
Decision Tree-Based Adaptive Reconfigurable Cache Scheme


Abstract
1. Introduction
2. Related Work
3. Proposed Adaptive Reconfigurable Cache Scheme Based on Decision Tree
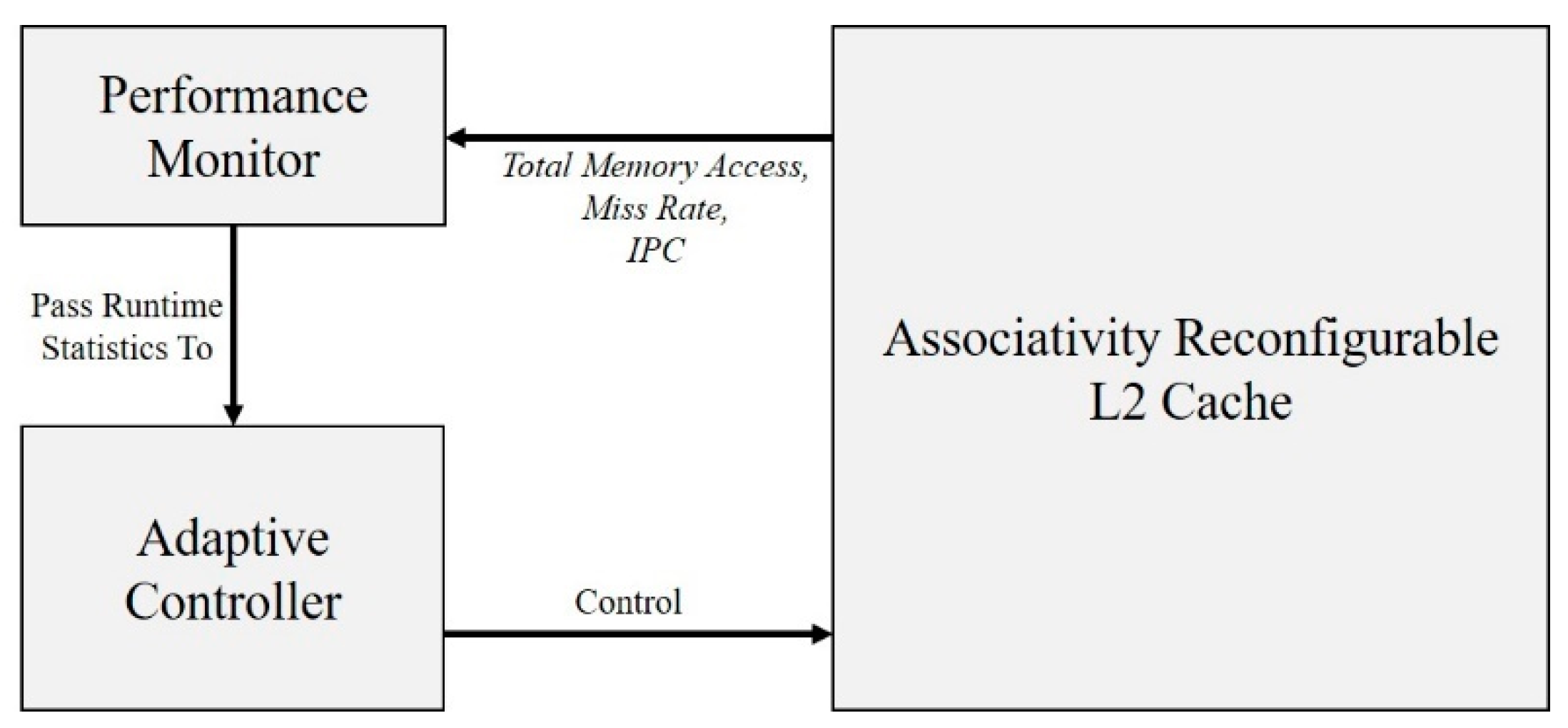
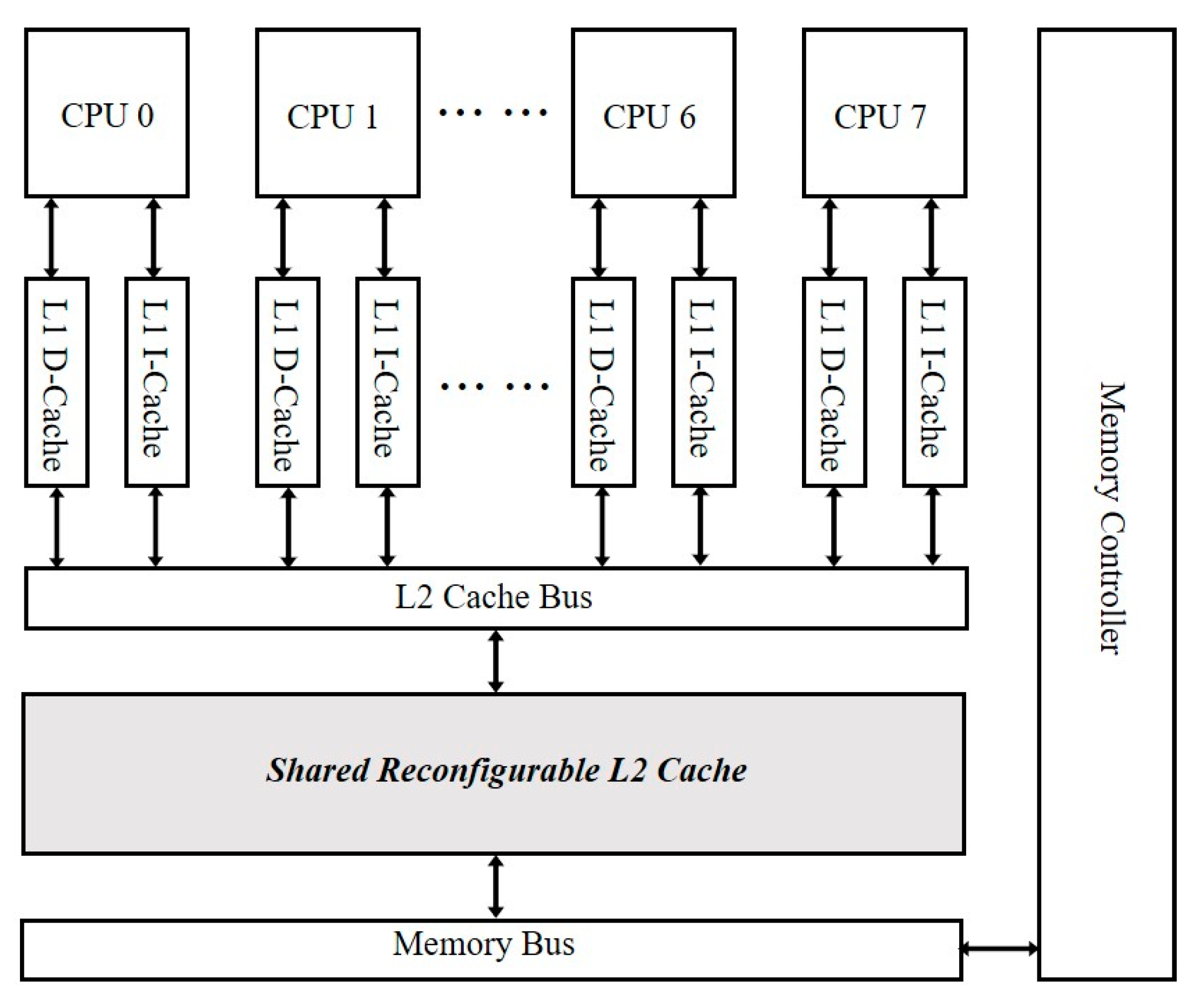
3.1. Overview of Adaptive Reconfigurable Cache
