
A Similarity Measurement with Entropy-Based Weighting for Clustering Mixed Numerical and Categorical Datasets


Abstract
:1. Introduction
2. Methods
2.1. Problem Formulation
2.2. Similarity Measurement for Categorical Attributes
- ;
- only if none of the attribute ’s values of the objects belonging to cluster are equal to ;
- only if all of the Non NULL attribute ’s values of the objects belonging to cluster are equal to .
2.3. Similarity Measurement for Numerical Attributes
| Algorithm 1 Automatic categorization for numerical attributes. |
| Input:: the lth numerical attribute in the dataset X; : a clustering function that partitions into q clusters and returns the corresponding assignments; : maxmum number of categories to examine; Output: : the categorical values of ;
|
2.4. Similarity Measurement for Mixed Data
2.5. Iterative Clustering Algorithm
| Algorithm 2 Iterative clustering algorithm with entropy-based weighting. |
| Input: (dataset to cluster with categorical attributes and numerical attributes); k (number of clusters); (a clustering function that partitions into q clusters and returns the corresponding assignments); (maximum number of categories to examine); Output: (an assignment of each point in X to one of k clusters);
|
3. Results and Discussion
3.1. Experiments on Mixed Datasets
3.2. Experiments on Numerical Datasets
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Jiawei, H.; Micheline, K. Data Mining: Concepts and Techniques. Data Min. Concepts Model. Methods Algorithms Second Ed. 2006, 5, 1–18. [Google Scholar]
- Rodoshi, R.T.; Kim, T.; Choi, W. Resource Management in Cloud Radio Access Network: Conventional and New Approaches. Sensors 2020, 20, 2708. [Google Scholar] [CrossRef]
- Khorraminezhad, L.; Leclercq, M.; Droit, A.; Bilodeau, J.F.; Rudkowska, I. Statistical and Machine-Learning Analyses in Nutritional Genomics Studies. Nutrients 2020, 12, 3140. [Google Scholar] [CrossRef] [PubMed]
- Macqueen, J. Some Methods for Classification and Analysis of Multivariate Observations. Berkeley Symp. Math. Stat. Probab. 1967, 1, 281–297. [Google Scholar]
