1. Introduction
Network traffic analysis is the process of recognizing user applications, networking protocols, and communication patterns flowing through the network [
1]. Traffic analysis is useful for identifying security threats, intrusion detection, server performance deterioration, configuration errors, and latency problems in some network components [
2]. The rapid evolution of new online applications, as well as the ubiquitous deployment of mobile and IoT devices [
3], have dramatically increased the complexity and diversity of network traffic analysis. Moreover, the new security requirements in modern networks, including packet encryption and port obfuscation, have elevated extra challenges in classifying network traffic [
4].
Despite the importance, the traditional network traffic classification approaches can only recognize user applications that are running over static well-known network ports such as FTP, SSH, HTTP, SMTP, etc. However, most online user applications use dynamic ports, virtual private networks, and encrypted tunnels [
5]. Furthermore, these applications are transported over HTTPS connections and have applied security protocols (e.g., SSH and SSL) for ensuring QoS provisioning, security, and privacy. This makes it very challenging for traditional port-based approaches to recognize such applications.
Machine learning (ML), including deep learning (DL), has already enabled game-changing traffic analysis capabilities by providing the ability to understand network traffic behavior and patterns, and distinguish between benign and abnormal traffic [
2,
6,
7]. For instance, ML-based cybersecurity approaches have made significant contributions in detecting various types of attacks [
8], such as multi-class distinction of Distributed Denial of Service (DDOS) attacks, DoS Hulk, DoS GoldenEye, Heartbleed, Bot, PortScan, and Web attacks. Imagine a user-friendly network traffic flow classifier that network administrators can use to identify the different types of online applications flowing their networks with high accuracy. Such systems would help them to perform administrative decisions, and detect malicious traffic and secure users’ data.
This paper presents NetScrapper, a lightweight ML-powered traffic flow classifier for online applications, which can be deployed on-site at the network edge. We compared three different ML models, namely K-Nearest Neighbors (KNN), Random Forest (RF), and Artificial Neural Network (ANN), for classifying the most popular 53 online user applications, including Amazon, Youtube, Google, Twitter, and many others. NetScrapper uses a network traffic dataset that consists of more than 3.5 M flow packets with different 78 features for training, validating, and testing the KNN, RF, and ANN models.
We developed a web-based interface using Python Flask Framework [
9], which enables users to either upload a snapshot of their traffic history or capture the traffic flow directly from the network interface card in real time. The GUI displays the confidence percentage and classification time taken to classify the traffic flow. The web application runs on top of KNN, RF, and ANN models. To enable seamless interfacing between the three ML models and the Flask GUI, we built a middleware pipeline that orchestrates the coordination between the different components of the traffic classifier.
The contributions of this paper are fourfold. First, we propose NetScrapper, an AI-powered network classifier for real-time flow streams that can help network administrators to monitor their network performance and detect any suspicious traffic circulating their networks. NetScrapper can be deployed on networking devices at the network edge with high prediction accuracy and low response time. Second, we carried out several sets of experiments for evaluating the classification accuracy and performance of three different ML models (i.e., ANN, RF, and KNN) implemented as part of NetScrapper. Third, we developed a user-friendly interface on top of the three ML models to allow users to interact with the network classifier conveniently. Fourth, the system is designed to be generic, making it applicable to different fields requiring real-time inference at the network edge with offline generated ML models.
The rest of the paper is organized as follows:
Section 2 presents related work.
Section 3 and
Section 4 present the design and prototype implementation of NetScrapper, respectively.
Section 5 experimentally evaluates NetScrapper in terms of classification time and accuracy. Finally,
Section 6 summarizes the results of this work.
2. Related Work
The evolution of traffic flow classification has gone through three stages: port-based, payload-based, and flow-based statistical characteristics. Port-based approaches assume that online applications consistently use well-known TCP or UDP port numbers; however, the emergence of port camouflage, random port, and tunneling technology makes these port-based approaches lose productiveness quickly [
10]. Payload-based methods, also called Deep Packet Inspection (DPI) techniques, depend on inspecting both the packet header and data parts to determine any non-compliance to transportation protocols or the existence of spam, viruses, or intrusions to take preventative actions by blocking, re-routing, or logging the packet accordingly. However, payload-based approaches cannot deal with encrypted traffic as it needs to match packet content to static routing rules [
2]. Additionally, DPI approaches tend to have high computational overhead, which precludes its real-time usage in mission-critical security tasks [
11].
In this paper, we focus on the flow-based approach that relies on network traffic statistical characteristics using ML algorithms [
7]. Flow-based techniques help network administrators and security personnel to monitor both ingress and egress traffic communicated from/to external networks to/from their enterprise networks [
11]. Furthermore, statistical characterization helps minimize the false positives in automated intrusion detection systems [
5]. This section provides an overview of the most important network traffic classification methods. In particular, we focus on statistical and machine learning approaches.
Deep Packet [
2] is an example of a DL-based scheme for traffic flow classification that integrates both feature extraction and classification phases into one system. Deep Packet focuses on traffic characterization, including encrypted traffic, to identify end-user applications (e.g., BitTorrent and Skype). The proposed method uses two DL models, namely Stacked Autoencoder (SAE) and Convolution Neural Network (CNN), to classify the encrypted traffic across VPN networks. Experimental results showed that the CNN model achieved an overall classification accuracy of 94% in recognizing the flow traffic. However, Deep Packet can only detect a limited range of online applications due to the relatively small training dataset.
In the field of cybersecurity, Rezaei et al. [
1] proposed a multi-task learning framework for network traffic classification. The proposed framework can predict the bandwidth requirement and duration of the traffic flow generated for online applications. The authors claim that their framework can achieve a high classification accuracy of user applications using easily obtainable data samples for bandwidth and duration, thus eliminating the need for a sizeable labeled traffic dataset. Experimental evaluation was conducted using ISCX and QUIC public datasets showed the efficacy of the proposed approach.
Another DL-based network encrypted traffic classifier and intrusion detection system, called Deep-Full-Range (DFR), was proposed in [
5]. DFR can use CNN, SAE, and Long Short-Term Memory (LSTM) models to classify encrypted and malware traffic without human intervention. DFR was compared to some state-of-the-art approaches using two public datasets. Experimental results showed that DFR slightly outperforms these approaches in terms of F1 score and storage resource requirements. However, DFR relies on manual feature extraction to train the DL models, limiting the system’s usability on a large scale.
Focusing on real-world network traffic, Hardegen et al. [
7] proposed a processing pipeline for flow-based traffic classification using machine learning. The proposed system is trained to predict the characteristics of real-world traffic flows (e.g., throughput and duration) from a campus network. The pipeline has preprocessing and anonymization modules that can protect sensitive user information circulating the campus network. A visualization module was developed to illustrate the network traffic data visually to system users. Although this work seems promising, no experimental evaluation was conducted to assess the proposed system’s performance and scalability.
Interesting work was presented in [
10] for online classification of user activities using machine learning on network traffic. The authors proposed a system for classifying user activities from network traffic using both supervised and unsupervised learning. The proposed method uses users’ behavior exhibited over the network to classify their activities within a given time window. An RF model was trained with features extracted from the network and transport layer headers in the traffic flows. The RF model achieved a prediction rate of 97.37% in recognizing the user activities over short temporal windows. However, this system assumes that users are performing a single activity anytime, thereby obtaining one label for each temporal window. This excludes simultaneous activities performed by one user, which is an essential requirement in modern networks.
In summary, most of the existing work on statistical [
1,
7,
10] and ML-based traffic classification [
2,
5,
11] focus on extracting low handcrafted features from the traffic flow, which always depends on the domain experts’ experience. These flow features must also be up-to-date to cope with the rapidly changing world of new online applications [
3]. Moreover, most of the surveyed DL-based models are designed to work offline, which is not appropriate for real-time network traffic analysis. Furthermore, to the best of our knowledge, none of the current ML-based approaches can be deployed on-site at the network edge with a user-friendly interface, which precludes minimizing the communication delays and enhancing the user experience in using the system.
3. System Design
This section presents the design of NetScrapper, including the system architecture, dataset, and the three ML models. In the rest of this section, we discuss these parts separately.
