Beyond Newton: A New Root-Finding Fixed-Point Iteration for Nonlinear Equations


Abstract
1. Introduction
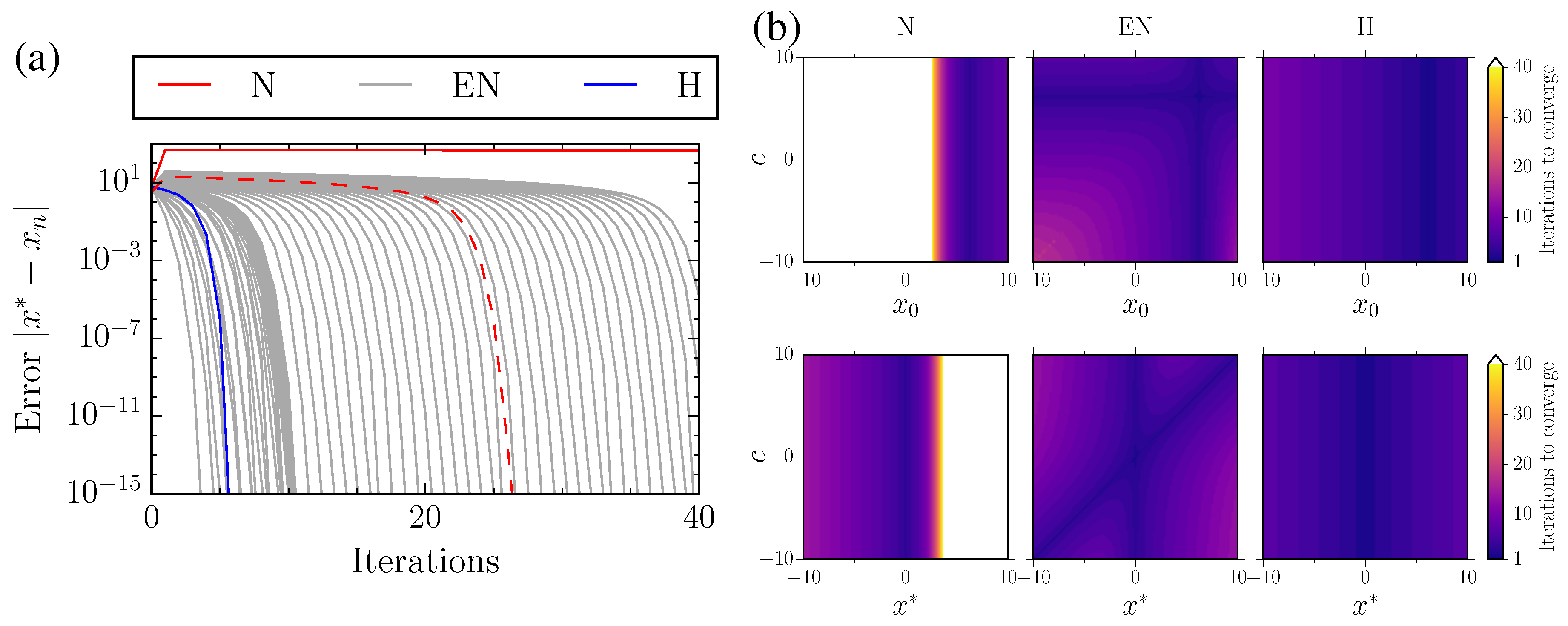
2. Methods and Results
2.1. Choice of c
2.2. Limiting Case of
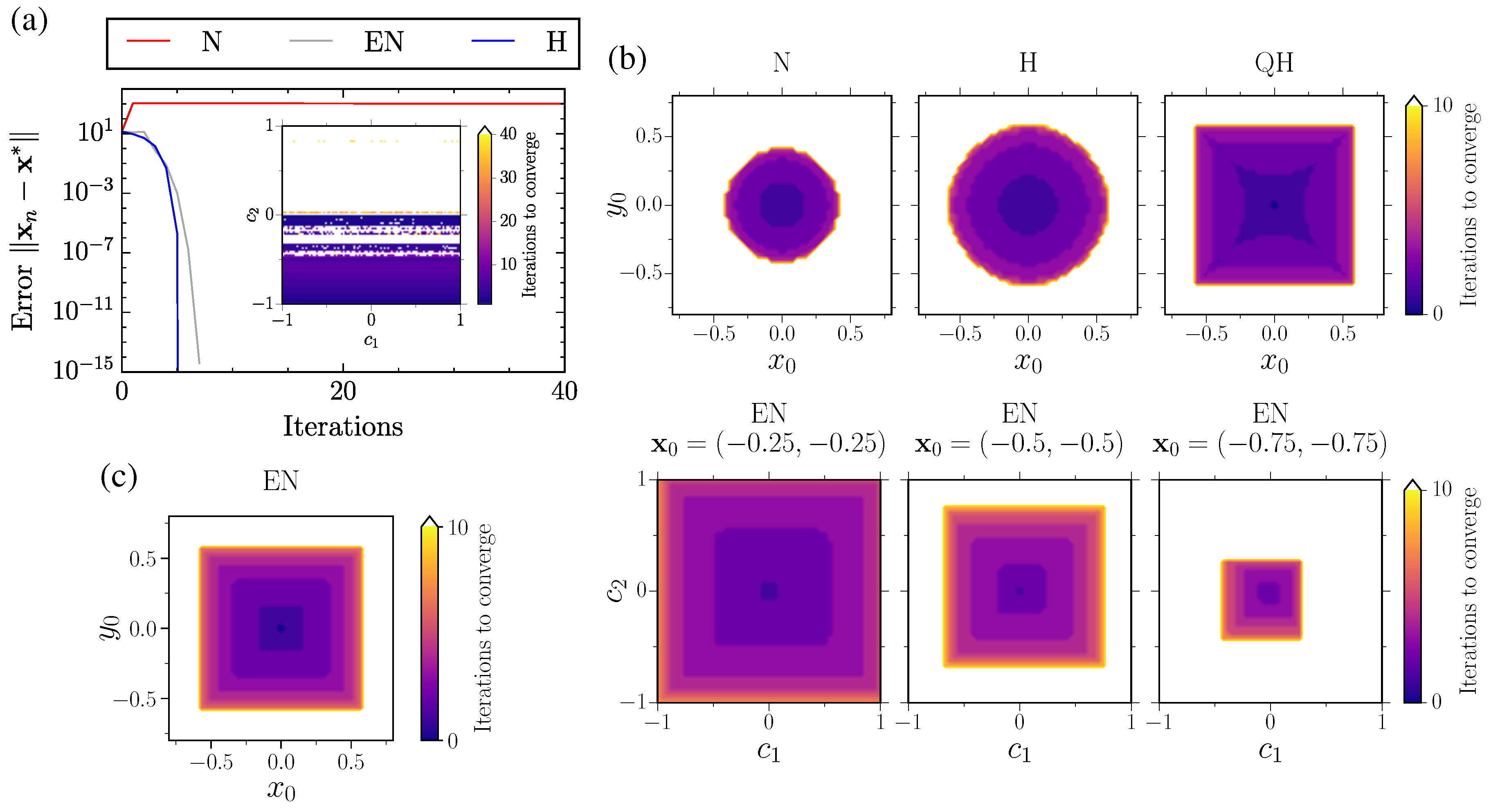
2.3. Extension to Multiple Unknowns
3. Discussion
3.1. Extended-Newton Method
3.2. Rediscovery of Halley’s Method
3.3. Vector Equations
3.4. Future Directions
3.5. Conclusions
Supplementary Materials
Author Contributions
Funding
Conflicts of Interest
References
- Apostol, T.M. Calculus; Jon Wiley & Sons: New York, NY, USA, 1967. [Google Scholar]
- Smale, S. Algorithms for solving equations. In Proceedings of the International Congress of Mathematicians, Berkeley, CA, USA, 3–11 August 1986; pp. 1263–1286. [Google Scholar]
- Traub, J.F. Iterative Methods for the Solution of Equations; American Mathematical Soc.: Washington, WA, USA, 1982. [Google Scholar]
- Kelley, C.T. Iterative Methods for Linear and Nonlinear Equations; SIAM: Philadelphia, PA, USA, 1995. [Google Scholar]
- Householder, A. The Numerical Treatment of a Single Nonlinear Equation; McGraw-Hill: New York, NY, USA, 1970. [Google Scholar]
- Osada, N. An optimal multiple root-finding method of order three. J. Comput. Appl. Math. 1994, 51, 131–133. [Google Scholar] [CrossRef]
- Amat, S.; Busquier, S.; Gutiérrez, J. Geometric constructions of iterative functions to solve nonlinear equations. J. Comput. Appl. Math. 2003, 157, 197–205. [Google Scholar] [CrossRef]
- Kou, J. Some variants of Cauchy’s method with accelerated fourth-order convergence. J. Comput. Appl. Math. 2008, 213, 71–78. [Google Scholar] [CrossRef]
