
Accelerate Incremental TSP Algorithms on Time Evolving Graphs with Partitioning Methods


Abstract
:1. Introduction
2. Background and Related Work
2.1. Time Evolving Graph
2.2. Traveling Salesman Problem
2.3. Incremental Algorithms
2.4. Graph Partitioning
3. Algorithms
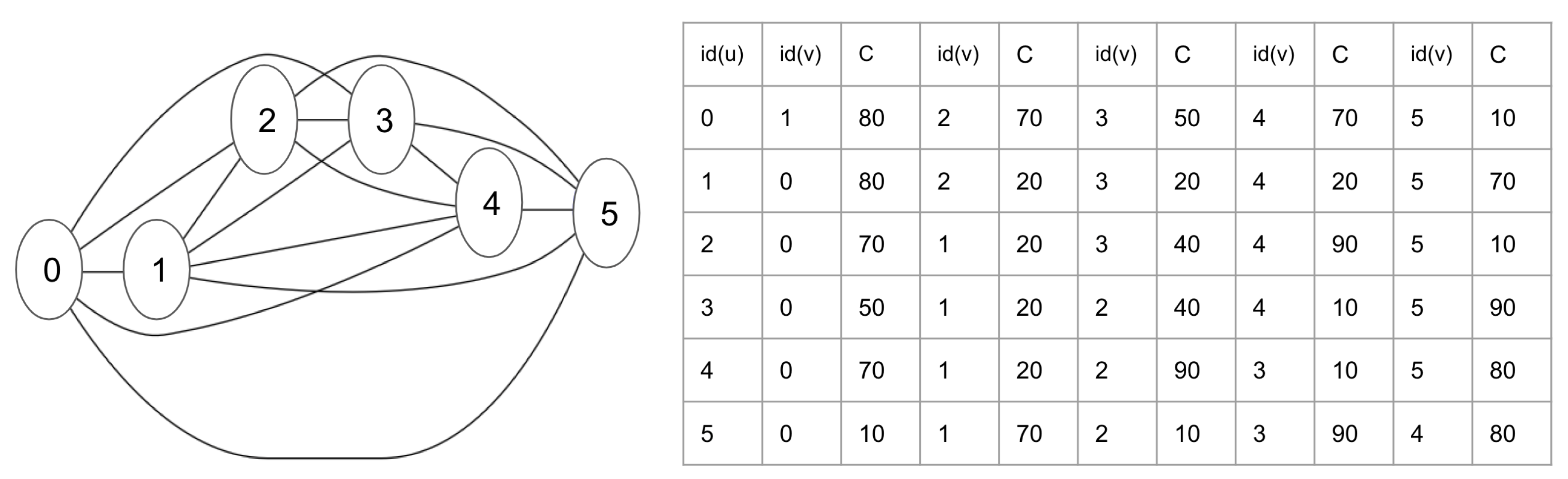
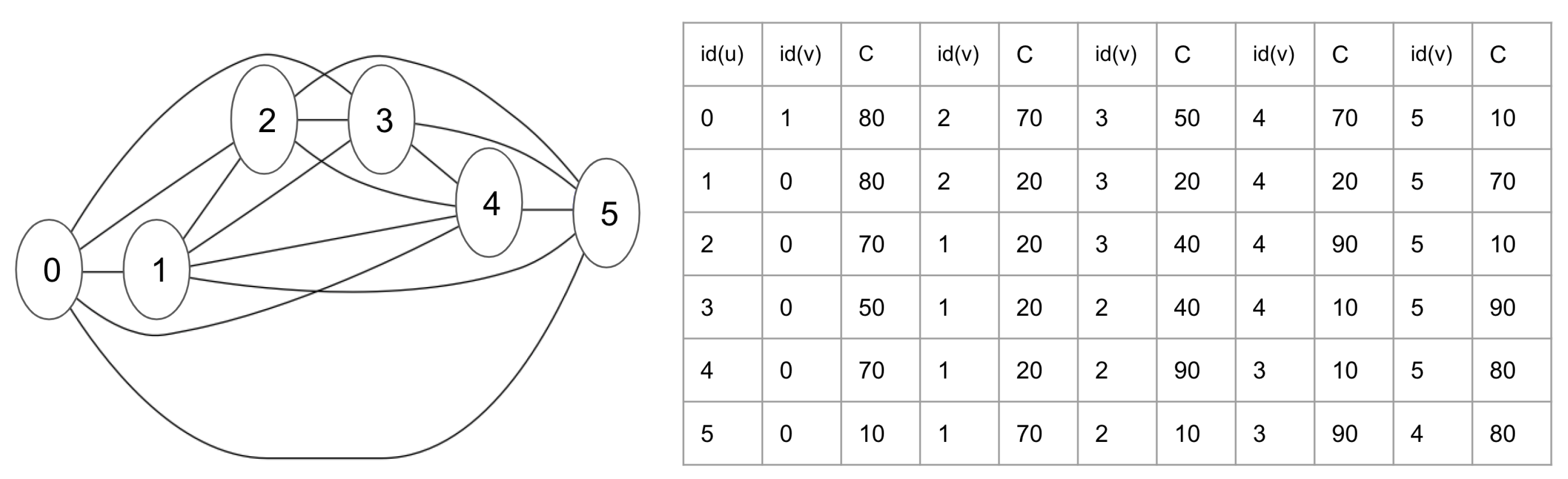
3.1. Problem Definition
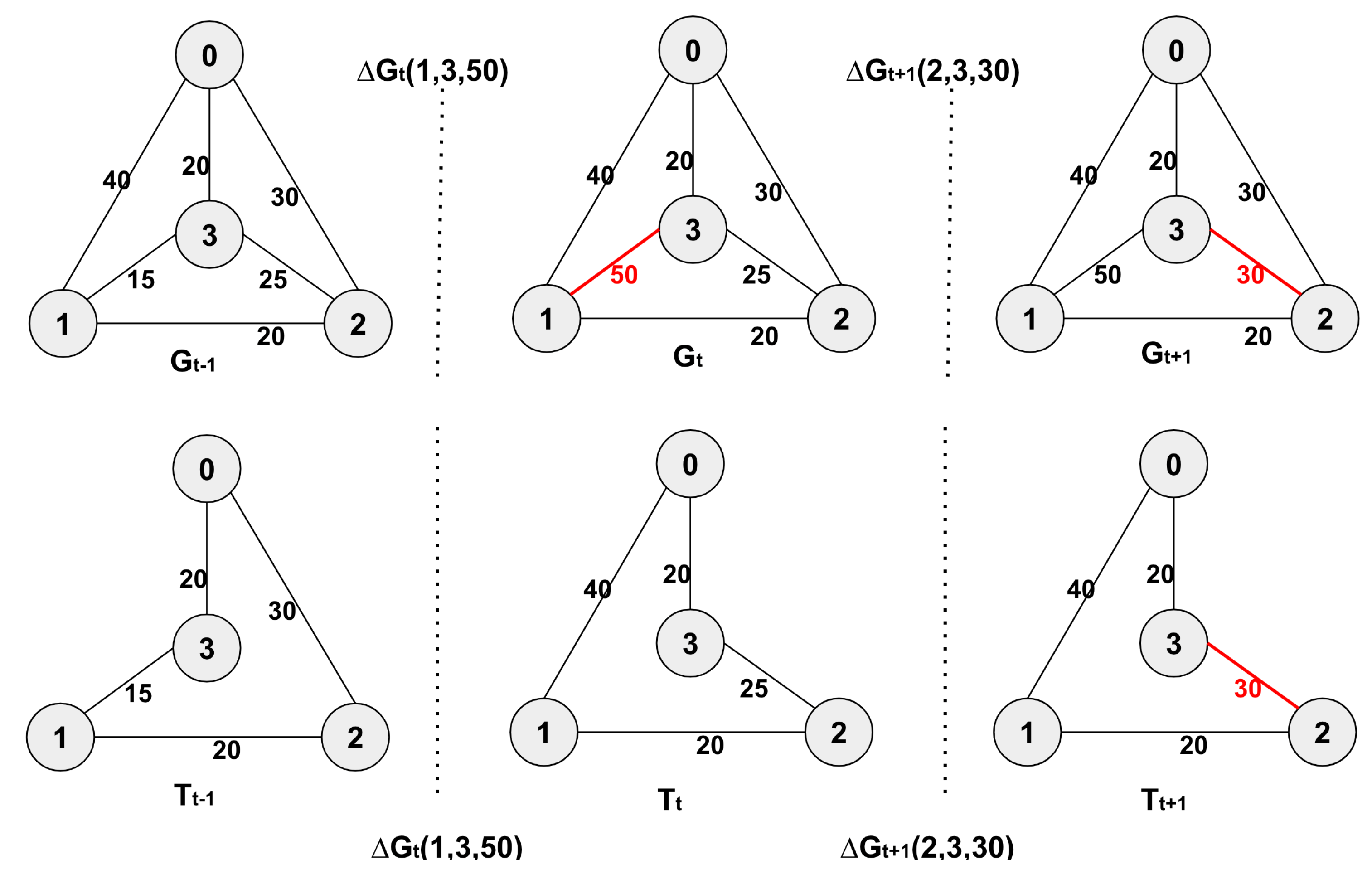
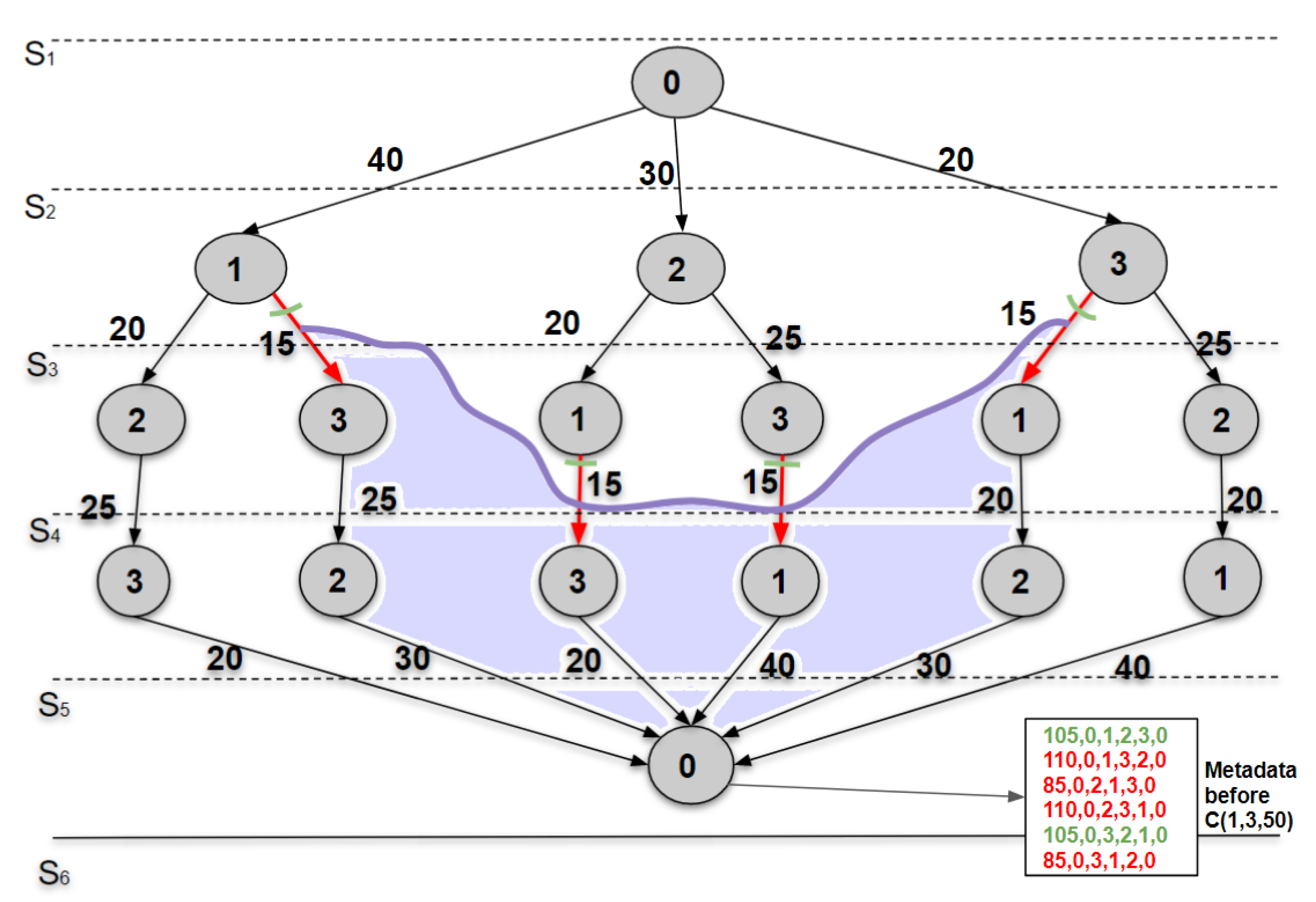
3.2. Incremental Algorithm
| Algorithm 1: Incremental distributed TSP Algorithms: I-TSP and Ig-TSP [14]. |
| Input:, pathList. Output: A TSP tour, T
|
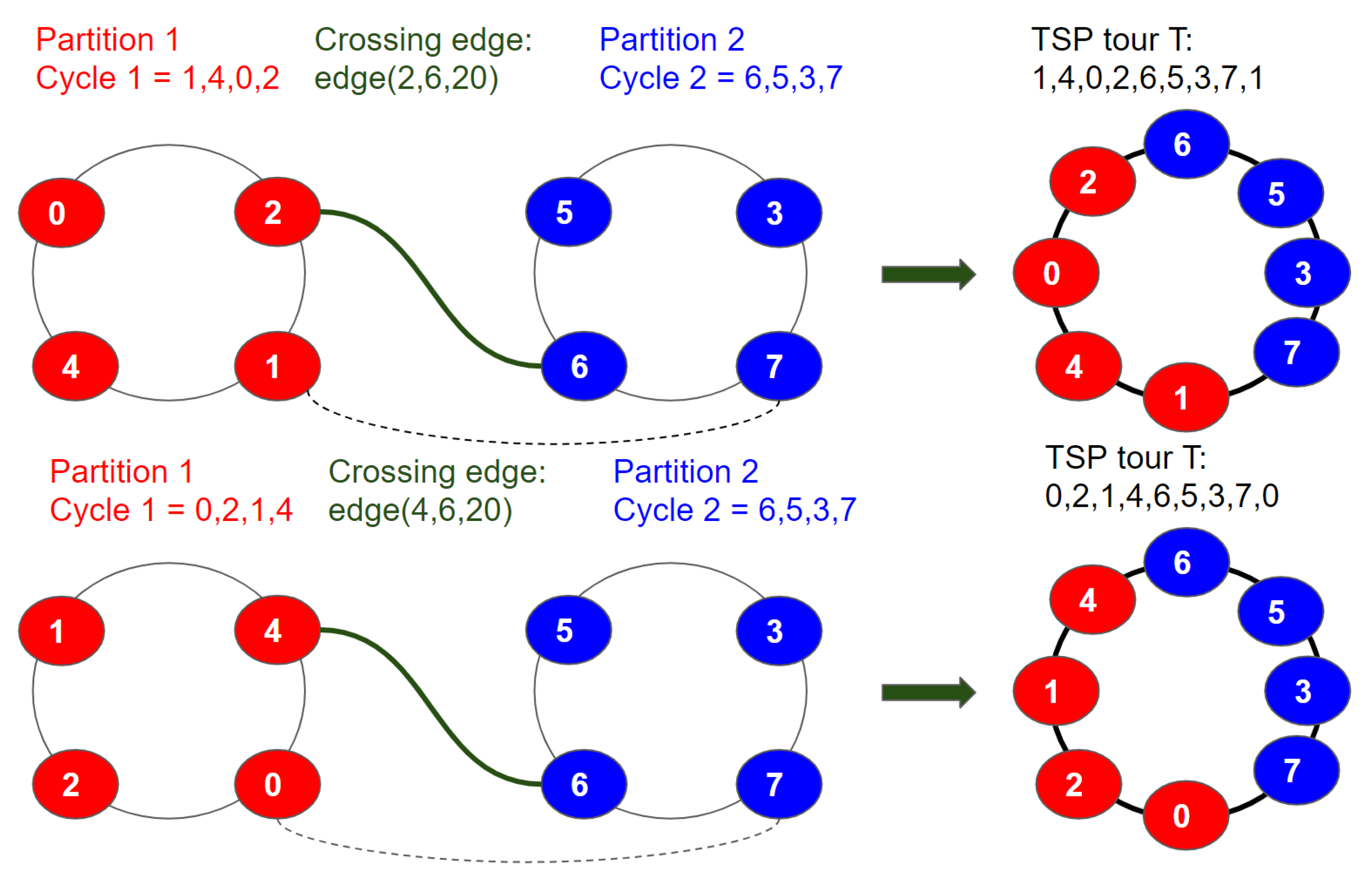
3.3. Graph Partitioning Algorithm
| Algorithm 2: Partitioned TSP Algorithms: P-TSP (Based on I-TSP) and Pg-TSP (Based on Ig-TSP). |
| Input:, pathList. Output: A TSP tour, T
|
3.4. Graph Partitioning Constraints
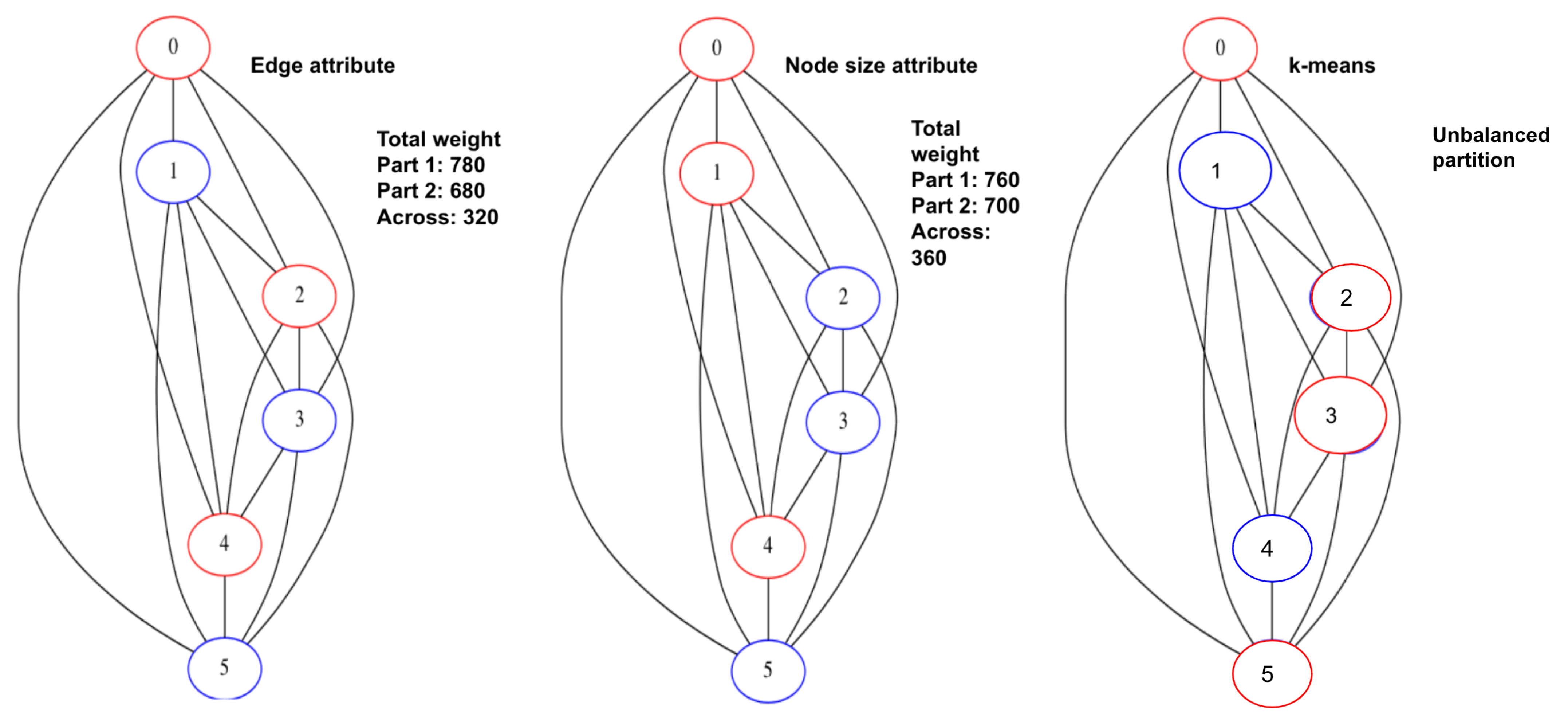
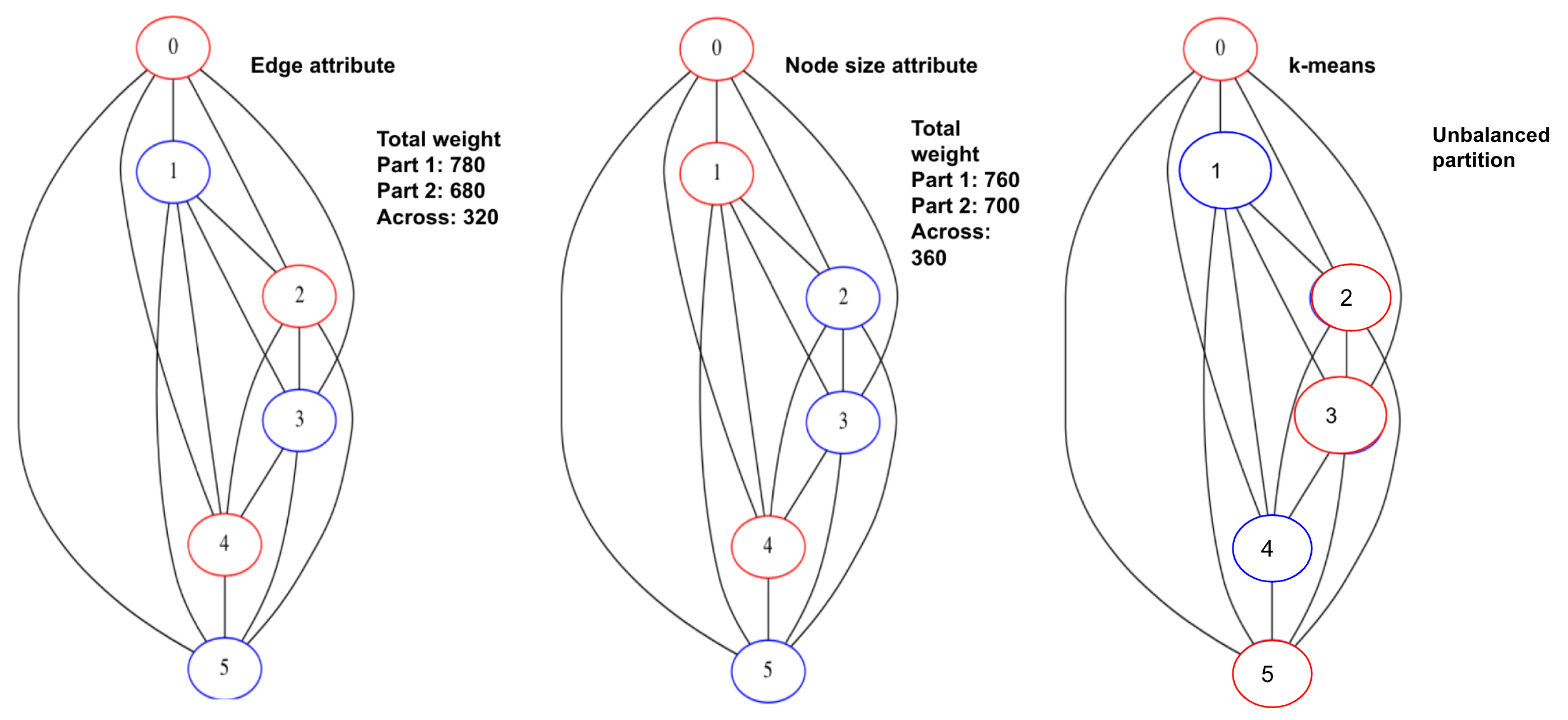
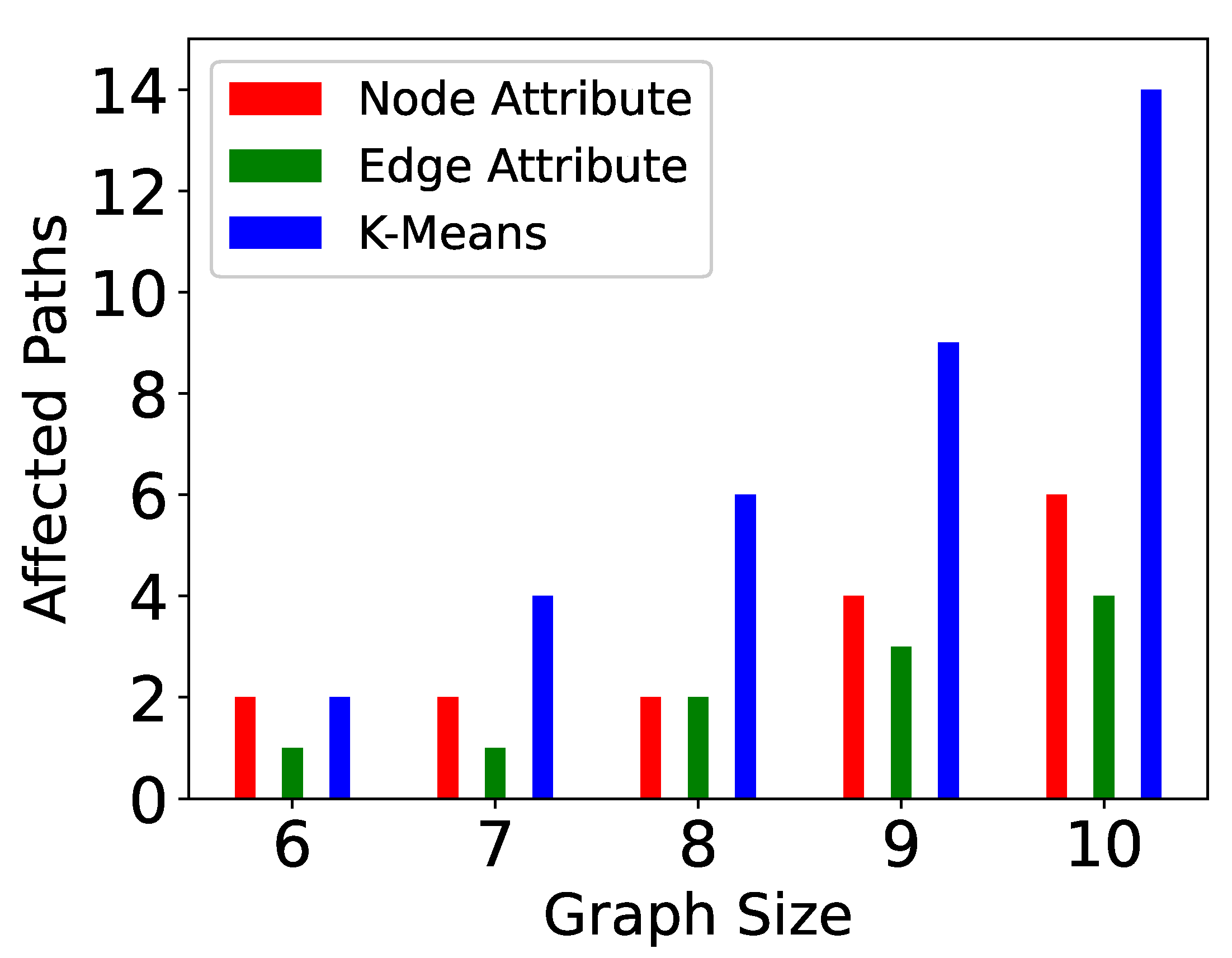
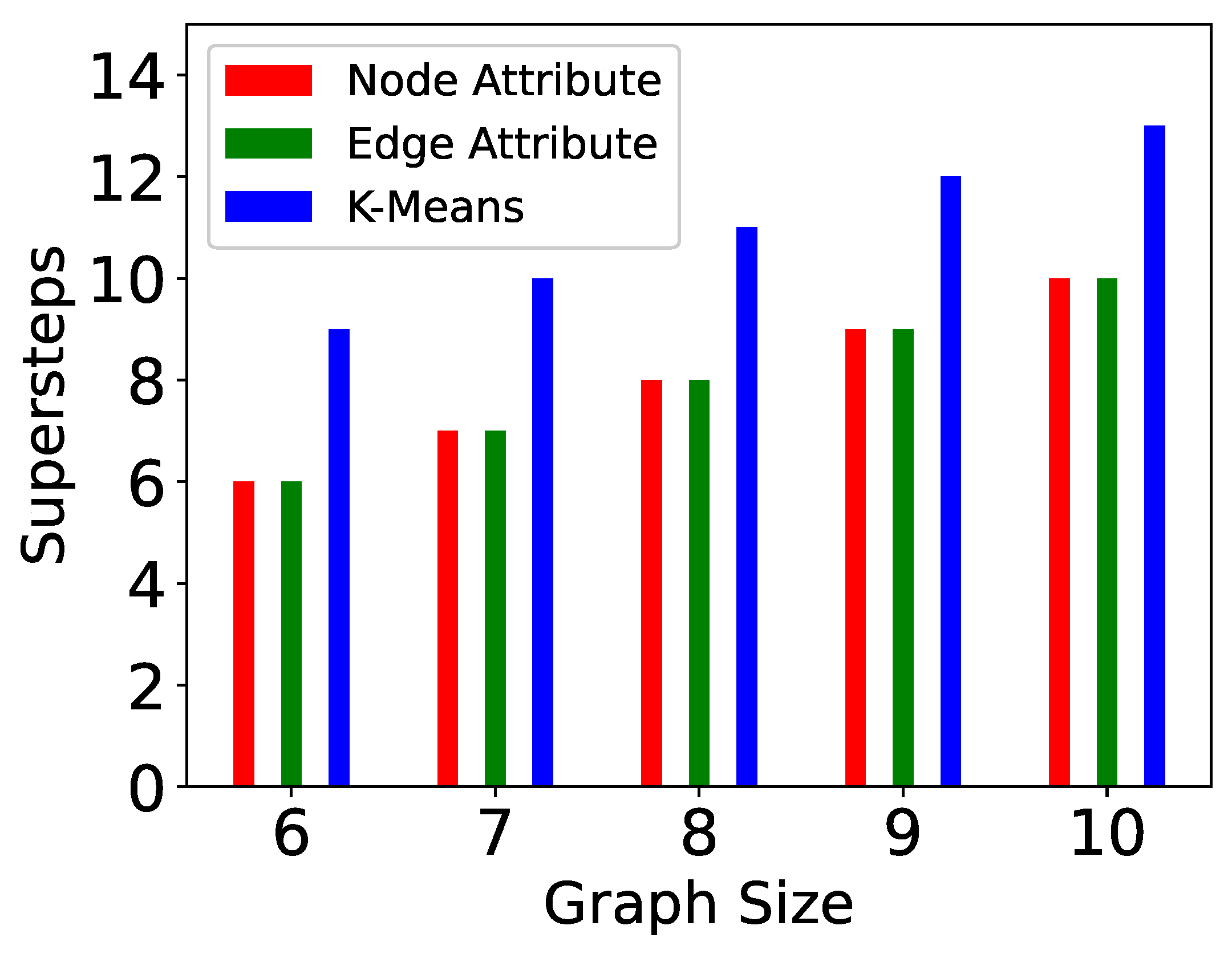
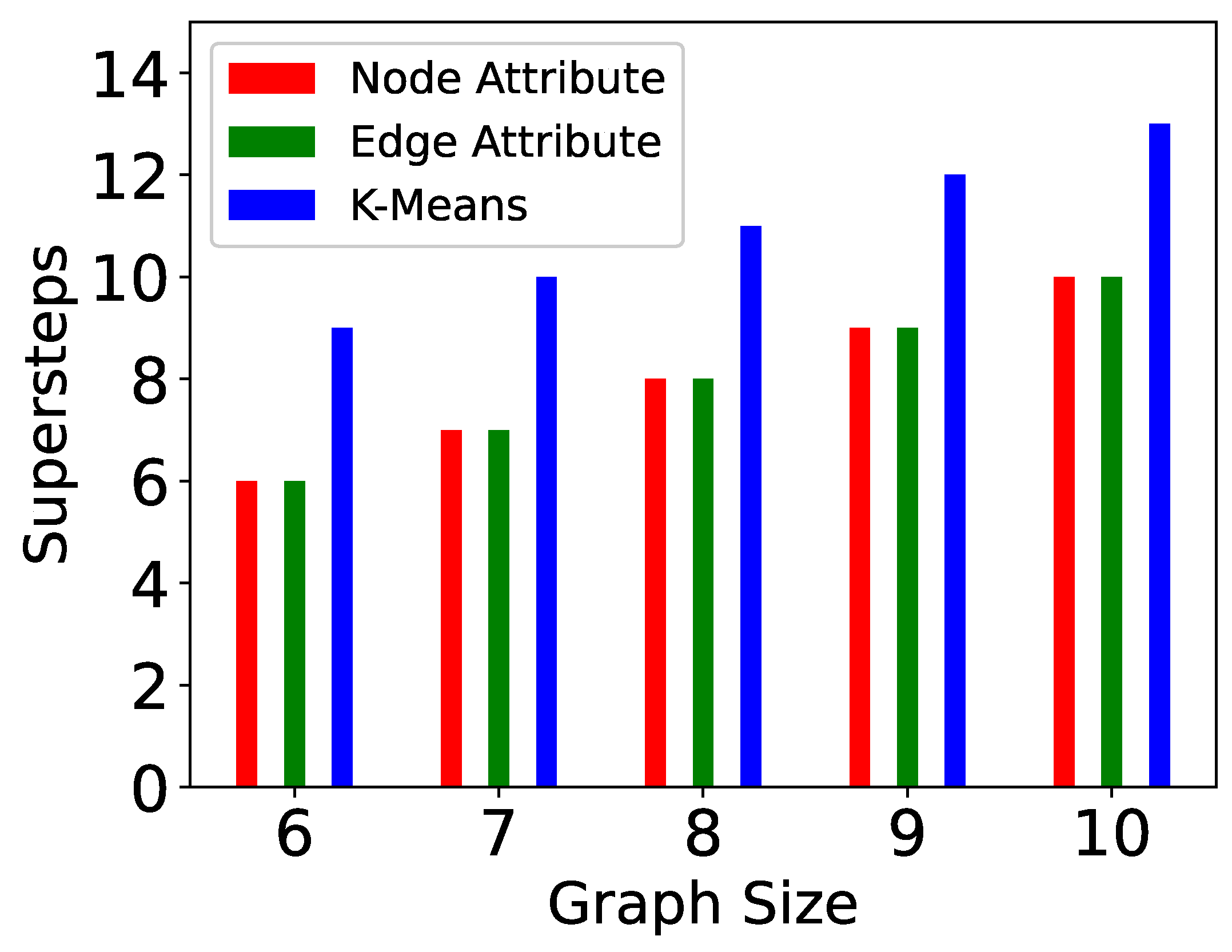
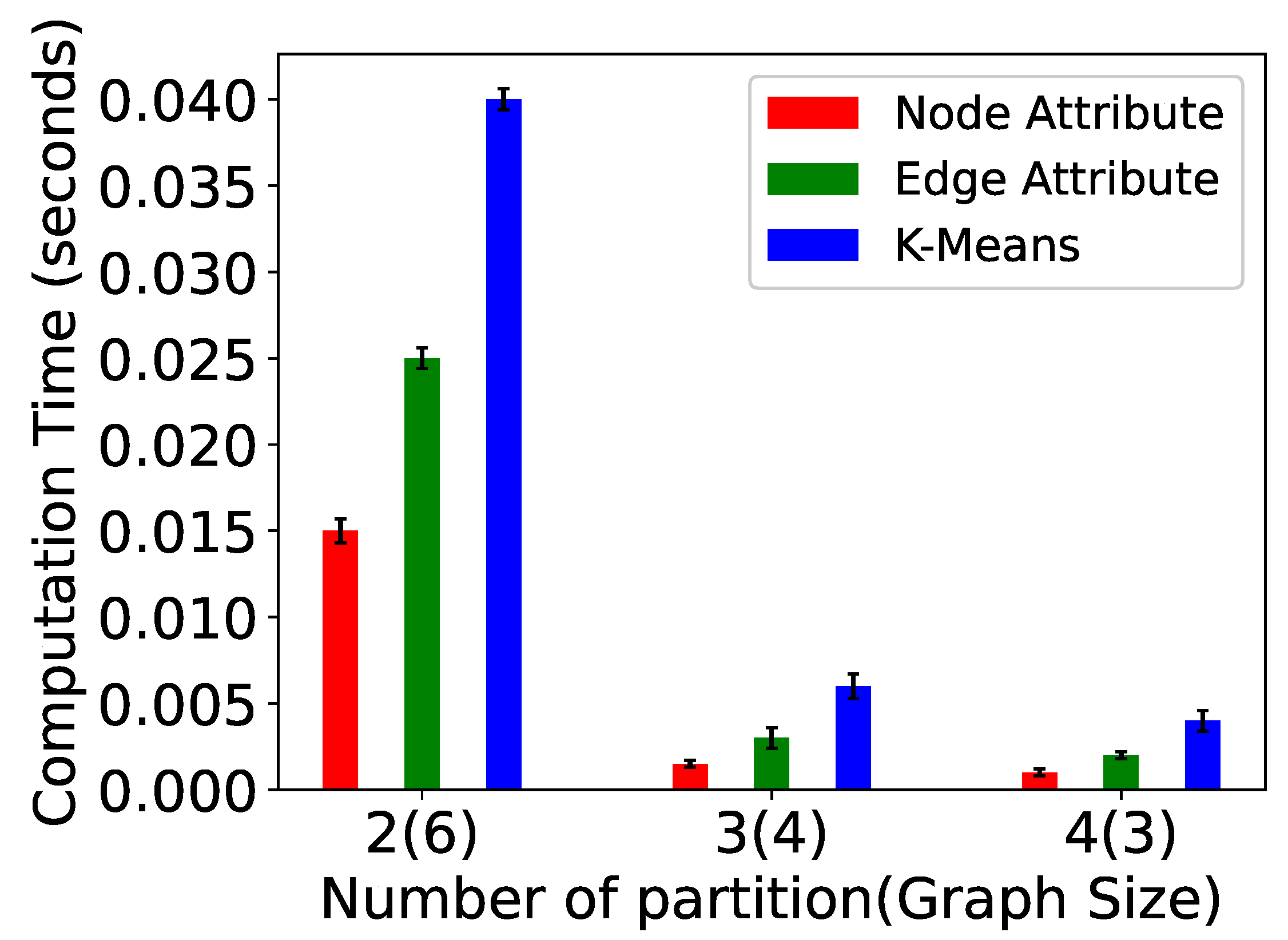
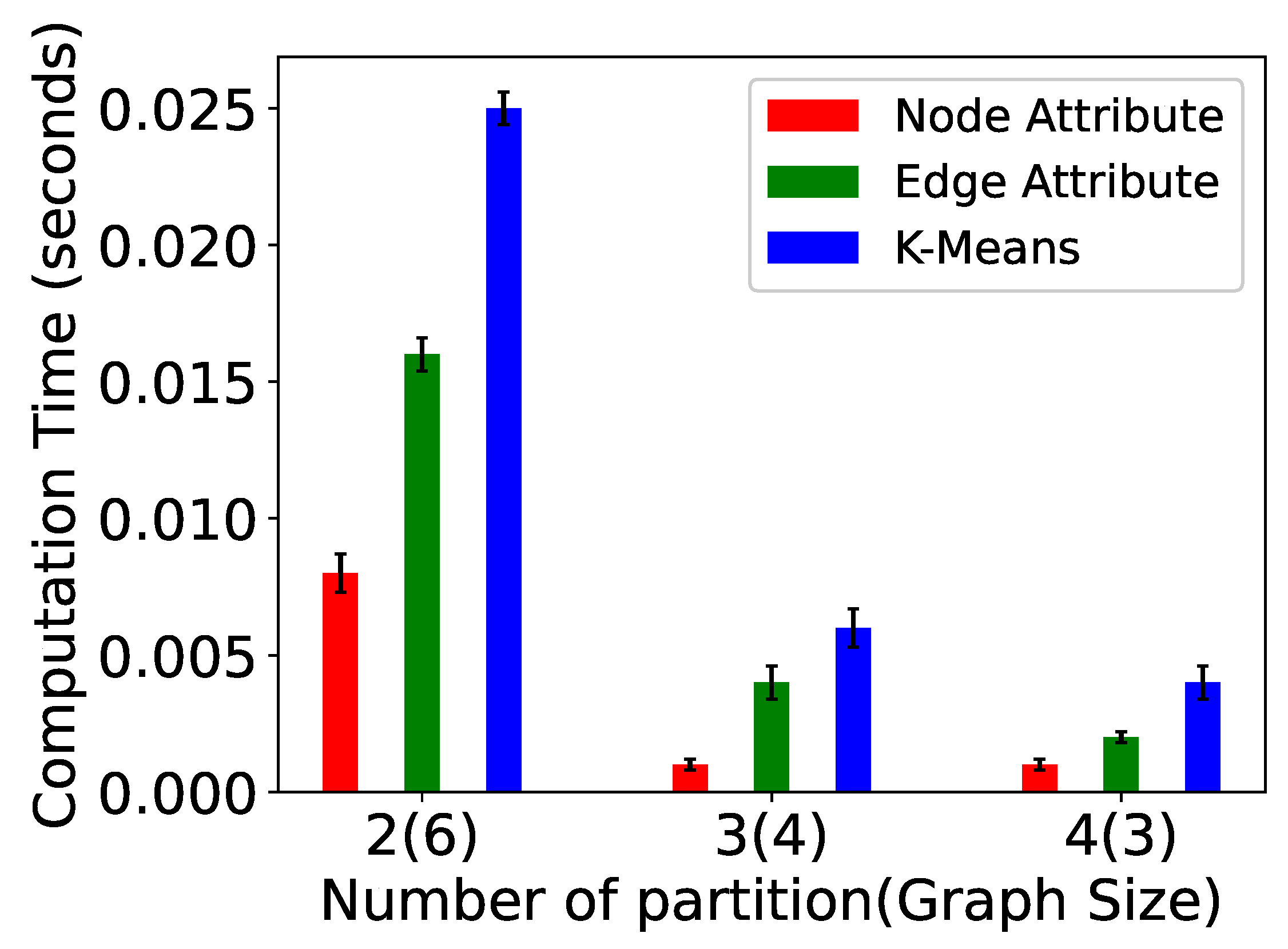
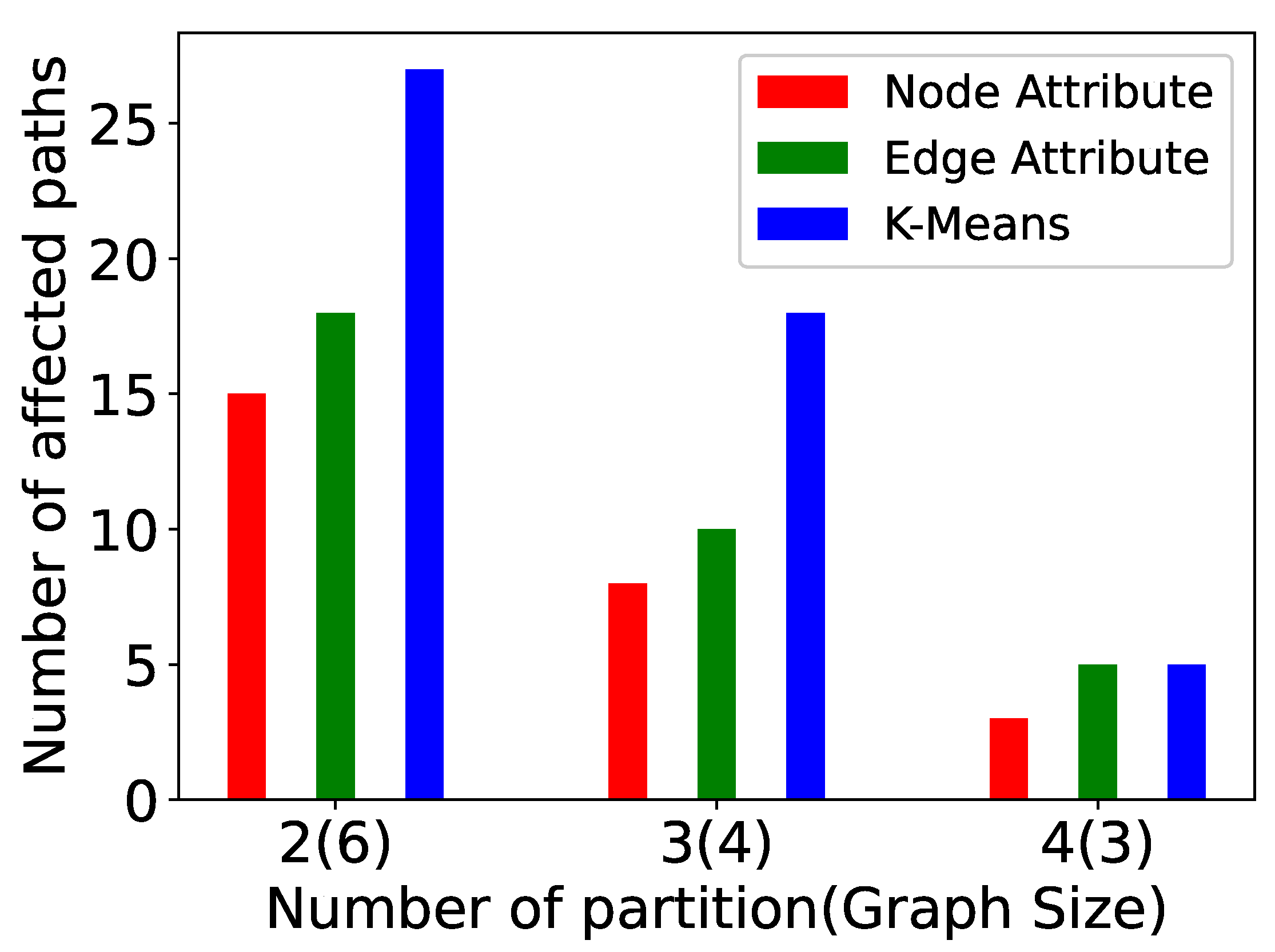
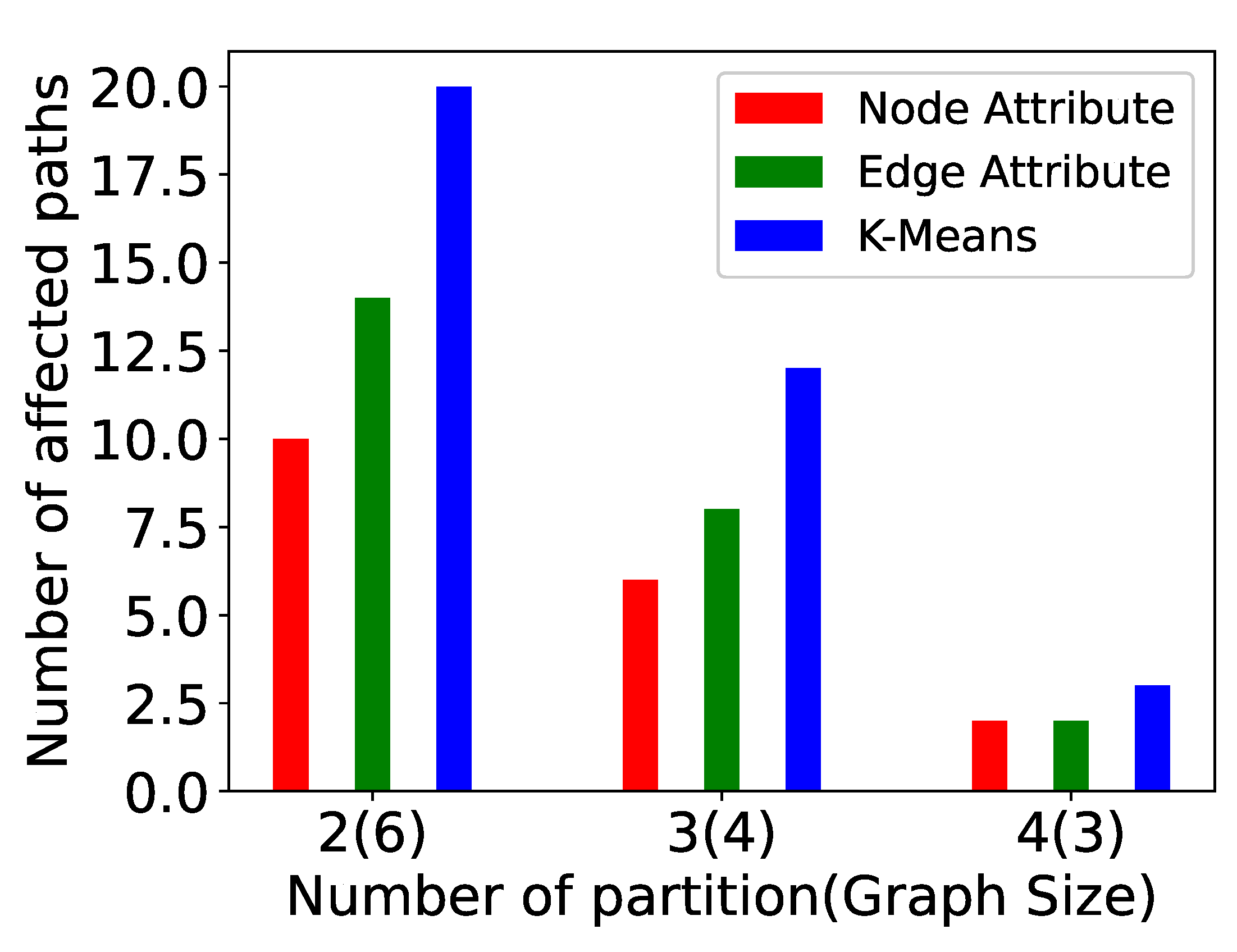
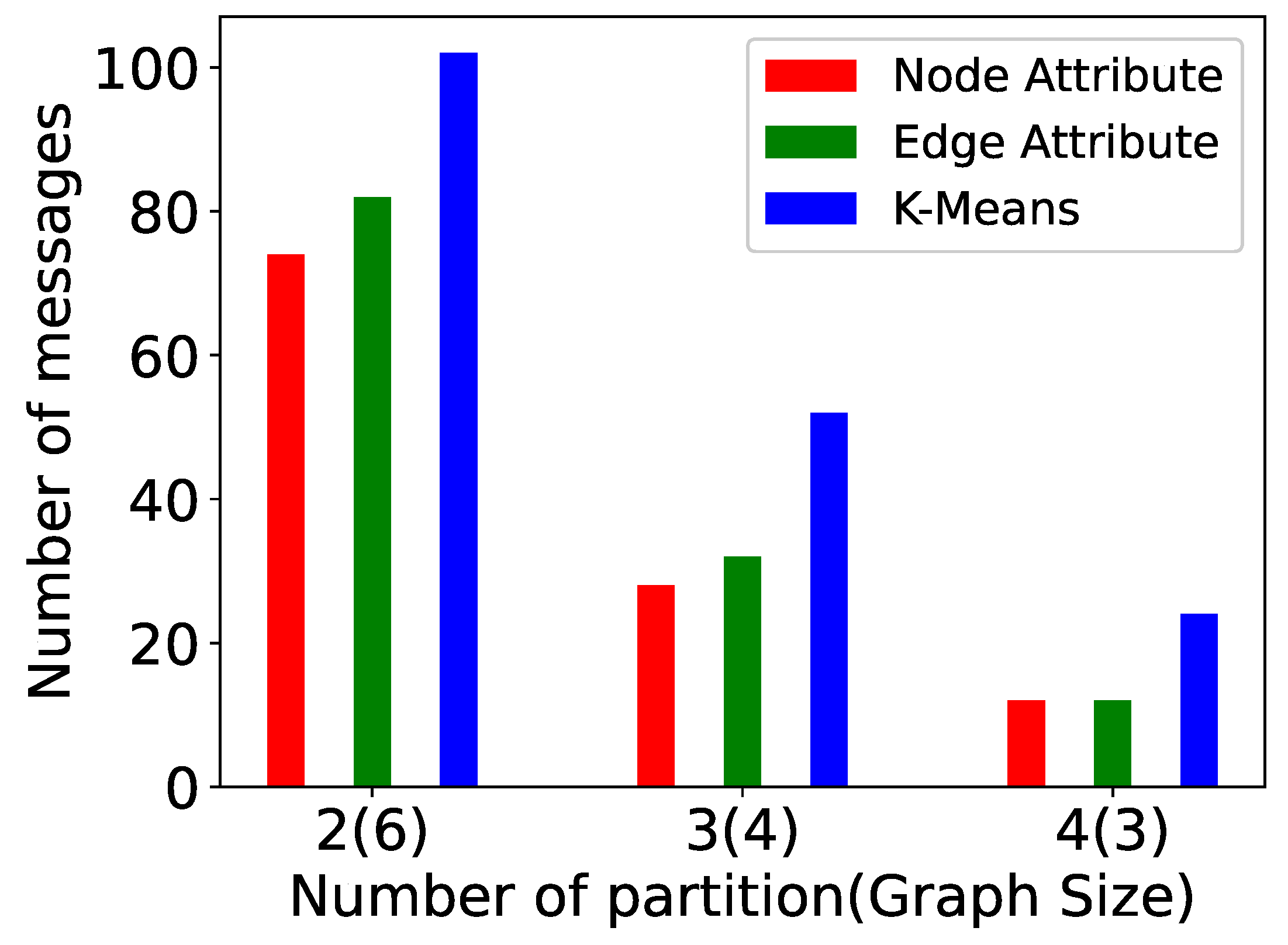
- Vertex size attribute partitioning (NP-TSP): The vertex size is defined as the total weight of outgoing edges from a vertex. This method focuses on balancing the partitions. The vertices in a partition are added in such a way that the difference between the total weight of each partition is minimum. For example, in Figure 5, the total difference between both the partitions is less than the edge attribute method. This is the baseline partitioning method without any constraint.
