
Stochastic Local Community Detection in Networks
Abstract
1. Introduction
2. Materials and Methods
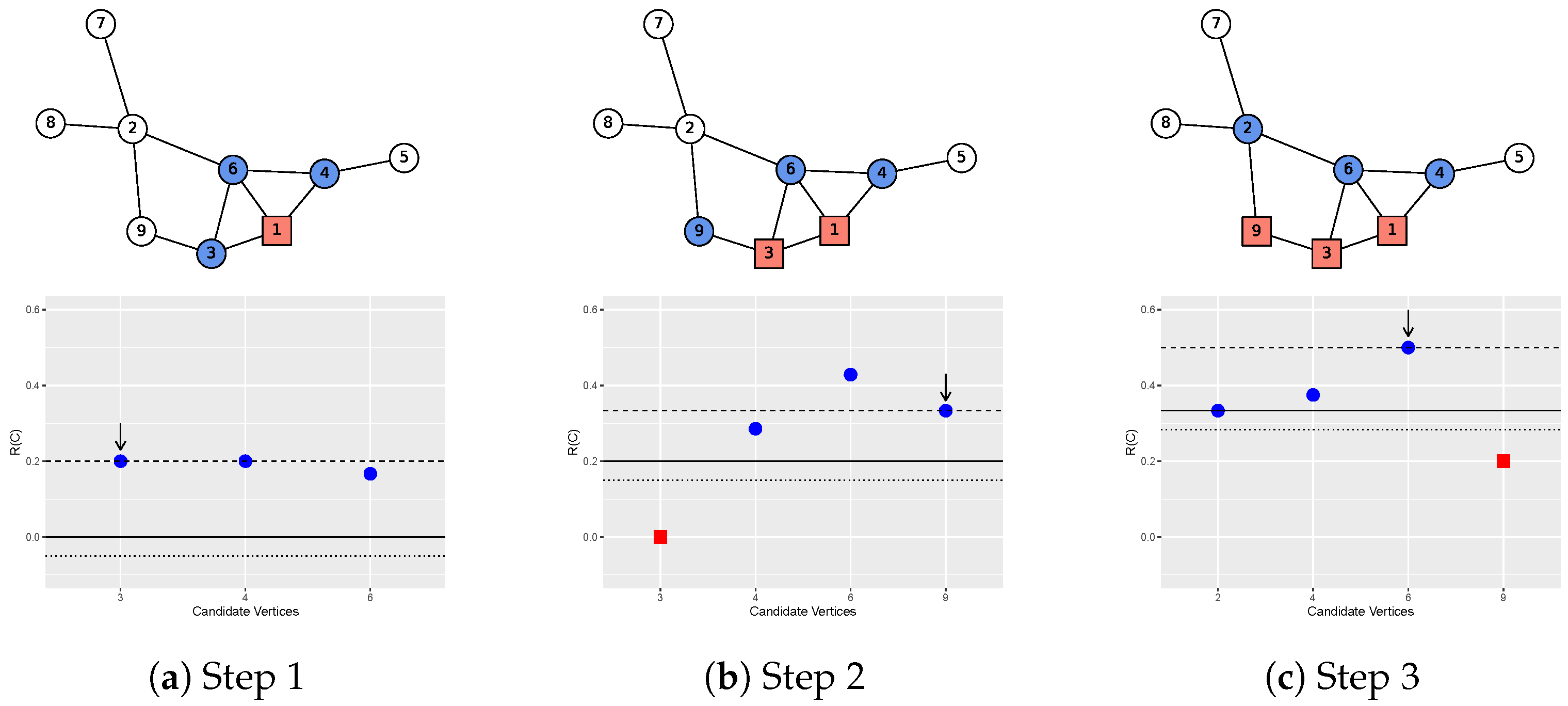
2.1. A Stochastic Algorithm
| Algorithm 1 The algorithm for the stochastic maximization of local modularity. |
|
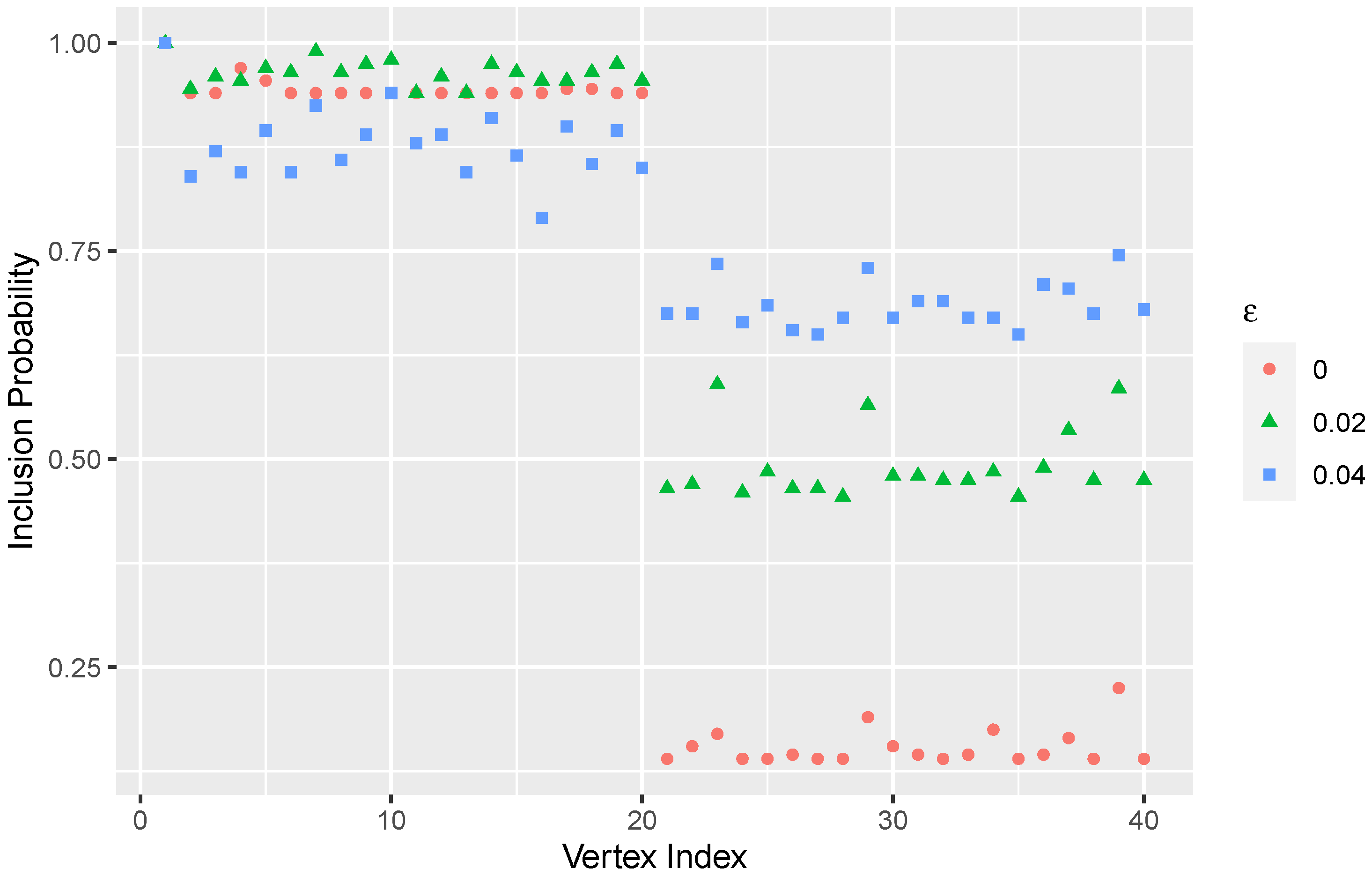
2.2. Tolerance Parameter and Stopping Criteria
2.3. Evaluation of Inclusion Significance
2.4. Computational Complexity
3. Results
3.1. A Simulation Study
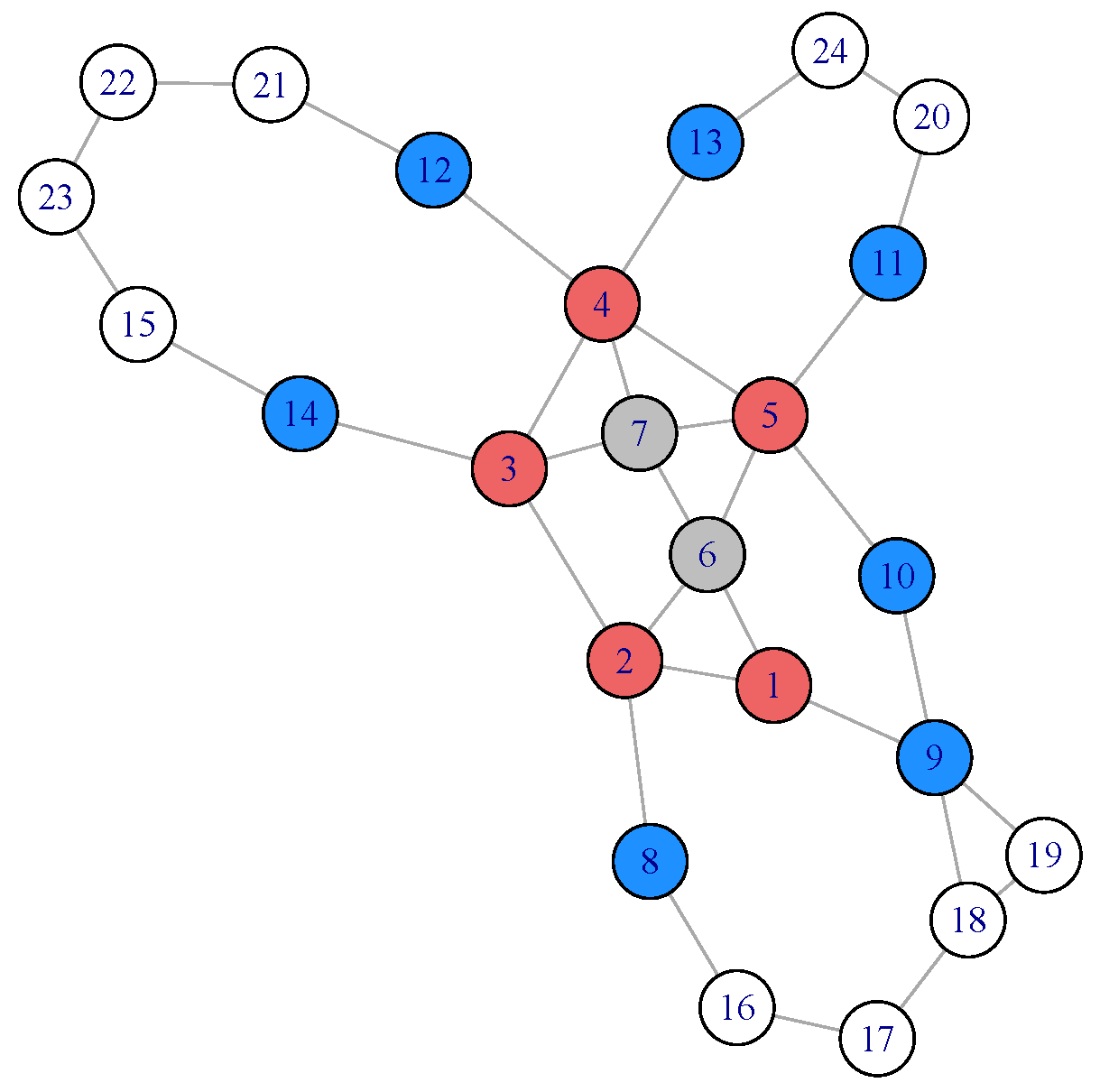
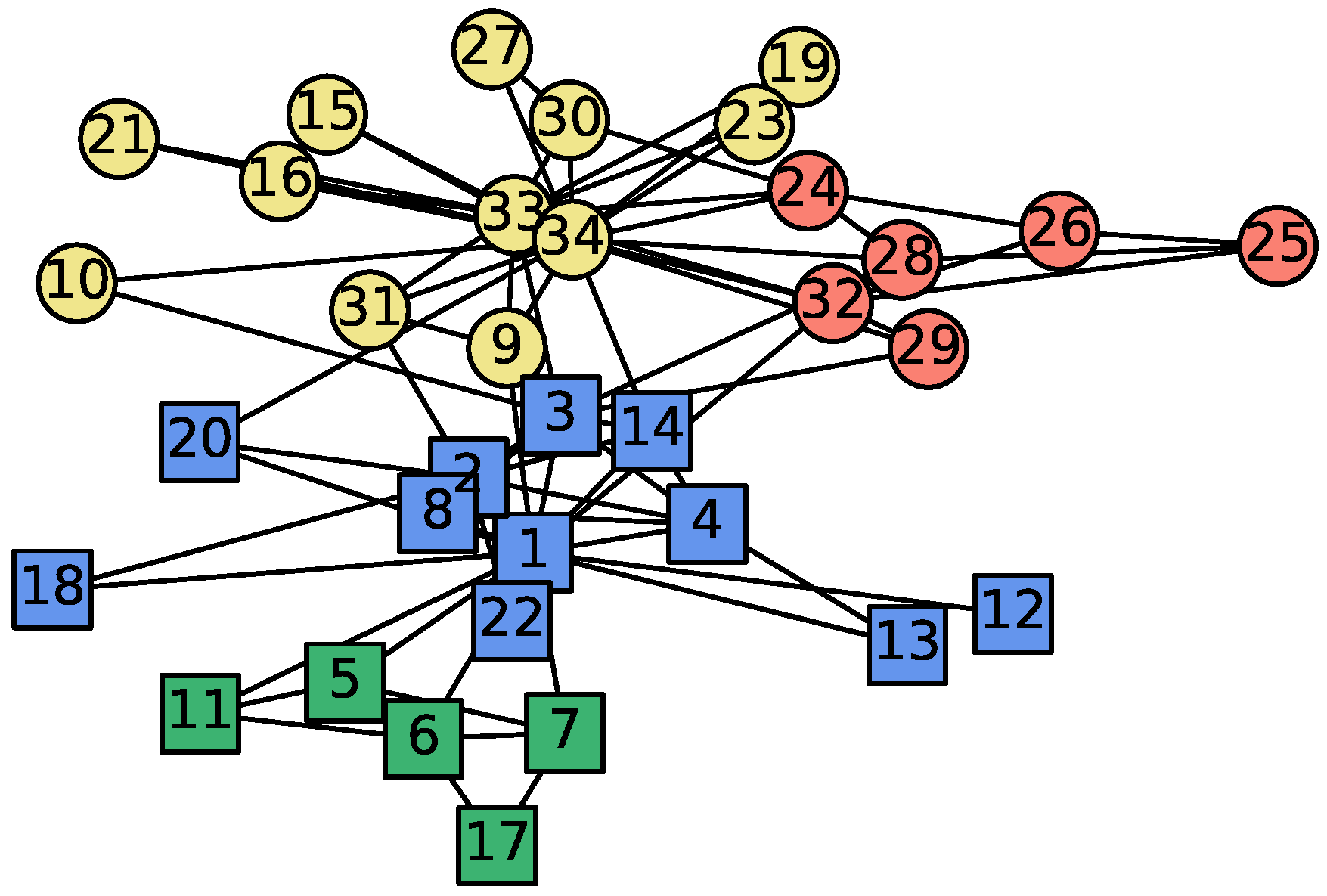
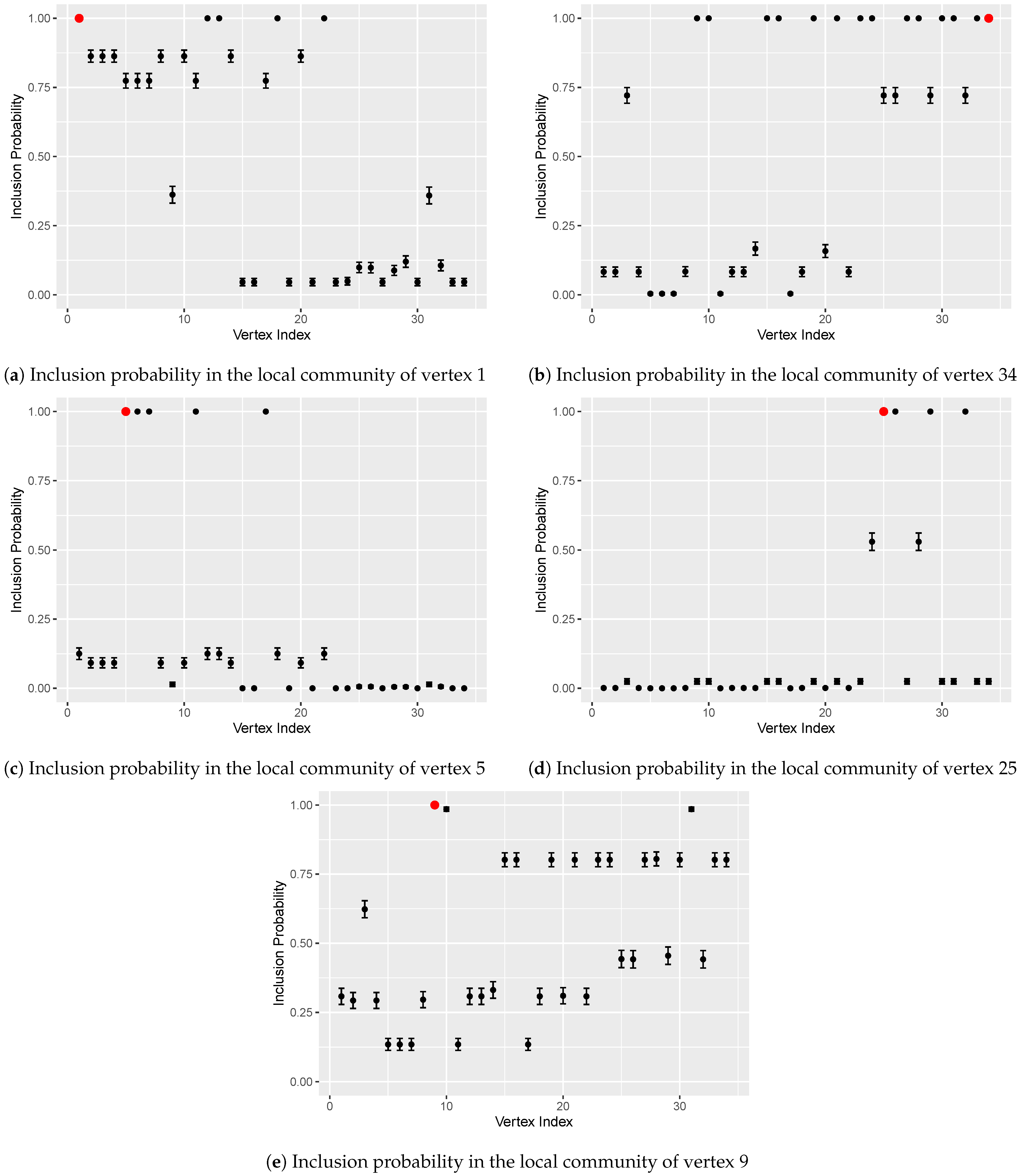
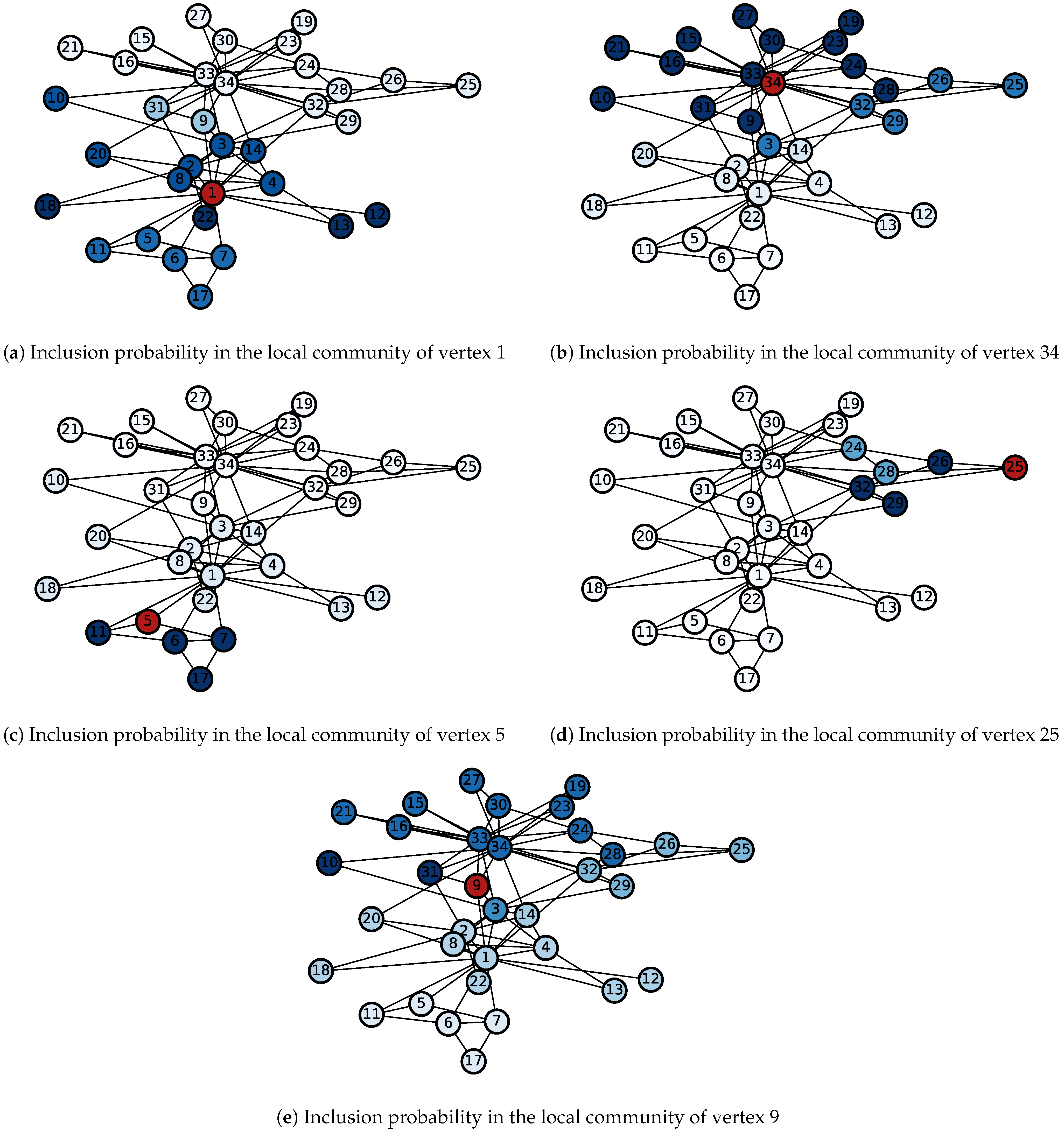
3.2. Zachary’s Karate Club Data
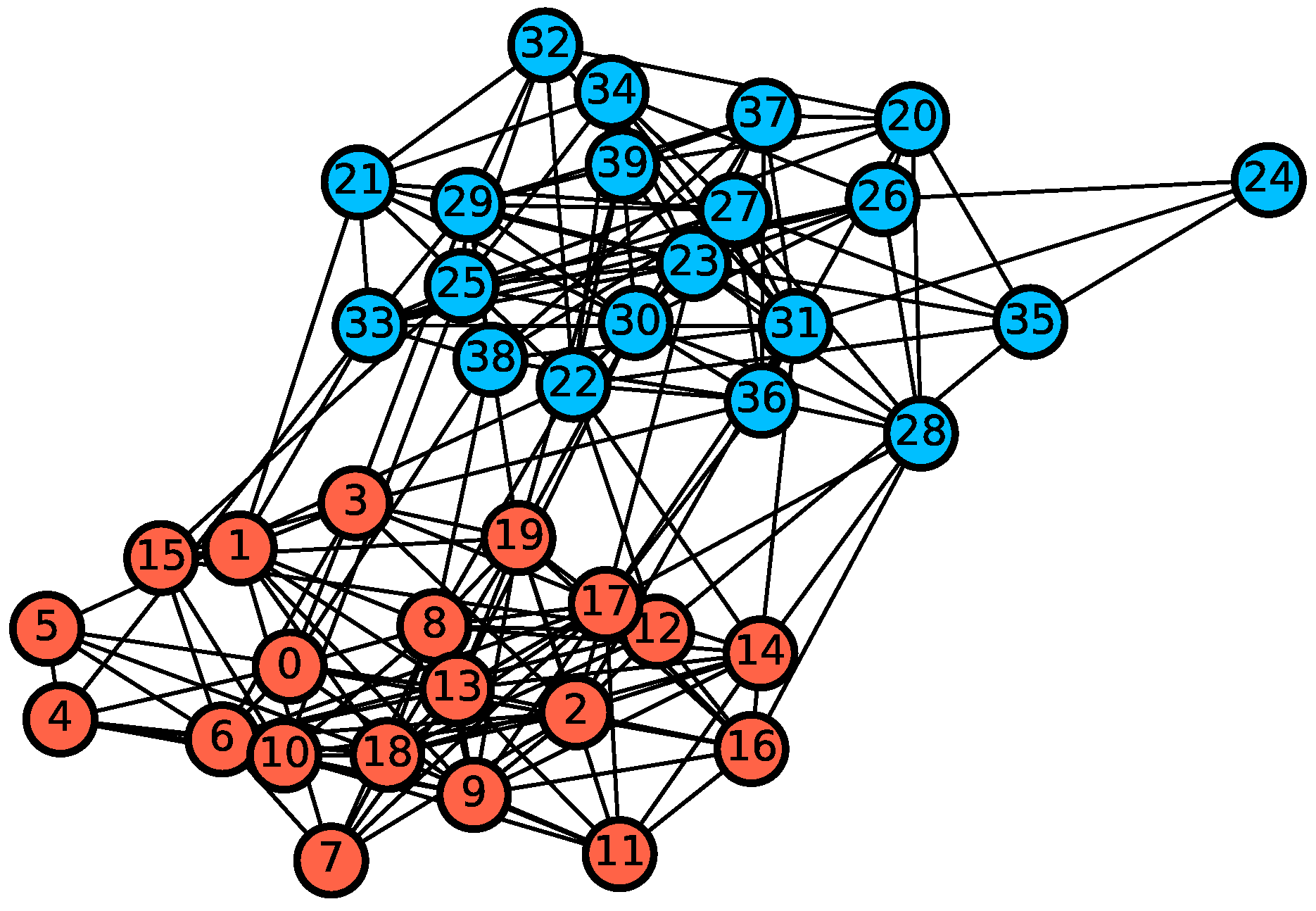
