
A General Computational Approach for Counting Labeled Graphs

1
Division of Infectious Diseases and Global Public Health, University of California San Diego, La Jolla, CA 92093, USA
2
Department of Biostatistics, Harvard T.H. Chan School of Public Health, Boston, MA 02115, USA
*
Author to whom correspondence should be addressed.
Algorithms 2023, 16(1), 16; https://doi.org/10.3390/a16010016
Submission received: 23 September 2022
/
Revised: 15 December 2022
/
Accepted: 16 December 2022
/
Published: 27 December 2022
(This article belongs to the Section Combinatorial Optimization, Graph, and Network Algorithms)
Abstract
:This paper presents a general recursive formula to estimate the number of labeled graphs as well as details to evaluate the formula for the following graph properties: number of edges (graph density), degree sequence, degree distribution, classification mixing, and degree mixing, i.e., the formula estimates the number of labeled graphs that have given values for graph properties. The proposed approach can be extended to additional graph properties (e.g., number of triangles) as well as properties of bipartite graphs. For special settings in which formulas exist from previous research, simulation studies demonstrate the validity of the proposed approach. In addition, we demonstrate how our approach can be used to quantify the level of variability in values of a graph property in the subset of graphs that hold a specified value of a different graph property (or properties) constant.
1. Introduction
Graph enumeration is a well-established area of combinatorics for counting graphs with particular features. Examples of such enumeration include determining how many graphs exist with a given number of vertices or edges, or a given degree sequence. Approaches for counting graphs fall into two categories based on whether their vertices are labeled or unlabeled. In the former case, vertices of a graph are labeled in a way that makes them distinguishable from one another. In the latter, all permutations of vertices are considered to form the same graph [1]. In social network analysis—our area of interest—vertices are most often distinguishable from each other; hence, we focus on labeled graph enumeration.
Recently, Iniquez et al. discussed bridging the gap between graph theory and social network analysis [2]. As they note, connecting these two disciplines may clarify the role of randomness in modeling dynamical systems, such as those that govern spread of infectious diseases within a population. Simulation studies that investigate such spread and the impact of interventions on it often make use of agent-based models (ABMs) [3,4]. An important component of ABMs is the formulation of interactions among the agents in the model; these interactions can be represented as a graph. We refer to the collection of such interactions as contact networks (in keeping with infectious disease transmission literature). Often ABMs generate the contact network from a stochastic process. Graph enumeration can aid in interpreting results of simulation studies of processes that operate on graphs (e.g., spread of infection) by permitting assessment of the contribution to variation in the results (e.g., total number infected in unit time) that arises from variation in the generated contact networks. Higher levels of the latter might be expected to lead to higher levels of the former. We provide an application of our methods to demonstrate how graph enumeration can help in quantifying variation in graphs.
Current solutions to graph enumeration problems are individually tailored to particular properties (such as degree sequence) [5]. These solutions are either closed-form mathematical expressions or asymptotic formulas. Equations to calculate the number of labeled graphs with various characteristics have been reported; these include rooted graphs, connected graphs, and directed graphs [1]. Considerable research has been devoted to estimating the number of labeled graphs with a given degree sequence—a property important in social network analysis [6,7,8,9]. However, there has been little research focusing on other important properties in social network analysis, such as degree mixing and number of triangles.
Below, we propose a general approach for counting labeled graphs that applies to several graph properties, including degree sequence. Furthermore, our approach deviates from the standard one of developing a closed-form or asymptotic formula. By contrast, we propose an algorithmic method to the graph enumeration problem. The next section provides terminology used in the paper. Section 3 presents a general recursive formula to estimate the number of labeled graphs as well as details to evaluate the formula for the following graph properties: number of edges (graph density), degree sequence, degree distribution, classification mixing, and degree mixing. For settings in which formulas exist from previous research, Section 4 presents simulation studies demonstrating the degree of similarity between our proposed methods and those that are currently available. In Section 5, we apply the proposed approach to estimate the number of labeled graphs associated with different values of degree distribution and degree mixing that arise from the Barabási–Albert model to investigate the variation across graphs generated with this model [10]. The paper concludes with a discussion and further research.
2. Terminology
We represent a graph, , as an adjacency matrix with dimensions equal to the size of set V. Therefore, G has dimensions , where denotes the size of set V. Let n and m represent the number of vertices in G, i.e., and number of edges, i.e., , respectively. Let denote the vertices in set V, which are labeled (arbitrarily) but enables them to be distinguishable from one another. Let denote an edge between and . Let indicate that there is an edge between and , where , while indicates that there is no edge. Denote the neighbors of as , i.e., . Let be the set of all simple labeled graphs with n vertices.
