A Hybrid Autoencoder Network for Unsupervised Image Clustering

Abstract
1. Introduction
2. Autoencoder-Based Networks for Clustering
3. Hybrid Autoencoder Network for Image Clustering
Clustering Criteria
4. Numerical Experiment
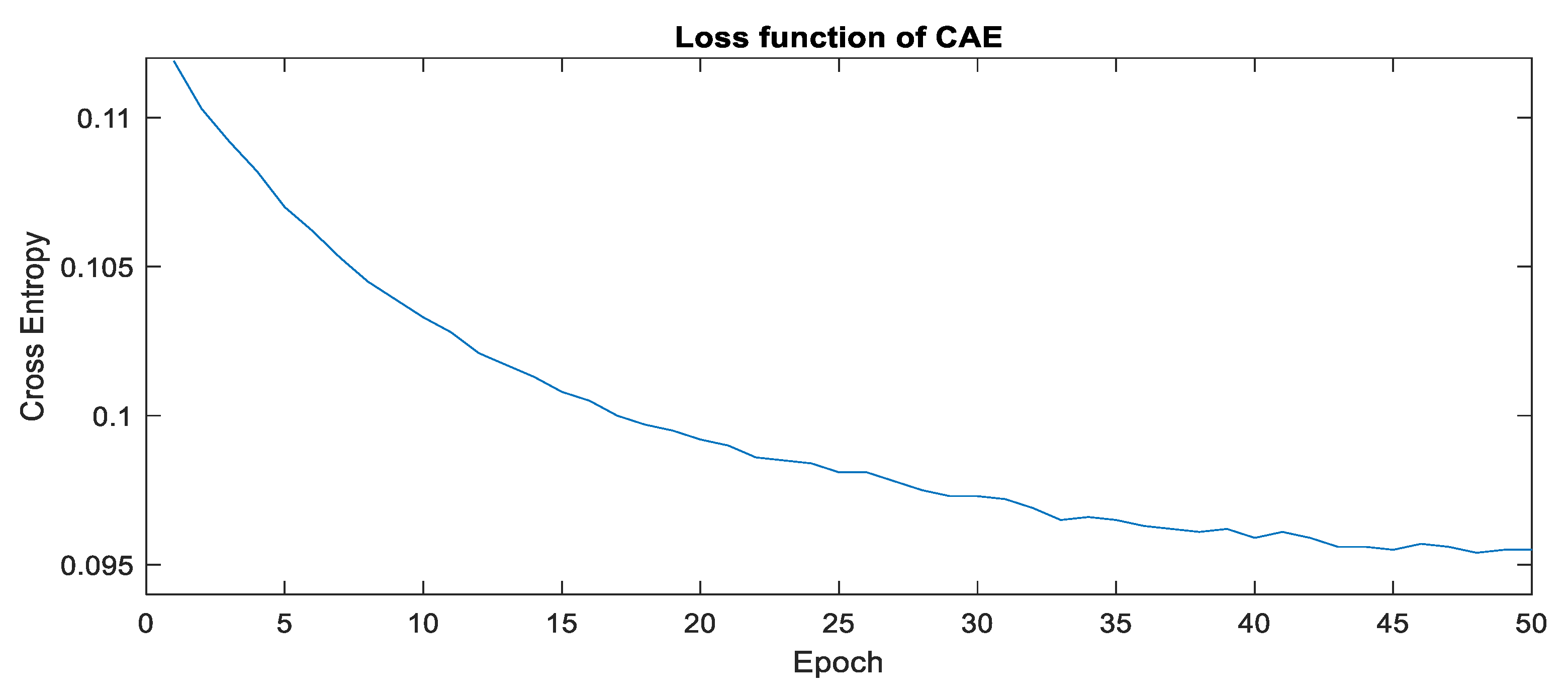
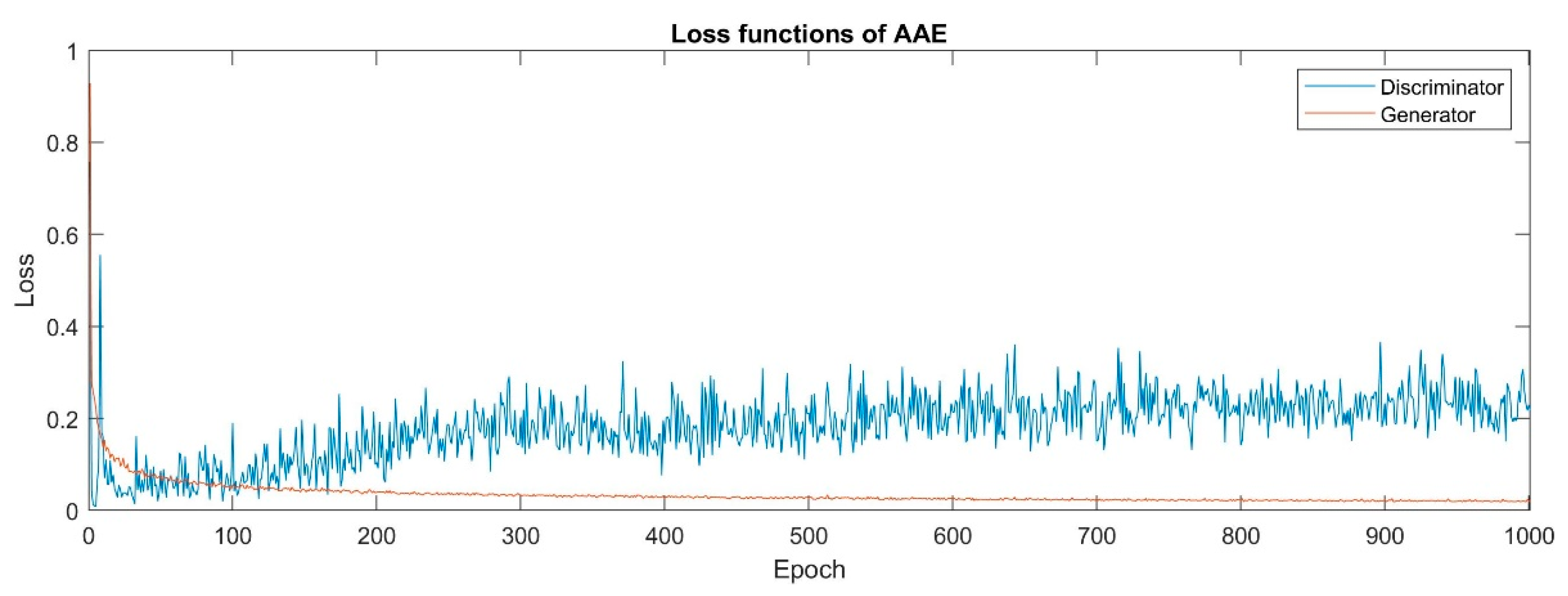
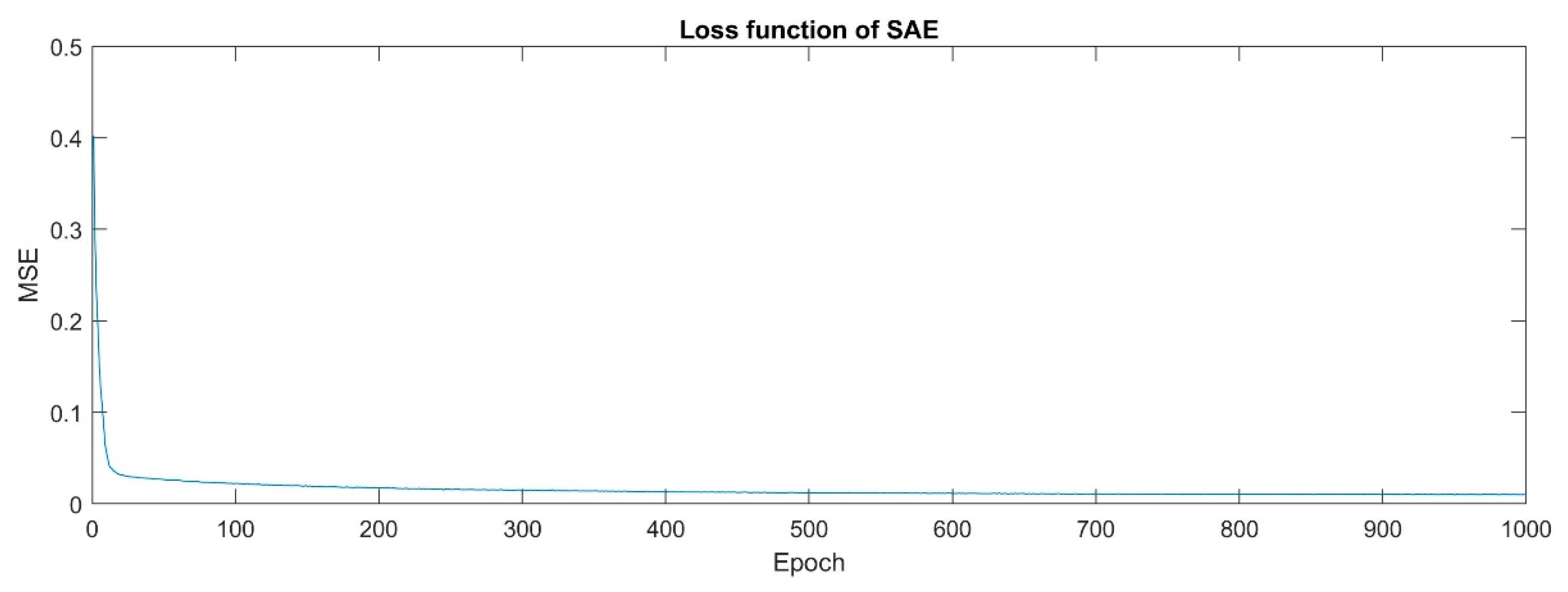
4.1. Parameter Setting
4.2. Experiment Result
5. Discussion
6. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Fayyad, U.; Piatetsky-Shapiro, G.; Smyth, P. The KDD process for extracting useful knowledge from volumes of data. Commun. ACM 1996, 39, 27–34. [Google Scholar] [CrossRef]
- Chang, J.; Wang, L.; Meng, G.; Xiang, S.; Pan, C. Deep adaptive image clustering. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5879–5887. [Google Scholar]
- Guo, X.; Liu, X.; Zhu, E.; Yin, J. Deep clustering with convolutional autoencoders. In Proceedings of the 24th International Conference on Neural Information Processing, Guangzhou, China, 14–17 November 2017; pp. 373–382. [Google Scholar]
- Alireza, M.; Shlens, J.; Jaitly, N.; Goodfellow, I.; Frey, B. Adversarial autoencoders. arXiv 2015, preprint. arXiv:1511.05644. [Google Scholar]
- Hinton, G.E.; Salakhutdinov, R.R. Reducing the Dimensionality of Data with Neural Networks. Science 2006, 313, 504–507. [Google Scholar] [CrossRef] [PubMed]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, preprint. arXiv:1312.6114. [Google Scholar]
- Rezende, D.J.; Mohamed, S.; Wierstra, D. Stochastic backpropagation and approximate inference in deep generative models. Int. Conf. Mach. Learn. 2014, 32, 1278–1286. [Google Scholar]
- Xie, J.; Girshick, R.; Farhadi, A. Unsupervised deep embedding for clustering analysis. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 19–24 June 2016; pp. 478–487. [Google Scholar]
- Dilokthanakul, N.; Mediano, P.A.M.; Garnelo, M.; Lee, M.C.H.; Salimbeni, H.; Arulkumaran, K.; Shanahan, M. Deep Unsupervised Clustering with Gaussian Mixture Variational Autoencoders. arXiv 2016, arXiv:1611.02648. [Google Scholar]
