
Long-Term EEG Component Analysis Method Based on Lasso Regression


Abstract
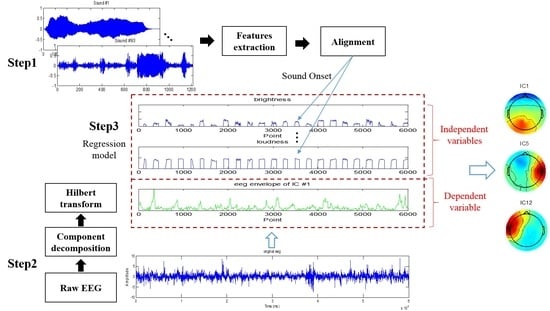
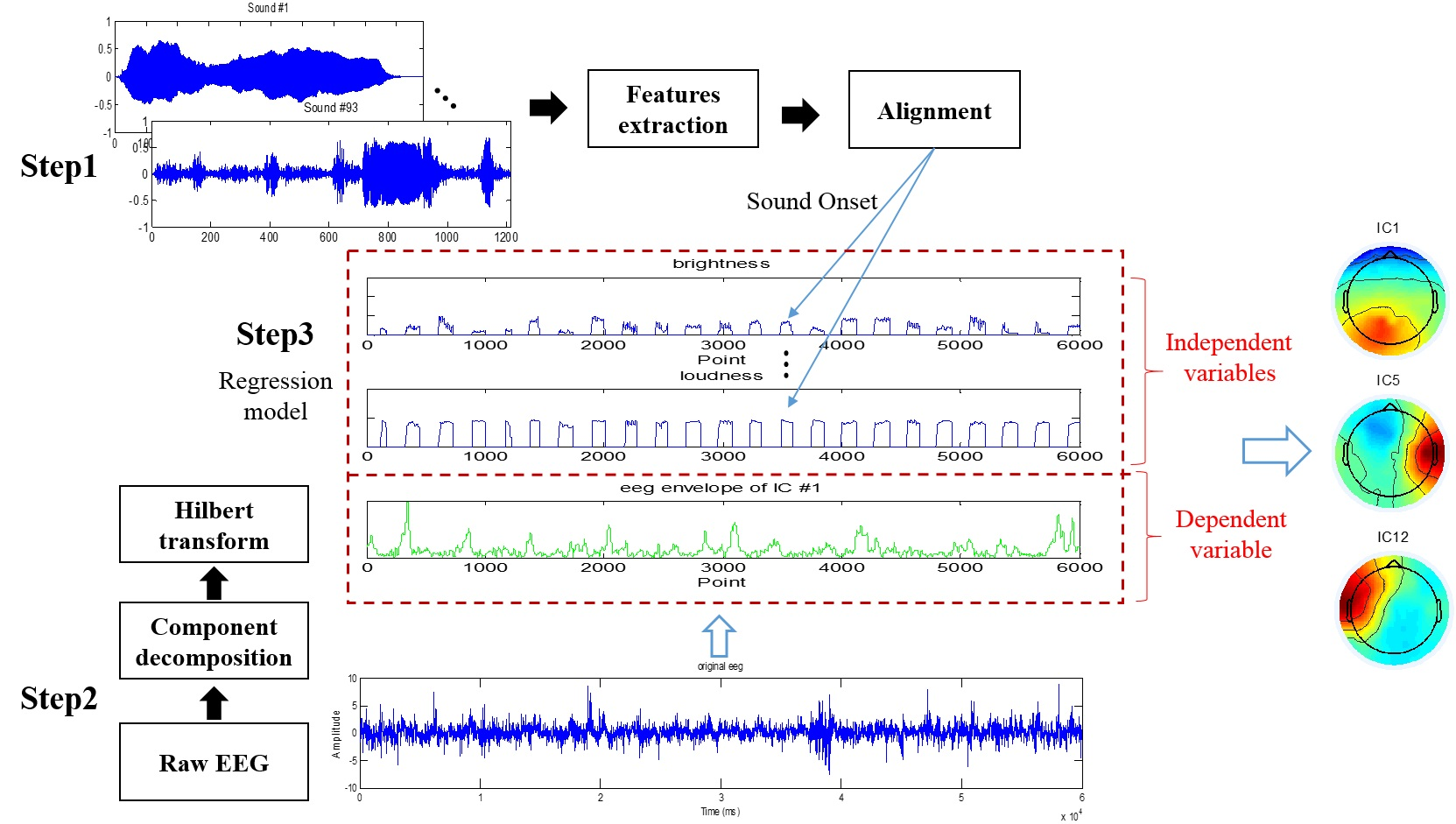{kind=link}
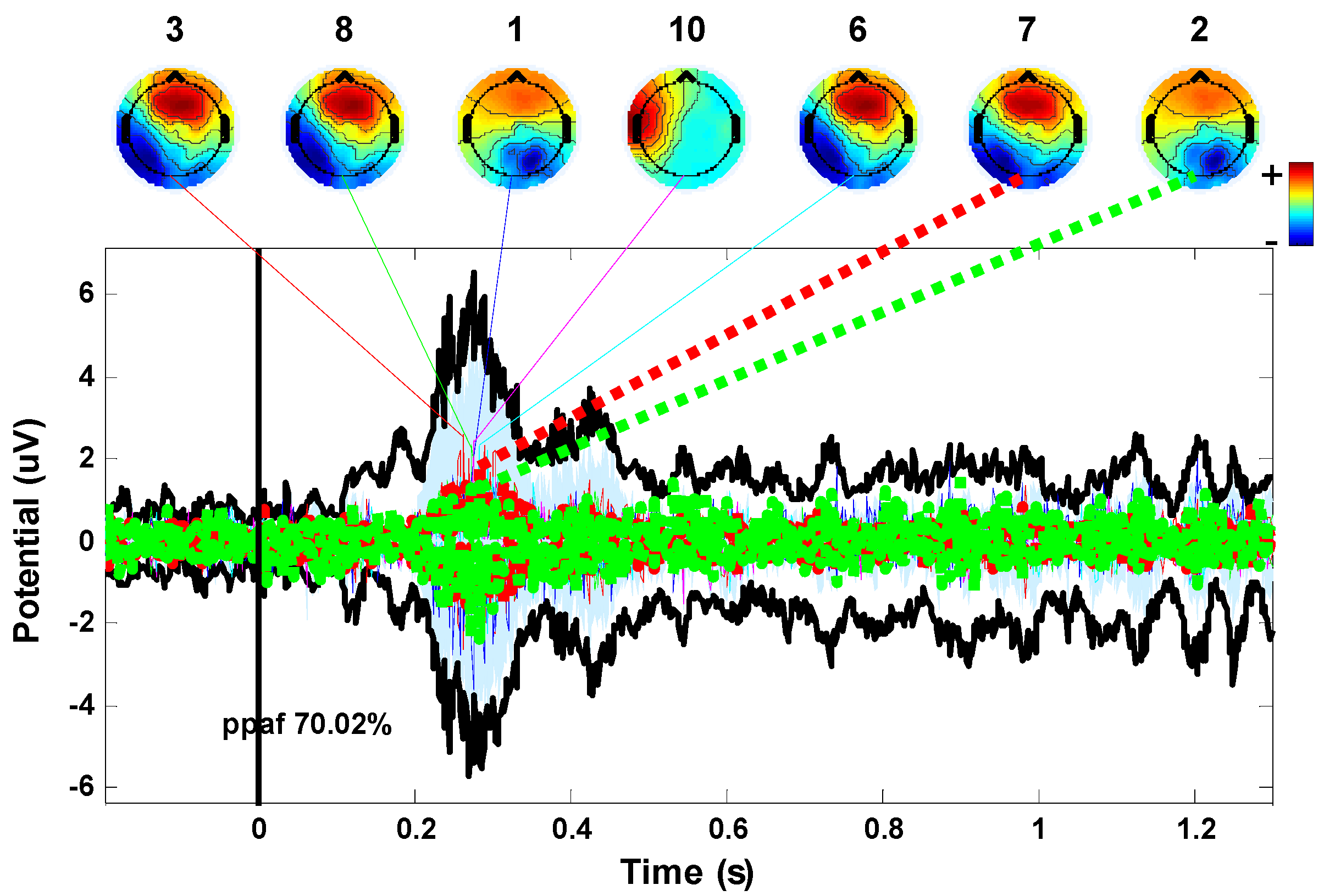{kind=link}
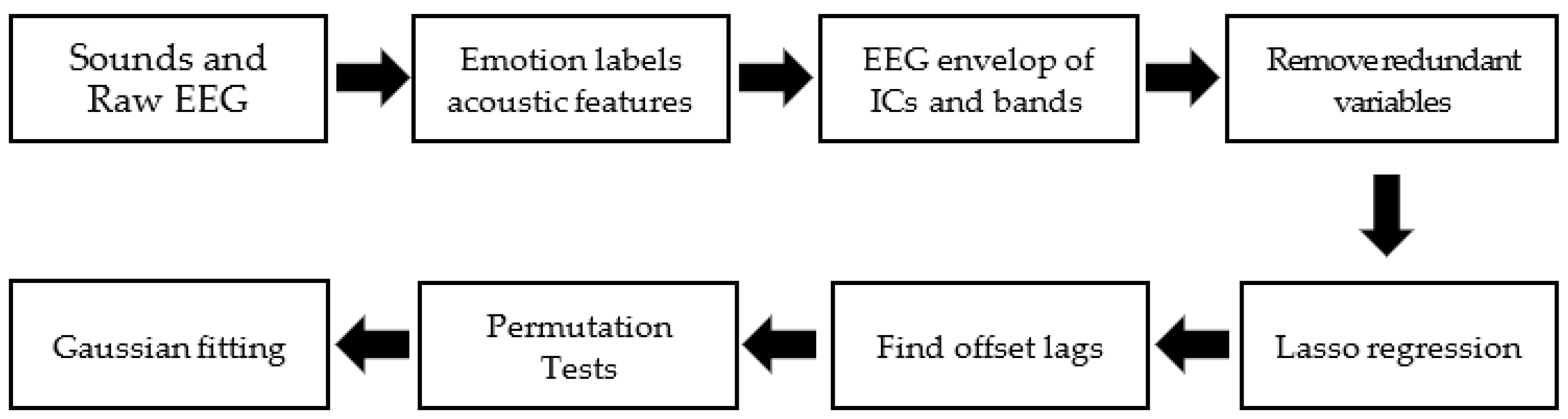{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
1.1. Related Works of Emotional EEG Analysis
- (1)
- There is no long-term analysis method of EEG components, or quantitative calculation method for EEG features;
- (2)
- In most of the existing methods, temporal information is ignored, and the characteristics of temporal variation of emotions are not considered.