- Edge attribute partitioning (EP-TSP): In this method, the graph is partitioned in such a way that the total weight of edges across the partitions will be minimum. The intuition behind this method is to minimize the cost of connecting the sub-tours when the number of partitions is higher. For example, in Figure 5, the total weight of edges across the partition is 320. Therefore, this method can save computation cost for graphs with a higher number of partitions because if the weight across the partition is already minimized, then the probability of getting a nearly optimal tour increases. This partitioning strategy avoids a higher cost edge in the partition.
- k-means partitioning (KP-TSP): The k-means method is an iterative partitioning algorithm where k random vertices are placed as a centroid in different partitions. In each partition, the vertices close to centroids are added iteratively. The intuition behind this method is to keep closer vertices together. This method is also useful for a larger graph with a higher number of partitions. In Figure 4, the centroids for both partitions are randomly chosen as 1 and 4, respectively. Partition 1 contains vertices 2 and 5 because they are closer to vertex 1, and partition 2 contains vertices 0 and 3 because they are closer to vertex 4.
4. Complexity Analysis
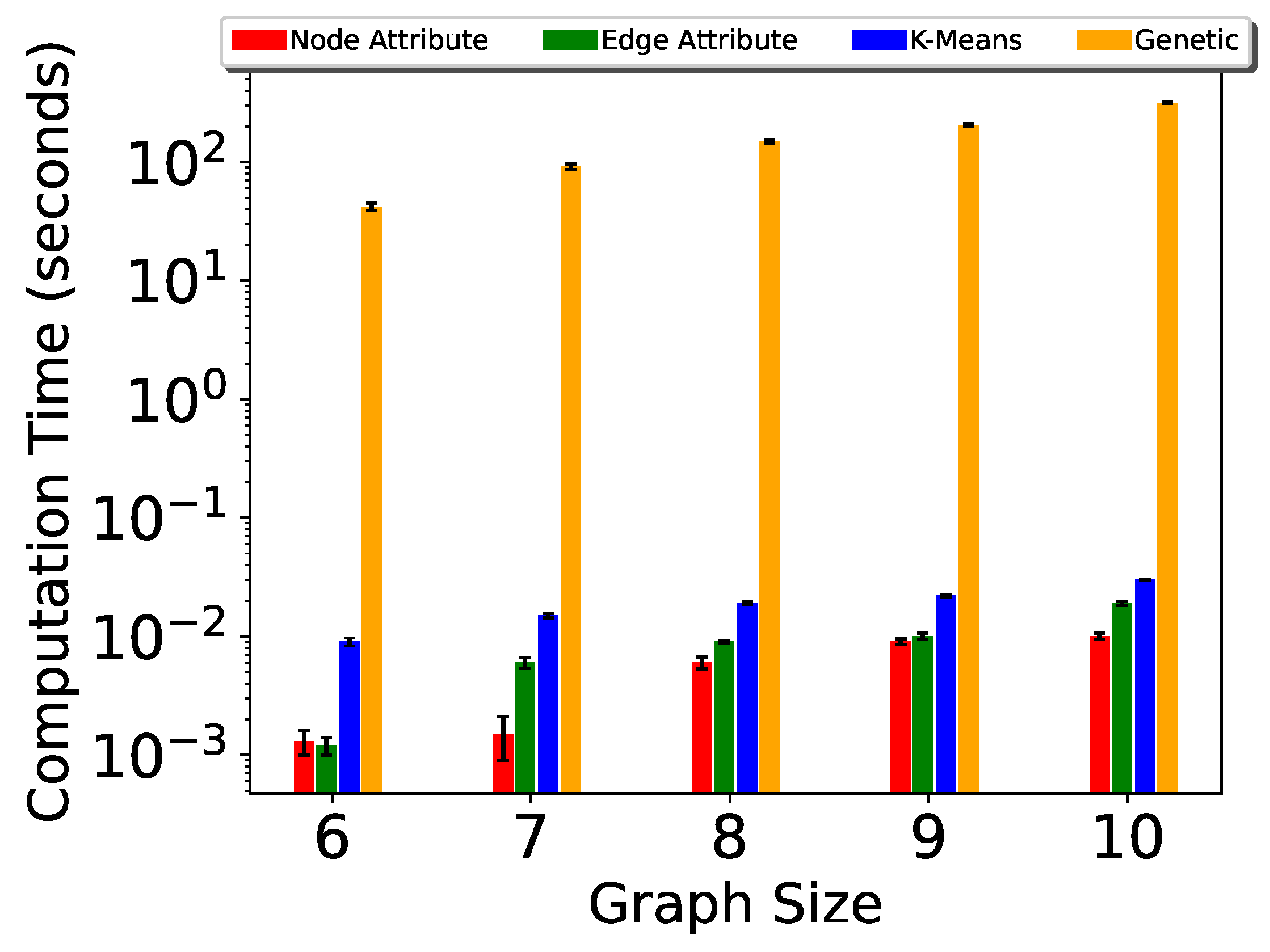
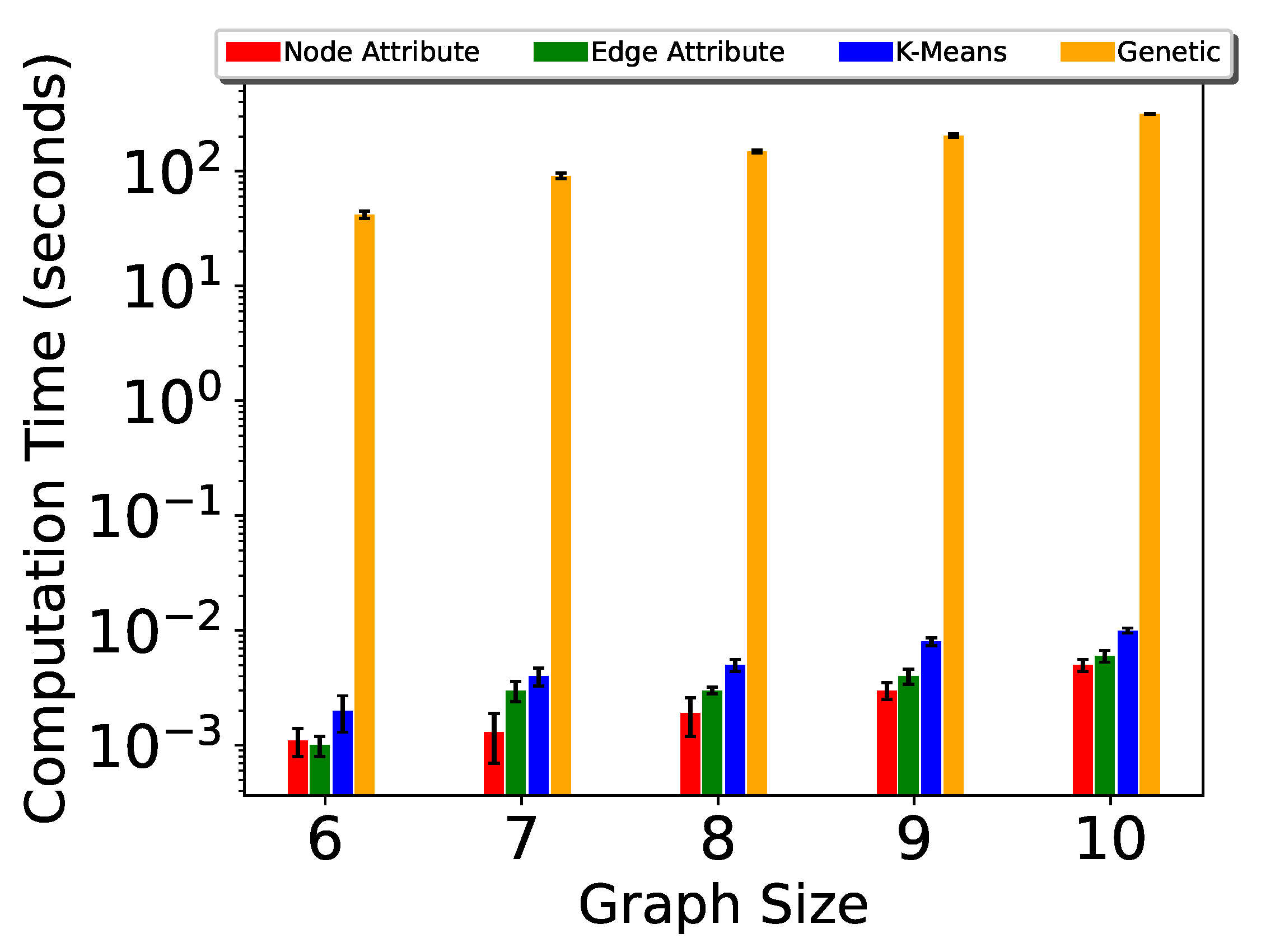
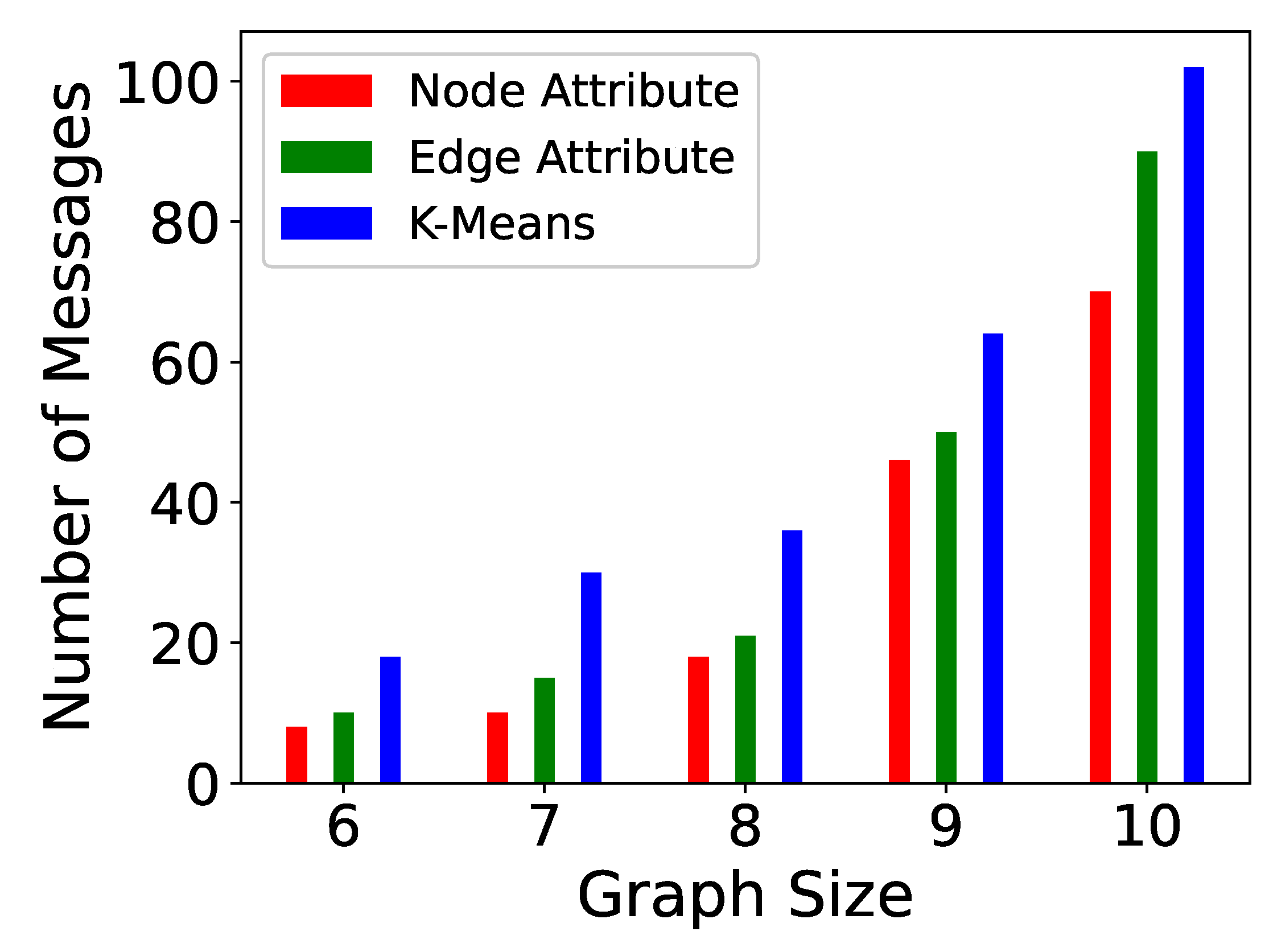
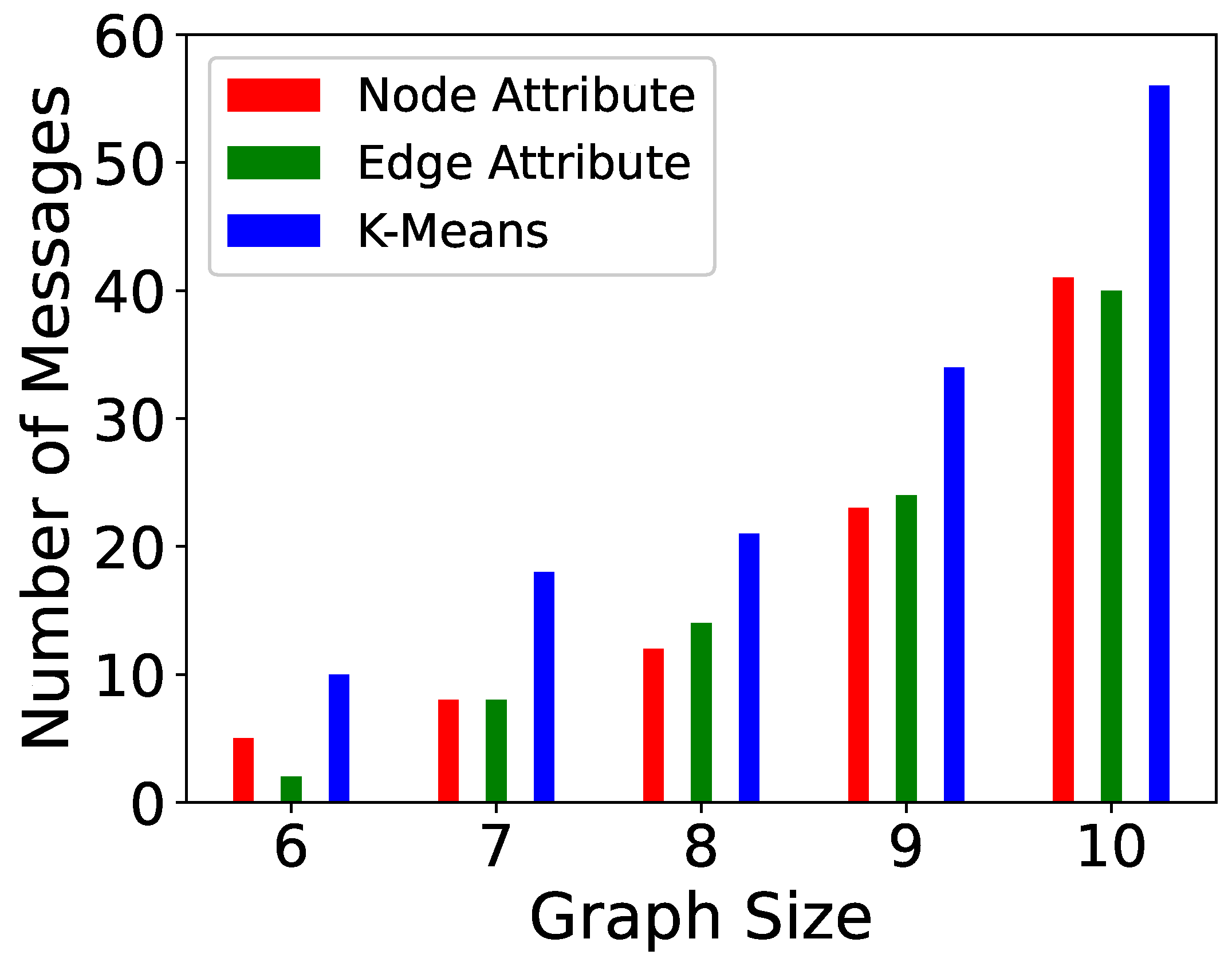
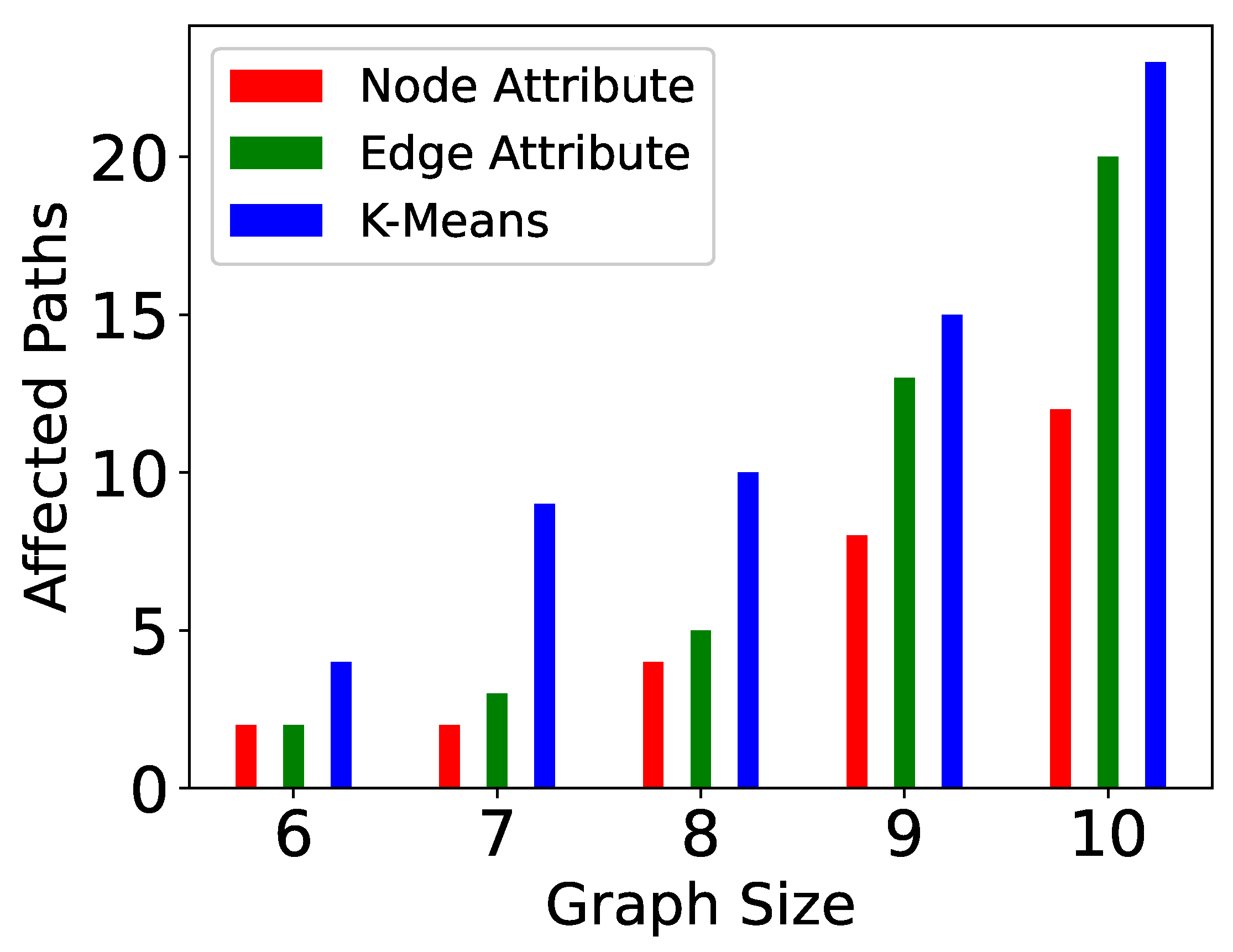
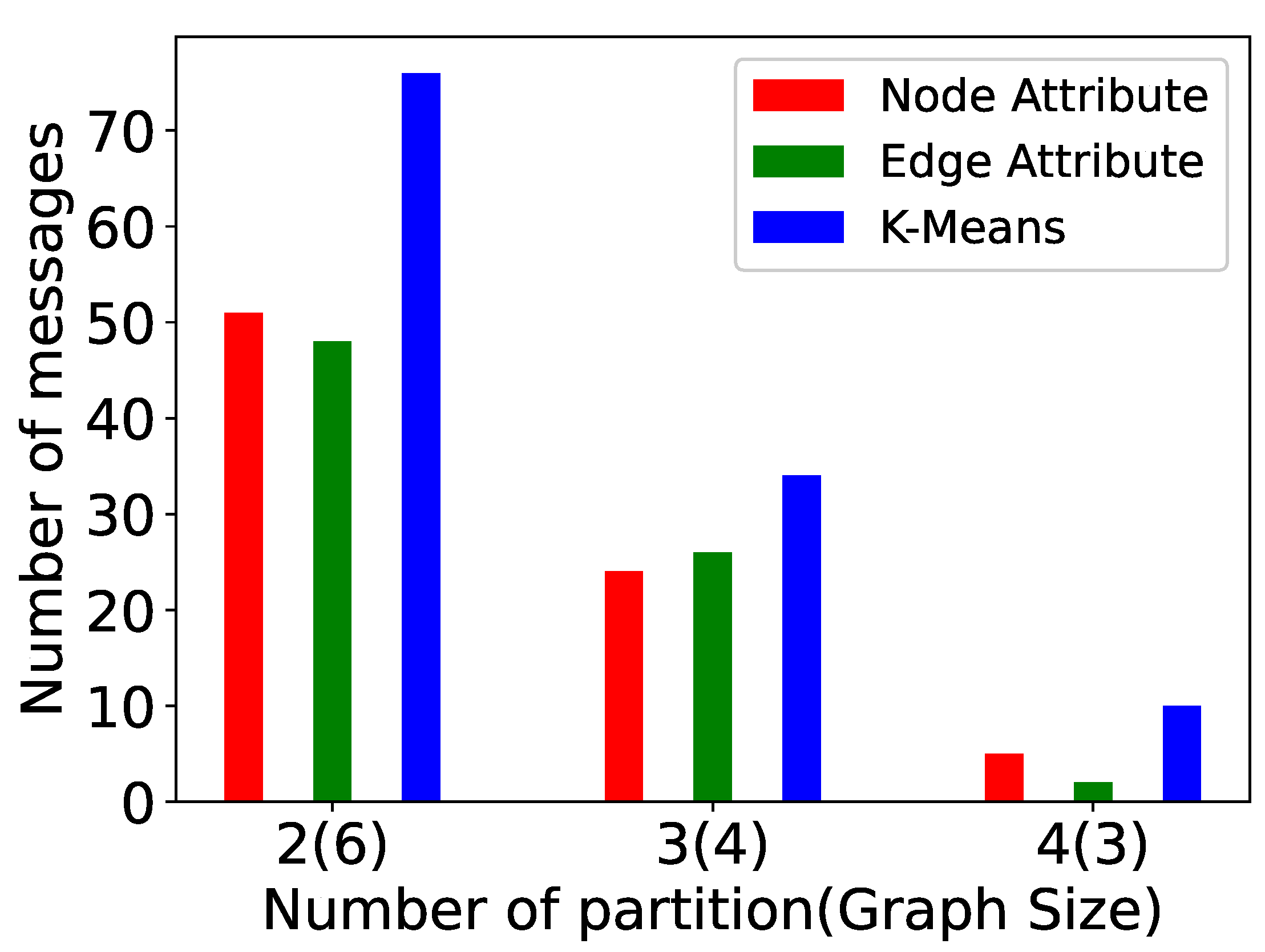
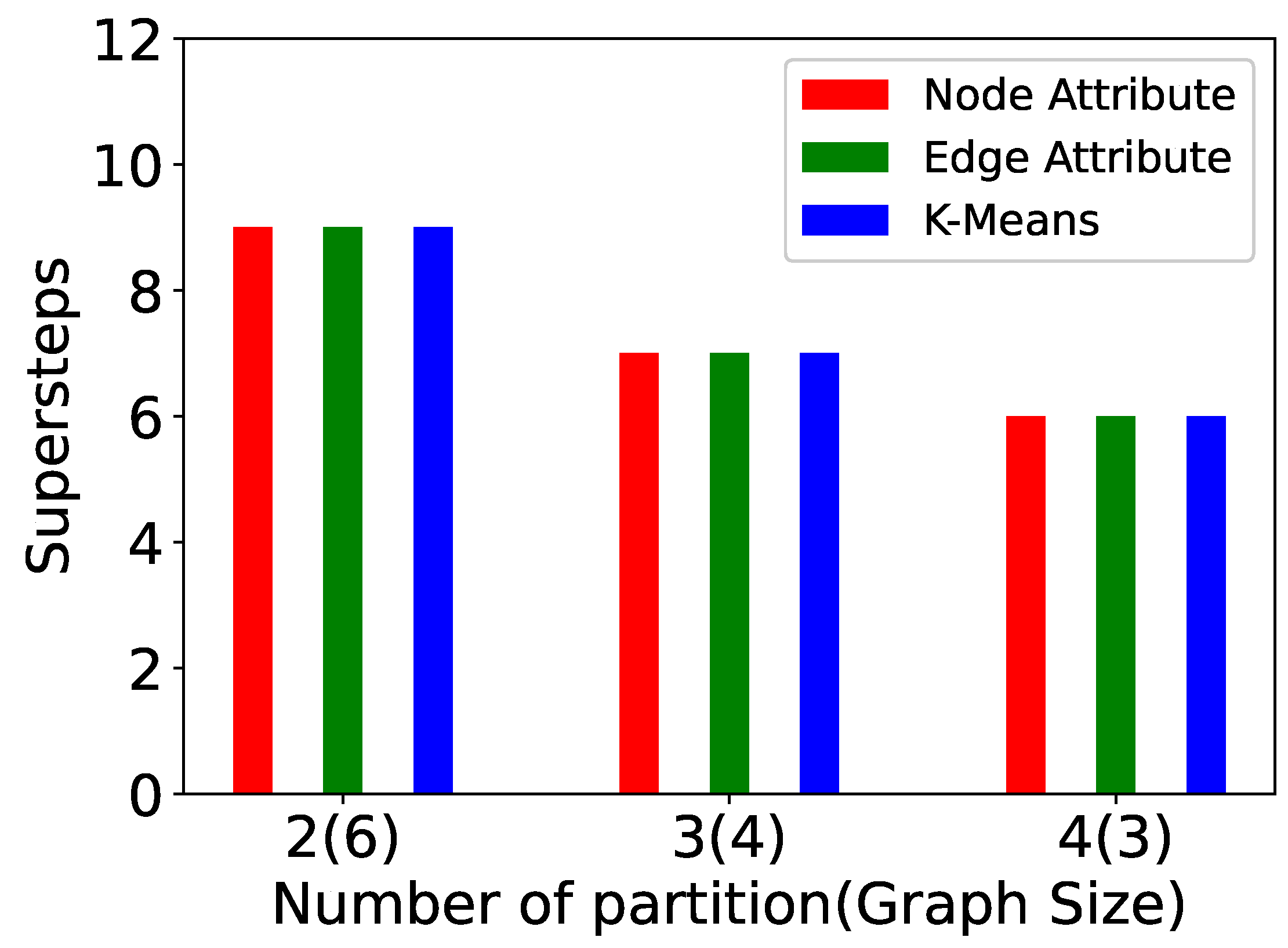
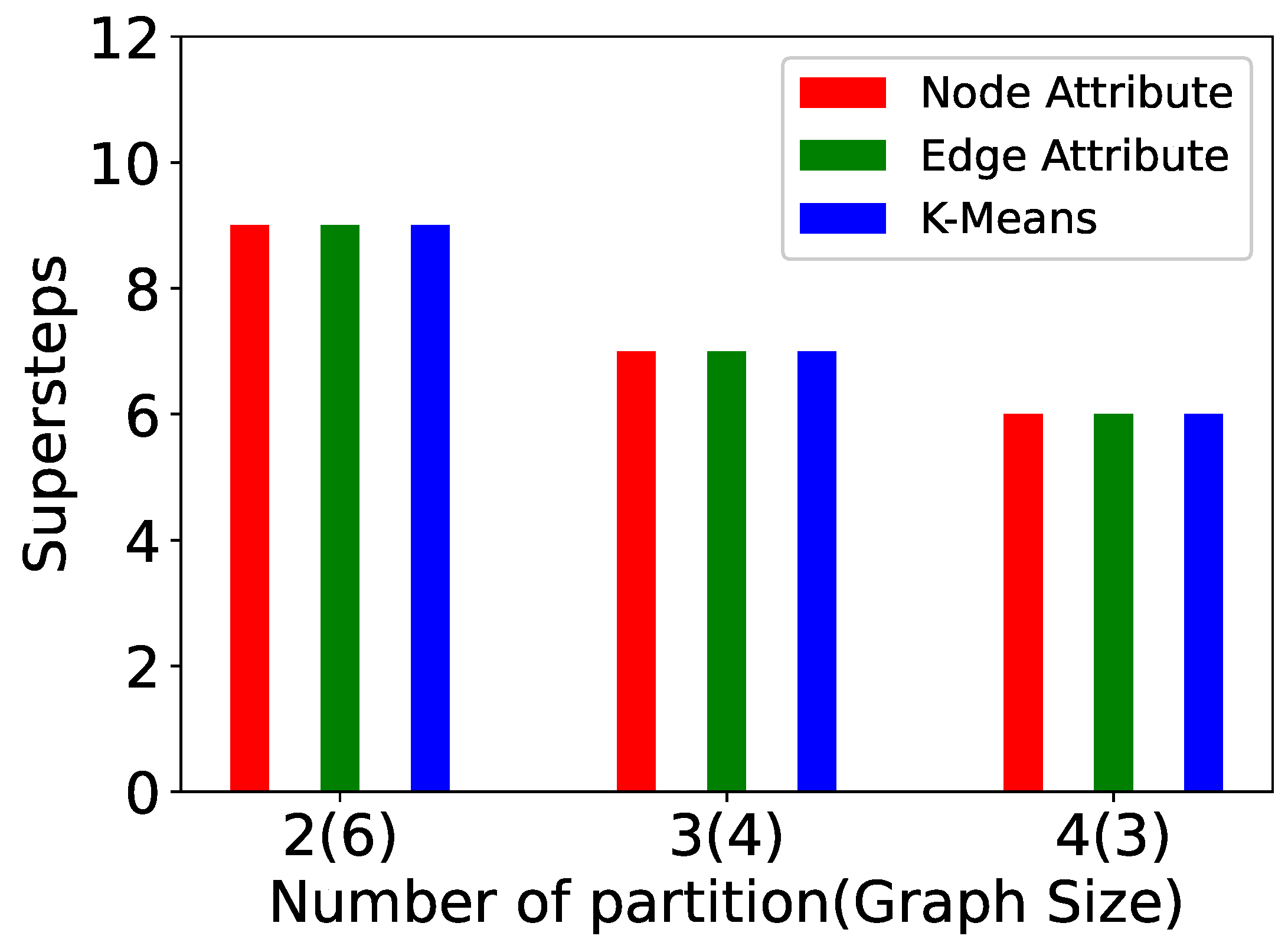
5. Experiments
6. Conclusions and Summary
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, S.; Kernighan, B.W. An Effective Heuristic Algorithm for the Traveling-Salesman Problem. Oper. Res. 1973, 21, 498–516. [Google Scholar] [CrossRef] [Green Version]