Let denoted an algebraic map from a graph G to its number of edges, i.e., . The degree of vertex , denoted as , is the number of edges the vertex has with other vertices in V; therefore . Let represent the vector of degrees for nodes in set V, commonly referred to as a degree sequence. The degree distribution, denoted as , is a vector representing the number of these degrees over all vertices in set V; the kth entry represents the number of vertices with degree k, i.e., . Let and denote the mapping from a graph to its degree distribution, i.e., , and degree sequence, i.e., , respectively.
Let represent a discrete classification for vertex in graph G; we denote the number of distinct classifications as q. Let be a vector containing the characteristics of all vertices. The classification distribution, denoted as , is a vector representing the number of individuals with these classification over all vertices; the kth entry represents the number of vertices with classification k, i.e., . Let be a symmetric matrix representing the mixing by classification of graph G; we refer to as a classification mixing matrix. The entry is the total number of edges between a vertex with classification k and vertex with classification l. Let denote the mapping from a graph to its classification mixing matrix. Let be a particular mixing matrix where the classification represents vertex degrees. Therefore, the entry is the total number of edges between vertices of degree k and l. Let denote the mapping from a graph to its degree mixing matrix.
Denote the inverse images associated with a map as . These inverse images of singleton sets have been referred to as fibers in algebraic statistics literature [11]. The graph enumeration problem is calculating the size of a fiber, denoted as , which represents the number of graphs where the graph property associated with equals x; this quantity has been referred to as a volume factor [12]. We refer to x as a graphical value associated with if .
3. Methods
This section first presents a general recursive formula to estimate the number of labeled graphs; details for specific graph properties, e.g., degree distribution, follow afterwards. Equation (1) provides a recursive formula to estimate the number of graphs, , with specific value(s), , for particular graph properties associated with :
where is the ratio between the sizes of fibers and , i.e.,
Goyal et al. [13] provides equations to calculate for a range of graph properties including number of edges, classification mixing, degree distribution, degree mixing, and number of triangles (controlling for degree mixing) when and are specified such that there exists graphs and where:
- s1.
- and differ by the presence or absence of a single edge;
- s2.
- ; and
- s3.
- .
To make use of the recursive formula and previous work by Goyal et al. [13], it is necessary to specify a sequence of values such that there exists graphs ,…, where each consecutive pair satisfies . In addition, we need to be able to calculate . Although there is no constraint on , it is often useful to set equal to the specific value of the graph properties associated with the empty graph; hence, typically, = 1. Throughout this paper, we follow this approach. In the sections below, we provide details for calculating for when and x are associated with a given number of edges, degree distribution, degree sequence, classification mixing matrix, and degree mixing matrix.
3.1. Graph Enumeration Problem: Calculate the Number of Labeled Graphs of Size n with m Edges
In this section, we calculate . To address this graph enumeration problem, we specify the following sequence of number of edges for the recursive procedure: where . Theorem 1 proves that there exists a collection of graphs that is consistent with this specification of number of edges, i.e., there exists a collection of graphs where each consecutive pair satisfies for .
Theorem 1.
For a sequence of number of edges: where and , there exists a collection of graphs where each consecutive pair satisfies for and for all .
Proof.
Let be a set of distinct edges among vertices ; this is possible because . Let denote the graph formed with the first i edges from E, i.e., contains edges . Based on the definition of , , , and and differ by a single edge. □
Since satisfies , we can use results from Goyal et al. [13] to calculate as shown below:
Using Equation (3) along with the specification of as and , it is possible to calculate . Section 4.1.1 provides a numerical example for calculating when , while Section 4.1.2 provides a comparison between the recursive formula and a previously established formula.
3.2. Graph Enumeration Problem: Calculate the Number of Labeled Graphs of Size n with Degree Distribution
To calculate , the number of labeled graphs with degree distribution D, using the recursive formula, we need to specify a sequence of degree distributions, . We specify such a sequence by leveraging the Havel–Hakimi algorithm [14,15]. Let be any degree sequence that is consistent with degree distribution . The Havel–Hakimi algorithm permits identification of a set of edges, denoted as E, that can be used to construct a graph with degree sequence d. Algorithm 1 provides a procedure to identify E.
| Algorithm 1: Degree distribution |
 |
Let denote the graph formed with the first i edges from E, i.e., contains edges . Let denote the degree distribution associated with graph , i.e., . Theorem 2 states that satisfies .
