1. Introduction
The Lempel-Ziv parsing (LZ77) [
1,
2] is one of the central techniques in data compression and string algorithms. Its idea is simple: to compress the data, we parse the data into phrases
such that each phrase
is either one letter or has an earlier occurrence in
, and the compressed encoding, instead of storing the phrases explicitly, stores the references to the occurrences. (In our investigation, we consider both non-overlapping and overlapping versions of LZ77; see precise definitions below.) Typically, algorithms that produce the parsing interpret the data as a sequence of bytes; however, some algorithms treat the data as a sequence of bits. What is the relationship between these parsings that differ only in the way they view the same input? In this paper, we investigate this question.
Our main result is that, for any integer
, the number
z of phrases in the LZ77 parsing of a string of length
n and the number
of phrases in the LZ77 parsing of the same string in which blocks of length
b are interpreted as separate letters (e.g.,
in case of bytes) are related as
(a more precise formulation follows). We partially complement this upper bound with a lower bound
in a series of examples. Further, we prove that a better bound
, which is tight, holds for the special case when each phrase
in the LZ77 parsing has a “phrase-aligned” earlier occurrence, i.e.,
, for some
. This special case is particularly interesting in connection to the grammar compression [
3]: a grammar of size
g that produces the string naturally induces such “phrase-aligned” LZ77 parsing of size
[
4].
The present work is a continuation of the line of research focused on the comparison of different efficiently computable measures of compression, mainly centering around the LZ77 parsing, the golden standard in this field (see a discussion of other close measures in [
5,
6,
7]). The results on this topic are too numerous to be listed here exhaustively. We, however, point out a couple of relevant studies and open problems.
The relations between the LZ77 parsing and the grammar-based compression, which naturally induces an LZ77 parsing [
4], are not sufficiently understood: known upper and lower bounds on their sizes differ by an
factor [
8,
9,
10]. A better lower bound
, which would show that our main result is tight, even only for
, would imply that the minimal grammar generating the string attaining this bound is of size
, thus removing the
-factor gap. This gives a new approach to attack this problem. However, it is still quite possible that our upper bound
can be improved and lowered to
.
The recently introduced LZ77 variant called ReLZ [
11] uses a certain preprocessing in the spirit of the so-called relative LZ77 (RLZ) [
12]. The efficiency of the obtained parsing was evaluated mostly experimentally, and there are no good upper bounds comparing it to the classical LZ77. Our present result actually stems from this work in an attempt to find a good upper (or lower) bound for this version of the LZ77 parsing. We believe that techniques developed in the present paper could help to obtain such bounds.
The paper is organized as follows. The following section provides all necessary definitions and known facts about the LZ77 parsings and related concepts. In
Section 3, we formalize the idea of “contracted” blocks of length
b and construct a series of examples showing that one of our upper bounds is tight. Then, in
Section 4, we prove our upper bound results. We conclude with some open problems in
Section 5.
2. LZ77 Parsings
A string s over an alphabet is a map , where n is referred to as the length of s, denoted by . The string of length zero is called the empty string. We write for the ith letter of s and for (which is empty if ). A string u is a substring of s if for some i and j; the pair is not necessarily unique, and we say that i specifies an occurrence of u in s starting at position i. We say that substrings and overlap if and . Throughout the text, substrings are sometimes identified with their particular occurrences; we do not emphasize this explicitly if it is clear from the context. We say that a substring has an earlier occurrence if there exist and such that and (note that the occurrences do not overlap). A substring (respectively, ) is a prefix (respectively, suffix) of s. For any i and j, the set (possibly empty) is denoted by . All logarithms have a base of two.
A parsing
of a given string
s is called a
Lempel-Ziv (LZ77) parsing if each string
(called
phrase) is non-empty, and it either is one letter or occurs in the string
(i.e., it has an earlier occurrence). The
size of the parsing is the number
z of phrases. The parsing is called
greedy if it is built greedily from left to right by choosing each phrase
as the longest substring that starts at a given position and occurs in
(see [
2]). It is known that the greedy parsing is, in a sense, optimal, as it is stated in the following lemma.
