1. Introduction
In last few years, many approaches have been proposed to detect communities in social networks using diverse ways. Community detection is one of the most important research topics in network science and graph analysis. Informally, a community is defined as a set of network’s elements that are highly linked within the group and weakly linked to the outside. Modeling and examining complex systems that contain biological, ecological, economic, social, technological, and other information is a very difficult process because the systems used for the real-world data representation contain highly important information, such as social relationships among people or information exchange interactions between molecular structures in a body. For this reason, the study of community structures inspires intense research activities to visualize and understand the dynamics of a network at different scales [
1,
2,
3]. In order to evaluate the quality of node partitions of a network, the
modularity is certainly the most used quality index [
4].
Taking the modularity (
Q) into account as an evaluation measure, community detection can easily be seen as a combinatorial optimization problem, since the problem aims to find a clustering that maximizes
It is also a hard optimization problem since Community Detection has been proven to be an
-complete problem [
5]. Therefore, several search algorithms (both exact and approximate) for clustering problems have been proposed, and, generally, they have been proven to be robust in finding as cohesive as possible communities in large and complex networks [
6,
7]. It is well known in the literature that metaheuristics work better than exact methods in large, complex, and uncertainty environments. Indeed, they are approximation methods successfully applied on many hard and complex problems able to find good solutions within reasonable computing times [
8].
In this paper, we propose two Immunological Algorithms for the community detection problem, called Opt-IA and Hybrid-IA, respectively. The first is based on a random and blind search, and employs specifically designed stochastic operators to carefully explore the search space, while Hybrid-IA uses a Local Search (LS) technique that deterministically tries to refine the solutions found so far.
The main goal in this paper is to prove the efficiency, robustness, and reliability of the two immune-inspired algorithms in community detection problem, as they have been successfully applied to several other areas and optimization tasks on networks. The efficiency and robustness of both algorithms were tested on several social networks (with different sizes), and, further, a comparison with seven other metaheuristic methods has also been performed in order to assess the reliability of Opt-IA and Hybrid-IA with respect to the state-to-the-art on community detection. In view of such comparisons, we are able to assert that both immunological algorithms outperforms all other methods used for comparison, and find the best modularity in all tested networks. By reducing the comparison to only Opt-IA and Hybrid-IA, it is possible to assert overall that the algorithms are comparable, although the first one, as expected, needs a higher number of generations due to its random and blind search.
Finally, it is important to underline the fact that, differently than all other algorithms used for comparison, which have been tested and refined over the years, Opt-IA and Hybrid-IA are already very competitive and successful, even though they are at a first stage of development in community detection tasks, and still need a deep study of their key parameters and operators.
The rest of the paper is organized as follows. In
Section 2, the problem of community detection is introduced and the definition of the modularity measure are formulated. In
Section 3, the two immunological algorithms are introduced and we focus the description primarily on their common concepts, whilst the detailed descriptions on their features and operators developed are presented, respectively, in
Section 3.1 (
Opt-IA) and
Section 3.2 (
Hybrid-IA). In
Section 4, all experiments performed and comparisons done are described in detail, including the used dataset and experimental protocol, and an analysis on the convergence behavior of the two proposed immunological algorithms (
Opt-IA and
Hybrid-IA). Finally, conclusions and some future research directions are presented in
Section 5.
2. Mathematical Definition of Modularity in Networks
The main aims in community detection are to uncover the inherent community structure of a network, that is to say, those groups of nodes sharing common and similar properties. This means, then, to detect groups (communities or modules) internally strongly connected, and externally weakly connected. Being able to detect community structures is a key and relevant task in many areas (biology, computer science, engineering, economics, and politics) because they allow for uncovering and understanding important information about the function of the network itself and how its elements affect and interact with each other. For instance, in World Wide Web networks, the communities can identify those pages dealing with topics which are related; in biological networks, instead, they correspond to proteins having the same specific function; in social sciences, they can identify circles of friends or people who have the same hobby, or those people who live in the same neighborhood.
In order to evaluate the quality of the uncovered groups in a network,
modularity is certainly the most used quality index [
4]. It is based on the idea that a random graph is not expected to have a community structure; therefore, the possible existence of communities can be revealed by the difference of density between vertices of the graph and vertices of a random graph with the same size and degree distribution. Formally, it can be defined as follows: given an undirected graph
, with
V the set of vertices (
), and
E the set of edges (
), the modularity of a community is defined as:
where
is the adjacency matrix of
G,
and
are the degrees of nodes
i and
j respectively, and
if
belong to the same community, 0 otherwise.