Theorem 2.
Let E denote the collection of edges outputted from Algorithm 1 with a graphical degree distribution as input. Let denote the graph formed with the first i edges from E, i.e., contains edges . Let . Each consecutive pair in the collection of graphs satisfies for .
Proof.
The edges in E are distinct. Therefore, by design, the conditions are satisfied. □
Let be the single edge that differs between and . Based on results from Goyal et al. [13]:
where
and based on Newman [16],
Using Equation (4) along with the specification of as defined above and (as only the empty graph has degree distribution ), it is possible to calculate .
3.3. Graph Enumeration Problem: Calculate the Number of Labeled Graphs of Size n with Degree Sequence
The number of graphs with degree sequence , , can be computed by dividing the number of labeled graphs with the degree distribution consistent with d, denoted as , by the number of permutations of assigning vertices to degrees. Specifically,
Section 4.2.1 provides a numerical example for calculating , while Section 4.2.2 provides a comparison between the presented recursive formula and a formula by Liebenau et al. [9].
3.4. Graph Enumeration Problem: Calculate the Number of Labeled Graphs of Size n with Classification Mixing Matrix
To calculate the number of labeled graphs with mixing matrix , we assume that the classification of all vertices, , is known and is graphical. We specify as the following for ( is symmetric):
where q is the number of distinct classifications. Theorem 3 proves that there are graphs consistent with that satisfy .
Theorem 3.
For a sequence of mixing matrices defined by Equation (9), there exists a collection of graphs where each consecutive pair satisfies for .
Proof.
To show this, let be a set of distinct edges where the first are between vertices with classification 1, the next are between vertices with classification 1 and 2, and so on. Let denote the graph formed with the first i edges from E, i.e., contains edges . Based on the definition of , , , and and differ by a single edge. □
Let be the single edge that differs between and . Given Theorem 3, is the following:
If
else,
3.5. Graph Enumeration Problem: Calculate the Number of Graphs of Size n with Degree Mixing Matrix
To calculate the number of labeled graphs with degree mixing , we follow a similar approach as that for degree distribution. Specifically, we use a constructive proof for assessing whether a degree mixing matrix is graphical to specify a set of edges, E, that can be used to construct a graph with degree mixing [13]; Algorithm 2 provides a procedure to construct E.
| Algorithm 2: Degree Mixing |
 |
Theorem 4.
Let E denote the collection of edges output from Algorithm 2 with a graphical degree mixing matrix as input. Let denote the graph formed with the first i edges from E, i.e., contains edges . Let . Each consecutive pair in the collection of graphs satisfies for .
Proof.
The edges in E are distinct. Therefore, by design, the conditions are satisfied. □
Based on the definition of in Theorem 4, . Let be the single edge that differs between and . Based on results from Goyal et al. [13]:
where
and based on concepts from Newman [16], if ,
else,
where if and if and and denote the number of vertices that are neighbors of i and j and equal to z.
Using Equation (12) along with the specification of as defined above and , it is possible to calculate .
3.6. Additional Graph Properties and Bipartite Graphs
The recursive formula and associated framework we propose can be used to calculate the number of labeled graphs for many additional graph properties. In particular, Goyal et al. [13] provide equations for for number of triangles (controlling for degree mixing) as well as jointly specifying classification mixing matrix and degree distribution. In addition, Goyal et al. [17] enables extending the calculation of to the setting of bipartite graphs.
4. Results
In this section, we present numerical examples—including validation results for estimating the number of labeled graphs—for two graph properties: number of edges (Section 4.1) and degree sequence (Section 4.2). To the author’s knowledge, our paper is the first to provide formulas for estimating the number of labeled graphs consistent with values for several graph properties (e.g., degree mixing matrix) described in Section 3; hence, for these properties, we are not able to compare our approach to any existing approach. In the application section (Section 5), we present results for the number of labeled graphs associated with particular degree distributions and degree mixing matrices using our presented approach.
4.1. Number of Edges
Although there is a closed-form expression for calculating the number of labeled graphs of size n with m number of edges, we use Equation (1) for calculation of this graph property to illustrate our recursive approach for graph enumeration.