- Rosenkrantz, D.J.; Stearns, R.E.; Lewis, P.M. Approximate Algorithms for the Traveling Salesperson Problem. In Proceedings of the 15th Annual Symposium on Switching and Automata Theory (Swat 1974), New Orleans, LA, USA, 14–16 October 1974; pp. 33–42. [Google Scholar] [CrossRef]
- Wang, G.Q.; Wang, J.; Li, M.; Li, H.; Yuan, Y. Robot Path Planning Based on the Travelling Salesman Problem. Chem. Eng. Trans. 2015, 46, 307–312. [Google Scholar]
- Shi, K.; Liu, C.; Sun, Z.; Yue, X. Coupled orbit-attitude dynamics and trajectory tracking control for spacecraft electromagnetic docking. Appl. Math. Model. 2022, 101, 553–572. [Google Scholar] [CrossRef]
- Liu, C.; Yue, X.; Yang, Z. Are nonfragile controllers always better than fragile controllers in attitude control performance of post-capture flexible spacecraft? Aerosp. Sci. Technol. 2021, 118, 107053. [Google Scholar] [CrossRef]
- Liu, C.; Yue, X.; Zhang, J.; Shi, K. Active Disturbance Rejection Control for Delayed Electromagnetic Docking of Spacecraft in Elliptical Orbits. IEEE Trans. Aerosp. Electron. Syst. 2021, 1. [Google Scholar] [CrossRef]
- Hoffman, K.L.; Padberg, M.; Rinaldi, G. Traveling Salesman Problem. In Encyclopedia of Operations Research and Management Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 1573–1578. [Google Scholar]
- Chisman, J.A. The clustered traveling salesman problem. Comput. Oper. Res. 1975, 2, 115–119. [Google Scholar] [CrossRef]
- Cosma, O.; Pop, P.C.; Cosma, L. An effective hybrid genetic algorithm for solving the generalized traveling salesman problem. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2021. [Google Scholar]
- Pop, P.C.; Matei, O.; Sabo, C. A New Approach for Solving the Generalized Traveling Salesman Problem. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2010. [Google Scholar]
