2.1. Oriented Trees and DFS-trees
A directed graph (digraph) G consists of a vertex set and a set of directed edges such that implies . H is a sub-digraph of G if and . is the subgraph induced by W if and if and only if and .
An oriented tree T is a connected digraph in which there is a single vertex, called the root with indegree zero, and every other vertex has in-degree one. The vertices with out-degree zero are the leaves. Given an edge , we say u is the parent of v, in symbols , while v is a child of u. By definition, there is a unique directed path from r to . The ancestor partial order ⪯ on is defined by if and only if v is on the path . The least common ancestor (lca) of two vertices is the ≺-minimal vertex in . The subtree rooted in v is the subgraph of T induced by the vertex set , i.e., those that are reachable along the directed path that contain v.
We assume that G is endowed with an arbitrary order of out-neighbors for each . We say that is a prior subtree of when u and v are both children of a common parent and u comes before v in the local ordering of the out-neighborhood of v. Now, consider two vertices u and v such that u and v are incomparable w.r.t. to the ancestor order and set . Note that u, v, and w are pairwise distinct. Let x and y be the children of w such that and . Then, we say that u is prior to v, in symbols , if is a prior subtree of , i.e., x comes before y in the local ordering of the out-neighborhood of w. The relation ◃ is a partial order known as the sibling partial order of T. The ancestor and the sibling orders are orthogonal, i.e., for any pair of vertices, exactly one of the relations , , , , or is true.
It is well known that the two fundamental traversal orders of trees are obtained as the two natural compositions of the ancestor and the sibling partial orders. Denote by
and
the order in which vertices are reported in
preorder and
postorder traversal, respectively. We have:
It follows immediately that preorder and postorder together determine the ancestor and sibling order:
Let G be a digraph. For every vertex , denote by the subset of vertices that are reachable from r, i.e., for which there is a directed path from r to . These paths can be chosen such that every is reachable from r along a unique path, and hence, there is an oriented tree T with that is a subgraph of G. An oriented tree T with root r is a search tree on G if there is no directed edge with and . An ordered tree T is a search tree if and only because a vertex by definition cannot be reached from anywhere in , and thus also not from the root, while every is by definition reachable from the root r.
Depth-first search (DFS) traverses a digraph
G in the following manner: (i) pick a root
; (ii) recursively, at
, proceed to the ◃ smallest, previously-unvisited out-neighbor of
v; (iii) if
v has no more unvisited out-neighbors, return to is “parent”, i.e., the vertex
from which
v was initially reached [
8]. Clearly, DFS generates a rooted tree
T with directed edges
, which are known as the DFS-tree.
Lemma 1. Let T be the ordered subtree generated by DFS on a digraph G, and let with . Then, and either (including ), , or . In particular, T is a search tree on G.
Proof. Consider a DFS reaching u. The search steps up to only after exhausting all out-neighbors of u; hence, any edge either has been visited before by the DFS process or, otherwise, it is included as an edge as DFS steps down to the subtree of u rooted in v. If v has been accessed before, then v is either an ancestor or descendant of u or u and v are incomparable w.r.t. ≺. In the latter case, there are distinct children x and y of such that and . In a DFS, is traversed before if y comes before x in the out-neighbor order of , and thus, .
By the construction of DFS, is reachable from the root r along a path in G; hence, . Suppose there is . Along a path p from r to x, let be the first vertex not reachable from , i.e., there is an edge with and , contradicting the first assertion of the lemma. □
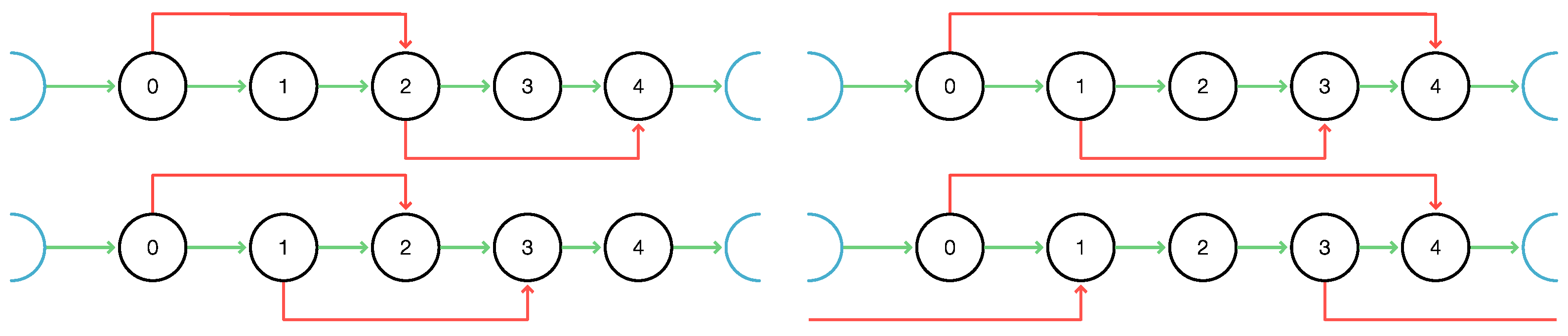
The DFS process proceeds on in such a way that the preorder of the DFS-tree T rooted at r records the order in which the vertices are discovered, while the postorder describes the order in which vertices are completed, i.e., “left”, by ascending back to their parent. To see this, denote by and the order in which vertices are discovered and completed by DFS started at r. By construction, DFS accesses the out-neighbors of v in ◃ order of the children of v and completes the traversal of a subtree rooted at a child of v before proceeding to the subtree of another child. Thus, if u and v are incomparable w.r.t. ≺ in T, then and if and only if in the sibling order. It also follows directly from the definition of DFS that we have if and if . Hence, and indeed coincide with the preorder and the postorder for the traversal of DFS tree T. DFS on a graph G is therefore completely described by the oriented DFS tree T, i.e., the sibling and ancestor order on , and coincides with DFS on T itself.
Hence, the condition that
v has been accessed before
u can expressed simply as
. If
u and
v are comparable on
T, their relative order is determined by Equation (
2). We therefore obtain the following simple characterization of DFS-trees:
Corollary 1. A search tree T with postorder ρ on G is a DFS-tree if and only if an edge is either (i) a tree edge, (ii) an edge connecting two non-adjacent comparable vertices in T, or (iii) whenever u and v are incomparable w.r.t. ≺ in T.
As a consequence, we have the following classification of edges w.r.t. a DFS-tree. is a:
- (i)
tree edge iff ;
- (ii)
forward edge iff and , i.e., and ;
- (iii)
back edge iff , i.e., and ;
- (iv)
cross edge iff , i.e., and .
2.2. Weak Superbubbloids
Superbubbles [
2] are a complex generalization of “bubbles”. Comprising two or more isolated paths connecting a source
s to a target
t, bubbles are the simplest obstacle in sequence assembly problems [
9]. We use here the terminology of [
7]:
Definition 1. Let G be a digraph, and let be an ordered pair of distinct vertices. Denote by the set of vertices reachable from s without passing through t, and write for the set of vertices from which t is reachable without passing through s. Then, the subgraph induced by is a superbubbloid in G if the following three conditions are satisfied:
- (S1)
, i.e., t is reachable from s (reachability condition).
- (S2)
(matching condition).
- (S3)
is acyclic (acyclicity condition).
We call s, t, and the entrance, exit, and interior of the superbubbloid. We denote the induced subgraph by if it is a superbubbloid with entrance s and exit t.
The reachability and matching conditions can equivalently be expressed in the following form, which usually is more convenient to use:
Lemma 2 ([7]).Let G be a digraph, , and . Then, U equals the set of Definition 1 and satisfies (S1)
and (S2)
if and only if the following conditions (S.i)
–(S.iv)
are satisfied. Moreover, U forms a superbubbloid with entrance s and exit t if and only if (S.i)
–(S.vi)
are satisfied: - (S.i)
Every is reachable from s.
- (S.ii)
t is reachable from every .
- (S.iii)
If and , then every path contains s.
- (S.iv)
If and , then every path contains t.
- (S.v)
If is an edge in , then every path in G contains both t and s.
- (S.vi)
G does not contain the edge .
If only (S.i)–(S.v) holds, the is a weak superbubbloid.
A (weak) superbubble is a (weak) superbubbloid that is minimal in the following sense:
Definition 2. A (weak) superbubbloid is a (weak) superbubble if there is no such that is a (weak) superbubbloid.
Weak superbubbles differ from superbubbles only by (S.vi), which can be checked in constant time for each candidate (weak) superbubble. The effort to recognize superbubbles and weak superbubbles is therefore essentially the same.
The following observation, which summarizes and slightly generalizes our previous analysis [
7], forms the basis of the present contribution. As in previous work on the topic [
5,
6,
7], DFS-trees are a key ingredient.
Lemma 3. Let G be a digraph and the vertex set of a weak superbubbloid in G, and suppose r is not an interior vertex or the exit of . Then, either or .
Proof. (i) Every digraph can be decomposed into strongly-connected components and acyclic components. If
, then every vertex reachable from
x is also contained in
. Thus, in particular, every strongly-connected component of
G is either contained in
or disjoint from
. Sung’s theorem ([
5] and [
7] (Thm.1)) ensures that every superbubbloid is either contained in a strongly- connected component
C or an acyclic component
A of
G. Now, suppose
, and let
be the first vertex of the DFS in
. By definition (of weak superbubbloids)
, since no other vertex in
is reachable from outside
, and the DFS assumption does not start at an interior vertex or the exit of
. The reachability axiom (S.ii) ensures that every
is reached by the DFS whenever
, i.e.,
. □
Lemma 3 is a variant of the key theorem of [
5].
Corollary 2. Let be a digraph and the vertex set of a weak superbubbloid in G. Let be such that none of the are an interior or an exit vertex of . Set and . Then, either or .
