
An Automatic Participant Detection Framework for Event Tracking on Twitter



Abstract
1. Introduction
- We define event participants and propose a six-step framework for APD. Differently from existing approaches that consider participants [1,2,3], APD extracts participants before the event starts, not while it is ongoing. This framework first confirms which named entities are relevant to the event. Then it looks for other participants that Twitter users are not discussing, and hence which NER cannot identify;
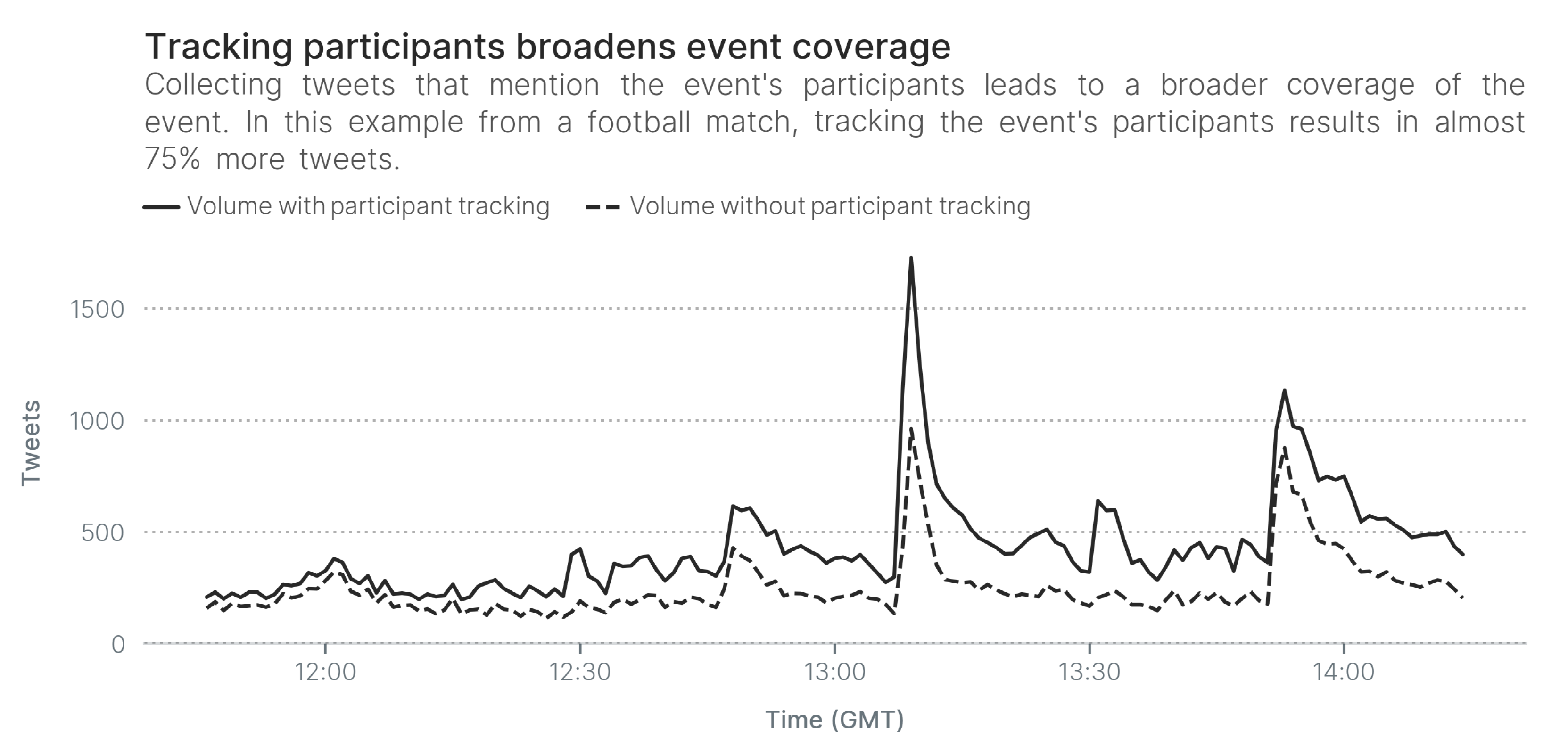
- We explore what named entities Twitter users talk about before sports events, with a focus on football matches and basketball games. We show that although NER toolkits are relatively capable of navigating Twitter’s informal tweeting habits, many of the named entities that users mention before events are spurious and not directly-related to the event. As a result, NER cannot be a stand-alone replacement for APD;
- We implement the APD framework based on the hypothesis that event participants are tightly-interconnected on Wikipedia. Our evaluation on football matches and basketball games shows that our approach is capable of identifying almost twice as many participants as traditional NER approaches. At the same time, our approach almost halves NER noise, which usually consists of irrelevant named entities that are only tangentially-related to events, and which therefore cannot be qualified as event participants.