- Yang, J.; Shi, X.; Marchese, M.; Liang, Y. Ant colony optimization method for generalized TSP problem. Prog. Nat. Sci. 2008, 18, 1417–1422. [Google Scholar] [CrossRef]
- Junjie, P.; Dingwei, W. An Ant Colony Optimization Algorithm for Multiple Travelling Salesman Problem. In Proceedings of the First International Conference on Innovative Computing, Information and Control–Volume I (ICICIC’06), Beijing, China, 30 August–1 September 2006; Volume 1, pp. 210–213. [Google Scholar]
- Holland, J.H. Adaptation in Natural and Artificial Systems: An Introductory Analysis with Applications to Biology, Control and Artificial Intelligence; University of Michigan Press: Ann Arbor, MI, USA, 1975. [Google Scholar]
- Sharma, S.; Chou, J. Distributed and incremental travelling salesman algorithm on time-evolving graphs. J. Supercomput. 2021, 77, 10896–10920. [Google Scholar] [CrossRef]
- Sharma, S.; Chou, J. Partitioning based incremental travelling salesman algorithm on time evolving graphs. In Proceedings of the PDPTA’21: Parallel & Distributed Processing Techniques & Applications, Las Vegas, NV, USA, 12–16 July 2010. [Google Scholar]
- Fan, W.; Li, J.; Luo, J.; Tan, Z.; Wang, X.; Wu, Y. Incremental Graph Pattern Matching. In Proceedings of the 2011 ACM SIGMOD International Conference on Management of Data, Athens, Greece, 12–16 June 2011; ACM: New York, NY, USA, 2011; pp. 925–936. [Google Scholar] [CrossRef] [Green Version]
- Kao, J.S.; Chou, J. Distributed Incremental Pattern Matching on Streaming Graphs. In Proceedings of the ACM Workshop on High Performance Graph Processing, Kyoto, Japan, 31 May 2016; ACM: New York, NY, USA, 2016; pp. 43–50. [Google Scholar] [CrossRef]
