A Novel Hybrid Genetic-Whale Optimization Model for Ontology Learning from Arabic Text



Abstract
1. Introduction
- Firstly, a text mining algorithm is proposed particularly for extracting the concepts and their semantic relations from the Arabic documents. The extracted set of concepts with the semantic relations constitutes the structure of the ontology. In this regard, the algorithm operates on the Arabic documents by calculating the concept frequency weights depending on the term frequency weights. Thereafter, it calculates the weights of concept similarity using the information-driven from the ontology structure involving the concept’s path distance, the concept’s distribution layer, and the mutual parent concept’s distribution layer. Eventually, it performs the mapping of features by assigning the concept similarity to the concept features. Unlike the ordinary text mining algorithms [9,10], this property is crucial because merging the concept frequency weights with the concept similarity weights supports the detection of Arabic semantic information and optimizes the ontology learning.
- Secondly, this is the first study to propose bio-inspired algorithms for optimization of Arabic ontology learning, in which a hybrid G-WOA algorithm is proposed in this context, to optimize the Arabic ontology learning from the raw text, by optimizing the exploration-exploitation trade-off. It can benefit from a priori knowledge (initial concept set obtained using the text mining algorithm) to create innovative solutions for the best concept/relation set that can constitute the ontology.
- Thirdly, investigating the comparable performance between the proposed G-WOA and five other bio-inspired optimization algorithms [32,39,44,45,46], when learning ontology from Arabic text, where its solutions are also compared to those obtained by the other algorithms, across different Arabic corpora. To the best of our knowledge, the proposed and compared bio-inspired algorithms have not been investigated in Arabic or non-Arabic ontology learning yet.
- Fourthly, the proposed ontology learning approach is applicable with the other languages, where it can be applied to extract the optimal ontology structure from the non-Arabic texts.
2. Literature Review
2.1. Literature Review on Arabic Text Mining
2.2. Literature Review on Arabic Ontology Learning
3. Preliminaries
3.1. Genetic Algorithm
- Reproduction. The reproduction means keeping chromosomes without changes and transferring them to the next generation. Inputs and outputs of this procedure are the same chromosomes.
- Crossover. This process concatenates two chromosomes to produce a new two ones through switching genes. On this basis, the input for this step is two chromosomes, whereas the output is two different ones.
- Mutation. This process reverses randomly one gene value of a chromosome. Thus, the input chromosome is completely different from the output one.
3.2. Whale Optimization Algorithm
3.2.1. Encircling Prey
3.2.2. Bubble-Net Attacking Method
3.2.3. Searching for Prey
3.3. Arabic Ontology Learning
3.3.1. The Semantic Field Linguistic Theory
3.3.2. The SEMANTIC analysis Linguistic Theory
3.3.3. The Semantic Relations Theory
- Synonymy. This relationship type aims concepts that hold nearly similar meanings. For instance, the concepts شهيق inspiration and استنشاق inhalation are synonyms.
- Antonyms. This relationship aims concepts that demonstrate opposite meanings, i.e., antonyms, like خبيث malignant, and حميد benign.
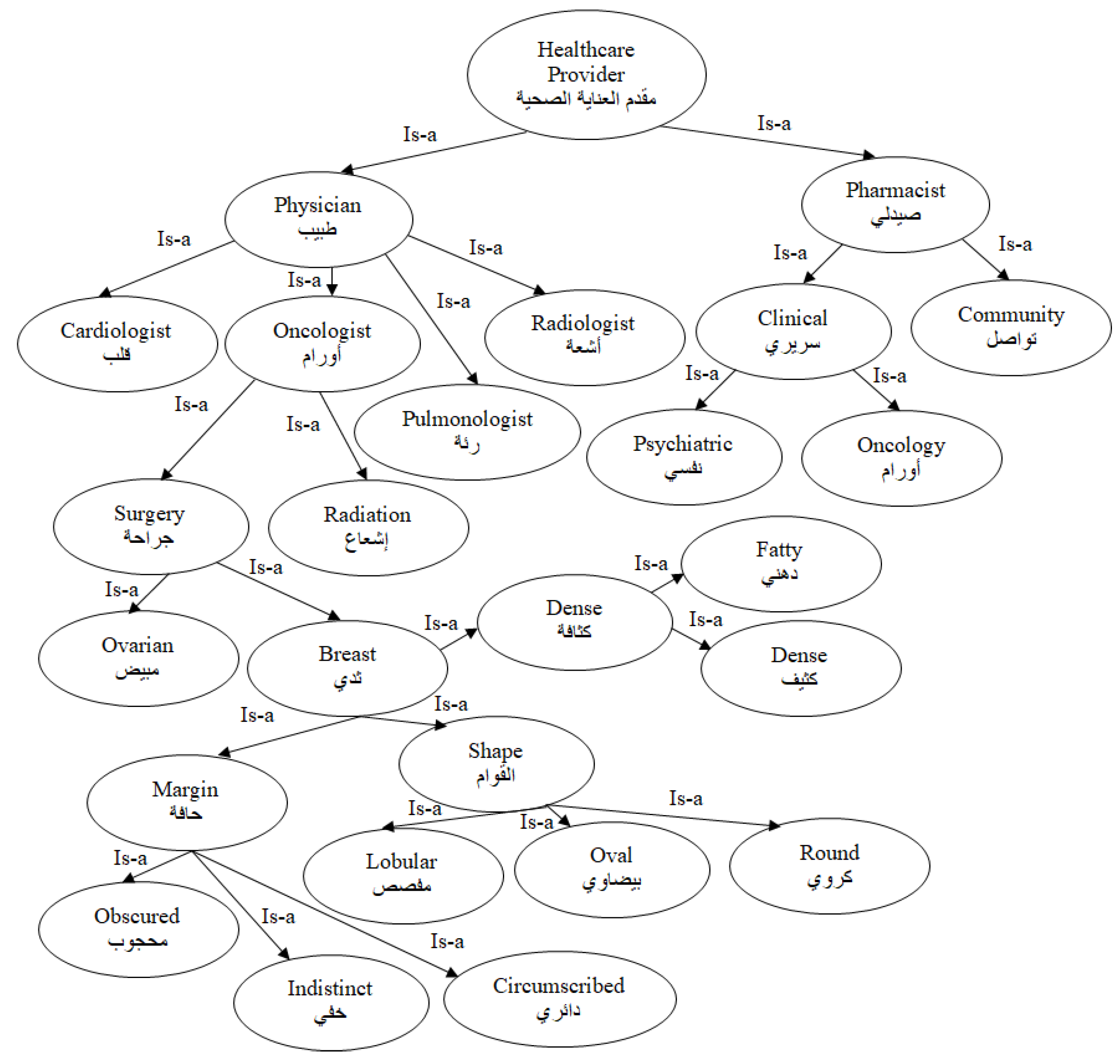
- Inclusion. This type of relation means that one entity-type comprises sub entity-types. For example, the concept صمام رئوي pulmonary valve with the concept قلب heart, can indicate a part-to-whole or Is-a relationship. Figure 1 presents an example of some biomedical knowledge concepts available in our corpus which are linked with an Is-a relationship.
4. Proposed Model for Arabic Ontology Learning
4.1. Pre-Processing
- Eliminating stop-words. Words like pronouns and conjunctions are extremely common and if we remove these words from text we can focus on important concepts. Examples of stop words are: ‘في’ → ‘in’, ‘هذا’ → this, ‘بين’ → ‘between’, ‘مع’ → ‘with’, ‘إلى’ → ‘to’, ‘أو’ → ‘or’, ‘و’ → ‘and’, etc.
- Stemming. This task leaves out the primitive form of a word. Thus, words or terms that share identical root but differ in their surface-forms due to their affixes can be determined. Such a procedure encompasses eliminating two things: a prefix, like ‘الـ’, at the start of words and as suffix such as ‘ية’at the end of words. An instance of eliminating a prefix and a suffix is the input word ‘’السرطانية ‘cancerous’ which is stemmed to ‘سرطان’ ‘cancer’.
4.2. Proposed Text Mining Algorithm
4.2.1. Term Weighting
| Algorithm 1: The Proposed Arabic Text Mining Algorithm |
| Input: A term weighting matrix of training set corresponding to term set Output: Matrix of mapped features obtained by assigning concept similarity weights to the concepts
|
4.2.2. Concept Similarity Weights
4.2.3. Feature Mapping (Assigning Similarity Weights to the Mapped Concepts)
- a diagonal matrix whose elements denote the non-negative eigenvalues of ,
- an orthogonal matrix whose columns point to the corresponding eigenvectors,
- a diagonal matrix whose diagonal items are the square root for diagonal elements.
- ,
- the frequency weight of “concept ” in document ,
- the documents number,
- the concepts number.