Proof. By Lemma 3, is either contained in the intersection of two or more reachable sets or is disjoint from it. As an immediate consequence, it is also either contained in the difference of two reachable sets or disjoint from it. □
Lemma 4. Let G be a digraph; let be the vertex set of a weak superbubbloid in G; let T be a DFS-tree on G with root ; and let π be the postorder w.r.t. T. Then:
- (i)
The induced subgraph contains no back edges w.r.t. T, except possibly .
- (ii)
If , then is an interval w.r.t. to π.
Proof. (i) The statement is trivial if
is not contained in
T. If
resides in an acyclic part
A of
G, there are no back edges because
A cannot contain back edges by acyclicity. If
is contained in a strongly-connected component
C, the proof of Lemma 9 of [
7] also implies Assertion (i) because the DFS-tree
T, in particular, contains a DFS-tree of
C as a subtree and back edges in
G can only be located within a strongly-connected component.
(ii) Since the DFS generating T enters through s and leaves it through t, the preorder satisfies . Since t is reachable from every , we conclude that any DFS reaches t before completing any ; hence, t precedes any other in postorder, i.e., . Since is not reachable without passing through s, every other vertex in precedes s in postorder, i.e., . Now, suppose there is some with . Then, w must be reachable from s along a directed path that does not pass through t, a contradiction to the definition of weak superbubbloids. Hence, the vertices of a superbubbloid form an interval in postorder of the DFS-tree T. □
Statement (ii) rephrases the key result of [
6], although we do not need to assume that
G is an acyclic digraph. Conceptually, Lemma 4 suggests that it might not be necessary to first identify the strongly-connected components of
G [
5] or the construct acyclic auxiliary digraphs [
6] in order to find all weak superbubbles. Lemma 2 then ensures that a single DFS-forest is sufficient.
2.3. Superbubble Detection
We next show how to retrieve all weak superbubbles of a digraph
G that are located within the induced subgraph
of
G. To this end, we use a slightly modified version of the algorithm
DAGsuperbubble described in [
7]. It was originally designed to operate on acyclic auxiliary graphs with a single source. Thus, it could be assumed that a DFS-tree rooted on this source reached all vertices. Here, we intend to apply it to the unmodified input graph, which is neither acyclic, nor guaranteed to have a single source. It, therefore, needs to be modified to deal appropriately with back edges within the DFS-tree and the existence of vertices outside the DFS-tree. To this end, vertices in
that cannot be contained in a superbubble have to be identified. By Lemma 4, there are two possible obstructions for a vertex
u: (i)
u has an edge that is a back edge in the DFS-tree; (ii)
u is incident to an edge
or
where
.
The basic idea of
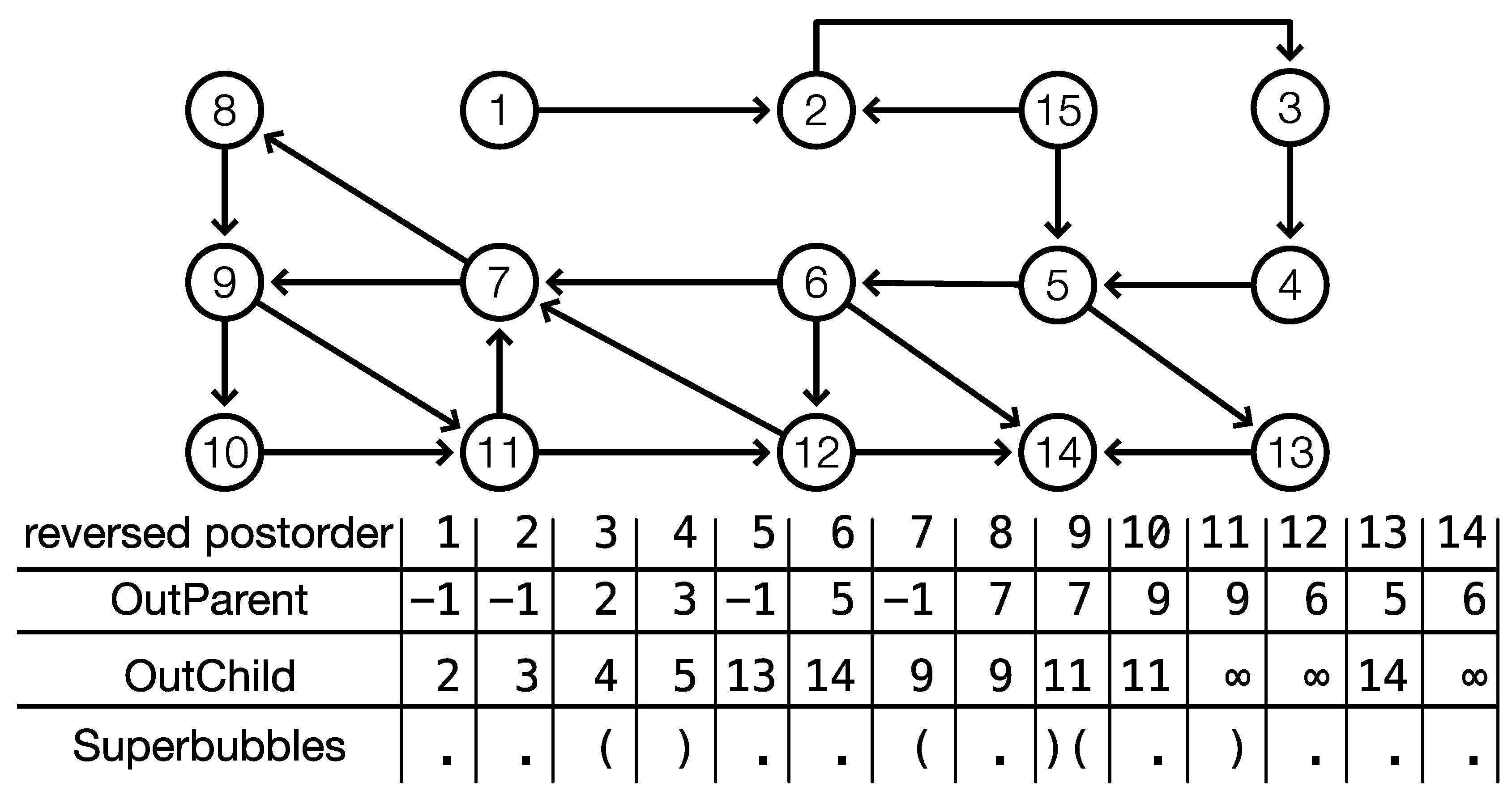
DAGsuperbubble is to identify minimal intervals in reverse postorder
of the DFS-tree
T that satisfy conditions equivalent to membership in a superbubbloid. These conditions are expressed in terms of a pair of helper functions with the help of reverse postorder
on
T. As in [
7],
denotes the first vertex (w.r.t. reverse postorder
) in
T from which
v can be reached. Similarly,
is the last child vertex reachable from
v.
These functions are extended to intervals on
as follows:
In [
7], we derived a characterization of weak superbubbloids in terms of
and
for the case of acyclic digraphs. Here, we generalize this condition to general graph using the modified definition of
and
. The difference is that the situation that back edges and edges connecting to the outside of the DFS-tree are considered. In either case, the corresponding vertices are marked by
or ∞, respectively, to indicate that they cannot be part of superbubbloids.
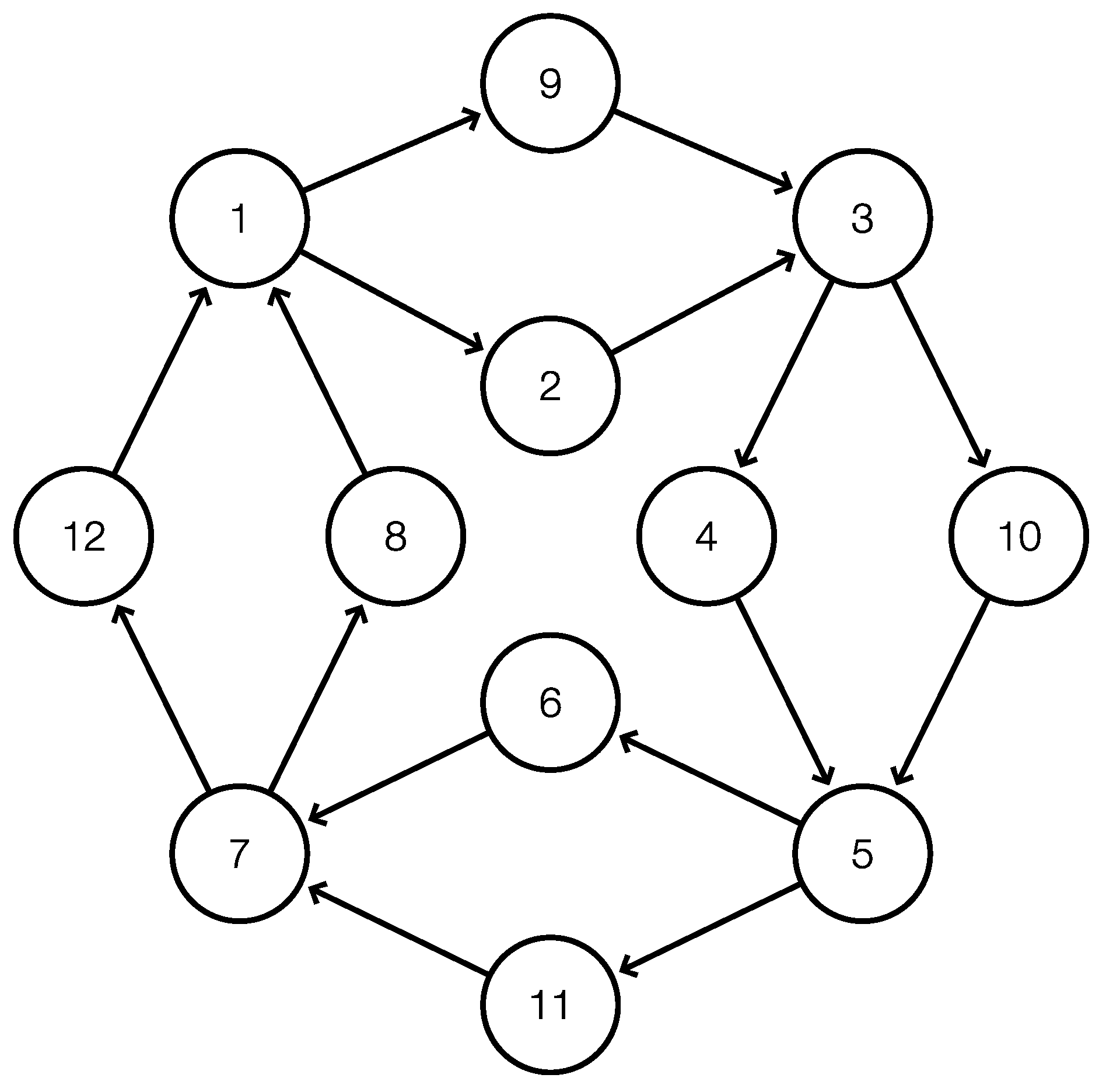
Theorem 1. Let G be a digraph; let T be a DFS-tree on G with a root r that is not an interior vertex or exit of a weak superbubbloid; and denote by the reverse postorder on T. Then, is a weak superbubbloid in G whose vertex set satisfies if and only if the following conditions are satisfied:
- (F1)
(predecessor property)
- (F2)
(successor property)
Proof. It was shown in [
7] (theorem 2) that the statement is true for acyclic digraphs. We first note that by Lemma 3, every weak superbubbloid intersecting
is contained in
, i.e., in
. For the purpose of the proof, consider the auxiliary graph
with edge set
. By construction,
is acyclic, and every vertex is in
T. Thus, every superbubbloid
(with vertex set
) in
is characterized by Conditions (F1) and (F2). It is, furthermore, a weak superbubbloid in
G if and only if the following conditions hold:
- (i)
For every , there is no edge such that ;
- (ii)
For every , there is no edge such that ; and
- (iii)
without the edge acyclic.