As asserted by Brandes et al. in [
5], the modularity value for unweighted and undirected graphs lies in the range
. Then, a low
Q value, i.e., close to the lower bound, reflects a bad clustering, and implies the absence of real communities, whilst good groups are identified by a high modularity value that implies the presence of highly cohesive communities. For a trivial clustering, with a single cluster, the modularity value is 0. However, the modularity has the tendency to produce large communities and, therefore, fails to detect communities which are comparatively small with respect to the network [
9].
3. Immunological Algorithms
Immunological Algorithms (IA) are among the most used population-based metaheuristics, successfully applied in search and optimization tasks. They take inspiration from the dynamics of the immune system in performing its job of protecting living organisms. One of the features of the immune system that makes it a very good source of inspiration is its ability to detect, distinguish, learn, and remember all foreign entities discovered [
10]. Both proposed algorithms,
Opt-IA and
Hybrid-IA, belong to the special class
Clonal Selection Algorithms (CSA) [
11,
12], whose efficiency is due to the three main immune operators: (i) cloning, (ii) hypermutation, and (iii) aging. Furthermore, both are based on two main concepts: antigen (
), which represents the problem to tackle, and B cell, or antibody (
) that represents a candidate solution, i.e., a point in the solution space. At each time step
t, both algorithms maintain a population of
d candidate solutions: each solution is a subdivision of the vertices of the graph
in communities. Let
, then a B cell
is a sequence of
N integers belonging to the range
, where
indicates that the vertex
i has been added to the cluster
j. The population, for both algorithms, is initialized at the time step
randomly assigning each vertex
i to a group
j, with
Then, just after the initialization step, the fitness function (Equation (
1)) is evaluated for each randomly generated element (
) by using the function
. The two algorithms end their evolutionary cycle when the halting criterion is reached. For this work, it was fixed to a maximum number of generations (
).
Among all immunological operators,
cloning is the only one that is roughly the same between
Opt-IA and
Hybrid-IA (6th line in Algorithms 1 and 2). This operator simply copies
times each B cell producing an intermediate population
of size
. We used a static cloning for both algorithms in order to avoid premature convergences. Indeed, if a number of clones proportional to to the fitness value is produced instead, we could have a population of B cells very similar to each other, and we would, consequently, be unable to perform a proper exploration of the search space getting easily trapped in local optima.
Hybrid-IA, more in detail, assigns an age to each cloned B cell, which determines how long it can live in the population, from the assigned age until it reaches the maximum age allowed
, a user-defined parameter). Specifically, a random age chosen in the range
In this way, each clone is guaranteed to stay in the population for at least a fixed number of generations (
in the worst case). The age assignment and the aging operator (see
Section 3.2) play a crucial role on
Hybrid-IA performances, and any evolutionary algorithm in general because they are able to keep a right amount of diversity among the solutions, thus avoiding premature convergences [
13].
3.1. Opt-IA
Opt-IA [
14] is a totally blind stochastic algorithm, a particular type of optimization method that generates a set of random solutions for the community detection problem. It is based on
- (i)
the hypermutation operator, which acts on each clone in order to explore its neighborhood;
- (ii)
the precompetition operator, which makes it possible to maintain a more heterogeneous population during the evolutionary cycle;
- (iii)
the stochastic aging operator whose aim is keep high diversity into the population and consequently help the algorithm in escaping from local optima; and, finally,
- (iv)
the selection operator which identifies the best d elements without repetition of fitness, ensuring heterogeneity into the population.
In Algorithm 1, the pseudocode of
Opt-IA, and its key parameters, are described:
| Algorithm 1: Pseudo-code of Opt-IA |
| 1: procedure Opt-IA(d, , m, ) |
| 2: |
| 3: ; |
| 4: |
| 5: while do |
| 6: |
| 7: |
| 8: |
| 9: |
| 10: |
| 11: |
| 12: ; |
| 13: end while |
| 14: end procedure |
The purpose of the hypermutation operator is to carefully explore the neighborhood of each solution in order to generate better solutions from iteration to iteration. It basically performs at most m mutations on each B cell, where m is a user-defined constant parameter. Unlike the other clonal selection algorithms, including Hybrid-IA, the m mutation rate of each element is not determined by a law inversely proportional to the fitness function, but it will be the same for anyone. In this way, possible premature convergences are avoided. In this algorithm, three different types of mutation have been designed, which can act on a single node (local operators) or a set of nodes (global operators):
equiprobability: randomly select a vertex from the solution and reassign it to a cluster among those existing at that time. Each cluster has the same probability of being selected;
destroy: randomly select a cluster from the solution , a percentage P in the range , and a cluster in the range . All vertices in are then moved to the cluster with P probability. Note that, if the cluster does not exist, then a new community is created;
fuse: randomly select a cluster and assign all its nodes to a randomly selected cluster among those existing.
