
Clustering with Nature-Inspired Algorithm Based on Territorial Behavior of Predatory Animals




Abstract
:1. Introduction
2. Methodological Background
2.1. Task of Clustering
2.2. Nature-Inspired Algorithms in Clustering
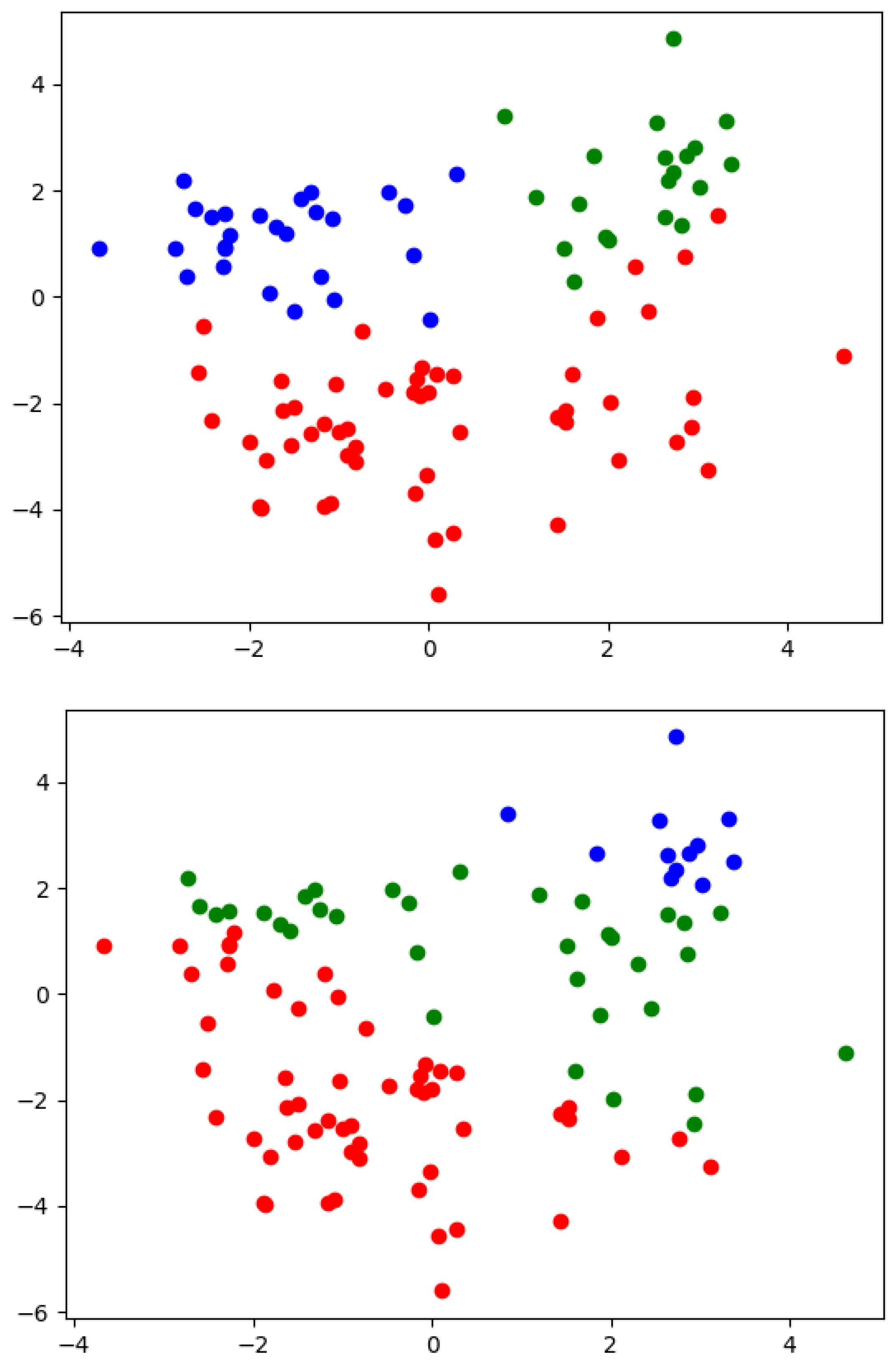
3. Proposed Approach
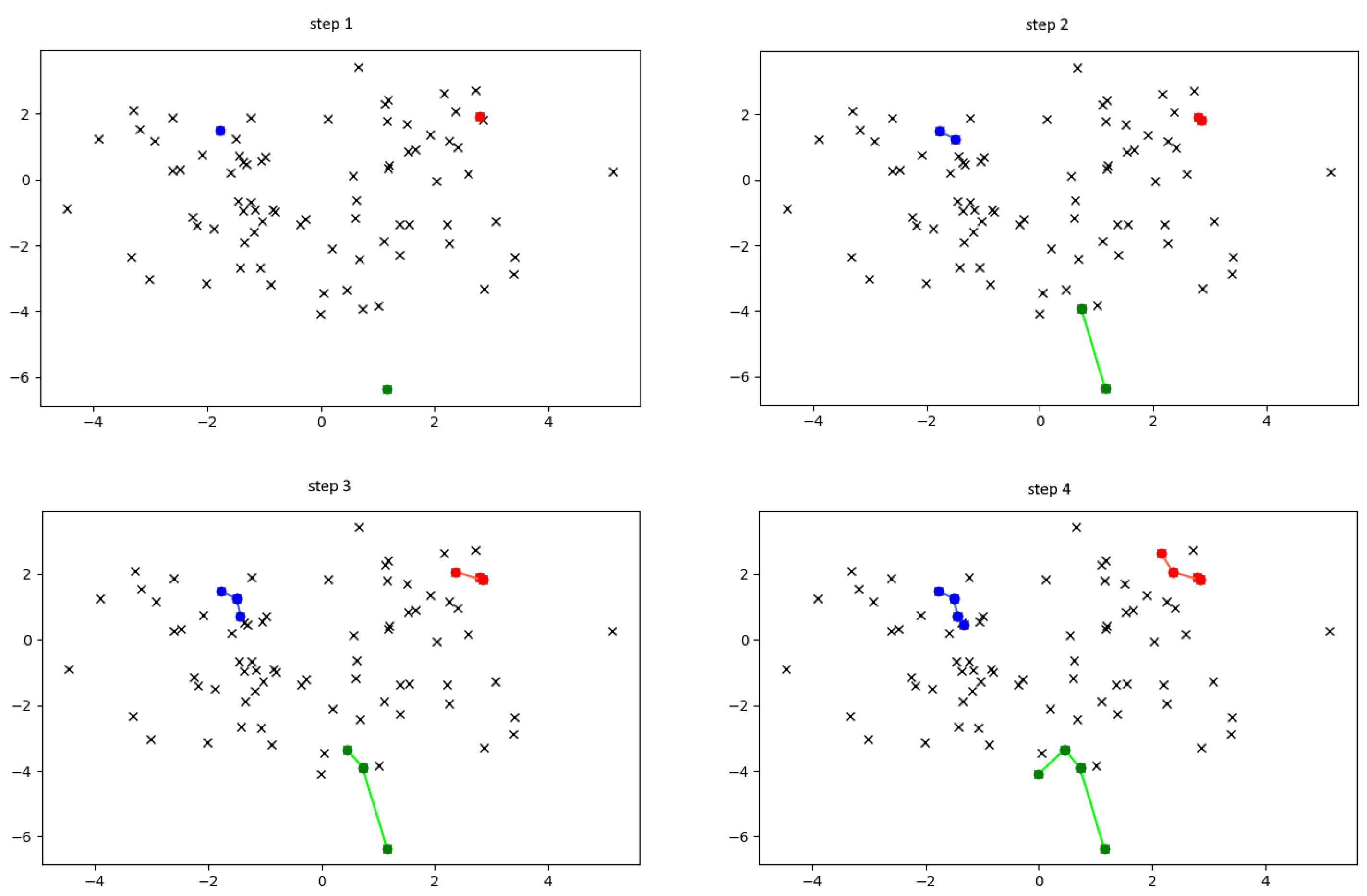
- Clustering is done by the set of (individuals). Each individual has their single position in the given space of instances. This point is always the position of one of the instances and represents the prey the individual is currently hunting. Each individual aims to create a cluster representing their territory.
