
A Two-Stage Multi-Objective Genetic Algorithm for a Flexible Job Shop Scheduling Problem with Lot Streaming



Abstract
:1. Introduction
2. Literature Review
2.1. Pure Flow Shop Lot Streaming (PFS-LS)
2.2. Hybrid Flow Shop Lot Streaming (HFS-LS)
2.3. Classical Job Shop Lot Streaming (CJS-LS)
2.4. Flexible Job Shop Lot Streaming (FJS-LS)
3. Mathematical Modeling
3.1. The Basic Problem
3.1.1. Problem Description and Notations
| Additional Parameters | |
| Rm | The maximum number of production runs of machine m where production runs are indexed by . Each of these production runs can be assigned to, at most, one operation of one sublot. Thus, the assignment of the operations to production runs of a given machine determines the sequence of the operations on that machine. |
| Po,j,m | A binary data point equal to 1 if operation o of job j can be processed on machine m, and 0 otherwise. |
| Ao,j | A binary data point equal to 1 if the setup of operation o of of job j is attached (non-anticipatory), or 0 if this setup is detached (anticipatory). |
| Ω | Large positive number. |
| Variables | |
| Continuous Variables | |
| Cmax | Makespan of the schedule. |
| Co,s,j | Completion time of operation o of sublot s of job j. |
| Completion time of the run of machine m. | |
| bs,j | Size of sublot s of job j. |
| Binary Integer Variables | |
| xr,m,o,s,j | A binary variable that takes the value 1 if the run on machine m is for operation o of sublot s of job j, and 0 otherwise. |
| yr,m,o,j | A binary variable that takes the value 1 if the run on machine m is for operation o of any one of the sublots of job j, and 0 otherwise. |
| γs,j | A binary variable that takes the value 1 if sublot s of job j is non-zero (), and 0 otherwise. |
| zr,m | A binary variable that takes the value 1 if the potential run of machine m has been assigned to an operation, and 0 otherwise. |
