
Prediction of Injuries in CrossFit Training: A Machine Learning Perspective

 ,
,  ,
,  ,
, 
 and
and
Abstract
:1. Introduction
2. Materials and Methods
2.1. Study Design
2.2. Data Preprocessing
2.3. Statistical Analysis and Feature Selection
2.4. Machine Learning Methodology
2.5. Validation
3. Results
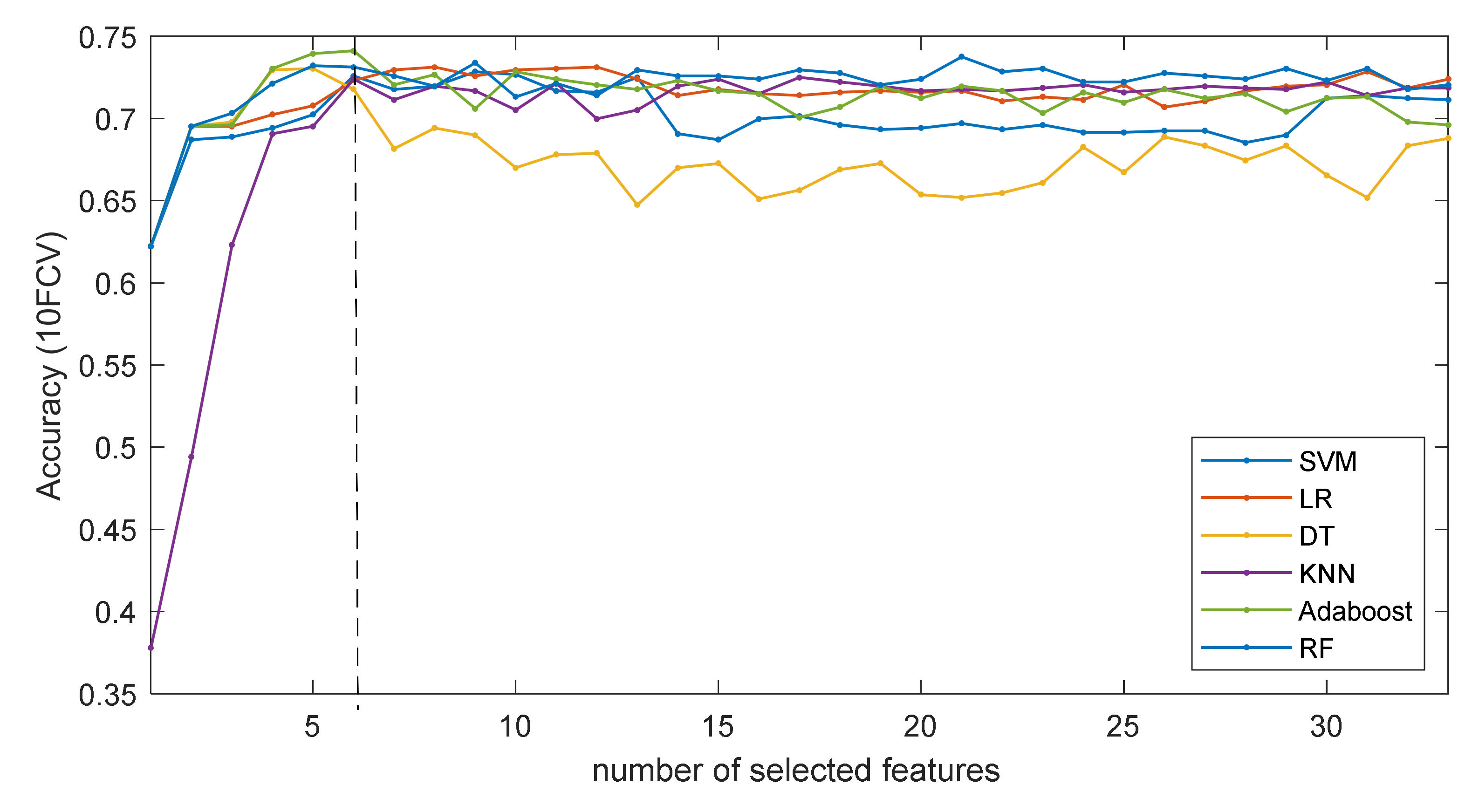
3.1. Identification of Important Risk Factors
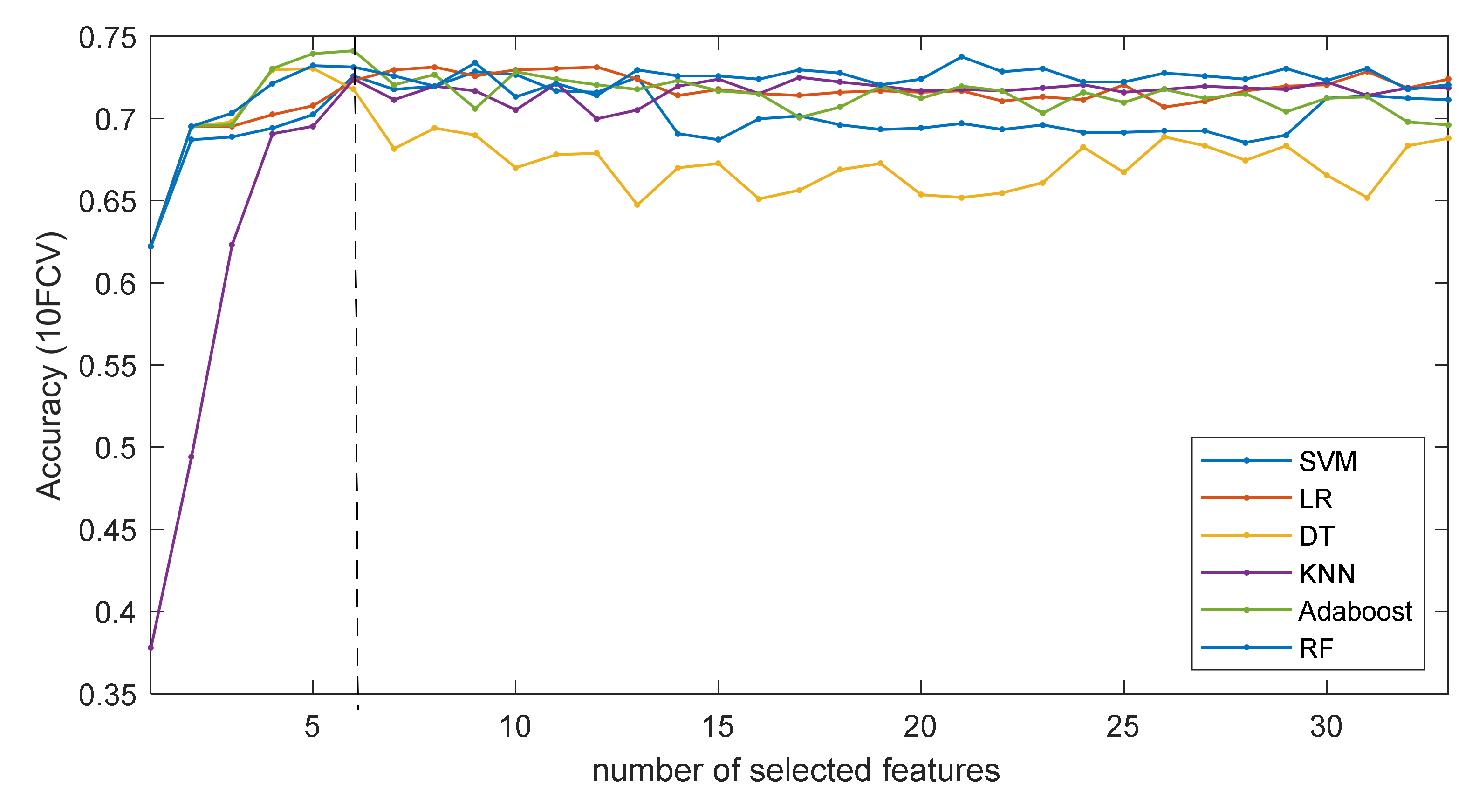
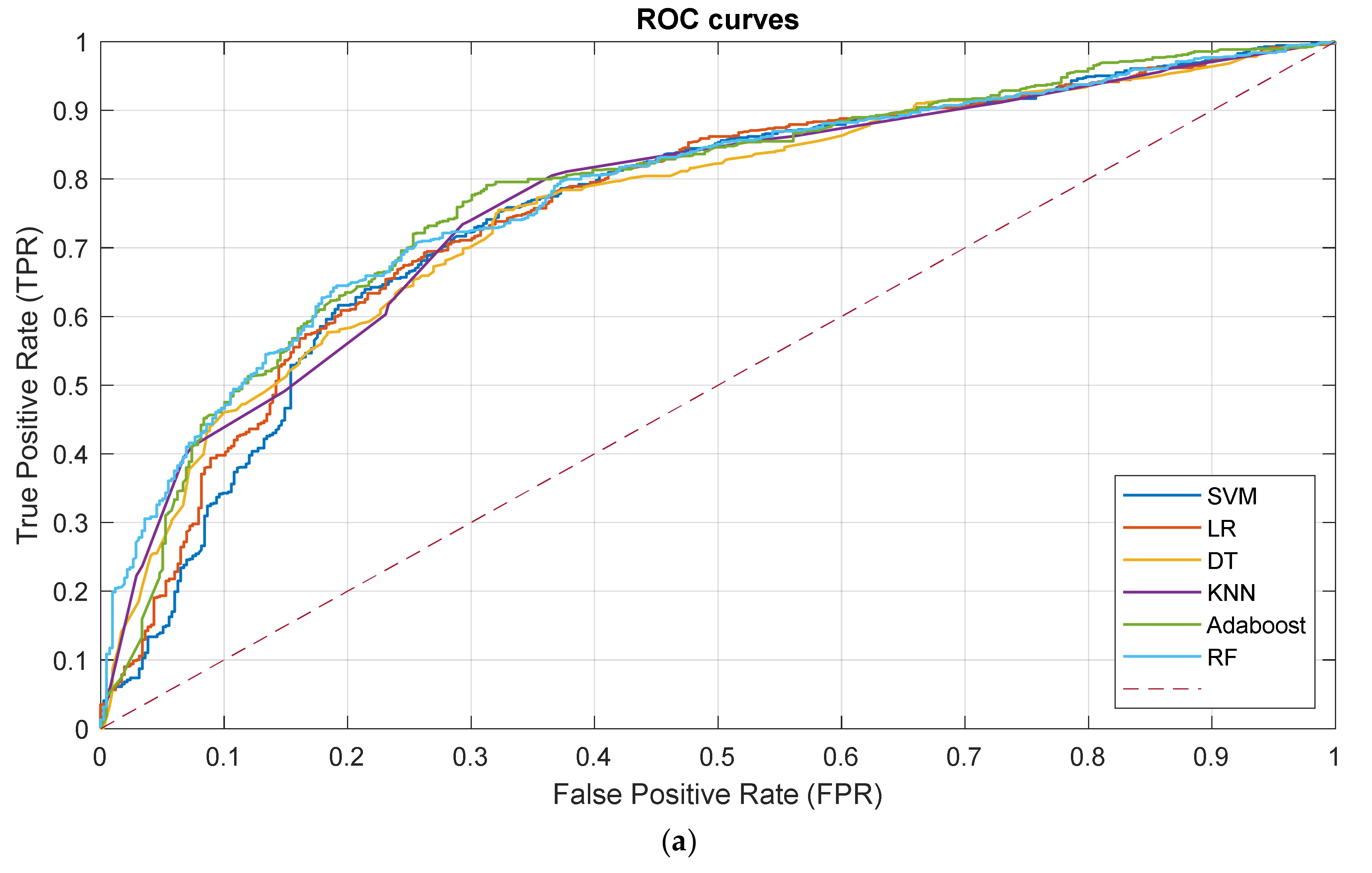
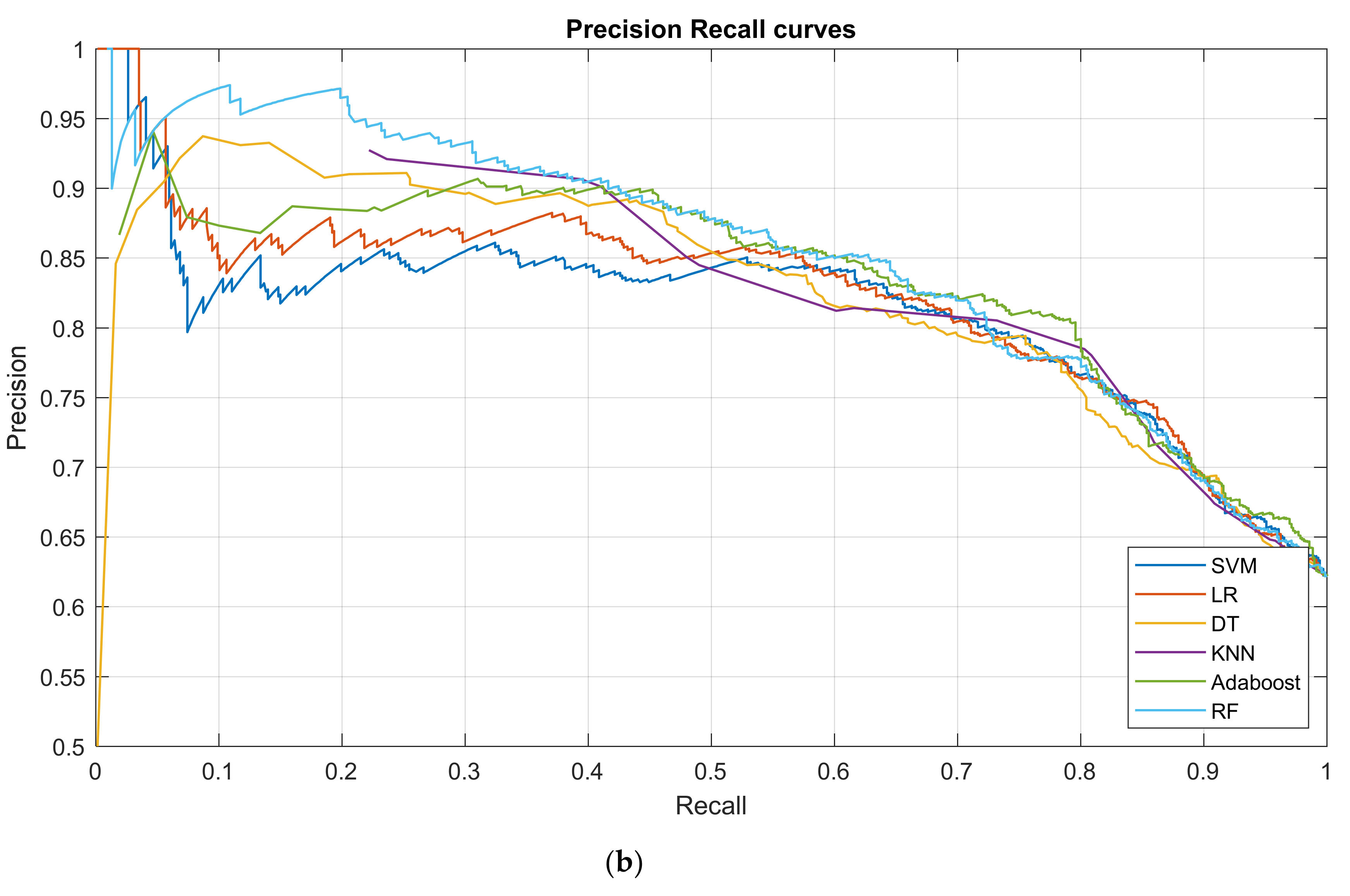
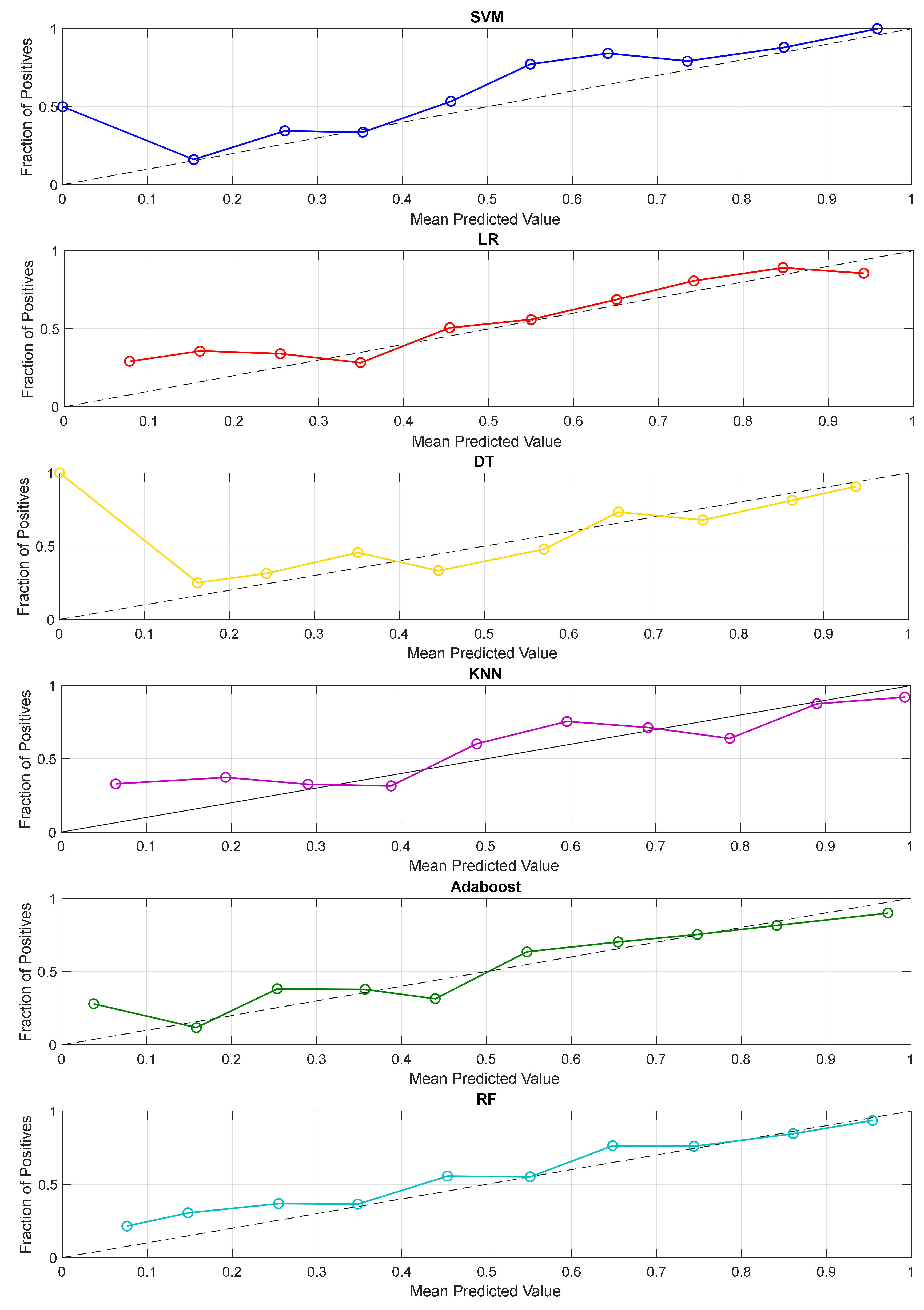
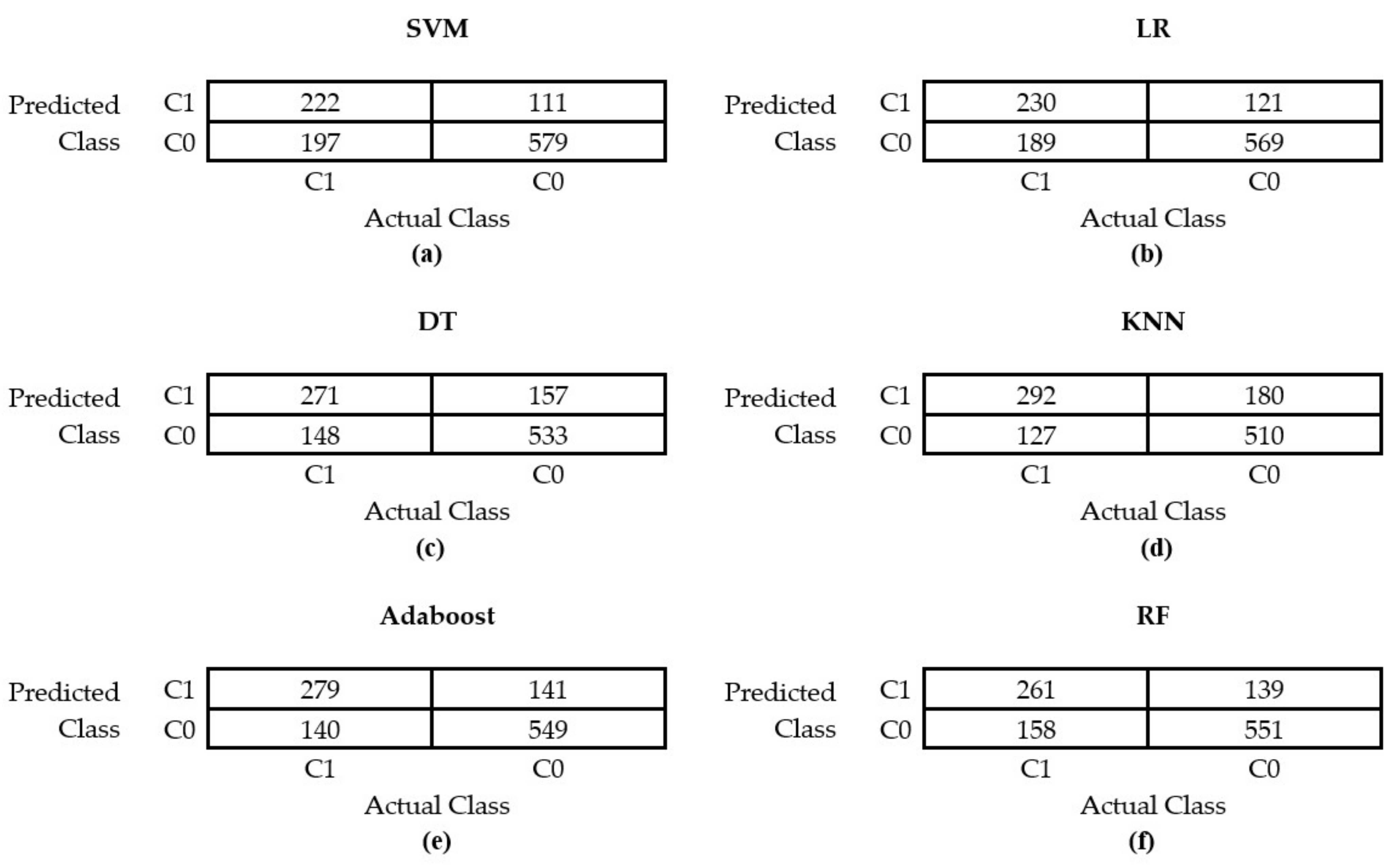
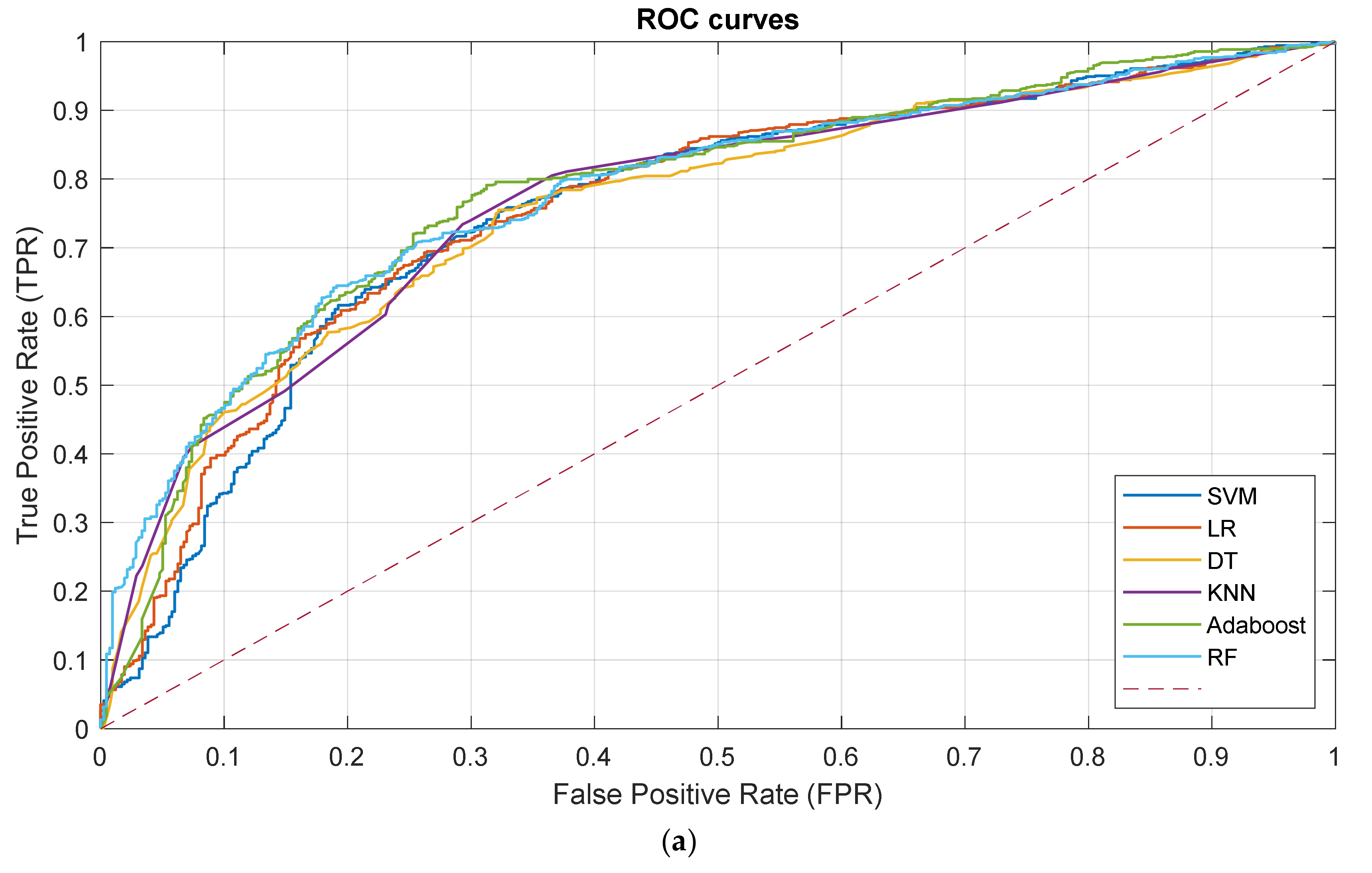
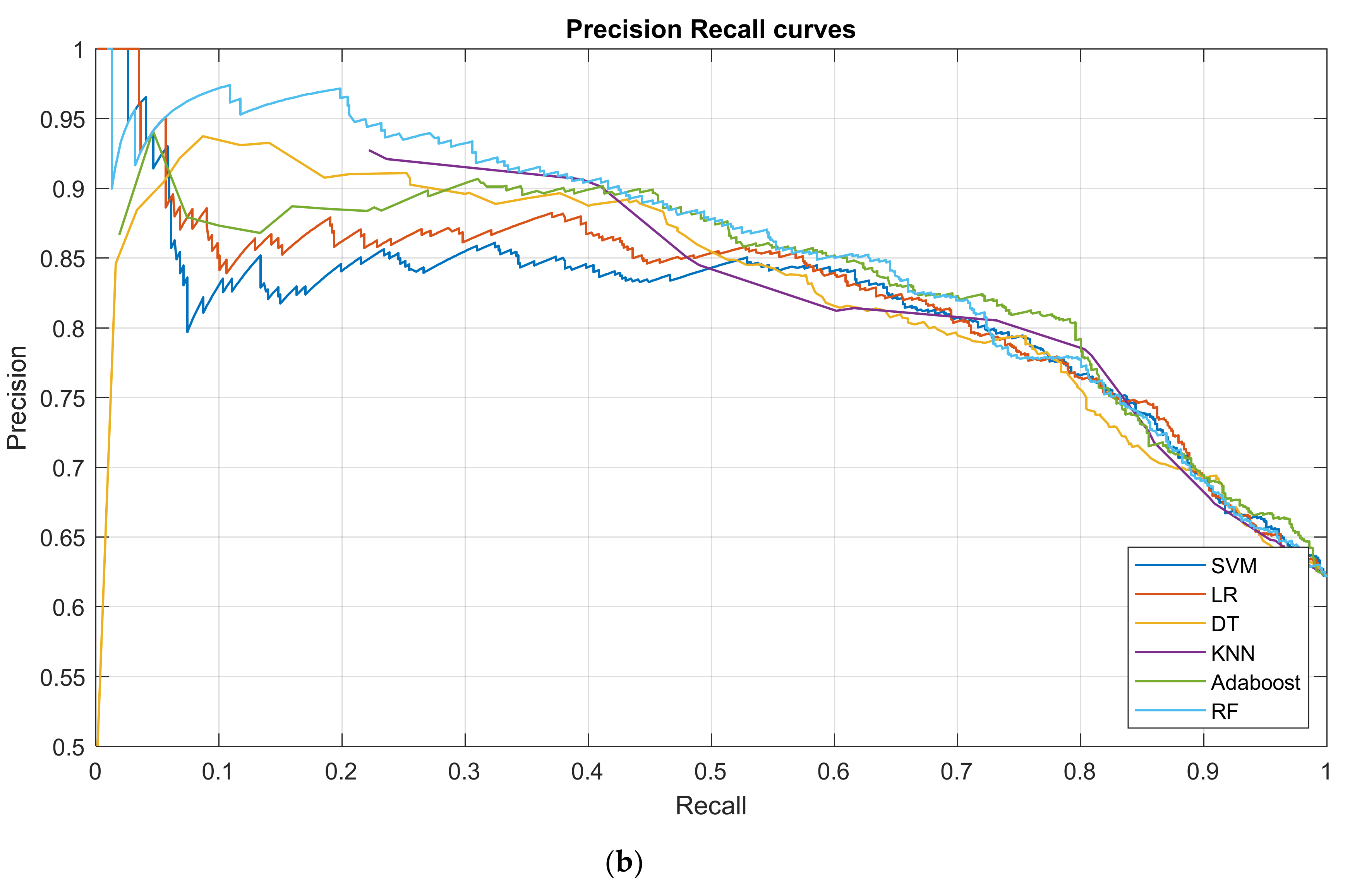
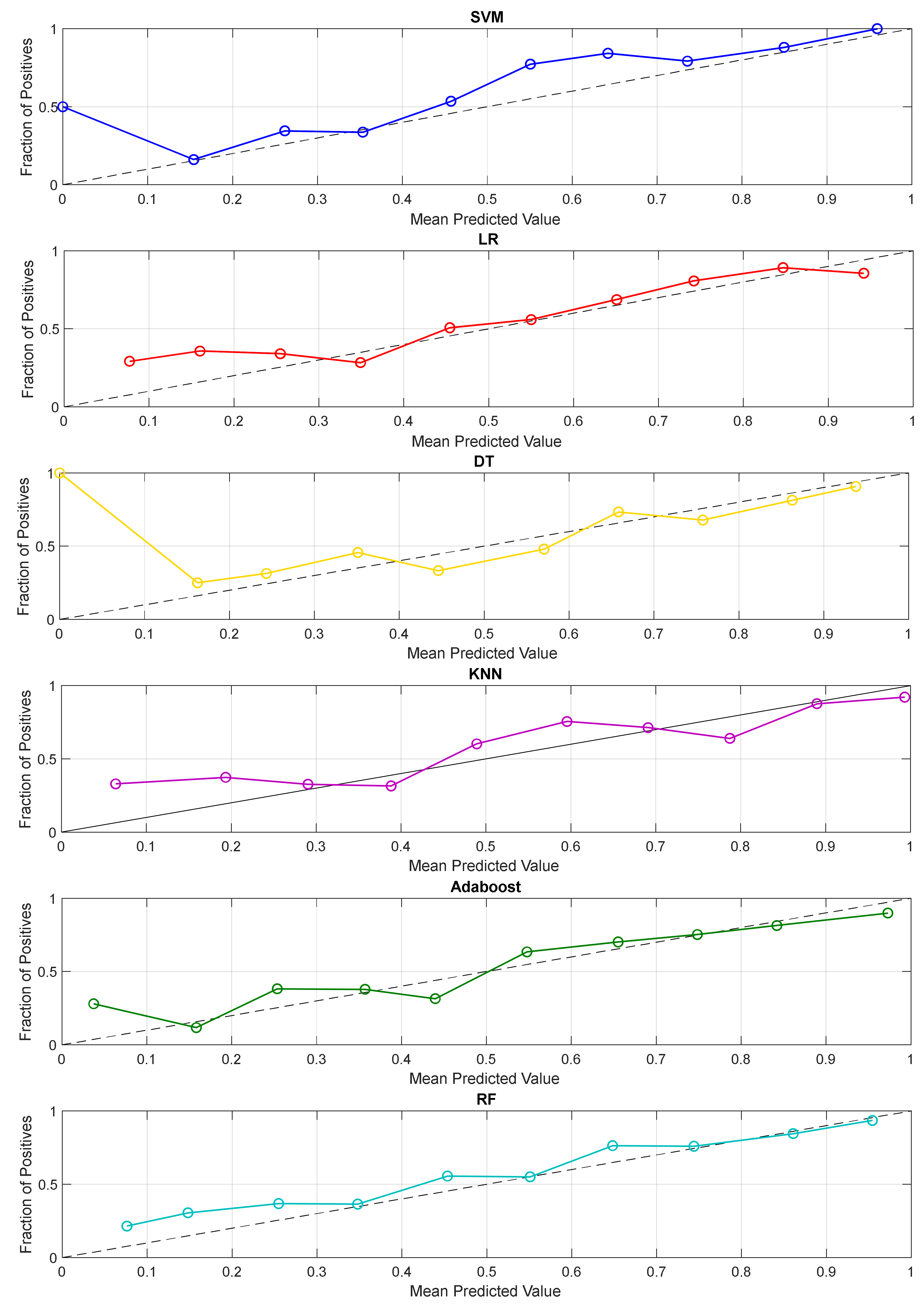