Only edges not contained in need to be considered for Conditions (i) and (ii), because no such edges exist within due to the assumption that is a weak superbubbloid in . For (iii), only the back edges are of interest. By definition, a back edge creates a cycle in . A back edge with would violate (iii) when or (i) if . Analogously, if and , then (ii) is violated. Thus, a weak superbubbloid cannot contain the head or tail of a back edge. Only for Condition (i), we also need to consider the case that .
(F1) can be satisfied only if
for every
. Analogously, (F2) can only be true if
for all
. Hence, it suffices to rule out false positive weak superbubbloids in
G by ensuring that every vertex
u that violates one of the three conditions also violates (F1) or (F2). This is achieved by setting
for a vertex
u if there is an edge
such that
or
is a back edge; analogously, we set
for all
v with an incident edge
such that
or
is a back edge. Equation (
3) implements exactly these conditions. Thus, only weak superbubbloids fulfill (F1) and (F2).
Conversely, it suffices to note that by Lemma 4(ii), every weak superbubbloid forms a contiguous interval w.r.t. the postorder of T and, thus, also w.r.t. the reverse postorder of T. □
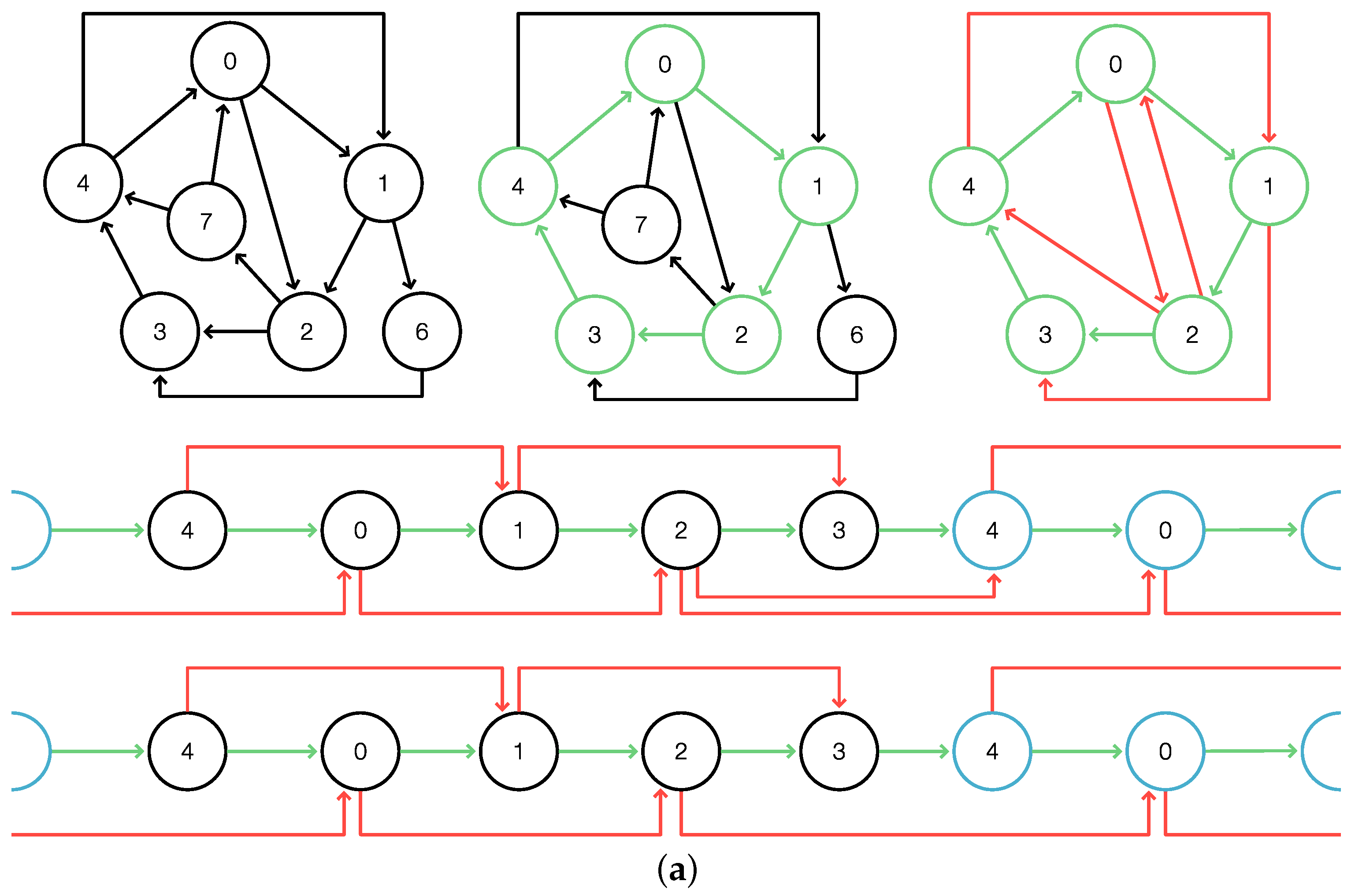
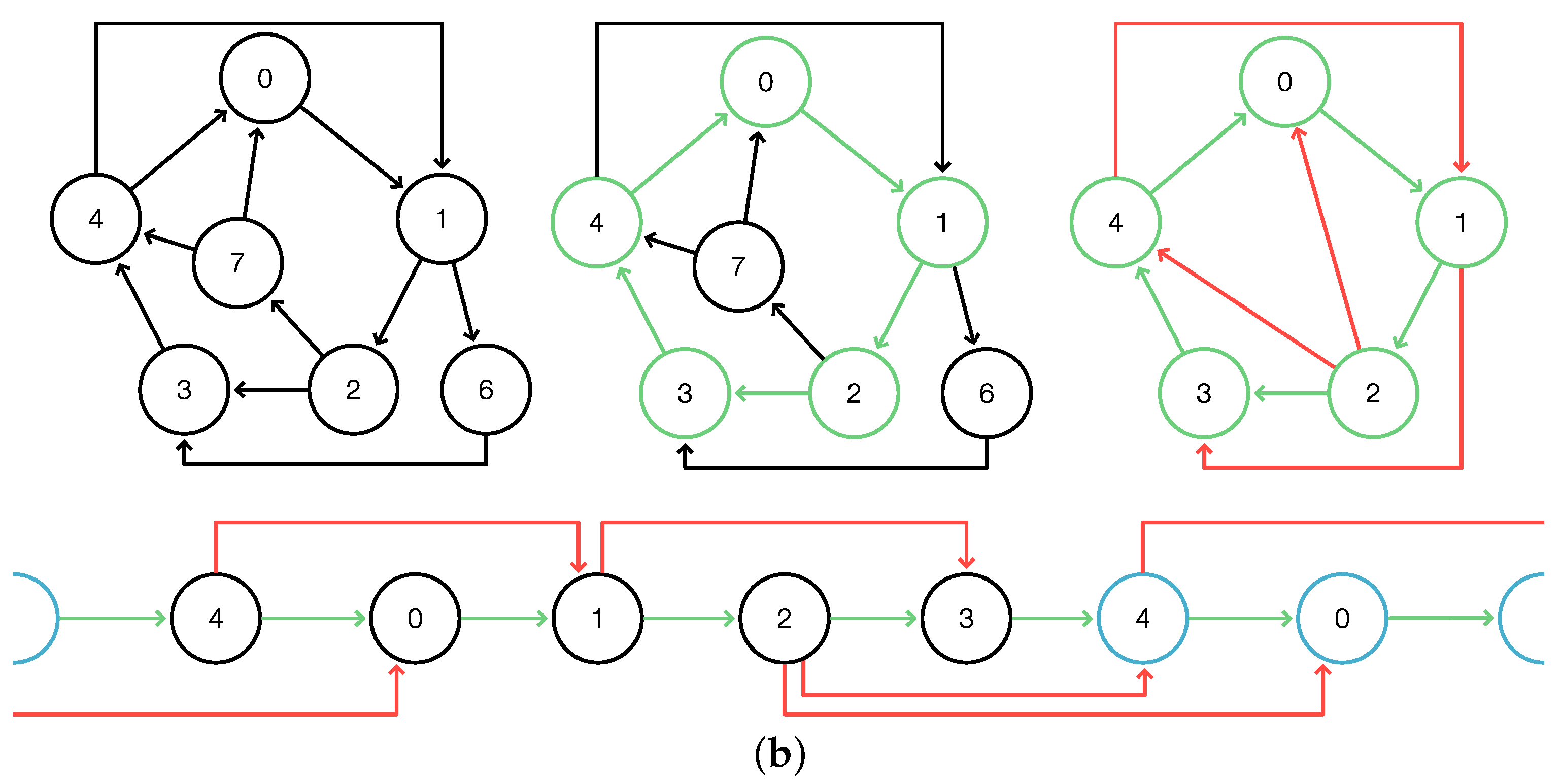
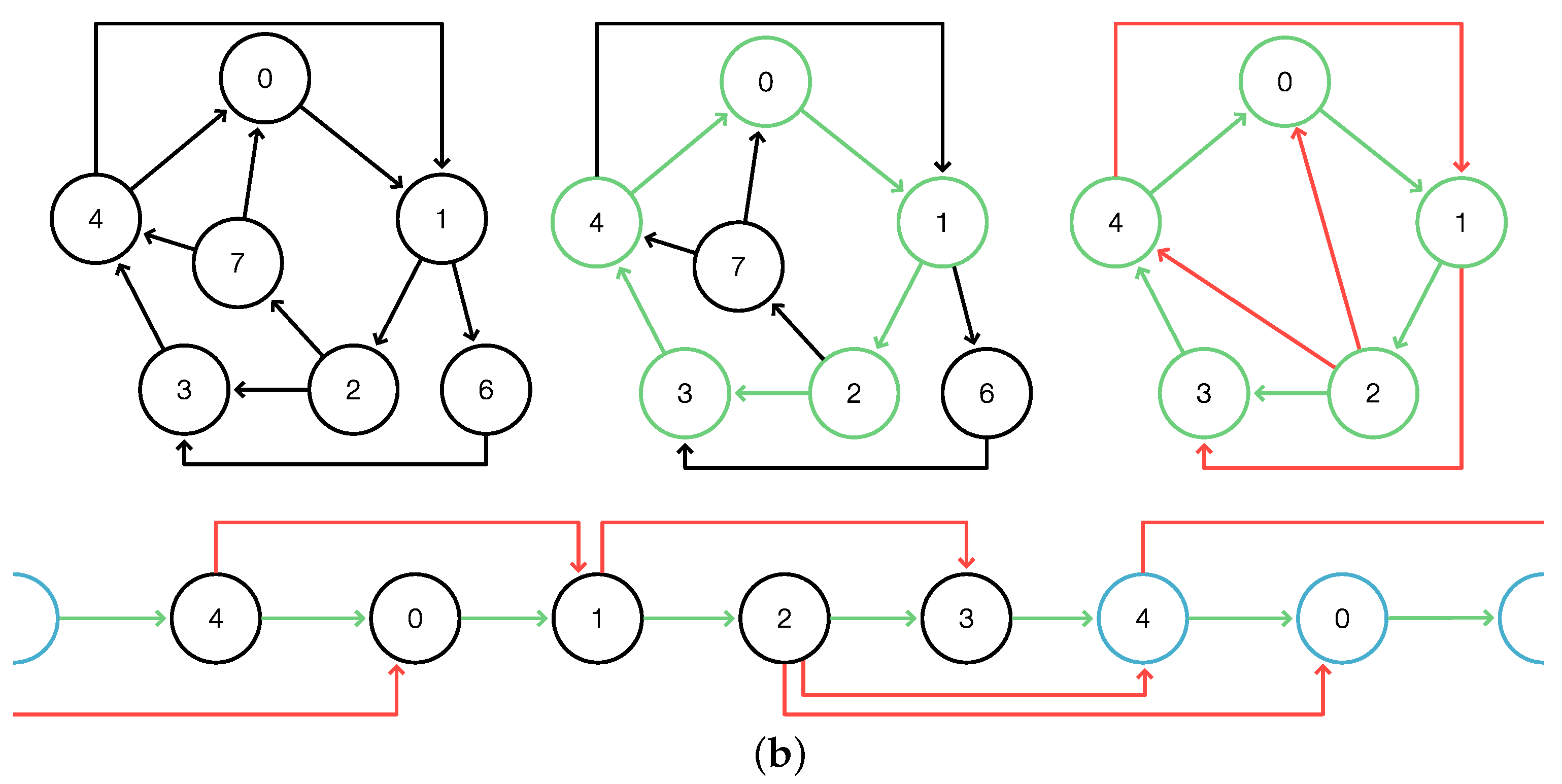
We denote by
Superbubble the algorithm
DAGsuperbubble with the modified functions
and
as described above. By construction,
Superbubble identifies minimal intervals of
that satisfy (F1) and (F2); see
Figure 1 for an illustration and [
7] for full details. Since the modification of
and
only amounts to setting additional entries to
or
∞, respectively, the performance remains unaffected. According to Theorem 1, the minimal intervals satisfying (F1) and (F2) are exactly the minimal weak superbubbloids and, thus, by definition, the weak superbubbles. Therefore, we have:
Corollary 3. Let G be a digraph, and let T be a DFS-tree on G with a root r that is not an interior vertex or exit of a weak superbubble. Then,Superbubblecorrectly identifies exactly the weak superbubbles in G whose vertex set satisfies .
It is straightforward to extend this result to a DFS-forest that covers entirely: This forest is constructed by first constructing with root covering . Then, is constructed from a root searching on , and so on; see Lemma 2. This amounts to constructing an auxiliary graph from G by adding an artificial root and out-edges , ,..., , and defining the sibling order of the roots as . The DFS-forest with given roots , ,..., on G is then equivalent to the DFS-tree rooted at on if we define the reverse postorder of such that . We note, furthermore, that sibling order, i.e., the order in which the roots are used to seed DFS, is arbitrary.
Corollary 4. Let G be a digraph, and let F be a DFS-forest on G comprising DFS-trees with roots , , none of which is an interior vertex or exit of a weak superbubble. Let be the reverse postorder on F, obtained by concatenating the reverse postorders on the constituent DFS-trees. Then,Superbubblecorrectly identifies exactly the weak superbubbles in G. Furthermore, given the roots ,Superbubblehas a running time of .
Proof. Correctness follows immediately from Corollary 3, the construction of
on the auxiliary digraph
, and Lemma 2. During the DFS, each out-edge is considered exactly once, and each vertex is traversed twice. The number