4.1.1. Example
To illustrate the use of the recursive formula, we provide a numerical example where we estimate the number of graphs of size with exactly edges; that is, we calculate . As discussed in Section 3.1, we set . Therefore, based on Equation (1):
Based on Equation (3),
Therefore,
The next step in the procedure is the calculation of using the following:
The procedure ends at . Therefore,
Table 1 provides the log values for for to 10. Based on these values and noting that , we calculate .
4.1.2. Comparison
To illustrate the validity of the recursive formula in this setting, we compare the estimates of the number of graphs of size n with m edges, , based on the proposed recursive formula to those based on the following existing formula [1]:
Our comparison considers values of x ranging from for graphs of size .
For each value of , Table 1 provides the log values for and based on Equations (1) and (22). The estimates obtained from the proposed recursive formula and the known formula are identical—an expected finding given that a closed-form equation for exists.
Regarding complexity, computing the recursive formula for requires computing as well as x number of subtractions and divisions. Therefore, the complexity of the recursive formula is where subtractions and divisions are .
4.2. Degree Sequence
This section illustrates the use of Equation (1) to estimate the number of graphs with a fixed degree sequence.
4.2.1. Example
To illustrate the use of the recursive formula, we provide a numerical example wherein we estimate the number of graphs with and fixed degree sequence. In particular, we estimate the number of 2-regular graphs of size ; a -regular graph is one in which each vertex has exactly degree . Therefore, the degree sequence for a -regular graph is .
As the number of distinct degree sequences for a degree distribution associated with a -regular graph is one, Equation (8) simplifies to:
Using Algorithm 1, we generate a sequence of edges E, where E specifies a 2-regular graph of size n. The edge list E contains 1000 edges. A partial list of the edges in E, denoted as a pair consisting of Vertex 1 and Vertex 2 , are shown in Table 2. Using the edge list E, we generate a series of graphs, , where is the graph that contains the first i edges in E. Next, we generate a series of degree distributions , where . Table 3 shows a partial list of the degree distribution sequences, i.e., . For each consecutive entry in the degree distribution sequences, we can use Equations (4)–(7) to estimate . As is only consistent with the empty graph, . We estimate the log number of 2-regular graphs as ; as we see in the next section an existing formula by Liebenau et al. [9] estimates this as .
4.2.2. Comparison