3.1.2. MILP Model for FJSP-LS
3.2. Multi-Objective Model for FJSP-LS
3.2.1. Additional Continuous Variables
| es,j | Entry time of sublot s of job j. |
| Entry time of job j (minimum of for all s of job j). | |
| ds,j | Departure time of sublot s of job j. |
| Departure time of job j (maximum of for all s of job j). | |
| fs,j | Flowtime of sublot s of job j. |
| Flowtime of job j. | |
| fmax | Maximum sublot flowtime. |
| Maximum job flowtime. | |
| ftotal | Total sublot flowtime. |
| Total job flowtime. | |
| Minimum sublot departure time of job j. | |
| Sublot finish separation time of job j. | |
| Maximum sublot finish separation time. | |
| Total sublot finish separation time. | |
| lm,o,s,j | Workload on machine m because of the setup and processing of operation o of sublot s of job j. |
| Workload on machine m. | |
| Minimum machine workload. | |
| Maximum machine workload. | |
| Total machine workload. | |
| Maximum machine workload difference. |
3.2.2. Objective Functions and Additional Constraints
3.2.3. Makespan ()
3.2.4. Maximum and Total Sublot Flowtime ( and )
3.2.5. Maximum and Total Job Flowtime ( and )
3.2.6. Maximum and Total Sublot Finish-Time Separation ( and )
3.2.7. Maximum Workload, Total Workload and Maximum Workload-Difference (, and )
4. Genetic Algorithm
4.1. Prototype Problem
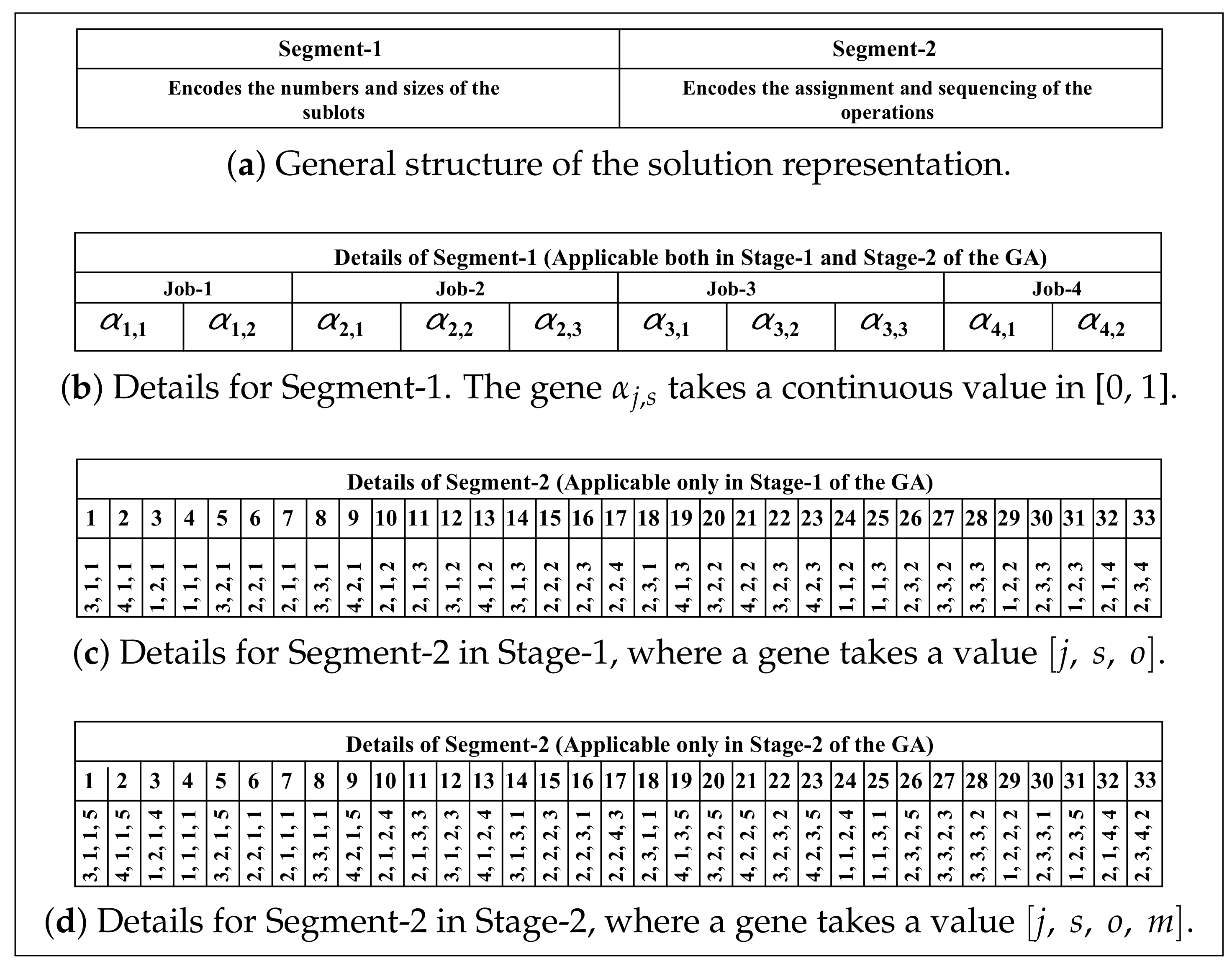
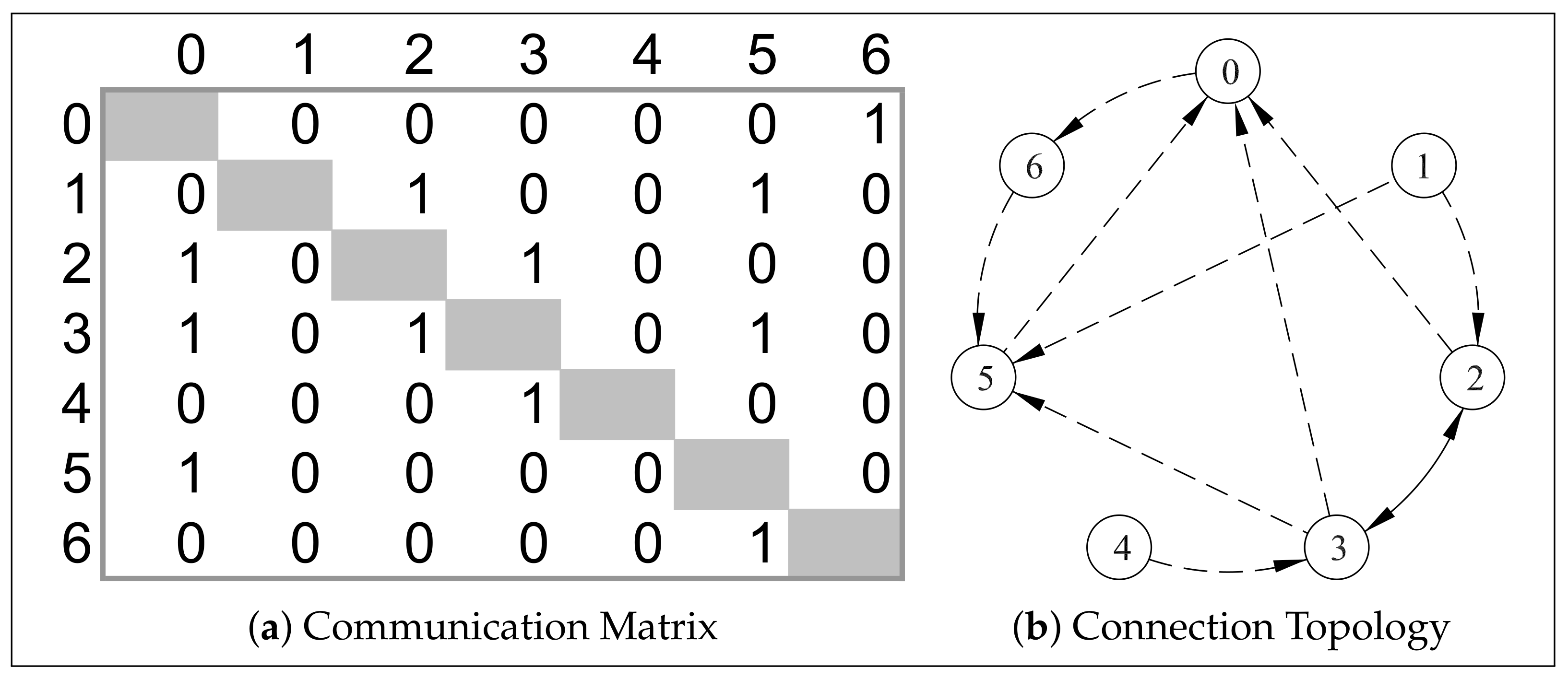
4.2. Solution Encoding
4.3. Solution Decoding
4.3.1. Number and Size of Sublots
4.3.2. Assignment, Sequencing, and Completion Time
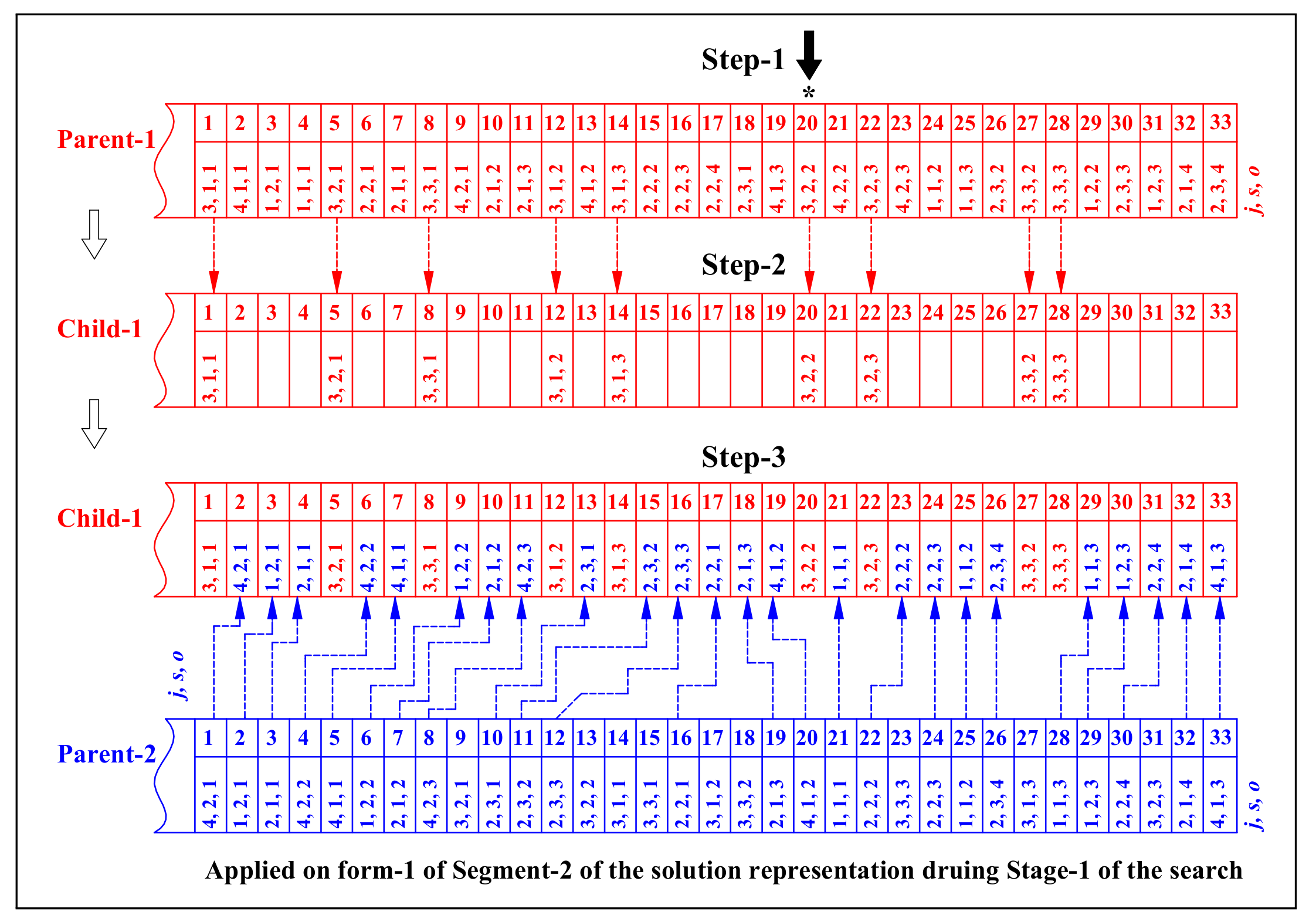
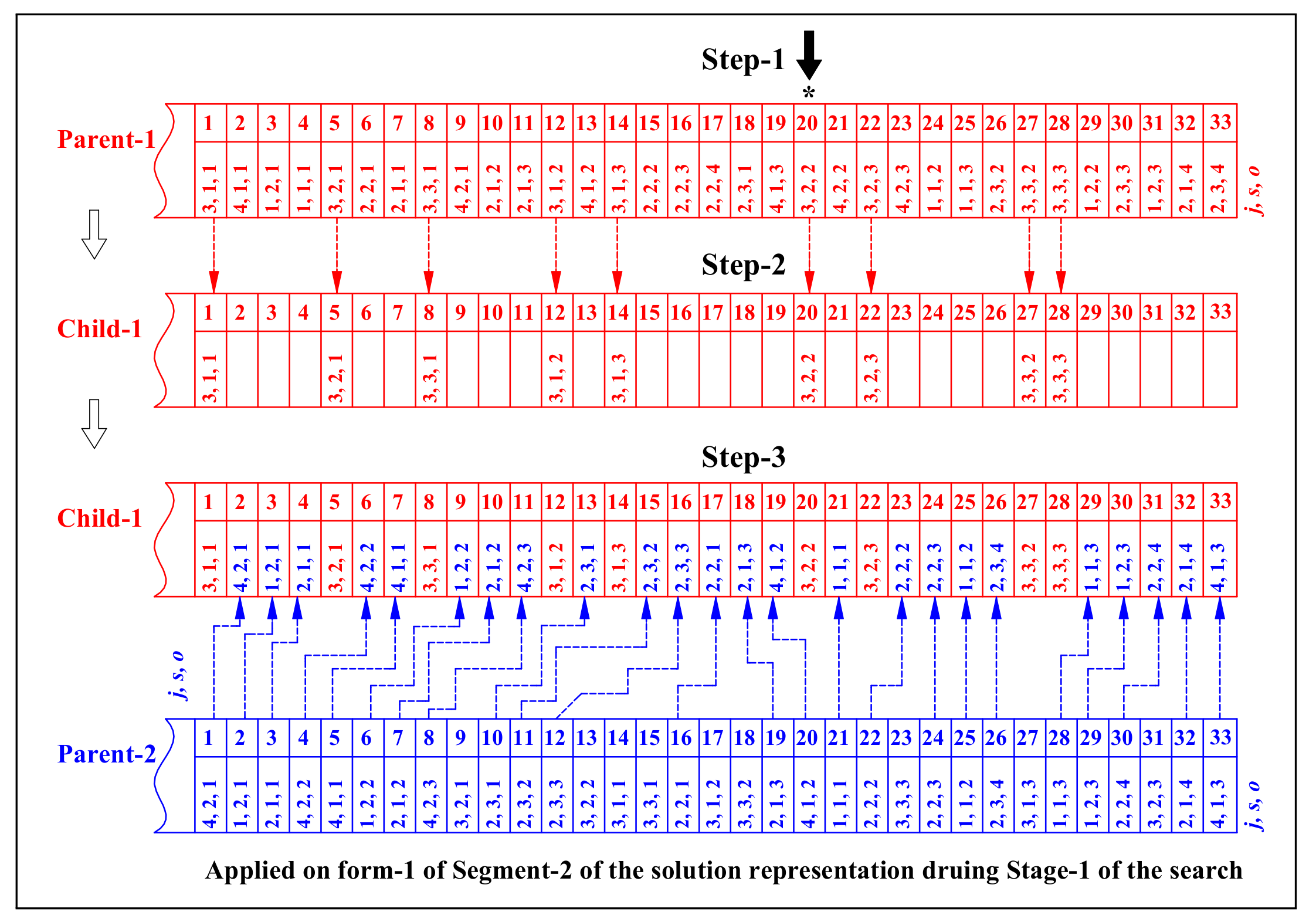
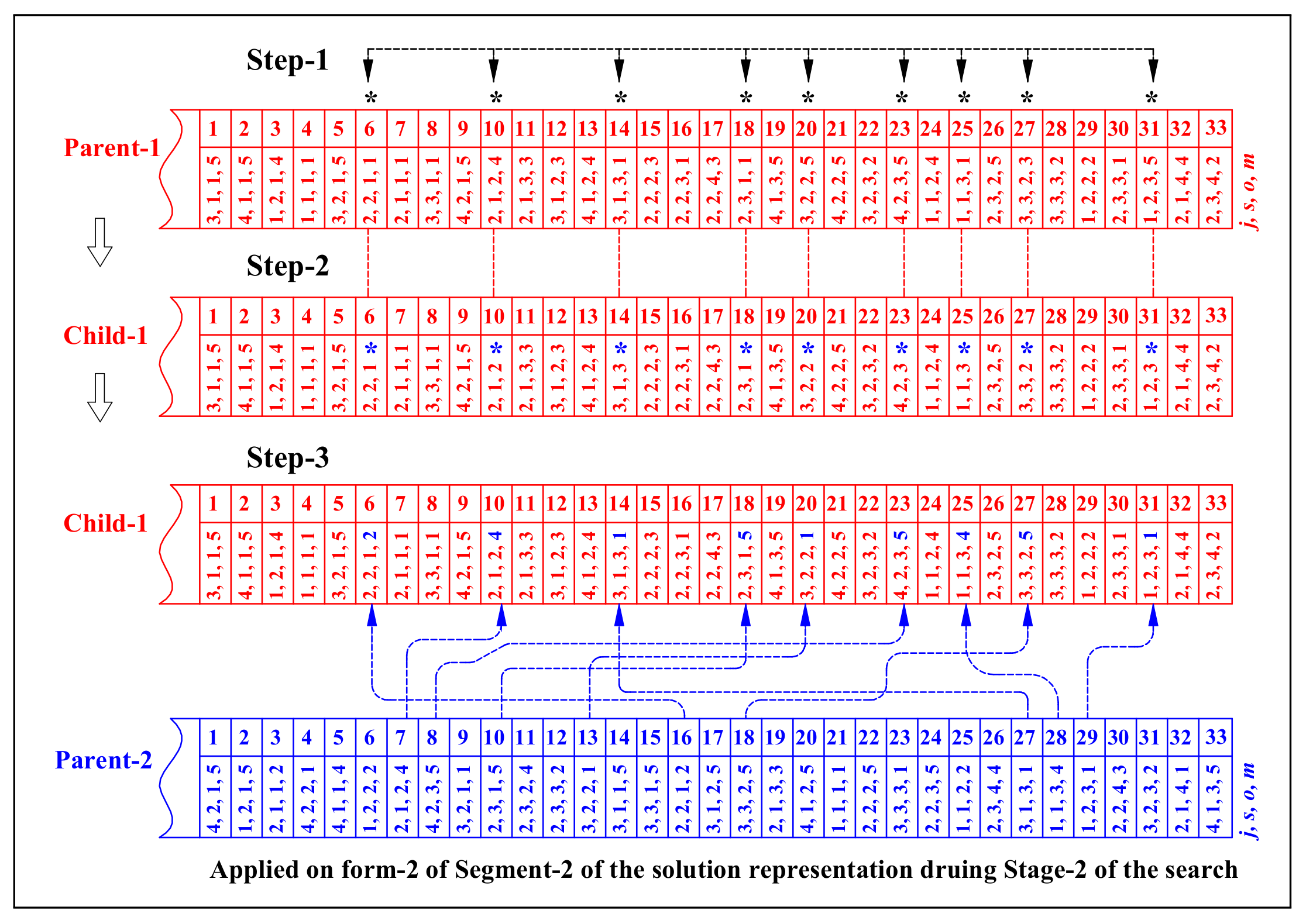
Stage-1
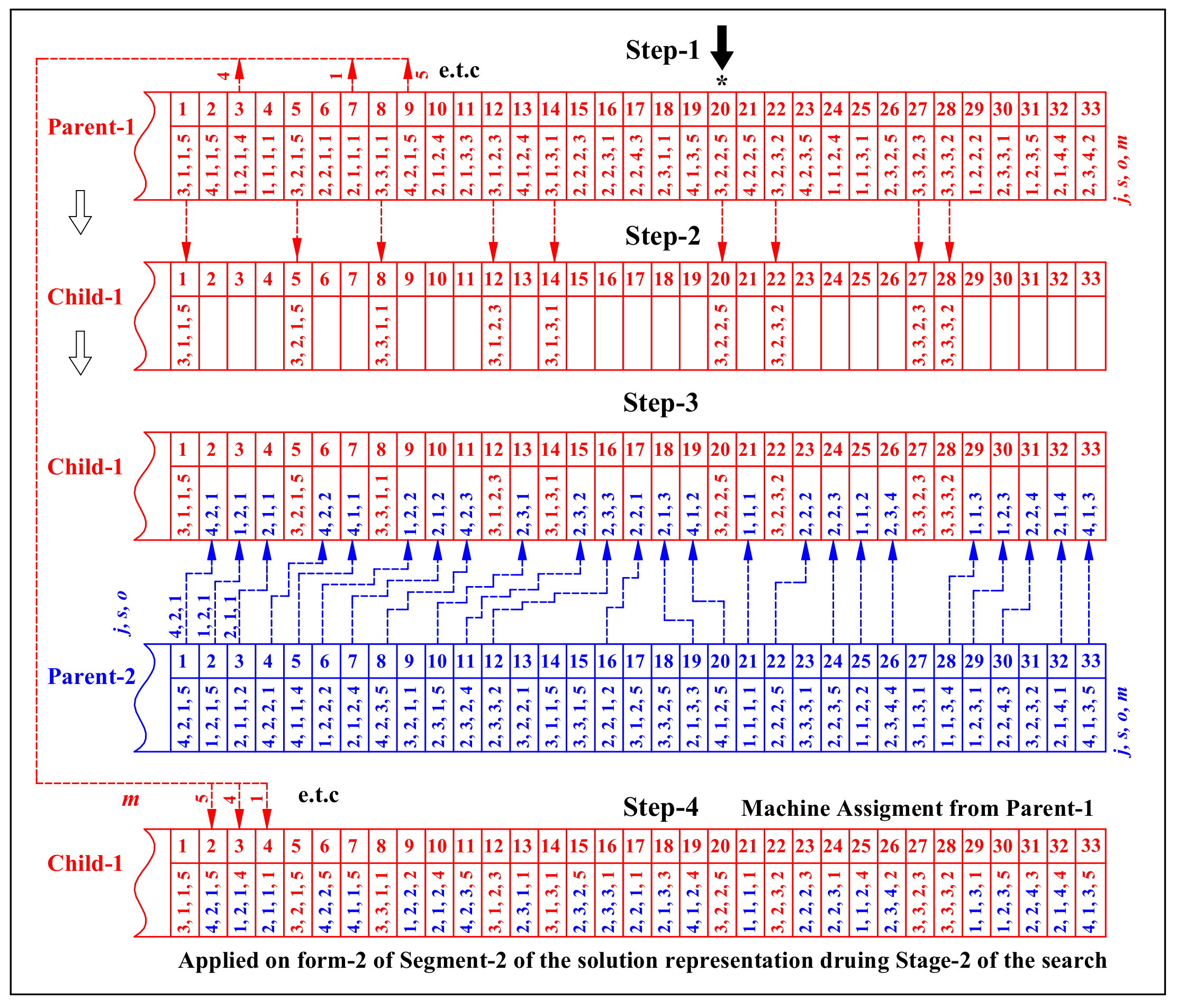
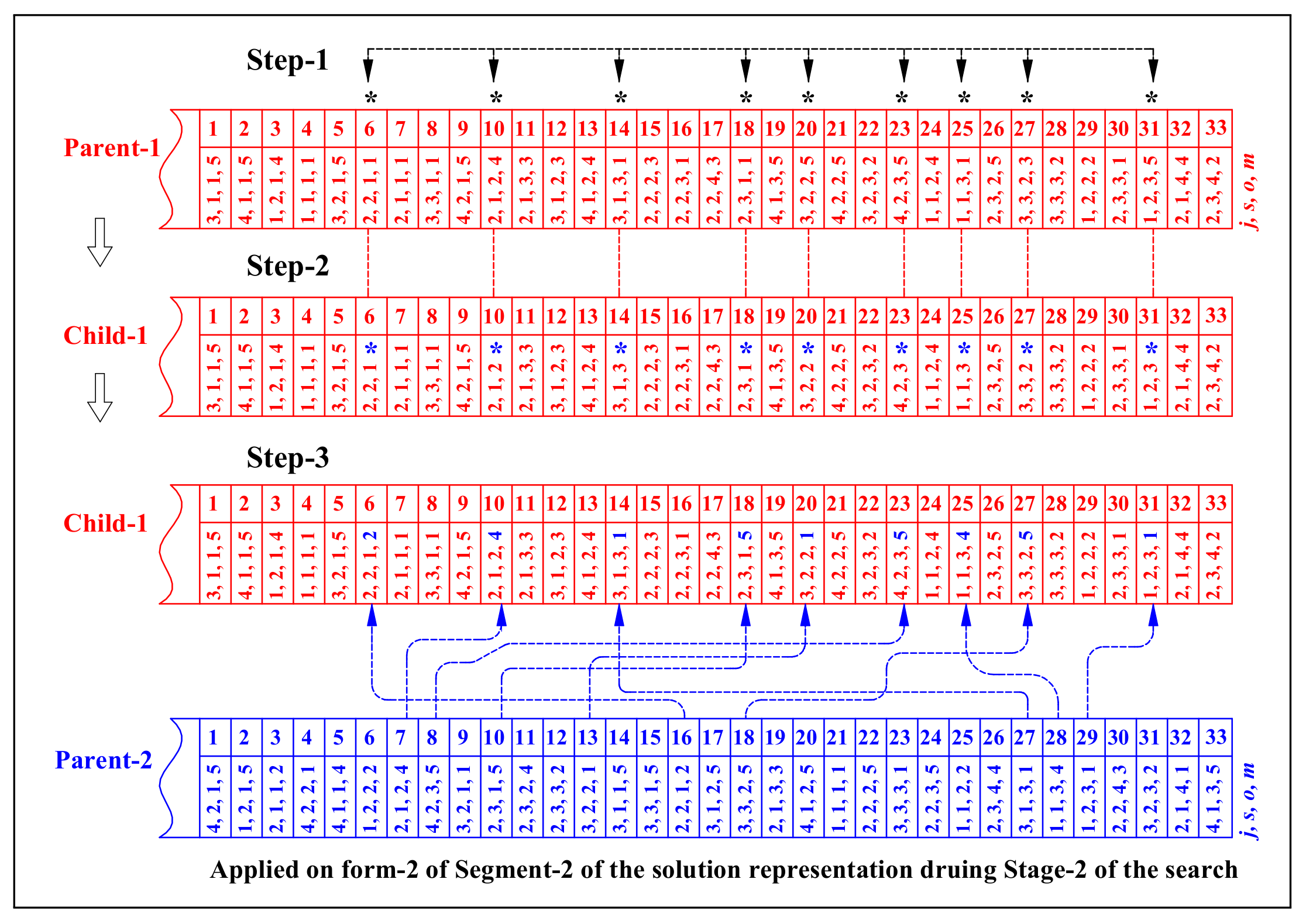
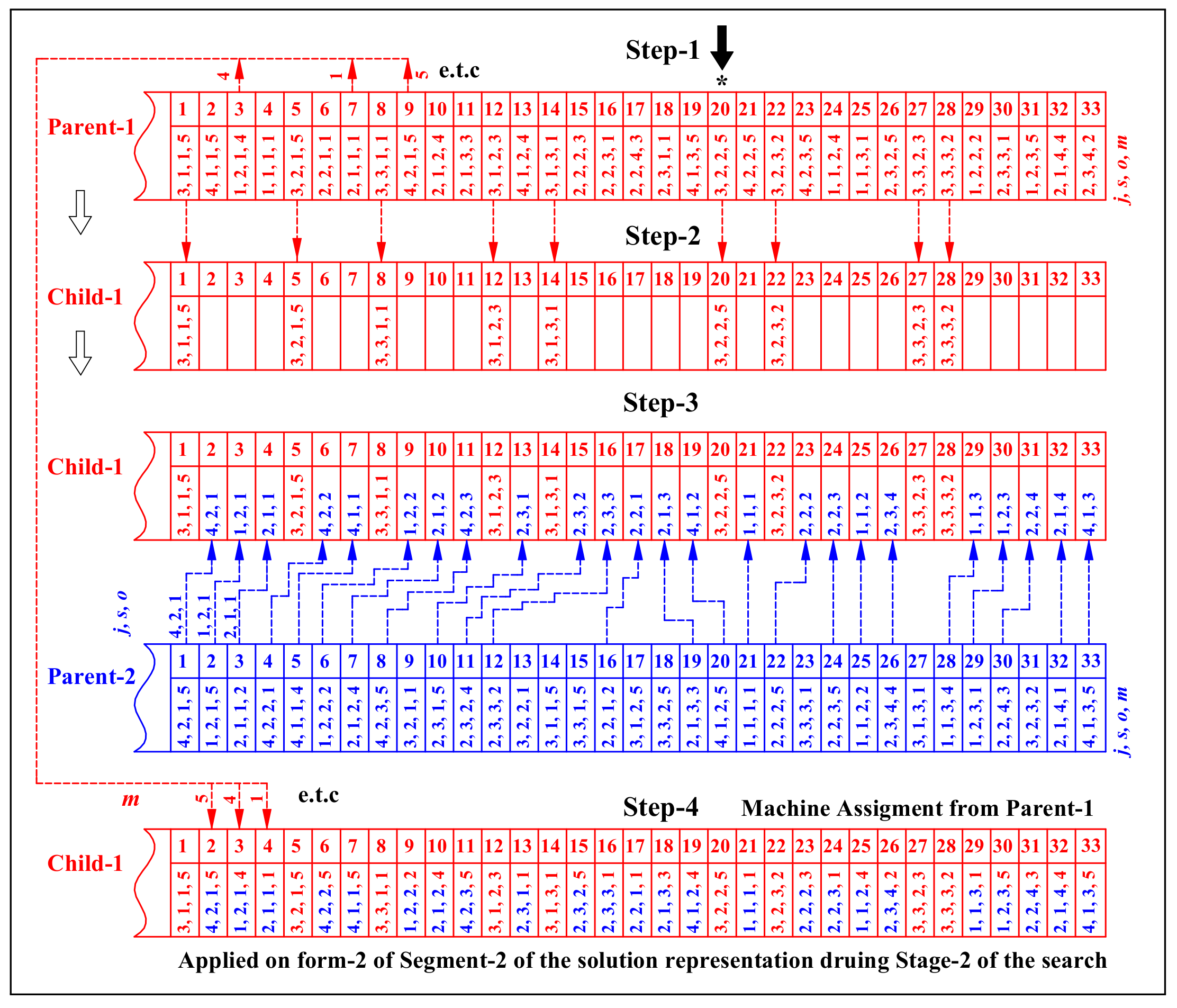
Stage-2
4.3.3. Calculating Objective Function Terms
4.4. Handling Multi-Objectives
4.5. Genetic Operators
4.5.1. Selection Operators