1.2. The Proposed Method and Article Structure
2. Methods
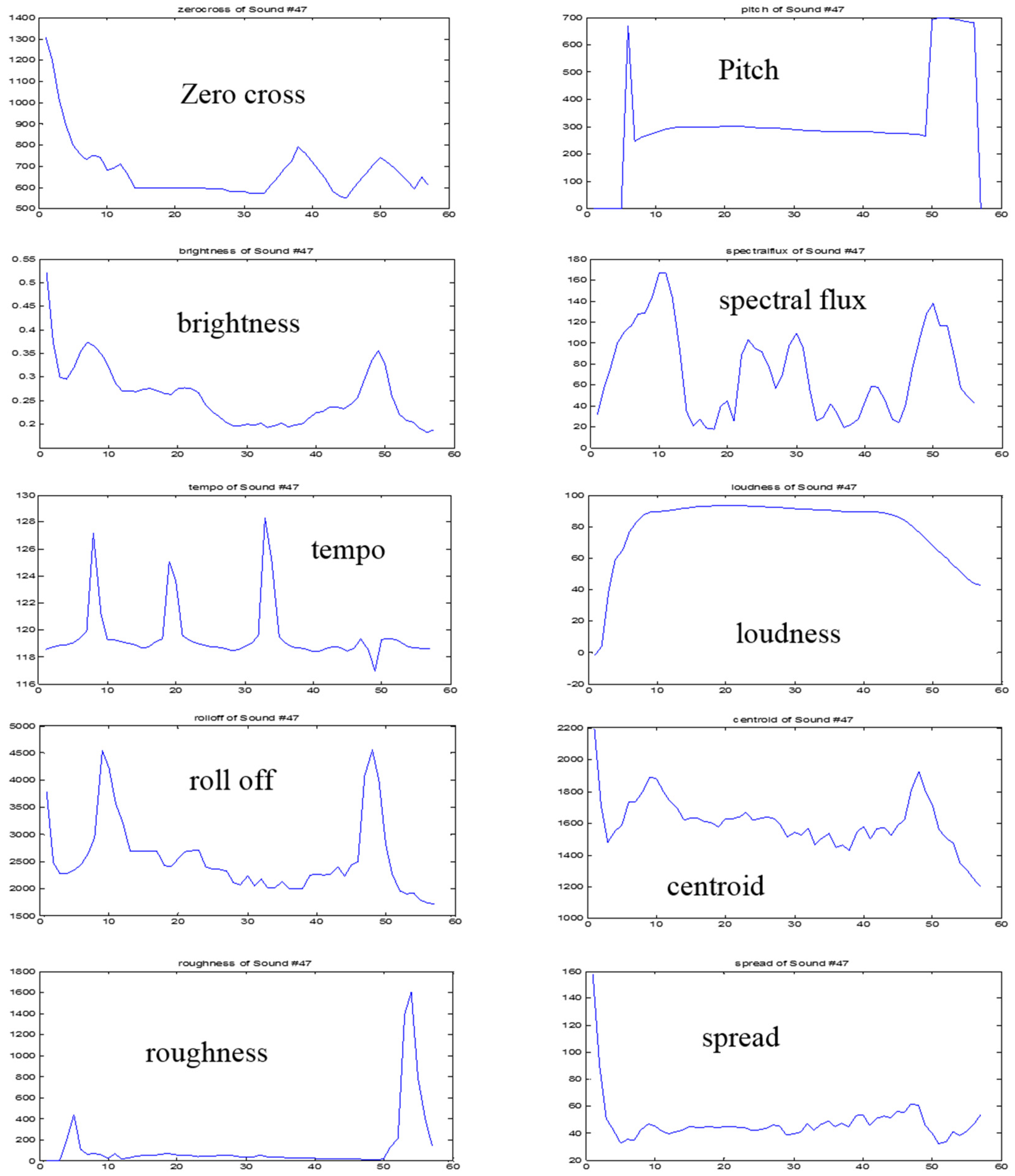
2.1. Acoustic Feature Extraction
2.2. EEG Component Decomposition and Feature Extraction
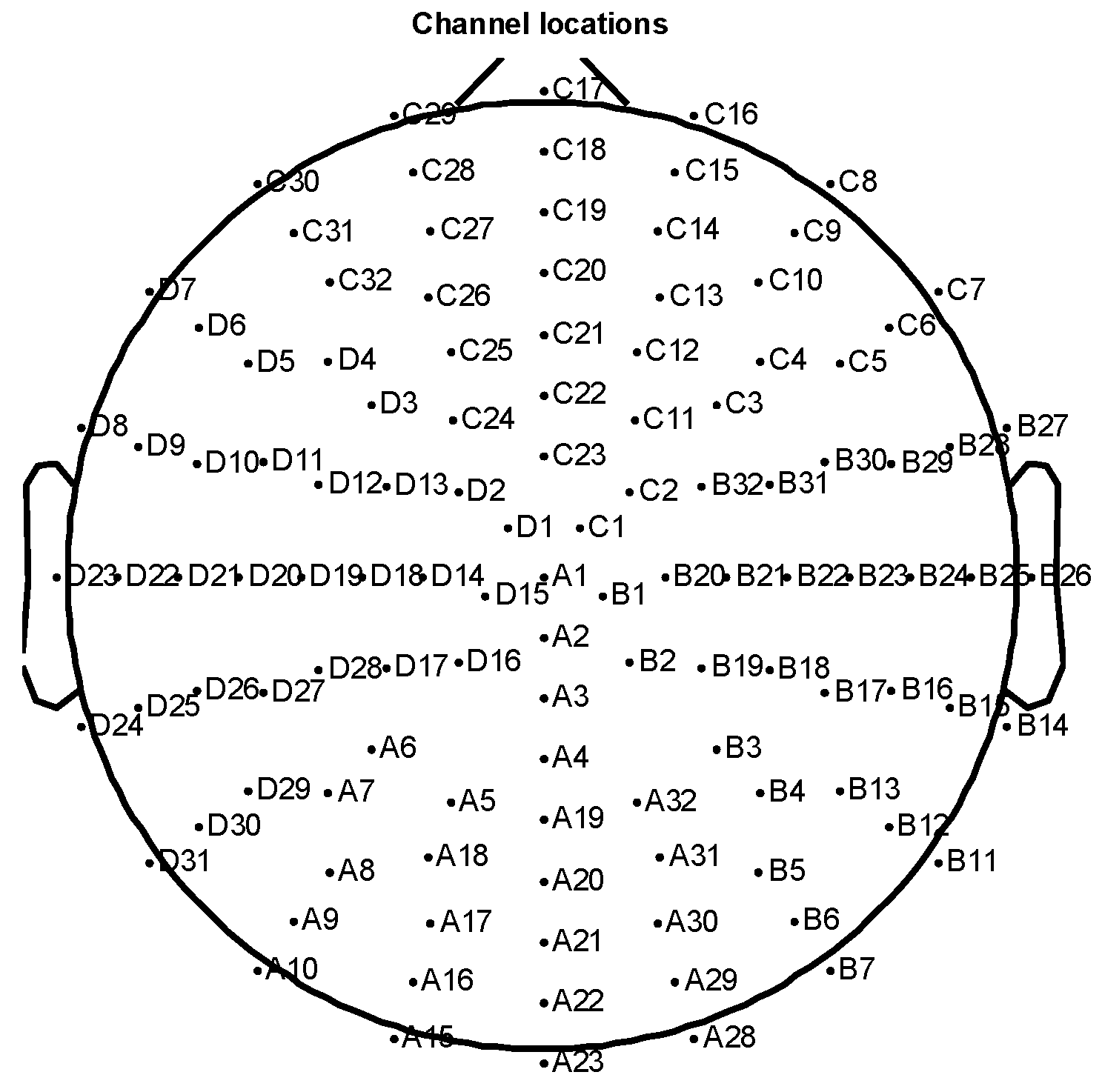
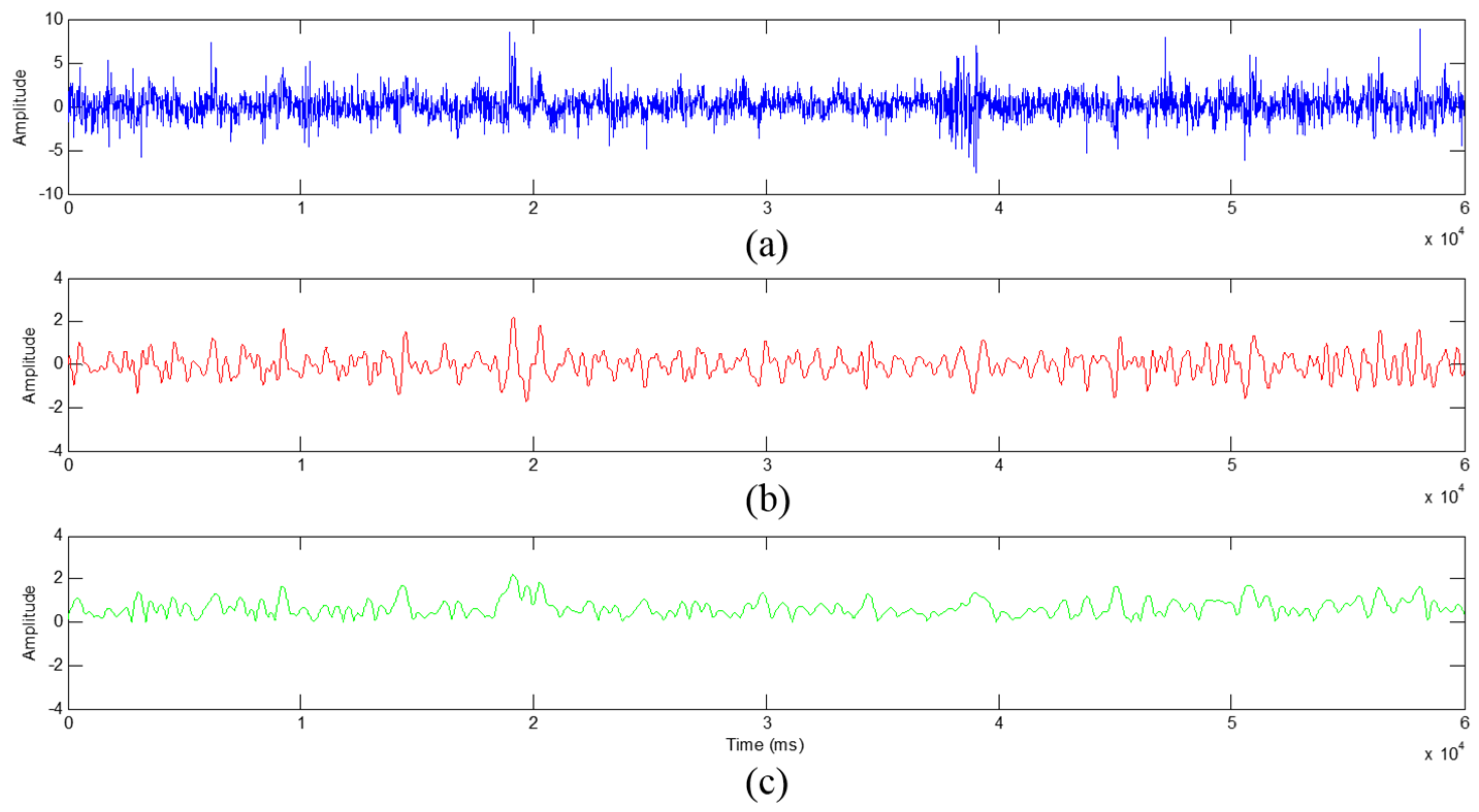
2.2.1. EEG Preprocessing
2.2.2. PSD Feature Extraction
2.2.3. Contour Extraction
2.3. Lasso Regression
2.4. Gaussian Fitting
3. Experiments and Results
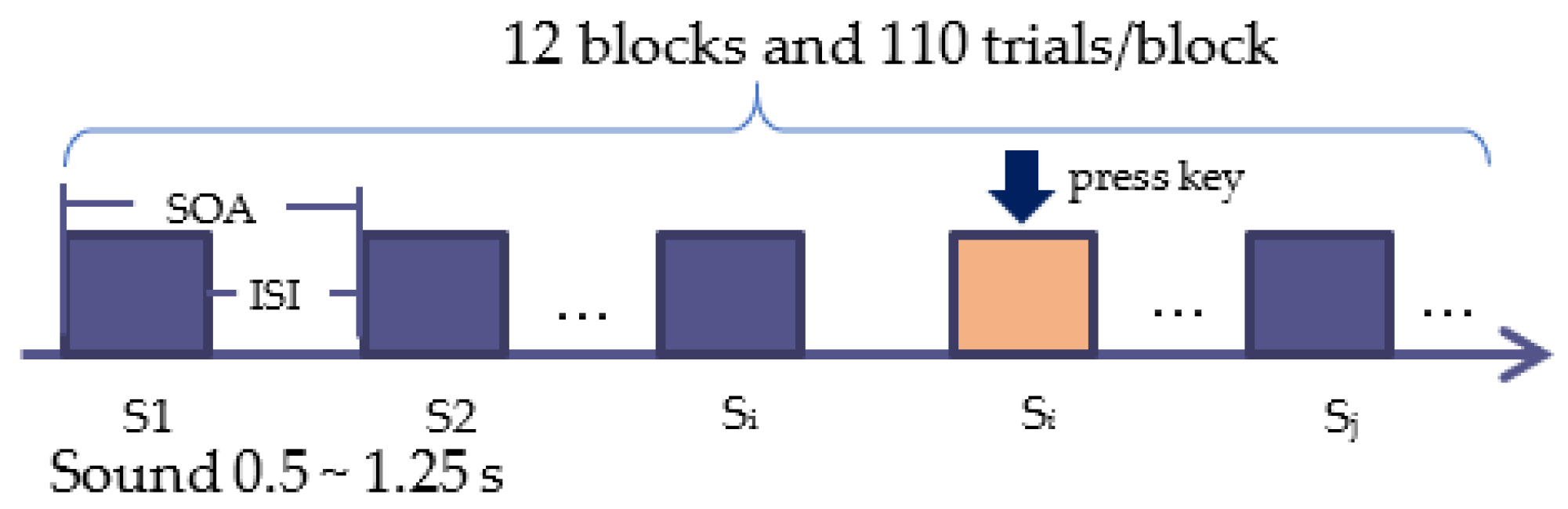
3.1. Cognitive Experiment and Data Description
3.2. Simulation and Results
- (1)
- Acoustic Feature Extraction
- (2)
- EEG Component Decomposition and Feature Extraction
- (3)
- Regression Model
4. Discussions
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Picard, R.W. Affective Computing; MIT Press: Cambridge, MA, USA, 1997; pp. 71–73. [Google Scholar]
- Paszkiel, S. Control based on brain-computer interface technology for video-gaming with virtual reality techniques. J. Autom. Mob. Robot. Intell. Syst. 2016, 10, 3–7. [Google Scholar]
- Juslin, P.N.; Västfjäll, D. Emotional responses to music: The need to consider underlying mechanisms. Behav. Brain Sci. 2008, 31, 751. [Google Scholar] [CrossRef]
- Bo, H.; Li, H.; Wu, B.; Ma, L.; Li, H. Brain Cognition of Musical Features Based on Automatic Acoustic Event Detection. In Proceedings of the International Conference on Multimedia Information Processing and Retrieval, Shenzhen, China, 6–8 August 2020; IEEE: New York, NY, USA, 2020; pp. 382–387. [Google Scholar]
- Chen, X.; Yang, D. Research Progresses in Music Emotion Recognition. J. Fudan Univ. 2017, 56, 136–148. [Google Scholar]
- Schaefer, H. Music-evoked emotions—Current studies. Front. Neurosci. 2017, 11, 600. [Google Scholar] [CrossRef]