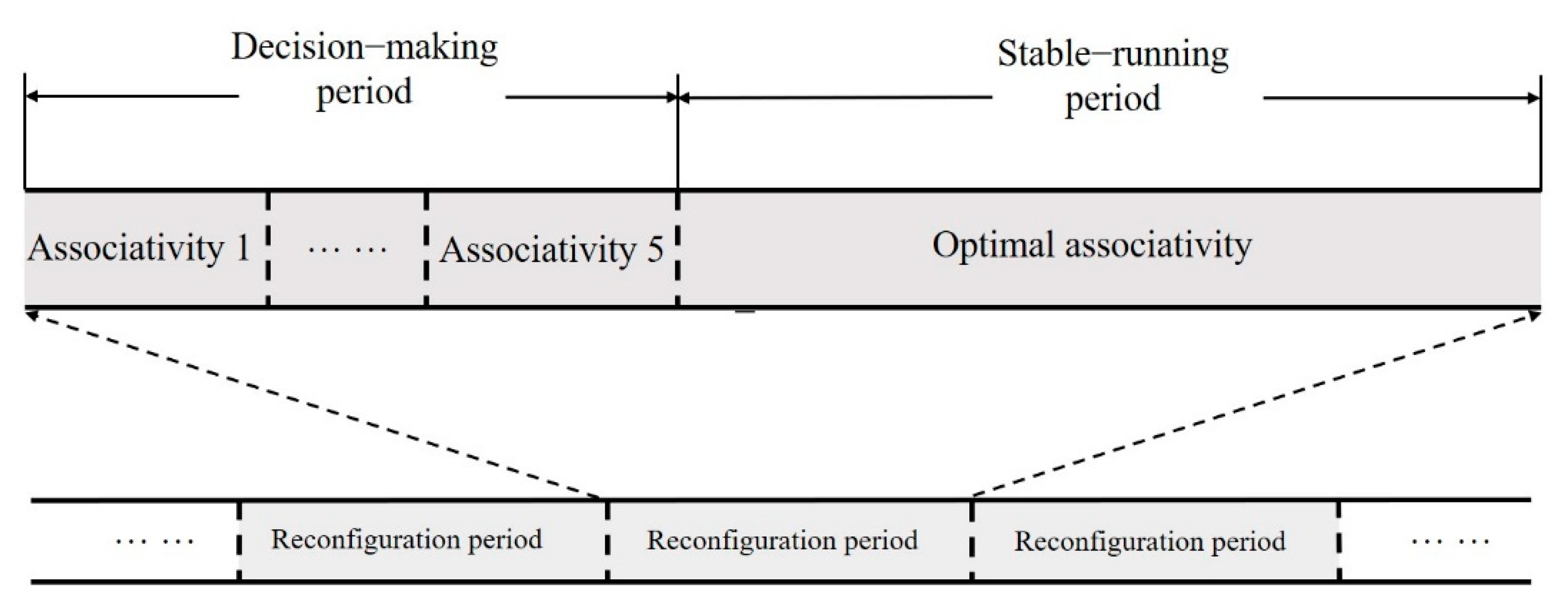
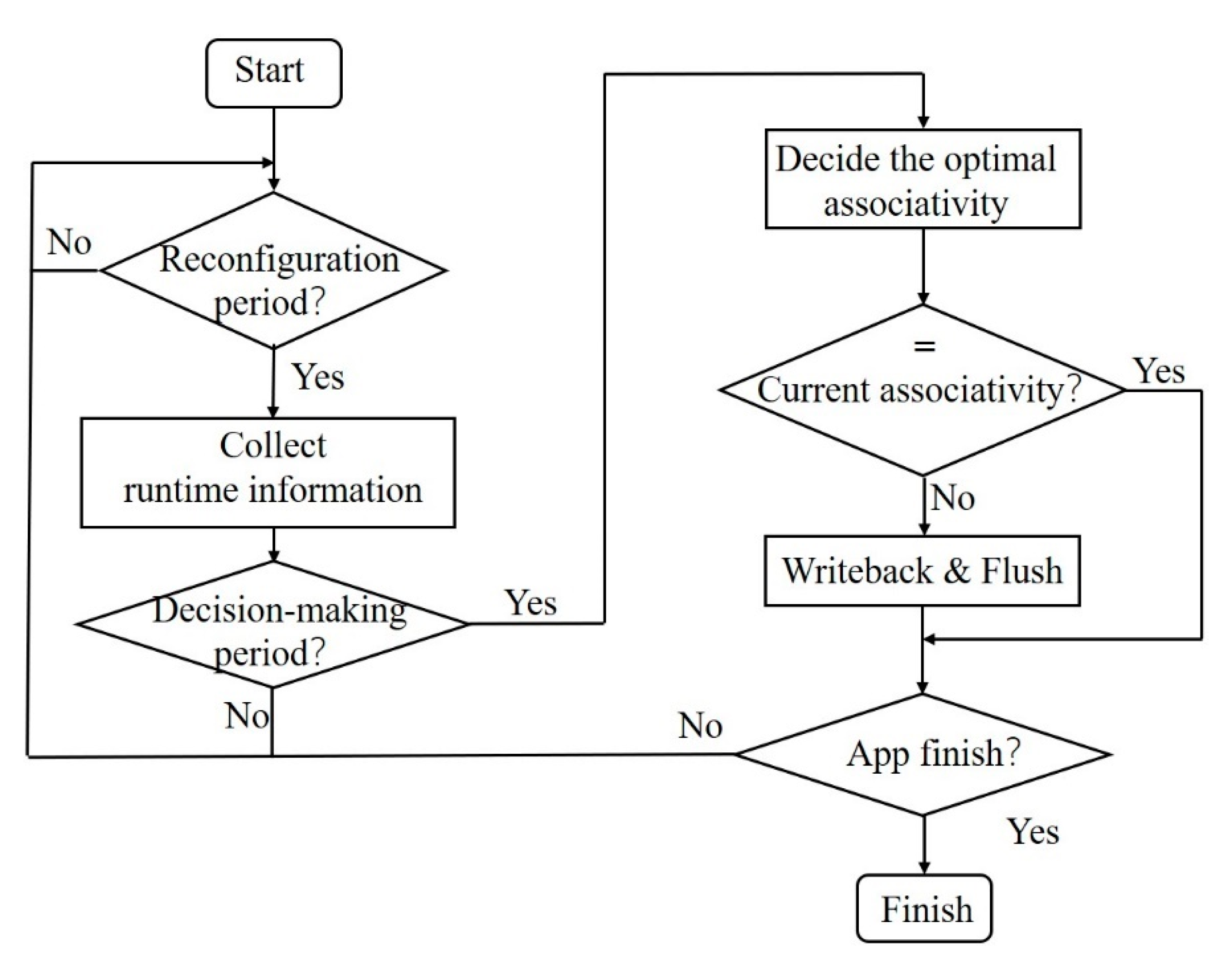
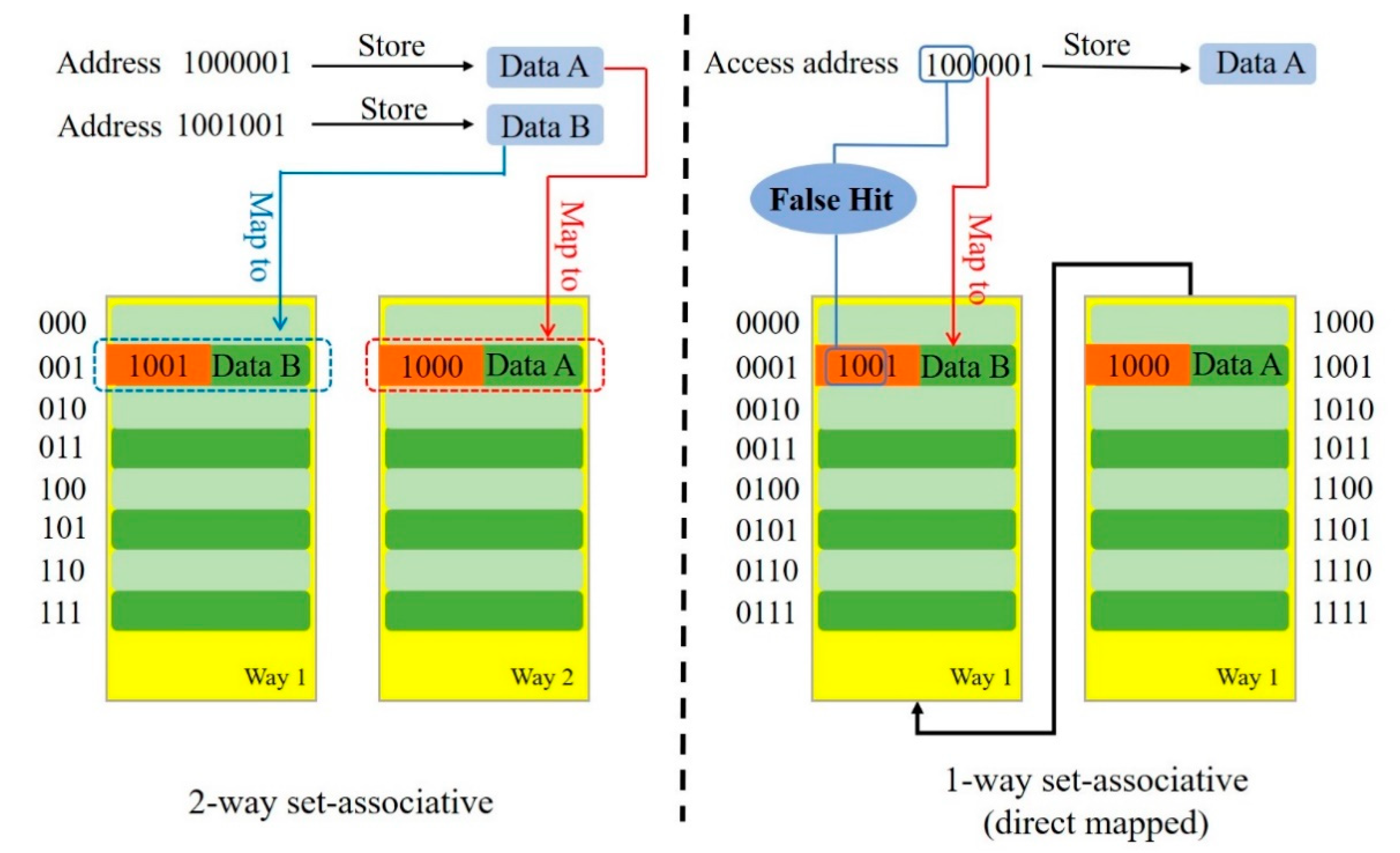
3.2. Optimal Associativity Search Scheme
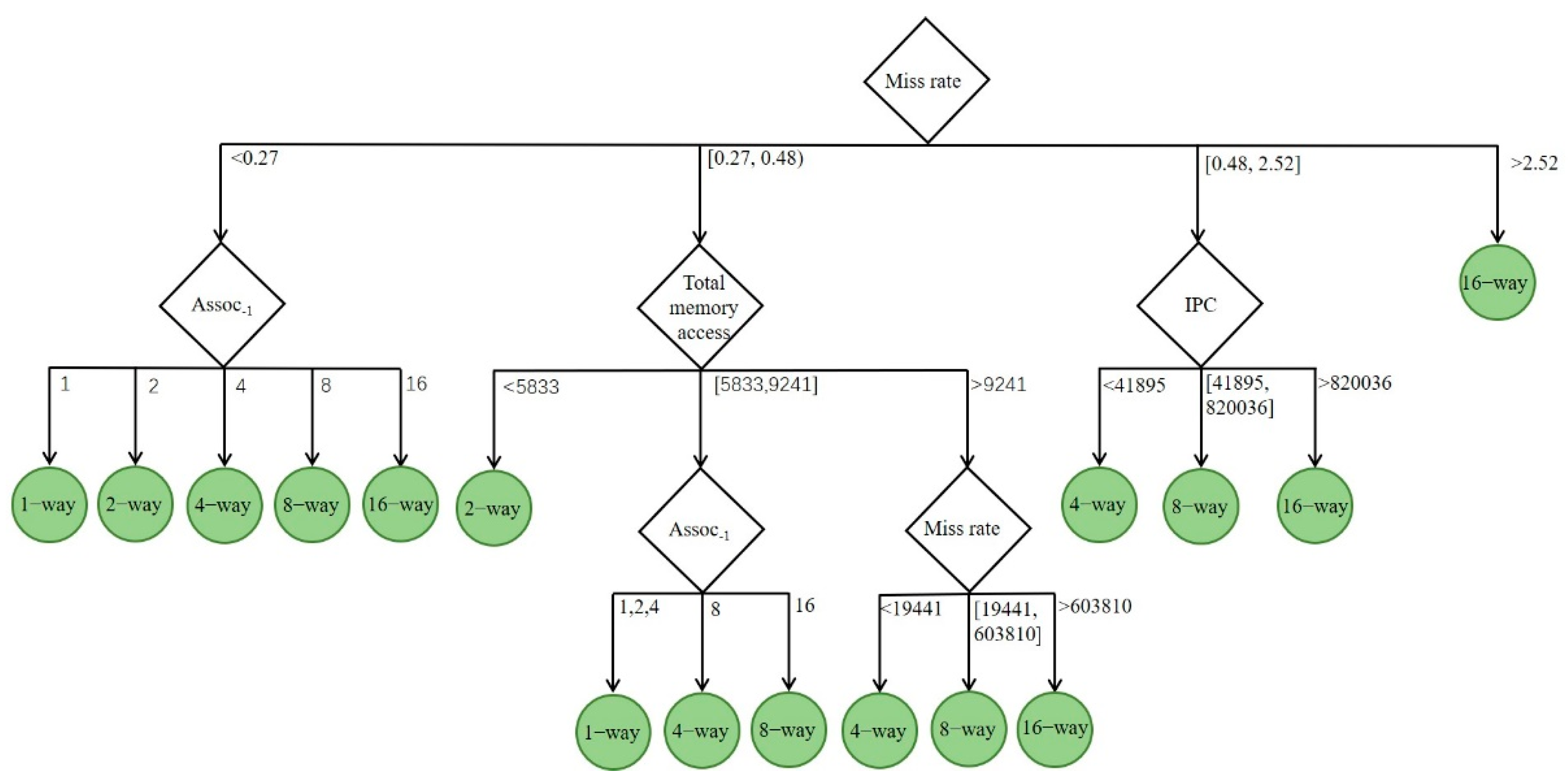
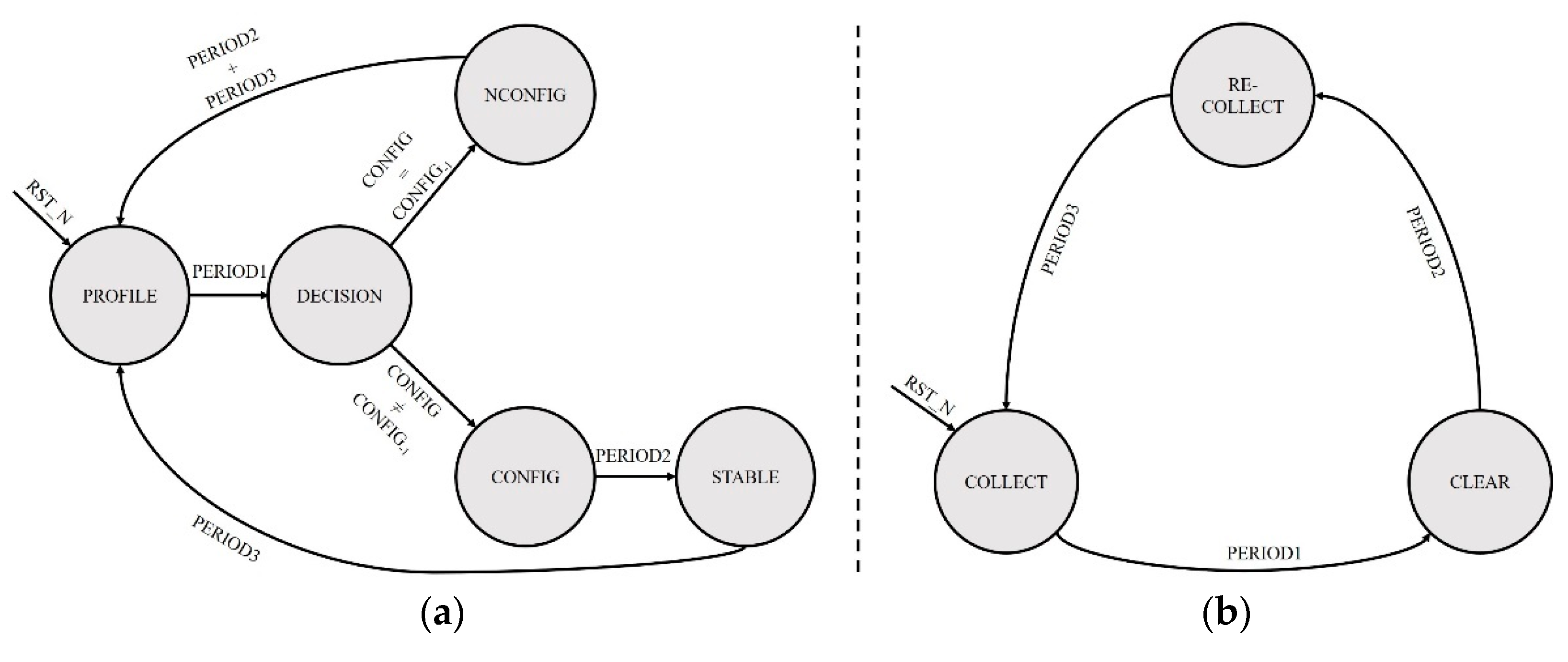
3.3. Adaptive Decision-Making Algorithm Based on Decision Tree