After the hypermutation operator, the fitness values for all mutated B cell are computed. Three operators act on the population at this point.
Precompetition operator: the primary aim of this operator is to obtain a more heterogeneous population by trying to maintain solutions which have different community numbers in order to better explore the search space. Basically, this operator randomly selects two different B cells from , and, if they have same community number, the one with a lower fitness value will be deleted with a probability.
StochasticAging operator: this operator helps the algorithm to escape from local optima by introducing diversity in the population. At each iteration, each B cell in will be removed with probability (a user-defined parameter). Using this type of aging operator, Opt-IA is able to, on one hand, to introduce diversity in the population, which is crucial for jumping out from local optima, and, on the other hand, to have an accurate exploration and exploitation of the neighborhoods.
Selection operator: finally, the selection operator has the task to generate the new population for the next generation made up of the best B cells discovered so far. Therefore, the new population is created by selecting the best d B cells among the survivors in and hypermutated B cells in . It is important to highlight that no redundancy is allowed during the selection: if a hypermutated B cell is candidate to be selected for the new population , but it has the same fitness value with someone in , then it will be discarded. This ensures monotonicity in the evolution dynamic.
3.2. Hybrid-IA
A fundamental difference between
Opt-IA and
Hybrid-IA is that the former, as described above, is a stochastic IA that finds solutions by random methods. The latter, instead, uses a deterministic local search, based on rational choices that refine and improve the solutions found so far. The pseudocode of
Hybrid-IA is described in Algorithm 2.
| Algorithm 2: Pseudo-code of Hybrid-IA. |
| 1: procedure Hybrid-IA(d, , , ) |
| 2: |
| 3: |
| 4: |
| 5: while do |
| 6: |
| 7: |
| 8: |
| 9: |
| 10: |
| 11: |
| 12: |
| 13: ; |
| 14: end while |
| 15: end procedure |
The hypermutation operator developed in Hybrid-IA has the main goal of exploring the neighborhoods of solutions by evaluating how good each clone is. Unlike Opt-IA, the mutation rate is determined through an inversely proportional law to the fitness function value of the B cell considered, that is, the better the fitness value of the element is, the smaller the mutation rate will be. In particular, let be a cloned B cell, the mutation rate is defined as the probability to move a node from one community to another one, where , a user-defined parameter that determines the shape of the mutation rate, and is the fitness function normalized in the range . Formally, the designed hypermutation works as follows: for each B cell, two communities and are randomly chosen (): the first is chosen among all existing ones, and the second in the range Then, all vertices in are moved to with probability given by . If a value that does not correspond to any currently existing community is assigned to , a new community is created and added to the existing ones. The idea behind this approach is to better explore the search space and create and discover new communities by moving a variable percentage of nodes from existing communities. This search method balances the effects of local search (as described below), by allowing the algorithm to avoid premature convergences towards local optima.
The static aging operator in Hybrid-IA acts on each mutated B cells by removing older ones from the two populations and Basically, let be the maximum number of generations allowed for every B cell to stay in its population; then, once the age of a B cell exceeds (i.e., age = +1), it will be removed independently from its fitness value. However, an exception may be done for the best current solution, which is kept into the population even if its age is older than . Such a variant of the aging operator is called elitist aging operator. In the overall, the main goal of this operator is to allow the algorithm to escape and jump out from local optima, assuring a proper turnover between the B cells in the population, and producing, consequently, high diversity among them.
After the aging operator, the best d survivors from both populations and are selected, in order to generate the temporary population , on the local search will be performed. Such a selection is performed by the -Selection operator, where and . The operator identifies the d best elements among the set of offsprings and the old parent B cells, ensuring consequently monotonicity in the evolution dynamics.
