1. Introduction
Using artificial neural networks (ANNs), a number of computationally complex or data-intensive computational problems have been successfully tackled in the last decade. Furthermore, ANNs can be applied to computational tasks with no rigorous mathematical model in the background; the structure of the neural network itself serves as a (sometimes, heuristic) model.
A natural idea is to employ this powerful tool for the classical computational problems such as the numerical solution of partial differential equations (PDEs). Accordingly, a number of different algorithms have been proposed.
The most-widespread family of the different approaches is the so-called physics-informed neural networks (PINNs), which were introduced in [
1]. For a detailed review on this topic, we refer to [
2].
In the first version of this popular family of methods, called the data-driven PINNs, we have a fixed PDE for the unknown function , where denotes the spatial computational domain and is a generic spatial differential operator. Furthermore, the equation should be equipped with an appropriate initial condition and boundary data for the well-posedness.
To prepare the computations with the ANN, a huge number of solution candidates
should be computed such that these determine a large variety of initial and boundary conditions. If
is only an approximation, the right-hand side defined by
is not necessarily zero. Furthermore,
has some initial value
and boundary value
. Within the frame of the conventional PINNs, for a given set
, an ANN is trained using the pairs:
In this way, the ANN will try to learn the solution at some points using the left-hand side
, the boundary data
, and the initial data
, such that it can be recognized as a solution operator. For a given structure of the ANN, the values of its parameters will be determined such that the error:
is minimal. Here,
denotes the ANN estimate of the original function
. To perform this, we should specify a norm to measure the error above. This norm is commonly called the loss function. Finally, applying this network to the input
, we obtain the desired approximation of
u.
This original idea was developed and extended to incorporate unknown parameters in the equation. In this way, it is perfectly fit to solve inverse problems; see, e.g., [
3]. The real-life case of noisy measurements or observation data can also be fit into this framework, linking this computational tool with the powerful Bayesian inversion approach [
4].
Furthermore, the methodology of computing with PINNs was refined and discussed for a number of cases concerning the Navier–Stokes equations [
5], as well as stochastic PDEs [
6]. Beyond these specific applications, the PINN-based methods were also extended to make them flexible in the choice of the computational domain [
7].
Due to the practical importance of developing efficient PDE solvers, a number of further ANN-based approaches have been proposed for this purpose. A new, promising methodology is based on mappings between function spaces. As the Galerkin methods became the leading tool in the case of conventional numerical methods, the function space approach, instead of working pointwise or with mesh-dependent data, seems to be an adequate direction for the learning algorithms. This was described in [
8], where also an extensive review is provided on further ANN-based methodologies.
Our present study was restricted to the numerical solution of the Laplace equation and, in particular, the corresponding Dirichlet-to-Neumann problem. At the same time, we combined here the knowledge of the classical analysis with the powerful tools given by the neural networks.
The numerical solution of the Laplace equation is a rather classical topic: It serves as an important building block for practical problems such as non-linear water waves [
9] or electrical impedance tomography (EIT), where very flexible and fast solvers for elliptic-boundary-value problems are needed. In the corresponding mathematical model, the Dirichlet-to-Neumann map is known at some boundary points. Using this information, the parameters of the original elliptic differential operator should be determined.
As EIT is an important non-invasive diagnostic tool in medicine, the corresponding computational algorithms are of interest [
10]. Accordingly, ANN-based approaches have also been elaborated for this; see [
11,
12].
Furthermore, the methodology we develop here can be easily extended to a number of PDEs, where the fundamental solution is known.
After stating the computational problem, we discuss some necessary tools in the mathematical analysis. Then, the main principles of the proposed algorithm are described in detail with the link to the classical methods of the numerical analysis. Afterwards, we give the algorithm in concrete terms. In the final section, the details of the implementation are given, and the efficiency of the present approach is demonstrated by some numerical experiments.
2. Materials and Methods
We first state the mathematical problems to be solved.
2.1. Problem Statement and Mathematical Background
The focus of the present study is the ANN-based approximation of some mathematical problems based on the Laplacian equation:
where
denotes the computational domain,
is an unknown function, and
is given.
The corresponding theory (see, e.g., [
13]) ensures that this problem is well-posed: for any
, it has a unique solution
depending continuously on
g.
Here, it was assumed that
is bounded and has a Lipschitz boundary, and we used the classical Sobolev spaces:
and
In practice, however, g is not given in all points of , and possibly, u is sought only in some interior points. Accordingly, as an introductory problem, we discuss the following case:
Problem 1. For given values of with , we should determine with .
Our objective was to reduce the computational costs and approximate
without computing a “complete” numerical solution
of (
2).
A related problem is computing the corresponding Dirichlet-to-Neumann map.
Problem 2. For given values of with , we should determine with .
The associated “full” mapping corresponding to (
2) is defined as
where
is the solution of (
2),
denotes the (space-dependent) outward normal on
, and
denotes the dual-space of
. This is called the Dirichlet-to-Neumann map. Of course, to develop an efficient procedure, we intended to perform it without approximating
u in the entire domain.
In a related mathematical model, the function g corresponds to an applied potential (using electrodes) at the surface of some organ and corresponds to the generated current on the boundary. Here, instead of the Laplacian, we used a general elliptic operator , where the space-dependent function describes the permittivity.
In this way, the Dirichlet-to-Neumann map can be measured, and in a real-life inverse problem (in EIT), the corresponding permittivity has to be determined.
Remark 1. Note that neither Problem 1 nor Problem 2 are well-posed. Therefore, we cannot perform a conventional error analysis.
Furthermore, an objective of our approach was to include and use knowledge from the PDE theory and the conventional numerical methods in the ANN-based algorithm. The most-important tool is the use of the fundamental solution, which, for
, is defined as
For a given , we also used its shifted version, which is given by .
As the main objective, we intend to construct neural networks, where the vector
serves as an input according to the given boundary data in (
2), and the output will approximate:
in the case of Problem 1;
in the case of Problem 2.
2.2. Principles and Details of the Algorithm
Observe that, for
, we have
for
, such that it satisfies the first equation in (
2). In this way, for a fixed value of
, we used the following.
Main Principle
The pair:
delivers a learning data pair (input and output) for Problem 1.
Likewise, the pair delivers a learning data pair for Problem 2.
Summarizing, the ANN can be trained with the above data for an arbitrary set of points . In this way, we easily obtain a learning dataset consisting of K input–output pairs.
Remark 2. - 1.
In practice, we did not choose , since in this case, Ψ will have a singularity here, which results in huge values in the vicinity of the boundary.