3.2. Prediction Performance
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ratey, J.J.; Loehr, J.E. The Positive Impact of Physical Activity on Cognition during Adulthood: A Review of Underlying Mechanisms, Evidence and Recommendations. Rev. Neurosci. 2011, 22, 171–185. [Google Scholar] [CrossRef]
- Sun, F.; Norman, I.J.; While, A.E. Physical Activity in Older People: A Systematic Review. BMC Public Health 2013, 13, 449. [Google Scholar] [CrossRef] [Green Version]
- Xiong, J.; Ye, M.; Wang, L.; Zheng, G. Effects of Physical Exercise on Executive Function in Cognitively Healthy Older Adults: A Systematic Review and Meta-Analysis of Randomized Controlled Trials: Physical Exercise for Executive Function. Int. J. Nurs. Stud. 2020, 114, 103810. [Google Scholar] [CrossRef]
- Bahr, R.; Holme, I. Risk Factors for Sports Injuries—A Methodological Approach. Br. J. Sports Med. 2003, 37, 384–392. [Google Scholar] [CrossRef] [PubMed]
- Myklebust, G.; Holm, I.; Mæhlum, S.; Engebretsen, L.; Bahr, R. Clinical, Functional, and Radiologic Outcome in Team Handball Players 6 to 11 Years after Anterior Cruciate Ligament Injury: A Follow-up Study. Am. J. Sports Med. 2003, 31, 981–989. [Google Scholar] [CrossRef]
- Alekseyev, K.; John, A.; Malek, A.; Lakdawala, M.; Verma, N.; Southall, C.; Nikolaidis, A.; Akella, S.; Erosa, S.; Islam, R. Identifying the Most Common CrossFit Injuries in a Variety of Athletes. Rehabil. Process Outcome 2020, 9, 1179572719897069. [Google Scholar] [CrossRef] [PubMed]