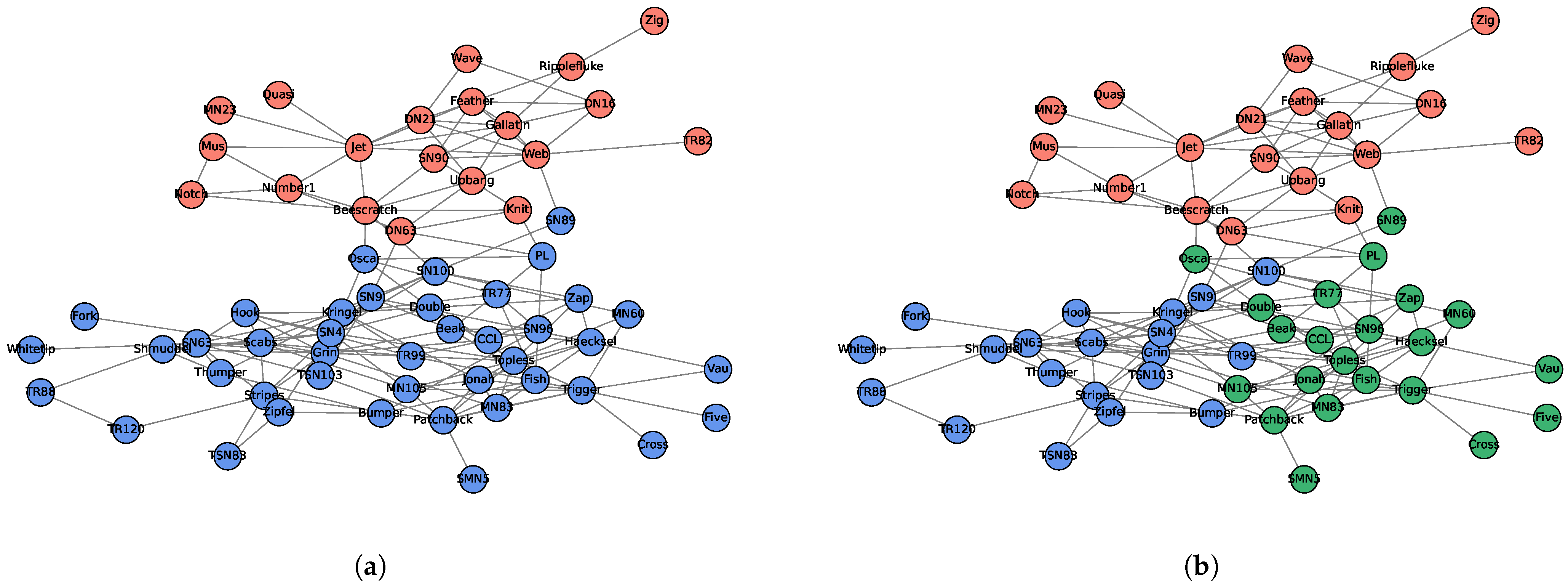
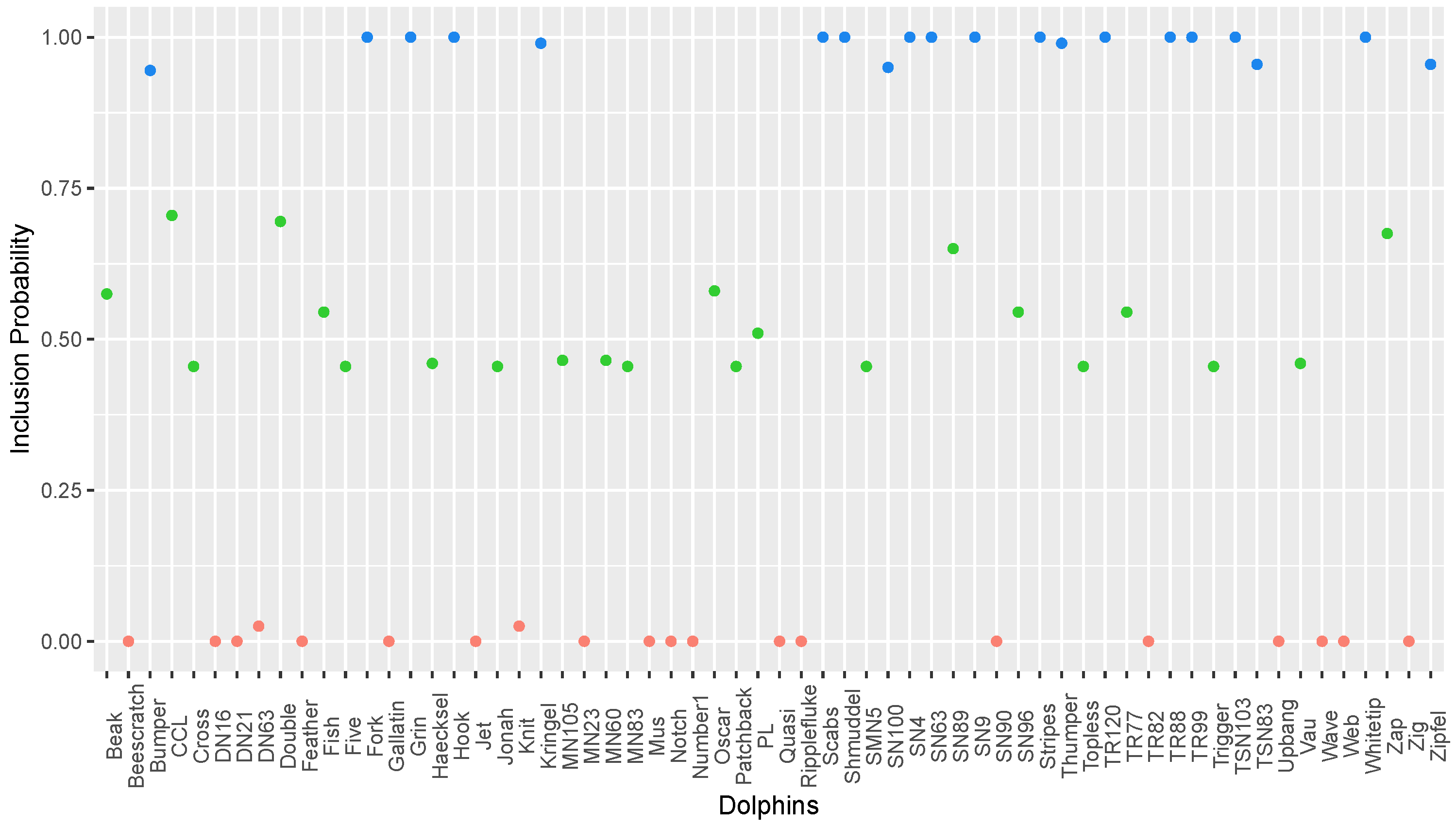
3.3. Lusseau’s Network of Bottlenose Dolphins
4. Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Newman, M. Networks: An Introduction; Oxford University Press: Oxford, UK, 2010. [Google Scholar]
- Newman, M.E. The structure and function of complex networks. SIAM Rev. 2003, 45, 167–256. [Google Scholar] [CrossRef]
- Strogatz, S.H. Exploring complex networks. Nature 2001, 410, 268. [Google Scholar] [CrossRef] [PubMed]
- Jackson, M.O. Social and Economic Networks; Princeton University Press: Princeton, NJ, USA, 2010. [Google Scholar]