- 2.
The present approach (3), compared to the conventional one (1), defines a much easier procedure: We can get rid of the first term in (1) automatically; Furthermore, for a stationary problem, we do not need the initial condition in the second term in (1).
In short, our approach results in a significant reduction of the parameters in the associated ANN. It seems obvious to employ this idea in general, for all stationary boundary values problems, if we know solutions with . However, one should be careful here: we can only approximate all possible solutions if we can state some approximation property on the linear hull of the family of functions .
- 3.
In other words, our approach can also be considered as a shortcut in the PINNs. As we do not have to compute solution candidates with different right-hand sides , the number of learning data is also reduced, and the ANN can be trained much faster.
Recall that, in the Dirichlet-to-Neumann problem, the natural norm of the Neumann data is , which can lead to the slow convergence of the result. In the ANN-based algorithm, this can also lead to the slowing down of the optimization procedure.
To try an alternative approach for Problem 2, observe that the Neumann boundary data of
u at
can also be estimated using the approximation:
for a small value
. Then, we have to estimate
and
to obtain the pointwise approximation in (
4). A motivation for this approach is the good performance of the estimation of
, which is shown later.
2.3. A Related Classical Approach
Both Problem 1 and Problem 2 are linear, and accordingly, we intended to construct the ANN as a linear map. In this case, it can be identified with a matrix
such that we have the approximation:
Keeping this in mind, any input vector:
in the ANN as the boundary data is first approximated as
where
are unknown real coefficients. Indeed, taking
and appropriate values of
such that
the approximation in (
6) becomes an equality.
This is the case in real-life situations, since we try to produce a large number
K of learning data pairs. Moreover, using the singular property of
, for each
, we can choose
in its vicinity such that
This means that the matrix composed by the vectors:
will be diagonally dominant, such that it is non-singular. Then, the rank of its columns is indeed
N.
In this case, using (
5) and (
6) with equality, the neural network with the input
gives
where the left-hand side is the prediction of
u at
. In summary, the linear ANN-based approximation can be recognized as an approximation:
This is exactly the idea of the
method of fundamental solutions (MFS), which was initiated in [
14]. Due to its simplicity and meshless property, this numerical method became extremely popular in the engineering community. At the same time, a rigorous and general convergence theory for the MFS is still missing. In any case, such a theory is based on the approximation property of the functions
. A nice summary of the related results can be found in [
15].
Furthermore, the approximation property of our neural network depends on the density properties of the above function space.
2.4. The Algorithm
Based on the above approach, we utilized the following algorithm:
- 1.
We define points , which are near and are distributed quasi-uniformly.
- 2.
For Problem 1, we computed the learning input–output pairs
.
- 3.
For Problem 2, in the first approach, we computed the learning input–output pairs
.
For Problem 2, in the second approach, we computed first the learning input–output pairs
and, then, additionally, the learning input–output pairs
- 4.
We define an appropriate neural network, with input size N and output size M.
- 5.
In the case of Problem 2, using the second approach, we used the predictions to compute the approximation in (
4). Additionally, in both approaches, we applied a post-smoothing.
In all cases, we first tried to use a simple ANN with only one input and one output layer, which are densely connected. The activation function was originally a simple linear one, and no bias term was applied. Then, we tried also more layers including convolutional ones to reduce the number of parameters. For the same reason, we also tried to add a dropout layer in the original setup.
3. Results
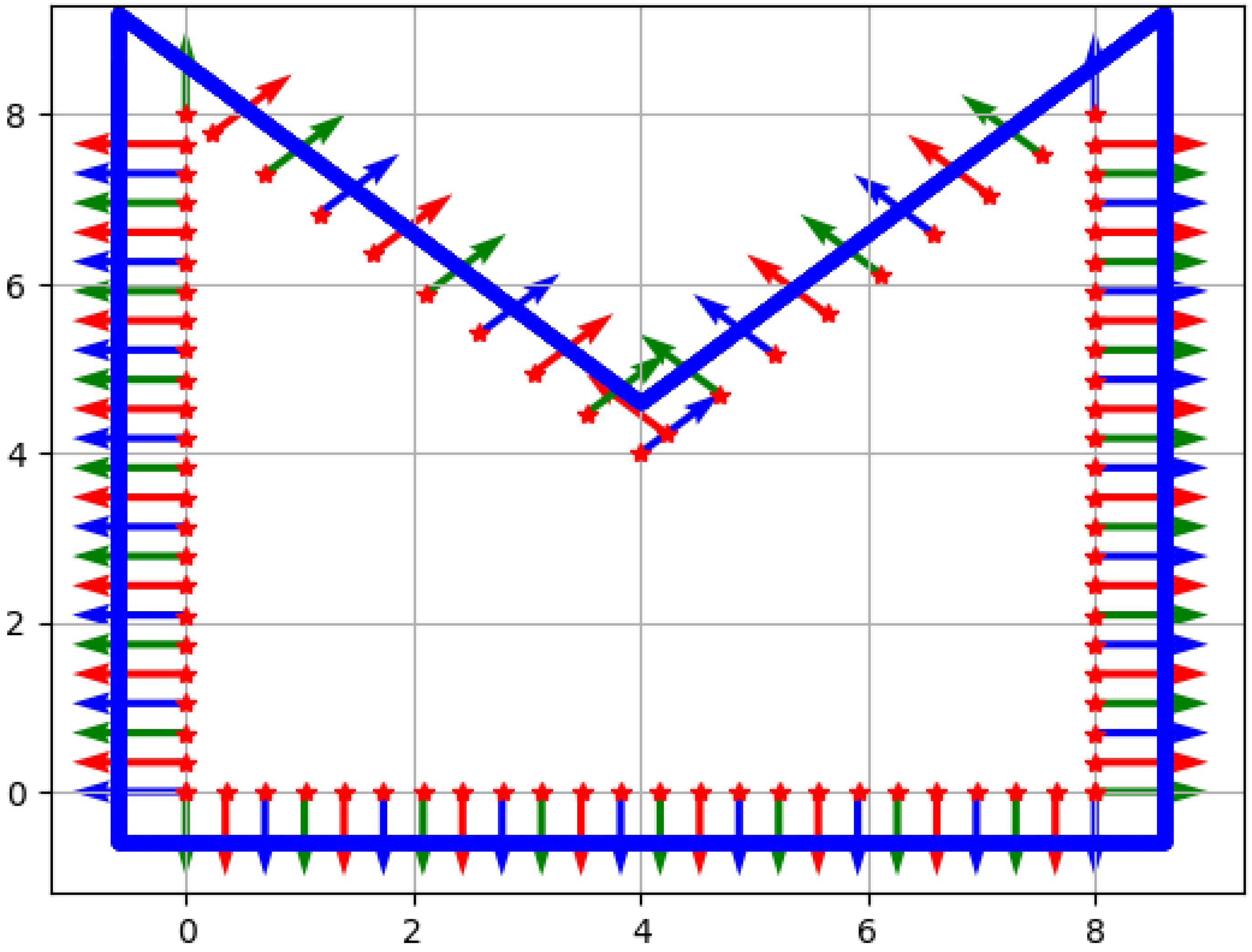
In the numerical experiments, we defined a non-convex domain
with sharp corners to demonstrate that the method also works for non-trivial geometries. This is shown in
Figure 1 together with the points and outward normal vectors, which were used in the computations:
: red stars on the boundary, where Dirichlet boundary conditions are given:
: we approximated the Neumann boundary data in the same points;
: red–green–blue outward normal vectors at the boundary;
: blue points (quite densely).