- Desikan, P.; Pathak, N.; Srivastava, J.; Kumar, V. Incremental Page Rank Computation on Evolving Graphs. In Proceedings of the Special Interest Tracks and Posters of the 14th International Conference on World Wide Web, Chiba, Japan, 10–14 May 2005; ACM: New York, NY, USA, 2005; pp. 1094–1095. [Google Scholar] [CrossRef] [Green Version]
- Bahmani, B.; Kumar, R.; Mahdian, M.; Upfal, E. PageRank on an Evolving Graph. In Proceedings of the 18th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Beijing, China, 12–16 August 2012; ACM: New York, NY, USA, 2012; pp. 24–32. [Google Scholar] [CrossRef]
- Anagnostopoulos, A.; Kumar, R.; Mahdian, M.; Upfal, E.; Vandin, F. Algorithms on Evolving Graphs. In Proceedings of the 3rd Innovations in Theoretical Computer Science Conference, Cambridge, MA, USA, 8–10 January 2012; ACM: New York, NY, USA, 2012; pp. 149–160. [Google Scholar]
- Sharma, S.; Chou, J. A survey of computation techniques on time evolving graphs. Int. J. Big Data Intell. (IJBDI) 2020, 7, 1–14. [Google Scholar] [CrossRef]
- Shang, Y. Laplacian Estrada and Normalized Laplacian Estrada Indices of Evolving Graphs. PLoS ONE 2015, 10, e0123426. [Google Scholar] [CrossRef] [PubMed]
- Abdolrashidi, A.; Ramaswamy, L. Continual and Cost-Effective Partitioning of Dynamic Graphs for Optimizing Big Graph Processing Systems. In Proceedings of the 2016 IEEE International Congress on Big Data (BigData Congress), San Francisco, CA, USA, 27 June–2 July 2016; pp. 18–25. [Google Scholar]
- Tsourakakis, C.; Gkantsidis, C.; Radunovic, B.; Vojnovic, M. FENNEL: Streaming Graph Partitioning for Massive Scale Graphs. In Proceedings of the 7th ACM International Conference on Web Search and Data Mining, New York, NY, USA, 24–28 February 2014; ACM: New York, NY, USA, 2014; pp. 333–342. [Google Scholar]
- Chen, P. An improved genetic algorithm for solving the Traveling Salesman Problem. In Proceedings of the 2013 Ninth International Conference on Natural Computation (ICNC), Shenyang, China, 23–25 July 2013; pp. 397–401. [Google Scholar] [CrossRef]