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Fortunato, S.; Hric, D. Community detection in networks: A user guide. Phys. Rep. 2016, 659, 1–44. [Google Scholar] [CrossRef]
- Bagrow, J.P.; Bollt, E.M. Local method for detecting communities. Phys. Rev. E 2005, 72, 046108. [Google Scholar] [CrossRef] [PubMed]
- Papadopoulos, S.; Skusa, A.; Vakali, A.; Kompatsiaris, Y.; Wagner, N. Bridge bounding: A local approach for efficient community discovery in complex networks. arXiv 2009, arXiv:0902.0871. [Google Scholar]
- Rodrigues, F.A.; Travieso, G.; Costa, L.d.F. Fast community identification by hierarchical growth. Int. J. Mod. Phys. C 2007, 18, 937–947. [Google Scholar] [CrossRef]
- Clauset, A. Finding local community structure in networks. Phys. Rev. E 2005, 72, 026132. [Google Scholar] [CrossRef] [PubMed]
- Hui, P.; Yoneki, E.; Chan, S.Y.; Crowcroft, J. Distributed community detection in delay tolerant networks. In Proceedings of the 2nd ACM/IEEE International Workshop on Mobility in the Evolving Internet Architecture, Kyoto, Japan, 27–30 August 2007; p. 7. [Google Scholar]
- Bagrow, J.P. Evaluating local community methods in networks. J. Stat. Mech. Theory Exp. 2008, 2008, P05001. [Google Scholar] [CrossRef]
- Eckmann, J.P.; Moses, E. Curvature of co-links uncovers hidden thematic layers in the world wide web. Proc. Natl. Acad. Sci. USA 2002, 99, 5825–5829. [Google