3.1. Architecture
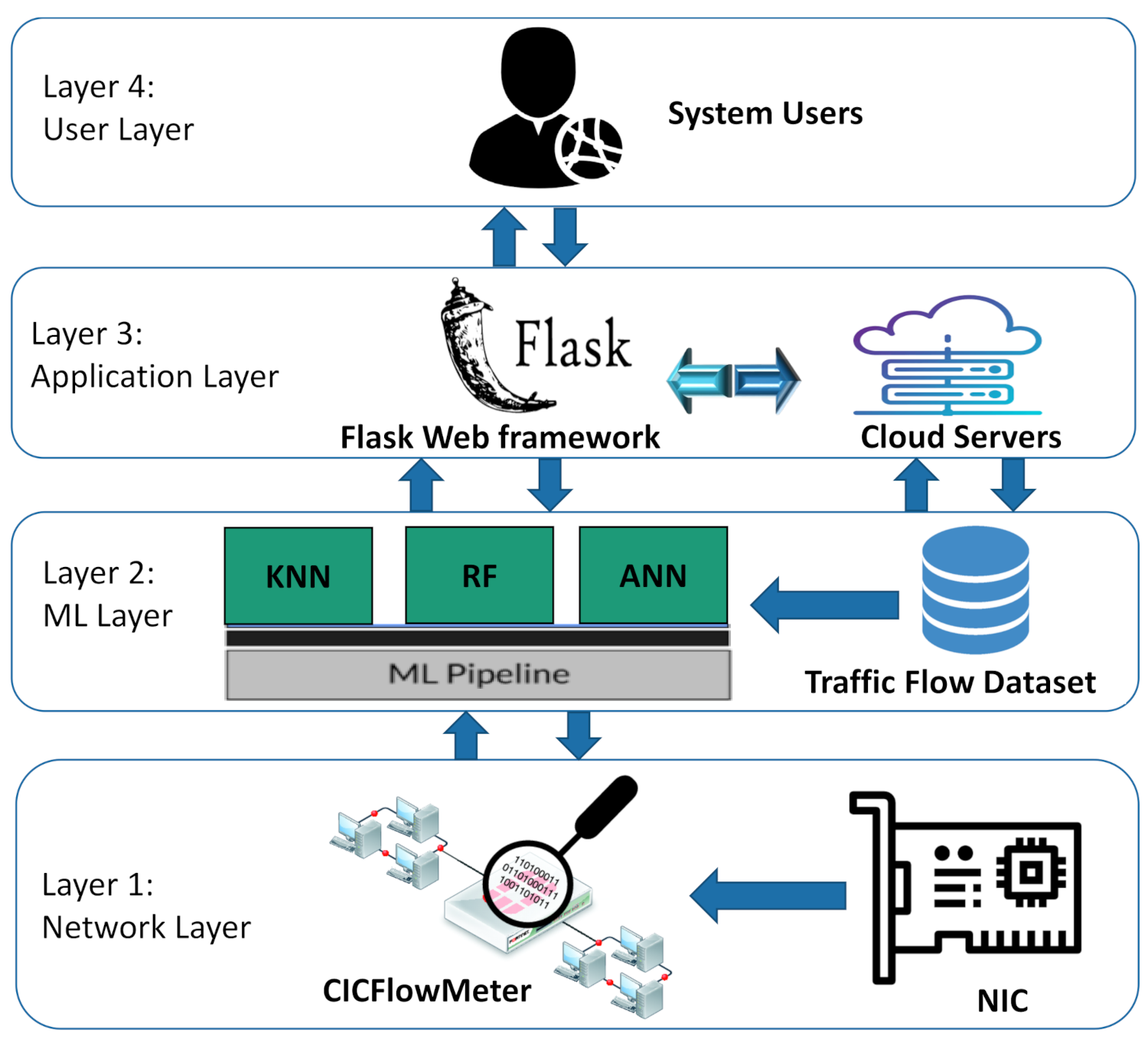
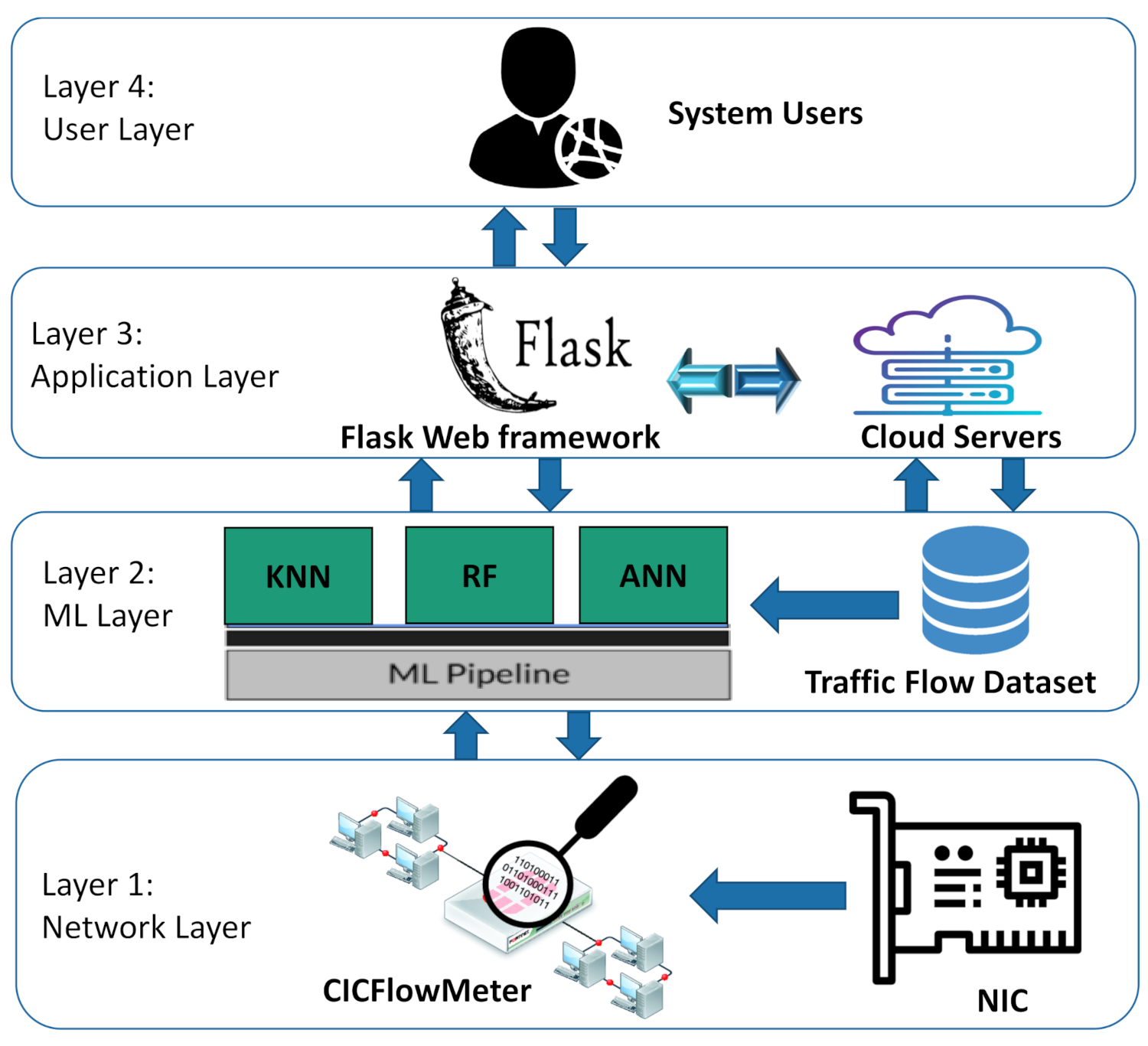
As illustrated in
Figure 1, the run-time system for NetScrapper is organized with parts executing on the network and application layers. Layer 1 shows that live traffic flows are extracted from the Network Interface Card (NIC), stored, and preprocessed in real time. The traffic stream is then fed into CICFlowMeter [
12], an open-source tool that extracts the time-related features from the network flow stream to train the ML models. CICFlowMeter can generate these features from bidirectional flows, purifying attributes from an existing feature set, and control the duration of flow timeout for both TCP and UDP protocols.
Layer 2 describes the machine learning models used in NetScrapper, including the KNN, RF, and ANN models. It also shows the Ml pipeline, which runs underneath the three ML models. The pipeline automates the ML workflow by enabling live traffic flows to be transformed and correlated into each ML model to achieve the desired classification outputs. It also works as a coordination interface between the Flask GUI and the ML models. The ML pipeline transformed our ML workflows into independent, reusable, modular components that can then be pipelined together to build a more efficient and simplified real-time traffic classifier. Layer 3 illustrates the web-based interface of NetScrapper running on the cloud server. We used Python Flask Framework to develop a user-friendly web application that enables users (shown in layer 4) to interact with the system.
3.2. Dataset
We collected more than labeled 3.5 M flow packets with different 78 feature attributes such as header length, flow duration, flow IAT mean, down–up ratio, segment size, acknowledge flag count, etc. As show in
Table 1, we categorized these attributes into seven main attribute categories, namely subflow descriptors (4 attributes), header descriptors (5 attributes), network identifiers (7 attributes), flow timers (8 attributes), flag features (12 attributes), interarrival times (15 attributes), and flow descriptors (36 attributes).
