Text Semantic Annotation: A Distributed Methodology Based on Community Coherence




Abstract
1. Introduction
2. Background
2.1. Word Sense Disambiguation Algorithms
- Supervised WSD: leveraging machine-learning techniques for training a classifier from labeled input training sets, containing appropriate sense label mappings along with other features.
- Unsupervised WSD: methods based on unlabeled corpora, lacking manual sense-tagged input context.
2.2. Community Detection Algorithms
- applying some predefined thresholds in the modularity gain on any possible merge,
- excluding all nodes of degree one from the original network and adding them back after the community computation and
- incorporating sophisticated data structures that simplify the hierarchical decomposition of the information network.
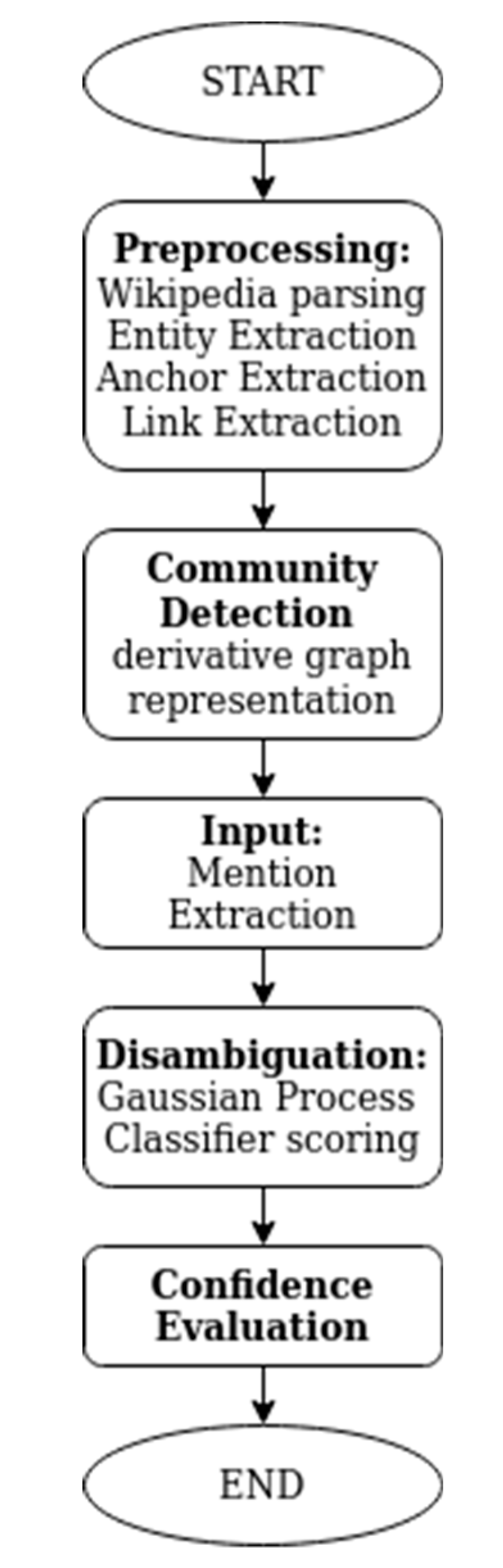
3. Materials and Methods
3.1. Terminology and Notation
- Wikipedia pages are also mentioned as Wikipedia entities. A Wikipedia page is denoted p.
- Inter-wiki hyperlinks are cited as anchors, using the notation a. A text anchor linking a Wikipedia page from another page or text is referred to as mention.
- The first anchor of a text fragment is denoted a0, ai the i+1th and so on.
- The anchor count of a text segment for annotation is denoted m.
- A Wikipedia page, as a mention (i.e., candidate sense) of the anchor a is denoted pa.
- Due to natural language polysemy, an anchor may bare several mentions, hence the notation Pg (a) is used for the set of Wikipedia entities linked by anchor a.
- A set of Entities formulating a community as segmented by a community detection algorithm execution is noted C
- The set of incoming links to Wikipedia Entity p is denoted in(p).
- The cardinality of all Wikipedia Entities as in [9], is denoted |W|
- Denoting the cardinality of the occurrences of an anchor text as mention in a text segment link(a), and the total frequency of occurrences of that anchor, either as a mention or not, freq(a), the link probability of a mention, aka commonness in related work, is cited as:
3.2. Preprocessing
3.3. Mention Extraction
3.4. Disambiguation
- the entity linking compatibility and
- the entity linking incompatibility
- The community coherence presented by Formula (2) is used for modeling the coherence of mentions as members of common communities.
