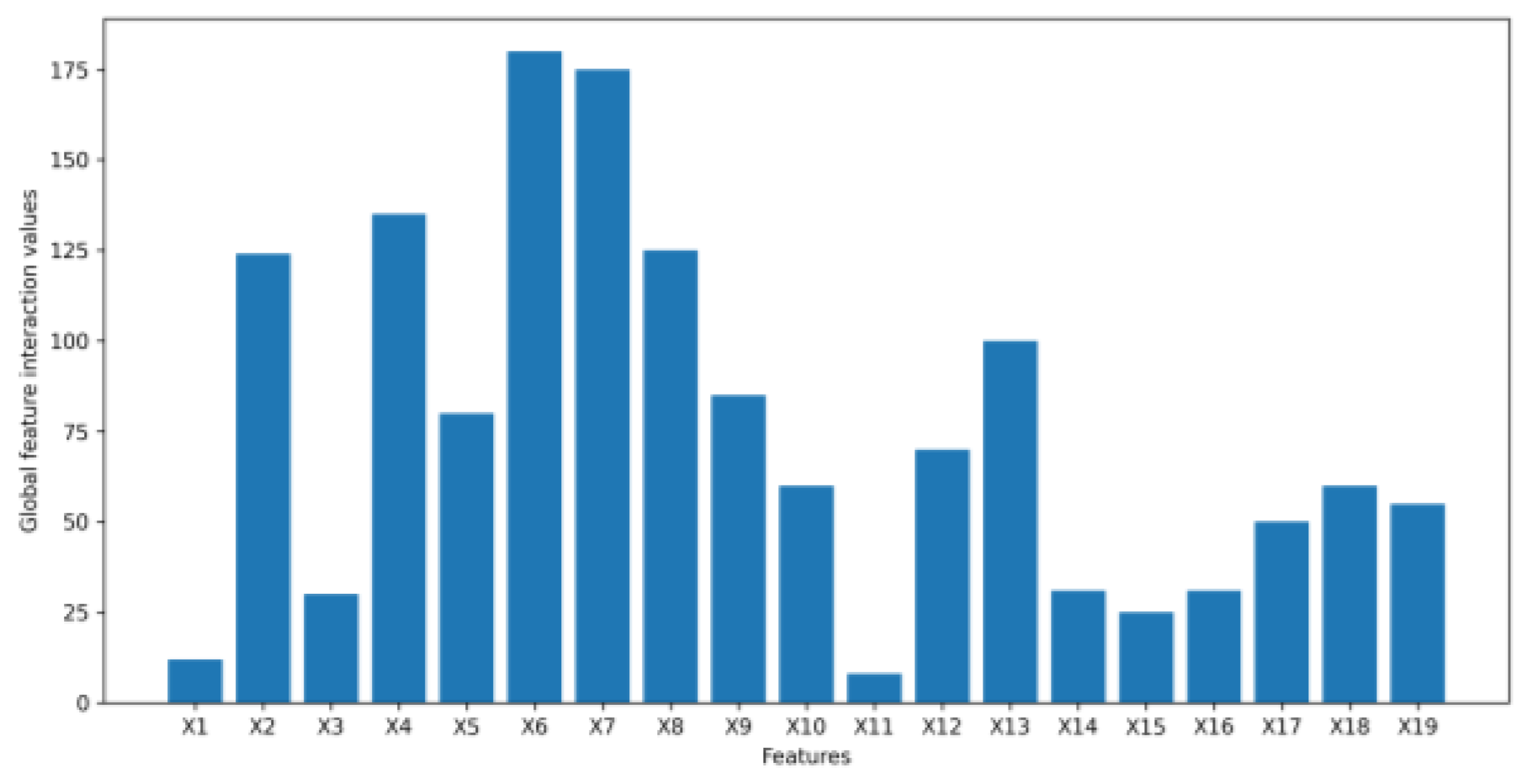
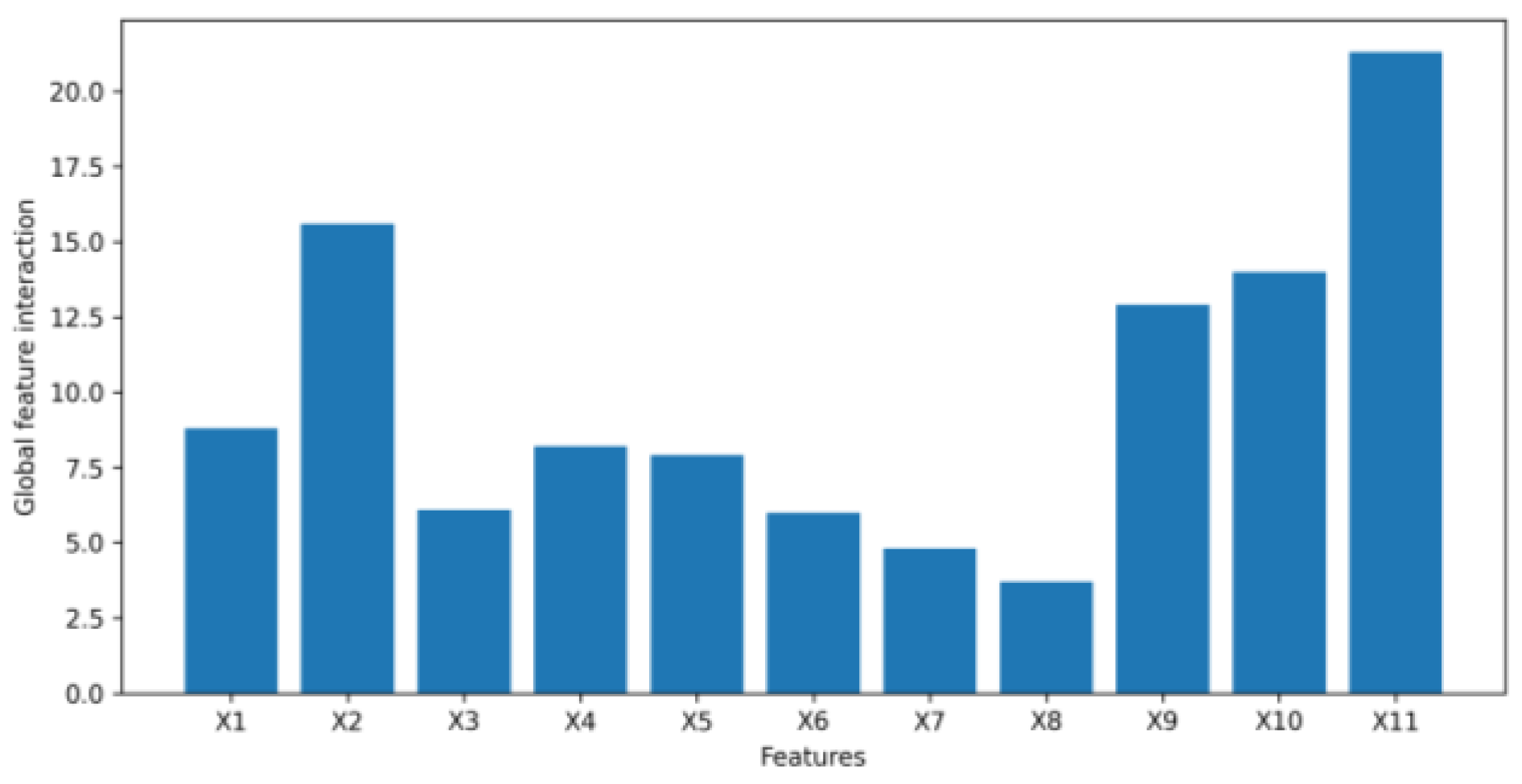
- We leverage the idea of a second-order partial derivative test to investigate feature interactions in an original tabular dataset that goes into a VAE to synthesize data. Measuring the feature interactions of a feature with the rest of the features can help us determine if we can safely remove the feature from a tabular dataset to reduce the dimensionality of the dataset to speed up the process of generating synthetic data without affecting the quality of the synthetic data being generated.