Scholar] [CrossRef] [PubMed]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by simulated annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Ott, R.L.; Longnecker, M.T. An Introduction to Statistical Methods and Data Analysis, 7th ed.; Cengage Learning: Boston, MA, USA, 2015. [Google Scholar]
- Hagberg, A.A.; Schult, D.A.; Swart, P.J. Exploring Network Structure, Dynamics, and Function using NetworkX. In Proceedings of the 7th Python in Science Conference, Pasadena, CA, USA, 19–24 August 2008; pp. 11–15. [Google Scholar]
- Holland, P.W.; Laskey, K.B.; Leinhardt, S. Stochastic blockmodels: First steps. Soc. Netw. 1983, 5, 109–137. [Google Scholar] [CrossRef]
- Zachary, W.W. An information flow model for conflict and fission in small groups. J. Anthropol. Res. 1977, 33, 452–473. [Google Scholar] [CrossRef]
- Donetti, L.; Munoz, M.A. Detecting network communities: A new systematic and efficient algorithm. J. Stat. Mech. Theory Exp. 2004, 2004, P10012. [Google Scholar] [CrossRef]
- Lü, L.; Zhou, T. Link prediction in complex networks: A survey. Phys. A Stat. Mech. Its Appl. 2011, 390, 1150–1170. [Google Scholar] [CrossRef]
- Lusseau, D.; Schneider, K.; Boisseau, O.J.; Haase, P.; Slooten, E.; Dawson, S.M. The bottlenose dolphin community of Doubtful Sound features a large proportion of long-lasting associations. Behav. Ecol. Sociobiol. 2003, 54, 396–405. [Google Scholar] [CrossRef]