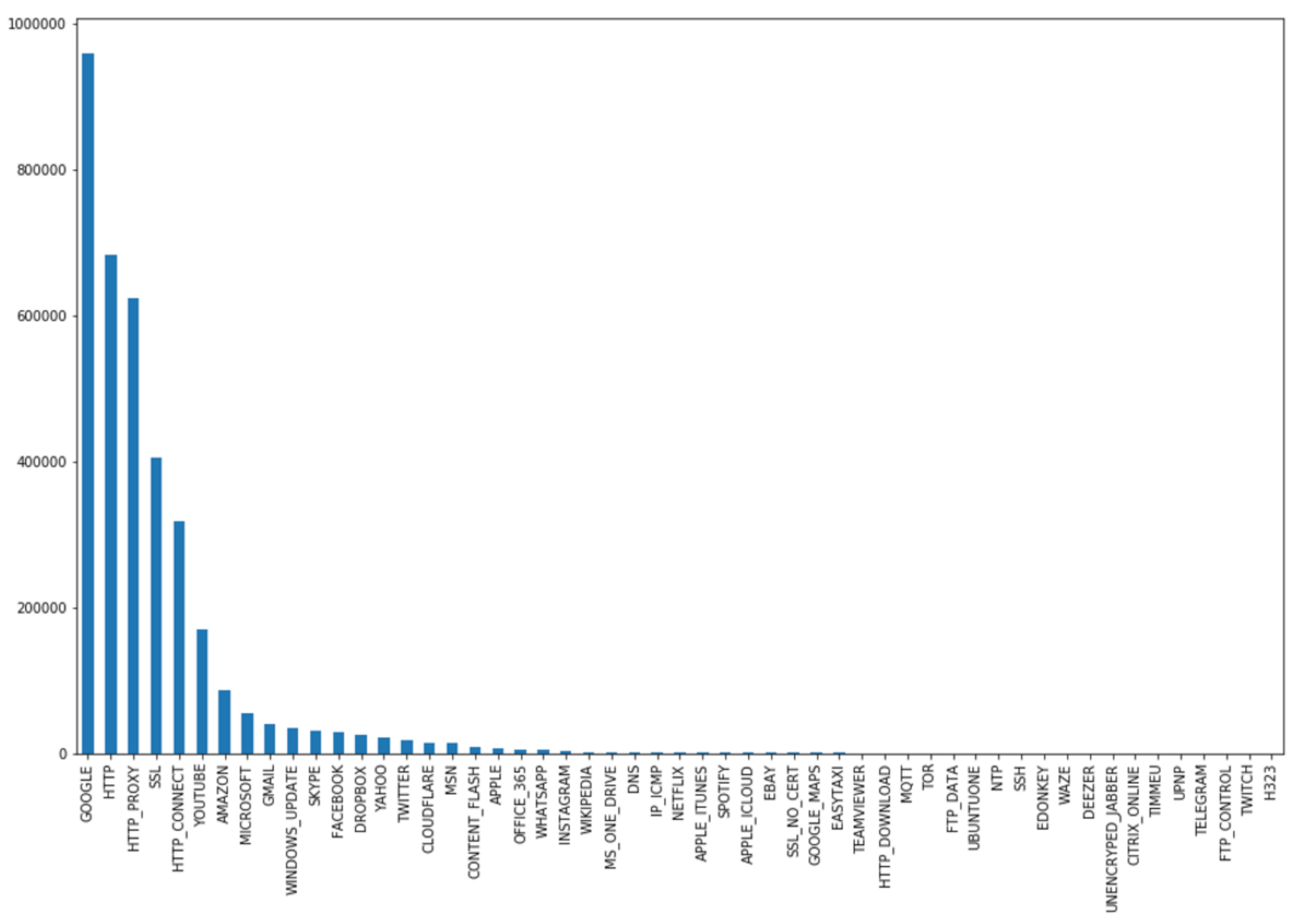
Table 2 shows the number of samples used in the training phase of the ML models across the 53 online popular applications, including Google, Youtube, Amazon, Microsoft, Dropbox, Facebook, Twitter, Instagram, Netflix, Apple, Skype, etc. The dataset was collected from different sources such as Kaggle [
13], Wireshark analysis [
14], and other sources. Our dataset is divided into three parts: training, validation, and testing. The number of samples in each phase is determined based on the fine-tuned hyperparameters and structure of the ML models. Specifically, 70% of the dataset is allocated for the training phase, while the remaining 30% is equally partitioned between the validation and testing phases.
We applied a series of preprocessing transformations to the training dataset to increase the training accuracy and minimize the training loss of the ML models. This had a better effect on learning the 53 classes more effectively and increased our ML models’ stability. First, we used CICFlowmeter to store the traffic stream into PCAP files temporarily. Then, the Scapy tool [
15] is used to manipulate the captured packets in these PCAP files to weaken the influence of the network noise factor and eliminate the incomplete records during the training process. The result data are stored in CSV files. Second, the ML pipeline performs a deep packet inspection on these CSV files to extract the feature attributes, including the application protocol (layer 7 in the TCP/IP stack), source IP address, source port, destination IP address, destination port, etc.
We also altered the Ethernet header for some packets in our dataset because the transport layer segments in the TCP and UDP protocols vary in header length. For instance, the TCP and UDP packets’ header lengths are 20 and 8 bytes, respectively. Therefore, we inserted zeros to the end of the UDP protocol’s packet headers to equalize all packets’ length in our dataset. These preprocessing and feature extraction steps are summarized in Algorithm 1.
| Algorithm 1 Preprocessing and Feature Extraction Algorithm |
- 1:
procedure Preprocess Training Dataset - 2:
Input: Raw Dataset () - 3:
Output 1: Preprocessed Dataset () - 4:
Output 2: Feature Attributes () - 5:
/* generate the PCAP files */ - 6:
PCAP-List = generatePCAP(); - 7:
/* purify the PCAP files */ - 8:
for each PCAP file in PCAP-List do - 9:
/* remove noise and incomplete traffic packets */ - 10:
CSV-File = purifyDataset(file); - 11:
/* Standardize the length of packets’ headers */ - 12:
packetList = alterPacketHeader(CSV-File); - 13:
.add(packetList); - 14:
/* extract the feature vector from each packet */ - 15:
v = getFeatureVector(packetList); - 16:
.add(v); - 17:
end for - 18:
return and ;
|
The preprocessing operation was customized for each ML model based on its hyperparameters and structure. Furthermore, the size of the training set and the number of feature attributes were reduced from 16,545,768 to 3,577,296 packet flows and from 86 to 78, respectively. We eliminated the following feature attributes from the dataset because they could be derived from other exciting attributes: URG Flag Count, CWE Flag Count, Flow Bytes S, Subflow Fwd Bytes, Subflow Bwd Bytes, Bytes Bulk, Bwd Avg Bytes Bulk, Init Win bytes forward, Init Win bytes backward.
Figure 2 gives a general overview of the number of samples in our dataset across the 53 classes after the preprocessing stage.
We had to normalize the range of values of the feature attributes in the dataset before training the ML models. This step was necessary because all dimensions of feature vectors extracted from input traffic data should be in the same range. This made the convergence of our ML models faster during the training phase. Statistical normalization (Z-transformation) was implemented by subtracting the input mean value
from each attribute’s value
, and then dividing the result by the standard deviation
of the input feature vector. The distribution of the output traffic values would resemble a Gaussian curve centered at zero. We used the following formula to normalize each feature vector in our training set:
where
I and
O are the input and output feature vectors, respectively; and
i is the current feature vector’s index to be normalized.
3.3. ML Models
3.3.1. ANN Structure
We trained a feed-forward ANN model with 2 hidden layers, one input layer and one output layer.
and
represent the input and output vectors, respectively, where
r represents the number of elements in the input feature set and
h is the number of classes. The main objective of the network is to learn a compressed representation of the dataset. In other words, it tries to approximately learns the identity function
F, which is defined as:
where
W and
B are the whole network weights and biases vectors.
A log sigmoid function is selected as the activation function
f in the hidden and output neurons. The log sigmoid function
s is a special case of the logistic function in the
t space, which is defined by the following formula:
The weights of the ANN network create the decision boundaries in the feature space, and the resulting discriminating surfaces can classify complex boundaries. During the training process, these weights are adapted for each new training image. In general, feeding the ANN model with more samples can recognize the online applications more accurately. We used the back-propagation algorithm, which has a linear time computational complexity, for training the ANN model.
The input value
going into a node
i in the network is calculated by the weighted sum of outputs from all nodes connected to it, as follows:
where
is the weight on the connections between neuron
j to
i;
is the output value of neuron
j;
is a threshold value for neuron
i, which represents a baseline input to neuron
i in the absence of any other inputs. If the value of
is negative, it is tagged as inhibitory value and excluded because it decreases net input.
The training algorithm involves two phases: forward and backward phases. During the forward phase, the network’s weights are kept fixed, and the input data is propagated through the network layer by layer. The forward phase is concluded when the error signal
computations converge as follows:
where
and
are the desired (target) and actual outputs of
ith training image, respectively.