Lemma 1 (see [
4,
10,
13]).
No LZ77 parsing of a string can have smaller size than the greedy LZ77 parsing. The defined LZ77 parsing is often called non-overlapping since its non-one-letter phrases have non-overlapping earlier occurrences. An analogously defined overlapping LZ77 parsing is its more popular variant: it is a parsing in which each non-one-letter phrase has at least two occurrences in the string (so that “earlier occurrences” of might overlap ). Consider for example. The greedy non-overlapping and overlapping LZ77 parsings of s are and , respectively.
In this paper, we mainly discuss the non-overlapping version and, hence, for brevity, often omit the term “non-overlapping”, which is assumed by default. Clearly, every LZ77 parsing is an overlapping LZ77 parsing, but the converse is not necessarily true. Indeed, one can show that the non-overlapping and overlapping LZ77 parsings are not equivalent in terms of size (see [
14]). Our results, however, hold for both variants.
An LZ77 parsing is phrase-aligned if each non-one-letter phrase has an earlier occurrence , for some . This particular type of parsing is interesting because of its close connections to the grammar compression, another popular compression technique.
A
grammar is a set of rules of the form
and
with a designated initial rule, where
a denotes a letter and
denote non-alphabet non-terminals; see [
15]. The
size of a grammar is the number of rules in it. A
straight line program (SLP) grammar is a grammar that infers exactly one string. The SLP grammars and LZ77 parsings are related as follows.
Lemma 2 (see [
4,
10]).
If a string s is produced by an SLP grammar of size g, then there exists a phrase-aligned LZ77 parsing for s of size at most g. By a non-constructive argument [
8,
10,
16], one can show that the converse equivalent reduction from LZ77 parsings to SLP grammars is not possible: in some cases, the size of the minimal SLP grammar can be
-times larger than the size of the greedy (i.e., minimal) LZ77 parsing. For completeness, let us show this by repeating here the counting argument essentially used in [
10,
17].
Consider all SLPs of size g that produce strings over the alphabet and contain the rules and . Since each rule can be constructed in, at most, ways by choosing a pair , there are at most possible configurations of the SLPs ( choices of the pairs and the choice of initial rule). Therefore, all such SLPs produce, at most, different strings. Further, for given n and , there are exactly strings of length n consisting of letters a and k letters b, and each such string has an LZ77 parsing of size . If each such string can be produced by an SLP of size g, then and, hence, . Choosing , we deduce that and, therefore, , which implies that , an -blow up in size compared to the LZ77 parsing of size .
Albeit there is no an equivalent reduction from LZ77 parsings to grammars, a slightly weaker reduction described in the following lemma still holds.
Lemma 3 (see [
4,
10,
18,
19]).
If a string s has an (overlapping or non-overlapping) LZ77 parsing of size z, then there exists an SLP grammar of size producing s. 3. Block Contractions and a Lower Bound for Their LZ77 Parsings
Fix an integer . A b-block contraction for a string s is a string t such that and, for any , we have iff . (The string s is padded arbitrarily with new letters so that these two substrings are well defined.) The substrings are called b-blocks or blocks if b is clear from the context. We say that a substring starts (respectively, ends) on a block boundary if (respectively, ). A substring is block-aligned if it starts and ends on block boundaries.
For example, consider and . A b-block contraction of s is , where the letter d corresponds to the blocks , e corresponds to , and f to . The string has two block-aligned occurrences at positions 1 and 3 and one non-block-aligned occurrence at position 6.
In this paper, we are interested in the comparison of LZ77 parsings for a string and its b-block contraction. The next theorem establishes a lower bound by providing a series of examples. We will then show in the following section that this lower bound is tight for phrase-aligned LZ77 parsings.
Theorem 1. For any integers b and z such that , there exists a string that has a phrase-aligned LZ77 parsing of size and whose b-block contraction can have only LZ77 parsings of size at least .