- The average interwiki Jaccard index of Formula (3) models the average intersection over the union of entity mentions in a text segment for annotation. This feature aims at introducing strong semantic coherence information. The Jaccard index is established by similar works such as WAT [16].
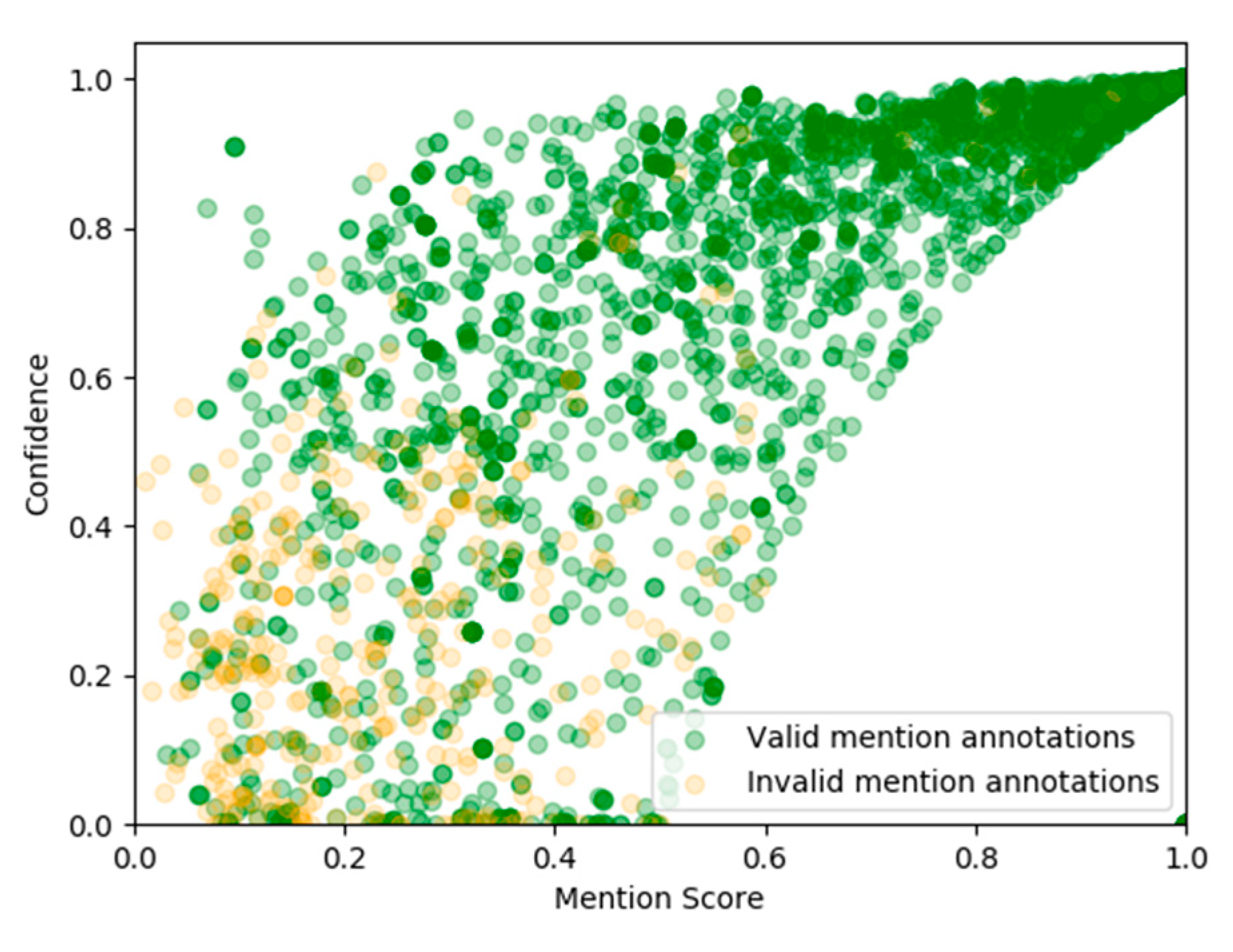
3.5. Disambiguation Confidence
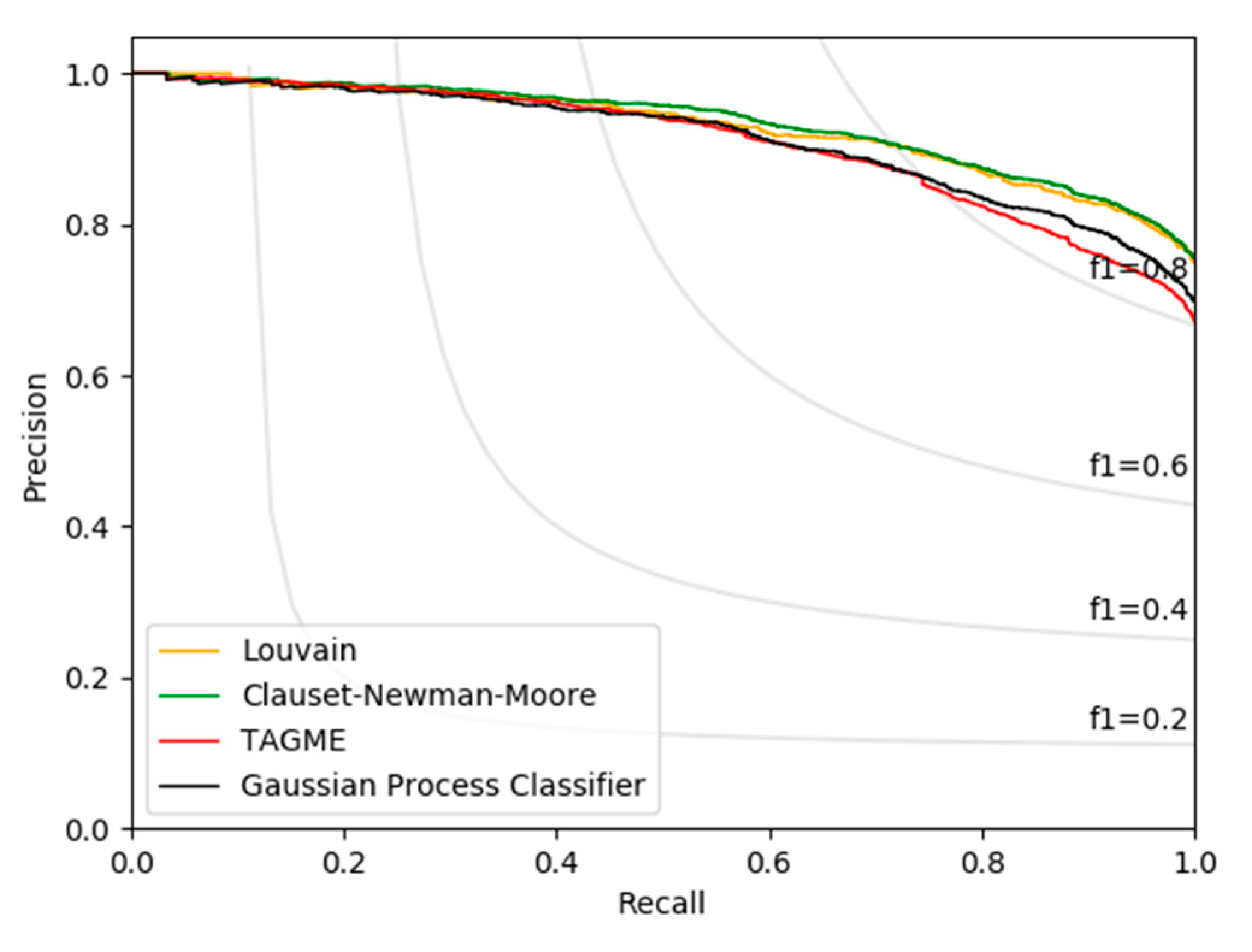
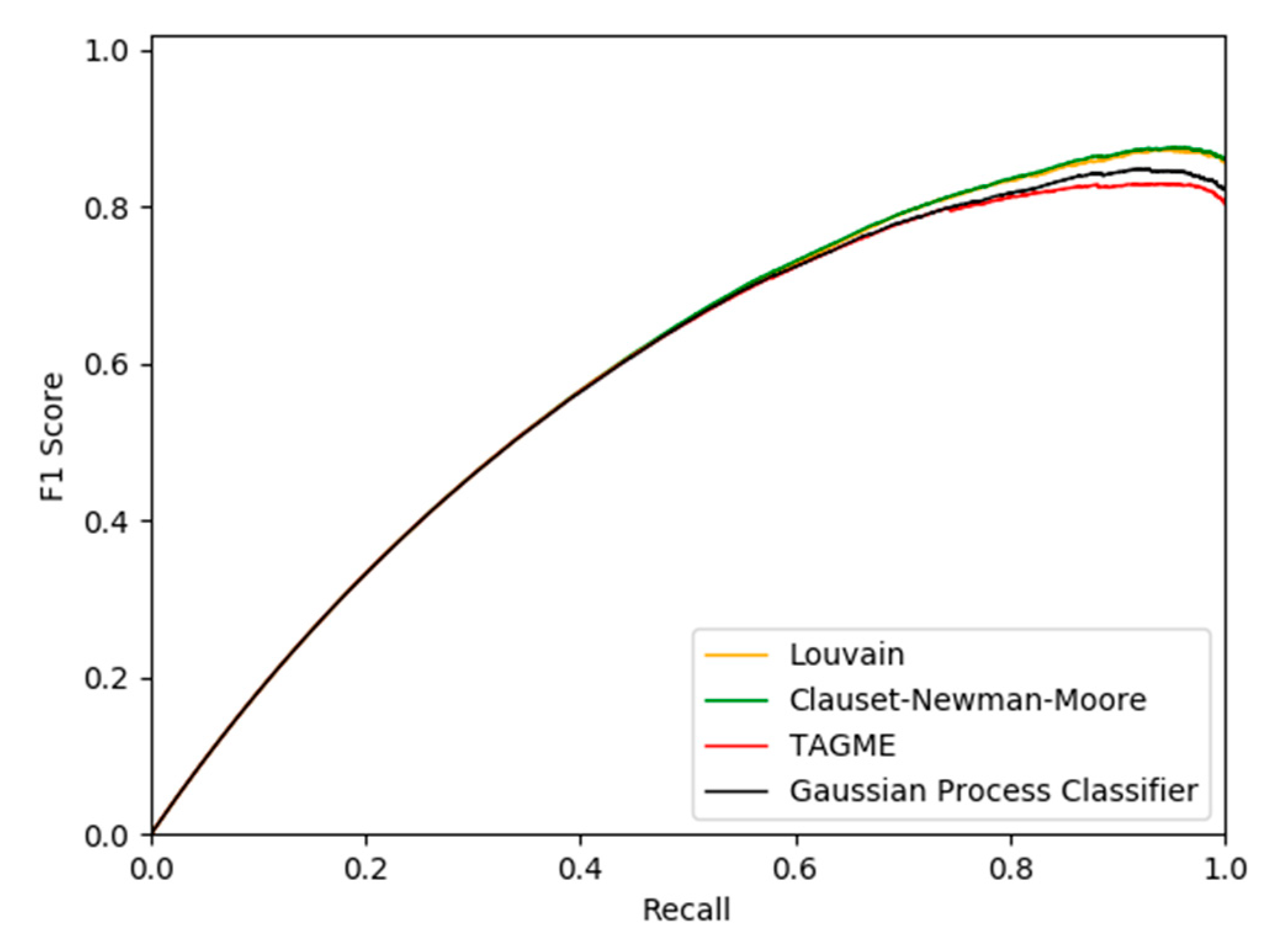
4. Results
- Precision: The fraction of the correctly annotated anchors over the valid mentions.
- Recall: The proportion of actual correctly annotated anchors.
- F1 Score: the harmonic mean of precision and recall.
5. Conclusions and Future Work
- Increased interpretability was apparently required to assess the value and benefits of this novel methodology, however, the adoption of less interpretable but more accurate classifiers is to be considered a future step.
- The introduction of well-established features in a classifier-based entity linking methodology combined with community coherence resulted in impressive results, however, our low dimensionality approach could be leveraged by some deep neural network architecture models, as the next focus on further improvements to accuracy performance.
- The classic sequential community detection algorithms, such as the Louvain [2] and Clauset–Newman–Moore [3] algorithms, are doubtlessly considered unscalable and thus the experimentation with different community extraction techniques, such as the community prediction introduced in [27], needs also to be evaluated in terms of performance improvement and overall efficiency.