| N | Number of individuals (solutions) in a population. |
| U(t) | Population of solution at generation t. |
| U(i,t) | The individual in the population at generation t. |
| M(t) | Mating pool created via selection operator from the population (the size of the mating pool is the same as that of the population). |
| M(i,t) | The individual in the mating pool at generation t. |
| Z(i,t) | The weighted objective function value corresponding to the individual in the population at generation t. |
| Zmin(t) | The minimum observed weighted objective function value in the population at generation t. |
| Zmax(t) | The maximum observed weighted objective function value in the population at generation t. |
| F(i,t) | The fitness value of the individual in the population at generation t. |
| R(i,t) | The rank of the individual in the population at generation t for linear ranking selection. |
| P(i,t) | Probability of selection of individual in the population at generation t for proportional or linear ranking selection method. |
| T | Tournament size for tournament selection. |
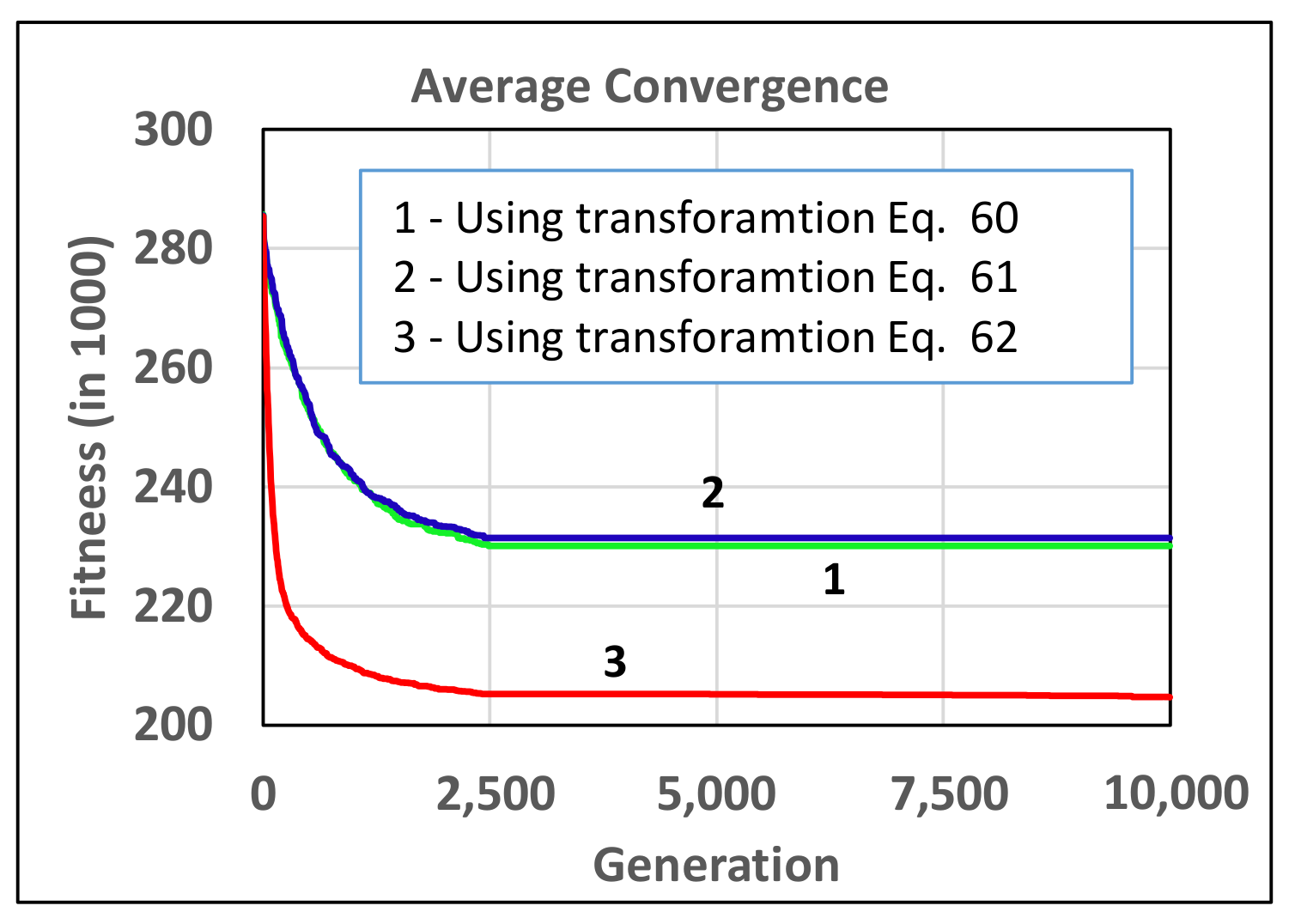
4.5.2. Proportional Selection
| Algorithm 1: Monte Carlo simulation of roulette wheel spinning for proportional or ranked selection. |
 |
| Algorithm 2: Creating the mating pool . |
 |
| Algorithm 3: Monte Carlo Simulation of Tournament selection. |
 |
4.5.3. Linear Ranking Selection
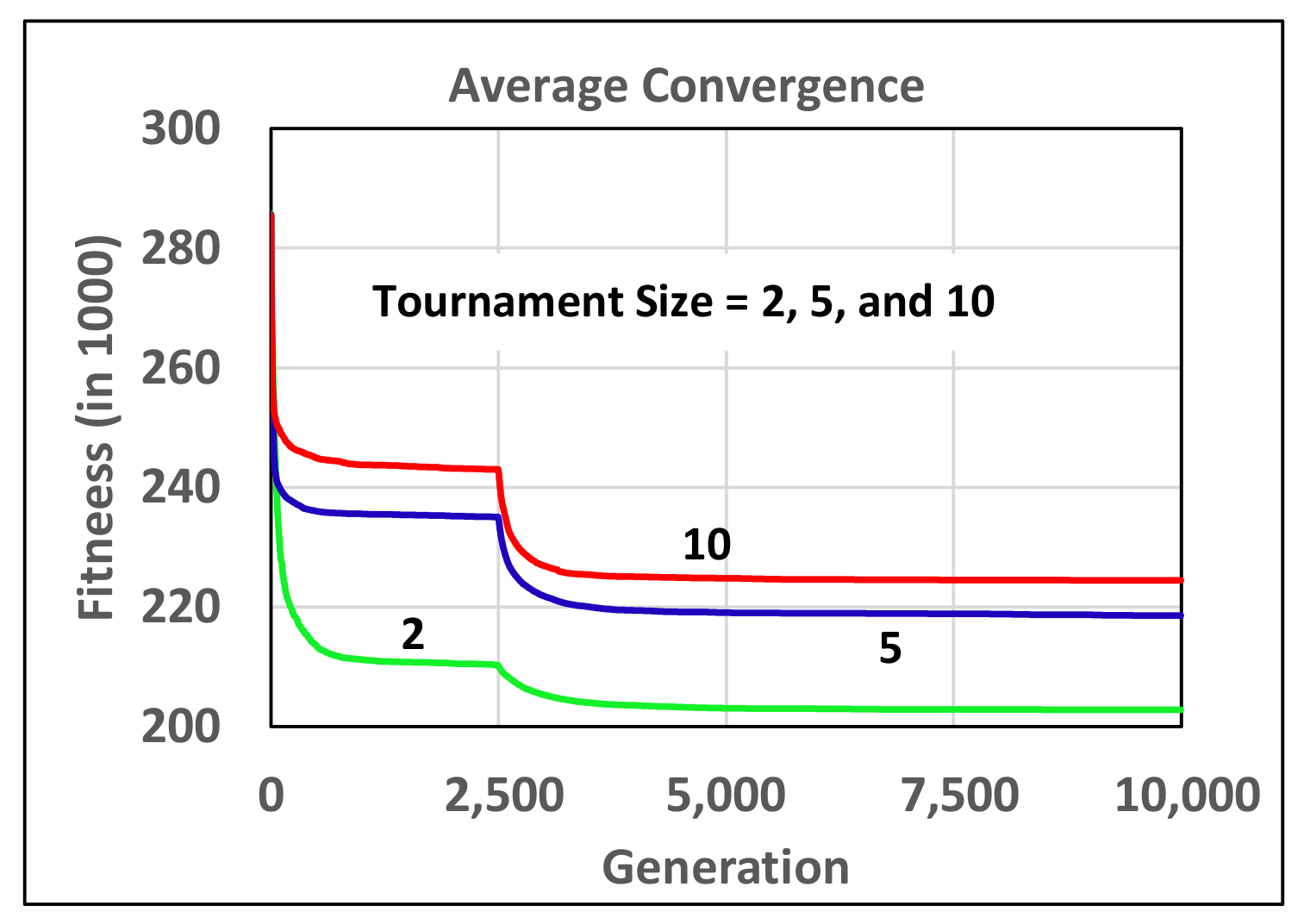
4.5.4. Tournament Selection
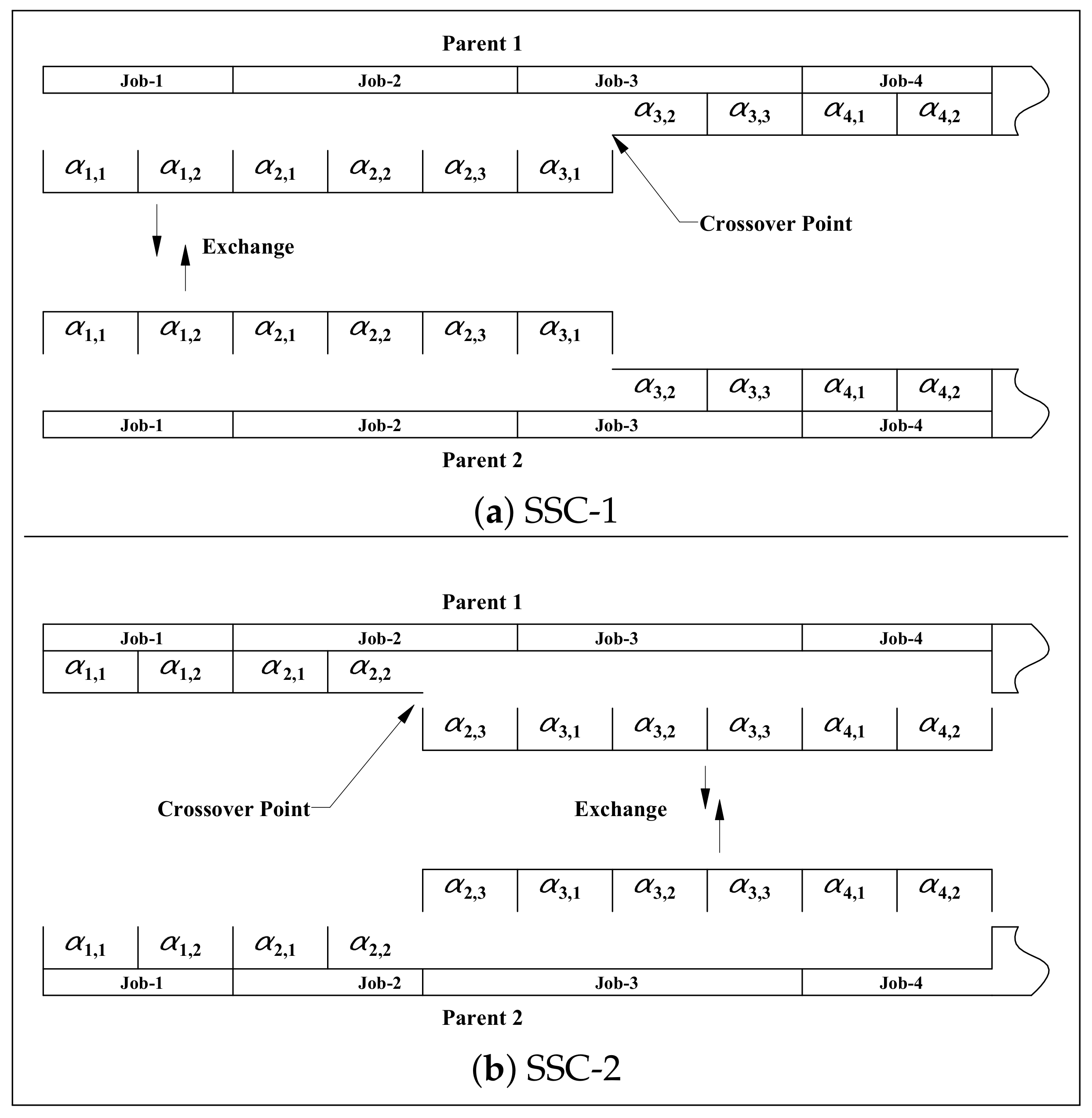
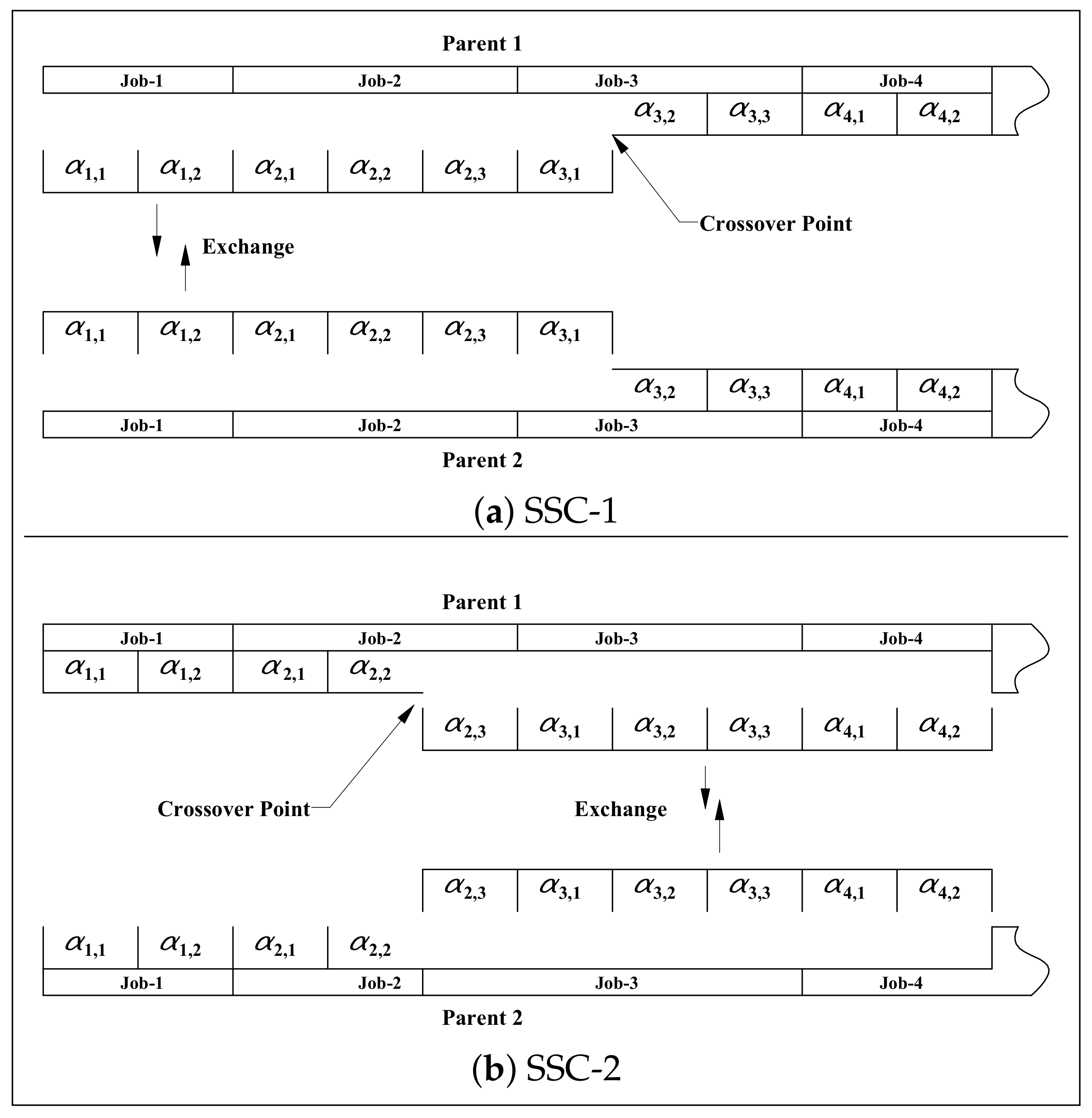
4.5.5. Crossover Operators
- (a)
- Sublot-Size Crossover-1 (SSC1).
- (b)
- Sublot-Size Crossover-2 (SSC2).
- (c)
- Job Level Gene Sequence Crossover (JLGSC).
- (d)
- Sublot Level Gene Sequence Crossover (SLGSC).
- (e)
- Job Level Operation Sequence Crossover (JLOSC).
- (f)
- Sublot Level Operation Sequence Crossover (SLOSC).
