



Multiprocessor Fair Scheduling Based on an Improved Slime Mold Algorithm


Abstract
:1. Introduction
- A reverse learning initialization population strategy based on Bernoulli chaotic mapping is introduced to increase the diversity of populations.
- Cauchy mutations are introduced to help slime mold populations jump out of a local optimal solution.
- A nonlinear dynamic boundary improvement strategy is introduced to accelerate the convergence rate of the population.
- The IMSMA is applied to solving the fair scheduling problem on multiprocessors to minimize the average processing time on each processor.
2. Related Work
3. Standard Slime Mold Algorithm (SMA)
4. Improved Slime Mold Algorithm (IMSMA)
4.1. Population Initialization Strategy Based on Bernoulli Mapping and Reverse Learning
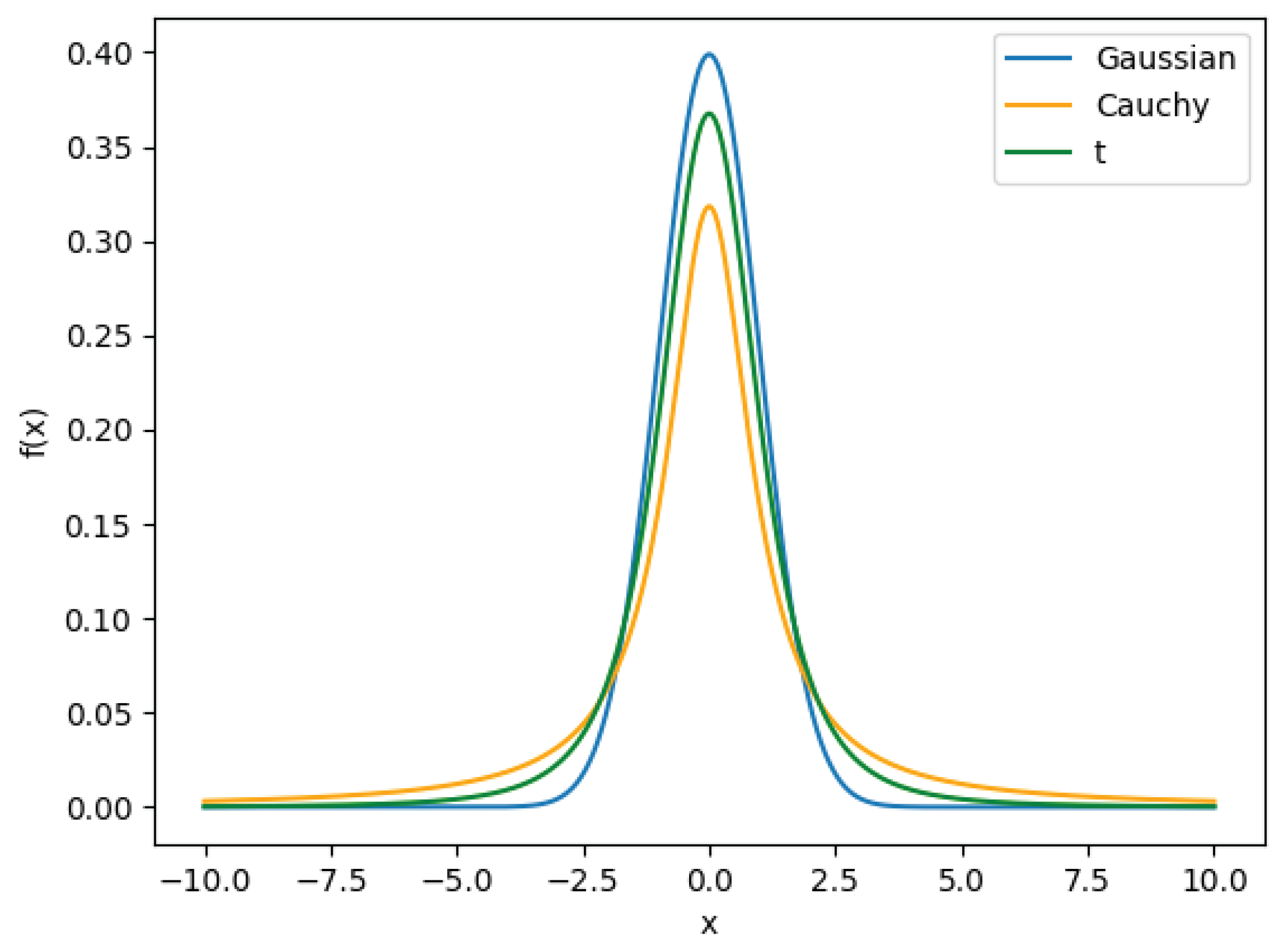
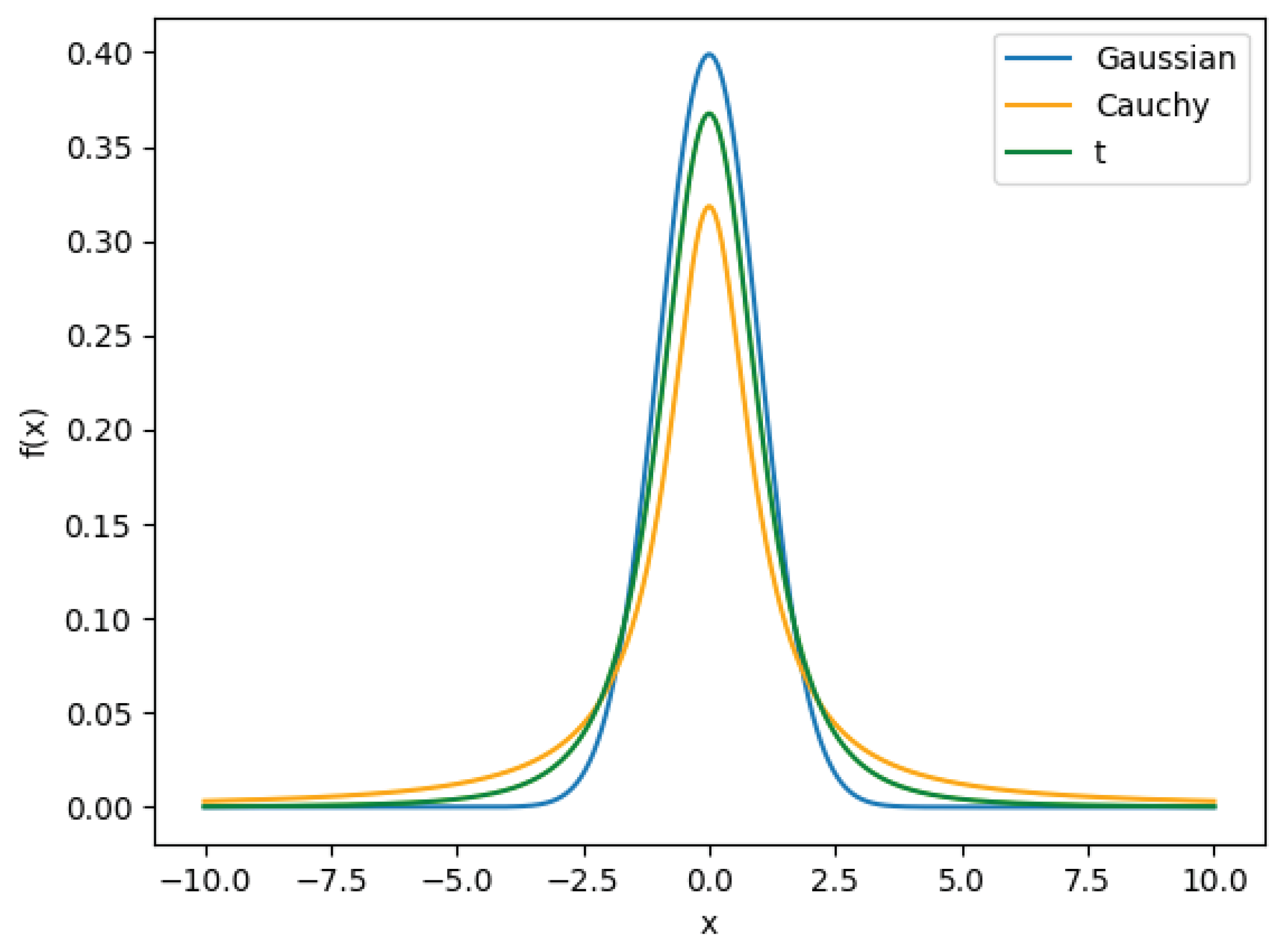
4.2. Cauchy Mutation Strategy for Escaping Local Optima
4.3. Nonlinear Dynamic Boundary Conditions
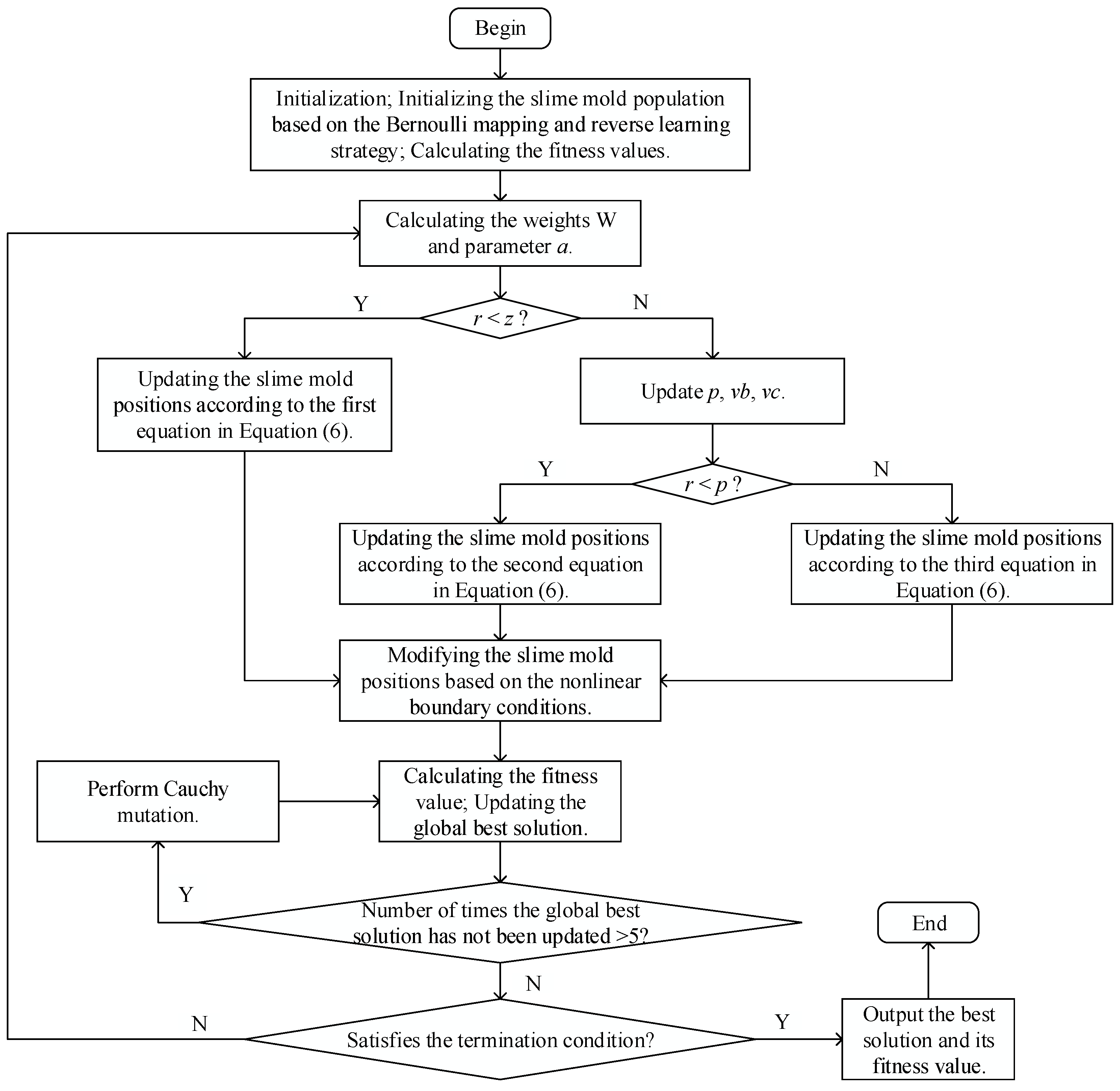
4.4. IMSMA Flowchart and Pseudocode
- Step 1.