- The underlying challenge of the text annotation tasks, in conjunction with the Entity Linking tasks in general, would be the Knowledge Acquisition Bottleneck, namely the lack of semantically annotated corpora of the underlying knowledge ontology (i.e., Wikipedia). Addressing this challenge via an unsupervised machine learning approximation is among our future plans, aiming at improving knowledge acquisition closure from all available corpora resources.
Author Contributions
Funding
Conflicts of Interest
References
- Fortunato, S. Community detection in graphs. Phys. Rep. 2010, 486, 75–174. [Google Scholar] [CrossRef]
- Blondel, V.D.; Guillaume, J.-L.; Lambiotte, R.; Lefebvre, E. Fast unfolding of communities in large networks. J. Stat. Mech. Theory Exp. 2008, 10008. [Google Scholar] [CrossRef]
- Clauset, A.; Newman, M.E.J.; Moore, C. Finding community structure in very large networks. Phys. Rev. E 2004, 70, 066111. [Google Scholar] [CrossRef] [PubMed]
- Navigli, R. Word sense disambiguation: A survey. ACM Comput. Surv. 2009, 41, 1–69. [Google Scholar] [CrossRef]
- Mallery, J.C. Thinking about Foreign Policy: Finding an Appropriate Role for Artificial Intelligence Computers. Ph.D. Thesis, MIT Political Science Department, Cambridge, MA, USA, 1988. [Google Scholar]
- Gale, W.A.; Church, K.W.; Yarowsky, D. A method for disambiguating word senses in a large corpus. Comput. Humanit. 1992, 26, 415–439. [Google Scholar] [CrossRef]
- Mihalcea, R.; Csomai, A. Wikify! Linking Documents to Encyclopedic Knowledge. In Proceedings of the CIKM 2007, Lisboa, Portugal, 6–8 November 2007; pp. 233–242. [Google Scholar] [CrossRef]
- Silviu, C. Large-Scale Named Entity Disambiguation Based on Wikipedia Data. In Proceedings of the EMNLP-CoNLL 2007, Prague, Czech, 28–30 June 2007; pp. 708–716. [Google Scholar]
- Milne, D.; Witten, I. Learning to link with wikipedia. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, Napa Valley, CA, USA, 26–30 October 2008; pp. 509–518. [Google Scholar] [CrossRef]
- Milne, D.N.; Witten, I. An Effective, Low-cost Measure of Semantic Relatedness Obtained from Wikipedia Links; AAAI Workshop on Wikipedia and Artificial Intelligence: Menlo Park, CA, USA, 2008. [Google Scholar]
- Kulkarni, S.; Singh, A.; Ramakrishnan, G.; Chakrabarti, S. Collective annotation of Wikipedia entities in web text. In Proceedings of the 15th ACM SIGKDD International Conference, Paris, France, 28 June–1 July 2009; pp. 457–466. [Google Scholar] [CrossRef]
- Ferragina, P.; Scaiella, U. TAGME: On-the-fly annotation of short text fragments (by wikipedia entities). In Proceedings of the 19th ACM International Conference on Information and Knowledge Management 2010, Toronto, ON, Canada, 26–30 October 2010; pp. 1625–1628. [Google Scholar] [CrossRef]
- Hoffart, J.; Yosef, M.A.; Bordino, I.; Fürstenau, H.; Pinkal, M.; Spaniol, M.; Taneva, B.; Thater, S.; Weikum, G. Robust Disambiguation of Named Entities in Text. In Proceedings of the 2011 Conference on Empirical Methods in Natural Language Processing, Edinburgh, UK, 27–31 July 2011; pp. 782–792. [Google Scholar]
- Han, X.; Sun, L.; Zhao, J. Collective entity linking in web text: A graph-based method. In Proceedings of the 34th International ACM SIGIR Conference on Research and Development in Information Retrieval, Beijing, China, 25–29 July 2011; pp. 765–774. [Google Scholar] [CrossRef]
- Usbeck, R.; Ngomo, A.-C.N.; Röder, M.; Gerber, D.; Coelho, S.A.; Auer, S.; Both, A. AGDISTIS—Agnostic Disambiguation of Named Entities Using Linked Open Data. In Proceedings of the ECAI 2014 21st European Conference on Artificial Intelligence, Prague, Czech, 18–22 August 2014; pp. 1113–1114. [Google Scholar] [CrossRef]