- (g)
- Machine Assignment Crossover (MAC).
4.5.6. Mutation Operators
- (a)
- Sublot Gene Value Mutation (SGVM).
- (b)
- Sublot Gene Swap Mutation (SGSM).
- (c)
- Operation Gene Shift Mutation (OGSM).
- (d)
- Operations Sequence Shift Mutation (OSSM).
- (e)
- Random Operation Assignment Mutation (ROAM).
- (f)
- Intelligent Operations Assignment Mutation (IOAM).
5. Numerical Studies
5.1. Model Analysis
5.1.1. Illustration of Objective Function Terms
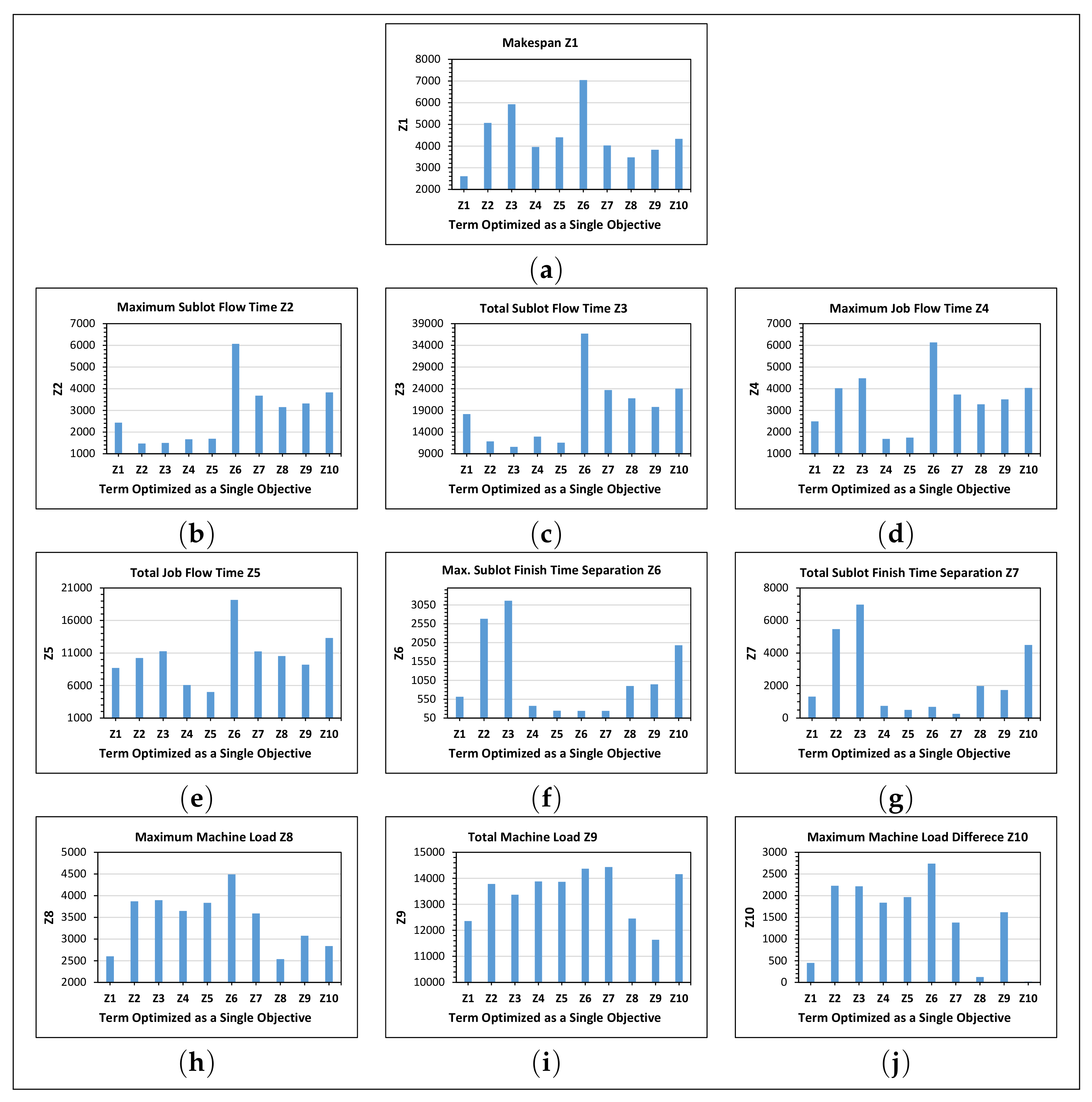
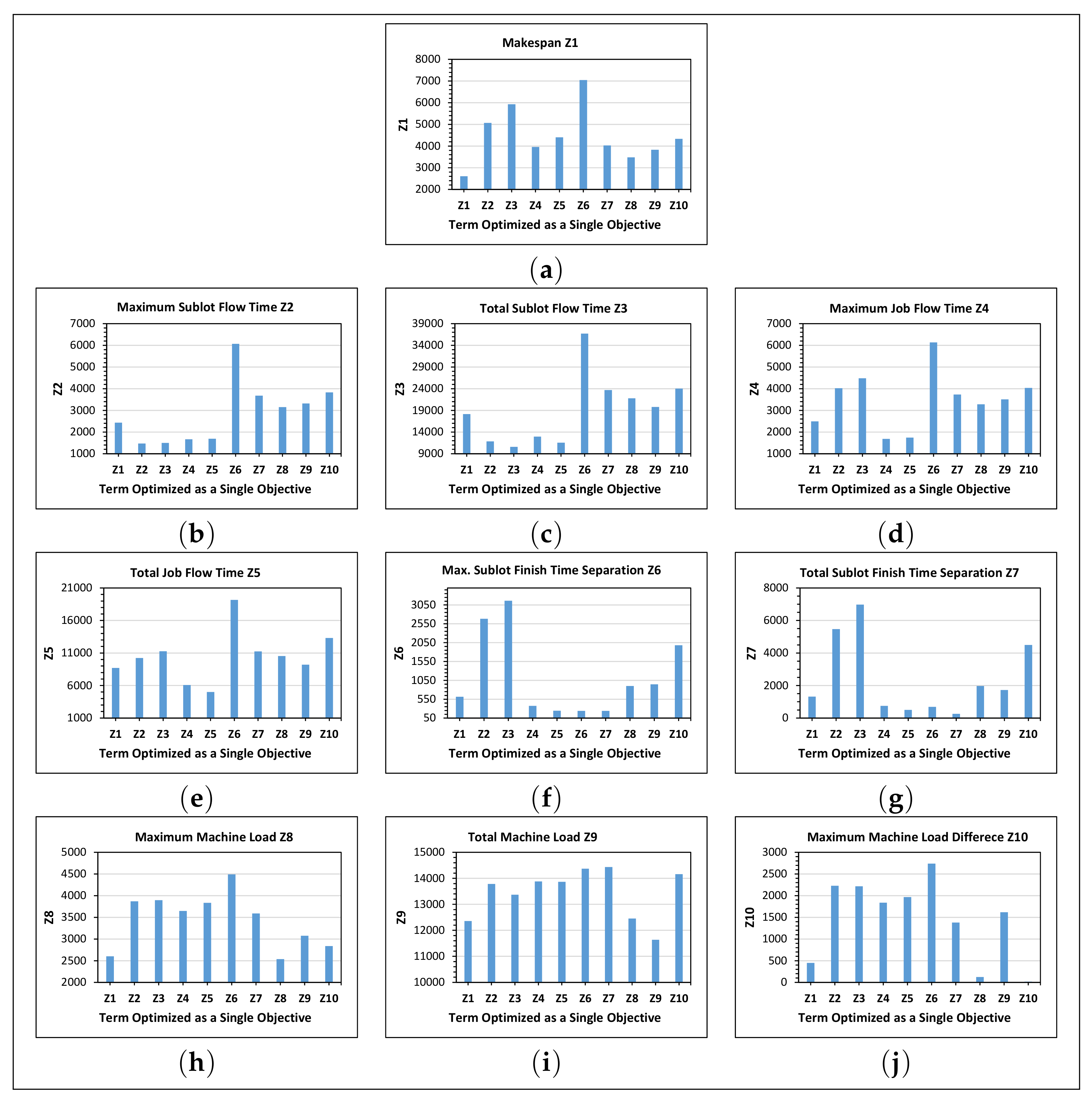
5.1.2. Optimizing a Single Objective
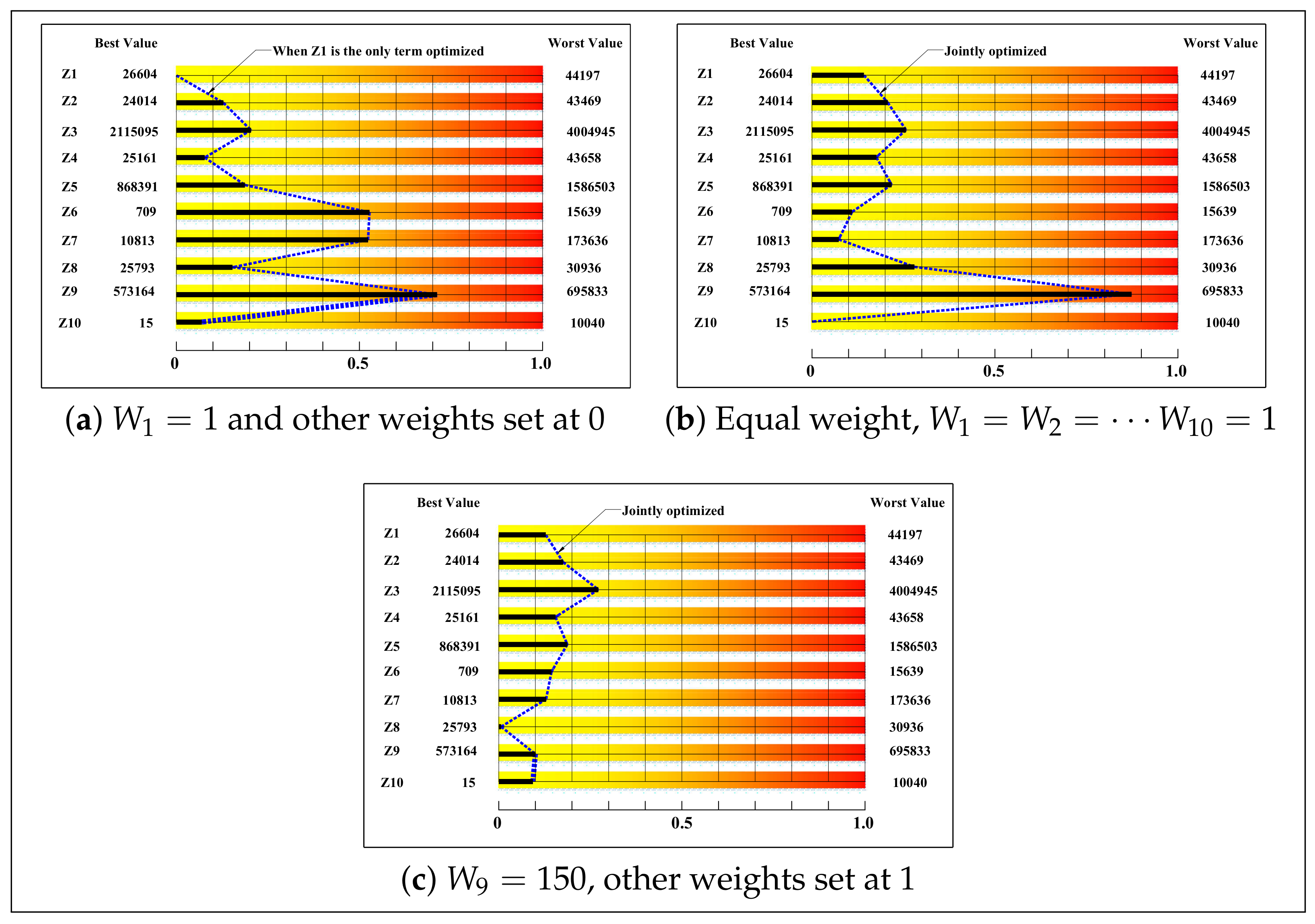
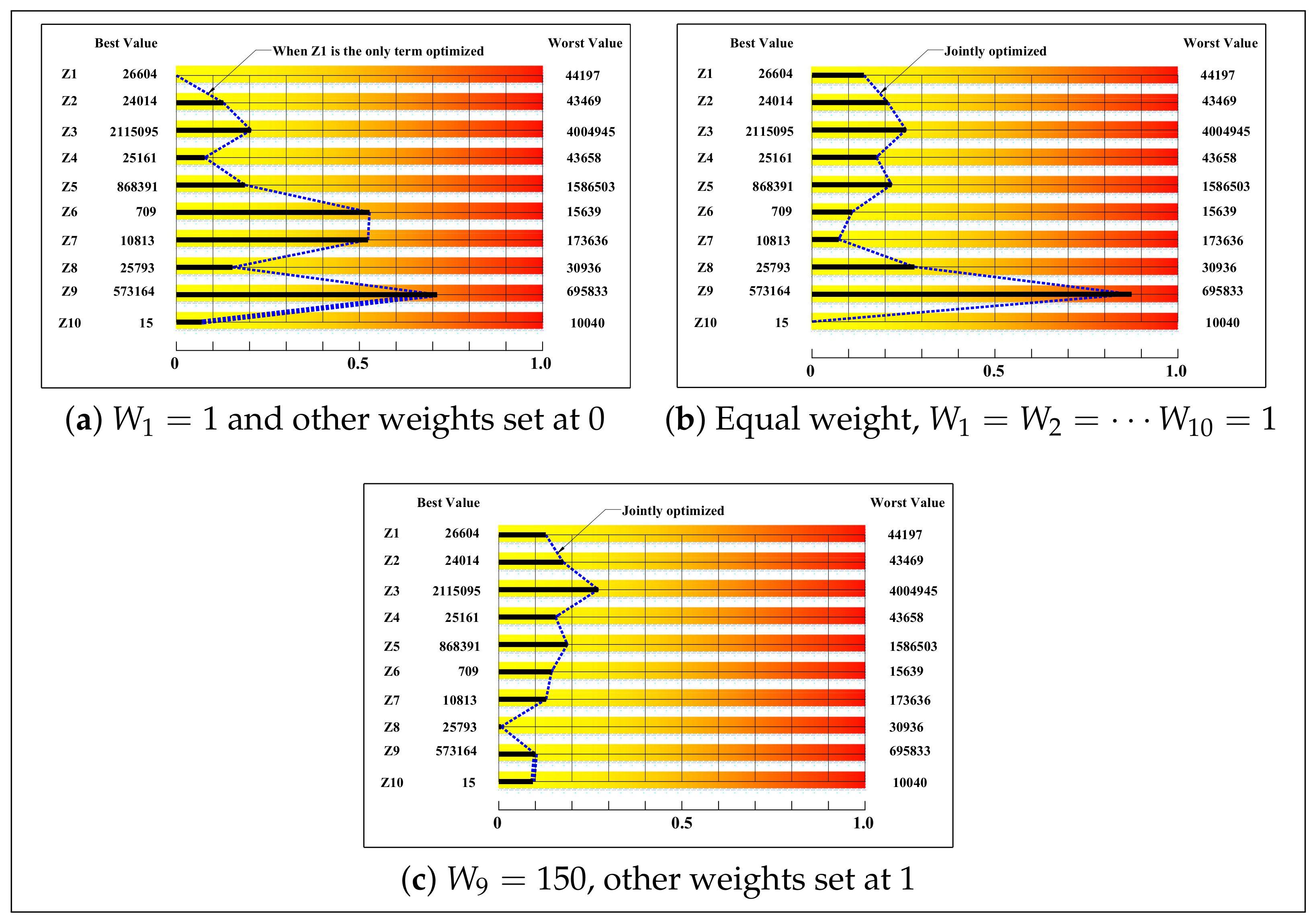
5.1.3. Jointly Optimizing
5.1.4. Further Empirical Study of Objective Functions
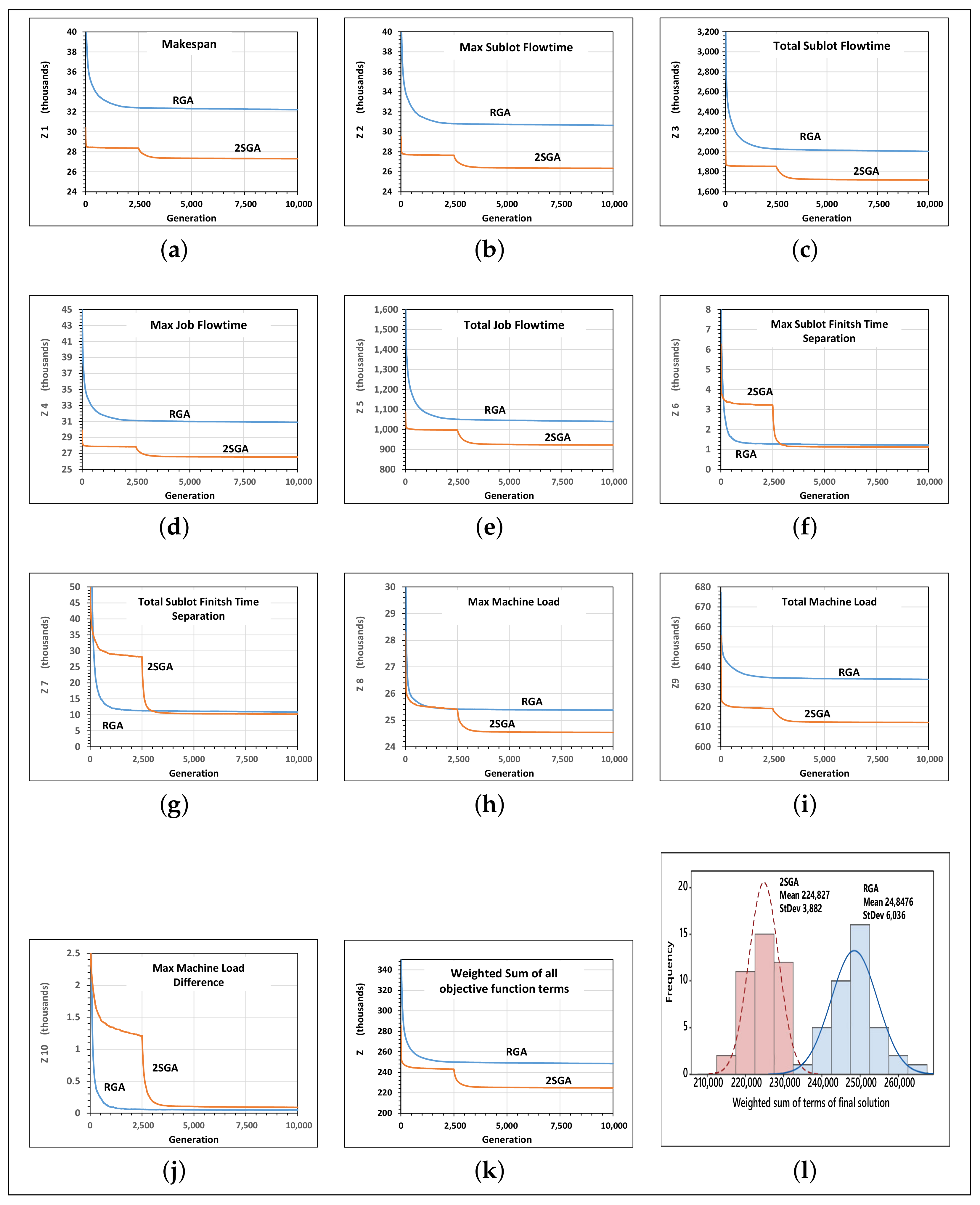
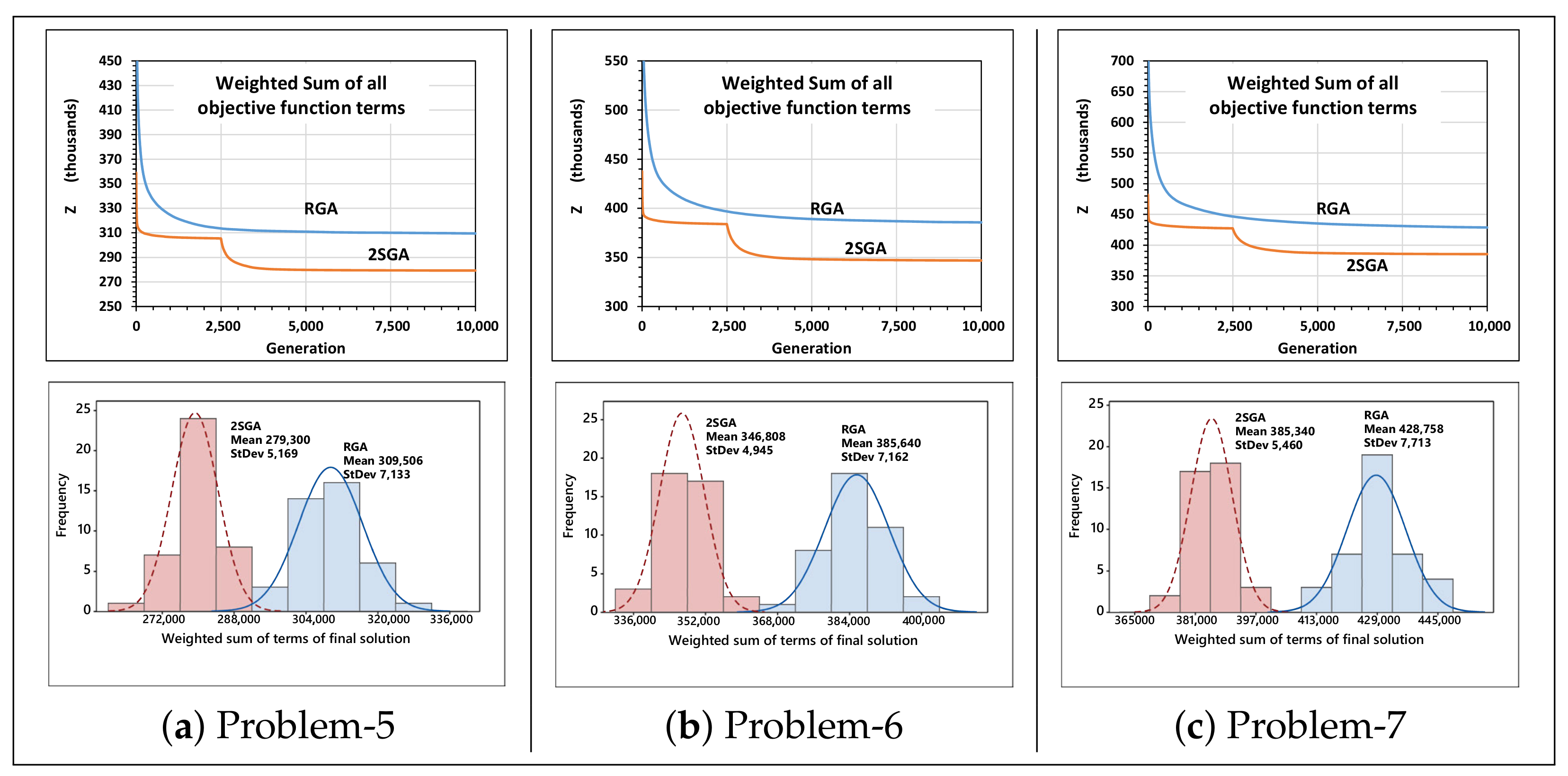
5.2. Performance Evaluation of RGA and 2SGA
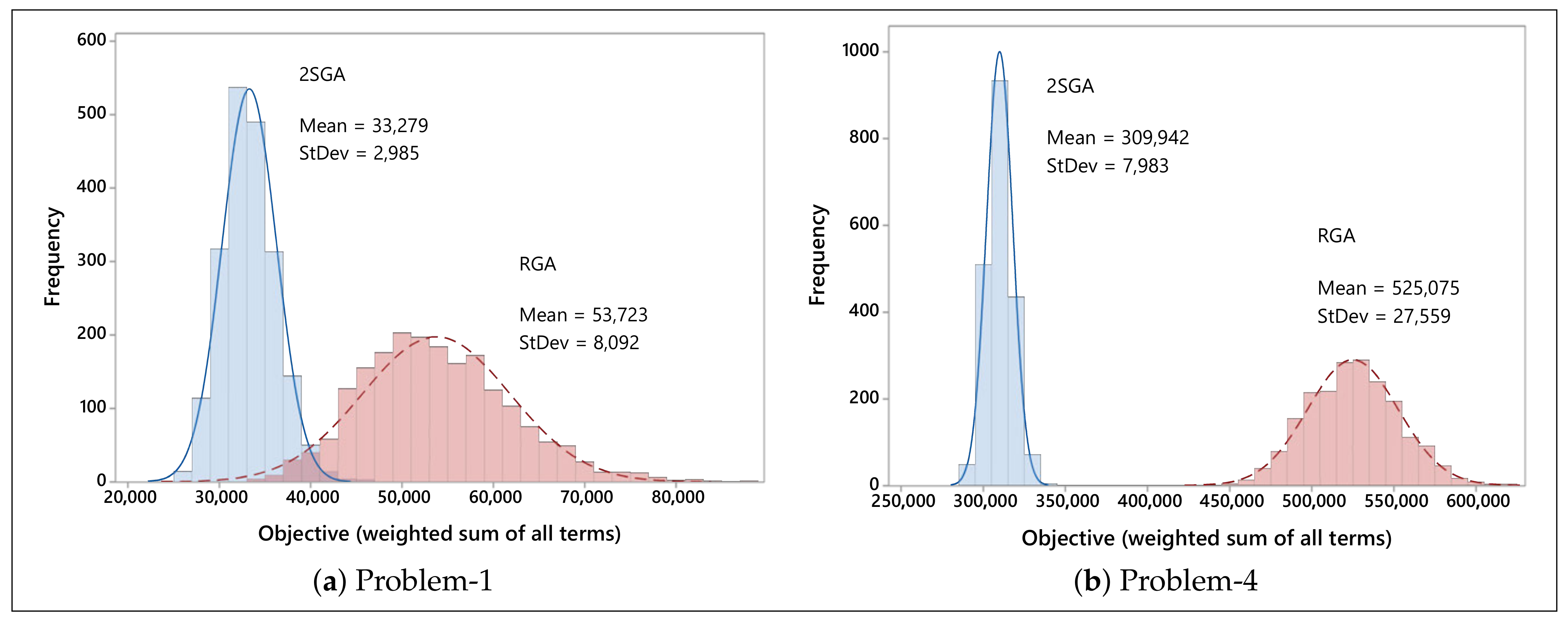
5.2.1. Initial Solution Quality
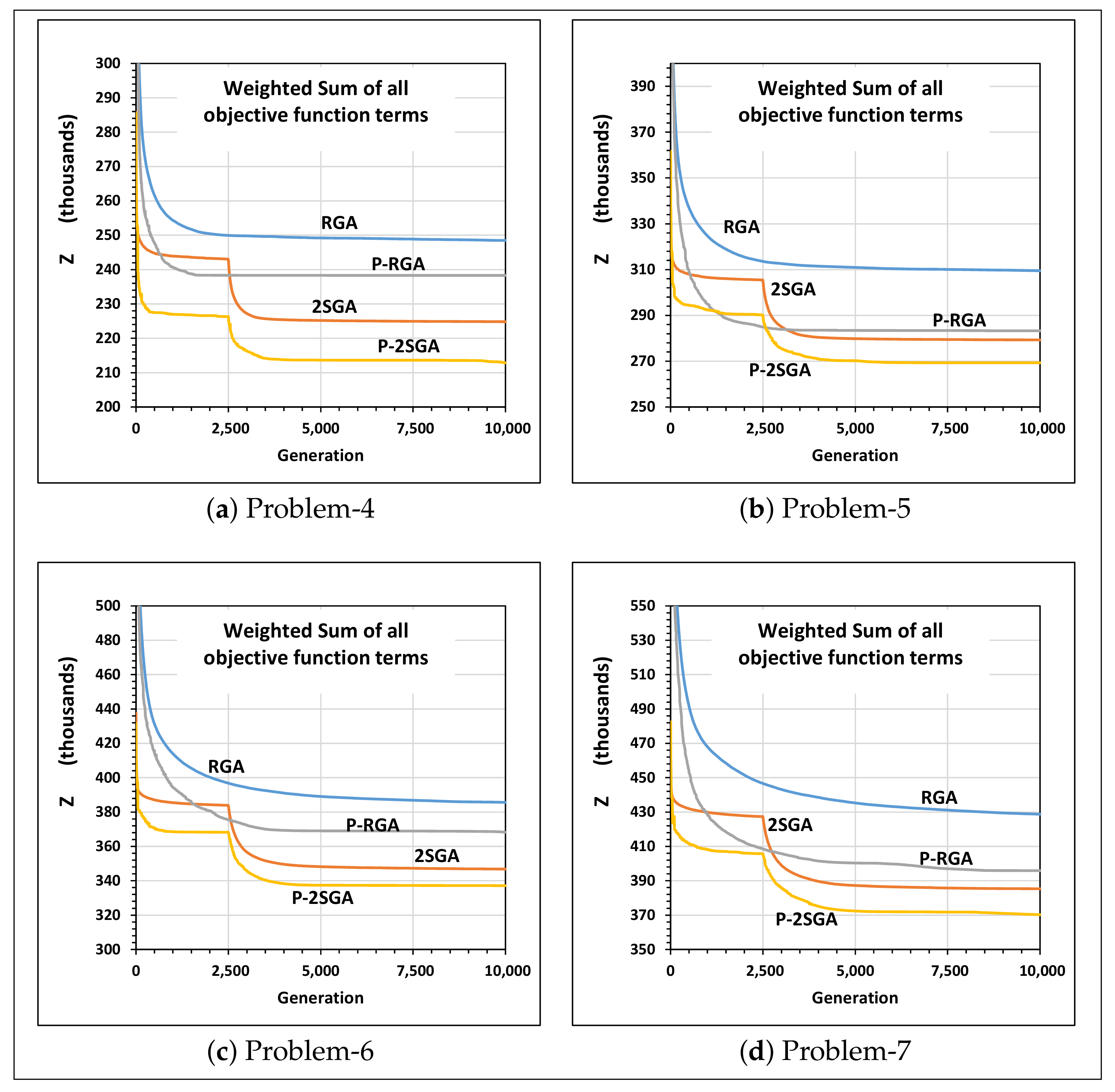
5.2.2. Convergence Behaviors
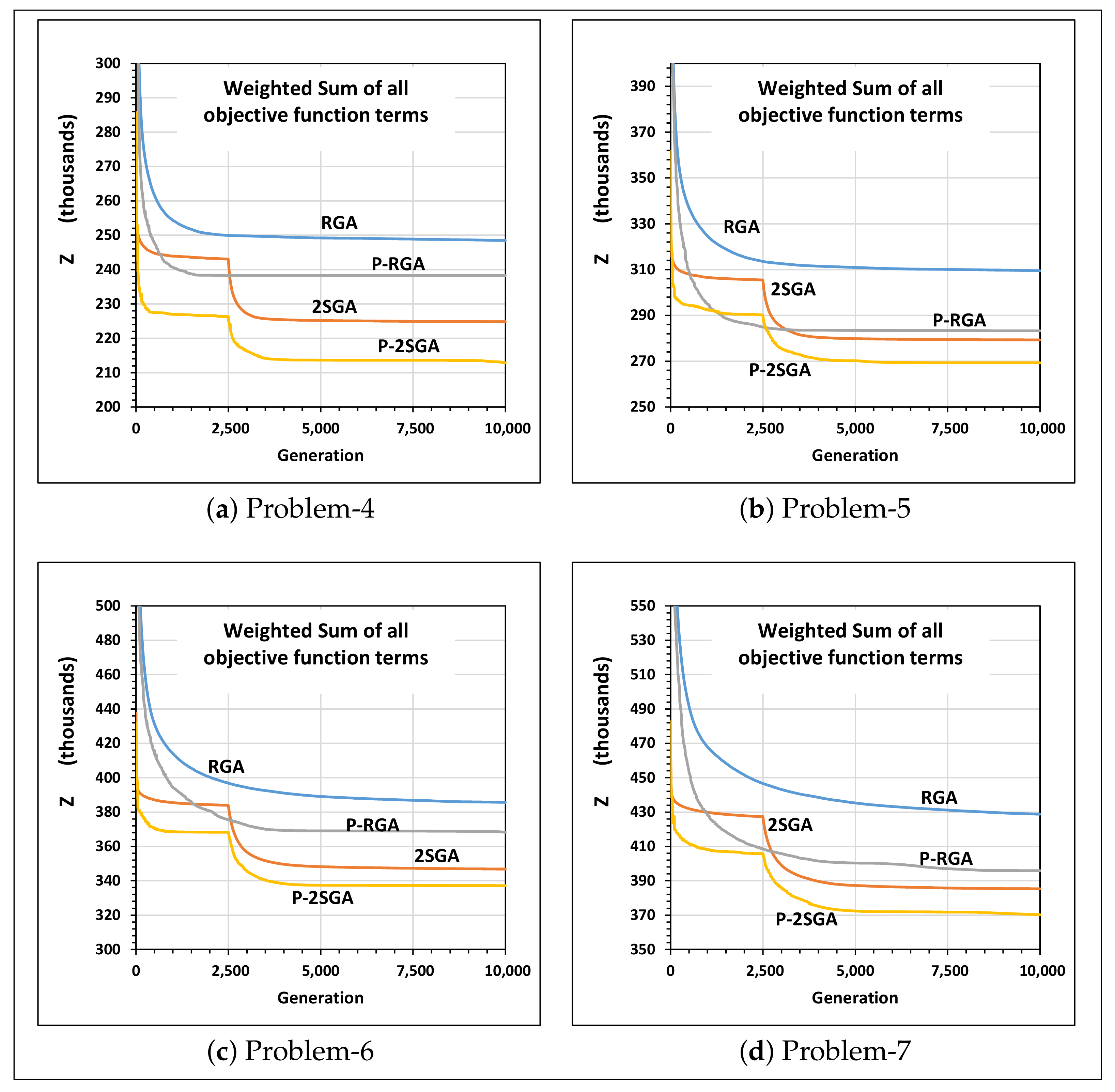
5.2.3. Improvement through Parallelization
5.3. Empirical Analysis of the Algorithm Parameters
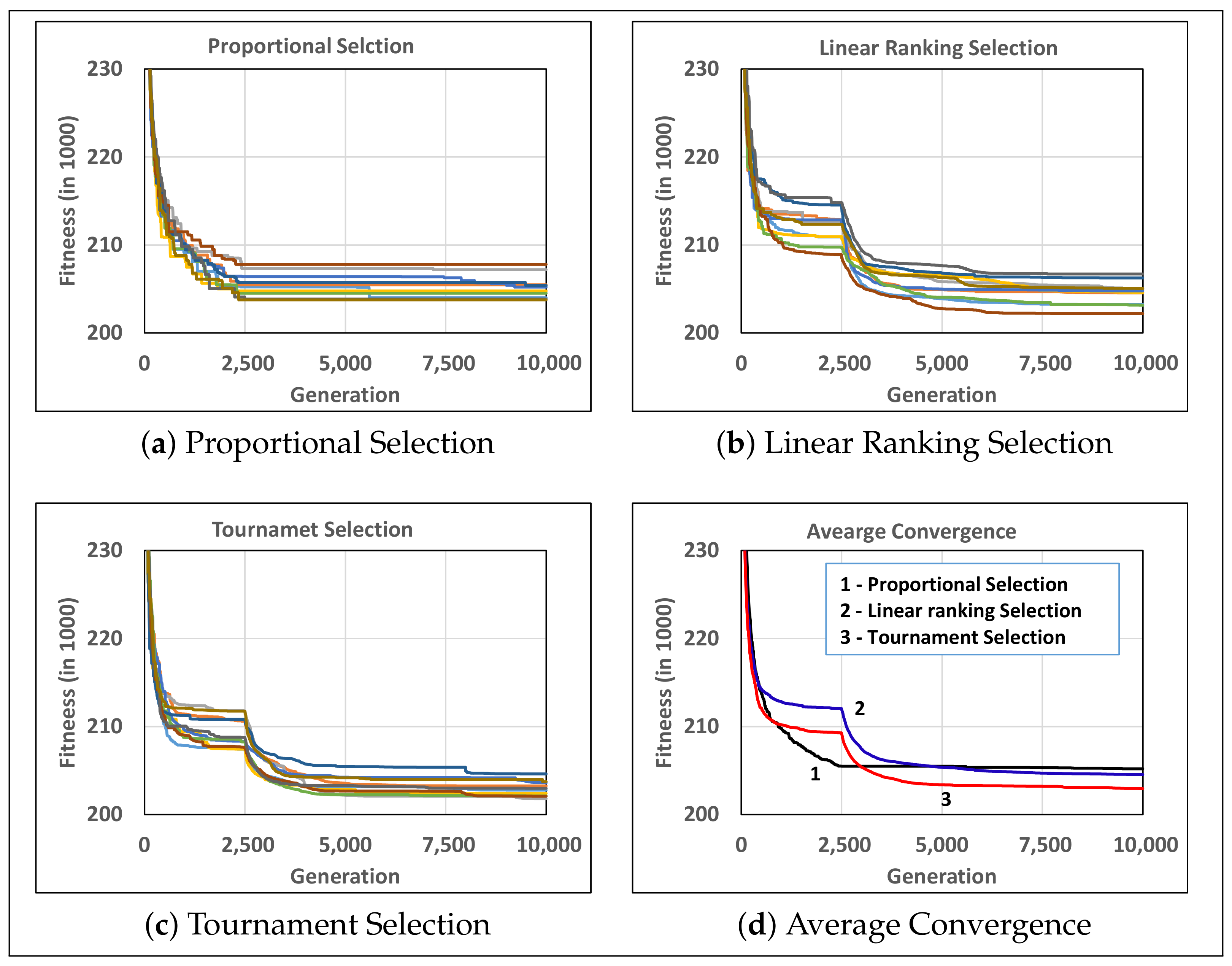
5.3.1. Selection Operators
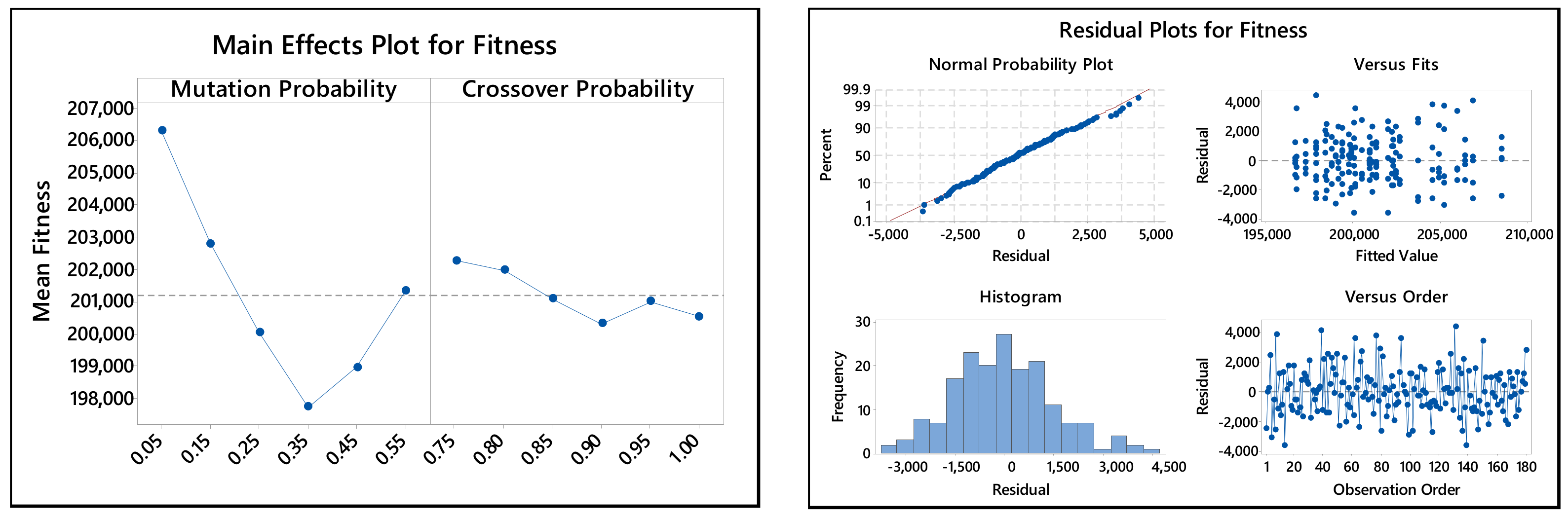
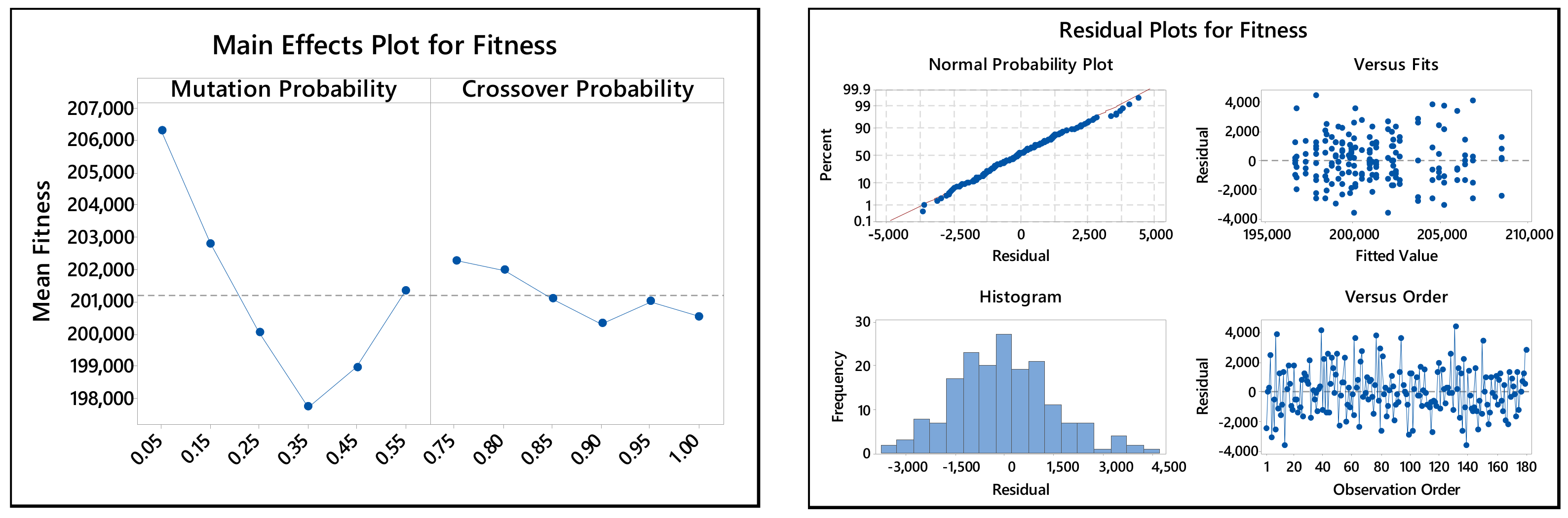
5.3.2. Crossover and Mutation Probabilities
6. Discussion, Conclusions, and Future Research