- Daly, I.; Nicolaou, N.; Williams, D.; Hwang, F.; Kirke, A.; Miranda, E.; Nasuto, S.J. Neural and physiological data from participants listening to affective music. Sci. Data 2020, 7, 177. [Google Scholar] [CrossRef]
- Madsen, J.; Sand Jensen, B.O.R.; Larsen, J. Modeling temporal structure in music for emotion prediction using pairwise comparisons. In Proceedings of the International Society of Music Information Retrieval Conference, Taipei, Taiwan, 27–31 October 2014. [Google Scholar]
- Saari, P.; Eerola, T.; Fazekas, G.O.R.; Barthet, M.; Lartillot, O.; Sandler, M.B. The role of audio and tags in music mood prediction: A study using semantic layer projection. In Proceedings of the International Society for Music Information Retrieval Conference, Curitiba, Brazil, 4–8 November 2013; pp. 201–206. [Google Scholar]
- Han, W.; Li, H.; Han, J. Speech emotion recognition with combined short and long term features. Tsinghua Sci. Technol. 2007, 48, 708–714. [Google Scholar]
- Hu, L.; Zhang, Z. EEG Signal Processing and Feature Extraction, 1st ed.; Science Press: Beijing, China, 2020. [Google Scholar]
- Yu, B.; Wang, X.; Ma, L.; Li, L.; Li, H. The Complex Pre-Execution Stage of Auditory Cognitive Control: ERPs Evidence from Stroop Tasks. PLoS ONE 2015, 10, e0137649. [Google Scholar] [CrossRef]
- Luck, S.J. An Introduction to the Event-Related Potential Technique; MIT Press: Cambridge, MA, USA, 2014. [Google Scholar]
- Poikonen, H.; Alluri, V.; Brattico, E.; Lartillot, O.; Tervaniemi, M.; Huotilainen, M. Event-related brain responses while listening to entire pieces of music. Neuroscience 2016, 312, 58–73. [Google Scholar] [CrossRef]
- Welch, P.D. The use of fast Fourier transform for the estimation of power spectra: A method based on time averaging over short, modified periodograms. IEEE Trans. Audio Electroacoust. 1967, 15, 70–73. [Google Scholar] [CrossRef]