- Ahmad, A.; Hashmi, S. K-Harmonic means type clustering algorithm for mixed datasets. Appl. Soft Comput. 2016, 48, 39–49. [Google Scholar] [CrossRef]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data via the EM Algorithm. J. R. Stat. Soc. 1977, 39, 1–38. [Google Scholar]
- Cao, F.; Liang, J.; Li, D.; Bai, L.; Dang, C. A dissimilarity measure for the k-Modes clustering algorithm. Knowl. Based Syst. 2012, 26, 120–127. [Google Scholar] [CrossRef]
- Guha, S.; Rastogi, R.; Shim, K. ROCK: A robust clustering algorithm for categorical attributes. Inf. Syst. 1999, 25, 345–366. [Google Scholar] [CrossRef]
- Huang, Z. Clustering large data sets with mixed numeric and categorical values. In Proceedings of the 1st Pacific-Asia Conference on Knowledge Discovery and Data Mining, Singapore, 23–24 February 1997; pp. 21–34. [Google Scholar]
- Ahmad, A.; Khan, S. Survey of State-of-the-Art Mixed Data Clustering Algorithms. IEEE Access 2019, 7, 31883–31902. [Google Scholar] [CrossRef]
- Huang, Z. Extensions to the k-means Algorithm for Clustering Large Data Sets with Categorical Values. Data Min. Knowl. Discov. 1998, 2, 283–304. [Google Scholar] [CrossRef]
- Cheung, Y.M.; Jia, H. Categorical-and-numerical-attribute data clustering based on a unified similarity metric without knowing cluster number. Pattern Recognit. 2013, 45, 2228–2238. [Google Scholar] [CrossRef]
- David, G.; Averbuch, A. SpectralCAT: Categorical spectral clustering of numerical and nominal data. Pattern Recognit. 2012, 45, 416–433. [Google Scholar] [CrossRef]
- Ng, A.; Jordan, M.; Weiss, Y. On spectral clustering: Analysis and an algorithm. Adv. Neural Inf. Process. Syst. 2001, 14, 849–856. [Google Scholar]
- Hsu, C.C. Generalizing self-organizing map for categorical data. IEEE Trans. Neural Netw. 2006, 17, 294–304. [Google Scholar] [CrossRef]
- Liang, J.; Chin, K.S.; Dang, C.; Yam, R.C. A new method for measuring uncertainty and fuzziness in rough set theory. Int. J. Gen. Syst. 2002, 31, 331–342. [Google Scholar] [CrossRef]
- Ng, M.K.; Li, M.J.; Huang, J.Z.; He, Z. On the impact of dissimilarity measure in k-modes clustering algorithm. IEEE Trans. Pattern Anal. Mach. Intell. 2007, 29, 503. [Google Scholar] [CrossRef]
- Chen, L.F.; Guo, G.D. Non-mode clustering of categorical data with attributes weighting. J. Softw. 2013, 14, 2628–2641. [Google Scholar] [CrossRef]