k of required roots is limited by
. For each vertex
v, checking whether
or
requires checking all neighbors only; hence, the total effort is no more than
. The linear time complexity of
DAGsuperbubble, finally, is proven in [
7]. □
It is important to note the correctness of Superbubble, Corollary 3, crucially depends on the correct choice of the root r of the DFS-tree. The remaining problem thus is to find a suitable sequence of roots , ,..., .
Definition 3. A vertex is a legitimate root if for every weak superbubble in G with vertex set , we have either and (in the ancestor order of a search tree with root r), or .
We can summarize the discussion in the following form:
Corollary 5. The algorithmSuperbubbledetects all weak superbubbles in G if and only if there is a set of legitimate roots such that the DFS-forest covers .
Corollary 6. A vertex is a legitimate root if and only if r is neither an interior nor an exit of a weak superbubble.
Proof. By Corollary 4, a root is legitimate if it is not the exit or an interior vertex of a weak superbubble. Conversely, if r is an interior vertex or the exit of , then a DFS-tree rooted in r reaches the entrance s either not at all or there is not search tree with root r such that , since by definition of a weak superbubble, the exit t is found before s along every path from r to s. □
Lemma 5. Let G be a digraph and a source, i.e., a vertex with in-degree zero. Then, v is a legitimate root.
Proof. Since v is not reachable from any other vertex, it is only reachable by DFS if the traversal starts in v. By the same argument, v is neither an interior vertex, nor the exit of a weak superbubble and, thus, is a legitimate root. □
Unfortunately, there is no guarantee that a digraph G has source vertices, and even if they exist, not every vertex of G is necessarily reachable from them. The task is, therefore, to identify legitimate roots located within strongly-connected components.
2.4. Cycles, -Covers, and -Cuts
Definition 4. Let G be a digraph. A set is a cycle
in G if and . A pair of vertices determines a cycle interval:
By definition, the vertices
are pairwise distinct and indexed consecutively along
C. Importantly, cycle intervals contain only the interior of the unique path in
C connecting the defining endpoints
and
. Thus,
if
and
for all
. The
C-distance of two vertices
and
along a cycle
C is the length of the directed path, i.e., the number of edges, from
to
. More explicitly,
since the number of inner vertices is one less than the number of edges. In particular,
for all
. The
C-distance
is not symmetric. Instead, we have
for all two vertices
. Another useful consequence of the definition of
is:
The following implication will be useful later on:
Corollary 7. Let G be a digraph; let C a cycle in G; and let . Then, if and only if .
Proof. If , , and are pairwise distinct, the l.h.s. is true if the path from to is a subpath of the path from to , i.e., and, thus, . The converse is obvious. The statement is trivial for . If , the l.h.s. is always true, while on the r.h.s., we have . For , both the l.h.s. and the r.h.s. are satisfied only if . □
In the following, it will be useful to know whether two vertices on a cycle are also reachable via a directed path that is disjoint from C. We formalize this idea as a binary relation on C.