- Minghelli, B.; Vicente, P. Musculoskeletal Injuries in Portuguese CrossFit Practitioners. J. Sports Med. Phys. Fit. 2019, 59, 1213–1220. [Google Scholar] [CrossRef]
- Weisenthal, B.M.; Beck, C.A.; Maloney, M.D.; DeHaven, K.E.; Giordano, B.D. Injury Rate and Patterns among CrossFit Athletes. Orthop. J. Sports Med. 2014, 2, 2325967114531177. [Google Scholar] [CrossRef] [PubMed]
- Montalvo, A.M.; Shaefer, H.; Rodriguez, B.; Li, T.; Epnere, K.; Myer, G.D. Retrospective Injury Epidemiology and Risk Factors for Injury in CrossFit. J. Sports Sci. Med. 2017, 16, 53. [Google Scholar] [PubMed]
- Moran, S.; Booker, H.; Staines, J.; Williams, S. Rates and Risk Factors of Injury in CrossFit: A Prospective Cohort Study. J. Sports Med. Phys Fit. 2017, 57, 1147–1153. [Google Scholar]
- Sprey, J.W.C.; Ferreira, T.; de Lima, M.V.; Duarte Jr, A.; Jorge, P.B.; Santili, C. An Epidemiological Profile of Crossfit Athletes in Brazil. Orthop. J. Sports Med. 2016, 4, 2325967116663706. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Meyer, J.; Morrison, J.; Zuniga, J. The Benefits and Risks of CrossFit: A Systematic Review. Workplace Health Saf. 2017, 65, 612–618. [Google Scholar] [CrossRef] [PubMed]
- Da Silva, C. A Profile of Injuries among Participants at the 2013 CrossFit Games in Durban 2015. Diss. 2015. Available online: https://openscholar.dut.ac.za/handle/10321/1415 (accessed on 10 December 2021).
