5.1. Experimental Setting
Dataset description. We have evaluated our approach on two datasets that are classical in the fairness literature, namely the
Adult Census Income as well as on
German Credit. Both are available on the UCI repository (
https://archive.ics.uci.edu/ml/index.php) (accessed on 20 November 2017). Adult Census reports the financial situation of individuals, with 45,222 records after the removal of rows with empty values. Each record is characterized by 15 attributes among which we selected the
gender (i.e., male or female) as the sensitive one and the
income level (i.e., over or below 50 K
$) as the decision. German Credit is composed of 1000 applicants to a credit loan, described by 21 of their banking characteristics. Previous work [
49] have found that using the
age as the sensitive attribute by binarizing it with a threshold of 25 years to differentiate between old and young yields the maximum discrimination based on
. In this dataset, the decision attribute is the quality of the customer with respect to their credit score (i.e., good or bad).
Table 2 summarizes the distribution of the different groups with respect to
S and Y. We will mostly discuss the results on Adult dataset in this section. However, the results obtained on German credit were quite similar.
Datasets preprocessing. The preprocessing step consists in shaping and formatting the data such that it can be used by the neural network models. The first step consists in the one-hot encoding of categorical and numerical attributes with less than 5 values, followed by a scaling between 0 and 1.
Besides on Adult dataset, we need to apply a logarithm on columns
-
and
-
before any step because those attributes exhibit a distribution close to a Dirac delta [
50], with the maximal values being, respectively, 9999 and 4356, and a median of 0 for both (respectively
and
of records have a value of 0). Since most values are equal to 0, the sanitizer will always nullify both attributes and the approach will not converge. Afterward, postprocessing steps consisting of reversing the preprocessing ones are performed in order to remap the generated data onto their original shape.
Models hyper-parameters.Table 3 details the structure of neural networks that have yielded the best results, respectively, on the Adult and German credit datasets. The training rate represents the number of times for which an instance is trained during a single iteration. For instance, for an iteration
i, the discriminator is trained with
records while the sanitizer is trained with
records. The number of iterations is equal to:
. Our experiments were run for a total of 40 epochs and the value of
was varied using a geometric progression:
. We refer the reader to
Section 5.4 for a comparison of the execution time of our approach compared to other methods.
Training process. We will evaluate
GANSan using metrics such as the fidelity
, the
as well as the demographic parity
(cf.
Section 4.2). For this, we have conducted a 10-fold cross-validation during which the dataset is divided into ten blocks. During each fold, 8 blocks are used for the training, while another one is retained as the validation set and the last one as the test set.
We computed the
and
using the internal discriminator of
GANSan and three external classifiers independent of the
GANSan framework, namely
Support Vector Machines (SVM) [
51],
Multilayer Perceptron (MLP) [
52] and
Gradient Boosting (GB) [
53]. For all these external classifiers and all epochs, we report the space of achievable points with respect to the fidelity/fairness trade-off. Note that most approaches described in the related work (cf.
Section 3) do not validate their results with independent external classifiers trained outside of the sanitization procedure. The fact that we rely on three different families of classifiers is not foolproof, in the sense that it might exist other classifiers that we have not tested that can do better, but it provides higher confidence in the strength of the sanitization than simply relying on the internal discriminator.
For each fold and each value of
, we train the sanitizer during 40 epochs. At the end of each epoch, we save the state of the sanitizer and generate a sanitized dataset on which we compute the
,
and
. Afterwards,
is used to select the sanitized dataset that is closest to the “ideal point” (
). More precisely,
is defined as follows:
with
referring to the minimum value of
obtained with the external classifiers. For each value of
,
selects among the sanitizers saved at the end of each epoch, the one achieving the highest fairness in terms of
for the lowest damage. We will use the three families of external classifiers for computing
,
and
. We also used the same chosen sanitized test set to conduct a detailed analysis of its reconstruction’s quality (
and quantitative damage on attributes).
5.2. Evaluation Scenarios
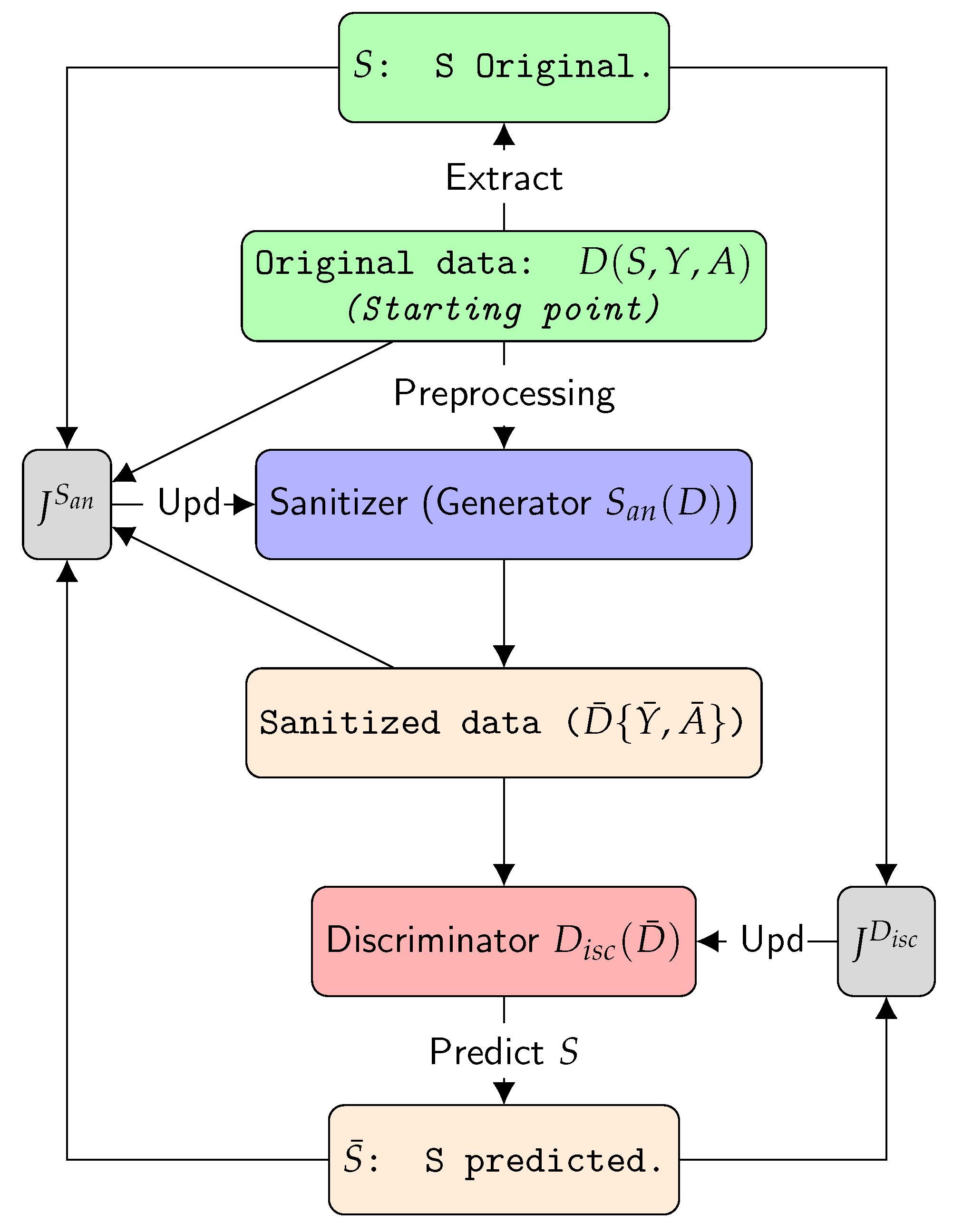
Recall that GANSan takes as input the whole original dataset (including the sensitive and the decision attributes) and outputs a sanitized dataset (without the sensitive attribute) in the same space as the original one, but from which it is impossible to infer the sensitive attribute. In this context, the overall performance of GANSan can be evaluated by analyzing the reachable space of points characterizing the trade-off between the fidelity to the original dataset and the fairness enhancement. More precisely, during our experimental evaluation, we will measure the fidelity between the original and the sanitized data, as well as the , both in relation with the and , computed on this dataset.
However, in practice, our approach can be used in several situations that differ slightly from one another. In the following, we detail four scenarios that we believe are representing most of the possible use cases of
GANSan. To ease the understanding, we will use the following notation: the subscript
(respectively
) will denote the data in the training set (respectively test set). For instance,
,
,
or
represent, respectively, the attributes of the original training set (not including the sensitive and the decision attributes), the decision in the original training set, the attributes of the sanitized training set and the decision attribute in the sanitized training set.
Table 4 describes the composition of the training and the testings sets for these four scenarios.
Scenario 1: complete data debiasing. This setting corresponds to the typical use of the sanitized dataset, which is the prediction of a decision attribute through a classifier. The decision attribute is also sanitized as we assumed that the original decision holds information about the sensitive attribute. Here, we quantify the accuracy of prediction of
as well as the discrimination represented by the
demographic parity (Equation (
1)) and
equalized odds (Equation (
2)).
Scenario 2: partial data debiasing.
In this scenario, similarly to the previous one, the training and the test sets are sanitized with the exception that the sanitized decision in both these datasets
is replaced with the original one
. This scenario is generally the one considered in the majority of papers on fairness enhancement [
24,
26,
34], the accuracy loss in the prediction of the original decision
between this classifier and another trained on the original dataset without modifications
is a straightforward way to quantify the utility loss due to the sanitization.
Scenario 3: building a fair classifier. This scenario was considered in [
23] and is motivated by the fact that the sanitized dataset might introduce some undesired perturbations (e.g., changing the education level from Bachelor to PhD). Thus, a third party might build a fair classifier but still apply it directly on the unperturbed data to avoid the data sanitization process and the associated risks. More precisely in this scenario, a fair classifier is obtained by training it on the sanitized dataset
to predict the sanitized decision
. Afterwards, this classifier is tested on the original data (
) by measuring its fairness through the demographic parity (Equation (
1),
Section 2). We also compute the accuracy of the fair classifier with respect to the original decision of the test set
.
Scenario 4: local sanitization. The local sanitization scenario corresponds to the local use of the sanitizer by the individual himself. For instance, the sanitizer could be used as part of a mobile phone application providing individuals with a means to remove some sensitive attributes from their profile before disclosing them to an external entity. In this scenario, we assume the existence of a biased classifier, trained to predict the original decision on the original dataset . The user has no control over this classifier, but he is allowed nonetheless to perform the sanitization locally on their profile before submitting it to the existing classifier similarly to the recruitment scenario discussed in the introduction. This classifier is applied on the sanitized test set and its accuracy is measured with respect to the original decision as well as its fairness quantified by .
The local sanitization let the user chooses whether or not he wants to sanitize their data, which may lead to the situation in which some users decide not to apply the sanitization process on their data. We evaluate this setting in
Section 5.3.1, in particular with respect to the amount of protection provided to users.
