1. Introduction
Many problems from various research areas can be considered as classification or regression problems, such as problems from physics [
1,
2,
3,
4], chemistry [
5,
6,
7], economics [
8,
9], pollution [
10,
11,
12], medicine [
13,
14], etc. These problems are usually tackled by learning models such as Artificial Neural Networks [
15,
16], Radial Basis Function (RBF) networks [
17,
18], Support Vector Machines (SVM) [
19], Parse-matrix evolution [
20], Multilevel Block Building [
21], Development of Mathematical Expressions [
22], etc. A review of the methods used in classification can be found in the work of Kotsiantis et al. [
23].
Learning data are usually divided into two parts: training data and test data. Learning models adjust their parameters, taking the training data as input, and are evaluated on the test data. The number of learning model parameters directly depends on the dimension of the input problem (number of features) and this means that for large problems, large amounts of memory are required to store and manage the learning models. In addition, as the number of parameters of the computational models grows, a longer time is required to adjust the parameters. Moreover, as the dimension of the data grows, more samples (patterns) are required in order to achieve high learning rates. A discussion on how the dimensionality of the input problems affects the effectiveness of neural networks is presented in [
24]. A common approach to reduce the dimension of the input data is the Principal Component Analysis (PCA) technique [
25,
26,
27] or the Minimum redundancy Feature Selection (MRMR) technique [
28,
29]. Furtheromre, Wang et al. [
30] proposed an auto-encoder based dimensionality reduction method for large datasets. An overview of dimensionality reduction techniques can be found in the work of Ayesha et al. [
31].
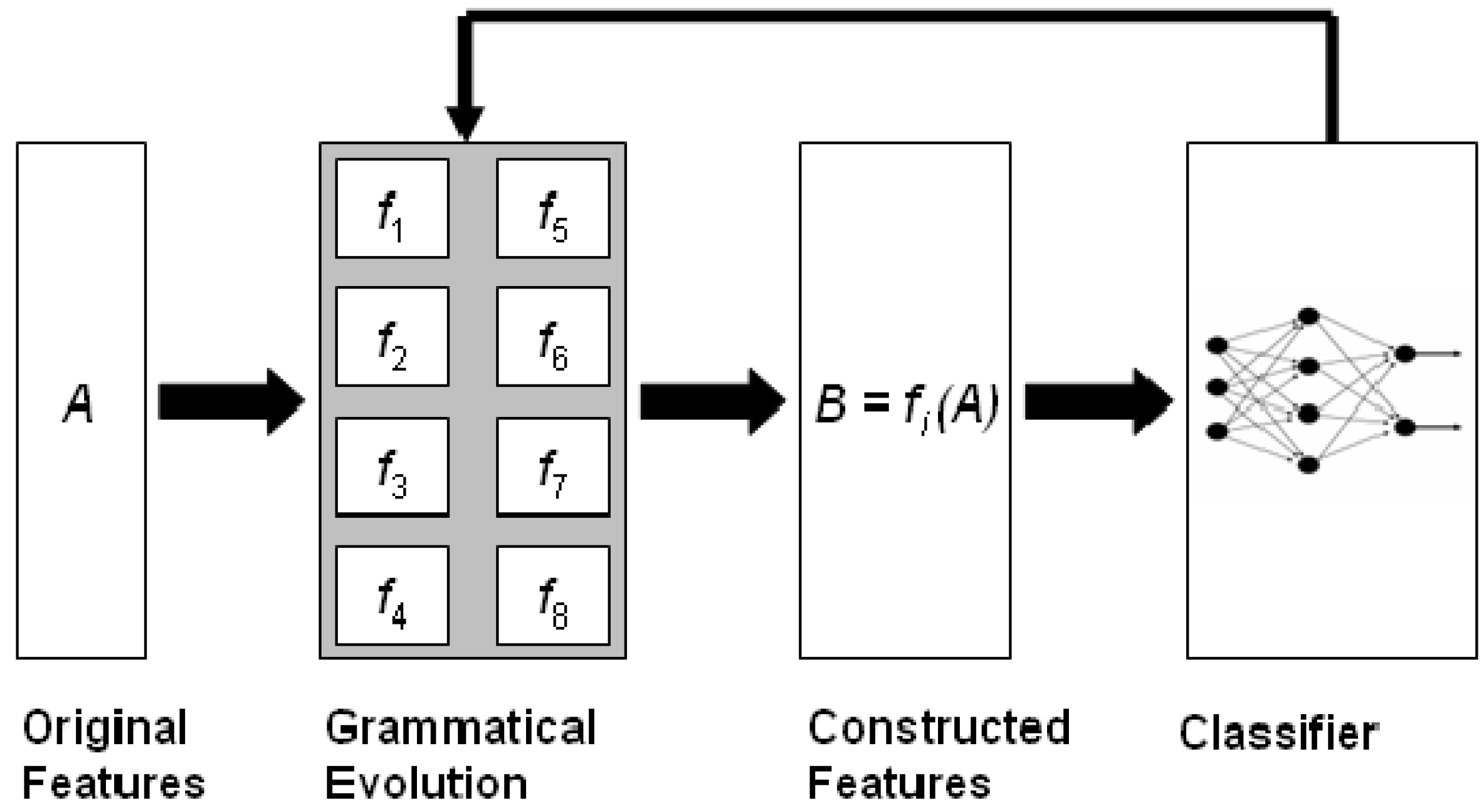
The current article describes the method and the software associated with a feature construction method based on grammatical evolution [
32], which is an evolutionary process that can create programs in any programming language. The described method constructs subsets of features from the original ones using non-linear combinations of them. The method is graphically illustrated in
Figure 1. Initially, the method was described in [
33], and it has been utilized in a variety of cases, such as spam identification [
34], fetal heart classification [
35], epileptic oscillations in clinical intracranial electroencephalograms [
36], classification of EEG signals [
37], etc.
Feature construction methods have been thoroughly examined and analyzed in the relevant literature such as the work of Smith and Bull [
38], where tree genetic programming is used to construct artificial features. Devi uses the Simulated Annealing method [
39] to identify the features that are most important for data classification. Neshatian et al. [