- Individuals perform jumps between the prey during consecutive turns. On each turn, each individual jumps to a semi-randomly chosen point in the set from the fraction of their closest points, unmarked by other individuals.
- Upon a jump, the individual marks the point they jumped to. From now, it is considered a part of their territory (i.e., their cluster).
- After an individual performs a vast number of jumps far from a point they marked, the traces they left fade, and the location becomes unmarked once again.
- After all points are marked by individuals, small adjustments are made to simulate fading of areas left behind and making their shape more convex and condensed.
- consists of N points, each having their and (initialized as );
- k is the number of clusters to partition the set into—it has to be predetermined in advance;
- is a fraction of the set that will be taken into consideration while determining the next jump of an individual;
- is a is a fraction of the set that will be taken into consideration while determining if it should be corrected;
- b, and S are the parameters of the exponential function used in determining the jump weights;
- is the multiplier factor for correction that simulates the reluctance of changing a set during the correction phase;
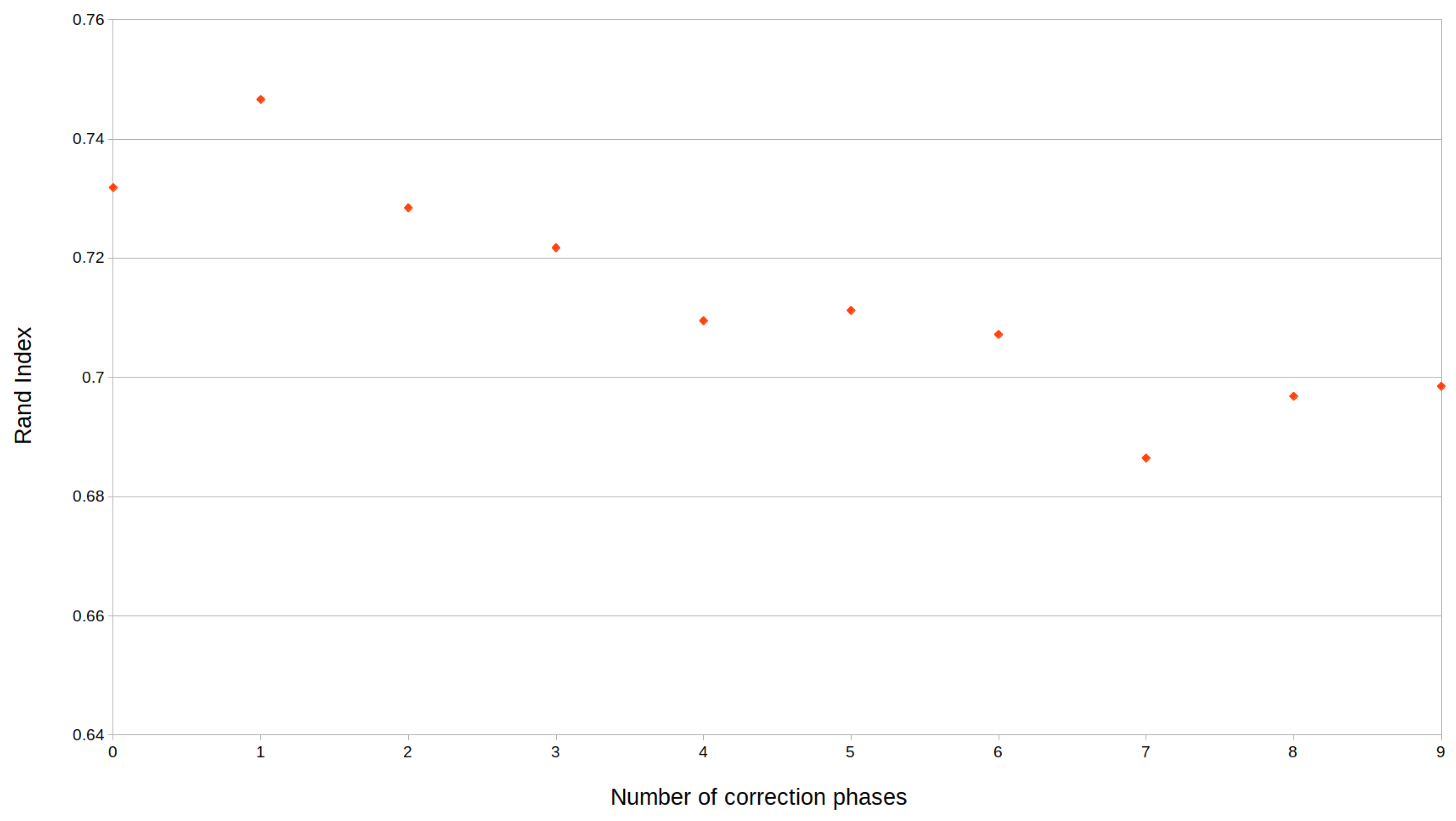
- is the number of times the correction phase is applied;
- F is correction function. Its arguments are ; the mean distance of points from a given cluster and p, the percentage amount of points from a certain cluster in total points surrounding a point;
- t determines how long does an individual needs to stray from a point it marked for it to become an unmarked point again;
- the algorithm requires the initialization of k; individuals. In this example, their numbers are also the number of their clusters, while the ID of a point is its index.
| Algorithm 1 Clustering with Predatory Animals Algorithm. |
|
- Each individual considers closest points. For each of those points, the individual calculates weight according to the equation , where is the point being evaluated, and b are the parameters of the algorithm, and u is the ratio of unmarked points in the evaluated set of points.
- After assigning weights, individuals ‘jump’ to single points they draw with weights they calculated. Those points become their new positions.
- Each marked point is assigned a Time-to-Live value that begins at 0. Each time any of the individuals others than the one that marked the point is the closest individual to that point, the Time-to-Live is incremented. As it reaches , the point becomes unmarked again. Should the individual that marked it become the closest individual, the Time-to-Live value is set to 0 again.