- Bai, L.; Liang, J.; Dang, C.; Cao, F. A novel attribute weighting algorithm for clustering high-dimensional categorical data. Pattern Recognit. 2011, 44, 2843–2861. [Google Scholar] [CrossRef]
- Ahmad, A.; Dey, L. A k-mean clustering algorithm for mixed numeric and categorical data. Data Knowl. Eng. 2007, 63, 503–527. [Google Scholar] [CrossRef]
- Basak, J.; Krishnapuram, R. Interpretable Hierarchical Clustering by Constructing an Unsupervised Decision Tree. IEEE Trans. Knowl. Data Eng. 2005, 17, 121–132. [Google Scholar] [CrossRef]
- Dougherty, J.; Kohavi, R.; Sahami, M. Supervised and Unsupervised Discretization of Continuous Features. Mach. Learn. Proc. 1995, 2, 194–202. [Google Scholar]
- Grzymala-Busse, J.W. Data reduction: Discretization of numerical attributes. Handbook of Data Mining and Knowledge Discovery; Oxford University Press, Inc.: Oxford, UK, 2002; pp. 218–225. [Google Scholar]
- Jung, Y.; Park, H.; Du, D.Z.; Drake, B.L. A Decision Criterion for the Optimal Number of Clusters in Hierarchical Clustering. J. Glob. Optim. 2003, 25, 91–111. [Google Scholar] [CrossRef]
- Bayati, H.; Davoudi, H.; Fatemizadeh, E. A heuristic method for finding the optimal number of clusters with application in medical data. Conf. Proc. IEEE Eng. Med. Biol. Soc. 2008, 2008, 4684–4687. [Google Scholar]
- UCI Machine Learning Repository. Available online: http://archive.ics.uci.edu/ml (accessed on 15 June 2021).
- Zhu, L.; Miao, L.; Zhang, D. Iterative Laplacian Score for Feature Selection. In Chinese Conference on Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 80–87. [Google Scholar]
- Kononenko, I. Estimating attributes: Analysis and extensions of RELIEF. In European Conference on Machine Learning; Springer: Berlin/Heidelberg, Germany, 1994; pp. 171–182. [Google Scholar]
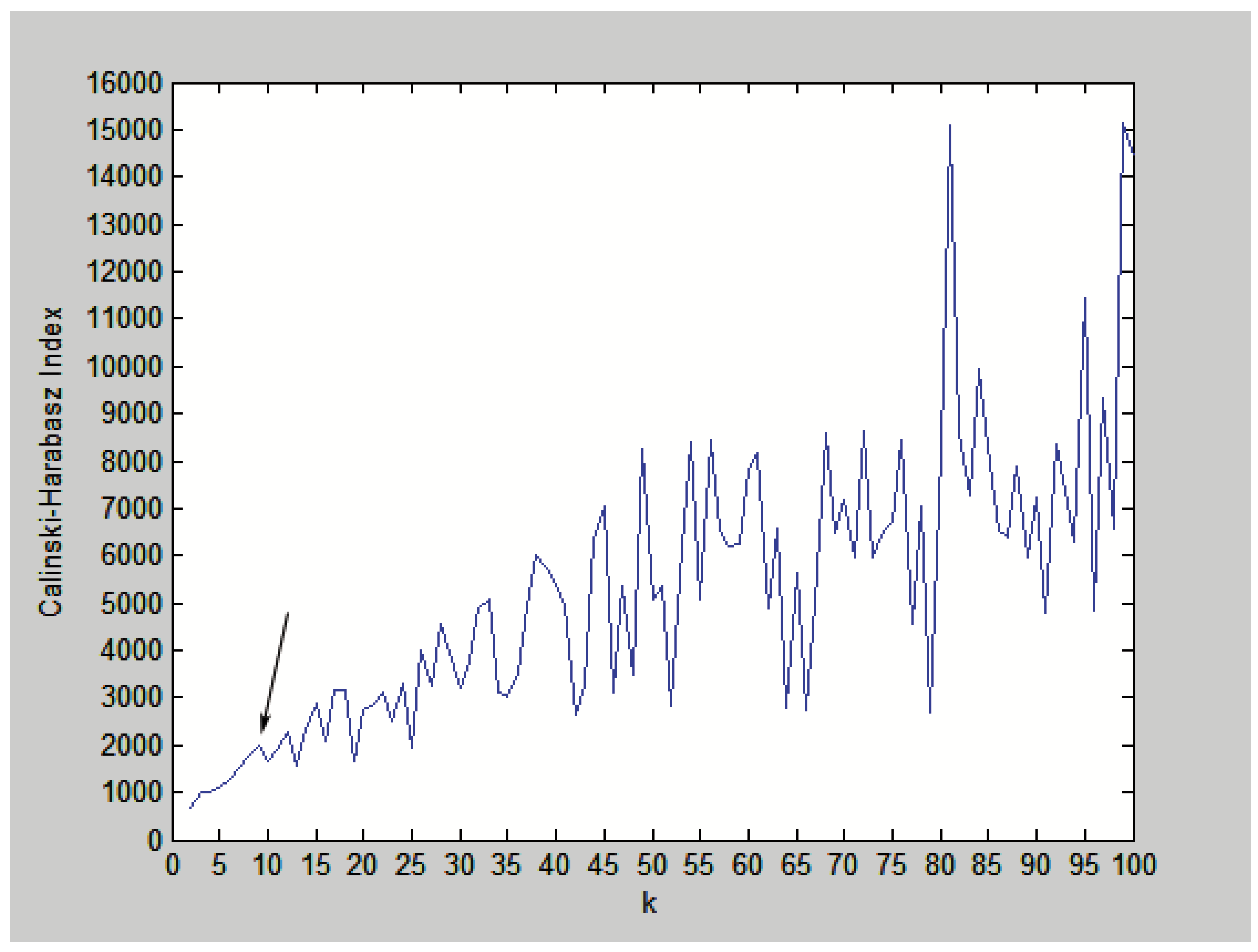

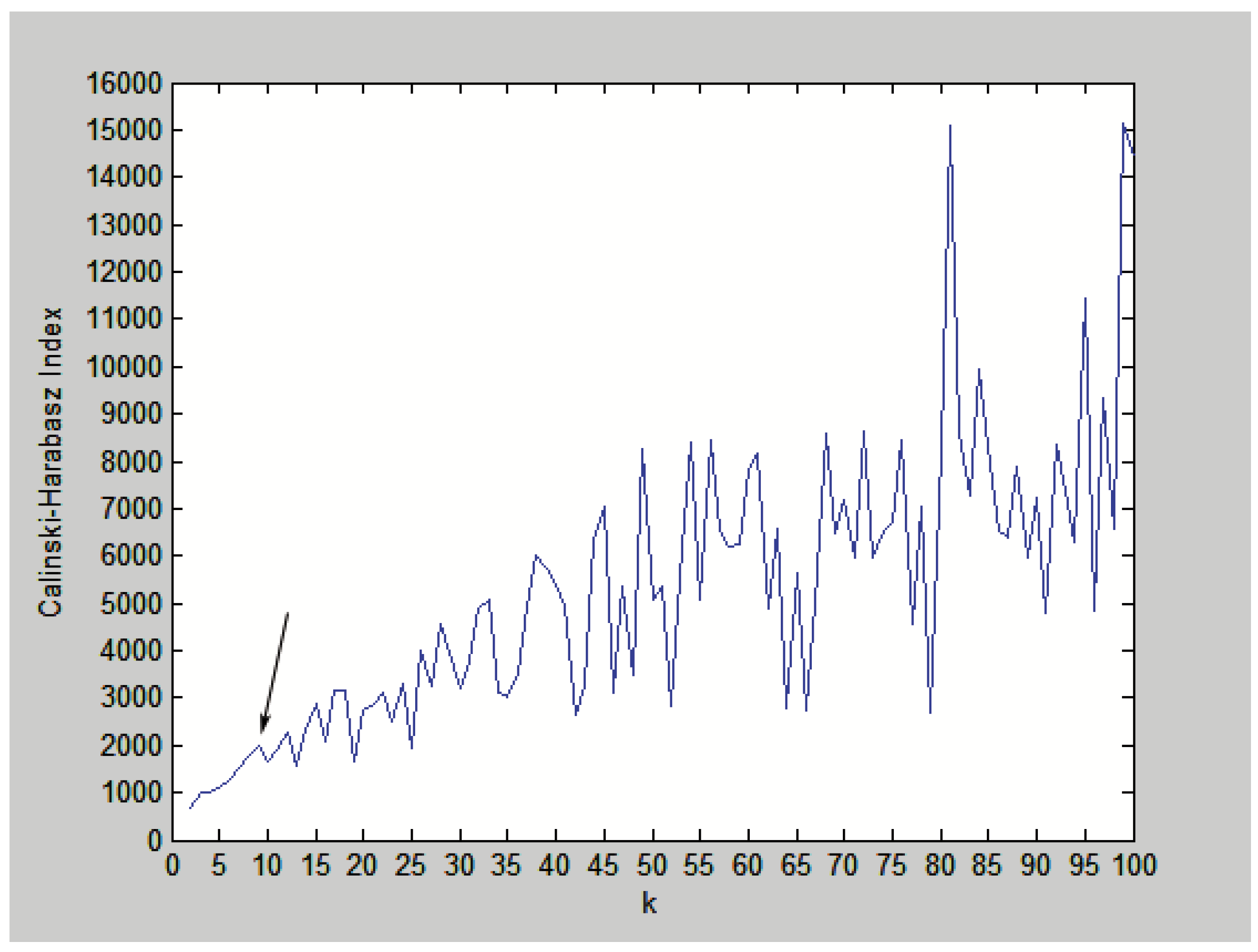{kind=link}
| Dataset | Instance | Attribute () | Class | Class Distribution |
|---|---|---|---|---|
| Statlog(Heart) | 270 | 7 + 6 | 2 | 55.56%, 44.44% |
| Hepatitis | 155 | 13 + 6 | 2 | 20.65%, 79.35% |
| Cylinder Bands | 540 | 19 + 20 | 2 | 42.33%, 57.67% |
| Australian | 690 | 8 + 6 | 2 | 55.51%, 44.49% |
| Dermatology | 366 | 33 + 1 | 6 | 30.60%, 16.67%, 19.67%, 13.39%, 14.21%, 5.46% |