- Liu, H.; Shao, M.; Li, S.; Fu, Y. Infinite ensemble for image clustering. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1745–1754. [Google Scholar]
- Miguel, N.; McDermott, J. A hybrid autoencoder and density estimation model for anomaly detection. In International Conference on Parallel Problem Solving from Nature; Springer: Cham, Switzerland, 2016; pp. 717–726. [Google Scholar]
- Wang, C.; Pan, S.; Long, G.; Zhu, X.; Jiang, J. Mgae: Marginalized graph autoencoder for graph clustering. In Proceedings of the 2017 ACM on Conference on Information and Knowledge Management, Singapore, 6–10 November 2017; pp. 889–898. [Google Scholar]
- Sakurada, M.; Yairi, T. Anomaly detection using autoencoders with nonlinear dimensionality reduction. In Proceedings of the 2nd MLSDA Workshop on Machine Learning for Sensory Data Analysis, Gold Coast, Australia, 2 December 2014; p. 4. [Google Scholar]
- Wang, Y.; Yao, H.; Zhao, S. Auto-encoder based dimensionality reduction. Neurocomputing 2016, 184, 232–242. [Google Scholar] [CrossRef]
- Sun, W.; Shao, S.; Zhao, R.; Yan, R.; Zhang, X.; Chen, X. A sparse auto-encoder-based deep neural network approach for induction motor faults classification. Measurement 2016, 89, 171–178. [Google Scholar] [CrossRef]
- Bose, T.; Majumdar, A.; Chattopadhyay, T. Machine Load Estimation Via Stacked Autoencoder Regression. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 2126–2130. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Computer Vision and Pattern Recognition 2005, Proceedings of the IEEE Computer Society Conference (CVPR 2005), San Diego, CA, USA, 20–25 June 2005; IEEE: New York, NY, USA, 2005; Volume 1, pp. 886–893. [Google Scholar]