40] construct artificial features using an entropy based fitness function for the associated genetic algorithm. Li and Yin use another evolutionary approach for feature selection using gene expression data [
41]. Furthermore, Ma and Teng proposed [
42] a genetic programming approach that utilizes information gain ratio (IGR) to construct artificial features.
The proposed software has been implemented in ANSI C++ utilizing the freely available library of QT from
https://www.qt.io (accessed on 18 August 2022). The user should supply the training and test data of the underlying problem as well as the desired number of features that will be created. The evaluation of the constructed features can be made using a variety of machine learning models, and the user can easily extend the software to add more learning models. Moreover, the software has a variety of command line options to control the parameters of the learning models or to manage the output of the method. Finally, since the process of grammatical evolution can require a lot of execution time, parallel computation is included in the proposed software through the OpenMP programming library [
43].
The proposed method differs from similar ones as it does not require any prior knowledge of the objective problem and can be applied without any change to both classification problems and regression problems. In addition, the method can discover any functional dependencies between the initial features and can drastically reduce the number of input features, significantly reducing the time required to train the subsequent machine learning model.
Related freely available software packages on feature selection and construction are also the Mlpack package [
44], which implements the PCA method; the GSL software package obtained from
https://www.gnu.org/software/gsl/doc/html/index.html (accessed on 18 August 2022), which also implements the PCA method, among others; the MRMR package writen in ANSI C++ by Hanchuan Peng [
28,
29]; etc.
The rest of this article is organized as follows: in
Section 2, the grammatical evolution procedure is briefly described and the proposed method is analyzed; in
Section 3, the proposed software is outlined in detail; in
Section 4, a variety of experiments are conducted and presented; and finally in
Section 5, some conclusions and future guidelines are discussed.
2. Methods
In this section, a brief overview of grammatical evolution, its applications and its advantages is given and then presented: the creation of artificial features using grammatical evolution, the first phase of the method where features are constructed and evaluated, and the second phase of the method, where the characteristics from the first phase are evaluated.
2.1. Grammatical Evolution
Grammatical evolution is a biologically inspired procedure that can create artificial programs in any language. In grammatical evolution, the chromosomes enclose production rules from a BNF (Backus–Naur form) grammar [
45]. These grammars are usually described as a set
, where
N is the set of non-terminal symbols.