The Local Search designed and introduced in
Hybrid-IA is the key operator to properly speed up the convergence of the algorithm, and, in a way, drive it towards more promising regions. Furthermore, it intensifies the search and explore the neighborhood of each solution using the well-known
Move Vertex approach (MV) [
15]. The basic idea of the proposed LS is to assess deterministically if it is possible to move a node from its community to another one within its neighbors. The MV approach takes into account the
move gain that can be defined as the variation in modularity produced when a node is moved from a community to another. Before formally defining the move gain, it is important to point out that the modularity
Q, defined in Equation (
1), can be rewritten as:
where
k is the number of the found communities;
is the set of communities that is the partitioning of the set of vertice V;
and
are, respectively, the number of links inside the community
i, and the sum of the degrees of vertices belonging to the
i community. The
move gain of a vertex
is, then, the modularity variation produced by moving
u from
to
, that is:
where
and
are the number of links from
u to nodes in
and
respectively, and
is the degree of
u when considering all the vertices
V. If
, then moving node
u from
to
produces an increment in modularity, and then a possible improvement. Consequently, the goal of MV is to find a node
u to move to an adjacent community in order to maximize
:
where
,
and
is the adjacency list of node
u.
For each solution in
, the Local Search begins by sorting the communities in increasing order with respect to the ratio between the sum of inside links and the sum of the node degrees in the community. In this way, poorly formed communities are identified. After that, MV acts on each community of the solution, starting from nodes that lie on the border of the community, that is, those that have at least an outgoing link. In addition, for communities, the nodes are sorted with respect to the ratio between the links inside and node degree. The key idea behind LS is to deterministically repair the solutions which were produced by the hypermutation operator, by discovering then new partitions with higher modularity value. Equation (
3) can be calculated efficiently because
M and
are constants, the terms
and
can be stored and updated using appropriate data structures, while the terms
can be calculated during the exploration of all adjacent nodes of
u. Therefore, the complexity of the move vertex operator is linear on the dimension of the neighborhood of node
u.
4. Results
In this section, all the experiments and comparisons performed on the two proposed algorithms, Opt-IA and Hybrid-IA, are presented, in order to assess their efficiency and robustness in detecting highly linked communities. Different social networks have been taken into account for the experimental analyses conducted on the two algorithms, and for their comparison with other efficient metaheuristics which are present in literature.
The instances are well-known networks used for the community detection problem and their characteristics are summarized and reported in
Table 1.
Gravy’s Zebra [
16] is a network created by Sundaresan et al. in which a link between to nodes indicates that a pair of zebras appeared together at least once during the study. In
Zachary’s Karate Club [
17] network, collected by Zachary in 1977, a node represents a member of the club and an edge represents a tie between two members of the club.
Bottlenose Dolphins [
18] is an undirected social network of dolphins where an edge represents a frequent association.
Books about US Politics [
19] is a network of books sold, compiled by Krebs, where edges represent frequent co-purchasing of books by the same buyers. Another network considered is
American College Football [
1], a network of football games between colleges.
Jazz Musicians [
20] is the collaboration network between Jazz musicians. Each node is a Jazz musician and an edge denotes that two musicians have played together in a band. These specific networks have been chosen because they are the most used as test benches and, consequently, allowed us to compare our algorithms with several others and, in particular, with different metaheuristics. Although there exist bigger networks in literature, large and meaningful comparisons are more difficult to develop.
For all experiments carried out and presented in this section, both Opt-IA and Hybrid-IA maintain a population of B cells of size , whereas the number of generated clones depends upon the approach used. Since Opt-IA needs high variability, has been set for larger networks (), and for smaller ones (); , has been, instead, set in Hybrid-IA for all tested network types.
Moreover, the
m and
parameters in
Opt-IA have been set to 1 and
, respectively; however, for
Hybrid-IA,
and
have been set to
and 5. Note that all parameters of
Opt-IA have been determined through careful tuning experiments, whilst those of
Hybrid-IA have been identified both from the knowledge learned by previous works [
11,
12], and from a preliminary and not in-depth experiments. As described above, the maximum number of generations has been taken into account as stopping criterion. For all experiments performed in this research work, it was fixed
for
Opt-IA, and
for
Hybrid-IA. Note that a higher iterations number has been considered for
Opt-IA due to its blind search, which, for obvious reasons, requires larger time steps to reach acceptable solutions.