- Bo, H. Research on Affective Computing Methods Based on Auditory Cognitive Principles. Ph.D. Thesis, Harbin Institute of Technology, Harbin, China, 2019. [Google Scholar]
- Wright, J.J.; Kydd, R.R.; Sergejew, A.A. Autoregression models of EEG. Biol. Cybern. 1990, 62, 201–210. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, S.; Ji, X. EEG-based classification of emotions using empirical mode decomposition and autoregressive model. Multimed. Tools Appl. 2018, 77, 26697–26710. [Google Scholar] [CrossRef]
- Li, H.; Li, H.; Ma, L. Long-term Music Emotion Research Based on Dynamic Brain Network. J. Fudan Univ. Nat. 2020, 59, 330–337. [Google Scholar]
- Murugappan, M.; Rizon, M.; Nagarajan, R.; Yaacob, S.; Zunaidi, I.; Hazry, D. EEG feature extraction for classifying emotions using FCM and FKM. Int. J. Comput. Commun. 2007, 1, 21–25. [Google Scholar]
- Lin, Y.; Wang, C.; Jung, T.; Wu, T.; Jeng, S.; Duann, J.; Chen, J. EEG-based emotion recognition in music listening. IEEE. Trans. Biomed. Eng. 2010, 57, 1798–1806. [Google Scholar] [PubMed]
- Petrantonakis, P.C.; Hadjileontiadis, L.J. Adaptive emotional information retrieval from EEG signals in the time-frequency domain. IEEE Trans. Signal Process. 2012, 60, 2604–2616. [Google Scholar] [CrossRef]
- Tripathi, S.; Acharya, S.; Sharma, R.D.; Mittal, S.; Bhattacharya, S. Using deep and convolutional neural networks for accurate emotion classification on DEAP dataset. In Proceedings of the Twenty-ninth Innovative Applications of Artificial Intelligence Conference, San Francisco, CA, USA, 6–9 February 2017; pp. 4746–4752. [Google Scholar]