Definition 5. Let G be a digraph and C a cycle in G and . Then, t isC-reachable from s, in symbols , if there is a path such that and for .
We have used the letters s and t here since C-reachability will be used to identify potential candidates for entrance and exit of superbubbles. C-reachability is defined not only for vertices in the “reference cycle” C. It satisfies a restricted transitivity property: If , , and , then . Another interesting observation is that implies that there is a directed cycle such that . As an immediate consequence of Definition 5, we obtain:
Lemma 6. Let G be a digraph, C a cycle in G, such that , and . Then, and are connected by (at least) two edge-disjoint directed paths. In particular, .
Definition 6. Let C be a cycle in the digraph G and . Then, is-covered if .
As an immediate consequence of the definition, implies that is covered, while nothing is covered if .
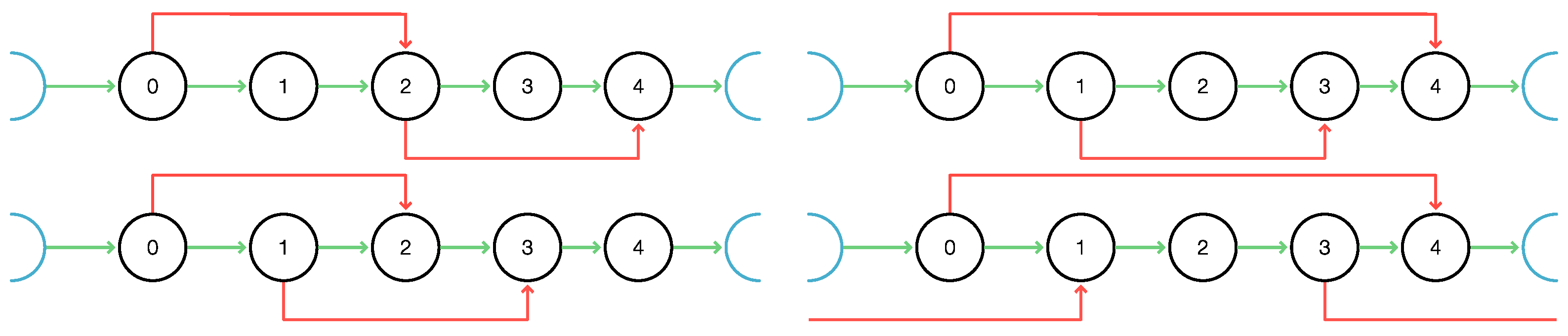
Consider two
C-intervals
and
on the same cycle
C of the digraph
G. We say that
is included in if
,
and
are
disjoint if
, and
extends if
and
. In particular, if
extends
, then
, since the interval boundaries themselves are not considered part of the
C-intervals. For each pair of distinct
C-intervals, thus exactly one of the following four statements is true: (a) the
C-interval are disjoint; (b) one
C-interval is contained in (i.e., a proper subset of) the other one; (c) one
C-interval, say
, extends the other one, but not
vice versa, i.e.,
and
; (d) both
C-intervals extend each other, i.e.,
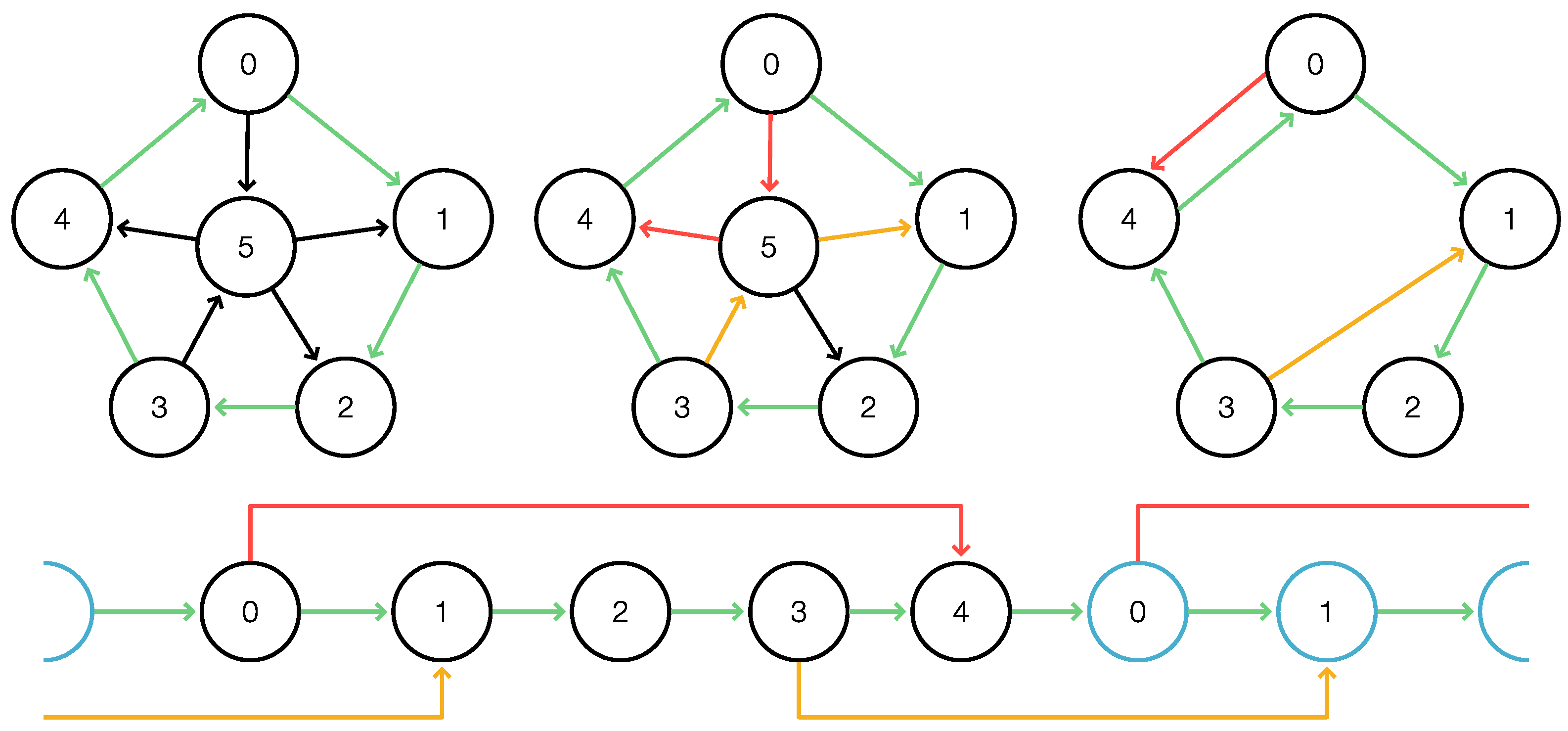
.
Figure 2 illustrates the four cases. Note that in Case (c), the interval boundaries are arranged in the order
along the cycle, while in Case (d), the arrangement is
along
C.
In the following, we will use the notation:
for the set of all
-covered intervals and the set of all
-covered vertices of
C, respectively. Note that
since
holds for
. By the same argument, there is at least one interval
for each
, albeit some or even all of these may be empty.
Definition 7. A subset is a-cover of C if , and is a total -cover of C if . We say that C is totally -covered if C has a total -cover.
Note that C is totally -covered if and only if .
Definition 8. A vertex in is a-cut vertex.
Obviously, C is either totally -covered or it has a non-empty set of -cut vertices.
Definition 9. Let C be a cycle in the digraph G. A-cover of C is clean if and implies .
In other words, in a clean -cover, no -covered interval is contained within another one.
Corollary 8. Let C be a cycle in the digraph G, and let be a clean -cover. Then, either or, for every , .
Proof. Recall that if and only if . Thus, if and only if there is no with . Since the empty set is a subset of every other set, for every unless . □
Lemma 7. Let C be a cycle in the digraph G. Then, contains a clean -cover .
Proof. Let be a set of -covered intervals that together -cover . Suppose is not clean. Then, there are two intervals and such that . Then, still -cover . The removal of such redundant intervals can be repeated until no further removable interval can be found. By Definition 9, the remaining -cover is clean. □
Definition 10. Let C be a cycle in a digraph G. Then: By definition, consists of all -covered intervals for which there is no larger -covered interval with the same starting point. Since every is contained in a interval with the same starting point, is a -cover of C. Thus, Lemma 7 implies:
Corollary 9. Let C be a cycle in a digraph G. Then, there is clean cover .
Lemma 8. Let C be a cycle in the digraph G. A clean -cover of C is total if and only if and every is extended by at least one .
Proof. If , then , and thus, is not total. In the following, we assume is a clean -cover. Suppose, for contradiction, that is not extended by any . Then, any interval -covering v would have to contain , contradicting the assumption that is clean. Thus, v is a -cut vertex, and hence, is not total. If , therefore it is non-empty, and every is extended by some .
Conversely, suppose c is a -cut vertex of C. If for some u, then the first part of the proof implies that is not extended by any . If contains no interval , then consider the vertex v such that for which is minimal. Since c is a -cut vertex, there is no extension of , since any such extension would either contradict the minimality of or -cover c, thereby contradicting the assumption that c is a -cut vertex. Thus, v is again a -cut vertex. As shown in the first part of the proof, ; therefore, it is not extended by any . We conclude that unless is a total -cover or , there is an interval without an extension. □
Figure 3 shows an example of a cycle with a total
-cover and a cycle with a
-cut, respectively. Since the largest
-interval in
C is
for some
v, every total
-cover comprises at least two
-covered intervals.