T is the set of terminal symbols.
S is a non-terminal symbol defined as the start symbol of the grammar.
P is a set of production rules in the form or .
In order for grammatical evolution to work, the original grammar is expanded by enumerating all production rules. For example, consider the modified grammar of
Figure 2. The symbols that are in <> are considered as non-terminal symbols. The numbers in parentheses are the production sequence numbers for each non-terminal symbol. The constant N is the original number of features for the input data. In grammatical evolution, the chromosomes are expressed as vectors of integers. Every element of each chromosome denotes a production rule from the provided BNF grammar. The algorithm starts from the start symbol of the grammar and gradually produces some program string by replacing non-terminal symbols with the right hand of the selected production rule. The selection of the rule has two steps:
Take the next element from the chromosome and denote it as V.
Select the next production rule according to the the scheme Rule = V mod R, where R is the number of production rules for the current non-terminal symbol.
For example, consider the chromosome
and
. The steps of mapping this chromosome to the valid expression
are illustrated in
Table 1.
Initially, grammatical evolution was used in cases of learning functions [
46,
47] and solving trigonometric identities [
48], but then it was also applied in other fields such as automatic composition of music [
49], construction of neural networks [
50,
51], automatic constant creation [
52], evolution of video games [
53,
54], energy demand estimation [
55], combinatorial optimization [
56], cryptography [
57], etc.
A key advantage of the grammatical evolution is its easy adaptability to a wide range of problems, as long as the grammar of the problem and a fitness method are provided. No additional knowledge of the problem is required such as using derivatives. Furthermore, the method can be easily parallelized, since it is essentially a genetic algorithm of integer values. However, there are a number of disadvantages that must be taken into account when using the technique. In principle, in many cases a chromosome may not be able to produce a valid expression in the underlying grammar if its elements run out. In this case, wrapping an effect can be executed, but it is not always certain that this can again provide a valid solution. Moreover, another important issue is the initialization of the chromosomes of grammatical evolution. Usually the rules are very few in number and therefore, different numbers on the chromosomes may produce the same rules.
In the next subsection, the steps of producing artificial features from the original ones are provided and discussed.
2.2. The Feature Construction Procedure
The proposed technique is divided into two phases: in the first phase, new features are constructed from the old ones using grammatical evolution and in the second phase, these new features modify the control set, and a machine learning model is applied to the new control set. The following procedure is executed in order to produce features from the original ones for a given chromosome X:
Every feature
is considered as a mapping function that transforms the original features to a new one. For example, the feature
is a non-linear function that maps the original feature
into
. Let
. The mapping procedure will create the value
.
2.3. The Feature Construction Step
This is the first phase of the proposed method and it has the following steps:
- 1
Initialization step.
- (a)
Read the train data. The train data contain M patterns as pairs , where is the actual output for pattern .
- (b)
Set , the maximum number of generations.
- (c)
Set , the number of chromosomes.
- (d)
Set , the selection rate.
- (e)
Set, the desired number of features.
- (f)
Set , the mutation rate.
- (g)
Initialize the chromosomes of the population. Every element of each chromosome is initialized randomly in the range [0, 255].
- (h)
Set iter = 1.
- 2
Genetic step.
- (a)
For do
- i
Create, using the procedure of
Section 2.2, a set of
for the corresponding chromosome
.
- ii
Transform the original train data to the new train data using the previously created features. Denote the new train set as .
- iii
Apply a learning model
C (such as RBF) to the new data and
calculate the fitness
as
- iv
Apply the selection procedure. During selection, the chromosomes are classified according to their fitness. The best chromosomes are transferred without changes to the next generation of the population. The rest will be replaced by chromosomes that will be produced at the crossover.