- Giannakakis, G.; Grigoriadis, D.; Giannakaki, K.; Simantiraki, O.; Roniotis, A.; Tsiknakis, M. Review on psychological stress detection using biosignals. IEEE Trans. Affect. Comput. 2019. [Google Scholar] [CrossRef]
- Xie, Y.; Liang, R.; Liang, Z.; Huang, C.; Zou, C.; Schuller, B. Speech emotion classification using attention-based LSTM. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1675–1685. [Google Scholar] [CrossRef]
- Levy, D.A.; Granot, R.; Bentin, S. Neural sensitivity to human voices: ERP evidence of task and attentional influences. Psychophysiology 2003, 40, 291–305. [Google Scholar] [CrossRef]
- Klug, M.; Gramann, K. Identifying key factors for improving ICA-based decomposition of EEG data in mobile and stationary experiments. Eur. J. Neurosci. 2020. [Google Scholar] [CrossRef]
- Jung, T.; Makeig, S.; Westerfield, M.; Townsend, J.; Courchesne, E.; Sejnowski, T.J. Removal of eye activity artifacts from visual event-related potentials in normal and clinical subjects. Clin. Neurophysiol. 2000, 111, 1745–1758. [Google Scholar] [CrossRef]
- Li, Y.; Qiu, Y.; Zhu, Y. EEG Signal Analysis Method and Its Application; Science Press: Beijing, China, 2009. [Google Scholar]
- Hettich, D.T.; Bolinger, E.; Matuz, T.; Birbaumer, N.; Rosenstiel, W.; Spüler, M. EEG responses to auditory stimuli for automatic affect recognition. Front. Neurosci. 2016, 10, 244. [Google Scholar] [CrossRef]
- Masuda, F.; Sumi, Y.; Takahashi, M.; Kadotani, H.; Yamada, N.; Matsuo, M. Association of different neural processes during different emotional perceptions of white noise and pure tone auditory stimuli. Neurosci. Lett. 2018, 665, 99–103. [Google Scholar] [CrossRef]
- Raheel, A.; Anwar, S.M.; Majid, M. Emotion recognition in response to traditional and tactile enhanced multimedia using electroencephalography. Multimed. Tools Appl. 2019, 78, 13971–13985. [Google Scholar] [CrossRef]