2. Literature Review
3. Materials and Methods
3.1. Feature Importance
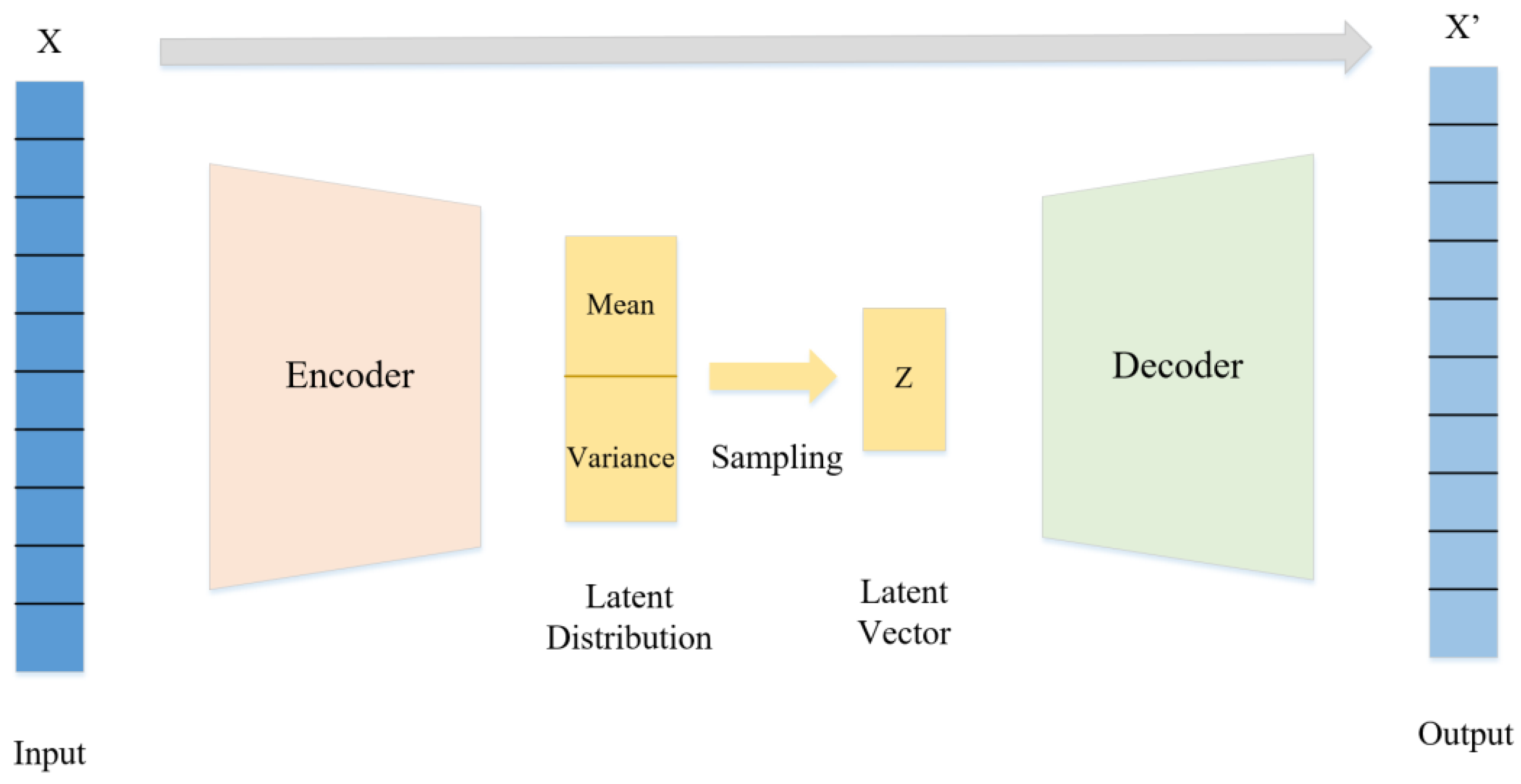
3.2. Structure of the VAE
3.3. Sensitivity Analysis
3.4. Framework Design
3.5. Experiment Preparation
3.5.1. Numerical Example
3.5.2. Application Examples
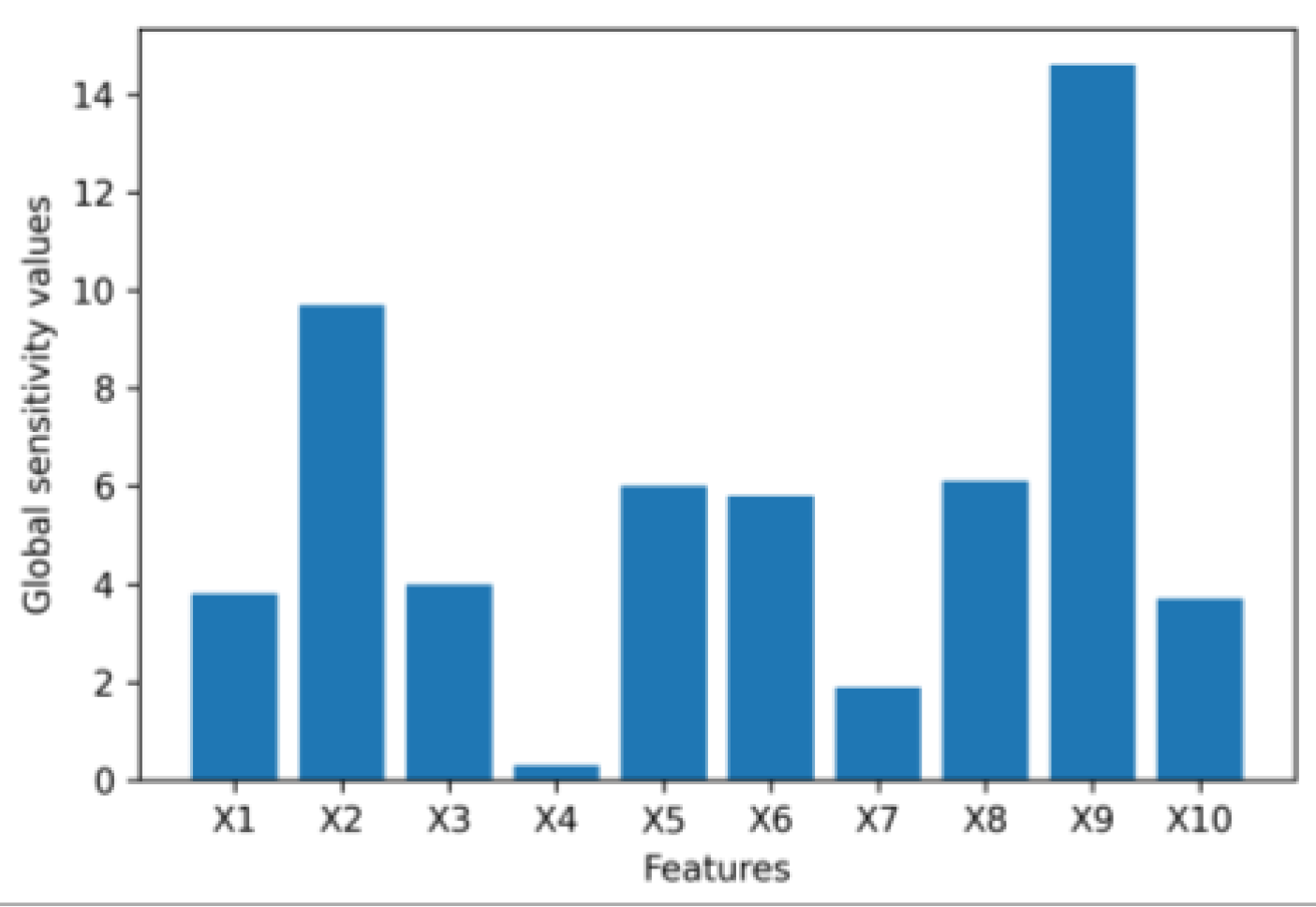
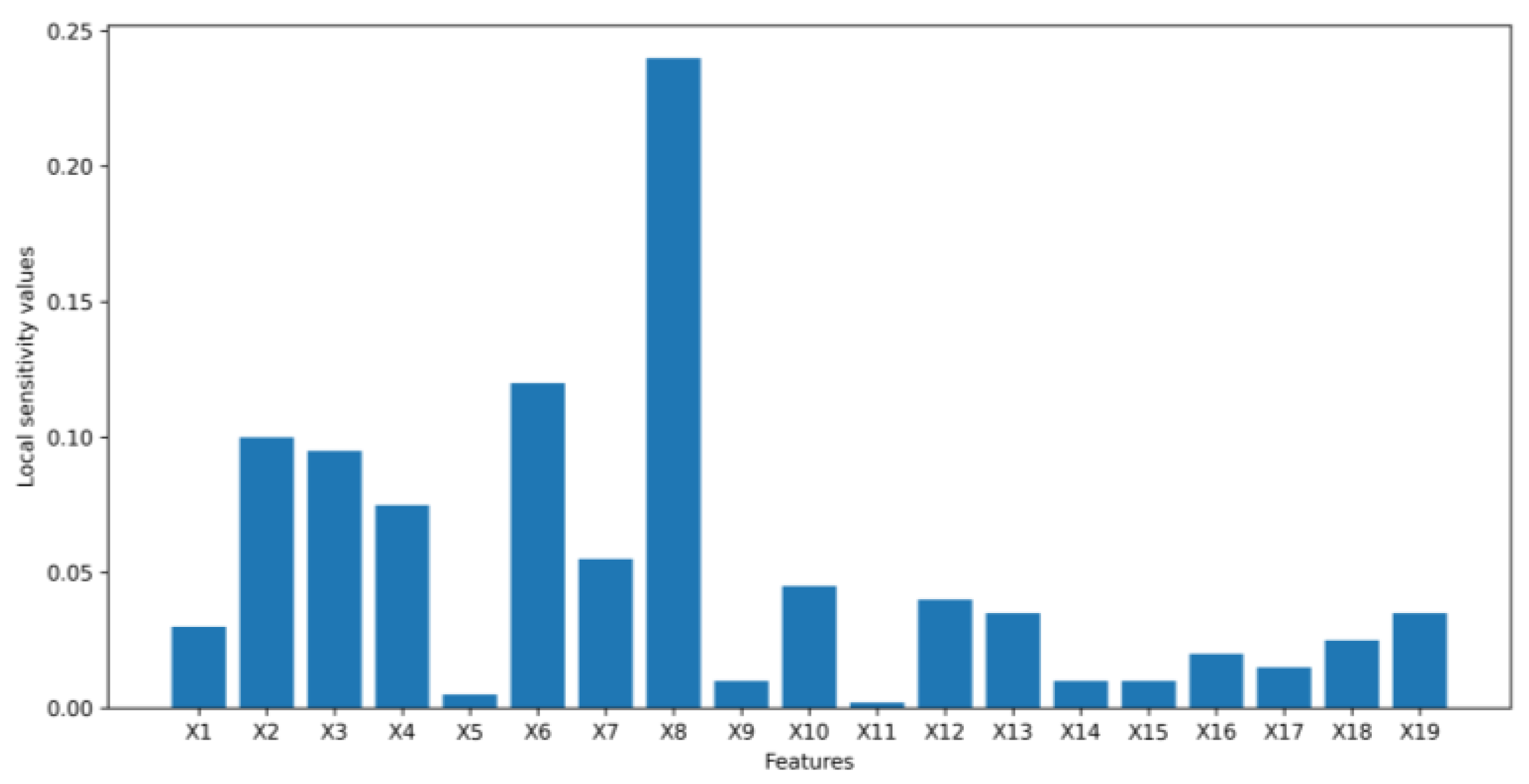
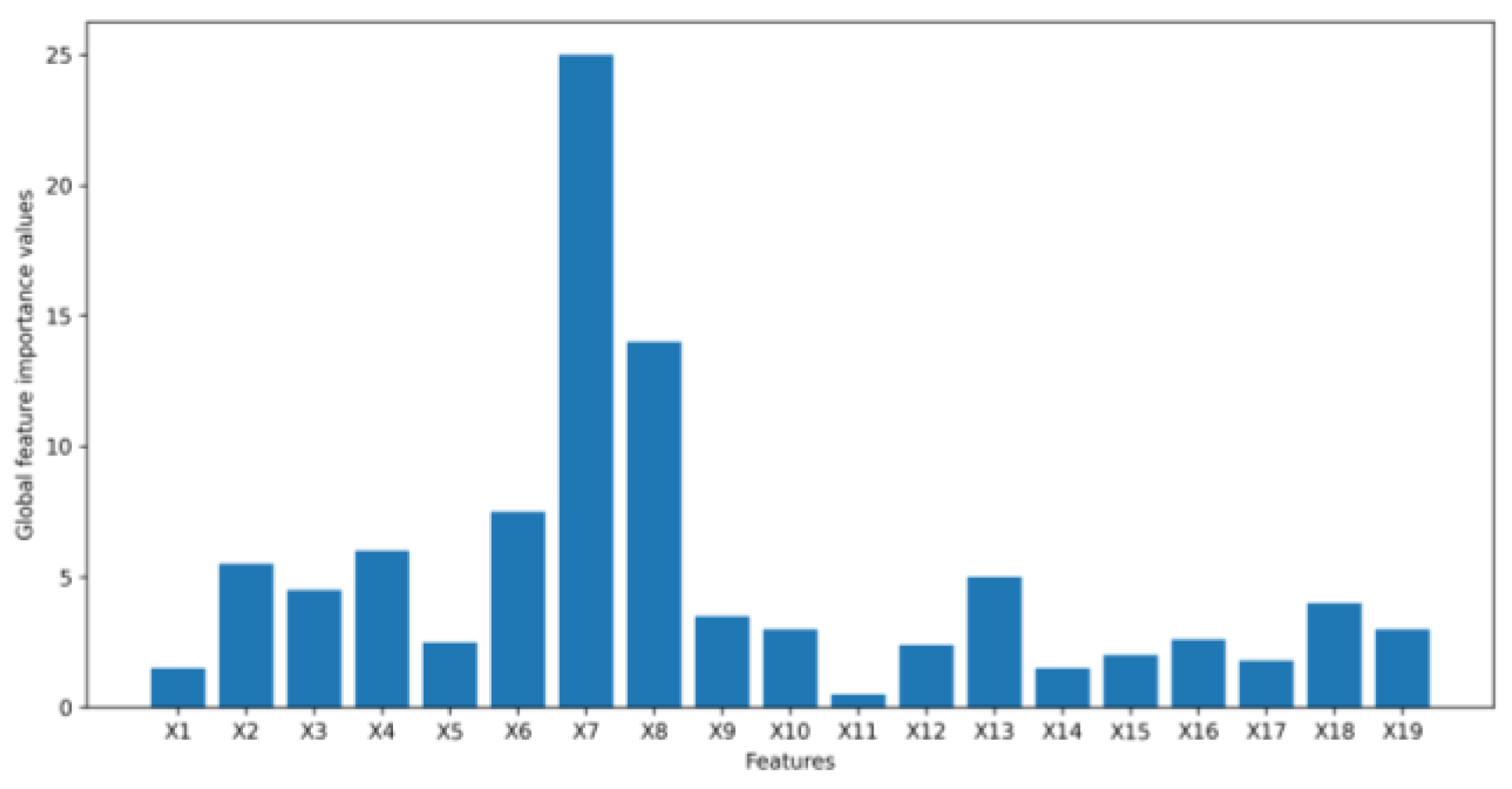
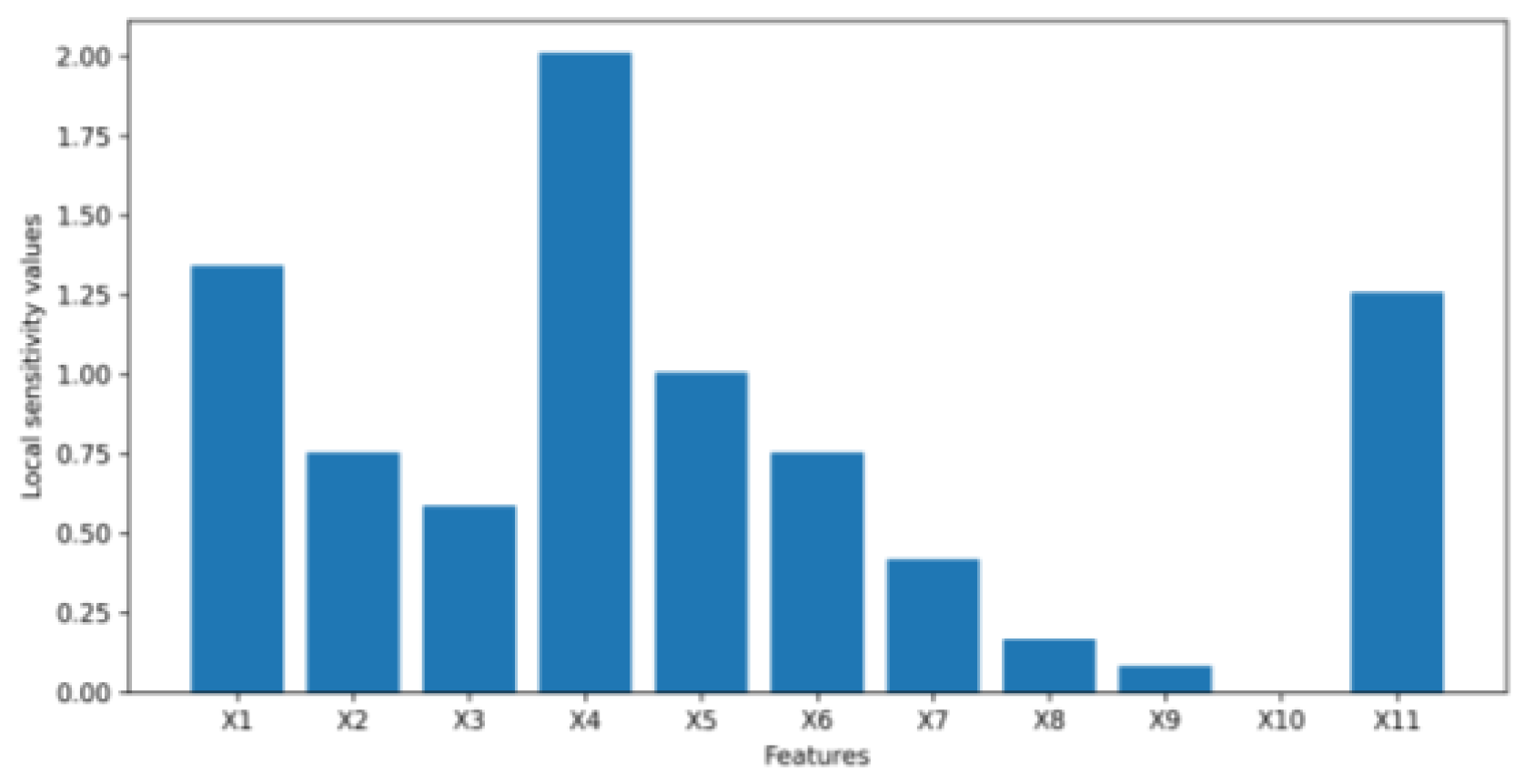
4. Results
4.1. Numerical Example Results
4.2. Application Example Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alabdullah, B.; Beloff, N.; White, M. Rise of Big Data–Issues and Challenges. In Proceedings of the 2018 21st Saudi Computer Society National Computer Conference (NCC), Riyadh, Saudi Arabia, 25–26 April 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Assefa, S.A.; Dervovic, D.; Mahfouz, M.; Tillman, R.E.; Reddy, P.; Veloso, M. Generating synthetic data in finance: Opportunities, challenges and pitfalls. In Proceedings of the First ACM International Conference on AI in Finance, New York, NY, USA, 15–16 October 2020; pp. 1–8. [Google Scholar] [CrossRef]