Proof. Consider a string t over the alphabet whose greedy LZ77 parsing is phrase-aligned and has size . For , define a morphism such that and , where c is a letter different from a and b. Note that . The example string is . It has a phrase-aligned LZ77 parsing of size constructed as follows. The first occurrences of the substrings and take phrases to encode; therefore, can be encoded into phrases by mimicking the parsing of t. Further, each substring , for , occurs at position and, thus, can be encoded by one phrase referring to this occurrence. The latter referenced occurrence is phrase-aligned provided the prefix and the substring were parsed trivially as sequences of b letters. □
At the same time, any LZ77 parsing of a b-block contraction of the string s must have size at least : the b-block contraction of each substring produces a “copy” of t over a different alphabet, but the new “contracted” letters of these “copies” are pairwise distinct; therefore, each contraction should be parsed without references to other substrings, hence, occupying at least phrases. It remains to note that . □
4. Upper Bounds on LZ77 Parsings for Block Contractions
We first consider the case of phrase-aligned LZ77 parsings in the following theorem. As will be seen later, it easily implies our result for arbitrary parsings. The proof of this theorem is quite complicated and long, occupying most of the present section.
Theorem 2. Suppose that is a phrase-aligned LZ77 parsing of a string s, i.e., every non-one-letter phrase has an earlier occurrence , for some . Then, for any integer , the size of the greedy LZ77 parsing of a b-block contraction for s is .
Proof. Let
s be a given string and
be a
b-block contraction of
s. Assume that the alphabets of
s and
do not intersect. We are to show that there exists
some LZ77 parsing of
of size
. Then, the statement of the theorem immediately follows from Lemma 1. The proof is split into five
Section 4.1–
Section 4.5. □
4.1. Basic Ideas
For simplicity, assume that
is a multiple of
b (if not,
s is padded with at most
b new letters). Our construction relies on the following notion: for
, the
h-shifted block parsing of s is the following parsing for the string
:
where
, and each phrase
is the longest substring starting at position
, whose length is a multiple of
b and that is entirely contained in the phrase
covering the position
p, i.e.,
and
(in particular,
might be empty if
is too short). It might be viewed also as a parsing constructed by a greedy process that, starting from the position
, alternatively chooses first a longest substring
whose length is a multiple of
b that starts at the current position and is “inscribed” in the current phrase
, and then chooses a phrase
of length exactly
b, which “bridges” neighboring phrases in
. It is straightforward that
. It is instructive to imagine the
h-shifted block parsings (for
) written one after another as in
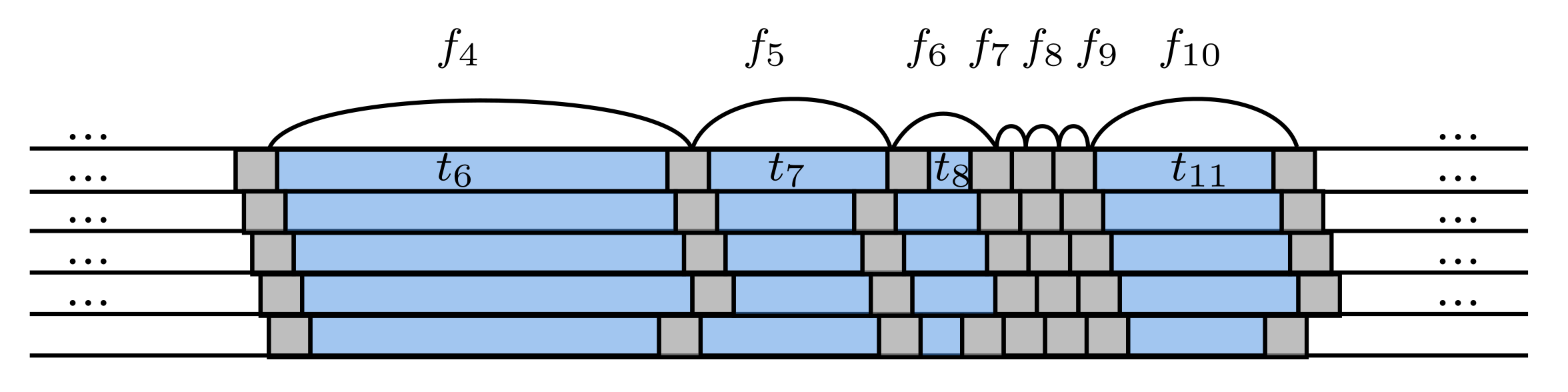
Figure 1. Let us describe briefly the rationale behind the definition.