5.3. Experimental Results
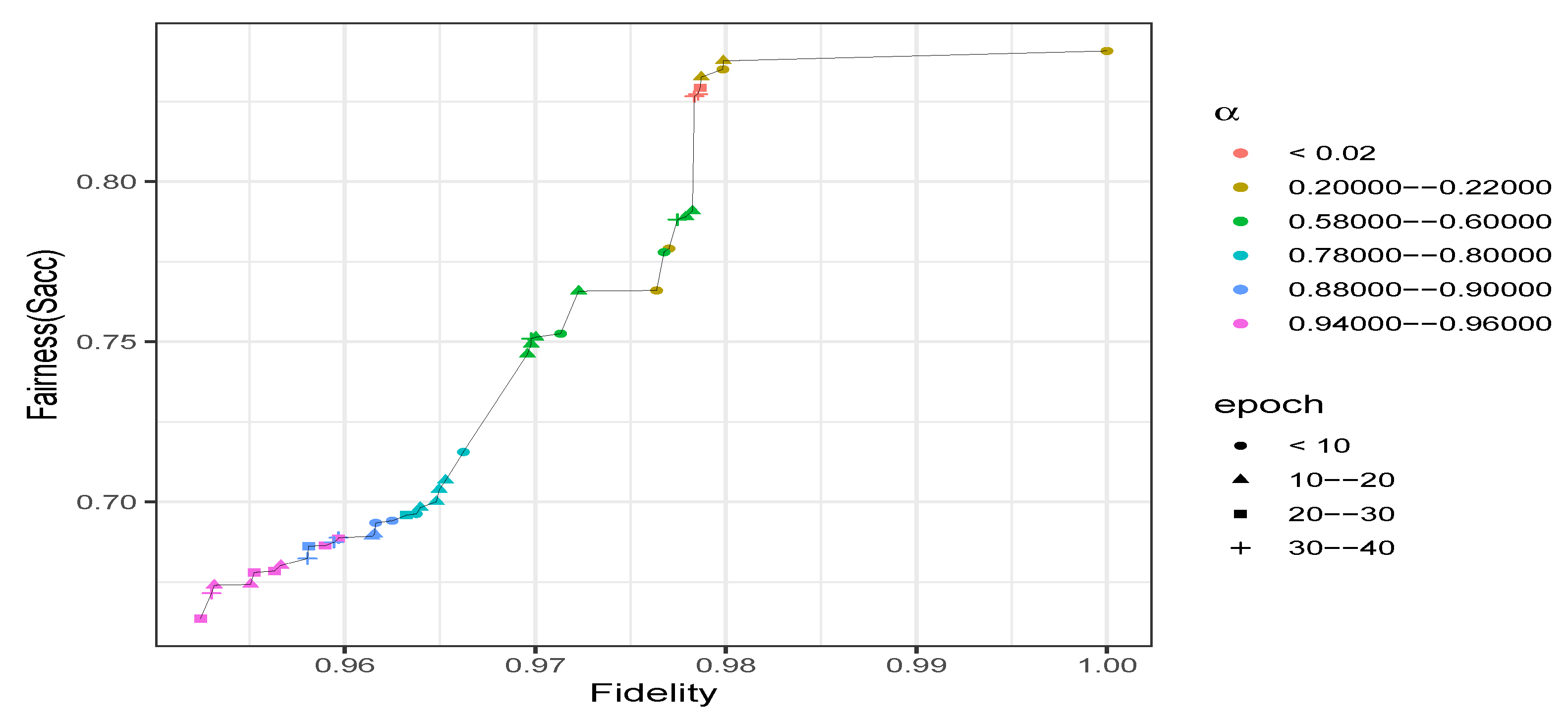
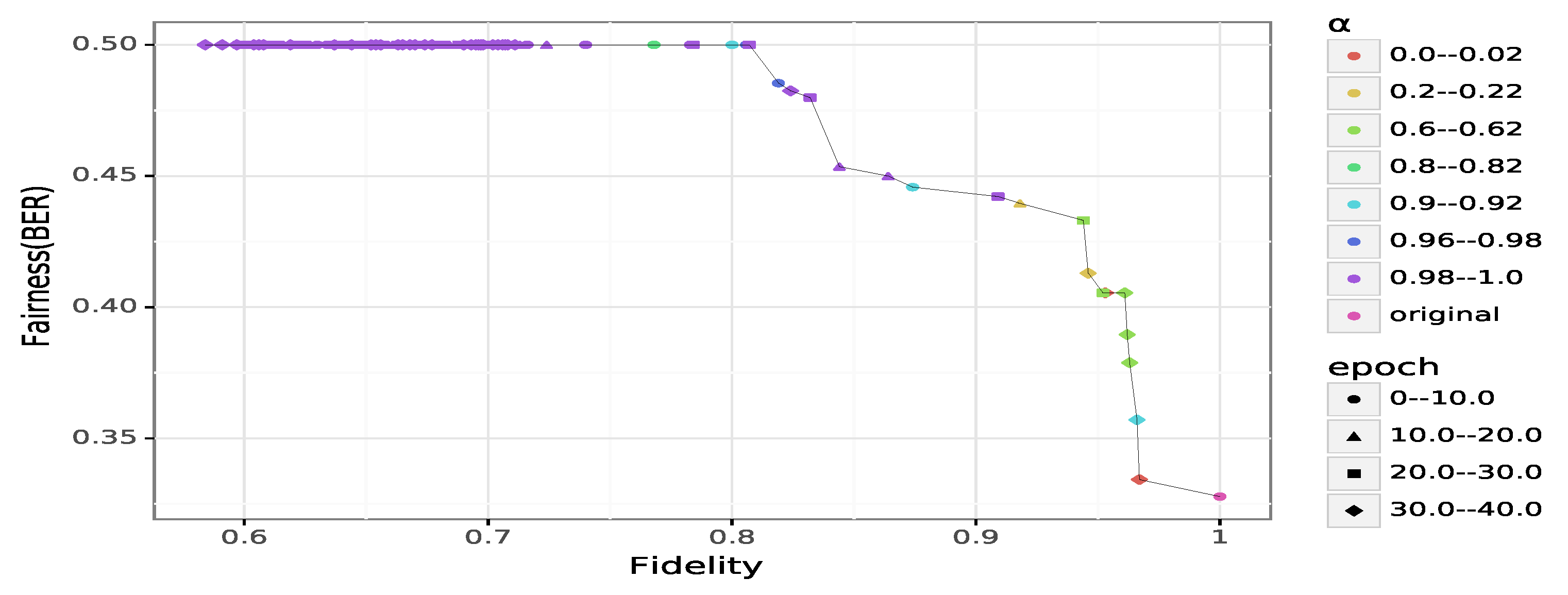
General results on Adult.Figure 2 describes the achievable trade-off between fairness and fidelity obtained on Adult. First, we can observe that fairness improves when
increased as expected. Even with
(i.e., maximum utility with no focus on the fairness), we cannot reach a perfect fidelity to the original data as we get at most
(cf.
Figure 2). Increasing the value of
from 0 to a low value such as
provides a fidelity close to the highest possible (
), but leads to a BER that is poor (i.e., not higher than
). Nonetheless, we still have a fairness enhancement, compared to the original data (
,
).
At the other extreme in which , the data is sanitized without any consideration of the fidelity. In this case, the is optimal as expected and the fidelity is lower than the maximum achievable (). However, slightly decreasing the value of , such as setting , allows the sanitizer to significantly remove the unwarranted correlations () with a cost of on fidelity ().
With respect to
, the accuracy drops significantly when the value of
increases (cf.
Figure 3).
GANSan renders the accuracy of predicting
S from the sanitized set closer to the optimal values, which is the proportion of the privileged group in this case. However, it is nearly impossible to reach that ideal value, even at the extreme sanitization
. Similarly to BER, slightly decreasing
(from 1) by setting
improves the sanitization while leading to a fidelity closer to the achievable maximum.
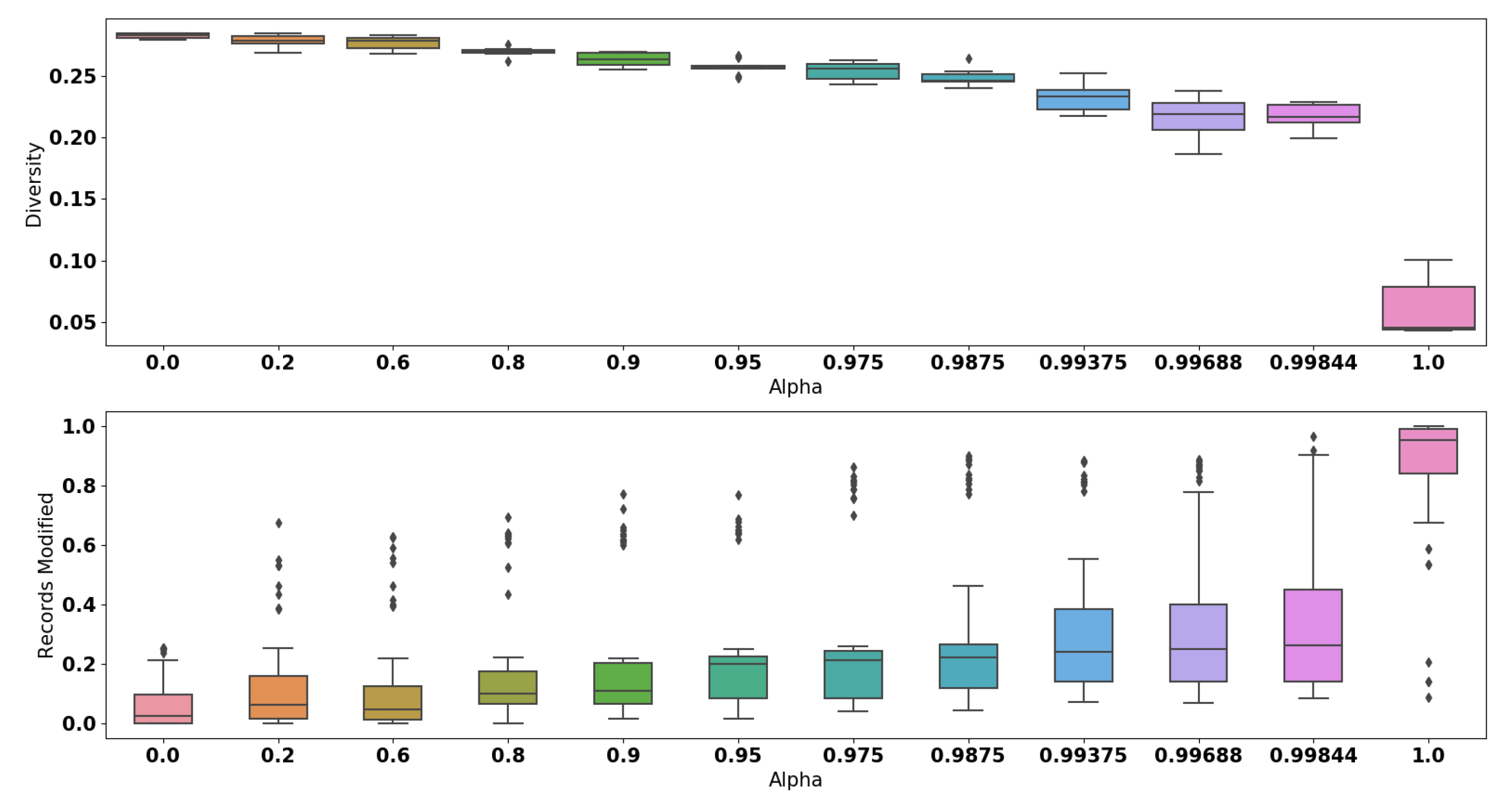