2. Related Work
2.1. Query Expansion
2.2. Entity Set Expansion
3. Materials & Methods
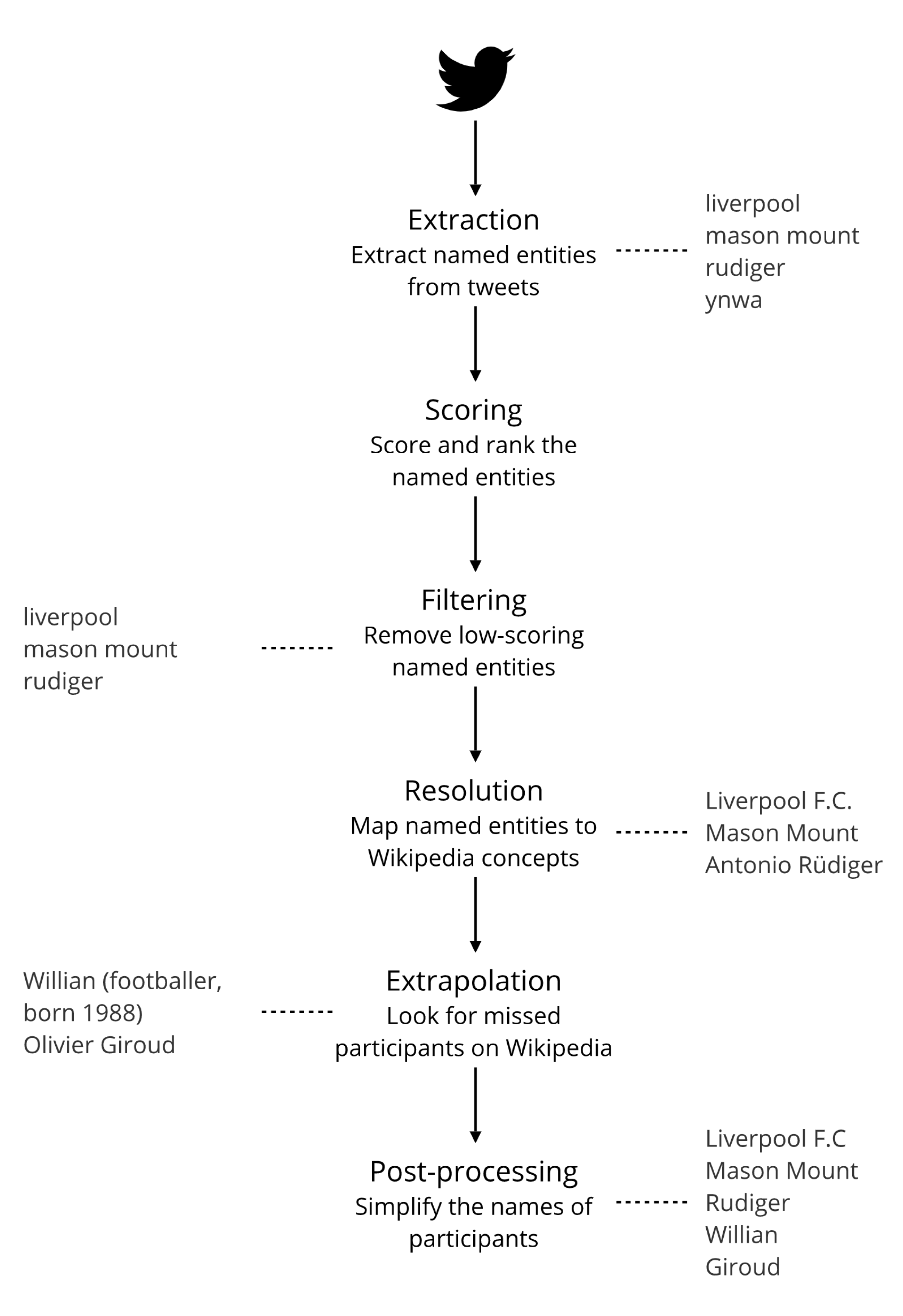
3.1. Framework
- Extract named entities, or candidate participants, from the corpus;
- Score and rank the candidates;
- Filter out the low-scoring candidates;
- Resolve valid candidates to a semantic form so they become participants;
- Extrapolate the seed set of participants; and
- Post-process the participants.
3.1.1. Extraction
3.1.2. Scoring
3.1.3. Filtering
3.1.4. Resolution
Alexandre Lacazette […] is a French professional footballer who plays as a forward for Premier League club Arsenal and the France national team. He is known for his pace, hold-up play, and work-rate. […]
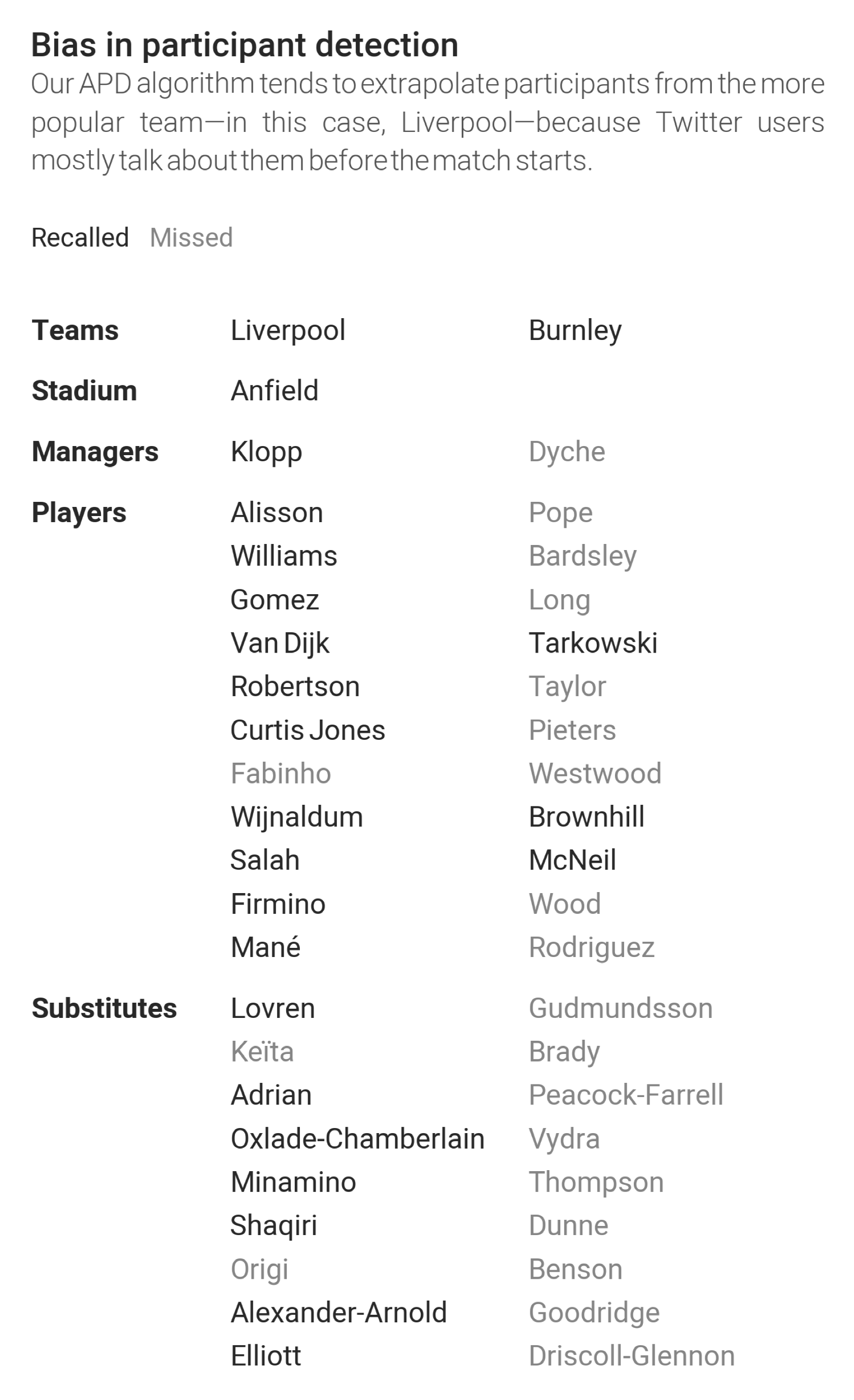
3.1.5. Extrapolation
3.1.6. Post-Processing
3.2. Evaluation Metrics
4. Results
4.1. Evaluation Set-up
4.1.1. Datasets
4.1.2. Ground Truth
4.1.3. Baselines
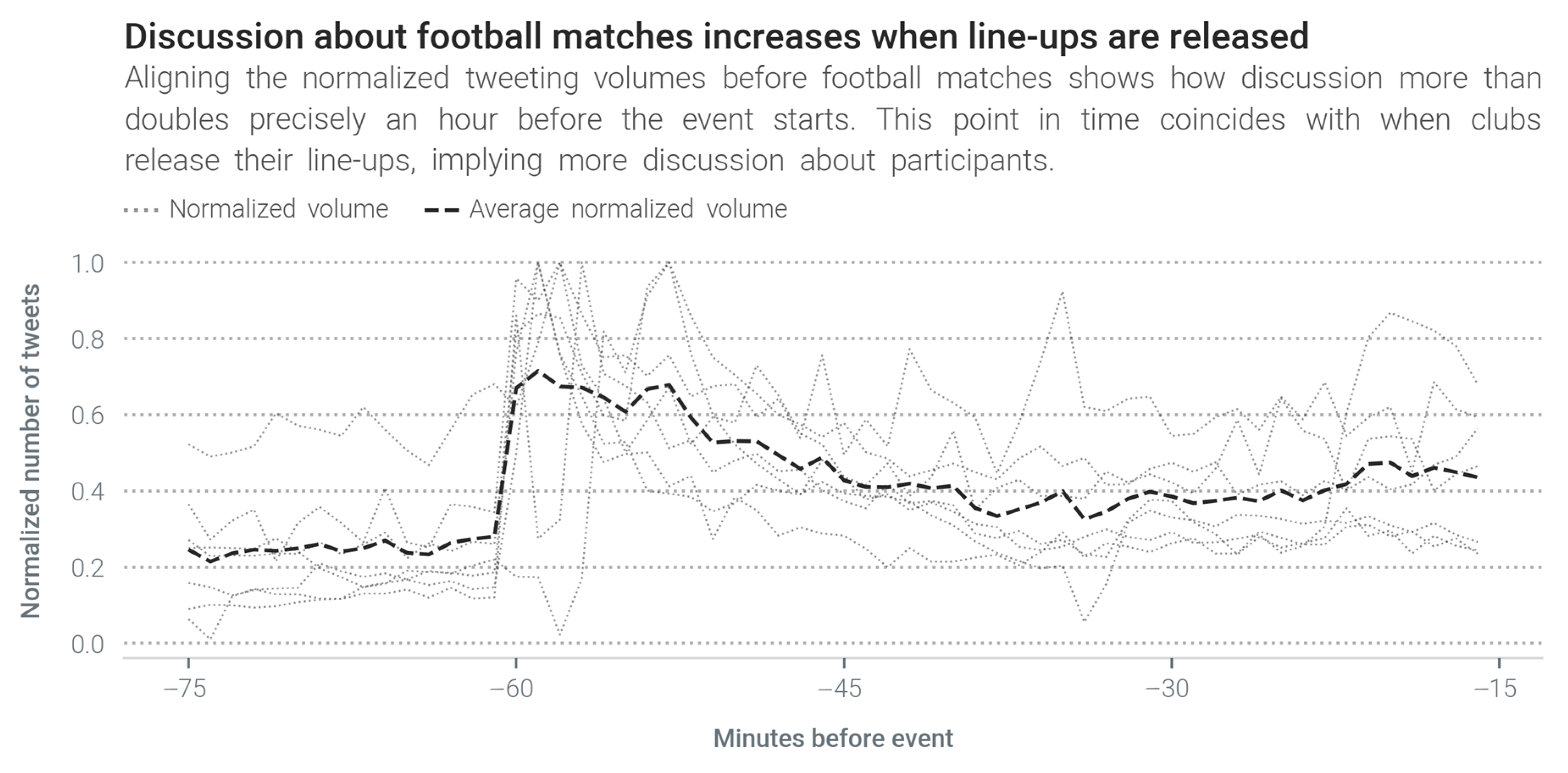
4.2. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Shen, C.; Liu, F.; Weng, F.; Li, T. A Participant-Based Approach for Event Summarization Using Twitter Streams. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, GA, USA, 9–14 June 2013; Association for Computational Linguistics: Atlanta, GA, USA, 2013; pp. 1152–1162. [Google Scholar]