- v
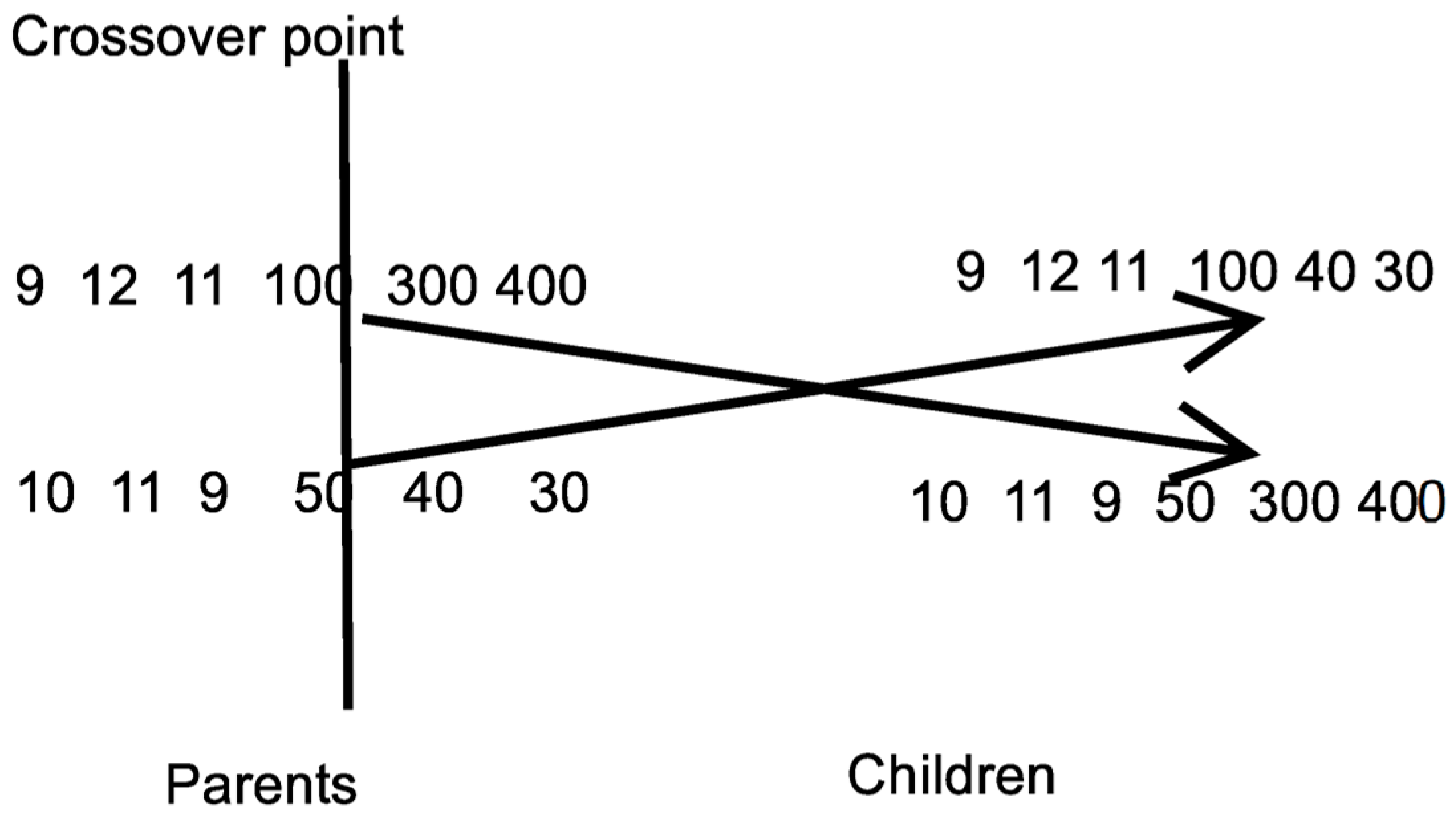
Apply the crossover procedure. During this process,
chromosomes will be created. Firstly, for every pair of produced offsprings, two distinct chromosomes (parents) are selected from the current population using tournament selection: First, a subset of
randomly selected chromosomes is created and the chromosome with the best fitness value is selected as parent. For every pair
of parents, two new offsprings
and
are created through one point crossover as graphically shown in
Figure 3.
- vi
Apply the mutation procedure. For every element of each chromosome, select a random number and alter the corresponding chromosome if .
- (b)
End For
- 3
Set iter = iter + 1.
- 4
If, goto Genetic Step, else terminate and obtain as the best chromosome in the population.