- Initialization: T, , slime mold population N, z, , .
- Step 2.
- Based on the Bernoulli mapping reverse learning strategy, initialize the positions of the slime mold population. Do the fitness calculations and rank them in order to find the best fitness value and the poorest fitness value .
- Step 3.
- Calculate the values of the weight W and the parameter a.
- Step 4.
- If rand < z: on the basis of the first equation in Equation (6), adjust the locations of the slime molds; go to step 6.
- Step 5.
- If r < p: on the basis of the second equation in Equation (6), adjust the locations of the slime molds; go to step 6.
- Step 6.
- Revise the locations of the slime molds based on the nonlinear dynamic boundary conditions. Update the global optimal solution after calculating the fitness values.
- Step 7.
- If the global best solution has not changed more than five times, perform a Cauchy mutation on the positions of the slime molds; go to step 6.
- Step 8.
- If the termination condition is not satisfied, go to step 3.
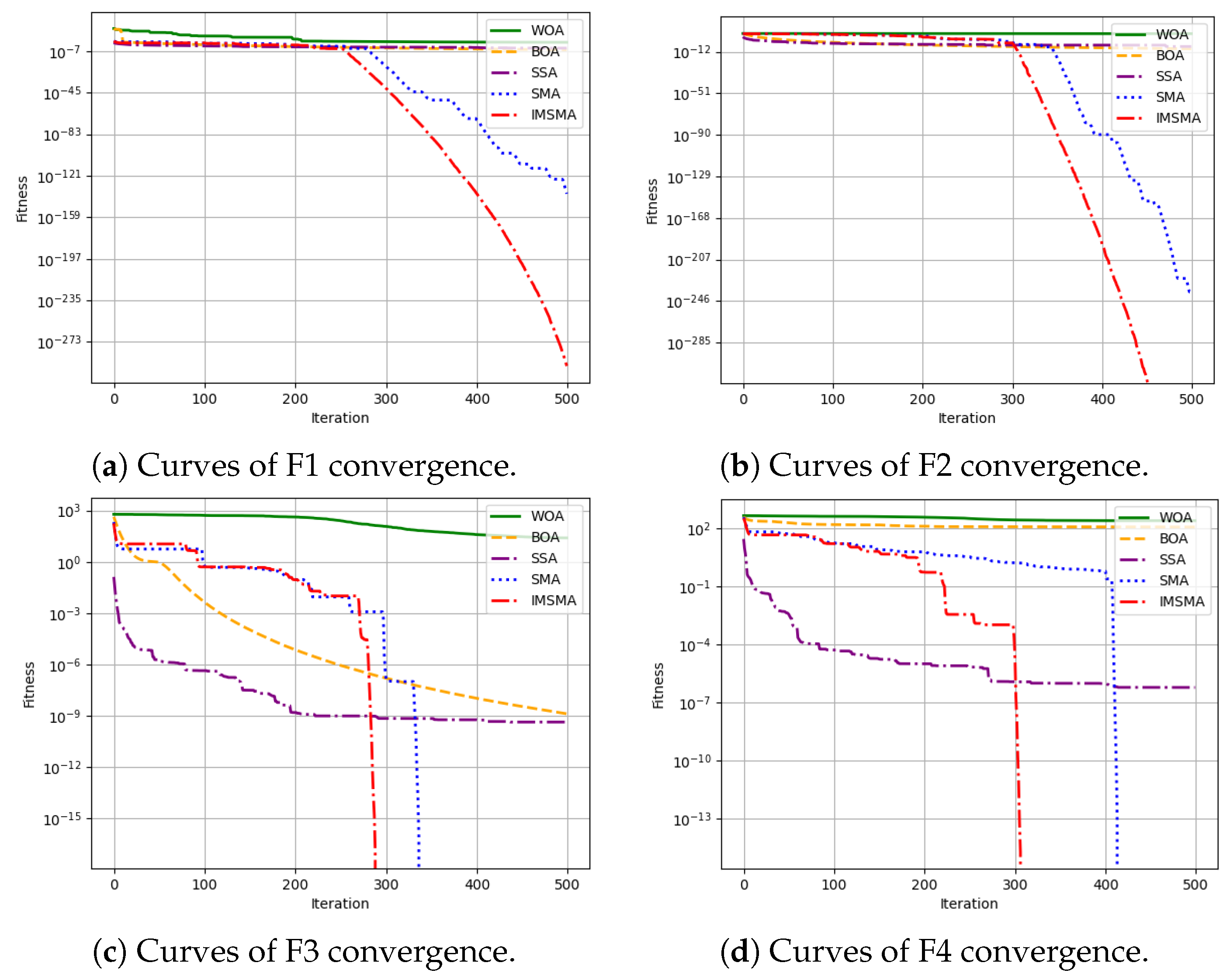
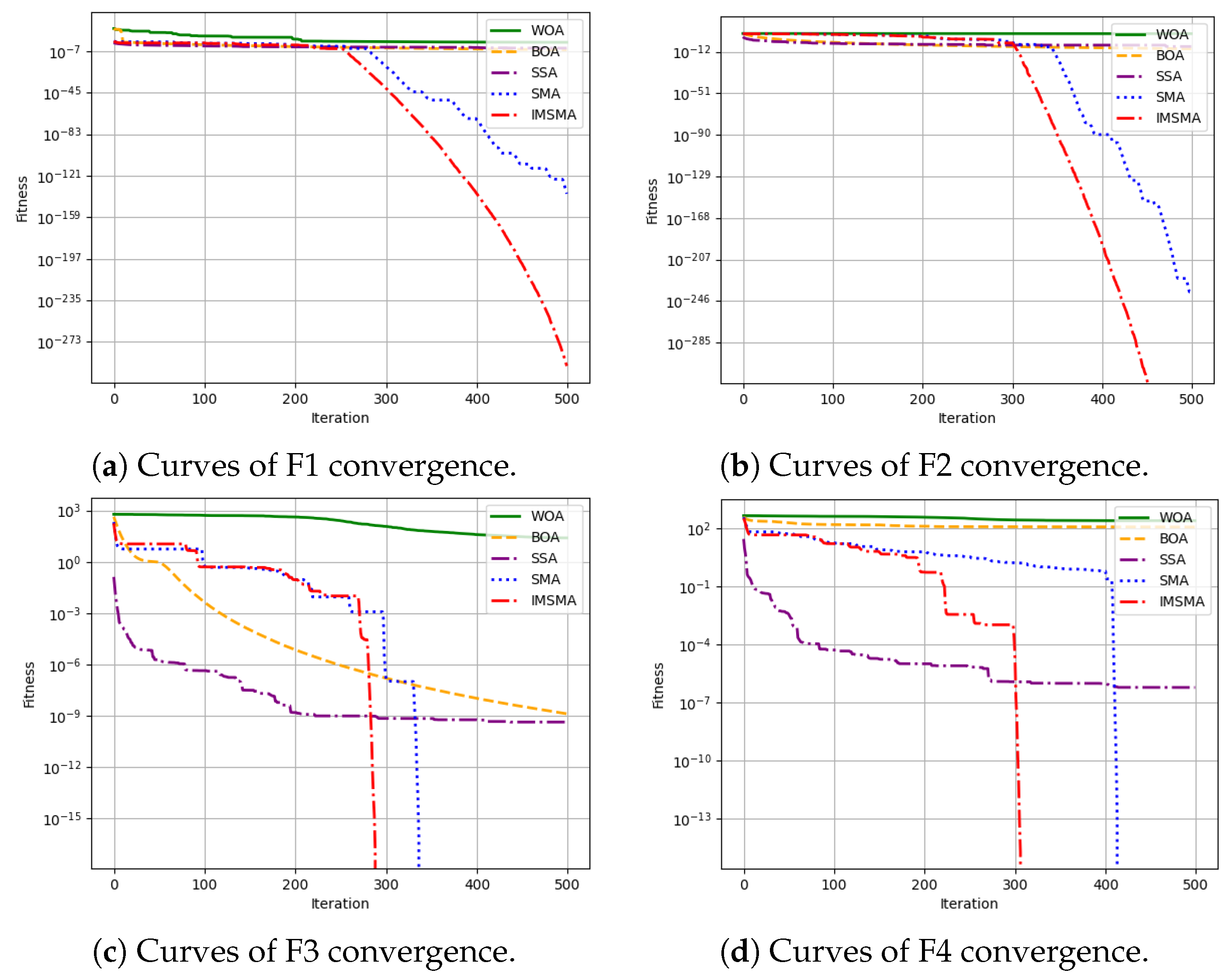
5. Performance Testing and Analysis of the Improved Slime Mold Algorithm
6. Solving Multiprocessor Fair Scheduling Problem with IMSMA
6.1. Establishment of the Multiprocessor Fair Scheduling Problem Model
6.2. Description of Multiprocessor Fair Scheduling Algorithm Based on IMSMA
- Step 1.
- Initialization: T, , slime mold population N, z, , , n, m.
- Step 2.
- Based on the Bernoulli mapping reverse learning strategy, initialize the positions of the slime mold population.
- Step 3.
- Input the objective function for multiprocessor fair scheduling. Calculate the fitness values and sort them to obtain the greatest fitness value and the poorest fitness value .
- Step 4.
- Calculate the values of the weight W and the parameter a.
- Step 5.
- If rand < z: on the basis of the first equation in Equation (6), adjust the locations of the slime molds; go to step 7.
- Step 6.
- If r < p: on the basis of the second equation in Equation (6), adjust the locations of the slime molds; go to step 7.
- Step 7.
- Revise the locations of the slime molds based on the nonlinear dynamic boundary conditions. Update the global optimal solution after calculating the fitness values.
- Step 8.