- Individuals perform their jumps in turns until there are no unmarked points. After each turn Time-to-Live values are evaluated for all points in the dataset.
- During the correction phase, all points are evaluated separately.
- nearest points to the evaluated one are considered.
- For each point, for each cluster, values and p are calculated. is the mean normalized distance between the point and points from the currently evaluated cluster and p is the percentage of points from this cluster in the neighbors of the evaluated point.
- Weights determining the cluster to which the given point should be assigned are calculated using correction function . A cluster with maximum weight is chosen. Function F should be nondecreasing for increasing values of p and not increasing for increasing values of . In practice a simple formula can be used.
4. Experimental Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Sathya, R.; Abraham, A. Comparison of Supervised and Unsupervised Learning Algorithms for Pattern Classification. Int. J. Adv. Res. Artif. Intell. 2013, 2, 34–38. [Google Scholar] [CrossRef] [Green Version]
- Celebi, M.; Aydin, K. Unsupervised Learning Algorithms; Springer International Publishing: Berlin/Heidelberg, Germany, 2016. [Google Scholar]
- Srikanth, R.; George, R.; Warsi, N.; Prabhu, D.; Petry, F.; Buckles, B. A variable-length genetic algorithm for clustering and classification. Pattern Recognit. Lett. 1995, 16, 789–800. [Google Scholar] [CrossRef]
- Bong, C.W.; Mandava, R. Multiobjective clustering with metaheuristic: Current trends and methods in image segmentation. Image Process. IET 2012, 6, 1–10. [Google Scholar] [CrossRef]
- MacQueen, J. Some methods for classification and analysis of multivariate observations. In Proceedings of the Fifth Berkeley Symposium on Mathematical Statistics and Probability, University of California, Berkeley, CA, USA, 21 June–18 July 1967; pp. 281–297. [Google Scholar]
- Ward, J.H., Jr. Hierarchical Grouping to Optimize an Objective Function. J. Am. Stat. Assoc. 1963, 58, 236–244. [Google Scholar] [CrossRef]
- Ester, M.; Kriegel, H.P.; Sander, J.; Xu, X. A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise; AAAI Press: Menlo Park, CA, USA, 1996; pp. 226–231. [Google Scholar]