Here, according to the numerical experiments, and .
We dealt only with Problem 2, but within the second approach, we have to compute pointwise values in (
4), which is the issue of Problem 1.
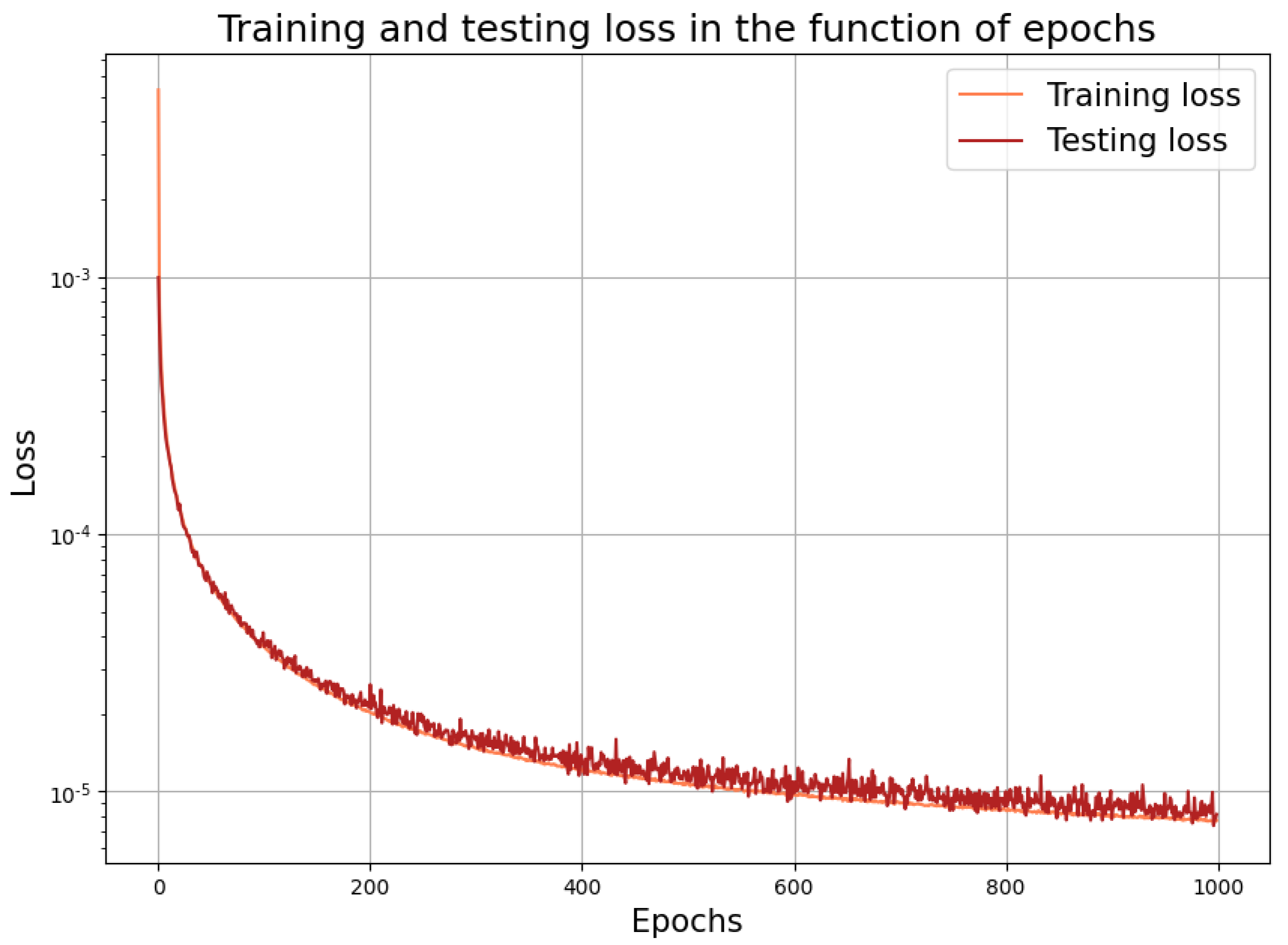
Problem 2, first approach: Using with means that the input and the output layers both have a size of 89. Assuming a dense connection between them without any intermediate layers and bias terms, we have as the number of parameters. In this way, we really need a number of learning data for a reliable fit. This suggests trying as an optimistic guess. The forthcoming figures all correspond to this case. For an experimental error analysis, in the next subsection, we perform a series of further experiments using a variety of parameters.