- Tucker, A.; Wang, Z.; Rotalinti, Y.; Myles, P. Generating high-fidelity synthetic patient data for assessing machine learning healthcare software. NPJ Digit. Med. 2020, 3, 147. [Google Scholar] [CrossRef] [PubMed]
- Joseph, A. We need Synthetic Data. Available online: https://towardsdatascience.com/we-need-synthetic-data-e6f90a8532a4 (accessed on 26 March 2022).
- Christoph, M. How do You Generate Synthetic Data? Available online: https://www.statice.ai/post/how-generate-synthetic-data (accessed on 26 March 2022).
- Mi, L.; Shen, M.; Zhang, J. A Probe Towards Understanding GAN and VAE Models. arXiv 2018, arXiv:1812.05676. [Google Scholar] [CrossRef]
- Singh, A.; Ogunfunmi, T. An Overview of Variational Autoencoders for Source Separation, Finance, and Bio-Signal Applications. Entropy 2022, 24, 55. [Google Scholar] [CrossRef] [PubMed]
- van Bree, M. Unlocking the Potential of Synthetic Tabular Data Generation with Variational Autoencoders. Master’s Thesis, Tilburg University, Tilburg, The Netherlands, 2020. [Google Scholar]
- Shankaranarayana, S.M.; Runje, D. ALIME: Autoencoder Based Approach for Local. arXiv 2019, arXiv:1909.02437. [Google Scholar] [CrossRef]