- McMinn, A.J.; Jose, J.M. Real-Time Entity-Based Event Detection for Twitter. In Proceedings of the 6th International Conference of the Cross-Language Evaluation Forum for European Languages, Toulouse, France, 8–11 September 2015; Springer: Toulouse, France, 2015; pp. 65–77. [Google Scholar]
- Huang, Y.; Shen, C.; Li, T. Event Summarization for Sports Games using Twitter Streams. World Wide Web 2018, 21, 609–627. [Google Scholar] [CrossRef]
- Mamo, N.; Azzopardi, J.; Layfield, C. ELD: Event TimeLine Detection—A Participant-Based Approach to Tracking Events. In Proceedings of the HT ’19: 30th ACM Conference on Hypertext and Social Media, Hof, Germany, 17–20 September 2019; ACM: Hof, Germany, 2019; pp. 267–268. [Google Scholar]
- Kubo, M.; Sasano, R.; Takamura, H.; Okumura, M. Generating Live Sports Updates from Twitter by Finding Good Reporters. In Proceedings of the 2013 IEEE/WIC/ACM International Joint Conferences on Web Intelligence (WI) and Intelligent Agent Technologies (IAT), Atlanta, GA, USA, 17–20 November 2013; IEEE Computer Society: Atlanta, GA, USA, 17 November 2013; Volume 1, pp. 527–534. [Google Scholar]
- Panagiotou, N.; Katakis, I.; Gunopulos, D. Detecting Events in Online Social Networks: Definitions, Trends and Challenges; Lecture Notes in Computer Science; Springer: Cham, Germany, 2016; Volume 9580, pp. 42–84. [Google Scholar]