- If the global best solution has not been changed more than five times, perform Cauchy mutation on the positions of the slime molds; go to step 7.
- Step 9.
- If the termination condition is not satisfied, go to step 4;
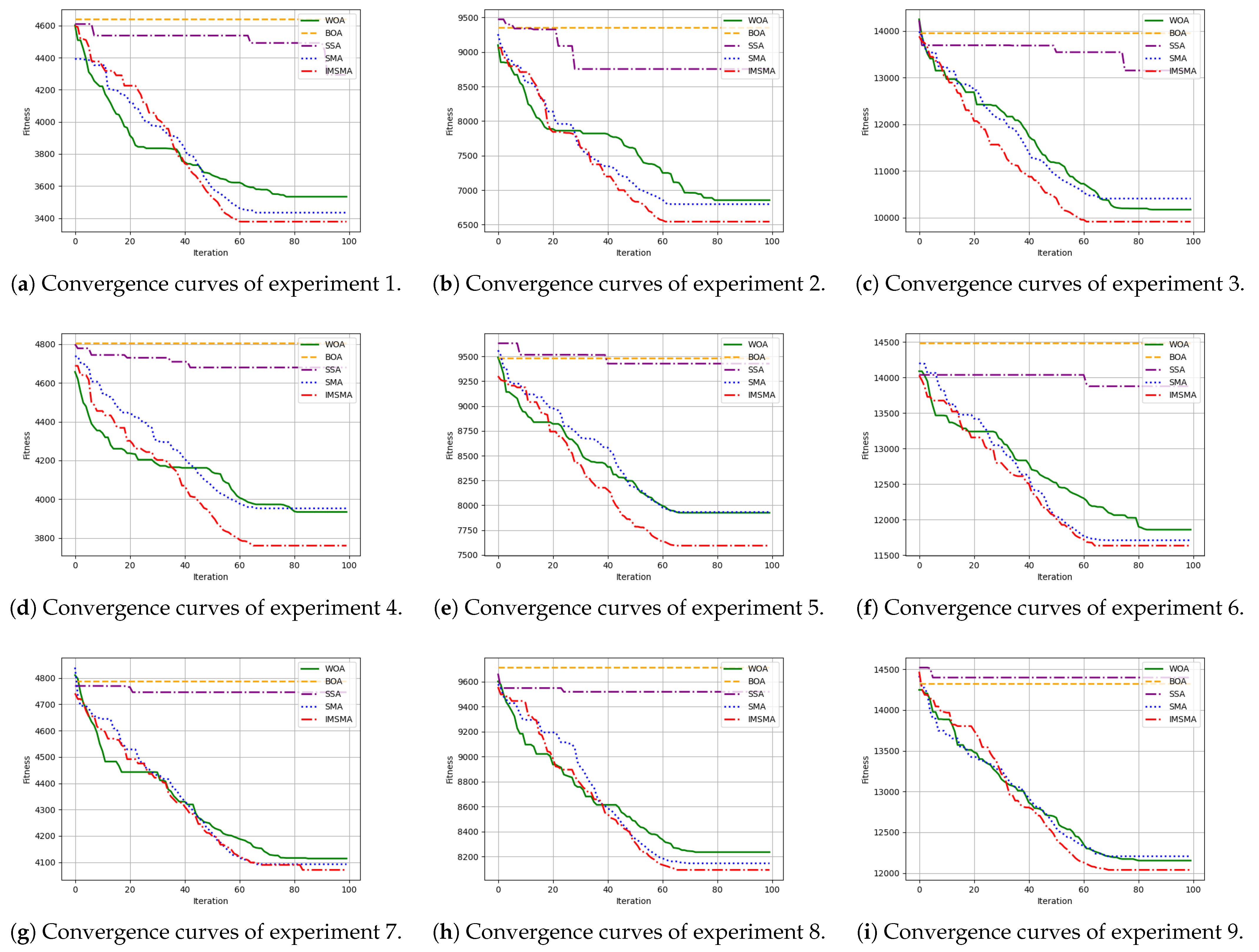
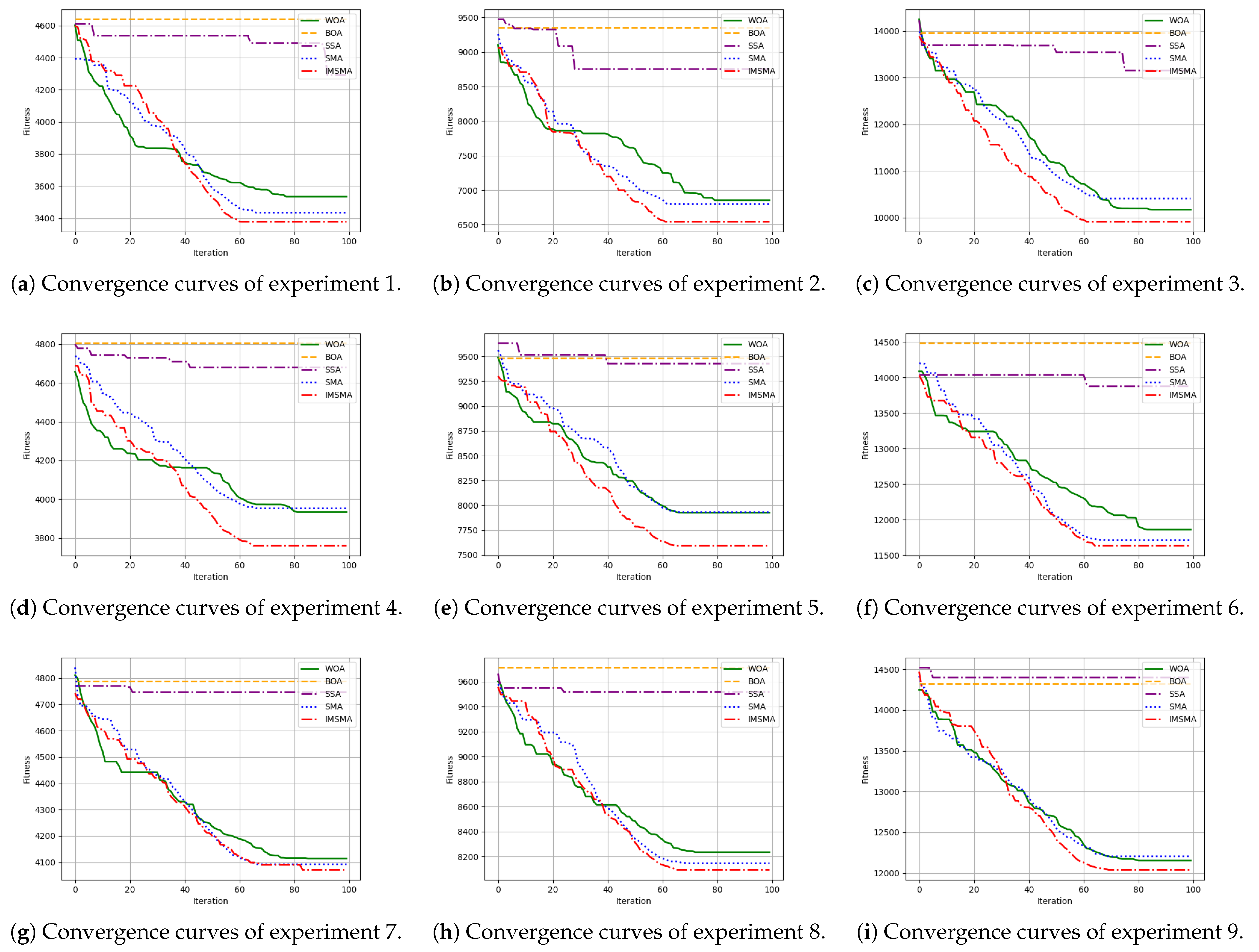
7. Numerical Experiment
8. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Agarwal, G.; Gupta, S.; Ahuja, R.; Rai, A.K. Multiprocessor task scheduling using multi-objective hybrid genetic Algorithm in Fog–cloud computing. Knowl.-Based Syst. 2023, 272, 110563. [Google Scholar]
- Tang, Q.; Zhu, L.H.; Zhou, L.; Xiong, J.; Wei, J.B. Scheduling directed acyclic graphs with optimal duplication strategy on homogeneous multiprocessor systems. J. Parallel Distrib. Comput. 2020, 138, 115–127. [Google Scholar]
- Fagin, R.; Williams, J.H. A fair carpool scheduling algorithm. IBM J. Res. Dev. 1983, 27, 133–139. [Google Scholar]
- Alhussian, H.; Zakaria, N.; Hussin, F.A. An efficient real-time multiprocessor scheduling algorithm. J. Converg. Inf. Technol. 2014, 9, 136. [Google Scholar]
- Li, T.; Baumberger, D.; Hahn, S. Efficient and scalable multiprocessor fair scheduling using distributed weighted round-robin. ACM Sigplan Not. 2009, 44, 65–74. [Google Scholar]
- Nair, P.P.; Sarkar, A.; Biswas, S. Fault-tolerant real-time fair scheduling on multiprocessor systems with cold-standby. IEEE Trans. Dependable Secur. Comput. 2019, 18, 1718–1732. [Google Scholar]
- Li, Z.; Bai, Y.; Liu, J.; Chen, J.; Chang, Z. Adaptive proportional fair scheduling with global-fairness. Wirel. Netw. 2019, 25, 5011–5025. [Google Scholar]
- Wei, D.; Wang, Z.; Si, L.; Tan, C. Preaching-inspired swarm intelligence algorithm and its applications. Knowl.-Based Syst. 2021, 211, 106552. [Google Scholar]
- Hou, J.; Liu, Z.; Wang, S.; Chen, Z.; Han, J.; Xie, W.; Fang, C.; Liu, J. Intelligent coordinated damping control in active distribution network based on PSO. Energy Rep. 2022, 8, 1302–1312. [Google Scholar]
- Nasiri, J.; Khiyabani, F.M. A whale optimization algorithm (WOA) approach for clustering. Cogent Math. Stat. 2018, 5, 1483565. [Google Scholar]
- Xue, J.; Shen, B. A novel swarm intelligence optimization approach: Sparrow search algorithm. Syst. Sci. Control Eng. 2020, 8, 22–34. [Google Scholar] [CrossRef]
- Arora, S.; Singh, S. Butterfly optimization algorithm: A novel approach for global optimization. Soft Comput. 2019, 23, 715–734. [Google Scholar]
- Dong, M.; Hu, J.; Yang, J.; Song, D.; Wan, J. Jiyu gaijin nianjun youhua shuanfa de guangfu duofeng MPPT kongzhi celue [Multi-peak MPPT Control Strategy for Photovoltaic Systems Based on Improved Slime Mould Optimization Algorithm]. Control Theory Appl. 2023, 40, 1440–1448. (In Chinese) [Google Scholar]
- Premkumar, M.; Jangir, P.; Sowmya, R.; Alhelou, H.H.; Heidari, A.A.; Chen, H. MOSMA: Multi-objective slime mould algorithm based on elitist non-dominated sorting. IEEE Access 2020, 9, 3229–3248. [Google Scholar] [CrossRef]
- Al-Qaness, M.A.; Ewees, A.A.; Fan, H.; Abualigah, L.; Abd Elaziz, M. Marine predators algorithm for forecasting confirmed cases of COVID-19 in Italy, USA, Iran and Korea. Int. J. Environ. Res. Public Health 2020, 17, 3520. [Google Scholar]