- Xu, F.; Uszkoreit, H.; Du, Y.; Fan, W.; Zhao, D.; Zhu, J. Explainable AI: A Brief Survey on History, Research Areas, Approaches and Challenges. In Natural Language Processing and Chinese Computing, Proceedings of the 8th CCF International Conference, NLPCC, Dunhuang, China, 9–14 October 2019; Springer International Publishing: Manhattan, NY, USA, 2019; Volume 11839, pp. 563–574. [Google Scholar] [CrossRef]
- Bengio, Y.; Courville, A.; Vincent, P. Representation Learning: A Review and New Perspectives. arXiv 2013, arXiv:1206.5538. [Google Scholar] [CrossRef] [PubMed]
- Yeh, I.-C.; Cheng, W.-L. First and second order sensitivity analysis of MLP. Neurocomputing 2010, 73, 2225–2233. [Google Scholar] [CrossRef]
- Shah, C.; Du, Q.; Xu, Y. Enhanced TabNet: Attentive Interpretable Tabular Learning for Hyperspectral Image Classification. Remote Sens. 2022, 14, 716. [Google Scholar] [CrossRef]
- Arik, S.Ö.; Pfister, T. TabNet: Attentive Interpretable Tabular Learning. arXiv 2020, arXiv:1908.07442. [Google Scholar] [CrossRef]
- Kingma, D.P.; Welling, M. Auto-Encoding Variational Bayes. arXiv 2014, arXiv:1312.6114. [Google Scholar] [CrossRef]
- Spinner, T.; Körner, J.; Görtler, J.; Deussen, O. Towards an Interpretable Latent Space. In Proceedings of the Workshop on Visualization for AI Explainability, Berlin, Germany, 22 October 2018. [Google Scholar]