2.4. The Feature Evaluation Step
During the feature evaluation step, the following steps are executed:
Denote as the original test set.
Obtain the best chromosome of the feature construction step.
Construct features for
using the procedure of
Section 2.2.
TransformT into using the previously constructed features.
Apply a learning model such as RBF or a neural network to and obtain the test error.
4. Experiments
A series of experiments were performed in order to evaluate the reliability and accuracy of the proposed methodology. In these experiments, the accuracy of the proposed methodology against other techniques, the running time of the experiments, and the sensitivity of the experimental results to various critical parameters, such as the number of features or the maximum number of generations of the genetic algorithm, were measured. All the experiments were conducted 30 times with different seeds for the random number generator each time and averages were taken. All the experiments were conducted on an AMD Ryzen 5950X equipped with 128GB of RAM. The operating system used was OpenSUSE Linux, and all the programs were compiled using the GNU C++ compiler. In all the experiments, the parameter
featureCreateModel had the value rbf, since it is the fastest model that could be used and it has high learning rates. For classification problems, the average classification error on the test set is shown and, for regression datasets, the average mean squared error on the test set is displayed. In all cases, 10-fold cross-validation was used, and the number of parameters for neural networks and for RBF networks was set to 10. The evaluation of the features constructed by grammatical evolution was made using the Function Parser library [
65].
4.1. Experimental Datasets
The validity of the method was tested on a series of well-known datasets from the relevant literature. The main repositories for the testing were:
The classification datasets are:
Australian dataset [
66], a dataset related to credit card applications.
Alcohol dataset, a dataset about Alcohol consumption [
67].
Balance dataset [
68], which is used to predict psychological states.
Cleveland dataset, a dataset used to detect heart disease and used in various papers [
69,
70].
Dermatology dataset [
71], which is used for differential diagnosis of erythemato-squamous diseases.
Glass dataset. This dataset contains glass component analysis for glass pieces that belong to six classes.
Hayes Roth dataset [
72]. This dataset contains
5 numeric-valued attributes and 132 patterns.
Heart dataset [
73], used to detect heart disease.
HouseVotes dataset [
74], which is about votes in the U.S. House of Representatives Congressmen.
Liverdisorder dataset [
75], used to detect liver disorders in peoples using blood analysis.
Ionosphere dataset, a meteorological dataset used in various research papers [
76,
77].
Mammographic dataset [
78]. This dataset can be used to identify the severity (benign or malignant) of a mammographic mass lesion from BI-RADS attributes and the patient’s age. It contains 830 patterns of 5 features each.
PageBlocks dataset. The dataset contains blocks of the page layout of a document that has been detected by a segmentation process. It has 5473 patterns with 10 features each.
Parkinsons dataset, ref. [
79], which is created using a range of biomedical voice measurements from 31 people, 23 with Parkinson’s disease (PD). The dataset has 22 features.
Pima dataset [
80], used to detect the presence of diabetes.
PopFailures dataset [
81], used in meteorology.
Regions2 dataset. It is created from liver biopsy images of patients with hepatitis C [
82]. From each region in the acquired images, 18 shape-based and color-based features were extracted, while it was also annotated from medical experts. The resulting dataset includes 600 samples belonging to 6 classes.
Saheart dataset [
83], used to detect heart disease.
Segment dataset [
84]. This database contains patterns from a database of seven outdoor images (classes).
Sonar dataset [
85]. The task here is to discriminate between sonar signals bounced off a metal cylinder and those bounced off a roughly cylindrical rock.
Spiral dataset, which is an artificial dataset with two classes. The features in the first class are constructed as: and for the second class the used equations are:.
Wine dataset, which is related to chemical analysis of wines [
86,
87].
Wdbc dataset [
88], which contains data for breast tumors.
EEG dataset. As a real-world example, an EEG dataset described in [
89,
90] is used here. The dataset consists of five sets (denoted as Z, O, N, F, and S), each containing 100 single-channel EEG segments and each having a 23.6 sec duration. Sets Z and O have been taken from surface EEG recordings of five healthy volunteers with eye open and closed, respectively. Signals in two sets have been measured in seizure-free intervals from five patients in the epileptogenic zone (F) and from the hippocampal formation of the opposite hemisphere of the brain (N). Set S contains seizure activity, selected from all recording sites exhibiting ictal activity. Sets Z and O have been recorded extracranially, whereas sets N, F, and S have been recorded intracranially.