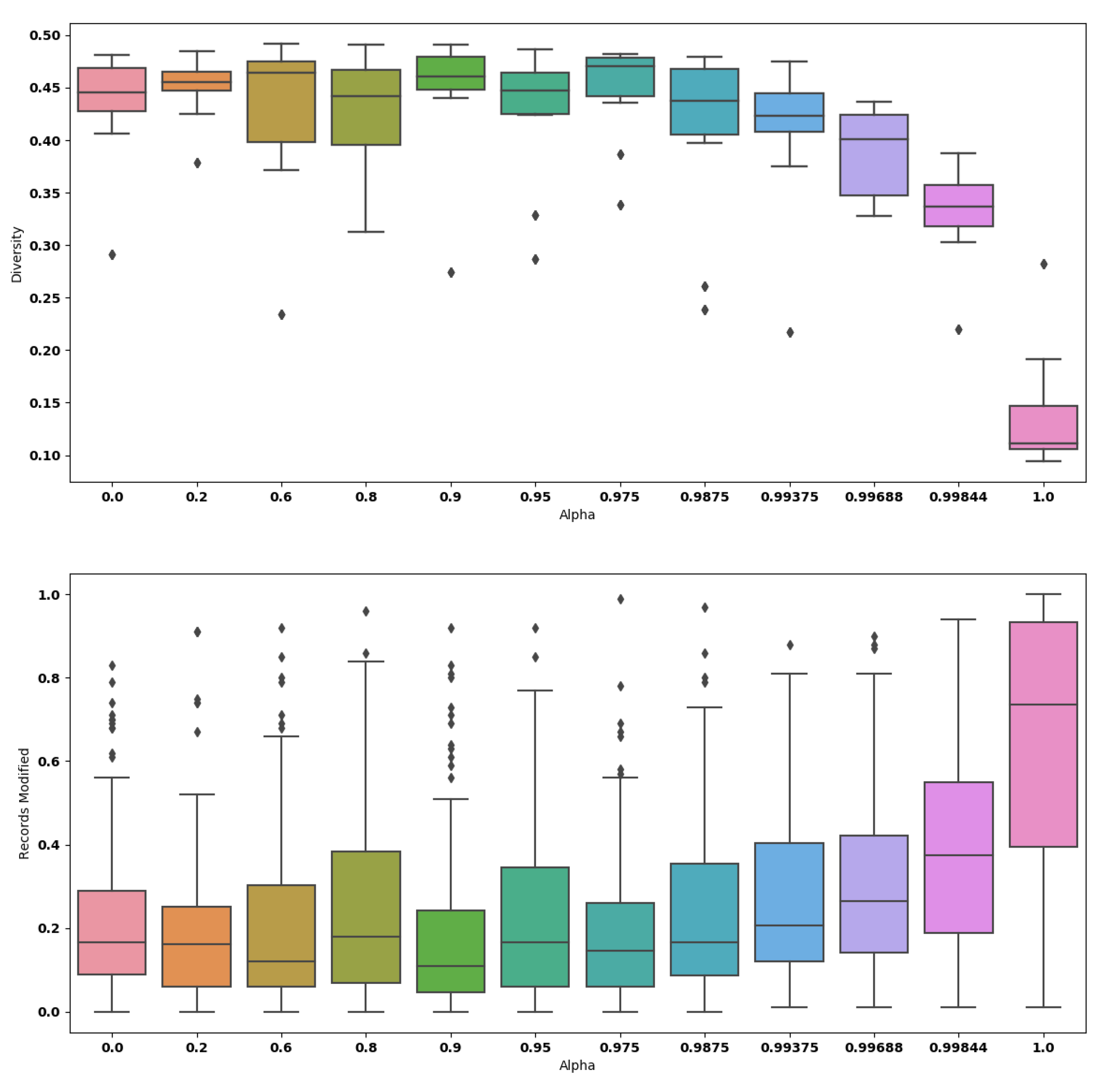
The quantitative analysis with respect to the diversity is shown in
Figure 4. More precisely, the smallest drop of diversity obtained is
, which is achieved when we set
. Among all values of
, the biggest drop observed is
. The application of
GANSan, therefore introduces an irreversible perturbation as observed with the fidelity. This loss of diversity implies that the sanitization reinforces the similarity between sanitized profiles as
increases, rendering them almost identical or mapping the input profiles to a small number of stereotypes. When
is in the range
(i.e., complete sanitization),
of categorical attributes have a proportion of modified records between
and
(cf.
Figure 4).
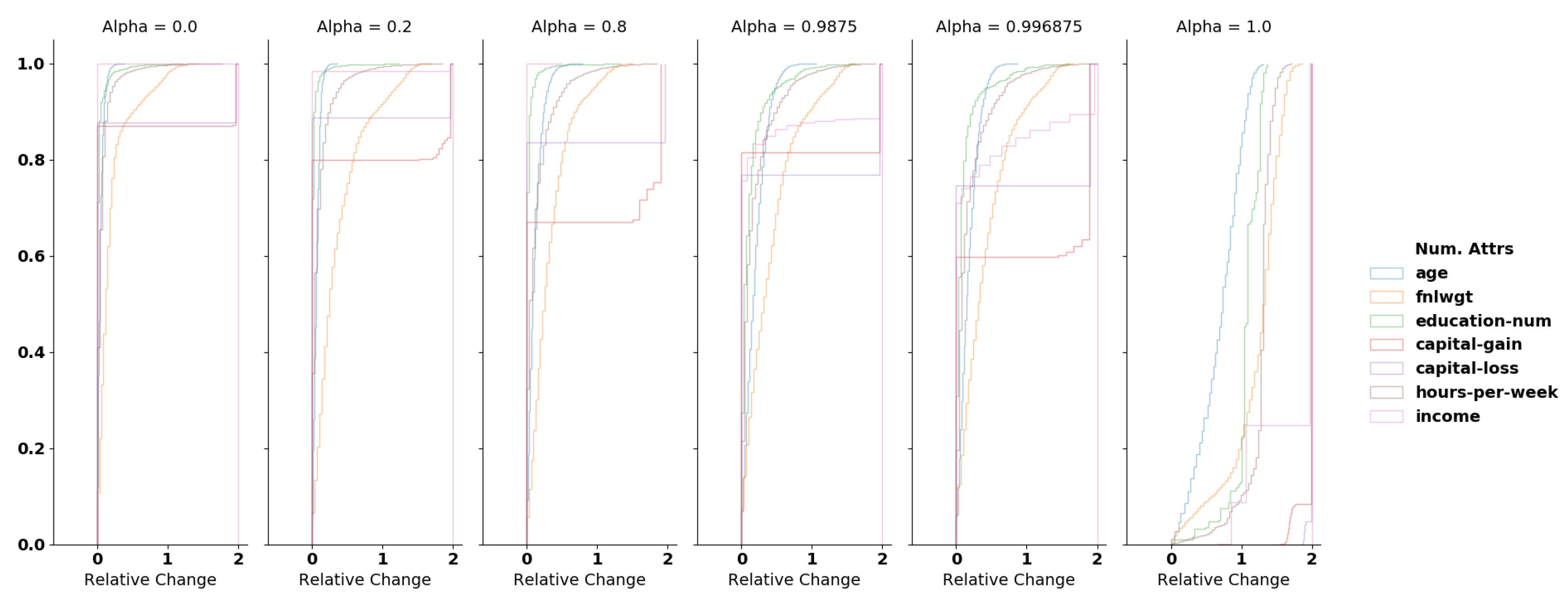
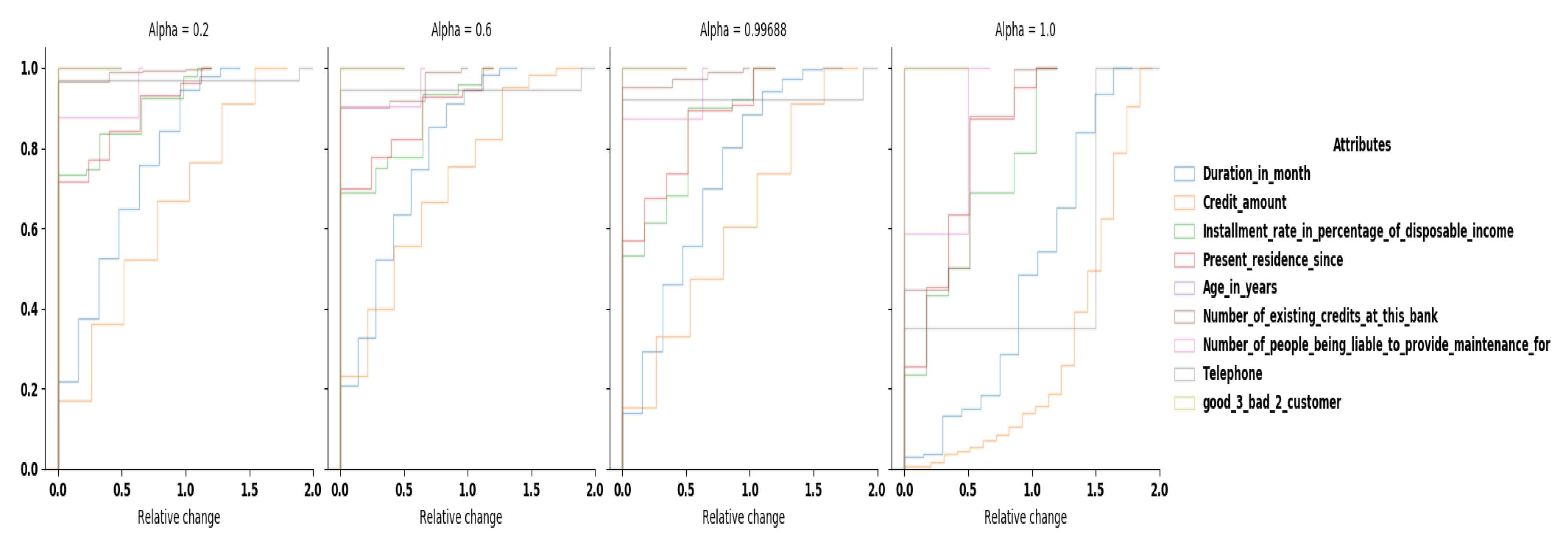
For numerical attributes, we compute the relative change (
RC) normalized by the mean of the original and sanitized values:
We normalize the RC using the mean (since all values are positives) as it allows us to handle situations in which the original values are equal to 0. With the exception of the extreme sanitization (
), at least
of records in the dataset have a relative change lower than
for most of the numerical attributes. Selecting
leads to
of records being modified with a relative change less than
(cf.
Figure A1 in
Appendix A).
General results on German.
Similarly to Adult, the protection increases with . More precisely (maximum reconstruction) achieves a fidelity of almost . The maximum protection of corresponds to a fidelity of and a sensitive accuracy value of .