We summarize the common setup of the corresponding computations as follows:
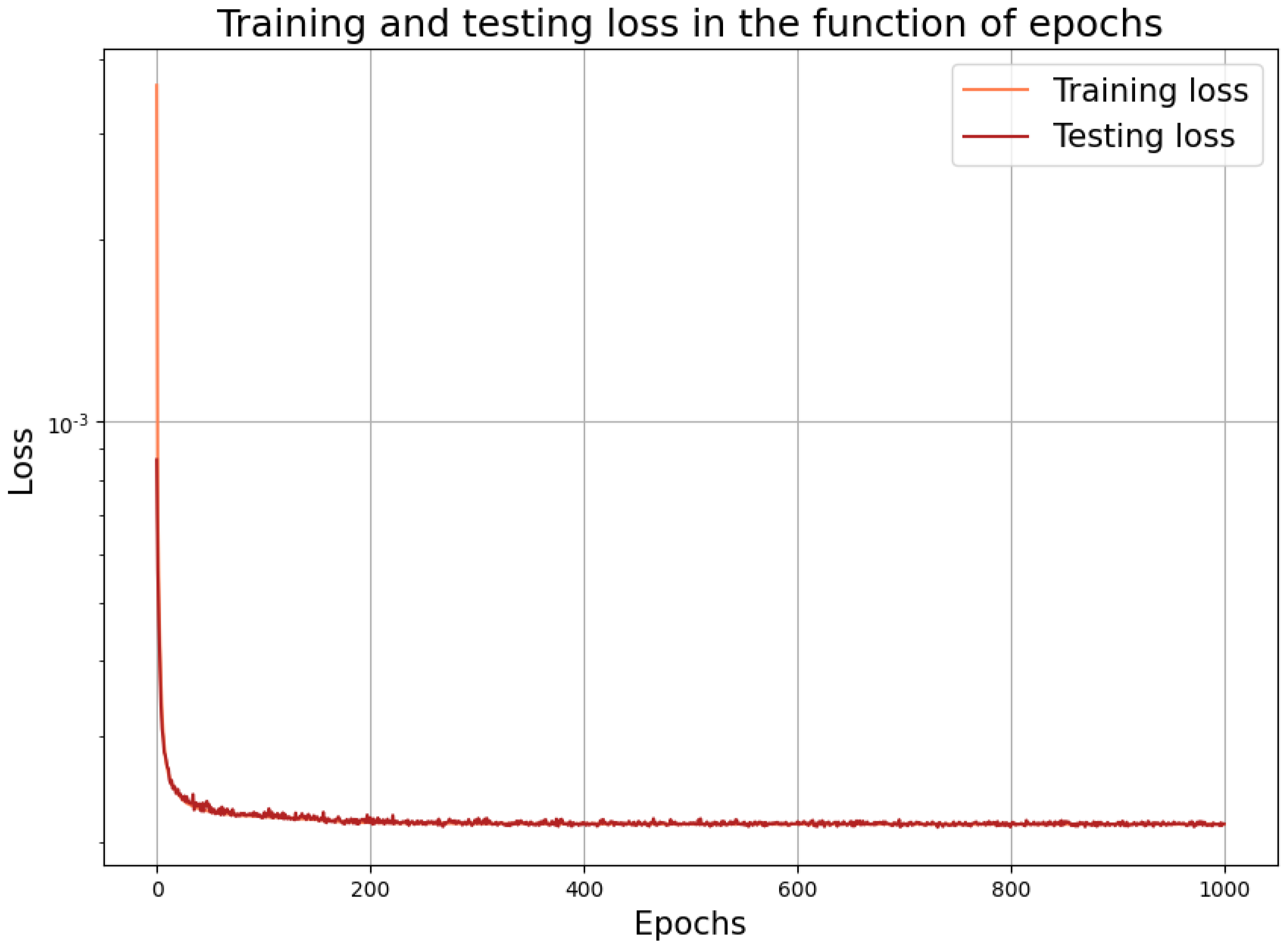
The learning performance of the neural network is shown in
Figure 2. The above setup with all of the parameters was the result of a series of experiments.
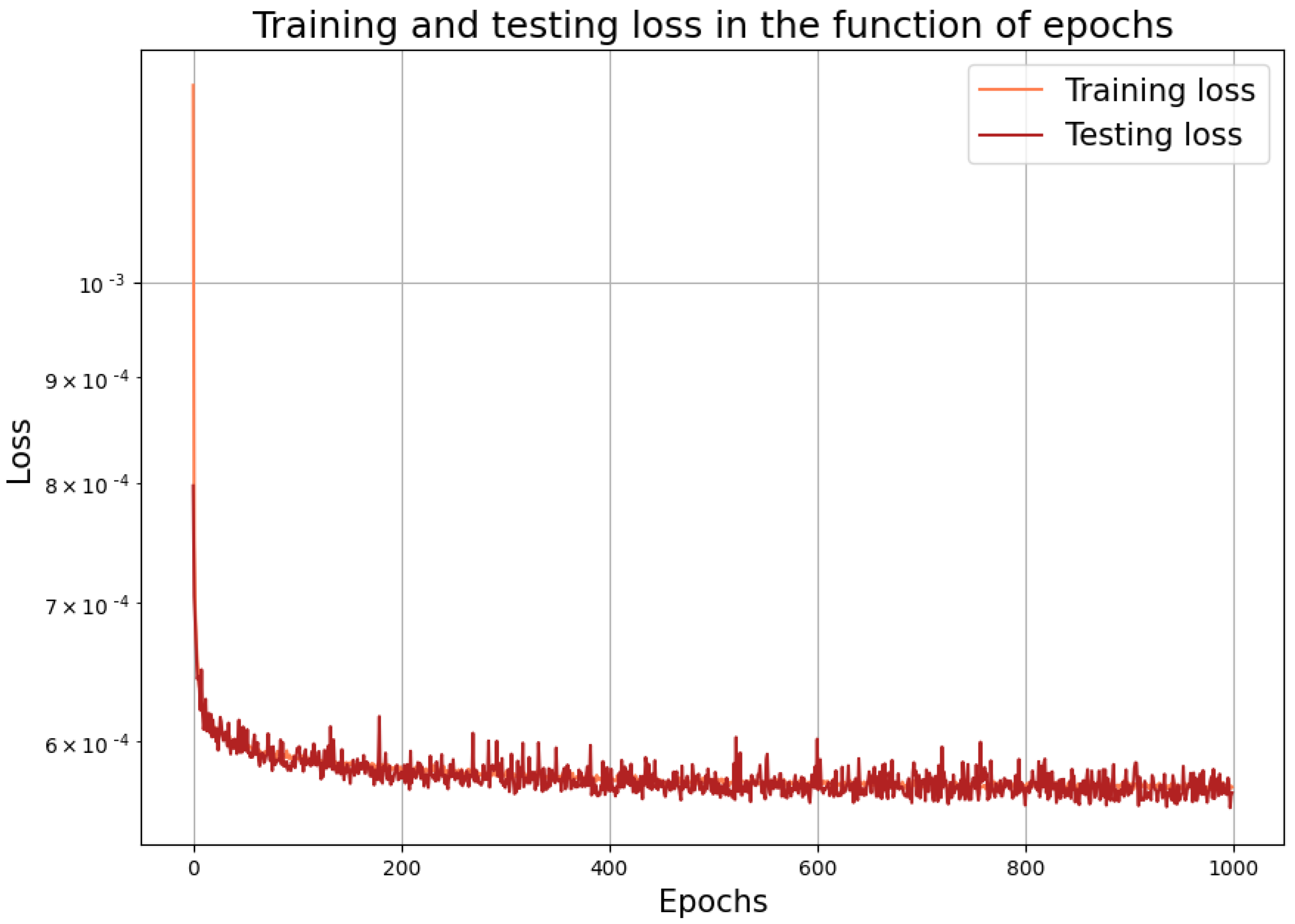
To reduce the computational costs, we have more options. For this, in any case, we should reduce the number of parameters in the neural network. The simplest option is to apply an additional dropout procedure. This, however, really harms the accuracy of the approximation. We can guess this: for solving the Dirichlet-to-Neumann problems, we need dense matrices, where we cannot just change some elements to be zero. Instead, a more sophisticated strategy is to try to use more sparse layers instead of the original one dense layer. As a realistic choice, one could use, e.g., some locally connected ones. At the matrix level, this means that the original dense matrix can be well approximated with the product of some sparse ones. To mimic this, we incorporated 1, 2, 3, 4, and 5 locally connected hidden layers with kernel sizes 3, 4, and 5. This strategy, however, still did not lead to a better performance: one try is shown in
Figure 3.