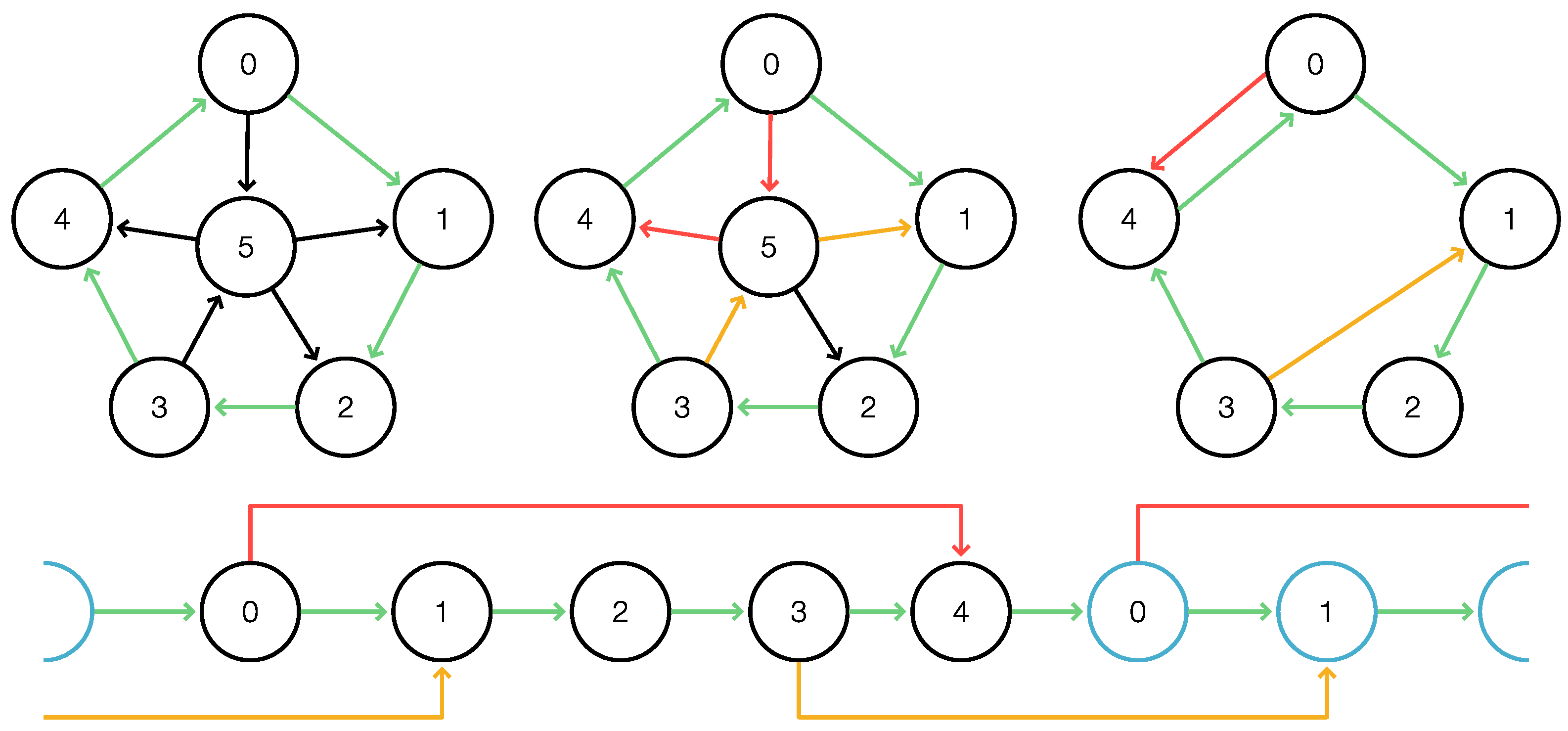
The following lemma provides us with a convenient way to obtain a total -cover.
Lemma 9. Let C be a cycle in G, , and with . Then, , , , and imply that is a total clean -cover of C.
Proof. By construction, and are -covered intervals. By definition, we have , and extends . Since , the two intervals cover all of C. Furthermore, the cover consists of only two intervals that are not subsets of each other; thus, it is clean. □
We will refer to this type of total clean
-cover as a
single-vertex cover of
C. An example is shown in
Figure 4.
2.5. Cycles, -Cover, -Cuts, and Superbubbles
A key result of [
5] states that every superbubble is either contained in or disjoint of any strongly-connected components. The following results on the interaction of cycles and superbubbles are a generalization of this observation. The acyclicity condition (S.v) can be restated in the following way:
Lemma 10. Let be a weak superbubbloid in the digraph G and . Then, every cycle containing u also contains s and t.
Proof. If , then all in-neighbors of u are contained in . Similarly, if , then all out-neighbors of u are contained in . Since every cycle through u contains both in- and out-neighbors of u, it, in particular, contains an edge e in . (S.v) now implies any cycle through e contains both s and t. □
Lemma 11. Let C be a cycle in the digraph G, and let be a total clean -cover of C. If , then v is neither an interior, nor an exit of a weak superbubble, i.e., v is a legitimate root.
Proof. Assume, for contradiction, that v is an interior or the exit of the superbubble . Since C is totally -covered by assumption, Corollary 8 implies . Thus, by Lemma 6, there are (at least) two edge-disjoint paths from u to v. Since neither path can leave before passing through s, neither of them contains the entrance s, and hence, both are contained in the weak superbubble. Thus, contains .
Since is a total clean -cover of C, there is an interval that extends , i.e., , and hence, p is an inner vertex of . Therefore, contains , and it again has an extending -interval. Repeating the argument, we conclude that every vertex of is an inner vertex of . Since the cover is total, , i.e., the cycle C consists entirely of interior vertices of , i.e., C is a proper subset of . This contradicts the acyclicity condition (S.v). □
Corollary 10. Let C be a cycle in the digraph G. Suppose C is totally -covered, and let such that for all . Then, v is a legitimate root.
Proof. The longest -interval by construction cannot be contained within another -interval. Therefore, is contained in the clean cover of Corollary 9. By Lemma 11, its endpoint v is a legitimate root. □
Let us now turn to cycles with -cut vertices:
Lemma 12. Let C be a cycle of the digraph G, and let c be a -cut point of C, i.e., . Then, c is not an interior vertex of any weak superbubble.
Proof. Assume, for contradiction, that
c is an interior vertex of a weak superbubble
. Then, there is a path
p from
s to
t not passing through
c. Otherwise,
is a superbubbloid, contradicting the assumption that
is a weak superbubble; see corollary 5 in [
7]. Along
p, let
u be the last vertex on
C before
c, and let
v be the first vertex on
C after
c. Thus,
. Therefore,
c is
-covered in
C, a contradiction. □
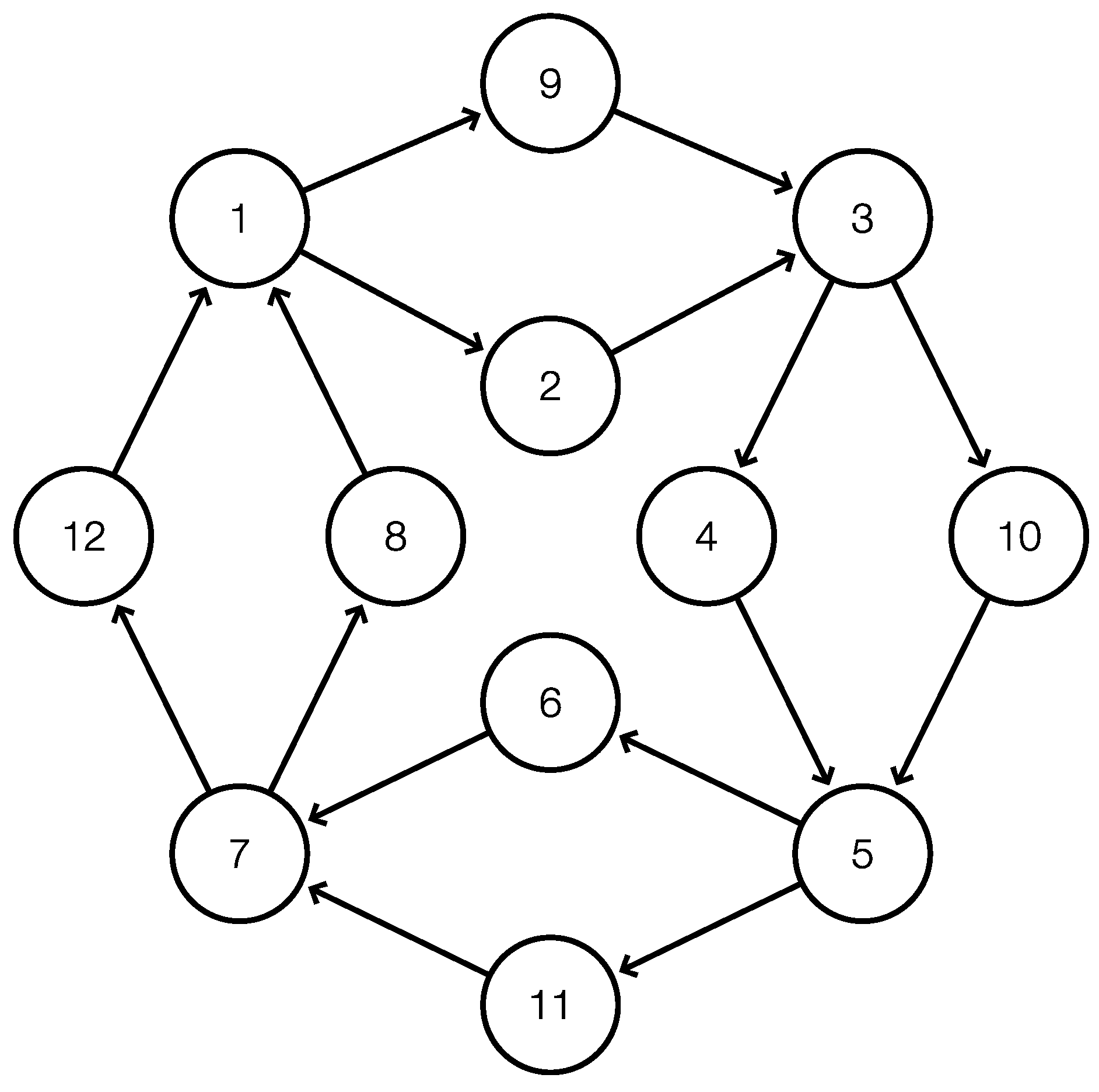
The example in
Figure 5 shows that it is possible that every entrance of superbubble is at the same time the exit of another superbubble. Such graphs do not have any legitimate root. Nevertheless, it is easily possible to obtain all the superbubbles. To this end, fix a
-cut vertex
c for some cycle
C in
G, and consider the auxiliary digraph
obtained from
G by splitting
c into two vertices
and
so that
retains only the in-edges and
retains only the out-edge.