As in the previous section, we illustrate the validity of the recursive formula in this setting by comparing the estimates of based on the proposed recursive formula to those that result from an existing formula. In particular, we compare results of the proposed recursive approach to those resulting from the available formula for estimating the number of -regular graphs of size .
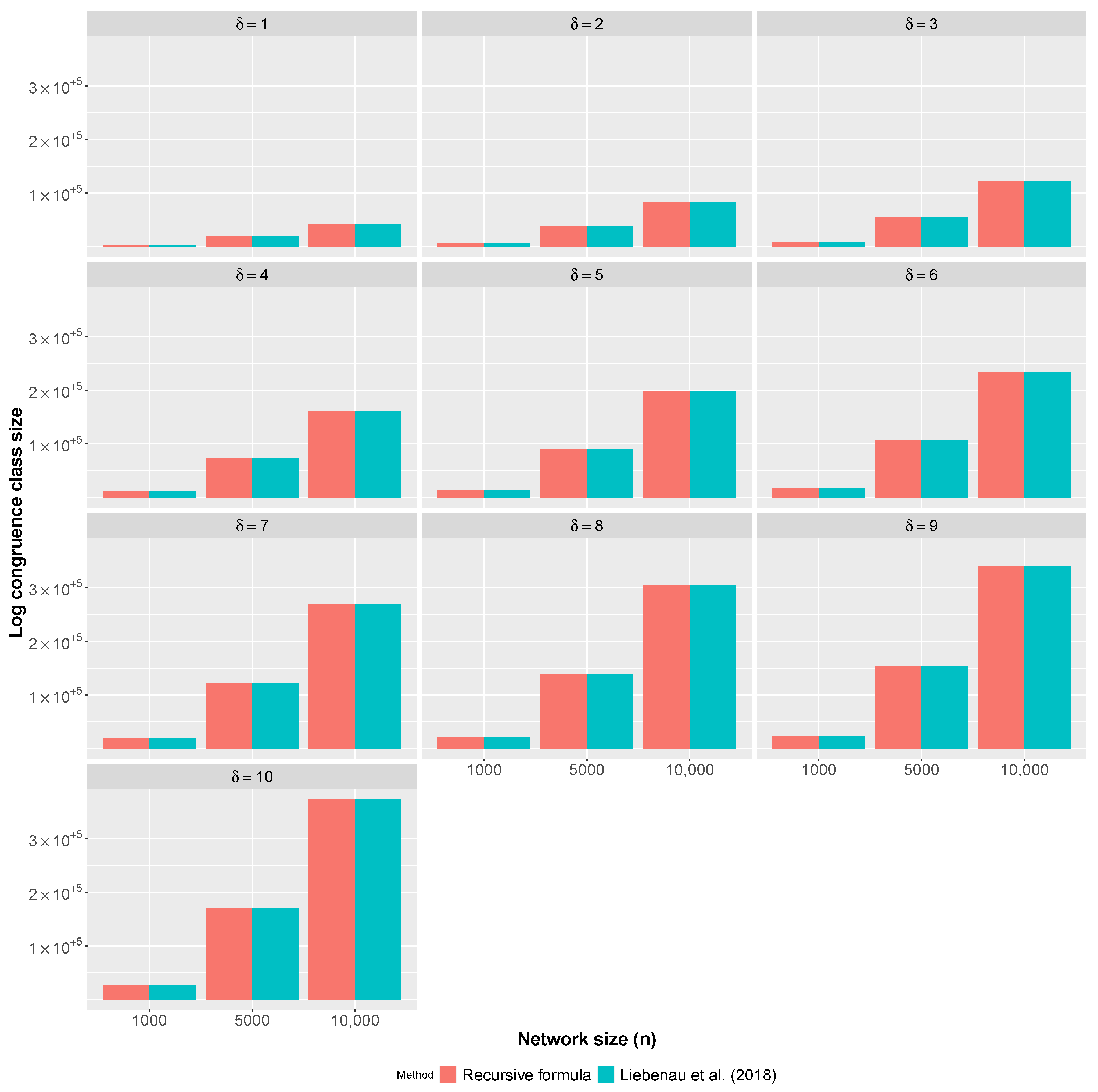
Liebenau et al. [9] proved the validity of a general asymptotic formula—conjectured in 1990—for the number of graphs with given degree sequence. They also provide a formula that converges to the number of -regular graphs as . This formula allows comparison of , where d is the degree sequence , obtained from this asymptotic formula to those from the proposed recursive formula.
Figure 1 shows log estimates for the number of -regular graphs for from 1 to 10 for the two approaches. The red bars depict estimates based on the recursive formula introduced in this paper; the blue bars are estimates based on Liebenau et al. [9]. Each plot in Figure 1 shows log estimates for graphs of size 1000, 5000, and 10,000. The log estimates differ by less than . To calculate the number of graphs with a given degree sequence based on the recursive formula, we first make use of the Havel–Hakimi algorithm, which has a complexity of [18]. Next, the ratio presented in Equation (4) must be computed times, where each calculation of the ratio is . Finally, we calculate the number of degree sequences that are associated with a degree distribution, which has complexity . Therefore, the complexity of the recursive formula for calculating the number of graphs of size n with a degree sequence d is .
5. Application
In this section, we estimate the variation in degree mixing matrices consistent with degree distributions formed by the Barabási–Albert (BA) model [10]. The BA model can be initiated with a small seed graph that grows by the addition of new vertices one at a time. Each new vertex forms a new edge with an existing vertex based on preferential attachment rules. Vertices and edges, once introduced, are never deleted. The BA model fixes the number of (undirected) edges connected to each new vertex. The BA model provides a mechanism to generate graphs with a fat-tailed degree distribution—specifically a power-law degree distribution—wherein the probability, , that a vertex in the graph has degree k, decays as a power-law .
To calculate the variation in degree mixing matrices consistent with degree distributions formed by the BA model, we first estimate the number graphs consistent with a degree distribution associated with the BA. Second, we estimate the number of graphs consistent with a degree mixing matrix associated with a degree distribution from the BA model. Third, we estimate the number of distinct degree mixing matrices associated with a degree distribution generated from the BA model, which provides a metric for the variation of graphs generated by the BA model.