Zoo dataset [
91], where the task is to classify animals in seven predefined classes.
The regression datasets used are the following:
Abalone dataset [
92]. This dataset can be used to obtain a model to predict the age of abalone from physical measurements.
Airfoil dataset, which is used by NASA for a series of aerodynamic and acoustic tests [
93].
Baseball dataset, a dataset to predict the salary of baseball players.
BK dataset, used to estimate the points scored per minute in a basketball game.
BL dataset, which is related to the effects of machine adjustments on the time to count bolts.
Concrete dataset. This dataset is taken from civil engineering [
94].
Dee dataset, used to predict the daily average price of the electricity energy in Spain.
Diabetes dataset, a medical dataset.
FA dataset, which contains percentage of body fat and ten body circumference measurements. The goal is to fit body fat to the other measurements.
Housing dataset. This dataset was taken from the StatLib library and it is described in [
95].
MB dataset. This dataset is available from Smoothing Methods in Statistics [
96], and it includes 61 patterns.
MORTGAGE dataset, which contains economic data information from the USA.
NT dataset [
97], which is related to the body temperature measurements.
PY dataset [
98], used to learn Quantitative Structure Activity Relationships (QSARs).
Quake dataset, used to estimate the strength of an earthquake.
Treasure dataset, which contains economic data information from the USA from 1 April 1980 to 2 April 2000 on a weekly basis.
Wankara dataset, which contains weather information.
4.2. Experimental Results
The parameters for the used methods are listed in
Table 2. In all tables, an additional row was added at the end showing the average classification or regression error for all datasets, and it is denoted by the name AVERAGE. The columns of all tables have the following meaning:
The column RBF stands for the results from an RBF network with H Gaussian units.
The column MLP stands for the results of a neural network with
H sigmoidal nodes trained by a genetic algorithm. The parameters of this genetic algorithm are listed in
Table 2.
The column FCRBF represents the results of the proposed method, when an RBF network with H Gaussian units was used as the evaluation model.
The column FCMLP represents the results of the proposed method, when a neural network trained by a genetic algorithm was used as the evaluation model. The parameters of this genetic algorithm are listed in
Table 2.
The column FCNNC stands for the results of the proposed method, when the neural network construction model (nnc) was utilized as the evaluation model.
The column MRMR stands for the Minimum Redundancy Maximum Relevance Feature Selection method with two selected features. The features selected by MRMR are evaluated using an artificial neural network trained by a genetic algorithm using the parameters of
Table 2.
The Principal Component Analysis (PCA) method, as implemented in Mlpack software [
44], was used to construct two features. The features constructed by PCA are evaluated using an artificial neural network trained by a genetic algorithm using the parameters of
Table 2.
The experimental results for the classification datasets are listed in
Table 3, and for regression datasets in
Table 4. Furtheromre, a comparison against MRMR and PCA is performed in
Table 5 and
Table 6, respectively.
Summarizing the conclusions of the experiments, one can say that the proposed method obviously outperforms the other techniques in most cases, especially in the case of regression datasets. In the case of data classification, there is a gain of the order of 30%, and in the case of regression data, the gain from the application of the proposed technique exceeds 50%. The gain in many cases from the application of the proposed technique can even reach 90%. In addition, the MRMR method seems to be superior in most cases to the PCA, possibly pointing the way for a future research on the combination of grammatical evolution and MRMR. Furthermore, among the three cases of models used to evaluate the constructed features (FCRBF, FCMLP, FCNNC), there does not seem to be any clear superiority of any of the three. However, we would say that the nnc method slightly outperforms the simple genetic algorithm.
In addition, one more experiment was done in order to establish the impact of the number of features on the accuracy of the proposed method. In this case, the RBF (FCRBF) network was used as the feature evaluator, and the number of generated features was in the interval [1…4]. The average classification error and the average regression error for all datasets are shown in
Table 7. From the experimental results, the robustness of the proposed methodology is clearly visible, as one or two features seem to be enough to achieve high learning rates for the experimental data used.