4.3. The Proposed Hybrid Genetic-Whale Optimization Algorithm for Arabic Ontology Learning
| Algorithm 2: The proposed hybrid G-WOA Algorithm for ontology learning from Arabic text |
| Input: A vector assigns the document’s mapped features. //The G-WOA algorithm parameters: population size, crossover rate, mutation rate, The stopping criterion, constant defines the logarithmic spiral shape, random variable, where , coefficient vector of WOA, and is linearly decreased from 2 to 0 along iterations (). //Fitness function parameters weight of false alarm rate, weight of detection rate, and selected features weight. Output: the solution with the optimal concept/semantic relation set contributing to the ontology.
|
4.3.1. Initial Population
4.3.2. Fitness Evaluation
4.3.3. Mutation
4.3.4. Crossover
4.3.5. Selection
4.3.6. Termination Phase
5. Experimental Results
5.1. Corpora
5.2. Performance Measures
5.3. Cross Validation
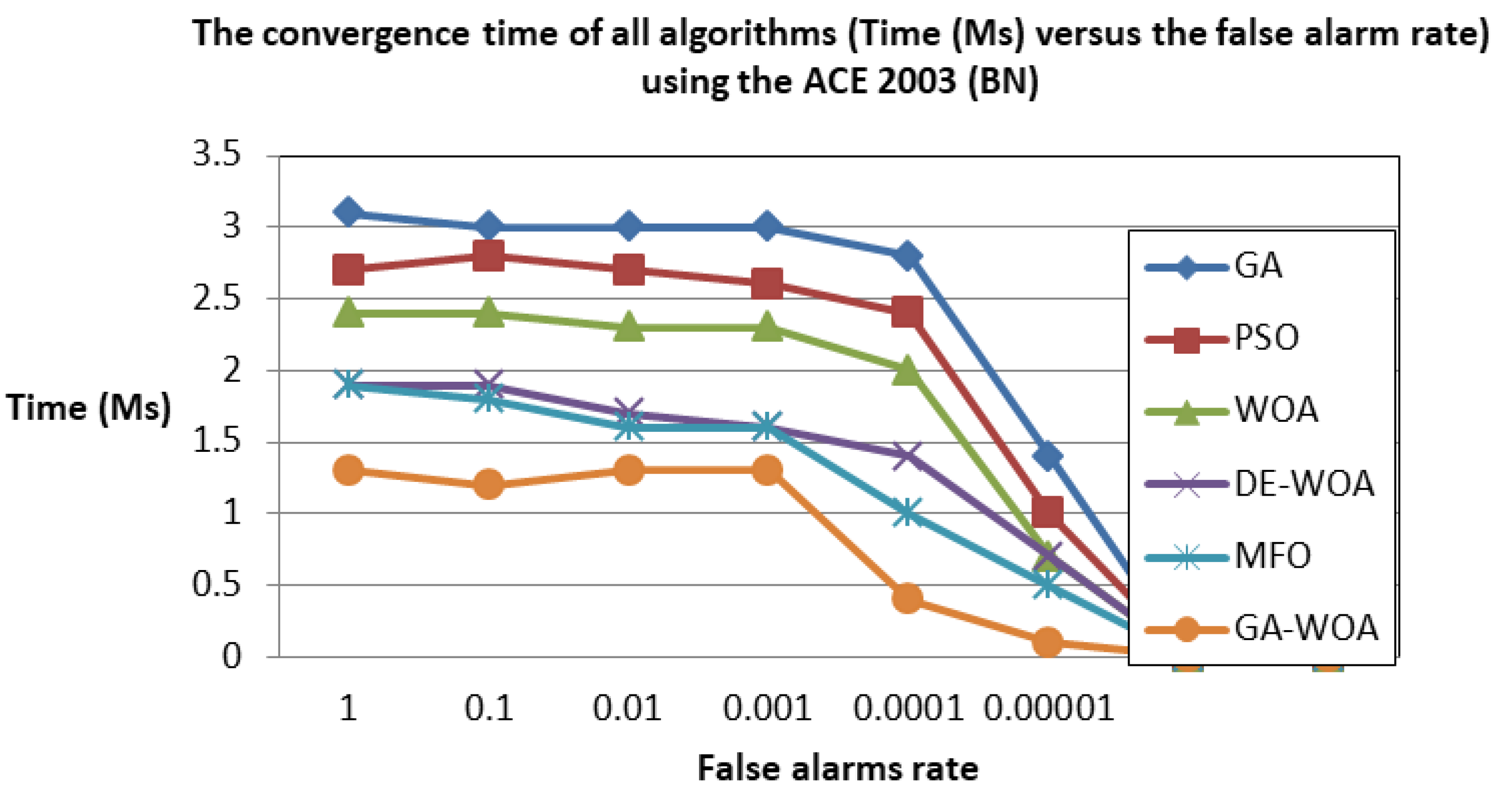
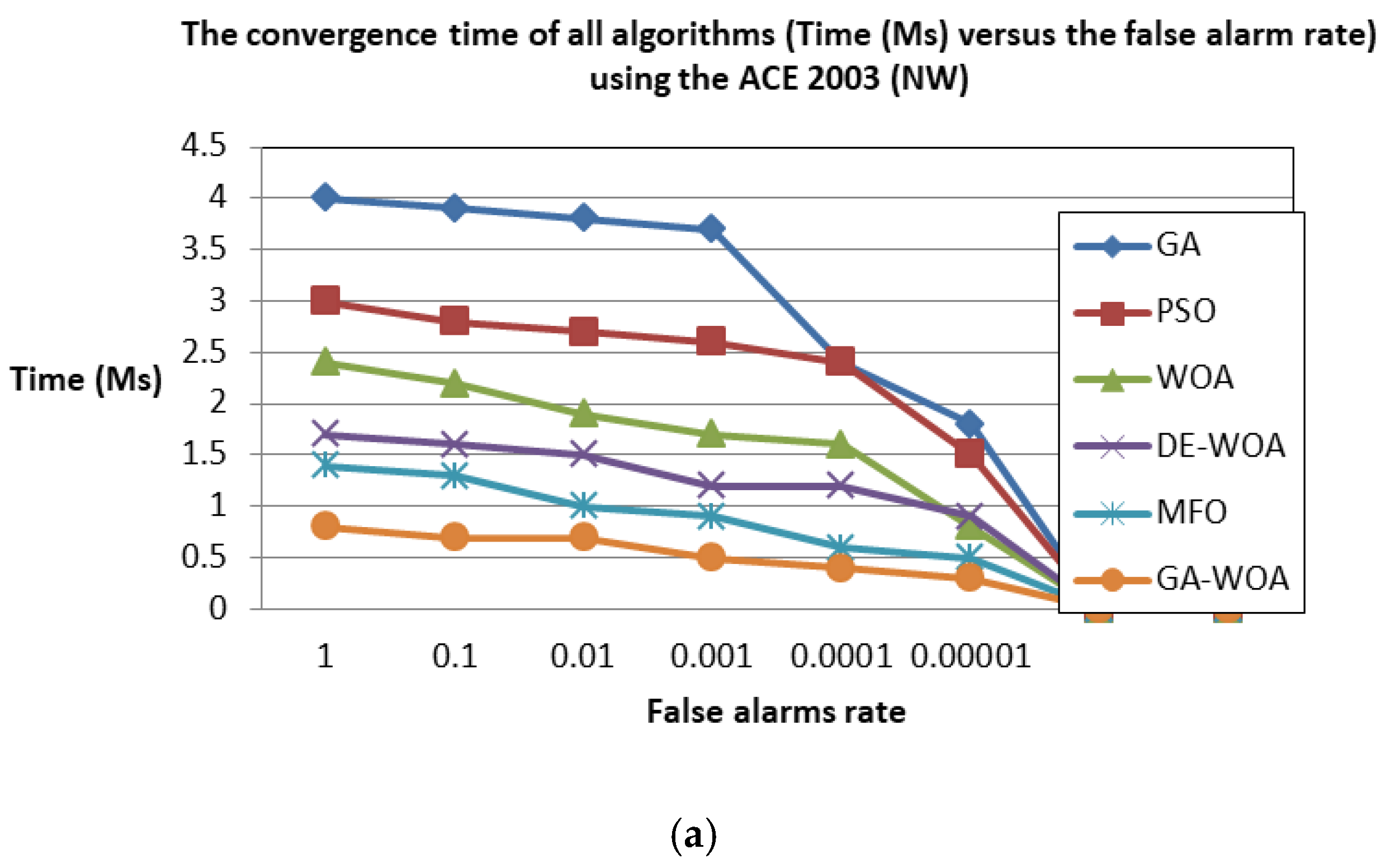
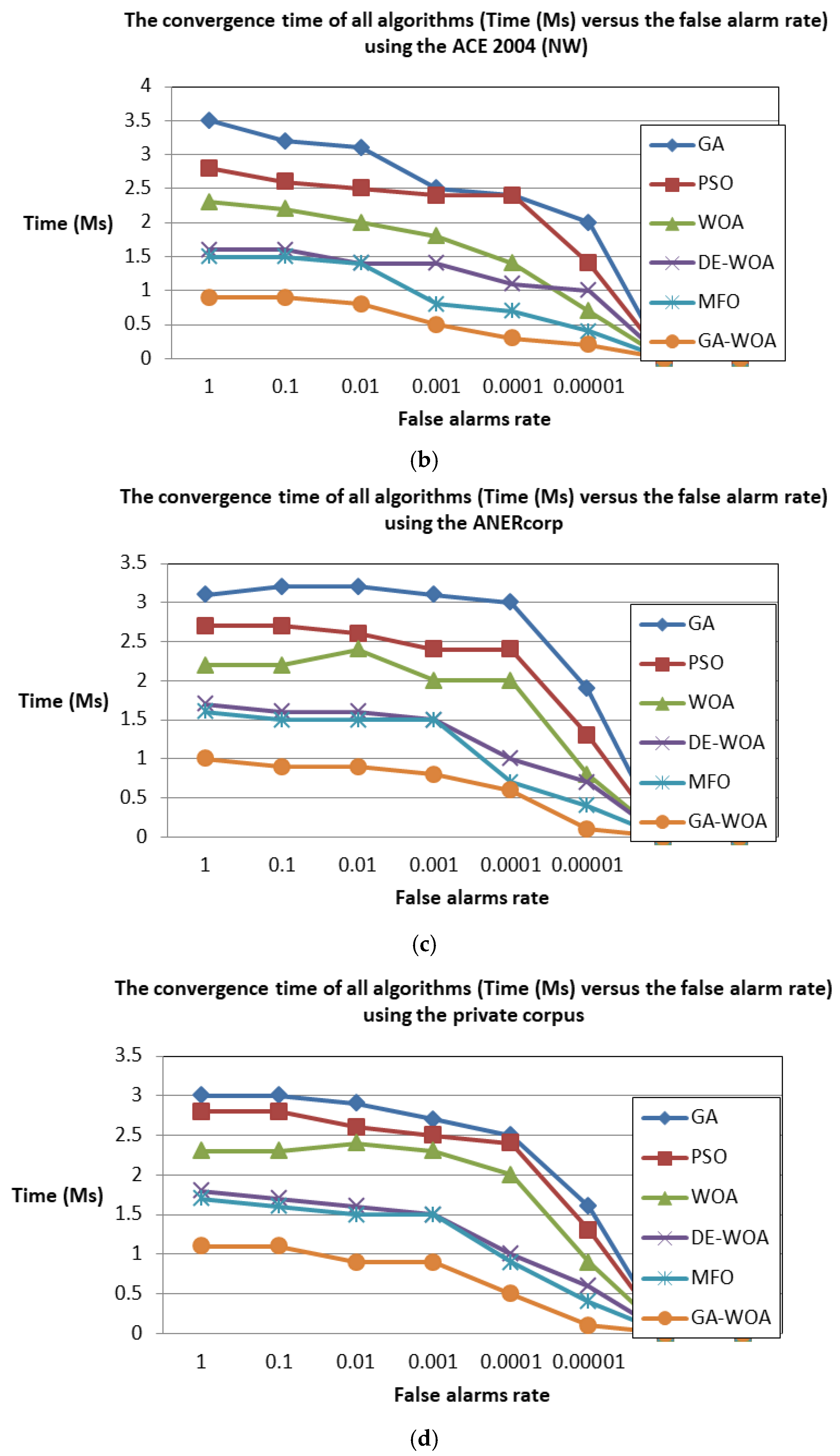
5.4. Discussion
5.4.1. Comparison to the State-of-the-Art
5.4.2. Contributions to the Literature
5.4.3. Implications for Practice
6. Conclusions
Limitations and Future Research Directions
Author Contributions
Funding
Conflicts of Interest
Appendix A: Tables of Results

{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Hybrid G-WOA | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fold | ACE 2003 (BN) | ACE 2003 (NW) | ACE 2004 (NW) | ANERcorp | Private Corpus | ||||||||||
| (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | |
| 1 | 99 | 99.12 | 99.06 | 99.42 | 98.84 | 99.13 | 97.78 | 98.55 | 98.16 | 98.49 | 98.95 | 98.72 | 98.83 | 99.01 | 98.92 |
| 2 | 98.3 | 99.04 | 98.67 | 99.53 | 98.66 | 99.09 | 98.86 | 99.78 | 99.32 | 98.57 | 97.05 | 97.8 | 98.06 | 98.72 | 98.39 |
| 3 | 97.93 | 99.79 | 98.85 | 99.31 | 98.98 | 99.14 | 97.09 | 99.39 | 98.23 | 98.82 | 97.89 | 98.35 | 97.03 | 99.65 | 98.32 |
| 4 | 97.61 | 99.11 | 98.35 | 99.28 | 97.68 | 98.47 | 98.39 | 99.19 | 98.79 | 98.76 | 98.96 | 98.86 | 98.52 | 98.97 | 98.74 |
| 5 | 98.38 | 98.21 | 98.29 | 99.4 | 98.45 | 98.92 | 98.54 | 98.36 | 98.45 | 99.18 | 98.24 | 98.71 | 97.97 | 99.55 | 98.75 |
| 6 | 98.09 | 98.11 | 98.1 | 98.5 | 97.31 | 97.9 | 97.94 | 98.21 | 98.07 | 99.28 | 98.24 | 98.76 | 97.32 | 99.43 | 98.36 |
| 7 | 97.76 | 99.28 | 98.51 | 99.94 | 99 | 99.47 | 97.05 | 99.47 | 98.25 | 99.82 | 97.52 | 98.66 | 98.57 | 99.11 | 98.84 |
| 8 | 97.8 | 98.94 | 98.37 | 99.74 | 98.11 | 98.92 | 97.14 | 99.54 | 98.33 | 98.99 | 98.76 | 98.87 | 97.83 | 98.76 | 98.29 |
| 9 | 98.67 | 99.52 | 99.09 | 98.52 | 97.95 | 98.23 | 98.66 | 98.2 | 98.43 | 98.13 | 98.43 | 98.28 | 98.48 | 98.44 | 98.46 |
| 10 | 97.9 | 99.22 | 98.56 | 99.04 | 98.22 | 98.63 | 97.51 | 99.2 | 98.35 | 99.89 | 97.56 | 98.71 | 98.62 | 99.86 | 99.24 |
| Average | 98.14 | 99.03 | 98.59 | 99.27 | 98.32 | 98.79 | 97.9 | 98.99 | 98.44 | 98.99 | 98.16 | 98.57 | 98.12 | 99.15 | 98.63 |
| GA | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fold | ACE 2003 (BN) | ACE 2003 (NW) | ACE 2004 (NW) | ANERcorp | Private Corpus | ||||||||||
| (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | |
| 1 | 93.08 | 93.87 | 93.48 | 93.2 | 93.52 | 93.36 | 93.83 | 94.96 | 94.4 | 93.71 | 92.44 | 93.08 | 93.82 | 93.29 | 93.56 |
| 2 | 93.23 | 93.75 | 93.49 | 94.05 | 92.16 | 93.1 | 93.14 | 93.41 | 93.28 | 93.89 | 93.83 | 93.86 | 93.2 | 93.77 | 93.49 |
| 3 | 92.19 | 93.52 | 92.86 | 94.92 | 93.08 | 94 | 93.31 | 95.47 | 94.38 | 93.22 | 92.32 | 92.77 | 93.96 | 92.65 | 93.31 |
| 4 | 93.31 | 93.56 | 93.44 | 93.61 | 93.27 | 93.44 | 92.38 | 94.38 | 93.37 | 95.36 | 93.03 | 94.19 | 93.81 | 92.22 | 93.01 |
| 5 | 93.14 | 95.71 | 94.41 | 93.01 | 93.95 | 93.48 | 92.67 | 94.65 | 93.65 | 95.45 | 93.62 | 94.53 | 94.74 | 92.09 | 93.4 |
| 6 | 92.55 | 93.88 | 93.22 | 95.48 | 92.38 | 93.91 | 93.51 | 94.23 | 93.87 | 94.7 | 92.73 | 93.71 | 93.4 | 93.72 | 93.56 |