6.1. Discussion and Conclusions
- The magnitude of the severity of a single objective optimization on the objective function terms that are not incorporated increased as the problem size increased. The result emphasizes the need for multi-objective optimization in real industrial scheduling problems that are typically large in size.
- Optimizing the sublot flowtime is more desirable than optimizing the job flowtime. However, optimizing both terms simultaneously can also result in favorable solutions with respect to the overall flowtime performance.
- In lot streaming, one sublot of a given job may be finished much sooner than the other sublot of the same job. This may increase the work-in-process inventory. The newly proposed objective function terms (to minimize the maximum sublot finish-time separation and total sublot finish-time separation) can alleviate this problem with minimal impacts on the sublot and job flowtime.
- Instead of minimizing the maximum or the total sublot flowtime, it is advantageous to minimize both its maximum and total values simultaneously. The same is true with the other performance measures (the job flowtime, sublot finish-time separation, and machine workload).
- Workload balancing in FJSP may not be fully achieved by minimizing the maximum or the total workload or both. A newly proposed objective function term (minimizing the maximum workload difference), can result in a better workload balance when considered along with the minimization of the maximum and/or the total workload.
- The solution representation and the corresponding decoding of the first stage of the two-stage genetic algorithm can generate initial solutions that are highly improved in all the ten objective function terms.
- The two-stage genetic algorithm can jointly optimize all the ten objective function terms of the multi-objective FJSP lot streaming considered in this paper and greatly outperform the regular genetic algorithm.
- Parallel computation can bring performance improvements in both the two-stage GA and the regular GA. However, the crucial finding is that the sequential two-stage GA using a single CPU outperformed the parallel regular genetic algorithm that uses many CPUs in solving the proposed multi-objective FJSP lot streaming problem.
- The performance of the proportional selection method can be significantly improved by the appropriate choice of the fitness transformation function.
- Both proportional, linear ranking and tournament selection can result in comparable performance. However, tournament selection with smaller size of tournament slightly outperformed the other two.
- Analysis of variance shows the lack of interaction between mutation and crossover probabilities. Thus, the two probabilities can be tuned independently.