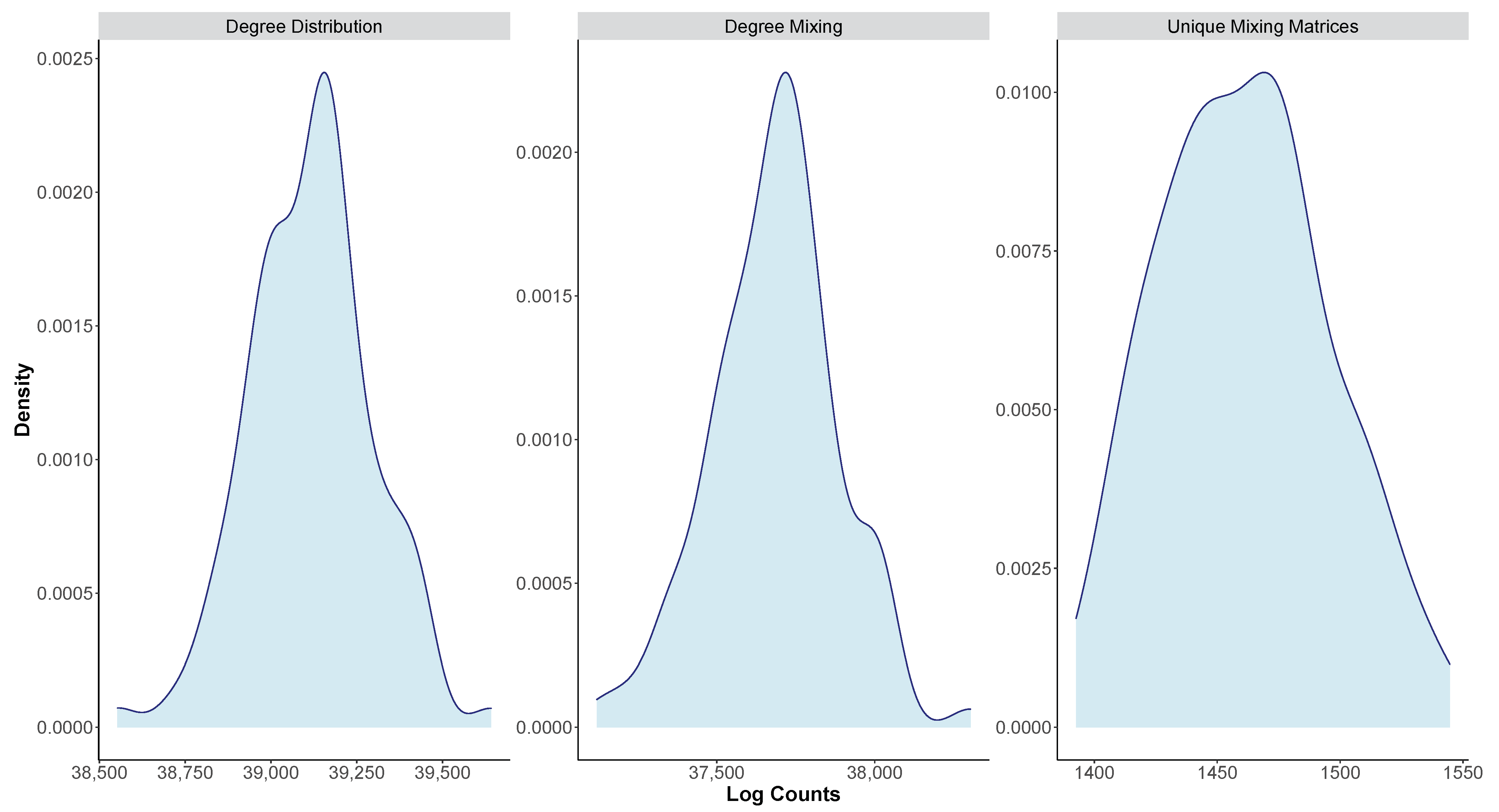
For the first step, we generate 100 graphs using the BA model (), denoted as . Figure 2 shows density plots for the log estimates for in the first panel. The average number of labeled graphs associated with a degree distribution generated from the BA model was estimated as (exponential of the mean of the first panel in Figure 2). Second, for each graph, we estimate . Figure 2 (second panel) shows density plots for the log estimates for . Figure 2 (third panel) shows a density plot for the log estimates for the number of distinct degree mixing matrices associated with a degree distribution generated from the BA model. The exponential of the mean gives an estimate of distinct degree mixing matrices associated with a degree distribution generated from the BA model.
6. Discussion
This paper presents a general recursive formula to estimate the number of labeled graphs with specific values for graph properties of interest. We consider those with particular relevance for social network analysis: number of edges (graph density), degree sequence, degree distribution, classification mixing, and degree mixing. The proposed method can easily be extended to additional graph properties, including number of triangles (controlling for degree mixing), as well as to bipartite graphs; the formulas for Equation (2) are currently available. The proposed recursive formula differs from other available approaches for graph enumeration both in its overall approach and in the breadth of graph properties that can be considered; it may be profitable to investigate the theoretical connections between the proposed method and other approaches. Furthermore, graph enumeration has the potential to play an important role in statistical network analysis, because formulating the likelihood of observing a real-world graph with particular properties is necessary for making principled inferences.