- Chen, X.; Li, Q. Event Modeling and Mining: A Long Journey Toward Explainable Events. VLDB J. 2020, 29, 459–482. [Google Scholar] [CrossRef]
- Atefeh, F.; Khreich, W. A Survey of Techniques for Event Detection in Twitter. Comput. Intell. 2015, 31, 132–164. [Google Scholar] [CrossRef]
- Allan, J.; Papka, R.; Lavrenko, V. On-Line New Event Detection and Tracking. In Proceedings of the SIGIR ’98: 21st Annual ACM/SIGIR International Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; ACM: Melbourne, Australia, 1998; pp. 37–45. [Google Scholar]
- Makkonen, J.; Ahonen-Myka, H.; Salmenkivi, M. Simple Semantics in Topic Detection and Tracking. Inf. Retr. 2004, 7, 347–368. [Google Scholar] [CrossRef] [PubMed]
- Li, B.; Li, W.; Lu, Q.; Wu, M. Profile-Based Event Tracking. In Proceedings of the SIGIR ’05: The 28th ACM/SIGIR International Symposium on Information Retrieval 2005, Salvador, Brazil, 15–19 August 2005; ACM: Salvador, Brazil, 2005; pp. 631–632. [Google Scholar]
- Nakade, V.; Musaev, A.; Atkison, T. Preliminary Research on Thesaurus-Based Query Expansion for Twitter Data Extraction. In Proceedings of the ACM SE ’18: Southeast Conference, Richmond, KY, USA, 29–31 March 2018; ACM: Richmond, KY, USA, 2018; pp. 1–4. [Google Scholar]