- Seninge, L.; Anastopoulos, I.; Ding, H.; Stuart, J. VEGA is an interpretable generative model for inferring biological network activity in single-cell transcriptomics. Nat. Commun. 2021, 12, 5684. [Google Scholar] [CrossRef] [PubMed]
- Fortuin, V.; Hüser, M.; Locatello, F.; Strathmann, H.; Rätsch, G. Som-vae: Interpretable discrete representation learning on time series. arXiv 2019, arXiv:1806.02199. [Google Scholar] [CrossRef]
- Pizarroso, J.; Pizarroso, J.; Muñoz, A. NeuralSens: Sensitivity Analysis of Neural Networks. arXiv 2021, arXiv:2002.11423. [Google Scholar] [CrossRef]
- Mison, V.; Xiong, T.; Giesecke, K.; Mangu, L. Sensitivity based Neural Networks Explanations. arXiv 2018, arXiv:1812.01029. [Google Scholar] [CrossRef]
- Saarela, M.; Jauhiainen, S. Comparison of feature importance measures as explanations for classification models. SN Appl. Sci. 2021, 3, 272. [Google Scholar] [CrossRef]
- Terence, S. Understanding Feature Importance and How to Implement it in Python. Available online: https://towardsdatascience.com/understanding-feature-importance-and-how-to-implement-it-in-python-ff0287b20285 (accessed on 26 March 2022).