In the backward phase, the error signal is propagated through the network in the backward direction. During this phase, error adjustments are applied to the ANN network’s weights for minimizing .
We used the gradient descent first-order iterative optimization algorithm to calculate the change of each neuron weight
, which is defined as follows:
where
is the intermediate output of the previous neuron
n,
is the learning rate, and
is the error signal in the entire output.
is calculated as follows:
As shown in
Figure 3, the ANN model generated more than 81 k parameters during the training phase. The Adam optimization algorithm is used to update the network weights iteratively based on training data. We used the categorical cross-entropy as a loss function,
, which is defined as follows:
3.3.2. RF Structure
RF is a supervised learning algorithm that constructs multiple decision trees. To get an accurate and stable prediction, the final model’s prediction is derived by voting on the class prediction of the individual trees in the forest. Each branch of the tree represents a possible decision, occurrence, or reaction. FR model can be used for both classification and regression problems with a high classification rate.
We built an RF model with a maximum tree depth of 60 and 8 node splits. For an ensembles construct
f that has a collection of ensemble classifiers
, …,
, the ensemble predictor
f for a class
x is calculated as follows:
where
is the most frequently predicted class determined by voting between the outputs of
, …,
and
I is the indicator function that measures the extent to which the average number of votes for the right class exceeds the average vote for any other class. An immense margin value gives more confidence in the classification results.
We used an entropy-based splitting criterion that controls how each tree node splits the data. This has a significant effect on how each decision tree in the forest draws its boundaries.
3.3.3. KNN Structure
We built a KNN model with a
K value of 7, which gave us a slightly better classification accuracy. We validated the KNN model using the cross-validation strategy that assesses how our model’s prediction results will generalize to an independent dataset. To recognize an individual class using KNN, we select the
K nearest classes to the feature vector by comparing their Euclidean distances. We used the following similarity equation between the two comparable feature vectors (
,
):
where
is the Euclidean distance between
and
, and
d is calculated as:
where
and
are the Euclidean feature vectors, and
n is the n-space dimension of
and
.
4. Implementation
This section presents the implementation details of NetScrapper, including the implementation details of the ML models and the web-based graphical user interface.
4.1. ML Models
Both the RF and ANN models are implemented using Keras development environment [
16]. Keras is an open-source neural network library written in Python, which uses TensorFlow [
17] as a back-end engine. Keras libraries running on top of TensorFlow make it relatively easy for developers to build and test deep learning models written in Python. The KNN model is implemented using Python programming language.
We set the batch size and number of epochs to be 150 k packet flows and 10 epochs, respectively. The model training was carried out using a server computer equipped with a 4.50 GHz Intel Core™ i7-16MB CPU processor, 16 GB of RAM, and CUDA GPU capability. The training phase took approximately 2 days to run 10 epochs. We took a snapshot of the trained weights every 2 epochs to monitor the progress.
The training error and loss of the ML models are calculated as follows:
where
M is the mean square error of the model,
y is the value calculated by the model, and
x is the actual value.
M represents the error in class detection.
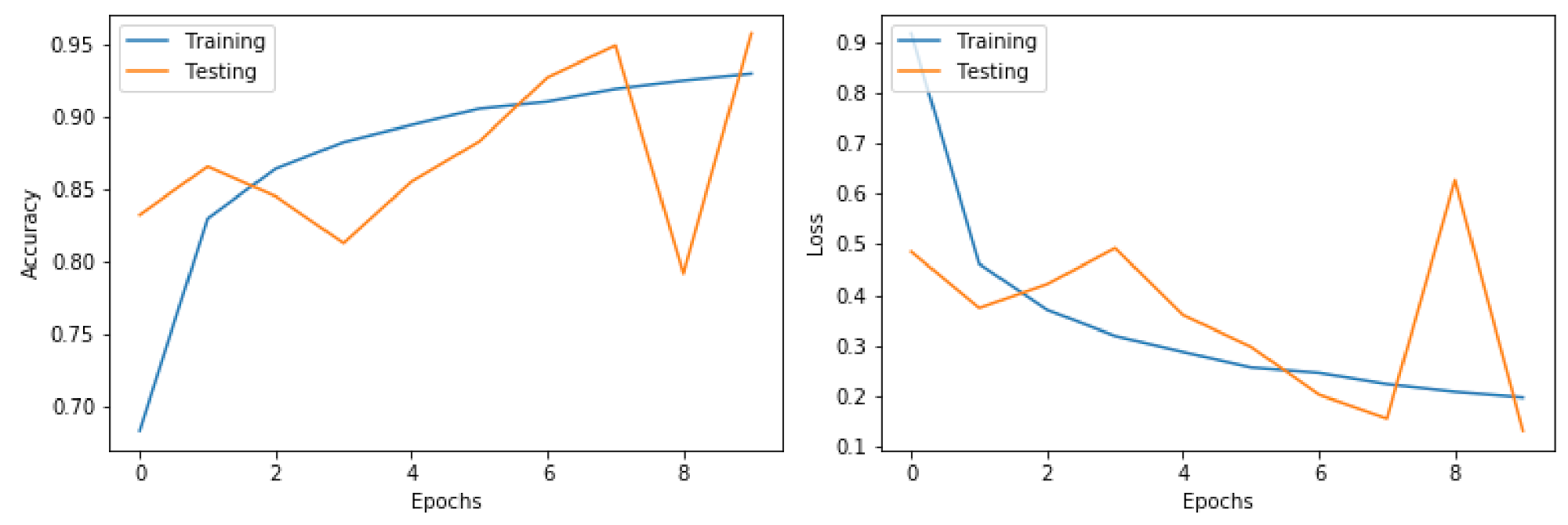
Figure 4 illustrates the calculated training error and loss of the ANN model graphically. As shown in the figure, the mean squared error loss decreases over the ten training epochs, while the accuracy increases consistently. We can see that our ANN model converged after the 8th epoch, which means that our dataset and the fine-tuned parameters were a good fit for the model.
4.2. User Interface
The user interface is developed as a responsive, mobile-first, and user-friendly web application to enhance user experience using the system. We built the web application using Python Flask Framework, HTML5, CSS3, JavaScript, and JSON. All web pages are designed to be device-agnostic that can accommodate visitors using mobile devices, desktops, or televisions to visit the web site.
To run the web application on top of the RF and ANN models, we had to wrap both models, implemented on Keras, as a Representational State Transfer (REST) API using the Flask web framework. REST is a software architectural style used to provide interoperability between heterogeneous computer systems connected via the internet. All communication between Keras and Flask is coordinated through that REST API. When the user captures fresh traffic flow, Flask uses the
POST method to send the traffic data from the user browser to Keras via an HTTP header. The Flask service can be accessed by the IP address and port number of the web server without an extension as follows:
http://127.0.0.1:5000, accessed on 9 July 2021.