- Rodriguez, A.; Laio, A. Clustering by fast search and find of density peaks. Science 2014, 344, 1492–1496. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kowalski, P.A.; Łukasik, S.; Charytanowicz, M.; Kulczycki, P. Clustering based on the Krill Herd Algorithm with selected validity measures. In Proceedings of the 2016 Federated Conference on Computer Science and Information Systems (FedCSIS), Gdansk, Poland, 11–14 September 2016; pp. 79–87. [Google Scholar]
- Caliński, T.; Harabasz, J. A dendrite method for cluster analysis. Commun. Stat. 1974, 3, 1–27. [Google Scholar] [CrossRef]
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef] [Green Version]
- Arbelaitz, O.; Gurrutxaga, I.; Muguerza, J.; Pérez, J.M.; Perona, I. An extensive comparative study of cluster validity indices. Pattern Recognit. 2013, 46, 243–256. [Google Scholar] [CrossRef]
- Cebeci, Z. Comparison of Internal Validity Indices for Fuzzy Clustering. J. Agric. Inform. 2019, 10, 1–14. [Google Scholar] [CrossRef]
- Alswaitti, M.; Albughdadi, M.; Isa, N.A.M. Density-based particle swarm optimization algorithm for data clustering. Expert Syst. Appl. 2018, 91, 170–186. [Google Scholar] [CrossRef]
- Abualigah, L.M.; Khader, A.T.; Hanandeh, E.S. Hybrid Clustering Analysis Using Improved Krill Herd Algorithm. Appl. Intell. 2018, 48, 4047–4071. [Google Scholar] [CrossRef]
- Han, X.; Quan, L.; Xiong, X.; Almeter, M.; Xiang, J.; Lan, Y. A novel data clustering algorithm based on modified gravitational search algorithm. Eng. Appl. Artif. Intell. 2017, 61, 1–7. [Google Scholar] [CrossRef]
- Shukla, U.P.; Nanda, S.J. Parallel social spider clustering algorithm for high dimensional datasets. Eng. Appl. Artif. Intell. 2016, 56, 75–90. [Google Scholar] [CrossRef]
- Łukasik, S.; Kowalski, P.A.; Charytanowicz, M.; Kulczycki, P. Clustering using flower pollination algorithm and Calinski–Harabasz index. In Proceedings of the 2016 IEEE Congress on Evolutionary Computation (CEC), Vancouver, BC, Canada, 24–29 July 2016; pp. 2724–2728. [Google Scholar] [CrossRef]
- Nanda, S.J.; Panda, G. A survey on nature inspired metaheuristic algorithms for partitional clustering. Swarm Evol. Comput. 2014, 16, 1–18. [Google Scholar] [CrossRef]
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml/ (accessed on 19 February 2021).
- Fränti, P.; Virmajoki, O. Iterative shrinking method for clustering problems. Pattern Recognit. 2006, 39, 761–775. [Google Scholar] [CrossRef]
- Aeberhard, S.; Coomans, D.; de Vel, O. Comparative analysis of statistical pattern recognition methods in high dimensional settings. Pattern Recognit. 1994, 27, 1065–1077. [Google Scholar] [CrossRef]
- Evett, I.W.; Spiehler, E.J. Rule Induction in Forensic Science; Technical Report; Central Research Establishment, Home Office Forensic Science Service: London, UK, 1987.