6.2. Future Research
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Defersha, F.M.; Rooyani, D. An efficient two-stage genetic algorithm for a flexible job-shop scheduling problem with sequence dependent attached/detached setup, machine release date and lag-time. Comput. Ind. Eng. 2020, 147, 106605. [Google Scholar] [CrossRef]
- Defersha, F.M.; Chen, M. Jobshop lot streaming with routing flexibility, sequence-dependent setups, machine release dates and lag time. Int. J. Prod. Res. 2012, 50, 2331–2352. [Google Scholar] [CrossRef]
- Chang, J.H.; Chiu, H.N. A comprehensive review of lot streaming. Int. J. Prod. Res. 2005, 43, 1515–1536. [Google Scholar] [CrossRef]
- Reiter, S. A system for managing job shop production. J. Buss. 1966, 34, 371–393. [Google Scholar] [CrossRef]
- Cheng, M.; Mukherjee, N.J.; Sarin, S.C. A review of lot streaming. Int. J. Prod. Res. 2013, 51, 7023–7046. [Google Scholar] [CrossRef]
- Lu, H.D.; He, W.P.; Zhou, X.; Li, Y.J. An integrated tabu search algorithm for the lot streaming problem in flexible job shops. J. Shanghai Jiaotong Univ. 2012, 46, 2003–2008. [Google Scholar]
- Defersha, F.M.; Chen, M. A hybrid genetic algorithm for flowshop lot streaming with setups and variable sublots. Int. J. Prod. Res. 2010, 48, 1705–1726. [Google Scholar] [CrossRef]
- Ventura, J.A.; Yoon, S.H. A new genetic algorithm for lot-streaming flow shop scheduling with limited capacity buffers. J. Intell. Manuf. 2013, 24, 1185–1196. [Google Scholar] [CrossRef]
- Han, Y.Y.; Gong, D.w.; Sun, X.Y.; Pan, Q.K. An improved NSGA-II algorithm for multi-objective lot-streaming flow shop scheduling problem. Int. J. Prod. Res. 2014, 52, 2211–2231. [Google Scholar] [CrossRef]
- Meng, T.; Pan, Q.K.; Li, J.Q.; Sang, H.Y. An improved migrating birds optimization for an integrated lot-streaming flow shop scheduling problem. Swarm Evol. Comput. 2018, 38, 64–78. [Google Scholar] [CrossRef]
- Gong, D.; Han, Y.; Sun, J. A novel hybrid multi-objective artificial bee colony algorithm for blocking lot-streaming flow shop scheduling problems. Knowl.-Based Syst. 2018, 148, 115–130. [Google Scholar] [CrossRef]
- Alfieri, A.; Zhou, S.; Scatamacchia, R.; van de Velde, S.L. Dynamic programming algorithms and Lagrangian lower bounds for a discrete lot streaming problem in a two-machine flow shop. 4OR 2021, 19, 265–288. [Google Scholar] [CrossRef]
- Fang, K.; Luo, W.; Che, A. Speed scaling in two-machine lot-streaming flow shops with consistent sublots. J. Oper. Res. Soc. 2021, 72, 2429–2441. [Google Scholar] [CrossRef]
- Wang, W.; Xu, Z.; Gu, X. A two-stage discrete water wave optimization algorithm for the flowshop lot-streaming scheduling problem with intermingling and variable lot sizes. Knowl.-Based Syst. 2022, 238, 107874. [Google Scholar] [CrossRef]
- Tsubone, H.; Ohba, M.; Uetake, T. The impact of lot sizing and sequencing on manufacturing performance in a two-stage hybrid flow shop. Int. J. Prod. Res. 1996, 34, 3037–3053. [Google Scholar] [CrossRef]
- Kim, J.S.; Kang, S.H.; Lee, S. Transfer batch scheduling for a two-stage flowshop with identical parallel machines at each stage. Omega 1997, 25, 547–555. [Google Scholar] [CrossRef]
- Zhang, W.; Yin, C.; Liu, J.; Linn, R.J. Multi-job lot streaming to minimize the mean completion time in m-1 hybrid flowshops. Int. J. Prod. Econ. 2005, 96, 189–200. [Google Scholar] [CrossRef]
- Liu, J. Single-job lot streaming in m - 1 two-stage hybrid flowshops. Eur. J. Oper. Res. 2008, 187, 1171–1183. [Google Scholar] [CrossRef]
- Cheng, M.; Sarin, S.C.; Singh, S. Two-stage, single-lot, lot streaming problem for a 1 + 2 hybrid flow shop. J. Glob. Optim. 2016, 66, 263–290. [Google Scholar] [CrossRef]
- Wang, S.; Kurz, M.; Mason, S.J.; Rashidi, E. Two-stage hybrid flow shop batching and lot streaming with variable sublots and sequence-dependent setups. Int. J. Prod. Res. 2019, 57, 6893–6907. [Google Scholar] [CrossRef]
- Defersha, F.M.; Chen, M. Mathematical model and parallel genetic algorithm for hybrid flexible flowshop lot streaming problem. Int. J. Adv. Manuf. Technol. 2012, 62, 249–265. [Google Scholar] [CrossRef]
- Nejati, M.; Mahdavi, I.; Hassanzadeh, R.; Mahdavi-Amiri, N.; Mojarad, M. Multi-job lot streaming to minimize the weighted completion time in a hybrid flow shop scheduling problem with work shift constraint. Int. J. Adv. Manuf. Technol. 2014, 70, 501–514. [Google Scholar] [CrossRef]
- Zhang, B.; ke Pan, Q.; Gao, L.; Zhang, X.L.; Sang, H.Y.; Li, J.Q. An effective modified migrating birds optimization for hybrid flowshop scheduling problem with lot streaming. Appl. Soft Comput. J. 2017, 52, 14–27. [Google Scholar] [CrossRef] [Green Version]
- Wang, P.; Sang, H.; Tao, Q.; Guo, H.; Li, J.; Gao, K.; Han, Y. Improved Migrating Birds Optimization Algorithm to Solve Hybrid Flowshop Scheduling Problem with Lot-Streaming. IEEE Access 2020, 8, 89782–89792. [Google Scholar] [CrossRef]
- Chen, T.L.; Cheng, C.Y.; Chou, Y.H. Multi-objective genetic algorithm for energy-efficient hybrid flow shop scheduling with lot streaming. Ann. Oper. Res. 2020, 290, 813–836. [Google Scholar] [CrossRef]
- Li, J.Q.; Tao, X.R.; Jia, B.X.; Han, Y.Y.; Liu, C.; Duan, P.; Zheng, Z.X.; Sang, H.Y. Efficient multi-objective algorithm for the lot-streaming hybrid flowshop with variable sub-lots. Swarm Evol. Comput. 2020, 52, 100600. [Google Scholar] [CrossRef]
- Zhang, B.; Pan, Q.K.; Meng, L.L.; Lu, C.; Mou, J.H.; Li, J.Q. An automatic multi-objective evolutionary algorithm for the hybrid flowshop scheduling problem with consistent sublots. Knowl.-Based Syst. 2022, 238, 107819. [Google Scholar] [CrossRef]
- Chan, F.T.; Wong, T.C.; Chan, L.Y. Lot streaming for product assembly in job shop environment. Robot. -Comput.-Integr. Manuf. 2008, 24, 321–331. [Google Scholar] [CrossRef]
- Wong, T.C.; Chan, F.T.; Chan, L.Y. A resource-constrained assembly job shop scheduling problem with Lot Streaming technique. Comput. Ind. Eng. 2009, 57, 983–995. [Google Scholar] [CrossRef]
- Chan, F.T.; Wong, T.C.; Chan, P.L. Equal size lot streaming to job-shop scheduling problem using genetic algorithms. In Proceedings of the IEEE International Symposium on Intelligent Control, Taipei, Taiwan, 2–4 September 2004; pp. 472–476. [Google Scholar]
- Chan, F.T.; Wong, T.C.; Chan, L.Y. The application of genetic algorithms to lot streaming in a job-shop scheduling problem. Int. J. Prod. Res. 2009, 47, 3387–3412. [Google Scholar] [CrossRef]
- Liu, C.H. Lot streaming for customer order scheduling problem in job shop environments. Int. J. Comput. Integr. Manuf. 2009, 22, 890–907. [Google Scholar] [CrossRef]
- Liu, C.H.; Chen, L.S.; Lin, P.S. Lot streaming multiple jobs with values exponentially deteriorating over time in a job-shop environment. Int. J. Prod. Res. 2013, 51, 202–214. [Google Scholar] [CrossRef]
- Lei, D.; Guo, X. Scheduling job shop with lot streaming and transportation through a modified artificial bee colony. Int. J. Prod. Res. 2013, 51, 4930–4941. [Google Scholar] [CrossRef]
- Demir, Y.; Işleyen, S.K. An effective genetic algorithm for flexible job-shop scheduling with overlapping in operations. Int. J. Prod. Res. 2014, 52, 3905–3921. [Google Scholar] [CrossRef]
- Meng, T.; Pan, Q.K.; Sang, H.Y. A hybrid artificial bee colony algorithm for a flexible job shop scheduling problem with overlapping in operations. Int. J. Prod. Res. 2018, 56, 5278–5292. [Google Scholar] [CrossRef]
- Bożek, A.; Werner, F. Flexible job shop scheduling with lot streaming and sublot size optimisation. Int. J. Prod. Res. 2018, 56, 6391–6411. [Google Scholar] [CrossRef]
- Defersha, F.M.; Bayat Movahed, S. Linear programming assisted (not embedded) genetic algorithm for flexible jobshop scheduling with lot streaming. Comput. Ind. Eng. 2018, 117, 319–335. [Google Scholar] [CrossRef]
- Novas, J.M. Production scheduling and lot streaming at flexible job-shops environments using constraint programming. Comput. Ind. Eng. 2019, 136, 252–264. [Google Scholar] [CrossRef]
- Daneshamooz, F.; Fattahi, P.; Hosseini, S.M.H. Scheduling in a flexible job shop followed by some parallel assembly stations considering lot streaming. Eng. Optim. 2022, 54, 614–633. [Google Scholar] [CrossRef]
- Li, L. Research on discrete intelligent workshop lot-streaming scheduling with variable sublots under engineer to order. Comput. Ind. Eng. 2022, 165, 107928. [Google Scholar] [CrossRef]
- Sang, H.Y.; Duan, J.H. An efficient discrete artificial bee colony algorithm for total flowtime lot-streaming flowshop. In Proceedings of the 2012 9th International Conference on Fuzzy Systems and Knowledge Discovery, (FSKD 2012), Chongqing, China, 29–31 May 2012; pp. 1585–1588. [Google Scholar] [CrossRef]
- Chiang, T.C.; Lin, H.J. A simple and effective evolutionary algorithm for multiobjective flexible job shop scheduling. Int. J. Prod. Econ. 2013, 141, 87–98. [Google Scholar] [CrossRef]
- Bajer, D.; Martinović, G.; Brest, J. A population initialization method for evolutionary algorithms based on clustering and Cauchy deviates. Expert Syst. Appl. 2016, 60, 294–310. [Google Scholar] [CrossRef]
- Rahnamayan, S.; Tizhoosh, H.R.; Salama, M.M. A novel population initialization method for accelerating evolutionary algorithms. Comput. Math. Appl. 2007, 53, 1605–1614. [Google Scholar] [CrossRef] [Green Version]
- Luo, J.; El Baz, D. A survey on parallel genetic algorithms for shop scheduling problems. In Proceedings of the 2018 IEEE 32nd International Parallel and Distributed Processing Symposium Workshops, (IPDPSW 2018), Vancouver, BC, Canada, 21–25 May 2018; pp. 629–636. [Google Scholar] [CrossRef] [Green Version]
- Defersha, F.M.; Chen, M. A parallel genetic algorithm for dynamic cell formation in cellular manufacturing systems. Int. J. Prod. Res. 2008, 46, 6389–6413. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (Eligible Machine, Processing Time) = (m, ) | |||||||||
|---|---|---|---|---|---|---|---|---|---|
| j | o | i | ii | iii | iv | ||||
| 1 | 100 | 2 | 1 | 0 | 0 | (1, 6.75) | (4, 6.50) | (5, 6.50) | |
| 2 | 1 | 120 | (1, 3.00) | (2, 2.25) | (4, 2.75) | ||||
| 3 | 0 | 120 | (1, 3.50) | (2, 3.25) | (4, 3.75) | (5, 3.50) | |||
| 2 | 250 | 3 | 1 | 0 | 0 | (1, 1.75) | (2, 2.00) | (5, 1.25) | |
| 2 | 1 | 0 | (2, 5.00) | (3, 4.25) | (4, 5.00) | (5, 4.75) | |||
| 3 | 1 | 40 | (1, 7.00) | (2, 7.00) | (3, 6.50) | (5, 6.50) | |||
| 4 | 0 | 40 | (1, 2.50) | (2, 2.50) | (3, 2.75) | (4, 2.75) | |||
| 3 | 200 | 3 | 1 | 0 | 0 | (1, 5.25) | (5, 5.75) | ||
| 2 | 1 | 0 | (1, 4.50) | (3, 4.25) | (5, 4.25) | ||||
| 3 | 1 | 0 | (1, 3.50) | (2, 3.50) | |||||
| 4 | 100 | 2 | 1 | 0 | 0 | (4, 6.00) | (5, 6.00) | ||
| 2 | 0 | 0 | (1, 4.25) | (3, 4.75) | (4, 4.75) | (5, 4.75) | |||
| 3 | 1 | 0 | (2, 2.00) | (4, 1.25) | (5, 1.25) | ||||
| Setup Time and | ||||
|---|---|---|---|---|
| j | o | m | () | (, , ) |
| 1 | 1 | 1 | (120) | (1,1,20)(1,2,100)(1,3,120)(2,1,210)(2,3,210)(2,4,240)(3,1,240)(3,2,210)(3,3,240)(4,2,210) |
| 4 | (140) | (1,1,15)(1,2,80)(1,3,120)(2,2,180)(2,4,240)(4,1,210)(4,2,210)(4,3,240) | ||
| 5 | (100) | (1,1,20)(1,3,80)(2,1,210)(2,2,180)(2,3,240)(3,1,180)(3,2,240)(4,1,180)(4,2,180)(4,3,180) | ||
| 2 | 1 | (140) | (1,1,100)(1,2,20)(1,3,80)(2,1,240)(2,3,210)(2,4,180)(3,1,240)(3,2,210)(3,3,240)(4,2,210) | |
| 2 | (100) | (1,2,15)(1,3,100)(2,1,180)(2,2,210)(2,3,180)(2,4,180)(3,3,180)(4,3,210) | ||
| 4 | (140) | (1,1,80)(1,2,10)(1,3,80)(2,2,240)(2,4,180)(4,1,240)(4,2,210)(4,3,240) | ||
| 3 | 1 | (80) | (1,1,80)(1,2,120)(1,3,10)(2,1,180)(2,3,240)(2,4,180)(3,1,240)(3,2,180)(3,3,210)(4,2,180) | |
| 2 | (160) | (1,2,120)(1,3,20)(2,1,180)(2,2,210)(2,3,180)(2,4,180)(3,3,210)(4,3,210) | ||
| 4 | (80) | (1,1,100)(1,2,100)(1,3,15)(2,2,240)(2,4,240)(4,1,240)(4,2,240)(4,3,210) | ||
| 5 | (120) | (1,1,100)(1,3,20)(2,1,180)(2,2,180)(2,3,210)(3,1,180)(3,2,210)(4,1,180)(4,2,210)(4,3,240) | ||
| 2 | 1 | 1 | (80) | (1,1,240)(1,2,240)(1,3,240)(2,1,20)(2,3,120)(2,4,120)(3,1,210)(3,2,210)(3,3,180)(4,2,240) |
| 2 | (120) | (1,2,180)(1,3,180)(2,1,10)(2,2,100)(2,3,120)(2,4,120)(3,3,180)(4,3,180) | ||
| 5 | (160) | (1,1,240)(1,3,180)(2,1,15)(2,2,100)(2,3,100)(3,1,180)(3,2,210)(4,1,180)(4,2,180)(4,3,240) | ||
| 2 | 2 | (120) | (1,2,180)(1,3,210)(2,1,80)(2,2,15)(2,3,120)(2,4,100)(3,3,240)(4,3,210) | |
| 3 | (100) | (2,2,20)(2,3,80)(2,4,120)(3,2,240)(4,2,210) | ||
| 4 | (120) | (1,1,210)(1,2,180)(1,3,240)(2,2,10)(2,4,80)(4,1,180)(4,2,240)(4,3,240) | ||
| 5 | (120) | (1,1,180)(1,3,240)(2,1,120)(2,2,20)(2,3,80)(3,1,210)(3,2,240)(4,1,240)(4,2,210)(4,3,240) | ||
| 3 | 1 | (80) | (1,1,210)(1,2,240)(1,3,240)(2,1,80)(2,3,10)(2,4,80)(3,1,240)(3,2,240)(3,3,240)(4,2,210) | |
| 2 | (100) | (1,2,210)(1,3,180)(2,1,120)(2,2,80)(2,3,15)(2,4,80)(3,3,210)(4,3,180) | ||
| 3 | (140) | (2,2,80)(2,3,10)(2,4,100)(3,2,240)(4,2,180) | ||
| 5 | (160) | (1,1,240)(1,3,210)(2,1,80)(2,2,120)(2,3,10)(3,1,240)(3,2,180)(4,1,180)(4,2,240)(4,3,210) | ||
| 4 | 1 | (160) | (1,1,180)(1,2,210)(1,3,210)(2,1,80)(2,3,100)(2,4,10)(3,1,240)(3,2,180)(3,3,180)(4,2,210) | |
| 2 | (140) | (1,2,180)(1,3,180)(2,1,120)(2,2,80)(2,3,120)(2,4,10)(3,3,180)(4,3,210) | ||