In the case , we omit the first index “h” in the notation , and write the zero-shifted block parsing as . Note that the phrases in this parsing are block-aligned, and each phrase has an earlier occurrence; however, it is not an LZ77 parsing of s since substrings might not have earlier occurrences. Moreover, the zero-shifted block parsing could have served as a generator of a correct LZ77 parsing for if every substring had a block-aligned earlier occurrence in s: then, the required parsing for would have consisted of phrases obtained by the b-block contractions of , respectively. (Note that each string has length b and, thus, is contracted into one letter.) Unfortunately, albeit each substring has earlier occurrences in s, it does not necessarily have an occurrence starting and ending on block boundaries. However, each earlier occurrence is block-aligned in the h-shifted block parsing of s with . This observation is the primary motivation for the introduction of the h-shifted block parsings, and we use it in the sequel.
Informally, our idea is as follows. Consider a phrase whose earlier occurrence does not start and end on block boundaries. The occurrence is block-aligned according to an h-shifted block parsing and, since the initial parsing was phrase-aligned, coincides with the concatenation of some consecutive phrases in this h-shifted block parsing (details are discussed below). The phrase will be disassembled in place into smaller block-aligned chunks that have earlier occurrences starting and ending on block boundaries. Thus, a block-aligned copy of the fragment will appear in place of and, if a following phrase refers to the same fragment , we can instead refer to this reconstructed block-aligned copy without the need to disassemble into chunks again. Suppose that each phrase in the decomposition of has a block-aligned occurrence before the phrase . Then, the number of chunks in place of is : the “reconstruction” proceeds as consecutive “concatenations” of , skipping “concatenations” that already occurred before. There are, at most, such concatenations in total. After this, all substrings block-aligned according to the h-shifted block parsing will have occurrences starting and ending on block boundaries according to the string s itself. For all , we obtain “concatenations” in total. (This informal argument requires further clarifications and details that follow below.) We note, however, that this is only an intuition, and there are many details on this way. For instance, if a phrase had no block-aligned occurrences before the phrase , we would have to “reconstruct” by disassembling it analogously into chunks, thus recursively performing the same process. The counting of “concatenations” during the “reconstructions” has many details too.
4.2. Greedy Phrase-Splitting Procedure
Our construction of an LZ77 parsing for transforms the zero-shifted block parsing of s. We consecutively consider the phrases from left to right: for each , we emit a one-letter phrase—the b-block contraction of —into the resulting parsing for ; for each , we perform a process splitting into chunks whose lengths are multiples of b, and each of which either is of length b or has a block-aligned earlier occurrence, and the b-block contractions of these chunks are the new phrases emitted into the resulting parsing for . Let us describe the process splitting .
Consider a phrase
and suppose that the phrases
were already processed, and new phrases corresponding to them in the parsing of
under construction were emitted. If
, we skip this step. If
, we simply emit a new one-letter phrase by contracting
. Suppose that
. Denote by
the phrase into which
is “inscribed”, i.e.,
. By the assumption of the theorem, there exists a phrase-aligned earlier occurrence of
, i.e., there exist
j and
such that
and
. Thus, there is a copy of the phrase
in the substring
. While the phrase
itself is block-aligned, its copy does not have to be block-aligned. However, the copy is necessarily block-aligned in the
h-shifted block parsing with appropriate
h, namely with
; see
Figure 2.