- Li, S.; Chen, H.; Wang, M.; Heidari, A.A.; Mirjalili, S. Slime mould algorithm: A new method for stochastic optimization. Future Gener. Comput. Syst. 2020, 111, 300–323. [Google Scholar]
- Gong, X.; Rong, Z.; Wang, J.; Zhang, K.; Yang, S. A hybrid algorithm based on state-adaptive slime mold model and fractional-order ant system for the travelling salesman problem. Complex Intell. Syst. 2023, 9, 3951–3970. [Google Scholar]
- Chen, H.; Li, X.; Li, S.; Zhao, Y.; Dong, J. Improved slime mould algorithm hybridizing chaotic maps and differential evolution strategy for global optimization. IEEE Access 2022, 10, 66811–66830. [Google Scholar]
- Abdel-Basset, M.; Chang, V.; Mohamed, R. HSMA_WOA: A hybrid novel Slime mould algorithm with whale optimization algorithm for tackling the image segmentation problem of chest X-ray images. Appl. Soft Comput. 2020, 95, 106642. [Google Scholar]
- Gush, T.; Kim, C.H.; Admasie, S.; Kim, J.S.; Song, J.S. Optimal Smart Inverter Control for PV and BESS to Improve PV Hosting Capacity of Distribution Networks Using Slime Mould Algorithm. IEEE Access 2021, 9, 52164–52176. [Google Scholar] [CrossRef]
- Vakilian, A.; Yalciner, M. Improved approximation algorithms for individually fair clustering. Proc. Mach. Learn. Res. 2022, 151, 8758–8779. [Google Scholar]
- Zhong, J.H.; Peng, Z.P.; Li, Q.R.; He, J.G. Multi workflow fair scheduling scheme research based on reinforcement learning. Procedia Comput. Sci. 2019, 154, 117–123. [Google Scholar]
- Xiao, Z.; Chen, L.; Wang, B.; Du, J.; Li, K. Novel fairness-aware co-scheduling for shared cache contention game on chip multiprocessors. Inf. Sci. 2020, 526, 68–85. [Google Scholar]
- Salami, B.; Noori, H.; Naghibzadeh, M. Fairness-aware energy efficient scheduling on heterogeneous multi-core processors. IEEE Trans. Comput. 2020, 70, 72–82. [Google Scholar]
- Mohtasham, A.; Filipe, R.; Barreto, J. FRAME: Fair resource allocation in multi-process environments. In Proceedings of the 2015 IEEE 21st International Conference on Parallel and Distributed Systems (ICPADS), Melbourne, Australia, 14–17 December 2015; pp. 601–608. [Google Scholar]
- Jung, J.; Shin, J.; Hong, J.; Lee, J.; Kuo, T.W. A fair scheduling algorithm for multiprocessor systems using a task satisfaction index. In Proceedings of the International Conference on Research in Adaptive and Convergent Systems, Kraków, Poland, 20–23 September 2017; pp. 269–274. [Google Scholar]
- Kanwal, S.; Inam, S.; Othman, M.T.B.; Waqar, A.; Ibrahim, M.; Nawaz, F.; Nawaz, Z.; Hamam, H. An Effective Color Image Encryption Based on Henon Map, Tent Chaotic Map, and Orthogonal Matrices. Sensors 2022, 22, 4359. [Google Scholar] [CrossRef]
- Zhang, C.; Ding, S. A stochastic configuration network based on chaotic sparrow search algorithm. Knowl.-Based Syst. 2021, 220, 106924. [Google Scholar]
- Yang, C.; Pan, P.; Ding, Q. Image encryption scheme based on mixed chaotic bernoulli measurement matrix block compressive sensing. Entropy 2022, 24, 273. [Google Scholar] [CrossRef]