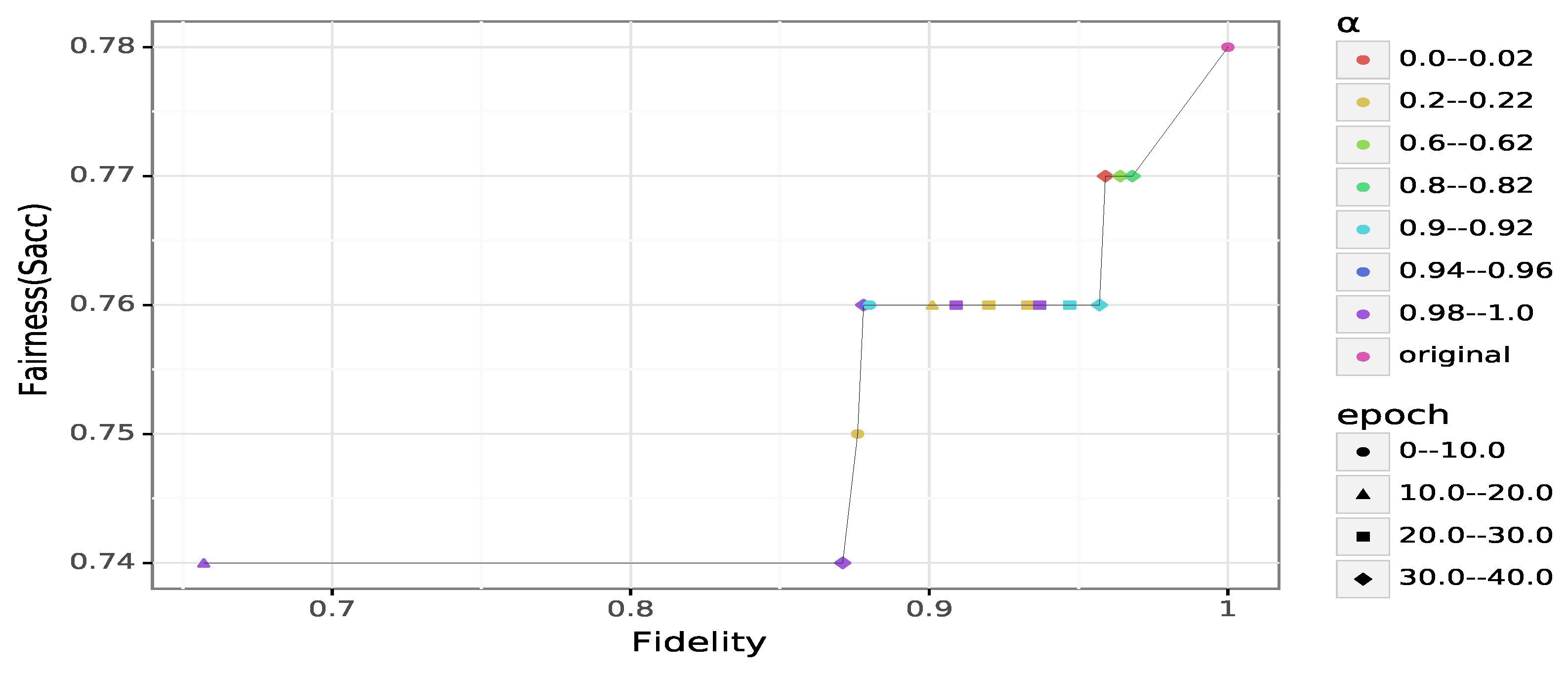
We can observe on
Figure 5 that most values are concentrated on the
plateau, regardless of the fidelity and the value of
. We believe this is due to the high disparity of the dataset. The fairness on German credit is initially quite high, being close to
. Nonetheless, we can observe three interesting trade-offs on
Figure 6, each located at a different shoulder of the Pareto front. These trade-offs are
A (
),
B (
) and
C (
), each achievable with
for the first one, and
for the rest.
We review the diversity and the sanitization induced damage on categorical attributes in
Figure 7. As expected, the diversity decreases with alpha, rendering most profiles identical with
. We can also observe some instabilities: higher
values produce a shallow range of diversities (i.e.,
) while smaller values have a higher range of diversities. Such instability is mainly explained by the size and the imbalance of the dataset, which does not allow the sanitizer to correctly learn the distribution (such phenomenon is common when training GANs with a small dataset). Nonetheless, most of the diversity results prove close to the original one, that is
. The same trend is observed on the categorical attribute damage. For most values of
, the median damage is below or equal to
, meaning that we have to modify only two categorical columns in a record to remove unwanted correlations. For the numerical damage, most columns have a relative change lower than
for more than
of the dataset, regardless of the value of
. Only columns
Duration in month and
Credit amount have a higher damage. This is due to the fact that these columns have a very large range of possible values compared to the other columns (33 and 921), especially for column
Credit amount which also exhibits a nearly uniform distribution. Our reference points
A,
B and
C have a median damage close to
for
A and
for both
B and
C. The damage on categorical columns is also acceptable.
To summarise our results, GANSan is able to maintain an important part of the dataset structure despite sanitization, making it usable for other analysis tasks. This is notably demonstrated by the lower damage and modifications, which preserve as much as possible of the original data values. Thus, results obtained on the sanitized dataset would therefore be close to those obtained on the original data, except on tasks involving the correlations with the sensitive attribute.
Nonetheless, at the individual level, some perturbations might have a more fundamental impact on some profiles than on others. Future work will investigate the relationship between the characteristics of a profile and the damage introduced. For the different scenarios investigated hereafter, we fixed the values of
to
and
, which provides nearly a perfect level of sensitive attribute protection (respectively,
and
) while leading to an acceptable damage on Adult (
and
). With respect to German, the results obtained for the different scenarios are analyzed and discussed in Appendix
B.2.
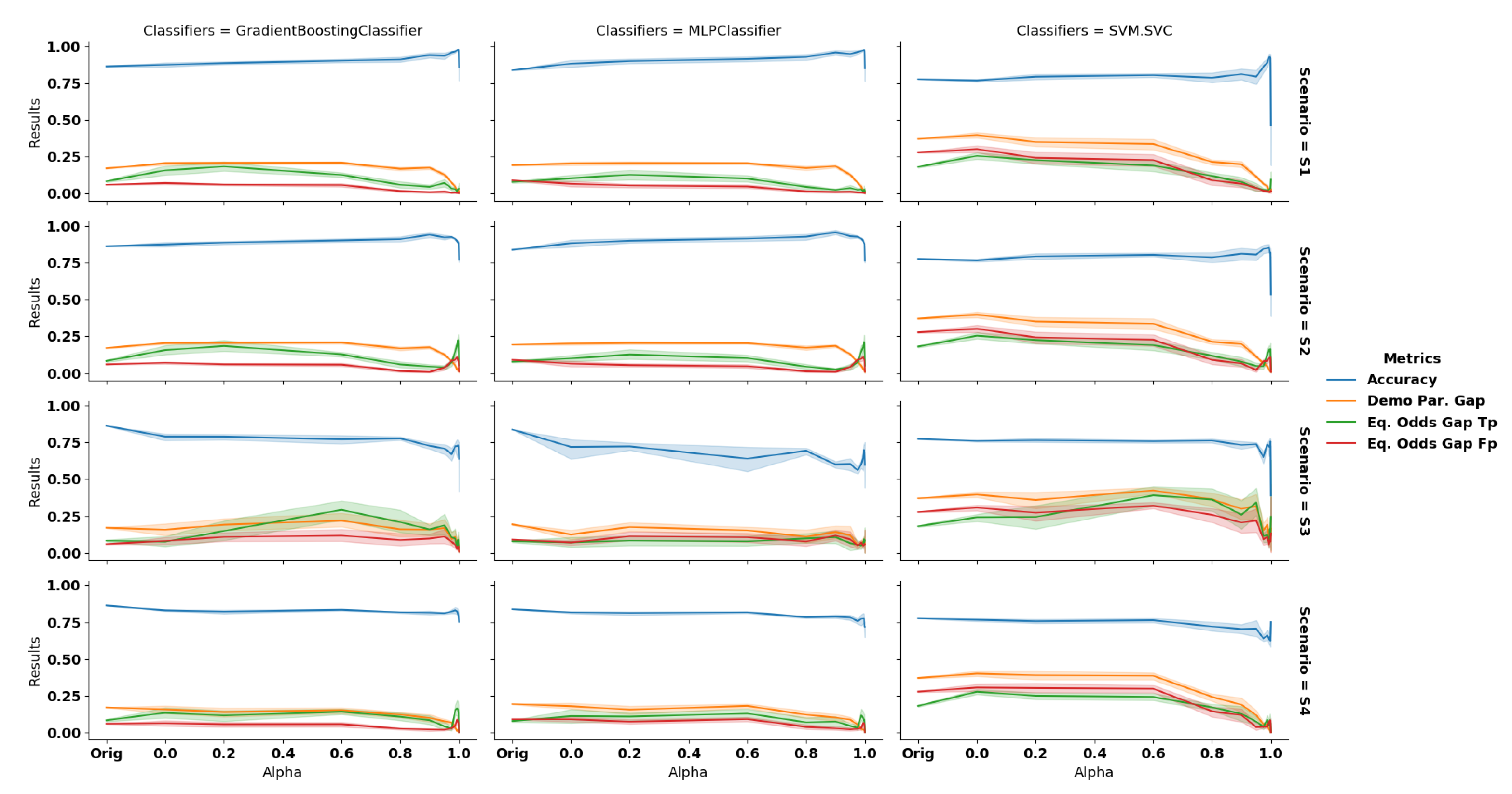
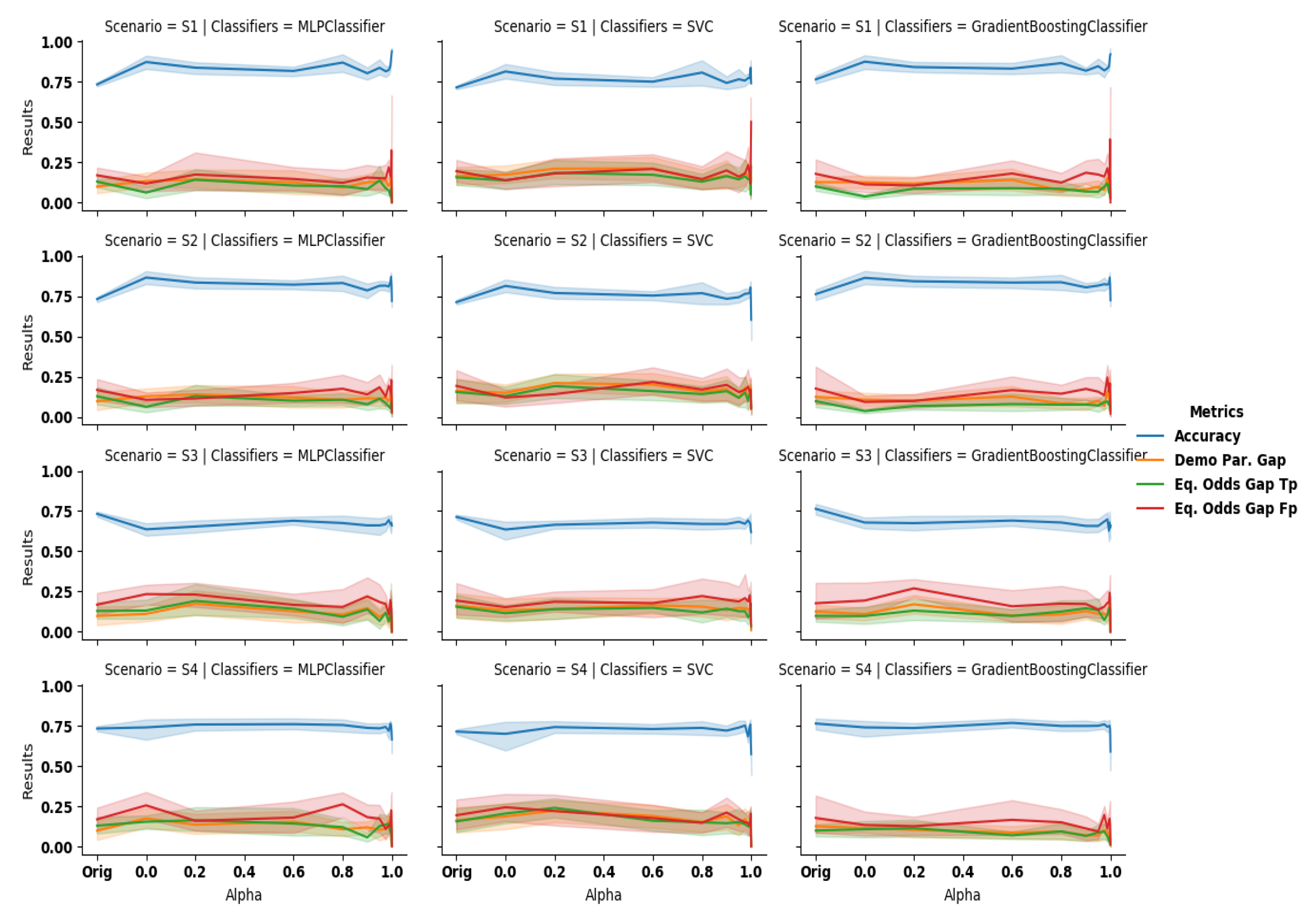
Scenario 1: complete data debiasing. In this scenario, we observe that
GANSan preserves the accuracy of the dataset. More precisely, it increases the accuracy of the decision prediction on the sanitized dataset for all classifiers (cf.