Therefore, in the forthcoming simulations, we use a densely connected input–output layer pair. At the end, we return back to this problem and try another strategy to reduce the number of parameters.
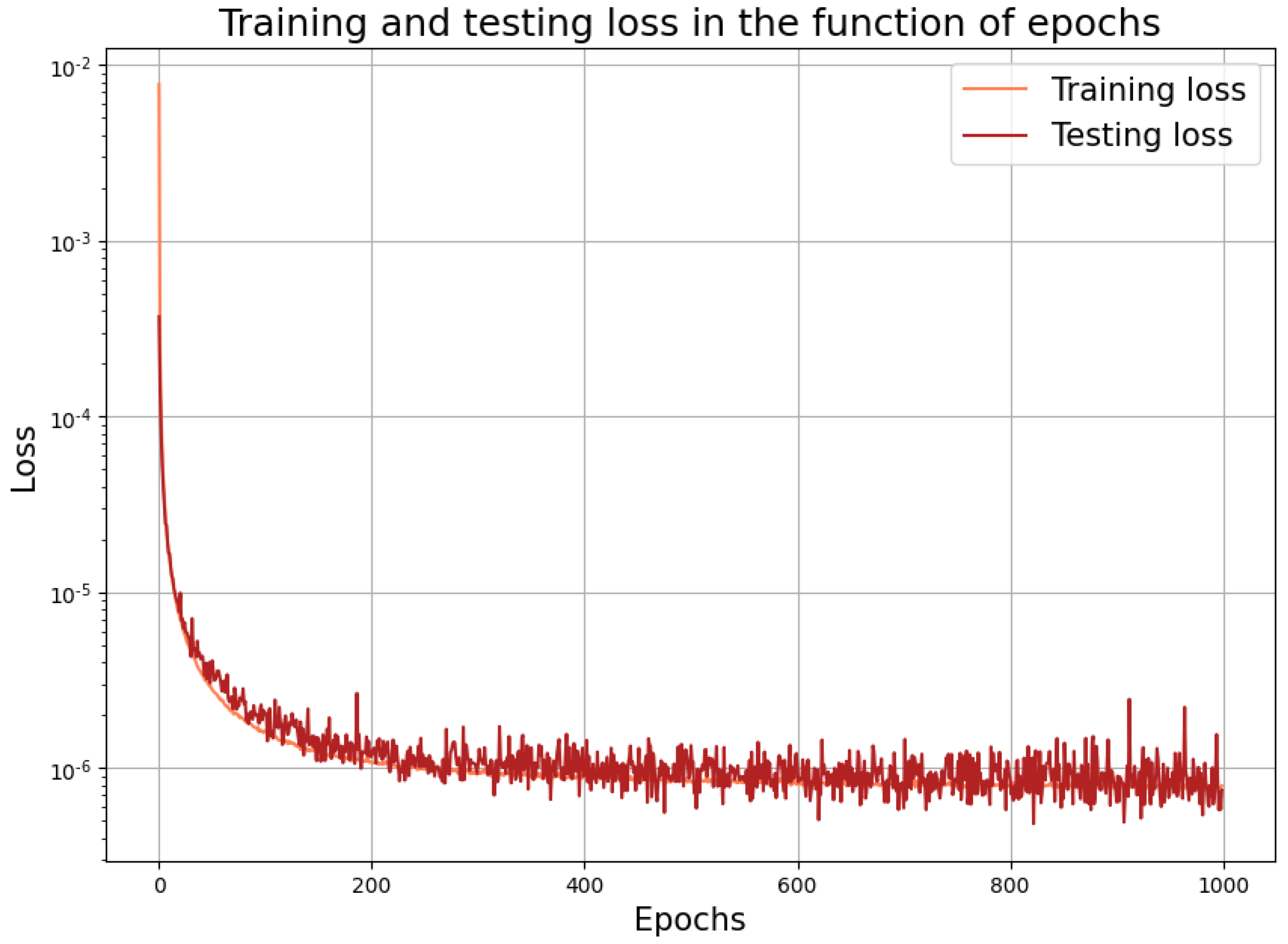
In the course of the second approach, using
, we have to predict only the point values
according to the third point of our algorithm. We used the same setup as given above with
, and the corresponding learning performance is depicted in
Figure 4. This prediction is quite accurate, as suggested by the low loss value here.