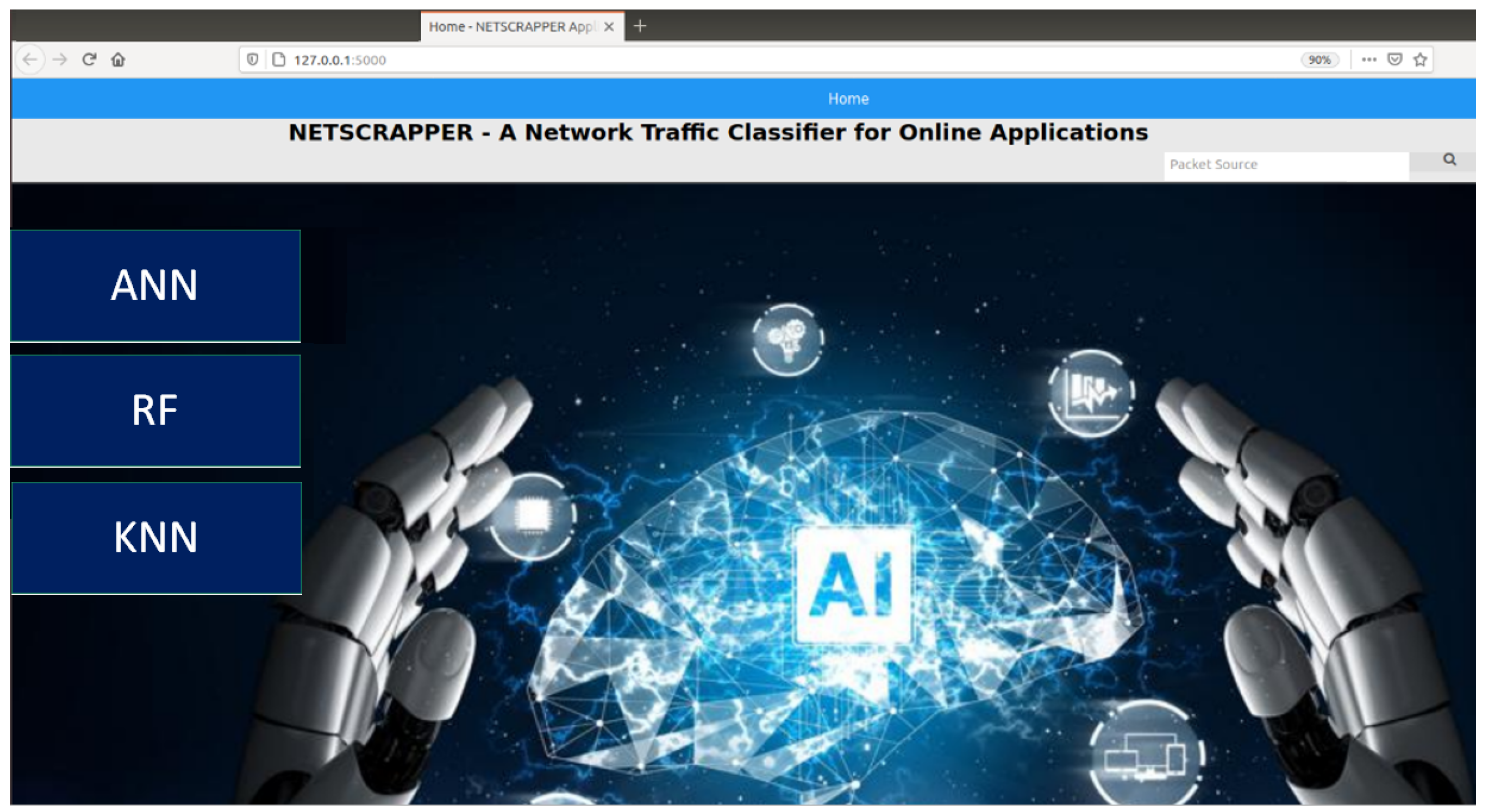
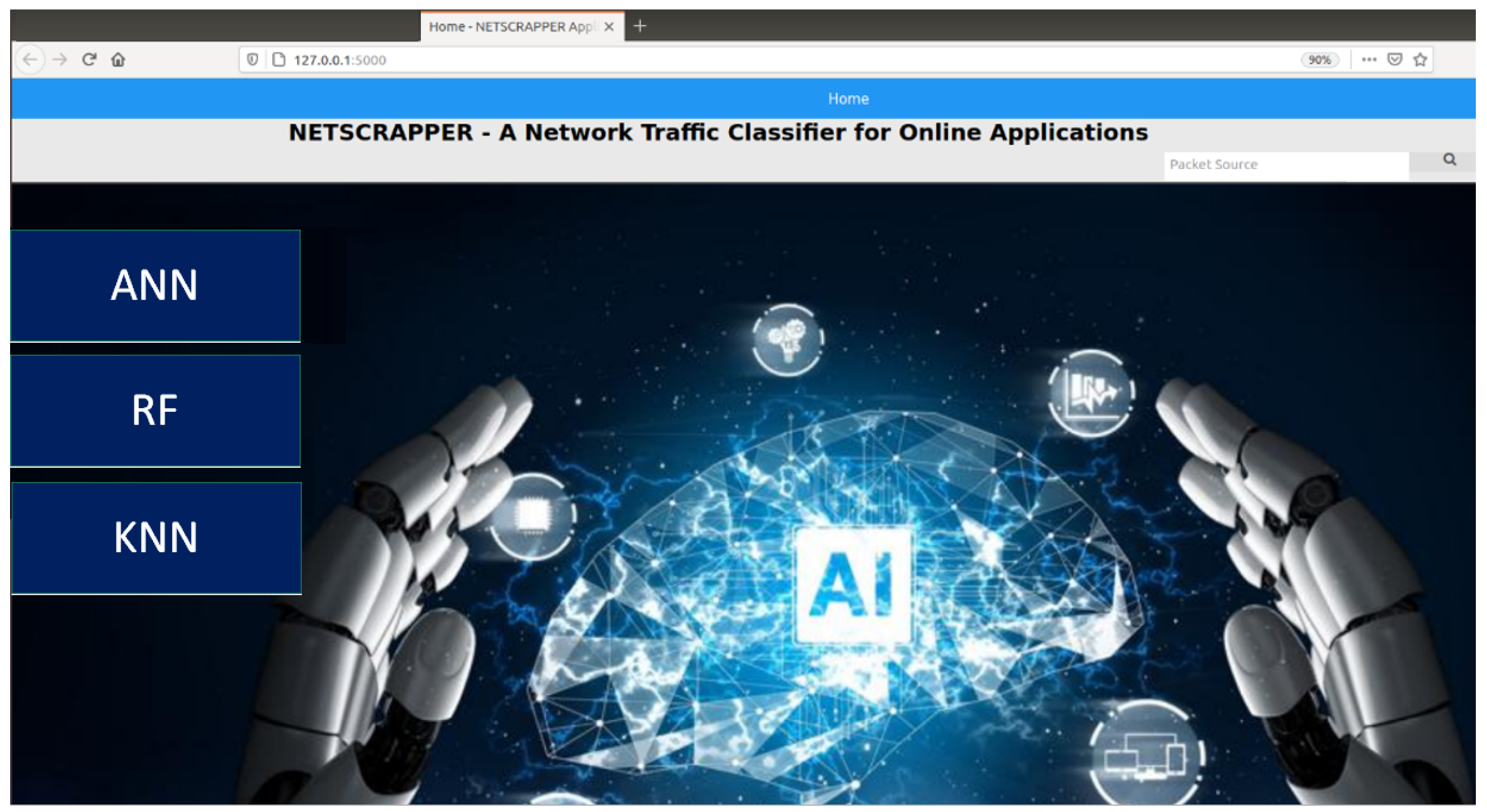
Figure 5 shows a snapshot of the homepage of the web application, which is divided into three modules: ANN, RF, and KNN. Each module allows users to upload a saved snapshot of the traffic flows or capture fresh traffic steam directly from NIC.
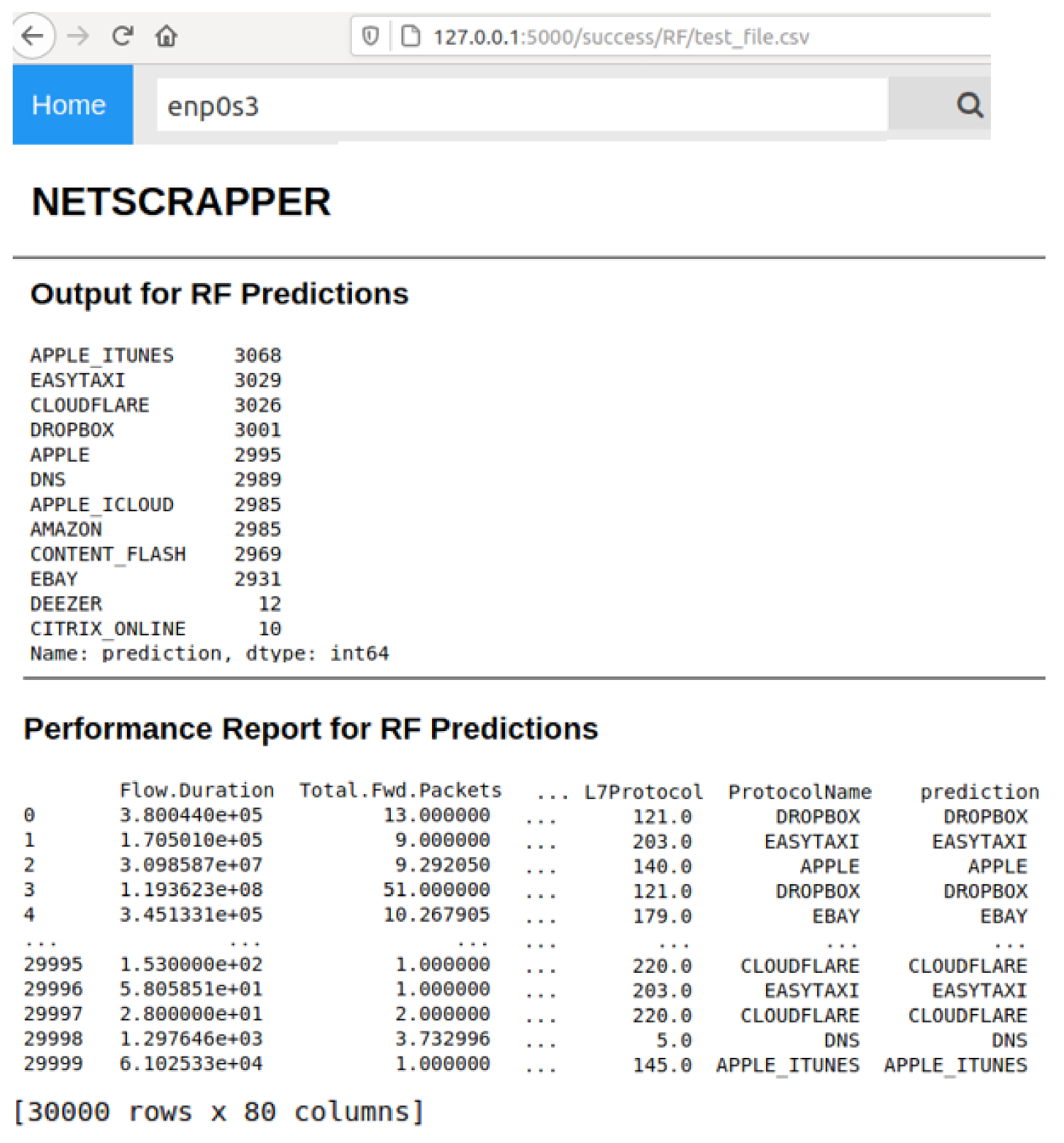
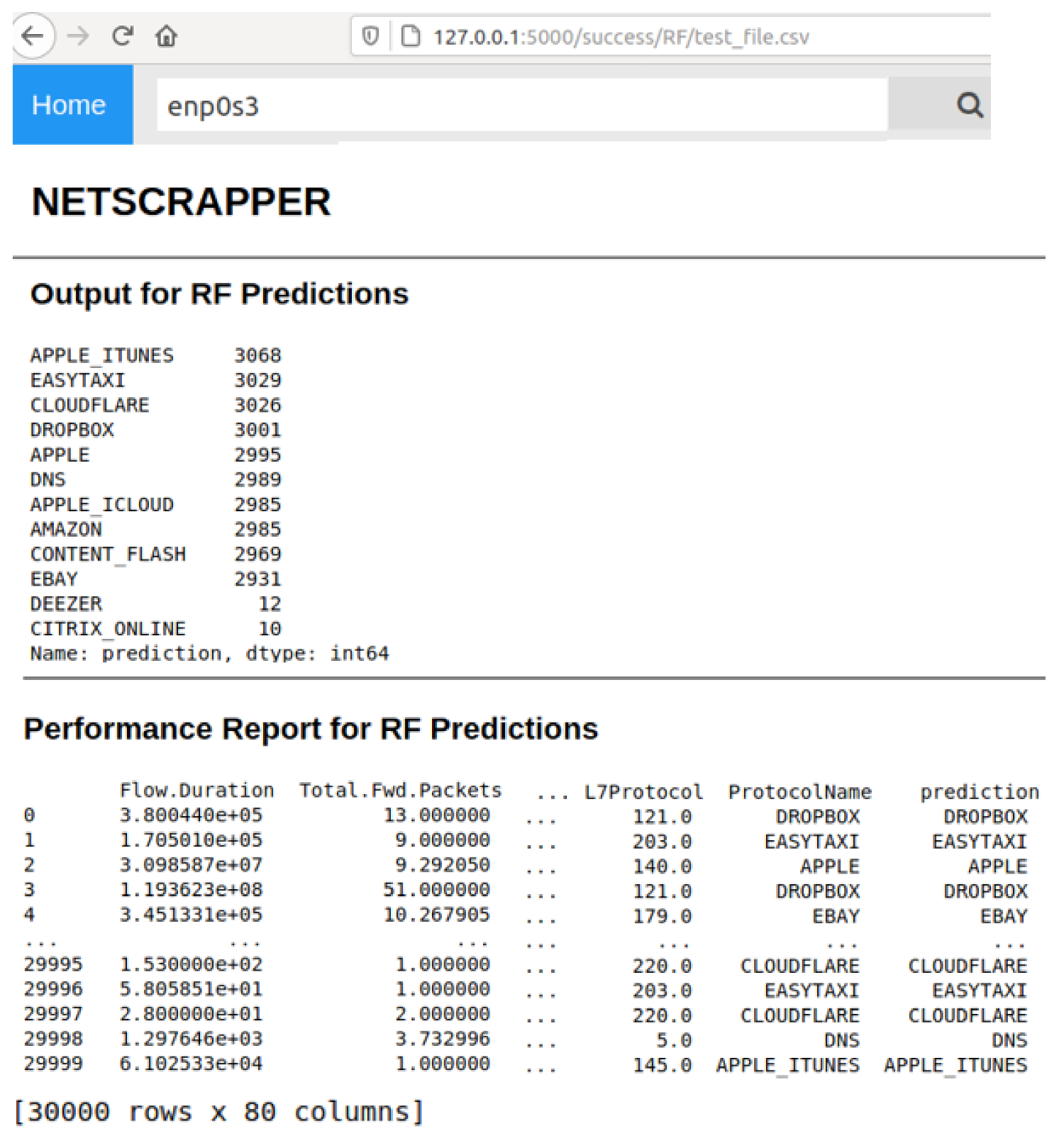
Figure 6 shows a snapshot of the inference result of the RF model on the web-based GUI. As illustrated in the figure, the web interface displays the flow predictions for all the testing datasets (30 k flow packets × 78 feature attributes), along with the confidence score and prediction time. The additional two columns:
ProtocolName and
Prediction represent the actual and predicated class names, respectively.
Figure 7 shows a snapshot of the packet sniffing result on the web-based GUI. As shown in the figure, the packet sniffing module can capture and display live network traffic directly from the NIC’s ethernet network peripheral (
enp0s3). This raw data is then processed using the CICFlowMeter to extract the required feature vector for the classification phase via the ML pipeline.
5. Experimental Evaluation
We experimentally evaluated our prototype implementation regarding classification accuracy and performance. We installed instrumentation in the web application running on the server to measure the processor time taken to perform various tasks, including packet capturing, traffic flow preprocessing, and prediction processes. Each experiment presented in this section is carried out for ten trials, then we took the average of these trials’ results.
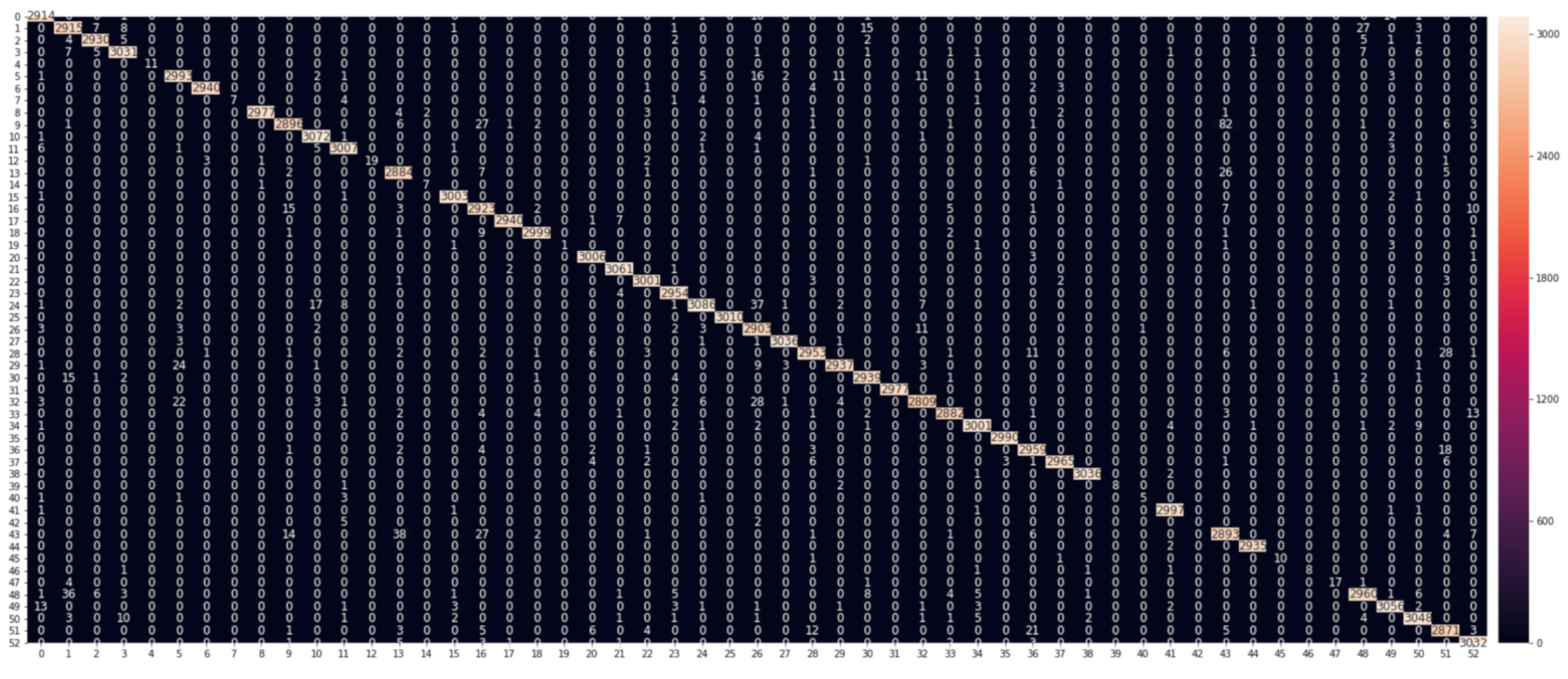
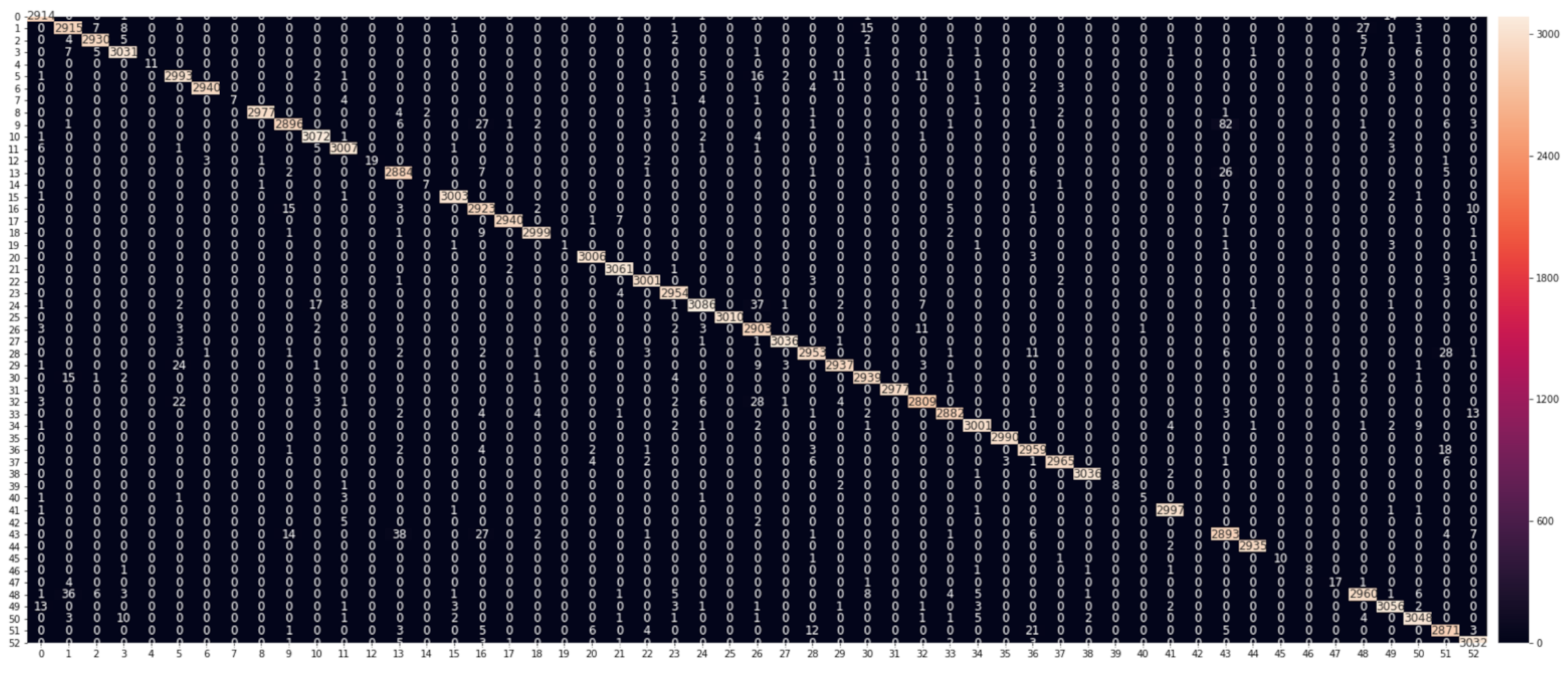
Figure 8 shows the RF model’s confusion matrix, with a heat map for clarity. The matrix gives a detailed analysis of how the model performance changes for different online application classes. The matrix rows represent the actual (true) application classes, and the columns correspond to the predicted application classes. The diagonal cells show the proportion of the correct predictions of our RF model, whereas the off-diagonal cells illustrate the error rate of our model.
The confusion matrix demonstrates that our model, in most cases, can differentiate between the application classes and achieve high levels of prediction accuracy. For the three most common types of online applications, Google, Youtube, and Amazon, the model achieves classification accuracies above 95%, 96%, and 98%, respectively.