| 7 | 93.17 | 95.97 | 94.55 | 94.2 | 92.68 | 93.44 | 93.45 | 94.27 | 93.86 | 93.51 | 93.22 | 93.37 | 94.12 | 92.66 | 93.39 |
| 8 | 93.51 | 93.61 | 93.56 | 95.8 | 92.29 | 94.02 | 93.29 | 94.48 | 93.89 | 93.18 | 93.6 | 93.39 | 93.38 | 93.4 | 93.39 |
| 9 | 92.29 | 95.96 | 94.09 | 94.48 | 92.97 | 93.72 | 92.32 | 94.14 | 93.23 | 94.83 | 92.24 | 93.52 | 93.52 | 92.05 | 92.78 |
| 10 | 93.25 | 95.48 | 94.36 | 94.41 | 93.18 | 93.8 | 92.78 | 93.99 | 93.39 | 94.55 | 93.5 | 94.03 | 95.37 | 92.98 | 94.16 |
| Average | 92.97 | 94.53 | 93.75 | 94.32 | 92.95 | 93.63 | 93.07 | 94.40 | 93.73 | 94.24 | 93.05 | 93.65 | 93.93 | 92.88 | 93.41 |
| WOA | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fold | ACE 2003 (BN) | ACE 2003 (NW) | ACE 2004 (NW) | ANERcorp | Private Corpus | ||||||||||
| (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | |
| 1 | 95.25 | 97.16 | 96.2 | 97.44 | 95.87 | 96.65 | 95.43 | 98.09 | 96.74 | 96 | 97.6 | 96.79 | 96.09 | 97.02 | 96.55 |
| 2 | 96.29 | 97.03 | 96.66 | 97.86 | 95.74 | 96.79 | 96.22 | 98.03 | 97.12 | 95.02 | 97.25 | 96.12 | 95.77 | 97.2 | 96.48 |
| 3 | 96.76 | 97.28 | 97.02 | 97.24 | 95.02 | 96.12 | 95.49 | 97.7 | 96.58 | 96.09 | 97.53 | 96.8 | 95.89 | 97.09 | 96.49 |
| 4 | 96.16 | 97.78 | 96.96 | 98.64 | 95.74 | 97.17 | 95.38 | 97.84 | 96.59 | 96.32 | 97.19 | 96.75 | 95.13 | 97.31 | 96.21 |
| 5 | 95.32 | 97.82 | 96.55 | 98.58 | 95.65 | 97.09 | 96.11 | 97.73 | 96.91 | 95.64 | 97.12 | 96.37 | 95.96 | 98.19 | 97.06 |
| 6 | 95.55 | 97.57 | 96.55 | 97.07 | 96.26 | 96.66 | 95.08 | 97.37 | 96.21 | 96.38 | 97.07 | 96.72 | 95.63 | 98.55 | 97.07 |
| 7 | 96.44 | 97 | 96.72 | 97.06 | 95.39 | 96.22 | 96.82 | 97.53 | 97.17 | 96.76 | 98.79 | 97.76 | 96.01 | 97.82 | 96.91 |
| 8 | 95.34 | 97.77 | 96.54 | 98.99 | 95.65 | 97.29 | 95.75 | 97.46 | 96.6 | 95.27 | 98.01 | 96.62 | 96.97 | 98.45 | 97.7 |
| 9 | 95.53 | 97.43 | 96.47 | 99 | 96.1 | 97.53 | 95.46 | 98.97 | 97.18 | 96.43 | 98.97 | 97.68 | 95.32 | 98.8 | 97.03 |
| 10 | 96.57 | 97.28 | 96.92 | 97.93 | 96.41 | 97.16 | 95.71 | 97.83 | 96.76 | 96.57 | 98.99 | 97.77 | 95.67 | 97.62 | 96.64 |
| Average | 95.92 | 97.41 | 96.66 | 97.98 | 95.78 | 96.87 | 95.75 | 97.86 | 96.79 | 96.05 | 97.85 | 96.94 | 95.84 | 97.81 | 96.81 |
| PSO | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fold | ACE 2003 (BN) | ACE 2003 (NW) | ACE 2004 (NW) | ANERcorp | Private Corpus | ||||||||||
| (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | |
| 1 | 95.79 | 95.7 | 95.75 | 94.37 | 94.09 | 94.23 | 94.63 | 94.77 | 94.7 | 95.88 | 94.15 | 95.01 | 94.01 | 95.41 | 94.71 |
| 2 | 94.46 | 95.5 | 94.98 | 95.71 | 94.17 | 94.94 | 94.41 | 95.66 | 95.04 | 95.42 | 94.41 | 94.92 | 94.15 | 95.4 | 94.78 |
| 3 | 95.35 | 94.06 | 94.71 | 94.03 | 95.93 | 94.98 | 95.76 | 95.77 | 95.77 | 94.1 | 94.64 | 94.37 | 95.39 | 95.1 | 95.25 |
| 4 | 94.16 | 94.47 | 94.32 | 94.86 | 95.46 | 95.16 | 95.85 | 95.18 | 95.52 | 95.45 | 95.53 | 95.49 | 95.98 | 95.2 | 95.59 |
| 5 | 95.25 | 95.03 | 95.14 | 95.91 | 94.59 | 95.25 | 95.51 | 94.24 | 94.88 | 95.45 | 94.33 | 94.89 | 95.33 | 95.4 | 95.37 |
| 6 | 94.54 | 95.59 | 95.07 | 95.95 | 94.64 | 95.3 | 95.6 | 94.75 | 95.18 | 94.47 | 94.31 | 94.39 | 94.97 | 95.91 | 95.44 |
| 7 | 96 | 94.87 | 95.44 | 95.72 | 94.72 | 95.22 | 94.27 | 94.92 | 94.6 | 94.47 | 95.25 | 94.86 | 95.7 | 95.1 | 95.4 |
| 8 | 94.19 | 94.1 | 94.15 | 94.13 | 94.17 | 94.15 | 94.8 | 94.9 | 94.85 | 94.12 | 95.21 | 94.67 | 95.57 | 94.15 | 94.86 |
| 9 | 94.29 | 95.46 | 94.88 | 95.75 | 95.89 | 95.82 | 94.36 | 94.53 | 94.45 | 94.79 | 95.36 | 95.08 | 94.34 | 94.1 | 94.22 |
| 10 | 95.47 | 95.78 | 95.63 | 95.55 | 95 | 95.28 | 95.4 | 94.29 | 94.85 | 95.88 | 95.85 | 95.87 | 94.25 | 94.22 | 94.24 |
| Average | 94.95 | 95.06 | 95 | 95.2 | 94.87 | 95.03 | 95.06 | 94.9 | 94.98 | 95 | 94.9 | 94.96 | 94.97 | 95 | 94.99 |
| DE-WOA | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fold | ACE 2003 (BN) | ACE 2003 (NW) | ACE 2004 (NW) | ANERcorp | Private Corpus | ||||||||||
| (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | |
| 1 | 97.36 | 96.35 | 96.86 | 97.2 | 96.71 | 96.96 | 97.33 | 96.74 | 97.04 | 98.21 | 97.24 | 97.73 | 98.9 | 96.43 | 97.65 |
| 2 | 97.42 | 96.01 | 96.71 | 97.58 | 97.69 | 97.64 | 98.58 | 97.04 | 97.81 | 98.45 | 97.63 | 98.04 | 97.5 | 96.03 | 96.76 |
| 3 | 97.02 | 97.33 | 97.18 | 97.96 | 96.16 | 97.06 | 97.06 | 97.01 | 97.04 | 98.91 | 97.87 | 98.39 | 98.59 | 97.9 | 98.25 |
| 4 | 97.25 | 97.21 | 97.23 | 97.07 | 97.3 | 97.19 | 97.62 | 97.75 | 97.69 | 97.37 | 96.61 | 96.99 | 97.8 | 97.64 | 97.72 |
| 5 | 97.84 | 97.14 | 97.49 | 97.26 | 97.45 | 97.36 | 97.48 | 96.15 | 96.82 | 97.47 | 97.27 | 97.37 | 97.73 | 97.15 | 97.44 |
| 6 | 97.42 | 96.87 | 97.15 | 97.99 | 96.95 | 97.47 | 98.43 | 97.45 | 97.94 | 97.72 | 97.86 | 97.79 | 98.25 | 97.19 | 97.72 |
| 7 | 97.49 | 96.14 | 96.82 | 97.01 | 97.24 | 97.13 | 98.9 | 96.74 | 97.81 | 98.08 | 96.35 | 97.21 | 97.2 | 96.16 | 96.68 |
| 8 | 97.32 | 96.73 | 97.03 | 97.56 | 96.89 | 97.23 | 97.53 | 96.23 | 96.88 | 98.82 | 96.58 | 97.69 | 97.8 | 97.67 | 97.74 |
| 9 | 97.27 | 96.7 | 96.99 | 97.07 | 96.09 | 96.58 | 98.32 | 97.03 | 97.68 | 97.31 | 97.9 | 97.61 | 98.36 | 96.49 | 97.42 |
| 10 | 97.27 | 96.43 | 96.85 | 97.88 | 96.1 | 96.99 | 97.13 | 96.61 | 96.87 | 97.01 | 97.9 | 97.46 | 98.48 | 97.61 | 98.05 |
| Average | 97.37 | 96.69 | 97.03 | 97.46 | 96.86 | 97.16 | 97.84 | 96.88 | 97.36 | 97.94 | 97.32 | 97.63 | 98.061 | 97.03 | 97.54 |
| MFO | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Fold | ACE 2003 (BN) | ACE 2003 (NW) | ACE 2004 (NW) | ANERcorp | Private Corpus | ||||||||||
| (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | (%) | |
| 1 | 97.12 | 95.28 | 96.2 | 96.57 | 95.46 | 96.02 | 97.43 | 95.16 | 96.29 | 96.33 | 95.15 | 95.74 | 98.13 | 96.36 | 97.24 |
| 2 | 97.27 | 95.16 | 96.21 | 97.21 | 95.69 | 96.45 | 96.27 | 95.06 | 95.67 | 97.09 | 96.39 | 96.74 | 97.23 | 96.9 | 97.07 |
| 3 | 97.29 | 95.5 | 96.39 | 97.74 | 95.95 | 96.84 | 97.71 | 96.51 | 97.11 | 96.3 | 96.53 | 96.42 | 97.5 | 96.03 | 96.76 |
| 4 | 97.89 | 95.5 | 96.69 | 96.35 | 96.25 | 96.3 | 96.08 | 95.11 | 95.6 | 96.64 | 95.43 | 96.04 | 98.9 | 95.51 | 97.18 |
| 5 | 97.1 | 95.39 | 96.24 | 97.57 | 95.15 | 96.35 | 97.71 | 96.25 | 96.98 | 97.37 | 95.72 | 96.54 | 97.75 | 96.37 | 97.06 |
| 6 | 97.05 | 96.53 | 96.79 | 96.48 | 96.74 | 96.61 | 97.44 | 96.52 | 96.98 | 97.4 | 96.31 | 96.86 | 98.24 | 96.17 | 97.2 |
| 7 | 97.47 | 95.16 | 96.31 | 96.74 | 95.85 | 96.3 | 96.58 | 96.22 | 96.4 | 97.54 | 95.48 | 96.5 | 98.34 | 95.2 | 96.75 |
| 8 | 97.07 | 95.8 | 96.44 | 97.16 | 95.66 | 96.41 | 97.67 | 96.32 | 97 | 96.95 | 96.12 | 96.54 | 97.1 | 95.22 | 96.16 |
| 9 | 97.1 | 96.44 | 96.77 | 96.61 | 96.24 | 96.43 | 97.91 | 96.43 | 97.17 | 97.81 | 96.11 | 96.96 | 97.29 | 95.84 | 96.56 |
| 10 | 97.71 | 96.96 | 97.34 | 96.22 | 96.81 | 96.52 | 96.31 | 96.45 | 96.38 | 96.44 | 96.9 | 96.67 | 97.5 | 95.13 | 96.31 |
| Average | 97.31 | 95.77 | 96.54 | 96.87 | 95.98 | 96.42 | 97.11 | 96 | 96.56 | 96.99 | 96.01 | 96.5 | 97. 8 | 95.87 | 96.83 |


| Fold | Non-Arabic Corpus | |||||
|---|---|---|---|---|---|---|
| LLL | IEPA | |||||
| 1 | 97.28 | 97.44 | 97.36 | 97.77 | 97.8 | 97.78 |
| 2 | 98.45 | 97.78 | 98.11 | 97.63 | 97.92 | 97.77 |
| 3 | 98.33 | 98.77 | 98.55 | 98.08 | 97.59 | 97.83 |
| 4 | 98.19 | 98.59 | 98.39 | 98.38 | 97.86 | 98.12 |
| 5 | 98.31 | 98.95 | 98.63 | 98.85 | 97.46 | 98.15 |
| 6 | 97.82 | 96.93 | 97.37 | 98.34 | 97.14 | 97.74 |
| 7 | 98.28 | 98.24 | 98.26 | 98.33 | 97.89 | 98.11 |
| 8 | 98.84 | 96.87 | 97.85 | 98.6 | 97.06 | 97.82 |
| 9 | 98.58 | 98.51 | 98.54 | 98.74 | 97.74 | 98.24 |
| 10 | 97.92 | 97.91 | 97.91 | 97.86 | 97.94 | 97.9 |
| Average | 98.2 | 98 | 98.1 | 98.26 | 97.64 | 97.95 |
References
- Hawalah, A. A Framework for Building an Arabic Multi-disciplinary Ontology from Multiple Resources. Cogn. Comput. 2017, 10, 156–164. [Google Scholar] [CrossRef]
- Al-Zoghby, A.M.; Elshiwi, A.; Atwan, A. Semantic Relations Extraction and Ontology Learning from Arabic Texts—A Survey. In Intelligent Natural Language Processing: Trends and Applications Studies in Computational Intelligence; Springer: Cham, Switzerland, 2017; pp. 199–225. [Google Scholar]