Lemma 13. Let C be a cycle in the digraph G, a -cut vertex, and the digraph obtained from G by splitting c. If is a weak superbubble in G, then it is also a weak superbubble in , where c as an entrance in G corresponds to in and c as an exit in G corresponds to in . Conversely, every weak superbubble with in is also a weak superbubble in G.
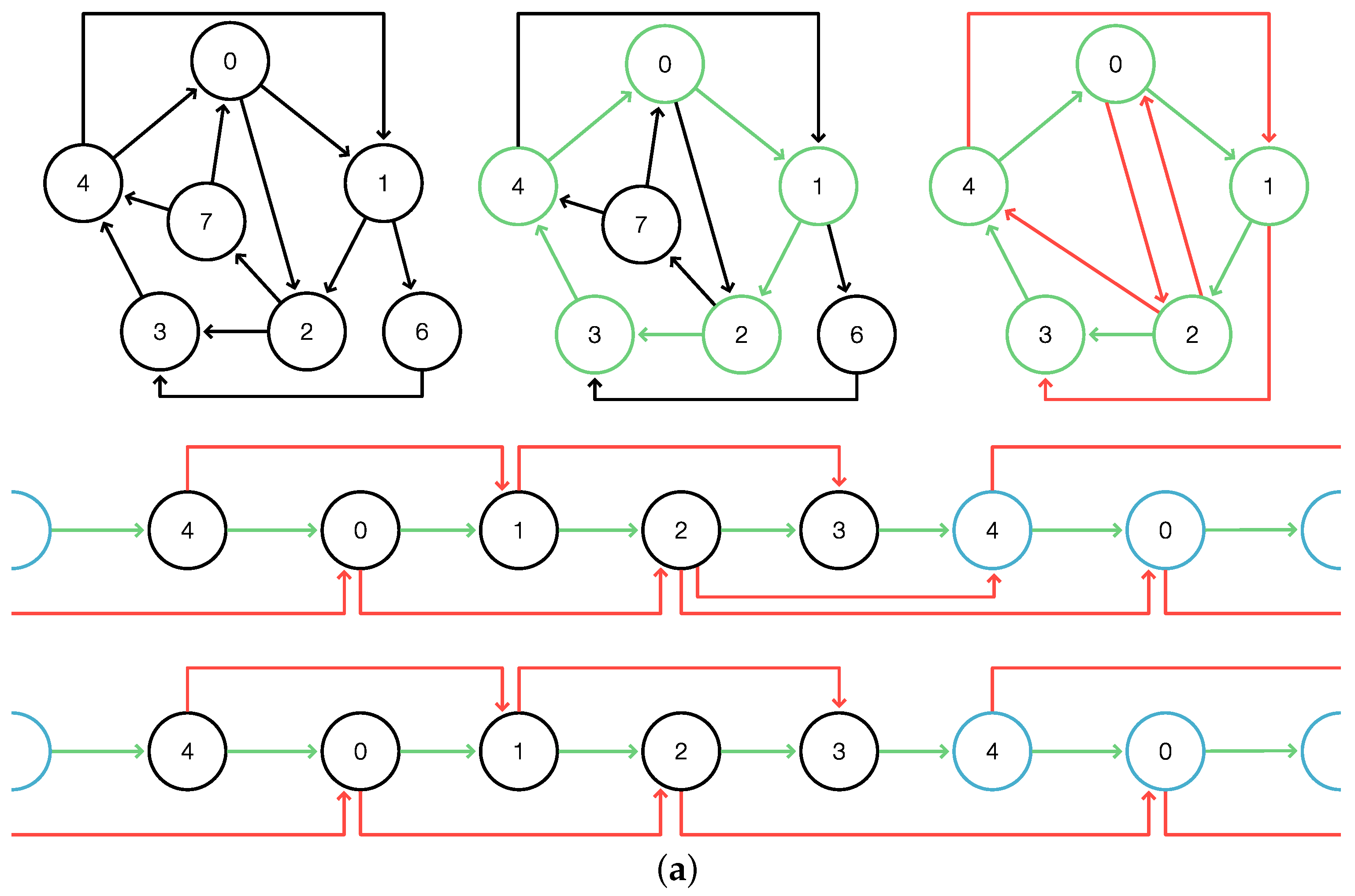
Proof. For the proof, we construct the auxiliary graph by inserting the edge into . Then, there is a 1-1 relationship between the set of paths in G and the set of paths that do not start or end with the edge in , which is constructed as follows: If p starts at c in G, it starts in in ; if p ends at c in G, it ends at in ; and if p runs through c in G, then it runs through the edge in . The 1-1 correspondence of weak superbubbles now follows immediately from the equivalence of the path systems in G and since reachability is the same for every pair , with c as the starting point corresponding to and c as the endpoint corresponding to . Thus, G and have the same superbubbles, except possibly for the ones with in . Now, consider a DFS-tree on rooted in . The edge is not a tree edge and necessarily appears as a back edge. Since c is a -cut vertex, and are not interior vertices of any weak superbubble in . Thus, the edge does not affect any weak superbubble of , and thus, and have the same weak superbubbles, except possibly the ones with . □
The only potential differences between the weak superbubbles of
G and
is, therefore, the possibility that
contains
or
as an additional weak superbubble. Of course, it is easy to detect and remove the additional weak superbubble. Since
is a source in
, we can apply
Superbubble to
and remove the possible spurious weak superbubble
in order to obtain the correct set of weak superbubbles of
G. In contrast to the auxiliary digraph constructions suggested in [
5],
contains only a single extra vertex instead of doubling the size. More importantly, however, it not necessary to construct
explicitly. Instead, on can modify the DFS starting at
c in
G in the following manner: when
c is encountered for the first time as an out-neighbor of a tree vertex
u, then
is inserted as with parent
u and no further out-neighbors, with only a constant overhead. The algorithm
Superbubble applied to
extracts the minimal intervals satisfying (F1) and (F2) (w.r.t.) the reverse postorder
of the DFS-tree rooted as
, and thus correctly identifies the weak superbubbles of
. The modified DFS on
G rooted at
c by construction yields the same DFS-tree on
, and thus the same reverse postorder. Together with setting
,
,
, and
,
Superbubble operating on the modified DFS-tree thus correctly identifies the weak superbubbles in
. We refer to this algorithm, which is equivalent to applying
Superbubble to
, as
Superbubble#.
Definition 11. Let G be a digraph. Then, is a quasi-legitimate root if either:
- (i)
r is source in G,
- (ii)
r is the end point of an interval of a total clean -cover of some cycle C in G, or
- (iii)
r is -cut vertex of some cycle C in G.
Our discussion so far can be summarized as:
Corollary 11. Algorithm Superbubble# correctly identifies the superbubbles in if and only if r is a quasi-legitimate root.
As an immediate consequence of Lemmas 11 and 12, every cycle contains a quasi-legitimate root. Recalling that every vertex in the digraph G can be reached either from a source vertex or from a cycle, we finally obtain:
Theorem 2. Every digraph G contains a set of quasi-legitimate roots . Given these roots, the algorithmSuperbubble# correctly identifies all superbubbles of G in linear time.
It remains to show, therefore, that a suitable set of roots can be identified in linear time. Clearly, this is possible for the sources. For superbubbles that cannot be reached from a source vertex, a suitable set of cycles needs to be identified.
Lemma 14. Let be an arbitrary DFS-forest of G with constituent ordered trees rooted at , and let C be a cycle in G. Then, implies , and there is a such that .
Proof. Let be the first root of F that can reach any vertex of C. Then, by definition of a cycle, . Thus, . Further, let u be the first vertex that is reached from in the DFS. Then, every other vertex of C is reached from u in the DFS. Thus, . □
The same is true for strongly-connected components:
Lemma 15. [8] (corollary 11) Let S be a strongly-connected component in G, and let T be a DFS-tree with . Then, there is a vertex such that . We call v the root of the strongly-connected component S in T. Our aim is now to find a set of “start cycles” such that every cycle C is reachable from at least one of these start cycles.
Lemma 16. Let T be a DFS-tree on the digraph G rooted in v, and let W be the set of ≺-maximal vertices w that have an incoming back edge . Then, (i) is contained in a cycle, and (ii) every cycle is satisfied for some .
Proof. Property (i) is an immediate consequence of the definition of DFS. Now, suppose for some . Then, by construction, none of the vertices along the path from the root v to u have an incoming back edge, and thus, neither u, nor one of its ancestors are contained in a cycle. Thus, if for some cycle , then a vertex exists such that , and thus, . □
Note that if does not contain a cycle. Since the vertex set of every cycle in the digraph G is necessarily contained in one of the constituent trees of a DFS-forest, we immediately obtain:
Corollary 12. Let F be a DFS-forest on the digraph G, and let W by the set of ≺-maximal vertices w that have an incoming back edge . Then, (i) is contained in a cycle, and (ii) every cycle C in G is satisfied for some and some .
Lemma 17. A set of cycles from which all cycles in G are reachable can be constructed in time.