| Algorithm 1 Pseudocode of the J48 algorithm [21]. |
| J48 (Training data D, Attribute A): |
| if all samples in D have the same label: |
| return a leaf node with that label |
| let X∈A be the attribute with the largest information gain ratio |
| let R be a tree root labeled with attribute X |
| let D1, D2, …, Dk be the partition produced by splitting D on attribute X |
| for each Di∈D1, D2, …, Dk: |
| let Ri = J48(Di, A − {X}) |
| add Ri as a new branch of R |
| returnR |
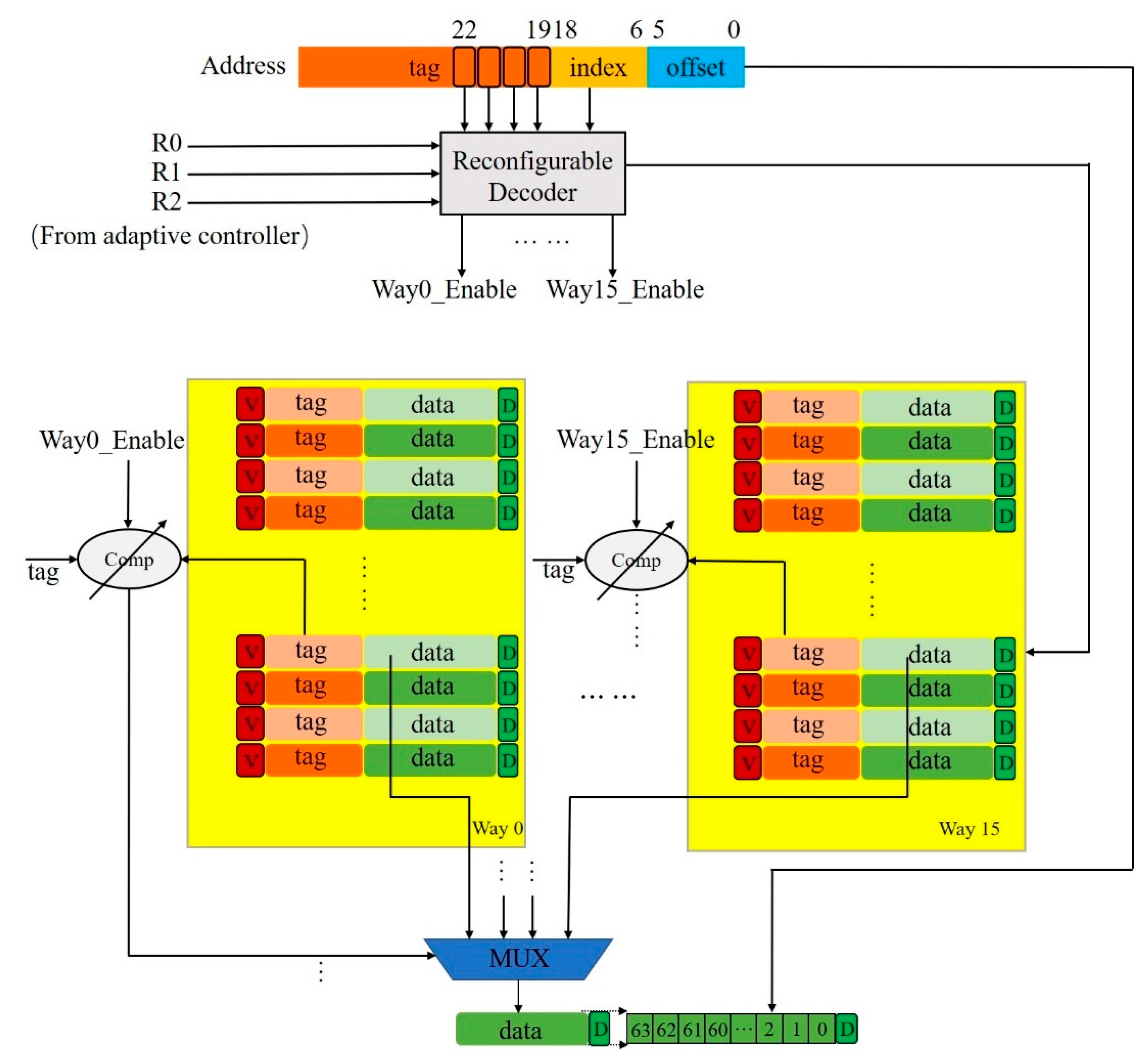
3.4. Associativity Reconfigurable Cache
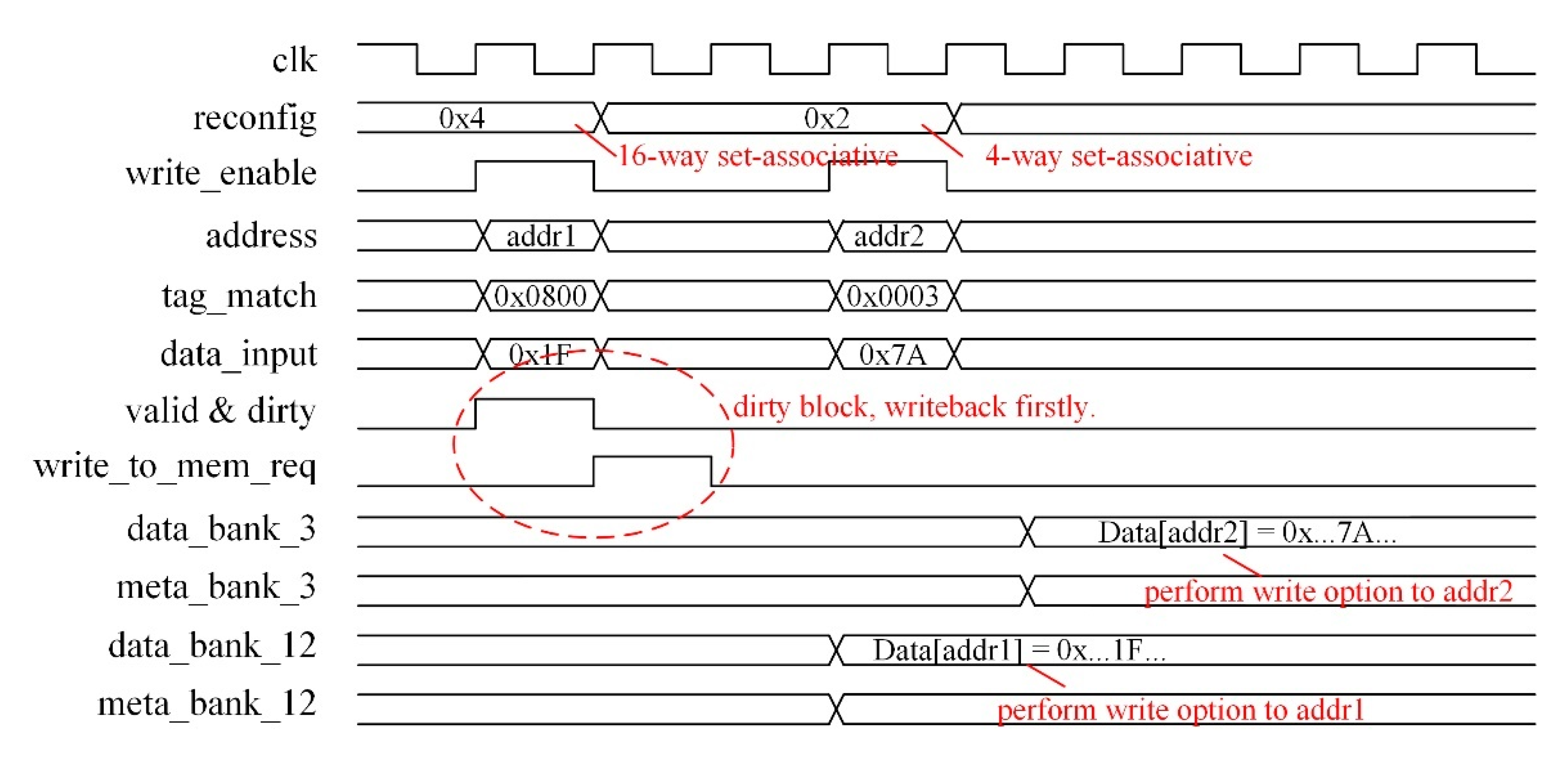
4. Hardware Design