- Piccinno, F.; Ferragina, P. From TagME to WAT: A new entity annotator. In Proceedings of the First International Workshop on Entity Recognition & Disambiguation, Gold Coast Queensland, Australia, 11 July 2014; pp. 55–62. [Google Scholar] [CrossRef]
- Sun, Y.; Lin, L.; Tang, D.; Yang, N.; Ji, Z.; Wang, X. Modeling Mention, Context and Entity with Neural Networks for Entity Disambiguation. In Proceedings of the IJCAI 2015 Twenty-Fourth International Joint Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 1333–1339. [Google Scholar]
- Yamada, I.; Shindo, H.; Takeda, H.; Takefuji, Y. Joint Learning of the Embedding of Words and Entities for Named Entity Disambiguation. arXiv 2016, arXiv:1601.01343. [Google Scholar]
- Ganea, O.-E.; Hofmann, T. Deep joint entity disambiguation with local neural attention. arXiv 2017, arXiv:1704.04920. [Google Scholar]
- Sil, A.; Kundu, G.; Florian, R.; Hamza, W. Neural Cross-Lingual Entity Linking. arXiv 2018, arXiv:1712.01813. [Google Scholar]
- Shnayderman, I.; Ein-Dor, L.; Mass, Y.; Halfon, A.; Sznajder, B.; Spector, A.; Katz, Y.; Sheinwald, D.; Aharonov, R.; Slonim, N. Fast End-to-End Wikification. arXiv 2019, arXiv:1908.06785. [Google Scholar]
- Rasmussen, C.E.; Williams, C.K. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006. [Google Scholar]
- Index of /enwiki/. Available online: https://dumps.wikimedia.org/enwiki (accessed on 5 May 2020).
- Clauset-Newman-Moore Algorithm Implementation. Available online: https://networkx.github.io/documentation/stable/_modules/networkx/algorithms/community/modularity_max.html#greedy_modularity_communities (accessed on 5 May 2020).
- Louvain Algorithm Implementation. Available online: https://github.com/Sotera/spark-distributed-louvain-modularity (accessed on 5 May 2020).
- sklearn.gaussian_process.GaussianProcessClassifier. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.gaussian_process.GaussianProcessClassifier.html (accessed on 5 May 2020).
- Makris, C.; Pispirigos, G.; Rizos, I.O. A Distributed Bagging Ensemble Methodology for Community Prediction in Social Networks. Information 2020, 11, 199. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Recall | 1.0 | 0.9 | 0.8 | 0.6 | 0.4 | 0.2 |
|---|---|---|---|---|---|---|
| Louvain (Precision) | 0.7491 | 0.8294 | 0.8693 | 0.9201 | 0.9643 | 0.9836 |
| Louvain (F1) | 0.8563 | 0.8632 | 0.8330 | 0.7262 | 0.5622 | 0.1809 |
| CNM 1 (Precision) | 0.7554 | 0.8362 | 0.8738 | 0.9337 | 0.9678 | 0.9866 |
| CNM 1 (F1) | 0.8606 | 0.8667 | 0.8351 | 0.7287 | 0.5659 | 0.3325 |
| TAGME (Precision) | 0.6720 | 0.7640 | 0.8242 | 0.9101 | 0.9619 | 0.9832 |
| TAGME (F1) | 0.8038 | 0.8264 | 0.8118 | 0.7222 | 0.5650 | 0.3323 |
| GPC 2 (Precision) | 0.6980 | 0.7946 | 0.8351 | 0.9108 | 0.9540 | 0.9808 |
| GPC 2 (F1) | 0.8221 | 0.8440 | 0.8171 | 0.7232 | 0.5633 | 0.3320 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Makris, C.; Pispirigos, G.; Simos, M.A. Text Semantic Annotation: A Distributed Methodology Based on Community Coherence. Algorithms 2020, 13, 160. https://doi.org/10.3390/a13070160
Makris C, Pispirigos G, Simos MA. Text Semantic Annotation: A Distributed Methodology Based on Community Coherence. Algorithms. 2020; 13(7):160. https://doi.org/10.3390/a13070160
Chicago/Turabian StyleMakris, Christos, Georgios Pispirigos, and Michael Angelos Simos. 2020. "Text Semantic Annotation: A Distributed Methodology Based on Community Coherence" Algorithms 13, no. 7: 160. https://doi.org/10.3390/a13070160
APA StyleMakris, C., Pispirigos, G., & Simos, M. A. (2020). Text Semantic Annotation: A Distributed Methodology Based on Community Coherence. Algorithms, 13(7), 160. https://doi.org/10.3390/a13070160