- Kirkpatrick, S.; Gelatt, C.D.; Vecchi, M.P. Optimization by Simulated Annealing. Science 1983, 220, 671–680. [Google Scholar] [CrossRef] [PubMed]
- Dorigo, M.; Maniezzo, V.; Colorni, A. Ant system: Optimization by a colony of cooperating agents. IEEE Trans. Syst. Man Cybern. Part B (Cybernetics) 1996, 26, 29–41. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the ICNN’95—International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [Google Scholar] [CrossRef]
- Glover, F.; Laguna, M. Tabu Search I; Springer: Berlin/Heidelberg, Germany, 1999; Volume 1. [Google Scholar] [CrossRef] [Green Version]
- Lin, B.; Sun, X.; Salous, S. Solving Travelling Salesman Problem with an Improved Hybrid Genetic Algorithm. J. Comput. Commun. 2016, 4, 98–106. [Google Scholar] [CrossRef] [Green Version]
- Valenzuela, C. A parallel implementation of evolutionary divide and conquer for the TSP. In Proceedings of the First International Conference on Genetic Algorithms in Engineering Systems: Innovations and Applications, Sheffield, UK, 12–14 September 1995; pp. 499–504. [Google Scholar]
- Blelloch, G.E.; Gu, Y.; Shun, J.; Sun, Y. Randomized Incremental Convex Hull is Highly Parallel. In Proceedings of the 32nd ACM Symposium on Parallelism in Algorithms and Architectures, Virtual Event, 15–17 July 2020; Association for Computing Machinery: New York, NY, USA, 2020; pp. 103–115. [Google Scholar] [CrossRef]
- Yuan, L.; Qin, L.; Lin, X.; Chang, L.; Zhang, W. Effective and Efficient Dynamic Graph Coloring. Proc. VLDB Endow. 2017, 11, 338–351. [Google Scholar] [CrossRef] [Green Version]
- Fan, W.; Liu, M.; Tian, C.; Xu, R.; Zhou, J. Incrementalization of Graph Partitioning Algorithms. Proc. VLDB Endow. 2020, 13, 1261–1274. [Google Scholar] [CrossRef]