- Arenas, A.; Fernandez, A.; Gomez, S. Analysis of the structure of complex networks at different resolution levels. New J. Phys. 2008, 10, 053039. [Google Scholar] [CrossRef]
- Isufi, E.; Pocchiari, M.; Hanjalic, A. Accuracy-diversity trade-off in recommender systems via graph convolutions. Inf. Process. Manag. 2021, 58, 102459. [Google Scholar] [CrossRef]
- Vargas, S.; Castells, P. Rank and relevance in novelty and diversity metrics for recommender systems. In Proceedings of the Fifth ACM Conference on Recommender Systems, Chicago, IL, USA, 23–27 October 2011; pp. 109–116. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| N | 20 | 50 | 100 | 250 | 500 |
| 0.913 | 0.934 | 0.918 | 0.925 | 0.932 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Papei, H.; Li, Y. Stochastic Local Community Detection in Networks. Algorithms 2023, 16, 22. https://doi.org/10.3390/a16010022
Papei H, Li Y. Stochastic Local Community Detection in Networks. Algorithms. 2023; 16(1):22. https://doi.org/10.3390/a16010022
Chicago/Turabian StylePapei, Hadi, and Yang Li. 2023. "Stochastic Local Community Detection in Networks" Algorithms 16, no. 1: 22. https://doi.org/10.3390/a16010022
APA StylePapei, H., & Li, Y. (2023). Stochastic Local Community Detection in Networks. Algorithms, 16(1), 22. https://doi.org/10.3390/a16010022