One current area of research addresses the question of how to make use of results obtained from a study in one population setting to predict what results of a similar study would have been in a different setting. Causal methodologists refer to such research as the study of transportability. This notion is related to the idea of generalizability of results to populations different from the one under study, but true generalizability requires that two populations be similar in all factors that impact study results in important ways. For example, if characteristics such as age or sex of recipients of interventions impacted their efficacy, then generalizability would require that the two populations be similar in these characteristics. Transportability analyses attempt to adjust for differences in populations in prediction of quantities such as intervention effects in new populations. In the settings we consider, adjustment would be required not only for individual characteristics, but also potentially for graph features that impact intervention effects. For example, if degree assortativity—a summary measure of the degree mixing matrix—impacts the spread of disease or the effectiveness of interventions, then this factor would need to be taken into account when predicting spread or effectiveness in a population different from the one that was studied. The methods we describe would aid in investigation of transportability in such settings by facilitating development of ABM-based simulation studies in which graph properties can be chosen to reflect knowledge about those properties (including their uncertainty) in the setting of interest. Of course, in many settings detailed information about potentially important properties may be unavailable. This issue can be addressed using the methods described above to assess the extent to which the unknown properties might impact intervention effectiveness (or other quantities of interest) in the new population [19]. Ideally it would be safe to exclude these properties from the graph model; but if not, an investigator could use the proposed methods to consider plausible ranges of these properties. Doing so would appropriately increase the uncertainty of the prediction of intervention effectiveness in the new population.
Author Contributions
Conceptualization, R.G. and V.D.G.; methodology, R.G. and V.D.G.; software, R.G.; validation, R.G.; writing—original draft preparation, R.G.; writing—review and editing, V.D.G.; visualization, R.G.; funding acquisition, R.G. and V.D.G. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Institute of Health grants R37 AI-51164 and R01 AI-147441.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the collection, analyses, or interpretation of data; in the writing of the paper; or in the decision to publish the results.
References
- Harary, F.; Palmer, E.M. Graphical Enumeration; Elsevier: Amsterdam, The Netherlands, 2014. [Google Scholar]
- Iñiguez, G.; Battiston, F.; Karsai, M. Bridging the gap between graphs and networks. Commun. Phys. 2020, 3, 1–5. [Google Scholar] [CrossRef]
- Goyal, R.; Hotchkiss, J.; Schooley, R.T.; De Gruttola, V.; Martin, N.K. Evaluation of SARS-CoV-2 transmission mitigation strategies on a university campus using an agent-based network model. Clin. Infect. Dis. 2021, 73, 1735–1741. [Google Scholar] [CrossRef]
- Hambridge, H.L.; Kahn, R.; Onnela, J.P. Examining sars-cov-2 interventions in residential colleges using an empirical network. Int. J. Infect. Dis. 2021, 113, 325–330. [Google Scholar] [CrossRef]
- Lucatero, C.R. Combinatorial Enumeration of Graphs. In Probability, Combinatorics and Control; IntechOpen: London, UK, 2019. [Google Scholar]
- Read, R. The enumeration of locally restricted graphs (I). J. Lond. Math. Soc. 1959, 1, 417–436. [Google Scholar] [CrossRef]
- Bender, E.A.; Canfield, E.R. The asymptotic number of labeled graphs with given degree sequences. J. Combin. Theory Ser. A 1978, 24, 296–307. [Google Scholar] [CrossRef] [Green Version]
- Bollobás, B. A probabilistic proof of an asymptotic formula for the number of labelled regular graphs. Eur. J. Combin. 1980, 1, 311–316. [Google Scholar] [CrossRef] [Green Version]