- Mezghanni, I.B.; Gargouri, F. CrimAr: A Criminal Arabic Ontology for a Benchmark Based Evaluation. Procedia Comput. Sci. 2017, 112, 653–662. [Google Scholar] [CrossRef]
- Mezghanni, I.B.; Gargouri, F. Deriving ontological semantic relations between Arabic compound nouns concepts. J. King Saud Univ.-Comput. Inf. Sci. 2017, 29, 212–228. [Google Scholar] [CrossRef]
- Gruber, T.R. A translation approach to portable ontology specifications. Knowl. Acquis. 1993, 5, 199–220. [Google Scholar] [CrossRef]
- Hazman, M.; El-Beltagy, S.R.; Rafea, A. A Survey of Ontology Learning Approaches. Int. J. Comput. Appl. 2011, 22, 36–43. [Google Scholar] [CrossRef]
- Benaissa, B.-E.; Bouchiha, D.; Zouaoui, A.; Doumi, N. Building Ontology from Texts. Procedia Comput. Sci. 2015, 73, 7–15. [Google Scholar] [CrossRef][Green Version]
- Zamil, M.G.A.; Al-Radaideh, Q. Automatic extraction of ontological relations from Arabic text. J. King Saud Univ.-Comput. Inf. Sci. 2014, 26, 462–472. [Google Scholar] [CrossRef]
- Benabdallah, A.; Abderrahim, M.A.; Abderrahim, M.E.-A. Extraction of terms and semantic relationships from Arabic texts for automatic construction of an ontology. Int. J. Speech Technol. 2017, 20, 289–296. [Google Scholar] [CrossRef]
- Al-Zoghby, A.M.; Shaalan, K. Ontological Optimization for Latent Semantic Indexing of Arabic Corpus. Procedia Comput. Sci. 2018, 142, 206–213. [Google Scholar] [CrossRef]
- Albukhitan, S.; Helmy, T.; Alnazer, A. Arabic ontology learning using deep learning. In Proceedings of the International Conference on Web Intelligence-WI 17, Leipzig, Germany, 23–26 August 2017. [Google Scholar]
- Sadek, J.; Meziane, F. Extracting Arabic Causal Relations Using Linguistic Patterns. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2016, 15, 1–20. [Google Scholar] [CrossRef]
- Kaushik, N.; Chatterjee, N. Automatic relationship extraction from agricultural text for ontology construction. Inf. Process. Agric. 2018, 5, 60–73. [Google Scholar] [CrossRef]
- Alami, N.; Meknassi, M.; En-Nahnahi, N. Enhancing unsupervised neural networks based text summarization with word embedding and ensemble learning. Expert Syst. Appl. 2019, 123, 195–211. [Google Scholar] [CrossRef]
- Chi, N.-W.; Jin, Y.-H.; Hsieh, S.-H. Developing base domain ontology from a reference collection to aid information retrieval. Autom. Constr. 2019, 100, 180–189. [Google Scholar] [CrossRef]
- Al-Arfaj, A.; Al-Salman, A. Towards Ontology Construction from Arabic Texts-A Proposed Framework. In Proceedings of the 2014 IEEE International Conference on Computer and Information Technology, Xi’an, China, 11–13 September 2014. [Google Scholar]
- Al-Rajebah, N.I.; Al-Khalifa, H.S. Extracting Ontologies from Arabic Wikipedia: A Linguistic Approach. Arab. J. Sci. Eng. 2013, 39, 2749–2771. [Google Scholar] [CrossRef]
- Albukhitan, S.; Alnazer, A.; Helmy, T. Semantic Web Annotation using Deep Learning with Arabic Morphology. Procedia Comput. Sci. 2019, 151, 385–392. [Google Scholar] [CrossRef]
- Boujelben, I.; Jamoussi, S.; Hamadou, A.B. Enhancing Machine Learning Results for Semantic Relation Extraction. In Natural Language Processing and Information Systems Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 337–342. [Google Scholar]
- Albarghothi, A.; Saber, W.; Shaalan, K. Automatic Construction of E-Government Services Ontology from Arabic Webpages. Procedia Comput. Sci. 2018, 142, 104–113. [Google Scholar] [CrossRef]
- Bentrcia, R.; Zidat, S.; Marir, F. Extracting semantic relations from the Quranic Arabic based on Arabic conjunctive patterns. J. King Saud Univ.-Comput. Inf. Sci. 2018, 30, 382–390. [Google Scholar] [CrossRef]
- Kramdi, S.E.; Haemmerl, O.; Hernandez, N. Approche générique pour l’xtraction de relations partir de texts. Journées Francoph. D’ingénierie Des Connaiss. 2009, 97–108. Available online: https://hal.archives-ouvertes.fr/hal-00384415/document (accessed on 26 June 2019).
