
Approximately Optimal Control of Nonlinear Dynamic Stochastic Problems with Learning: The OPTCON Algorithm


Abstract
1. Introduction
2. Theoretical Background
2.1. Optimal Control Problem
- -
- is a vector of state variables that describes the state of the system at any point in time t,
- -
- is a vector of control variables; we assume that the decision maker determines the values of the control variables exactly (without randomization) according to the approximately optimal solution of the problem,
- -
- denotes a vector of non-controlled deterministic exogenous variables, whose values are known to the decision maker at time t,
- -
- T denotes the terminal time period of the finite planning horizon.
- -
- denotes a vector of stochastic variables of system parameters (parameter uncertainty),
- -
- is a vector of true parameters whose values are assumed to be constant but unknown to the policy maker,
- -
- is a vector of additive stochastic disturbances (system error).
- -
- are given target (‘ideal’) values (for ) of the state variables,
- -
- are given target (‘ideal’) values (for ) of the control variables,
- -
- is an symmetric matrix defining the relative weights of the state and control variables in the objective function. In a frequent special case, includes a discount factor with .
2.2. Linear-Quadratic Optimal Control (LQ) Framework
2.3. Solving Nonlinear Dynamic Systems
3. The OPTCON Algorithm
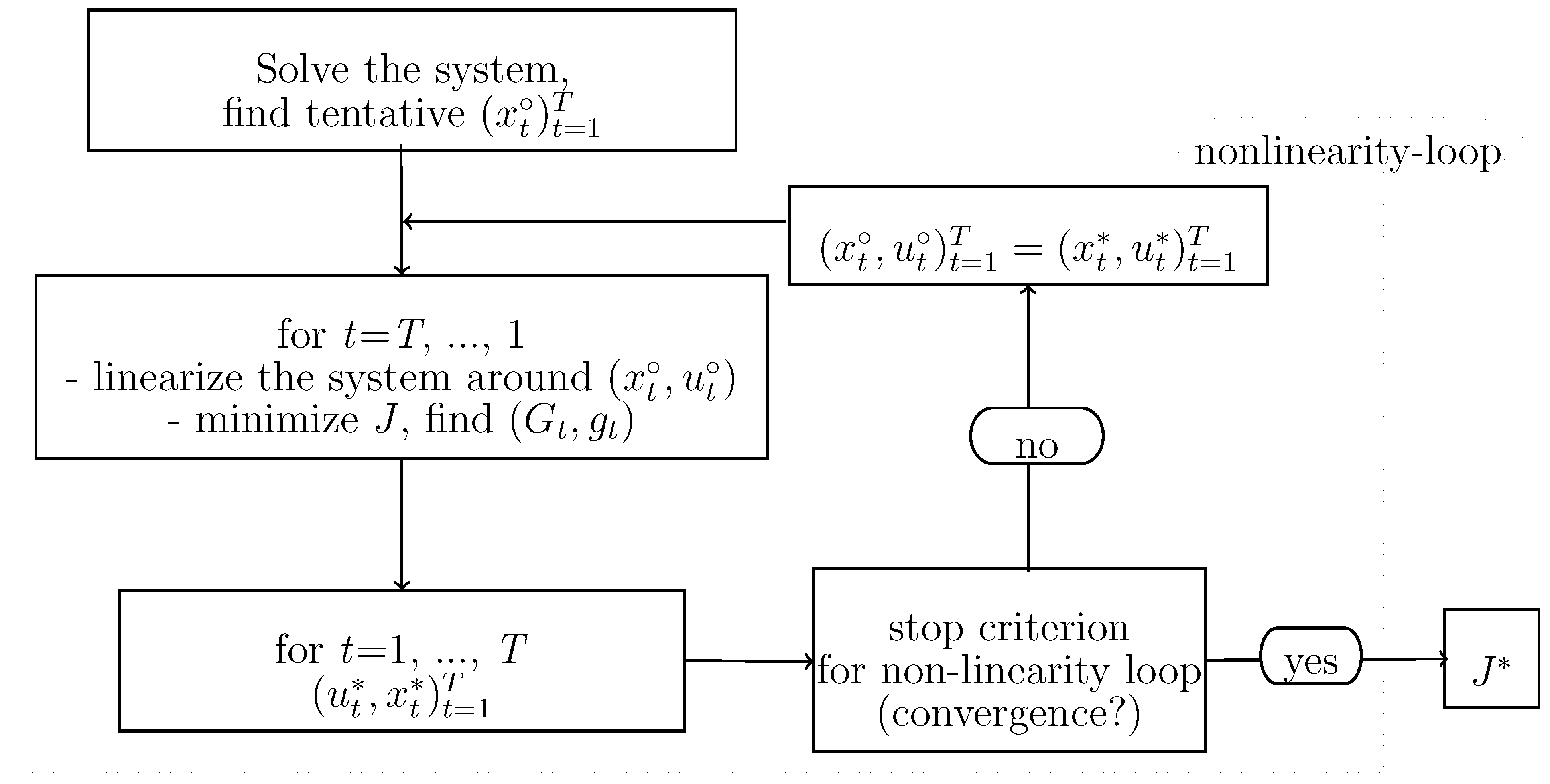
3.1. The OPTCON1 Algorithm
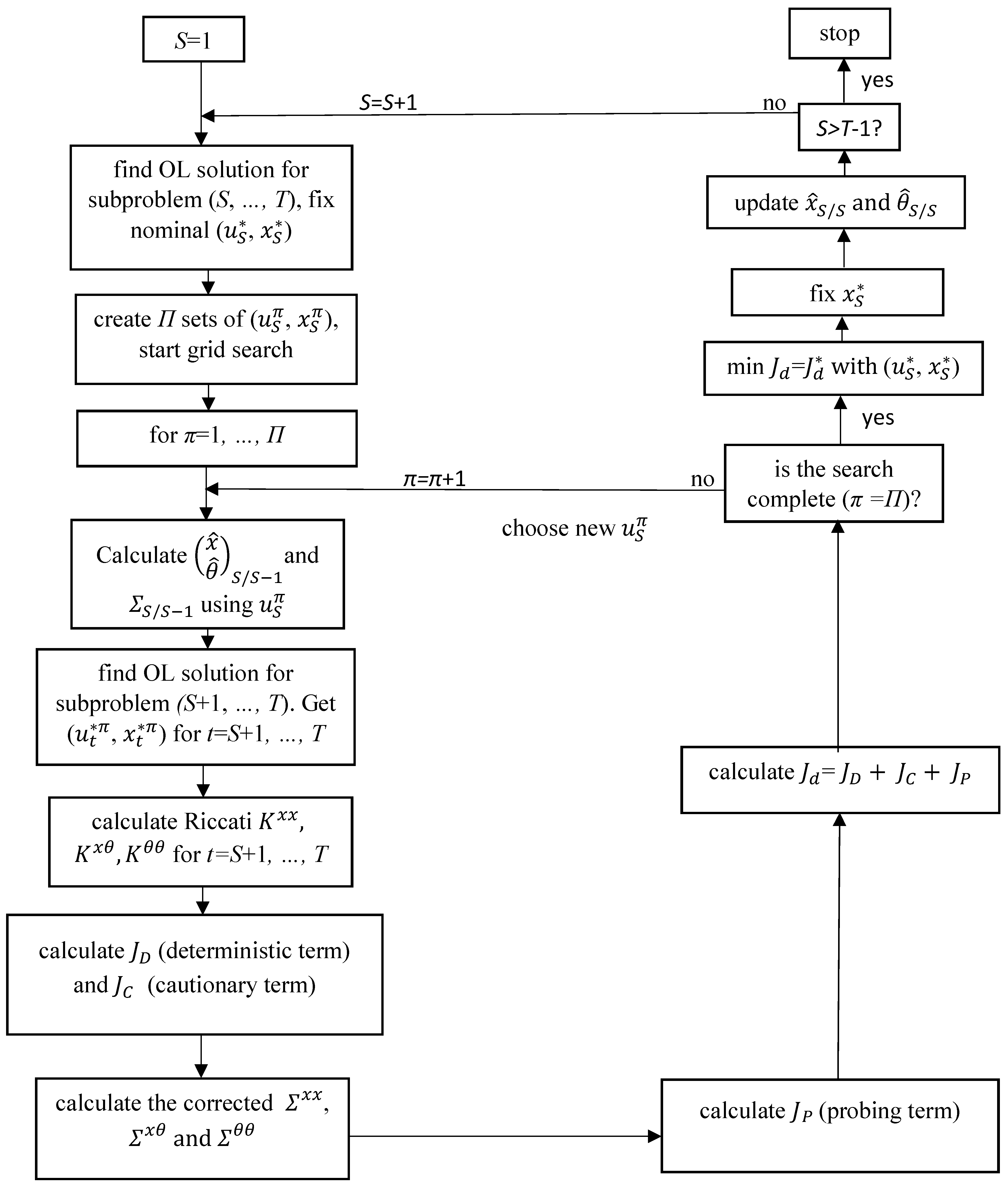
3.2. The OPTCON2 Algorithm
- Find an (approximately) optimal open-loop solution for the remaining subproblem (for the time periods from S to T) using the OPTCON1 algorithm.
- Fix the predicted solution for time period S, namely and .