| 3 | (160) | (2,2,100)(2,3,100)(2,4,10)(3,2,240)(4,2,210) | ||
| 4 | (120) | (1,1,240)(1,2,240)(1,3,180)(2,2,120)(2,4,10)(4,1,210)(4,2,180)(4,3,210) | ||
| 3 | 1 | 1 | (80) | (1,1,240)(1,2,240)(1,3,240)(2,1,180)(2,3,180)(2,4,210)(3,1,15)(3,2,120)(3,3,100)(4,2,180) |
| 5 | (80) | (1,1,210)(1,3,240)(2,1,240)(2,2,180)(2,3,240)(3,1,15)(3,2,100)(4,1,210)(4,2,180)(4,3,210) | ||
| 2 | 1 | (120) | (1,1,240)(1,2,240)(1,3,180)(2,1,240)(2,3,240)(2,4,240)(3,1,80)(3,2,20)(3,3,100)(4,2,210) | |
| 3 | (140) | (2,2,240)(2,3,240)(2,4,240)(3,2,15)(4,2,180) | ||
| 5 | (160) | (1,1,180)(1,3,210)(2,1,240)(2,2,180)(2,3,180)(3,1,100)(3,2,10)(4,1,240)(4,2,240)(4,3,240) | ||
| 3 | 1 | (120) | (1,1,180)(1,2,240)(1,3,240)(2,1,210)(2,3,180)(2,4,180)(3,1,120)(3,2,100)(3,3,10)(4,2,210) | |
| 2 | (160) | (1,2,240)(1,3,210)(2,1,210)(2,2,180)(2,3,240)(2,4,180)(3,3,15)(4,3,210) | ||
| 4 | 1 | 4 | (100) | (1,1,210)(1,2,240)(1,3,210)(2,2,240)(2,4,180)(4,1,10)(4,2,100)(4,3,100) |
| 5 | (100) | (1,1,180)(1,3,210)(2,1,180)(2,2,180)(2,3,210)(3,1,210)(3,2,210)(4,1,10)(4,2,120)(4,3,100) | ||
| 2 | 1 | (100) | (1,1,240)(1,2,240)(1,3,210)(2,1,180)(2,3,180)(2,4,240)(3,1,180)(3,2,240)(3,3,240)(4,2,20) | |
| 3 | (80) | (2,2,240)(2,3,240)(2,4,240)(3,2,210)(4,2,20) | ||
| 4 | (140) | (1,1,180)(1,2,210)(1,3,180)(2,2,240)(2,4,240)(4,1,100)(4,2,10)(4,3,100) | ||
| 5 | (80) | (1,1,180)(1,3,180)(2,1,240)(2,2,210)(2,3,210)(3,1,240)(3,2,180)(4,1,80)(4,2,15)(4,3,80) | ||
| 3 | 2 | (100) | (1,2,210)(1,3,210)(2,1,210)(2,2,210)(2,3,180)(2,4,210)(3,3,210)(4,3,20) | |
| 4 | (140) | (1,1,240)(1,2,210)(1,3,240)(2,2,180)(2,4,180)(4,1,120)(4,2,100)(4,3,15) | ||
| 5 | (140) | (1,1,180)(1,3,240)(2,1,210)(2,2,180)(2,3,210)(3,1,240)(3,2,240)(4,1,100)(4,2,100)(4,3,10) | ||
| Intermediate Calculation | Obj. Function Term |
|---|---|
| } | |
| } | |
| } | |
| j | s | o | m | r | LB | LE | SB | SE/PB | PE | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 100.0 | 1 | 5 | 1 | 0.0 | 0.0 | 0.0 | 100.0 | 750.0 |
| 2 | 4 | 6 | 750.0 | 870.0 | 1577.5 | 1817.5 | 2092.5 | |||
| 3 | 4 | 7 | 2092.5 | 2212.5 | 2112.5 | 2212.5 | 2587.5 | |||
| 2 | 1 | 90.8 | 1 | 2 | 2 | 0.0 | 0.0 | 303.0 | 313.0 | 494.6 |
| 2 | 3 | 2 | 494.6 | 494.6 | 792.0 | 812.0 | 1197.8 | |||
| 3 | 3 | 3 | 1197.8 | 1237.8 | 1237.8 | 1317.8 | 1907.8 | |||
| 4 | 3 | 4 | 1907.8 | 1947.8 | 1907.8 | 2007.8 | 2257.4 | |||
| 2 | 67.7 | 1 | 2 | 3 | 0.0 | 0.0 | 494.6 | 504.6 | 640.0 | |
| 2 | 2 | 4 | 640.0 | 640.0 | 640.0 | 720.0 | 1058.5 | |||
| 3 | 2 | 5 | 1058.5 | 1098.5 | 1098.5 | 1178.5 | 1652.5 | |||
| 4 | 2 | 7 | 1652.5 | 1692.5 | 2308.1 | 2428.1 | 2597.4 | |||
| 3 | 91.5 | 1 | 2 | 1 | 0.0 | 0.0 | 0.0 | 120.0 | 303.0 | |
| 2 | 3 | 1 | 303.0 | 303.0 | 303.0 | 403.0 | 792.0 | |||
| 3 | 2 | 6 | 792.0 | 832.0 | 1652.5 | 1667.5 | 2308.1 | |||
| 4 | 3 | 5 | 2308.1 | 2348.1 | 2338.1 | 2348.1 | 2599.8 | |||
| 3 | 1 | 80.4 | 1 | 1 | 1 | 0.0 | 0.0 | 840.0 | 920.0 | 1342.0 |
| 2 | 1 | 2 | 1342.0 | 1342.0 | 1342.0 | 1422.0 | 1783.8 | |||
| 3 | 1 | 3 | 1783.8 | 1783.8 | 1783.8 | 1883.8 | 2165.2 | |||
| 2 | 39.2 | 1 | 5 | 2 | 0.0 | 0.0 | 750.0 | 960.0 | 1185.5 | |
| 2 | 5 | 5 | 1185.5 | 1185.5 | 2104.4 | 2114.4 | 2281.1 | |||
| 3 | 1 | 5 | 2281.1 | 2281.1 | 2456.5 | 2466.5 | 2603.8 | |||
| 3 | 80.4 | 1 | 5 | 3 | 0.0 | 0.0 | 1185.5 | 1200.5 | 1662.8 | |
| 2 | 5 | 4 | 1662.8 | 1662.8 | 1662.8 | 1762.8 | 2104.4 | |||
| 3 | 1 | 4 | 2104.4 | 2104.4 | 2165.2 | 2175.2 | 2456.5 | |||
| 4 | 1 | 50.0 | 1 | 4 | 2 | 0.0 | 0.0 | 520.0 | 530.0 | 830.0 |
| 2 | 4 | 3 | 830.0 | 830.0 | 830.0 | 930.0 | 1167.5 | |||
| 3 | 5 | 6 | 1167.5 | 1167.5 | 2281.1 | 2521.1 | 2583.6 | |||
| 2 | 50.0 | 1 | 4 | 1 | 0.0 | 0.0 | 120.0 | 220.0 | 520.0 | |
| 2 | 4 | 4 | 520.0 | 520.0 | 1167.5 | 1177.5 | 1415.0 | |||
| 3 | 4 | 5 | 1415.0 | 1415.0 | 1415.0 | 1515.0 | 1577.5 |
| j | s | |||
|---|---|---|---|---|
| 1 | 1 | 100.0 | 2587.5 | 2487.5 |
| 2 | 1 | 313.0 | 2257.4 | 1944.4 |
| 2 | 504.6 | 2597.4 | 2092.8 | |
| 3 | 120.0 | 2599.8 | 2479.8 | |
| 3 | 1 | 920.0 | 2165.2 | 1245.2 |
| 2 | 960.0 | 2603.8 | 1643.8 | |
| 3 | 1200.5 | 2456.5 | 1256.0 | |
| 4 | 1 | 530.0 | 2583.6 | 2053.6 |
| 2 | 220.0 | 1577.5 | 1357.5 | |
| Maximum | 2487.5 | |||
| Total | 16,560.6 | |||
| j | ||||
|---|---|---|---|---|
| 1 | 100.0 | 2587.5 | 2487.5 | 0.0 |
| 2 | 120.0 | 2599.8 | 2479.8 | 342.4 |
| 3 | 920.0 | 2603.8 | 1683.8 | 438.6 |
| 4 | 220.0 | 2583.6 | 2363.6 | 1006.1 |
| Maximum | 2487.5 | 1006.1 | ||
| Total | 9014.7 | 1787 | ||
| m | r | j | s | o | SB | SE/PB | PE |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 3 | 1 | 1 | 840.0 | 920.0 | 1342.0 |
| 2 | 3 | 1 | 2 | 1342.0 | 1422.0 | 1783.8 | |
| 3 | 3 | 1 | 3 | 1783.8 | 1883.8 | 2165.2 | |
| 4 | 3 | 3 | 3 | 2165.2 | 2175.2 | 2456.5 | |
| 5 | 3 | 2 | 3 | 2456.5 | 2466.5 | 2603.8 | |
| 2 | 1 | 2 | 3 | 1 | 0.0 | 120.0 | 303.0 |
| 2 | 2 | 1 | 1 | 303.0 | 313.0 | 494.6 | |
| 3 | 2 | 2 | 1 | 494.6 | 504.6 | 640.0 | |
| 4 | 2 | 2 | 2 | 640.0 | 720.0 | 1058.5 | |
| 5 | 2 | 2 | 3 | 1098.5 | 1178.5 | 1652.5 | |
| 6 | 2 | 3 | 3 | 1652.5 | 1667.5 | 2308.1 | |
| 7 | 2 | 2 | 4 | 2308.1 | 2428.1 | 2597.4 | |
| 3 | 1 | 2 | 3 | 2 | 303.0 | 403.0 | 792.0 |
| 2 | 2 | 1 | 2 | 792.0 | 812.0 | 1197.8 | |
| 3 | 2 | 1 | 3 | 1237.8 | 1317.8 | 1907.8 | |
| 4 | 2 | 1 | 4 | 1907.8 | 2007.8 | 2257.4 | |
| 5 | 2 | 3 | 4 | 2338.1 | 2348.1 | 2599.8 | |
| 4 | 1 | 4 | 2 | 1 | 120.0 | 220.0 | 520.0 |
| 2 | 4 | 1 | 1 | 520.0 | 530.0 | 830.0 | |
| 3 | 4 | 1 | 2 | 830.0 | 930.0 | 1167.5 | |
| 4 | 4 | 2 | 2 | 1167.5 | 1177.5 | 1415.0 | |
| 5 | 4 | 2 | 3 | 1415.0 | 1515.0 | 1577.5 | |
| 6 | 1 | 1 | 2 | 1577.5 | 1817.5 | 2092.5 | |
| 7 | 1 | 1 | 3 | 2112.5 | 2212.5 | 2587.5 | |
| 5 | 1 | 1 | 1 | 1 | 0.0 | 100.0 | 750.0 |
| 2 | 3 | 2 | 1 | 750.0 | 960.0 | 1185.5 | |
| 3 | 3 | 3 | 1 | 1185.5 | 1200.5 | 1662.8 | |
| 4 | 3 | 3 | 2 | 1662.8 | 1762.8 | 2104.4 | |
| 5 | 3 | 2 | 2 | 2104.4 | 2114.4 | 2281.1 | |
| 6 | 4 | 1 | 3 | 2281.1 | 2521.1 | 2583.6 |
| m | Workload | Utilization |
|---|---|---|
| 1 | 2603.8 | 100.0 |
| 2 | 2557.4 | 98.2 |
| 3 | 2176.1 | 83.6 |
| 4 | 2567.5 | 98.6 |
| 5 | 2583.6 | 99.2 |
| Objective Term | Notation | Value |
|---|---|---|
| Makespan | 2603.8 | |
| Maximum Sublot Flowtime | 2487.5 | |
| Total Sublot Flowtime | 16,560.6 | |
| Maximum Job flowtime | 2487.5 | |
| Total job flowtime | 9014.7 | |
| Maximum Sublot Finish-time Separation | 1006.1 | |
| Total Sublot finish-time Separation | 1787.1 | |
| Maximum Machine Load | 2603.8 | |
| Total Machine Load | 2603.8 | |
| Maximum Machine Load Difference | 427.7 |
| Term Optimized as a Single | Objective Function Term Evaluated | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Objective Function | |||||||||||
| Makespan | 26,604 | 26,511 | 2,500,084 | 26,594 | 1,002,941 | 8580 | 96,070 | 26,593 | 660,550 | 715 | |
| Maximum Sublot Flowtime | 28,756 | 24,014 | 2,495,091 | 28,367 | 1,016,441 | 9426 | 110,413 | 28,175 | 665,522 | 3063 | |
| Total Sublot Flowtime | 28,822 | 27,596 | 2,115,095 | 27,977 | 951,313 | 13,437 | 173,636 | 27,964 | 667,816 | 2747 | |
| Maximum Job Flowtime | 28,619 | 25,156 | 2,520,010 | 25,161 | 990,089 | 8029 | 71,921 | 28,155 | 663,042 | 2989 | |
| Total Job Flowtime | 27,316 | 26,770 | 2,312,532 | 26,846 | 868,391 | 6431 | 41,727 | 27,071 | 652,393 | 2169 | |
| Maximum Sublot Finish-Time Separation | 37,849 | 37,323 | 3,417,121 | 37,608 | 1,337,687 | 709 | 19,222 | 30,936 | 695,833 | 6275 | |
| Total Sublot Finish-Time Separation | 30,966 | 30,475 | 2,857,497 | 30,561 | 1,110,654 | 1788 | 10,813 | 29,629 | 690,055 | 4700 | |
| Maximum Machine Load | 44,197 | 43,469 | 4,004,945 | 43,658 | 1,586,503 | 14,786 | 158,042 | 25,793 | 643,747 | 227 | |
| Total Machine Load | 43,242 | 41,933 | 3,926,277 | 42,356 | 1,494,746 | 15611 | 76,124 | 28,123 | 573,164 | 10,040 | |
| Maximum Machine Load Difference | 36,943 | 36,238 | 3,314,121 | 36,671 | 1,348,060 | 15,639 | 161,671 | 27,729 | 693,034 | 15 | |
| Minimum (Best Value) | 26,604 | 24,014 | 2,115,095 | 25,161 | 868,391 | 709 | 10,813 | 25,793 | 573,164 | 15 | |
| Maximum (Worst Value) | 44,197 | 43,469 | 4,004,945 | 43,658 | 1,586,503 | 15,639 | 173,636 | 30,936 | 695,833 | 10,040 | |
| Objective Function Term Weight | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Case | ||||||||||
| 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 1 | 1 | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
| 2 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 1 | 1 |
| 3 | 1 | 1 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 |
| 4 | 1 | 0 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| 5 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
| 6 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 1 | 1 |
| 7 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | 1 | 1 |
| 8 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 |
| 9 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 0 |
| 10 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 |
| Objective Function Terms | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Case | ||||||||||
| 0 | 24,550 | 23,710 | 1,057,020 | 23,762 | 822,152 | 425 | 2030 | 22,909 | 565,394 | 559 |
| 1 | 24,524 | 23,684 | 1,017,100 | 24,206 | 829,235 | 4642 | 15,476 | 22,657 | 561,306 | 366 |
| 2 | 24,640 | 23,964 | 1,143,060 | 24,021 | 823,195 | 3222 | 14,307 | 23,047 | 571,702 | 372 |
| 3 | 24,891 | 24,183 | 1,053,079 | 24,286 | 847,180 | 375 | 1337 | 22,717 | 562,619 | 396 |
| 4 | 24,789 | 24,322 | 1,127,425 | 24,355 | 835,824 | 579 | 2680 | 22,959 | 569,595 | 376 |
| 5 | 24,503 | 23,470 | 1,195,014 | 24,297 | 877,040 | 5370 | 23,064 | 23,073 | 573,483 | 285 |
| 6 | 24,737 | 24,578 | 1,013,725 | 24,618 | 831,675 | 4550 | 14,209 | 22,639 | 561,504 | 308 |
| 7 | 24,406 | 23,822 | 1,176,456 | 23,839 | 874,850 | 4198 | 17,824 | 22,977 | 571,159 | 258 |
| 8 | 24,546 | 24,447 | 1,088,981 | 24,476 | 815,426 | 4218 | 15,152 | 22,872 | 568,343 | 289 |
| 9 | 24,842 | 23,935 | 998,845 | 23,950 | 811,569 | 84 | 376 | 22,987 | 562,417 | 2047 |
| 10 | 24,756 | 23,870 | 958,741 | 23,881 | 804,054 | 94 | 319 | 23,844 | 552,727 | 4202 |
| Problem-1 | Problem-4 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Objective | Mean | StDev | Percentage | Mean | StDev | Percentage | ||||
| Term | RGA | 2SGA | RGA | 2SGA | Improvement * | RGA | 2SGA | RGA | 2SGA | Improvement * |
| 6317 | 3767 | 972 | 412 | (40, 58) | 58,513 | 31,277 | 3293 | 748 | (47, 77) | |
| 5477 | 3221 | 1045 | 447 | (41, 57) | 57,435 | 30,524 | 3336 | 690 | (47, 79) | |
| 30,138 | 18,243 | 6116 | 2422 | (39, 60) | 4,574,999 | 2,476,978 | 299,643 | 89,360 | (46, 70) | |
| 5895 | 3483 | 1003 | 438 | (41, 56) | 57,957 | 30,846 | 3312 | 705 | (47, 79) | |
| 18,954 | 10,829 | 3420 | 1035 | (43, 70) | 2,081,854 | 1,122,475 | 119,664 | 17,273 | (46, 86) | |
| 2896 | 1491 | 1171 | 581 | (49, 50) | 21,250 | 10,607 | 4788 | 2282 | (50, 52) | |
| 6297 | 3084 | 2772 | 1232 | (51, 56) | 248,166 | 116,497 | 40,929 | 15,422 | (53, 62) | |
| 5058 | 3336 | 894 | 291 | (34, 67) | 37,728 | 29,216 | 2621 | 538 | (23, 79) | |
| 14,816 | 13,835 | 596 | 550 | (7, 8) | 682,856 | 667,035 | 6709 | 6442 | (2, 4) | |
| 3789 | 1197 | 1228 | 532 | (68, 57) | 19,471 | 5945 | 3411 | 1183 | (69, 65) | |
| Problem | M | J | (max) | (min, max) | NAMPJ (min, max) * |
|---|---|---|---|---|---|
| 4 | 25 | 40 | 4 | (8 15) | (3, 6) |
| 5 | 30 | 60 | 4 | (8, 16) | (3, 6) |
| 6 | 40 | 80 | 4 | (10, 18) | (2, 8) |
| 7 | 50 | 100 | 4 | (10, 20) | (2, 8) |
| Parameters | Values |
|---|---|
| Population Size | 2000 |
| Tournament Size Factor | 0.005 |
| Crossover Probability | 0.85 |
| Mutation Probability | 0.15 |
| Number of generation for the first sage in 2SGA | 2500 |
| Total number of genration | 10,000 |
| 1.0 |
| Source | DF | Adj SS | Adj MS | F-Value | p-Value |
|---|---|---|---|---|---|
| Mutation Probability | 5 | 1,418,299,280 | 283,659,856 | 93.7 | 0.000 |
| Crossover Probability | 5 | 91,944,634 | 18,388,927 | 6.03 | 0.000 |
| Mutation Probability*Crossover Probability | 25 | 49,082,335 | 1,963,293 | 0.64 | 0.901 |
| Error | 144 | 438,889,368 | 3,047,843 | ||
| Total | 179 | 1,998,215,617 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rooyani, D.; Defersha, F. A Two-Stage Multi-Objective Genetic Algorithm for a Flexible Job Shop Scheduling Problem with Lot Streaming. Algorithms 2022, 15, 246. https://doi.org/10.3390/a15070246
Rooyani D, Defersha F. A Two-Stage Multi-Objective Genetic Algorithm for a Flexible Job Shop Scheduling Problem with Lot Streaming. Algorithms. 2022; 15(7):246. https://doi.org/10.3390/a15070246
Chicago/Turabian StyleRooyani, Danial, and Fantahun Defersha. 2022. "A Two-Stage Multi-Objective Genetic Algorithm for a Flexible Job Shop Scheduling Problem with Lot Streaming" Algorithms 15, no. 7: 246. https://doi.org/10.3390/a15070246
APA StyleRooyani, D., & Defersha, F. (2022). A Two-Stage Multi-Objective Genetic Algorithm for a Flexible Job Shop Scheduling Problem with Lot Streaming. Algorithms, 15(7), 246. https://doi.org/10.3390/a15070246