- Boujelben, I.; Jamoussi, S.; Hamadou, A.B. A hybrid method for extracting relations between Arabic named entities. J. King Saud Univ.-Comput. Inf. Sci. 2014, 26, 425–440. [Google Scholar] [CrossRef]
- Karimi, H.; Kamandi, A. A learning-based ontology alignment approach using inductive logic programming. Expert Syst. Appl. 2019, 125, 412–424. [Google Scholar] [CrossRef]
- Juckett, D.A.; Kasten, E.P.; Davis, F.N.; Gostine, M. Concept detection using text exemplars aligned with a specialized ontology. Data Knowl. Eng. 2019, 119, 22–35. [Google Scholar] [CrossRef]
- Petruccia, G.; Rospocher, M.; Ghidini, C. Expressive Ontology Learning as Neural Machine Translation. SSRN Electron. J. 2018, 52–53, 66–82. [Google Scholar] [CrossRef]
- Luan, J.; Yao, Z.; Zhao, F.; Song, X. A novel method to solve supplier selection problem: Hybrid algorithm of genetic algorithm and ant colony optimization. Math. Comput. Simul. 2019, 156, 294–309. [Google Scholar] [CrossRef]
- Alsaeedan, W.; Menai, M.E.B.; Al-Ahmadi, S. A hybrid genetic-ant colony optimization algorithm for the word sense disambiguation problem. Inf. Sci. 2017, 417, 20–38. [Google Scholar] [CrossRef]
- Gaidhane, P.J.; Nigam, M.J. A hybrid grey wolf optimizer and artificial bee colony algorithm for enhancing the performance of complex systems. J. Comput. Sci. 2018, 27, 284–302. [Google Scholar] [CrossRef]
- Elrehim, M.Z.A.; Eid, M.A.; Sayed, M.G. Structural optimization of concrete arch bridges using Genetic Algorithms. Ain Shams Eng. J. 2019. [Google Scholar] [CrossRef]
- Liu, P.; Basha, M.D.E.; Li, Y.; Xiao, Y.; Sanelli, P.C.; Fang, R. Deep Evolutionary Networks with Expedited Genetic Algorithms for Medical Image Denoising. Med. Image Anal. 2019, 54, 306–315. [Google Scholar] [CrossRef] [PubMed]
- Ghoniem, R.M. Deep Genetic Algorithm-Based Voice Pathology Diagnostic System. In Natural Language Processing and Information Systems Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; pp. 220–233. [Google Scholar]
- Gupta, R.; Nanda, S.J.; Shukla, U.P. Cloud detection in satellite images using multi-objective social spider optimization. Appl. Soft Comput. 2019, 79, 203–226. [Google Scholar] [CrossRef]
- Nguyen, T.T. A high performance social spider optimization algorithm for optimal power flow solution with single objective optimization. Energy 2019, 171, 218–240. [Google Scholar] [CrossRef]
- Jayaprakash, A.; Keziselvavijila, C. Feature selection using Ant Colony Optimization (ACO) and Road Sign Detection and Recognition (RSDR) system. Cogn. Syst. Res. 2019, 58, 123–133. [Google Scholar] [CrossRef]
- Chen, L.; Xiao, C.; Li, X.; Wang, Z.; Huo, S. A seismic fault recognition method based on ant colony optimization. J. Appl. Geophys. 2018, 152, 1–8. [Google Scholar] [CrossRef]
- Aziz, M.A.E.; Ewees, A.A.; Hassanien, A.E. Whale Optimization Algorithm and Moth-Flame Optimization for multilevel thresholding image segmentation. Expert Syst. Appl. 2017, 83, 242–256. [Google Scholar] [CrossRef]
- Elaziz, M.A.; Mirjalili, S. A hyper-heuristic for improving the initial population of whale optimization algorithm. Knowl.-Based Syst. 2019, 172, 42–63. [Google Scholar] [CrossRef]
- Mirjalili, S.; Lewis, A. The Whale Optimization Algorithm. Adv. Eng. Softw. 2016, 95, 51–67. [Google Scholar] [CrossRef]
- Goldbogen, J.A.; Friedlaender, A.S.; Calambokidis, J.; Mckenna, M.F.; Simon, M.; Nowacek, D.P. Integrative Approaches to the Study of Baleen Whale Diving Behavior, Feeding Performance, and Foraging Ecology. BioScience 2013, 63, 90–100. [Google Scholar] [CrossRef]
- Habib, Y.; Sadiq, M.S.; Hakim, A. Applications and Science of Neural Networks, Fuzzy Systems, and Evolutionary Computation; Society of Photo Optical: Bellingham, WA, USA, 1998. [Google Scholar] [CrossRef]
- Xue, X.; Chen, J. Using Compact Evolutionary Tabu Search algorithm for matching sensor ontologies. Using Compact Evolutionary Tabu Search algorithm for matching sensor ontologies. Swarm Evol. Comput. 2019, 48, 25–30. [Google Scholar] [CrossRef]
- Afia, A.E.; Lalaoui, M.; Chiheb, R. A Self Controlled Simulated Annealing Algorithm using Hidden Markov Model State Classification. Procedia Comput. Sci. 2019, 148, 512–521. [Google Scholar] [CrossRef]
- Ghoniem, R.M.; Shaalan, K. FCSR-Fuzzy Continuous Speech Recognition Approach for Identifying Laryngeal Pathologies Using New Weighted Spectrum Features. In Proceedings of the International Conference on Advanced Intelligent Systems and Informatics 2017 Advances in Intelligent Systems and Computing, Cairo, Egypt, 9–11 September 2017; 2017; pp. 384–395. [Google Scholar]
- Das, A.; Mandal, D.; Ghoshal, S.; Kar, R. Concentric circular antenna array synthesis for side lobe suppression using moth flame optimization. AEU-Int. J. Electron. Commun. 2018, 86, 177–184. [Google Scholar] [CrossRef]
- Pourmousa, N.; Ebrahimi, S.M.; Malekzadeh, M.; Alizadeh, M. Parameter estimation of photovoltaic cells using improved Lozi map based chaotic optimization Algorithm. Sol. Energy 2019, 180, 180–191. [Google Scholar] [CrossRef]
- Prabhu, Y.; Kag, A.; Harsola, S.; Agrawal, R.; Varma, M. Parabel: Partitioned label trees for extreme classification with application to dynamic search advertising. In Proceedings of the 2018 World Wide Web Conference on World Wide Web-WWW, Lyon, France, 23–27 April 2018. [Google Scholar]
- Khandagale, S.; Xiao, H.; Babbar, R. Bonsai-Diverse and Shallow Trees for Extreme Multi-label Classification. Available online: https://arxiv.org/abs/1904.08249 2109 (accessed on 6 August 2019).
- Babbar, R.; Partalas, I.; Gaussier, E.; Amini, M.-R. On Flat versus Hierarchical Classification in Large-Scale Taxonomies. In Proceedings of the 27th Annual Conference on Neural Information Processing Systems (NIPS 26), Lake Tao, NV, USA, 5–10 December 2013; pp. 1824–1832. [Google Scholar]
- Babbar, R.; Partalas, I.; Gaussier, E.; Amini, M.-R.; Amblard, C. Learning taxonomy adaptation in large-scale classification. J. Mach. Learn. Res. 2016, 17, 1–37. [Google Scholar]
- Moradi, M.; Ghadiri, N. Different approaches for identifying important concepts in probabilistic biomedical text summarization. Artif. Intell. Med. 2018, 84, 101–116. [Google Scholar] [CrossRef]
- Mosa, M.A.; Anwar, A.S.; Hamouda, A. A survey of multiple types of text summarization with their satellite contents based on swarm intelligence optimization algorithms. Knowl.-Based Syst. 2019, 163, 518–532. [Google Scholar] [CrossRef]
- Ababneh, J.; Almomani, O.; Hadi, W.; El-Omari, N.K.T.; Al-Ibrahim, A. Vector Space Models to Classify Arabic Text. Int. J. Comput. Trends Technol. 2014, 7, 219–223. [Google Scholar] [CrossRef]
- Fodil, L.; Sayoud, H.; Ouamour, S. Theme classification of Arabic text: A statistical approach. In Proceedings of the Terminology and Knowledge Engineering, Berlin, Germany, 19–21 June 2014; pp. 77–86. Available online: https://hal.archives-ouvertes.fr/hal-01005873/document (accessed on 25 May 2019).
- Al-Tahrawi, M.M.; Al-Khatib, S.N. Arabic text classification using Polynomial Networks. J. King Saud Univ. -Comput. Inf. Sci. 2015, 27, 437–449. [Google Scholar] [CrossRef]
- Al-Anzi, F.S.; Abuzeina, D. Toward an enhanced Arabic text classification using cosine similarity and Latent Semantic Indexing. J. King Saud Univ.-Comput. Inf. Sci. 2017, 29, 189–195. [Google Scholar] [CrossRef]
- Abuzeina, D.; Al-Anzi, F.S. Employing fisher discriminant analysis for Arabic text classification. Comput. Electr. Eng. 2018, 66, 474–486. [Google Scholar] [CrossRef]
- Al-Anzi, F.S.; Abuzeina, D. Beyond vector space model for hierarchical Arabic text classification: A Markov chain approach. Inf. Process. Manag. 2018, 54, 105–115. [Google Scholar] [CrossRef]
- Alkhatib, M.; Barachi, M.E.; Shaalan, K. An Arabic social media based framework for incidents and events monitoring in smart cities. J. Clean. Prod. 2019, 220, 771–785. [Google Scholar] [CrossRef]
- Ben Hamadou, A.; Piton, O.; Fehri, H. Multilingual extraction of functional relations between Arabic named entities using Nooj platform. In Proceedings of the Nooj 2010 International Conference and Workshop, Komotini, Greece, 27–28 May 2010; Gavriilidou, Z., Chadjipapa, E., Papadopoulou, L., Silberztein, M., Eds.; 2010; pp. 192–202. [Google Scholar]
- Boujelben, I.; Jamoussi, S.; Ben Hamadou, A. Rules based approach for semantic relations extraction between Arabic named entities. In Proceedings of the International NooJ 2012 Conference, Paris, France, 14–16 June 2012; pp. 123–133. [Google Scholar]
- Mesmia, F.B.; Zid, F.; Haddar, K.; Maurel, D. ASRextractor: A Tool extracting Semantic Relations between Arabic Named Entities. Procedia Comput. Sci. 2017, 117, 55–62. [Google Scholar] [CrossRef]
- Celli, F. Searching for Semantic Relations between Named Entities in I-CAB 2009. Available online: http://clic.cimec.unitn.it/fabio (accessed on 28 April 2019).