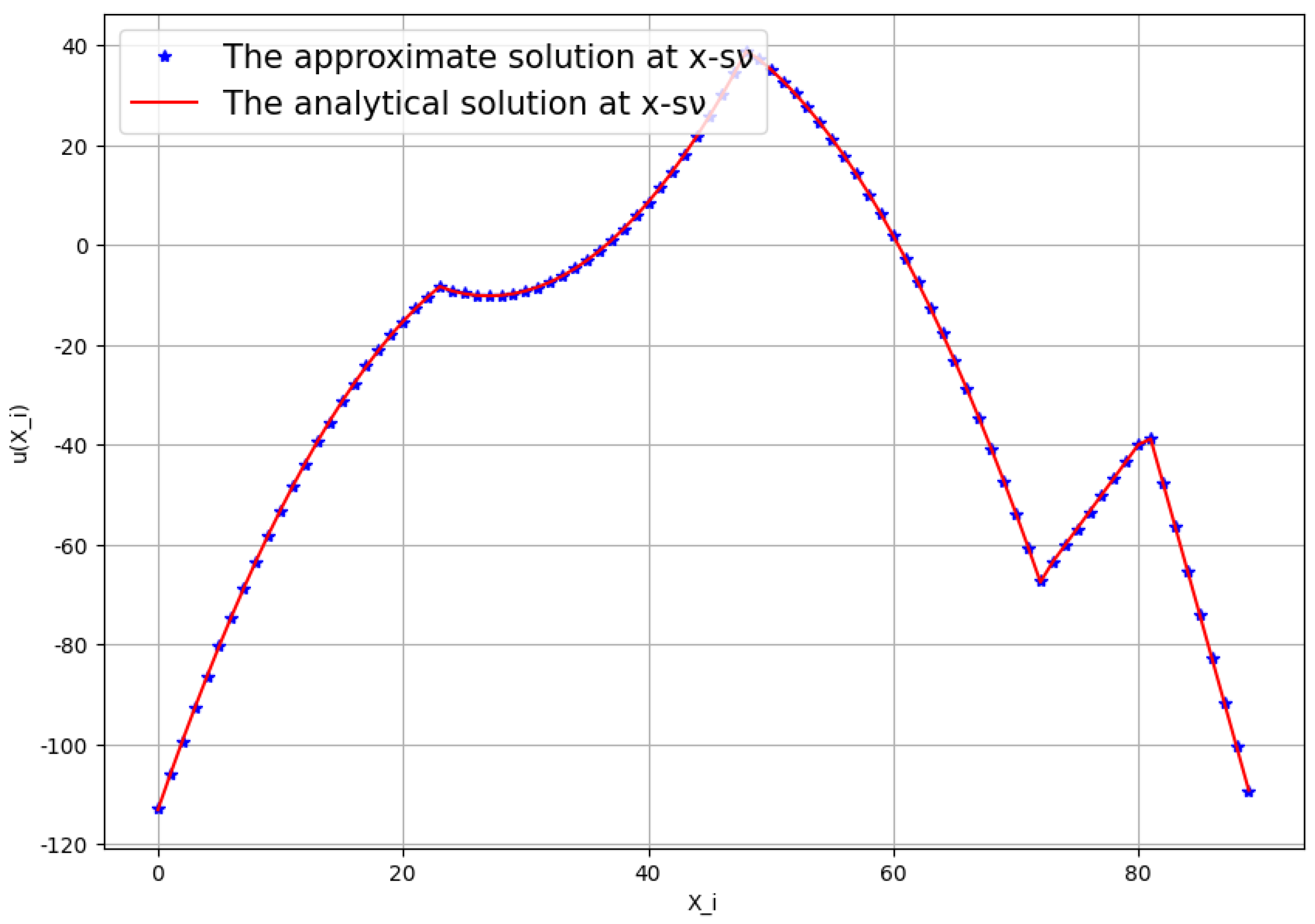
To test the performance of the prediction, we took a model problem with the analytic solution
. The trained neural network was applied for the boundary values of this function. We first confirmed the accuracy of the predicted point values corresponding to
Figure 4. The results, which are shown in
Figure 5, are convincing.
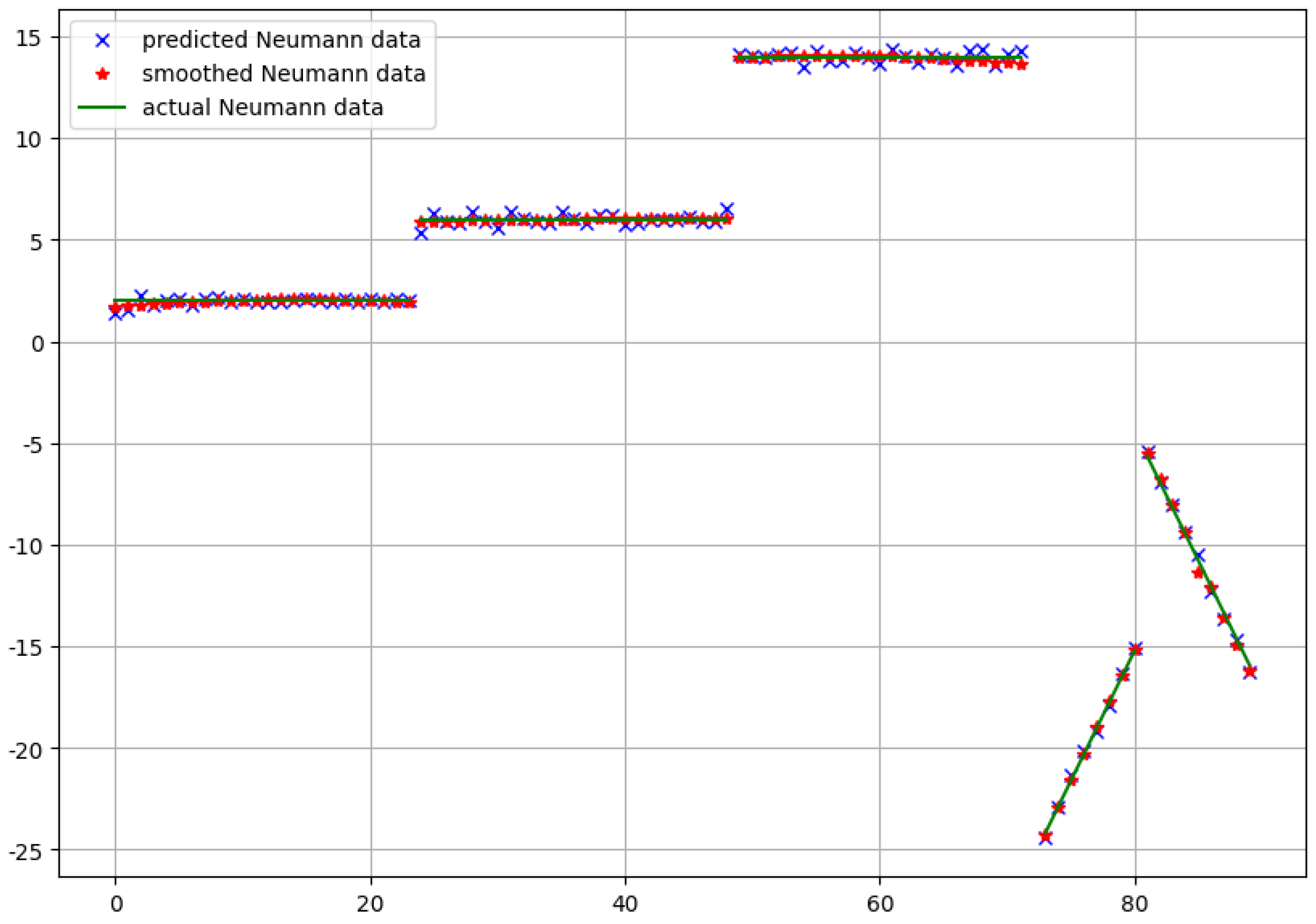
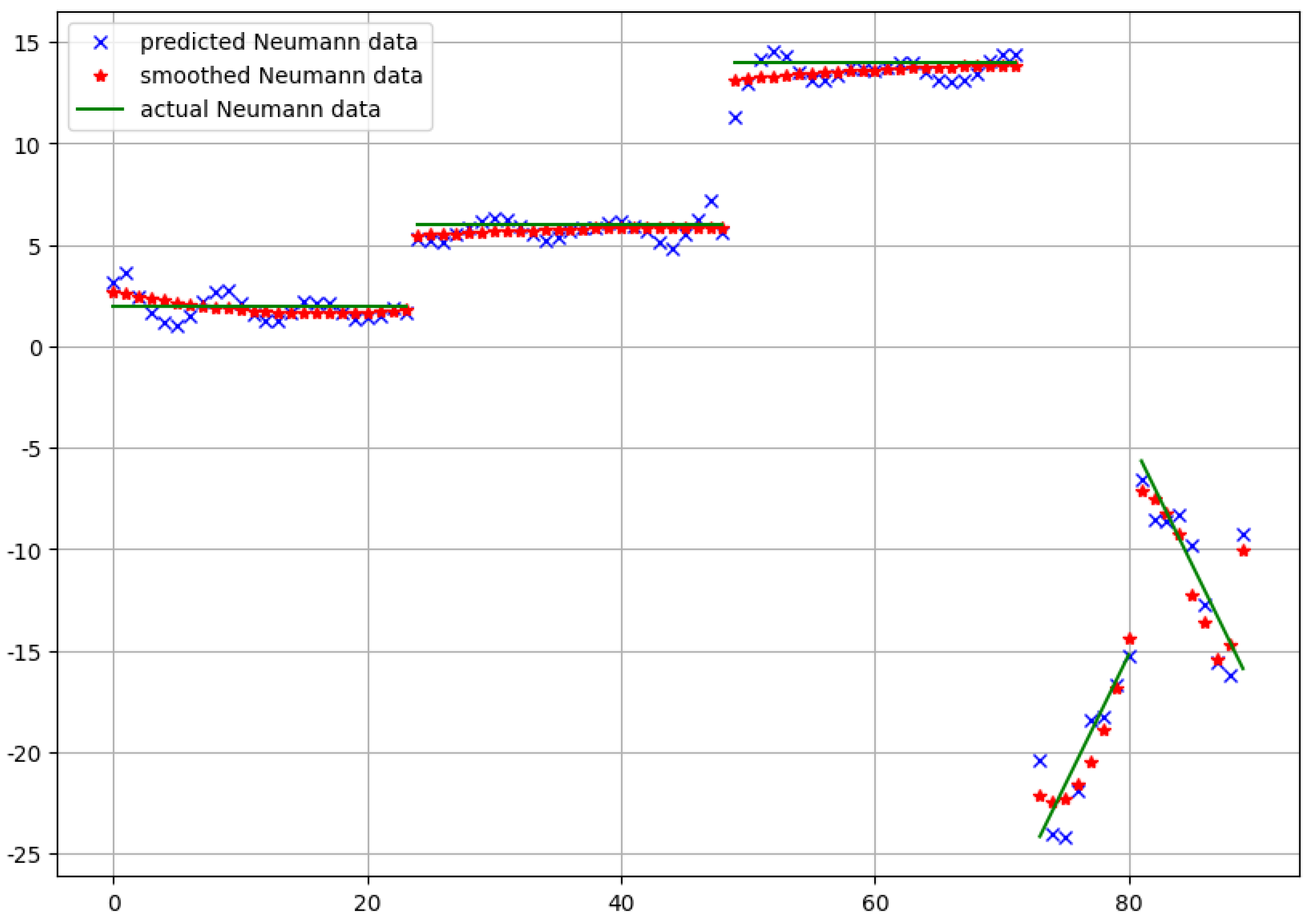
For this test problem, we also performed a comparison between the predicted Neumann data and the real ones given with
. Since our domain has sharp non-convex corners with discontinuous outward normals, our approximation still needs some postprocessing. Accordingly, a kind of piecewise smoothing should be performed. For this purpose, in each case, we applied the Savitzky–Golay filter [
17] with the polynomial degree 3.
The results in the case of the first and the second approach are depicted in
Figure 6 and
Figure 7, respectively. Both the predicted raw data and the smoothed version are shown in the figures.
Until now, our best neural-network-based approach has delivered a full matrix. This corresponds to a linear function transforming the Dirichlet boundary data into the Neumann data. Whenever, in practice, this really completely describes the conductivity properties of the domain , it contains a huge number of parameters. In the case of inverse problems, e.g., for EIT, we need these parameters as the input data. Therefore, to reduce the computational complexity of these problems, it would be highly desirable to reduce the number of parameters.
In other words, we should try to reduce the dimension of the data without a significant loss in the accuracy of our approximation of the Dirichlet-to-Neumann problem. This motivated us to perform also low-rank approximations. In practice, we can easily implement it in the framework of the neural networks. We only have to insert an extra layer of length L between the input and output layers. Of course, we need a dense layer for minimizing the loss of information. In this case, the neural network corresponds to a product of matrices of size and , which altogether resulted again in a matrix of size . At the same time, whenever it is dense, its rank is only L and is automatically decomposed as a product of the above matrices.