| Zoo | 101 | 16 + 1 | 7 | 40.59%, 19.80%, 4.95%, 12.87%, 3.96%, 7.92%, 9.90% |
| Dataset | OCIL | K-Prototype | The Proposed Algorithm |
|---|---|---|---|
| Statlog (Heart) | |||
| Hepatitis | |||
| Cylinder Bands | |||
| Australian | |||
| Dermatology | |||
| Zoo |
| Dataset | Correlation Coefficient for Categorical Attributes | Correlation Coefficient for Numerical Attributes |
|---|---|---|
| Statlog (Heart) | −0.2602 | 0.3885 |
| Hepatitis | −0.0151 | 0.7953 |
| Cylinder Bands | 0.3648 | 0.3955 |
| Australian | 0.9314 | 0.7281 |
| Dermatology | 0.7822 | ∖ |
| Zoo | −0.2878 | ∖ |
| Dataset | Instance | Attribute | Class | Class Distribution |
|---|---|---|---|---|
| Waveform | 5000 | 40 | 3 | 33.84%, 33.06%, 33.10% |
| Wine | 178 | 13 | 3 | 33.15%, 39.89%, 26.97% |
| Mass | 961 | 5 | 2 | 53.69%, 46.31% |
| Seeds | 210 | 7 | 3 | 33.33%, 33.33%, 33.33% |
| Iris | 150 | 4 | 3 | 33.33%, 33.33%, 33.33% |
| Fertility | 100 | 9 | 2 | 88.00%, 12.00% |
| Dataset | k-Means | The Proposed Algorithm |
|---|---|---|
| Waveform | ||
| Wine | ||
| Mass | ||
| Seeds | ||
| Iris | ||
| Fertility |
| Dataset | Correlation Coefficient |
|---|---|
| Waveform | 0.1200 |
| Wine | −0.1458 |
| Mass | 0.9245 |
| Seeds | 0.0944 |
| Iris | −0.6511 |
| Fertility | 0.5526 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Que, X.; Jiang, S.; Yang, J.; An, N. A Similarity Measurement with Entropy-Based Weighting for Clustering Mixed Numerical and Categorical Datasets. Algorithms 2021, 14, 184. https://doi.org/10.3390/a14060184
Que X, Jiang S, Yang J, An N. A Similarity Measurement with Entropy-Based Weighting for Clustering Mixed Numerical and Categorical Datasets. Algorithms. 2021; 14(6):184. https://doi.org/10.3390/a14060184
Chicago/Turabian StyleQue, Xia, Siyuan Jiang, Jiaoyun Yang, and Ning An. 2021. "A Similarity Measurement with Entropy-Based Weighting for Clustering Mixed Numerical and Categorical Datasets" Algorithms 14, no. 6: 184. https://doi.org/10.3390/a14060184
APA StyleQue, X., Jiang, S., Yang, J., & An, N. (2021). A Similarity Measurement with Entropy-Based Weighting for Clustering Mixed Numerical and Categorical Datasets. Algorithms, 14(6), 184. https://doi.org/10.3390/a14060184