- Kingma, D.P.; Welling, M. An Introduction to Variational Autoencoders. Found. Trends R Mach. Learn. 2019, 12, 307–392. [Google Scholar] [CrossRef]
- Zurada, J.M.; Malinowski, A.; Cloete, I. Sensitivity analysis for minimization of input data dimension for feedforward neural network. In Proceedings of the IEEE International Symposium on Circuits and Systems-ISCAS’94, London, UK, 30 May–2 June 1994; Volume 6, pp. 447–450. [Google Scholar] [CrossRef]
- Chandran, S. Significance of I.I.D in Machine Learning. Available online: https://medium.datadriveninvestor.com/significance-of-i-i-d-in-machine-learning-281da0d0cbef (accessed on 26 March 2022).
- Saarela, M.; Heilala, V.; Jääskelä, P.; Rantakaulio, A.; Kärkkäinen, T. Explainable student agency analytics. IEEE Access 2021, 9, 137444–137459. [Google Scholar] [CrossRef]
- Linardatos, P.; Papastefanopoulos, V.; Kotsiantis, S. Explainable AI: A Review of Machine Learning Interpretability Methods. Entropy 2021, 23, 18. [Google Scholar] [CrossRef] [PubMed]





















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Meaning |
|---|---|
| N | total number of data points in a dataset |
| M | total number of input features |
| H | total number of means or standard deviations in the latent space of a VAE where 2H will be the layer size |
| a random data sample | |
| mth input feature | |
| Other input features except mth feature | |
| sensitivity of the latent space with respect to mth input feature for the data sample | |
| sensitivity of means in the latent space of a VAE with respect to mth input feature for the data sample | |
| sensitivity of standard deviations in the latent space of a VAE with respect to mth input feature for the data sample | |
| sensitivity of hth mean in the latent space of a VAE () with respect to mth input feature for the data sample | |