Figure 8,
Scenario S1),compared to the original one which is
,
and
, respectively, for GB, MLP, and SVM. This increase can be explained by the fact that
GANSan modifies the profiles to make them more coherent with the associated decision, by removing correlations between the sensitive attribute and the decision one. As a consequence, this sets the same decision to similar profiles in both the protected and the privileged groups. In fact, nearly the same distributions of decision attribute are observed before and after the sanitization but some record’s decisions are shifted (
of decision shifted in the sanitized whole set,
of decision shifted in the sanitized sensitive group for
). Such decision shift could be explained by the similarity between those profiles to others with the opposite decisions in the original dataset. We also believe that the increase in accuracy is correlated with the drop of diversity. More precisely, if profiles become similar to each other, the decision boundary might be easier to find.
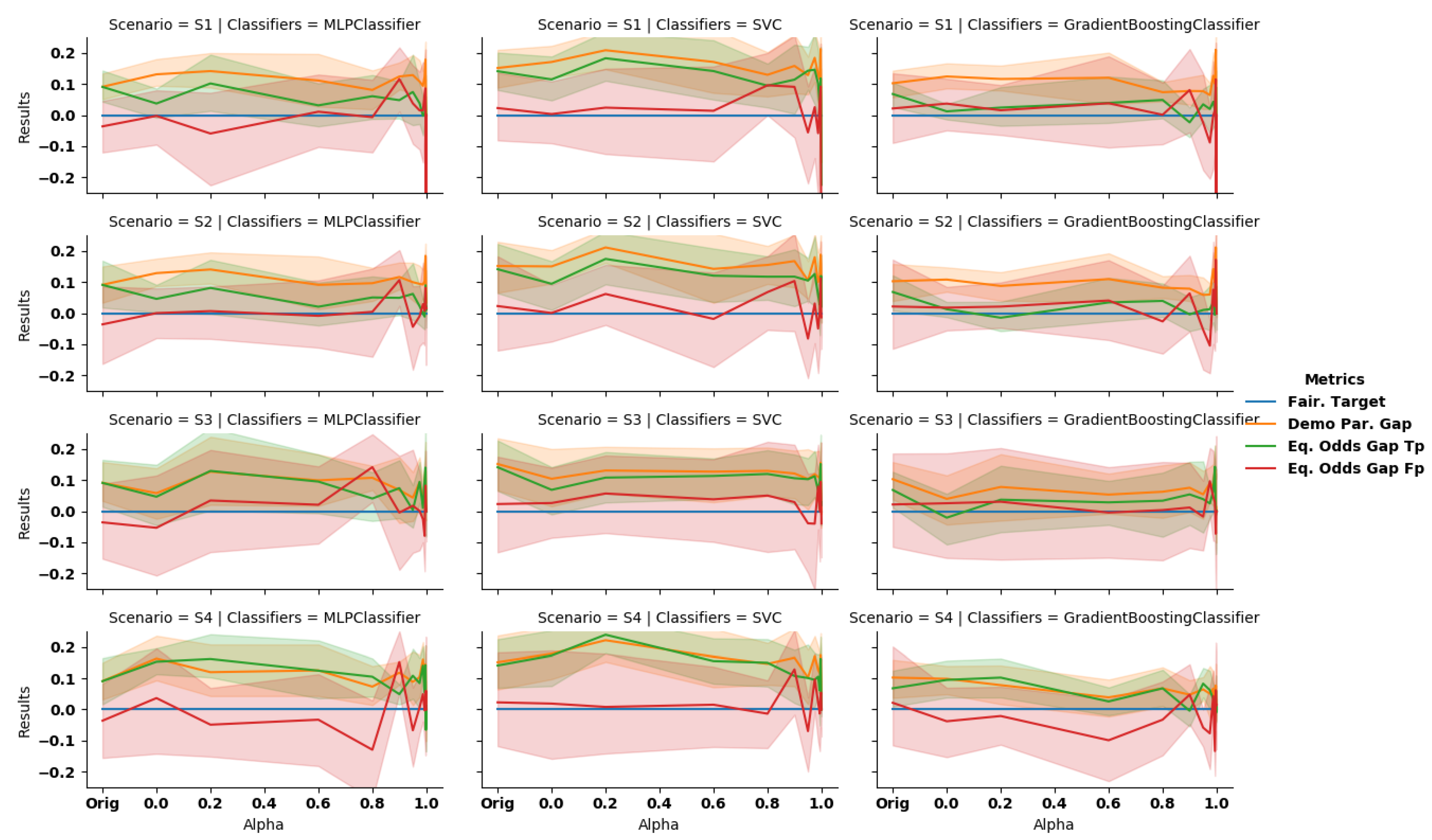
The discrimination is reduced as observed through
,
and
, which all exhibit a negative slope. When correlations with the sensitive attribute are significantly removed (
), those metrics also significantly decrease. For
,
,
,
,
and
for GB; whereas as the original demographic parity gap and equalized odds gap are, respectively,
,
. The performances are improved further for
. In this situation, the results obtained are, respectively,
,
,
,
and
(cf.,
Table A1 and
Table A2 in appendices for more details). In this setup,
FairGan [
23] achieves a BER of
an accuracy of
and a demographic parity of
, while
FairGan+ [
40] reached a protection of BER of
an accuracy of
and a demographic parity of
.
Scenario 2: partial data debiasing. Somewhat surprisingly, we observe an increase in accuracy for most values of alpha. The demographic parity also decreases while the equalized odds remains nearly constant (
, green line on
Figure 8).
Table 5 compare the results obtained to other existing work from the state-of-the-art. We include the classifier with the highest accuracy (MLP) and the one with the lowest one (SVM).
From these results, we can observe that
GANSan outperforms the other methods in terms of accuracy, but the lowest demographic parity is achieved with
FairGan+ [
40] (
). This is not surprising as this method is precisely tailored to reduce this metric. Our approach, as well as
FairGan [
23], do not perform well with the use of the original decisions (metric
). We believe that these poor performances are due to the fact that correlations with original decisions have been removed from the dataset, thus making the new predictions not aligned with the original ones. We also observe that the demographic parity has been improved and our method provides one of the best results on this metric.
FairGan+ [
36] and MUBAL [
36] achieve the best results on the equalized odds metrics as they have been specifically tailored to tackle these metrics. Even though our method is not specifically constrained to mitigate the demographic parity, we can observe that it significantly improve it. Thus, while partial data debiasing is not the best application scenario for our approach as the original decision might be correlated with the sensitive attribute, it still mitigates its effect to some extent.
Scenario 3: building a fair classifier. The sanitizer helps to reduce discrimination based on the sensitive attribute, even when using the original data on a classifier trained on the sanitized one. As presented in the third row of
Figure 8, as we force the system to completely remove the unwarranted correlations, the discrimination observed when classifying the original unperturbed data is reduced. On the other hand, the accuracy exhibits here the highest negative slope with respect to all the scenarios investigated. More precisely, we observe a drop of
for the best classifier in terms of accuracy on the original set, which can be explained by the difference of correlations between
A and
Y and between
and
. As the fair classifiers are trained on the sanitized set (
and
), the decision boundary obtained is not relevant for
A and
Y.
FairGan [
23], which also investigated this scenario, achieves
and
whereas our GB classifier achieves
and
for
and
and
for
.
Scenario 4: local sanitization. On this setup, we observe that the discrimination is lowered as the coefficient increases. Similarly to other scenarios, the larger the correlations with the sensitive attribute are removed, the higher the drop of discrimination as quantified by the , as well as , and the lower the accuracy on the original decision attribute. For instance, with GB we obtain , at and , for (the original values were and ). We have also evaluated the metric using sanitized decisions instead of the original ones We observed that the results significantly improve, especially for equalized odds. More precisely, the accuracy of GB increases to for , while the equalized odds varies from and (original decision) to and (sanitized decision). As explained in scenario S2, this suggests that correlations with the original decisions are not preserved by the sanitization process (DemoParity remains unchanged as they only involve the predicted decisions, which is independent of the ground truth).
Our observations highlights the possibility that GANSan can be used locally, thus allowing users to contribute to large datasets by sanitizing and sharing their information without relying on any third party, with the guarantee that the sensitive attribute GANSan has been trained for is removed.
The drop of accuracy due to the local sanitization is on GB ( with MLP). Thus, for applications requiring a time-consuming training phase, using GANSan to sanitize profiles without retraining the classifier seems to be a good compromise.
5.3.1. Effect of Mixed Data Composition
In the local sanitization scenario, the user could possibly decide to sanitize their data or publish it unmodified. In this section, we assess the amount of protection and fairness obtained when some users decide not to sanitize their data, resulting in a dataset composed of original and sanitized data. In fact, some users might believe that the sanitization would reduce the advantage due to their group membership and would not sanitize their data in consequence. More precisely, we consider the following settings:
All. A random (i.e., regardless of their group membership) proportion of users did not use the sanitizer and instead submitted their profiles unmodified.
Prt. All users of the privileged group sanitized their respective profiles while some others from the protected group published their original profiles.
Prv. All members of the protected group deemed the application of the sanitization process useful while some users from the privileged group disregarded it. Thus, the dataset is composed of all sanitized profiles from the protected group and a mix of sanitized and original profiles from the privileged one.