5. Results and Analysis
5.1. Experimental Setup
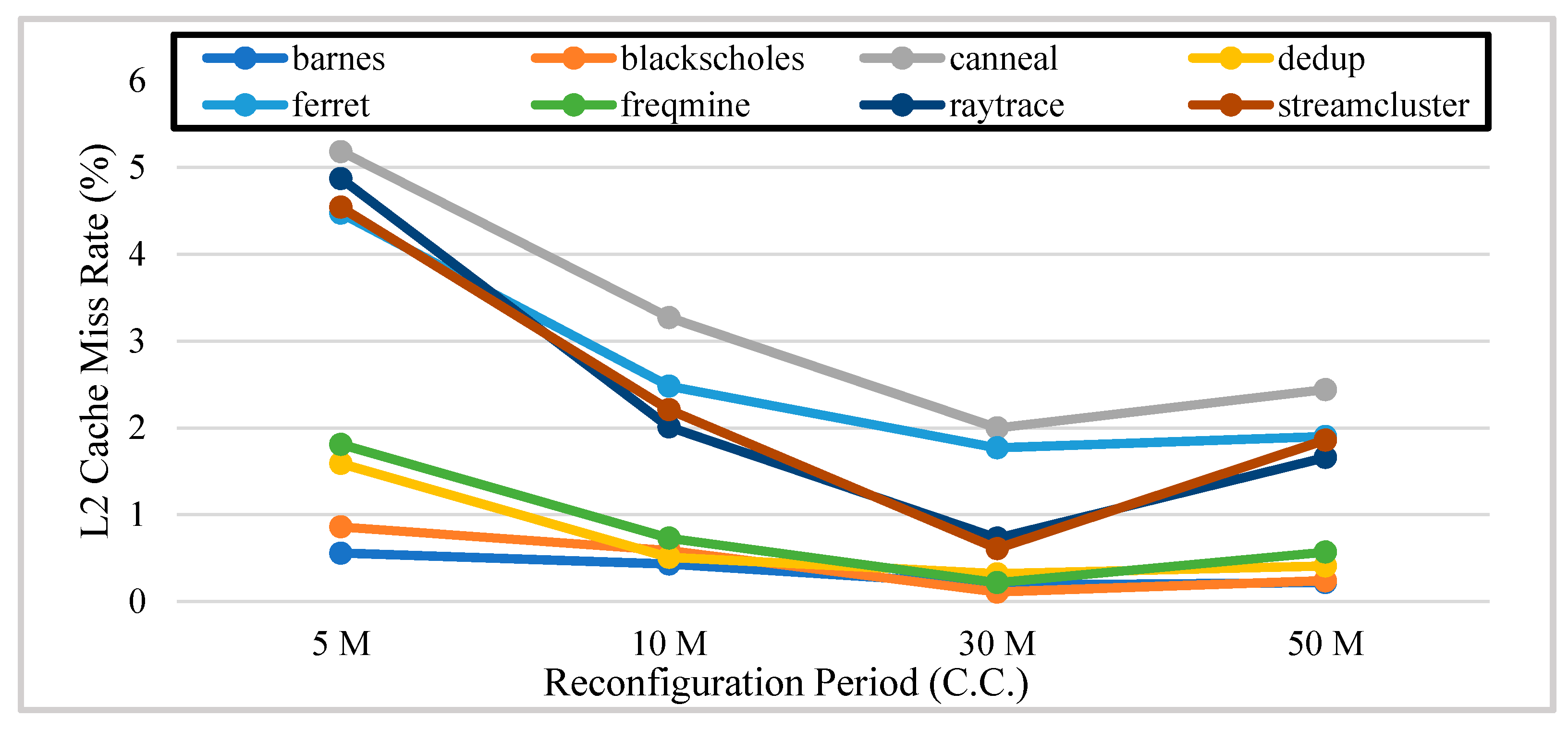
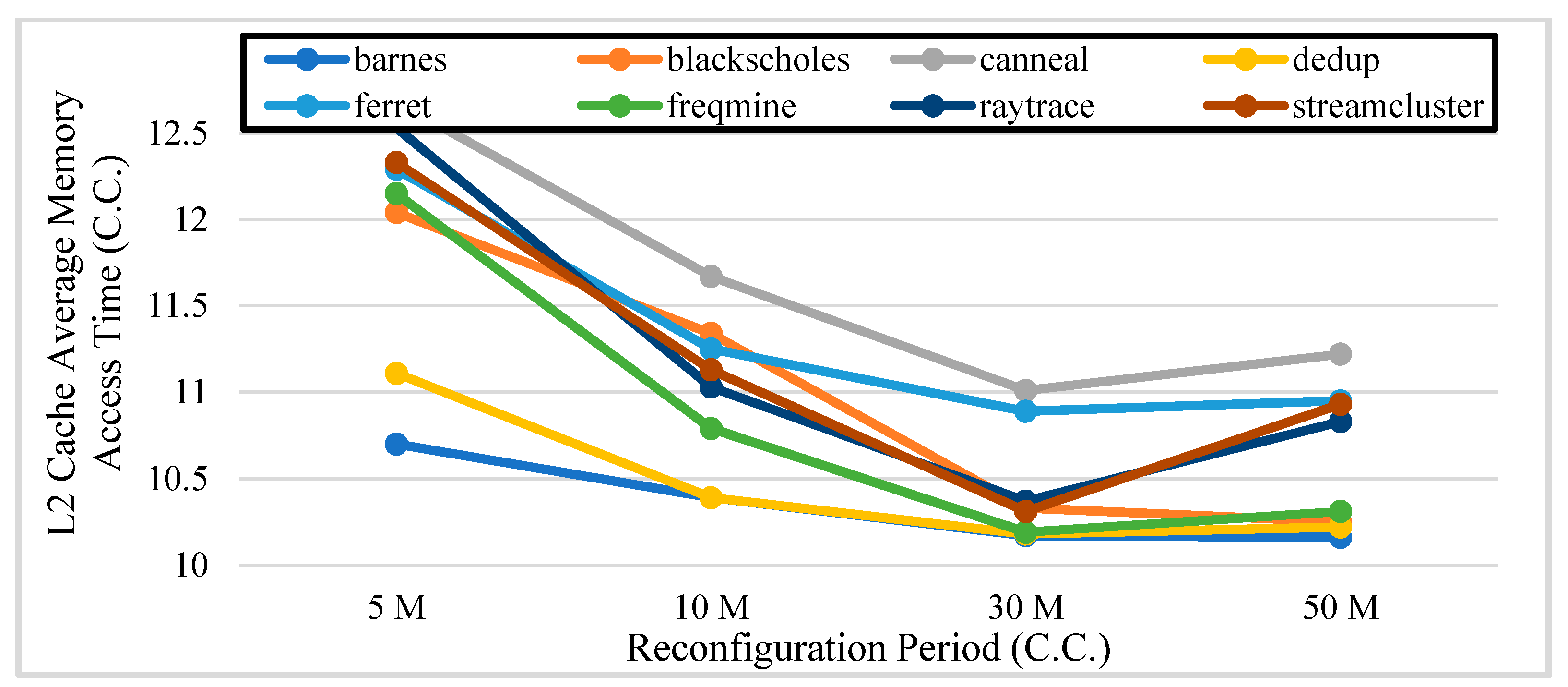
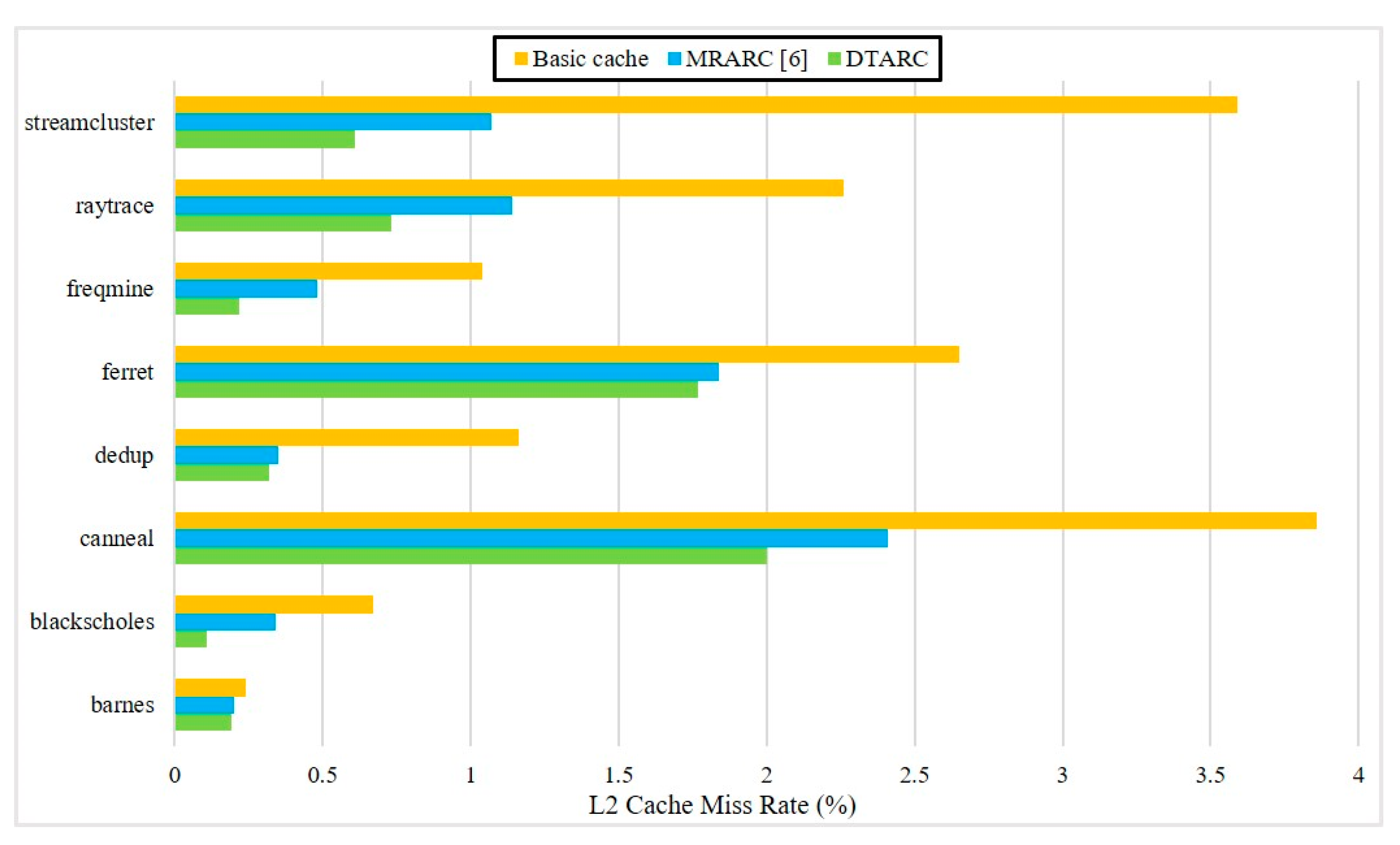
5.2. Software Full-System Simulation Results and Analysis
5.3. Hardware Pre-Synthesis Simulation Results and Analysis
5.4. Complexity and Overhead
- Reconfiguration overhead: This is an intuitive performance loss. During reconfiguration, the adaptive reconfiguration controller sends an interruption to the CPU to block the current operating until the cache finishes writing back dirty blocks and flushing. Each reconfiguration takes 500 clock cycles.