- Observe the realized state variables which result from the chosen control variables (), the true law of motion with parameter vector , and the realization of the random disturbances . The main difference between and is that the former is driven by the true dynamic process with parameter vector and the latter by the estimated dynamic system with .
- Update the parameter estimate (via the Kalman filter and using the difference between and ) and use it in the next iteration step .
3.3. The OPTCON3 Algorithm
| f | system function |
| initial values of state variables | |
| tentative path of control variables | |
| expected values of system parameters | |
| covariance matrix of system parameters | |
| covariance matrix of system noise | |
| system noises | |
| path of exogenous variables | |
| target path for state variables | |
| target path for control variables | |
| , , | weighting matrices of objective function |
| , | weighting vectors of objective function |
| discount factor of objective function. |
- -
- After several runs of the nonlinearity loop, only the solution ( for the time period will be taken as the optimal (nominal) solution. The calculations of the pairs for other periods ( > ) have to be done again, taking into account the re-estimated parameters for all periods.
- -
- After linearization the parameter matrices for the linearized system are obtained: and , where , , and are the derivatives of the system function f with respect to , , and respectively.
- [a]:
- Calculate the components and :
- [b]:
- Calculate the matrix :with
- [c]:
- Compute the probing component :
- (a)
- (b)
3.4. Computational Details for the AL Procedure
3.5. Extension of the System
4. Computational Aspects
5. Concluding Remarks
Author Contributions
Funding
Conflicts of Interest
References
- Athans, M. The role and use of the stochastic linear-quadratic-Gaussian problem in control system design. IEEE Trans. Autom. Control 1971, 16, 529–552. [Google Scholar] [CrossRef]
- Bellman, R. Dynamic Programming; Princeton University Press: Princeton, NJ, USA, 1957. [Google Scholar]
- Bellman, R. Adaptive Control Processes: A Guided Tour; Princeton University Press: Princeton, NJ, USA, 1961. [Google Scholar]
- Fel’dbaum, A.A. Optimal Control Systems; New York Academic Press: New York, NY, USA, 1965. [Google Scholar]
- Aoki, M. Optimization of Stochastic Systems: Topics in Discrete-Time Systems; Academic Press: Cambridge, MA, USA, 1967; Volume 32. [Google Scholar]
- Bertsekas, D.P. Dynamic Programming and Optimal Control; Athena Scientific: Belmont, MA, USA, 2005; Volume 1, 2. [Google Scholar]
- Powell, W. Approximate Dynamic Programming: Solving the Curses of Dimensionality; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Si, J.; Barto, A.; Powell, W.; Wunsch, D. Handbook of Learning and Approximate Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2004; Volume 2. [Google Scholar]
- Matulka, J.; Neck, R. OPTCON: An Algorithm for the Optimal Control of Nonlinear Stochastic Models. Ann. Oper. Res. 1992, 37, 375–401. [Google Scholar] [CrossRef]
- Blueschke-Nikolaeva, V.; Blueschke, D.; Neck, R. Optimal Control of Nonlinear Dynamic Econometric Models: An Algorithm and an Application. Comput. Stat. Data Anal. 2012, 56, 3230–3240. [Google Scholar] [CrossRef]
- Kendrick, D.A.; Amman, H.M. A Classification System for Economic Stochastic Control Models. Comput. Econ. 2006, 27, 453–481. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Tse, E. Dual effect, certainty equivalence, and separation in stochastic control. IEEE Trans. Autom. Control 1974, 19, 494–500. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Tse, E. Caution, probing, and the value of information in the control of uncertain systems. In Annals of Economic and Social Measurement; NBER: Cambridge, MA, USA, 1976; Volume 5, pp. 323–337. [Google Scholar]
- Tse, E.; Bar-Shalom, Y.; Meier, L. Wide-sense adaptive dual control for nonlinear stochastic systems. IEEE Trans. Autom. Control 1973, 18, 98–108. [Google Scholar] [CrossRef]
- Kendrick, D.A. Stochastic Control for Economic Models; McGraw-Hill: New York, NY, USA, 1981. [Google Scholar]
- Kendrick, D.A. Caution and probing in a macroeconomic model. J. Econ. Dyn. Control 1982, 4, 149–170. [Google Scholar] [CrossRef]