- Lowe, D.G. Distinctive Image Features from Scale-Invariant Keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Roy, M.; Bose, S.K.; Kar, B.; Gopalakrishnan, P.K.; Basu, A. A Stacked Autoencoder Neural Network based Automated Feature Extraction Method for Anomaly detection in On-line Condition Monitoring. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bengaluru, India, 18–21 November 2018; pp. 1501–1507. [Google Scholar]
- Li, W.; Fu, H.; Yu, L.; Gong, P.; Feng, D.; Li, C.; Clinton, N. Stacked Autoencoder-based deep learning for remote-sensing image classification: a case study of African land-cover mapping. Int. J. Remote. Sens. 2016, 37, 5632–5646. [Google Scholar] [CrossRef]
- Ian, G.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Advances in Neural Information Processing Systems 27, Proceedings of the Neural Information Processing Systems Conference (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014; Curran Associates Inc.: Red Hook, NY, USA, 2014; pp. 2672–2680. [Google Scholar]
- Mukherjee, S.; Asnani, H.; Lin, E.; Kannan, S. ClusterGAN: Latent Space Clustering in Generative Adversarial Networks. arXiv 2018, preprint. arXiv:1809.03627. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximizing Generative Adversarial Nets. In Advances in Neural Information Processing Systems 29, Proceedings of the 2016 Conference on Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Curran Associates Inc.: Red Hook, NY, USA, 2016; pp. 2172–2180. [Google Scholar]
- Vincent, P.; Larochelle, H.; Lajoie, I.; Bengio, Y.; Manzagol, P.A. Stacked denoising autoencoders: Learning useful representations in a deep network with a local denoising criterion. J. Mach. Learn. Res. 2010, 11, 3371–3408. [Google Scholar]
- Ralf, S.; Kurths, J.; Daub, C.O.; Weise, J.; Selbig, J. The mutual information: detecting and evaluating dependencies between variables. Bioinformatics 2002, 18 (Suppl. 2), S231–S240. [Google Scholar]
- Peng, X.; Zhou, J.T.; Zhu, H. k-meansNet: When k-means Meets Differentiable Programming. arXiv 2018, arXiv:1808.07292. [Google Scholar]