- Shahine, M.; Sakre, M. Hybrid Feature Selection Approach for Arabic Named Entity Recognition. In Computational Linguistics and Intelligent Text Processing Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2018; pp. 452–464. [Google Scholar]
- Kadir, R.A.; Bokharaeian, B. Overview of Biomedical Relations Extraction using Hybrid Rule-based Approaches. J. Ind. Intell. Inf. 2013, 1, 169–173. [Google Scholar] [CrossRef]
- Landauer, T.K.; Dumais, S.T. A solution to Platos problem: The latent semantic analysis theory of acquisition, induction, and representation of knowledge. Psychol. Rev. 1997, 104, 211–240. [Google Scholar] [CrossRef]
- Alkhatib, M.; Monem, A.A.; Shaalan, K. A Rich Arabic WordNet Resource for Al-Hadith Al-Shareef. Procedia Comput. Sci. 2017, 117, 101–110. [Google Scholar] [CrossRef]
- Salton, G.; Buckley, C. Term-weighting approaches in automatic text retrieval. Inf. Process. Manag. 1988, 24, 513–523. [Google Scholar] [CrossRef]
- Wei, Y.-Y.; Wang, R.-J.; Hu, Y.-M.; Wang, X. From Web Resources to Agricultural Ontology: A Method for Semi-Automatic Construction. J. Integr. Agric. 2012, 11, 775–783. [Google Scholar] [CrossRef]
- Zhang, X.; Chan, F.T.; Yang, H.; Deng, Y. An adaptive amoeba algorithm for shortest path tree computation in dynamic graphs. Inf. Sci. 2017, 405, 123–140. [Google Scholar] [CrossRef][Green Version]
- Shojaedini, E.; Majd, M.; Safabakhsh, R. Novel adaptive genetic algorithm sample consensus. Appl. Soft Comput. 2019, 77, 635–642. [Google Scholar] [CrossRef]
- AbdelRahman, S.; Elarnaoty, M.; Magdy, M.; Fahmy, A. Integrated Machine Learning Techniques for Arabic Named Entity Recognition. IJCSI Int. J. Comput. Sci. Issues 2010, 7, 27–36. [Google Scholar]
- Oudah, M.; Shaalan, K. Person Name Recognition Using the Hybrid Approach. In Natural Language Processing and Information Systems Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; pp. 237–248. [Google Scholar]
- Benajiba, Y.; Rosso, P.; Benedíruiz, J.M. ANERsys: An Arabic Named Entity Recognition System Based on Maximum Entropy. In Computational Linguistics and Intelligent Text Processing Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; pp. 143–153. [Google Scholar]
- Abdul-Hamid, A.; Darwish, K. Simplified Feature Set for Arabic Named Entity Recognition. Available online: https://www.aclweb.org/anthology/W10-2417 (accessed on 24 April 2019).
- Nédellec, C.; Nazarenko, A. Ontologies and Information Extraction. 2005. Available online: https://hal.archives-ouvertes.fr/hal-00098068/document (accessed on 18 April 2019).
- Ding, J.; Berleant, D.; Nettleton, D.; Wurtele, E. Mining Medline: Abstracts, Sentences, Or Phrases? Biocomputing 2002 2001, 7, 326–337. [Google Scholar] [CrossRef]
- Gridach, M. Deep Learning Approach for Arabic Named Entity Recognition. In Computational Linguistics and Intelligent Text Processing Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; pp. 439–451. [Google Scholar]
- Khalifa, M.; Shaalan, K. Character convolutions for Arabic Named Entity Recognition with Long Short-Term Memory Networks. Comput. Speech Lang. 2019, 58, 335–346. [Google Scholar] [CrossRef]
- Taghizadeh, N.; Faili, H.; Maleki, J. Cross-Language Learning for Arabic Relation Extraction. Procedia Comput. Sci. 2018, 142, 190–197. [Google Scholar] [CrossRef]
- Oudah, M.; Shaalan, K. Studying the impact of language-independent and language-specific features on hybrid Arabic Person name recognition. Lang. Resour. Eval. 2016, 51, 351–378. [Google Scholar] [CrossRef]
- Shaalan, K.; Oudah, M. A hybrid approach to Arabic named entity recognition. J. Inf. Sci. 2013, 40, 67–87. [Google Scholar] [CrossRef]
- Lima, R.; Espinasse, B.; Freitas, F. A logic-based relational learning approach to relation extraction: The OntoILPER system. Eng. Appl. Artif. Intell. 2019, 78, 142–157. [Google Scholar] [CrossRef]
- Ma, C.; Zhang, Y.; Zhang, M. Tree Kernel-based Protein-Protein Interaction Extraction Considering both Modal Verb Phrases and Appositive Dependency Features. In Proceedings of the 24th International Conference on World Wide Web-WWW 15 Companion, Florence, Italy, 18–22 May 2015. [Google Scholar]
- Li, L.; Guo, R.; Jiang, Z.; Huang, D. An approach to improve kernel-based Protein–Protein Interaction extraction by learning from large-scale network data. Methods 2015, 83, 44–50. [Google Scholar] [CrossRef] [PubMed]
- Qian, L.; Zhou, G. Tree kernel-based protein–protein interaction extraction from biomedical literature. J. Biomed. Inform. 2012, 45, 535–543. [Google Scholar] [CrossRef] [PubMed]


| Reference | Year of Publication | Arabic Text Mining Algorithm | Corpus | Accuracy |
|---|---|---|---|---|
| [53] | 2014 | Cosine Coefficient, Jacaard Coefficient, and Dice Coefficient | Saudi Newspapers (SNP) | Cosine coefficient outperformed Jaccard and Dice coefficients with 0.917, 0.979, and 0.947 for Precision, Recall, and F-measure, respectively. |
| [54] | 2014 | Term frequency (TF), and Term Frequency/Inverse Document Frequency (TF/IDF) for feature extraction, Semi-Automatic Categorization (SAC), and Automatic Categorization (AC) for feature selection. | News books: Arabic Dataset for Theme Classification (subsets 1 & 2) | Global recognition score is used to measure the ratio of correctly-classified documents: employing TF/IDF (95%), and TF (88%) |
| [55] | 2015 | TF/IDF, Chi Square for selecting feature, besides a local class-based policy for feature reduction | Al-Jazeera News | Recall of 0.967%, and F-measure of 0.959 |
| [56] | 2017 | Latent Semantic Indexing | Alqabas newspaper in Kuwait | 82.50% |
| [57] | 2018 | Vector Space Model (VSM) | Set by Alqabas newspaper, in Kuwait | 84.4% |
| [58] | 2018 | VSM | Alqabas newspaper | 90.29% |
| [59] | 2019 | Removing the stop words existed in the collected tweets, extracting the keywords and sorting them into one of the corresponding categories: classified words or unclassified words. Then, applying named entity recognition as well as data analysis rules on the classified words to generate final report. The lexical features along with Twitter-specific features were employed in classification. | A private database of collected Arabic tweets | 96.49% |
| Methodology | Works | Year of Publication | Contribution |
|---|---|---|---|
| Rule-based approaches | [60,61] | 2010 & 2012 | Extracting a set of linguistic patterns from text then rewriting it into finite state transducers |
| [12] | 2016 | The authors developed a model of pattern recognizer that targets to signal the existence of cause–effect information in sentences from non-specific domain texts. The model incorporated 700 linguistic patterns to distinguish the sentence parts representing the cause, besides to these representing the effect. To construct patterns, various sets of the syntactic features were considered through analyzing the untagged corpus. | |
| [62] | 2017 | The authors introduced a rule-based system namely, ASRextractor, to extract and annotate semantic relations relating Arabic named entities. The semantic relation extraction was based upon an annotated corpus of Arabic Wikipedia. The corpus incorporated 18 types of semantic relations like synonymy and origin. | |
| [20] | 2018 | A statistical parsing method was adopted to estimate the key-phrase/keyword from the Arabic dataset. The extracted dataset was converted to an OWL ontology format. Then, the mapping rules were used to link the components of ontology to corresponding keywords. | |
| [21] | 2018 | A set of rules/conjunctive patterns were defined for extracting the semantic relations of the Quranic Arabic according to a deep study for Arabic grammar, POS tagging, as well as the morphology features appears in the corpus of Quranic Arabic. | |
| Machine learning-based approaches | [63] | 2009 | With the objective of semantic relation extraction, the authors amalgamated two supervised methods, to be specific, the basic Decision Tree as well as Decision Lists-based Algorithm. They estimated Three semantic relations (i.e., location, social and role) among named entities (NEs). |
| [22] | 2009 | On the basis of the dependency graph producing by syntactic analysis, the authors adopted a learning pattern algorithm, denoted for generating annotation rules. | |
| [19] | 2013 | A rule mining approach has been proposed to be applied on an Arabic corpus using lexical, numerical, and semantic features. After the learning features were extracted from the annotated instances, a set of rules were generated automatically by three learning algorithms, namely, Apriori, decision tree algorithm C4.5, and Tertius. | |