- Amman, H.; Kendrick, D. Active learning monte carlo results. J. Econ. Dyn. Control 1994, 18, 119–124. [Google Scholar] [CrossRef]
- Blueschke-Nikolaeva, V.; Blueschke, D.; Neck, R. OPTCON3: An Active Learning Control Algorithm for Nonlinear Quadratic Stochastic Problems. Comput. Econ. 2019, 56, 145–162. [Google Scholar] [CrossRef] [PubMed]
- Behrens, D.; Neck, R. Approximating Solutions for Nonlinear Dynamic Tracking Games. Comput. Econ. 2015, 45, 407–433. [Google Scholar] [CrossRef]
- Athans, M.; Falb, P. Optimal Control: An Introduction to the Theory and Its Applications; McGraw-Hill Book Co.: New York, NY, USA, 1966. [Google Scholar]
- Chow, G.C. Analysis and Control of Dynamic Economic Systems; John Wiley & Sons: New York, NY, USA, 1975. [Google Scholar]
- Chow, G.C. Econometric Analysis by Control Methods; John Wiley & Sons: New York, NY, USA, 1981. [Google Scholar]
- Blueschke-Nikolaeva, V. OPTCON2: An Algorithm for the Optimal Control of Nonlinear Stochastic Models; Südwestdeutscher Verlag für Hochschulschriften: Saarbrücken, Germany, 2013. [Google Scholar]
- Conn, A.R.; Gould, N.I.M.; Toint, P.L. Trust-Region Methods; Society for Industrial and Applied Mathematics and Mathematical Programming Society: Philadelphia, PA, USA, 2000. [Google Scholar]
- Coleman, T.; Li, Y. An interior trust region approach for nonlinear minimization subject to bounds. SIAM J. Optim. 1996, 6, 418–445. [Google Scholar] [CrossRef]
- Kelley, C. Solving Nonlinear Equations with Newton’s Method; SIAM: Philadelphia, PA, USA, 2003. [Google Scholar]
- Rheinboldt, W. Methods for Solving Systems of Nonlinear Equations; SIAM: Philadelphia, PA, USA, 1998. [Google Scholar]
- Kalman, R.E. A new approach to linear filtering and prediction problems. J. Basic Eng. 1960, 82D, 33–45. [Google Scholar] [CrossRef]
- Welch, G.; Bishop, G. An Introduction to the Kalman Filter; Technical Report; Department of Computer Science, University of North Carolina: Chapel Hill, NC, USA, 2006. [Google Scholar]
- Blueschke, D.; Blueschke-Nikolaeva, V.; Neck, R. Stochastic control of linear and nonlinear econometric models: Some computational aspects. Comput. Econ. 2013, 42, 107–118. [Google Scholar] [CrossRef]
- Bar-Shalom, Y.; Tse, E.; Larson, R. Some recent advances in the development of closed-loop stochastic control and resource allocation algorithms. In Proceedings of the IFAC Symposium on Stochastic Control, Budapest, Hungary, 25–27 September 1974. [Google Scholar]
- Neck, R.; Matulka, J. Stochastic optimum control of macroeconometric models using the algorithm OPTCON. Eur. J. Oper. Res. 1994, 73, 384–405. [Google Scholar] [CrossRef]
- Neck, R.; Karbuz, S. Optimal budgetary and monetary policies under uncertainty: A stochastic control approach. Ann. Oper. Res. 1995, 58, 379–402. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Method | Computational Time | Convergence 1 |
|---|---|---|
| det | 0.024879 sec. | 2 |
| OL | 0.036867 sec. | 2 |
| OLF | 0.134725 sec. | 2 |
| AL | 0.771425 sec. | 2 |
| Method | Computational Time | Convergence |
|---|---|---|
| det | 0.148106 sec. | 15 |
| OL | 0.134021 sec. | 7 |
| OLF | 0.265504 sec. | 7 |
| AL | 15.726499 sec. | 7 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Blueschke, D.; Blueschke-Nikolaeva, V.; Neck, R. Approximately Optimal Control of Nonlinear Dynamic Stochastic Problems with Learning: The OPTCON Algorithm. Algorithms 2021, 14, 181. https://doi.org/10.3390/a14060181
Blueschke D, Blueschke-Nikolaeva V, Neck R. Approximately Optimal Control of Nonlinear Dynamic Stochastic Problems with Learning: The OPTCON Algorithm. Algorithms. 2021; 14(6):181. https://doi.org/10.3390/a14060181
Chicago/Turabian StyleBlueschke, Dmitri, Viktoria Blueschke-Nikolaeva, and Reinhard Neck. 2021. "Approximately Optimal Control of Nonlinear Dynamic Stochastic Problems with Learning: The OPTCON Algorithm" Algorithms 14, no. 6: 181. https://doi.org/10.3390/a14060181
APA StyleBlueschke, D., Blueschke-Nikolaeva, V., & Neck, R. (2021). Approximately Optimal Control of Nonlinear Dynamic Stochastic Problems with Learning: The OPTCON Algorithm. Algorithms, 14(6), 181. https://doi.org/10.3390/a14060181