- Bezdek, J.C. Pattern Recognition with Fuzzy Objective Function Algorithms; Springer Science & Business Media: Berlin, Germany, 2013. [Google Scholar]
- Nie, F.; Zeng, Z.; Tsang, I.W.; Xu, D.; Zhang, C. Spectral Embedded Clustering: A Framework for In-Sample and Out-of-Sample Spectral Clustering. IEEE Trans. Neural Netw. 2011, 22, 1796–1808. [Google Scholar] [PubMed]
- Liu, G.; Lin, Z.; Yan, S.; Sun, J.; Yu, Y.; Ma, Y. Robust recovery of subspace structures by low-rank representation. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 35, 171–184. [Google Scholar] [CrossRef] [PubMed]
- Lu, C.Y.; Min, H.; Zhao, Z.Q.; Zhu, L.; Huang, D.S.; Yan, S. Robust and efficient subspace segmentation via least squares regression. In Computer Vision—ECCV 2012, Proceedings of the European Conference on Computer Vision, Florence, Italy, 7–13 October 2012; Springer: Berlin/Heidelberg, Germany, 2012; pp. 347–360. [Google Scholar]
- You, C.; Li, C.-G.; Robinson, D.P.; Vidal, R. Oracle Based Active Set Algorithm for Scalable Elastic Net Subspace Clustering. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016; pp. 3928–3937. [Google Scholar]
- Cai, D.; Chen, X. Large scale spectral clustering via landmark-based sparse representation. IEEE Trans. Cybern. 2014, 45, 1669–1680. [Google Scholar] [PubMed]
- Cai, D.; He, X.; Han, J. Locally consistent concept factorization for document clustering. IEEE Trans. Knowl. Data Eng. 2010, 23, 902–913. [Google Scholar] [CrossRef]
- Zhao, D.; Tang, X. Cyclizing clusters via zeta function of a graph. In Advances in Neural Information Processing Systems, Proceedings of the 23rd Annual Conference on Neural Information Processing Systems, Vancuver, BC, Canada, 7–10 December 2009; MIT Press: Cambridge, MA, USA, 2009; pp. 1953–1960. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Output Shape | Number of Parameters |
|---|---|---|
| Conv2D | (28,18,16) | 160 |
| Maxpooling | (14,14,16) | 0 |
| Conv2D | (14,14,2) | 290 |
| Maxpooling | (7,7,2) | 0 |
| Conv2D | (7,7,2) | 38 |