- Johansson, M. The Hilbert Transform. Ph.D. Thesis, Växjö University, Växjö, Suecia, 1999. [Google Scholar]
- Huang, N.E. Hilbert-Huang Transform and Its Applications, 1st ed.; World Scientific Publishing: Singapore, 2014. [Google Scholar]
- Gifi, A. Nonlinear Multivariate Analysis; Wiley-Blackwell: New York, NY, USA, 1990. [Google Scholar]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. 1996, 58, 267–288. [Google Scholar] [CrossRef]
- Meziani, A.; Djouani, K.; Medkour, T.; Chibani, A. A Lasso quantile periodogram based feature extraction for EEG-based motor imagery. J. Neurosci. Methods 2019, 328, 108434. [Google Scholar] [CrossRef] [PubMed]
- Chowdhury, T.T.; Fattah, S.A.; Shahnaz, C. Seizure activity classification based on bimodal Gaussian modeling of the gamma and theta band IMFs of EEG signals. Biomed. Signal Process. Control 2021, 64, 102273. [Google Scholar] [CrossRef]
- Li, H.; Chen, J.; Ma, L.; Bo, H.; Xu, C.; Li, H. Dimensional Speech Emotion Recognition Review. J. Softw. 2020, 31, 2465–2491. [Google Scholar]
- Feldman, L.A. Valence focus and arousal focus: Individual differences in the structure of affective experience. J. Pers. Soc. Psychol. 1995, 69, 153–166. [Google Scholar] [CrossRef]
- Yu, X.; Chen, Y.; Luo, T.; Huang, X. Neural oscillations associated with auditory duration maintenance in working memory in tasks with controlled difficulty. Front. Psychol. 2020, 11, 545935. [Google Scholar] [CrossRef]
- Billig, A.J.; Herrmann, B.; Rhone, A.E.; Gander, P.E.; Nourski, K.V.; Snoad, B.F.; Kovach, C.K.; Kawasaki, H.; Howard, M.A., 3rd; Johnsrude, I.S. A sound-sensitive source of alpha oscillations in human non-primary auditory cortex. J. Neurosci. 2019, 39, 8679–8689. [Google Scholar] [CrossRef]