- Gonzalez, J.E.; Low, Y.; Gu, H.; Bickson, D.; Guestrin, C. PowerGraph: Distributed Graph-parallel Computation on Natural Graphs. In Proceedings of the 10th USENIX Conference on Operating Systems Design and Implementation, Hollywood, CA, USA, 8–10 October 2012; USENIX Association: Berkeley, CA, USA, 2012; pp. 17–30. [Google Scholar]
- Filippidou, I.; Kotidis, Y. Online and on-demand partitioning of streaming graphs. In Proceedings of the 2015 IEEE International Conference on Big Data (Big Data), Santa Clara, CA, USA, 29 October–1 November 2015; pp. 4–13. [Google Scholar] [CrossRef]
- Salihoglu, S.; Widom, J. GPS: A Graph Processing System. In Proceedings of the 25th International Conference on Scientific and Statistical Database Management, Baltimore, MD, USA, 29–31 July 2013; Association for Computing Machinery: New York, NY, USA, 2013. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Changes, Allowed | Distributed | Incremental | Partitioning | Result | Boundedness |
|---|---|---|---|---|---|---|
| Fan et al. [16] | Insertions, Deletions | X | ✓ | X | Optimal | Unbounded |
| Kao et al. [17] | Insertions, Deletions | ✓ | ✓ | X | Optimal | Unbounded |
| Desikan et al. [18] | Insertions;Deletions | X | ✓ | ✓ | Optimal | Locally bounded |
| Bahmani et al. [19] | Insertions;Deletions | X | X | X | Approx. | Locally bounded |
| Anagnostopouloset al. [20] | Edge-Swapping | X | X | X | Approx. | Relatively bounded |
| Anagnostopouloset al. [20] | Edge-Swapping | X | X | X | Approx. | Relatively bounded |
| Sharma et al. [14] (Previous work 1) | Edge-weight | ✓ | ✓ | X | OptimalApprox. | Bounded (I-TSP)Unbounded (Ig-TSP) |
| Current work | Edge-weight | ✓ | ✓ | ✓ | Approx. | Unbounded |
| Algorithm | Paths | Messages |
|---|---|---|
| Distributed-TSP (D-TSP) | ||
| Incremental-TSP (I-TSP) | ||
| Partitioning-TSP (P-TSP) |