- Corney, D.; Martin, C.; Göker, A. Spot the Ball: Detecting Sports Events on Twitter. In Proceedings of the ECIR 2014: Advances in Information Retrieval, Amsterdam, The Netherlands, 13–16 April 2014; Springer: Amsterdam, The Netherlands, 2014; pp. 449–454. [Google Scholar]
- Mishra, S.; Diesner, J. Semi-Supervised Named Entity Recognition in Noisy-Text. In Proceedings of the WNUT 2016: The 2nd Workshop on Noisy User-generated Text, Osaka, Japan, 11–16 December 2016; The COLING 2016 Organizing Committee: Osaka, Japan, 2016; pp. 203–212. [Google Scholar]
- Yang, Z.; Li, C.; Fan, K.; Huang, J. Exploiting Multi-Sources Query Expansion in Microblogging Filtering. Neural Netw. World 2017, 27, 59–76. [Google Scholar] [CrossRef]
- Zingla, M.A.; Chiraz, L.; Slimani, Y. Short Query Expansion for Microblog Retrieval. Procedia Comput. Sci. 2016, 96, 225–234. [Google Scholar] [CrossRef]
- Albishre, K.; Li, Y.; Xu, Y. Effective Pseudo-Relevance for Microblog Retrieval. In Proceedings of the ACSW 2017: Australasian Computer Science Week 2017, Geelong, Australia, 31 January–3 February 2017; ACM: Geelong, Australia, 2017; pp. 1–6. [Google Scholar]
- Massoudi, K.; Tsagkias, M.; de Rijke, M.; Weerkamp, W. Incorporating Query Expansion and Quality Indicators in Searching Microblog Posts. In Advances in Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2011; Volume 6611, pp. 362–367. [Google Scholar]