We noticed that the application classes in the video streaming category (e.g., Youtube, Netflix, and Twitch) appear easier to identify than the e-commerce (e.g., Amazon and eBay) and social media (e.g., Facebook and Twitter) categories. This seems to make sense as video streaming applications usually use the Secure Reliable Transport (SRT) protocol [
18], which is normally carried on UDP connections with low latency and minimal buffering. The SRT protocol relies on establishing a logical channel of communication in which messages flow between the broadcasting server and client, called message stream. Message stream attributes appear more straightforward to identify than those generated by the encrypted communication carried out by e-commerce and social media applications.
As shown in the confusion matrix, our FR model, in some cases, confuses the online applications within the same category (e.g., social media) as they share some common networking attributes such as header and flow descriptors. Note that our ML models can still identify emailing applications (e.g., Gmail and Yahoo) quite well because of their discriminative characteristics compared to the other classes in our dataset. Most notably, although SSL and SSL are considered non-linearly separable classes because of their similar security attributes, our ML models could separate them effectively.
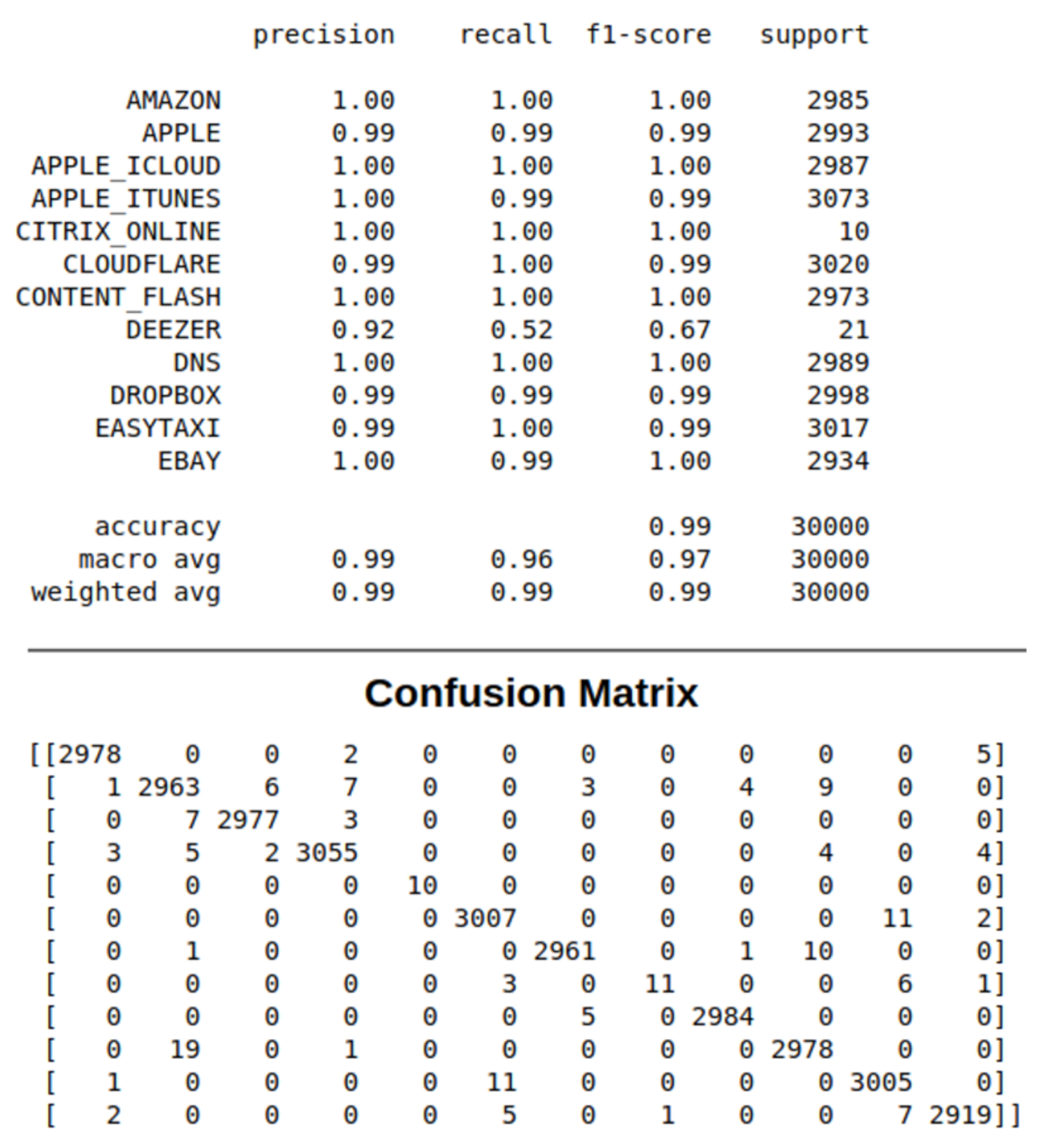
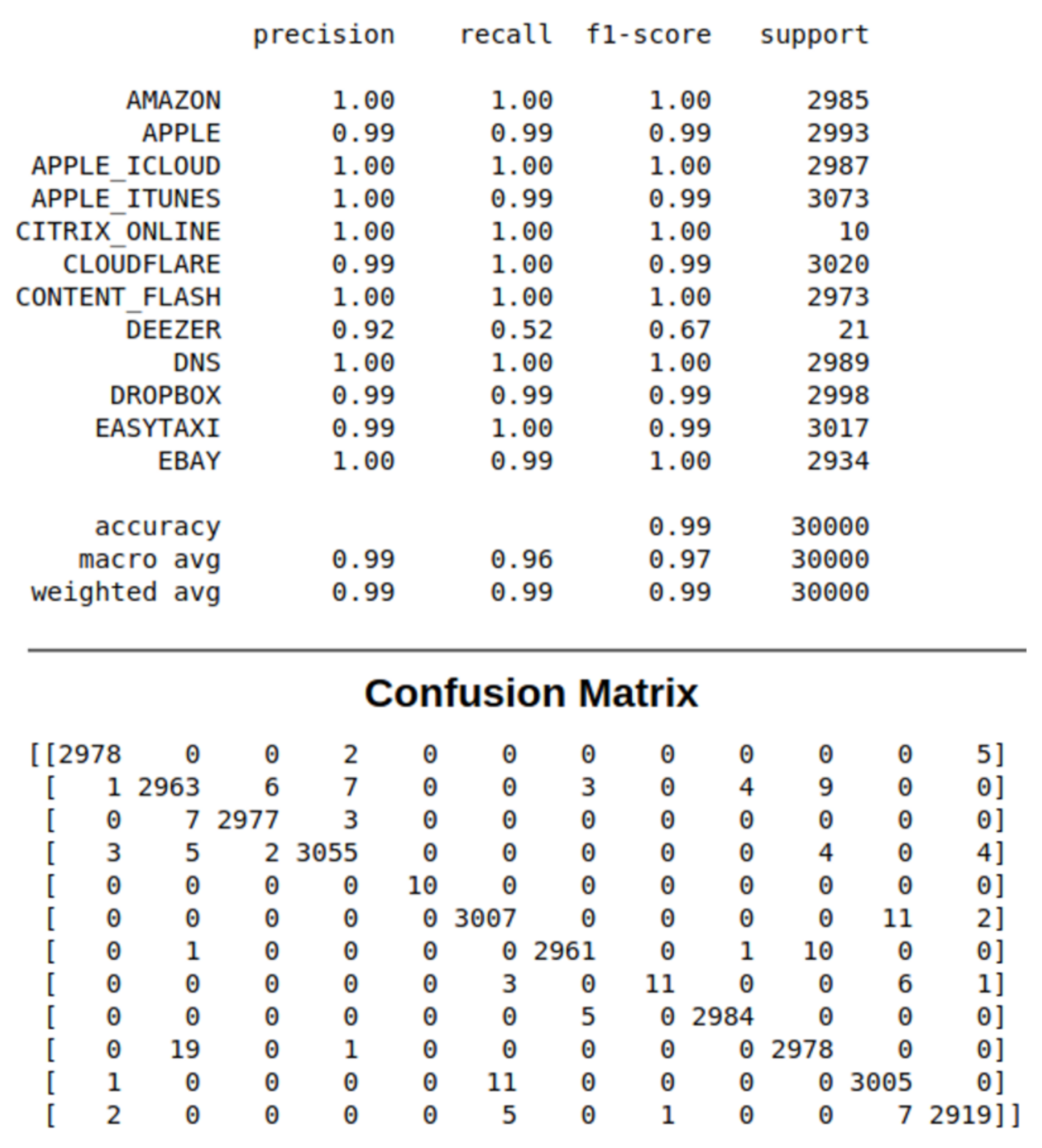
The precision, recall, and F1-score ratios, shown in
Table 3, summarize the trade-off between the true-positive rate and the positive predictive value for our RF model using different probability thresholds. Precision represents the positive predictive value of our model, while recall is a measure of how many true positives are identified correctly, and F1-score takes into account the number of false positives and false negatives. The support metric represents the number of samples of the application class in the dataset. As shown in the table, most of the precision vs. recall values tilts towards 1.0, which means that our RF model achieves high accuracy while minimizing the number of false negatives.
The precision ratio describes the performance of our model at predicting the positive class. It is calculated by dividing the number of true positives by the sum of the true positives and false positives, as follows:
The recall ratio is calculated as the ratio of the number of true positives divided by the sum of the true positives and the false negatives, as follows:
F1-score ratio is calculated by a weighted average of both precision and recall, as follows:
We also observed that our model delivers good results even when flow packets are captures directly from NIC in real time.
Figure 9 shows a snapshot of the classification report of the RF model on the web-based GUI. The figure shows that traffic flows from 12 different online applications are captured and predicted using the RF model. Furthermore, our GUI shows the precision, recall, and F1-score ratios of these live streams.
Table 4 compares the KNN, RF, and ANN models in terms of classification accuracy and prediction time across the 53 classes. For instance, the ANN model achieved an overall average classification accuracy of 99.86%. The average prediction time of the model was measured to be 0.25 s. This is evident that administrators can detect any security vulnerability in their networks using a handy web-based GUI in a quarter of a second. Furthermore, we noted that the prediction accuracy of many classes (e.g., Netflix, Dropbox, and WhatsApp) was 100%. This shows that our model is robust and can operate in real-time inference in real-world network settings with high accuracy.
Compared to ANN and RF, KNN is considered a significantly slower model in the case of having a large dataset because it needs to scan all the training databases each time a prediction is required; thus, it cannot generalize over the dataset in advance. That is why we believe that the KNN model is not adequate to be used for real-time inference. In contrast, on average, the ANN model requires around 250 ms only to detect a security thread in a traffic flow. To put these numbers in some context, consider a firewall service installed in a gateway router; our ANN model can inspect around four applications’ flow streams per second, which would have a negligible latency overhead over the network stream.
6. Conclusions and Future Work
This paper presented the design and implementation of NetScrapper, an AI-enabled network classifier for real-time flow streams. The developed prototype showed that NetScrapper could be deployed on networking devices at the edge with high prediction accuracy and low response time. It is expected that NetScrapper would make a better opportunity for network administrators to monitor their network performance and detect any suspicious traffic that could harm the network components and legitimate users. Unlike most of the existing ML-based classifiers, NetScrapper can automatically extract the feature attributes of the online traffic flow without human intervention, which undoubtedly makes it a highly desirable traffic classification approach, especially for mobile services encrypted traffic.