| sensitivity of hth standard deviation in the latent space of a VAE () with respect to mth input feature for the data sample | |
| mean squared sensitivity of means in the latent space with respect to mth input feature for the entire dataset | |
| mean squared sensitivity of standard deviations in the latent space with respect to mth input feature for the entire dataset | |
| mean squared sensitivity of hth mean in the latent space of a VAE () with respect to mth input feature for the entire dataset | |
| mean squared sensitivity of hth standard deviation in the latent space of a VAE () with respect to mth input feature for the entire dataset | |
| mean squared sensitivity of the latent space with respect to mth input feature for the entire dataset | |
| relative feature importance | |
| normalization factor | |
| at a local level or at a global level | |
| interactions between the feature and other features for the data sample, , in a tabular dataset | |
| global interactions between mth feature and other features |
| Variable | Feature Name | Variable | Feature Name |
|---|---|---|---|
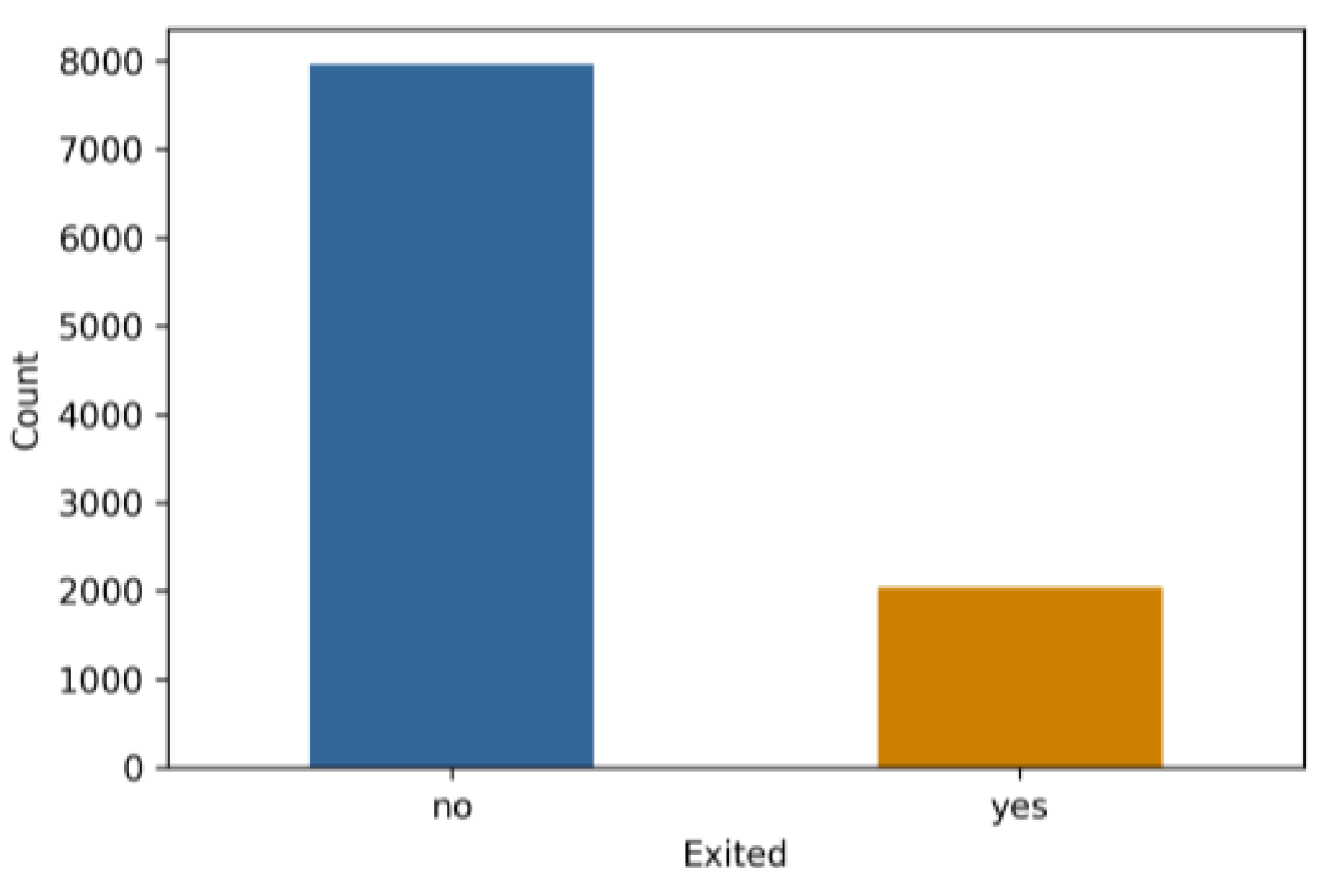
| X1 | credit score | X6 | balance |
| X2 | geography | X7 | number of products |
| X3 | gender | X8 | if the client has a credit card |
| X4 | age | X9 | if the client is an active member |
| X5 | tenure | X10 | estimated salary |
| Variable | Feature Name | Variable | Feature Name |
|---|---|---|---|
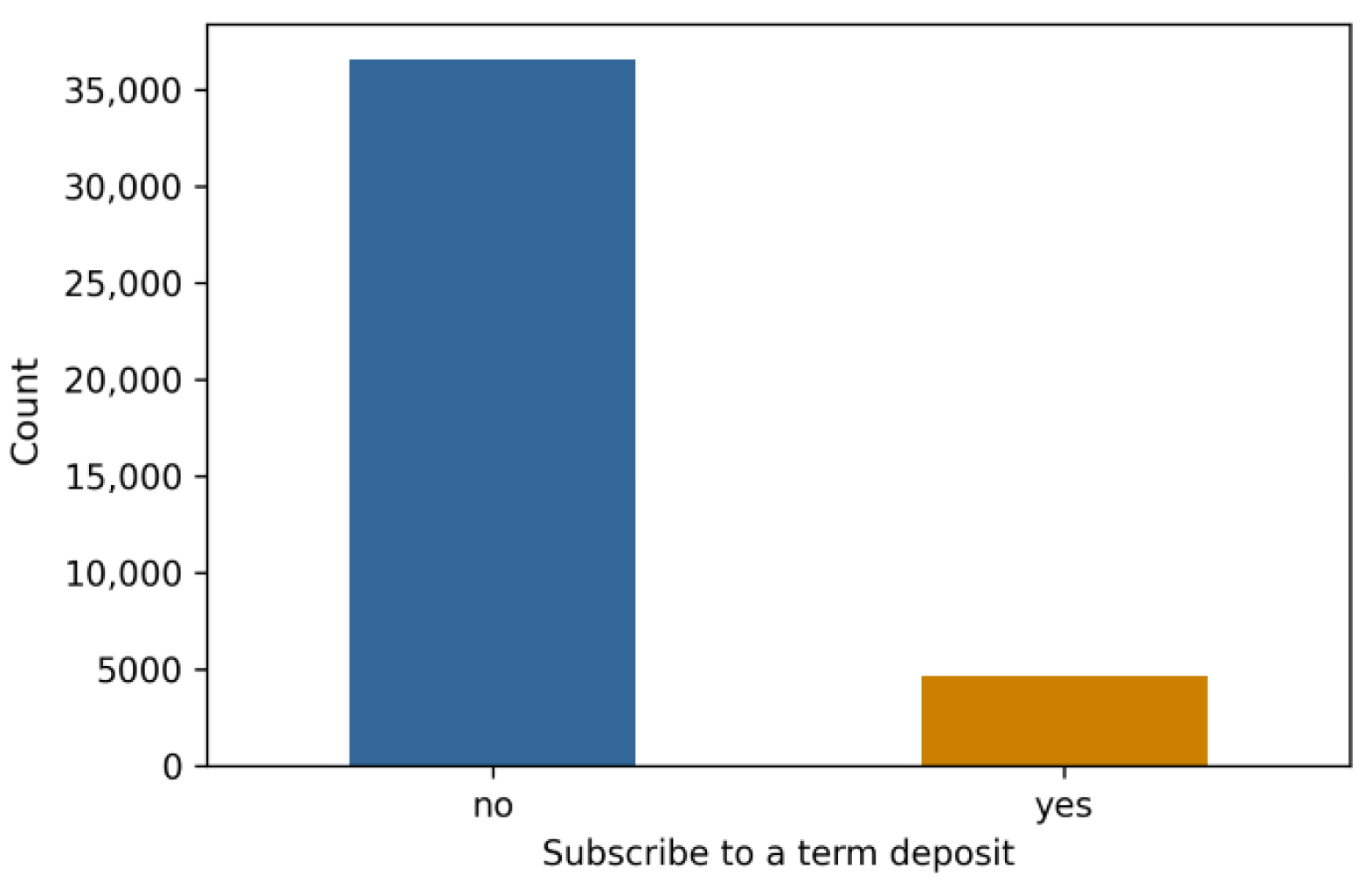
| X1 | age | X11 | number of contacts performed during this campaign |
| X2 | job | X12 | number of days since the client was contacted from a previous campaign |
| X3 | marital status | X13 | number of contacts performed before this campaign |