| Upsampling | (14,14,2) | 0 |
| Conv2D | (14,14,16) | 304 |
| Upsampling | (14,14,16) | 0 |
| Conv2D | (28,28,1) | 145 |
| Models | MNIST | CIFAR-10 | ||||
|---|---|---|---|---|---|---|
| ACC | NMI | ARI | ACC | NMI | ARI | |
| k-means | 0.7832 | 0.7775 | 0.7053 | 0.1981 | 0.0594 | 0.0301 |
| FCM | 0.2156 | 0.1239 | 0.0510 | 0.1702 | 0.0392 | 0.0256 |
| SC | 0.7128 | 0.7318 | 0.6218 | 0.1981 | 0.0472 | 0.0322 |
| LRR | 0.2107 | 0.1043 | 0.1003 | 0.1307 | 0.0430 | 0.0030 |
| LSR1 | 0.4042 | 0.3151 | 0.2135 | 0.1979 | 0.0605 | 0.0364 |
| LSR2 | 0.4143 | 0.3003 | 0.2000 | 0.1908 | 0.0637 | 0.0316 |
| SLRR | 0.2175 | 0.0757 | 0.5550 | 0.1309 | 0.0131 | 0.0094 |
| LSC-R | 0.5964 | 0.5668 | 0.4598 | 0.1839 | 0.0567 | 0.0258 |
| LSC-K | 0.7207 | 0.6988 | 0.6081 | 0.1929 | 0.0634 | 0.0389 |
| NMF | 0.4635 | 0.4358 | 0.3120 | 0.1968 | 0.0620 | 0.0321 |
| ZAC | 0.6000 | 0.6547 | 0.5407 | 0.0524 | 0.0036 | 0.0000 |
| DEC | 0.8365 | 0.7360 | 0.7010 | 0.1809 | 0.0456 | 0.0247 |
| CAE | 0.6809 | 0.6963 | 0.5666 | 0.2232 | 0.0870 | 0.0451 |
| AAE | 0.6217 | 0.5910 | 0.4351 | 0.1310 | 0.0204 | 0.0071 |
| Hybrid Model 1 | 0.8367 | 0.8031 | 0.7490 | 0.2308 | 0.1002 | 0.0543 |
| Hybrid Model 2 | 0.8104 | 0.8085 | 0.7580 | 0.2217 | 0.1017 | 0.0573 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, P.-Y.; Huang, J.-J. A Hybrid Autoencoder Network for Unsupervised Image Clustering. Algorithms 2019, 12, 122. https://doi.org/10.3390/a12060122
Chen P-Y, Huang J-J. A Hybrid Autoencoder Network for Unsupervised Image Clustering. Algorithms. 2019; 12(6):122. https://doi.org/10.3390/a12060122
Chicago/Turabian StyleChen, Pei-Yin, and Jih-Jeng Huang. 2019. "A Hybrid Autoencoder Network for Unsupervised Image Clustering" Algorithms 12, no. 6: 122. https://doi.org/10.3390/a12060122
APA StyleChen, P.-Y., & Huang, J.-J. (2019). A Hybrid Autoencoder Network for Unsupervised Image Clustering. Algorithms, 12(6), 122. https://doi.org/10.3390/a12060122