- Letham, B.; Rudin, C.; Heller, K. Growing a List. Data Min. Knowl. Discov. 2013, 27, 372–395. [Google Scholar] [CrossRef][Green Version]
- Sarmento, L.; Jijkuon, V.; de Rijke, M.; Oliveira, E. “More Like These”: Growing Entity Classes from Seeds. In Proceedings of the CIKM ’07: Conference on Information and Knowledge Management, Lisboa, Portugal, 6–7 November 2007; ACM: New York, NY, USA, 2007; pp. 959–962. [Google Scholar]
- Zhang, Z.; Sun, L.; Han, X. A Joint Model for Entity Set Expansion and Attribute Extraction from Web Search Queries. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; AAAI Press: Phoenix, AZ, USA, 2016; pp. 3101–3107. [Google Scholar]
- Wang, R.C.; Cohen, W.W. Language-Independent Set Expansion of Named Entities Using the Web. In Proceedings of the Seventh IEEE International Conference on Data Mining (ICDM 2007), Omaha, NE, USA, 28–31 October 2007; IEEE: Omaha, NE, USA, 2007; pp. 342–350. [Google Scholar]
- Wang, R.C.; Cohen, W.W. Iterative Set Expansion of Named Entities Using the Web. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: Pisa, Italy, 2008; pp. 1091–1096. [Google Scholar]
- Mamo, N. APD: The tools and data used in the article ’An Automatic Participant Detection Framework for Event Tracking on Twitter’. Available online: https://github.com/NicholasMamo/apd/ (accessed on 29 January 2021).