The system implementation compared three ML models, namely ANN, RF, and KNN, in terms of classification accuracy and performance. To increase the system usability, we developed a user-friendly interface on top of these models to allow users to interact with the system conveniently. We carried out several sets of experiments for evaluating the performance and classification accuracy of our system, paying particular attention to the prediction time. Our ANN model could most notably inspect four applications’ flow streams per second, which proves that NetScrapper is suitable for real-time inference at the edge with offline generated ML models.
We expect that this research would increase the open-source knowledge base in the area of traffic analysis and machine learning on the network edge by publishing the source code and dataset to the public domain. Both the source code and dataset are available online:
https://github.com/ahmed-pvamu/NetScrapper (accessed on 9 July 2021).
In on-going work, we are looking into opportunities for generalizing our approach to be deployed locally at all types of network devices at the edge, where administrators can use to monitor their network from any point in the network topology. This would give them a richer picture of their network performance and reduce the time associated with detecting security threats and intrusions.
We also plan to train a multi-level classification algorithm to enable NetScrapper to identify traffic flows from unknown application sources. If an unknown packet is detected, the system will automatically add it to our training database of unknown classes. This technique would also use an unsupervised clustering algorithm to label the unknown packets as discrete classes. We are also working on using the Actor model of concurrency [
19], leveraging multi-threaded computation for massive live traffic streams. It will be useful for supporting the sensing needs of a wide range of researches [
20,
21,
22,
23,
24,
25,
26,
27,
28,
29,
30] and applications [
31,
32,
33,
34,
35,
36,
37,
38,
39,
40]. Finally, experiments with more massive datasets are needed to study the robustness of our system at a large scale, and improve the prediction accuracy of the less performing application classes.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}