Let
be the phrases of the
h-shifted block parsing that are “inscribed” into the substring
(the phrase
could be “inscribed” too, but we omit it in this case). The key observation for our construction is that the following equality holds (see
Figure 2):
Now consider the following parsing:
which is the zero-shifted block parsing of
s up to the phrase
in which phrase
was expanded into the chunks
. If each of the chunks
,
from the expansion of
in Parsing (
1) either is of length, at most,
b or has a block-aligned earlier occurrence, then, in principle, we could have emitted into the resulting parsing of
the
b-block contractions of
, generating, at most,
new phrases for
in total. Unfortunately, this simple approach produces too many phrases for
in the end. Instead, we greedily unite the chunks
from left to right so that the resulting united chunks still either have length
b or have block-aligned earlier occurrences. Namely, we greedily take the maximum
such that the substring
either has length
b or has a block-aligned earlier occurrence (i.e., a block-aligned occurrence in the prefix
); then, the
b-block contraction of the string
is emitted as a new phrase into the parsing of
under construction. If
, then the whole string
was “split” into one chunk
and we are done. Otherwise (if
), we further emit the next (one-letter) phrase, the
b-block contraction of
, and proceed taking the maximum
such that the substring
either has length
b or has a block-aligned earlier occurrence (i.e., a block-aligned occurrence in the prefix
). Similarly, we emit the contraction of
and the one-letter contraction of
into the resulting parsing of
. The greedy procedure then analogously continues reading
from left to right until the whole string
is decomposed into chunks
and all the corresponding new phrases for
are emitted.
The described process works correctly if each of the chunks
,
in the expansion of
in Parsing (
1) either has a block-aligned earlier occurrence or is of length at most
b. What if this is not the case? Suppose that
is such a “bad” chunk in Parsing (
1): it does not have a block-aligned earlier occurrence and
. In a certain sense, we arrive at an analogous problem that we had with the phrase
: we have to split
(here, we are talking about the occurrence of
from the expansion of
in Parsing (
1)) into a number of chunks whose lengths are multiples of
b and each of which either is of length
b or has a block-aligned earlier occurrence; we will then emit the
b-block contractions of these chunks into the resulting parsing for
. We solve this problem recursively by the same procedure, which can be roughly sketched as follows. The phrase
from the
h-shifted block parsing of
s (not
from the expansion of
in Parsing (
1)!) was “inscribed” into a phrase
(such as, analogously,
was “inscribed” into
), which, by the assumption of the theorem, has a phrase-aligned earlier occurrences
, for some
(like, similarly,
had an occurrence
). There is, thus, a copy of
in the substring
. This copy is not necessarily block-aligned according to neither zero-shifted nor
h-shifted block parsings. However, the copy is block-aligned with respect to the
-shifted block parsing for appropriate
(for example, the copy of
from
was block-aligned according to the
h-shifted block parsing). We then consider a fragment
of the
-shifted block parsing “inscribed” into the substring
and conclude that this fragment is equal to
(such as, analogously, the fragment
“inscribed” into
was equal to
). We proceed recursively decomposing
into chunks by greedily uniting
by analogy to the procedure for
. This recursion, in turn, itself can arrive at an analogous splitting problem for another chunk (say,
), which, in the same way, is solved recursively.
4.3. Formalized Recursive Phrase-Splitting Procedure
We formalize the described recursive procedure as a function , which is called with parameters k, , h, p such that the substring from the h-shifted block parsing of s occurs before the position p and its copy occurs at position p, i.e., and , for an appropriate . In order to process , we call , where k, , and h are determined as explained above. The function emits phrases of the resulting parsing of from left to right and works as follows:
- 1.
If the substring starting at position p does not have a block-aligned earlier occurrence and , then, as was described above, we find numbers , , such that , and we first recursively call , thus processing , then we emit a one-letter phrase by contracting , and finally, call , ending the procedure afterwards;
- 2.
Otherwise, we compute the maximal number such that the substring starting at position p either has length of, at most, b or has a block-aligned earlier occurrence;
- 3.
We emit the b-block contraction of unless is empty (which happens if and is empty);
- 4.
If , we exit; otherwise, we emit a one-letter phrase by contracting and call recursively .
In the sequel, we refer to the steps of the splitting procedure as “item 1, 2, 3, 4”.
It is easy to see that the generated parsing of after processing is a correct LZ77 parsing. It remains to estimate its size.