- Cordero, A.; Torregrosa, J.R.; Vindel, P. Dynamics of a family of Chebyshev–Halley type methods. Appl. Math. Comput. 2013, 219, 8568–8583. [Google Scholar] [CrossRef]
- Sahu, D.R.; Agarwal, R.P.; Singh, V.K. A Third Order Newton-Like Method and Its Applications. Mathematics 2018, 7, 31. [Google Scholar] [CrossRef]
- Li, J.; Wang, X.; Madhu, K. Higher-Order Derivative-Free Iterative Methods for Solving Nonlinear Equations and Their Basins of Attraction. Mathematics 2019, 7, 1052. [Google Scholar] [CrossRef]
- Kantorovich, L. Functional analysis and applied mathematics. Uspehi Mat. Nauk 1948, 3, 89–185. [Google Scholar]
- Dedieu, J.P.; Priouret, P.; Malajovich, G. Newton’s method on Riemannian manifolds: Covariant alpha theory. IMA J. Numer. Anal. 2003, 23, 395–419. [Google Scholar] [CrossRef]
- Argyros, I.K.; Magreñán, Á.A.; Orcos, L.; Sarría, Í. Advances in the Semilocal Convergence of Newton’s Method with Real-World Applications. Mathematics 2019, 7, 299. [Google Scholar] [CrossRef]
- Yong, Z.; Gupta, N.; Jaiswal, J.P.; Madhu, K. On the Semilocal Convergence of the Multi–Point Variant of Jarratt Method: Unbounded Third Derivative Case. Mathematics 2019, 7, 540. [Google Scholar] [CrossRef]
- Dennis, J., Jr. On the Kantorovich hypothesis for Newton’s method. SIAM J. Numer. Anal. 1969, 6, 493–507. [Google Scholar] [CrossRef]
- Ortega, J.M. The newton-kantorovich theorem. Am. Math. Mon. 1968, 75, 658–660. [Google Scholar] [CrossRef]
- Tapia, R. The Kantorovich theorem for Newton’s method. Am. Math. Mon. 1971, 78, 389–392. [Google Scholar] [CrossRef]