- Reed, J.W.; Jiao, Y.; Potok, T.E.; Klump, B.A.; Elmore, M.T.; Hurson, A.R. TF-ICF: A New Term Weighting Scheme for Clustering Dynamic Data Streams. In Proceedings of the 5th International Conference on Machine Learning and Applications, Orlando, FL, USA, 14–16 December 2006; IEEE: Orlando, FL, USA, 2006; pp. 258–263. [Google Scholar]
- Girvan, M.; Newman, M.E.J. Community Structure in Social and Biological Networks. Proc. Natl. Acad. Sci. USA 2002, 99, 7821–7826. [Google Scholar] [CrossRef] [PubMed]
- Hripcsak, G.; Rothschild, A.S. Agreement, the F-Measure, and Reliability in Information Retrieval. J. Am. Med Informatics Assoc. JAMIA 2005, 12, 296–298. [Google Scholar] [CrossRef] [PubMed]
- Buckley, C.; Voorhees, E. Evaluating evaluation measure stability. In Proceedings of the 23rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Athens Greece, 24–28 July 2000; Association for Computing Machinery: Athens, Greece, 24 July 2000; pp. 33–40. [Google Scholar]
- Löchtefeld, M.; Jäckel, C.; Krüger, A. TwitSoccer: Knowledge-Based Crowd-Sourcing of Live Soccer Events. In Proceedings of the MUM ’15: 14th International Conference on Mobile and Ubiquitous Multimedia, Linz, Austria, 30 November–2 December 2015; ACM: Linz, Austria, 2015; pp. 148–151. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Event Query | Collected (UTC) | Tweets |
|---|---|---|
| #BarcaAtleti, Barca, Barcelona, Atleti, Atletico | 30 June 2020 18:45–19:45 | 6889 |
| #WOLARS, Wolves, Arsenal | 4 July 2020 15:15–16:15 | 26,467 |
| #AVLMUN, Villa, Manchester United | 9 July 2020 18:00–19:00 | 16,044 |
| #LIVBUR, Liverpool, Burnley | 11 July 2020 12:45–13:45 | 9491 |
| #ARSLIV, Arsenal, Liverpool | 15 July 2020 18:00–19:00 | 26,498 |
| #TOTLEI, Tottenham, Leicester | 19 July 2020, 13:45–14:45 | 4006 |
| #LIVCHE, Liverpool, Chelsea | 22 July 2020 18:00–19:00 | 32,360 |
| Nets, Warriors | 22 December 2020 23:00–00:00 | 14,333 |
| Lakers, Clippers | 23 December 2020 02:00–03:00 | 48,141 |
| Celtics, Nets | 25 December 2020 21:00–22:00 | 7030 |
| Lakers, Mavericks | 26 December 2020 00:00–01:00 | 9508 |
| Baseline | Resolution | |||||||
|---|---|---|---|---|---|---|---|---|
| NLTK | TwitterNER | APDNLTK | APDTwitterNER | |||||
| Match | Precision | Recall | Precision | Recall | Precision | Recall | Precision | Recall |
| Barcelona-Atlético Madrid | 0.16 | 0.16 | 0.14 | 0.14 | 0.73 | 0.16 | 0.70 | 0.14 |