Initially, the experimental analysis has been focused on the inspection of the efficiency of both algorithms,
Opt-IA and
Hybrid-IA, in terms of convergence and solution quality found. In
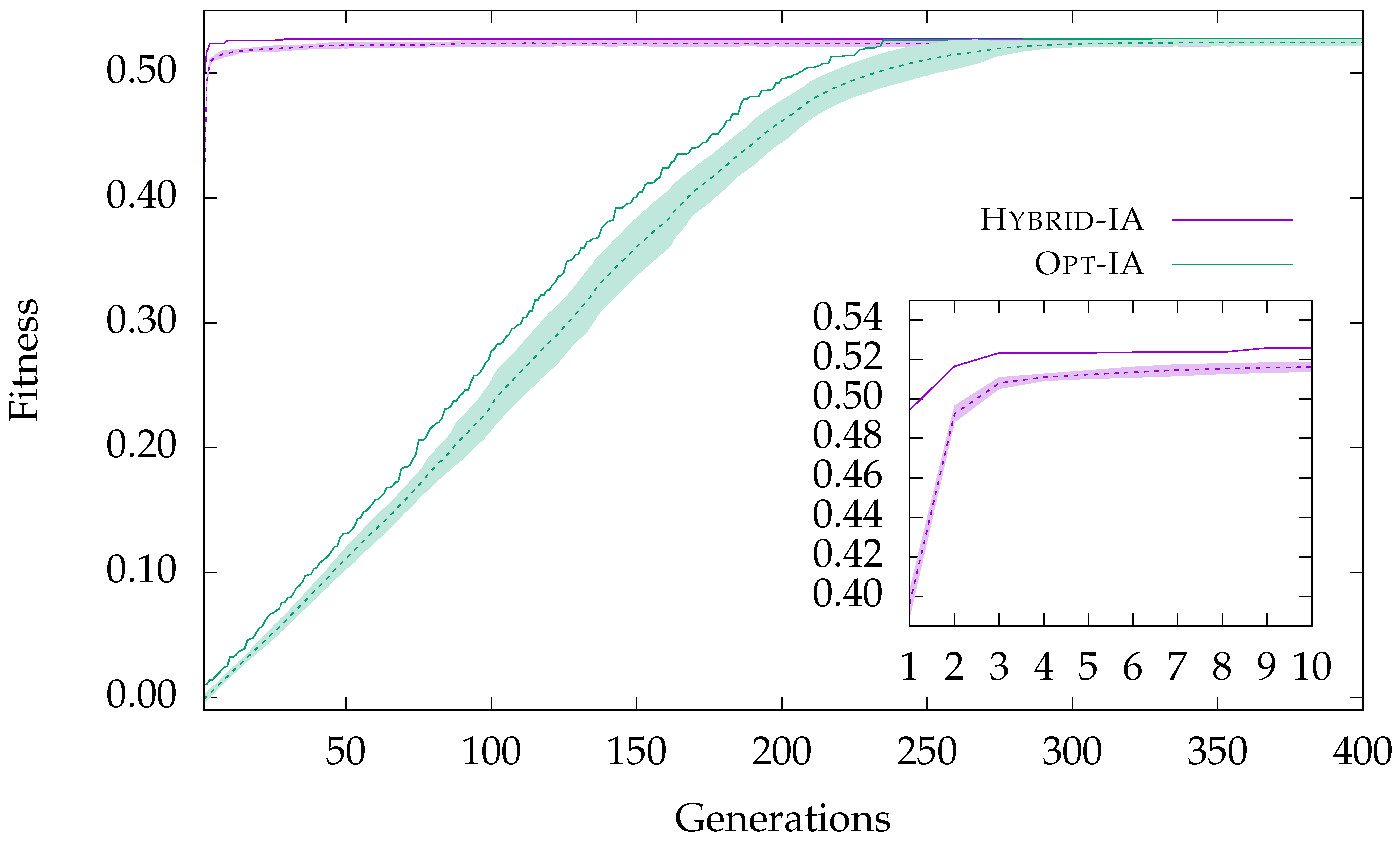
Figure 1, the convergence behavior of both
Opt-IA and
Hybrid-IA on the
Books about US Politics network is showed. In this plot, the curves represent the evolution of the best and average fitness of the population; the standard deviation of the fitness values of the population is superimposed onto the average fitness and gives an idea about how heterogeneous the elements in the population are.