4.4. Basic Analysis of the Number of Produced Phrases
Suppose that every time a new phrase is emitted by the described procedure, we “pay” one point. We are to show that the total payment is , which is . For the “payment”, it will suffice to reserve a budget of points. In this section of the proof, we explain how points are spent (4 points per phrase ; details follow); the remaining points will be discussed in the following final section of the proof.
The described process reads the string s from left to right, emitting new phrases for the parsing of and, during the run, advances a pointer p, the last parameter of the function , from 1 to n. Along the way, block-aligned occurrences of some fragments from h-shifted block parsings appear. The key observation is that once a block-aligned occurrence of a fragment appeared in the string s at a position p, any subsequent block-aligned substring with that appears during the processing of phrases after the position p can be united into one chunk, and there is no need to analyze it by splitting into smaller chunks again.
For each phrase with and , we reserve four points (hence, points in total). These points are spent when the string is first encountered in the function (the spending scheme is detailed below), namely when the function is invoked as with parameters such that and occur at the position p (the position is necessarily block-aligned; therefore, this is a block-aligned occurrence of ). We note that this case includes the initial calls that process phrases : it is a particular case where . We call such an invocation of for the phrase a generating call. The generating call “generates” a block-aligned occurrence of in the string s. For each phrase , at most, one generating call might happen: the only place where a generating call could have happened twice is in item 1 of the description of the function , but any subsequent occurrence of will have a block-aligned earlier occurrence, and hence, the condition in item 1 could not be satisfied. Therefore, there are, at most, generating calls in total, and we spend, at most, points on all of them.
Let us consider the work of a generating call. For simplicity, let it be a call for a phrase as in the description of above, i.e., we have , , and , for an appropriate (the analysis for phrases from other -shifted block parsings is analogous to the analysis for ). The work of can be essentially viewed as follows. The function splits greedily into chunks of two types:
- (a)
chunks of the form with that either have a length of, at most, b or have block-aligned earlier occurrences (such chunks are built in item 2 of the description of the function , where they are denoted as );
- (b)
chunks on which a generating call is invoked in item 1, which further recursively splits into “subchunks” (recall that, according to item 1, this is the case when did not have block-aligned earlier occurrences before and ).
Such possible splitting of
is schematically depicted in
Figure 3, where there is only one recursive generating call (for
), and there are four chunks of type (a). The
b-block contractions of the chunks of type (a) and the contractions of short phrases
,
surrounding them are emitted as new phrases for the parsing of
. We spend the whole four-point budget allocated for
by paying two points for the leftmost chunk of type (a) and the phrase
that follows after it, and by paying two points for the rightmost chunk of type (a) and the phrase
that precedes it (for the example from
Figure 3, these are the chunks
and
, and the short phrases
and
).
For each chunk of type (b), the corresponding generating call recursively produces “subchunks” splitting . We delegate the payment for these subchunks to the budget allocated for . It remains to pay somehow for other chunks of type (a) between the leftmost and rightmost chunks from the decomposition of . To this end, we introduce a separate common budget of points.
4.5. Total Number of Type (a) Chunks
We estimate the total number of chunks of type (a) by connecting them to a common combinatorial structure defined as follows. The structure is called a segment system: it starts with unit integer segments , and we can perform merge queries, which, given two neighboring segments and with , create a new united segment and remove the old segments and . Clearly, after merge queries, everything will be fused into one segment . Fix . We maintain a segment system connected with h, and we associate with each phrase the segment . During the work of the function , the following invariant is maintained:
if a segment such that belongs to the current segment system, then there is a block-aligned occurrence of the string before the currently processed position p.
Observe that, at most, merge queries can be performed in total on all introduced segment systems. We will spend 3 points per query from our remaining budget of points. The segment systems, their merge queries, and chunks of type (a) are related as follows.