| Wolves-Arsenal | 0.20 | 0.22 | 0.14 | 0.16 | 0.56 | 0.11 | 0.67 | 0.13 |
| Aston Villa-Manchester United | 0.32 | 0.36 | 0.42 | 0.47 | 0.93 | 0.31 | 0.95 | 0.40 |
| Liverpool-Burnley | 0.34 | 0.38 | 0.38 | 0.42 | 0.82 | 0.31 | 0.48 | 0.24 |
| Arsenal-Liverpool | 0.34 | 0.38 | 0.28 | 0.31 | 0.76 | 0.29 | 0.80 | 0.27 |
| Tottenham-Leicester | 0.30 | 0.33 | 0.36 | 0.40 | 0.71 | 0.22 | 0.56 | 0.20 |
| Liverpool-Chelsea | 0.20 | 0.22 | 0.26 | 0.29 | 0.50 | 0.20 | 0.53 | 0.22 |
| Nets-Warriors | 0.18 | 0.27 | 0.28 | 0.42 | 0.69 | 0.27 | 0.78 | 0.42 |
| Lakers-Clippers | 0.16 | 0.24 | 0.20 | 0.30 | 0.62 | 0.24 | 0.67 | 0.30 |
| Celtics-Nets | 0.10 | 0.15 | 0.20 | 0.30 | 0.63 | 0.15 | 0.67 | 0.24 |
| Lakers-Mavericks | 0.16 | 0.24 | 0.18 | 0.27 | 0.71 | 0.15 | 0.78 | 0.21 |
| Average | 0.22 | 0.27 | 0.26 | 0.32 | 0.70 | 0.22 | 0.69 | 0.25 |
| APDNLTK | APDTwitterNER | |||
|---|---|---|---|---|
| Match | Precision | Recall | Precision | Recall |
| Barcelona-Atlético Madrid | 0.46 | 0.45 | 0.43 | 0.35 |
| Wolves-Arsenal | 0.58 | 0.47 | 0.65 | 0.49 |
| Aston Villa-Manchester United | 0.54 | 0.60 | 0.70 | 0.78 |
| Liverpool-Burnley | 0.48 | 0.53 | 0.48 | 0.53 |
| Arsenal-Liverpool | 0.58 | 0.64 | 0.58 | 0.64 |
| Tottenham-Leicester | 0.36 | 0.40 | 0.46 | 0.51 |
| Liverpool-Chelsea | 0.58 | 0.64 | 0.66 | 0.73 |
| Nets-Warriors | 0.46 | 0.70 | 0.54 | 0.82 |
| Lakers-Clippers | 0.47 | 0.61 | 0.46 | 0.64 |
| Celtics-Nets | 0.17 | 0.24 | 0.40 | 0.61 |
| Lakers-Mavericks | 0.36 | 0.55 | 0.45 | 0.52 |
| Average | 0.46 | 0.53 | 0.53 | 0.60 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mamo, N.; Azzopardi, J.; Layfield, C. An Automatic Participant Detection Framework for Event Tracking on Twitter. Algorithms 2021, 14, 92. https://doi.org/10.3390/a14030092
Mamo N, Azzopardi J, Layfield C. An Automatic Participant Detection Framework for Event Tracking on Twitter. Algorithms. 2021; 14(3):92. https://doi.org/10.3390/a14030092
Chicago/Turabian StyleMamo, Nicholas, Joel Azzopardi, and Colin Layfield. 2021. "An Automatic Participant Detection Framework for Event Tracking on Twitter" Algorithms 14, no. 3: 92. https://doi.org/10.3390/a14030092
APA StyleMamo, N., Azzopardi, J., & Layfield, C. (2021). An Automatic Participant Detection Framework for Event Tracking on Twitter. Algorithms, 14(3), 92. https://doi.org/10.3390/a14030092