| Algorithm | 6-Vertex | 7-Vertex | 8-Vertex | 9-Vertex |
|---|---|---|---|---|
| I-TSP | 11.33 | 28.57 | 86.04 | 528 |
| Ig-TSP | 6.33 | 18.00 | 48.60 | 174.18 |
| Genetic Algorithm [25] | 42.00 | 91.35 | 148.67 | 204.71 |
| P-TSP(Node size) | 0.0013 | 0.0015 | 0.006 | 0.009 |
| P-TSP(Edge size) | 0.0012 | 0.006 | 0.009 | 0.01 |
| P-TSP(k-means) | 0.009 | 0.015 | 0.019 | 0.022 |
| Pg-TSP(Node size) | 0.0011 | 0.0013 | 0.0019 | 0.003 |
| Pg-TSP(Edge size) | 0.001 | 0.003 | 0.003 | 0.004 |
| Pg-TSP(k-means) | 0.002 | 0.004 | 0.005 | 0.008 |
| Algorithm | Propagation | Recomputation Area | Partitions | Result |
|---|---|---|---|---|
| I-TSP | Brute Force | All affected paths | Not allowed | Optimal |
| Ig-TSP | Greedy | All affected paths | Not allowed | Non-Optimal |
| P-TSP | Brute Force | All affected paths in one partition | Node size attribute Edge size attribute k-means method | Non-Optimal |
| Pg-TSP | Greedy | All affected paths in one partition | Node size attribute Edge size attribute k-means method | Non-Optimal |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sharma, S.; Chou, J. Accelerate Incremental TSP Algorithms on Time Evolving Graphs with Partitioning Methods. Algorithms 2022, 15, 64. https://doi.org/10.3390/a15020064
Sharma S, Chou J. Accelerate Incremental TSP Algorithms on Time Evolving Graphs with Partitioning Methods. Algorithms. 2022; 15(2):64. https://doi.org/10.3390/a15020064
Chicago/Turabian StyleSharma, Shalini, and Jerry Chou. 2022. "Accelerate Incremental TSP Algorithms on Time Evolving Graphs with Partitioning Methods" Algorithms 15, no. 2: 64. https://doi.org/10.3390/a15020064
APA StyleSharma, S., & Chou, J. (2022). Accelerate Incremental TSP Algorithms on Time Evolving Graphs with Partitioning Methods. Algorithms, 15(2), 64. https://doi.org/10.3390/a15020064