- Compulsory cache miss: After reconfiguration, all cache blocks are in an invalid state, and the temporary increase in cache miss rate caused by this increases the AMAT.
- Performance monitor: To obtain the runtime statistics required for decision-making, three additional 32-bit counters need to be allocated to each core to save the IPC, total memory access, and miss rate parameters of the current reconfiguration period. Therefore, for a multi-core system with 8 cores, a total of 24 additional 32-bit counters are required.
- Adaptive controller: The adaptive controller is implemented by FSM, and the decision of the optimal associativity is realized by a three-level conditional judgment statement.
5.5. Comparison
- DTARC: The proposed adaptive reconfigurable cache is based on the decision tree algorithm.
- MRARC [6]: The adaptive control algorithm works by the following process. If the miss rate is beyond the system threshold, the associativity is tuned up one or two levels. We re-implement this approach in the multicore system.
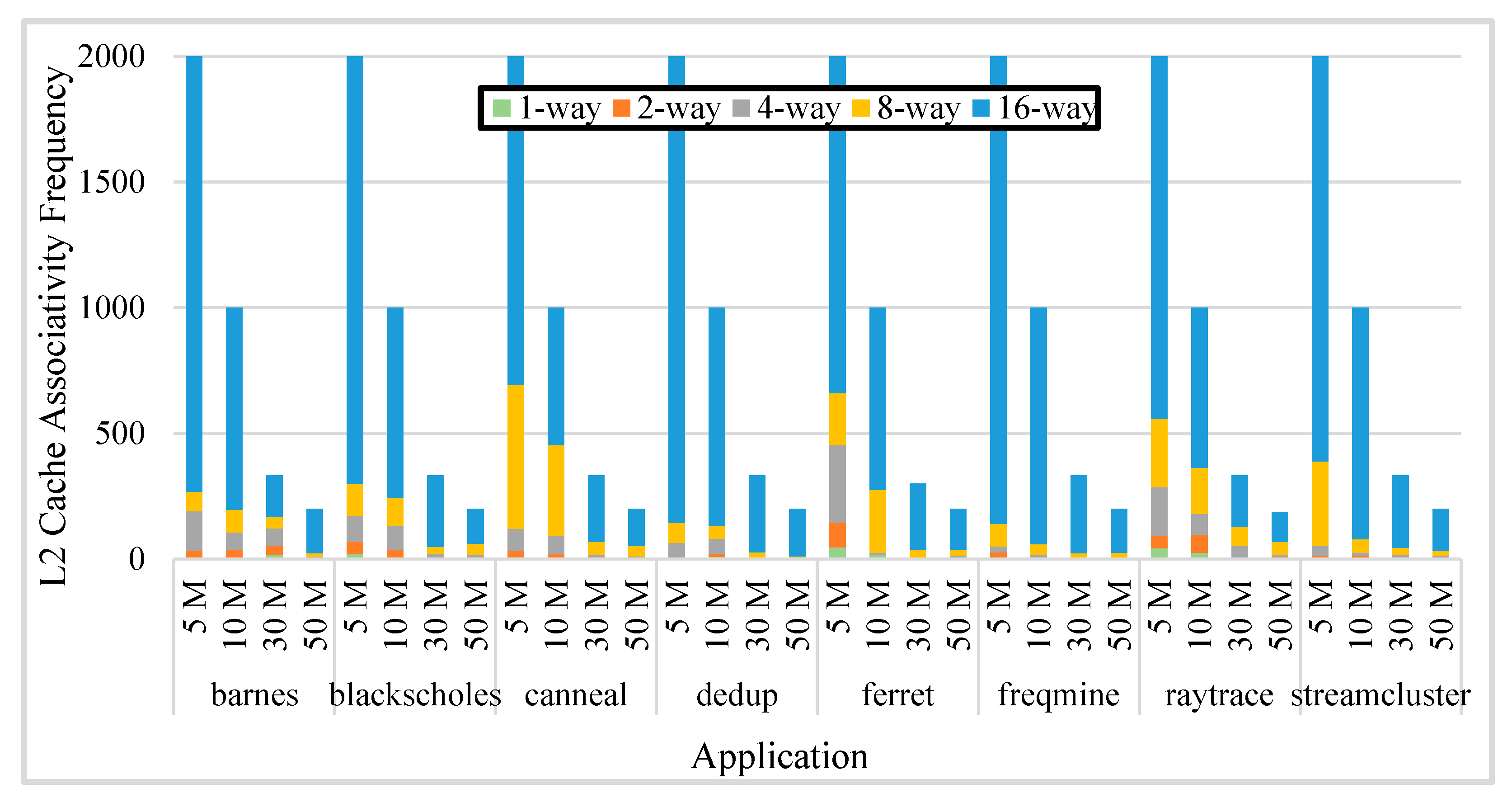
- Basic cache: A fixed 16-way set-associative cache. According to Figure 12, this associativity appears most frequently across all applications.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Hennessy, J.L.; Patterson, D.A. Computer Architecture: A Quantitative Approach, 5th ed.; Elsevier: Amsterdam, The Netherlands, 2011; pp. 71–144. [Google Scholar]
- Adegbija, T.; Gordon-Ross, A.; Munir, A. Dynamic phase-based tuning for embedded systems using phase distance mapping. In Proceedings of the 2012 IEEE 30th International Conference on Computer Design (ICCD), Montreal, QC, Canada, 30 September–3 October 2012; pp. 284–290. [Google Scholar]
- El-Sayed, N.; Mukkara, A.; Tsai, P.-A.; Kasture, H.; Ma, X.; Sanchez, D. KPart: A hybrid cache partitioning-sharing technique for commodity multicores. In Proceedings of the 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), Vienna, Austria, 24–28 February 2018; pp. 104–117. [Google Scholar]
- Aupy, G.; Benoit, A.; Goglin, B.; Pottier, L.; Robert, Y. Co-Scheduling HPC Workloads on Cache-Partitioned CMP Platforms. In Proceedings of the 2018 IEEE International Conference on Cluster Computing (CLUSTER), Belfast, UK, 10–13 September 2018; pp. 348–358. [Google Scholar]
- Gordon-Ross, A.; Vahid, F.; Dutt, N.D. Fast Configurable-Cache Tuning with a Unified Second-Level Cache. IEEE Trans. Very Large Scale Integr. Syst. 2009, 17, 80–91. [Google Scholar] [CrossRef]
- Xie, J.; Zhang, Y.; Wang, Q. The Design of Reconfigurable Cache Scheme in Multi-core Processor. Microelectron. Comput. 2016, 33, 1–5. [Google Scholar]
- Hsu, P.-Y.; Hwang, T. Thread-criticality aware dynamic cache reconfiguration in multi-core system. In Proceedings of the 2013 IEEE/ACM International Conference on Computer-Aided Design (ICCAD), San Jose, CA, USA, 18–21 November 2013; pp. 413–420. [Google Scholar]
- Huang, Y.; Mishra, P. Vulnerability-aware energy optimization using reconfigurable caches in multicore systems. In Proceedings of the 2017 IEEE International Conference on Computer Design (ICCD), Boston, MA, USA, 5–8 November 2017; pp. 241–248. [Google Scholar]
- Huang, Y.; Mishra, P. Reliability and energy-aware cache reconfiguration for embedded systems. In Proceedings of the 2016 17th International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, USA, 15–16 March 2016; pp. 313–318. [Google Scholar]
- Ahmed, A.; Huang, Y.; Mishra, P. Cache Reconfiguration Using Machine Learning for Vulnerability-aware Energy Optimization. ACM Trans. Embed. Comput. Syst. 2019, 18, 15. [Google Scholar] [CrossRef]
- Charles, S.; Ahmed, A.; Ogras, U.Y.; Mishra, P. Efficient Cache Reconfiguration Using Machine Learning in NoC-Based Many-Core CMPs. ACM Trans. Des. Autom. Electron. Syst. 2019, 24, 60. [Google Scholar] [CrossRef]
- Wang, W.; Mishra, P.; Gordon-Ross, A. Dynamic Cache Reconfiguration for Soft Real-Time Systems. ACM Trans. Embed. Comput. Syst. 2012, 11, 28. [Google Scholar] [CrossRef]
- Chen, Y.-H.; Wu, A.C.-H.; Hwang, T. A Dynamic Link-latency Aware Cache Replacement Policy (DLRP). In Proceedings of the 26th Asia and South Pacific Design Automation Conference, Tokyo, Japan, 18–21 January 2021; pp. 210–215. [Google Scholar]