- Summitt, R.J.; Cotton, R.A.; Kays, A.C.; Slaven, E.J. Shoulder Injuries in Individuals Who Participate in CrossFit Training. Sports Health 2016, 8, 541–546. [Google Scholar] [CrossRef] [Green Version]
- Mehrab, M.; de Vos, R.-J.; Kraan, G.A.; Mathijssen, N.M.C. Injury Incidence and Patterns among Dutch CrossFit Athletes. Orthop. J. Sports Med. 2017, 5, 2325967117745263. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Soares, M.R.A.D.R. An Epidemiological Profile of Crossfit Participants in Portugal 2017. Master’s Thesis, Universidade Lusófona de Humanidades e Tecnologias, Lisabon, Portugal, 2017. [Google Scholar]
- Tafuri, S.; Salatino, G.; Napoletano, P.; Monno, A.; Notarnicola, A. The Risk of Injuries among CrossFit Athletes: An Italian Observational Retrospective Survey. J. Sports Med. Phys. Fit. 2019, 59, 1544–1550. [Google Scholar] [CrossRef] [PubMed]
- Feito, Y.; Burrows, E.K.; Tabb, L.P. A 4-Year Analysis of the Incidence of Injuries Among CrossFit-Trained Participants. Orthop. J. Sports Med. 2018, 6, 2325967118803100. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Da Costa, T.S.; Louzada, C.T.N.; Miyashita, G.K.; da Silva, P.H.J.; Sungaila, H.Y.F.; Lara, P.H.S.; Pochini, A.D.C.; Ejnisman, B.; Cohen, M.; Arliani, G.G. CrossFit®: Injury Prevalence and Main Risk Factors. Clinics 2019, 74, e1402. [Google Scholar] [CrossRef] [Green Version]
- de Oliveira, M.G.; Pereira, L.G.C.; Teymeny, A.A.T.A.T. Incidência de lesões musculoesqueléticas em praticantes de CrossFit. Rev. Ciências da Saúde-UNIPLAN 2019, 1, 11. [Google Scholar]
- Szeles, P.R.D.Q.; da Costa, T.S.; da Cunha, R.A.; Hespanhol, L.; de Castro Pochini, A.; Ramos, L.A.; Cohen, M. CrossFit and the Epidemiology of Musculoskeletal Injuries: A Prospective 12-Week Cohort Study. Orthop. J. Sports Med. 2020, 8, 2325967120908884. [Google Scholar]
- Gile, M.; Petit, J.; Gremeaux, V. Évaluation Du Taux de Blessures Chez Les Pratiquants de CrossFit En France. J. Traumatol. du Sport 2020, 37, 2–9. [Google Scholar] [CrossRef]
- Rodríguez, M.Á.; García-Calleja, P.; Terrados, N.; Crespo, I.; Del Valle, M.; Olmedillas, H. Injury in CrossFit®: A Systematic Review of Epidemiology and Risk Factors. Phys. Sportsmed. 2021, 50, 3–10. [Google Scholar] [CrossRef] [PubMed]
- Bini, S.A. Artificial Intelligence, Machine Learning, Deep Learning, and Cognitive Computing: What Do These Terms Mean and How Will They Impact Health Care? J. Arthroplasty 2018, 33, 2358–2361. [Google Scholar] [CrossRef] [PubMed]
- Belk, J.W.; Marshall, H.A.; McCarty, E.C.; Kraeutler, M.J. The Effect of Regular-Season Rest on Playoff Performance among Players in the National Basketball Association. Orthop. J. Sports Med. 2017, 5, 2325967117729798. [Google Scholar] [CrossRef] [PubMed]
- Ofoghi, B.; Zeleznikow, J.; MacMahon, C.; Raab, M. Data Mining in Elite Sports: A Review and a Framework. Meas. Phys. Educ. Exerc. Sci. 2013, 17, 171–186. [Google Scholar] [CrossRef]
- Zelič, I.; Kononenko, I.; Lavrač, N.; Vuga, V. Induction of Decision Trees and Bayesian Classification Applied to Diagnosis of Sport Injuries. J. Med. Syst. 1997, 21, 429–444. [Google Scholar] [CrossRef] [PubMed]
- Fielitz, L.; Scott, D. Prediction of Physical Performance Using Data Mining.(Measurement). Res. Q. Exerc. Sport 2003, 74, A25. [Google Scholar]
- Andrews, P.J.D.; Sleeman, D.H.; Statham, P.F.X.; McQuatt, A.; Corruble, V.; Jones, P.A.; Howells, T.P.; Macmillan, C.S.A. Predicting Recovery in Patients Suffering from Traumatic Brain Injury by Using Admission Variables and Physiological Data: A Comparison between Decision Tree Analysis and Logistic Regression. J. Neurosurg. 2002, 97, 326–336. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Richter, C.; King, E.; Falvey, E.; Franklyn-Miller, A. Supervised Learning Techniques and Their Ability to Classify a Change of Direction Task Strategy Using Kinematic and Kinetic Features. J. Biomech. 2018, 66, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Wright, A.; Karnuta, J.; Luu, B.; Haeberle, H.; Makhni, E.; Schickendantz, M.; Ramkumar, P. Machine Learning Accurately Predicts Next Season NHL Player Injury Before It Occurs: Validation of 10,449 Player-Years from 2007-17. Orthop. J. Sports Med. 2020, 8, 2325967120S00360. [Google Scholar] [CrossRef]
- Rommers, N.; Rössler, R.; Verhagen, E.; Vandecasteele, F.; Verstockt, S.; Lenoir, M.; D’Hondt, E.; Witvrouw, E. 009 Big Data in Youth Elite Football: Could Machine Learning Help Us to Better Understand Injury Risk? Br. J. Sports Med. 2020, 54, A5. [Google Scholar]
- Jaspers, A.; De Beéck, T.O.; Brink, M.S.; Frencken, W.G.P.; Staes, F.; Davis, J.J.; Helsen, W.F. Relationships between the External and Internal Training Load in Professional Soccer: What Can We Learn from Machine Learning? Int. J. Sports Physiol. Perform. 2018, 13, 625–630. [Google Scholar] [CrossRef] [PubMed]
- Ruddy, J.D.; Shield, A.J.; Maniar, N.; Williams, M.D.; Duhig, S.; Timmins, R.G.; Hickey, J.; Bourne, M.N.; Opar, D.A. Predictive Modeling of Hamstring Strain Injuries in Elite Australian Footballers. Med. Sci. Sports Exerc. 2018, 50, 906–914. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Karnuta, J.M.; Luu, B.C.; Haeberle, H.S.; Saluan, P.M.; Frangiamore, S.J.; Stearns, K.L.; Farrow, L.D.; Nwachukwu, B.U.; Verma, N.N.; Makhni, E.C. Machine Learning Outperforms Regression Analysis to Predict Next-Season Major League Baseball Player Injuries: Epidemiology and Validation of 13,982 Player-Years from Performance and Injury Profile Trends, 2000–2017. Orthop. J. Sports Med. 2020, 8, 2325967120963046. [Google Scholar] [CrossRef] [PubMed]