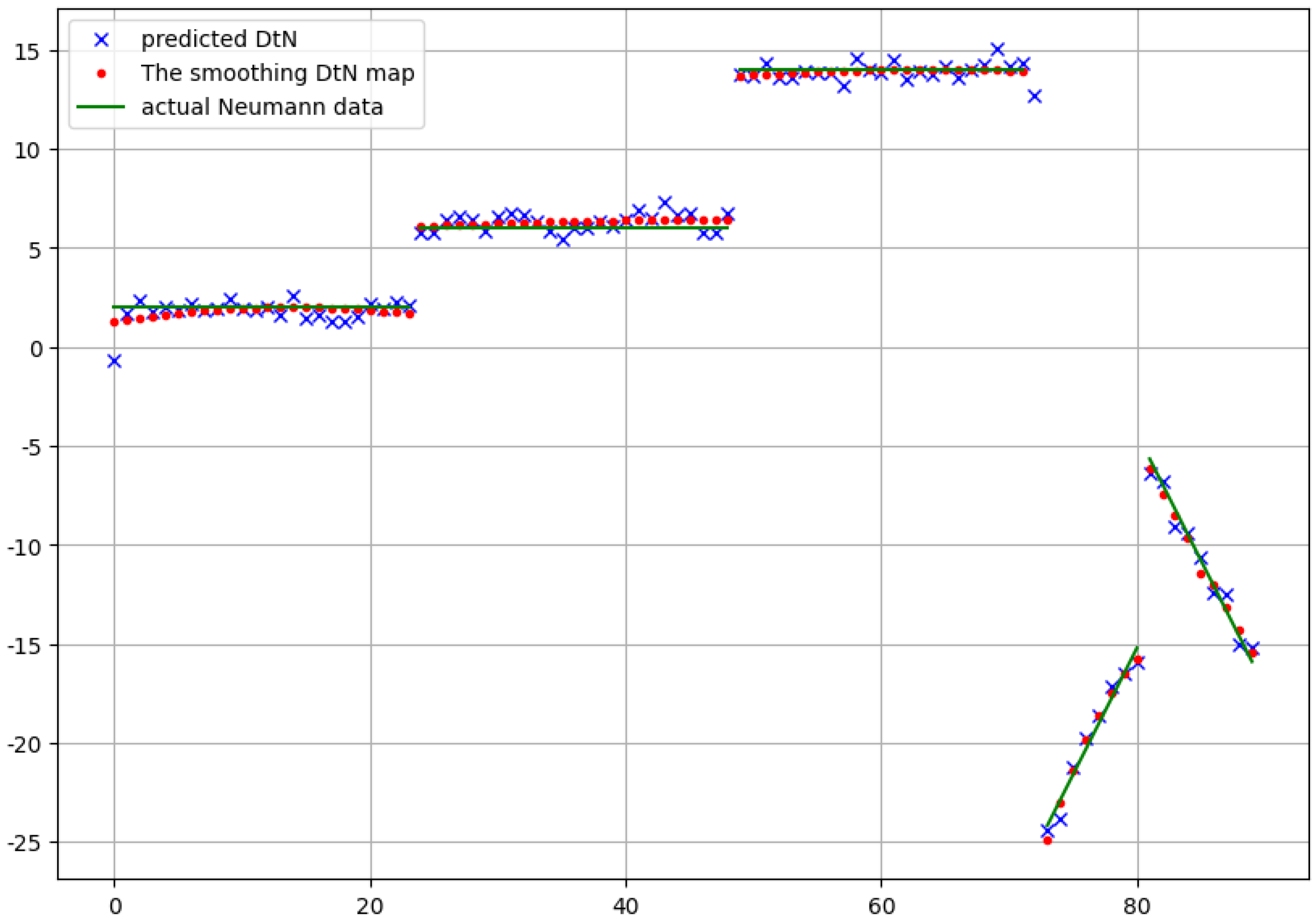
In the simulations, we tried more values
L to be the size of the intermediate layer. For example, taking
with
resulted in
parameters. Accordingly, the number of parameters was only 47 percent of the original number. Here, as we can observe in
Figure 8, the learning process became faster. After some tens of epochs, the loss did not decrease any more significantly. At the same time, due to the relatively small number of parameters, we did not obtain a low loss value compared to the original model. Nevertheless, looking at the approximation of the final Neumann data in
Figure 9, nearly the same accuracy was obtained as those in
Figure 6 and
Figure 7.
3.1. Extension to Poisson Problems
The above technique can also be extended to the case of the Poisson equation:
where, in addition to (
2), we have a given source function
. We also assumed that this has an extension to a differentiable function:
We applied here a lifting, by taking first
which, using the assumptions on
, implies
In this way, using (
7),
satisfies the following Laplace equation:
Computing an approximation of the Dirichlet-to-Neumann map for (
8), we obtain
. In this way, adding the known term
to this, we finally obtain the desired Neumann data
.
Using Approach 1, this is given formally in the following steps.
- (i)
Compute the Dirichlet data:
and similarly,
- (ii)
Apply the trained ANN with the input .
- (iii)
Add the term to the output of the ANN, to have an approximation of .
3.2. Experimental Error Analysis
We performed a quantitative evaluation of the proposed algorithms using the above simulation results.
We begin with the experimental analysis of the first approach. The computational error between the smoothed Neumann data and the real Neumann data is displayed in a number of cases in
Table 1. We applied a series of uniform discretizations of the boundary consisting of
N points. For each case, two different numbers
K of learning data were applied. This should be larger than the number of parameters, which is also shown. The first series corresponds to
Figure 6, where
and K = 10,125. In the second series, the performance of the low-rank approximation was evaluated. Here, one intermediate dense layer was also inserted. The related number of parameters is shown in the third column. The line with K = 10,125 and
corresponds to
Figure 9.
In the case of the second approach, we used the same parameters in the computation. At the same time, corresponding to
Figure 5, we also evaluated the pointwise error in the interior points. Recall that, here, no smoothing is necessary. In the last two columns, again, the computational error between the smoothed Neumann data and the real Neumann data is displayed. This corresponds to
Figure 7. The results in the case of the low-rank approximation are also shown. See the details in
Table 2.
4. Discussion and Conclusions
The mathematical basis of our approach was the approximation property of the shifted fundamental solutions of the free-space Laplacian operator. Our linear ANN-based approach can be considered as an extension of the classical MFS in the following sense:
The ANN approach delivers an automatic way to obtain linear mappings
also with different input values. This is the case if, in an implicit discretization of time-dependent problems, more Laplacian problems have to be solved on the same domain.
We were faced with such a computational task in the implicit time discretization of problems containing the Laplacian operators:
The optimal linear combination of the fundamental solution was found using a stochastic optimization method, which, for a large number of unknowns, can result in an efficient approach.
The ANN-based approach also confirmed that an accurate discretization of the Dirichlet-to-Neumann map should consist of a dense matrix. At the same time, using our approach, its rank can be reduced without a significant increase in the computational error.
Using the first approach, the low-rank case can deliver the same accuracy using a reduced number of parameters. The same applies to the pointwise values, which can be approximated accurately using our ANN-based approach. At the same time, the Neumann data should be approximated rather immediately using the first approach.
We finally note that, recently, a number of promising new ANN-based approaches have been developed for solving PDEs numerically. For recent reviews on this topic, see, e.g., [
8,
18].















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}