| [9] | 2017 | A statistical algorithm was used to extract the simple and complex terms, namely, “the repeated segments algorithm”. For selecting segments that have sufficient weight, the authors used the Weighting Term Frequency–Inverse Document Frequency algorithm (WTF-IDF). Further, a learning approach was proposed based upon the analysis of examples for learning extraction markers to detect new pairs of relations. | |
| [64] | 2018 | Genetic algorithm (GA) was proposed to minimize the computation time needed to search out the informative and appropriate Arabic text features needed for classification. The SVM was used as machine learning algorithm that evaluates the accuracy of the Arabic named entities recognition. | |
| Hybrid approaches | [65] | 2013 | Three methodologies were encompassed: kernel method, co-occurrence, and later rule-based. These methods were utilized for extracting simple and complicated relations regard the biomedical domain. For mapping the data into a feature space of high-dimensionality, Kernel-based algorithms have been used. |
| [23] | 2014 | The authors proposed a hybrid rule-based/machine learning approach and a manual technique for extracting semantic relations between pairs on named entities. | |
| [4] | 2017 | A rules patterns set was defined from compound concepts for inducing of general relations. It utilized a gamification mechanism to specify relations based on prepositions semantics. The Formal Concept Analysis/Relational Concept Analysis approaches were employed for modeling the hierarchical as well as transversal relations of concepts. |
| Corpus | Total | |||||
|---|---|---|---|---|---|---|
| ACE 2003 (BN) | ACE 2003 (NW) | ACE 2004 (NW) | ANERcorp | Private Corpus | ||
| Person | 517 | 711 | 1865 | 3602 | 6695 | |
| Date | 20 | 58 | 357 | - | 435 | |
| Time | 1 | 15 | 28 | - | 44 | |
| Price | 3 | 17 | 105 | - | 125 | |
| Measurement | 14 | 28 | 51 | - | 93 | |
| Percent | 3 | 35 | 54 | 92 | ||
| Location | 1073 | 1292 | 493 | 4425 | 7283 | |
| Organization | 181 | 493 | 1313 | 2025 | 4012 | |
| Healthcare Provider | - | - | - | - | 8097 | 8097 |
| Health Disorder | - | - | - | - | 13,502 | 13,502 |
| Cancers | - | - | - | - | 9072 | 9072 |
| Surgeries | - | - | - | - | 7055 | 7055 |
| GA | WOA | PSO | MFO | GA-WOA | DE-WOA |
|---|---|---|---|---|---|
| Population size: 100 | Population size: 100 | Particles number P: 10 | Population size: 100 | Population size: 100 | Population size: 100 |
| Maximum generations: 500 | The random variable | Iterations number t: 10 | The constant defines the logarithmic spiral shape h: 1 | Maximum generations: 500 | Scaling factor for DE: Random between 0.2 and 0.8 |
| Crossover probability : 0.9 | Logarithmic spiral shape h: 1 | Acceleration : 2 | The random variable | Crossover probability : 0.9 | DE mutation scheme: DE/best/1/bin |
| Mutation rate : 0.05 | e: Decreased from 2 to 0 | Acceleration : 2 | Mutation rate : 0.05 | The random variable | |
| Reproduction ratio: 0.18 | Maximal weight of inertia: 0.7 | Maximum iterations number: 10 | Logarithmic spiral shape h: 1 | ||
| Selection: weighted Roulette Wheel | Minimal weight of inertia: 0.1 | The random variable | e: Decreased from 2 to 0 | ||
| Logarithmic spiral shape h: 1 | |||||
| e: Decreased from 2 to 0 |
| Algorithm | Average Measures | ||
|---|---|---|---|
| Proposed GA-WOA | 98.48 | 98.73 | 98.6 |
| GA | 93.71 | 93.56 | 93.63 |
| WOA | 96.31 | 97.34 | 96.81 |
| PSO | 95.04 | 94.95 | 94.99 |
| MFO | 97.73 | 96.96 | 97.34 |
| DE-WOA | 97.07 | 95.93 | 96.57 |
| Reference | Year | Corpus | Approach | Accuracy |
|---|---|---|---|---|
| [79] | 2019 | ACE 2003 (NW), ACE 2003 (BN), ACE 2004 (NW), and ANERcorp. | The Long-Short-Term-Memory neural tagging model was augmented with the Convolutional Neural Network to extract the character-level features. | = 91.2%, 94.12%, 91.47%, and 88.77%, respectively, for the four corpora. |
| [78] | 2018 | ANERcorp | A deep neural network-based method. | = 95.76%, = 82.52%, and = 88.64%. |
| [80] | 2018 | ANERcorp | Integration of some tree and polynomial kernels for feature representation. The universal dependency parsing was used for the relation extraction. | = 63.5%. |
| [64] | 2016 | ANERcorp | A hybrid approach of the GA and SVM. | = 82%. |
| [81] | 2016 | ACE 2003 (NW), ACE 2003 (BN), ACE 2004 (NW), and ANERcorp. | Hybridization of the rule-based and machine learning approaches. The feature space comprised the language-specific and language independent features. The decision tree classifier was used as a machine learning algorithm. | = 92.7%, = 88.1%, and = 90.3% for the ACE 2003 (BN), while they are 92.9%, 93.4%, 93.2%, for the ACE 2003 (NW), respectively. = 82.8%, = 82%, and 82.4%, for the ACE 2004 (NW), while they are 94.9%, 94.2%, and 94.5%, respectively, for the ANERcorp. |
| [82] | 2013 | ACE 2003 (NW), ACE 2003 (BN), ACE 2004 (NW), and ANERcorp. | Hybrid rule-based/machine learning approach. The features comprised: Rule-based features estimated from the rule-based decisions, morphological features derived from morphological analysis of decisions, POS features, contextual features, Gazetteer features, and word-level features. The J48, Libsvm, and Logistic classifiers were used. | The highest results were achieved when applying the proposed method to the ANERcorp: = 87%, = 60%, and = 94%. |
| Proposed approach | 2019 | A text mining algorithm to extract the initial concept set from the Arabic documents. A proposed G-WOA algorithm to get the best solutions that optimize the ontology learning through selecting only the optimal concept set with their semantic relations, which contribute to the ontology structure. | = 98.14%, = 99.03%, and = 98.59%, for the ACE 2003 (BN) while their values are 99.27%, 98.32%, and 98.79%, respectively, for the ACE 2003 (NW). = 97.9%, = 98.99%, and = 98.44%, for the ACE 2004 (NW), while their values are 98.99%, 98.16%, and 98.57% for ANERcorp, and 98.12%, 99.15%, 98.63%, for the private corpus. |
| Reference | Year | Corpus | Approach | Accuracy |
|---|---|---|---|---|
| [83] | 2019 | LLL and IEPA | A logic-based relational learning method for Relation Extraction utilizing the Inductive Logic Programming, namely OntoILPER, to generate symbolic extraction rules. | = 79.9% and 76.1%, respectively, for the two corpora. |
| [84] | 2015 | LLL and IEPA | An optimized tree kernel-based Protein–protein extraction approach. The modal verbs together with the appositive dependency features were used for defining some relevant rules that expand and optimize the shortest dependency path in between two proteins. | = 82.3% and 68.7%, respectively, for the two corpora. |
| [85] | 2015 | LLL and IEPA | Three word representational techniques including vector clustering, distributed representation, and Brown clusters. The SVM was used for unsupervised learning. | = 87.3% and 76.5%, respectively, for the two corpora. |
| [86] | 2012 | LLL and IEPA | Tree kernel-based extraction approach, in which the tree representation produced from constituent syntactic parser, was refined utilizing the shortest dependency route in between two proteins estimated from the dependency parser. | = 84.6% and 69.8%, respectively, for the two corpora. |
| Proposed approach | 2019 | LLL and IEPA | Integrating text mining and G-WOA algorithms. | 98.1% and 97.95%, respectively, for the two corpora. |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ghoniem, R.M.; Alhelwa, N.; Shaalan, K. A Novel Hybrid Genetic-Whale Optimization Model for Ontology Learning from Arabic Text. Algorithms 2019, 12, 182. https://doi.org/10.3390/a12090182
Ghoniem RM, Alhelwa N, Shaalan K. A Novel Hybrid Genetic-Whale Optimization Model for Ontology Learning from Arabic Text. Algorithms. 2019; 12(9):182. https://doi.org/10.3390/a12090182
Chicago/Turabian StyleGhoniem, Rania M., Nawal Alhelwa, and Khaled Shaalan. 2019. "A Novel Hybrid Genetic-Whale Optimization Model for Ontology Learning from Arabic Text" Algorithms 12, no. 9: 182. https://doi.org/10.3390/a12090182
APA StyleGhoniem, R. M., Alhelwa, N., & Shaalan, K. (2019). A Novel Hybrid Genetic-Whale Optimization Model for Ontology Learning from Arabic Text. Algorithms, 12(9), 182. https://doi.org/10.3390/a12090182