Furthermore, one more experiment was conducted to determine the effect of the maximum number of generations on the accuracy of the proposed method. Again, as an evaluator model, the RBF was used. The number of generations was varied from 50 to 400, and the average classification error and average regression error for all datasets were measured. The results for this experiment are presented in
Table 8. Once again, the dynamics of the proposed method appear as a few generations are enough to achieve high learning rates.
5. Conclusions
A feature construction method and the accompanying software were analyzed in detail in this paper. The software is developed in ANSI C++ and is freely available on the internet. The proposed technique constructs technical features from the existing ones by exploiting the possible functional dependencies between the features, but also the possibility that some of the original features do not contribute anything to the learning. The method does not require any prior knowledge of the objective problem and can be applied without any change to both regression and classification problems. The method is divided into two phases: in the first phase, a genetic algorithm using grammatical evolution is used to construct new features from the original ones. These features are evaluated for their accuracy with some machine learning model. However, this process can be very time consuming and as a consequence, fast learning models or parallel algorithms should be used. Radial basis networks were used in the first phase of the method during the experiments, which are known to have short training times, but other models could be used in their place. In the second phase of the method after the features are generated, a machine learning method is applied to them and the error on the test set is evaluated.
The user can choose between several learning models and can customize the course of the technique through a series of command line parameters. From the extensive execution of experiments and the comparison with other learning methods, the superiority of the proposed technique and its ability to achieve high learning rates even with a limited number of constructed features or a maximum number of iterations emerge. These results combined with the ability of the method to run on multiple threads through the OpenMP library make it ideal for learning large sets of data in a satisfactory execution time.
The method can be extended in several ways, such as:
Incorporation of advanced stopping rules.
Usage of more advanced learning models such as SVM.
Addition of more input formats such as the ARFF format or CSV format.
Incorporation of the MPI library [
99] for a large network of computers.








{kind=link}
{kind=link}
{kind=link}
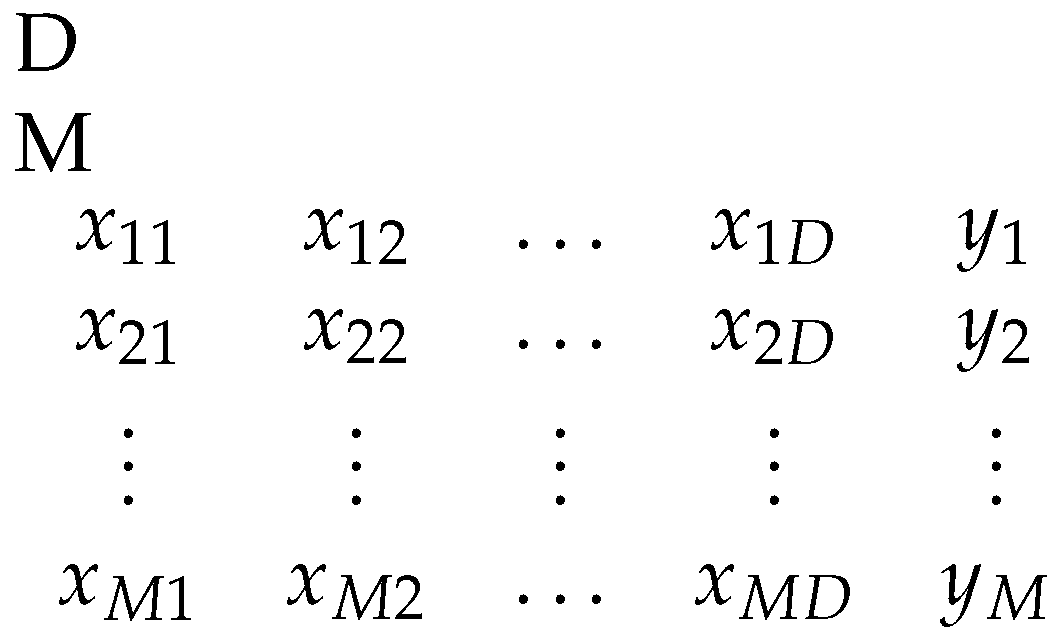{kind=link}
{kind=link}