- Zhu, Y.; Zhang, C.; Poikonen, H.; Toiviainen, P.; Huotilainen, M.; Mathiak, K.; Ristaniemi, T.; Cong, F. Exploring Frequency-Dependent Brain Networks from Ongoing EEG Using Spatial ICA During Music Listening. Brain Topogr. 2020, 33, 289–302. [Google Scholar] [CrossRef] [PubMed]
- Mei, J.; Wang, X.; Liu, Y.; Li, J.; Liu, K.; Yang, Y.; Cong, F. The Difference of Music Processing among Different State of Consciousness: A Study Based on Music Features and EEG Tensor Decomposition. Chin. J. Biomed. Eng. 2021, 40, 257–265. [Google Scholar]
- Dey, A.; Palit, S.K.; Bhattacharya, D.K.; Tibarewala, D.N.; Das, D. Study of the effect of music on central nervous system through long term analysis of EEG signal in time domain. Int. J. Eng. Sci. Emerg. Technol. 2013, 5, 59–67. [Google Scholar]
- Yang, W.; Wang, K.; Zuo, W. Fast neighborhood component analysis. Neurocomputing 2012, 83, 31–37. [Google Scholar] [CrossRef]














Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bo, H.; Li, H.; Wu, B.; Li, H.; Ma, L. Long-Term EEG Component Analysis Method Based on Lasso Regression. Algorithms 2021, 14, 271. https://doi.org/10.3390/a14090271
Bo H, Li H, Wu B, Li H, Ma L. Long-Term EEG Component Analysis Method Based on Lasso Regression. Algorithms. 2021; 14(9):271. https://doi.org/10.3390/a14090271
Chicago/Turabian StyleBo, Hongjian, Haifeng Li, Boying Wu, Hongwei Li, and Lin Ma. 2021. "Long-Term EEG Component Analysis Method Based on Lasso Regression" Algorithms 14, no. 9: 271. https://doi.org/10.3390/a14090271
APA StyleBo, H., Li, H., Wu, B., Li, H., & Ma, L. (2021). Long-Term EEG Component Analysis Method Based on Lasso Regression. Algorithms, 14(9), 271. https://doi.org/10.3390/a14090271