- Colonna, J.G.; Cristo, M.; Júnior, M.S.; Nakamura, E.F. An incremental technique for real-time bioacoustic signal segmentation. Expert Syst. Appl. 2015, 42, 7367–7374. [Google Scholar] [CrossRef]
- Gardner, A.; Kanno, J.; Duncan, C.A.; Selmic, R. Measuring Distance between Unordered Sets of Different Sizes. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 137–143. [Google Scholar] [CrossRef] [Green Version]
- Dias, D.B.; Madeo, R.C.B.; Rocha, T.; Bíscaro, H.H.; Peres, S.M. Hand Movement Recognition for Brazilian Sign Language: A Study Using Distance-Based Neural Networks. In Proceedings of the 2009 International Joint Conference on Neural Networks, Atlanta, GA, USA, 14–19 June 2009; pp. 2355–2362. [Google Scholar]
- Horton, P.; Nakai, K. A Probabilistic Classification System for Predicting the Cellular Localization Sites of Proteins. In Proceedings of the Fourth International Conference on Computational Biology: Intelligent Systems for Molecular Biology, Washington University, St. Louis, MO, USA, 12–15 June 1996; Volume 4, pp. 109–115. [Google Scholar]
- Parvin, H.; Alizadeh, H.; Minati, B. Objective criteria for the evaluation of clustering methods. J. Am. Stat. Assoc. 1971, 66, 846–850. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
| Name | Dimensionality | Number of Clusters | Number of Instances | Source |
|---|---|---|---|---|
| wine | 13 | 3 | 178 | [22] |
| glass | 10 | 7 | 214 | [23] |
| anuran calls | 22 | 10 | 7195 | [24] |
| gestures | 33 | 5 | 1000 | [25] |
| libras | 90 | 15 | 360 | [26] |
| yeast | 8 | 10 | 1484 | [27] |
| s1 | 2 | 15 | 5000 | [21] |
| s2 | 2 | 15 | 5000 | [21] |
| s3 | 2 | 15 | 5000 | [21] |
| s4 | 2 | 15 | 5000 | [21] |
| Parameter | Value |
|---|---|
| 0.05 | |
| 0.05 | |
| 2 | |
| S | 1 |
| 0.8 | |
| b | 0.001 |
| T | 0.3 |
| Significant Diff. | |||
|---|---|---|---|
| wine | 0.646324 | 0.658763 | 0 |
| glass | 0.60919 | 0.506494 | 0 |
| anuran calls | 0.682589 | 0.471739 | + |
| gestures | 0.7235056 | 0.6380335 | + |
| libras | 0.856796 | 0.8072391 | + |
| yeast | 0.621127 | 0.627 | 0 |
| s1 | 0.871717 | 0.934503 | − |
| s2 | 0.869067 | 0.924032 | 0 |
| s3 | 0.840887 | 0.896415 | − |
| s4 | 0.876354 | 0.874768 | + |
| DBSCAN Parameters | |||
|---|---|---|---|
| wine | 0.646324 | 0.408029 | |
| glass | 0.60919 | 0.59830 | |
| anuran calls | 0.682589 | 0.749186 | |
| gestures | 0.7235056 | 0.1193016 | |
| libras | 0.856796 | 0.74157 | |
| yeast | 0.621127 | 0.394240 | |
| s1 | 0.871717 | 0.7987187 | |
| s2 | 0.869067 | 0.8243575 | |
| s3 | 0.840887 | 0.7602578 | |
| s4 | 0.876354 | 0.7737063 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Trzciński, M.; Kowalski, P.A.; Łukasik, S. Clustering with Nature-Inspired Algorithm Based on Territorial Behavior of Predatory Animals. Algorithms 2022, 15, 43. https://doi.org/10.3390/a15020043
Trzciński M, Kowalski PA, Łukasik S. Clustering with Nature-Inspired Algorithm Based on Territorial Behavior of Predatory Animals. Algorithms. 2022; 15(2):43. https://doi.org/10.3390/a15020043
Chicago/Turabian StyleTrzciński, Maciej, Piotr A. Kowalski, and Szymon Łukasik. 2022. "Clustering with Nature-Inspired Algorithm Based on Territorial Behavior of Predatory Animals" Algorithms 15, no. 2: 43. https://doi.org/10.3390/a15020043
APA StyleTrzciński, M., Kowalski, P. A., & Łukasik, S. (2022). Clustering with Nature-Inspired Algorithm Based on Territorial Behavior of Predatory Animals. Algorithms, 15(2), 43. https://doi.org/10.3390/a15020043