For these settings, we varied the proportion p () of the original data composing each group (settings Prt and Prv) or composing the dataset (setting All). For instance, in setting with (), the dataset is composed of all of the protected group sanitized profiles, and of the privileged group data are unmodified.
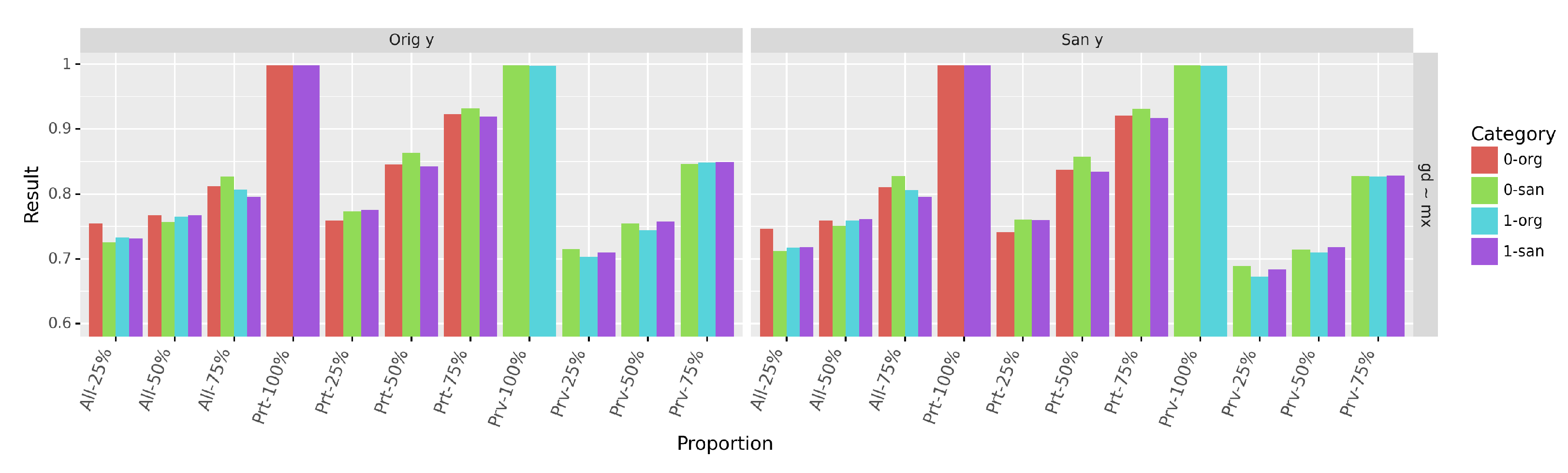
For each sanitized profile, we have carried out experiments using both the original (Orig y) and the sanitized decisions (San y). The resulting dataset (mixed dataset ) is randomly split into a training and a testing set of size and of the total dataset. Furthermore, each experiment is repeated across the 10-fold cross-validation of the sanitization process. We computed the between a classifier trained on mixed data () and the same classifier trained on the sanitized data () to predict the decision: . We also computed the agreement obtained when training a classifier and predicting decisions using the mixed data and using the original one (). In a nutshell, the quantifies how much a classifier behaves similarly in different contexts, by looking at the proportion of data points that received the same predicted decision across all contexts. A high indicates that the impact on the original data is limited, in which case the sanitization neither hinders the performance of the predictor nor disadvantages a particular group.
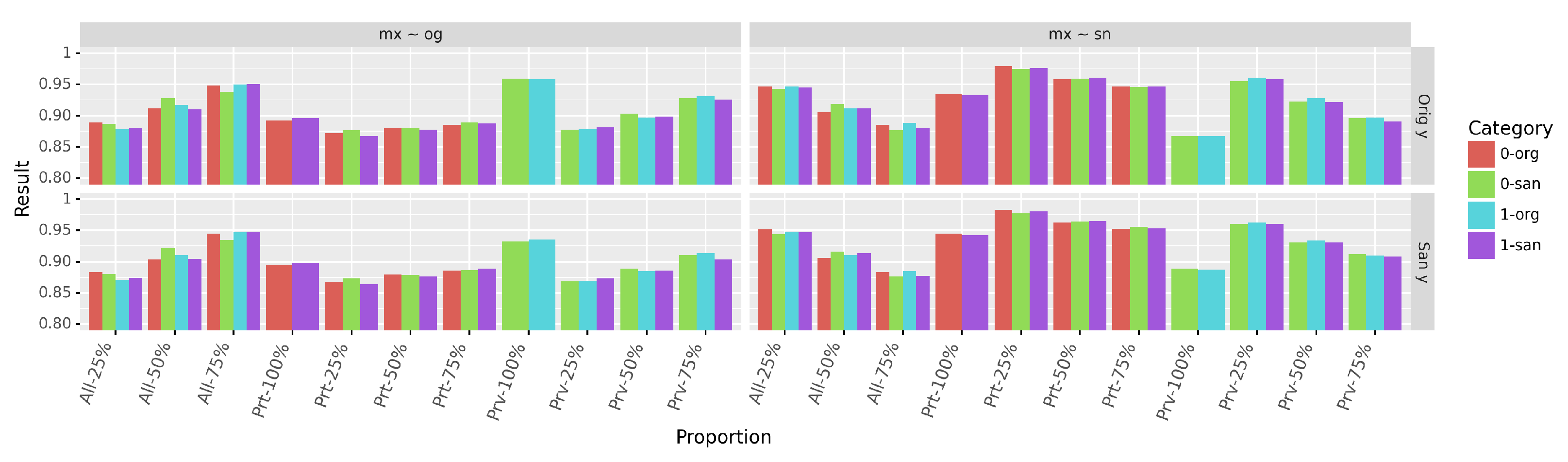
As shown in
Figure 9, agreements
(second column of
Figure 9) and
(first column of
Figure 9) are above
for all proportions of mixed data, regardless of the decisions. More generally, we have observed that the use of original decisions (
Orig y) results in a lower agreement than with sanitized ones (
San y), because of the reduction of correlations between the data and the original decision. If original decisions are not transformed (by the sanitization) in relation to other attributes, they could still incorporate some form of unfairness (as observed with scenarios
and
).
Sanitizing the privileged group data have the highest impact on both and since it is the largest group of the dataset. This impact is also more pronounced with the original decisions. As a consequence, the highest agreement overall is achieved at - with sanitized decisions ( and San y). The agreement is the lowest at proportion - when using the sanitized decisions and at proportion - when using original ones. These drops are explained by the fact that most original profiles have not been sanitized, as well as the reduction of correlations between the sanitized profiles and original decisions. In fact, the agreement is maximal at those identical proportions.
The high values of demonstrates that a classifier trained to predict decisions with the sanitized data and one trained on mixed data (as obtained with the local sanitization) behave similarly. Thus, we can expect both classifiers to achieve similar performances with respect to fairness metrics.
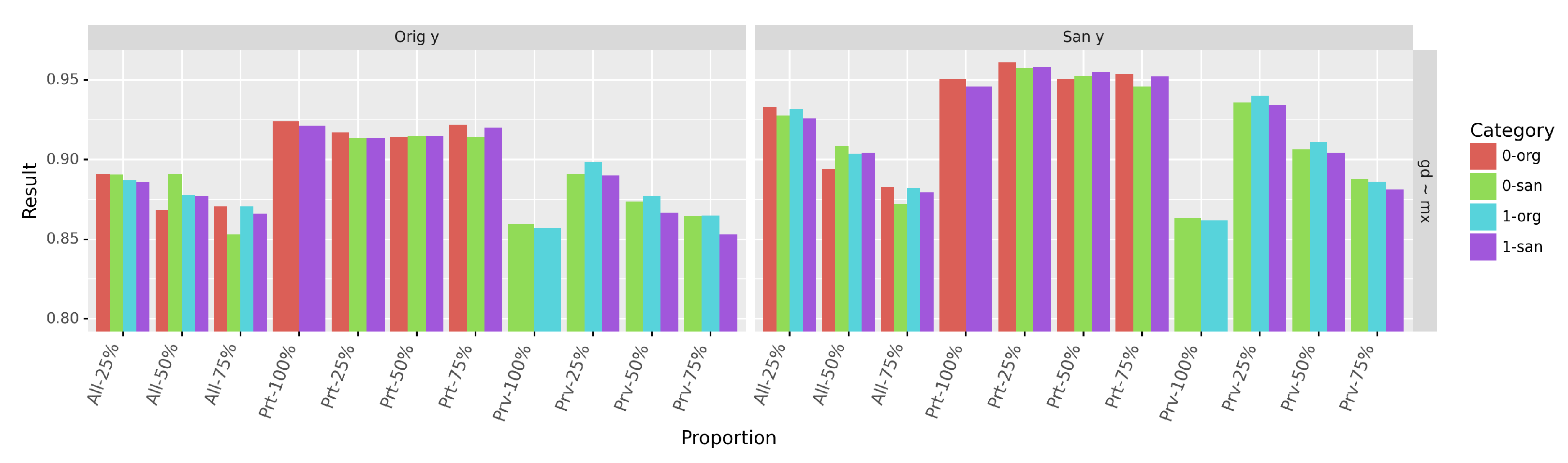
We report in
Figure 10 the accuracy of predicting the sensitive attribute (
) on each group and each data version (
original and
sanitized). As expected, the small proportion of the protected group causes the accuracy to increase with the proportion
p, especially when the profiles of the protected group are not sanitized
-
or when then sanitization is applied on randomly selected profiles (
-
).
By looking at the classifier behavior on both the original and the sanitized parts of the mixed data, we can conclude that predicting the sensitive attribute could be viewed as two different operations: distinguishing the original from the sanitized profiles (which is easily performed as observed on proportions
-
and
-
) and distinguishing between the sanitized privileged and the sanitized protected profiles by leveraging on the additional information provided by the original profiles. We can also observe on
Figure 10 that the impact of this additional information is highly dependent on the underlying distribution. For the same proportion
p, keeping the original data from the privileged group (
-
) has a limited impact on the accuracy compared to the increase due to the original data from the protected one (
-
).