From
Figure 1, one can note how
Opt-IA converges more slowly towards the best solution, as expected, always keeping a certain variability within the population. This allows the algorithm to better explore the search space. When the population is composed of very different elements, i.e., when the standard deviation is high, the algorithm discovers new solutions, significantly improving the current best solution. However, after about 250 generations,
Opt-IA reaches the optimal solution and the curves (best and average fitness) tend to overlap. Moreover, the achievement of the optimal solution helps the creation of better clones, reducing the variability of the population. Unlike
Opt-IA,
Hybrid-IA converges easily thanks to the local search applied to the elements after the selection phase. As can be noted from the inset plot in
Figure 1,
Hybrid-IA reaches the optimal solution after a few generations. Even in this case, once the best solution is reached, the population follows the same trend of the curve of the best fitness, and both curves continue (almost) as a single line. If on one hand the local search helps to quickly discover good solutions, on the other, it reduces the diversity inside the population, reducing then the exploration of the search space. In particular, as demonstrated by the worst value found in the
Jazz Musicians network, reported in
Table 2,
Hybrid-IA prematurely converges towards local optima, from which it will hardly be able to get out. At the end of the analysis of
Figure 1, it is possible to conclude that the stochastic operators designed in
Opt-IA guarantee an excellent and large exploration of the search space, but with the disadvantage of requiring a longer evolution time; however, the local search developed in
Hybrid-IA, and relative sorting criteria, allow for quickly discovering good solutions to exploit during the evolutionary process.
In order to evaluate the performances and reliability of both immunological algorithms with respect the state-of-the-art, a wide comparison has been performed with several metaheuristics, and a well-known deterministic algorithm, on the all dataset reported in
Table 1. In particular,
Opt-IA and
Hybrid-IA have been compared with:
Louvain [
21], a greedy optimization method; HDSA, a Hyper-Heuristics Differential Search Algorithm based on the migration of artificial superorganisms [
22]; BADE, an improved Bat Algorithm based on Differential Evolution algorithm [
23,
24]; SSGA, a Scatter Search [
25,
26] based on Genetic Algorithm; BB-BC, a modified Big Bang–Big Crunch algorithm [
27]; BA, an adapted Bat Algorithm for community detection [
28]; GSA, a Gravitational Search Algorithm re-designed for solving the community detection problem [
29]; and
MA-Net, a Memetic Algorithm [
30]. For all algorithms, we considered
, except for
Opt-IA, as described above, and
MA-Net whose stopping criterion has been set to 30 generations without improvement (see [
30] for details). All results of the above methods, as well as the experimental protocol, have been taken from Atay et al. [
31], except for
Louvain and
MA-Net.
The comparison performed on all dataset is reported in
Table 2, where we show for each algorithm (where possible) the
best,
mean, and
worst values of the
Q modularity; standard deviation (
), and, finally, the created communities number (
k). Furthermore, whilst the experiments for
Opt-IA and
Hybrid-IA were performed on 100 independent runs, for all other compared algorithms, only 30 independent runs have been considered, excepts for
MA-Net with 50 runs. It is important to note that, for the
MA-Net outcomes, the values reported, and taken from [
30], have been rounded to third decimal places unlike the others that are instead based on four decimals. Obviously, all 10 algorithms optimize the same fitness function reported in Equation (
1) and rewritten in a simpler way in Equation (
2).
From
Table 2, it is possible to note that all algorithms reach the optimal solution in the first two networks
Zebra and
Karate Club, except
Louvain, which fails on the second; on all the other network instances, both
Opt-IA and
Hybrid-IA outperform all other compared algorithms, matching their best values only with HDSA and
MA-Net ones. It is important to point out, which proves even more the efficiency of the two proposed immunological algorithms, how the
mean values obtained by
Opt-IA and
Hybrid-IA, on all tested networks, are better than the best modularity found by the other algorithms, such as: BADE, SSGA, BB-BC, BA, and GSA; even on the
Dolphins and
Football networks, the worst modularity value obtained by
Opt-IA is equal to or greater than the best one obtained by the same algorithms. On the
Dolphins network,
Opt-IA reaches a better mean value than
Hybrid-IA, HDSA, and
MA-Net, since, because of its random/blind exploration of the search space, it jumps out from local optima more easily than the other three. The opposite behavior of
Opt-IA occurs when the size and complexity of the networks increase. In such a case, it obviously needs more generations to converge towards the optimal solutions and this is highlighted by the mean value and the standard deviation obtained for
Political Books and
Football. Note that, with longer generations,
Opt-IA finds roughly the same mean values as
Hybrid-IA.