- Jauhiainen, S.; Kauppi, J.-P.; Leppänen, M.; Pasanen, K.; Parkkari, J.; Vasankari, T.; Kannus, P.; Äyrämö, S. New Machine Learning Approach for Detection of Injury Risk Factors in Young Team Sport Athletes. Int. J. Sports Med. 2021, 42, 175–182. [Google Scholar] [CrossRef] [PubMed]
- Arifin, W.N. Introduction to Sample Size Calculation. Educ. Med. J. 2013, 2, e89–e96. [Google Scholar] [CrossRef]
- Moustakidis, S.P.; Theocharis, J.B. SVM-FuzCoC: A Novel SVM-Based Feature Selection Method Using a Fuzzy Complementary Criterion. Pattern Recognit. 2010, 43, 3712–3729. [Google Scholar] [CrossRef]
- Moustakidis, S.P.; Theocharis, J.B.; Giakas, G. Feature Selection Based on a Fuzzy Complementary Criterion: Application to Gait Recognition Using Ground Reaction Forces. Comput. Methods Biomech. Biomed. Eng. 2012, 15, 627–644. [Google Scholar] [CrossRef] [PubMed]
- Witten, I.; Frank, E.; Hall, M. Introduction to Data Mining. In Data Mining: Practical Machine Learning Tools and Techniques, 3rd ed.; Morgan Kaufmann-Elsevier: Burlington, MA, USA, 2011. [Google Scholar]
- Atkeson, C.G.; Moore, A.W.; Schaal, S. Locally Weighted Learning. In Lazy Learning; Springer: Berlin/Heidelberg, Germany, 1997; pp. 11–73. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-Vector Networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A Decision-Theoretic Generalization of on-Line Learning and an Application to Boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef] [Green Version]
- Breiman, L. Random Forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Le, N.Q.K.; Kha, Q.H.; Nguyen, V.H.; Chen, Y.-C.; Cheng, S.-J.; Chen, C.-Y. Machine Learning-Based Radiomics Signatures for EGFR and KRAS Mutations Prediction in Non-Small-Cell Lung Cancer. Int. J. Mol. Sci. 2021, 22, 9254. [Google Scholar] [CrossRef]
- Hung, T.N.K.; Le, N.Q.K.; Le, N.H.; Van Tuan, L.; Nguyen, T.P.; Thi, C.; Kang, J.-H. An AI-based Prediction Model for Drug-drug Interactions in Osteoporosis and Paget’s Diseases from SMILES. Mol. Inform. 2022, 2100264. [Google Scholar] [CrossRef] [PubMed]
- Kokkotis, C.; Ntakolia, C.; Moustakidis, S.; Giakas, G.; Tsaopoulos, D. Explainable Machine Learning for Knee Osteoarthritis Diagnosis Based on a Novel Fuzzy Feature Selection Methodology. Phys. Eng. Sci. Med. 2022, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Kampaktsis, P.N.; Tzani, A.; Doulamis, I.P.; Moustakidis, S.; Drosou, A.; Diakos, N.; Drakos, S.G.; Briasoulis, A. State-of-the-art Machine Learning Algorithms for the Prediction of Outcomes after Contemporary Heart Transplantation: Results from the UNOS Database. Clin. Transplant. 2021, 35, e14388. [Google Scholar] [CrossRef]
- Fagerland, M.W.; Lydersen, S.; Laake, P. The McNemar Test for Binary Matched-Pairs Data: Mid-p and Asymptotic Are Better than Exact Conditional. BMC Med. Res. Methodol. 2013, 13, 91. [Google Scholar] [CrossRef] [Green Version]
- Junior, L.C.H.; Costa, L.O.P.; Carvalho, A.C.A.; Lopes, A.D. A Description of Training Characteristics and Its Association with Previous Musculoskeletal Injuries in Recreational Runners: A Cross-Sectional Study. Braz. J. Phys. Ther. 2012, 16, 46–53. [Google Scholar]
- Ferguson, B. ACSM’s Guidelines for Exercise Testing and Prescription 9th Ed. 2014. J. Can. Chiropr. Assoc. 2014, 58, 328. [Google Scholar]
- Agresta, C.E.; Krieg, K.; Freehill, M.T. Risk Factors for Baseball-Related Arm Injuries: A Systematic Review. Orthop. J. Sports Med. 2019, 7, 2325967119825557. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Girometti, R.; De Candia, A.; Sbuelz, M.; Toso, F.; Zuiani, C.; Bazzocchi, M. Supraspinatus Tendon US Morphology in Basketball Players: Correlation with Main Pathologic Models of Secondary Impingement Syndrome in Young Overhead Athletes. Preliminary Report. Radiol. Med. 2006, 111, 42–52. [Google Scholar] [CrossRef]
- Giroto, N.; Hespanhol Junior, L.C.; Gomes, M.R.C.; Lopes, A.D. Incidence and Risk Factors of Injuries in Brazilian Elite Handball Players: A Prospective Cohort Study. Scand. J. Med. Sci. Sports 2017, 27, 195–202. [Google Scholar] [CrossRef]
- Saragiotto, B.T.; Yamato, T.P.; Junior, L.C.H.; Rainbow, M.J.; Davis, I.S.; Lopes, A.D. What Are the Main Risk Factors for Running-Related Injuries? Sports Med. 2014, 44, 1153–1163. [Google Scholar] [CrossRef] [PubMed]
- Grier, T.; Canham-Chervak, M.; McNulty, V.; Jones, B.H. Extreme Conditioning Programs and Injury Risk in a US Army Brigade Combat Team. US Army Med. Dep. J. 2013, 11, 36–47. [Google Scholar]
- Keogh, J.; Hume, P.A.; Pearson, S. Retrospective Injury Epidemiology of One Hundred One Competitive Oceania Power Lifters: The Effects of Age, Body Mass, Competitive Standard, and Gender. J. Strength Cond. Res. 2006, 20, 672–681. [Google Scholar] [CrossRef] [PubMed]
- Quatman, C.E.; Myer, G.D.; Khoury, J.; Wall, E.J.; Hewett, T.E. Sex Differences in “Weightlifting” Injuries Presenting to United States Emergency Rooms. J. Strength Cond. Res. Strength Cond. Assoc. 2009, 23, 2061–2067. [Google Scholar] [CrossRef] [PubMed] [Green Version]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| C1 | C0 | Total | p-Value | |
|---|---|---|---|---|
| Sex | n (%) | n (%) | n (%) | 0.00 |
| Female | 143 (11.68) | 300 (24.51) | 443 (36) | |
| Male | 391 (31.95) | 390 (31.86) | 781 (64) | |
| Age group | 0.00 | |||
| <18 | 0 | 0 | 0 (0) | |
| 18-29 | 230 (18.80) | 368 (30.07) | 598 (49) | |
| 30-39 | 212 (17.32) | 236 (19.28) | 448 (37) | |
| 40-49 | 84 (6.86) | 78 (6.37) | 162 (13) | |
| ≥50 | 8 (0.65) | 8 (0.65) | 16 (1) | |