- Lee, B.; Kim, K.; Chung, E. Replacement Policy Adaptable Miss Curve Estimation for Efficient Cache Partitioning. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2018, 37, 445–457. [Google Scholar] [CrossRef]
- Warrier, T.S.; Anupama, B.; Mutyam, M. An application-aware cache replacement policy for last-level caches. In Proceedings of the International Conference on Architecture of Computing Systems, Prague, Czech Republic, 19–22 February 2013; pp. 207–219. [Google Scholar]
- Danielsson, J.; Jägemar, M.; Behnam, M.; Seceleanu, T.; Sjödin, M. Run-time cache-partition controller for multi-core systems. In Proceedings of the IECON 2019—45th Annual Conference of the IEEE Industrial Electronics Society, Lisbon, Portugal, 14–17 October 2019; pp. 4509–4515. [Google Scholar]
- Tsai, P.-A.; Beckmann, N.; Sanchez, D. Jenga: Software-defined cache hierarchies. In Proceedings of the 44th Annual International Symposium on Computer Architecture, Toronto, ON, Canada, 24–28 June 2017; pp. 652–665. [Google Scholar]
- Basireddy, K.R.; Singh, A.K.; Al-Hashimi, B.M.; Merrett, G.V. AdaMD: Adaptive Mapping and DVFS for Energy-Efficient Heterogeneous Multicores. IEEE Trans. Comput. Aided Des. Integr. Circuits Syst. 2020, 39, 2206–2217. [Google Scholar] [CrossRef]
- DiTomaso, D.; Sikder, A.; Kodi, A.; Louri, A. Machine learning enabled power-aware network-on-chip design. In Proceedings of the Design, Automation & Test in Europe Conference & Exhibition (DATE), Lausanne, Switzerland, 27–31 March 2017; pp. 1354–1359. [Google Scholar]
- Frank, E.; Hall, M.; Holmes, G.; Kirkby, R.; Pfahringer, B.; Witten, I.H.; Trigg, L. Weka—A machine learning workbench for data mining. In Data Mining and Knowledge Discovery Handbook; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1269–1277. [Google Scholar]
- Aljawarneh, S.; Yassein, M.B.; Aljundi, M. An enhanced J48 classification algorithm for the anomaly intrusion detection systems. Clust. Comput. 2019, 22, 10549–10565. [Google Scholar] [CrossRef]
- Binkert, N.; Beckmann, B.; Black, G.; Reinhardt, S.K.; Saidi, A.; Basu, A.; Hestness, J.; Hower, D.R.; Krishna, T.; Sardashti, S. The gem5 simulator. ACM SIGARCH Comput. Archit. News 2011, 39, 1–7. [Google Scholar] [CrossRef]
- Bienia, C.; Li, K. Benchmarking Modern Multiprocessors; Princeton University: Princeton, NJ, USA, 2011. [Google Scholar]
- Woo, S.C.; Ohara, M.; Torrie, E.; Singh, J.P.; Gupta, A. The SPLASH-2 programs: Characterization and methodological considerations. In Proceedings of the 22nd Annual International Symposium on Computer Architecture, S. Margherita Ligure, Italy, 22–24 June 1995; pp. 24–36. [Google Scholar]

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CPU | ISA: X86-64 |
|---|---|
| 8 Cores/1 GHz | |
| L1 cache | private, fixed parameters |
| L1-I: 64 B/32 KB/4-way set-associative/1 clock cycle | |
| L1-D: 64 B/32 KB/4-way set-associative/1 clock cycle | |
| L2 cache | Shared, associativity reconfigurable |
| 64 B/4 MB/16,8,4,2,1-way set-associative/10 clock cycle | |
| Interconnect | Coherent Bus |
| Main memory | DDR3_1600_8 × 8 |
| 4 GB/50 clock cycle |
| Application | Basic Cache (C.C.) | MRARC [6] (C.C.) | DTARC (C.C.) |
|---|---|---|---|
| Barnes | 10.12 | 10.14 (−0.20%) | 10.17 (−0.49%) |
| Blackscholes | 10.34 | 10.24 (0.99%) | 10.33 (0.10%) |
| Canneal | 11.93 | 11.69 (2.04%) | 11.01 (7.71%) |
| Dedup | 10.58 | 10.25 (3.17%) | 10.18 (3.78%) |
| Ferret | 11.33 | 11.29 (0.33%) | 10.89 (3.84%) |
| Freqmine | 10.52 | 10.34 (1.75%) | 10.19 (3.14%) |
| Raytrace | 11.13 | 10.80 (2.98%) | 10.37 (6.83%) |
| Streamcluster | 11.80 | 10.75 (8.87%) | 10.31 (12.60%) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhu, W.; Zeng, X. Decision Tree-Based Adaptive Reconfigurable Cache Scheme. Algorithms 2021, 14, 176. https://doi.org/10.3390/a14060176
Zhu W, Zeng X. Decision Tree-Based Adaptive Reconfigurable Cache Scheme. Algorithms. 2021; 14(6):176. https://doi.org/10.3390/a14060176
Chicago/Turabian StyleZhu, Wei, and Xiaoyang Zeng. 2021. "Decision Tree-Based Adaptive Reconfigurable Cache Scheme" Algorithms 14, no. 6: 176. https://doi.org/10.3390/a14060176
APA StyleZhu, W., & Zeng, X. (2021). Decision Tree-Based Adaptive Reconfigurable Cache Scheme. Algorithms, 14(6), 176. https://doi.org/10.3390/a14060176