Hybrid-IA shows more stable results on all tested networks than Opt-IA, obtaining lower standard deviation values on all instances. On Dolphins network, Hybrid-IA has a mean value slightly lower than Opt-IA and HDSA, while in Political Books lower only than HDSA. As described above, this is due to the local search that leads the algorithm to a premature convergence towards local optima, obtaining the lowest worst value. Furthermore, HDSA is a hyper-heuristic which uses a genetic algorithm and scatter search to create the initial population for the differential search algorithm, speeding up the convergence of the algorithm, and reducing the spread of results. In Jazz Musicians network, both Opt-IA and Hybrid-IA algorithms obtain similar results, comparable to those obtained by MA-Net. Finally, if we focus on the comparison with only the deterministic Louvain algorithm, both immunological algorithms outperform it in almost all networks (3 out of 6). In conclusion, from the experimental analysis, it is possible to assert that both Opt-IA and Hybrid-IA perform very well on networks (large and small) considered for the experiments and are competitive with the state-of-the-art in terms of efficiency and robustness. Furthermore, inspecting the found mean values, we can see that both algorithms show themselves to be reliable optimization methods in detecting highly linked communities.
4.1. Large Synthetic Networks
In order to assess the scalability of
Hybrid-IA, as last step of this research work, we considered larger synthetic networks with 1000 and 5000 vertices. The clear advantages of using them are given by the knowledge of the communities and consequently by the possibility of evaluating the goodness of the detected communities, as well as the possibility of testing the algorithm on different scenarios and complexities. The validity of this benchmark is given by faithfully reproducing the keys features of real graphs communities. The new benchmark was produced using the
algorithm proposed by Lancichinetti and Fortunato in [
32]. Two different network instances were considered with
and
, respectively, considering
as average degree and
as maximum degree. For both values of
, we considered
as exponent of the degrees distribution and
for the one of the communities’ sizes. Moreover, about the community dimension, we fixed
and
, respectively, minimum and maximum sizes. Finally, the mixing parameter
was varied from
to
, which identifies the relationships percentage of a node with those belonging to different communities. Therefore, the larger the value of
, the larger are the relationships that a vertex has with other nodes outside its community. More details on the
algorithm, the key parameters, and the generated benchmark can be found in [
32,
33].
Thanks to the advantages offered by the synthetic networks, we took into account a new evaluation metric in order to confirm the efficiency of the proposed
Hybrid-IA in detecting strong communities. In particular, we considered the
Normalized Mutual Information (
) [
34], which is a widely used measure to compare community detection methods since it discloses the similarity between the true community and the detected community structures. Thus, while the modularity allows for assessing how cohesive the detected communities are, the
allows for evaluating how similar they are with respect to the real ones.
In
Table 3, the outcomes of
Hybrid-IA on these new synthetic datasets are then reported and compared to the ones obtained by
Louvain. Modularity (
Q) and
values are presented and considered for the comparisons. In the first column of the table, the features of each instance tackled are also shown.
Analyzing the comparison, it is possible to see how Hybrid-IA outperforms Louvain in all networks with 1000 vertices with respect to the Q modularity metric, whilst the opposite happens for those instances with 5000 vertices, where instead Louvain outperforms Hybrid-IA. This gap is due to the combination between the random search and local search that, together with the diversity produced by the immune operators, requires a longer convergence time than the Louvain one. It is important to point out that very likely, with a larger number of generations, Hybrid-IA would reach comparable results to Louvain in terms of Q modularity also on these larger networks.
Different instead is the assessment of the comparison if it is analyzed with respect the
metric [
34]:
Hybrid-IA outperforms
Louvain in all networks, and this proves a better ability of the hybrid immune algorithm proposed in detecting communities closer to the true ones than the greedy optimization algorithm. Note that, although modularity assesses the cohesion of the communities detected, maximizin
Q might not correspond to detect the true communities.
4.2. On the Computational Complexity of Opt-IA and Hybrid-IA
Both our algorithms are population based algorithms; therefore, any analysis of their computational complexity must deal not only with the size of the input problems and its implementation, which in turn implies the analysis of the computational cost of computing the fitness of any individual, but also with the choice of the key parameters, such as the number of elements in the population the total number of iterations , etc. We will discuss these issues properly in what follows.
When we look at the code for Opt-IA, we have the following:
Any element of the population, i.e., a tentative solution, is an array of length where N is the number of vertices of the input graph.