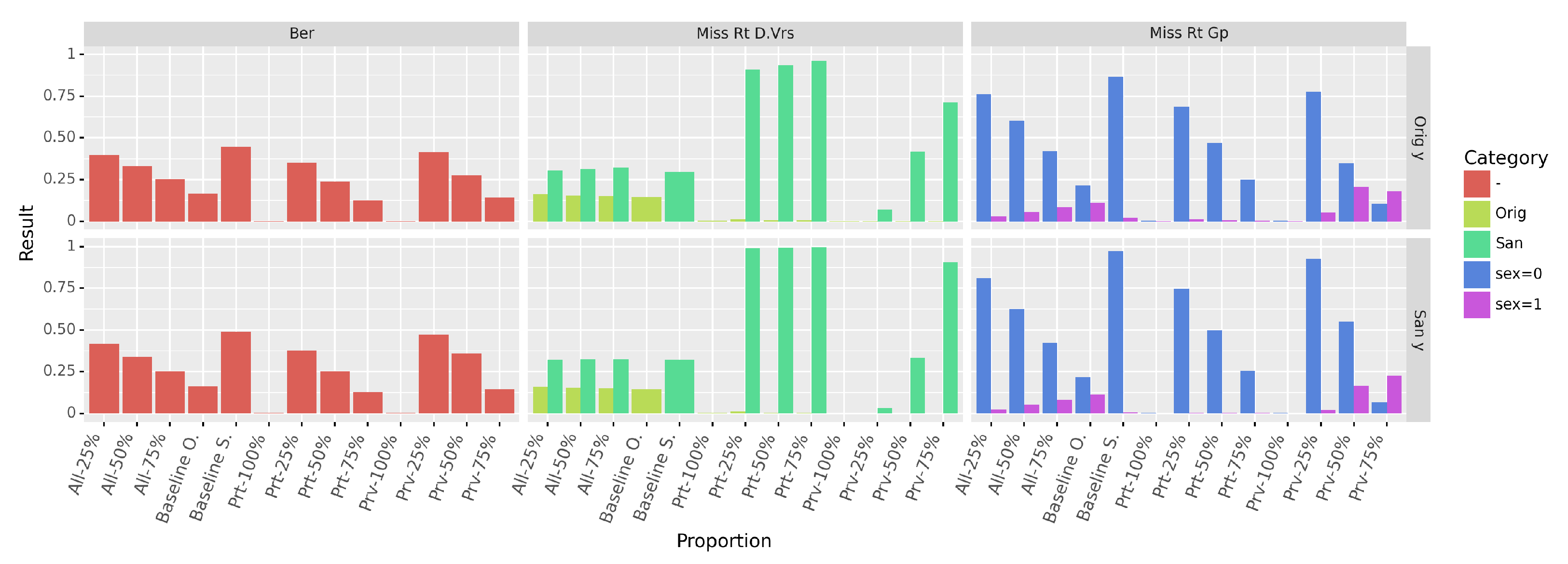
Figure 11 displays the
values obtained. Similary to the accuracy, the
decreases with the increase of the proportion of original profiles. The higher this sampling proportion, the easier the prediction of the sensitive attribute becomes as it consists in distinguishing original from sanitized profiles (column
Miss Rt D.Vrs of
Figure 11). From the miss prediction rate in each group (column
Miss Rt Gp), we can see that the classifier tends to always predict the majority class when it cannot successfully distinguish between groups. Finally, we also observe the impact of the original decision, which contributes to the lowering of the BER values.
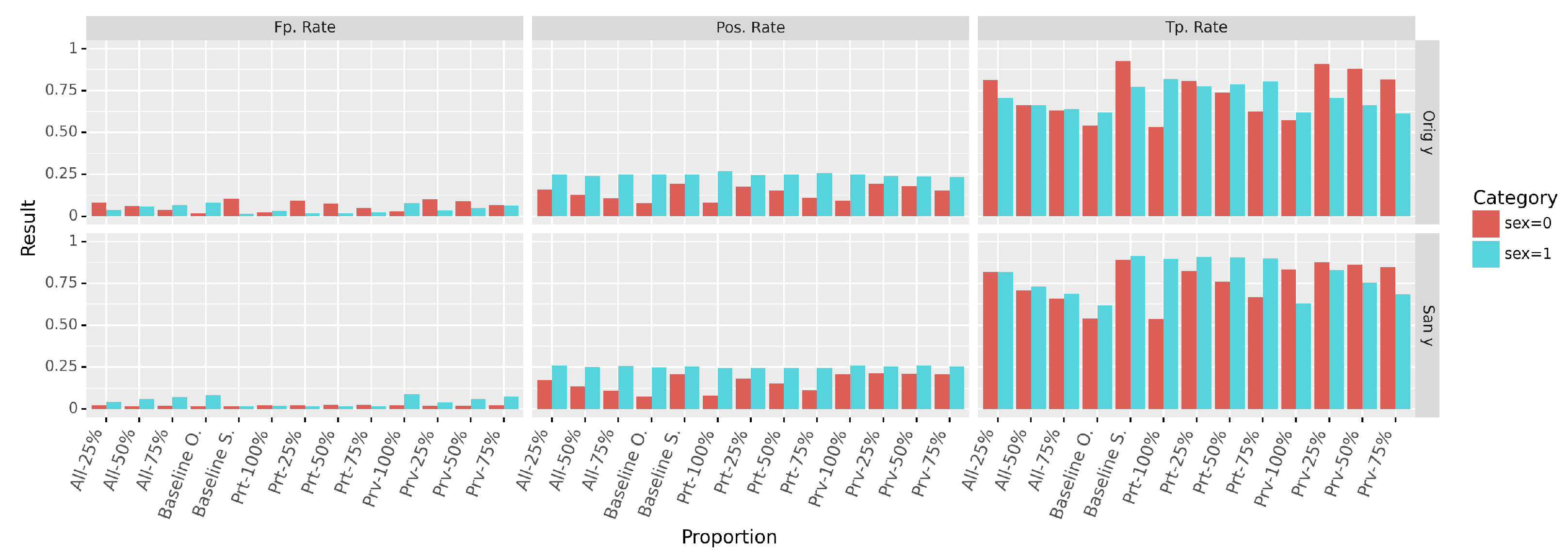
We have also evaluated the positive rate (
), the true positives (
) and false positives (
) rates in each group (cf.
Figure 12). The positive rate is used as the basis of the
demographic parity (
) computation, while the true positives and false positives rates are used to compute the gap in
equalized odds . The separate computation of these metrics allows us to observe the behavior of the classifier in each group.
Figure 12 demonstrates that the best results are achieved when using only the sanitized data. The mixed data produces intermediate results that get worse with the increase of the original data proportion, rendering the mixed data closer to the original one. One notable effect is that the group from which the original data is preserved affects the results in the same direction. More precisely if the original data from the protected group is preserved, all the metrics in the protected group will become closer to their original unfair values. The same trend is observed in the privileged group. These effects are particularly observable on the Positive and the True Positive Rates.
We can relate these observations to our previous hypothesis about the prediction (of S or Y) on the mixed data that can be considered as two separate operations. The invariance to of the predicted positive rate in the privileged group can be explained by the fact that the sanitization process did not modify the amount of positive decision in the privileged group, but rather enhance the protected one (Baseline S.). Another interesting aspect is that the false positive rates in the protected group remained unchanged when using San y, while it varied with the proportion in the privileged data. In fact, as the false positive rate in the protected group did not change with the sanitization (Baseline O. and Baseline S.), we can expect the metric in the protected group not to be affected by the amount of sanitized data. With the original decision, the metric varies significantly in both groups. This can be explained by the fact that the transformation of the data is made without having the correct decision, reflecting, in consequence, the disagreement between the profile and the associated decision.
Finally, in
Figure 13, we observe that the decision prediction accuracy is above
for any chosen proportion.
5.3.2. Decision Prediction Improvement Induced by the Sanitization
In Scenario S1—complete data debiasing, our results showed that the sanitization improves prediction of the decision. In addition to possible explanations (e.g., drop of diversity, the similarity between profiles), it suggests that the sanitization transforms the data such that all of the attributes-values are aligned with both the attribute distribution and the conditional distributions obtained by combining attributes. As an illustrative example, consider a dataset in which the profiles are composed of a binary sensitive attribute gender with values and , an attribute occupation and other attributes X which are identical for all profiles. Moreover, we assume that of profiles in the group have the value - for occupation, while the rest of the profiles have the value -. From this example, we can see that a classifier would predict the occupation attribute without difficulties if the attribute gender is included as the occupation is strongly correlated with the group membership. The sanitization process applied on this data would update the conditional distribution of occupation (since other attributes have identical values) by taking into account the predictability of the sensitive attribute (which should be reduced) and also aligning the value of attribute occupation with the distributions of other attributes. Thus, to prevent the inference of the sensitive attribute, the occupation values would be modified such that , while the alignment of the value would ensure that . The occupation would therefore be modified such that members of both groups and have the same decision. A similar, but more complex process could occur during the sanitization of data with higher and more complex distributions.
From this observation, if the decision attribute is strongly correlated with the sensitive attribute, the sanitization process would not necessarily result in a huge decrease of the accuracy in predicting the decision accuracy, even though the damage on the decision is significant. In other words, the sanitization transforms the data by removing correlations with the sensitive attribute, while correcting (based on the given data distributions) some distributions mismatch (as explained in our illustrative example) based on both the sensitive attribute and the characteristics of the dataset. The sanitization protocol does not take into account the semantic meaning of potential attribute-value combinations, but rather the alignment of conditional distributions.
To go one step further in our investigations, we considered the attribute
relationship of the dataset
Adult as the decision attribute, which is correlated with the sensitive attribute
gender. In
Table 6, we present the distribution of the attribute
relationship as well as the conditional distributions in the dataset. We observed that the value
Husband, which is predominant in the dataset, represents only the
Male group. The
Female group, is mostly identified with the values
Wife and
Unmarried, which represents almost
of the dataset. In addition, the attributes
Own-child and
Not-in-family are most present in the
Female group. Attributes
relationship and
gender are therefore correlated. We trained the Gradient Boosting (GB) classifier to predict the
relationship attribute, which achieves an accuracy of
on the original data. We observed that the precision and recall are especially high for the value
husband, but are not significant for other values. The decision accuracy is, respectively,
and
in the
Male and
Female groups.
On the sanitized dataset, the accuracies and distributions are also computed and presented in
Table 7. The value of attribute
relationship are less associated with the
gender. On the distribution of the attribute conditioned by the sensitive attribute, we observe a more balanced distribution of values in each group. The most discriminative value
Husband is more balanced in both groups. We also observe that the values on the conditional distribution of the
gender are more specific to each group. Nonetheless, the distribution is close to the dataset distribution of the same attribute (
and
). From a semantic perspective, at the time the data was collected, having a profile in the
Female group associated with the value
Husband might not be semantically meaningful, while from the distributional perspective, the sanitizer has aligned the profiles with their most appropriate values. As a consequence the accuracy of predicting the relationship increases from
to
(
and
in, respectively, the
Male and
Female groups), even though the damage on that attribute is
. We used the
cosine and
Euclidean (which is related to the
MSELoss in our sanitization objective) distances to verify whether the profiles whose values have been changed to
Husband are closer to other profiles in the
Husband-group, as profiles from the latter group had not had their values changed by the sanitization (up to
). However, no particular trends were observed. This observation does not exclude the possibility that a higher-dimensional similarity metric might be used by the sanitization process. The damage of almost
implies that using the original values as ground truth will cause a drop in the attribute prediction accuracy.
To further demonstrate the possibility of alignment, we created a balanced synthetic dataset with the gender (values 0 and 1) as the sensitive attribute. This dataset is composed of three numerical columns (, and ), each sampled from a Gaussian distribution of and deviation . The decision () for each row is generated by taking the mean of the three numerical columns (), and is biased toward the group 0 by applying different thresholds: for group , a positive decision is obtained if while for , the positive decision is obtained if . On this synthetic dataset, the decision is correlated with the sensitive attribute, while others are kept identical. Our alignment hypothesis states that the decision attribute will be modified such that the decision threshold is identical for both groups, and such that the decision is obtained as a function of the other columns. By having a threshold independent of groups, the sanitized decision is not correlated with the sensitive attribute and having the decision as a function of other columns ensures that the transformation is not just a randomization process with limited distortions.