- He, J.; Guo, X.; Chen, H.; Chai, F.; Liu, S.; Zhang, H.; Zang, W.; Wang, S. Application of HSMAAOA Algorithm in Flood Control Optimal Operation of Reservoir Groups. Sustainability 2023, 15, 933. [Google Scholar]
- Tizhoosh, H.R. Opposition-based learning: A new scheme for machine intelligence. In Proceedings of the International Conference on Computational Intelligence for Modelling, Control and Automation and International Conference on Intelligent Agents, Web Technologies and Internet Commerce (CIMCA-IAWTIC’06), Vienna, Austria, 28–30 November 2005; Volume 1, pp. 695–701. [Google Scholar]
- Yu, H.; Song, J.; Chen, C.; Heidari, A.A.; Liu, J.; Chen, H.; Zaguia, A.; Mafarja, M. Image segmentation of Leaf Spot Diseases on Maize using multi-stage Cauchy-enabled grey wolf algorithm. Eng. Appl. Artif. Intell. 2022, 109, 104653. [Google Scholar]
- Zhang, X.; Liu, Q.; Bai, X. Improved slime mould algorithm based on hybrid strategy optimization of Cauchy mutation and simulated annealing. PLoS ONE 2023, 18, e0280512. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Zhong et al. [22] | To optimize the scheduling order for multiple workflow tasks, they designed a reinforcement learning-based fair scheduling algorithm for multiworkflow tasks. | The authors created an evolving priority-driven method to avoid service level agreement violations through dynamic scheduling. Additionally, they implemented load balancing between virtual machines using a reinforcement learning algorithm. |
| Xiao et al. [23] | They proposed a fairness-aware thread collaborative scheduling algorithm based on uncooperative game theory, and the on-chip multiprocessor cache congestion problem was addressed. | The authors aimed to enhance the overall system performance by fairly scheduling threads. They employed an uncooperative game approach to address the thread collaborative schedule problem and introduced an iterative algorithm for finding the Nash equilibrium in non-cooperative games. This allowed them to obtain a collaborative scheduling solution for all threads. |
| Salami et al. [24] | Specifically addressing the different multicore processors’ fair energy-effective schedule dilemma, they proposed an energy-efficient framework that took into account fairness in a heterogeneous context. | Dynamic voltage and frequency scaling was used in the authors’ suggested energy-effective framework with a heterogeneous fairness awareness in order to satisfy fairness restrictions and offer an efficient energy-effective schedule. In comparison to the Linux regular scheduler, experimental results showed a significant improvement in both efficiency of energy and fairness. |
| Mohtasham et al. [25] | The authors proposed a fair distribution of resources method for a multiprocess context aimed at maximizing overall system utility and fairness. | The allocation of resources issue was first formalized as an NP-hard issue. Then, in pseudo-polynomial time, they employed approximation strategies and the convex optimization theory to identify the best answer to the posed problem. This fair resource allocation technique could run multiple scalable processes under CPU load constraints. |