| X4 | education | X14 | outcome of previous campaign |
| X5 | if has credit in default | X15 | employment variation rate |
| X6 | if has housing loan | X16 | consumer price index |
| X7 | if has personal loan | X17 | consumer confidence index |
| X8 | communication type | X18 | Euribor 3-month rate |
| X9 | last contact month | X19 | number of employees |
| X10 | last contact day |
| Variable | Feature Name | Variable | Feature Name |
|---|---|---|---|
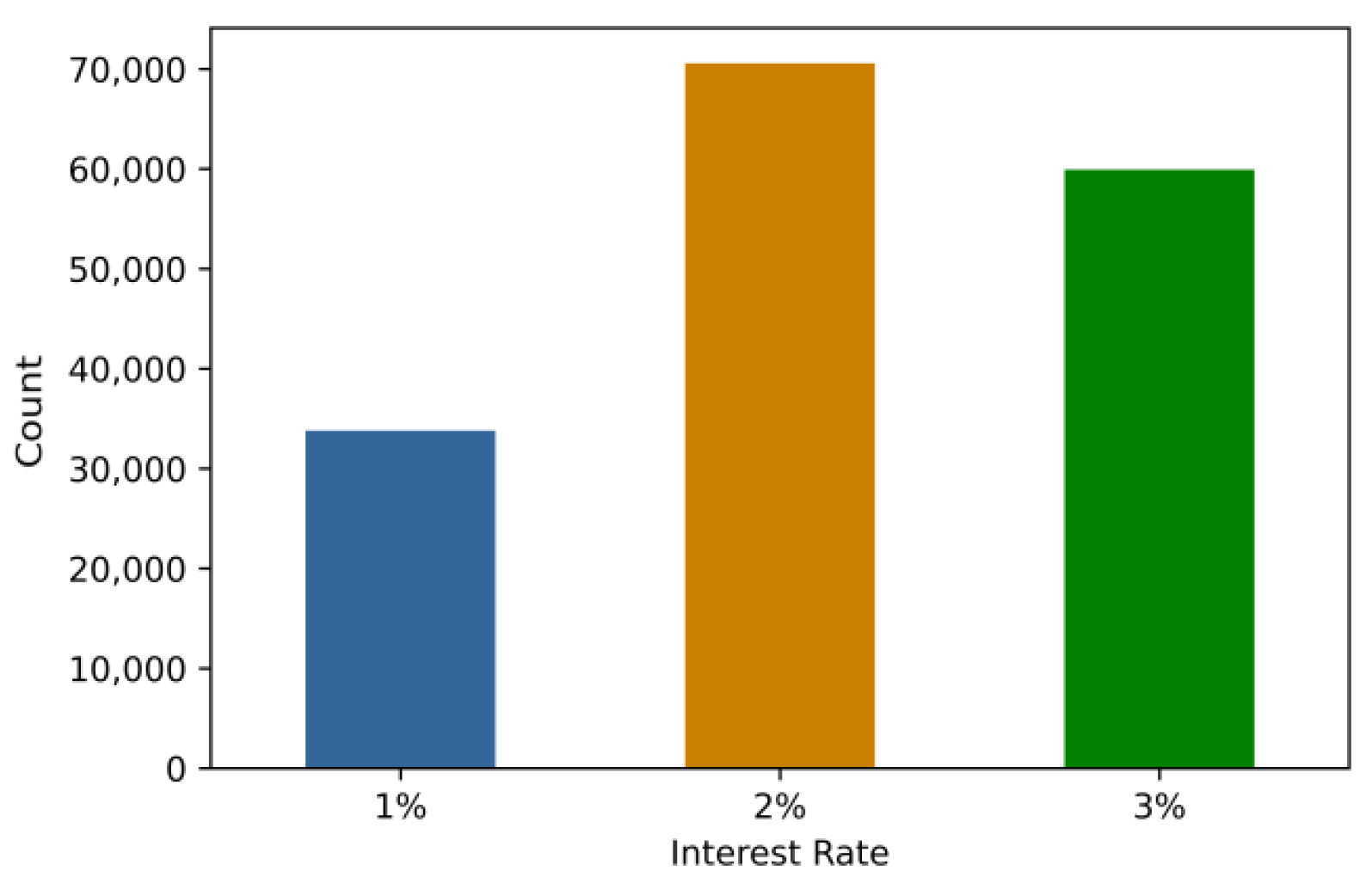
| X1 | requested loan amount | X7 | debt to income ratio |
| X2 | length of employment | X8 | number of inquiries in last 6 months |
| X3 | ownership of a house | X9 | number of open accounts |
| X4 | annual income | X10 | number of total accounts |
| X5 | if income is verified | X11 | gender |
| X6 | purpose of loan |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, J.; Plataniotis, K.; Liu, L.; Amjadian, E.; Lawryshyn, Y. Interpretation for Variational Autoencoder Used to Generate Financial Synthetic Tabular Data. Algorithms 2023, 16, 121. https://doi.org/10.3390/a16020121
Wu J, Plataniotis K, Liu L, Amjadian E, Lawryshyn Y. Interpretation for Variational Autoencoder Used to Generate Financial Synthetic Tabular Data. Algorithms. 2023; 16(2):121. https://doi.org/10.3390/a16020121
Chicago/Turabian StyleWu, Jinhong, Konstantinos Plataniotis, Lucy Liu, Ehsan Amjadian, and Yuri Lawryshyn. 2023. "Interpretation for Variational Autoencoder Used to Generate Financial Synthetic Tabular Data" Algorithms 16, no. 2: 121. https://doi.org/10.3390/a16020121
APA StyleWu, J., Plataniotis, K., Liu, L., Amjadian, E., & Lawryshyn, Y. (2023). Interpretation for Variational Autoencoder Used to Generate Financial Synthetic Tabular Data. Algorithms, 16(2), 121. https://doi.org/10.3390/a16020121