- Mei, Y.; Hurtado, D.E.; Pant, S.; Aggarwal, A. On improving the numerical convergence of highly nonlinear elasticity problems. Comput. Methods Appl. Mech. Eng. 2018, 337, 110–127. [Google Scholar] [CrossRef]
- Buchberger, B. Symbolic computation: Computer algebra and logic. In Frontiers of Combining Systems; Baader, F., Schulz, K.U., Eds.; Springer: Dordrecht, The Netherlands, 1996; Volume 3, pp. 193–219. [Google Scholar]
- Rall, L. Automatic Differentiation: Techniques and Applications. Lect. Notes. Comput. Sci. 1981, 120, 173. [Google Scholar]
- Cai, X.C.; Keyes, D.E. Nonlinearly preconditioned inexact Newton algorithms. SIAM J. Sci. Comput. 2002, 24, 183–200. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Method | Scalar Function Update | Vector Function Update |
|---|---|---|
| N | ||
| EN | ||
| H | ||
| QH | − |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aggarwal, A.; Pant, S. Beyond Newton: A New Root-Finding Fixed-Point Iteration for Nonlinear Equations. Algorithms 2020, 13, 78. https://doi.org/10.3390/a13040078
Aggarwal A, Pant S. Beyond Newton: A New Root-Finding Fixed-Point Iteration for Nonlinear Equations. Algorithms. 2020; 13(4):78. https://doi.org/10.3390/a13040078
Chicago/Turabian StyleAggarwal, Ankush, and Sanjay Pant. 2020. "Beyond Newton: A New Root-Finding Fixed-Point Iteration for Nonlinear Equations" Algorithms 13, no. 4: 78. https://doi.org/10.3390/a13040078
APA StyleAggarwal, A., & Pant, S. (2020). Beyond Newton: A New Root-Finding Fixed-Point Iteration for Nonlinear Equations. Algorithms, 13(4), 78. https://doi.org/10.3390/a13040078