| Jung et al. [26] | They proposed a multiprocessor-system fair scheduling algorithm based on task satisfaction metrics. | Their algorithm quantified and evaluated fairness using service time errors. It achieved a high proportion of fairness even under highly skewed weight distributions. |
| Function | Function Expressions | Number of Peaks | Variable Range |
|---|---|---|---|
| F1 | Unimodal | [−10, 10] | |
| F2 | Unimodal | [−100, 100] | |
| F3 | Multimodal | [−600, 600] | |
| F4 | Multimodal | [−5.12, 5.12] |
| Function | Algorithms | Average Fitness Value | Standard Deviation | Best Value | Worst Value |
|---|---|---|---|---|---|
| F1 | WOA | 8.5850 | 5.3670 | 1.3076 | 2.2033 |
| BOA | 1.2247 | 4.0456 | 3.7431 | 2.1905 | |
| SSA | 4.1472 | 0.0002 | 1.5931 | 0.0010 | |
| SMA | 3.2471 | 1.7486 | 2.9324 | 9.7413 | |
| IMSMA | 1.1214 | 0.0000 | 0.0000 | 3.3642 | |
| F2 | WOA | 9.2021 | 2.6686 | 4.9993 | 1.4113 |
| BOA | 5.5098 | 3.9426 | 4.7340 | 6.3100 | |
| SSA | 8.0274 | 3.2021 | 0.0000 | 1.7711 | |
| SMA | 5.3711 | 0.0000 | 0.0000 | 1.6113 | |
| IMSMA | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| F3 | WOA | 2.5141 | 2.5713 | 1.5288 | 1.0146 |
| BOA | 1.2962 | 2.4117 | 9.6035 | 2.0675 | |
| SSA | 4.2729 | 1.5760 | 0.0000 | 7.3477 | |
| SMA | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| IMSMA | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| F4 | WOA | 2.4084 | 8.0646 | 6.5122 | 3.4340 |
| BOA | 1.1291 | 8.6531 | 8.1465 | 2.0361 | |
| SSA | 5.8915 | 2.5701 | 0.0000 | 1.4265 | |
| SMA | 0.0000 | 0.0000 | 0.0000 | 0.0000 | |
| IMSMA | 0.0000 | 0.0000 | 0.0000 | 0.0000 |
| Number of Experiments | n | m | IMSMA | SMA | WOA | BOA | SSA |
|---|---|---|---|---|---|---|---|
| Experiment 1 | 500 | 10 | 3378 | 3434 | 3534 | 4639 | 4293 |
| Experiment 2 | 500 | 20 | 6544 | 6797 | 6854 | 9352 | 8753 |
| Experiment 3 | 500 | 30 | 9915 | 10,409 | 10,173 | 13,966 | 13,155 |
| Experiment 4 | 1000 | 10 | 3761 | 3953 | 3935 | 4804 | 4679 |
| Experiment 5 | 1000 | 20 | 7593 | 7932 | 7925 | 9483 | 9428 |
| Experiment 6 | 1000 | 30 | 11,634 | 11,709 | 11,858 | 14,483 | 13,878 |
| Experiment 7 | 1500 | 10 | 4070 | 4092 | 4114 | 4788 | 4746 |
| Experiment 8 | 1500 | 20 | 8092 | 8145 | 8235 | 9713 | 9519 |
| Experiment 9 | 1500 | 30 | 12,038 | 12,205 | 12,152 | 14,321 | 14,398 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dai, M.; Jiang, Z. Multiprocessor Fair Scheduling Based on an Improved Slime Mold Algorithm. Algorithms 2023, 16, 473. https://doi.org/10.3390/a16100473
Dai M, Jiang Z. Multiprocessor Fair Scheduling Based on an Improved Slime Mold Algorithm. Algorithms. 2023; 16(10):473. https://doi.org/10.3390/a16100473
Chicago/Turabian StyleDai, Manli, and Zhongyi Jiang. 2023. "Multiprocessor Fair Scheduling Based on an Improved Slime Mold Algorithm" Algorithms 16, no. 10: 473. https://doi.org/10.3390/a16100473
APA StyleDai, M., & Jiang, Z. (2023). Multiprocessor Fair Scheduling Based on an Improved Slime Mold Algorithm. Algorithms, 16(10), 473. https://doi.org/10.3390/a16100473