| Mean ± SD | 175.43 ± 8.56 | 175.37 ± 8.95 | 175.40 ± 8.78 | |
| Median (range) | 176 (150–203) | 176 (153–198) | 176 (150–203) | |
| Height | 0.00 | |||
| Mean ± SD | 175.43 ± 8.56 | 175.37 ± 8.95 | 175.40 ± 8.78 | |
| Median (range) | 176 (150–203) | 176 (153–198) | 176 (150–203) | |
| Weight | 0.00 | |||
| Mean ± SD | 77.26 ± 13.27 | 74.84 ± 13.23 | 75.89 ± 13.24 | |
| Median (range) | 77 (47–120) | 77 (47–120) | 77 (47–120) | |
| BMI, kg/m2 | 0.00 | |||
| Mean ± SD | 24.96 ± 2.71 | 24.14 ± 2.67 | 24.5 ± 2.72 | |
| Median (range) | 24.92 (17.93–35.92) | 24.13 (17.63–35.83) | 24.54 (17.63–35.92) |
| ML Model | Hyperparamaeters |
|---|---|
| LR | C: {0.01, 0.1, 1, 10, 100}, penalty: {‘l1’, ‘l2’} |
| DT | criterion: {‘gini’, ‘entropy’}, min_samples_leaf: {1, 2, 3, 4, 5}, min_samples_split: {2, 3, 4, 5, 6, 7} |
| KNN | algorithm: {‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’}, leaf_size: {1, 2, 3, 5}, n_neighbors: {3, 4, 5, 7, 9, 12, 14, 15, 16, 17}, weights: {‘uniform’, ‘distance’} |
| SVM | kernel: {‘rbf’, ‘linear’, ‘sigmoid’}, C: {0.001, 0.1, 0.1, 10, 25, 50, 100, 1000}, gamma: {0.01, 0.001, 0.0001, 1 × 10−5} |
| Adaboost | criterion: {‘gini’, ‘entropy’}, min_samples_leaf: {1, 2, 3, 4, 5}, min_samples_split: {2, 3, 4, 5, 6, 7}, n_estimators: {10, 15, 20, 25, 27, 30} |
| RF | criterion: {‘gini’, ‘entropy’}, min_samples_leaf: {1, 2, 3, 4, 5}, min_samples_split: {2, 3, 4, 5, 6, 7}, n_estimators: {10, 15, 20, 25, 27, 30} |
| # | Risk Factor Category | Questionnaire Items | t-Statistics | Pearson Chi-Square | p-Value |
|---|---|---|---|---|---|
| F1 | Demographics | Gender | 36.35 | 0.00 * | |
| F2 | CrossFit experience | How long have you been participating in CrossFit? | 11.462 | 0.00 * | |
| F3 | Days/weeks of training | On average, how many days a week do you train in CrossFit? | 4.121 | 0.00 * | |
| F4 | Training duration | On average, what is the duration of your workout (including warm-up)? | 7.352 | 0.00 * | |
| F5 | Prior to CrossFit level of activity | What was the level of your athletic activity—fitness in the last 1 year before you start CrossFit? | 38.43 | 0.00 * | |
| F6 | Medical history/previous injuries | Did you mention to your CrossFit trainer from the beginning (before you started training with him) a detailed medical history (with previous injuries or accompanying health problems you may have had)? | 26.84 | 0.00 * |
| # | Selected Risk Factor | N (%) | ||
|---|---|---|---|---|
| All | C0 | C1 | ||
| F1 | Gender | |||
| female | 443 (36) | 300 (24.5) | 143 (11.7) | |
| male | 781 (64) | 390 (31.9) | 391 (31.9) | |
| F2 | How long have you been participating in CrossFit? | |||
| 0–6 mo | 126 (10.3) | 89 (7.3) | 37 (3) | |
| 6–12 mo | 143 (11.7) | 113 (9.2) | 30 (2.5) | |
| 12–24 mo | 361 (29.5) | 254 (21) | 107 (8.5) | |
| ≥24 mo | 594 (48.5) | 234 (19.1) | 360 (29.4) | |
| F3 | On average, how many days a week do you train in CrossFit? | |||
| 1–2 times/wk | 69 (6) | 45 (4) | 24 (2) | |
| 3–4 times/wk | 592 (48) | 357 (29.1) | 235 (18.9) | |
| >4 times/wk | 563 (46) | 288 (23.5) | 275 (22.5) | |
| F4 | On average, what is the duration of your workout (including warm-up)? | |||
| <1 h | 98 (8) | 55 (4.5) | 43 (3.5) | |
| ≥1 h | 1126 (92) | 635 (51.9) | 491 (40.1) | |
| F5 | What was the level of your athletic activity–fitness in the last 1 year before you started CrossFit? | |||
| Low | 216 (17.6) | 116 (9.4) | 100 (8.2) | |
| Medium | 598 (48.9) | 388 (31.7) | 210 (17.2) | |
| High | 410 (33.5) | 186 (15.2) | 224 (18.3) | |
| F6 | Did you mention to your CrossFit trainer from the beginning (before you started training with him) a detailed medical history (with previous injuries or accompanying health problems you may have had)? | |||
| yes | 1009 (82) | 603 (49) | 406 (33) | |
| no | 215 (18) | 87 (7.3) | 128 (10.7) | |
| ML Algorithm | Accuracy | Precision (C0/C1) | Sensitivity (C0/C1) | Specificity (C0/C1) | AUC [Confidence Interval] |
|---|---|---|---|---|---|
| SVM | 0.7222 | 0.7461/0.6667 | 0.8391/0.5298 | 0.5298/0.8391 | 0.7550 [0.7240,0.7845] |
| LR | 0.7204 | 0.7506/0.6553 | 0.8246/0.5489 | 0.5489/0.8246 | 0.7610 [0.7341,0.7871] |
| DT | 0.7249 | 0.7826/0.6332 | 0.7724/0.6467 | 0.6467/0.7724 | 0.7590 [0.7295,0.7881] |
| KNN | 0.7231 | 0.8006/0.6186 | 0.7391/0.6968 | 0.6968/0.7391 | 0.7658 [0.7353,0.7933] |
| AdaBoost | 0.7466 | 0.7968/0.6643 | 0.7956/0.6658 | 0.6658/0.7956 | 0.7793 [0.7466,0.8064] |
| RF | 0.7322 | 0.7772/0.6525 | 0.7986/0.6229 | 0.6229/0.7986 | 0.7790 [0.7528,0.8063] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Moustakidis, S.; Siouras, A.; Vassis, K.; Misiris, I.; Papageorgiou, E.; Tsaopoulos, D. Prediction of Injuries in CrossFit Training: A Machine Learning Perspective. Algorithms 2022, 15, 77. https://doi.org/10.3390/a15030077
Moustakidis S, Siouras A, Vassis K, Misiris I, Papageorgiou E, Tsaopoulos D. Prediction of Injuries in CrossFit Training: A Machine Learning Perspective. Algorithms. 2022; 15(3):77. https://doi.org/10.3390/a15030077
Chicago/Turabian StyleMoustakidis, Serafeim, Athanasios Siouras, Konstantinos Vassis, Ioannis Misiris, Elpiniki Papageorgiou, and Dimitrios Tsaopoulos. 2022. "Prediction of Injuries in CrossFit Training: A Machine Learning Perspective" Algorithms 15, no. 3: 77. https://doi.org/10.3390/a15030077
APA StyleMoustakidis, S., Siouras, A., Vassis, K., Misiris, I., Papageorgiou, E., & Tsaopoulos, D. (2022). Prediction of Injuries in CrossFit Training: A Machine Learning Perspective. Algorithms, 15(3), 77. https://doi.org/10.3390/a15030077