Let us temporarily alter the algorithm
as follows: item 2 first chooses the number
as in the original version (as the maximal
such that
can serve as a new chunk), but then, we take the segment
containing
k from the segment system, i.e.,
, and we assign
. Thus, possibly,
m in the altered version will be smaller than in the original version. Such choice of
m is correct too since, due to our invariant, the altered condition still guarantees that the substring
is either of length
b or has a block-aligned earlier occurrence. It is obvious that the case when
in the altered function
can only occur for the leftmost chunk in the decomposition of
into chunks. Further, the number of chunks of type (a) obtained for
by the altered procedure is not less than the number of chunks of type (a) constructed by the original greedy version. It follows straightforwardly from the description that each chunk of type (a) in the altered version that is not the leftmost or rightmost chunk corresponds to a segment from the segment system associated with
h, i.e., if
, is such a chunk, then
belongs to the system. Similarly, the invariant implies that the unit segments
corresponding to chunks
of type (b) belong to the system too. For instance, if the example of
Figure 3 was obtained by this altered way, the segments
would belong to the segment system for some
and
. We then perform merge queries uniting the segments corresponding to all chunks generated for
, except the leftmost and rightmost chunks. (For the example in
Figure 3, we unite all subsegments of
, performing two merge queries in total.) The number of merge queries for
is equal to the number of chunks between the leftmost and rightmost chunks from the decomposition of
minus one. The invariant of the segment system is maintained: the substring of the
h-shifted block parsing that corresponds to the new united segment now has a block-aligned occurrence, which is precisely the occurrence in the substring
.
Suppose that we maintain in a similar way b segment systems for all , performing analogous merge queries in every generating call. Then, the total number of merge queries among all and all chunks during the work of all calls to the function does not exceed (at most, queries for each system). Therefore, it suffices to spend the budget of points for all phrases corresponding to all chunks of type (a) as follows. We pay three points for each merge query: two for the emitted phrases corresponding to two merged chunks and one for a phrase separating the chunks. □
As a corollary of Theorem 2, we obtain our main upper bound.
Theorem 3. For any integer , the size of the greedy LZ77 parsing of a b-block contraction for a string of length n is , where z is the size of the greedy (overlapping or non-overlapping) LZ77 parsing of this string.
Proof. We apply Lemma 3 to obtain a “phrase-aligned” LZ77 parsing of size , and then, using Theorem 2, we obtain the bound on the size of the greedy LZ77 parsing of the b-block contraction. □
5. Conclusions
Given the results obtained in this paper, the main open problem is to verify whether the upper bound from Theorem 3 is tight. To this end, one either has to improve the upper bound
or has to provide a more elaborate series of examples improving the lower bound
from
Section 3 (obviously, the examples must deal with non-phrase-aligned parsings). We point out, however, that the tightness of the bound from Theorem 3 would necessarily imply the tightness of the currently best upper bound
[
4,
18] from Lemma 3 that relates the size
g of the minimal grammar generating the string and the size
z of the LZ77 parsing for the string (the best lower bound up-to-date is
[
8,
10]). Indeed, for a constant
, if there exists a string whose LZ77 parsing has size
z and whose
b-block contraction can have only LZ77 parsings of size at least
, then the minimal grammar of such string must have a size of at least
since, by Lemma 3, the string has a phrase-aligned LZ77 parsing of size
g, and thus, by Theorem 2, the
b-block contraction has an LZ77 parsing of size
, which is
as
b is constant.
The present work stems from the paper [
11] where the following LZ77 parsing was considered: we first parse the input string
s into phrases
such that each phrase
is either one letter or has an earlier occurrence in the prefix
, for a fixed
, and then we treat every phrase
as a separate letter and construct the greedy LZ77 parsing for the obtained “contracted” string of length
k. The resulting parsing naturally induces an LZ77 parsing for
s. The motivation for this variant is in the considerable reduction in space during the construction of the parsing that allowed us to compress very large chunks of data using this two-pass scheme. The problem that was investigated in the present paper can be interpreted as a special case when all phrases
have the same length
b (at least those phrases that are located outside of the prefix
). The following question can be posed: can we adapt the techniques developed here to a more general case in order to find an upper bound for the LZ77 parsing from [
11] in terms of the optimal greedy LZ77 parsing for
s?



{kind=link}
{kind=link}
{kind=link}