The operator randomly creates a population of d tentative solutions. Thus, total cost is However, we stress here the fact that which is set experimentally, is actually constant, i.e., it does not depend on the size of the input. In our case, we fixed to the value 100 for all of the experiments. This allows us to say that the cost of the procedure is actually
The operator
computes the fitness for all the
elements of the population. A bound on the cost of the procedure can easily be computed using Equation (
1), and it clearly is
The operator creates copies of each of the elements of the population. As you can see from our settings, is a parameter which does not depend on the size of the input graph, but just on the nature of the algorithm. This allows us to say that the cost of is
The operator mutates each element of the population with constant probability As we described earlier, we have three different implementations. In all three cases, we have either the random selection of a vertex or the random selection of a cluster. In the two most time-consuming implementations, namely destroy and fuse, we might have the reallocation of several vertices. Thus, all in all, has an upper bound
The operator randomly selects two vertices, checks their community numbers, and, if they are the same, it deletes with probability the one with lower fitness. Since the fitness value was already computed, the overall cost of the operator is clearly
The operator goes through all the elements of the population and removes an element with the user defined probability . Thus, its overall cost is
Finally, the operator chooses, without repetition of fitness values, the best d B cells among and . As we underlined before, the number of elements in these two populations is constant with respect to the size of the input, so we can simply say that the cost of the operator is
In summary, the cost of one iteration of
Opt-IA has a computational upper bound
Finally, let us take into consideration the number of iterations. We mentioned that for all the experiments concerning
Opt-IA the number of generations was fixed to
For the bigger graphs, it is a number smaller than the number of edges and about five times the number of vertices. It is clear, though, that, contrary to the other parameters, the number of generations cannot be considered independent from the size of the input. The bigger the input, the bigger is the number of generations that we expect to need. However, how does it grow with respect to
N? The possibility of keeping it constant for large graphs, and the results of our experiments tell us that such a growth is at worst linear with respect to
Thus, if we want to be very cautious in estimating the overall complexity of
Opt-IA, we can say that we need at most
generations to obtain good results. If we check again
Figure 1, we see that. after about
generations,
Opt-IA reaches the optimal solution. In general, we estimate that the number of generations is at most
If we add such a bound on the overall computational analysis of
Opt-IA, we can certainly claim that the upper bound for its running time is
If we study the computational cost of Hybrid-IA, we find very few differences with what we saw for Opt-IA. Namely,
The operator in the worst case moves all the vertices from one community to another, but it is still obviously
The operator goes through all the elements of the populations which we consider a constant number, again independent from the size of the input graph, so, all in all, it is
The operator acts on every vertex of the given graph and explores its vicinity. Therefore, we can estimate that its work has an upper bound
In summary, the cost of one iteration of Hybrid-IA has a computational upper bound just like Opt-IA, though clearly higher internal constant factors. Such a constant factor is balanced by the number of generations. We fixed it to 100 for all the experiments, including the very large synthetic graphs, where we noted we should have probably had a larger number of generations. Once again, the number of generations cannot be considered independent from the size of the input. However, certainly for Hybrid-IA, it is asymptotically not larger than what we estimated for Opt-IA. Moreover, even assuming that its growth is linear with respect to , the constant factor is definitively smaller. In any case, we can conclude that, also for Hybrid-IA, we have a computational upper bound
5. Conclusions
Two novel immunological algorithms have been developed for the community detection, one of the most challenging problems in network science, with an important impact on many research areas. The two algorithms, respectively Opt-IA and Hybrid-IA, are inspired by the clonal selection principle, and take advantage of the three main immune operators of cloning, hypermutation, and aging. The main difference between the two algorithms is the designed search strategy: Opt-IA performs a random and blind search in the search space, and it is coupled with pure stochastic operators, whilst Hybrid-IA is based on a refinement of the current best solutions through a deterministic local search. The efficiency and efficacy of both algorithms have been tested on several real social networks, different both in complexity and size. From the experimental analysis, it emerges that Opt-IA, thanks to its structure, carries out a careful exploration of the solutions space, but it needs a larger number of iterations, whilst Hybrid-IA quickly discovers good solutions, and exploits them during the evolutionary cycle. Opt-IA and Hybrid-IA have also been compared with seven efficient metaheuristics (included one Hyper-Heuristic), and one greedy optimization method. The obtained outcomes prove the reliability of both algorithms, showing competitiveness, and efficiency with respect to all other algorithms to which they are compared. In particular, they prove that, under the same conditions, both Opt-IA and Hybrid-IA reach better solutions (i.e., higher modularity) than the other algorithms, including Louvain. Moreover, these results, along with previous successful applications in several optimization tasks on networks, prove once again that our proposed immunological approach and algorithm is one of the best metaheuristics methods in literature.
Several points need to be carefully analyzed as future work, such as an appropriate parameters tuning, an improvement of effectiveness of the hypermutation operator, and local search method in order to build more efficiently the clusters, better guide the move of the nodes between the clusters, and speed up the convergence. Finally, an obvious future research direction is to tackle larger networks, especially biological ones, which are harder and of high relevance.





{kind=link}