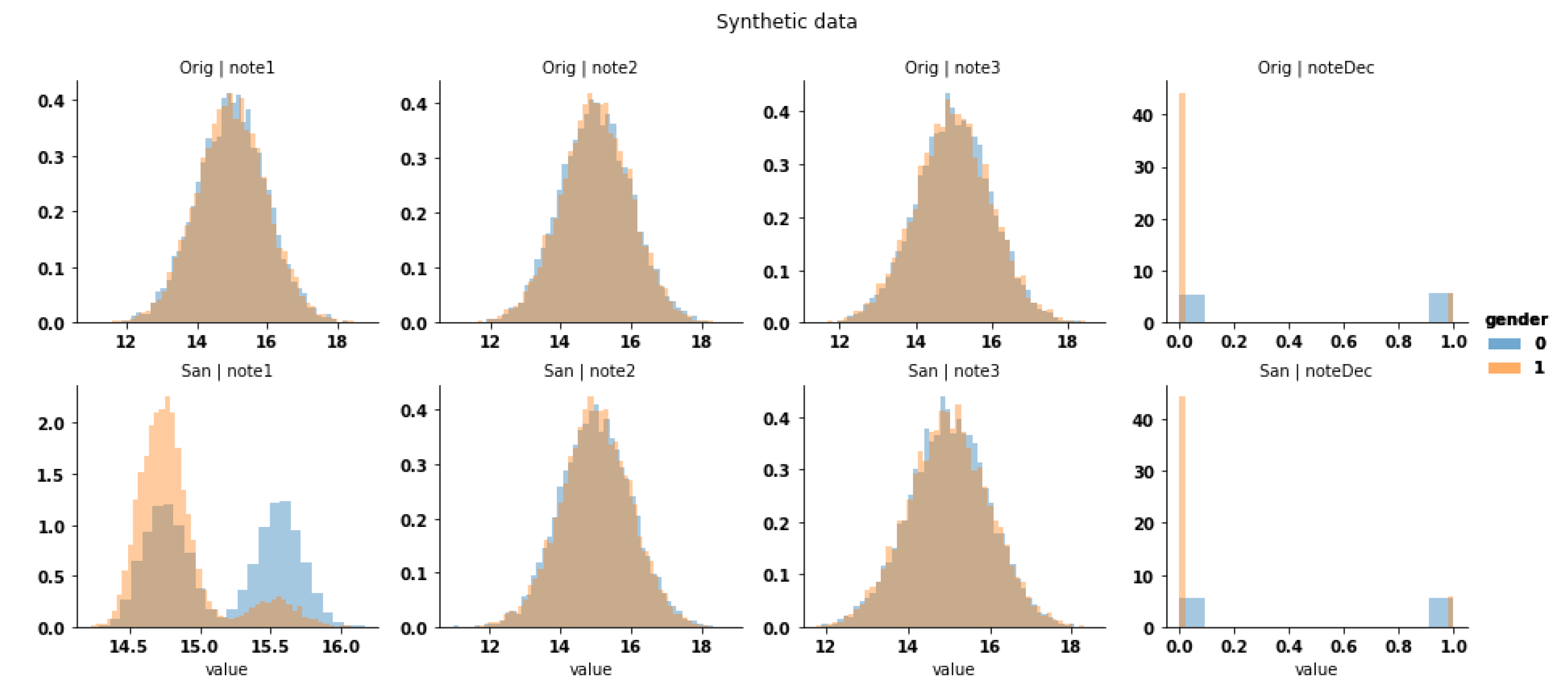
Our observations are presented in
Figure 14, on which the sanitized dataset has the same protection (
) as the original one. Unexpectedly, the sanitization process did not modify the decision attribute but instead modified the attribute
such that the
attribute is a result of a function applied on other attributes, as well as the similarity of their conditional distributions as we expected (
Figure 15). We can also observe that the original
does not follow the same distribution as its sanitized counterpart. As a consequence, it would be difficult to train a classifier on one version to predict the other.
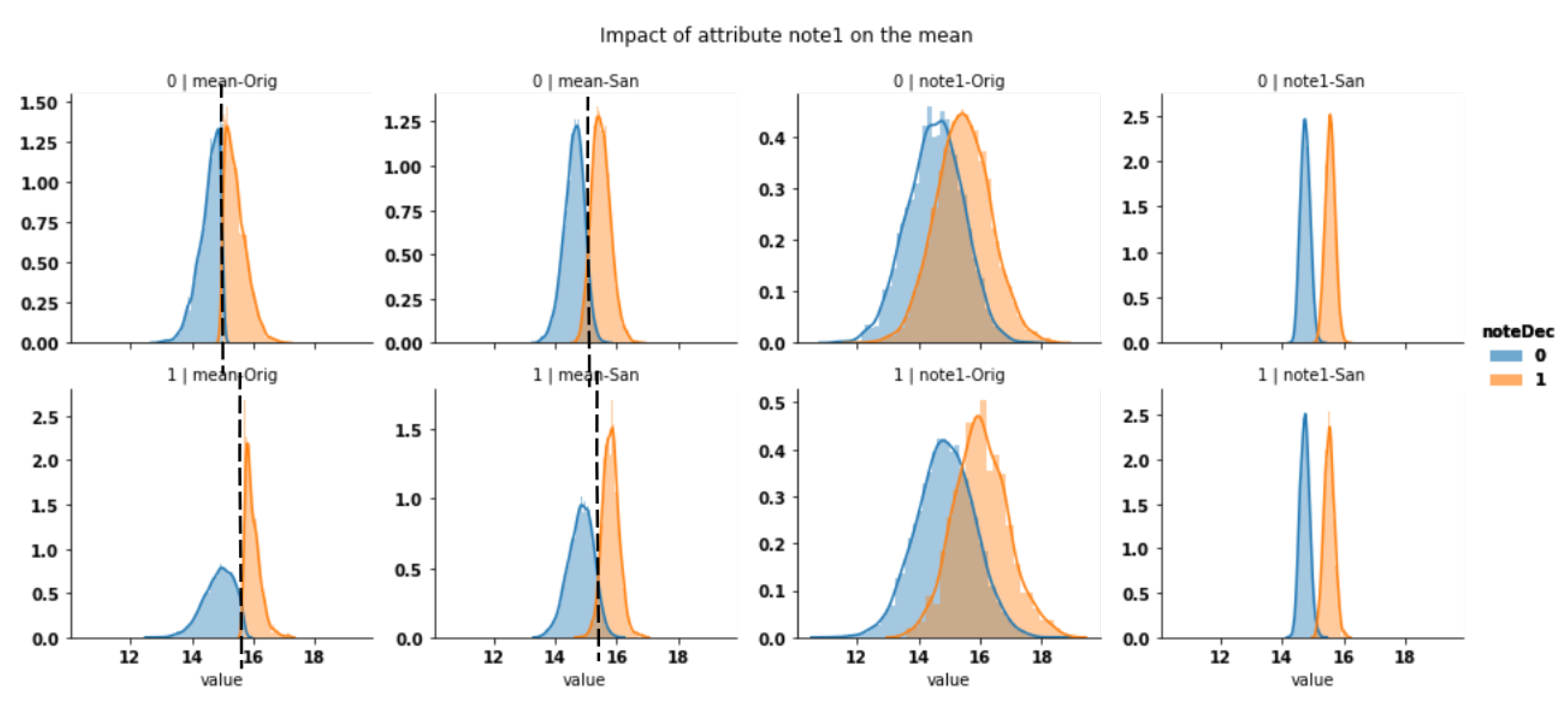
On a similar synthetic dataset in which we have augmented the discrimination (the threshold is increased for group
and decreased for the other), we obtained similar observations about the
alignment. In addition, attribute
is rendered nearly identical for both groups (
Figure 16). The state of
is due to either the prevention of inference or the improper reconstruction which has not been completed yet.
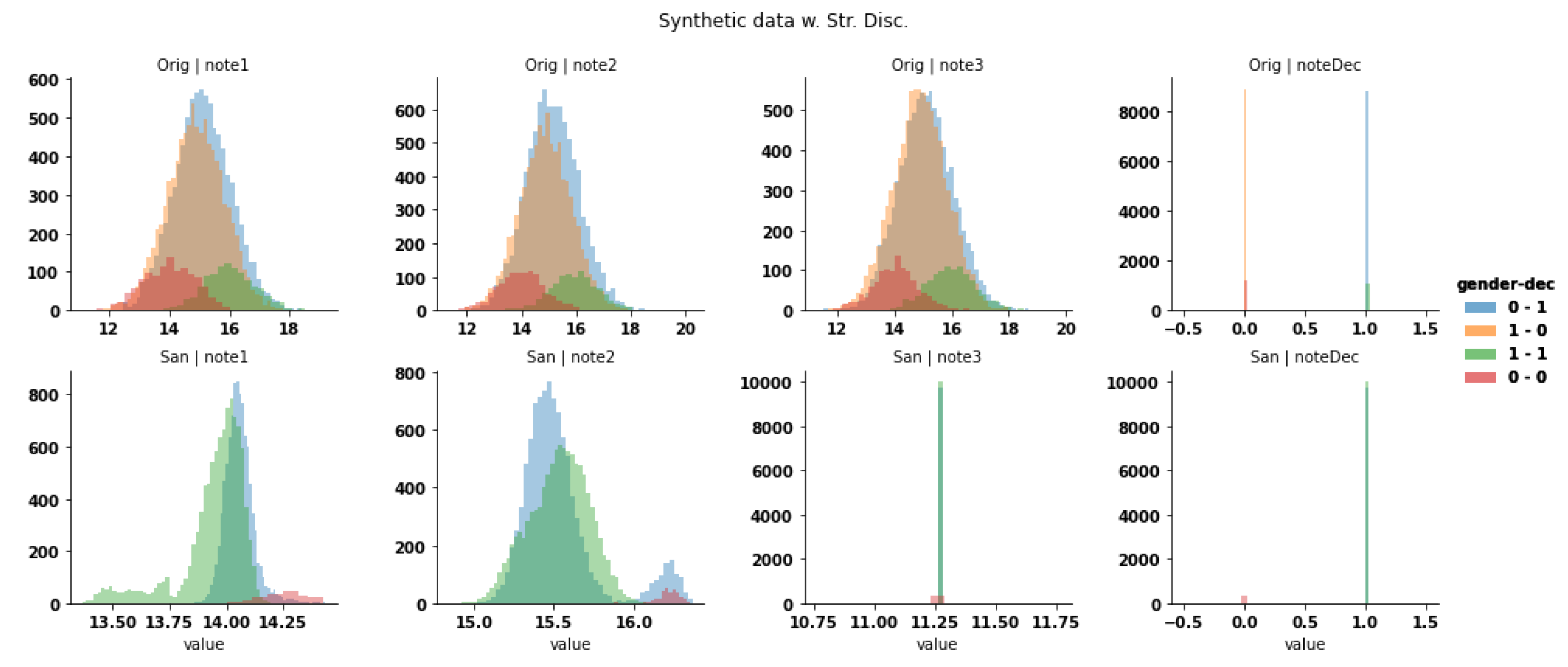
When pushed further on this dataset, the sanitization process triples the protection, by modifying all attributes such that the sensitive attribute is protected. The overall similarity of distributions is preserved while the deviation is reduced as shown in
Figure 17.
We believe that the alignment due to the sanitization explains the discordance between the sanitized decisions and the original ones.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}



