- Liebenau, A.; Wormald, N. Asymptotic enumeration of graphs by degree sequence, and the degree sequence of a random graph. arXiv 2017, arXiv:1702.08373. [Google Scholar]
- Barabasi, A.L.; Albert, R. Emergence of Scaling in Random Networks. Science 1999, 286, 509–512. [Google Scholar] [CrossRef] [Green Version]
- Petrovic, S. A survey of discrete methods in (algebraic) statistics for networks. Algebr. Geom. Methods Discret. Math. 2017, 685, 260–281. [Google Scholar]
- Shalizi, C.R.; Rinaldo, A. Consistency under sampling of exponential random graph models. Ann. Stat. 2013, 41, 508–535. [Google Scholar] [CrossRef]
- Goyal, R.; Blitzstein, J.; De Gruttola, V. Sampling networks from their posterior predictive distribution. Netw. Sci. 2014, 2, 107–131. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hakimi, S.L. On realizability of a set of integers as degrees of the vertices of a linear graph. J. SIAM 1962, 10, 496–506. [Google Scholar] [CrossRef]
- Havel, V. A remark on the existence of Finite graphs. Časopis Pest. Mat. 1955, 80, 477–480. [Google Scholar] [CrossRef]
- Newman, M. Assortative mixing in networks. Phys. Rev. Lett. 2002, 89, 208701. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Goyal, R.; De Gruttola, V. Inference on network statistics by restricting to the network space: Applications to sexual history data. Stat. Med. 2018, 37, 218–235. [Google Scholar] [CrossRef] [PubMed]
- Sensarma, D.; Sen Sarma, S. Role of graphic integer sequence in the determination of graph integrity. Mathematics 2019, 7, 261. [Google Scholar] [CrossRef] [Green Version]
- DeGruttola, V.; Goyal, R.; Martin, N.K.; Wang, R. Network methods and design of randomized trials: Application to investigation of COVID-19 vaccination boosters. Clin. Trials 2022, 19, 363–374. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Comparison: Log estimates the number of -regular graphs for degrees from 1 to 10. The red bars depict estimates based on the recursive formula introduced in this paper; the blue bars are estimates based on Liebenau et al. [9]. Each plot shows log estimates for graphs of size 1000, 5000, and 10,000.
Figure 1.
Comparison: Log estimates the number of -regular graphs for degrees from 1 to 10. The red bars depict estimates based on the recursive formula introduced in this paper; the blue bars are estimates based on Liebenau et al. [9]. Each plot shows log estimates for graphs of size 1000, 5000, and 10,000.

Figure 2.
Barabási–Albert (BA) model: Density plots for the log estimates for (first panel) [degree distribution], (second panel) [degree mixing], and number of distinct degree mixing matrices associated with a degree distribution generated from the BA model.
Figure 2.
Barabási–Albert (BA) model: Density plots for the log estimates for (first panel) [degree distribution], (second panel) [degree mixing], and number of distinct degree mixing matrices associated with a degree distribution generated from the BA model.


{kind=link}
{kind=link}
Table 1.
Comparison of methods to calculate number of edges.
| x | |||
|---|---|---|---|
| [Equation (1)] | [Equation (22)] | ||
| 0 | − | 0 | 0 |
| 1 | |||
| 2 | |||
| 3 | |||
| 4 | |||
| 5 | |||
| 6 | |||
| 7 | |||
| 8 | |||
| 9 | |||
| 10 |
Table 2.
A partial list of the edges in E, denoted as a pair consisting of Vertex 1 and Vertex 2.
| Vertex 1 | Vertex 2 |
|---|---|
| … | … |
Table 3.
A partial list of the degree distribution sequences.
| Degree 0 | Degree 1 | Degree 2 | Degree 3 | |
|---|---|---|---|---|
| 1000 | 0 | 0 | 0 | |
| 998 | 2 | 0 | 0 | |
| 997 | 2 | 1 | 0 | |
| 995 | 4 | 1 | 0 | |
| 994 | 4 | 2 | 0 | |
| … | … | … | … | … |
| 0 | 8 | 992 | 0 | |
| 0 | 6 | 994 | 0 | |
| 0 | 4 | 996 | 0 | |
| 0 | 2 | 998 | 0 | |
| 0 | 0 | 1000 | 0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Goyal, R.; De Gruttola, V. A General Computational Approach for Counting Labeled Graphs. Algorithms 2023, 16, 16. https://doi.org/10.3390/a16010016
AMA Style
Goyal R, De Gruttola V. A General Computational Approach for Counting Labeled Graphs. Algorithms. 2023; 16(1):16. https://doi.org/10.3390/a16010016
Chicago/Turabian StyleGoyal, Ravi, and Victor De Gruttola. 2023. "A General Computational Approach for Counting Labeled Graphs" Algorithms 16, no. 1: 16. https://doi.org/10.3390/a16010016
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.