Proof. The DFS-forest F on the digraph G is obtained in time. The set W is easily identified by a preorder traversal of F omitting a subtree as soon as a vertex w has an incoming back edge. The worst-case effort is since we only traverse the forest, not the entire digraph G. Given W and the associated back edges identified in the previous step for each , the cycle is explicitly retrieved by following the parent links of F from back to in time. □
Lemma 17 ensures that a sufficient set of cycles can be found in linear time. More precisely, using the sources of G and a quasi-legitimate root in each cycle as roots, the algorithm Superbubble# correctly identifies all superbubbles in G in linear time. It remains to show that we can identify a quasi-legitimate root in a cycle .
2.6. Identification of Quasi-Legitimate Roots
The obvious approach to identify quasi-legitimate roots is to construct a clean -cover. The obvious starting point is since it requires the construction of no more than the -path. This can be achieved in polynomial time, e.g., using an independent DFS-tree rooted at that ignores the edges of C. This naive approach, however, exceeds linear time even for a single cycle.
For , we construct a modified DFS-tree by excluding all other vertices of C from G. By construction, is -reachable from c if and only if contains an in-neighbor of u, i.e., there is an edge with .
For each , we are interested in the vertices and that are -reachable from v and minimize and maximize and . These can be recursively computed on by traversing in postorder. For each , and are obtained by comparing the and values for the out-neighbors of v along T, and the vertices reachable directly from v. More precisely, at each leaf v of , is initialized by the vertex such that and maximizes . At each inner vertex v of , is computed as the vertex maximizes from the following set of candidates: . The vertex -reachable from c with the maximal value of is thus . The same computations are used for , except that is minimized instead of maximized. The computations of and values of and clearly can be performed in linear time. Repeating this for each , however, will, in general, exceed linear time since the length is not bounded in general.
We can mostly reuse the information stored in , however. A crucial observation is the following:
Lemma 18. Let C be a cycle of the digraph G; consider two distinct cycle vertices ; and let with and . If , then and . Otherwise, forms a one-vertex -cover.
Proof. For simplicity, we write and . By definition of and , we have (1) , and (2) for every satisfying , we have . Starting from Property (1), Corollary 7 implies . As a consequence, for every , we have . Since is just a constant, implies for all .
First, assume . Then, Corollary 7 implies . The same arguments as for show that implies , which in turn implies for all . Because of Property (2), this implication can be used in particular for every for which might hold. Therefore, the same two vertices minimize and maximize and , and thus, we arrive at and .
Now, suppose . Then, (otherwise, the distances would be equal), and Corollary 7 implies . Since , we obtain . By Lemma 9, is a one-vertex cover of C. □
The use of Lemma 18 is that it allows either to use the and values also for , or we obtain a one-vertex -cover, which immediately provides us with a legitimate root according to Lemma 11. Thus, we need to continue the computation of and only until we encounter a one-vertex cover. Up to this point, the values of and are independent of by Lemma 18.
The difficulty is to compute the and for all correctly. We have already seen above how to handle tree edges. Forward-edges in do not effectively contribute, because the same information (minimization or maximization over values of ) is also propagated stepwise along the tree-edges. Cross edges, on the other hand, could add information. Postorder traversal ensures, however, that the pertinent information at their starting points is already computed in time to include them to compute the correct value, i.e., we simply have to include the cross-edges in the minimization/maximization step.
Back edges are problematic when belonging to the same strongly-connected component S as . In this case, they can be reached from a cycle vertex and themselves reach a cycle vertex . Such back edge, therefore, influence which cycle vertices are reachable. To handle this information, S is split into parts that are strongly connected components under the use of -reachability. More precisely, we define a -SCC as a strongly-connected component on the induced subgraph .
Consider the auxiliary graph with vertex set and all edges of , as well as all edges with . Then, c is not contained in a cycle of , and thus, the SCC of are exactly the -SCC and the single vertex c. By construction, is also a DFS-tree for . Thus, Tarjan’s DFS-based SCC-detection algorithm (see Lemma 15) on identifies the -SCC as the SCC of . To mimic the traversal on instead on , the graph on which was originally defined, it suffices to ignore the back edge leading to the root, i.e., edges of the form for . It is thus not necessary to construct the graph explicitly.
The definitions of and imply:
Corollary 13. Let C be a cycle in the digraph G; let be a modified DFS-tree rooted at ; and let S be a -SCC with . Then, and are independent of v for every .
This begs the question of whether the v-independent values of and can be obtained while traversing G. A partial answer is provided by:
Corollary 14. Let C be a cycle in the digraph G; let be a modified DFS-tree rooted at ; and let v be the root of a -SCC. Suppose the values of and are known for . Then, and are obtained correctly by postorder traversal of considering all tree and cross edges.
Proof. The only missing information could be a back edge with and . Such a back edge cannot exist because v is by assumption the root of a -SCC, and thus, there is no cycle including u, v, and . □
This observation yields a simple solution to obtain the correct entries for and for every : determine the -SCC and its root v, and set and .
Tarjan [
8] showed that SCC can be found efficiently by DFS. Below, we will modify the approach slightly to operate on a given DFS-tree. We therefore briefly outline Tarjan’s SSC algorithm; for full details, we refer to [
8]: First, the vertices are enumerated in preorder. Then, a postorder traversal is used to compute, for each
v, the
lowlink , which is recursively defined as:
A cross edge is only included if it is “unfinished”, i.e., if its endpoint w has not been reported as part of a previously-completed SCC. A vertex v is the root of an SSC if . Tarjan’s SSC algorithm now uses a stack to iterate over every vertex of the SCC S to mark them as finished. This cannot be done in the same way in a predefined DFS-tree.
The stack can be replaced, however, by an equally-efficient iterative method: Starting from v with , simple traverse starting at v; report all “unfinished” vertices as members of the SSC; and omit every subtree rooted in a “finished” vertex. To see that this is correct, note that for all , and hence, w is “unfinished” when the postorder traversal encounters v. Lemma 15 implies that there is a path from v to w in T, with and thus also “unfinished”. Thus, if u is “finished”, so are all its descendants, and the subtree does not need to be considered. The only difference from Tarjan’s SSC algorithm tree traversal is to retrieve S, which considers every edge of T once and thus runs in a total time of . We summarize the discussion above as:
Lemma 19. The modified version of Tarjan’s SCC algorithm correctly identifies all strongly-connected components in T in time.
Since the correct values of and are computed by postorder traversal of , they are already available when the root v of a -SCC is encountered. Thus, identification of the -SCC and the computation of and can be combined in the same tree traversal. The same tree traversal also guarantees that for every cross edge , we have either (i) u and w in the same -SCC or (ii) the values of and are computed correctly.
Now, consider the vertex along C, and suppose we have not encountered a one-vertex -cover so far. Let be the DFS-tree rooted in that ignores all vertices already included in a previous DFS-tree. As for , we can compute and with along this tree. Then, either equals computed on or for some u such that , depending on which has the smaller value of , and either equals computed on or , depending on which has the larger value of . Note that and do not actually depend on i. In a practical implementation, it is simply stored in dependence of v. The index only is used to keep track of the individual, disjoint DFS-trees rooted in in our arguments.
After processing all vertices of
C, we have either found a one-vertex
-cover of
C, or we know, for every
, the largest
-covered interval
. Thus, we directly conclude:
In particular, we have shown that for each C, or a one-vertex cover can be constructed in linear time.
To detect a quasi-legitimate root, it is necessary to first decide whether C has a total -cover or a non-empty set of -cut vertices exists. To this end, a clean -cover can be used efficiently. Recall that by Lemma 8, every interval in a clean -cover is extended by at least one other interval from the -cover. Since a clean -cover contains at most intervals, it is easy to check in linear time whether a -cut vertex exists: starting from an arbitrary , we initialize the upper bound of the -covered part of C that starts at the successor of u by . For every with , we check whether , in which case a total cover is found, and otherwise, we update x with . If no total cover is found when the intervals are exhausted, then x is a -cut vertex (see the proof of Lemma 8). With the stored, e.g., as array , a total cover or the -cut vertex x is found in operations.
In practice, however, we do not have access to a clean -cover. However, can be computed in linear time. By Corollary 9, there is a clean -cover . We can thus use the same procedure. The redundant intervals in are, by definition, contained within intervals belonging to , and thus, they do not change the results provided the initial interval is contained in the clean cover . By Corollary 10, this is true for the longest interval . Since contains at most intervals, the longest interval and a cut point or the validation of a total cover can be computed in . When it is a total -cover, the longest interval is contained in a total clean cover, and thus, v is a legitimate root by Lemma 10. Thus, a quasi-legitimate root v can be retrieved in time. The entire procedure is summarized in Algorithm 1.
Lemma 20. Given a cycle C in the digraph G, Algorithm 1 identifies a quasi-legitimate root in C in linear time w.r.t. the size of , the induced subgraph of G reachable from C.
Proof. The correctness of the algorithm follows from the discussion in the previous paragraphs. The construction of DFS-trees together is linear in the size of since each edge in is considered once. The recursive computation along each is also linear. Since the are disjoint, the total effort is still linear. □
Finally, we note that by construction, no vertex in reaches any cycle disjoint from . Hence, when processing the next cycle , the vertices (and edges) already visited in the context of processing C are irrelevant, and thus, can be disregarded. In other words, the DFS for the next cycle can be performed in the same digraph G, with all previously processed induced subgraphs marked as finished. This ensures an overall linear running time for the identification of starting points for all cycles as in Lemma 17.
| Algorithm 1 computes a -cover and determines , as well as a quasi-legitimate root in C. |
Require: digraph and cycle C for do create DFS-tree with root c by ignoring finished and cycle vertices with preorder . while v traverses in postorder do for do if then Update with u Update with u else if is a back edge then Update with else if then return legitimate root Update with Update with if u is unfinished then Update with if then for u in -SCC with root v do Set u as finished Set u such that for every for in cycle order starting from the successor of u do if then return quasi-legitimate root c if then return legitimate root
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}